一期3.信息自动投递项目
第一章:项目背景与分析
1.1 项目背景介绍
信息自动投递项目背景介绍¶
学习目标¶
- 理解项目的开发背景.
- 熟悉相关数据的格式和样例.
投满分项目背景¶
- 对于字节跳动这家公司来说, 虽然产品线众多但是抖音, 今日头条是最大的两个王牌. 分别代表了基于短视频的推荐, 和基于短文本的推荐. 背后融合了众多CV, NLP, 推荐系统, 大数据等知识, 可以说是人工智能时代的集大成者.
- 针对于今日头条来说, 用户在众多新闻, 资讯中, 一定有更感兴趣的类别. 比如男生的历史, 军事, 足球等, 女生的财经, 八卦, 美妆等. 如果能将用户更感兴趣的类别新闻主动筛选出来, 并进行推荐阅读, 那么点击量, 订阅量, 付费量都会有明显增长.
- 基于上述原因, 字节内部今日头条的推荐系统中, 就需要内嵌一个子任务: 将短文本自动进行多分类, 然后像快递一样的"投递"到对应的"频道"中, 因此本项目应运而生.
项目数据概览¶
-
项目中的数据来源基本分为3大种类: - 第一类: 公司内部数据部门提供. - 情况1: 数据平台有预处理, 提供的是"成品数据".
-
情况2: 数据平台没有预处理, 只告诉开发人员"数据路径".
-
情况3: 原始数据就没有, 需要开发人员沟通不同部分, 获取"业务数据".
-
第二类: 甲方提需求, 并提供数据. - 情况1: 甲方有预处理数据, 提供的基本是"半成品数据".
- 情况2: 甲方只负责"埋点", 后续数据需要开发人员处理.
- 情况3: 甲方数据"匮乏", 甚至数据"缺失".
-
第三类: 需求画大饼阶段, 没有数据, 没有GPU, 只有"蓝图"和"展望".
-
-
本项目中的数据已经由字节预处理并完成了标注信息. 属于第一类中的情况1.
- 数据路径: /home/ec2-user/toutiao/data/data/
-
data文件夹内容展示:
-rw-r--r-- 1 ec2-user ec2-user 82 class.txt
-rw-r--r-- 1 ec2-user ec2-user 551313 dev.txt
-rw-r--r-- 1 ec2-user ec2-user 551596 test.txt
-rw-r--r-- 1 ec2-user ec2-user 9946122 train.txt
- 训练集数据: /home/ec2-user/toutiao/data/data/train.txt, 共180000条.
中华女子学院:本科层次仅1专业招男生 3
两天价网站背后重重迷雾:做个网站究竟要多少钱 4
东5环海棠公社230-290平2居准现房98折优惠 1
卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7
82岁老太为学生做饭扫地44年获授港大荣誉院士 5
记者回访地震中可乐男孩:将受邀赴美国参观 5
冯德伦徐若�隔空传情 默认其是女友 9
传郭晶晶欲落户香港战伦敦奥运 装修别墅当婚房 1
《赤壁OL》攻城战诸侯战硝烟又起 8
“手机钱包”亮相科博会 4
上海2010上半年四六级考试报名4月8日前完成 3
李永波称李宗伟难阻林丹取胜 透露谢杏芳有望出战 7
3岁女童下体红肿 自称被幼儿园老师用尺子捅伤 5
金证顾问:过山车行情意味着什么 2
谁料地王如此虚 1
《光环5》Logo泄露 Kinect版几无悬念 8
海淀区领秀新硅谷宽景大宅预计10月底开盘 1
柴志坤:土地供应量不断从紧 地价难现07水平(图) 1
伊达传说EDDA Online 8
三联书店建起书香巷 4
宇航员尿液堵塞国际空间站水循环系统 4
研究发现开车技术差或与基因相关 6
皇马输球替补席闹丑闻 队副女球迷公然调情(视频) 7
北京建工与市政府再度合作推出郭庄子限价房 1
组图:李欣汝素颜出镜拍低碳环保大片 9
- 测试集数据: /home/ec2-user/toutiao/data/data/test.txt, 共10000条.
词汇阅读是关键 08年考研暑期英语复习全指南 3
中国人民公安大学2012年硕士研究生目录及书目 3
日本地震:金吉列关注在日学子系列报道 3
名师辅导:2012考研英语虚拟语气三种用法 3
自考经验谈:自考生毕业论文选题技巧 3
本科未录取还有这些路可以走 3
2009年成人高考招生统一考试时间表 3
去新西兰体验舌尖上的饕餮之旅(组图) 3
四级阅读与考研阅读比较分析与应试策略 3
备考2012高考作文必读美文50篇(一) 3
名师详解考研复试英语听力备考策略 3
热议:艺考合格证是高考升学王牌吗(组图) 3
研究生办替考网站续:幕后老板年赚近百万(图) 3
2011年高考文科综合试题(重庆卷) 3
56所高校预估2009年湖北录取分数线出炉 3
公共英语(PETS)写作中常见的逻辑词汇汇总 3
时评:高考应成为教育公平的“助推器” 3
九成外国人愿继续在日生活 六成留学生未返校 3
教育部回应“取消高考户籍限制” 3
2008年甘肃省高招不同于往年悬念叠出(图) 3
送考队伍成海 高考场外那些煎熬的心 3
09年小语种报考完全指南:仍须以高考为重(图) 3
四六级考前阅读冲刺:如何发挥正常水平 3
北京市海淀区09年高考第二次模拟考试题 3
倪震:我国首位参加GRE考试的盲人大学生 3
- 验证集数据: /home/ec2-user/toutiao/data/data/dev.txt, 共10000条.
体验2D巅峰 倚天屠龙记十大创新概览 8
60年铁树开花形状似玉米芯(组图) 5
同步A股首秀:港股缩量回调 2
中青宝sg现场抓拍 兔子舞热辣表演 8
锌价难续去年辉煌 0
2岁男童爬窗台不慎7楼坠下获救(图) 5
布拉特:放球员一条生路吧 FIFA能消化俱乐部的攻击 7
金科西府 名墅天成 1
状元心经:考前一周重点是回顾和整理 3
发改委治理涉企收费每年为企业减负超百亿 6
一年网事扫荡10年纷扰开心网李鬼之争和平落幕 4
2010英国新政府“三把火”或影响留学业 3
俄达吉斯坦共和国一名区长被枪杀 6
朝鲜要求日本对过去罪行道歉和赔偿 6
《口袋妖怪 黑白》日本首周贩售255万 8
图文:借贷成本上涨致俄罗斯铝业净利下滑21% 2
组图:新《三国》再曝海量剧照 火战场面极震撼 9
麻辣点评:如何走出“被留学”的尴尬 3
美股评论:SUN的苦涩曙光 2
拾荒男子捡到任命书假冒老总 连骗二十多位女子 5
英国夫妇再育“黑白”双胞胎 4
从跟班到战友 灵兽伴你畅游传奇世界 8
你有随身听 我有随身看:掌上故事会 8
一封1968年的平信45.92万元成交 0
女主人成功说服杀人躲避者自首 5
- 类别集合数据: /home/ec2-user/toutiao/data/data/class.txt, 共10条.
finance
realty
stocks
education
science
society
politics
sports
game
entertainment
小节总结¶
- 本小节介绍了投满分项目的背景, 是属于整个今日头条项目中的一个功能子集, 完成新闻, 咨询等短文本的多分类, 将各个子类的资料推送到对应的推荐流中.
- 对项目数据进行了介绍, 本项目拿到手的已经是数据平台部门处理好的"优质数据", 我们只需要将全部精力放在功能实现, 模型优化上即可.
1.2 baseline解决方案实现
随机森林的快速基线模型1.0¶
学习目标¶
- 掌握对数据进行快速分析的代码实现.
- 掌握利用随机森林快速实现并评估基线模型.
数据分析¶
-
数据分析代码位置: /home/ec2-user/toutiao/baseline/random_forest/analysis.py
- 第一步: 读数据并统计分类数量
- 第二步: 分析样本分布
- 第三步: 进行分词预处理
- 第四步: 处理验证集和测试集数据
-
第一步: 读数据并统计分类数量
import pandas as pd
from collections import Counter
import numpy as np
import jieba
content = pd.read_csv('./data/data/train.txt', sep='\t')
print(content.head(10))
print(len(content))
count = Counter(content.label.values)
print(count)
print(len(count))
print('***************************************')
- 调用:
python analysis.py
- 输出结果:
sentence label
0 中华女子学院:本科层次仅1专业招男生 3
1 两天价网站背后重重迷雾:做个网站究竟要多少钱 4
2 东5环海棠公社230-290平2居准现房98折优惠 1
3 卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7
4 82岁老太为学生做饭扫地44年获授港大荣誉院士 5
5 记者回访地震中可乐男孩:将受邀赴美国参观 5
6 冯德伦徐若�隔空传情 默认其是女友 9
7 传郭晶晶欲落户香港战伦敦奥运 装修别墅当婚房 1
8 《赤壁OL》攻城战诸侯战硝烟又起 8
9 “手机钱包”亮相科博会 4
180000
Counter({3: 18000, 4: 18000, 1: 18000, 7: 18000, 5: 18000, 9: 18000, 8: 18000, 2: 18000, 6: 18000, 0: 18000})
10
***************************************
- 第二步: 分析样本分布
total = 0
for i, v in count.items():
total += v
print(total)
for i, v in count.items():
print(i, v / total * 100, '%')
print('***************************************')
content['sentence_len'] = content['sentence'].apply(len)
print(content.head(10))
length_mean = np.mean(content['sentence_len'])
length_std = np.std(content['sentence_len'])
print('length_mean = ', length_mean)
print('length_std = ', length_std)
- 输出结果:
180000
3 10.0 %
4 10.0 %
1 10.0 %
7 10.0 %
5 10.0 %
9 10.0 %
8 10.0 %
2 10.0 %
6 10.0 %
0 10.0 %
***************************************
sentence label sentence_len
0 中华女子学院:本科层次仅1专业招男生 3 18
1 两天价网站背后重重迷雾:做个网站究竟要多少钱 4 22
2 东5环海棠公社230-290平2居准现房98折优惠 1 25
3 卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7 25
4 82岁老太为学生做饭扫地44年获授港大荣誉院士 5 23
5 记者回访地震中可乐男孩:将受邀赴美国参观 5 20
6 冯德伦徐若�隔空传情 默认其是女友 9 17
7 传郭晶晶欲落户香港战伦敦奥运 装修别墅当婚房 1 22
8 《赤壁OL》攻城战诸侯战硝烟又起 8 16
9 “手机钱包”亮相科博会 4 11
length_mean = 19.21257222222222
length_std = 3.863787253359747
- 第三步: 进行分词预处理.
def cut_sentence(s):
return list(jieba.cut(s))
content['words'] = content['sentence'].apply(cut_sentence)
print(content.head(10))
content['words'] = content['sentence'].apply(lambda s: ' '.join(cut_sentence(s)))
content['words'] = content['words'].apply(lambda s: ' '.join(s.split())[:30])
content.to_csv('./data/data/train_new.csv')
- 输出结果:
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.908 seconds.
Prefix dict has been built successfully.
sentence label sentence_len words
0 中华女子学院:本科层次仅1专业招男生 3 18 [中华, 女子, 学院, :, 本科, 层次, 仅, 1, 专业, 招, 男生]
1 两天价网站背后重重迷雾:做个网站究竟要多少钱 4 22 [两天, 价, 网站, 背后, 重重, 迷雾, :, 做个, 网站, 究竟, 要, 多少, 钱]
2 东5环海棠公社230-290平2居准现房98折优惠 1 25 [东, 5, 环, 海棠, 公社, 230, -, 290, 平, 2, 居, 准现房, 9...
3 卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7 25 [卡佩罗, :, 告诉, 你, 德国, 脚, 生猛, 的, 原因, , 不, 希望, 英德...
4 82岁老太为学生做饭扫地44年获授港大荣誉院士 5 23 [82, 岁, 老太, 为, 学生, 做饭, 扫地, 44, 年, 获授, 港大, 荣誉, 院士]
5 记者回访地震中可乐男孩:将受邀赴美国参观 5 20 [记者, 回访, 地震, 中, 可乐, 男孩, :, 将, 受邀, 赴美国, 参观]
6 冯德伦徐若�隔空传情 默认其是女友 9 17 [冯德伦, 徐若, �, 隔空, 传情, , 默认, 其是, 女友]
7 传郭晶晶欲落户香港战伦敦奥运 装修别墅当婚房 1 22 [传, 郭晶晶, 欲, 落户, 香港, 战, 伦敦, 奥运, , 装修, 别墅, 当婚, 房]
8 《赤壁OL》攻城战诸侯战硝烟又起 8 16 [《, 赤壁, OL, 》, 攻城战, 诸侯, 战, 硝烟, 又, 起]
9 “手机钱包”亮相科博会 4 11 [“, 手机, 钱包, ”, 亮相, 科博会]
- 第四步: 依次同样的代码处理验证集dev.txt, 测试集test.txt, 同一个文件夹下生成dev_new.csv, test_new.csv文件.
随机森林模型¶
- 编写代码实现随机森林的模型训练.
- 代码位置: /home/ec2-user/toutiao/baseline/random_forest/random_forest_baseline1.py
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
from icecream import ic
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import f1_score
TRAIN_CORPUS = './data/data/train_new.csv'
STOP_WORDS = './data/data/stopwords.txt'
WORDS_COLUMN = 'words'
content = pd.read_csv(TRAIN_CORPUS)
corpus = content[WORDS_COLUMN].values
stop_words_size = 749
WORDS_LONG_TAIL_BEGIN = 10000
WORDS_SIZE = WORDS_LONG_TAIL_BEGIN - stop_words_size
stop_words = open(STOP_WORDS).read().split()[:stop_words_size]
tfidf = TfidfVectorizer(max_features=WORDS_SIZE, stop_words=stop_words)
text_vectors = tfidf.fit_transform(corpus)
print(text_vectors.shape)
targets = content['label']
x_train, x_test, y_train, y_test = train_test_split(text_vectors, targets, test_size=0.2, random_state=0)
print('数据分割完毕, 开始模型训练...')
model = RandomForestClassifier()
model.fit(x_train, y_train)
print('模型训练结束, 开始预测...')
accuracy = accuracy_score(model.predict(x_test), y_test)
ic(accuracy)
- 调用:
python random_forest_baseline1.py
- 输出结果:
(180000, 9251)
数据分割完毕, 开始模型训练...
模型训练结束, 开始预测...
ic| accuracy: 0.7989444444444445
- 结论: 随机森林构建模型简单, 训练快, 最终79.89%的准确率(可以视作80%)对于10分类任务来说也是不错的模型. 重要的是我们快速拥有了一个准确率达到80%的基线模型1.0
FastText的快速基线模型2.0¶
数据准备¶
-
首先明确fasttext所要求的数据格式:
- 文本: 正常的连续字符串即可.
- 标签: 采用__label__name的格式.
-
代码位置: /home/ec2-user/toutiao/baseline/fast_text/data/data/preprocess.py
import os
import sys
import jieba
id_to_label = {}
idx = 0
with open('class.txt', 'r', encoding='utf-8') as f1:
for line in f1.readlines():
line = line.strip('\n').strip()
id_to_label[idx] = line
idx += 1
print('id_to_label:', id_to_label)
count = 0
train_data = []
with open('train.txt', 'r', encoding='utf-8') as f2:
for line in f2.readlines():
line = line.strip('\n').strip()
sentence, label = line.split('\t')
# 1: 首先处理标签部分
label_id = int(label)
label_name = id_to_label[label_id]
new_label = '__label__' + label_name
# 2: 然后处理文本部分, 为了便于后续增加n-gram特性, 可以按字划分, 也可以按词划分
sent_char = ' '.join(list(sentence))
# 3: 将文本和标签组合成fasttext规定的格式
new_sentence = new_label + ' ' + sent_char
train_data.append(new_sentence)
count += 1
if count % 10000 == 0:
print('count=', count)
with open('train_fast.txt', 'w', encoding='utf-8') as f3:
for data in train_data:
f3.write(data + '\n')
print('FastText训练数据预处理完毕!')
- 调用:
python preprocess.py
- 输出结果: 查看train_fast.txt文件如下
__label__education 中 华 女 子 学 院 : 本 科 层 次 仅 1 专 业 招 男 生
__label__science 两 天 价 网 站 背 后 重 重 迷 雾 : 做 个 网 站 究 竟 要 多 少 钱
__label__realty 东 5 环 海 棠 公 社 2 3 0 - 2 9 0 平 2 居 准 现 房 9 8 折 优 惠
__label__sports 卡 佩 罗 : 告 诉 你 德 国 脚 生 猛 的 原 因 不 希 望 英 德 战 踢 点 球
__label__society 8 2 岁 老 太 为 学 生 做 饭 扫 地 4 4 年 获 授 港 大 荣 誉 院 士
__label__society 记 者 回 访 地 震 中 可 乐 男 孩 : 将 受 邀 赴 美 国 参 观
__label__entertainment 冯 德 伦 徐 若 � 隔 空 传 情 默 认 其 是 女 友
__label__realty 传 郭 晶 晶 欲 落 户 香 港 战 伦 敦 奥 运 装 修 别 墅 当 婚 房
__label__game 《 赤 壁 O L 》 攻 城 战 诸 侯 战 硝 烟 又 起
__label__science “ 手 机 钱 包 ” 亮 相 科 博 会
__label__education 上 海 2 0 1 0 上 半 年 四 六 级 考 试 报 名 4 月 8 日 前 完 成
__label__sports 李 永 波 称 李 宗 伟 难 阻 林 丹 取 胜 透 露 谢 杏 芳 有 望 出 战
__label__society 3 岁 女 童 下 体 红 肿 自 称 被 幼 儿 园 老 师 用 尺 子 捅 伤
__label__stocks 金 证 顾 问 : 过 山 车 行 情 意 味 着 什 么
__label__realty 谁 料 地 王 如 此 虚
__label__game 《 光 环 5 》 L o g o 泄 露 K i n e c t 版 几 无 悬 念
__label__realty 海 淀 区 领 秀 新 硅 谷 宽 景 大 宅 预 计 1 0 月 底 开 盘
__label__realty 柴 志 坤 : 土 地 供 应 量 不 断 从 紧 地 价 难 现 0 7 水 平 ( 图 )
__label__game 伊 达 传 说 E D D A O n l i n e
__label__science 三 联 书 店 建 起 书 香 巷
__label__science 宇 航 员 尿 液 堵 塞 国 际 空 间 站 水 循 环 系 统
__label__politics 研 究 发 现 开 车 技 术 差 或 与 基 因 相 关
__label__sports 皇 马 输 球 替 补 席 闹 丑 闻 队 副 女 球 迷 公 然 调 情 ( 视 频 )
__label__realty 北 京 建 工 与 市 政 府 再 度 合 作 推 出 郭 庄 子 限 价 房
__label__entertainment 组 图 : 李 欣 汝 素 颜 出 镜 拍 低 碳 环 保 大 片
- 同上处理测试集数据, 得到test_fast.txt; 同上处理验证集的数据, 得到dev_fast.txt
模型搭建¶
- 代码位置: /home/ec2-user/toutiao/baseline/fast_text/fast_text_baseline2.py
import fasttext
train_data_path = './data/data/train_fast.txt'
test_data_path = './data/data/test_fast.txt'
# 开启模型训练
model = fasttext.train_supervised(input=train_data_path, wordNgrams=2)
# 开启模型测试
result = model.test(test_data_path)
print(result)
- 调用:
python fast_text_baseline2.py
- 输出结果:
Read 3M words
Number of words: 4760
Number of labels: 10
Progress: 100.0% words/sec/thread: 1267929 lr: 0.000000 avg.loss: 0.279528 ETA: 0h 0m 0s
(10000, 0.9162, 0.9162)
- 结论: 在10000条测试集上, 我们的模型得到了0.9162的精确率, 0.9162的召回率. 相比较随机森林已经有了大幅度的提升.
模型优化¶
- 对于任意表现良好的模型, 优化的脚步都不能停止!
优化fasttest第一版¶
- 在真实的生产环境下, 对于fasttext模型一般不会采用费时费力的人工调参, 而都是用自动化最优参数搜索的模式. - 代码位置: /home/ec2-user/toutiao/baseline/fast_text/fast_text_baseline2.py
import fasttext
import time
train_data_path = './data/data/train_fast.txt'
dev_data_path = './data/data/dev_fast.txt'
test_data_path = './data/data/test_fast.txt'
# autotuneValidationFile参数需要指定验证数据集所在路径,
# 它将在验证集上使用随机搜索方法寻找可能最优的超参数.
# 使用autotuneDuration参数可以控制随机搜索的时间, 默认是300s,
# 根据不同的需求, 我们可以延长或缩短时间.
# verbose: 该参数决定日志打印级别, 当设置为3, 可以将当前正在尝试的超参数打印出来.
model = fasttext.train_supervised(input=train_data_path,
autotuneValidationFile=dev_data_path,
autotuneDuration=600,
wordNgrams=2,
verbose=3)
# 在测试集上评估模型的表现
result = model.test(test_data_path)
print(result)
# 模型保存
time1 = int(time.time())
model_save_path = "./toutiao_fasttext_{}.bin".format(time1)
model.save_model(model_save_path)
- 调用:
python fast_text_baseline2.py
- 输出结果:
Trial = 1
epoch = 5
lr = 0.1
dim = 100
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 2000000
dsub = 2
loss = softmax
Progress: 0.5% Trials: 1 Best score: unknown ETA: 0h 9m56scurrentScore = 0.9119
train took = 3.20856
Trial = 2
epoch = 2
lr = 0.169298
dim = 105
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 10000000
dsub = 16
loss = softmax
Progress: 1.4% Trials: 2 Best score: 0.911900 ETA: 0h 9m51scurrentScore = 0.906
train took = 5.66037
Trial = 3
epoch = 1
lr = 0.463758
dim = 52
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 1036295
dsub = 2
loss = softmax
Progress: 1.6% Trials: 3 Best score: 0.911900 ETA: 0h 9m50scurrentScore = 0.9053
......
......
......
train took = 102.365
Trial = 18
epoch = 29
lr = 0.100404
dim = 318
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 2932604
dsub = 16
loss = softmax
Progress: 94.0% Trials: 18 Best score: 0.913600 ETA: 0h 0m36scurrentScore = 0.9123
train took = 29.9363
Trial = 19
epoch = 61
lr = 0.230535
dim = 364
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 3220875
dsub = 8
loss = softmax
Progress: 100.0% Trials: 19 Best score: 0.913600 ETA: 0h 0m 0s
Training again with best arguments
Best selected args = 0
epoch = 100
lr = 0.173311
dim = 355
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 5091406
dsub = 16
loss = softmax
Read 3M words
Number of words: 4760
Number of labels: 10
Progress: 100.0% words/sec/thread: 571851 lr: 0.000000 avg.loss: 0.016739 ETA: 0h 0m 0s
(10000, 0.9173, 0.9173)
- 查看模型:
# 命令行直接ll可以查看保存后的模型详情
# 可以看到保存后的模型大小为4.95GB
# 说明fasttext虽然效果好, 速度快, 但是占用很大存储空间, 比BERT大得多!
-rw-rw-r-- 1 ec2-user ec2-user 4949204992 1月 9 02:25 toutiao_fasttext_1640744707.bin
- 结论: 经过参数的自动搜索, 得到了最好的一版模型, 主要参数包括词嵌入维度dim=355, wordNgrams=2等. 模型的最终表现精准率等于91.73%, 召回率也是91.73%, 相比较最初的91.62%有稍许提升但并不显著.
优化fasttext第二版¶
-
模型的优化不仅仅在架构上, 更要注意回溯到源头, 也就是数据端的优化.
- 第一步: 原始数据采用词向量级别.
- 第二步: 重新训练模型并评估.
-
第一步: 原始数据采用词向量级别.
- 代码位置: /home/ec2-user/toutiao/baseline/fast_text/data/data/preprocess1.py
import os
import sys
import jieba
id_to_label = {}
idx = 0
with open('class.txt', 'r', encoding='utf-8') as f1:
for line in f1.readlines():
line = line.strip('\n').strip()
id_to_label[idx] = line
idx += 1
# print('id_to_label:', id_to_label)
count = 0
train_data = []
with open('train.txt', 'r', encoding='utf-8') as f2:
for line in f2.readlines():
line = line.strip('\n').strip()
sentence, label = line.split('\t')
# 1: 首先处理标签部分
label_id = int(label)
label_name = id_to_label[label_id]
new_label = '__label__' + label_name
# 2: 然后处理文本部分, 区别于之前的按字划分, 此处按词划分文本
sent_char = ' '.join(jieba.lcut(sentence))
# 3: 将文本和标签组合成fasttext规定的格式
new_sentence = new_label + '\t' + sent_char
train_data.append(new_sentence)
count += 1
if count % 10000 == 0:
print('count=', count)
with open('train_fast1.txt', 'w', encoding='utf-8') as f3:
for data in train_data:
f3.write(data + '\n')
print('FastText训练数据预处理完毕!')
- 调用:
python preprocess1.py
- 输出结果(查看train_fast1.txt文件):
__label__education 中华 女子 学院 : 本科 层次 仅 1 专业 招 男生
__label__science 两天 价 网站 背后 重重 迷雾 : 做个 网站 究竟 要 多少 钱
__label__realty 东 5 环 海棠 公社 230 - 290 平 2 居 准现房 98 折 优惠
__label__sports 卡佩罗 : 告诉 你 德国 脚 生猛 的 原因 不 希望 英德 战 踢 点球
__label__society 82 岁 老太 为 学生 做饭 扫地 44 年 获授 港大 荣誉 院士
__label__society 记者 回访 地震 中 可乐 男孩 : 将 受邀 赴美国 参观
__label__entertainment 冯德伦 徐若 � 隔空 传情 默认 其是 女友
__label__realty 传 郭晶晶 欲 落户 香港 战 伦敦 奥运 装修 别墅 当婚 房
__label__game 《 赤壁 OL 》 攻城战 诸侯 战 硝烟 又 起
__label__science “ 手机 钱包 ” 亮相 科博会
__label__education 上海 2010 上半年 四六级 考试 报名 4 月 8 日前 完成
__label__sports 李永波 称 李宗伟 难 阻林丹 取胜 透露 谢杏芳 有望 出战
__label__society 3 岁 女童 下体 红肿 自称 被 幼儿园 老师 用 尺子 捅 伤
__label__stocks 金证 顾问 : 过山车 行情 意味着 什么
__label__realty 谁料 地 王 如此 虚
__label__game 《 光环 5 》 Logo 泄露 Kinect 版几无 悬念
__label__realty 海淀区 领秀新 硅谷 宽景 大宅 预计 10 月底 开盘
__label__realty 柴志坤 : 土地 供应量 不断 从 紧 地价 难现 07 水平 ( 图 )
__label__game 伊达 传说 EDDA Online
__label__science 三联书店 建起 书香 巷
__label__science 宇航员 尿液 堵塞 国际 空间站 水 循环系统
__label__politics 研究 发现 开车 技术 差 或 与 基因 相关
__label__sports 皇马 输球 替补席 闹 丑闻 队 副 女球迷 公然 调情 ( 视频 )
__label__realty 北京 建工 与 市政府 再度 合作 推出 郭 庄子 限价 房
__label__entertainment 组图 : 李欣汝素 颜 出镜 拍低 碳 环保 大片
- 测试集同样的方法进行处理, 得到结果文件test_fast1.txt; 验证集同样的方法进行处理, 得到结果文件dev_fast1.txt
- 模型训练, 代码位置: /home/ec2-user/toutiao/baseline/fast_text/fast_text_baseline3.py
import fasttext
import time
train_data_path = './data/data/train_fast1.txt'
dev_data_path = './data/data/dev_fast1.txt'
test_data_path = './data/data/test_fast1.txt'
# autotuneValidationFile参数需要指定验证数据集所在路径,
# 它将在验证集上使用随机搜索方法寻找可能最优的超参数.
# 使用autotuneDuration参数可以控制随机搜索的时间, 默认是300s,
# 根据不同的需求, 我们可以延长或缩短时间.
# verbose: 该参数决定日志打印级别, 当设置为3, 可以将当前正在尝试的超参数打印出来.
model = fasttext.train_supervised(input=train_data_path,
autotuneValidationFile=dev_data_path,
autotuneDuration=600,
wordNgrams=2,
verbose=3)
# 在测试集上评估模型的表现
result = model.test(test_data_path)
print(result)
# 模型保存
time1 = int(time.time())
model_save_path = "./toutiao_fasttext_{}.bin".format(time1)
model.save_model(model_save_path)
- 调用:
python fast_text_baseline3.py
- 输出结果:
al = 1
epoch = 5
lr = 0.1
dim = 100
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 2000000
dsub = 2
loss = softmax
Progress: 0.5% Trials: 1 Best score: unknown ETA: 0h 9m56scurrentScore = 0.9009
train took = 3.00675
Trial = 2
epoch = 2
lr = 0.169298
dim = 105
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 10000000
dsub = 16
loss = softmax
Progress: 1.4% Trials: 2 Best score: 0.900900 ETA: 0h 9m51scurrentScore = 0.9003
train took = 5.71447
Trial = 3
epoch = 1
lr = 0.463758
dim = 52
minCount = 1
wordNgrams = 2
minn = 0
maxn = 0
bucket = 1036295
dsub = 2
loss = softmax
Progress: 1.7% Trials: 3 Best score: 0.900900 ETA: 0h 9m49scurrentScore = 0.897
......
......
......
train took = 59.9728
Trial = 34
epoch = 52
lr = 0.0350906
dim = 57
minCount = 1
wordNgrams = 2
minn = 3
maxn = 6
bucket = 191750
dsub = 2
loss = softmax
Progress: 96.0% Trials: 34 Best score: 0.912800 ETA: 0h 0m24scurrentScore = 0.9066
train took = 19.7419
Trial = 35
epoch = 100
lr = 0.0425606
dim = 71
minCount = 1
wordNgrams = 2
minn = 2
maxn = 5
bucket = 152421
dsub = 2
loss = softmax
Progress: 100.0% Trials: 35 Best score: 0.912800 ETA: 0h 0m 0s
Training again with best arguments
Best selected args = 0
epoch = 11
lr = 0.0573768
dim = 64
minCount = 1
wordNgrams = 2
minn = 2
maxn = 5
bucket = 255766
dsub = 2
loss = softmax
Read 2M words
Number of words: 118456
Number of labels: 10
Progress: 100.0% words/sec/thread: 616381 lr: 0.000000 avg.loss: 0.296281 ETA: 0h 0m 0s
(10000, 0.9193, 0.9193)
- 查看模型:
# 命令行直接ll可以查看保存后的模型详情
# 可以看到保存后的模型大小为98MB, 相比于第一个模型小了太多, 同时效果反倒提升了!
# 参考与第一版优化中dim=355, 模型4.95GB, 此处最关键的参数dim=64, 是模型大幅度缩小的最重要原因.
-rw-rw-r-- 1 ec2-user ec2-user 97828230 1月 9 02:42 toutiao_fasttext_1640745760.bin
- 结论: 采用词为单位的模型效果又有一次提升, 精准率和召回率都达到了91.93%, 相比于初始的91.62%和第一版优化的91.73%又有稍许提升, 但效果依然不显著. 同时我们注意到, fasttext模型可大可小, 存储空间的占用范围相差极大!
模型部署¶
- 工业界中的AI是指"能落地的AI", 即指在生产环境中可以部署并提供在线, 或离线作业的模型. - 第一步: 编写主服务逻辑代码.
- 第二步: 启动Flask服务.
- 第三步: 编写测试代码.
- 第四步: 执行测试并检验结果.
- 第一步: 编写主服务逻辑代码. - 代码位置: /home/ec2-user/toutiao/baseline/fast_text/app.py
import time
import jieba
import fasttext
# 服务框架使用Flask, 导入工具包
from flask import Flask
from flask import request
app = Flask(__name__)
# 导入发送http请求的requests工具
import requests
# 加载自定义的停用词字典
jieba.load_userdict('./data/data/stopwords.txt')
# 提供已训练好的模型路径+名字
model_save_path = 'toutiao_fasttext_1640745760.bin'
# 实例化fasttext对象, 并加载模型参数用于推断, 提供服务请求
model = fasttext.load_model(model_save_path)
print('FastText模型实例化完毕...')
# 设定投满分服务的路由和请求方法
@app.route('/v1/main_server/', methods=["POST"])
def main_server():
# 接收来自请求方发送的服务字段
uid = request.form['uid']
text = request.form['text']
# 对请求文本进行处理, 因为前面加载的是基于词的模型, 所以这里用jieba进行分词
input_text = ' '.join(jieba.lcut(text))
# 执行预测
res = model.predict(input_text)
predict_name = res[0][0]
return predict_name
- 第二步: 启动Flask服务.
cd /home/ec2-user/toutiao/baseline/fast_text/
gunicorn -w 1 -b 0.0.0.0:5000 app:app
- 输出结果:
[2022-1-10 07:42:28 +0000] [24922] [INFO] Starting gunicorn 20.0.4
[2022-1-10 07:42:28 +0000] [24922] [INFO] Listening at: http://0.0.0.0:5000 (24922)
[2022-1-10 07:42:28 +0000] [24922] [INFO] Using worker: sync
[2022-1-10 07:42:28 +0000] [24928] [INFO] Booting worker with pid: 24928
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.744 seconds.
Prefix dict has been built successfully.
FastText模型实例化完毕...
- 第三步: 编写测试代码. - 代码位置: /home/ec2-user/toutiao/baseline/fast_text/test.py
import requests
import time
# 定义请求url和传入的data
url = "http://0.0.0.0:5000/v1/main_server/"
data = {"uid": "AI-6-202104", "text": "公共英语(PETS)写作中常见的逻辑词汇汇总"}
start_time = time.time()
# 向服务发送post请求
res = requests.post(url, data=data)
cost_time = time.time() - start_time
# 打印返回的结果
print('输入文本:', data['text'])
print('分类结果:', res.text)
print('单条样本预测耗时: ', cost_time * 1000, 'ms')
- 第四步: 执行测试并检验结果.
cd /home/ec2-user/toutiao/baseline/fast_text/
python test.py
- 输出结果:
输入文本: 公共英语(PETS)写作中常见的逻辑词汇汇总
分类结果: __label__education
单条样本预测耗时: 4.739046096801758 ms
- 结论: 预测结果非常准确, 同时更重要的是预测时间仅仅不到5ms!!! 这是工业界场景下fasttext工具最大的意义!!!
第二章:迁移学习的优化
2.1 数据处理
基于BERT模型的数据处理¶
学习目标¶
- 掌握BERT模型的相关细节.
- 掌握数据处理的工具函数代码实现.
投满分项目数据预处理¶
- 本项目中对数据部分的预处理步骤如下:
- 第一步: 查看项目数据集
- 第二步: 查看预训练模型相关数据
- 第三步: 编写工具类函数
第一步: 查看项目数据集¶
- 数据集的路径: /home/ec2-user/toutiao/data/data/
- 项目的数据集包括5个文件, 依次来看一下:
- 标签文件/home/ec2-user/toutiao/data/data/class.txt
finance
realty
stocks
education
science
society
politics
sports
game
entertainment
- class.txt中包含10个类别标签, 每行一个标签, 为英文单词的展示格式.
- 训练数据集/home/ec2-user/toutiao/data/data/train.txt
中华女子学院:本科层次仅1专业招男生 3
两天价网站背后重重迷雾:做个网站究竟要多少钱 4
东5环海棠公社230-290平2居准现房98折优惠 1
卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7
82岁老太为学生做饭扫地44年获授港大荣誉院士 5
记者回访地震中可乐男孩:将受邀赴美国参观 5
冯德伦徐若�隔空传情 默认其是女友 9
传郭晶晶欲落户香港战伦敦奥运 装修别墅当婚房 1
《赤壁OL》攻城战诸侯战硝烟又起 8
“手机钱包”亮相科博会 4
- train.txt中包含180000行样本, 每行包括两列, 第一列为待分类的中文文本, 第二列是数字化标签, 中间用\t作为分隔符.
- 验证数据集/home/ec2-user/toutiao/data/data/dev.txt
体验2D巅峰 倚天屠龙记十大创新概览 8
60年铁树开花形状似玉米芯(组图) 5
同步A股首秀:港股缩量回调 2
中青宝sg现场抓拍 兔子舞热辣表演 8
锌价难续去年辉煌 0
2岁男童爬窗台不慎7楼坠下获救(图) 5
布拉特:放球员一条生路吧 FIFA能消化俱乐部的攻击 7
金科西府 名墅天成 1
状元心经:考前一周重点是回顾和整理 3
发改委治理涉企收费每年为企业减负超百亿 6
- dev.txt中包含10000行样本, 每行包括两列, 第一列为待分类的中文文本, 第二列是数字化标签, 中
间用\t作为分隔符. - 测试数据集/home/ec2-user/toutiao/data/data/test.txt
词汇阅读是关键 08年考研暑期英语复习全指南 3
中国人民公安大学2012年硕士研究生目录及书目 3
日本地震:金吉列关注在日学子系列报道 3
名师辅导:2012考研英语虚拟语气三种用法 3
自考经验谈:自考生毕业论文选题技巧 3
本科未录取还有这些路可以走 3
2009年成人高考招生统一考试时间表 3
去新西兰体验舌尖上的饕餮之旅(组图) 3
四级阅读与考研阅读比较分析与应试策略 3
备考2012高考作文必读美文50篇(一) 3
- test.txt中包含10000行样本, 每行包括两列, 第一列为待分类的中文文本, 第二列是数字化标签, 中
间用\t作为分隔符.
第二步: 查看预训练模型相关数据¶
- 预训练模型相关数据的文件夹路径为/home/ec2-user/toutiao/data/bert_pretrain/
- 预训练模型相关数据共包含3个文件:
- BERT模型的超参数配置文件/home/ec2-user/toutiao/data/bert_pretrain/bert_config.json
{
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128
}
- BERT预训练模型文件/home/ec2-user/toutiao/data/bert_pretrain/pytorch_model.bin
-rw-r--r-- 1 root root 411578458 1月 9 11:50 pytorch_model.bin
- BERT预训练模型词典文件/home/ec2-user/toutiao/data/bert_pretrain/vocab.txt
[PAD]
[unused1]
[unused2]
[unused3]
[unused4]
[unused5]
[unused6]
[unused7]
[unused8]
[unused9]
[unused10]
......
......
......
[unused98]
[unused99]
[UNK]
[CLS]
[SEP]
[MASK]
<S>
<T>
!
......
......
......
第三步: 编写工具类函数¶
- 工具类函数的路径为/home/ec2-user/toutiao/src/utils.py
- 第一个工具类函数build_vocab(), 位于utils.py中的独立函数.
def build_vocab(file_path, tokenizer, max_size, min_freq):
vocab_dic = {}
with open(file_path, "r", encoding="UTF-8") as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content = lin.split("\t")[0]
for word in tokenizer(content):
vocab_dic[word] = vocab_dic.get(word, 0) + 1
vocab_list = sorted(
[_ for _ in vocab_dic.items() if _[1]>=min_freq],key=lambda x:x[1],reverse=True)[:max_size]
vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}
vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})
return vocab_dic
- 第二个工具类函数build_dataset(), 位于utils.py中的独立函数.
def build_dataset(config):
def load_dataset(path, pad_size=32):
contents = []
with open(path, "r", encoding="UTF-8") as f:
for line in tqdm(f):
line = line.strip()
if not line:
continue
content, label = line.split("\t")
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += [0] * (pad_size - len(token))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return train, dev, test
- 第三个工具函数build_iterator(), 包括数据迭代器的类class DatasetIterater(), 位于utils.py中的独立函数和类.
class DatasetIterater(object):
def __init__(self, batches, batch_size, device, model_name):
self.batch_size = batch_size
self.batches = batches
self.model_name = model_name
self.n_batches = len(batches) // batch_size
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas):
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
if self.model_name == "bert" or self.model_name == "multi_task_bert":
mask = torch.LongTensor([_[3] for _ in datas]).to(self.device)
return (x, seq_len, mask), y
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.batches[self.index * self.batch_size : len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)
return batches
elif self.index >= self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size : (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
def build_iterator(dataset, config):
iter = DatasetIterater(dataset, config.batch_size, config.device, config.model_name)
return iter
- 第四个工具类函数get_time_dif(), 位于utils.py中的独立函数.
def get_time_dif(start_time):
# 获取已使用时间
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
小节总结¶
- 本小节讲解了BERT模型的相关技术细节, 并实现了若干工具函数, 这些工具函数会在未来的项目代码中应用.
2.2 模型搭建与训练
BERT分类模型搭建¶
学习目标¶
- 掌握基于BERT的分类模型搭建的代码实现.
- 掌握迁移学习模型的训练, 测试, 评估的代码实现.
BERT模型搭建¶
- 本项目中BERT模型搭建的步骤如下:
- 第一步: 编写两个模型类的代码
- 第二步: 编写训练函数,测试函数,评估函数
- 第三步: 编写运行主函数
第一步: 编写两个模型类的代码¶
-
迁移学习预训练模型采用BERT, 类的代码路径为/home/ec2-user/toutiao/src/models/bert.py
- 第一步: 实现Config类代码.
- 第二步: 实现Model类代码.
-
第一步: 实现Config类代码.
# coding: UTF-8
import torch
import torch.nn as nn
import os
from transformers import BertModel, BertTokenizer, BertConfig
class Config(object):
def __init__(self, dataset):
self.model_name = "bert"
self.data_path = "/home/ec2-user/toutiao/data/data/"
self.train_path = self.data_path + "train.txt" # 训练集
self.dev_path = self.data_path + "dev.txt" # 验证集
self.test_path = self.data_path + "test.txt" # 测试集
self.class_list = [
x.strip() for x in open(self.data_path + "class.txt").readlines()
] # 类别名单
self.save_path = '/home/ec2-user/toutiao/src/saved_dict'
if not os.path.exists(self.save_path):
os.mkdir(self.save_path)
self.save_path += "/" + self.model_name + ".pt" # 模型训练结果
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "/home/ec2-user/toutiao/data/bert_pretrain"
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.bert_config = BertConfig.from_pretrained(self.bert_path + '/bert_config.json')
self.hidden_size = 768
- 第二步: 实现Model类代码.
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path, config=config.bert_config)
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
# 输入的句子
context = x[0]
# 对padding部分进行mask, 和句子一个size, padding部分用0表示, 比如[1, 1, 1, 1, 0, 0]
mask = x[2]
_, pooled = self.bert(context, attention_mask=mask)
out = self.fc(pooled)
return out
第二步: 编写训练函数,测试函数,评估函数¶
- 这3个函数共同编写在一个代码文件中: /home/ec2-user/toutiao/src/train_eval.py - 第1步: 导入相关工具包.
- 第2步: 编写训练函数.
- 第3步: 编写测试函数.
- 第4步: 编写验证函数.
- 第1步: 导入相关工具包.
# coding: UTF-8
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from torch.optim import AdamW
from tqdm import tqdm
import math
import logging
- 第2步: 编写训练函数.
def loss_fn(outputs, labels):
return nn.CrossEntropyLoss()(outputs, labels)
def train(config, model, train_iter, dev_iter):
start_time = time.time()
param_optimizer = list(model.named_parameters())
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
"weight_decay": 0.01
},
{
"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
"weight_decay": 0.0
}]
optimizer = AdamW(optimizer_grouped_parameters, lr=config.learning_rate)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float("inf")
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
model.train()
for epoch in range(config.num_epochs):
total_batch = 0
print("Epoch [{}/{}]".format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(tqdm(train_iter)):
outputs = model(trains)
model.zero_grad()
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 200 == 0 and total_batch != 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = "*"
last_improve = total_batch
else:
improve = ""
time_dif = get_time_dif(start_time)
msg = "Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}"
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
# 评估完成后将模型置于训练模式, 更新参数
model.train()
# 每个batch结束后累加计数
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
- 第3步: 编写测试函数.
def test(config, model, test_iter):
# model.load_state_dict(torch.load(config.save_path))
# 采用量化模型进行推理时需要关闭
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = "Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}"
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
- 第4步: 编写验证函数.
def evaluate(config, model, data_iter, test=False):
# 采用量化模型进行推理时需要关闭
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all,predict_all,target_names=config.class_list,digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)
第三步: 编写运行主函数¶
- 运行主函数依次调用前面的函数, 完成模型的训练和评估. - 代码位置: /home/ec2-user/toutiao/src/run.py
import time
import torch
import numpy as np
from train_eval import train, test
from importlib import import_module
import argparse
from utils import build_dataset, build_iterator, get_time_dif
parser = argparse.ArgumentParser(description="Chinese Text Classification")
parser.add_argument("--model", type=str, required=True, help="choose a model: bert")
args = parser.parse_args()
if __name__ == "__main__":
dataset = "toutiao" # 数据集
if args.model == "bert":
model_name = "bert"
x = import_module("models." + model_name)
config = x.Config(dataset)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
print("Loading data for Bert Model...")
train_data, dev_data, test_data = build_dataset(config)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
model = x.Model(config).to(config.device)
train(config, model, train_iter, dev_iter)
test(config,model, test_iter)
- 调用:
cd /home/ec2-user/toutiao/src/
python run.py --model bert
- 输出结果:
Loading data for Bert Model...
180000it [00:37, 4820.80it/s]
10000it [00:02, 4954.00it/s]
10000it [00:02, 4952.50it/s]
Epoch [1/3]
14%|█████████▉ | 200/1407 [02:06<13:26, 1.50it/s]Iter: 200, Train Loss: 0.3, Train Acc: 91.41%, Val Loss: 0.29, Val Acc: 90.86%, Time: 0:02:26 *
28%|███████████████████▉ | 400/1407 [04:44<11:46, 1.43it/s]Iter: 400, Train Loss: 0.34, Train Acc: 90.62%, Val Loss: 0.26, Val Acc: 92.10%, Time: 0:05:07 *
43%|█████████████████████████████▊ | 600/1407 [07:26<09:25, 1.43it/s]Iter: 600, Train Loss: 0.29, Train Acc: 91.41%, Val Loss: 0.25, Val Acc: 92.10%, Time: 0:07:49 *
57%|███████████████████████████████████████▊ | 800/1407 [10:08<07:06, 1.42it/s]Iter: 800, Train Loss: 0.15, Train Acc: 94.53%, Val Loss: 0.22, Val Acc: 92.85%, Time: 0:10:31 *
71%|█████████████████████████████████████████████████ | 1000/1407 [12:50<04:43, 1.44it/s]Iter: 1000, Train Loss: 0.17, Train Acc: 94.53%, Val Loss: 0.22, Val Acc: 93.00%, Time: 0:13:10
No optimization for a long time, auto-stopping...
Test Loss: 0.2, Test Acc: 93.64%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9246 0.9320 0.9283 1000
realty 0.9484 0.9370 0.9427 1000
stocks 0.8787 0.8980 0.8882 1000
education 0.9511 0.9730 0.9619 1000
science 0.9236 0.8950 0.9091 1000
society 0.9430 0.9270 0.9349 1000
politics 0.9267 0.9100 0.9183 1000
sports 0.9780 0.9780 0.9780 1000
game 0.9514 0.9600 0.9557 1000
entertainment 0.9390 0.9540 0.9464 1000
accuracy 0.9364 10000
macro avg 0.9365 0.9364 0.9364 10000
weighted avg 0.9365 0.9364 0.9364 10000
Confusion Matrix...
[[932 10 37 2 5 5 7 1 1 0]
[ 13 937 11 2 4 10 5 5 5 8]
[ 49 12 898 1 19 1 15 0 2 3]
[ 1 1 0 973 0 8 7 0 1 9]
[ 4 4 28 7 895 10 12 2 27 11]
[ 2 8 4 16 5 927 18 1 5 14]
[ 3 8 34 12 9 19 910 0 0 5]
[ 2 3 2 1 1 1 4 978 1 7]
[ 0 2 4 0 24 1 3 1 960 5]
[ 2 3 4 9 7 1 1 12 7 954]]
Time usage: 0:00:19
71%|█████████████████████████████████████████████████ | 1000/1407 [13:29<05:29, 1.24it/s]
- 结论: BERT模型在测试集上的表现是Test Acc: 93.64% , 对比于第一章的fasttext模型最好的表现91.93%, 有了1.71%的提升, 可以说是显著性提升了!
小节总结¶
- 本小节实现了基于BERT实现投满分分类的模型, 并完成了训练和测试评估.
第三章:模型的量化
3.1 模型量化概念和理论
模型量化的概念介绍¶
学习目标¶
- 理解什么是模型量化.
- 掌握BERT模型的量化操作.
- 掌握量化模型的性能测试.

什么是模型的量化¶
- 通俗的理解, 就是将模型的参数精度进行降低操作, 用更少的比特位(torch.qint8)代替较多的比特位(torch.float32), 从而缩减模型, 并加速推断速度.
- 如上图所示, 左侧的是原始模型拥有更高的参数精度(float32), 等效于像素高, 看的清晰; 右侧的是量化后的模型, 拥有较低的参数精度(int8), 等效于像素低, 看的模糊, 但依然可以准确的识别图像内容. - Pytorch的静态量化(Static Quantization).
- Pytorch的动态量化(Dynamic Quantization).
Pytorch的动态量化¶
- 保证Pytorch的版本在1.3.0以上, 支持动态量化.
- 直接使用torch.quantization.quantize_dynamic()来实现量化操作即可.
- 对于BERT模型的量化, 分2个步骤进行:
- 第一步: 对模型进行动态量化并评估
- 第二步: 对比模型压缩后的大小
第一步: 对模型进行动态量化并评估¶
- 首先需要修改配置类文件中的Config类.
- 代码位置: /home/ec2-user/toutiao/src/models/bert.py
# 在class Config中的__init__函数中修改下列代码部分
# 模型训练+预测的时候, 放开下一行代码, 在GPU上运行.
# self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备
# 模型量化的时候, 放开下一行代码, 在CPU上运行.
self.device = 'cpu'
- 然后编写新的主函数代码文件run1.py
- 代码位置: /home/ec2-user/toutiao/src/run1.py
# coding: UTF-8
import time
import torch
import numpy as np
from train_eval import train, test
from importlib import import_module
import argparse
from utils import build_dataset, build_iterator, get_time_dif
parser = argparse.ArgumentParser(description="Chinese Text Classification")
parser.add_argument("--model", type=str, required=True, help="choose a model: bert")
args = parser.parse_args()
if __name__ == "__main__":
dataset = "toutiao" # 数据集
if args.model == "bert":
model_name = "bert"
x = import_module("models." + model_name)
config = x.Config(dataset)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
# 数据迭代器的预处理和生成
print("Loading data for Bert Model...")
train_data, dev_data, test_data = build_dataset(config)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
# 实例化模型并加载参数, 注意不要加载到GPU之上, 只能在CPU上实现模型量化
model = x.Model(config)
model.load_state_dict(torch.load(config.save_path))
# 量化BERT模型
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
p
print(quantized_model)
# 测试量化后的模型在测试集上的表现
test(config, quantized_model, test_iter)
# 保存量化后的模型
torch.save(quantized_model, config.save_path2)
- 输出结果:
## 模型中的所有Linear层变成了DynamicQuantizedLinear层
Loading data for Bert Model...
180000it [00:42, 4212.75it/s]
10000it [00:02, 3893.41it/s]
10000it [00:02, 4367.20it/s]
Model(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(key): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(value): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
(output): BertOutput(
(dense): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
(activation): Tanh()
)
)
(fc): DynamicQuantizedLinear(in_features=768, out_features=10, dtype=torch.qint8, qscheme=torch.per_tensor_affine)
)
Test Loss: 0.25, Test Acc: 91.92%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9561 0.8490 0.8994 1000
realty 0.9499 0.9300 0.9399 1000
stocks 0.8478 0.8580 0.8529 1000
education 0.9740 0.9360 0.9546 1000
science 0.8407 0.9080 0.8731 1000
society 0.9173 0.9100 0.9137 1000
politics 0.8961 0.9230 0.9094 1000
sports 0.9836 0.9620 0.9727 1000
game 0.9562 0.9390 0.9475 1000
entertainment 0.8898 0.9770 0.9314 1000
accuracy 0.9192 10000
macro avg 0.9212 0.9192 0.9194 10000
weighted avg 0.9212 0.9192 0.9194 10000
Confusion Matrix...
[[849 9 99 0 8 14 14 2 2 3]
[ 7 930 15 0 8 13 8 1 3 15]
[ 26 18 858 0 54 1 35 1 3 4]
[ 1 3 1 936 15 17 11 1 0 15]
[ 1 2 15 2 908 12 8 1 28 23]
[ 0 13 1 14 11 910 27 1 4 19]
[ 3 2 18 5 31 13 923 0 0 5]
[ 1 2 2 0 3 5 0 962 1 24]
[ 0 0 3 1 37 4 0 3 939 13]
[ 0 0 0 3 5 3 4 6 2 977]]
- 结论: 经过量化后的BERT模型, F1=91.92%, 相比于量化前的F1=93.64%有比较显著的下降, 但还可以接受, 也说明BERT模型的鲁棒性非常高!
第二步: 对比模型压缩后的大小¶
# 首先查看量化前的BERT模型大小
cd /home/ec2-user/toutiao/saved_dic/
ll
-rw-rw-r-- 1 ec2-user ec2-user 409190601 1月 20 07:47 bert.pt
# 然后查看量化后的BERT模型大小
cd /home/ec2-user/toutiao/saved_dic1/
ll
-rw-rw-r-- 1 ec2-user ec2-user 152612233 Dec 30 10:20 bert_quantized.pt
- 对比结论:
## 模型参数文件大小缩减了256.6MB, 同时考虑到F1值仅仅下降了不到2个百分点, 效果非常优异!
BERT初始模型 Size (MB): 409.2MB
BERT量化模型 Size (MB): 152.6MB
- 注意: 如果将模型加载到GPU上直接量化, 会报错如下:
# 这说明动态量化目前在Pytorch平台上仅仅支持CPU上的操作!
RuntimeError: Could not run 'quantized::linear_prepack' with arguments from the 'UNKNOWN_TENSOR_TYPE_ID' backend. 'quantized::linear_prepack' is only available for these backends: [QuantizedCPU].
- 模型量化的硬件支持: PyTorch支持在具有AVX2支持或者更高版本的x86 CPU或者ARM CPU上运行量化运算符.
小节总结¶
- 本小节实现了对模型的动态量化, 并在CPU上测试了量化后的模型的表现, 验证了BERT模型具有良好的鲁棒性.
- 本小节对比了BERT模型量化前后的大小, 说明BERT模型的压缩率很高, 同时还能保持表现不会显著下降.
第四章:模型的剪枝
4.1 模型剪枝概念和理论
模型剪枝的概念和理论¶
学习目标¶
- 理解什么是模型剪枝.
- 掌握模型剪枝的基本操作.

什么是模型的剪枝¶
- 基于深度神经网络的大型预训练模型拥有庞大的参数量, 才能达到SOTA的效果. 但是我们参考生物的神经网络, 发现却是依靠大量稀疏的连接来完成复杂的意识活动.
- 仿照生物的稀疏神经网络, 将大型网络中的稠密连接变成稀疏的连接, 并同样达到SOTA的效果, 就是模型剪枝的原动力.
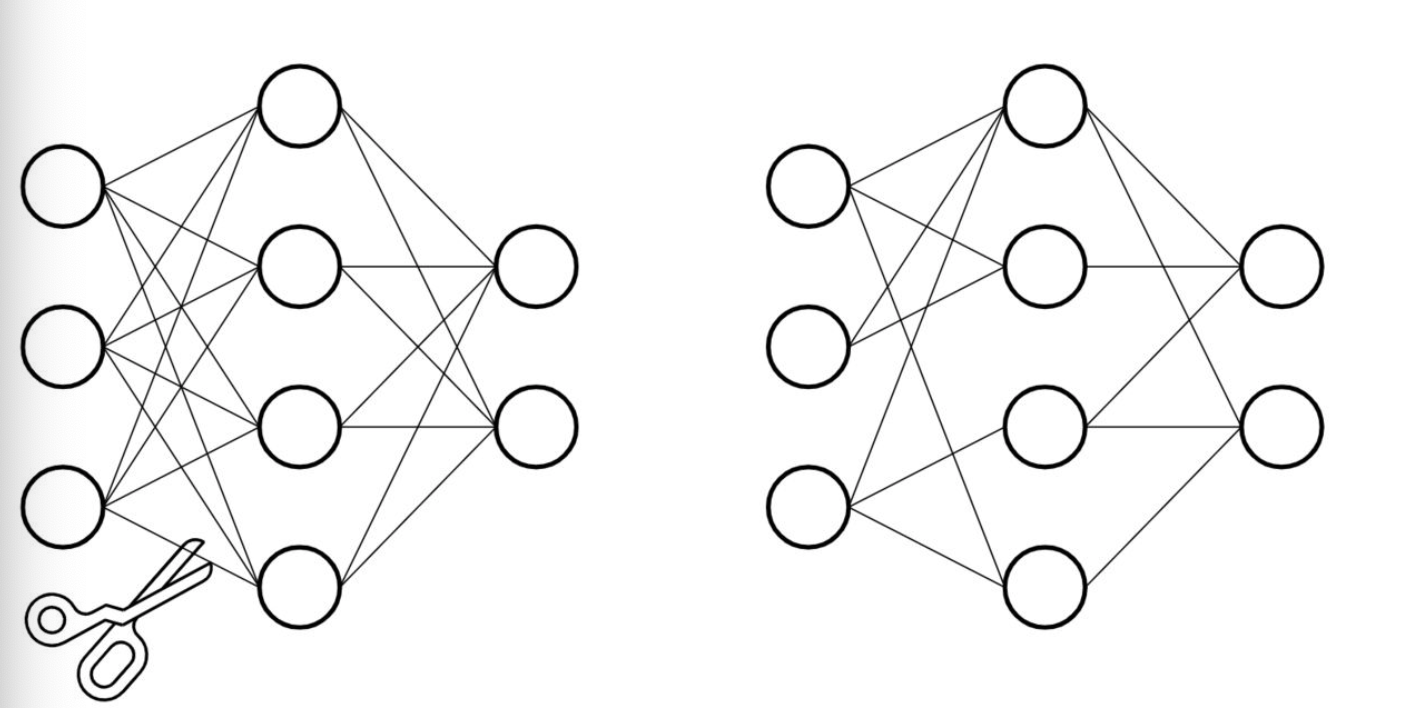
- Pytorch中对模型剪枝的支持在torch.nn.utils.prune模块中, 分以下几种剪枝方式:
- 对特定网络模块的剪枝(Pruning Model).
- 多参数模块的剪枝(Pruning multiple parameters).
- 全局剪枝(GLobal pruning).
- 用户自定义剪枝(Custom pruning).
Pytorch的模型剪枝实践¶
- 在这一小节中我们依次展示4种不同的剪枝方式, 并展示剪枝后的模型效果.
- 第一种: 对特定网络模块的剪枝(Pruning Model).
- 第二种: 多参数模块的剪枝(Pruning multiple parameters).
- 第三种: 全局剪枝(GLobal pruning).
- 第四种: 用户自定义剪枝(Custom pruning).
- 注意: 保证Pytorch的版本在1.4.0以上, 支持剪枝操作.
第一种: 对特定网络模块的剪枝(Pruning Model).¶
- 首先导入工具包:
import torch
from torch import nn
import torch.nn.utils.prune as prune
import torch.nn.functional as F
- 创建一个网络, 我们以经典的LeNet来示例:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1: 图像的输入通道(1是黑白图像), 6: 输出通道, 3x3: 卷积核的尺寸
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 是经历卷积操作后的图片尺寸
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet().to(device=device)
- 调用:
module = model.conv1
print(list(module.named_parameters()))
- 输出结果:
[('weight', Parameter containing:
tensor([[[[ 0.0853, -0.0203, -0.0784],
[ 0.3327, -0.0904, -0.0374],
[-0.0037, -0.2629, -0.2536]]],
[[[ 0.1313, 0.0249, 0.2735],
[ 0.0630, 0.0625, -0.0468],
[ 0.3328, 0.3249, -0.2640]]],
[[[ 0.1931, -0.2246, 0.0102],
[ 0.3319, 0.1740, -0.0799],
[-0.0195, -0.1295, -0.0964]]],
[[[ 0.3005, 0.2704, 0.3162],
[-0.2560, 0.0295, 0.2605],
[-0.1056, -0.0730, 0.0436]]],
[[[-0.3205, 0.1927, -0.0761],
[ 0.0142, -0.0562, -0.3087],
[ 0.1202, 0.1119, -0.1336]]],
[[[ 0.0568, 0.1142, 0.3079],
[ 0.2000, -0.1661, -0.2935],
[-0.1652, -0.2606, -0.0559]]]], device='cuda:0', requires_grad=True)), ('bias', Parameter containing:
tensor([ 0.1085, -0.1044, 0.1366, 0.3240, -0.1522, 0.1630], device='cuda:0',
requires_grad=True))]
- 再打印一个特殊的属性张量
print(list(module.named_buffers()))
- 输出结果
# 这里面打印出一个空列表, 至于这个空列表代表什么含义? 剪枝操作后同学们就明白了!
[]
- 直接调用prune函数对模型进行剪枝操作:
# 第一个参数: module, 代表要进行剪枝的特定模块, 之前我们已经制定了module=model.conv1,
# 说明这里要对第一个卷积层执行剪枝.
# 第二个参数: name, 指定要对选中的模块中的哪些参数执行剪枝.
# 这里设定为name="weight", 意味着对连接网络中的weight剪枝, 而不对bias剪枝.
# 第三个参数: amount, 指定要对模型中多大比例的参数执行剪枝.
# amount是一个介于0.0-1.0的float数值, 或者一个正整数指定剪裁掉多少条连接边.
prune.random_unstructured(module, name="weight", amount=0.3)
- 调用:
print(list(module.named_parameters()))
print(list(module.named_buffers()))
- 输出结果:
[('bias', Parameter containing:
tensor([ 0.1861, 0.2483, -0.3235, 0.0667, 0.0790, 0.1807], device='cuda:0',
requires_grad=True)), ('weight_orig', Parameter containing:
tensor([[[[-0.1544, -0.3045, 0.1339],
[ 0.2605, -0.1201, 0.3060],
[-0.2502, -0.0023, -0.0362]]],
[[[ 0.3147, -0.1034, -0.1772],
[-0.2250, -0.1071, 0.2489],
[ 0.2741, -0.1926, -0.2046]]],
[[[-0.1022, -0.2210, -0.1349],
[-0.2938, 0.0679, 0.2485],
[ 0.1108, -0.0564, -0.3328]]],
[[[-0.0464, 0.0138, 0.0283],
[-0.3205, 0.0184, 0.0521],
[ 0.2219, -0.2403, -0.2881]]],
[[[ 0.3320, -0.0684, -0.1715],
[-0.0381, 0.1819, 0.1796],
[-0.3321, -0.2684, -0.0477]]],
[[[-0.1638, -0.0969, 0.0077],
[ 0.0906, 0.2051, 0.2174],
[-0.2174, 0.1875, -0.2978]]]], device='cuda:0', requires_grad=True))]
[('weight_mask', tensor([[[[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.]]],
[[[0., 0., 0.],
[0., 1., 1.],
[0., 0., 1.]]],
[[[1., 1., 1.],
[0., 1., 1.],
[1., 1., 1.]]],
[[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]],
[[[1., 1., 1.],
[1., 0., 1.],
[1., 1., 0.]]],
[[[1., 0., 1.],
[0., 0., 1.],
[1., 1., 0.]]]], device='cuda:0'))]
- 结论: 模型经历剪枝操作后, 原始的权重矩阵weight参数不见了, 变成了weight_orig. 并且刚刚打印为空列表的module.named_buffers(), 此时拥有了一个weight_mask参数.
- 这时打印module.weight属性值, 看看有什么启发?
print(module.weight)
- 输出结果:
tensor([[[[-0.1544, -0.0000, 0.1339],
[ 0.2605, -0.0000, 0.3060],
[-0.2502, -0.0000, -0.0362]]],
[[[ 0.0000, -0.0000, -0.0000],
[-0.0000, -0.1071, 0.2489],
[ 0.0000, -0.0000, -0.2046]]],
[[[-0.1022, -0.2210, -0.1349],
[-0.0000, 0.0679, 0.2485],
[ 0.1108, -0.0564, -0.3328]]],
[[[-0.0464, 0.0138, 0.0283],
[-0.3205, 0.0184, 0.0521],
[ 0.2219, -0.2403, -0.2881]]],
[[[ 0.3320, -0.0684, -0.1715],
[-0.0381, 0.0000, 0.1796],
[-0.3321, -0.2684, -0.0000]]],
[[[-0.1638, -0.0000, 0.0077],
[ 0.0000, 0.0000, 0.2174],
[-0.2174, 0.1875, -0.0000]]]], device='cuda:0',
grad_fn=<MulBackward0>)
- 结论: 经过剪枝操作后的模型, 原始的参数存放在了weight_orig中, 对应的剪枝矩阵存放在weight_mask中, 而将weight_mask视作掩码张量, 再和weight_orig相乘的结果就存放在了weight中.
- 注意: 剪枝操作后的weight已经不再是module的参数(parameter), 而只是module的一个属性(attribute).
- 对于每一次剪枝操作, 模型都会对应一个具体的_forward_pre_hooks函数用于剪枝.
print(module._forward_pre_hooks)
- 输出结果:
OrderedDict([(0, <torch.nn.utils.prune.RandomUnstructured object at 0x7f9c6a945438>)])
- 我们可以对模型的任意子结构进行剪枝操作, 除了在weight上面剪枝, 还可以对bias进行剪枝.
# 第一个参数: module, 代表剪枝的对象, 此处代表LeNet中的conv1
# 第二个参数: name, 代表剪枝对象中的具体参数, 此处代表偏置量
# 第三个参数: amount, 代表剪枝的数量, 可以设置为0.0-1.0之间表示比例, 也可以用正整数表示剪枝的参数绝对数量
prune.l1_unstructured(module, name="bias", amount=3)
# 再次打印模型参数
print(list(module.named_parameters()))
print('*'*50)
print(list(module.named_buffers()))
print('*'*50)
print(module.bias)
print('*'*50)
print(module._forward_pre_hooks)
- 输出结果
[('weight_orig', Parameter containing:
tensor([[[[-0.0159, -0.3175, -0.0816],
[ 0.3144, -0.1534, -0.0924],
[-0.2885, -0.1054, -0.1872]]],
[[[ 0.0835, -0.1258, -0.2760],
[-0.3174, 0.0669, -0.1867],
[-0.0381, 0.1156, 0.0078]]],
[[[ 0.1416, -0.2907, -0.0249],
[ 0.1018, 0.1757, -0.0326],
[ 0.2736, -0.1980, -0.1162]]],
[[[-0.1835, 0.1600, 0.3178],
[ 0.0579, -0.0647, -0.1039],
[-0.0160, -0.0715, 0.2746]]],
[[[-0.2314, -0.1759, -0.1820],
[-0.0594, 0.2355, -0.2087],
[ 0.0216, 0.0066, -0.0624]]],
[[[-0.2772, 0.1479, -0.0983],
[-0.3307, -0.2360, -0.0596],
[ 0.2785, 0.0648, 0.2869]]]], device='cuda:0', requires_grad=True)), ('bias_orig', Parameter containing:
tensor([-0.1924, -0.1420, -0.0235, 0.0325, 0.0188, 0.0120], device='cuda:0',
requires_grad=True))]
**************************************************
[('weight_mask', tensor([[[[0., 0., 0.],
[1., 1., 1.],
[1., 0., 1.]]],
[[[1., 0., 1.],
[1., 0., 1.],
[1., 0., 1.]]],
[[[1., 1., 0.],
[1., 1., 1.],
[1., 1., 1.]]],
[[[1., 1., 1.],
[1., 0., 0.],
[0., 1., 0.]]],
[[[1., 1., 1.],
[1., 1., 1.],
[0., 1., 1.]]],
[[[1., 1., 1.],
[0., 0., 1.],
[1., 1., 0.]]]], device='cuda:0')), ('bias_mask', tensor([1., 1., 0., 1., 0., 0.], device='cuda:0'))]
**************************************************
tensor([-0.1924, -0.1420, -0.0000, 0.0325, 0.0000, 0.0000], device='cuda:0',
grad_fn=<MulBackward0>)
**************************************************
OrderedDict([(0, <torch.nn.utils.prune.RandomUnstructured object at 0x7fd406b617f0>), (1, <torch.nn.utils.prune.L1Unstructured object at 0x7fd3aa9ba048>)])
- 结论: 在module的不同参数集合上应用不同的剪枝策略, 我们发现模型参数中不仅仅有了weight_orig, 也有了bias_orig. 在起到掩码张量作用的named_buffers中, 也同时出现了weight_mask和bias_mask. 最后, 因为我们在两类参数上应用了两种不同的剪枝函数, 因此_forward_pre_hooks中也打印出了2个不同的函数结果.
- 序列化一个剪枝模型(Serializing a pruned model):
# 对于一个模型来说, 不管是它原始的参数, 拥有的属性值, 还是剪枝的mask buffers参数
# 全部都存储在模型的状态字典中, 即state_dict()中.
# 将模型初始的状态字典打印出来
print(model.state_dict().keys())
print('*'*50)
# 对模型进行剪枝操作, 分别在weight和bias上剪枝
module = model.conv1
prune.random_unstructured(module, name="weight", amount=0.3)
prune.l1_unstructured(module, name="bias", amount=3)
# 再将剪枝后的模型的状态字典打印出来
print(model.state_dict().keys())
- 输出结果:
odict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc3.weight', 'fc3.bias'])
**************************************************
odict_keys(['conv1.weight_orig', 'conv1.bias_orig', 'conv1.weight_mask', 'conv1.bias_mask', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc3.weight', 'fc3.bias'])
- 关键一步: 对模型执行剪枝remove操作. - 通过module中的参数weight_orig和weight_mask进行剪枝, 本质上属于置零遮掩, 让权重连接失效.
- 具体怎么计算取决于_forward_pre_hooks函数.
- 这个remove是无法undo的, 也就是说一旦执行就是对模型参数的永久改变.
- 执行remove操作的演示代码:
# 打印剪枝后的模型参数
print(list(module.named_parameters()))
print('*'*50)
# 打印剪枝后的模型mask buffers参数
print(list(module.named_buffers()))
print('*'*50)
# 打印剪枝后的模型weight属性值
print(module.weight)
print('*'*50)
# 打印模型的_forward_pre_hooks
print(module._forward_pre_hooks)
print('*'*50)
# 执行剪枝永久化操作remove
prune.remove(module, 'weight')
print('*'*50)
# remove后再次打印模型参数
print(list(module.named_parameters()))
print('*'*50)
# remove后再次打印模型mask buffers参数
print(list(module.named_buffers()))
print('*'*50)
# remove后再次打印模型的_forward_pre_hooks
print(module._forward_pre_hooks)
- 输出结果:
[('weight_orig', Parameter containing:
tensor([[[[ 0.1668, 0.0369, -0.2930],
[-0.2630, -0.1777, -0.1096],
[ 0.0481, -0.0898, 0.1920]]],
[[[ 0.0729, 0.1445, -0.0471],
[ 0.1525, 0.2986, 0.2602],
[-0.0929, -0.2725, -0.0069]]],
[[[-0.2006, -0.2577, 0.2754],
[ 0.0999, 0.2106, -0.0046],
[-0.2813, -0.2794, -0.0580]]],
[[[-0.2944, -0.2214, -0.0795],
[-0.0773, 0.2931, -0.2249],
[-0.0796, -0.2343, -0.0457]]],
[[[-0.1965, 0.2550, 0.2606],
[ 0.0213, -0.2839, 0.2037],
[-0.2068, -0.0507, -0.3097]]],
[[[ 0.0030, 0.2340, -0.1122],
[-0.0302, -0.0261, 0.1168],
[ 0.0927, 0.1553, 0.1167]]]], device='cuda:0', requires_grad=True)), ('bias_orig', Parameter containing:
tensor([ 0.1147, 0.2439, -0.1753, -0.2578, -0.0994, 0.0588], device='cuda:0',
requires_grad=True))]
**************************************************
[('weight_mask', tensor([[[[0., 0., 0.],
[1., 1., 1.],
[0., 1., 1.]]],
[[[1., 1., 1.],
[1., 0., 1.],
[1., 1., 1.]]],
[[[1., 1., 0.],
[1., 1., 1.],
[1., 0., 1.]]],
[[[0., 1., 1.],
[1., 1., 1.],
[1., 1., 0.]]],
[[[1., 0., 1.],
[0., 1., 0.],
[0., 1., 1.]]],
[[[1., 1., 1.],
[1., 0., 0.],
[0., 1., 1.]]]], device='cuda:0')), ('bias_mask', tensor([0., 1., 1., 1., 0., 0.], device='cuda:0'))]
**************************************************
tensor([[[[ 0.0000, 0.0000, -0.0000],
[-0.2630, -0.1777, -0.1096],
[ 0.0000, -0.0898, 0.1920]]],
[[[ 0.0729, 0.1445, -0.0471],
[ 0.1525, 0.0000, 0.2602],
[-0.0929, -0.2725, -0.0069]]],
[[[-0.2006, -0.2577, 0.0000],
[ 0.0999, 0.2106, -0.0046],
[-0.2813, -0.0000, -0.0580]]],
[[[-0.0000, -0.2214, -0.0795],
[-0.0773, 0.2931, -0.2249],
[-0.0796, -0.2343, -0.0000]]],
[[[-0.1965, 0.0000, 0.2606],
[ 0.0000, -0.2839, 0.0000],
[-0.0000, -0.0507, -0.3097]]],
[[[ 0.0030, 0.2340, -0.1122],
[-0.0302, -0.0000, 0.0000],
[ 0.0000, 0.1553, 0.1167]]]], device='cuda:0',
grad_fn=<MulBackward0>)
**************************************************
OrderedDict([(0, <torch.nn.utils.prune.RandomUnstructured object at 0x7f65b879e7f0>), (1, <torch.nn.utils.prune.L1Unstructured object at 0x7f655c5ebfd0>)])
[('bias_orig', Parameter containing:
tensor([ 0.1147, 0.2439, -0.1753, -0.2578, -0.0994, 0.0588], device='cuda:0',
requires_grad=True)), ('weight', Parameter containing:
tensor([[[[ 0.0000, 0.0000, -0.0000],
[-0.2630, -0.1777, -0.1096],
[ 0.0000, -0.0898, 0.1920]]],
[[[ 0.0729, 0.1445, -0.0471],
[ 0.1525, 0.0000, 0.2602],
[-0.0929, -0.2725, -0.0069]]],
[[[-0.2006, -0.2577, 0.0000],
[ 0.0999, 0.2106, -0.0046],
[-0.2813, -0.0000, -0.0580]]],
[[[-0.0000, -0.2214, -0.0795],
[-0.0773, 0.2931, -0.2249],
[-0.0796, -0.2343, -0.0000]]],
[[[-0.1965, 0.0000, 0.2606],
[ 0.0000, -0.2839, 0.0000],
[-0.0000, -0.0507, -0.3097]]],
[[[ 0.0030, 0.2340, -0.1122],
[-0.0302, -0.0000, 0.0000],
[ 0.0000, 0.1553, 0.1167]]]], device='cuda:0', requires_grad=True))]
**************************************************
[('bias_mask', tensor([0., 1., 1., 1., 0., 0.], device='cuda:0'))]
**************************************************
OrderedDict([(1, <torch.nn.utils.prune.L1Unstructured object at 0x7f655c5ebfd0>)])
- 结论: 对模型的weight执行remove操作后, 模型参数集合中只剩下bias_orig了, weight_orig消失, 变成了weight, 说明针对weight的剪枝已经永久化生效. 对于named_buffers张量打印可以看出, 只剩下bias_mask了, 因为针对weight做掩码的weight_mask已经生效完毕, 不再需要保留了. 同理, 在_forward_pre_hooks中也只剩下针对bias做剪枝的函数了.
第二种: 多参数模块的剪枝(Pruning multiple parameters).¶
model = LeNet().to(device=device)
# 打印初始模型的所有状态字典
print(model.state_dict().keys())
print('*'*50)
# 打印初始模型的mask buffers张量字典名称
print(dict(model.named_buffers()).keys())
print('*'*50)
# 对于模型进行分模块参数的剪枝
for name, module in model.named_modules():
# 对模型中所有的卷积层执行l1_unstructured剪枝操作, 选取20%的参数剪枝
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name="weight", amount=0.2)
# 对模型中所有全连接层执行ln_structured剪枝操作, 选取40%的参数剪枝
elif isinstance(module, torch.nn.Linear):
prune.ln_structured(module, name="weight", amount=0.4, n=2, dim=0)
# 打印多参数模块剪枝后的mask buffers张量字典名称
print(dict(model.named_buffers()).keys())
print('*'*50)
# 打印多参数模块剪枝后模型的所有状态字典名称
print(model.state_dict().keys())
- 输出结果:
odict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc3.weight', 'fc3.bias'])
**************************************************
dict_keys([])
**************************************************
dict_keys(['conv1.weight_mask', 'conv2.weight_mask', 'fc1.weight_mask', 'fc2.weight_mask', 'fc3.weight_mask'])
**************************************************
odict_keys(['conv1.bias', 'conv1.weight_orig', 'conv1.weight_mask', 'conv2.bias', 'conv2.weight_orig', 'conv2.weight_mask', 'fc1.bias', 'fc1.weight_orig', 'fc1.weight_mask', 'fc2.bias', 'fc2.weight_orig', 'fc2.weight_mask', 'fc3.bias', 'fc3.weight_orig', 'fc3.weight_mask'])
- 结论: 对比初始化模型的状态字典和剪枝后的状态字典, 可以看到所有的weight参数都没有了, 变成了weight_orig和weight_mask的组合. 初始化的模型named_buffers是空列表, 剪枝后拥有了所有参与剪枝的参数层的weight_mask张量.
第三种: 全局剪枝(GLobal pruning).¶
- 本章中的第一种, 第二种剪枝策略本质上属于局部剪枝(local pruning), 需要程序员按照自己的定义one by one的进行操作. 最主要的问题就是模型剪枝效果的好坏很大程度上取决于程序员的剪枝经验, 而且就算经验丰富的程序员也很难肯定的说某种剪枝策略一定更优.
- 更普遍也更通用的剪枝策略是采用全局剪枝(global pruning), 比如在整体网络的视角下剪枝掉20%的权重参数, 而不是在每一层上都剪枝掉20%的权重参数. 采用全局剪枝后, 不同的层被剪掉的百分比不同.
model = LeNet().to(device=device)
# 首先打印初始化模型的状态字典
print(model.state_dict().keys())
print('*'*50)
# 构建参数集合, 决定哪些层, 哪些参数集合参与剪枝
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'))
# 调用prune中的全局剪枝函数global_unstructured执行剪枝操作, 此处针对整体模型中的20%参数量进行剪枝
prune.global_unstructured(parameters_to_prune, pruning_method=prune.L1Unstructured, amount=0.2)
# 最后打印剪枝后的模型的状态字典
print(model.state_dict().keys())
- 输出结果:
odict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc3.weight', 'fc3.bias'])
**************************************************
odict_keys(['conv1.bias', 'conv1.weight_orig', 'conv1.weight_mask', 'conv2.bias', 'conv2.weight_orig', 'conv2.weight_mask', 'fc1.bias', 'fc1.weight_orig', 'fc1.weight_mask', 'fc2.bias', 'fc2.weight_orig', 'fc2.weight_mask', 'fc3.bias', 'fc3.weight_orig', 'fc3.weight_mask'])
- 针对模型剪枝后, 不同的层会有不同比例的权重参数被剪掉, 利用代码打印出来看看:
model = LeNet().to(device=device)
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'))
prune.global_unstructured(parameters_to_prune, pruning_method=prune.L1Unstructured, amount=0.2)
print(
"Sparsity in conv1.weight: {:.2f}%".format(
100. * float(torch.sum(model.conv1.weight == 0))
/ float(model.conv1.weight.nelement())
))
print(
"Sparsity in conv2.weight: {:.2f}%".format(
100. * float(torch.sum(model.conv2.weight == 0))
/ float(model.conv2.weight.nelement())
))
print(
"Sparsity in fc1.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc1.weight == 0))
/ float(model.fc1.weight.nelement())
))
print(
"Sparsity in fc2.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc2.weight == 0))
/ float(model.fc2.weight.nelement())
))
print(
"Sparsity in fc3.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc3.weight == 0))
/ float(model.fc3.weight.nelement())
))
print(
"Global sparsity: {:.2f}%".format(
100. * float(torch.sum(model.conv1.weight == 0)
+ torch.sum(model.conv2.weight == 0)
+ torch.sum(model.fc1.weight == 0)
+ torch.sum(model.fc2.weight == 0)
+ torch.sum(model.fc3.weight == 0))
/ float(model.conv1.weight.nelement()
+ model.conv2.weight.nelement()
+ model.fc1.weight.nelement()
+ model.fc2.weight.nelement()
+ model.fc3.weight.nelement())
))
- 输出结果:
Sparsity in conv1.weight: 1.85%
Sparsity in conv2.weight: 7.87%
Sparsity in fc1.weight: 21.99%
Sparsity in fc2.weight: 12.56%
Sparsity in fc3.weight: 9.17%
Global sparsity: 20.00%
- 结论: 当采用全局剪枝策略的时候(假定20%比例参数参与剪枝), 仅保证模型总体参数量的20%被剪枝掉, 具体到每一层的情况则由模型的具体参数分布情况来定.
第四种: 用户自定义剪枝(Custom pruning).¶
- 所谓用户自定义剪枝, 就是程序员自己定义通过什么样的规则进行剪枝, 而不是依赖Pytorch定义好的比如l1_unstructured, ln_structured等等预设好的剪枝规则来进行剪枝.
- 剪枝模型通过继承class BasePruningMethod()来执行剪枝, 内部有若干方法: call, apply_mask, apply, prune, remove等等. 一般来说, 用户只需要实现__init__, 和compute_mask两个函数即可完成自定义的剪枝规则设定.
# 自定义剪枝方法的类, 一定要继承prune.BasePruningMethod
class myself_pruning_method(prune.BasePruningMethod):
PRUNING_TYPE = "unstructured"
# 内部实现compute_mask函数, 完成程序员自己定义的剪枝规则, 本质上就是如何去mask掉权重参数
def compute_mask(self, t, default_mask):
mask = default_mask.clone()
# 此处定义的规则是每隔一个参数就遮掩掉一个, 最终参与剪枝的参数量的50%被mask掉
mask.view(-1)[::2] = 0
return mask
# 自定义剪枝方法的函数, 内部直接调用剪枝类的方法apply
def myself_unstructured_pruning(module, name):
myself_pruning_method.apply(module, name)
return module
- 调用:
# 实例化模型类
model = LeNet().to(device=device)
start = time.time()
# 调用自定义剪枝方法的函数, 对model中的第三个全连接层fc3中的偏置bias执行自定义剪枝
myself_unstructured_pruning(model.fc3, name="bias")
# 剪枝成功的最大标志, 就是拥有了bias_mask参数
print(model.fc3.bias_mask)
# 打印一下自定义剪枝的耗时
duration = time.time() - start
print(duration * 1000, 'ms')
- 输出结果:
tensor([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.], device='cuda:0')
1.7154216766357422 ms
- 结论: 打印出来的bias_mask张量, 完全是按照预定义的方式每隔一位遮掩掉一位, 0和1交替出现, 后续执行remove操作的时候, 原始的bias_orig中的权重就会同样的被每隔一位剪枝掉一位. 在GPU机器上执行自定义剪枝速度特别快, 仅需1.7ms.
第五章:迁移学习微调
5.1 BERT模型微调
模型微调的实践案例¶
学习目标¶
- 掌握基于BERT的微调模型.
- 掌握对BERT微调模型的参数配置方法.
本项目用到的数据集¶
-
投满分项目中用到的20万条数据, 文本长度在20到30之间, 共10个类别, 每类20000条.
- 类别: 财经, 房产, 股票, 教育, 科技, 社会, 时政, 体育, 游戏, 娱乐.
- 数据集划分: 训练集180000, 验证集10000, 测试集10000.
-
本项目中用到是数据集放在/home/bert/bert_finetuning/data/目录下, 该目录下有如下文件信息:
# 下列5个文件
class.txt
test.csv
train.csv
dev.csv
vocab.pkl
- 本项目中用到的预训练模型放在/home/bert/bert_finetuning/data/bert_pretrain目录下, 该目录下有如下文件信息:
bert_config.json
pytorch_model.bin
vocab.txt
本项目的实现步骤:¶
- 第1步: 熟悉数据文件和数据集
- 第2步: 构建基于BERT微调的多标签分类模型
- 第3步: 对BERT模型的参数执行微调
- 第4步: 编写textCNN模型类代码
第1步: 熟悉数据文件和数据集¶
- 打开class.txt文件, 文件位置/home/bert/bert_finetuning/data/data/
# 文件中存储的是10种分类标签的英文名称, 也可以按照程序员的喜好换成中文
finance
realty
stocks
education
science
society
politics
sports
game
entertainment
- 打开train.txt文件, 文件位置/home/bert/bert_finetuning/data/data/
# 这里只截取文件的一部分展示, 文件总共有180000行
中华女子学院:本科层次仅1专业招男生 3
两天价网站背后重重迷雾:做个网站究竟要多少钱 4
东5环海棠公社230-290平2居准现房98折优惠 1
卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7
82岁老太为学生做饭扫地44年获授港大荣誉院士 5
记者回访地震中可乐男孩:将受邀赴美国参观 5
冯德伦徐若�隔空传情 默认其是女友 9
传郭晶晶欲落户香港战伦敦奥运 装修别墅当婚房 1
《赤壁OL》攻城战诸侯战硝烟又起 8
“手机钱包”亮相科博会 4
上海2010上半年四六级考试报名4月8日前完成 3
李永波称李宗伟难阻林丹取胜 透露谢杏芳有望出战 7
3岁女童下体红肿 自称被幼儿园老师用尺子捅伤 5
金证顾问:过山车行情意味着什么 2
谁料地王如此虚 1
《光环5》Logo泄露 Kinect版几无悬念 8
海淀区领秀新硅谷宽景大宅预计10月底开盘 1
柴志坤:土地供应量不断从紧 地价难现07水平(图) 1
- 打开dev.csv文件, /home/bert/bert_finetuning/data/data/
# 这里只截取文件的一部分展示, 文件总共有10000行
体验2D巅峰 倚天屠龙记十大创新概览 8
60年铁树开花形状似玉米芯(组图) 5
同步A股首秀:港股缩量回调 2
中青宝sg现场抓拍 兔子舞热辣表演 8
锌价难续去年辉煌 0
2岁男童爬窗台不慎7楼坠下获救(图) 5
布拉特:放球员一条生路吧 FIFA能消化俱乐部的攻击 7
金科西府 名墅天成 1
状元心经:考前一周重点是回顾和整理 3
发改委治理涉企收费每年为企业减负超百亿 6
一年网事扫荡10年纷扰开心网李鬼之争和平落幕 4
2010英国新政府“三把火”或影响留学业 3
俄达吉斯坦共和国一名区长被枪杀 6
朝鲜要求日本对过去罪行道歉和赔偿 6
《口袋妖怪 黑白》日本首周贩售255万 8
图文:借贷成本上涨致俄罗斯铝业净利下滑21% 2
组图:新《三国》再曝海量剧照 火战场面极震撼 9
麻辣点评:如何走出“被留学”的尴尬 3
- 打开test.csv文件, /home/bert/bert_finetuning/data/data/
# 这里只截取文件的一部分展示, 文件总共有10000行
词汇阅读是关键 08年考研暑期英语复习全指南 3
中国人民公安大学2012年硕士研究生目录及书目 3
日本地震:金吉列关注在日学子系列报道 3
名师辅导:2012考研英语虚拟语气三种用法 3
自考经验谈:自考生毕业论文选题技巧 3
本科未录取还有这些路可以走 3
2009年成人高考招生统一考试时间表 3
去新西兰体验舌尖上的饕餮之旅(组图) 3
四级阅读与考研阅读比较分析与应试策略 3
备考2012高考作文必读美文50篇(一) 3
名师详解考研复试英语听力备考策略 3
热议:艺考合格证是高考升学王牌吗(组图) 3
研究生办替考网站续:幕后老板年赚近百万(图) 3
2011年高考文科综合试题(重庆卷) 3
56所高校预估2009年湖北录取分数线出炉 3
公共英语(PETS)写作中常见的逻辑词汇汇总 3
时评:高考应成为教育公平的“助推器” 3
- 还有一个文件vocab.pkl文件, 不是可打印文件, 是为后续的textCNN模型服务的.
- 进入文件夹/home/bert/bert_finetuning/data/bert_pretrain/, 有如下3个文件:
# BERT预训练模型的所有参数
config.json
# 基于bert-base-chinese预训练模型得到的模型文件
pytorch_model.bin
# bert-base-chinese模型的所有词汇表, 共21128个字符
vocab.txt
第2步: 构建基于BERT微调的多标签分类模型¶
- 首先编写经典的实现继承BERT预训练模型的分类任务类.
import torch.nn as nn
from transformers import BertPreTrainedModel, BertModel, BertConfig
# 构建基于BERT的微调模型类
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
# 导入参数设置对象
model_config = BertConfig.from_pretrained(config.bert_path, num_labels=config.num_classes)
# 导入基于bert-base-chinese的预训练模型
self.bert = BertModel.from_pretrained(config.bert_path, config=model_config)
# 此处用于调节是否将BERT纳入微调训练, 建议数据量+算力充足的情况下置为True
# 如果设置为False, 则保持整个BERT网络参数不变, 微调仅仅针对最后的全连接层进行训练
for param in self.bert.parameters():
param.requires_grad = True
# 全连接层的出口维度, 取决于具体的任务
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
# x[0]是输入的具体文本信息
context = x[0]
# x[1]是经过tokenizer处理后返回的attention mask张量
# mask的尺寸size和输入相同, padding部分用0遮掩, 比如[1, 1, 1, 0, 0]
mask = x[1]
# x[2]是字符类型id
token_type_ids = x[2]
# 利用BERT模型得到输出张量, 并且只保留BertPooler的输出, 即第一个字符CLS对应的输出张量
_, pooled = self.bert(context, attention_mask=mask, token_type_ids=token_type_id)
# 再利用微调网络进一步提取特征, 并利用全连接层对特征张量进行维度变换
out = self.fc(pooled)
return out
第3步: 对BERT模型的参数执行微调¶
- 首先展示BERT模型中的参数命名:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path,config=config.bert_config)
# 将BERT中所有的参数层名字打印出来
for name, param in self.bert.named_parameters():
print(name)
self.fc = nn.Linear(config.hidden_size, config.num_classes)
- 输出结果:
embeddings.word_embeddings.weight
embeddings.position_embeddings.weight
embeddings.token_type_embeddings.weight
embeddings.LayerNorm.weight
embeddings.LayerNorm.bias
encoder.layer.0.attention.self.query.weight
encoder.layer.0.attention.self.query.bias
encoder.layer.0.attention.self.key.weight
encoder.layer.0.attention.self.key.bias
encoder.layer.0.attention.self.value.weight
encoder.layer.0.attention.self.value.bias
encoder.layer.0.attention.output.dense.weight
encoder.layer.0.attention.output.dense.bias
encoder.layer.0.attention.output.LayerNorm.weight
encoder.layer.0.attention.output.LayerNorm.bias
encoder.layer.0.intermediate.dense.weight
encoder.layer.0.intermediate.dense.bias
encoder.layer.0.output.dense.weight
encoder.layer.0.output.dense.bias
encoder.layer.0.output.LayerNorm.weight
encoder.layer.0.output.LayerNorm.bias
encoder.layer.1.attention.self.query.weight
encoder.layer.1.attention.self.query.bias
encoder.layer.1.attention.self.key.weight
encoder.layer.1.attention.self.key.bias
encoder.layer.1.attention.self.value.weight
encoder.layer.1.attention.self.value.bias
encoder.layer.1.attention.output.dense.weight
encoder.layer.1.attention.output.dense.bias
encoder.layer.1.attention.output.LayerNorm.weight
encoder.layer.1.attention.output.LayerNorm.bias
encoder.layer.1.intermediate.dense.weight
encoder.layer.1.intermediate.dense.bias
encoder.layer.1.output.dense.weight
encoder.layer.1.output.dense.bias
encoder.layer.1.output.LayerNorm.weight
encoder.layer.1.output.LayerNorm.bias
......
......
......
encoder.layer.11.attention.self.query.weight
encoder.layer.11.attention.self.query.bias
encoder.layer.11.attention.self.key.weight
encoder.layer.11.attention.self.key.bias
encoder.layer.11.attention.self.value.weight
encoder.layer.11.attention.self.value.bias
encoder.layer.11.attention.output.dense.weight
encoder.layer.11.attention.output.dense.bias
encoder.layer.11.attention.output.LayerNorm.weight
encoder.layer.11.attention.output.LayerNorm.bias
encoder.layer.11.intermediate.dense.weight
encoder.layer.11.intermediate.dense.bias
encoder.layer.11.output.dense.weight
encoder.layer.11.output.dense.bias
encoder.layer.11.output.LayerNorm.weight
encoder.layer.11.output.LayerNorm.bias
pooler.dense.weight
pooler.dense.bias
- 针对BERT模型中的embedding层, 让其中的参数不参与微调, 代码1.
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path,config=config.bert_config)
# 希望锁定embeddings层的参数, 不参与更新
for name, param in self.bert.embeddings.named_parameters():
print(name)
param.requires_grad = False
self.fc = nn.Linear(config.hidden_size, config.num_classes)
- 输出结果:
word_embeddings.weight
position_embeddings.weight
token_type_embeddings.weight
LayerNorm.weight
LayerNorm.bias
- 针对BERT中的全连接层, 让其中的weight参数不参与微调, 代码2.
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path,config=config.bert_config)
# 希望将全连接层中的.weight部分参数锁定
for name, param in self.bert.named_parameters():
if name.endswith('weight'):
print(name)
param.requires_grad = False
self.fc = nn.Linear(config.hidden_size, config.num_classes)
- 输出结果:
embeddings.word_embeddings.weight
embeddings.position_embeddings.weight
embeddings.token_type_embeddings.weight
embeddings.LayerNorm.weight
encoder.layer.0.attention.self.query.weight
encoder.layer.0.attention.self.key.weight
encoder.layer.0.attention.self.value.weight
encoder.layer.0.attention.output.dense.weight
encoder.layer.0.attention.output.LayerNorm.weight
encoder.layer.0.intermediate.dense.weight
encoder.layer.0.output.dense.weight
encoder.layer.0.output.LayerNorm.weight
encoder.layer.1.attention.self.query.weight
encoder.layer.1.attention.self.key.weight
encoder.layer.1.attention.self.value.weight
encoder.layer.1.attention.output.dense.weight
encoder.layer.1.attention.output.LayerNorm.weight
encoder.layer.1.intermediate.dense.weight
encoder.layer.1.output.dense.weight
encoder.layer.1.output.LayerNorm.weight
......
......
......
encoder.layer.11.attention.self.query.weight
encoder.layer.11.attention.self.key.weight
encoder.layer.11.attention.self.value.weight
encoder.layer.11.attention.output.dense.weight
encoder.layer.11.attention.output.LayerNorm.weight
encoder.layer.11.intermediate.dense.weight
encoder.layer.11.output.dense.weight
encoder.layer.11.output.LayerNorm.weight
pooler.dense.weight
- 针对BERT中指定的若干层, 让其中的参数不参与微调, 代码3.
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path,config=config.bert_config)
# 封闭BERT中的第1, 3, 5层参数, 不参与微调
index_array = [1, 3, 5]
for name, param in self.bert.named_parameters():
new_x = name.split('.')[2]
if new_x in index_array:
print(name)
param.requires_grad = False
self.fc = nn.Linear(config.hidden_size, config.num_classes)
- 输出结果:
attention.self.query.weight
attention.self.query.bias
attention.self.key.weight
attention.self.key.bias
attention.self.value.weight
attention.self.value.bias
attention.output.dense.weight
attention.output.dense.bias
attention.output.LayerNorm.weight
attention.output.LayerNorm.bias
intermediate.dense.weight
intermediate.dense.bias
output.dense.weight
output.dense.bias
output.LayerNorm.weight
output.LayerNorm.bias
attention.self.query.weight
attention.self.query.bias
attention.self.key.weight
attention.self.key.bias
attention.self.value.weight
attention.self.value.bias
attention.output.dense.weight
attention.output.dense.bias
attention.output.LayerNorm.weight
attention.output.LayerNorm.bias
intermediate.dense.weight
intermediate.dense.bias
output.dense.weight
output.dense.bias
output.LayerNorm.weight
output.LayerNorm.bias
attention.self.query.weight
attention.self.query.bias
attention.self.key.weight
attention.self.key.bias
attention.self.value.weight
attention.self.value.bias
attention.output.dense.weight
attention.output.dense.bias
attention.output.LayerNorm.weight
attention.output.LayerNorm.bias
intermediate.dense.weight
intermediate.dense.bias
output.dense.weight
output.dense.bias
output.LayerNorm.weight
output.LayerNorm.bias
小节总结¶
- 本小节学习了如何对BERT模型进行微调, 以及微调过程中如何针对模型的不同部分进行微调, 并对比了放开不同的参数量对模型训练时间的影响.
- 关于常见的预训练模型, 可以直接到https://huggingface.co/models网站下载, 非常方便.
5.2 AlBERT模型介绍
AlBERT模型¶
学习目标¶
- 掌握AlBERT模型的架构.
- 掌握AlBERT模型的优化点.
AlBERT模型架构¶
- 经典Transformer的架构图如下:

- 左半部编码器就是BERT的前身, 右半部解码器就是GPT的前身.
- AlBERT模型发布于ICLR 2020会议, 是基于BERT模型的重要改进版本. 是谷歌研究院和芝加哥大学共同发布的研究成果.
- 论文全称<< A Lite BERT For Self-Supervised Learning Of Language Representations >>.
- 在本篇论文中, 首先对比了过去几年预训练模型的主流操作思路.
- 第一: 大规模的语料.
- 第二: 更深的网络, 更多的参数.
- 第三: 多任务训练.
- 关于词嵌入层, 对比了BERT和AlBERT对应于输入和输出的定量距离如下:

- 结论: 首先看原始论文中的论述, We observe that the transitions from layer to layer are much smoother for ALBERT than for BERT. These results show that weight-sharing has an effect on stabilizing network parameters. 可以看出BERT模型中词嵌入的L2距离和余弦相似度是震荡的, 而AlBERT显示出了更好的网络性能, 从一层到另一层的转换要平滑的多. 相当于AlBERT模型有效提升了神经网络参数的鲁棒性.
- 下图展示了主流的BERT和AlBERT的模型参数对比:

- 新模型的提出, 一个最重要的结论就是要在主流测试中超过老模型, 论文中展示了AlBERT在主流任务中的测试结果如下:
AlBERT模型的优化点¶
-
相比较于BERT模型, AlBERT的出发点即是希望降低预训练的难度, 同时提升模型关键能力. 主要引入了5大优化.
- 第一: 词嵌入参数的因式分解.
- 第二: 隐藏层之间的参数共享.
- 第三: 去掉NSP, 增加SOP预训练任务.
- 第四: 去掉dropout操作.
- 第五: MLM任务的优化.
-
第一: 词嵌入参数的因式分解.
-
AlBERT的作者认为, 词向量只记录了少量的词汇本身的信息, 更多的语义信息和句法信息包含在隐藏层中. 因此词嵌入的维度不一定非要和隐藏层的维度一致.
-
具体做法就是通过因式分解来降低嵌入矩阵的参数:
- BERT: embedding_dim * vocab_size = hidden_size * vocab_size, 其中embedding_dim=768, vocab_size大约为30000左右的级别, 大约等于30000 * 768 = 23040000(2300万).
- AlBERT: vocab_size * project + project * hidden_size, 其中project是因式分解的中间映射层维度, 一般取128, 参数总量大约等于30000 * 128 + 128 * 768 = 482304(48万).
-
第二: 隐藏层之间的参数共享.
-
在BERT模型中, 无论是12层的base, 还是24层的large模型, 其中每一个Encoder Block都拥有独立的参数模块, 包含多头注意力子层, 前馈全连接层. 非常重要的一点是, 这些层之间的参数都是独立的, 随着训练的进行都不一样了!
-
那么为了减少模型的参数量, 一个很直观的做法便是让这些层之间的参数共享, 本质上只有一套Encoder Block的参数!
-
在AlBERT模型中, 所有的多头注意力子层, 全连接层的参数都是分别共享的, 通过这样的方式, AlBERT属于Block的参数量在BERT的基础上, 分别下降到原来的1/12, 1/24.
-
第三: 去掉NSP, 增加SOP预训练任务.
-
BERT模型的成功很大程度上取决于两点, 一个是基础架构采用Transformer, 另一个就是精心设计的两大预训练任务, MLM和NSP. 但是BERT提出后不久, 便有研究人员对NSP任务提出质疑, 我们也可以反思一下NSP任务有什么问题?
-
在AlBERT模型中, 直接舍弃掉了NSP任务, 新提出了SOP任务(Sentence Order Prediction), 即两句话的顺序预测, 文本中正常语序的先后两句话[A, B]作为正样本, 则[B, A]作为负样本.
-
增加了SOP预训练任务后, 使得AlBERT拥有了更强大的语义理解能力和语序关系的预测能力.
-
第四: 去掉dropout操作.
-
原始论文中提到, 在AlBERT训练达到100万个batch_size时, 模型依然没有过拟合, 作者基于这个试验结果直接去掉了Dropout操作, 竟然意外的发现AlBERT对下游任务的效果有了进一步的提升. 这是NLP领域第一次发现dropout对大规模预训练模型会造成负面影响, 也使得AlBERT v2.0版本成为第一个不使用dropout操作而获得优异表现的主流预训练模型
-
第五: MLM任务的优化.
- segments-pair的优化:
- BERT为了加速训练, 前90%的steps使用了长度为128个token的短句子, 后10%的steps才使用长度为512个token的长句子.
- AlBERT在90%的steps中使用了长度为512个token的长句子, 更长的句子可以提供更多上下文信息, 可以显著提升模型的能力.
- BERT为了加速训练, 前90%的steps使用了长度为128个token的短句子, 后10%的steps才使用长度为512个token的长句子.
- Masked-Ngram-LM的优化:
- BERT的MLM目标是随机mask掉15%的token来进行预测, 其中的token早已分好, 一个个算.
- AlBERT预测的是Ngram片段, 每个片段长度为n (n=1,2,3), 每个Ngram片段的概率按照公式分别计算即可. 比如1-gram, 2-gram, 3-gram的概率分别为6/11, 3/11, 2/11.
- segments-pair的优化:
-
AlBERT系列中包含一个albert-tiny模型, 隐藏层仅有4层, 参数量1.8M, 非常轻巧. 相比较BERT, 其训练和推理速度提升约10倍, 但精度基本保留, 语义相似度数据集LCQMC测试集达到85.4%, 相比于bert-base仅下降1.5%, 非常优秀.
-
关于常见的预训练模型, 可以直接到https://huggingface.co/models网站下载, 非常方便.
小节总结¶
- 本小节学习了AlBERT模型的架构和优化点.
- 主体网络结构采用和BERT一致的结构.
- 词嵌入部分采用了因式分解来降低参数量.
- 每一层的参数采用了参数共享的机制, 极大的降低了参数量.
- 去除掉BERT中的NSP任务, 新增SOP任务, 大大提升了模型的能力.
- AlBERT模型发现了dropout操作的负面作用.
- AlBERT在训练语句的长度上更倾向于长文本, 同时优化了Masked-Ngram-LM的训练细节.
- albert-tiny模型非常轻巧, 在语义相似度, 分类等工业场景下可以大大提升推理速度.
5.3 GPT2模型介绍
GPT2模型¶
学习目标¶
- 掌握GPT2的架构
- 掌握GPT2的训练任务和模型细节
GPT2的架构¶
- 从模型架构上看, GPT2并没有特别新颖的架构, 它和只带有解码器模块的Transformer很像.
- GPT2也是一个语言预测生成模型, 只不过比手机上应用的模型要大很多, 也更加复杂. 常见的手机端应用的输入法模型基本占用50MB空间, 而OpenAI的研究人员使用了40GB的超大数据集来训练GPT2, 训练后的GPT2模型最小的版本也要占用超过500MB空间来存储所有的参数, 至于最大版本的GPT2则需要超过6.5GB的存储空间.
- 自从Transformer问世以来, 很多预训练语言模型的工作都在尝试将编码器或解码器堆叠的尽可能高, 那类似的模型可以堆叠到多深呢? 事实上, 这个问题的答案也就是区别不同GPT2版本的主要因素之一. 比如最小版本的GPT2堆叠了12层, 中号的24层, 大号的36层, 超大号的堆叠了整整48层!

GPT2模型的细节¶
- 以机器人第一法则为例, 来具体看GPT2的工作细节. - 机器人第一法则: 机器人不得伤害人类, 或者目睹人类将遭受危险而袖手旁观.
- 首先明确一点: GPT2的工作流程很像传统语言模型, 一次只输出一个单词(token).
- GPT2之所以在生成式任务中表现优秀, 是因为在每个新单词(token)产生后, 该单词就被添加在之前生成的单词序列后面, 添加后的新序列又会成为模型下一步的新输入. 这种机制就叫做自回归(auto-regression), 如下所示:

- 其次明确一点: GPT2模型是一个只包含了Transformer Decoder模块的模型.
- 和BERT模型相比, GPT2的解码器在self-attention层上有一个关键的差异: 它将后面的单词(token)遮掩掉, 而BERT是按照一定规则将单词替换成[MASK].
- 举个例子, 如果我们重点关注4号位置的单词及其前序路径, 我们可以让模型只允许注意当前计算的单词和它之前的单词, 如下图所示:

- 注意: 能够清楚的区分BERT使用的自注意力模块(self-attention)和GPT2使用的带掩码的自注意力模块(masked self-attention)很重要! 普通的self-attention允许模型的任意一个位置看到它右侧的信息(下图左侧), 而带掩码的self-attention则不允许这么做(下图右侧).
- 在Transformer原始论文发表后, 一篇名为<< Generating Wikipedia by Summarizing Long Sequences >>的论文提出用另一种Transformer模块的排列方式来进行语言建模-它直接扔掉了编码器, 只保留解码器. 这个早期的基于Transformer的模型由6个Decoder Block堆叠而成:

- 上图中所有的解码器模块都是一样的, 因为只展开了第一个解码器的内部结构. 和GPT一样, 只保留了带掩码的self-attention子层, 和Feed Forward子层.
- 这些解码器和经典Transformer原始论文中的解码器模块相比, 除了删除了第二个Encoder-Decoder Attention子层外, 其他构造都一样.
- GPT2工作细节探究. - GPT2可以处理最长1024个单词的序列.
- 每个单词都会和它的前序路径一起"流经"所有的解码器模块.
- 对于生成式模型来说, 基本工作方式都是提供一个预先定义好的起始token, 比如记做"s".
- 此时模型的输入只有一个单词, 所以只有这个单词的路径是活跃的. 单词经过层层处理, 最终得到一个词向量. 该向量可以对于词汇表的每个单词计算出一个概率(GPT2的词汇表中有50000个单词). 在本例中, 我们选择概率最高的单词["The"]作为下一个单词.
- 注意: 这种选择最高概率输出的策略有时会出现问题-如果我们持续点击输入法推荐单词的第一个, 它可能会陷入推荐同一个词的循环中, 只有你点击第二个或第三个推荐词, 才能跳出这种循环. 同理, GPT2有一个top-k参数, 模型会从概率最大的前k个单词中抽样选取下一个单词.
- 接下来, 我们将输出的单词["The"]添加在输入序列的尾部, 从而构建出新的输入序列["s", "The"], 让模型进行下一步的预测:
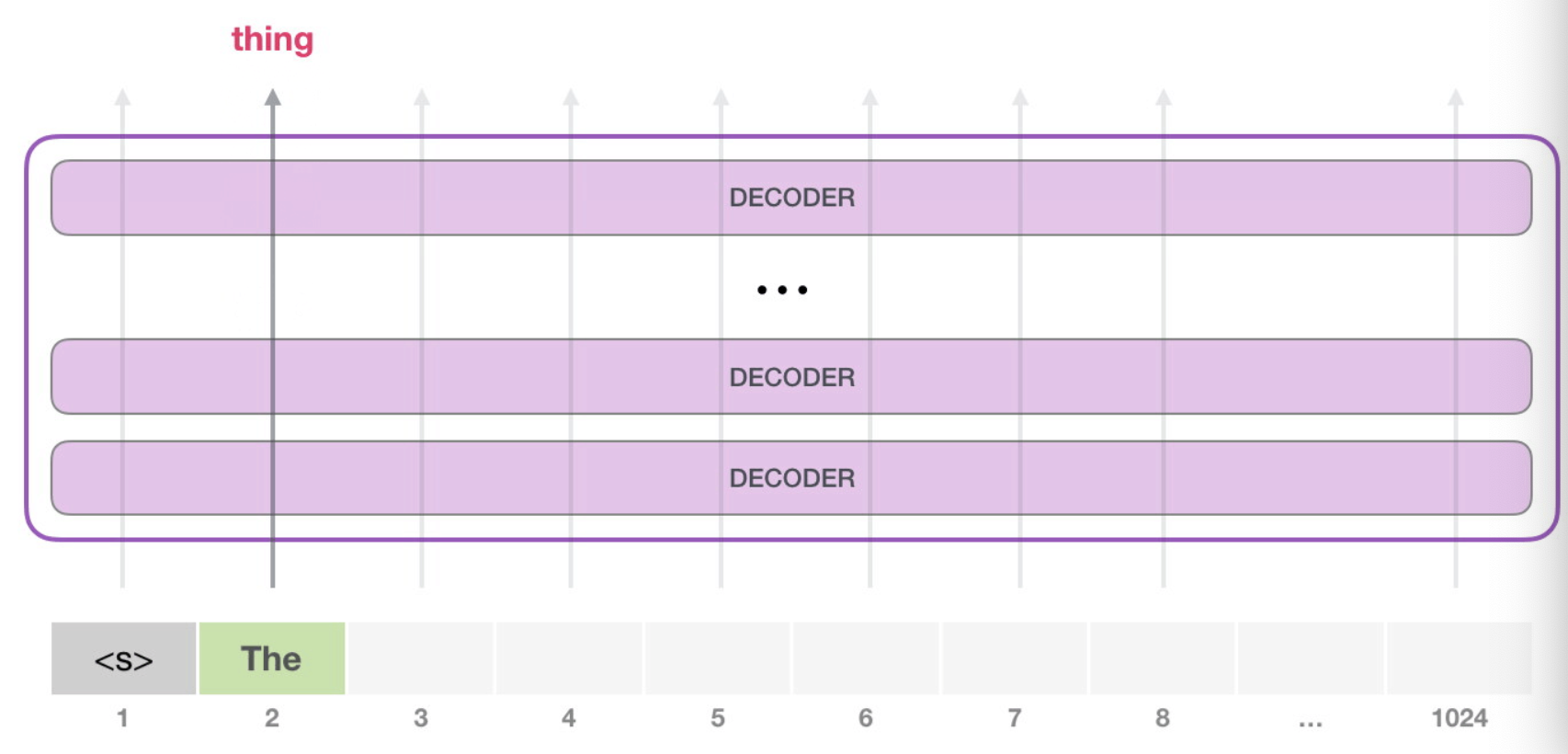
- 此时第二个单词的路径是当前唯一活跃的路径了. GPT2的每一层都保留了它们对第一个单词的解释, 并且将运用这些信息处理第二个单词, GPT2不会根据第二个单词重新来解释第一个单词.
- 关于输入编码: 当我们更加深入的了解模型的内部细节时, 最开始就要面对模型的输入, 和其他自然语言模型一样, GPT2同样从嵌入矩阵中查找单词对应的嵌入向量, 该矩阵(embedding matrix)也是整个模型训练结果的一部分.

- 1: 如上图所示, 每一行都是一个词嵌入向量: 一个能够表征某个单词, 并捕获其语义的数字向量. 嵌入的维度大小和GPT2模型的大小相关, 最小的模型采用了768这个维度, 最大的采用了1600这个维度.
- 2: 所以在整个模型运作起来的最开始, 我们需要在嵌入矩阵中查找起始单词"s"对应的嵌入向量. 但在将其输入给模型之前, 还需要引入位置编码(positional encoding), 1024分输入序列位置中的每一个都对应了一个位置编码, 同理于词嵌入矩阵, 这些位置编码组成的矩阵也是整个模型训练结果的一部分.

- 经历前面的1, 2两步, 输入单词在进入模型第一个transformer模块前的所有处理步骤就结束了. 综上所述, GPT2模型包含两个权值矩阵: 词嵌入矩阵和位置编码矩阵. 而输入到transformer模块中的张量就是这两个矩阵对应的加和结果.
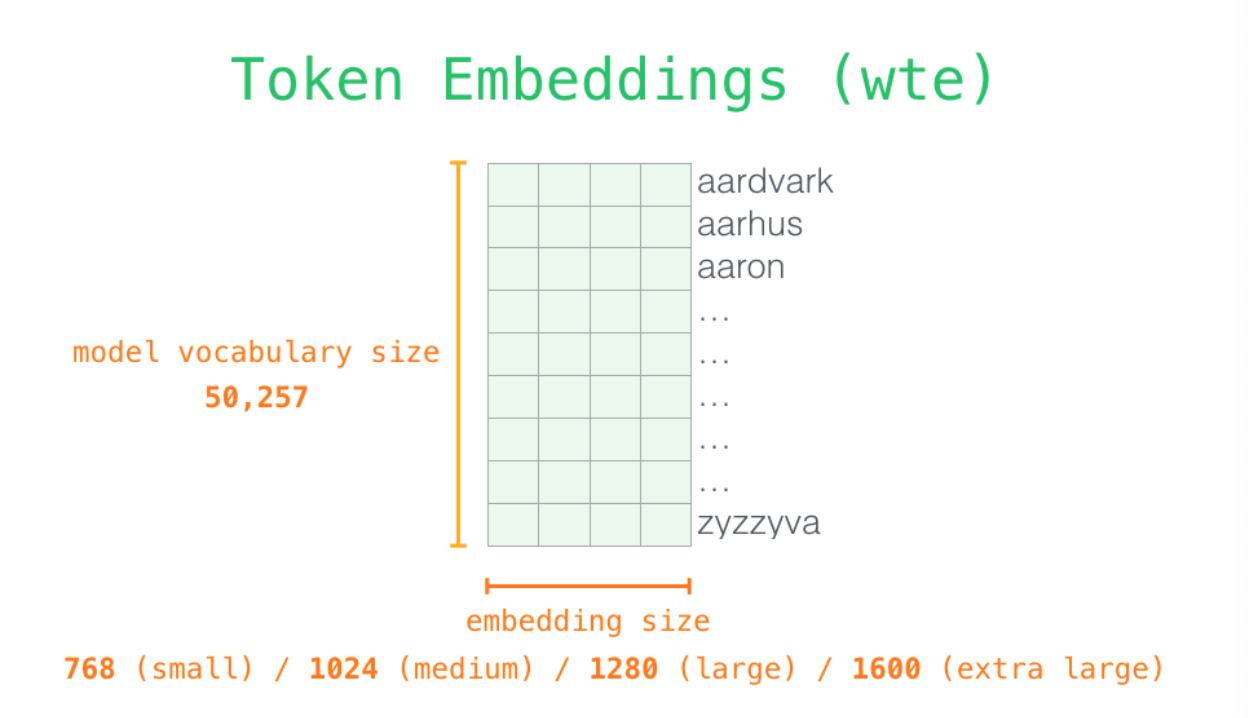
- transformer模块的堆叠: - 最底层的transformer模块处理单词的步骤:
- 首先通过自注意力层处理, 接着将其传递给前馈全连接层, 这其中包含残差连接和Layer Norm等子层操作.
- 最底层的transformer模块处理结束后, 会将结果张量传递给第二层的transformer模块, 继续进行计算.
- 每一个transformer模块的处理方式都是一样的, 不断的重复相同的模式, 但是每个模块都会维护自己的self-attention层和Feed Forward层的权重值.

- 首先通过自注意力层处理, 接着将其传递给前馈全连接层, 这其中包含残差连接和Layer Norm等子层操作.
- GPT2的自注意力机制回顾 - 自然语言的含义是极度依赖上下文的, 比如下面所展示的"机器人第二法则":
- 机器人必须遵守人类给它的命令, 除非该命令违背了第一法则.
- 在上述语句中, 有三处单词具有指代含义, 除非我们知道这些词所精确指代的上下文, 否则根本不可能理解这句话的真实语义.
- 当模型处理这句话的时候, 模型必须知道以下三点:
- [它]指代机器人.
- [命令]指代前半句话中人类给机器人下达的命令, 即[人类给它的命令].
- [第一法则]指代机器人第一法则的完整内容.
- 这就是自注意力机制所做的工作, 它在处理每个单词之前, 融入了模型对于用来解释某个单词的上下文的相关单词的理解. 具体的做法是: 给序列中的每一个单词都赋予一个相关度得分, 本质上就是注意力权重.
- 看下图, 举个例子, 最上层的transformer模块在处理单词"it"的时候会关注"a robot", 所以"a", "robot", "it", 这三个单词与其得分相乘加权求和后的特征向量会被送入之后的Feed Forward层.

- 自注意力机制沿着序列的每一个单词的路径进行处理, 主要由3个向量组成:
- 1: Query(查询向量), 当前单词的查询向量被用来和其它单词的键向量相乘, 从而得到其它词相对于当前词的注意力得分.
- 2: Key(键向量), 键向量就像是序列中每个单词的标签, 它使我们搜索相关单词时用来匹配的对象.
- 3: Value(值向量), 值向量是单词真正的表征, 当我们算出注意力得分后, 使用值向量进行加权求和得到能代表当前位置上下文的向量.
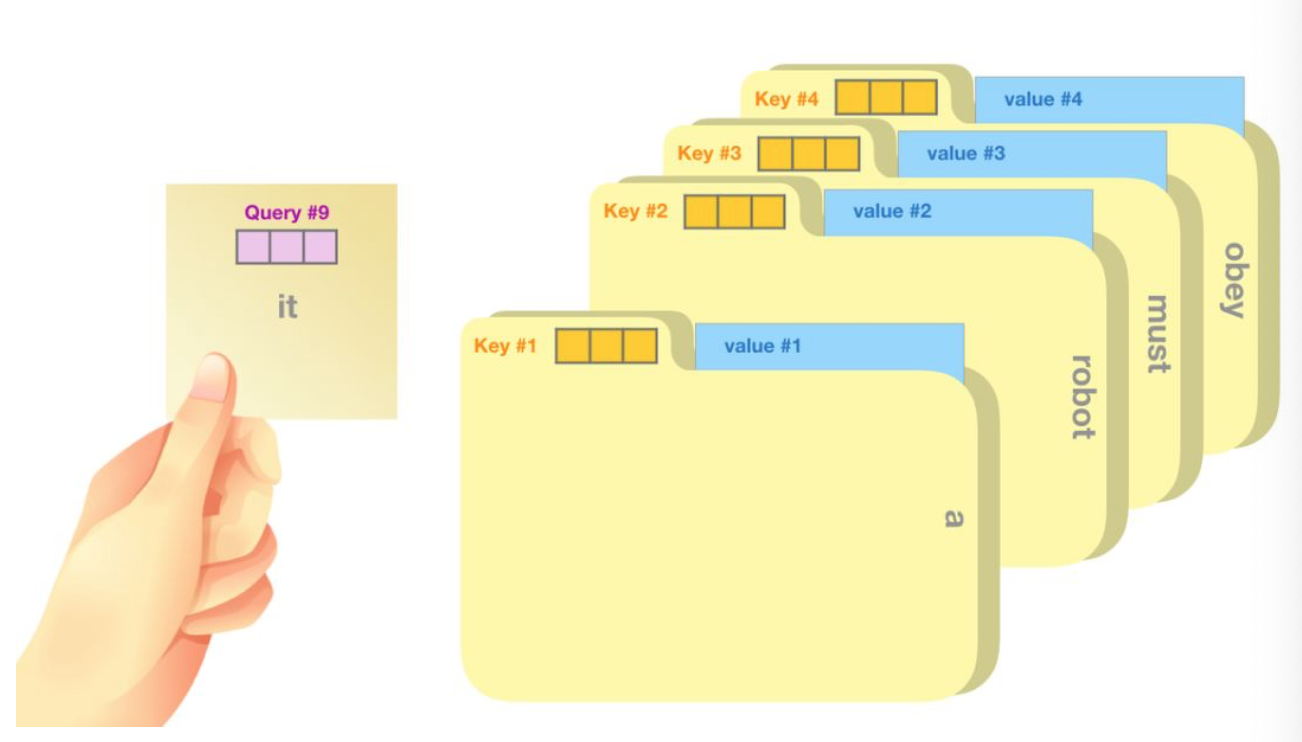
- 如上图所示, 一个简单的比喻是在档案柜中找文件. 查询向量Query就像一张便利贴, 上面写着你正在研究的课题. 键向量Key像是档案柜中文件夹上贴的标签. 当你找到和便利贴上所写相匹配的文件夹时, 拿出对应的文件夹, 文件夹里的东西便是值向量Value.
- 将单词的查询向量Query分别乘以每个文件夹的键向量Key,得到各个文件夹对应的注意力得分Score.
- 我们将每个文件夹的值向量Value乘以其对应的注意力得分Score, 然后求和, 得到最终自注意力层的输出, 如下图所示:
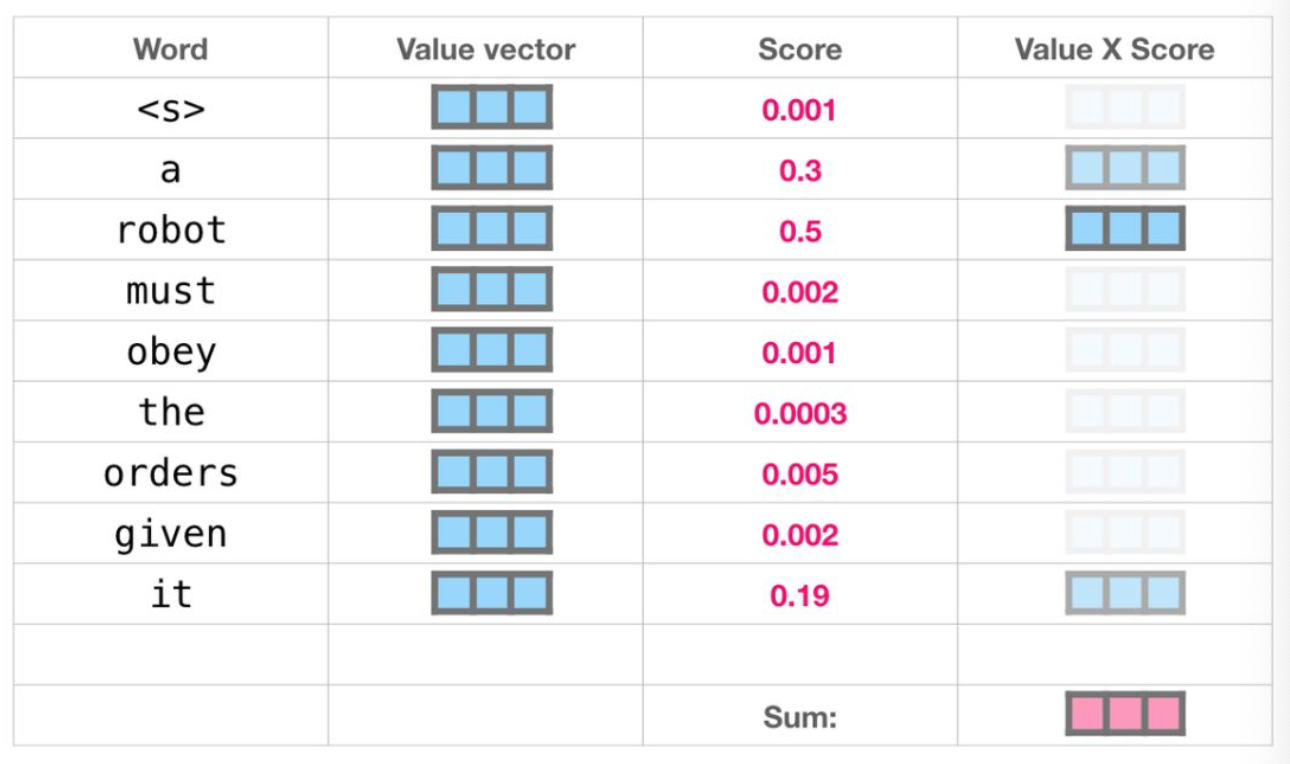
- 这样将值向量加权混合得到的结果也是一个向量, 它将其50%的注意力放在了单词"robot"上, 30%的注意力放在了"a"上, 还有19%的注意力放在了"it"上.
- 模型的输出:
- 当最后一个transformer模块产生输出之后, 模型会将输出张量乘上词嵌入矩阵:
- 我们知道, 词嵌入矩阵的每一行都对应模型的词汇表中一个单词的嵌入向量. 所以这个乘法操作得到的结果就是词汇表中每个单词对应的注意力得分, 如下图所示:

- 一般来说, 我们都采用贪心算法, 选取得分最高的单词作为输出结果(top_k = 1).
- 但是一个更好的策略是对于词汇表中得分较高的一部分单词, 将它们的得分作为概率从整个单词列表中进行抽样(得分越高的单词越容易被选中).
- 通常会用一个折中的方法, 即选取top_k = 40, 这样模型会考虑注意力得分排名前40的单词.
- 如上图所示, 模型就完成了一个时间步的迭代, 输出了一个单词. 接下来模型会不断的迭代, 直至生成完整的序列(序列长度达到1024的上限, 或者序列的某一个时间步生成了结束符).
GPT2模型代码细节¶
- GPT2模型是针对于生成式任务的最著名的预训练模型. 可以处理离线任务的生成, 也可以辅助在线任务的生成.
- 关于常见的预训练模型, 可以直接到https://huggingface.co/models网站下载, 非常方便.
小节总结¶
-
学习了GPT2的架构:
- GPT2只采用了Transformer架构中的Decoder模块.
- GPT2是在GPT基础上发展处的更强大的语言预训练模型.
-
学习了GPT2的工作细节:
- GPT2可以处理最长1024个单词的序列.
- 每个单词都会和它的前序路径一起"流经"所有的解码器模块.
- GPT2本质上也是自回归模型.
- 输入张量要经历词嵌入矩阵和位置编码矩阵的加和后, 才能输入进transformer模块中.
-
学习了GPT2自注意力机制的细节:
- 首先, GPT2的自注意力是Masked self-attention, 只能看见左侧的序列, 不能看见右侧的信息.
- Query, Key, Value这三个张量之间的形象化的例子, 生动的说明了各自的作用和运算方式.
- 最后的输出可以采用多个方法, 贪心方案, 概率分布方案, 或者top-k方案等.
5.4 T5模型介绍
T5模型¶
学习目标¶
- 掌握T5模型的架构.
- 掌握T5模型的优化点.
- 掌握T5模型的应用.
T5模型架构¶
- T5模型也是Google出品的精品预训练模型.
- << Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer >>.
- 简称Transfer Text-To-Text Transformer, 所以称呼T5.

- 简称Transfer Text-To-Text Transformer, 所以称呼T5.
- T5模型的内部基本采用了Transformer的结构, 但是核心思想在于将所有的NLP任务"大一统到seq2seq架构"中. 也就是说, 在T5模型中作者进行了多种优化方案的尝试, 各种对比实验, 消融实验, 得到一个最优的框架.
- T5本身没有什么算法上的亮点, 也没有模型结构上的巨大创新, 它最重要的作用是为NLP预训练模型提供了一个通用的框架, 为解决方案提供了一种通用思路, 那就是"万物皆可seq2seq"!
T5训练和应用流程¶
- T5模型在训练的时候所采用的的套路和应用时是一致的, 并且和下游任务一一对应, 非常清晰易懂.
- 比如当前任务是进行英德翻译, 只需要将训练数据集的输入部分前面加上"translate English to German"就行了. 假设我要把英文文本"That is good"翻译成德文, 只要把输入数据转换成"translate English to German: That is good", 直接输入模型中, 模型的输出就是翻译后的德文"Das ist gut".
- 再比如要进行情感分析(舆情监控)任务, 只需要将训练数据集的输入部分前面加上"sentiment"就行了. 假设我当前要对文本"This movie is terrible!"进行情感分析, 只要把输入数据转换成"sentiment: This movie is terrible!", 直接输入模型中, 模型的输出就是分析后的结果"negative".
- 比如我要进行STS-B(文本语义相似度任务), 原始的任务可以认为是一个回归任务, 因为需要得到一个连续值. 但是T5模型以每0.2为一个间隔, 从1分到5分之间分成21个离散值, 转换成了21分类任务. 比如架构图中的那个3.8其实并不是"浮点数值", 而是"字符串文本", 本质上是一个分类标签!
- T5模型的训练数据集 - T5模型的数据集是从Common Crawl (一个公开的网页存档数据集, 每个月大概抓取20TB的互联网文本数据)中清理出了750GB的训练数据, 取名为"Colossal Clean Crawled Corpus"(超大型干净的爬虫数据集), 简称"C4"! (不得不佩服谷歌起名的口味!)
- 关于C4数据集的清洗操作:
- 1: 只保留结尾是正常符号的行.
- 2: 删除任何包含脏词汇的页面.
- 3: 包含JavaScript词的行全部删除.
- 4: 包含编程语言中常用的大括号的页面全部删除.
- 5: 包含任何排版测试的页面全部删除.
- 6: 连续三句话重复出现的情况下, 只保留一行.
- 关于C4数据集的清洗操作:
- T5预训练策略的选择

- 关于预训练策略, 主流架构主要有3种:
- 第1种: Encoder-Decoder, 即大家熟悉的seq2seq架构, 分为编码器和解码器两部分. 对于Encoder可以看到前面, 也可以看到后面. 结果作为输入传递给Decoder. 对于Decoder只能看到前面的信息. BERT可以看做只有Encoder的模型.
- 第2种: 相当于只有Decoder部分, 只能看到前面的信息, 典型代表就是GPT2模型.
- 第3种: Prefix LM, 前缀模型, 可以看成是Encoder和Decoder的融合体, 一部分等效于Encoder可以看到前面, 也可以看到后面, 另一部分等效于Decoder只能看到前面的信息.
- 经过作者大量的对比实验后, 发现第1种Encoder-Decoder架构效果最优, 因此T5模型中采用了第1种架构.
- 其实上图中所展示的3种架构策略, 本质上内部结构都是基于Transformer, 只是MASK机制不同:
- T5文本MASK策略的选择
- 这里面有宏观角度和微观角度两方面: - 宏观角度: 可以理解为自监督训练方法, 总共有3种策略可选.
- 1: GPT-style, 生成式语言模型的方式, 类似于GPT2, 从左到右预测.
- 2: BERT-style, MLM的方式, 类似于BERT将token遮掩掉, 然后再还原出来.
- 3: Deshuffling-style, 将文本顺序打乱, 然后再还原出来.
- 微观角度: 可以理解为具体对什么粒度的文本进行MASK操作, 总共有3种策略可选.
- 1: token mask法, 即直接将单个token替换成[MASK].
- 2: replace span法, 可以将相邻的若干个token合并成一个[MASK].
- 3: drop法, 没有替换操作, 直接将随选定的token删除掉.

- 1: GPT-style, 生成式语言模型的方式, 类似于GPT2, 从左到右预测.
- 经过T5作者大量的试验, 发现宏观监督的BERT-style最好, 微观角度的replace span最好, 因此在T5模型中共同采用这两种策略.
- T5预训练百分比策略的选择
- 按照前面选定的策略, 最后一步就是确定一下训练语料中多大比例的文本参与这种MASK策略了. T5作者也进行了大量的对比实验如下:

- 最后T5的作者发现15%的MASK比例最优, 同时span=3这个值最优. 再次不得不佩服BERT的作者Devlin这个老司机的直觉真厉害!
- 关于T5的几个版本效果的对比. - Small: Encoder和Decoder都只有6层, 隐藏层的维度取512, head=8, 参数总量60 million.
- Base: Encoder和Decoder都采用BERT-base的参数, 参数总量220 million.
- Large: Encoder和Decoder都采用BERT-large的参数, 但层数保留12, 参数总量770 million.
- 3B: 在BERT-large的参数基础上, 层数采用24层, 参数总量3 Billion.
- 11B: 在3B参数基础上, FNN和head选取的更大, 参数总量11 Billion.

- 结论: 相比较之前的RoBERTa和AlBERT的SOTA基线, T5模型的Small, Base, Large并没有什么突出表现, 几乎在所有的基准测试中全部处于下风. 到了3B版本才有接近于Previous Best的表现. 直到继续暴力拉升到11B的参数版本, 才显示出T5模型的优势. 所以"Bigger is better?"真的是疑问句吗? 值得每一个AI科学家, AI工程师反思!!!
T5模型的应用¶
- 关于T5模型的具体应用, 包含文本分类, 机器翻译, 生成式对话, 摘要任务, 阅读理解等等.
- 关于常见的预训练模型, 可以直接到https://huggingface.co/models网站下载, 非常方便.
小节总结¶
- 本小节学习了T5模型的架构, 总结来看即如下5点:
- 1: 架构上采用了Encoder-Decoder模型.
- 2: 宏观上MASK策略采用了BERT-style的策略.
- 3: 微观上MASK策略采用replace span的段式MASK.
- 4: 宏观上进行MASK的比例采用15%.
- 5: 微观上进行MASK的段长span等于3.
5.5 XLNet模型介绍
XLNet模型¶
学习目标¶
- 掌握XLNet模型的架构.
- 掌握XLNet模型的优化点.
- XLNet相比于BERT, 在问答对话, 文本分类, 阅读理解等多项NLP任务上都得到了大幅提升, 再次刷新了AI研究者的认知边界.
- 关于语言模型的汇总:
- 1: AE模型(Auto Encoder LM), 经典代表为BERT.
- 2: AR模型(Auto Regression LM), 经典代表为GPT2.
- 3: 排列模型(Permutation LM), 经典代表为XLNet.
XLNet模型的架构¶
- 无论是AE模型还是AR模型, 都有自身难以克服的"硬伤".
- AE模型: 比如BERT采用随机MASK的方式舍掉一些单词, 利用模型的能力还原这些单词. 但是由于在预训练阶段接入了[MASK]标记, 导致了预训练和微调阶段的不一致, 也就是exposure bias问题. 另一方面, BERT模型有一个假设并不符合实际情况, 即假设所有的[MASK]之间是相互独立的. 例如, 对于"自然语言理解"这段文本, 假设BERT的输入是"自然语言[MASK][MASK]", 那么BERT模型的优化目标是P(处|自然语言) * P(理|自然语言), 反过来对于传统语言模型, 优化目标是P(处|自然语言) * P(理|自然语言处), 可以很清晰的看出BERT忽略的了[MASK]之间的相关性.
- AR模型: 比如GPT2模型, 最大的问题是只能看到前面的信息, 无法利用后面的信息.
- 出发点是既希望集合AE, AR模型的优点, 又能避免各自的缺点, 因而提出了XLNet模型! XLNet在实现双向Transformer编码的同时, 还能够避免BERT所产生的问题.
Permutation Language Modeling¶
- XLNet基于AR模型, 采用了一种全新的方法Permutation Language Model, 基本模式采用从左向右的输入, 也就是自回归的模式, 只能看到上文信息. XLNet将完整句子中的单词随机打乱顺序, 这样的话对于单词x_i, 它原先的上下文单词就都有可能出现在当前的上文中了.
- 如下图所示, 对于单词x3, 改变原始语句中x1, x2, x3, x4的排列组合, 那么x3的上文中就有机会出现x4. 等于通过"排列的技巧将下文信息强制搬迁到上文中". 在实际微调中我们不能直接去改变原始的输入, 输入的顺序还应该是x1, x2, x3, x4, 所以单词顺序的改变是通过人为的手段让它发生在模型内部, 这时候就要用到神奇的attention mask机制, 通过mask的方式来改变单词的顺序.

Two-Stream Self-Attention¶
- 通过PLM改变了文本单词的顺序后, 模型又产生了新的问题, 那就是不知道要预测句子中的哪一个单词?
- 传统的AR模型中, 预测的永远是序列的下一个位置的单词, 因此不存在这个问题.
- 在XLNet中, 因为单词顺序被打乱, 无法根据上文知道要预测的是哪一个位置的单词.
- 比如: 对于句子[x1, x2, x3, x4], 打乱顺序后对第三个位置的单词进行预测, 得到的上文信息是[x2, x4], 但是我们无法知道这个所谓的"第三个位置的单词", 到底是x1, 还是x3. - 打乱后的序列如果是[x2, x4, x1, x3], 那么第三个位置就是x1.
- 打乱后的序列如果是[x2, x4, x3, x1], 那么第三个位置就是x3.
- 通过上面的分析, 我们清楚了一个事实: 在XLNet中, 只知道上文信息是[x2, x4], 无法准确预测出下一个单词到底应该是谁? 由此XLNet引入了非常有技巧性的方法Two-Stream Self-Attention机制, 完美的解决了这个问题.
- 预测时需要在输入上文信息[x2, x4]的基础上, 额外再输入预测目标的信息, 比如位置z3=1, 这样就可以确定预测的目标是x1了.
- Two-Stream Self-Attention的原理图如下所示:

- Query Stream的目的是为了预测, 它用到的信息都是上下文信息, 没有涉及到任何关于预测单词内容本身的信息.
- Content Stram的目的是为了Query提供完备的信息. 可以看做一个标准的Transformer特征提取器, 正好可以弥补Query Stream缺少单词xi的内容信息, 有助于Content Stream更好的提取出有关预测单词上下文的特征.
- 注意: XLNet对了排列在比较靠前位置的单词, 预测难度较大. 因此在构造训练阶段, XLNet只做部分预测, 只预测后1/K个单词, 可以加快模型的收敛速度!
- Modeling Multiple Segments: 前面的两个最重要的优化都集中在token层面上, 但是NLP中还有一些下游任务是基于句子层面的, 比如BERT中的NSP, AlBERT中的SOP. XLNet论文作者也同意NSP任务没什么用, 因此提出了Relative Segment Encoding.
- Relative Segment Encoding: 借鉴了Transformer-XL模型中的相对位置编码的思想, 只判断两个单词是否在同一个segment中, 而不去判断各自属于哪个segment.
XLNet模型的成绩¶
- 相比较于BERT模型, XLNet在阅读理解任务上有非常突出的表现.

- 相比较于BERT模型, XLNet在经典GLUE任务中的成绩也都有明显什么巨大的优势.

小节总结¶
- 本小节学习了XLNet模型的架构和模型细节.
- XLNet模型可以说是预训练模型中的一个集大成之作, 它通过Permutation Language Modeling巧妙地将LM与BERT模型, GPT2模型中各自的优点结合了起来, 再加上引入的Transformer-XL和relative segment encoding等先进技术, 使得XLNet在模型表现上更上一层楼.
- 特别是对于BERT表现欠佳的生成式任务, XLNet的表现会更加突出.
5.6 Electra模型介绍
Electra模型¶
学习目标¶
- 掌握Electra模型的架构.
- 掌握Electra模型的优化点.
Electra模型架构¶
- Electra模型是2020年提出的最新版的预训练模型, 原始论文题目: << ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS >>, 由谷歌公司和斯坦福大学共同提出.
- 作者在论文中阐明, 模型的名称ELECTRA的由来是"Efficiently Learning an Encoder that Classifies Token Replacements Accurately".
总体架构¶
- 首先来看Electra模型的架构图
- 如上图所示, 整个模型分成两部分, 左半部是一个生成器Generator, 右半部是一个分类器Discriminator. - 生成器Generator: 在一个较小的网络上训练经典的MLM任务, 使得生成器能够准确的复现那些被[MASK]掉的token, 也就是说左侧的生成器负责还原原始输入.
- 分类器Discriminator: 是ELECTRA的主体, 训练一个二分类器, 使得分类器能够准确的判断Generator输出的每一个token, 到底是原始输入的token, 还是已经被替换掉的replaced token.
训练方法¶
- 首先专注于MLM任务的对比. 自从BERT模型中引入MLM任务预训练后, 诸多优秀的模型都采用这种任务(比如XLNet等), 尽管相比于传统语言模型, 他们使用Transformer在正反两个方向上对语义进行学习, 使得学习效率有了很大提升. 但是这些模型只对input中的一小部分进行学习(比如BERT的15%), 所以仍旧耗费了大量的算力.
- 为了进一步提升预训练语言模型的学习效率, 论文作者提出了新的任务RDT(Replaced Token Detection), 用以作为MLM任务的替代品.
- RDT任务就是两部分:
- 第1部分: 首先通过一个较小的Generator对BERT中的[MASK]进行预测还原.
- 第2部分: 然后通过一个Discriminator对步骤1中的每个单词进行二分类预测, 原始token还是replaced token?
- 通过上述的训练方法, 我们会发现整个模型会从input序列中的全部tokens进行学习, 这区别于BERT的15%的tokens, 而这也是ELECTRA总能使用更少的算力, 更少的参数, 达到比BERT更好的效果.

- 两阶段训练法:
- 首先, 只对Generator连续训练n-steps.
- 使用Generator的参数对Discriminator进行初始化, 然后对Discriminator连续训练n-steps, 与此同时保持Generator的参数不变.
- 两阶段训练法有一个前提: 要求Generator和Discriminator要有相同的规模.
- 两阶段训练的缺点:
- 经过试验发现, 如果在两阶段训练中不使用参数共享, 最终学到的判别器可能在很多类别上什么也没有学到. 分析原因后推测, 这可能是因为Generator启动速度比Discriminator快得多, 即Generator已经学会了高中知识并给出了高中阶段的题目, 而Discriminator还只是小学生水平.
- 因此, 在ELECTRA模型中采用了联合训练的方法.
损失函数¶
- 在ELECTRA中, Generator可以是任意模型, 它的任务是对被随机MASK掉的token进行预测, 一般实际采用一个较小的BERT模型, 与Discriminator一起进行训练. Discriminator的任务是分辨出到底哪个token是被Generator篡改过, 以至于和原始token不一致, 本质上是进行一次二分类, 判断Generator输出的任意一个token是原始token, 还是replaced token.
- 具体来说, Generator和Discriminator是我们训练得到的两个神经网络, 二者都包含Encoder(架构是Transformer网络), 从而将input序列从x映射到h(x). 但二者有不同的训练任务, 因此要用不同的损失函数对它们进行衡量.
- Generator: 任务是根据上下文对被随机MASK掉的token进行预测, 采样空间是全体词表V, 因此损失函数用softmax损失.
- Discriminator: 任务是对任意一个token是原始token, 还是replaced token进行二分类判断, 因此损失函数用sigmoid损失.
- ELECTRA的最终损失函数由Generator和Discriminator一同组成, 因为Generator模型较小且任务相对更难, 所以损失值更大. 对于联合多任务训练, 我们希望模型可以同时关注两者的loss, 所以在这里给Generator更大的关注度, 数学技巧上则是给Discriminator的损失值加上一个系数lambda:
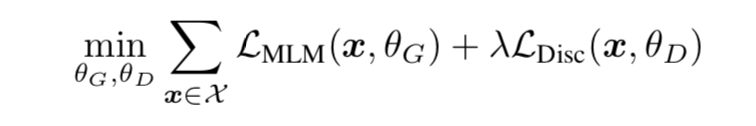
实验细节¶
- 参数共享机制: 预训练模型的时代, 参数共享机制是一个很常用的技巧, 既可以缩小模型规模, 又可以提升参数的学习效率. 当Generator和Discriminator规模相等时, 二者之间可以将参数完全共享.
- 经过大量的实验对比验证, 更小的Generator对结果更有帮助, 因此在ELECTRA中只共享了Generator和Discriminator中的embedding层参数(包括token embedding和positional embedding). 实验数据表明, 不进行参数共享GLUE score=83.6, 全部参数共享GLUE score=84.4, 只进行embedding层参数共享GLUE score=84.3, 分析原因后认为Discriminator只会更新input序列中涉及到判别token的参数, 而Generator会对词表中的全部单词进行权重更新, 所以共享参数会导致资源浪费.
- 更小的生成器: 如果设置Generator和Discriminator规模相当, 则整个预训练的时间会大约变成原来的2倍. 下图左侧所示, 当Discriminator规模不变的情况下, Generator的规模越大, 反倒会导致结果的下降. 最终实验发现最佳的Generator大小为Discriminator规模的¼ - ½.

- 结论: 更小的Generator有更优的结果, 可以理解为一个更强大的生成器会给出太难的题目, 以致于判别器无法学习, 跟不上节奏!!!
Electra模型的成绩¶
- 首先在经典的GLUE数据集上, ELECTRA模型在大部分任务上得到了更优的结果.

- 如下图所示, 在NLP领域中属于"难任务"的阅读理解SQuAD数据集上, ELECTRA的加大模型也几乎在所有的任务上得到了最优的结果, 仅仅在1个指标上低于强大的XLNet模型.

小节总结¶
- 本小节学习了Electra模型的架构.
- ELECTRA模型包含两部分, 生成器Generator和分类器Discriminator.
- 生成器Generator是在一个较小的网络上训练经典的MLM任务, 使得生成器能够准确的复现那些被[MASK]掉的token, 本质上是在负责还原原始的输入.
- 分类器Discriminator是训练一个二分类器, 使得分类器能够准确的判断Generator输出的每一个token, 到底是原始输入的token, 还是已经被替换掉的replaced token.
- 关于ELECTRA的训练:
- 联合训练法即同时训练Generator和Discriminator, 对于联合loss中的Generator给予更多的关注, 对Discriminator添加一个lambda系数来降低关注度.
5.7 BERT系列模型介绍
BERT模型¶
学习目标¶
- 掌握BERT源代码中的关键类的定义.
- 掌握BERT源代码中的核心操作.
- 掌握BERT模型中参数量的计算.
BERT关键类的定义¶
-
关于BERT源代码的分析, 主要基于以下几个核心类进行:
- 第一: BertEmbeddings类(词嵌入层)
- 第二: BertSelfAttention类(多头自注意力层)
- 第三: BertSelfOutput类(自注意力输出层)
- 第四: BertIntermediate类(前馈全连接层)
- 第五: BertPooler类(CLS层)
- 第六: BertLMPredictionHead类(语言模型预测头)
-
第一: BertEmbeddings类(词嵌入层)
class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
if version.parse(torch.__version__) > version.parse("1.6.0"):
self.register_buffer(
"token_type_ids",
torch.zeros(self.position_ids.size(), dtype=torch.long),
persistent=False,
)
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
- 关键点回顾: 嵌入层的3部分都是通过nn.Embedding()来定义的, 而且都映射成768的维度, 最终加和.
- 第二: BertSelfAttention类(多头自注意力层)
class BertSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(
config, "position_embedding_type", "absolute"
)
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view( *new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoders padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view( *new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
- 关键点: 自注意力机制中的query, key, value在代码中本质上都是nn.Linear()定义的全连接层, 多头机制通过函数transpose_for_scores()来进行维度拆解和维度变换.
- 第三: BertSelfOutput类(自注意力输出层)
class BertSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
- 核心点: 自注意力的输出层核心操作是一个变换方阵nn.Linear(768, 768), 外加LayerNorm和Dropout操作.
- 第四: BertIntermediate类(前馈全连接层)
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
- 核心点: 前馈全连接层的类名是BertIntermediate, 不要记成BertFeedForward. 本质上就是一个全连接层, 外加激活函数的操作.
- 第五: BertPooler类(CLS层)
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
- 核心点: BertPooler的操作对象即BERT中的CLS, 即最后一层输出张量的第一个位置CLS的后续处理. 一般该类的输出用于分类任务.
- 第六: BertLMPredictionHead类(语言模型预测头)
class BertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
- 核心点: 语言模型预测头的核心操作就是slef.decoder, 用于将隐藏层维度映射到词表大小vocab_size上, 后续进行单词预测.
BERT模型中参数量的计算¶
- 详细理解BERT模型中参数量的计算, 可以更加深入细致的掌握BERT结构, 从细节到宏观都有更好的把握. 分三个部分进行计算:
- Embedding层的参数计算.
- Encoder层的参数计算.
- Pooling层的参数计算.
- 计算举例以bert-base-case模型为参考, 核心参数如下:
- 层数layer = 12
- 隐藏层维度hidden_size = 768
- 多头注意力数head = 12
- 参数总量 = 110M
Embedding层¶
- BERT的Embedding分为三个部分Token Embedding, Segment Embedding, Position Embedding. 其中Token Embedding包括词表V有30522个, 对应30522个单词(或token, 不同的语言模型数量不同). Segment Embedding包括2个取值, 分别表示当前token属于第1个句子, 还是第2个句子, 这是和BERT预训练的NSP任务直接相关的. Position Embedding包括512个取值(因为BERT要求编码序列的长度不超过512). 最后每种embedding都会把token映射到H维(当前默认为768)的隐向量中.
- 这3部分词嵌入的参数量为(30522 + 512 + 2) * 768 = 23835648
- 在完成词嵌入后, 每个位置的隐向量维度都是768, 还要经过一层LayerNorm, LayerNorm的参数就是均值和方差, 所以这个模块的参数量是768 * 2.
- 综上所述: Embedding层的参数总量就是(30522 + 512 + 2) * 768 + 768 * 2 = 23837184
Encoder层¶
- BERT中的Encoder是由12个Encoder Block堆叠在一起的, 而每一个Encoder Block的内部结构完全一样, 从下到上依次是:
- Multi-head Attention
- Add & Norm
- Feed Forward
- Add & Norm
- Multi-head Attention
- 每个Block包含12个head, 每个head拥有不同的3个自注意力矩阵Q, K, V, 通过矩阵乘法将上一层的输出跟着3个矩阵分别相乘, 得到新的Q, K, V向量. 需要注意的是这里有12个head, 所以每个head的每个矩阵都会把上一层的768维度向量的输出, 映射成768 / 12 = 64维的新向量, 最后通过concat操作进行拼接, 重新得到新的768维隐向量.
- 因此这里每个head的每个矩阵的参数包括weights = 768 * (768 / 12), bias = 768 / 12. 每个head同时拥有Q, K, V这3个矩阵, 每个Block又有12个head, 因此参数量 = 12 * 3 * (768 * (768 / 12) + 768 / 12) = 1771776.
- 在将12个head的输出concat到一起后, 还会经过一个全连接层的操作, 本质上是一个方阵映射, 这部分weight = 768 * 768, bias = 768.
- 因此整个Multi-head Attention模块的参数量 = 12 * 3 * (768 * (768 / 12) + 768 / 12) + 768 * 768 + 768 = 2362368
- Add & Norm
- Add本质上是跨层连接, 起到残差连接的作用, 没有额外的参数.
- Norm在这里指代LayerNorm操作, 参数包括均值和方差, 它接收的是上一层Multi-head Attention的768维的输出结果, 处理后的输出张量维度不变, 所以Norm总共有768 * 2个参数
- Feed Forward
- Feed Forward是前馈全连接层, 这里包括2层全连接层, 第1层全连接层会进行升维, 会把输入从当前维度(768)映射成4倍当前维度的中间层(3072), 第2层全连接层会进行降维, 会把4倍初始输入维度的中间层结果(3072)映射到初始维度(768).
- 第1层全连接层的weight = 768 * (768 * 4), bias = 768 * 4; 第2层全连接层的weight = (768 * 4) * 768, bias = 768.
- 综上所述, Feed Forward层的参数量 = 768 * (768 * 4) + 768 * 4 + (768 * 4) * 768 + 768 = 4722432
- Add & Norm
- 这里的Add & Norm和前面的论述一样, 参数量768 * 2.
- 综上所述, 整个Encoder部分拥有12个Block, 每个Block的参数前面已经详细计算过了, 因为总量是12 * (2362368 + 1536 + 4722432 + 1536) = 85054464
Pooling层¶
- Pooling层本质是一层全连接层, 它的输入是Encoder层输出的768维隐向量, 输出保持维度不变. 因此只包括weight = 768 * 768, bias = 768, 参数量 = 768 * 768 + 768 = 590592
结论: 整个BERT模型的参数量为前述3部分的总和, Embedding + Encoder + Pooling = 23837184 + 85054464 + 590592 = 109482240.
AlBERT模型¶
- 掌握AlBERT模型的微调.
- 了解AlBERT模型的底层原理.
AlBERT模型微调¶
- 基于第5章5.2节的介绍, 此处展示一下AlBERT模型处理投满分项目的微调效果.
- 在模型构建部分引入的预训练模型从BERT换成AlBERT即可. - 代码位置: /home/ec2-user/toutiao/albert/src/models/albert.py
import torch
import torch.nn as nn
import os
from transformers import AlbertModel, BertTokenizer, AlbertConfig
class Config(object):
def __init__(self, dataset):
self.model_name = "albert"
self.data_path = "/home/ec2-user/toutiao/albert/data/data/"
self.train_path = self.data_path + "train.txt" # 训练集
self.dev_path = self.data_path + "dev.txt" # 验证集
self.test_path = self.data_path + "test.txt" # 测试集
self.class_list = [
x.strip() for x in open(self.data_path + "class.txt").readlines()
] # 类别名单
self.save_path = "/home/ec2-user/toutiao/albert/src/saved_dic"
if not os.path.exists(self.save_path):
os.mkdir(self.save_path)
self.save_path += "/" + self.model_name + ".pt" # 模型训练结果
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备
# self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 5 # epoch数
self.batch_size = 256 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "/home/ec2-user/toutiao/albert/data/albert_chinese_base/"
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.bert_config = AlbertConfig.from_pretrained(self.bert_path + '/config.json')
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.albert = AlbertModel.from_pretrained(config.bert_path,config=config.bert_config)
for name, param in self.albert.named_parameters():
param.requires_grad = True
print(name)
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.albert(context, attention_mask=mask)
out = self.fc(pooled)
return out
- 调用:
cd /home/ec2-user/toutiao/albert/src/
python run.py --task train_albert
- 输出结果:
Loading data for Bert Model...
180000it [00:42, 4244.76it/s]
10000it [00:02, 3933.59it/s]
10000it [00:02, 4433.94it/s]
embeddings.word_embeddings.weight
embeddings.position_embeddings.weight
embeddings.token_type_embeddings.weight
embeddings.LayerNorm.weight
embeddings.LayerNorm.bias
encoder.embedding_hidden_mapping_in.weight
encoder.embedding_hidden_mapping_in.bias
encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.weight
encoder.albert_layer_groups.0.albert_layers.0.full_layer_layer_norm.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.query.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.query.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.key.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.key.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.value.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.value.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.dense.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.dense.bias
encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.weight
encoder.albert_layer_groups.0.albert_layers.0.attention.LayerNorm.bias
encoder.albert_layer_groups.0.albert_layers.0.ffn.weight
encoder.albert_layer_groups.0.albert_layers.0.ffn.bias
encoder.albert_layer_groups.0.albert_layers.0.ffn_output.weight
encoder.albert_layer_groups.0.albert_layers.0.ffn_output.bias
pooler.weight
pooler.bias
Epoch [1/5]
57%|██████████████████████████████████████▋ | 400/704 [07:32<05:50, 1.15s/it]Iter: 400, Train Loss: 0.53, Train Acc: 86.33%, Val Loss: 0.51, Val Acc: 84.59%, Time: 0:07:51 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:41<00:00, 1.17s/it]
Epoch [2/5]
57%|██████████████████████████████████████▋ | 400/704 [07:43<05:53, 1.16s/it]Iter: 400, Train Loss: 0.34, Train Acc: 89.45%, Val Loss: 0.37, Val Acc: 88.71%, Time: 0:21:43 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:52<00:00, 1.18s/it]
Epoch [3/5]
57%|██████████████████████████████████████▋ | 400/704 [07:44<05:53, 1.16s/it]Iter: 400, Train Loss: 0.26, Train Acc: 92.58%, Val Loss: 0.33, Val Acc: 90.04%, Time: 0:35:36 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:52<00:00, 1.18s/it]
Epoch [4/5]
57%|██████████████████████████████████████▋ | 400/704 [07:44<05:53, 1.16s/it]Iter: 400, Train Loss: 0.21, Train Acc: 95.70%, Val Loss: 0.32, Val Acc: 90.85%, Time: 0:49:29 *
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:54<00:00, 1.18s/it]
Epoch [5/5]
57%|██████████████████████████████████████▋ | 400/704 [07:44<05:52, 1.16s/it]Iter: 400, Train Loss: 0.16, Train Acc: 96.48%, Val Loss: 0.33, Val Acc: 90.92%, Time: 1:03:24
100%|████████████████████████████████████████████████████████████████████| 704/704 [13:53<00:00, 1.18s/it]
Test Loss: 0.31, Test Acc: 90.73%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9213 0.8900 0.9054 1000
realty 0.9220 0.9100 0.9160 1000
stocks 0.8264 0.8520 0.8390 1000
education 0.9749 0.9340 0.9540 1000
science 0.8781 0.8430 0.8602 1000
society 0.8941 0.9120 0.9030 1000
politics 0.8644 0.8990 0.8814 1000
sports 0.9616 0.9760 0.9687 1000
game 0.9676 0.8950 0.9299 1000
entertainment 0.8761 0.9620 0.9171 1000
accuracy 0.9073 10000
macro avg 0.9087 0.9073 0.9075 10000
weighted avg 0.9087 0.9073 0.9075 10000
Confusion Matrix...
[[890 15 59 1 3 11 12 3 0 6]
[ 10 910 26 0 4 13 5 9 2 21]
[ 45 19 852 0 25 4 48 4 2 1]
[ 1 5 2 934 6 19 16 2 2 13]
[ 3 5 53 3 843 20 27 4 15 27]
[ 6 17 1 10 4 912 19 1 3 27]
[ 8 7 23 6 7 27 899 2 0 21]
[ 0 1 3 0 2 1 5 976 1 11]
[ 2 2 9 2 62 8 6 5 895 9]
[ 1 6 3 2 4 5 3 9 5 962]]
- 结论: 通过对AlBERT模型的微调, 得到测试集上的F1=90.73%, 这个分数相比较于BERT有接近3个百分点的下降, 还是比较显著的! 由此得出亲身实践的结论, 不要迷信任何模型, 因为基于标准数据集跑出来的效果, 在工业界落地中几乎不可能有"几乎一样优秀的"结果!
AlBERT核心解密¶
- Emebdding因式分解(Factorized embedding parameterization)
class AlbertEncoder(nn.Module):
def __init__(self, config):
super(AlbertEncoder, self).__init__()
self.hidden_size = config.hidden_size
self.embedding_size = config.embedding_size
self.embedding_hidden_mapping_in = nn.Linear(self.embedding_size, self.hidden_size)
self.transformer = AlbertTransformer(config)
def forward(self, hidden_states, attention_mask=None, head_mask=None):
if self.embedding_size != self.hidden_size:
prev_output = self.embedding_hidden_mapping_in(hidden_states)
else:
prev_output = hidden_states
outputs = self.transformer(prev_output, attention_mask, head_mask)
return outputs # last-layer hidden state, (all hidden states), (all attentions)
- 在代码中的体现则是在Encoder层中增加了embedding_hidden_mapping_in层, 即增加了E * H的矩阵, 使得Embedding层和Encoder层解除绑定.
- 跨层参数共享(Cross-layer parameter sharing)
def _tie_or_clone_weights(self, first_module, second_module):
""" Tie or clone module weights depending of weither we are using TorchScript or not
"""
if self.config.torchscript:
first_module.weight = nn.Parameter(second_module.weight.clone())
else:
first_module.weight = second_module.weight
if hasattr(first_module, 'bias') and first_module.bias is not None:
first_module.bias.data = torch.nn.functional.pad(
first_module.bias.data,
(0, first_module.weight.shape[0] - first_module.bias.shape[0]),
'constant',
0
)
- 在Albert的源码中, 模型的参数共享是通过modeling_utils中PreTrainedModel的_tie_or_clone_weights实现的. PreTrainedModel作为基类实现了_tie_or_clone_weights, 它的子类在init_weight之后调用tie_weight实现参数共享, 而tie_weight的核心就是_tie_or_clone_weights.
RoBERTa模型¶
- 掌握RoBERTa模型的架构.
- 理解RoBERTa模型的优化点.
- 掌握RoBERTa模型的微调.
RoBERTa模型的架构¶
- 原始论文<< RoBERTa: A Robustly Optimized BERT Pretraining Approach >>, 由FaceBook和华盛顿大学联合于2019年提出的模型.
- 从模型架构上看, RoBERTa和BERT完全一致, 核心模块都是基于Transformer的强大特征提取能力. 改进点主要集中在一些训练细节上.
- 第1点: More data
- 第2点: Larger batch size
- 第3点: Training longer
- 第4点: No NSP
- 第5点: Dynamic masking
- 第6点: Byte level BPE
RoBERTa模型的优化点¶
- 针对于上面提到的7点细节, 一一展开说明:
- 第1点: More data (更大的数据量)
- 原始BERT的训练语料采用了16GB的文本数据.
- RoBERTa采用了160GB的文本数据.
- 1: Books Corpus + English Wikipedia (16GB): BERT原文使用的之数据.
- 2: CC-News (76GB): 自CommonCrawl News数据中筛选后得到数据, 约含6300万篇新闻, 2016年9月-2019年2月.
- 3: OpenWebText (38GB): 该数据是借鉴GPT2, 从Reddit论坛中获取, 取点赞数大于3的内容.
- 4: Storie (31GB): 同样从CommonCrawl获取, 属于故事类数据, 而非新闻类.
- 第2点: Larger batch size (更大的batch size) - BERT采用的batch size等于256.
- RoBERTa的训练在多种模式下采用了更大的batch size, 从256一直到最大的8000.
- 第3点: Training longer (更多的训练步数) - RoBERTa的训练采用了更多的训练步数, 让模型充分学习数据中的特征.
- 第4点: No NSP (去掉NSP任务) - 从2019年开始, 已经有越来越多的证据表明NSP任务对于大型预训练模型是一个负面作用, 因此在RoBERTa中直接取消掉NSP任务.
- 论文作者进行了多组对照试验:
- 1: Segment + NSP (即BERT模式). 输入包含两部分, 每个部分是来自同一文档或者不同文档的segment(segment是连续的多个句子), 这两个segment的token总数少于512, 预训练包含MLM任务和NSP任务.
- 2: Sentence pair + NSP (使用两个连续的句子 + NSP, 并采用更大的batch size). 输入也是包含两部分, 每个部分是来自同一个文档或者不同文档的单个句子, 这两个句子的token 总数少于512. 由于这些输入明显少于512个tokens, 因此增加batch size的大小, 以使tokens总数保持与SEGMENT-PAIR + NSP相似, 预训练包含MLM任务和NSP任务.
- 3: Full-sentences (如果输入的最大长度为512, 那么尽量选择512长度的连续句子; 如果跨越document, 就在中间加上一个特殊分隔符, 比如[SEP]; 该试验没有NSP). 输入只有一部分(而不是两部分), 来自同一个文档或者不同文档的连续多个句子, token总数不超过512. 输入可能跨越文档边界, 如果跨文档, 则在上一个文档末尾添加文档边界token, 预训练不包含NSP任务.
- 4: Document-sentences (和情况3一样, 但是步跨越document; 该实验没有NSP). 输入只有一部分(而不是两部分), 输入的构造类似于Full-sentences, 只是不需要跨越文档边界, 其输入来自同一个文档的连续句子, token总数不超过512. 在文档末尾附近采样的输入可以短于512个tokens, 因此在这些情况下动态增加batch size大小以达到与Full-sentecens相同的tokens总数, 预训练不包含NSP任务.
- 论文作者进行了多组对照试验:
- 总的来说, 实验结果表明1 < 2 < 3 < 4.
- 真实句子过短的话, 不如拼接成句子段.
- 没有NSP任务更优.
- 不跨越document更优.
- 第5点: Dynamic masking (采用动态masking策略)
- 原始静态mask: 即BERT版本的mask策略, 准备训练数据时, 每个样本只会进行一次随机mask(因此每个epoch都是重复的), 后续的每个训练步都采用相同的mask方式, 这是原始静态mask.
- 动态mask: 并没有在预处理的时候执行mask, 而是在每次向模型提供输入时动态生成mask, 所以到底哪些tokens被mask掉了是时刻变化的, 无法提前预知的.
- 第6点: Byte level BPE (采用字节级别的Encoding)
- 基于char-level: 原始BERT的方式, 在中文场景下就是处理一个个的汉字.
- 基于bytes-level: 与char-level的区别在于编码的粒度是bytes, 而不是unicode字符作为sub-word的基本单位.
- 当采用bytes-level的BPE之后, 词表大小从3万(原始BERT的char-level)增加到5万. 这分别为BERT-base和BERT-large增加了1500万和2000万额外的参数. 之前有研究表明, 这样的做法在有些下游任务上会导致轻微的性能下降. 但论文作者相信: 这种统一编码的优势会超过性能的轻微下降.
- RoBERTa模型在多个标准数据集测试中展现了优秀的结果:

- RoBERTa模型在阅读理解任务中的表现则更加突出:

RoBERTa模型的微调¶
- 在投满分项目中, 应用预训练的RoBERTa模型实行微调:
class Config(object):
def __init__(self, dataset):
self.model_name = "roberta"
pass
class Model(nn.Module):
def __init__(self, config):
pass
- 结论: RoBERTa模型在测试集上达到了什么表现? 同学们回去自己尝试.
MacBert模型¶
- 掌握MacBert模型的架构.
- 掌握MacBert模型的优化点.
- 掌握MacBert模型的微调.
MacBert模型的架构¶
- MacBert模型由哈工大NLP实验室于2020年11月提出, 2021年5月发布应用, 是针对于BERT模型做了优化改良后的预训练模型.
- << Revisiting Pre-trained Models for Chinese Natural Language Processing >>, 通过原始论文题目也可以知道, MacBert是针对于中文场景下的BERT优化.
- MacBert模型的架构和BERT大部分保持一致, 最大的变化有两点: - 第一点: 对于MLM预训练任务, 采用了不同的MASK策略.
- 第二点: 删除了NSP任务, 替换成SOP任务.
MacBert模型的优化点¶
- 第一点: 对于MLM预训练任务, 采用了不同的MASK策略. - 1: 使用了全词masked以及n-gram masked策略来选择tokens如何被遮掩, 从单个字符到4个字符的遮掩比例分别为40%, 30%, 20%, 10%
- 2: 原始BERT模型中的[MASK]出现在训练阶段, 但没有出现在微调阶段, 这会造成exposure bias的问题. 因此在MacBert中提出使用类似的单词来进行masked. 具体来说, 使用基于Word2Vec相似度计算包训练词向量, 后续利用这里面找近义词的功能来辅助mask, 比如以30%的概率选择了一个3-gram的单词进行masked, 则将在Word2Vec中寻找3-gram的近义词来替换, 在极少数情况下, 当没有符合条件的相似单词时, 策略会进行降级, 直接使用随机单词进行替换.
- 3: 使用15%的百分比对输入单词进行MASK, 其中80%的概率下执行策略2(即替换为相似单词), 10%的概率下替换为随机单词, 10%的概率下保留原始单词不变.
- 第二点: 删除了NSP任务, 替换成SOP任务.
- 第二点优化是直接借鉴了AlBERT模型中提出的SOP任务.
- 在NLP著名的难任务阅读理解中, MacBert展现出非常优秀的表现:
MacBert模型微调¶
- 在投满分项目中, 应用预训练的MacBert模型实行微调:
import torch
import torch.nn as nn
class Config(object):
def __init__(self, dataset):
self.model_name = "macBert"
pass
class Model(nn.Module):
def __init__(self, config):
pass
- 结论: 采用macBert模型后, 在测试集上得到XXX分数, 同学们的作业.
FinBERT模型¶
- 掌握FinBERT模型的架构.
- 掌握FinBERT模型的优化点.
- 掌握FinBERT模型的应用.
FinBERT模型的架构¶
- 首先展示一下FinBERT的架构图, 分为Pre-training和Fine-tuning两大部分, 在通用语料和金融专属语料上, 引入多个预训练任务用以增强模型的能力, 最后在特定任务上进行微调即可.
- 首先回顾一下原始论文<< FinBERT: Financial Sentiment Analysis with Pre-trained Language Models >>, 当前许多情感分类解决方案在产品或电影评论数据集中获得了很高的分数, 但是在金融领域这些方法的性能却大大落后. 出现这种差距的根本原因是垂直领域的专用语言表达, 它降低了现有模型的适用性, 并且缺乏高质量的标记数据来学习特定领域的积极, 消极, 中性表达的新的上下文.
- 论文探讨了NLP迁移学习在金融领域情感分类任务中的有效性, 提出了一个基于BERT的新语言模型FinBERT, 将一个金融领域情感分类在FinancialPhrasebank数据集中的最新性能提高了14个百分点, 直接拿下SOTA天花板级别的表现!!!
- 背景介绍: 由于互联网时代每天都要产生数量空前的文本数据, 因此分析来自医学领域, 金融领域, 法律领域的大量文本更具显示意义. 在这些垂直领域中应用监督方法比应用于更一般化的文本困难得多. 主要困难有两点: - 第一点: 利用基于神经网络的深度学习技术需要大量的标注数据, 而垂直领域(典型的是医疗, 金融, 法律等)的标注数据需要昂贵的人工成本.
- 第二点: 在一般语料库上训练的NLP模型不适用于监督任务, 因为垂直领域的文本有专门的语言习惯和独特的词汇表达.
FinBERT模型的优化点¶
- 关于FinBERT具体的优化任务, 我们一一列举如下:
- Capitalization Prediction Task: 预测单词的大小写, 因为一些专有名词是大写的, 所以这个任务可能对NER任务更加有用.
- Token-Passage Prediction Task: 预测当前句子中的这个单词是否会出现在该文档的其他句子中, 这种词往往是常见词, 或该文档的主题词.
- Sentence Deshuffling Task: 将句子拆分成几个片段, 然后打乱顺序, 最后预测原始顺序.
- Sentence Distance Task: 是对BERT中NSP任务的推广. BERT中的NSP只预测两个句子是否连续. SDT需要预测三种情况: - 情况1: 两个句子连续, 且同属一个文档.
- 情况2: 两个句子不连续, 且同属一个文档.
- 情况3: 两个句子不属于一个文档.
- 为了训练金融领域的模型, 需要大量垂直领域的数据, 论文中所涉及到的数据集有: - FinancialWeb: 从CommonCrawl News数据集中提取到的一个金融新闻数据集.
- FinSBD-2019 dataset: 一个用于金融句子边界检测任务(Financial Sentence Boundary Detection)的数据集, 任务是从文本中提取出金融相关的语句.
- Financial Phrasebank dataset: 一个金融情感分析数据集.
- FiQA SA dataset: 这个数据集出自WWW18, 包含金融新闻头条和金融微博文本, label有命名实体, 情感分数以及aspect.
- Financial QA dataset: 一个金融领域的问答数据集, 爬取自Stack Exchange投资主体的博文.
- FinBERT模型在几个主流金融垂直领域的数据集上, 得到了远超BERT的表现, 非常出众!

百度¶
ERNIE1.0¶
- 百度的NLP团队也于2019年提出了ERNIE1.0, 原始论文<< ERNIE: Enhanced Representation through Knowledge Integration >>.
- 百度ERNIE1.0的基础是BERT模型, 但是和BERT最大的区别就在于MASK的对象不同.
- BERT是输入字掩码.
- ERNIE是输入词掩码.
- 这个识别词的过程就是加入知识整合的最关键的核心点.

- ERNIE was chosen to have the same model size as BERT-base for comparison purposes. ERNIE uses 12 encoder layers, 768 hidden units and 12 attention heads.
- ERNIE1.0是通过建模海量数据中的词, 实体及实体关系, 学习真实世界的语义知识. 相较于BERT学习原始语言信号, ERNIE1.0可以直接对先验语义知识单元进行建模, 增强了模型语义表示能力.
- 例如对于下面的例句: "哈尔滨是黑龙江的省会, 国际冰雪文化名城".

- ERNIE1.0与BERT词屏蔽方式的比较: BERT在预训练过程中使用的数据仅是对单个字符进行MASK, 如上图所示, 训练BERT通过"哈"与"滨"的局部共现判断出"尔"字, 但是模型其实并没有学习到与"哈尔滨"相关的知识, 只是学习到"哈尔滨"这个词, 但是并不知道"哈尔滨"所代表的含义. 而ERNIE1.0在预训练时使用的数据是对整个词进行MASK, 从而学习词与实体的表达, 例如屏蔽"哈尔滨"与"冰雪"这样的词, 使模型能够建模出"哈尔滨"与"黑龙江"的关系, 学到"哈尔滨"是"黑龙江"的省会以及"哈尔滨"是个"冰雪城市"这样的含义.
- 为了增强ERNIE1.0模型对于词汇和实体的理解能力, 论文中使用先验知识来进行增强. 具体方法使用了多阶段的知识掩码策略, 通过不同的MASK策略将短语和实体知识集成到语言模型中, 而不是像KG-BERT模型那样直接向模型中添加知识.

- Basic-level Masking: 第一个学习阶段是使用基本元素级别MASK, 它将句子作为基本语言单位的序列, 对于英语, 基本语言单位是单词, 对于中文, 基本语言单位是汉字. 在训练过程中, 我们随机掩盖15%的基本语言单元, 并使用句子中的其他基本单元作为输入, 训练一个Transformer来预测掩盖单元. 和BERT一样的操作, 基于基本级别的掩码, 主要学习低级语义.
- Entity-level Masking: 第二阶段是采用实体级别的MASK, 词组是一小部分单词或字符, 一起充当概念和实体单元. 对于英语, 我们使用词法分析和分块工具来获取句子中短语的边界, 并使用一些依赖于语言的分段工具来获取其他语言(例如中文场景下使用jieba分词工具等)的词/短语信息. 在实体级掩码阶段, 我们还使用基本语言单元作为训练输入, 这与随机基本单元掩码不同, 这次我们随机选择句子中的几个短语, 掩盖并预测同一短语中的所有基本单元. 在此阶段, 短语信息被编码到单词嵌入中.
- Phrase-level Masking: 第三阶段是短语级别MASK, 短语包含人员, 位置, 组织, 产品等, 可以用专有名称表示. 它可以是抽象的, 也可以是物理存在的. 通常, 实体在句子中包含重要信息, 与实体MASK阶段一样, 我们首先分析句子中的命名实体, 然后屏蔽并预测其中的所有短语. 经过三个阶段的学习, 获得了通过更丰富的语义信息增强的单词表示.
- ERNIE1.0采用异构语料库进行预训练. 我们构建了混合语料库-中国Wikepedia, 百度百科, 百度新闻, 百度贴吧. 句子数分别是21M, 51M, 47M, 54M. 百度百科包含用正式语言编写的百科全书文章, 这些文章被用作语言建模的强大基础. 百度新闻提供有关电影名称, 演员名称, 足球队名称等的最新信息. 百度贴吧是一个类似Reddits的开放讨论论坛, 每个帖子都可以视为对话话题. 在DLM任务中使用Tieba语料库. 论文中对汉字执行从传统到简体的转换, 对英文字母执行大写到小写的转换, 为模型使用了17964个unicode字符的共享词汇表.
- DLM(Dialogue Language Model, 对话语言模型):
- 对话数据对于语义表示很重要, 因为相同答复的相应查询语义通常很相似. ERNIE1.0在DLM(对话语言模型)任务上对查询-响应对话结构进行建模. 如下图(Figure 3)所示, 引入了对话嵌入(dialogue embedding)来识别对话中的角色. ERNIE1.0的"对话"嵌入功能与BERT中的令牌类型嵌入功能相同, 不同之处在于ERNIE1.0还可以表示多回合对话(例如QRQ, QRR, QQR, 其中Q和R分别代表"查询"和"响应", 起到"Question"和"Answer"的作用). 像BERT中的MLM一样, 掩码来强制使模型预测以查询和响应为条件的缺失词. 论文中通过用随机选择的句子替换查询或响应来生成假样本. 该模型旨在判断多回合对话是真实的还是假的.
- DLM任务可帮助ERNIE1.0学习对话中的隐式关系, 这也增强了模型学习语义表示的能力. DLM任务的模型体系结构与MLM任务的模型体系结构兼容, 因此可以通过MLM任务对其进行预训练.

- ERNIE1.0被应用于5个中文NLP任务:
- 自然语言推理(XNLI)
- 语义相似性(LCQMC)
- 命名实体识别(MSRA-NER)
- 情感分析(ChnSentiCorp)
- 检索问题回答(NLPCC-DBQA)
- 自然语言推理(XNLI): 跨语言自然语言推理(XNLI)语料库(2019)是MultiNLI语料库的众包集合. 两对文字加上文字说明, 并被翻译成包括中文在内的14种语言. 标签包含矛盾, 中立, 包含.
- 语义相似性(LCQMC): 大规模中文问题匹配语料库(LCQMC)(2018)旨在识别两个句子是否具有相同的意图. 数据集中的每一对句子都与一个二进制标签相关联, 该二进制标签指示两个句子是否共享相同的意图, 并且可以将该任务形式化为预测二进制标签.
- 命名实体识别(MSRA-NER): MSRA-NER数据集用于命名实体识别, 由Microsoft Research Asia发布. 实体包含几种类型, 包括人员姓名, 地名, 组织名称等. 该任务可以看作是序列标记任务.
- 情感分析(ChnSentiCorp): ChnSentiCorp是一个数据集, 旨在判断句子的情感. 它包括酒店, 书籍和电子计算机等多个领域的评论. 该任务的目的是判断句子的情感倾向是是肯定态度的还是否定态度.
- 检索问题回答(NLPCC-DBQA): NLPCC-DBQA数据集(http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf)的目标是选择相应问题的答案的目标是选择相应问题的答案). 该数据集的评估方法包括MRR(Voorhees, 2001)和F1得分.
- ERNIE1.0在5个中文NLP任务中展现出了优秀的结果:
- ERNIE1.0模型在完形填空上也展现了优秀的结果:
- 在情况1中, BERT尝试复制出现在上下文中的名称, 而ERNIE1.0则记住了文章中提到的有关关系的知识.
- 在情况2和情况5中, BERT可以根据上下文成功学习模式, 因此可以正确预测命名的实体类型, 但是无法使用正确的实体填充插槽. 相反, ERNIE1.0可以使用正确的实体填充插槽.
- 在情况3, 4, 6中, BERT用与句子相关的几个字符填充了空位, 但是很难预测语义概念. ERNIE1.0可以预测除情况4之外的正确实体. 尽管ERNIE1.0在情况4中预测了错误的实体, 但它可以正确地预测语义类型, 并用一个澳大利亚城市填充该位置.
ERNIE2.0¶
- 百度的NLP团队于2020年提出ERNIE2.0模型, 原始论文<< ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding >>.
- 近两年, 以BERT, XLNet为代表的无监督预训练技术在多个自然语言处理任务上取得了技术突破. 基于大规模数据的无监督预训练技术在自然语言处理领域变得至关重要. 百度发现, 之前的工作主要通过词或句子的共现信号, 构建语言模型任务进行模型预训练. 例如, BERT通过掩码语言模型和下一句预测任务进行预训练. XLNet构建了全排列的语言模型, 并通过自回归的方式进行预训练. 然而, 除了语言共现信息之外, 语料中还包含词法、语法、语义等更多有价值的信息. 例如, 人名、地名、机构名等词语概念知识, 句子间顺序和距离关系等结构知识, 文本语义相似度和语言逻辑关系等语义知识. 那么如果持续地学习各类任务, 模型的效果能否进一步提升? 这就是ERNIE2.0希望探索的.
- ERNIE2.0开源地址: https://github.com/PaddlePaddle/ERNIE
- ERNIE2.0论文地址: https://arxiv.org/pdf/1907.12412v1.pdf
- ERNIE2.0框架支持增量引入不同角度的自定义预训练任务, 以捕捉语料中词法、语法、语义等信息. 这些任务通过多任务学习对模型进行训练更新, 每当引入新任务时, 该框架可在学习该任务的同时, 不遗忘之前学到过的信息.
- ERNIE2.0框架支持随时引入各种自定义任务, 这些任务共享相同的编码网络并通过多任务学习实现训练. 这种多任务学习的方法使得不同任务中词汇、句法和语义信息的编码能共同学习. 此外, 当我们给出新的任务时, ERNIE2.0框架可以根据先前预训练的权重增量地学习分布式表征.
- ERNIE2.0与BERT或XLNet等经典预训练方法的不同之处在于, 它并不是在少量的预训练任务上完成的, 而是通过不断引入大量预训练任务, 从而帮助模型高效地学习词汇、句法和语义表征.
- ERNIE2.0框架能通过多任务学习持续更新预训练模型, 这也就是"连续预训练"的含义. 在每一次微调中, ERNIE2.0会首先初始化已经预训练的权重, 然后再使用具体任务的数据微调模型.

ERNIE3.0¶
- 百度公司于2021年7月发布ERNIE3.0版本, 参数规模达到100亿, 原始论文<< ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION >>.
- 开放版本的试用demo可以访问: https://wenxin.baidu.com/wenxin/ernie
- ERNIE3.0模型最重大的两个改进点:
- 预训练中加入知识图谱三元组.
- 模型基本单元从ERNIE2.0的transformer换成transformer-XL
- Universal representation Module(通用语义表示网络): 通用语义层一旦预训练完成, 就不再更新参数(即便在fine-tuning时也不再更新).
- Task-specific Representation Modules(特定任务语义表示): Task-specific Representation层则会在fine-tuning下游任务时候更新, 这样保证了fine-tuning的高效, 其中NLG和NLU参数非共享.

ERNIE3.0 TITAN¶
- 百度公司于2022年1月发布ERNIE3.0 TITAN版本, 原始论文<< ERNIE 3.0 TITAN: EXPLORING LARGER-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION >>.
- 相比于ERNIE3.0的100亿参数量, ERNIE3.0 TITAN模型的参数量达到了2600亿!!!
- ERNIE3.0 TITAN是一种具有2600亿个参数的预训练语言模型, 它是世界上第一个知识增强的千亿参数模型, 也是中国最大的单例模型.
- ERNIE3.0 TITAN具有不同于稀疏专家混合(MoE)系统的密集模型结构, 该模型在海量知识图谱和海量非结构化数据上进行训练, 在自然语言理解(NLU)和生成(NLG)方面表现出色. TITAN 在60多个NLP任务中取得了SOTA成果, 包括机器阅读理解, 文本分类和语义相似性等. 该模型在30个少样本和零样本基准测试中也表现良好, 这表明它可以用少量标记数据泛化各种下游任务, 并降低识别阈值.
轩辕1.0¶
- 百度下属的度小满金融公司AI-Lab于2021年提出轩辕1.0(XuanYuan)预训练模型在CLUE1.1分类任务中"力压群雄"获得了排名第一的好成绩, 距离人类"表现"仅差3.38分!
- CLUE是中文语言理解领域最具权威性的测评基准之一, 涵盖了文本相似度、分类、阅读理解共10项语义分析和理解类子任务. 其中, 分类任务需要解决6个问题, 例如传统文本分类, 文本匹配, 关键词分类等等, 能够全方面衡量模型性能. 该榜单竞争激烈, 几乎是业内兵家必争之地, 例如快手搜索, 优图实验室, 腾讯云等等研究机构也都提交了比赛方案.
- 轩辕1.0模型是基于Transformer架构的预训练语言模型, 涵盖了金融、新闻、百科、网页等多领域大规模数据. 因此, 该模型"内含"的数据更全面, 更丰富, 面向的领域更加广泛.
- 传统预训练模型采取"训练-反馈"模式, 度小满金融AI-Lab在训练轩辕1.0的时候细化了这一过程, 引入了任务相关的数据, 融合不同粒度不同层级的交互信息, 从而改进了传统训练模式.
- 模型预训练思路主要从宏观和微观来看:
- 宏观角度: 先从通用大规模的数据逐渐迁移到小规模的特定业务以及特定任务, 然后去通过不同的阶段逐渐训练, 直到满足目标任务.
- 微观角度: 针对不同的下游分类任务, 会相应的设计出定制化的分类模型. 然后采用自监督学习, 迁移学习等等提升模型的性能.
- 轩辕还处于1.0的版本, 更侧重于自然语言理解能力, 在接下来的2.0版本中, 研发人员会采用更大规模的数据, 训练出更加通用的预训练模型, 从而赋能更多的业务和领域.
轩辕2.0¶
- XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters
- 百度金融2023年10月正式发布最大的中文金融聊天模型: 轩辕 2.0 (XuanYuan 2.0), 以填补专为中文金融领域设计的开源亿级聊天模型的空白.
- 提出了一种名为混合调整 (hybrid-tuning) 的新型训练方法, 以减少灾难性遗忘. 通过将一般领域与特定领域知识相结合, 并整合预训练和微调阶段, "轩辕 2.0"实现了在中文金融领域提供精确且与上下文相关的回复的卓越能力. 百度金融将继续收集更大规模的中文金融领域数据, 以进一步优化模型.
创新工场¶
Mengzi模型¶
- 澜舟科技-创新工场于2021年10月提出Mengzi模型, 原始论文<< Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese >>. Mengzi只用10亿参数就杀进中文自然语言理解CLUE榜单前三!!!
- 对于CLUE榜单近年来一直是AI玩家们的兵家必争之地, 通常来说在榜单排名靠前的模型都是百亿, 千亿级别的超大模型, 而Mengzi模型是唯一一个以10亿参数进入TOP3的"小而美"模型.
- 本次澜舟科技开源了4个模型, 架构如下图所示:

- 它可处理多语言, 多模态数据, 同时支持多种文本理解和文本生成任务. 在文本分类, 阅读理解等各类任务上表现出色. 目前开源的4个模型分别在金融, 文案生成, 图像理解, 语言理解上分别发挥优势作用, 不同的模型参数列表展示如下:

- Mengzi模型主要有三方面的贡献:
- 第一: 研究了各种预训练策略来训练轻量级语言模型, 表明精心设计良好的目标可以进一步显著提高模型的容量, 而不需要扩大模型的大小.
- 第二: 发布了Mengzi模型, 包括判别式、生成式、金融和多模态模型变体, 能够胜任广泛的语言和视觉任务. 这些模型中的文本编码器只包含1.03亿个参数, 论文作者希望这能够促进学术界和工业界的相关研究.
- 第三: 通过大量基准任务测试表明, 孟子模型在一系列语言理解和生成任务上取得了很强的性能.
- 关于Mengzi模型的训练:
- 数据预处理:训练前的语料库来源于中文维基百科、中文新闻和爬虫语料,总数据大小为300GB。通过使用探索性的数据分析技术来清理数据,删除HTML标签、url、电子邮件、表情符号等。由于在原始语料库中有简体标记和传统的中文标记,使用OpenCC将传统标记转换为简体形式,重复的文章也会被删除.
- 模型结构:RoBERTa被选做为 Mengzi预训练的骨干模型,12层transformers,hidden size为768,12个attention heads,预训练任务为MLM.
- 预训练细节: - 1: 词汇表包含21,128个字符,看了下与Bert大小保持一致。句子长度限制在512个字符,batch size为128.
- 2: 在训练前,每个序列中有15%的单词被随机屏蔽以进行MLM预测.
- 3: 使用LAMB优化器的mixed-batch训练方式,它涉及两个阶段:总epoch的前9/10使用序列长度为128,总epoch的最后1/10使用序列长度为512。这两个阶段的批次规模分别为16384和32768.
- 4: 采用PostgreSQL对训练示例进行全局抽样,以避免两阶段训练中样本权重的不平衡。整个培训前的过程需要100万步。使用32个3090 24G,使用FP16和深度4进行训练加速.
- Mengzi模型在CLUE榜单上几乎全部任务都得到最优结果, 展现了强大的能力. 具体来说, 包含了9种自然语言理解任务:
- 蚂蚁金融问题匹配(AFQMC)
- 新闻标题文本分类(TNEWS)
- 科大讯飞文本测试(IFLYTEK)
- 中文翻译多基因自然语言推理(CMNLI)
- 中文机器智能测试(WSC)
- 中文科学文献(CSL)
- 中国机器阅读理解(CMRC)
- 中文语言完形填空(CHID)
- 中文多项选择阅读理解(C3)

- Mengzi模型的预训练主要在3方面进行了优化:
- Linguistic-motivated Objectives: 语义信息已被证明对语言建模是有效的。受LIMIT-Bert的启发,在训练前使用了词性(POS)和命名实体(NE)序列标记任务,并结合了原始的MLM和NSP目标。原始文本中的POS和NE标签由spaCy标注.
- Sequence Relationship Objectives: 为了更好地对句子间的句子对信息进行建模,Mengzi在模型预训练中添加了句子顺序预测(SOP)任务.
- Dynamic Gradient Correction: 广泛使用的MLM会引起原始句子结构的干扰,导致语义丢失,增加了模型预测的难度,不可避免地导致训练不足和效率低下。为了缓解这一问题,本文提出了一系列的动态梯度校正技术来提高模型的性能和鲁棒性.
- Mengzi模型在生成式任务上有优秀的表现, 开源模型中的Mengzo-T5-base就是专门为生成式任务而打造的:

- Mengzi模型在图像理解任务上也有优秀的表现, 开源模型中的Mengzi-Oscar-base就是专门为图像理解任务而打造的:

- 2024年3月, 澜舟科技发布Mengzi3-13B大模型.
- 2024年8月, 澜舟科技发布MengziGPT-40B大模型.
- 综合能力接近GPT-3.5
华为¶
NeZha模型¶
- NeZha模型是华为诺亚方舟实验室于2021年11月提出的大型中文预训练模型, 原始论文<< NEZHA: NEURAL CONTEXTUALIZED REPRESENTATION FOR CHINESE LANGUAGE UNDERSTANDING >>.
- NeZha模型的基础架构基于Transformer, 对BERT模型进行了4点重要的改进:
- 1: 增加相对位置编码函数(Functional Relative Positional Encoding)
- 2: 全词掩码(Whole Word Masking)
- 3: 混合精度训练(Mixed Precision Training)
- 4: 优化器改进(LAMB Optimizer)
- 1: 增加相对位置编码函数(Functional Relative Positional Encoding)
- Transformer为了增加模型的并行效率, 采用的是Multi-Head Attention机制. 虽然Multi-Head Attention相较于RNN可以增加运算效率, 但是它丢失了句子中每个token的位置信息. 为了使模型更加稳定有效, Transformer和Bert分别在模型中增加了函数式和参数式绝对位置编码.
- 那么问题来了, 既然有了绝对位置编码, 句子中每个token的位置信息已经在模型中有所体现, 为什么还要有相对位置编码呢? 那是因为在BERT模型预训练时, 很多数据的真实数据长度达不到最大长度, 因此靠后位置的位置向量训练的次数要比靠前位置的位置向量的次数少, 造成靠后的参数位置编码学习的不够. 在计算当前位置的向量的时候, 应该考虑与它相互依赖的token之间相对位置关系, 可以更好地学习到信息之间的交互传递.
- 2: 全词掩码(Whole Word Masking)
- 华为通过大量实验证实, 将随机掩码词汇替换成全词掩码, 可以有效提高预训练模型效果, 即如果有一个汉字被掩蔽, 属于同一个汉语词的其他汉字都被一起掩蔽, 会让模型学习到更高级的语义.
- 3: 混合精度训练(Mixed Precision Training)
- 在实现混合精度训练时, 是在训练过程中的每一个step, 为模型的所有weights维护一个float32的copy, 称为Master Weights. 在做前向和反向传播过程中, Master Weights会转换成float16(半精度浮点数)格式, 其中权重, 激活函数和梯度都是用float16进行表示, 最后梯度会转换成float32格式去更新Master Weights.
- 核心目的: 为了提高训练速度, 计算float16比float32快!!!
- 4: 优化器改进(LAMB Optimizer)
- 通常在深度神经网络训练的Batch Size很大的情况下(超过一定阈值)会给模型的泛化能力带来负面影响, 而LAMB优化器通过一个自适应的方式为每个参数调整learning rate, 能够在Batch Size很大的情况下不损失模型的效果, 使得模型训练能够采用很大的Batch Size, 进而极大提高训练速度.
- LAMB是论文<< Large Batch Optimization for Deep Learning: Training BERT in 76 minutes >> 提出的一个新型优化器, 它可以将预训练BERT的时间从三天降到76分钟!!!
- NeZha base模型每个GPU的batch大小为180, NeZha large模型每个GPU的batch大小为64.
- NeZha模型在若干标准测试集上的表现列举如下:

浪潮¶
源1.0¶
- 浪潮公司人工智能研究院于2021年10月发布"源1.0"超级大模型, 参数量达到2457亿, 原始论文<< YUAN 1.0: LARGE-SCALE PRE-TRAINED LANGUAGE MODEL IN ZERO-SHOT AND FEW-SHOT LEARNING >>.
- “源1.0”在语言智能方面表现优异,获得中文语言理解评测基准CLUE榜单的零样本学习(zero-shot)和小样本学习(few-shot)两类总榜冠军。测试结果显示,人群能够准确分辨人与“源1.0”作品差别的成功率为49.16%, 这意味着一个二分类的问题, 竟然人类能判对的概率低于50%!!!

- 结论: 上图显示的结果直接表明, 源1.0的强大能力"几乎"可以和人类以假乱真!!!
- 源1.0在数据处理上的显著工作:
- 互联网语料基本上可以分为3大类: 高质量语料(语句通顺且包含一定知识), 低质量语料(语句不通顺), 广告语料(语句通顺但重复率过高, 如广告, 网站说明, 免责声明等). 为了给"源1.0"模型提供高质量的预训练数据集, 浪潮人工智能研究院使用BERT训练了一个语料质量三分类模型. 整个方案包括数据采样, 语料标注, 模型训练和效果评估四部分.
- 在"源1.0"训练时, 由于爬取的互联网语料非常庞大, 即便经过敏感信息过滤, 文章去重, 数据集仍在TB级别. 如此大规模的数据集难以直接进行处理, 分析, 需要进行采样. 将经过粗略过滤之后的数据, 以文章为单位进行采样, 再将所有采样数据分别写入到2个文件中, 其中一个用来标注训练集语料(构建训练集, 称之为"训练集"), 另外一个则用来验证分类模型的效果(称之为"测试集"). 另外, 为了使采样数据具有充分的代表性, 在整个数据集内采用均匀采样.
- 先使用"训练集"中的部分数据自动构建训练语料, 然后使用分类模型进行训练, 最后在剩余采样数据("验证集")上进行评估, 并将得分较高的低质量语料和广告语料加入到标注数据中, 如此循环多次.
- 为了给"源1.0"提供高质量的预训练数据集, 我们采用了一种海量互联网语料的质量清洗和分析方法. 首先对海量文本数据进行采样, 通过PPL, 关键词密度筛选, 聚类等方法自动筛选出低质量语料, 然后使用分类模型在标注数据上进行训练, 经过不断调优得到最终的文本质量分类模型. 这一方法可以极大减少人工标注成本, 从语义层面更加充分地去除各类低质量文本, 有效提高预训练语言模型的理解能力.
- "源1.0"几乎是把近5年整个中文互联网的浩瀚内容全部"读"完了. 通过自研的文本分类模型, 获得了5TB高质量中文数据集, 在训练数据集规模上领先近10倍. 源1.0还阅读了大约2000个亿词.
- 我们可以先感受一下在不同任务上源1.0模型展示出的杰出能力:

- 源1.0这种巨大体量的模型, 必然采用了分布式训练的架构, 如下图所示:
- 源1.0在零样本测试, 小样本测试中有非常好的结果, 具体展示如下:

- 看完了前面比较"空空如也"的数据, 肯定不那么直观, 我们看看具体的案例, 下图展示了在不同训练模式下模型的输出能力:

- 源1.0模型拥有很强大的模仿能力:

- 源1.0在零样本基准测试中的得分表现:

- 源1.0在少样本基准测试中的得分表现:

- 最后总结一下源1.0的杰出贡献: 通过协同优化, 源1.0攻克了在巨量数据和超大规模分布式训练的扩展性, 计算效率, 巨量模型算法及精度提升等方面的业界难题.
- 算法方面:
1: 解决了巨量模型训练不稳定的业界难题, 提出了稳定训练巨量模型的算法.
2: 提出了巨量模型新的推理方法, 提升模型的泛化能力, 让一个模型可以应用于更多的场景. - 数据方面:
1: 创新地提出了中文数据集的生成方法, 通过全新的文本分类模型, 可以有效过滤垃圾文本, 并生成高质量中文数据集. - 算力方面:
- 1: 通过算法与算力协同优化, 使模型更利于GPU性能发挥, 极大的提升了计算效率, 并实现业界第一训练性能的同时实现业界领先的精度.
微软¶
威震天1.0¶
- 微软联合英伟达共同推出的超级大模型Megatron-Turing1.0, 拥有5300亿参数量, 是迄今为止参数最多, 功能最强大的解码语言模型.
- 模型训练是在基于NVIDIA DGX SuperPOD的Selene超级计算机上以混合精度完成的, 该超级计算机由560个DGX A100服务器提供支持, 这些服务器以完整的胖树配置与HDR InfiniBand联网. 每个DGX A100有8个NVIDIA A100 80GB Tensor Core GPU, 通过NVLink和NVSwitch相互完全连接. 微软Azure NDv4云超级计算机使用了类似的参考架构.
- 威震天1.0模型的参数数量是同类现有最大模型GPT-3的3倍, 并在一系列广泛的自然语言任务中展示了无与伦比的准确性:
- 完成预测
- 阅读理解
- 常识推理
- 自然语言推理
- 词义消歧
智源人工智能研究院¶
悟道2.0¶
- 2021年6月第三届北京智源大会正式开幕, 智源副院长, 清华唐杰教授重磅发布了超级模型"悟道2.0", 拥有1.75万亿个参数, 是迄今全球最大的预训练模型.

- 大家还记得2021年夏天网上的那个叫"华智冰"的女同学吧? 她可以创作音乐, 写诗作画, 而且已经被清华大学唐杰教授录取为学生! 未来她将在清华大学里成长学习, 变成一个真正的"智能人", 而这里面最关键的就是她的内核: 悟道2.0!
- 悟道2.0超级模型在参数规模上爆发级增长, 达到1.75万亿参数, 创下全球最大预训练模型纪录!!!
- 研究团队希望让"悟道2.0"像人一样思考, 在多项任务中超越图灵测试, 最终迈向通用工智能.
- 悟道2.0从原来的文本为主逐渐往更强大, 更通用的方向上发力, 并可以根据文字生成高精度的图片, 根据图像去检索文字, 实现图像和文字的互相检索.
- 目前, 悟道2.0在问答、作诗、配文案、视频、绘画、菜谱多项任务中正逼近图灵测试.

粤港澳大湾区数字经济研究院(IDEA)¶
封神榜¶
- 2021年11月22号, IDEA创新研究院理事长沈向洋在IDEA大会上, 宣布开启"封神榜"大模型开源计划:
- 二郎神系列
- 余元系列
- 周文王系列
- 闻仲系列
- 燃灯系列
- 二郎神: Encoder结构为主的双向语言模型, 专注于解决各种自然语言理解任务, 13亿参数的"二郎神-1.3B"大模型, 是最大的开源中文BERT大模型.
- 余元: 已开源医疗领域的35亿参数"余元-3.5B"大模型, 其对医疗事实判断准确率接近90%.
- 周文王: IDEA联合追一科技开发的新结构大模型, 目前开源的13亿参数的"周文王-1.3B"大模型, 是中文领域同时做LM和MLM任务最大的模型.
- 闻仲: Decoder结构为主的单向语言模型, 是一系列强大的生成模型, 目前开源了35亿参数的"闻仲-3.5B"大模型.
- 燃灯: Transformer结构为主的编解码语言模型, 目前开源了7.7亿参数的"燃灯"大模型.
5.8 消融实验
消融实验¶
学习目标¶
- 理解消融实验的概念和原理.
- 掌握消融实验在模型调优中的应用.
消融实验的概念和原理¶
- 术语"消融研究"通常用于神经网络, 尤其是相对复杂的神经网络. 核心思想是通过删除部分网络并研究网络的性能来更深入的考察网络.
- ablation experiment: 原意是医学术语, 通过机械方法切除身体组织, 如通过手术从身体中去除, 尤指器官, 异常生成或有害物质.
- 消融实验的起源是2018年6月由Keras的主要作者Francois Chollet提出, 他主张在目前的深度学习中, 理解系统中的因果关系是产生可靠知识的最直接方式, 消融实验是一种非常省力的研究因果关系的方式.
- 比如作者提出在进行图像搜索的时候, 要面对一个大的卷积神经网络(共有5个卷积层, 2个全连接层), 为了更好的理解该系统, 作者进行了一项消融实验, 系统中的各个子层被依次移除(比如移除掉第2个卷积层, 或移除掉第1个全连接层等), 实验发现移除网络中的1个或2个全连接层, 只保留卷积层, 所导致的性能损失惊人的小!!! 因此得出结论: CNN的大部分代表性力量来自卷积层, 而不是来自更多参数的全连接层!!!
- 形象化的例子: 小明同学发明了一种非常美味的馅饼A, 创新点是因为加了豆沙和红糖, 味道更好吃了. 消融实验的做法就是你要做一个馅饼B, 单独添加豆沙; 再做一个馅饼C, 单独添加红糖. 然后再综合评判馅饼A, B, C哪个更好吃? 还是说某两个一样好吃? 哪个策略作用更大? 这样的话馅饼的改良策略就非常清晰了.
消融实验的应用¶
- 比如在从BERT向AlBERT进化的过程中, 删除NSP任务, 添加SOP任务, 也是消融实验的一种.
- 比如在T5模型中, 不同的Encoder和Decoder的组合, 进行不同的对比实验, 也是消融实验的一种.
- 同学们在自己的模型搭建中, 也可以加入消融实验, 比如你的迁移学习模型是如何微调的, 你的量化模型, 剪枝模型, 知识蒸馏模型, 多方对比来验证网络的哪些部分对最终的性能更加重要? 哪些模型鲁棒性更强? 最终来更好的验证自己的模型是更优的.
小节总结¶
- 本小节学习了消融实验的概念和原理.
- 在投满分项目上进行了消融实验的初步应用.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号