day 23
文本摘要介绍


文本摘要项目数据集

























Day23问题点
- 问题1: 项目中会提供一些更接近原始的数据.
- 工业界的一线生产数据: 最大的特点就是"噪声多"!!!
- 这数据清洗是不是把语音的全闪了 (咖啡猫🐱)
- 情况1: 我们拿到的原始数据, 里面的语音只是文本格式的[语音], 文本格式的[图片], 本质上我们就没法拿到对应的信息.
- 情况2: 我们拿到的原始数据, 里面的[语音]是一段真实语音, [图片]是真图片, 就复杂了!!!
- 2.1: 需要直接动用ASR技术, 把语音信息翻译成文本.
- 2.2: 需要利用CV, CNN卷积技术, 把图片翻译成"张量", 后续这个image的张量和文本embedding后的张量直接concat就行了.
- 问题2: 基于计数的模型 PK 基于训练的模型, 有什么本质区别?
- ⭕️TFIDF算法: 第一个作业!!!
- TF算法: Term Frequency --- 词频算法
- 核心: 统计一个单词在文档中的出现频次(次数), 单词出现越多, 重要性越大!!!
- IDF算法: Inverse Document Frequency --- 逆文档频率算法
- 栗子🌰: 你, 我, 他, 的, 啊, 怎么办??? --- 有些单词出现的次数确实多, 但是是很普通的词, 停用词.
- 核心: 在更广泛的文档集合中, 10000篇文章中出现次数都很多的词 == 常见词 (恰恰不更要)
- TFIDF = TF * IDF
- TextRank: 也是基于计数的模型.
- ⭕️基于训练的模型(BERT, GPT, T5, macBERT)有什么本质的区别???
- 这些模型的参数是训练出来的!!! --- 大量的反向传播 + 梯度计算 + 参数更新
- 对比TFIDF (TextRank) --- 这些模型的参数是"数数出来的" --- 不需要学习!!!
- 问题3: 做AI项目的基线思路?
- 无论如何, 只要是一个AI项目, 我们一定要尽快的提供一个baseline模型 + baseline基准.
- 分类任务:
- 文本摘要任务:
day24
seq2seq架构实现本摘要












































利预训练词向量对baseline1模型优化



























Day24问题点
- 问题1: 编码器向解码器就是要多次输送张量吗? (李辉)
- 为啥不一次性全部给呢,反正解码器有look-ahead-mask?
- 在Transformer架构中, 我们也是每一个时间步都把Encoder Hidden States最后一层的输出张量输送给Decoder!!!
- 在不是GPT的情况下, 有Encoder的情况下.
- 问题2: 一个总体的模型思路是什么?
- 1: 首先数据集清洗
- 2: 搞定词向量
- 2.1: 自己写代码构造vocab, 然后依靠nn.Embedding()产生词向量
- 2.2: 直接引用预训练模型BERT, GPT, macBERT
- 2.3: 利用Word2Vec自己训练出一版词向量, 然后在模型中用
- 百度阿里腾讯字节 --- 互联网大厂, 都有自己的词向量 (都有自己的大模型)
- 垂直行业的AI公司 --- 非常讲究自己训练独特的词向量
- 3: 构造数据迭代器
- 重要的一项工作1: 就是按照模型的需求, 对数据进行一些特殊的处理!!!
- 3.1: 第一个项目, 为了适配BERT, 原始数据 [CLS], 构造mask
- 3.2: 第二个项目, 会为训练语料添加 < SEP >, 追加其他的辅助数据
- 重要的一项工作2: 完成文本到数字化id的映射的工作
- 4: 构造模型 class Model()
- 5: 训练的代码 + 测试的代码
- 问题3: 大厂练的词向量 一般都是用word2vec吗 还有别的吗? (阿诺)
- 如果计划训练一版静态词向量: 类Word2Vec
- 如果计划训练一版动态词向量: 类BERT
- 不同公司的词向量区别大吗, 感觉都是给一堆文本, 算词频排序, 区别是喂的那堆文本不同? (Will sezna)
- 区别还是挺大的:
- 词派: 百度, 阿里
- 字派: 字节, 快手, 华为
- 词频的设置也不同
- 词汇表的大小也不同
- 词嵌入维度也不同
- ⭕️原理上几乎都一样!!!
- 问题4: embedding用專門的embedding模型效果會比用gpt那些toekenizer生成的效果好嗎? 如果是要用於embedding相似度比較?
- 大多数情况下, 直接用类似BGE (M3 Embedding)模型效果更好.
- 问题5: 老师 指点一些方向性的建议呀 第一个项目的蒸馏 建不建议用多教师下的蒸馏模式 采用基于置信度的加权平均,加权平均或投票机制等计算软标签 但是试了一下感觉没有单教师蒸馏的方法效果好 是不是我自己写的有问题? 还看到微软用了强化学习下的多教师蒸馏模式,听说效果好, 但是不了解强化学习复现不了 (阿诺)
- 知识蒸馏: multi-teacher 的蒸馏难度大, 属于"调参侠"的高级阶段.....
- 强化学习: 自从2022.11 ChatGPT之后已经成为大模型阶段的神器, 肯定效果好.
- 讲少了很难懂, 讲多了容易懵😳
- DQN: 2016-2017年当年玩的模型, 也是DeepMind下围棋的背后模型.
- ChatGPT: PPO
- 2024: DPO
- 问题6: 数据预处理结束后, 有什么结论???
- 暂缓写模型 + 训练......
- 回头看看数据端能不能有什么改善? 或者新的数据处理方法?
- ⭕️AI原则: 绝大多数情况下(99%), 人类很难读懂或者处理的文本, 模型也难以处理!!!
- 大模型判断 9.11 > 9.9 的问题.
- 数据决定了模型的上限
- 小作业:
- 总结:1.回去复习GRNN 2.回去复习vord2vector
- 2: 所有的数据处理流程跑完
- 3: gensim词向量训练完毕
day25
PGN模型架构







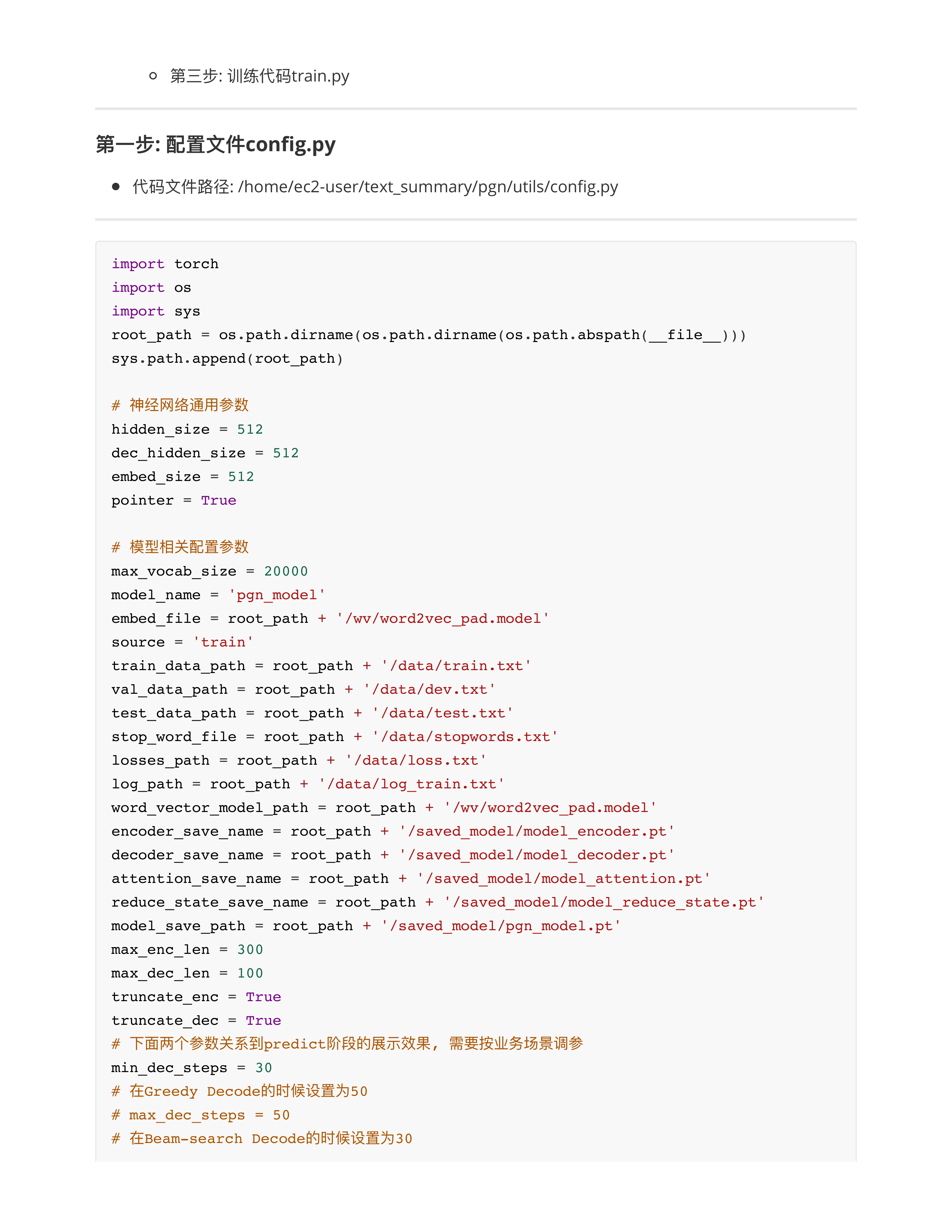
PGN数据预处理
























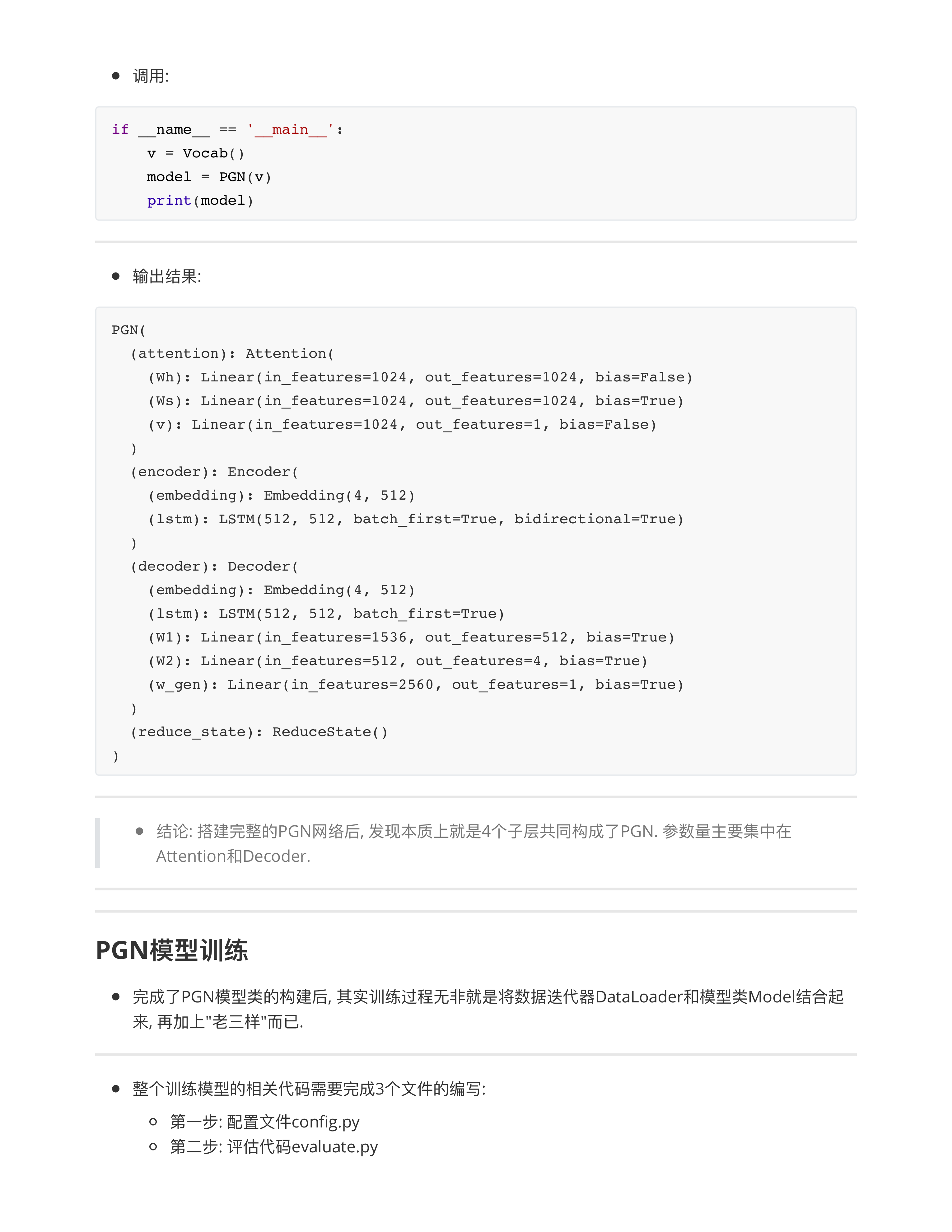
PGN模型的实现





















day25课堂问题
- 问题1: 关于GPU和CPU的对比?
- CPU + GPU: 都有一级缓存, 二级缓存的概念.
- GPU: 16GB (40GB, 80GB, 180GB) 显存 --- 是不是GPU内部运行最快, 存取效率最高的部分?
- 本质上缓存最快!!!
- 3090, 4090, A100 --- 显存存取效率 --- 100GB ~ 500GB / s
- 一级缓存: 2TB ~ 3TB / s
- 二级缓存: 9TB ~ 12TB / s
- 问题2: 注意力的算法不是说好 softmax(Q * KT / dk)* V吗? 现在怎么又是tanh, 又是相加, 是不是用这个注意力算法, 得出的结果更加准确? (何方)
- 因为这个我们没有用transformer架构, 也没有用预训练模型, 所以自由度很高.
- 这里是故意给同学们展示一下注意力机制有很多.
- 即使在咱们这里, 也完全可以继续用经典的transformer注意力计算规则!!!
- 宏观上依然是经典注意力效果最好!!!
- 问题3: transformer 不就是encoder 一次吗? 完了之后, decoder 时间步循环吗??? (苹果)
- Encoder的输出张量是否只往Decoder里面传一次??? (小朱的问题)
- ❌ 每一个时间步都要传一次!!!
- 基于GRU (RNN/LSTM) 的模型:
- 1: pred, dec_hidden = self.decoder(dec_input, context_vector)
- 2: dec_input = dec_target[:, t].unsqueeze(1)
- ⭕️本质上是每一个时间步t对应的token, 作为下一个时间步t + 1预测的输入token
- 基于Transformer的模型:
- 不同!!! ❎
- ⭕️本质上是每一个时间步t对应的token + 从第1步到第t-1步所有的结果tokens, 作为下一个时间步t + 1预测的输入tokens
- 问题4: 感觉这个交叉熵就是算了和标签一样, 没有考虑不同字符相同意思的表达? (王晨欢)
- 🍊未来生成式任务看多了, 你就会发现都是傻瓜式计算!!!
- 完全没达到考虑不同字符相同意思的这个程度!!!
- 生成式任务的损失函数不仅仅这一种哦!!!
- 还有好几个.......
- 主流大模型的损失函数的计算并不是nn.CrossEntropyLoss()
- 问题5: 自由 : 这个任务的交叉熵的计算最后一步nn.crossEntropyloss和分类的看起来也没区别来着。为什么这个任务还多了一步取均值。分类的没有这一步。
- 分类任务: 一个样本有一个预测结果 PK 唯一的标签🏷label对比
- 文本摘要: 一个样本有一堆seq_len个预测结果 PK 一堆标签🏷seq_len个tokens
- 问题6: 我问个基础问题,交叉熵跟soft(q*KT/dk) * V是独立的么?既然都是权重损失计算? (纯木)
- 问题7: 训练的输入 VS 预测的输入?
- 训练: dec_input = dec_target[:, t].unsqueeze(1)
- 训练的时候解码器的dec_input输入的是"真实标签" --- 有label ✅
- 预测: dec_input = predict_ids.unsqueeze(1)
- 预测时候解码器的dec_input输入的是"上一步的预测结果" --- 没有label ❎
- 作业:
- 1: 2022 ~ 2024 面试题发给同学们一部分 (翻来覆去大概就是100道)
- 要求节后交作业 --- 把面试题的详细回答提交上来!!! (回答面试题的过程就是对知识的一次大整理)
- 2: 文本摘要项目:
- 第2章的TextRank部分所有代码, 截图提交.
- 第3章的Seq2Seq, 结果不重要(loss), 重点在于理解代码流程.
- 3: 提前预习PGN模型 --- 只会发第4章的讲义.
- 同学们预习为主, 不强求跑模型.......(不预习的话节后上课很难理解)
- 一个epoch大概GPU上耗时1个小时!!!
day26课堂问题
- 问题1: seq2seq架构模型效果为什么很差 --- 重复?
- 从零训练的模型, 没有对其进行任何的优化.
- 自回归模型: 最后一步预测的时候softmax --- top 1, 最大概率的那一个.
- 教训: 自从2022大模型时代以来, 所有的模型都变成top K, 而不是仅仅取最大概率的token!!!
- 其实从2019年开始就有很多模型开始采用top K的预测.
- 包括不适用贪心算法的预测.
- 问题2: 在PGN的模型架构下, 永远不可能出现3-0这个token?
- 是的🙆🏻♀️✅
- 3-0这个单词是OOV单词, 并且从来没有在source document中出现.
- OpenAI, GPT o1, GPT 4o --- 能不能生成3-0的结果? (假设3-0也不在OpenAI的词典中)
- 文心一言, 豆包, DeepSeek都算在内.
- AI常识 (同学们一定要提高注意力) --- 面试中, 工作中, 常识问题最容易暴露新手
- 常识1: 主流大模型的训练语料大概使用清洗后的 8万亿tokens ~ 13万亿tokens
- 基本上把过去10年的互联网的所有的语料都学过了!!!
- 常识2: BERT模型单次预测一条样本耗时多少?
- CPU: 100ms ~ 200ms --- QPS: 5 ~ 10 (Query Per Second)
- GPU: 10ms ~ 20ms --- QPS: 50 ~ 100
- LR: 1 ~ 2ms
- 阿里11.11, Flink实时流处理工具 --- QPS: 100万
- 带来意外的惊喜???
- 不可能!!! ❌
- 大模型 (任意AI模型), 可以带来惊喜, 但是这个惊喜的token是在词表中的.
- 如果不在词表中, 也不在原始文档中, 就不可能被生成出来!!!
- 问题3: 神经网络真的跟物理有很大关系嘛? (❓)
- 机器学习 --- 统计力学
- 损失值优化 --- 最小化自由能量
- 模型收敛 --- 热力平衡
- KL散度 --- 自由能差
- 高斯噪声 --- 随机热涨落
- 随机梯度下降 --- 布朗运动
- 强化学习 --- 控制理论
- 音频, 图像, 视频 --- 信息处理 (卷积核 --- 噪声过滤 --- 特征过滤 (特征筛选))
- 扩散模型 --- 郎之万动力学
- 问题4: 关于source2ids函数.
- 原始文本BERT: YGDHGJKPEWJHVIDI
- Oovs = [21128, 21129, 21130]
- Ids: [100, 200, 21128, 500, 28, 21129, 66, 99, 321, 21130]
- 作业1: 简单的预习一下什么叫"小顶堆"?
- 作业2: 本次课讲解的函数回去复习 + 理解, 尤其是文本数字化映射的3个函数.
day27课堂问题
- 问题1: 小顶堆现实中最大的一个作用?
- 一方面进行查找加速.
- Leetcode: 10亿个参数, 希望提取TOP 100的值, 尽量减少时间复杂度?
- 1: 排序 --- O(nlogn) --- x[:100]取出了TOP 100的值
- 2: 小顶堆 --- O(nlog100)
- 3: 哈希
- 问题2: 未来同学们工作中需要对数据进行特殊处理的时候?
- 一定要重写collate_fn() --- 个性化数据处理函数
- 问题3: 关于论文复现的问题?
- 核心: 论文复现其实是AI领域中的一个高阶能力!!!
- 论文中只要有一个矩阵出现 == 对应代码中的一个nn.Linear()的定义.
- 定义的维度一般都要回到原始论文中找答案, 如果论文中没有明确说明:
- 程序员自由发挥, 你按照自己的理解"随意定义就好".....
- 未来大家会看到很多这样的处理.
- 论文复现的时候, 为了让模型精简一些, 或者考虑到计算的复杂度, 有些时候可以在代码层面简约化一些.
- 核心: 代码不一定严格按照论文公式来!!!
- 按照小朱老师的代码, 公式变成: $ W [c_t, s_t, x] $
- ⭕️作业1: 留给同学们一个小作业: 回去尝试严格按照论文公式来写一遍!!!
- extension = torch.zeros((batch_size, max_oov)).float().to(self.DEVICE)
- Extension: [16, 3] --- 假设当前批次16个样本最大的oovs列表长度为3
- p_vocab_extended = torch.cat([p_vocab_weighted, extension], dim=1)
- 相当于把单词分布矩阵 concat 扩展矩阵
- p_vocab_weighted: [16, 30000] --- extention: [16, 3]
- p_vocab_extended: [16, 30003] --- 相当于矩阵最后增加了3列, 这3列完全是留给oov单词的.
- final_distribution = p_vocab_extended.scatter_add_(dim=1, index=x, src=attention_weighted)
- 2-0这个OOV单词, 就有机会通过attention_weighted被加入到30001列中!!!
- Argintina在p_vocab中有一定权重, 在attention_weighted中也有一定权重, 会被加和在一起!!!
- target_probs = torch.gather(final_dist, 1, y_t.unsqueeze(1))
- gather()函数就是scatter函数的逆操作!!!
- ⭕️作业2: 深入理解PGN总共5个类的代码, 建议把训练跑起来, 然后看中间结果加深理解
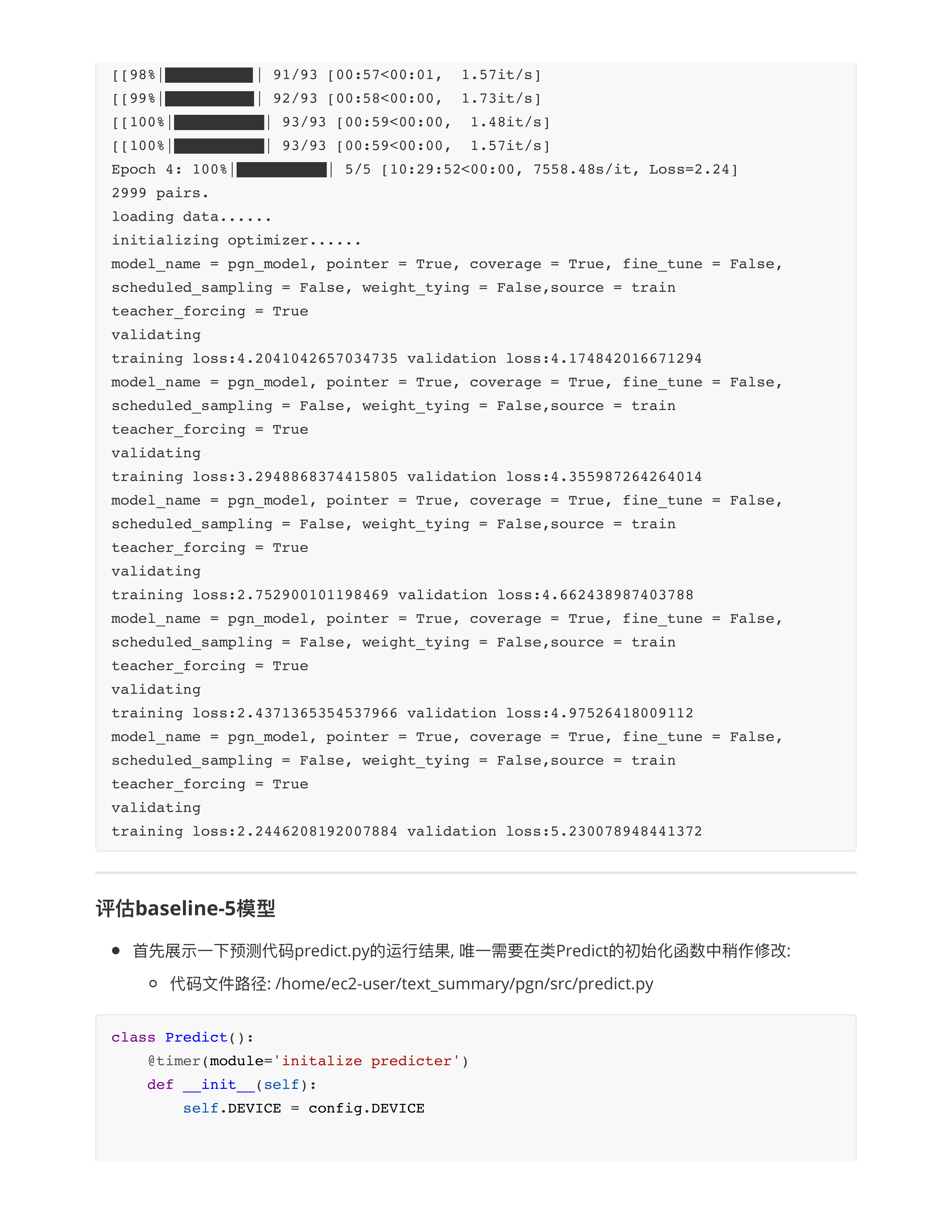
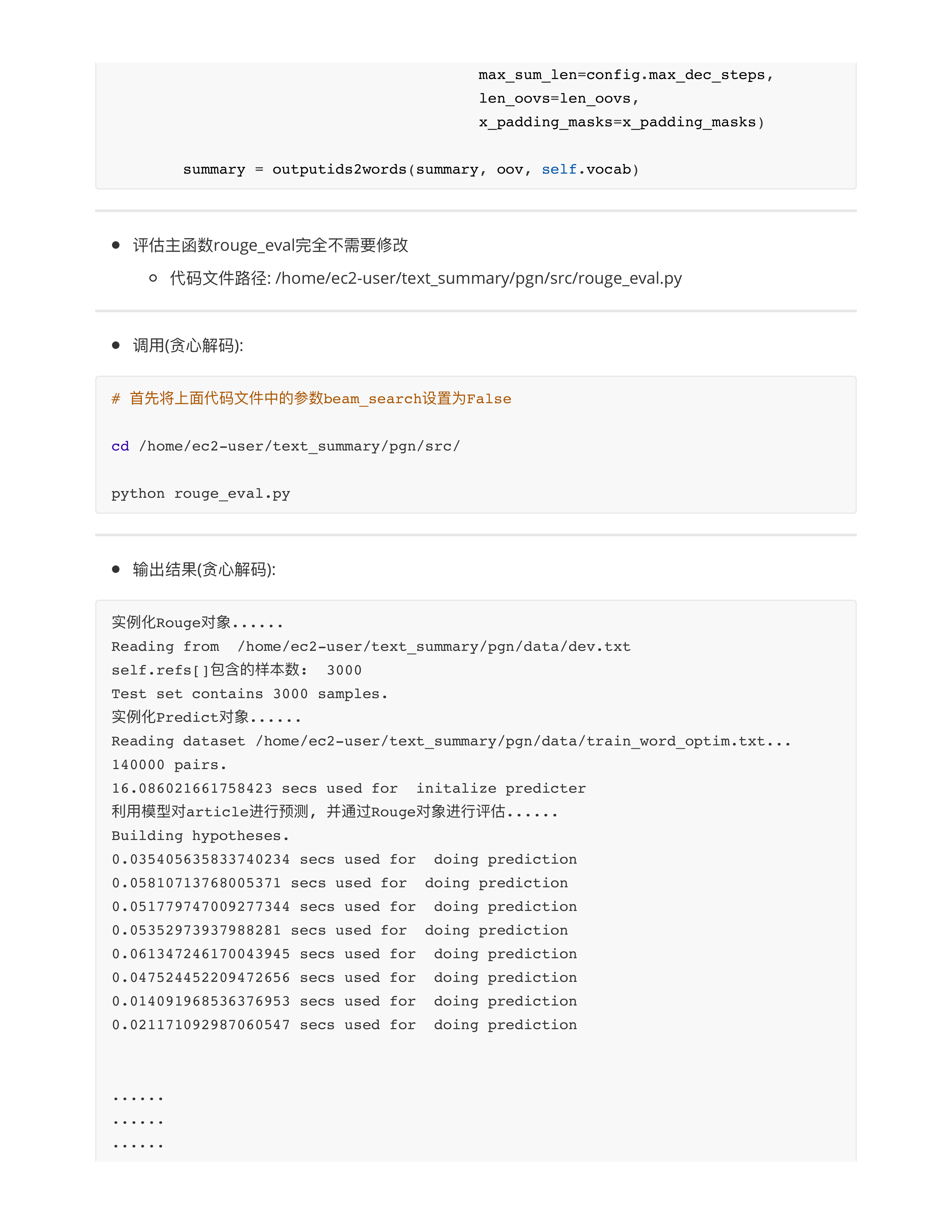
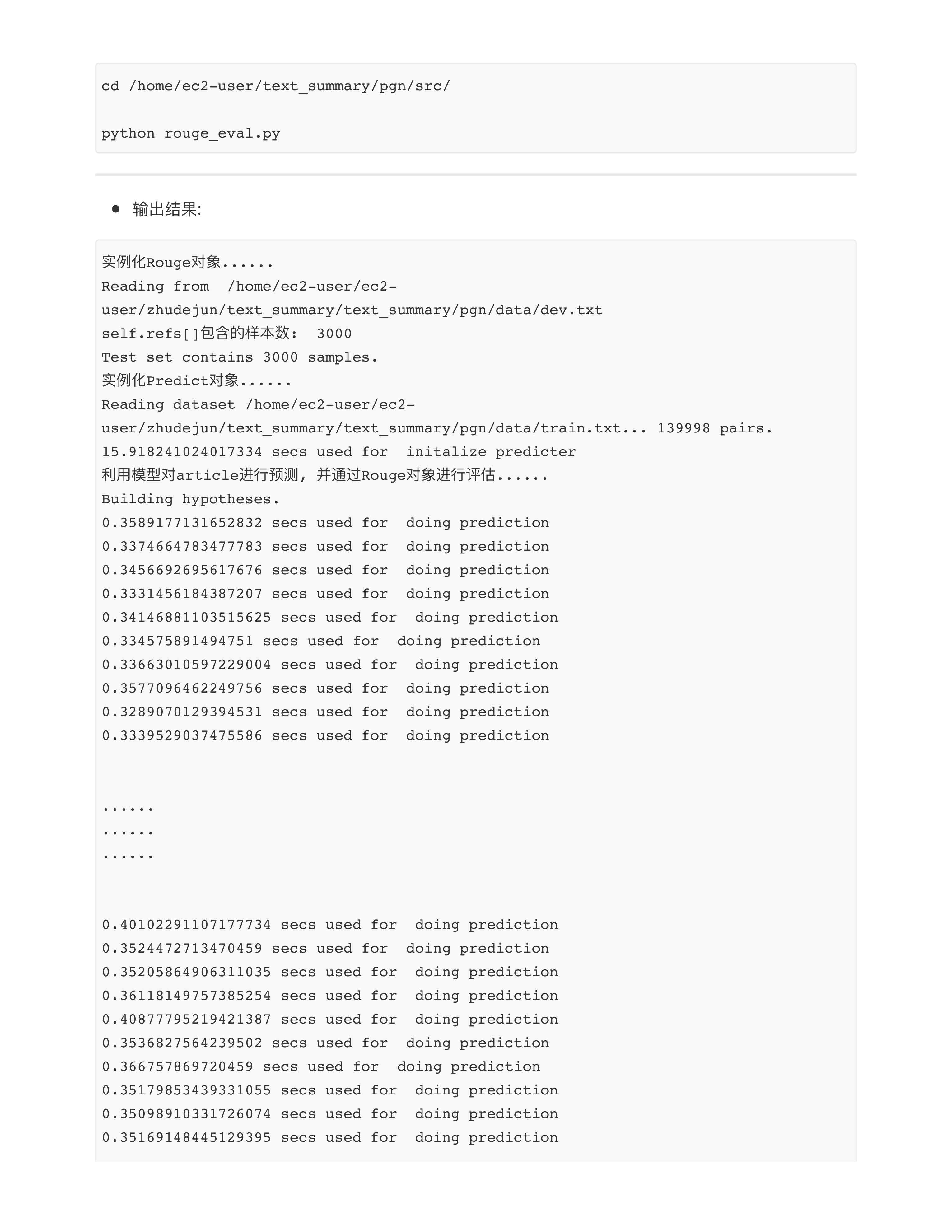
day28
文本摘要评估法









ROUGE算法代码实现





day28课堂问题
- 问题1: 梯度消失和梯度爆炸哪个更难处理?
- 梯度消失✅
- 面试题: Transformer解决梯度消失问题的效果为什么比传统的RNN/LSTM要好?
- RNN/LSTM: 从左向右传!!! 梯度是一步步传递的, 第100步的token一定要等待1~99的tokens处理完毕后, 梯度传过来再处理.
- 在seq_len这个维度上传递梯度.
- RNN: 有效训练长度30~50
- LSTM: 有效训练长度80~100, (paper: 500)
- Transformer: 从下往上传!!! 如果我们的模型有12层, 意味着梯度只传了12层.
- 不在seq_len这个维度上传递梯度.
- 在num_layer这个维度上传递梯度.
- 问题2: rouge-L针对的是最长公共子序列问题(LCS)?
- 最长公共子序列 (纯木回去复习)
- 最长公共子串
- leetcode题目建议同学们回去刷刷
- 问题3: 为什么机器翻译的评估标准是BLEU或者rouge?
- 翻译曾经有一个经典的标准: 信, 达, 雅 --- 严复.
- 不能通过训练一个神经网络来评估哪个机器翻译的结果更好!!! ✅
- 问题4: 抛硬币, 能不能通过训练一个神经网络来预测?
- 信息论 --- 香农
- 一件事物 = 信息 + 噪声
- 抛硬币这件事 --- 它只能提供给神经网络的是"噪声"
- 每次输入网络的input_x其实都是噪声, 没有信息输入, 本质上没法训练, 也没法收敛!!!
- ⭕️第8次作业:
- 跑通PGN模型, 训练2~3个epochs, 截图提交.
- 完成第5章的评估代码 + 评估的结果, 截图提交.
- 截止时间: 2024.10.16 20:00
day29
对baseline2模型的优化











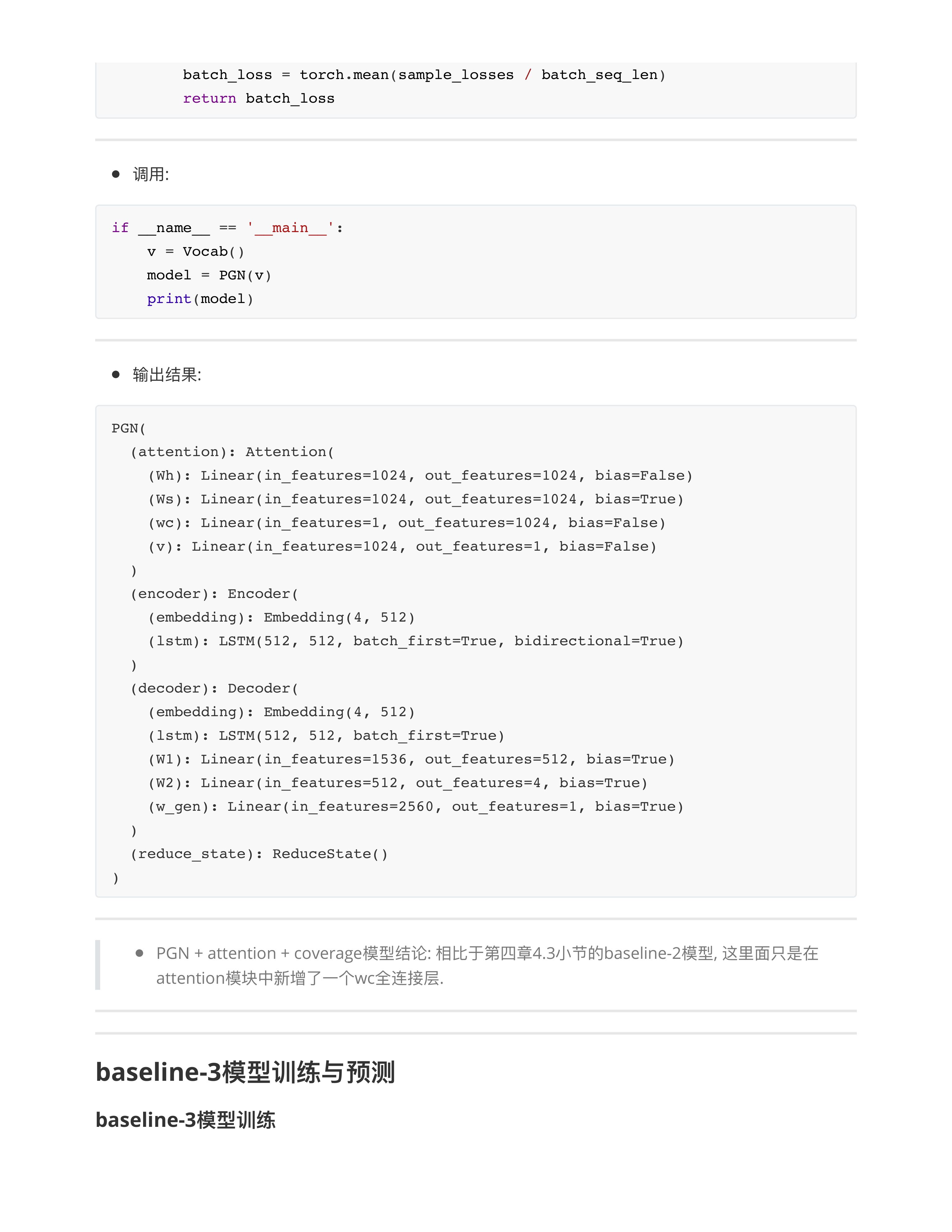
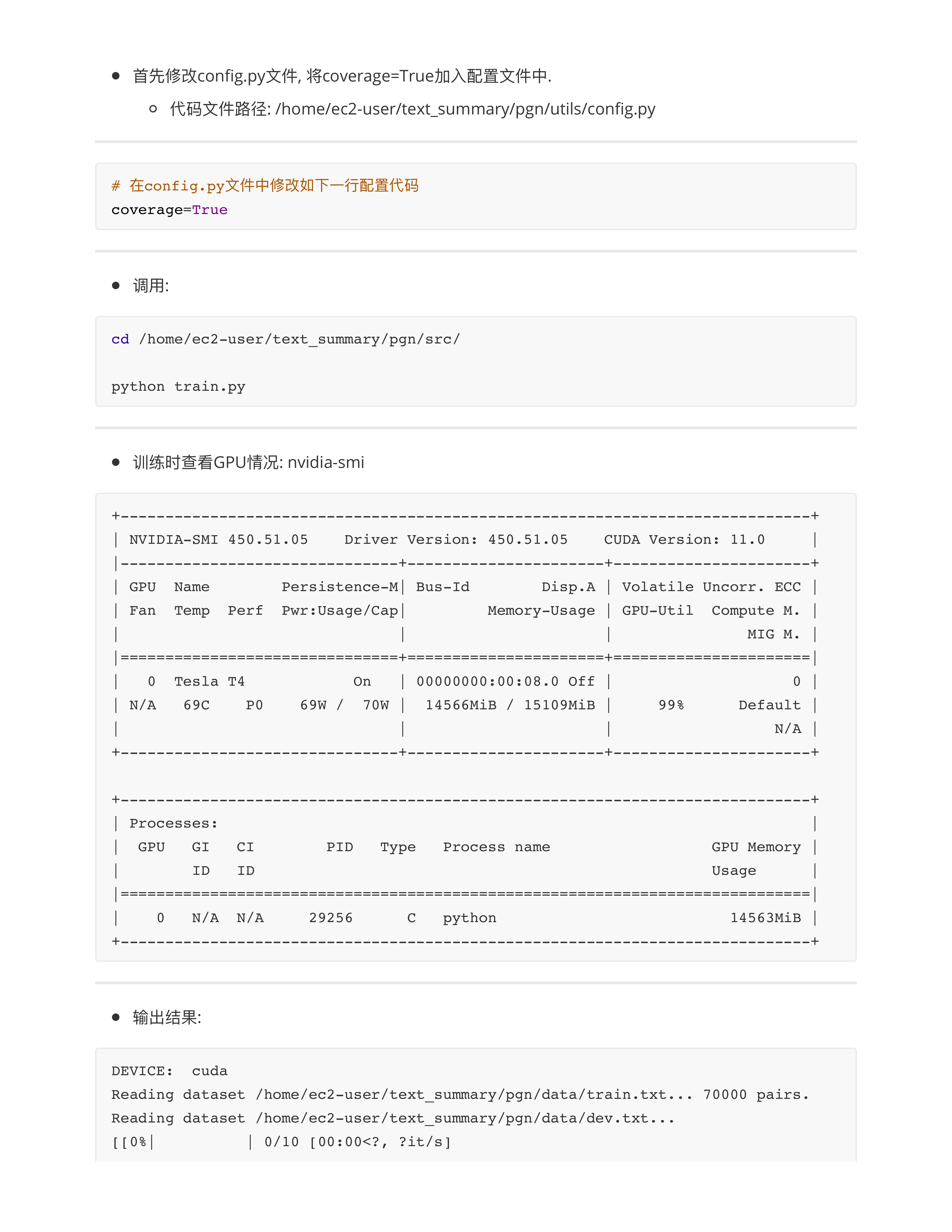






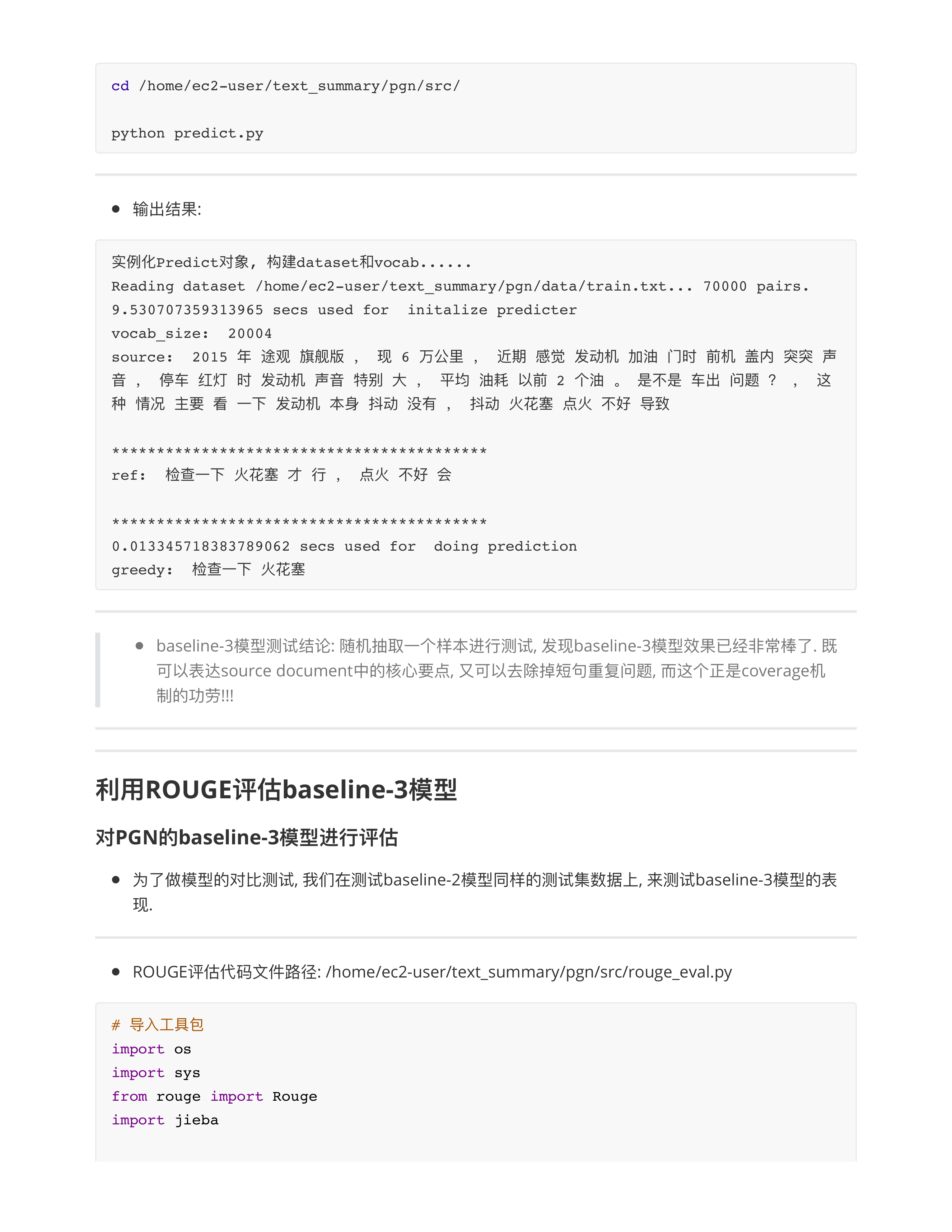





对baseline3模型的优化

















day29课堂问题
- 问题1: 那之前是小的, 当前时间步比较大, 按照这个逻辑, 取得是小的那个, 是不是就把当前注意力大的损失掉了? (azg)
- 注意力主要靠谁??? --- 公式11里面的前2项负责主干的注意力, 后面的第3项负责覆盖损失, 只是一个旁支!!!
- 问题2: 某一个单词懂了,但是一句话很多单词,每个单词都要算一下历史前后吗? (李辉)
- 因为a就是长度为seq_len的张量, 累加和c就是计算所有token的历史attention分布值的加和.
- 问题3: 关于PGN代码中的几个难点?
- 关于公式10 --- 代码class Attention --- 只进行了一次attention_weights + coverage_vector
- 原因: 公式中的累加和, 也就是for循环放在class PGN中, 等于在外层才有for循环进行累加和.
- PGN的代码只有Attention和PGN两个类的代码需要改变!!!
- 问题4: 老师, 那越往序列后面, 因为前面的注意力是累加的 (前面的注意力累加和会越来越大), 那到越后面的时间步的时候, 会不会出现该时间步的a总是比前面累加的小? (苹果)
- 会的✅
- 那取当前时间步的注意力分布张量a作为覆盖损失值loss_coverage.
- 核心: 经过100个时间步的迭代, 其实模型已经学会了尽量分散注意力, 不过度的聚焦在某几个字上, 所以不用担心后面的只取a
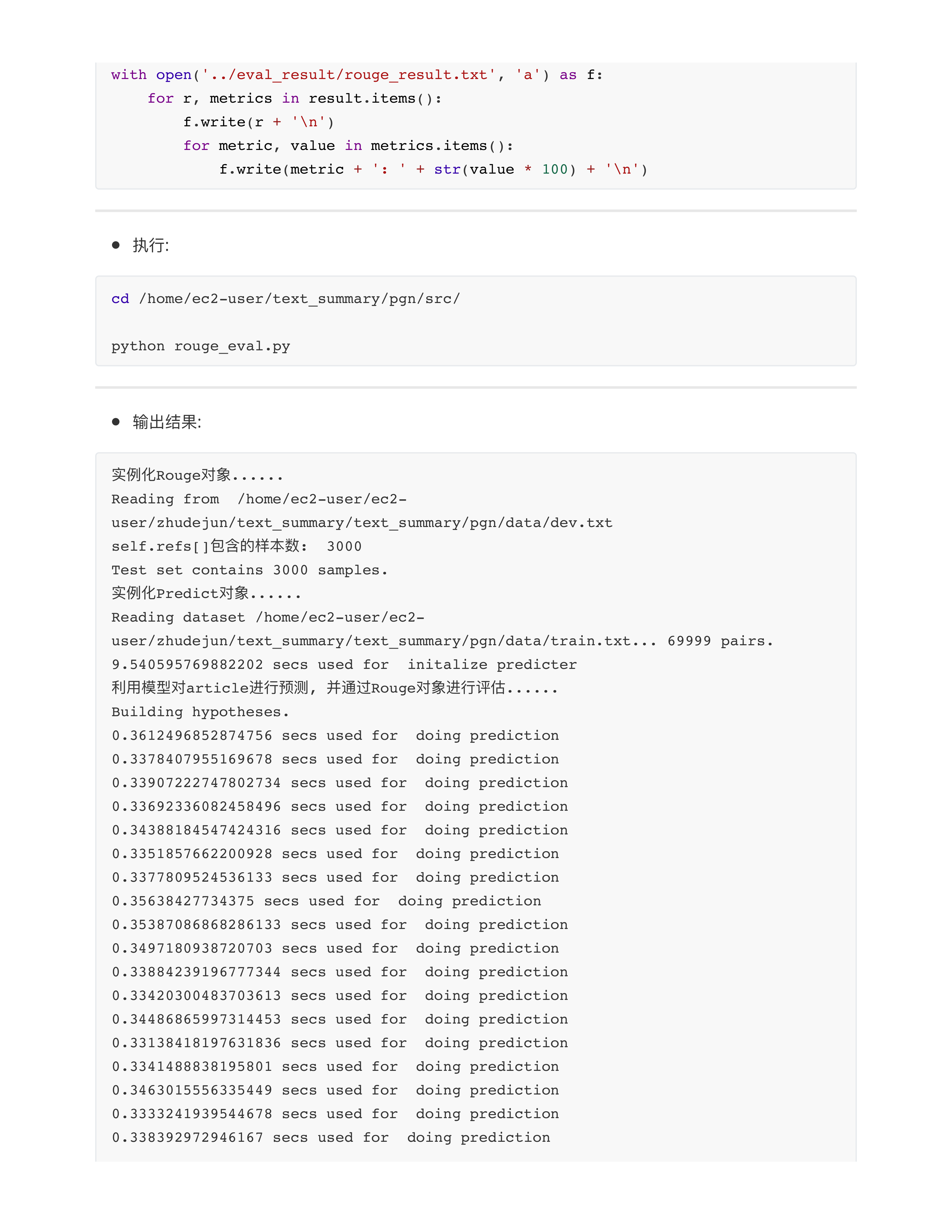
- 面试中问题: rouge指标大概多少算好?
- 因为咱们得训练数据太差了, 所以rouge-1 = 23.89, rouge-2 = 8.14 太低了!!!
- 正常的工业界能上线用的文本摘要, rouge-1: 60.0 ~ 90.0, rouge-2: 30.0 ~ 60.0
- 小朱老师提问: 这个项目让你大的升级, 你准备怎么办? (不用LLM)
- 🍊数据端的精细化处理:
- 1: 所有的[语音], 全部采用ASR进行文本化处理!!!
- 2: 图片, 也要处理, 利用image_to_text (看图说话) 进行二次处理.
- 3: < SEP >随时 联系 --- 这种样本都应该delete掉
- 数据端的处理有很多工作值得做!!!
- 大厂, 中小厂, AI独角兽
- AI四小龙 + AI六小虎
- 模型组(算法组) + 数据组 + 系统组 + 开发组 + 产品组 + 安全组 + 商业化组
- ✅第1个项目给同学们专门说过这件事
- 1: 公司数据 --- 大厂, 业务线
- 2: 甲方数据 --- 中小公司, 外包公司, 大厂给中石油做项目
- 3: 爬虫数据 + 采买数据 --- AI很主流, 占比最大的一个方式
- ⭕️同学们一定要遵守的原则: 简历中可以不写 (不建议写), 但是面试前一定要想好怎么说, 想好了就咬死!!!
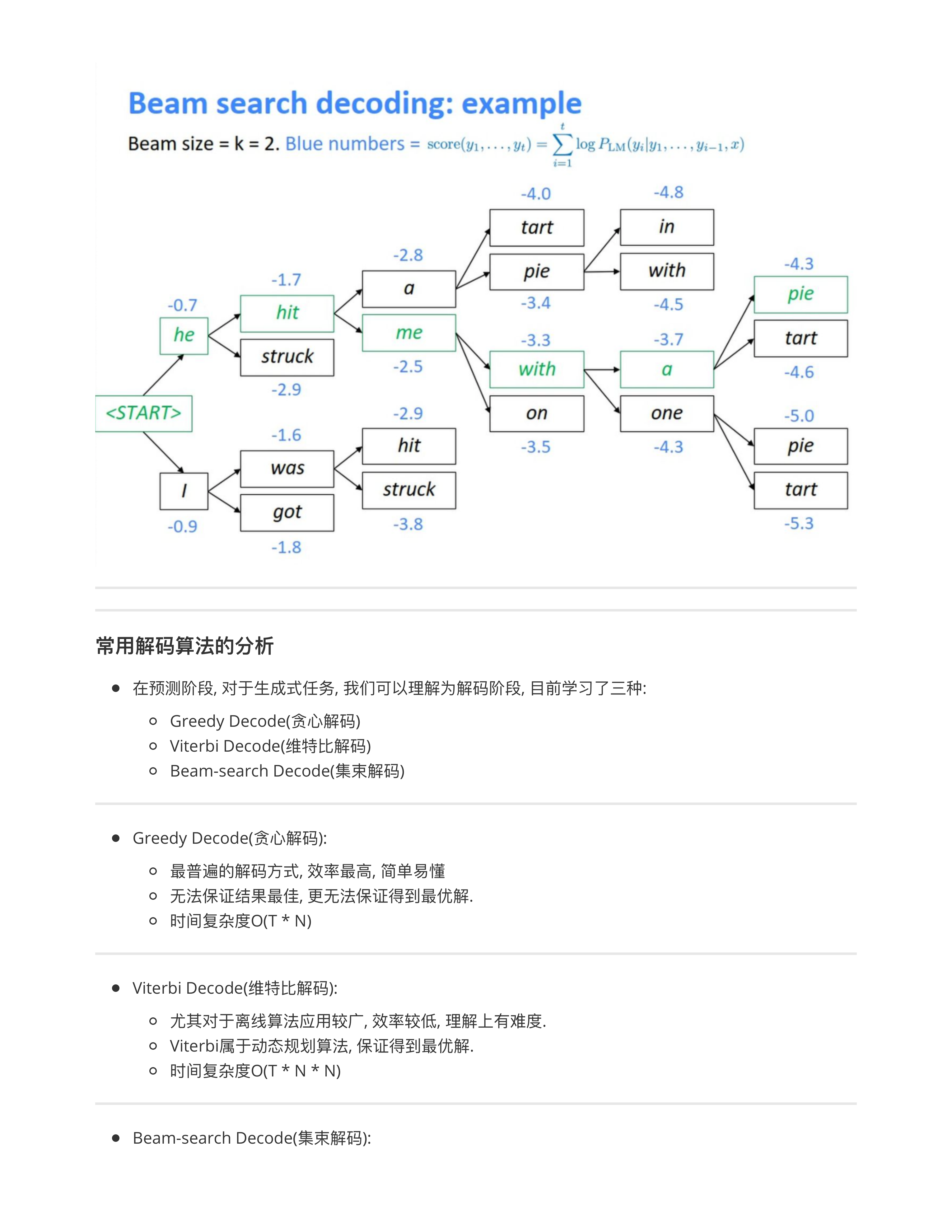
- 小作业: 回去查维特比解码的算法!!!
- 后面第三个项目知识图谱中的模型会用到viterbi decode --- 时间复杂度很高 O(T * N * N), 但是保证找到最优解!!!
day30
从数据度优化模型


























day30课堂问题
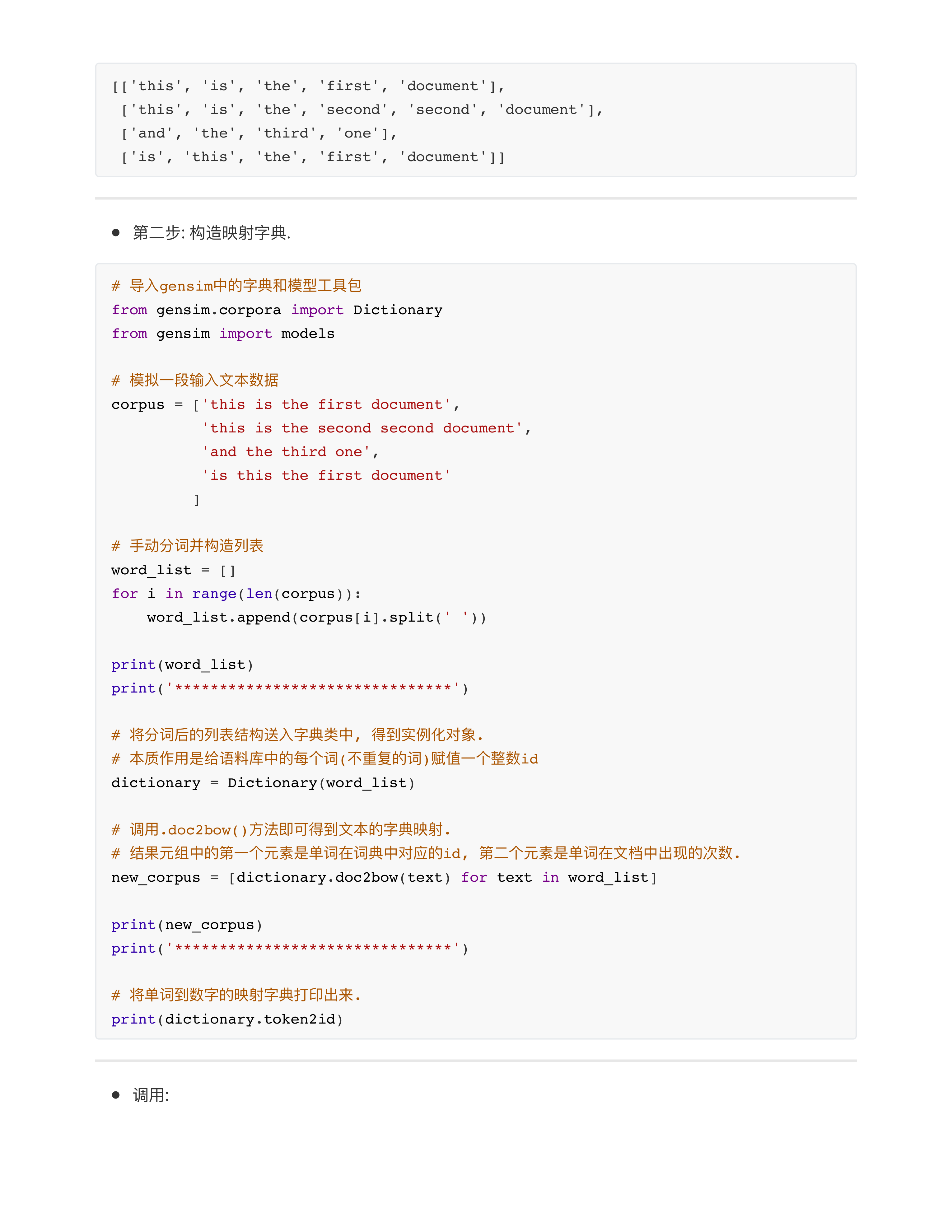
- 问题1: 关于gensim工具包的一些细节?
- 1: gensim有自动去除停用词的功能, 比如the
- 2: gensim会自动去除单个字母, 比如i
- 3: gensim会去除没有在训练集中的词, 比如name
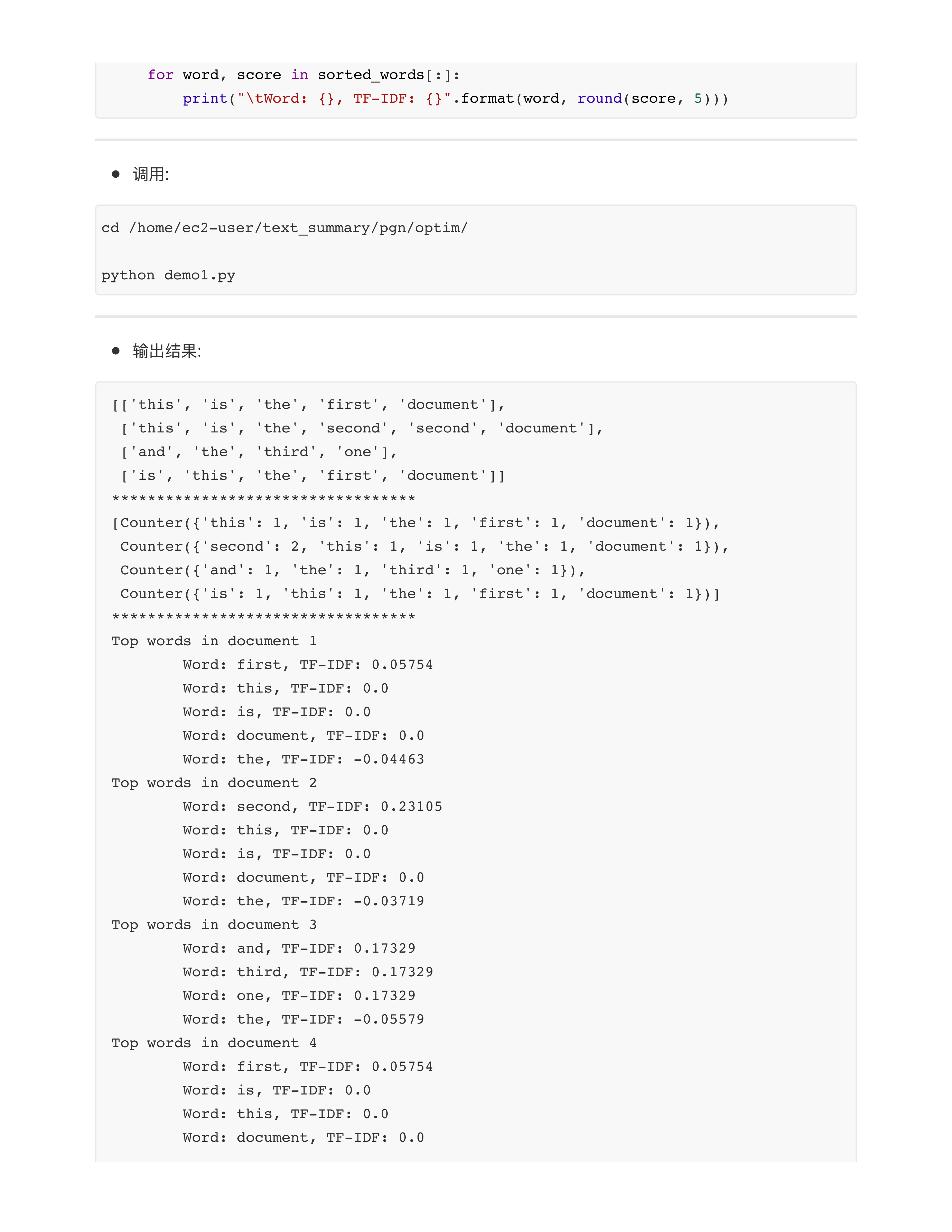
- 问题2: 关于TF-IDF模型的训练?
- 本质上TF-IDF模型是一个计数模型, 核心操作是数数!!!
- 没有反向传播, 没有梯度计算, 没有所谓的参数更新!!!
- 这种计数模型训练起来超级快!!!
- 70000行文本训练集 --- 大概训练5秒钟!!!
- 问题3: 关于单词替换法的步骤?
- 1: 首先需要训练好一个Word2Vec的模型.
- 2: 其次需要训练好一个TF-IDF的模型.
- 3: 按照一定规则进行替换即可.
- 3.1: token必须是中文词.
- 3.2: token不能是TF-IDF关键词.
- 3.3: token必须在Word2Vec字典中.
- 4: 单词替换法的目的是为了丰富样本的表达 + 扩充训练集.
- 问题4: 关于6.3小节数据优化的目的是什么?
- 1: 第一个目的是为了扩充数据集. (主要)
- CV: 只有6000张图片, 不足以训练大模型 (或者一个优秀的模型)
- NLP: 第一个项目中有18万条训练数据, 如果在你的某一次项目中只有3000条数据, 不足以训练模型.
- 单词替换法
- 回译数据法
- 半监督学习法
- 大模型生成法 (2023 - 2024)
- 注意📢: 数据优化的扩充是不是可以任意扩充?
- 一般来说, 数据的扩充不会超过原始数据的10倍以上 (一般在5倍以内, 最好1:1扩充)
- 2: 第二个目的才是为了优化数据. (次要)
- 问题5: 关于回译数据法?
- ⭕️数据增强都是离线任务 --- 不怕慢, 慢慢跑!!!
- 真正难点: 在线任务 --- 要求响应速度 (RT, QPS)
- 🍊建议跑通代码就行了, 你选取100条训练集的样本, 练练手就行了.
- 千万别把全量70000个样本全部翻译了, 充值的钱就花光啦!!!
- ⭕️关键点: 回译数据法工业界普遍做法, 针对小语种进行翻译!!! 而且可以多跳翻译!!!
- 中文 --- 韩文 --- 俄语 --- 中文
- 一般来说最多3跳!!!
- ✅小作业: 留给同学们完成3跳翻译 --- 有2个中间语言.
- pip install openai
- openai 1.45.0
day31
训练策略优化模型






























硬件优化与模型部署




















文本摘要项总结


day31课堂问题
- 问题1: 关于曝光偏差问题有哪些情况?
- 本质: 模型训练的时候 != 模型预测的时候
- 1: Dropout --- 这个机制训练阶段有, 预测阶段没有......
- 2: BERT的预训练任务MLM --- [MASK]机制在训练阶段有, 预测阶段没有......
- 3: Teacher forcing --- 训练阶段有标签🏷label, 预测阶段没有......
- 关于Scheduled sampling的使用尽量采用粗粒度, 也就是按照epochs进行划分!!!
- 问题2: 模型的训练中还存在一种不一致现象是什么?
- Encoder: self.embedding = nn.Embedding(vocab_size, embed_size)
- Decoder: self.embedding = nn.Embedding(vocab_size, embed_size)
- 小朱老师👩🏻🏫的问题: 这两个词嵌入模块是不是一回事???
- 不是❌!!!
- 两个embedding模块没理由一模一样, 他们是两个模块.
- 解决方法:
- 1: embedding.from_pretrain(word2vector)可以解决吧 (李辉) --- 本质上是调用预训练模型.
- 2: nn.Embedding()只写一遍, 另一个模块去复用它即可!!!
- if config.weight_tying:
- embedded = decoder_embedding(x)
- 问题3: 理论上来说为什么encoding和decoding的矩阵内容不一样会对模型造成损害? 你的意思是两个一模一样矩阵过两次会对loss变得更小对么? (纯木)
- 跟后半句没有关系......
- 项目中处理的都是中文, 不是在进行机器翻译......
- "你好", 进Encoder得到的embedding vector != 进Decoder得到的embedding vector
- 问题4: 关于利用GPU和CPU的性能差异?
- 分类任务:
- 文本摘要任务:
- GPU和CPU在训练时差距 10 ~ 1000倍
- GPU和CPU在推理时差距 3 ~ 10倍
- 作业:
- 1: 第二个项目里面的每一章节代码跑通, 已经在homework08提交过的部分不用再次提交了.
- 2: 主要针对5,6,7章节的内容, 截图提交.
- 3: 截止时间 2024.10.23 18:00, homework09
posted @
2025-07-28 09:07
凫弥
阅读(
434)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号