Day2526272829-langchain框架基础+进阶+langgraph+RAG理论+RAG实操+项目实战
1. 什么是LangChain
LangChain现在归属于LangChain AI公司,LangChain作为其中的一个核心项目,开源发布在Gitub上:https://github.com/langchain-ai/langchain
LangChain给自身的定位是:用于开发由大语言模型支持的应用程序的框架。它的做法是:通过提供标准化且丰富的模块抽象,构建大语言模型的输入输入规范,利用其核心概念chains,灵活地连接整个应用开发流程。而针对每个功能模块,都源于对大模型领域的深入理解和实践经验,开发者提供出来的标准化流程和解决方案的抽象,再通过灵活的模块化组合,才有了目前这样一款在大模型应用开发领域内被普遍高度认可的通用框架。
1.1 为什么需要学习LangChain?
首先,我们需考虑当前大模型的发展态势。尽管OpenAI的GPT系列模型作为大模型领域的领军人物,在很大程度上了影响了大模型的使用规范和基于大模型进行应用开发的范式,但并不意味着所有大模型间的使用方式完全相同。因此,对于每个新模型都要花费大量时间学习其特定规范再进行应用探索,这种工作效率显然是十分低下的。
其次,必须谈论的是大模型目前面临的局限,如知识更新的滞后性、外部API调用能力、私有数据连接方式以及输出结果的不稳定性等问题。在应用开发中,如何找到这些问题的有效解决策略?
上述提到的每个限制都紧密关联于大模型本身的特性。尽管理论上可以通过重新训练、微调来增强模型的原生能力,这种方法确实有效,但实际上,大多数开发者并不具备进行这样操作所需的技术资源、时间和财力,选择这条路径一定会导致方向越来越偏离目标。我们之前讨论的Function Calling接入第三方API能够提供一些解决方案,但这每一步都需大量的研发投入,而且最终实现后的应用效果,也取决于研发人员的个人技术能力。在这种背景下,既然大家都有不同的想法和解决方案,那LangChain就来集中做这件事,提供一个统一的平台和明确的定义,来实现应用框架的快速搭建,这就是LangChain一直想要做到,且正在做的事情。
1.2 LangChain的做法
从本质上分析,LangChain还是依然采用从大模型自身出发的策略,通过开发人员在实践过程中对大模型能力的深入理解及其在不同场景下的涌现潜力,使用模块化的方式进行高级抽象,设计出统一接口以适配各种大模型。到目前为止,LangChain抽象出最重要的核心模块如下:
模型(Model I/O)
LangChain支持主流的大型语言模型哦,像DeepSeek这种,它都能轻松对接并进行接口调用。并且langchain还合理规范了大模型的输入(提示词)和输出(输出解析器)。
提示模板(Prompts)
这个提示模板功能可不得了!它可以动态地生成提示词哦。比如说,我们可以根据具体的任务需求,让系统自动生成合适的提示词来引导模型进行回答或者操作。
链(Chains)
想象一下,我们要把多个任务步骤连接起来,形成一个完整的工作流程,就像搭建一条流水线一样,这就是链(Chains)的作用啦。比如说,我们可以把“用户输入 → 检索知识库 → 模型生成 → 结果解析”这样一个流程串联起来,形成一个高效的工作流。这样一来,每个步骤都能有条不紊地进行,大大提高了工作效率。
记忆(Memory)
记忆这个组件也很关键哦。它可以帮助我们管理对话历史呢。这里面又分为短时记忆和长时记忆。短时记忆就像是我们的短期记忆,主要是会话上下文,能让我们记住当前这次对话的一些关键信息;长时记忆呢,就像是长期存储在大脑里的知识一样,它会把数据存储到数据库里,方便我们以后随时查阅和使用。
代理(Agents)
代理这个组件就像一个聪明的小助手,它可以动态地调用外部工具哦。比如说,当我们需要计算一些复杂的数学问题时,它可以调用计算器这个外部工具来帮忙;要是我们需要查找一些特定的信息,它还能调用搜索引擎为我们寻找答案呢。这样一来,就大大扩展了模型的功能,让它能做更多的事情啦。
数据检索(Indexes)
最后再给大家介绍一下数据检索这个组件哈。它能集成向量数据库,然后构建本地知识库哦。这就好比是为模型建立了一个专属的知识宝库,当模型需要回答问题的时候,就可以从这个宝库里获取更准确、更丰富的信息,从而提高回答的准确性。
2. langchain环境安装
LangChain的安装过程非常简单,可以通过常用的Python包管理工具,如pip或conda,直接进行安装。稍复杂一点的还可以通过源码进行安装。但有一点大家一定要明确:LangChain的真正价值在于它能够与多种模型提供商、数据存储解决方案等进行集成。默认情况下,使用上述两种安装方式中的任意一种来进行LangChain安装后,安装的仅仅是LangChain的默认功能,并不包括这些集成所需的额外依赖项。
也就是说,如果我们想要使用特定的集成功能,还需要额外安装这些特定的依赖。以调用OpenAI的API为例,我们首先需要通过运行命令pip install langchain-openai安装OpenAI的合作伙伴包,安装此依赖包后,LangChain才能够与OpenAI的API进行交互。后续我们在使用相关功能的时候,会提供额外的说明。
LangChain安装官方说明文档:https://python.langchain.com/docs/get_started/installation
2.1 使用包版本管理工具安装
LangChain可以使用pip 或者 conda直接安装,适用于仅使用的场景,即不需要了解其源码构建过程。这种安装方法十分简洁明了,只需执行一条命令,就可以在当前的虚拟环境中迅速完成LangChain的安装。具体操作如下:
pip install langchain==0.3.20
验证LangChain的安装情况,执行命令如下:
import langchain
print(langchain.__version__)
如果能正常输出LangChain的版本,说明在当前环境下的安装成功。
2.2 源码安装
除了通过pip安装外,还有一种通过源码安装的方法。这需要使用git拉取远程仓库,然后进入项目文件夹并执行pip install -e .命令。这种方法不仅会安装必要的依赖,同时也将程序的源代码保存在本地对于课程学习而言,我们推荐采用源码安装方式,这将非常有助于在后续的LangChain功能探索中,通过源码分析深入理解框架的构建原理和详细机制。
源码安装LangChain的详细步骤:
-
Step 1. 安装Anaconda
按照对应的教程内容配置好Anaconda。
-
Step 2. 使用Conda创建LangChain的Python虚拟环境
安装好Anaconda后,我们需要借助Conda包版本工具,为LangChain项目创建一个新的Python虚拟运行环境,执行代码如下:
conda create --name langchain python==3.11创建完成后,通过如下命令进入该虚拟环境,执行后续的操作:
conda activate langchain -
Step 3. 下载LangChain的项目文件
进入LangChain的官方Github,地址:https://github.com/langchain-ai/langchain , 在 GitHub 上将项目文件下载到有两种方式:克隆 (Clone) 和 下载 ZIP 压缩包。推荐使用克隆 (Clone)的方式。
-
Step 4. 升级pip版本
建议在执行项目的依赖安装之前升级 pip 的版本,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。升级 pip 很简单,只需要运行命令如下命令:
python -m pip install --upgrade pip -
Step 5. 源码安装项目依赖
不同于我们之前一直使用的
pip install -r requirements.txt方式,这种方法用于批量安装多个依赖包,是在部署项目或确保开发环境与其他开发者/环境一致时的常用方式。而对于LangChain,我们需要使用pip install -e的方式,以可编辑模式安装包。这种方式主要用于开发过程中。当以可编辑模式安装一个包时,依赖包会被直接从源代码所在位置安装,而不是复制到Python的site-packages目录,是开发模式下用于安装并实时反映对本地包更改的方法。需要执行的步骤如下:cd langchain-master/libs/langchain/ #进入到LangChain源码的libs下的langchain目录中 pip install -e .
如在安装过程未发生任何报错,则说明安装成功。在安装完依赖后,我们就正式进入LangChain的Model I/O模块的实践。
3.Models I/O模块
LangChain的Model I/O模块提供了标准的、可扩展的接口实现与大语言模型的外部集成。所谓的Model I/O,包括模型输入(Prompts)、模型输出(OutPuts)和模型本身(Models),简单理解就是通过该模块,我们可以快速与某个大模型进行对话交互
任何语言模型应用的核心都是大语言模型(LLMs)。因此,在讨论和实践Model I/O模块时,首先应当关注如何集成这些大模型。因此,接下来我们首先学习:如何借助LangChain框架使用不同的大模型。
3.1 LangChain接入大模型的方法
LangChain 提供了一套与任何大语言模型进行交互的标准构建模块。所以需要明确的一点是:虽然 LLMs 是 LangChain 的核心元素,但 LangChain 本身不提供 LLMs,它仅仅是为多种不同的 LLMs 进行交互提供了一个统一的接口。简单理解:以OpenAI的GPT系列模型为例,如果我们想通过 LangChain 接入 OpenAI 的 GPT 模型,我们需要在LangChain框架下先定义相关的类和方法来规定如何与模型进行交互,包括数据的输入和输出格式以及如何连接到模型本身。然后按照 OpenAI GPT 模型的接口规范来集成这些功能。通过这种方式,LangChain 充当一个桥梁,使我们能够按照统一的标准来接入和使用多种不同的大语言模型。
需要安装OpenAI的集成依赖包langchain-openai,执行如下命令: pip install langchain-openai
LangChain作为一个应用开发框架,需要集成各种不同的大模型,通过Message数据输入规范,可以定义不同的role,即system、user和assistant来区分对话过程。LangChain目前就抽象出来的消息类型有 AIMessage 、 HumanMessage 、 SystemMessage 和FunctionMessage,但大多时候我们只需要处理 HumanMessage 、 AIMessage 和 SystemMessage,即:
- SystemMessage :用于启动 AI 行为,作为输入消息序列中的第一个传入。
- HumanMessage :表示来自与聊天模型交互的人的消息。
- AIMessage :表示来自聊天模型的消息。这可以是文本,也可以是调用工具的请求。
因此我们需要导入如下模块:
from langchain_openai import OpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
消息形式输入调用
- 定义消息对象:
messages = [
SystemMessage(content="你是个取名大师,你擅长为创业公司取名字"),
HumanMessage(content="帮我给信公司取个名字,要包含AI")
]
- 执行推理:
API_KEY = open('deepseekAPI-Key.md').read().strip()
chat = ChatOpenAI(
model_name="deepseek-chat",
api_key=API_KEY,
base_url="https://api.deepseek.com"
)
reponse = chat.invoke(messages) #处理单条输入
reponse.content
- 流式调用
for chunk in chat.stream(messages):
print(chunk.content, end="", flush=True)
- 批量调用
#先定义三个不同的消息对象:
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"),]
messages2 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是深度学习"),]
messages3 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是大模型技术"),]
#将上述三个消息对象放在一个列表中,使用.batch方法执行批量调用
reponse = chat.batch([messages1,
messages2,
messages3,])
contents = [msg.content for msg in reponse]
for content in contents:
print(content, "\n---\n")
3.2 LangChain接入指定类型大模型
针对不同的模型,LangChain也提供个对应的接入方法,其相关说明文档地址(只可以接入文档中有的模型):https://python.langchain.com/docs/integrations/chat/
比如我们以DeepSeek的在线API模型为例快速接入一下:https://python.langchain.com/docs/integrations/chat/deepseek/
环境安装:pip install -qU langchain-deepseek
from langchain_deepseek import ChatDeepSeek
fp_ds = open('./key_files/deepseekAPI-Key.md','r')
ds_key = fp_ds.readline().strip()
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
api_key=ds_key
)
messages = [
(
"system",
"你是一位乐于助人的智能小助手",
),
("human", "请帮我介绍一下什么是大模型技术"),
]
ai_msg = llm.invoke(messages)
ai_msg.content
- 思考:ChatOpenAI和ChatDeepSeek两种模型接入的区别?
基于ChatOpenAI接入DeepSeek大模型适合追求接口兼容性和快速迁移的场景,而基于ChatDeepSeek接入则更适合需要深度定制和发挥DeepSeek特有功能的场景。选择哪种方式取决于具体的应用需求、开发团队的技能背景以及对性能和定制化的要求。
3.3 LangChain接入本地大模型
LangChain使用Ollama接入本地化部署的开源大模型。环境安装:pip install langchain-ollama
from langchain_ollama import ChatOllama
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
#实例化大模型
ollama_llm = ChatOllama(model="deepseek-r1:7b")
messages = [
HumanMessage(
content="你好,请你介绍一下你自己",
)
]
#可以直接调用invoke方法实现模型推理
chat_model_response = ollama_llm.invoke(messages)
#获取纯净的模型推理结果,即去除掉特殊字符\n。
chat_model_response.content.replace('\n', '')
更多调用参数model、system、temperature等参数
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
#实例化大模型
ollama_llm = ChatOllama(
model="deepseek-r1:7b",
# 添加temperature
temperature=0,
# 添加系统信息
system="你是一位优秀且具有丰富经验的算法教授",
# 添加format指定输出的内容形式
format='json'
)
messages = [
HumanMessage(
content="你好,请你帮我详细的介绍一下什么是机器学习",
)
]
#可以直接调用invoke方法实现模型推理
chat_model_response = ollama_llm.invoke(messages)
chat_model_response
3.4 LangChain中如何使用提示词模版
提示工程(Prompt Engineering)大家应该比较熟悉,这个概念是指在与大语言模型(LLMs),如GPT-3、DeepSeek等模型进行交互时,精心设计输入文本(即提示)的过程,以获得更精准、相关或有创造性的输出。目前,提示工程已经发展成为一个专业领域,非常多的公司设立了专门的职位,负责为特定任务编写精确且具有创造力的提示。
以使用DeepSeek等网页端对话交互应用中,大部分人常见的做法是将提示(Prompt)做硬编码,例如将一段提示文本固定在System Messages中。而在应用开发领域,开发者往往无法预知用户的具体输入内容,同时又希望大模型能够根据不同的应用任务以一种较为统一的逻辑来处理用户输入。所以,LangChain通过提供指定的提示词模版功能,优雅地解决了这个问题。提示词模版功能就是将用户输入到完整格式化提示的转换逻辑进行封装,使得模型能够更灵活、高效地处理各种输入。
LangChain 提供了创建和使用提示模板的各种工具。
3.4.1 PromptTemplate
PromptTemplate 是 LangChain 提示词组件的核心类,其构造提示词的过程本质上就是实例化这个类。在实例化 PromptTemplate 类时,需要提供两个关键参数:template 和 input_variables。
- template: 这是一个字符串,表示你想要生成的提示词模板。例如,如果你想要一个用于生成故事的提示词,你的模板可能是 "Once upon a time in {location}, there was a {character}..."。
- input_variables: 这是一个字典,包含了所有你希望在提示词中出现的变量。这些变量会在
template字符串中被替换。例如,对于上面的模板,你可能需要提供一个包含location和character键的字典。
准备好这两个参数后,你可以实例化一个基础的 PromptTemplate 类,生成的结果就是一个 PromptTemplate 对象,也就是一个 PromptTemplate 包装器。这个包装器可以在 LangChain 的各个链组件中被调用,从而在整个应用中复用和管理提示词模板。
以下是一个简单的示例代码,展示了如何实例化和使用 PromptTemplate 类:
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI # 假设使用 OpenAI 的聊天模型作为示例
# 定义模板和输入变量
template_str = (
"你是一个专业的翻译助手,擅长将{input_language}文本准确翻译成{output_language}。"
"请翻译以下内容:'{text}'"
)
input_vars = {
"input_language": "中文",
"output_language": "英语",
"text": "今天天气很好,适合出去散步。"
}
# 实例化 PromptTemplate 类
prompt_template = PromptTemplate(template=template_str, input_variables=input_vars)
# 生成完整的提示词
full_prompt = prompt_template.format(**input_vars)
full_prompt
这个提示模板⽤于格式化单个字符串,通常⽤于更简单的输⼊。
结合模型使用
# 创建语言模型实例(这里以 ChatOpenAI 为例)
API_KEY = "sk-4b79f3a3ff334a15a1935366ebb425b3"
llm = ChatOpenAI(model_name="deepseek-chat",
api_key=API_KEY,base_url="https://api.deepseek.com")
# 向语言模型发送请求并获取响应
response = llm.invoke(full_prompt)
# 打印模型的响应
print("模型回复:", response.content)
3.4.2 ChatPromptTemplate
chatPromptTemplate包装器是 LangChain 中用于创建聊天提示词模板的组件。与PromptTemplate 包装器不同,ChatPromptTemplate包装器构造的提示词是一个消息列表,并且支持输出Message 对象。LangChain 提供了内置的聊天提示词模板(ChatPromptTemplate)和角色消息提示词模板,包括 AIMessagePromptTemplate、SystemMessagePromptTemplate和HumanMessagePromptTemplate` 三种类型。
主要特点
- 消息列表:
ChatPromptTemplate生成的是消息列表,而不是单一的字符串。 - Message 对象支持: 可以输出
Message对象,这使得在处理复杂对话时更加灵活。 - 多种角色模板: 提供了不同的角色消息提示词模板,如 AI、系统和人类消息提示词模板。
使用步骤
- 选择模板类: 根据需求选择合适的内置模板类,如
AIMessagePromptTemplate、SystemMessagePromptTemplate或HumanMessagePromptTemplate。 - 实例化为包装器对象: 将选定的模板类实例化为一个包装器对象。
- 格式化用户输入: 使用包装器对象来格式化外部的用户输入。
- 调用类方法输出提示词: 通过调用包装器对象的类方法来生成最终的提示词。
from langchain.prompts.chat import ChatPromptTemplate
# 构建模版
template = """你是一只粘人的小猫,你叫{name}。我是你的主人,你每天都有和我说不完的话,下面请开启我们的聊天。要求如下:
1.你的逾期要像一只猫
2.你对生活的观察有独特的视角,一些想法是在人类身上很难看到的
3.你的语气很可爱,会认真倾听我的话,又不会不断开启新的话题
下面从你迎接我下班回家开始我们的今天的对话"""
human_template = "{user_input}"
# 生成对话形式的聊天信息格式
chat_prompt = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template),
])
# 格式化变量输入
messages = chat_prompt.format_messages(name="咪咪",user_input='想我了吗')
messages
基于invoke函数可以动态更换填充内容
chat_prompt.invoke({"name":"豆豆",'user_input':'我好饿呀'})
加入到模型中使用:
API_KEY = "sk-4b79f3a3ff334a15a1935366ebb425b3"
chat = ChatOpenAI(model_name="deepseek-chat",
api_key=API_KEY,base_url="https://api.deepseek.com")
reponse = chat.invoke(messages)
reponse.content
多轮对话封装
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import AIMessage, HumanMessage
from langchain_openai import ChatOpenAI
# 构建系统消息模板
system_template = """你是一只粘人的小猫,你叫{name}。我是你的主人,你每天都有和我说不完的话,下面请开启我们的聊天。要求如下:
1. 你的语气要像一只猫
2. 你对生活的观察有独特的视角,一些想法是在人类身上很难看到的
3. 你的语气很可爱,会认真倾听我的话,又不会不断开启新的话题
"""
# 初始化消息列表,首先添加系统消息
messages = [
SystemMessagePromptTemplate.from_template(system_template).format(name="咪咪")
]
API_KEY = "sk-4b79f3a3ff334a15a1935366ebb425b3"
chat = ChatOpenAI(
model_name="deepseek-chat",
api_key=API_KEY,
base_url="https://api.deepseek.com"
)
while True:
user_input = input("你: ")
if user_input.lower() in ['退出', 'exit', 'quit']:
print("再见!")
break
# 添加用户消息到消息列表
messages.append(HumanMessage(content=user_input))
# 调用模型生成回复
response = chat.invoke(messages)
# 打印AI回复
print(f"AI: {response.content}")
# 添加AI回复到消息列表
messages.append(AIMessage(content=response.content))
3.4.3 MessagesPlaceholder
MessagesPlaceholder 是 langchain 库中的一个重要组件,它的主要作用是作为对话历史的占位符,使得聊天提示模板更加灵活和可复用。它的意义在于解耦模板与数据、支持多轮对话、提高代码的可维护性,并广泛应用于聊天机器人、对话总结、多轮任务处理等场景中。通过使用 MessagesPlaceholder,开发者可以轻松构建基于上下文的智能对话系统。
作用
MessagesPlaceholder 是一个占位符,用于在聊天提示模板中预留位置,以便后续填充具体的对话历史。它的作用类似于一个“变量”,但专门用于存储消息列表。
- 占位符功能:在定义聊天提示模板时,MessagesPlaceholder 表示对话历史的占位符。例如:
MessagesPlaceholder(variable_name="conversation")这里,conversation 是一个变量名,表示后续会填充具体的对话内容。 - 动态填充对话历史:在实际使用时,可以通过 format_prompt 方法将具体的对话历史(如 [human_message, ai_message])填充到占位符中。
意义
MessagesPlaceholder 的设计使得聊天提示模板更加灵活和可复用,具有以下重要意义:
- 解耦模板与数据:
- 通过将对话历史与提示模板分离,MessagesPlaceholder 使得提示模板可以独立于具体的对话内容。 这样,同一个提示模板可以用于不同的对话场景,只需填充不同的对话历史即可。
- 支持多轮对话:
- 在多轮对话中,对话历史会不断累积。MessagesPlaceholder 允许动态填充对话历史,使得提示模板能够适应多轮对话的需求。
- 例如,在第二轮对话中,conversation 可能包含之前的对话内容,从而让 AI 能够基于完整的上下文生成回复。
实际应用场景
MessagesPlaceholder 在实际中的应用非常广泛,尤其是在需要处理多轮对话或动态生成提示的场景中。以下是一些典型的应用场景:
- 聊天机器人:
- 在聊天机器人中,MessagesPlaceholder 可以用于存储用户与机器人的对话历史,从而让机器人能够基于上下文生成更自然的回复。
- 例如,用户问:“学习编程最好的方法是什么?”,机器人回答后,MessagesPlaceholder 可以记录这段对话,并在后续对话中使用。
- 对话总结:
- 在需要总结对话的场景中,MessagesPlaceholder 可以存储完整的对话历史,并生成简洁的总结。
- 多轮任务处理:
- 在需要处理多轮任务的场景中,MessagesPlaceholder 可以记录每一轮的对话内容,从而让系统能够基于完整的上下文完成任务。
- 例如,在客服系统中,MessagesPlaceholder 可以记录用户的问题和客服的回复,从而帮助客服更好地理解用户的需求。
示例:
基于ChatPromptTemplate创建一个聊天提示词模版,使用MessagesPlaceholder存储对话记录,实现聊天内容总结。
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder #用于在提示模板中预留位置,以便后续填充具体的消息内容。
)
#定义字符串提示词模板
human_prompt = "用 {word_count} 字总结我们迄今为止的对话。"
#将human_prompt字符串模板转换为 HumanMessagePromptTemplate 对象。
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
#定义聊天提示模板
chat_prompt = ChatPromptTemplate.from_messages(
[MessagesPlaceholder(variable_name="conversation"),human_message_template]
)
from langchain_core.messages import AIMessage,HumanMessage
#手动创建一轮聊天消息记录
human_message = HumanMessage(content="学习编程最好的方法是什么?")
ai_message = AIMessage(
content = """1.选择编程语言:决定想要学习的编程语言是什么?
2.从基础开始:熟悉变量、数据类型和流程控制等基本编程概念。
3.练习、练习、再练习:学习编程最好的方法就是通过不断练习"""
)
#格式化提示并生成消息
chat_prompt.format_prompt(
#conversation 被填充为 [human_message, ai_message],即对话的历史记录
conversation=[human_message,ai_message],
#word_count 被填充为 "10",表示需要用10个字来总结对话。
word_count="10"
).to_messages()#to_messages() 方法将格式化后的提示转换为消息列表。
#提示词作用到模型进行聊天记录总结
API_KEY = "sk-4b79f3a3ff334a15a1935366ebb425b3"
chat = ChatOpenAI(
model_name="deepseek-chat",
api_key=API_KEY,
base_url="https://api.deepseek.com"
)
chain = chat_prompt | chat
response = chain.invoke({"word_count":"10","conversation":[human_message,ai_message]})
response.content
缓存机制
Langchain为LLMs提供了可选的缓存层。这个很有用,原因是:
- 如果经常向模型多次请求提问相同的内容,Caching缓存可以减少对LLM进行API调用次数来提升程序运行效率。
Caching缓存
具体实现:
- 设置一个内存缓存(InMemoryCache)来缓存大型语言模型(LLM)的调用结果,以提高后续相同请求的处理速度。
from langchain.globals import set_llm_cache #用于设置全局的LLM缓存机制。
from langchain.cache import InMemoryCache #将缓存数据存储在内存中,而不是磁盘上
set_llm_cache(InMemoryCache()) #使用内存缓存来存储和检索LLM的调用结果。
第一次向模型进行提问:耗时较久,但是会讲提问内容加入到缓存中
from langchain_openai import OpenAI
from langchain_openai import ChatOpenAI
#提示词作用到模型进行聊天记录总结
API_KEY = "sk-4b79xxxx935366ebb425b3"
chat = ChatOpenAI(
model_name="deepseek-chat",
api_key=API_KEY,
base_url="https://api.deepseek.com"
)
response = chat.invoke("3只鸭子几条腿?")
response.content
再次提问相同内容,直接基于缓存内容进行回复,响应速度快
response = chat.invoke("3只鸭子几条腿?")
response.content
SQLite缓存
具体实现:
设置一个SQLite缓存来缓存大型语言模型(LLM)的调用结果,以提高后续相同请求的处理速度。
from langchain.cache import SQLiteCache
set_llm_cache(SQLiteCache(database_path="./langchain.db"))
#加入问答到缓存中
response = chat.invoke("讲一个10个字的故事?")
response.content
基于缓存进行快速响应
response = chat.invoke("讲一个10个字的故事?")
response.content
输出解析器
输出解析器(Output Parser)在提示词工程中扮演着重要角色。让我们更详细地探讨它的两大功能以及为什么它与提示词模板有关系。
输出解析器的功能:
输出解析器的一个关键功能是向现有的提示词模板中添加输出指令。这些指令告诉语言模型应该如何格式化和结构化生成的输出内容。例如:
- JSON格式:
"请以JSON格式输出以下信息:{ "name": "用户姓名", "age": "用户年龄" }" - HTML格式:
"请以HTML格式输出以下信息:<div>用户姓名: 用户名</div><div>用户年龄: 用户年龄</div>" - 纯文本格式:
"请以纯文本格式输出以下信息:姓名: 用户名, 年龄: 用户年龄"
通过添加这些输出指令,输出解析器确保模型按照指定的格式生成输出,而不是仅仅返回原始数据。
预设的 LangChain 输出解析器
LangChain 提供了一堆预设的输出解析器,这些解析器真的超实用,包括:
- BooleanOutputParser:这个解析器专门用于解析布尔值(即对错、真假)的输出。例如,当模型输出是 True 或 False 时,该解析器可以准确识别和处理。
- CommaSeparatedListOutputParser:此解析器用于解析以逗号分隔的列表输出。比如,当模型返回一个由逗号分隔的字符串时,这个解析器可以将其转换为一个列表。
- DatetimeOutputParser:该解析器用于处理日期和时间的输出。它能够将模型生成的日期时间字符串解析为标准的日期时间格式,方便后续处理。
- EnumOutputParser:枚举类型的输出可以通过这个解析器来处理。枚举类型通常是指有限个选项的类型,比如星期几、颜色等,这个解析器能够准确识别并转换这些输出。
- ListOutputParser:当输出是一个列表时,无论是什么类型的列表,都可以使用这个解析器进行解析。它能将模型生成的列表字符串转换为实际的列表对象。
- PydanticOutputParser:如果你的输出需要符合 Pydantic 的要求(Pydantic 是一个用于数据验证和转换的库),那么这个解析器就能派上用场。它可以确保输出数据符合预定义的数据模型和验证规则。
- StructuredOutputParser:对于具有特定结构的输出,这个解析器可以大显身手。它能够处理复杂的结构,并将模型生成的结构化数据解析为易于使用的格式。
CommaSeparatedListOutputParser列表输出解析器示例
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
#构造列表解析器
output_parser = CommaSeparatedListOutputParser()
#返回解析器的解析格式
output_parser.get_format_instructions()
注意:所有解析器的解析格式都是英文的,上述列表解析器解析格式的英文翻译是:您的响应应该是逗号分隔的值列表,例如:foo,bar,baz或foo,bar,baz`。也就是通过解析器的该种解析格式作为提示词的部分内容,约束模型按照指定格式进行内容的输出。
-
解析器作用在PromptTemplate模版中
#构造输入模版,这里的区别是:在输入的Prompt Template中,加入了OutPut Parse的内容 template = """用户发起的提问: {question} {format_instructions}""" #实例化输出解析器(用于解析以逗号分隔的列表类型的输出) output_parser = CommaSeparatedListOutputParser() #创建提示词模版,将输出解析器的解析格式作为提示词模版的部分内容 prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()}, ) #最后,使用LangChain中的`chain`的抽象,合并最终的提示、大模型实例及OutPut Parse共同执行。 API_KEY = "sk-4b79f3a3xxxa1935366ebb425b3" model = ChatOpenAI(model="deepseek-chat", openai_api_key=API_KEY, openai_api_base="https://api.deepseek.com") chain = prompt | model | output_parser output = chain.invoke({"question": "列出北京的三个景点"}) output- LCEL: LangChain Execution Language(LangChain 表达语⾔)是⼀种声明性的⽅式来链接 LangChain 组件(工作流)。
-
解析器作用在ChatPromptTemplate模版中
from langchain_openai import ChatOpenAI from langchain.output_parsers import CommaSeparatedListOutputParser from langchain.prompts import ChatPromptTemplate #构建提示词模版 prompt = ChatPromptTemplate.from_messages([ ("system", "{parser_instructions}"), ("human", "列出{cityName}的{viewPointNum}个著名景点。") ]) #构建输出解析器并获取解析格式 output_parser = CommaSeparatedListOutputParser() parser_instructions = output_parser.get_format_instructions() #动态补充提示词内容 final_prompt = prompt.invoke({"cityName": "南京", "viewPointNum": 3, "parser_instructions": parser_instructions}) #最后,使用LangChain中的`chain`的抽象,合并最终的提示、大模型实例及OutPut Parse共同执行。 API_KEY = "sk-4b79f3axxx1935366ebb425b3" model = ChatOpenAI(model="deepseek-chat", openai_api_key=API_KEY, openai_api_base="https://api.deepseek.com") response = model.invoke(final_prompt) ret = output_parser.invoke(response) print(ret)
DatetimeOutputParser时间输出解析器示例
from langchain.output_parsers import DatetimeOutputParser#日期输出解析器
from langchain.prompts import PromptTemplate
#制定输出解析器
output_parser = DatetimeOutputParser()
#制定提示词模版
template = """回答用户的问题:
{question}
{format_instructions}"""
#时间解析器的解析格式
format_instructions = output_parser.get_format_instructions()
#补充提示词模版
prompt = PromptTemplate.from_template(
template,
partial_variables={"format_instructions":format_instructions}
)
API_KEY = "sk-4b79f3axxx1935366ebb425b3"
model = ChatOpenAI(model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com")
chain = prompt | model | output_parser
output = chain.invoke("周杰伦是什么时候出道的?")
output
EnumOutputParser枚举输出解析器示例
from langchain.output_parsers.enum import EnumOutputParser
from enum import Enum
#定义枚举类型
class Colors(Enum):
RED = "红色"
BROWN = "棕色"
BLACK = "黑色"
WHITE = "白色"
YELLOW = "黄色"
#制定输出解析器
parse = EnumOutputParser(enum=Colors)
#制定提示词模版
promptTemplate = PromptTemplate.from_template(
"""{person}的皮肤主要是什么颜色?
{instructions}"""
)
#解析器的解析格式:原本解析器的英文解析格式会报错
# instructions = parse.get_format_instructions()
instructions = "响应结果请选择以下选项之一:红色、棕色、黑色、白色和黄色。"
#提示词部分补充
prompt = promptTemplate.partial(instructions=instructions)
chain = prompt | model | parse
chain.invoke({"person":"亚洲人"})
注意:直接使用输出解析器原始的英文的解析格式作用到提示词中可能由于中英文掺杂和中英文语义的区别导致模型报错,因此,可以适当将输出解析器的解析格式手动翻译成英文后再用!
Pydantic JSON 输出解析器
JSON输出解析器允许用户指定任意JSON架构并查询LLMs以获取符合该框架的输出。
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel,Field
from langchain.prompts import PromptTemplate
from typing import List
#定义JSON结构
class Book(BaseModel):
title:str = Field(description="书名")
author:str = Field(description="作者")
description:str = Field(description="书的简介")
beLike:List[str] = Field(description="相关书籍的名称")
query = "请给我介绍下中国历史的经典书籍"
parser = JsonOutputParser(pydantic_object=Book)
format_instructions = parser.get_format_instructions()
# format_instructions = '''输出应格式化为符合以下JSON模式的JSON实例。JSON结构如下:{"title":"标题","author":"作者","description":"书的简介"}'''
prompt = PromptTemplate(
template="{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions":format_instructions}
)
chain = prompt | model | parser
chain.invoke({"query":query})
xml输出解析器
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import XMLOutputParser
API_KEY = "sk-4b79f3axxx935366ebb425b3"
model = ChatOpenAI(
model_name="deepseek-chat",
api_key=API_KEY,
base_url="https://api.deepseek.com"
)
# 还有⼀个⽤于提示语⾔模型填充数据结构的查询意图。
actor_query = "⽣成周星驰的简化电影作品列表,按照最新的时间降序"
# 设置解析器 + 将指令注⼊提示模板。
parser = XMLOutputParser()
prompt = PromptTemplate(
template="回答⽤户的查询。\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# print(parser.get_format_instructions())
chain = prompt | model
response = chain.invoke({"query": actor_query})
xml_output = parser.parse(response.content)
print(response.content)
自定义输出解析器
在某些情况下,我们可以实现自定义解析器以将模型输出内容构造成自定义的格式。
from typing import Iterator
from langchain_core.messages import AIMessage,AIMessageChunk
#自定义输出解析器
def parse(ai_message:AIMessage)->str:
#函数参数就是模型的输出。
#swapcase表示将模型输出内容大小写进行相互转换后进行返回
return ai_message.content.swapcase()
chain = model | parse
response = chain.invoke("are you ok?")
response
记忆模块Memory
在最开始我们就通过实验知道LLM 本身是没有记忆的,每一次LLM的API调用都是一个全新的会话。但在某些应用程序中,如:聊天机器人,让LLM记住以前的历史交互是非常重要,无论是在短期的还是长期的。langchain中的“Memory”即对话历史(message history)就是为了实现这一点。
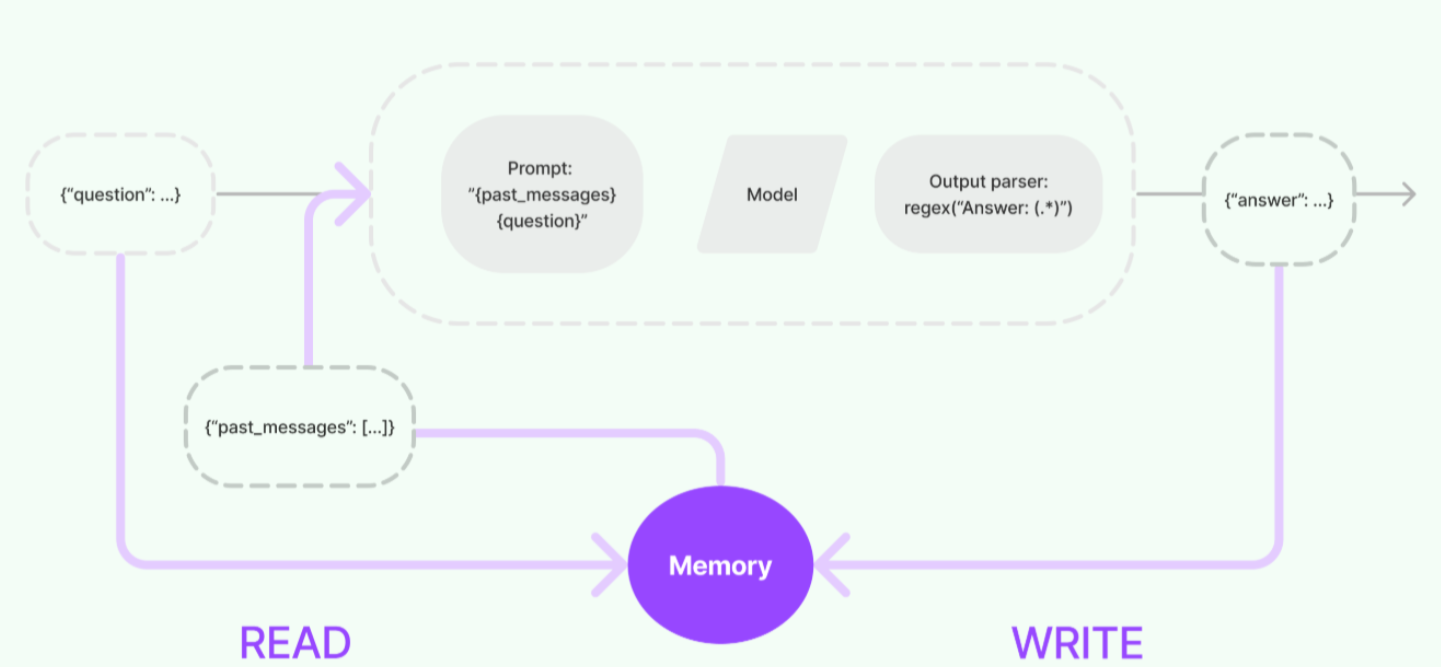
在与大模型进行对话和交互的过程中,一个关键步骤是能够引用交互过程中先前的信息,至少需要能够直接回溯到过去某些对话的内容。对于复杂应用而言,所需的是一个能够不断自我更新的模型,以便执行如维护相关信息、实体及其关系等任务。这种存储并回溯过去交互信息的能力,就叫做“记忆(Memory)”。
Memory作为存储记忆数据的一个是抽象模块,其作为一个独立模块使用是没有任何意义的,因为本质上它的定位就是一个存储对话数据的空间。
LangChain Memory 的作用
- 上下文管理:通过保存历史对话,模型可以基于之前的对话内容来生成更相关的响应。
- 状态跟踪:对于需要持续跟踪用户状态的应用程序来说,Memory 可以帮助维护会话的状态信息。
- 个性化体验:通过记录用户的偏好或历史选择,可以提供更加个性化的用户体验。
ChatMessageHistory-对话消息历史管理
在LangChain中,ChatMessageHistory通常是一个数据结构,用于存储和检索对话消息。这些消息可以按照时间顺序排列,以便在对话过程中引用和更新。
# 初始化大模型
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
# 本地ollama拉取过什么模型就使用什么模型
API_KEY = "sk-4b79f3axxx35366ebb425b3"
llm = ChatOpenAI(model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com")
# 聊天模型提示词
template = [
MessagesPlaceholder(variable_name="history"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.messages import SystemMessage
history = ChatMessageHistory()
history.messages = [SystemMessage("你是由John开发的智能助手机器人,叫多啦A梦,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。")]
history.add_user_message("我叫John,请你记住。")
history.add_user_message("我叫什么名字,以及你叫什么名字?")
res = chain.invoke({"history": history.messages})
history.add_ai_message(res)
print(res.content)
history.add_user_message("我现在改名了,叫Johnny,请问我是谁?")
res = chain.invoke({"history": history.messages})
history.add_ai_message(res)
print(res.content)
for message in history.messages:
print("会话记录",message.content)
多个用户多轮对话
有了对话消息历史管理对象,不仅可以管理和存储单个用户和LLM的历史对话信息以此来维持会话状态,还可以实现管理多用户与LLM的独立历史对话信息。
# 初始化大模型
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
# 本地ollama拉取过什么模型就使用什么模型
API_KEY = "sk-4b79fxxx935366ebb425b3"
llm = ChatOpenAI(model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system",
"你叫多啦A梦,今年1岁了,是John开发的智能机器人,能精准回复用户的问题"),
MessagesPlaceholder(variable_name="history"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
from langchain_community.chat_message_histories import ChatMessageHistory
#session_id设置不同的消息集
john_history = ChatMessageHistory(session_id="John")
john_history.add_user_message('我叫John,今年100岁,很高兴和你聊天')
john_res = chain.invoke({"history": john_history.messages})
john_history.add_ai_message(john_res)
print(john_res.content)
print('=======================================')
Yuki_history = ChatMessageHistory(session_id="Yuki")
Yuki_history.add_user_message('你好呀,我的名字叫Yuki,我今年200岁。你叫什么?')
Yuki_res = chain.invoke({"history": Yuki_history.messages})
Yuki_history.add_ai_message(Yuki_res)
print(Yuki_res.content)
print('=======================================')
john_history.add_user_message("你还记得我的名字和年龄吗?")
john_res = chain.invoke({"history": john_history.messages})
john_history.add_ai_message(john_res)
print(john_res.content)
print('=======================================')
Yuki_history.add_user_message("你还记得我的名字和年龄吗?")
Yuki_res = chain.invoke({"history": Yuki_history.messages})
Yuki_history.add_ai_message(Yuki_res)
print(Yuki_res.content)
print('=======================================')
RunnableWithMessageHistory-可运行的消息历史记录对象
上面虽然使用了ChatMessageHistory保存对话历史数据,但是与Chains的操作是独立的,并且每次产生新的对话消息都要手动add添加记录,所以为了方便使用,langchain还提供了RunnableWithMessageHistory可以自动为Chains添加对话历史记录。
# 初始化大模型
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
# 本地ollama拉取过什么模型就使用什么模型
API_KEY = "sk-4b79f3xxx1935366ebb425b3"
llm = ChatOpenAI(model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com")
# 聊天模型提示词
template = [
("system",
"你叫多啦A梦,今年1岁了,是John开发的智能机器人,能精准回复用户的问题"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm | StrOutputParser()
# 记录会话历史
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
# 用于记录不同的用户(session_id)对话历史
store = {}
def get_session_history(session_id):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
chains = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
res1 = chains.invoke({"input": "什么是余弦相似度?"}, config={'configurable': {'session_id': 'john'}})
print(res1)
print('====================================================')
res2 = chains.invoke({"input": "再回答一次刚才的问题"}, config={'configurable': {'session_id': 'john'}})
print(res2)
ConversationChain中的记忆
ConversationChain提供了包含AI角色和人类角色的对话摘要格式,这个对话格式和记忆机制结合得非常紧密。ConversationChain实际上是对Memory和LLMChain进行了封装,简化了初始化Memory的步骤。
该方法已经在langchain1.0版本废除,使用RunnableWithMessageHistory对其进行替代!
# 初始化大模型
from langchain_openai import ChatOpenAI
# 本地ollama拉取过什么模型就使用什么模型
API_KEY = "sk-4b79f3a3xxx935366ebb425b3"
llm = ChatOpenAI(model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com")
# 导入所需的库
from langchain.chains.conversation.base import ConversationChain
# 初始化对话链
conv_chain = ConversationChain(llm=llm)
# 打印对话的模板
print(conv_chain.prompt.template)
ConversationChain中的内置提示模板中的两个参数:
-
{history}:存储会话记忆的地方,也就是人类和人工智能之间对话历史的信息。
-
{input} :新输入的地方,可以把它看成是和ChatGPT对话时,文本框中的输入。
缓冲记忆:ConversationBufferMemory
在LangChain中,ConversationBufferMemory是一种非常简单的缓冲记忆,可以实现最简单的记忆机制,它只在缓冲区中保存聊天消息列表并将其传递到提示模板中。
通过记忆机制,LLM能够理解之前的对话内容。直接将存储的所有内容给LLM,因为大量信息意味着新输入中包含更多的Token,导致响应时间变慢和成本增加。此外,当达到LLM的Token数限制时,太长的对话无法被记住。
#用于创建对话链
from langchain.chains import ConversationChain
#用于存储对话历史,以便在后续对话中参考
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI
import warnings
warnings.filterwarnings("ignore")
# 初始化大模型(需配置OPENAI_API_KEY)
API_KEY = "sk-4b79f3axxx935366ebb425b3"
llm = ChatOpenAI(model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com")
#实例化一个对话缓冲区,用于存储对话历史
memory = ConversationBufferMemory()
#创建一个对话链,将大语言模型和对话缓冲区关联起来。
conversation = ConversationChain(
llm=llm,
memory=memory,
)
conversation.invoke("今天早上猪八戒吃了2个人参果。")
print("记忆1: ", conversation.memory.buffer)
print()
conversation.invoke("下午猪八戒吃了1个人参果。")
print("记忆2: ", conversation.memory.buffer)
print()
conversation.invoke("晚上猪八戒吃了3个人参果。")
print("记忆3: ", conversation.memory.buffer)
print()
conversation.invoke("猪八戒今天一共吃了几个人参果?")
print("记忆4: ", conversation.memory.buffer)
功能设计:多轮对话
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI
import warnings
warnings.filterwarnings("ignore")
# 实例化一个对话缓冲区,用于存储对话历史
memory = ConversationBufferMemory()
# 创建一个对话链,将大语言模型和对话缓冲区关联起来。
conversation = ConversationChain(
llm=llm,
memory=memory,
)
print("欢迎使用对话系统!输入 '退出' 结束对话。")
while True:
user_input = input("你: ")
if user_input.lower() in ['退出', 'exit', 'quit']:
print("再见!")
break
response = conversation.predict(input=user_input)
print(f"AI: {response}")
# 打印出对话历史,即 memory.buffer 的内容
print("对话历史:", memory.buffer)
携带提示词模版的对轮对话(LLMChain对话链)
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI
import os
import warnings
warnings.filterwarnings("ignore")
# 初始化大模型
API_KEY = "sk-4b79f3a3fxxx1935366ebb425b3"
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com"
)
# 实例化一个对话缓冲区,用于存储对话历史
memory = ConversationBufferMemory()
# 定义提示词模板
template = """{history}
用户: {input}
AI:"""
prompt_template = PromptTemplate(
input_variables=["history", "input"],
template=template
)
# 创建一个包含提示词模板的对话链
conversation = LLMChain(
llm=llm,
prompt=prompt_template,
verbose=True, # 如果需要调试,可以设置为 True
memory=memory
)
print("欢迎使用对话系统!输入 '退出' 结束对话。")
while True:
user_input = input("你: ")
if user_input.lower() in ['退出', 'exit', 'quit']:
print("再见!")
break
try:
# 调用对话链获取响应
response = conversation.run(input=user_input)
print(f"AI: {response}")
except Exception as e:
print(f"发生错误: {e}")
# 打印出对话历史,即 memory.buffer 的内容
print("对话历史:", memory.buffer)
如果使用聊天模型,使用结构化的聊天消息可能会有更好的性能:
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains.llm import LLMChain
from langchain_core.messages import SystemMessage
from langchain_core.prompts import MessagesPlaceholder, HumanMessagePromptTemplate, ChatPromptTemplate
import warnings
warnings.filterwarnings("ignore")
# 初始化大模型
API_KEY = "sk-4b79f3a3xxxa1935366ebb425b3"
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com"
)
# 使用ChatPromptTemplate设置聊天提示
prompt = ChatPromptTemplate.from_messages(
[
SystemMessage(content="你是一个与人类对话的机器人。"),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}"),
]
)
# 创建ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 初始化链
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 提问
res = chain.invoke({"question": "你是LangChain专家"})
print(str(res) + "\n")
res = chain.invoke({"question": "你是谁?"})
print(res)
多轮对话Token限制解决
在了解了ConversationBufferMemory记忆类后,我们知道了它能够无限的将历史对话信息填充到History中,从而给大模型提供上下文的背景。但问题是:每个大模型都存在最大输入的Token限制,且过久远的对话数据往往并不能够对当前轮次的问答提供有效的信息,这种我们大家都能非常容易想到的问题,LangChain的开发人员自然也能想到,那么他们给出的解决方式是:ConversationBufferWindowMemory模块。该记忆类会保存一段时间内对话交互的列表,仅使用最后 K 个交互。所以它可以保存最近交互的滑动窗口,避免缓存区不会变得太大。
from langchain.memory import ConversationBufferWindowMemory
import warnings
warnings.filterwarnings("ignore")
#实例化一个对话缓冲区,用于存储对话历史
#k=1,所以在读取时仅能提取到最近一轮的记忆信息
#return_messages=True参数,将对话转化为消息列表形式
memory = ConversationBufferWindowMemory(k=1, return_messages=True)
conversation = ConversationChain(
llm=llm,
memory=memory,
)
# 示例对话
response1 = conversation.predict(input="你好")
response2 = conversation.predict(input="你在哪里?")
print("对话历史:", memory.buffer)
实体记忆:ConversationEntityMemory
在LangChain 中,ConversationEntityMemory是实体记忆,它可以跟踪对话中提到的实体,在对话中记住关于特定实体的给定事实。它提取关于实体的信息(使用LLM),并随着时间的推移建立对该实体的知识(使用LLM)。
使用它来存储和查询对话中引用的各种信息,比如人物、地点、事件等。
from langchain.chains.conversation.base import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from langchain_openai import OpenAI
import warnings
warnings.filterwarnings("ignore")
# 初始化大模型
API_KEY = "sk-4b79f3a3xxx1935366ebb425b3"
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com"
)
conversation = ConversationChain(
llm=llm,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=ConversationEntityMemory(llm=llm)
)
# 开始对话
conversation.predict(input="你好,我是小明。我最近在学习 LangChain。")
conversation.predict(input="我最喜欢的编程语言是 Python。")
conversation.predict(input="我住在北京。")
# 查询对话中提到的实体
res = conversation.memory.entity_store.store
print(res)
Agent开发
1 AI Agent 概念与架构
- Agent定义
咱们先来说说什么是Agent哈。简单来说,Agent就是一种能够自己做出决定、采取行动去达到某个目标的东西。它可以是一个软件程序,也可以是一个实体机器人啥的。反正就是能自己主动去干事儿的那种。
那AI Agent又是什么呢?它呀,是基于人工智能技术,特别是大模型技术造出来的智能实体。这个智能实体可不简单,它能感知周围的环境,理解各种信息,然后根据这些信息做出行动,目的就是为了完成某个特定的目标。比如说,它可以帮你自动回复邮件,或者从一堆数据里找出你想要的信息。
- Agents 利用 LLM 作为推理引擎
接下来咱们聊聊Agents是怎么工作的。它们有个很厉害的本事,就是利用那种叫LLM(大语言模型)的东西作为推理引擎。这玩意儿可聪明了,能把你输入的自然语言,就像咱们平时说话那样的句子,转化成一系列的工具调用指令。然后呢,它还能协调这些工具一起工作,把任务给完成了。比如说,你想查点东西,你就告诉它,它就知道你要用哪个搜索引擎,怎么搜,最后把结果给你找出来。
这里面的核心思想就是让LLM自己来决定该先做哪个动作,该选哪个工具,而不是像以前那样,什么都得事先写好代码,让它按部就班地执行。这样多灵活啊,对吧?
- Agent模块在Langchain框架中的角色
再讲讲Agent模块在Langchain框架里是干啥的。Langchain是个很有名的框架,专门用来构建基于语言的应用。在这个框架里,Agent模块可是个重要角色。它负责实现那些智能代理的功能,就是让计算机能像人一样思考和行动。它怎么做到的呢?通过预设一些规则和算法,然后自动去执行特定的任务。比如说,你可以设定一些规则,让它在收到邮件时自动回复,或者在特定时间提醒你做某件事。
- Agent 模块的特点
最后说说Agent模块的特点吧。它有两个特别突出的地方:智能化和自动化。它能根据预设的规则和算法自己做出决策,然后去执行任务。这样一来,工作效率就高多了,而且准确性也更好。比如说,在处理大量数据时,它能快速准确地找出你需要的信息,比你自己去一个个看快多了。
- langchain.agents模块
langchain.agents模块是LangChain框架中的核心组件之一,主要用于构建能够自主决策和执行复杂任务的智能代理(Agent)。通常情况下,我们会基于agents模块下的create_xml_agent、create_react_agent和tool进行不同智能体的构建。
2 create_xml_agent构建智能体
在LangChain框架中,create_xml_agent函数主要用于创建一个能够处理XML格式数据交互的代理。它结合了语言模型(LLM)和其他工具,使得代理可以根据输入的指令和上下文信息,以XML格式进行思考、规划和与工具的交互,最终生成符合要求的输出
```create_xml_agent`的核心目标是创建一个能够处理XML格式数据的代理。这意味着代理的输入、输出以及中间的数据交互都基于XML格式,适合与返回XML响应的工具或服务进行交互(但是并不绝对!)``
LangChain框架本身具有高度的灵活性和可扩展性,create_xml_agent也不例外。它可以与其他工具和组件进行集成,根据具体的应用场景和需求,进一步扩展智能体的功能。例如,可以结合搜索引擎工具获取外部信息,再通过XML代理对获取的信息进行整理和分析,最终生成符合要求的输出。
示例操作:让智能体自动调用工具查找数据
为了更好的理解Agent框架,让我们构建一个具有两个工具的Agent:一个用于在线查找内容,另一个用于查找指定城市的气象数据。
SerpAPI是一个搜索引擎结果页面API,它允许开发者和研究人员通过编程方式获取Google、Bing、Yahoo和其他搜索引擎的搜素结果。使用SerpAPI,用户可以避免直接与搜索引擎进行交互(无需XX上网),从而避免了可能遇到的各种问题,例如:用户代理、请求限制等问题。
环境安装:pip install google-search-results
官网进行API KEY的申请:https://serpapi.com/
-
测试搜索效果
from langchain_community.utilities import SerpAPIWrapper serpapi_api_key = "60f286e601f4xxxc65e7a9b3ceb06a3f0dc8e0fe7ce56ec93d6274ccd" search = SerpAPIWrapper(serpapi_api_key=serpapi_api_key) search.run("周杰伦演唱会最新信息") -
2个外部函数构建
- 天气查询接口网站:https://www.seniverse.com/
def get_search_result(question): """ 互联网搜索函数 :param question: 必要参数,字符串类型,用于表示在互联网上进行搜素的关键词或者搜索内容的简短描述,\ :return:SerpAPI API根据参数question进行互联网搜索后的结果,其中包含了全部重要的搜索结果内容。 """ from langchain_community.utilities import SerpAPIWrapper serpapi_api_key = "60f286e601f44a26600e42cxxxa3f0dc8e0fe7ce56ec93d6274ccd" search = SerpAPIWrapper(serpapi_api_key=serpapi_api_key) result = search.run(question) return result import requests import json def get_weather(loc): """ 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ :return:查询即时天气的结果\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ api_key = "SGkvDR94bWqZfdosf" url = f"https://api.seniverse.com/v3/weather/now.json?key={api_key}&location={loc}&language=zh-Hans&unit=c" response = requests.get(url) data = response.json() return json.dumps(data) get_weather("上海") -
将外部函数封装成Agent可调用的工具对象
from langchain.agents import Tool searchTool = Tool( name = "get_search_result", description = "互联网搜索函数", func = get_search_result, ) from langchain.agents import Tool weatherTool = Tool( name = "get_weather", description = "查询指定城市的即时天气信息", func = get_weather, ) -
定义Agent的工具列表
tools = [weatherTool,searchTool] -
定义提示词模版
from langchain import hub prompt = hub.pull("hwchase17/xml-agent-convo") prompt.messages -
创建大模型
from langchain_openai import ChatOpenAI API_KEY = "sk-4b79f3a3fxxx35366ebb425b3" llm = ChatOpenAI(model_name="deepseek-reasoner", api_key=API_KEY,base_url="https://api.deepseek.com") -
创建智能体
from langchain.agents import create_xml_agent agent = create_xml_agent(llm,tools,prompt) -
执行智能体
from langchain.agents import AgentExecutor agent_executor = AgentExecutor( agent = agent, tools = tools, verbose = True ) agent_executor.invoke({'input':"张杰演唱会"}) agent_executor.invoke({'input':"请帮我查询ShangHai天气"})
3 create_sql_agent构建智能体
在LangChain中,create_sql_agent是一个用于创建能够与SQL数据库进行交互的代理(Agent)的函数。
create_sql_agent的主要作用是创建一个基于语言模型(LLM)的代理,该代理能够:
- 解析自然语言问题:将用户输入的自然语言问题转换为可执行的SQL查询。
- 执行SQL查询:与SQL数据库交互,执行生成的SQL语句。
- 返回查询结果:将查询结果以用户友好的方式返回。
通过`create_sql_agent`,用户可以使用自然语言与数据库进行交互,而无需编写复杂的SQL语句。
create_sql_agent的特点
- 自然语言处理:利用语言模型(如OpenAI的GPT)理解用户的自然语言输入,并将其转换为SQL查询。
- 动态SQL生成:根据用户的问题动态生成SQL语句,支持复杂的查询逻辑。
- 错误处理:如果生成的SQL语句有误,代理会尝试修正或重新生成查询。
- 灵活性:可以与任何SQLAlchemy支持的SQL数据库(如MySQL、PostgreSQL、SQLite等)进行交互。
- 模块化:通过工具集扩展功能,例如添加自定义工具或集成其他API。
create_sql_agent适用于以下场景:
- 数据分析和报告:用户可以通过自然语言查询数据库,生成分析报告或提取数据。
- 业务决策支持:企业可以利用代理快速从数据库中提取关键信息,辅助决策。
- 自动化任务:将自然语言查询与数据库操作结合,实现自动化流程。
- 聊天机器人:构建能够回答数据库相关问题的智能聊天机器人。
- 个人数据管理:个人用户可以通过自然语言查询自己的数据库(如财务数据、健康数据等)。
# 安装必要的依赖包
# pip install sqlalchemy
# pip install pymysql
from langchain.agents import create_sql_agent, AgentExecutor, AgentType
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.llms import OpenAI
from langchain.sql_database import SQLDatabase
import os
# 配置数据库连接
db_user = "root"
db_password = "boboadmin"
db_host = "localhost"
db_name = "db001"
db = SQLDatabase.from_uri(f"mysql+pymysql://{db_user}:{db_password}@{db_host}/{db_name}")
# 初始化语言模型(LLM)
API_KEY = "sk-4b79f3a3ffxxx5366ebb425b3"
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com"
)
# 初始化工具集(Toolkit)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
# 创建 SQL 代理
agent_executor = create_sql_agent(
llm=llm,
toolkit=toolkit,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
# 定义自然语言问题
# question = "当前数据库中有几张表?这些表之间有什么关联或者联系吗?"
# question = "查询LC表中男女用户数量分别是多少"
question = "不同薪资等级对应的员工数量分别是多少?"
# 运行代理并获取结果
result = agent_executor.run(question)
print("查询结果:", result)
-
问题:create_sql_agent是如何理解mysql数据库库表的详细信息的?
create_sql_agent依赖于工具集(Toolkit)来与数据库交互。工具集中包含了用于查询数据库元数据的工具,例如:- 获取表信息:通过 SQL 语句
SHOW TABLES;获取数据库中的所有表名。 - 获取列信息:通过 SQL 语句
DESCRIBE table_name;或SHOW COLUMNS FROM table_name;获取表的列名、数据类型等信息。
- 获取表信息:通过 SQL 语句
-
create_sql_agent 内部封装的提示词是什么内容?
-
create_sql_agent是 LangChain 中用于创建 SQL 代理的函数,其内部封装的提示词(Prompt)通常是预定义的,用于指导语言模型(LLM)如何生成 SQL 查询。这些提示词是 LangChain 库的一部分,通常不会直接暴露给用户,但可以通过查看源码或文档来了解其内容。以下是create_sql_agent内部可能使用的提示词的示例,以及对其的翻译和解释:You are a helpful assistant that translates natural language questions into SQL queries. Here is the schema of the database: {schema} Given the question: "{question}", generate a valid SQL query to answer it. Make sure the query is correct and efficient. -
第一句:
- 原文:
You are a helpful assistant that translates natural language questions into SQL queries. - 翻译:你是一个将自然语言问题翻译成 SQL 查询的助手。
- 解释:这句话明确了角色——语言模型的任务是将用户的自然语言问题转换为 SQL 查询。
- 原文:
-
第二句:
- 原文:
Here is the schema of the database: {schema} - 翻译:这是数据库的架构:{schema}。
- 解释:
{schema}是数据库的表结构信息(如表名、列名、数据类型等),语言模型需要根据这些信息生成有效的 SQL 查询。
- 原文:
-
第三句:
- 原文:
Given the question: "{question}", generate a valid SQL query to answer it. - 翻译:给定问题:“{question}”,生成一个有效的 SQL 查询来回答它。
- 解释:
{question}是用户输入的自然语言问题,语言模型需要根据这个问题和数据库架构生成 SQL 查询。
- 原文:
-
第四句:
- 原文:
Make sure the query is correct and efficient. - 翻译:确保查询是正确的且高效的。
- 解释:语言模型需要生成语法正确且性能良好的 SQL 查询。
- 原文:
-
4 create_react_agent构建智能体
对于一些复杂的任务,在langchain的agents模块下提供了create_react_agent可以构建用于处理复杂任务的智能体对象。大家思考下,复杂任务如何定义?
所谓的复杂任务就是需要进行多步推理和多种工具协作才可以解决的问题。
例如:
1.旅行规划与预订
- 任务描述:用户希望规划一次旅行,包括目的地天气查询、机票/酒店比价、行程安排等。
- 多步推理与工具协作:
- 天气查询工具:调用天气API获取目的地未来几天的天气数据。
- 航班/酒店比价工具:根据用户预算和时间,搜索并比较不同平台的机票和酒店价格。
- 行程生成工具:结合天气、交通、用户偏好(如景点、餐饮)生成合理行程。
- 预订工具:自动完成机票、酒店的预订操作。
2.电商购物决策支持
- 任务描述:用户输入商品需求下单最合适的商品。
- 多步推理与工具协作:
- 商品搜索工具:调用电商平台API,按关键词筛选商品。
- 评测分析工具:抓取社交媒体和专业网站的用户评测,分析优缺点。
- 价格对比工具:跨平台比较历史价格和促销活动。
- 下单工具:自动选择最优商品并完成支付流程。
核心功能与工作流程
create_react_agent生成的代理遵循“思考→行动→观察”的循环流程,具体如下:
- 思考(Reason):LLM基于用户输入和上下文生成推理步骤,决定是否需要调用工具、选择哪个工具,并生成工具调用的参数。
- 行动(Action):执行工具调用(如调用搜索引擎、数据库查询),或直接生成自然语言回复。
- 观察(Observe):获取工具执行结果或用户反馈,更新上下文并传递给LLM进行下一步推理。
示例操作
-
2个外部函数构建
def get_search_result(question): """ 互联网搜索函数 :param question: 必要参数,字符串类型,用于表示在互联网上进行搜素的关键词或者搜索内容的简短描述,\ :return:SerpAPI API根据参数question进行互联网搜索后的结果,其中包含了全部重要的搜索结果内容。 """ from langchain_community.utilities import SerpAPIWrapper serpapi_api_key = "60f286e601f44a26600e4xxxb06a3f0dc8e0fe7ce56ec93d6274ccd" search = SerpAPIWrapper(serpapi_api_key=serpapi_api_key) result = search.run(question) return result import requests import json def get_weather(loc): """ 查询即时天气函数 :param loc: 必要参数,字符串类型,用于表示查询天气的具体城市名称,\ :return:查询即时天气的结果\ 返回结果对象类型为解析之后的JSON格式对象,并用字符串形式进行表示,其中包含了全部重要的天气信息 """ api_key = "SGkvDRxxxfdosf" url = f"https://api.seniverse.com/v3/weather/now.json?key={api_key}&location={loc}&language=zh-Hans&unit=c" response = requests.get(url) data = response.json() return json.dumps(data) get_weather("上海") -
将外部函数封装成Agent可调用的工具对象
from langchain.agents import Tool searchTool = Tool( name = "get_search_result", description = "互联网搜索函数", func = get_search_result, ) from langchain.agents import Tool weatherTool = Tool( name = "get_weather", description = "查询指定城市的即时天气信息", func = get_weather, ) -
定义Agent的工具列表
tools = [weatherTool,searchTool] -
定义提示词模版
from langchain import hub prompt_react = hub.pull("hwchase17/react") prompt_react -
创建大模型
from langchain_openai import ChatOpenAI API_KEY = "sk-4b79f3a3fxxx1935366ebb425b3" llm = ChatOpenAI(model_name="deepseek-reasoner", api_key=API_KEY,base_url="https://api.deepseek.com") -
创建智能体
from langchain.agents import create_react_agent agent = create_react_agent(llm,tools,prompt_react) -
执行智能体
from langchain.agents import AgentExecutor agent_executor = AgentExecutor( agent = agent, tools = tools, verbose = True ) agent_executor.invoke({"input":"上海今天有雪吗?如果不下雪的话我想查询下近期上海是否有周杰伦演唱会举办?"})
6. langgraph(尽量进行深度了解)
LangGraph 是LangChain生态系统中的一个框架,用于构建基于大型语言模型(LLM)的复杂工作流和智能体系统。它通过有向图结构定义工作流程,使开发者能够创建动态、可控且可扩展的AI应用程序。使用LangGraph 需要pip install langgraph。
-
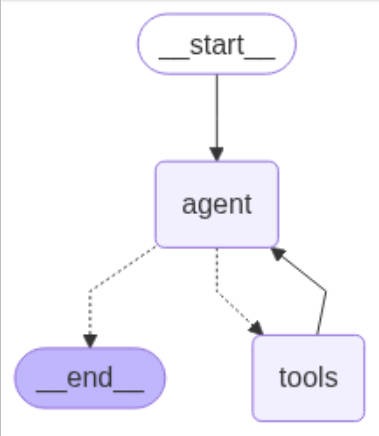
核心概念:
- 状态(State):是LangGraph应用的基础,包含了应用运行时的所有信息,如消息列表、当前输入、工具输出等。
- 节点(Node):通常是Python函数,代表不同的操作或步骤,如调用LLM、处理用户输入等,用于处理状态并返回更新后的状态。
- 边(Edge):定义了节点之间的连接关系和路由逻辑,包括标准边和条件边,标准边定义固定的执行路径,条件边可根据状态决定下一步走向。
-
主要特性:
- 结构化工作流:能创建具有分支、循环和条件逻辑的复杂工作流,相比单一的链式调用更具灵活性。
- 状态管理:提供强大的状态管理机制,自动保存和管理状态,支持暂停和恢复执行,便于处理长时间运行的对话。
- 与LangChain无缝集成:可复用现有的LangChain组件,还有丰富的工具和模型支持。
- 实现复杂逻辑:传统的智能体开发方式在处理复杂任务时存在局限,如缺乏对外部环境的感知能力、对话历史记忆有限等。LangGraph允许创建具有循环、条件分支等复杂逻辑的工作流,能更好地应对各种复杂场景和需求,例如根据不同的输入和状态动态调整执行路径,实现多步骤的推理和决策。
6.1 langgraph实现Agent基础操作
from typing import Literal
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END,StateGraph,MessagesState
from langgraph.prebuilt import ToolNode
#定义工具函数,用于Agent调用外部工具
@tool
def search(query:str):
"""模拟一个气象查询搜索工具"""
if "北京" in query.lower() or "Beijing" in query.lower():
return "阴天有雾,气温25度"
return "天气晴朗温度较高39度"
#将工具函数存放在工具列表中
tools = [search]
创建工具集节点:ToolNode是LangGraph中的一个预构建节点,用于封装一组工具函数。这些工具函数可以通过模型调用来执行特定的任务。
tool_node = ToolNode(tools)
定义模型对象
#定义模型对象
API_KEY = "sk-4b79f3a3ff334a15a1935366ebb425b3"
model = ChatOpenAI(model_name="deepseek-chat",
api_key=API_KEY,base_url="https://api.deepseek.com")
#将工具列表绑定到模型对象上
model = model.bind_tools(tools)
定义路由函数/状态转换函数:should_continue函数用于决定当前状态之后应该转移到哪个节点。它接收一个MessagesState对象作为输入,并返回一个字符串,表示下一个节点的名称。
消息状态:MessagesState是LangGraph中的一个状态类,用于存储对话过程中的消息列表。每个状态对象都包含一个messages字段,该字段是一个消息对象的列表。
from typing import Literal 是 Python 3.8 及以上版本中引入的一种类型注解工具,用于表示某个变量或函数参数只能是特定的几个值之一。Literal 是 typing 模块中的一个特殊类型,它允许你精确地指定一个或多个字面量作为类型约束。
def should_continue(state:MessagesState)->Literal["tools",END]:
messages = state['messages']
#获取用户提问消息
last_message = messages[-1]
#如果llm调用工具,则转到tools节点
if last_message.tool_calls:
return "tools"
return END
定义模型调用函数
def call_model(state:MessagesState):
#获取消息列表
messages = state['messages']
#调用模型返回结果
response = model.invoke(messages)
return {"messages":[response]}
定义一个新的状态图,使用MessagesState作为状态类型
workflow = StateGraph(MessagesState)
在状态图上添加节点
workflow.add_node("agent",call_model)
workflow.add_node("tools",tool_node)
设置入口节点为agent(入口节点指向agent节点),这意味着agent是第一个被调用的节点
workflow.set_entry_point("agent")
添加条件边:agent节点根据should_continue进行边的连接(虚线边)
workflow.add_conditional_edges('agent',should_continue)
定义普通边:tools工具节点连接agent节点的边(实线边)
workflow.add_edge("tools","agent")
初始化内存以在图运行之间持久化状态:MemorySaver是LangGraph中的一个检查点保存器,用于在内存中保存状态图的中间状态。这对于调试和监控非常有用,因为它允许你在运行时查看和恢复状态。
checkpointer = MemorySaver()
编译图:将其编译成一个langchain可运行的一个对象,在编译时传递内存
app = workflow.compile(checkpointer=checkpointer)
执行图
final_state = app.invoke(
{"messages":[HumanMessage(content="北京天气如何?")]},
config={"configurable":{"thread_id":42}}
)
result = final_state['messages'][-1].content
result
配置选项(config)实现上下文共享:如果两个任务在同一个线程上执行,它们可以共享同一个上下文(例如全局变量、线程本地存储等)。这对于需要维护状态或会话信息的应用非常重要。
final_state = app.invoke(
{"messages":[HumanMessage(content="我刚才问的是哪个城市?")]},
config={"configurable":{"thread_id":42}}
)
result = final_state['messages'][-1].content
result
保存图文件
graph_png = app.get_graph().draw_mermaid_png()
with open('graph.png','wb') as fp:
fp.write(graph_png)
点击查看代码
from typing import Literal
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END,StateGraph,MessagesState
from langgraph.prebuilt import ToolNode
#定义工具函数,用于Agent调用外部工具
@tool
def search(query:str):
"""模拟一个气象查询搜索工具"""
if "北京" in query.lower() or "Beijing" in query.lower():
return "阴天有雾,气温25度"
return "天气晴朗温度较高39度"
#将工具函数存放在工具列表中
tools = [search]
tool_node = ToolNode(tools)
#定义模型对象
API_KEY = "sk-4b79f3a3ff334a15a1935366ebb425b3"
model = ChatOpenAI(model_name="deepseek-chat",
api_key=API_KEY,base_url="https://api.deepseek.com")
#将工具列表绑定到模型对象上
model = model.bind_tools(tools)
def should_continue(state:MessagesState)->Literal["tools",END]:
messages = state['messages']
#获取用户提问消息
last_message = messages[-1]
#如果llm调用工具,则转到tools节点
if last_message.tool_calls:
return "tools"
return END
def call_model(state:MessagesState):
#获取消息列表
messages = state['messages']
#调用模型返回结果
response = model.invoke(messages)
return {"messages":[response]}
workflow = StateGraph(MessagesState)
# 添加节点
workflow.add_node("agent",call_model)
workflow.add_node("tools",tool_node)
# 添加边
workflow.set_entry_point("agent")
# 添加条件边
workflow.add_conditional_edges('agent',should_continue)
workflow.add_edge("tools","agent")
checkpointer = MemorySaver()
app = workflow.compile(checkpointer=checkpointer)
graph_png = app.get_graph().draw_mermaid_png()
with open(r'E:\my\fumi\E\myinstall\code\test\yewu\my\AI agent一期\graph.png','wb') as fp:
fp.write(graph_png)
print('生成思维图保存成功')
final_state = app.invoke(
{"messages":[HumanMessage(content="北京天气如何?")]},
config={"configurable":{"thread_id":42}}
)
result = final_state['messages'][-1].content
print(result)
final_state = app.invoke(
{"messages":[HumanMessage(content="我刚才问的是哪个城市?")]},
config={"configurable":{"thread_id":42}}
)
result = final_state['messages'][-1].content
print(result)
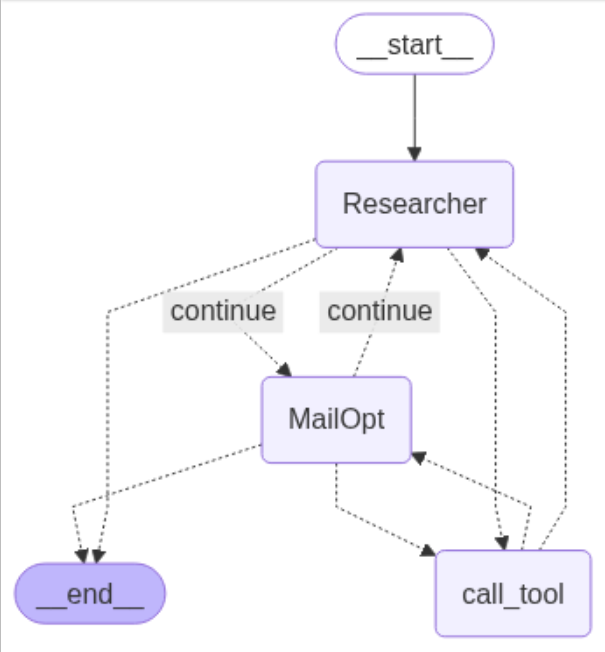
6.2 langgraph实现Multi-Agent Systems
from langchain_core.messages import (
BaseMessage,
HumanMessage,
ToolMessage,
)
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from typing import Literal
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END,StateGraph,MessagesState
from langgraph.prebuilt import ToolNode
# 导⼊聊天提示模板和消息占位符
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 导⼊状态图相关的常量和类
from langgraph.graph import END, StateGraph, START
API_KEY = "sk-4b79f3a3ff334a15a1935366ebb425b3"
llm = ChatOpenAI(model_name="deepseek-chat",
api_key=API_KEY,base_url="https://api.deepseek.com")
# 定义⼀个函数,⽤于创建代理
def create_agent(llm, tools, system_message: str):
"""创建⼀个代理。"""
# 创建⼀个聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是⼀个有帮助的AI助⼿,与其他助⼿合作。"
" 使⽤提供的⼯具来推进问题的回答。"
" 如果你不能完全回答,没关系,另⼀个拥有不同⼯具的助⼿"
" 会接着你的位置继续帮助。执⾏你能做的以取得进展。"
" 如果你或其他助⼿有最终答案或交付物,"
" 在你的回答前加上FINAL ANSWER,以便团队知道停⽌。"
" 你可以使⽤以下⼯具: {tool_names}。\n{system_message}",
),
# 消息占位符
MessagesPlaceholder(variable_name="messages"),
]
)
# 传递系统消息参数
prompt = prompt.partial(system_message=system_message)
# 传递⼯具名称参数
prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))
# 绑定⼯具并返回提示模板
return prompt | llm.bind_tools(tools)
#定义工具函数
@tool
def get_search_result(question):
"""
互联网搜索函数
:param question: 必要参数,字符串类型,用于表示在互联网上进行搜素的关键词或者搜索内容的简短描述,\
:return:SerpAPI API根据参数question进行互联网搜索后的结果,其中包含了全部重要的搜索结果内容。
"""
from langchain_community.utilities import SerpAPIWrapper
serpapi_api_key = "60f286e601f44a26600e42c65e7a9b3ceb06a3f0dc8e0fe7ce56ec93d6274ccd"
search = SerpAPIWrapper(serpapi_api_key=serpapi_api_key)
result = search.run(question)
return result
#定义工具函数,用于Agent调用外部工具
@tool
def send_email(query:str):
"""邮件发送工具,可以接受query内容,然后进行邮件发送"""
return "邮件已成功发送。"
#定义工具节点
# 导⼊预构建的⼯具节点
from langgraph.prebuilt import ToolNode
# 定义⼯具列表
tools = [get_search_result, send_email]
# 创建⼯具节点
tool_node = ToolNode(tools)
#定义状态:我们⾸先定义图的状态。这只是⼀个消息列表,以及⼀个⽤于跟踪最新发送者的键
# 导⼊操作符和类型注解
import operator
from typing import Annotated, Sequence, TypedDict
# 导⼊OpenAI聊天模型
from langchain_openai import ChatOpenAI
# 定义⼀个对象,⽤于在图的每个节点之间传递
# 我们将为每个代理和⼯具创建不同的节点
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
sender: str
#定义代理节点
import functools
from langchain_core.messages import AIMessage
# ⽤于为给定的Agent创建节点
def agent_node(state, agent, name):#name:agent代理的名字
# 调⽤代理
result = agent.invoke(state)
#将 result 转换为 AIMessage 类型,并进行进一步处理
#使用模型的 model_dump 方法将 result 转换为字典格式,同时排除 "type" 和 "name" 字段。这通常用于序列化对象以便传输或存储。
result = AIMessage(**result.model_dump(exclude={"type", "name"}), name=name)
return {
"messages": [result],
# 由于我们有⼀个严格的⼯作流程,我们可以跟踪发送者,以便知道下⼀个传递给谁。
"sender": name,
}
#创建搜索Agent代理对象和节点对象
research_agent = create_agent(
llm,
[get_search_result],
system_message="你应该提供准确的数据供MailOpt使⽤。",
)
# 创建Agent节点对象:使用agent和name的值填充到agent_node函数中对应的两个参数
research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")
#创建发邮件Agent代理对象和节点对象
mail_agent = create_agent(
llm,
[send_email],
system_message="你用于进行邮件发送业务实现",
)
# 创建Agent节点对象
mail_node = functools.partial(agent_node, agent=mail_agent, name="MailOpt")
#定义路由函数,决定是否继续执行
from typing import Literal
# 定义路由器函数,continue 表示代理应该继续处理消息队列中的下一条消息。
def router(state) -> Literal["call_tool", "__end__", "continue"]:
# 这是路由器
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
# 上⼀个代理正在调⽤⼯具
return "call_tool"
if "FINAL ANSWER" in last_message.content:
# 任何代理决定⼯作完成
return "__end__"
return "continue"
#图、节点和边的创建
# 创建状态图实例
workflow = StateGraph(AgentState)
# 添加搜索节点
workflow.add_node("Researcher", research_node)
# 添加邮件节点
workflow.add_node("MailOpt", mail_node)
# 添加⼯具调⽤节点
workflow.add_node("call_tool", tool_node)
# 添加条件边
workflow.add_conditional_edges(
"Researcher",
router,
{"continue": "MailOpt", "call_tool": "call_tool", "__end__": END},
)
workflow.add_conditional_edges(
"MailOpt",
router,
{"continue": "Researcher", "call_tool": "call_tool", "__end__": END},
)
# 添加条件边
workflow.add_conditional_edges(
"call_tool",
#如果 x["sender"] 的值是 "Researcher",那么边会连接到 "Researcher" 节点。
#如果 x["sender"] 的值是 "MailOpt",那么边会连接到 "MailOpt" 节点。
lambda x: x["sender"],
{
"Researcher": "Researcher",
"MailOpt": "MailOpt",
},
)
# 添加起始边
workflow.add_edge(START, "Researcher")
# 编译⼯作流图
graph = workflow.compile()
# 将⽣成的图⽚保存到⽂件
graph_png = graph.get_graph().draw_mermaid_png()
with open("collaboration.png", "wb") as f:
f.write(graph_png)
#调用
events = graph.invoke(
{
"messages": [
HumanMessage(
content="获取过去5年AI软件市场规模,归纳成100字"
" 然后进行邮件发送。"
" ⼀旦发送完邮件表示你完成了任务。"
)
],
}
)
#获取最终结果
result = events['messages'][-1].content
result
#查看中间结果
for message in events['messages']:
print(message.content)
print("-----------------------------------")
7. RAG与langchain应用
检索增强⽣成(RAG)是指对⼤型语⾔模型输出进⾏优化,使其能够在⽣成响应之前引⽤训练数据来源之外的权威知识库。⼤型语⾔模型(LLM)⽤海量数据进⾏训练,使⽤数⼗亿个参数为回答问题、翻译语⾔和完成句⼦等任务⽣成原始输出。在 LLM 本就强⼤的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,所有这些都⽆需重新训练模型。这是⼀种经济⾼效地改进 LLM 输出的⽅法,让它在各种情境下都能保持相关性、准确性和实⽤性。
7.1 RAG构建流程
假设现在我们有一个偌大的知识库,当想从该知识库中去检索最相关的内容时,最简单的方法是:接收到一个查询(Query),就直接在知识库中进行搜索。这种做法其实是可行的,但存在两个关键的问题:
- 假设提问的Query的答案出现在一篇文章中,去知识库中找到一篇与用户输入相关的文章是很容易的,但是我们将检索到的这整篇文章直接放入
Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越多,对大模型后续的推理影响越大。 - 任何一个大模型都存在最大输入的Token限制,一个流程中可能涉及多次检索,每次检索都会产生相应的上下文,无法容纳如此多的信息。
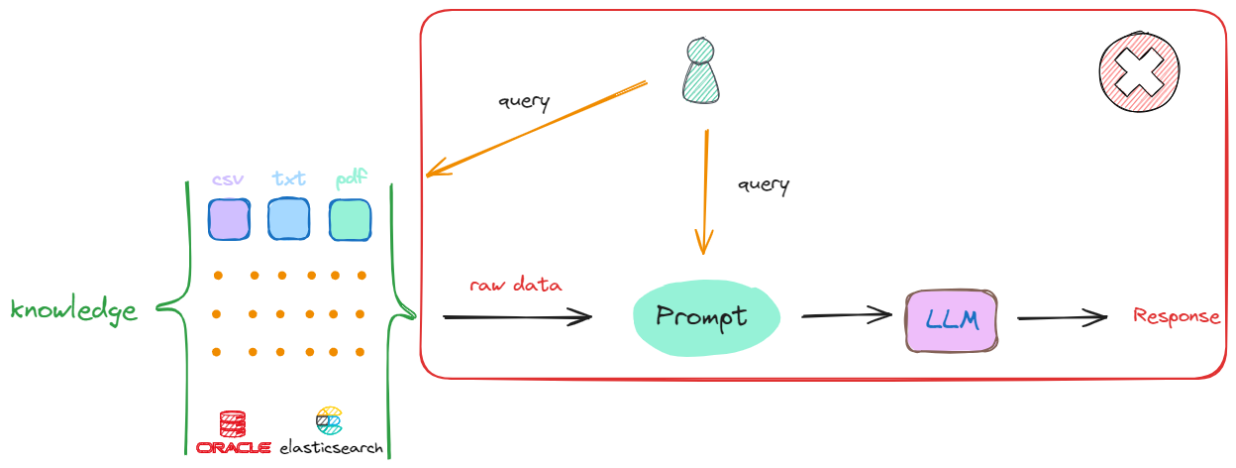
解决上述两个问题的方式是:把存放着原始数据的知识库(Knowledge)中的每一个raw data,切分成一个一个的小块,这些小块可以是一个段落,也可以是数据库中某个索引对应的值。这个切分过程被称为“分块”(chunking),如下述流程所示:
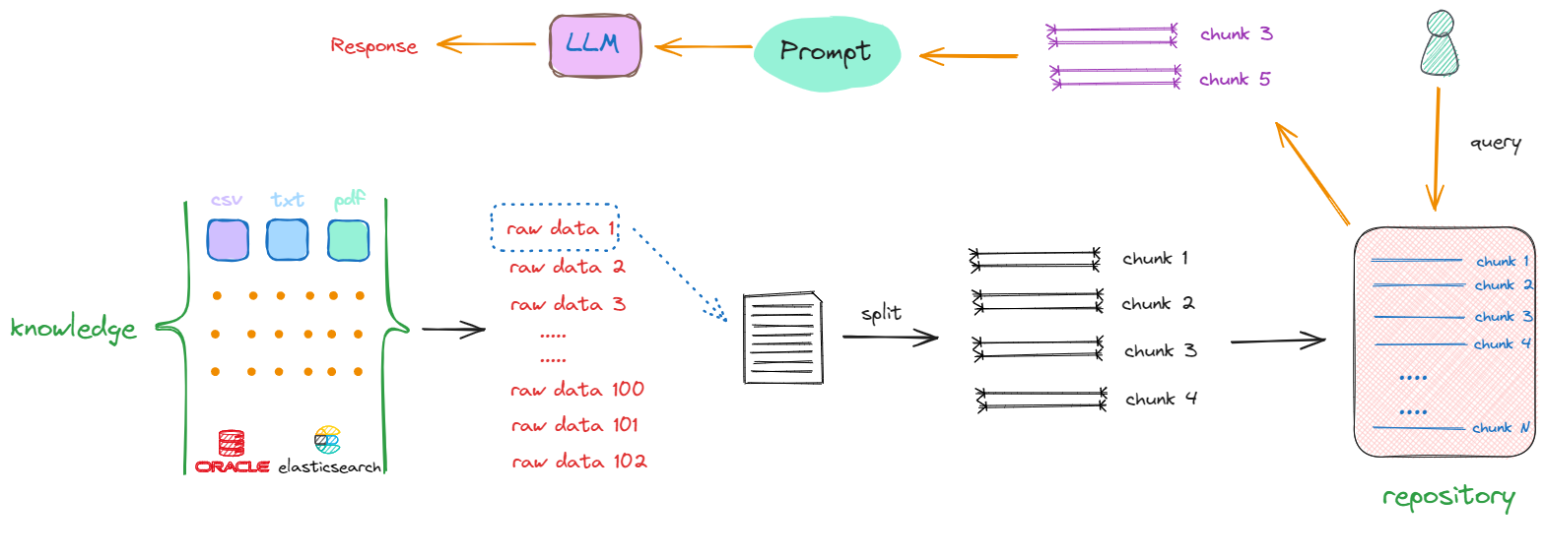
以第一个原始数据为例(raw data 1),通过一些特定的方法进行切分,一个完整的内容会被分割成 chunk1 ~ chunk4。采取相同的方法,继续对raw data 2、raw data 3直至raw data n进行切分。完成这一过程后,我们最终得到的是一个充满分块数据(chunks)的新的知识库(repository),其中每一项都是一个单独的chunk。例如,如果原始文档共有10个,那么经过切分,可能会产生出100个chunks。
完成这一转化后,当再次接收到一个查询(Query)时,就会在更新后的知识库(repository)中进行搜索,这时检索的范围就不再是某个完整的文档,而是其中的某一个部分,返回的是一个或多个特定的chunk,这样返回的信息量就会更小且更精确。随后,这些被检索到的chunk会被加入到Prompt中,作为上下文信息与用户原始的Query共同输入到大模型进行处理,以生成最终的回答。
在上述将原始数据(raw data)转化为chunk的过程中,就会包含构建RAG的第一部分开发工作:这包括如果做数据清洗,如去除停用词、标点符号等。此外,还涉及如何选择合适的split方法来进行数据切分的一系列技术。
接下来面临的问题是,尽管所有数据已经被切割成一个个chunk,其存储形式还是以字符串形式存在,如果想从repository中匹配到与输入的query相关的chunks,比较两句话是否相似,看一句话中相同字有几个,这显然是行不通的。我们需要获取的是句子所蕴含的深层含义,而非仅仅是表面的字面相似度。因此,大家也能想到,在NLP中去计算文本相似度的有效的方法就是Embedding,即将这些chunks转换成向量(vector)形式。所以流程会丰富如下:
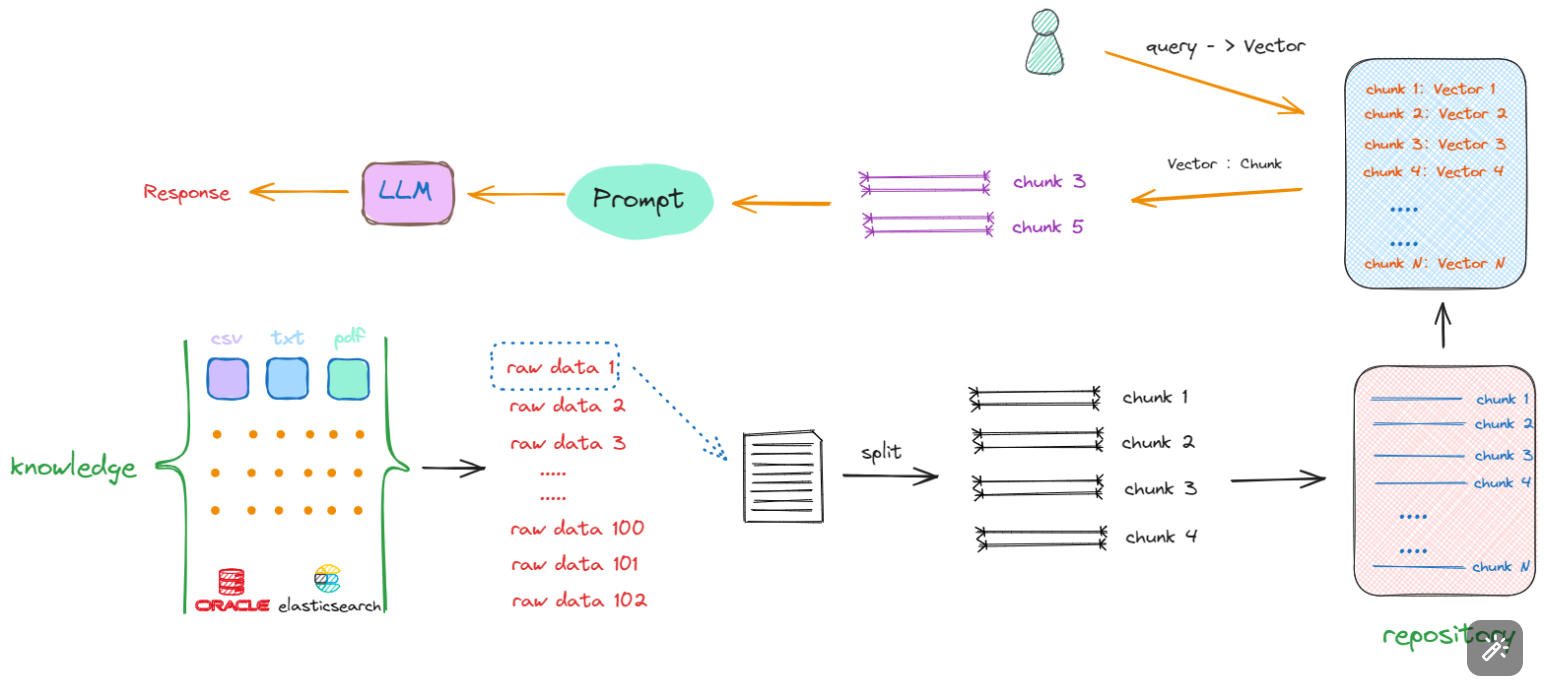
Embedding 是由向量模型⽣成的,它会根据不同的算法⽣成⾼维度的向量数据,代表着数据的不同特征,这些特征代表了数据的不同维度。例如,对于⽂本,这些特征可能包括词汇、语法、语义、情感、情绪、主题、上下⽂等。对于⾳频,这些特征可能包括⾳调、节奏、⾳⾼、⾳⾊、⾳量、语⾳、⾳乐等。
在这个流程中,会先将用户输入的 Query 转化成 Vector,然后再去与知识库中的向量进行相似度比较,检索出相似的Vector,最终返回其对应的Chunk(字符串形式的文本),再执行后续的流程。所以在这个过程中,就会产生构建RAG的第二部分的开发工作:如果将chunk转化成Vector及以何种形式进行存储。同时,我们要考虑的是:如何去计算向量之间的相似度?如果去和知识库中的向量一个一个比较,这个时间复杂度是非常高的,那么其解决办法又是什么呢?我们继续看下述流程:
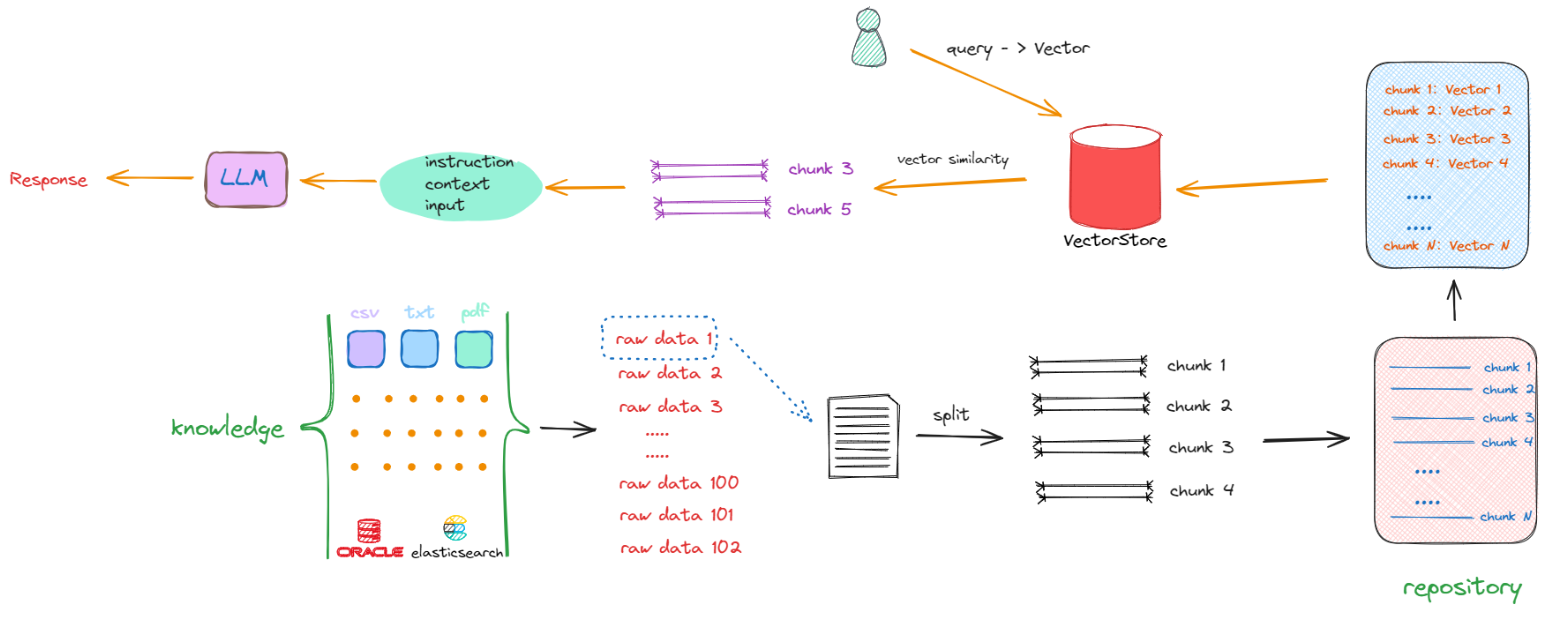
如上所示,解决搜索效率和计算相似度优化算法的答案就是:向量数据库。同时也产生了构建RAG的第三部分工作:我们要去了解和学习如何选择、使用向量数据库。
最终整体流程就如上图所示,一个基础的RAG架构会只要包含以下几方面的开发工作:
- 如何将原始数据转化成chunks;
- 如何将chunks转化成Vector;
- 如何选择计算向量相似度的算法;
- 如何利用向量数据库提升搜索效率;
- 如何把找到的chunks与原始query拼接在一起,产生最终的Prompt;
在以上5点开发任务中,我们确实是可以利用已经训练好的Embedding模型,开源的向量数据库等去直接解决某一类问题,所以我们前面才说一个基础架构的RAG系统搭建起来其实很简单,但搭建并不意味着直接就能用,毕竟RAG的核心是检索,检索出来的内容的准确率是衡量一个RAG系统的最基础的标准。目前没有任何一套理论、任何一套解决方案能够百分之百的指导着我们构建出一个最优的RAG系统。不同的需求,不同的数据,其构建方法也会大相径庭,需要我们在实践的过程中不断地去尝试,不断地去积累相关的经验,才能够将其真正落地。
7.2 相关核心概念和操作
7.2.1 向量数据库
向量数据库(Vector Database),也叫矢量数据库,主要用来存储和处理向量数据。
在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。两个向量的距离或者相似性可以通过欧式距离或者余弦距离得到。
图像、文本和音视频这种非结构化数据都可以通过某种变换或者嵌入学习转化为向量数据存储到向量数据库中,从而实现对图像、文本和音视频的相似性搜索和检索。这意味着您可以使用向量数据库根据语义或上下文含义查找最相似或相关的数据。
向量数据库的主要特点是高效存储与检索。利用索引技术和向量检索算法能实现高维大数据下的快速响应。
7.2.2 向量嵌入Vector Embeddings
对于传统数据库,搜索功能都是基于不同的索引方式加上精确匹配和排序算法等实现的。本质还是基于文本的精确匹配,这种索引和搜索算法对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
例如,如果你搜索 “小狗”,那么你只能得到带有“小狗” 关键字相关的结果,而无法得到 “柯基”、“金毛” 等结果,因为 “小狗” 和“金毛”是不同的词,传统数据库无法识别它们的语义关系,所以传统的应用需要人为的将 “小狗” 和“金毛”等词之间打上小狗特征标签进行关联,这样才能实现语义搜索。
同样,当你在处理非结构化数据时,你会发现非结构化数据的特征数量会迅速增加,处理过程会变得十分困难。比如我们处理图像、音频、视频等类型的数据时,这种情况尤为明显。就拿图像来说,可以标注的特征包括颜色、形状、纹理、边缘、对象、场景等多个方面。然而,这些特征数量众多,而且依靠人工进行标注的难度很大。因此,我们需要一种自动化的方式来提取这些特征,而Vector Embedding技术就能够实现这一目标。
Vector Embedding 是由专门的向量模型生成的,它会根据不同的算法生成高维度的向量数据,代表着数据的不同特征,这些特征代表了数据的不同维度。例如,对于文本,这些特征可能包括词汇、语法、语义、情感、情绪、主题、上下文等。对于音频,这些特征可能包括音调、节奏、音高、音色、音量、语音、音乐等。
7.2.3 相似性测量
如何衡量向量之间的相似性呢?有三种常见的向量相似度算法:欧几里德距离、余弦相似度和点积。
- 点积(内积): 两个向量的点积是一种衡量它们在同一方向上投影的大小的方法。如果两个向量是单位向量(长度为1),它们的点积等于它们之间夹角的余弦值。因此,点积经常被用来计算两个向量的相似度。
- 余弦相似度: 这是一种通过测量两个向量之间的角度来确定它们相似度的方法。余弦相似度是两个向量点积和它们各自长度乘积的商。这个值的范围从-1到1,其中1表示完全相同的方向,-1表示完全相反,0表示正交。
- 欧氏距离: 这种方法测量的是两个向量在n维空间中的实际距离。虽然它通常用于计算不相似度(即距离越大,不相似度越高),但可以通过某些转换(如取反数或用最大距离归一化)将其用于相似度计算。
像我们最常用的余弦相似度,其代码实现也非常简单,如下所示:
import numpy as np
def cosine_similarity(A, B):
# 使用numpy的dot函数计算两个数组的点积
# 点积是向量A和向量B在相同维度上对应元素乘积的和
dot_product = np.dot(A, B)
# 计算向量A的欧几里得范数(长度)
# linalg.norm默认计算2-范数,即向量的长度
norm_A = np.linalg.norm(A)
# 计算向量B的欧几里得范数(长度)
norm_B = np.linalg.norm(B)
# 计算余弦相似度
# 余弦相似度定义为向量点积与向量范数乘积的比值
# 这个比值表示了两个向量在n维空间中的夹角的余弦值
return dot_product / (norm_A * norm_B)
7.2.4 相似性搜素
既然我们知道了可以通过比较向量之间的距离来判断它们的相似度,那么如何将它应用到真实的场景中呢?如果想要在一个海量的数据中找到和某个向量最相似的向量,我们需要对数据库中的每个向量进行一次比较计算,但这样的计算量是非常巨大的,所以我们需要一种高效的算法来解决这个问题。
高效的搜索算法有很多,其主要思想是通过两种方式提高搜索效率:
1)减少向量大小——通过降维或减少表示向量值的长度。
2)缩小搜索范围——可以通过聚类或将向量组织成基于树形、图形结构来实现,并限制搜索范围仅在最接近的簇中进行。
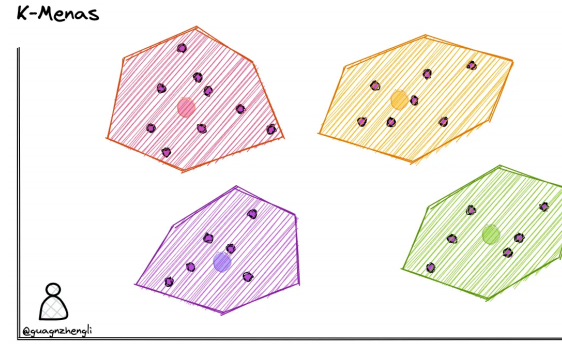
我们首先来介绍⼀下大部分算法共有的核心概念,也就是kmeans聚类。
K-Means聚类
我们可以在保存向量数据后,先对向量数据先进行聚类。例如下图在二维坐标系中,划定了 4 个聚类中心,然后将每个向量分配到最近的聚类中心,经过聚类算法不断调整聚类中心位置,这样就可以将向量数据分成 4 个簇。每次搜索时,只需要先判断搜索向量属于哪个簇,然后再在这一个簇中进行搜索,这样就从 4 个簇的搜索范围减少到了 1 个簇,大大减少了搜索的范围。
HNSW
除了聚类以外,也可以通过构建树或者构建图的方式来实现近似最近邻搜索。这种方法的基本思想是每次将向量加到数据库中的时候,就先找到与它最相邻的向量,然后将它们连接起来,这样就构成了一个图。当需要搜索的时候,就可以从图中的某个节点开始,不断的进行最相邻搜索和最短路径计算,直到找到最相似的向量。
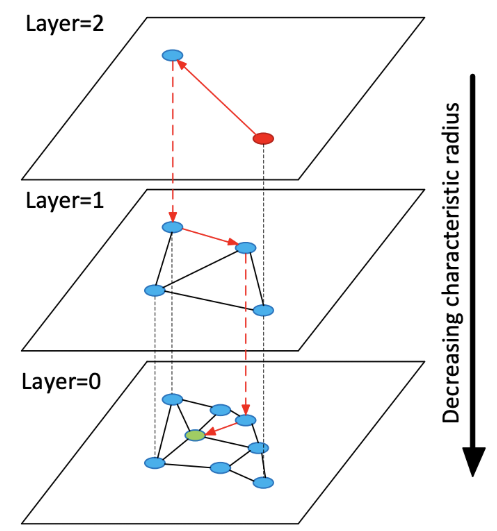
7.2.5 Embedding models
LangChain 设计了一个 Embeddings 类。该类是一个专为与文本嵌入模型进行交互而设计的类。有许多嵌入模型提供商(如OpenAI、BaiChuan、QianFan、Hugging Face等)这个类旨在为它们提供一个标准接口。
Embeddings类会为文本创建一个向量表示。这很有用,因为这意味着我们可以在向量空间中思考文本,并做一些类似语义搜索的事情,比如在向量空间中寻找最相似的文本片段。
对于Embedding Models我们只需要学会如何去使用就可以,是因为有非常多的模型供应商,如OpenAI、Hugging Face国内的有百川、千帆都提供了标准接口并集成在LangChian框架中,这意味着:Embedding Models已经有人帮我们训练好了,我们只要按照其提供的接口规范,将自然语言文本传入进去,就能得到其对应的向量表示。这显然是非常简单的。
那么在如此多的Embedding Models都可以使用的情况下,应该如何选择呢? 首先,我们在使用形式上把 Embedding Models分为两类:
- 在线Embedding Models,仅提供API服务,需要按照Token付费;
- 开源Embedding Models可以下载到本地免费使用,但在运行过程中会消耗GPU资源。
在线Embedding Models
LangChain接入了国内的Baidu Qianfan,Baichuan Text Embeddings等向量模型,具体支持的平台可以在如下位置进行查看:https://python.langchain.com/docs/integrations/text_embedding/

接下来我们以Baichuan Text Embeddings为例展开讲解。注意:Baichuan Text Embeddings目前仅支持中文文本嵌入。
-
如何使用Baichuan Text Embeddings
-
获取API Key
- 要使用Baichuan Text Embeddings,首先需要获取API密钥。您可以通过以下步骤获取:
- 访问百川智能官方网站
- 注册并创建一个账户
- 在控制台中申请并获取API密钥
- 要使用Baichuan Text Embeddings,首先需要获取API密钥。您可以通过以下步骤获取:
-
安装必要的库
pip install langchain_community
-
-
代码示例
from langchain_community.embeddings import BaichuanTextEmbeddings import os # 设置API密钥 key = open('./key_files/baichuan_API-Key.md').read().strip() embeddings = BaichuanTextEmbeddings(api_key=key) # 示例文本 text_1 = "今天天气不错" text_2 = "今天阳光很好" # 获取单个文本的嵌入 query_result = embeddings.embed_query(text_1) print("单个文本嵌入结果:", query_result[:5]) # 只打印前5个元素 # 获取多个文本的嵌入 doc_result = embeddings.embed_documents([text_1, text_2]) print("多个文本嵌入结果:", [vec[:5] for vec in doc_result]) # 每个向量只打印前5个元素 -
BaichuanTextEmbeddings主要参数介绍
- api_key:这是调用Baichuan Text Embeddings服务的身份验证凭证。只有拥有有效API Key的用户才能访问和使用该模型进行文本嵌入操作。
-
BaichuanTextEmbeddings对象主要操作介绍
- 单向量查询(embed_query):法用于将单个文本嵌入为向量表示。它接受一个字符串类型 的文本作为输入,并返回该文本对应的向量表示。这个向量是一个高维向量(1024维),包含了文本的语义信息,可以用于后续的各种自然语言处理任务。
- 多向量查询(embed_documents):法用于将多个文本同时嵌入为向量表示。
这里模拟一个QA场景,我们定义一个问题,然后定义10条文本作为回答。然后分别对问题和回答各自进行词向量转换:
query = "早睡早起到底是不是保持身体健康的标准?"
sentences = ["早睡早起确实是保持身体健康的重要因素之一。它有助于同步我们的生物钟,并提高睡眠质量。",
"早睡早起可以帮助人们更好地适应自然光周期,从而优化褪黑激素的产生,这种激素是调节睡眠和觉醒的关键。",
"关于提高工作效率,确保在日常饮食中包含充足的蛋白质、复合碳水化合物和健康脂肪非常关键。",
"投资可再生能源项目和推广电动汽车可以显著减少温室气体排放,从而缓解气候变化带来的负面影响。",
"多发性硬化症是一种影响中枢神经系统的自身免疫疾病,导致神经传导受损。虽然与阿尔茨海默症类似,多发性硬化症的主要症状包括疲劳、视觉障碍和肌肉控制问题。",
"今天的天气太好了,可以早点起床去爬山",
"如果下班特别晚的话,我建议你还是打车回家吧",
"提升学术研究质量需侧重于多学科融合和国际合作。研究机构应该鼓励学者之间的交流,通过共享数据和研究方法,来推动科学发现和技术创新。",
"如果你认为我说的没用,那你大可以不必理会。",
"衡量一个人是否成功的标准在于他到底能不能让身边的人都变的优秀"
]
使用embed_documents方法,传入sentences列表,得到每条文本的向量表示
sentence_embeddings = embeddings_model.embed_documents(sentences)
通过embed_query方法生成问题的向量表示
embedded_query = embeddings_model.embed_query(query)
开源EMbedding Models
ollama官网进行开源模型下载:https://ollama.com/search?q=embedding
我们以nomic-embed-text向量模型为例:
def ollama_embedding_by_api(text):
res = requests.post(
url = 'http://127.0.0.1:11434/api/embeddings',
json = {
"model":'nomic-embed-text:latest',
'prompt':text
}
)
embedding_list = res.json()['embedding']
return embedding_list
代码构建简易RAG
pip install chromadb
pip install requests
import uuid
import chromadb
import requests
import os
from openai import OpenAI
#创建数据库,类似创建一个文件夹
client = chromadb.PersistentClient(path="./db/chroma_demo")
#创建数据集合(库表)
collection = client.get_or_create_collection(name="collection_v2")
#数据集切分-分块处理
def file_chunk_list():
#1.读取文件内容
with open('中医问诊.txt','r',encoding='utf-8') as fp:
data = fp.read()
#2.根据换行切割:将一个病症作为一个列表元素数据
chunk_list = data.split('\n\n')
chunk_list = [chunk for chunk in chunk_list if chunk]
return chunk_list
#数据集向量化封装
def ollama_embedding_by_api(text):
#使用nomic向量模型
# res = requests.post(
# url = 'http://127.0.0.1:11434/api/embeddings',
# json = {
# "model":'nomic-embed-text:latest',
# 'prompt':text
# }
# )
# embedding_list = res.json()['embedding']
# return embedding_list
#使用阿里百炼向量模型(效果超级好)
client = OpenAI(
api_key="sk-52xxxd1e203c6712", # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
completion = client.embeddings.create(
model="text-embedding-v3",
input=text,
dimensions=1024,
encoding_format="float"
)
return completion.data[0].embedding
#deepseek模型调用
def ollama_generate_by_api(prompt):
res = requests.post(
url = 'http://127.0.0.1:11434/api/generate',
json = {
"model":'deepseek-r1:7b',
'prompt':prompt,
'stream':False
}
)
res = res.json()['response']
return res
#整体集成
def initial():
#构造数据
documents = file_chunk_list()
#给每一个数据创建唯一的id标识
ids = [str(uuid.uuid4()) for _ in documents]
embeddings = [ollama_embedding_by_api(text) for text in documents]
#插入数据
collection.add(
ids = ids,
documents=documents,
embeddings=embeddings
)
def run():
qs = '我好像是感冒了,症状是头痛、轻微发烧、肢节酸痛、打喷嚏和流鼻涕。'
qs_embedding = ollama_embedding_by_api(qs)
#n_results表示匹配几个最高相似度的结果
res = collection.query(query_embeddings=[qs_embedding,],query_texts=qs,n_results=2)
result = res['documents'][0]
context = '\n'.join(result)
prompt = f'''你是一个中医问答机器人,任务是根据参考信息回答用户问题,如果你参考信息不足以回答用户问题,请回复不知道,切记不要去杜撰和自由发挥任何内容和信息,请用中文回答,参考信息:{context},来回答问题:{qs},'''
result = ollama_generate_by_api(prompt)
print(result)
调用测试:
initial() #执行一次即可
run() #可多次测试
7.3 Source 与 data loaders
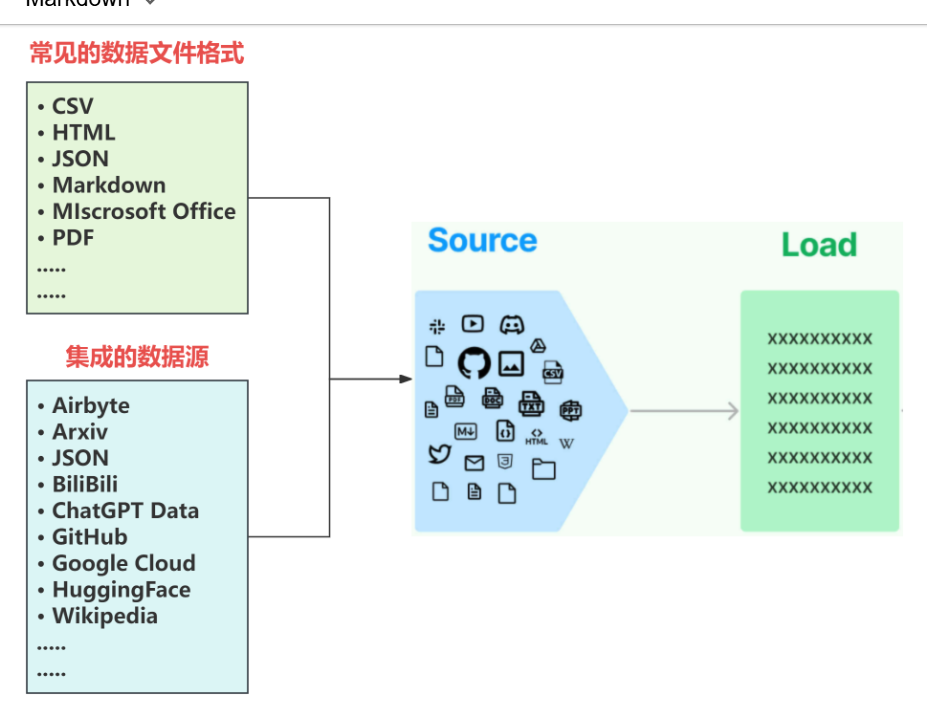
Source概念指的是RAG架构中所外挂的知识库。正如我们之前所讨论的,因为大模型的原生能力很强,所以它可以识别多种不同的类型的原始数据而不用做额外的处理,而且在实际场景中,私有数据通常也并不是单一的,可以来自多种不同的形式,可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件,同时如果对接到具体的业务,可以是某一个业务流程外放的API,可以是某个网站的实时数据等多种情况。
所以LangChain首先做的就是:将常见的数据格式和数据来源使用LangChain的规范,抽象出一个一个的单独的集成模块,称为文档加载器(Document loaders),用于快速加载某种形式下的文本数据。如下图所示:
这意味着,我们可以通过调用LangChain抽象好的方法直接处理私有数据,无需手动编写中间的处理流程,并且每一种文档的加载器,在LangChain官方文档中都有基本的调用示例供我们快速上手使用,具体位置如下:https://python.langchain.com/docs/integrations/document_loaders/
我们以加载txt文件为示例:
将文件作为文本读入,并将其全部放入一个文档中,这是最简单的一个文档加载程序,使用方式如下:
from langchain.document_loaders import TextLoader
docs = TextLoader('./data/reason.txt', encoding="utf-8").load()
对于TextLoader,使用.page_content和.metadata去访问数据。
加载csv文件为示例:
逗号分隔值(CSV)文件是⼀种使用逗号分隔值的定界文本文件。文件的每一行是⼀个数据记录。每个记录由⼀个或多个字段组成,字段之间用逗号分隔。LangChain 实现了⼀个 CSV 加载器,可以将 CSV 文件加载为⼀系列 Document 对象。CSV 文件的每⼀行都会被翻译为⼀个文档。
from langchain_community.document_loaders.csv_loader import CSVLoader
file_path = (
"csv_loader.py"
)
loader = CSVLoader(file_path=file_path,encoding="UTF-8")
data = loader.load()
for record in data[:2]:
print(record)
加载pdf文件为示例:
这⾥我们使用pypdf 将PDF加载为文档数组,其中每个文档包含页面内容和带有 page 编号的元数据。
pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
file_path = ("pytorch.pdf")
loader = PyPDFLoader(file_path)
#加载并分割 PDF 文件。将其按页分割成多个部分。返回的结果是一个包含每一页内容的列表 pages。
pages = loader.load_and_split()
print(pages[0])
7.4 Text Splitters 详解
7.4.1 如何将文本切分成Chunks
分块(Chunking),其实现形式上是将长文档拆分为较小的块的过程,目的是在检索时能够准确地找到最直接和最相关的段落。由于文章通常包含大量不相关信息,在进行分块之前,也常常需要进行一些预处理工作,如文本清洗、停用词处理等。
转回到核心内容来看,一个有效的分块策略,可以确保搜索结果精确地反映用户查询的实际需求。如果分块过小或过大,都可能导致搜索结果不准确或提取不到最相关的内容。理想的文本块应尽可能语义独立,即不过度依赖上下文,这样的文本是语言模型最易于理解的。因此,为文档确定最佳的块大小是确保搜索结果准确性和相关性的关键。这涉及多个决策因素,如块的大小;如果句子太短,模型可能难以理解其意义,且句子越短,包含的有效信息就越少。比较常用的有如下4种不同的方法来优化分块策略:
- 根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
- 按照固定字符数来切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置切断句子。
- 按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
- 递归方法:通过递归方式动态确定切分点,这种方法可以根据文档的复杂性和内容密度来调整块的大小。
第二种方法(按照字符数切分)和第三种方法(按固定字符数切分结合重叠窗口)主要基于字符进行文本的切分,而不考虑文章的实际内容和语义。这种方式虽简单,但可能会导致主题或语义上的断裂。相对而言,递归方法更加灵活和高效,它结合了固定长度切分和语义分析。通常是首选策略,因为它能够更好地确保每个段落包含一个完整的主题。
这些方法各有优势和局限,选择适当的分块策略取决于具体的应用需求和预期的检索效果。接下来我们依次尝试用常规手段应该如何实现上述几种方法的文本切分。
接下来就具体来上上述4中切分方式的具体实现~
7.4.2 按照句子切分
按照句子切分,其实就是通过标点符号来进行文本切分(分割),这可以直接使用Python的标准库来完成这个任务。一种简单的方法是使用re模块,它提供了正则表达式的支持,可以方便地根据标点符号来分割文本。如下示例中,展示了如何使用re.split()函数来根据中文和英文的标点符号进行文本切分。代码如下:
import re
def split_text_by_punctuation(text):
# 定义一个正则表达式,包括常见的中英文标点
# pattern = r"[。!?。"#$%&'()*+,-/:;<=>@[\]^_`{|}~\s、]+"
pattern = r"[。!?。]+"
# 使用正则表达式进行分割
segments = re.split(pattern, text)
# 过滤掉空字符串
return [segment for segment in segments if segment]
这个函数会根据中文和英文的标点符号来分割文本,并移除空字符串。定义好分割函数后,我们可以尝试进行功能测试:
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 调用函数进行分割
segments = split_text_by_punctuation(text)
# 使用循环来打印每个chunk
for i, segment in enumerate(segments):
print("Chunk {}: {}".format(i + 1, segment))
7.4.3 按照固定字符数切分
如果想按照固定字符数来切分文本,这种方法就不再依赖于标点符号,而是简单地按照给定的字符数来切分文本。我们可以编写一个函数,用来将文本分割成指定长度的片段。代码如下:
def split_text_by_fixed_length(text, length):
# 使用列表推导式按固定长度切分文本
return [text[i:i + length] for i in range(0, len(text), length)]
这个函数的作用是根据指定的长度(在这个例子中为100个字符)来切分文本。我们可以根据具体需要调整这个长度。
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 定义每个片段的长度
chunk_length = 100
# 调用函数进行分割
result = split_text_by_fixed_length(text, chunk_length)
# 打印结果
for i, segment in enumerate(result):
print(f"Chunk {i+1}: {segment}")
然而,这种方法的一个明显缺点是由于仅依据长度进行切分,切分后的片段可能无法保持完整的语义。但并不意味着它不适用于文本切分任务。例如,这种方法非常适合于处理日志文件或代码块,其中文本通常以固定长度或格式出现,或者在处理来自传感器或其他实时数据源的流数据时,固定长度切分可以确保数据被均匀地处理和分析。这些应用场景中,数据的结构和形式通常是预定和规范的,因此即便是按固定长度进行切分,反而会更有利于对数据的理解和使用。
7.4.4 结合重叠窗口的固定字符数切分
重复窗口的意义是:块之间保持一些重叠,以确保语义上下文不会在块之间丢失。在文本处理和其他数据分析领域,"重叠"(overlap)指的是连续数据块之间共享的部分。这种方法特别常见于信号处理、语音分析、自然语言处理等领域,其中数据的连续性和上下文信息非常重要。比如下述代码所示:
def split_text_by_fixed_length_with_overlap(text, length, overlap):
# 使用列表推导式按固定长度及重叠长度切分文本
return [text[i:i + length] for i in range(0, len(text) - overlap, length - overlap)]
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"
# 定义每个片段的长度和重叠长度
chunk_length = 100
overlap_length = 30
# 调用函数进行分割
result = split_text_by_fixed_length_with_overlap(text, chunk_length, overlap_length)
# 打印结果
for i, segment in enumerate(result):
print(f"Chunk {i+1}: {segment}")
如上所示,每个文本片段长度为100个字符,并且每个片段与下一个片段有30个字符的重叠。这样,每个窗口实际上是在上一个窗口向前移动30个字符的基础上开始的。这种方法特别适用于需要数据重叠以保持上下文连续性的情况,能够较好的在某一个chunk中保存某个完整的语义信息,比如在第一个Chunk中的:'他在街上走着,看到小朋友们手持烟花棒,欢笑'被截断,但是完整的语义能够在Chunk2中被存储:'他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。' 那么当这条语义信息是有关于Query的上下文,就可以在chunk2中被检索出来。
7.4.5 递归字符文本切分
在前面讲的三种切分方法,虽然简单且更容易理解,但其存在的核心问题是:完全忽视了文档的结构,只是单纯按固定字符数量进行切分。所以难免要更进一步地去做优化,那么一个更进阶的文本分割器应该具备的是:
- 能够将文本分成小的、具有语义意义的块(通常是句子)。
- 可以通过某些测量方法,将这些小块组合成一个更大的块,直到达到一定的大小。
- 一旦达到该大小,请将该块设为自己的文本片段,然后创建具有一些重叠的新文本块,以保持块之间的上下文。
根据上述需求,衍生出来的就是递归字符文本切分器,在langChain中的抽象类为:RecursiveCharacterTextSplitter,同时它也是Langchain的默认文本分割器。
文档切分的可视化工具
我们可以用LangChain提供的文本切分可视化小工具进行直观的理解:https://langchain-text-splitter.streamlit.app/
如上代码所展示的就是RecursiveCharacterTextSplitter类的核心逻辑。所谓的按字符递归分割,就是使用一组分隔符以分层和迭代的方式将输入文本分成更小的块。默认使用[“\n\n” ,"\n" ," ",""] 这四个特殊符号作为分割文本的标记,如果分割文本开始的时候没有产生所需大小或结构的块,那么这个方法会使用不同的分隔符或标准对生成的块递归调用,直到获得所需的块大小或结构。这意味着虽然这些块的大小并不完全相同,但它们仍然会逼近差不多的大小。其中的关键参数:
- separators:指定分割文本的分隔符
- chunk_size:被切割字符的最大长度
- chunk_overlap:如果仅仅使用chunk_size来切割时,前后两段字符串重叠的字符数量。
- length_function:如何计算块的长度。默认情况下,只计算字符数,也可以选择按照Token。
这里我们可以使用同样的文本进行文本切分测试。示例文本如下所示:
春节的脚步越来越近,大街小巷都布满了节日的气氛。
商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。
这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。
同时调整Chunk Size,因为默认的是1000,很明显我们的测试文本长度低于1000,这里我们降低为100,同时将overlap设置为20:
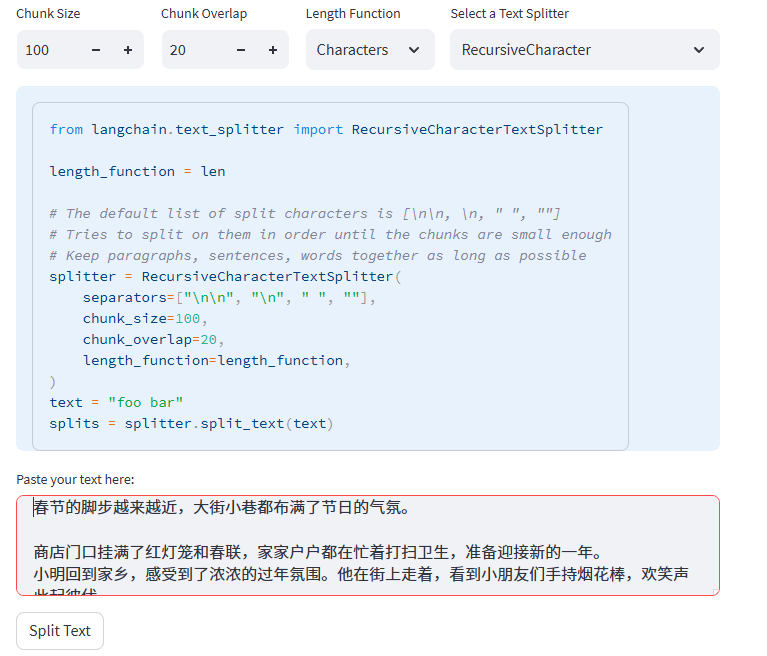
切分结果如下所示,会正常的切分为四个较为完整的chunks。
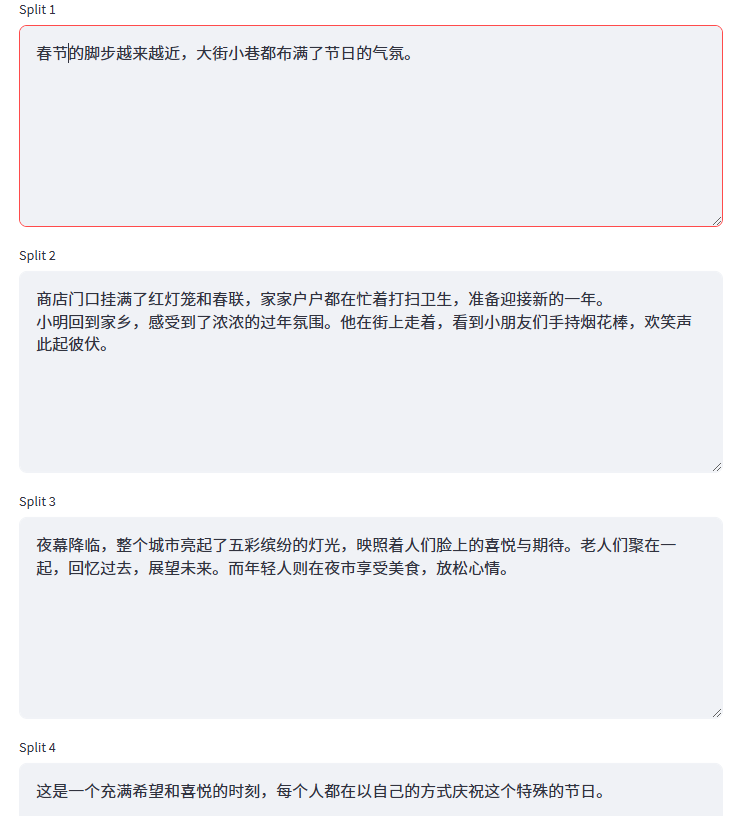
这里我们需要强调的两个关键点是:
- 切分的结果是由
length_function = len决定的,按照设置的切分规则,依次对文本进行分割; - 能不能进行分割,并不是由Chunk Size决定,超出Chunk Size只是触发条件,而真正会不会实际执行分割操作,取决于separator设置的切分符。
比如我们调低Chunk Size为50,再次执行。它会由原来的4个Chunk增加到8个Chunk,这里我们以chunk 4 和 chunk 5 举例说明:
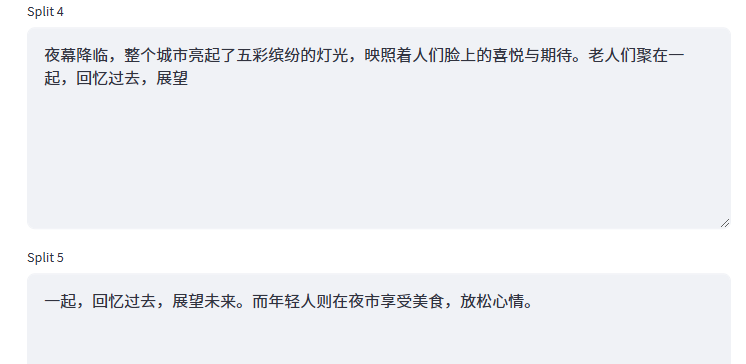
当Chunk Size设置为50时,夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望展望未来。是超出50个字符,此时就会触发Chunk Overlap。也就说:当某一个片段溢出了Chunk Size设定的值,才会在下一个分片段中触发 Chunk Overlap,没有触发时,就不需要补充上下文,但当触发了以后,补充的上下文不能超过设定的Chunk Overlap,这是一个非常重要的点,一定要理解。
在这种情况下虽然超出了 Chunk Size,但是按照separators=["\n\n", "\n", " ", ""]的规则,没有任何一条命中,所以不能分割。因此我们才说:超出Chunk Size只是触发条件,而能不能分割,取决于separator设置的关键词。
当然,除了按照 length_function = len(即字符长度)来进行切分,也可以按照Token切分,Token和字符大概是1 :4 这样一个比例,原理是一致的,大家可以自行尝试。
7.5 langchain中的Text Splitters设计
我们首先需要明确的是:在RAG流程中,我们不仅仅处理原始字符串,更常见的是处理文档。文档不仅包含我们关注的文本,还包括额外的元数据(文档标题、发布日期、摘要或者作者信息等),而这两点,均在LangChain的Document Loader的设计中通过 Document对象的Page_content和metadata设定中进行了定义。所以TextSplitter的核心不仅仅是为了划分数据块,而是要以一种便于日后检索和提取价值的格式来整理我们的数据。那么这里我们首先要进行探索的就是:如何去接收不同的数据形式,并能够按照预定的切分方式进行切分。
下面我们就具体来看在langchain中对于Text Splitters是如何进行设计和实现的。
CharacterTextSplitter
这是最简单的方法。其基于字符(默认为“”)进行分割,并通过字符数来测量块长度。要使用该方法,需要先进行导入:
# 如果未安装过该模块,需要先进行安装
pip install -qU langchain-text-splitters
这里先导入一个测试文本:
from langchain.text_splitter import CharacterTextSplitter
# This is a long document we can split up.
with open("./data/reason.txt", encoding="utf-8") as f:
reason_desc = f.read()
split_text进行文本切分:
- chunk_size: 每个块的最大字符数为 100。
- chunk_overlap: 相邻两个块之间会有 20 个字符的重叠部分。这是为了确保在处理或分析时,相邻块之间有足够的上下文信息。
#定义的文本分割器实例
text_splitter = CharacterTextSplitter(separator='',
chunk_size = 100,
chunk_overlap=20,)
text_res = text_splitter.split_text(reason_desc)
len(text_res) #查看切分块的个数
text_res[0],text_res[1],text_res[2] #查看每一块的内容
split_documents进行切分
要使用split_documents方法,需要的是我们使用文档加载器,将str形式的文本数据先转换为Document对象,如下代码所示:
from langchain.document_loaders import TextLoader
docs = TextLoader('./data/reason.txt', encoding="utf-8").load()
#定义的文本分割器实例
text_splitter = CharacterTextSplitter(separator='',
chunk_size = 100,
chunk_overlap=20,)
text_res = text_splitter.split_documents(docs)
len(text_res) #查看切分块的个数
text_res[0],text_res[1],text_res[2] #查看每一块的内容
split_documents与split_text定义的文本分割器实例text_splitter参数是一致的。但不同的是,split_documents其接收的是Document对象,返回的chunks也是Docement对象。
通过上述操作过程不难发现,LangChain通过巧妙的设计通过CharacterTextSplitter这一文档分割器就可以通过separator、chunk_size、chunk_overlap参数的灵活组合,实现了我们在前面。
7.6 综合应用
把向量化流程、数据加载和分块策略应用在LangChain的数据处理流中。
首先,我们通过Document Loaders读取到一个外部的.txt文件。
from langchain.document_loaders import TextLoader
docs = TextLoader('./data/Chinese.txt', encoding="utf-8").load()
这份文档中的文本内容覆盖了多个主题,用来增强测试的复杂性。接下来,使用Text Splitters中的RecursiveCharacterTextSplitter进行文本分块:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(docs)
#查看每一个chunk的内容
for index, doc in enumerate(docs):
print(f"Chunk {index + 1}: {doc.page_content}\n")
接下来,通过BaiChuan获取每个Chunk的向量表示:
def baichuan_embedding_by_api(text):
# 设置API密钥
key = open('./key_files/baichuan_API-Key.md').read().strip()
embeddings = BaichuanTextEmbeddings(api_key=key)
text = text.replace("\n", " ").strip()
return embeddings.embed_query(text)
embeddings = [baichuan_embedding_by_api(doc.page_content) for doc in docs]
然后,通过如下代码获取到query的向量表示:
query_embedding = baichuan_embedding_by_api("现在科技创新方面有什么进展?")
在有了原始文档和query的向量表示后,我们通过余弦相似度去匹配哪一个Chunk中的内容,与输入的query是最相近的。
import numpy as np
def cosine_similarity(A, B):
# 使用numpy的dot函数计算两个数组的点积
# 点积是向量A和向量B在相同维度上对应元素乘积的和
dot_product = np.dot(A, B)
# 计算向量A的欧几里得范数(长度)
# linalg.norm默认计算2-范数,即向量的长度
norm_A = np.linalg.norm(A)
# 计算向量B的欧几里得范数(长度)
norm_B = np.linalg.norm(B)
# 计算余弦相似度
# 余弦相似度定义为向量点积与向量范数乘积的比值
# 这个比值表示了两个向量在n维空间中的夹角的余弦值
return dot_product / (norm_A * norm_B)
# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)
从输出上看,当query为现在科技创新方面有什么进展?,涉及到原始文档科技创新这一主题时,检索出来的最匹配内容就是存储着科技创新内容的这一个chunk。同样,我们可以继续进行测试,此次提问的query涉及经济问题:
query_embedding = baichuan_embedding_by_api("现在的经济趋势怎么样?")
# 计算与查询最相近的文档块
similarities = [cosine_similarity(query_embedding, emb) for emb in embeddings]
max_index = np.argmax(similarities) # 找到最高相似性的索引
# 打印最相似的文档块
print(f"The most similar chunk is Chunk {max_index + 1} with similarity {similarities[max_index]}:")
print(docs[max_index].page_content)
对于经济问题,也能够很好的检索出原始文档中存储经济相关内容的chunk,这样的流程从本质上就是RAG检索的过程,只不过,一个应用级的RAG系统仅通过这样的简单设计肯定是不行的,首先,知识库存储的内容不可能这么少,chunks也不可能只有我们示例中的6个,那么当一个用户的query进入到这个RAG系统,query作为一个向量,要去偌大的知识库中(可能有几万、上千万个chunks)中找到与其最接近、内容最相关的问题,这就变成了一个搜索问题。
如果每个都去一一进行比较,这肯定是不现实的,它的时间复杂度会非常高,那有效的解决办法就是向量数据库,所以向量数据库,解决的核心问题是:如何以一种高效的搜索策略快速的返回检索结果。
接下来,我们就详细探讨一下向量数据库的应用方法和使用技巧。
7.7 Vector stores
向量数据库,其解决的就是一个问题:更高效的实现搜索(Search)过程。传统数据库是先存储数据表,然后用查询语句(SQL)进行数据搜索,本质还是基于文本的精确匹配,这种方法对于关键字的搜索非常合适,但对于语义的搜索就非常弱。那么把传统数据库的索引思想引用到向量数据库中,同样是做搜索,在向量数据库的应用场景中就变成了:给定一个查询向量,然后在众多向量中找到最为相似的一些向量返回。
目前市面上充斥着非常多的向量数据库,从整体上可以分为开源和闭源,当然闭源意味着我们需要付费使用,而对于开源的向量数据库来说,可以下载免费使用。通过官方的数据来看,最常用的向量数据库如下:

其中Chroma为LangChain官方主推的向量数据库,因此我们就以Chroma 为示例,尝试一下在LangChain中如何使用集成的向量数据库。Faiss与Chrom的使用方式基本保持一致,所以我们就不再重复的说明,大家可以根据官方文档,结合我们接下来对Chroma的实操自行尝试。
7.7.1 Chroma的使用方法
Chroma 是一家构建开源项目(也称为 Chroma)的公司,其官网:https://www.trychroma.com/
它支持用于搜索、过滤等的丰富功能,并能与多种平台和工具(如LangChain,, OpenAI等)集成。Chroma的核心API包括四个命令,分别用于创建集合、添加文档、更新和删除,以及执行查询。Chroma向量数据库官方原生支持Python和JavaScript,也有其他语言的社区版本支持。所以可以直接通过Python或JS操作,具体的操作文档可查阅其官方:https://docs.trychroma.com/
在使用时,因为Chroma是作为第三方集成,所以需要安装依赖包,执行如下代码:
pip install langchain-chroma
如果安装langchain-chroma报错:
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Micro
soft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-
tools/
[end of output]
解决⽅案:需要点击【下载生成工具】进行下载,再执⾏pip install langchain-chroma
下载地址:https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/
具体操作:
加载一个本地的.txt文档
from langchain.document_loaders import TextLoader
raw_documents = TextLoader('./data/sora.txt', encoding="utf-8").load()
接下来,通过文档切割器RecursiveCharacterTextSplitter,将上面完整的Docement对象切分为多个chunks。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""], # 默认
chunk_size=500, #块长度
chunk_overlap=20, #重叠字符串长度
add_start_index=True
)
documents = text_splitter.split_documents(raw_documents)
准备向量模型,这里我们依然使用BaiChuan。
from langchain_community.embeddings import BaichuanTextEmbeddings
import os
# 设置API密钥
key = open('./key_files/baichuan_API-Key.md').read().strip()
embeddings_model = BaichuanTextEmbeddings(api_key=key)
创建 Chroma 数据库实例
from langchain_community.vectorstores import Chroma
#documents:文档将被转换为向量并存储在数据库中
#embeddings_model:向量的嵌入模型
#persist_directory:如果指定路径,向量存储将被持久化到此目录。如果未指定,数据将只在内存中临时存在。
db = Chroma.from_documents(documents, embeddings_model)
使用向量数据库(db)来查找与查询语句 query 相似的文档
query = "什么是Sora"
#在数据库中进行相似性搜索
#通过关键词k,可以设置返回多少个在查询过程中与Query最接近的Chunks
docs = db.similarity_search(query,k=2)
print(docs[0].page_content)
query = "Sora在训练时消耗了多少算力?"
docs = db.similarity_search(query)
print(docs[0].page_content)
在上⼀个示例的基础上,如果您想要保存到磁盘,只需初始化 Chroma 客户端并传递要保存数据的目录。
# 保存到磁盘
db2 = Chroma.from_documents(documents,embeddings_model,persist_directory="./chroma_db")
docs = db2.similarity_search(query)
# 从磁盘加载
db3 = Chroma(persist_directory="./chroma_db", embeddings_model)
docs = db3.similarity_search(query)
print(docs[0].page_content)
在构建实际应用程序时,除了添加和检索,非常多的情况下还需要更新和删除数据,这就需要借助到Chroma类定义的 ids 参数,它可以传入文件名或任意的标识。我们需要先根据分成Chunks构建起唯一的对应id。
import uuid
ids = [str(uuid.uuid4()) for _ in documents]
new_db = Chroma.from_documents(documents, embeddings_model,ids=ids)
接着,执行update_document方法进行更新,如下所示:
new_db.update_document(ids[0], docs[0])
与任何其他数据库一样,在向量数据库中,也可以使用.add、.get 、.update .delete等方法,但如果想直接访问,需要执行._collection.method()。所以我们可以通过如下的代码形式,查看更新后的内容:
print(new_db._collection.get(ids=[ids[0]]))
当然,也可以直接进行删除操作,在删除之前,先看一下有多少个Chunks,代码如下所示:
print(new_db._collection.count())
删除最后一个chunk
new_db._collection.delete(ids=[ids[-1]])
再次查看存储的总Chunks数
print(new_db._collection.count())
拓展:MMR
MMR(Maximal Marginal Relevance,最大边际相关性)是一种信息检索和文本摘要技术,用于在选择文档或文本片段时平衡相关性和多样性。其主要目的是在检索结果中既包含与查询高度相关的内容,又避免结果之间的高度冗余。因此MMR的作用就是:
- 提高结果的多样性:通过引入多样性,MMR可以避免检索结果中出现重复信息,从而提供更全面的答案。
- 平衡相关性和新颖性:MMR在选择结果时,既考虑与查询的相关性,也考虑新信息的引入,以确保结果的多样性和覆盖面。
- 减少冗余:通过避免选择与已选结果高度相似的文档,MMR可以减少冗余,提高信息的利用效率。
MMR使用流程:
- 计算相关性:首先,计算每个候选文档与查询的相似性得分。
- 计算多样性:然后,计算每个候选文档与已选文档集合的相似性得分。
- 选择文档:在每一步选择一个文档,使得该文档在相关性和多样性之间达到最佳平衡。
retriever = db.as_retriever(search_type="mmr")
retriever.invoke(query)[0]
7.7.2 Faiss的使用(拓展)
Faiss 是由 Facebook 团队开源的向量检索工具,专为高维空间的海量数据提供高效、可靠的相似性检索方案。Faiss 支持 Linux、macOS 和 Windows 操作系统,在处理百万级向量的相似性检索时,Faiss 可以在牺牲一定搜索准确度的情况下,实现小于 10ms 的响应时间。
集成位于 langchain-community 包中。我们还需要安装 faiss 包本身。
pip install -U faiss-cpu tiktoken
如果您想使用启用了 GPU 的版本,也可以安装 faiss-gpu 。
from langchain_community.vectorstores import FAISS
db = FAISS.from_documents(docs, embeddings_model)
query = "Pixar公司是做什么的?"
docs = db.similarity_search(query)
print(docs[0].page_content)
MMR使用:
retriever = db.as_retriever()
docs = retriever.invoke(query)
print(docs[0].page_content)
您还可以保存和加载 FAISS 索引。这样做很有用,因为您不必每次使用时都重新创建它。
#保存索引
db.save_local("faiss_index")
#读取索引
new_db = FAISS.load_local("faiss_index", embeddings_model,allow_dangerous_deseria
lization=True)
#进行检索
docs = new_db.similarity_search(query)
Faiss与Chroma使用场景的区别
-
数据规模和性能需求:
- Faiss:更适合处理大规模数据,尤其是在需要利用GPU加速来提高搜索性能的场景下表现出色。例如在处理海量的图像特征向量、大规模的文本嵌入向量等场景中,Faiss能够快速地进行相似性搜索,满足对实时性和高性能的要求。
- Chroma:适用于中小规模数据或对性能要求不是特别极致的场景。虽然Chroma也具有一定的性能优化,但在处理超大规模数据时,其性能可能受限于硬件资源,不过对于一般的小型项目或原型开发来说已经足够。
-
开发和集成难度:
- Faiss:需要开发者对向量检索算法和索引结构有一定的了解,手动管理索引的创建、训练和持久化等操作,开发和集成难度相对较大。但它的灵活性也使得在一些特定场景下可以根据需求进行深度定制。
- Chroma:提供了更简单的API和更便捷的使用方式,开箱即用,类似于一个完整的数据库,对于开发者来说更容易上手和使用,能够快速集成到各种应用中,特别适合快速原型开发和那些对数据库内部细节不太关注的应用场景。
7.8 项目实战
点击查看代码
import streamlit as st
import tempfile #创建临时文件和目录,并提供了自动清理这些临时文件和目录的机制,以避免占用不必要的磁盘空间
import os
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain_community.document_loaders import TextLoader
from langchain_openai import ChatOpenAI
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.agents import create_react_agent, AgentExecutor
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import BaichuanTextEmbeddings
# 设置Streamlit应⽤的⻚⾯标题和布局
st.set_page_config(page_title="Rag Agent", layout="wide")
# 设置应⽤的标题
st.title("Rag Agent")
#上传txt⽂件,允许上传多个⽂件
uploaded_files = st.sidebar.file_uploader(
label="上传txt⽂件", type=["txt"], accept_multiple_files=True
)
# 如果没有上传⽂件,提示⽤户上传⽂件并停⽌运⾏
if not uploaded_files:
st.info("请先上传按TXT⽂档。")
st.stop()
#实现检索器函数封装:文件读取、分块、向量转换、向量数据库、MMR信息检索
def configure_retriever(uploaded_files):
try:
docs = [] #存储用户上传文件的文件内容(字符串)
#创建临时文件和目录
temp_dir = tempfile.TemporaryDirectory()
st.write("📄 正在加载文件...")
for file in uploaded_files:
temp_filepath = os.path.join(temp_dir.name, file.name)
with open(temp_filepath, "wb") as f:
f.write(file.getvalue())
# 使用TextLoader加载文本文件
loader = TextLoader(temp_filepath, encoding="utf-8")
docs.extend(loader.load())
st.write(f"✅ 已加载 {len(docs)} 个文档")
# 进行文档分割
st.write("✂️ 正在分割文档...")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
st.write(f"✅ 已分割为 {len(splits)} 个片段")
# 使用BaichuanTextEmbeddings向量模型生成文档的向量表示
st.write("🔄 正在生成向量嵌入(这可能需要一些时间)...")
key = "sk-83cd52e5dfd7a1c0ca6f57952d76f95d"
embeddings = BaichuanTextEmbeddings(api_key=key)
st.write("💾 正在创建向量数据库...")
vectordb = Chroma.from_documents(splits, embeddings)
st.write("✅ 向量数据库创建完成")
# 创建文档检索器
retriever = vectordb.as_retriever()
#返回检索器对象
return retriever
except Exception as e:
st.error(f"❌ 处理文档时出错: {str(e)}")
st.exception(e)
return None
# 配置检索器:使用 session_state 来缓存检索器,避免重复处理
# 生成文件标识符(基于文件名和大小)
file_ids = tuple((f.name, f.size) for f in uploaded_files)
# 如果文件发生变化,重新创建检索器
if "file_ids" not in st.session_state or st.session_state.file_ids != file_ids:
st.session_state.retriever = configure_retriever(uploaded_files)
if st.session_state.retriever is None:
st.error("文档处理失败,请检查文件格式或网络连接")
st.stop()
st.session_state.file_ids = file_ids
st.success("🎉 文档处理完成!现在可以开始提问了")
retriever = st.session_state.retriever
# 如果session_state中没有消息记录或用户点击了清空聊天记录按钮,则初始化消息记录
if "messages" not in st.session_state or st.sidebar.button("清空聊天记录"):
st.session_state["messages"] = [{"role": "assistant", "content": "您好,我是AI智能助手,我可以查询文档"}]
# 加载历史聊天记录
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 下一步工作就是将文档检索作用在Agent对象中。创建Agent时需要让其对多轮对话具备上下文记忆能力
# 创建用于文档检索的工具
'''
create_retriever_tool:
功能:创建具体的检索工具实例
用途:从文档库中检索信息
典型场景:问答系统、文档搜索
langchain.agents.Tool:
功能:定义工具的通用接口
用途:自定义工具或扩展工具功能
典型场景:创建自定义工具或扩展现有工具
'''
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever = retriever,
name = "文档检索",
description = "用于检索用户提出的问题,并基于检索到的文档内容进行回复.",
)
tools = [tool]
# 创建聊天消息历史记录
'''
StreamlitChatMessageHistory 是一个专为 Streamlit 应用设计的聊天历史管理工具,适用于需要保存和管理对话上下文的场景。
支持实时更新聊天历史,并在界面上动态显示。和之前学过的ChatMessageHistory消息集工具对象类似。
'''
msgs = StreamlitChatMessageHistory()
# 创建对话缓冲区
'''
参数介绍:
chat_memory:指定初始的对话历史记录。 用于加载已有的对话历史,以便在后续对话中参考之前的上下文。
return_messages:控制是否在返回结果中包含消息对象。如果设置为 True,则在调用 memory.load_memory() 时,返回的结果中会包含完整的消息对象(包括角色、内容等)。如果设置为 False,则只返回字符串形式的消息的内容。
memory_key:指定在内存中存储对话历史的键名。当从内存中加载或保存对话历史时,使用这个键名来标识对话历史。例如,如果内存中存储了多个键值对,可以通过 memory_key 来指定要加载的对话历史。
output_key:指定在内存中存储模型输出的键名。当将模型的输出保存到内存中时,使用这个键名来标识输出内容。例如,如果内存中存储了多个键值对,可以通过 output_key 来指定要加载的模型输出。
'''
memory = ConversationBufferMemory(
chat_memory=msgs, return_messages=True, memory_key="chat_history", output_key="output"
)
# 指令模板
instructions = """你是一个设计用于查询文档来回答问题的代理对象。
你可以使用文档检索工具,并基于检索内容来回答问题
你可能不查询文档就知道答案,但是你仍然应该查询文档来获得答案。
如果你从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
"""
# 基础提示模板-React提示词
base_prompt_template = """
{instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: {input}
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}"""
# 创建基础提示模板
base_prompt = PromptTemplate.from_template(base_prompt_template)
# 创建部分填充的提示模板
prompt = base_prompt.partial(instructions=instructions)
# 创建llm - 使用 deepseek-chat 而不是 deepseek-reasoner
# deepseek-reasoner 不适合做 Agent,因为它的输出格式不符合 ReAct 要求
API_KEY = "sk-e18a9a1a837e44xxxx0dc550e"
llm = ChatOpenAI(
model="deepseek-chat",
openai_api_key=API_KEY,
openai_api_base="https://api.deepseek.com",
temperature=0
)
# 创建react Agent
agent = create_react_agent(llm, tools, prompt)
# 创建Agent执行器
'''
memory:指定用于存储和管理对话历史的内存对象。
用途:
- 存储对话历史,包括用户输入和机器人回复。
- 在多轮对话中提供上下文,帮助机器人更好地理解用户意图。
handle_parsing_errors:控制是否在解析用户输入时自动处理错误。
用途:
- 如果设置为 True,当用户输入无法被正确解析时,系统会自动尝试修复或忽略错误,而不是直接抛出异常。
- 如果设置为 False,系统会在遇到解析错误时抛出异常,可能导致程序中断。
'''
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory, verbose=True, handle_parsing_errors=True)
# 创建聊天输入框
user_query = st.chat_input(placeholder="请开始提问吧!")
# 如果有用户输入的查询
if user_query:
# 添加用户消息到session_state
st.session_state.messages.append({"role": "user", "content": user_query})
# 显示用户消息
st.chat_message("user").write(user_query)
#创建一个 Streamlit 的聊天消息块,用于显示助手(机器人)的回复。
with st.chat_message("assistant"):
# st.container(): 创建一个 Streamlit 的容器组件,用于动态更新内容。
#StreamlitCallbackHandler 是 LangChain 的一个回调处理器,用于将模型的输出或日志信息显示在 Streamlit 界面中。通过将 st.container() 传递给 StreamlitCallbackHandler,可以将 LangChain 的输出直接渲染到 Streamlit 的容器中。
st_cb = StreamlitCallbackHandler(st.container())
# 配置 LangChain 的回调函数列表,将 StreamlitCallbackHandler 添加到回调中。通过配置回调函数,LangChain 可以在处理过程中调用StreamlitCallbackHandler,从而将输出或日志信息显示在 Streamlit 界面中。这种方式可以实现实时更新界面。
config = {"callbacks": [st_cb]}
# 执行Agent并获取响应
response = agent_executor.invoke({"input": user_query}, config=config)
# 添加助手消息到session_state
st.session_state.messages.append({"role": "assistant", "content": response["output"]})
# 显示助手响应
st.write(response["output"])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号