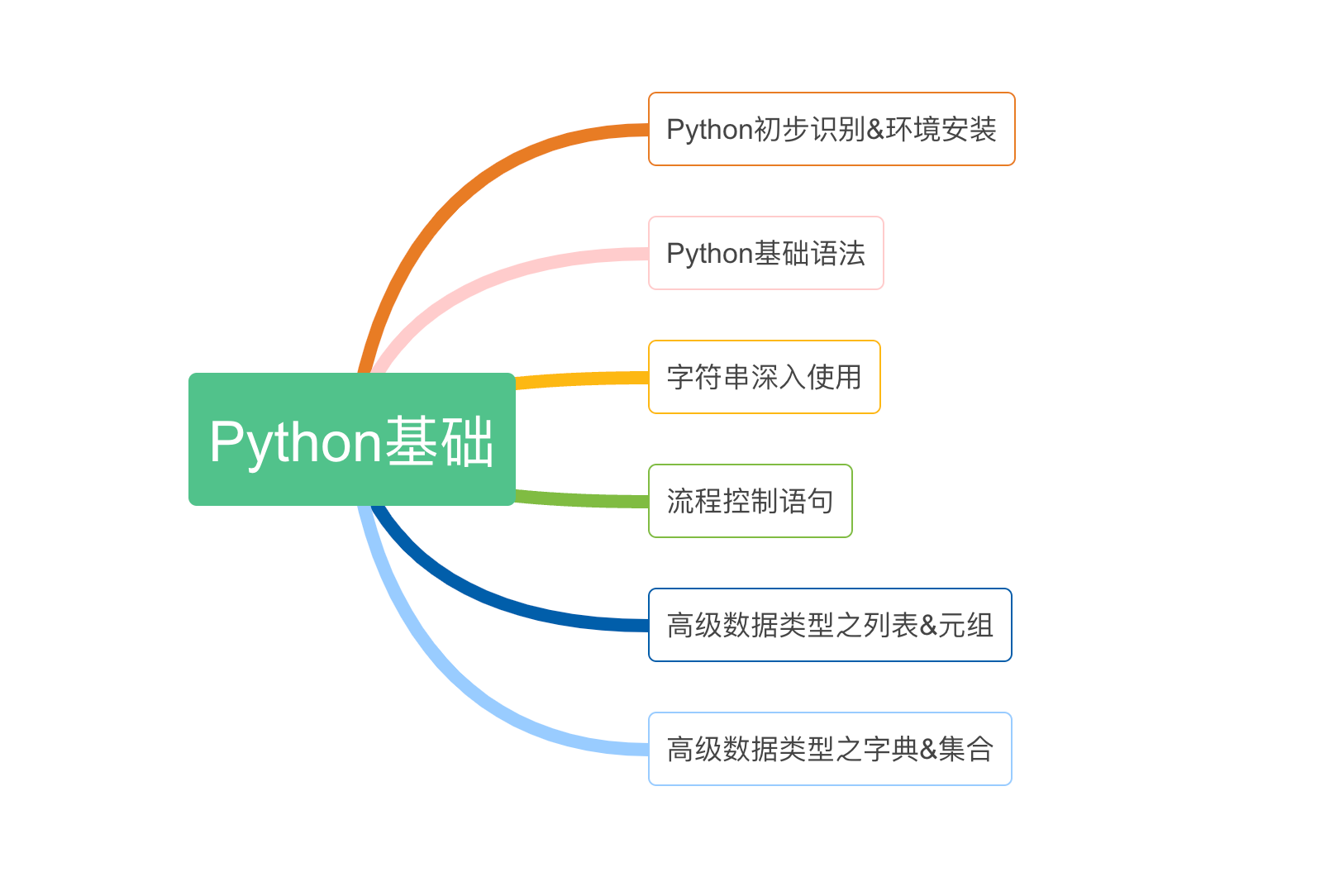
python基础
模块1:Python基础
模块概述
欢迎来到本书的第一模块——Python基础!在这个模块中,我们将为您介绍Python编程语言最基础、最重要的概念和技术。
我们将从变量开始,通过学习运算符操作基本数据类型完成对于语句的学习,这是构建任何程序的基础。随后,我们将深入研究高级数据类型,包括列表和字典。列表是序列类型中的代表,而字典则是一种键值对的数据结构,用于存储和检索具有唯一标识符的值。通过列表和字典地学习,我们能够更加高级有效地组织管理数据。
除了基本和高级数据类型,我们还将介绍Python的流程控制语句。这些语句允许您根据条件执行不同的代码块、进行循环迭代和创建函数。通过学习流程控制语句,您将能够编写更加灵活和逻辑清晰的程序,实现不同的控制流程和决策。
在本模块中,我们将提供丰富的示例代码和练习,通过实践来巩固您的学习成果。我们将逐步引导您掌握Python的基础概念,培养解决问题的思维方式,并为您打下坚实的编程基础。
Day01:Python初识&环境安装

1. 计算机组成原理
计算机组成原理是研究计算机硬件和软件组成及其相互关系的学科领域。它涵盖了计算机系统的各个方面,包括计算机的功能、组件、数据表示、指令集体系结构、处理器设计、存储器层次结构、输入输出系统、总线结构、操作系统以及计算机网络等。
冯·诺依曼体系结构:计算机通常采用冯·诺依曼体系结构,包括中央处理器(CPU)、存储器(内存)、输入设备和输出设备。它们通过总线进行数据和指令的传输。
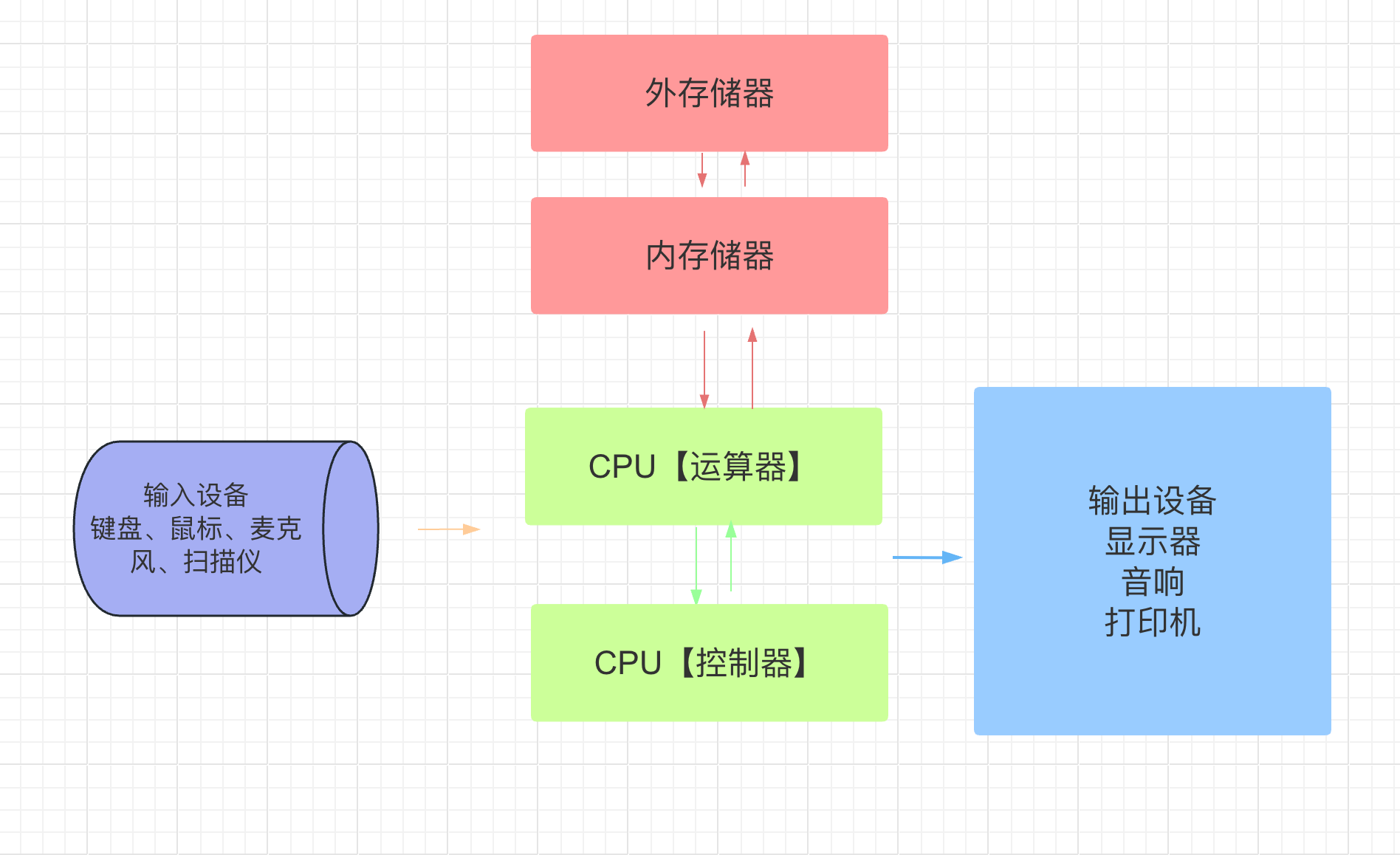
- 中央处理器(CPU):CPU是计算机的核心部件,负责执行指令和处理数据。它包括控制单元和算术逻辑单元(ALU),控制单元负责指令的解码和控制,ALU负责执行算术和逻辑操作。
- 存储器:存储器用于存储数据和指令。计算机中的存储器层次结构包括寄存器、、主存(内存)和辅助存储器。寄存器是最快速但容量最小的存储器,用于存储处理器中的数据和指令。主存是计算机的主要存储器,用于存储程序和数据。辅助存储器(如硬盘、固态硬盘)用于长期存储大量的数据。
- 输入输出设备:输入输出设备用于与计算机进行交互和数据的输入输出。常见的输入设备包括键盘、鼠标、扫描仪等,输出设备包括显示器、打印机、音频设备等。输入输出设备通过接口和控制器与计算机连接。
- 总线:总线是计算机中各个组件之间进行数据传输的通道。它包括数据总线、地址总线和控制总线。数据总线用于传输数据,地址总线用于指定数据的存储位置,控制总线用于传输控制信号。
2. 编程语言
【1】什么是编程语言
编程语言是一种用于编写计算机程序的形式化语言。它是一种人与计算机之间进行交流的工具,用于描述和指示计算机执行特定任务或完成特定操作的步骤和逻辑。
编程语言可以分为多种类型,包括低级语言和高级语言。低级语言如汇编语言直接与计算机硬件交互,更接近机器语言。高级语言如Python、Java、C++等提供了更高级别的抽象和功能,使开发人员能够更快速、易读、易维护地编写程序。
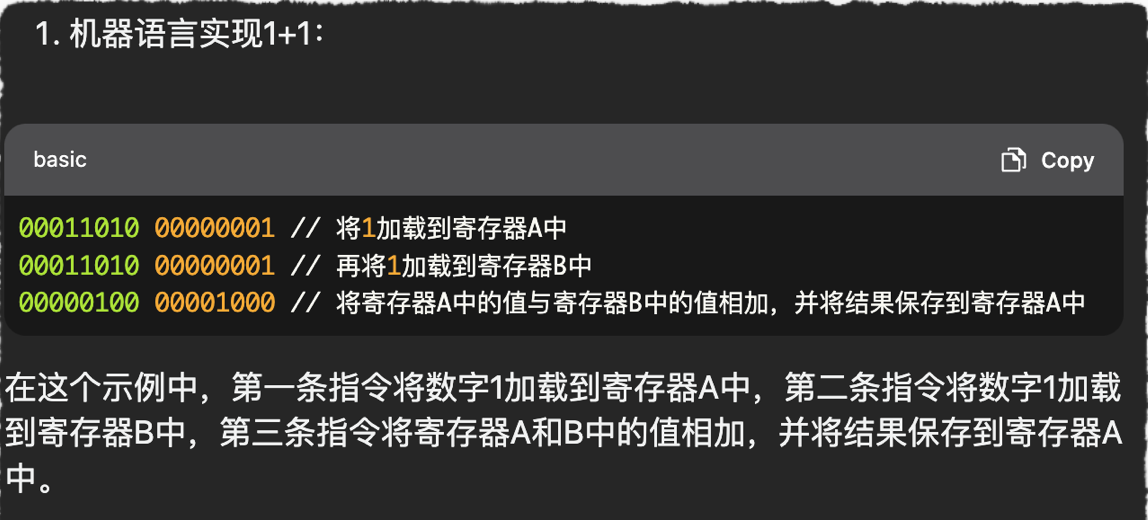
机器指令(1930-1960s)
机器语言阶段:计算机本质上就是是一台只懂得执行简单指令的机器。而执行的指令也就是我们说的机器指令,其实背后对应的就是一个个电路运算,例如算术运算、逻辑运算、存储等等。指令的执行本质就是由CPU来触发这些对应的电路执行从而完成特定的功能。
二进制的数字指令映射电路运算
汇编语言(1947 )
汇编语言阶段:机器语言对人类来说非常晦涩和难以理解。这使得编写和理解机器语言程序非常困难和容易出错。为了让人类能够更方便地编写和理解计算机程序,汇编语言应运而生。汇编语言本质就是数字符号化。
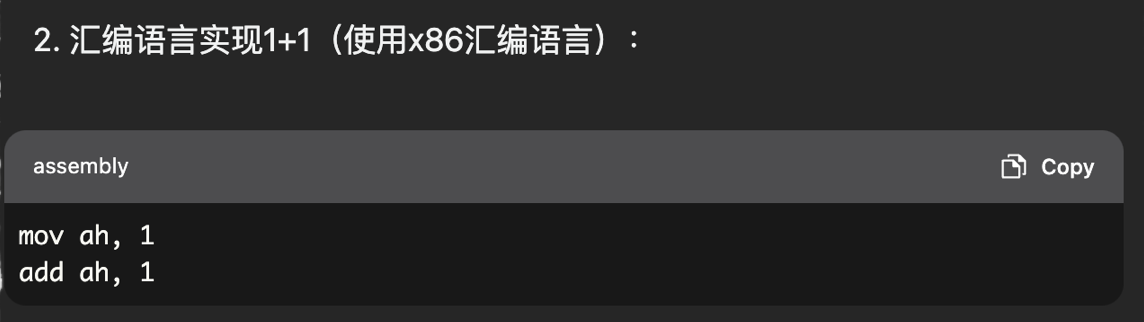
- 汇编核心就是指令符号化
- 什么是汇编器
高级语言(1972 )
尽管汇编语言比机器语言更容易理解,但仍然需要编写大量的指令来完成复杂的任务,包括各种底层硬件的直接操作。这对于开发人员来说是一项繁琐和容易出错的工作。为了进一步提高编程效率和可读性,高级语言应运而生。
高级语言是一种更加抽象和易用的编程语言,如C,Java、Python等。它们提供了更高级别的抽象,包括更丰富的数据类型、复杂的数据结构、函数、类、库等。使用高级语言,开发人员可以用更简洁、易读的方式表达程序的逻辑和算法,而不需要关注底层的机器细节。
随着计算机硬件的发展,高级语言的应用越来越广泛,例如 C、C++、Java、Python、JavaScript 等。
- 高级语言的核心就是语句封装了指令
- 什么是编译器或解释器
总之,高级语言的出现使得编程变得更加高效、易读和易维护。它们提供了更强大、更友好的工具和库,使开发人员能够更快速地构建复杂的应用程序,并推动了软件开发的快速发展。
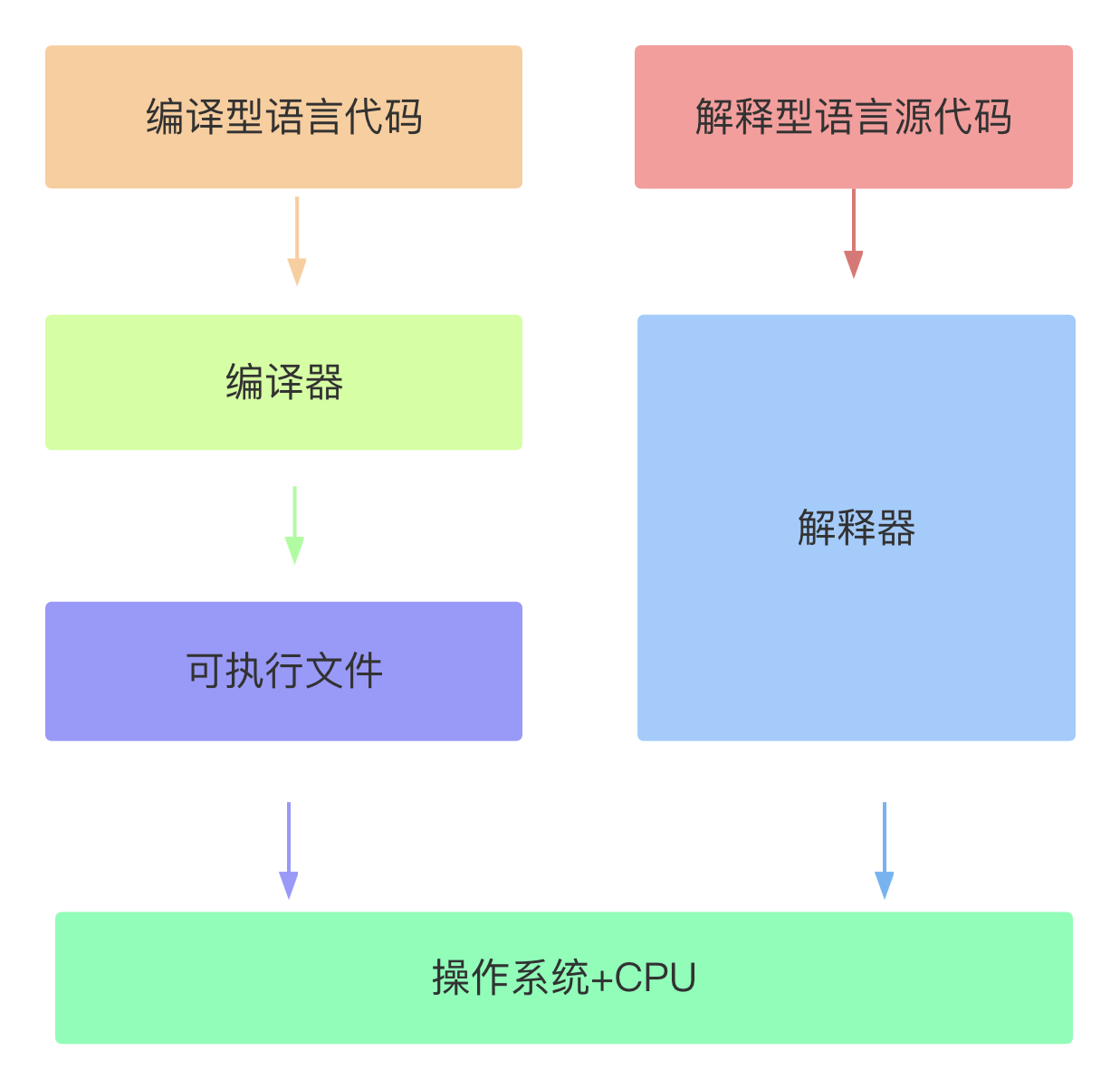
【2】编译型语言与解释型语言
编译型语言的代码在执行之前需要经过编译器的处理。编译器将源代码作为输入,通过多个阶段的处理生成机器码(目标代码),然后将目标代码链接为可执行文件。这个可执行文件可以直接在计算机上执行。编译型语言的典型代表是C、C++和Pascal等。
编译型语言的特点包括:
- 编译过程在代码执行之前进行,只需要进行一次编译。
- 编译后的代码执行效率高,因为它是直接由计算机硬件执行的机器码。
- 可执行文件独立于源代码,可以在不同的计算机上执行,前提是目标机器上有相应的编译器和运行时支持。
- 编译型语言对代码的静态类型检查较为严格,需要在编译时确定变量的类型和错误检查。
解释型语言的代码在执行时逐行被解释器解释执行,不需要显式的编译过程。解释器将源代码逐行解释翻译成机器码或虚拟机指令,并实时执行。解释型语言的典型代表是Python、JavaScript和Ruby等。
解释型语言的特点包括:
- 不需要显式的编译过程,代码可以直接执行。
- 每次执行都需要解释器逐行解释代码,因此执行效率相对较低。
- 源代码可以跨平台执行,只需要针对不同平台提供相应的解释器。
- 解释型语言通常具有动态类型检查的特性,变量的类型在运行时确定。
【3】主流编程语言
3. Python介绍

Python 是1989 年荷兰人 Guido van Rossum (简称 Guido)在圣诞节期间为了打发时间,发明的一门面向对象的解释性编程语言。Python来自Guido所挚爱的电视剧Monty Python’s Flying Circus。

Guido对于Python的设计理念就是一门介于shell和C之间的语言。可以像shell那样,轻松高效编程,也可以像C语言那样,能够全面调用计算机的功能接口。
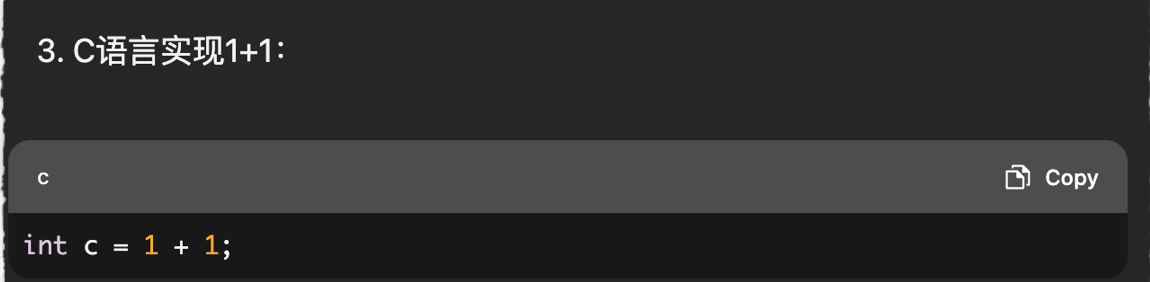
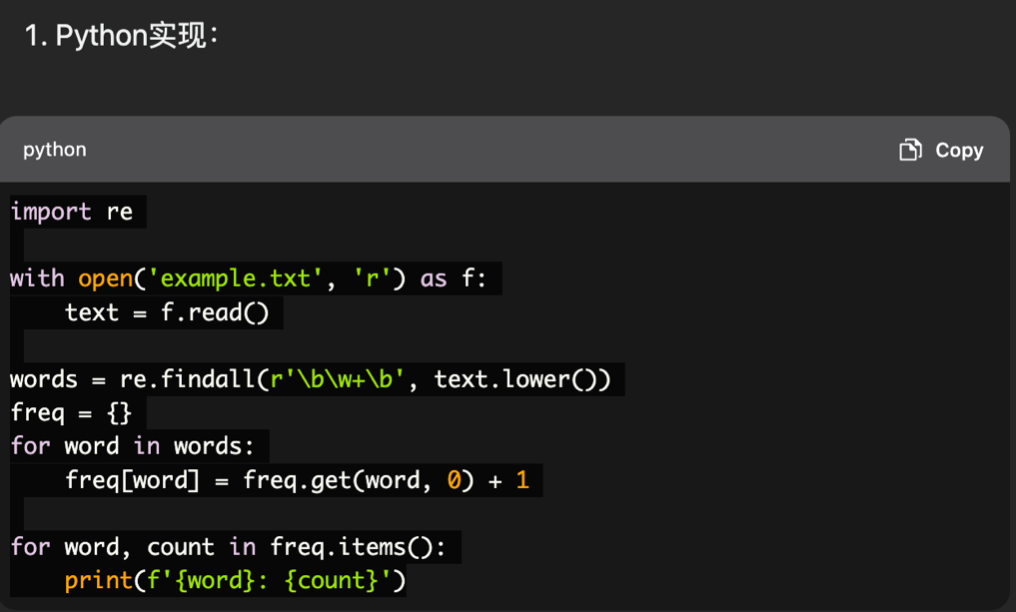
比如实现一个文件单词频率统计,分别通过C语言和Python实现:
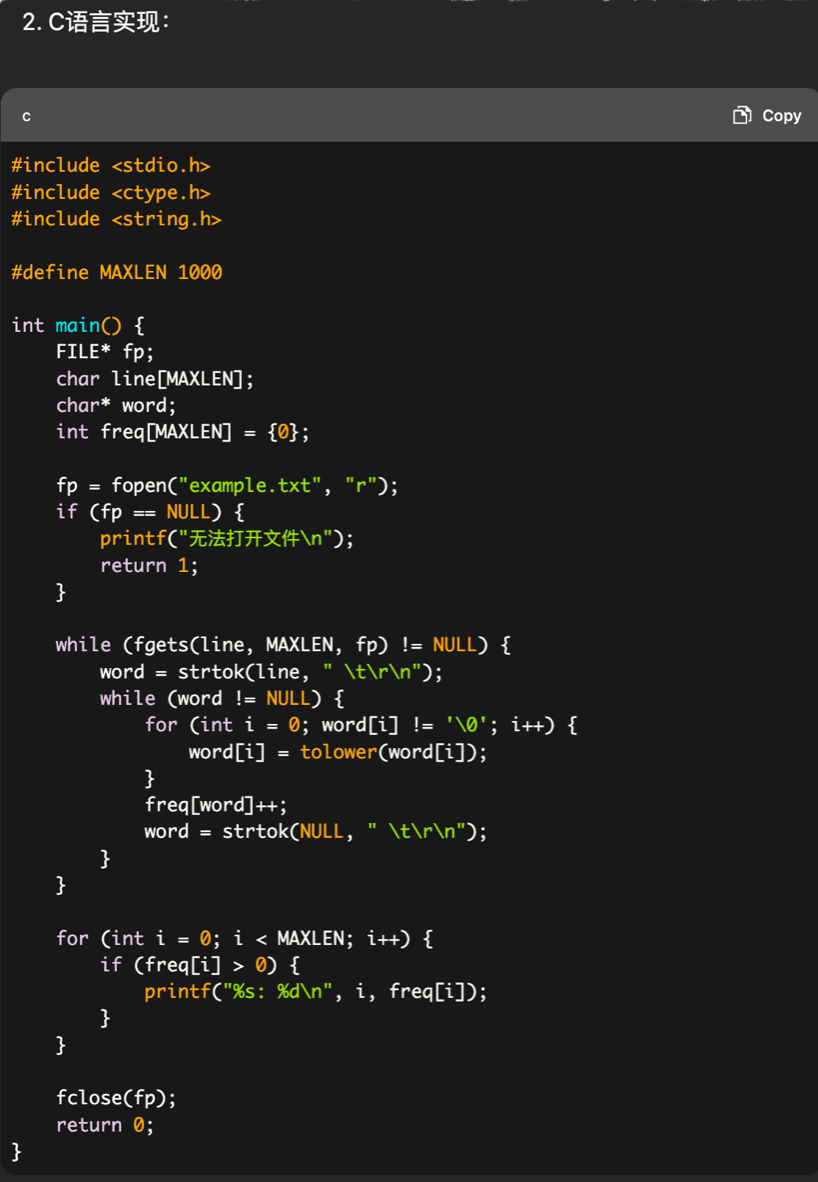
python的设计哲学:优雅、明确、简洁。
简洁优雅:Python的语法非常简洁,使用空格缩进来表示代码块,而不是使用大括号。这使得代码更加易读、易维护和易于理解。
易学易用:Python具有较低的学习曲线,语法简单直观,对初学者非常友好。它提供了丰富的标准库和第三方库,用于处理各种任务,如数据处理、网络编程、图形界面开发等。
大量的库和生态系统:Python拥有强大的库生态系统,如NumPy、Pandas、Matplotlib、SciPy、TensorFlow、Django等。这些库提供了丰富的功能和工具,加速了开发过程,使得开发者能够快速构建复杂的应用程序。
跨平台性:Python可以在多个操作系统上运行,包括Windows、Linux、macOS等。这使得开发者能够轻松地在不同平台上部署和运行他们的应用程序。
社区支持:Python拥有庞大的开发者社区,提供了丰富的文档、教程和资源。开发者可以从社区中获取帮助、分享经验和学习最佳实践。
Python在各个领域得到广泛应用,包括科学计算、数据分析、人工智能、机器学习、Web开发、网络爬虫、自动化脚本、游戏开发等。

总之,Python是一种强大而灵活的编程语言,适用于从小型脚本到大型应用程序的开发。其简洁的语法、丰富的库和友好的社区使得Python成为许多开发者的首选语言。
4. 终端环境
终端环境是计算机操作系统提供的一种命令行界面,也称为命令行终端或控制台。它允许用户通过键盘输入命令并接收计算机的输出结果。终端环境提供了一种直接而强大的方式来与计算机交互和管理系统。

【1】win系统
# (1) cd 路径切换
cd:切换当前工作目录。例如:
cd /path/to/directory:切换到指定路径的目录。
cd ~:切换到当前用户的主目录。
cd ..:切换到上级目录。
D: # 切换另外一个盘符,再继续cd
# (2) 创建文件夹
mkdir 文件夹名
# (3) 创建文件:echo命令将空内容输出到一个新文件中
echo. > filename.txt
# (4) 显示文件内容
type file_name
# (4) 清空终端显示
cls
# (5) 删除
del file_name # 删除文件
rmdir /s yuan # 删除文件夹
【2】Mac系统
cd / # 进入根路径
touch 文件名 # 创建文件
open 文件名 # 打开文件
cat file_name # 显示文件的内容
clear # 清空终端显示
rm file_name # 删除文件
rm -r directory_name # 递归删除文件夹
5. Python环境安装
进入Python官网:
https://www.python.org/
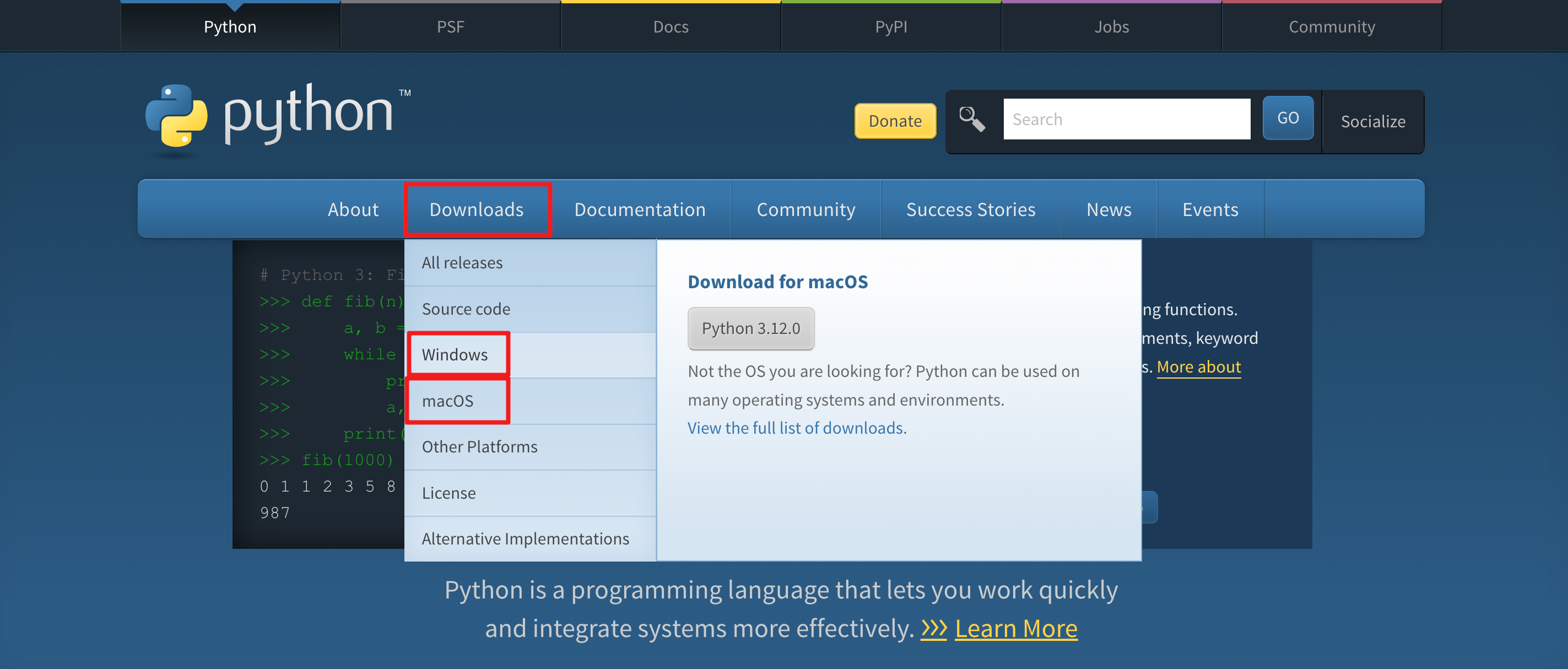
【1】window版本
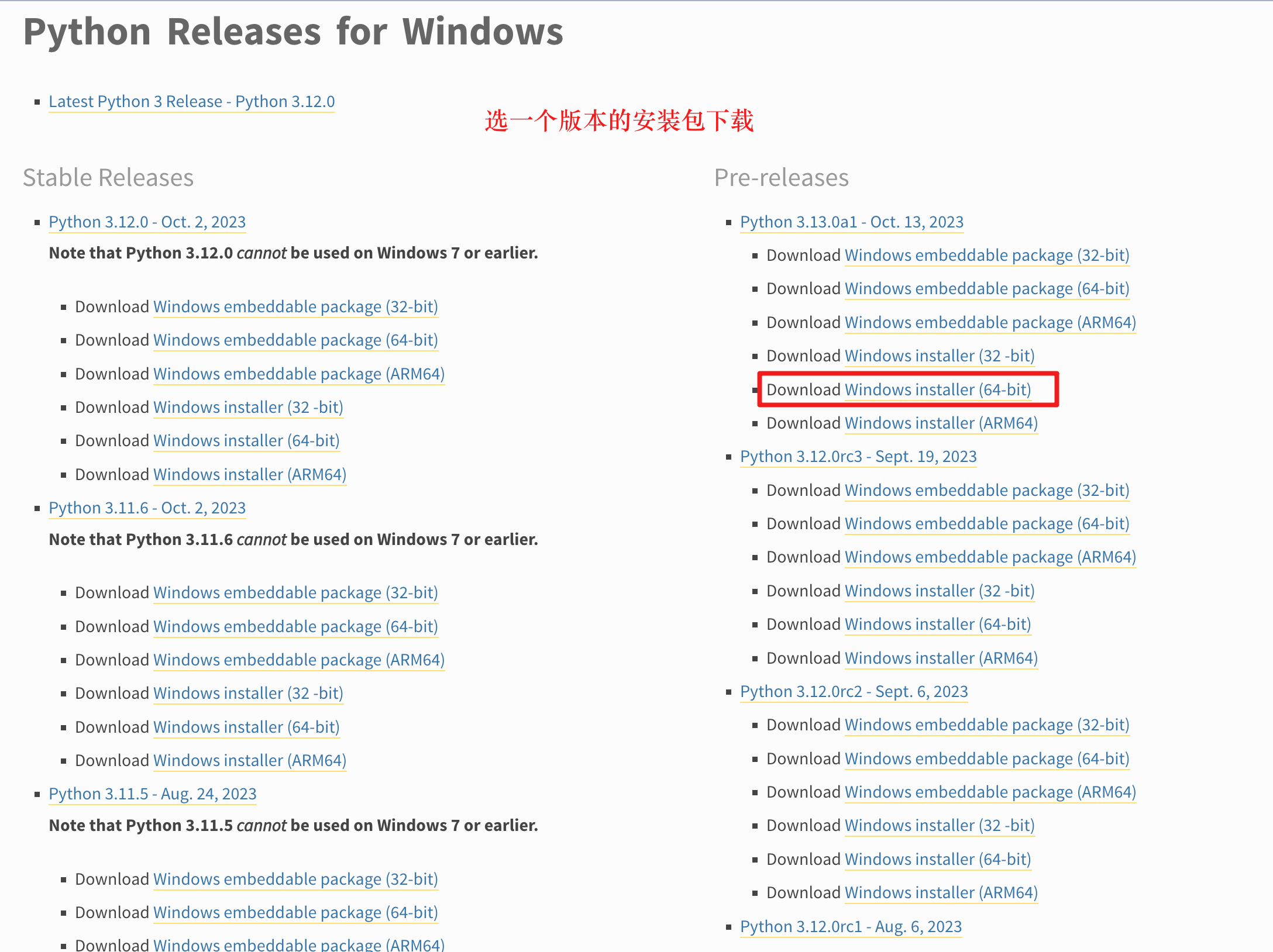
安装包:
安装过程:
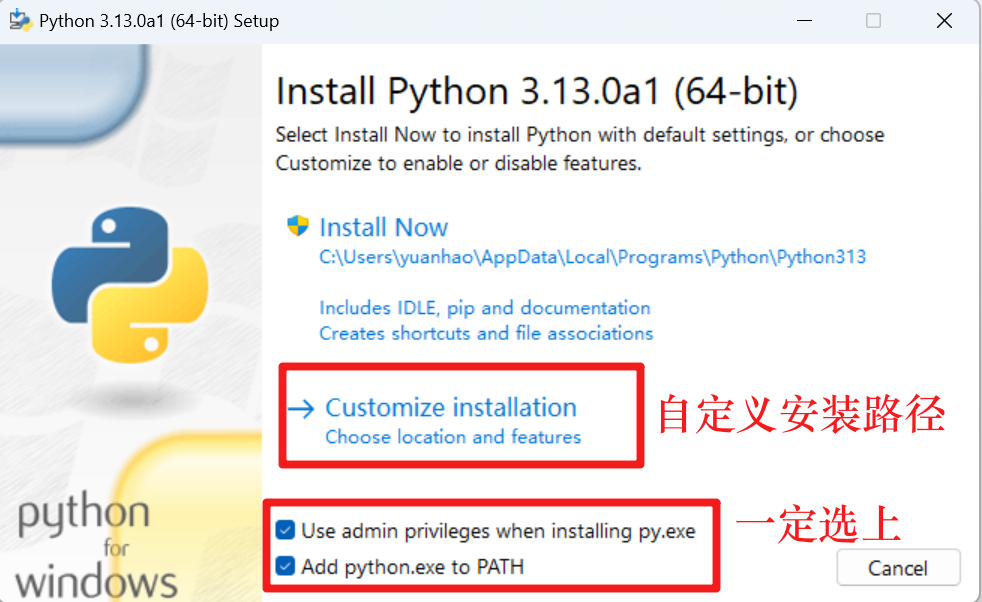
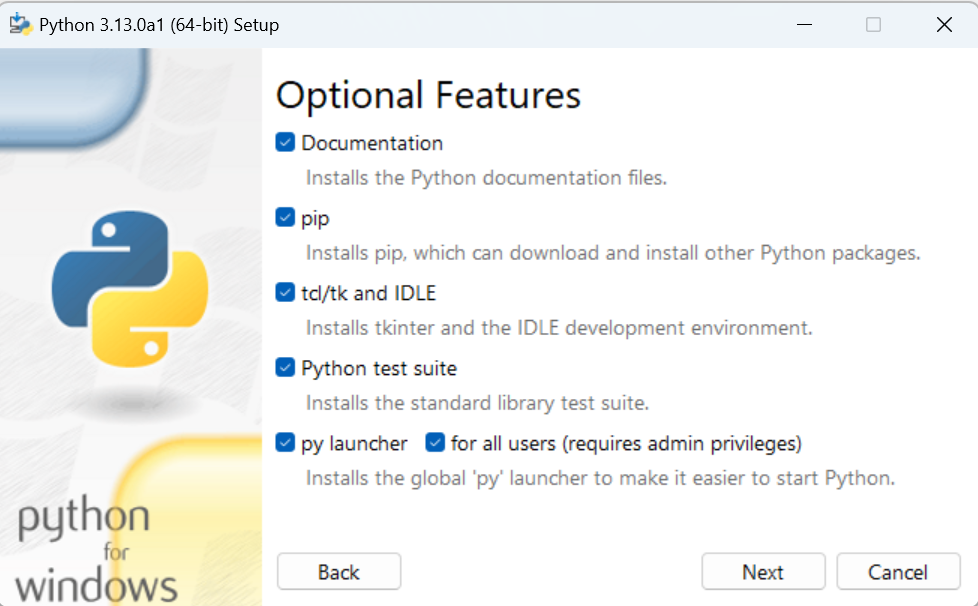
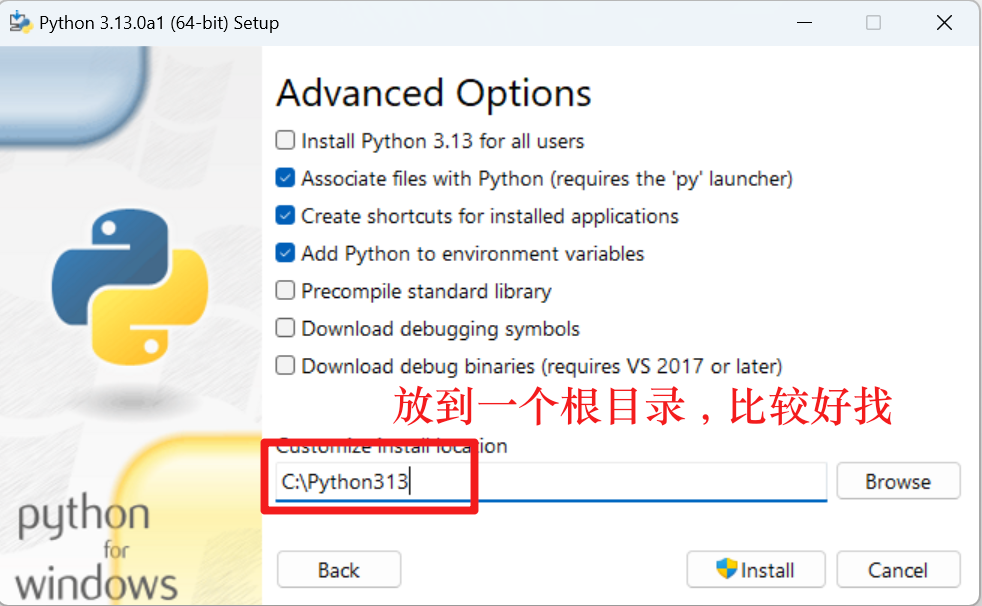

打开终端【win+R】
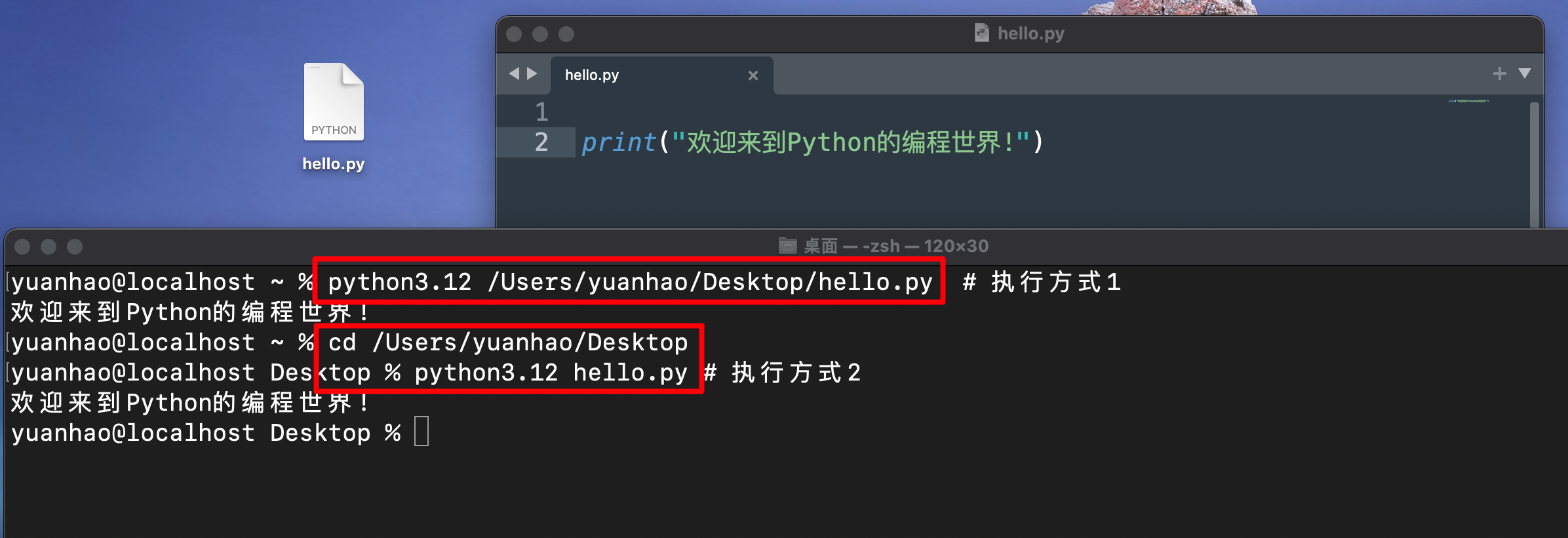
我们的第一个Python程序:

- 内置函数print(),可以打印文本字符串到控制台
- 顶格位置
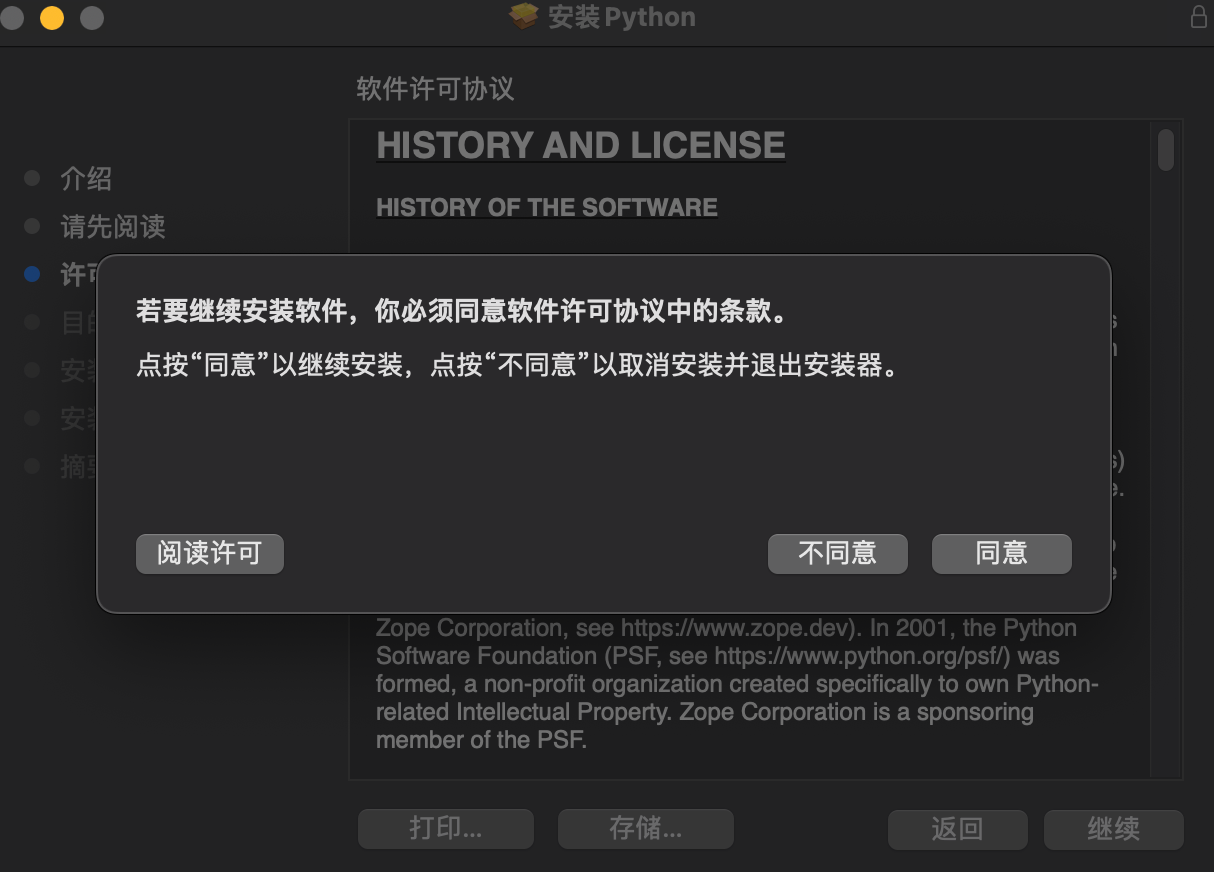
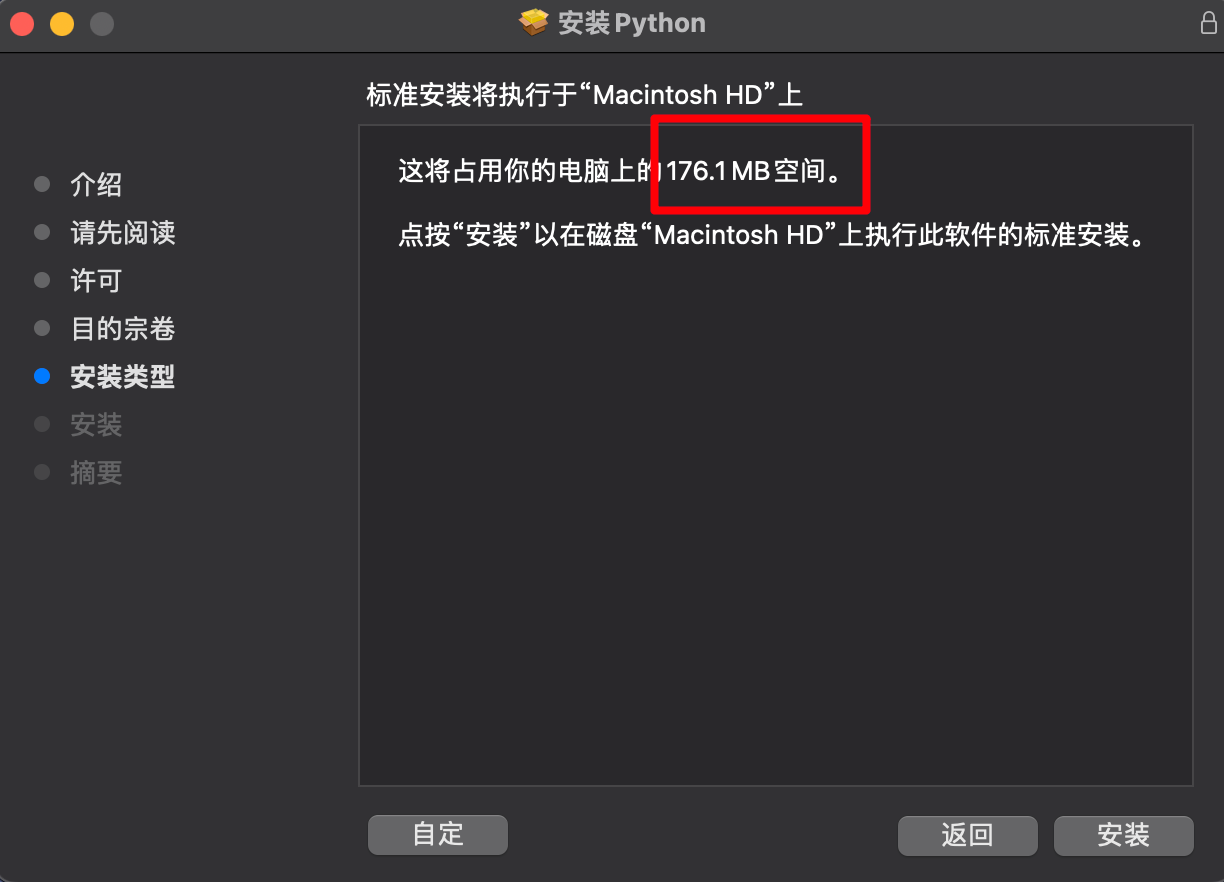
【2】MAC版本
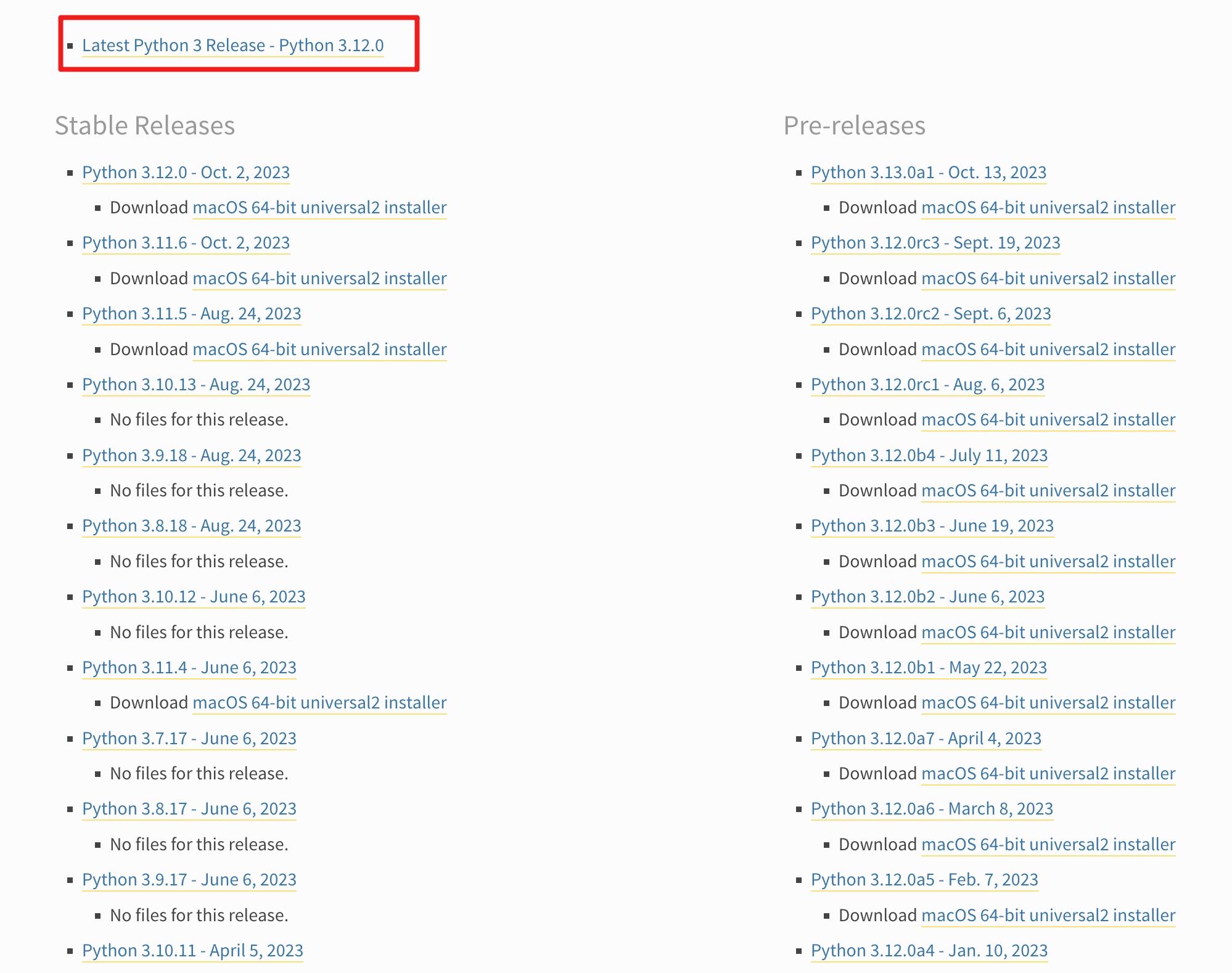
进入页面,拉到最后:
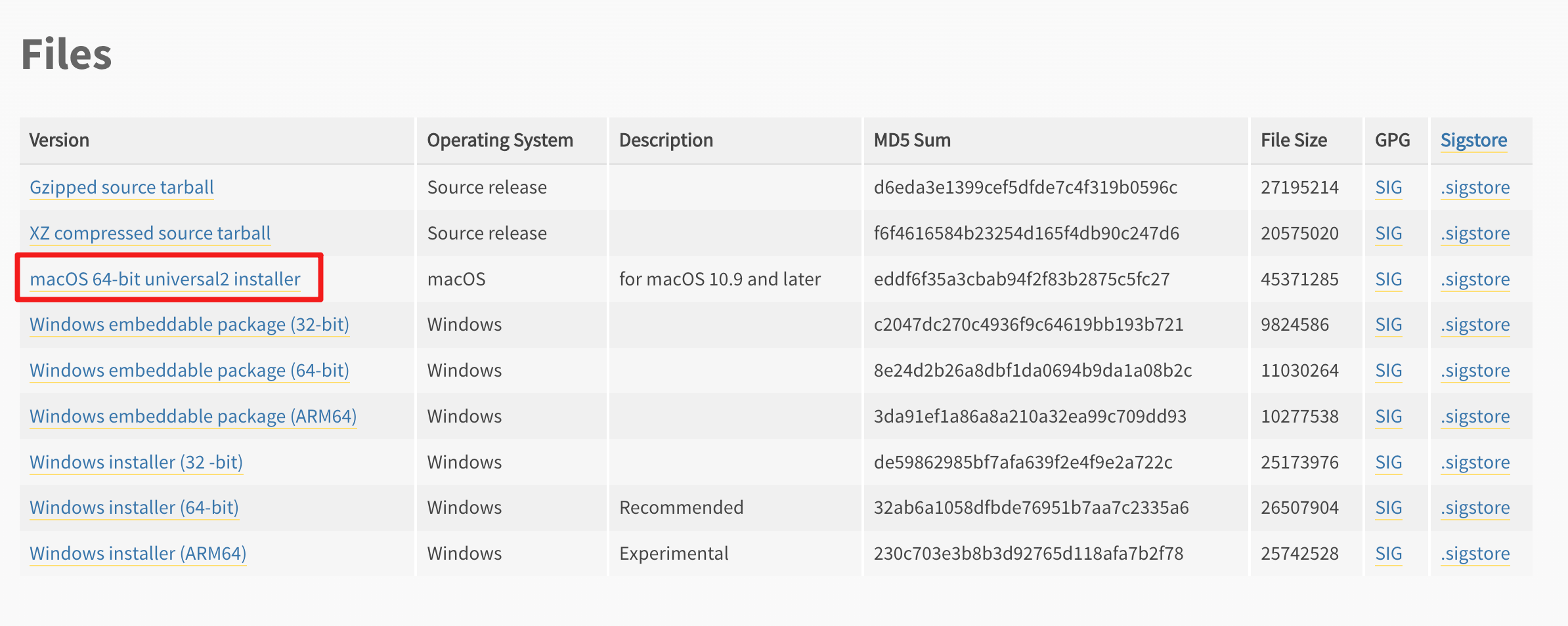
此时正在下载mac系统的Python安装包【注意不是解释器】

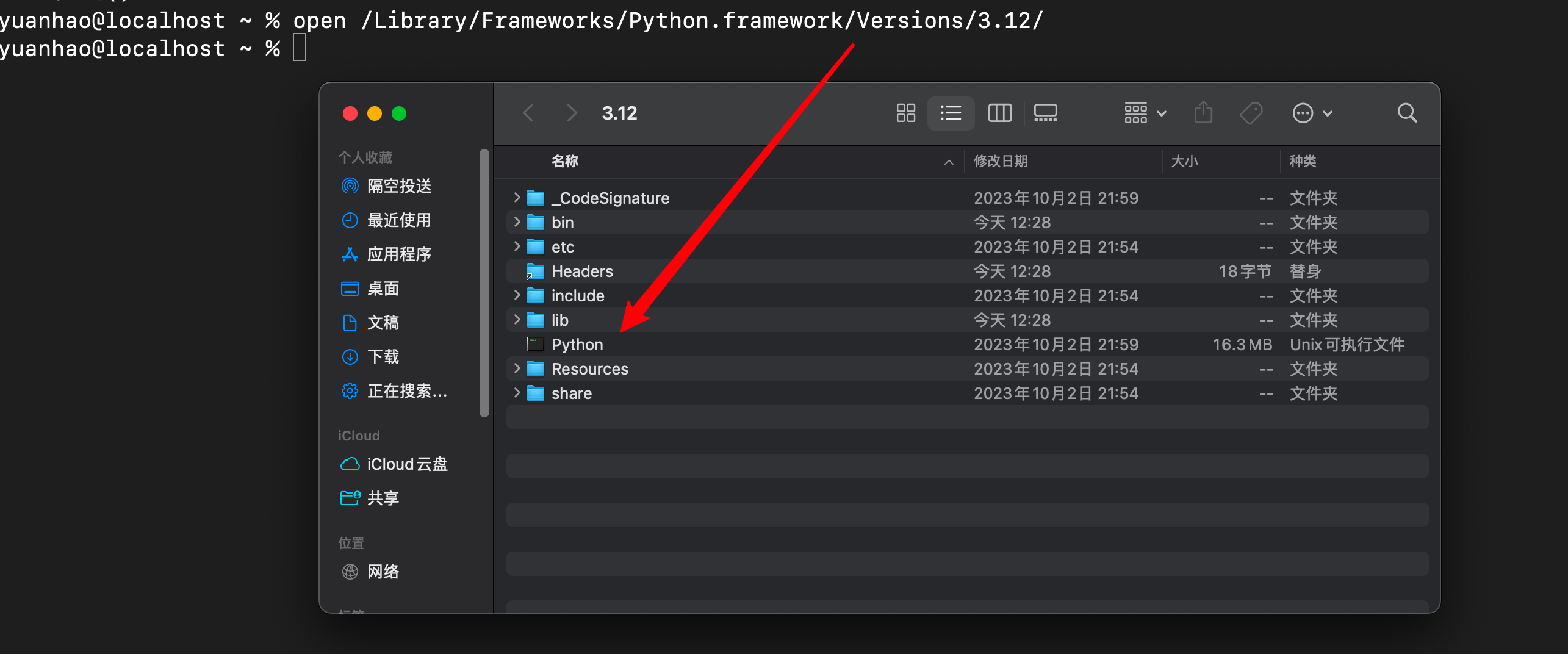
open /Library/Frameworks/Python.framework/Versions/3.12/

环境变量:

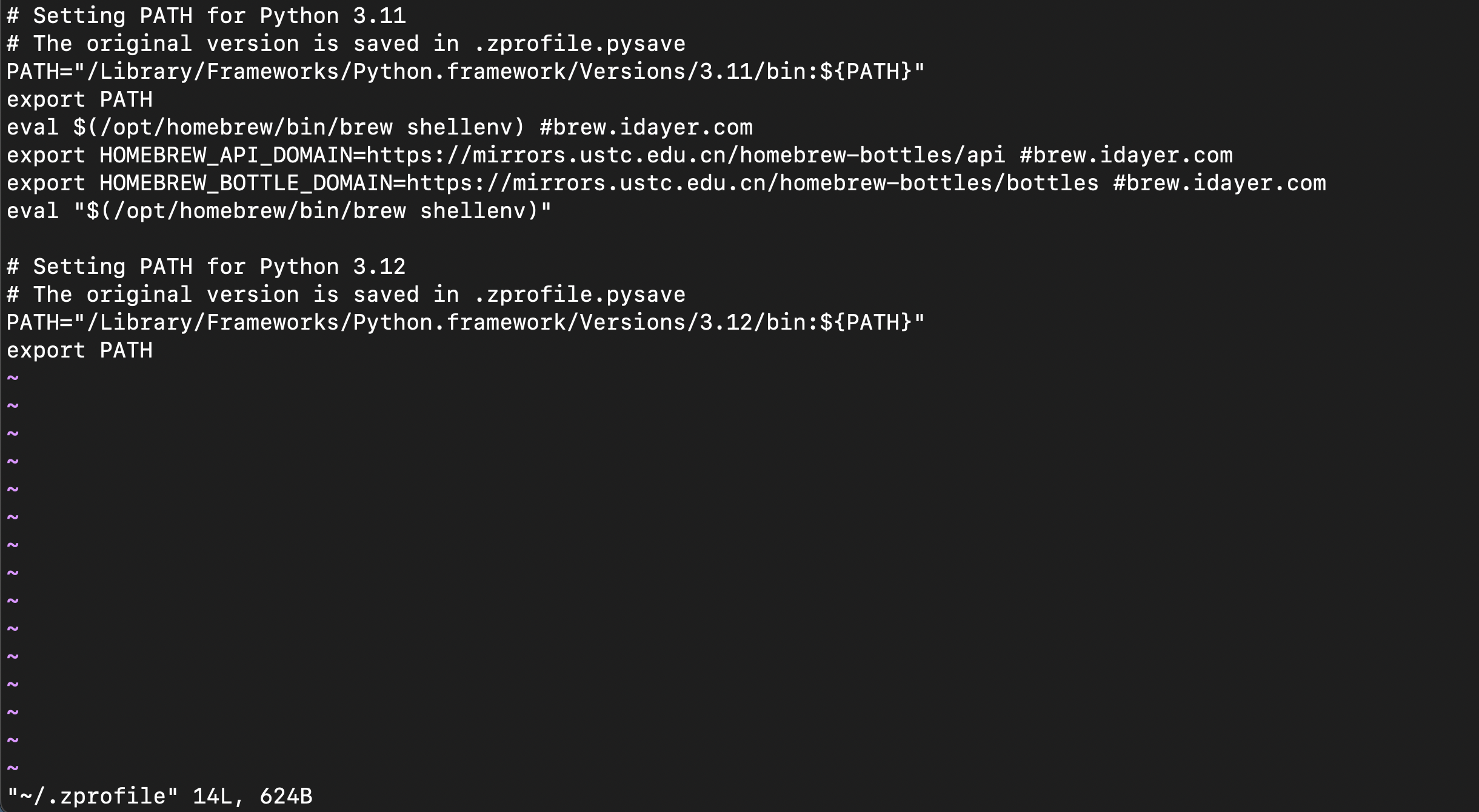
- Python的环境变量可以放在
zprofile和bash_profile中的任意一个文件中,具体取决于你使用的是哪个Shell。
- 如果你使用的是Zsh Shell,你可以将Python的环境变量设置放在
~/.zprofile文件中。- 如果你使用的是Bash Shell,你可以将Python的环境变量设置放在
~/.bash_profile文件中。
如果全局变量没有配置,手动配置:
1. vim ~/.zprofile
2. PATH="/Library/Frameworks/Python.framework/Versions/3.12/bin:${PATH}"
export PATH
内置函数print(),可以打印文本字符串到控制台
6. Pycharm安装与使用
【1】Pycharm下载与安装
官网:
https://www.jetbrains.com/zh-cn/pycharm/

安装包:
安装流程:

启动Pycharm:
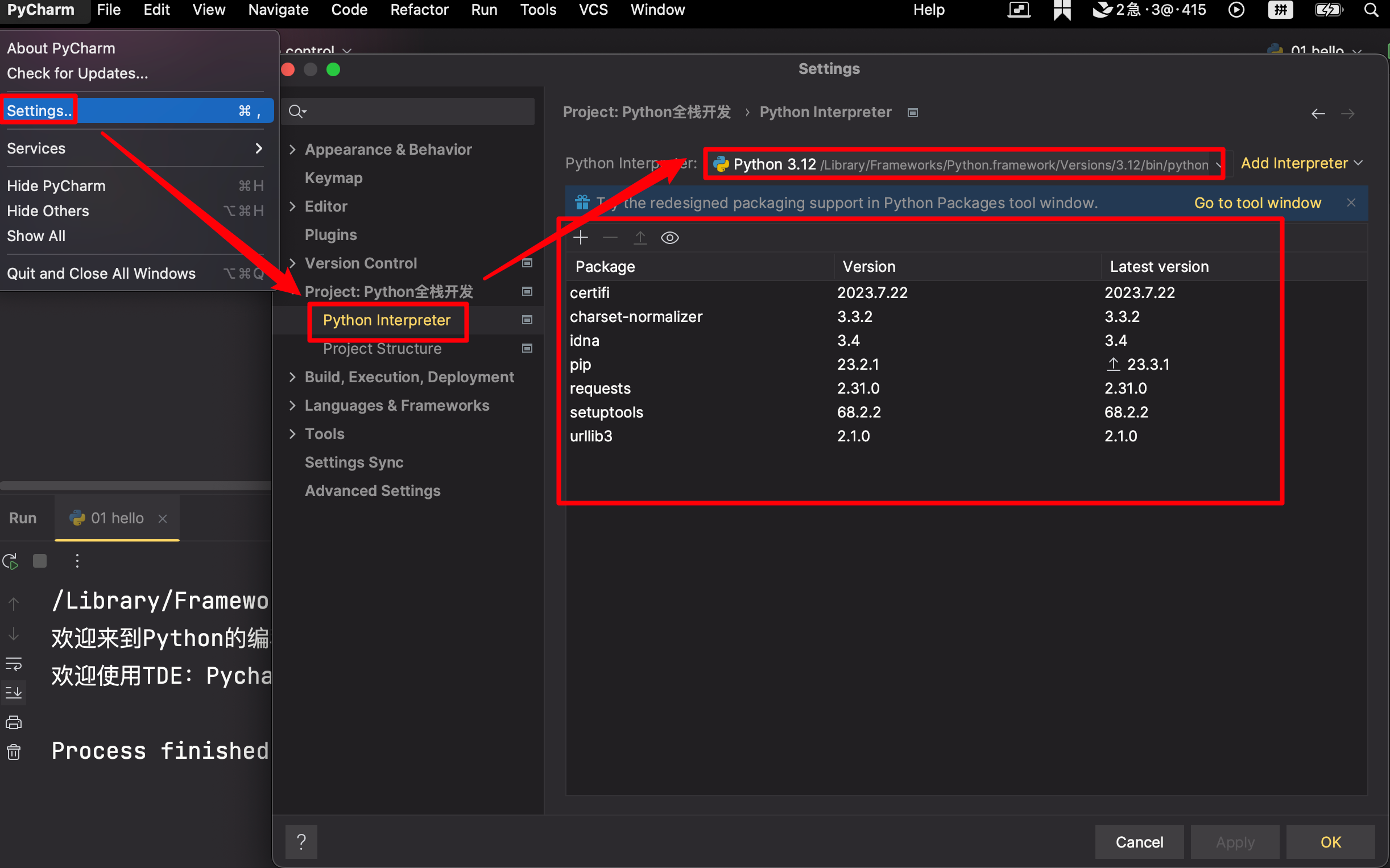
【2】Pycharm的基本使用

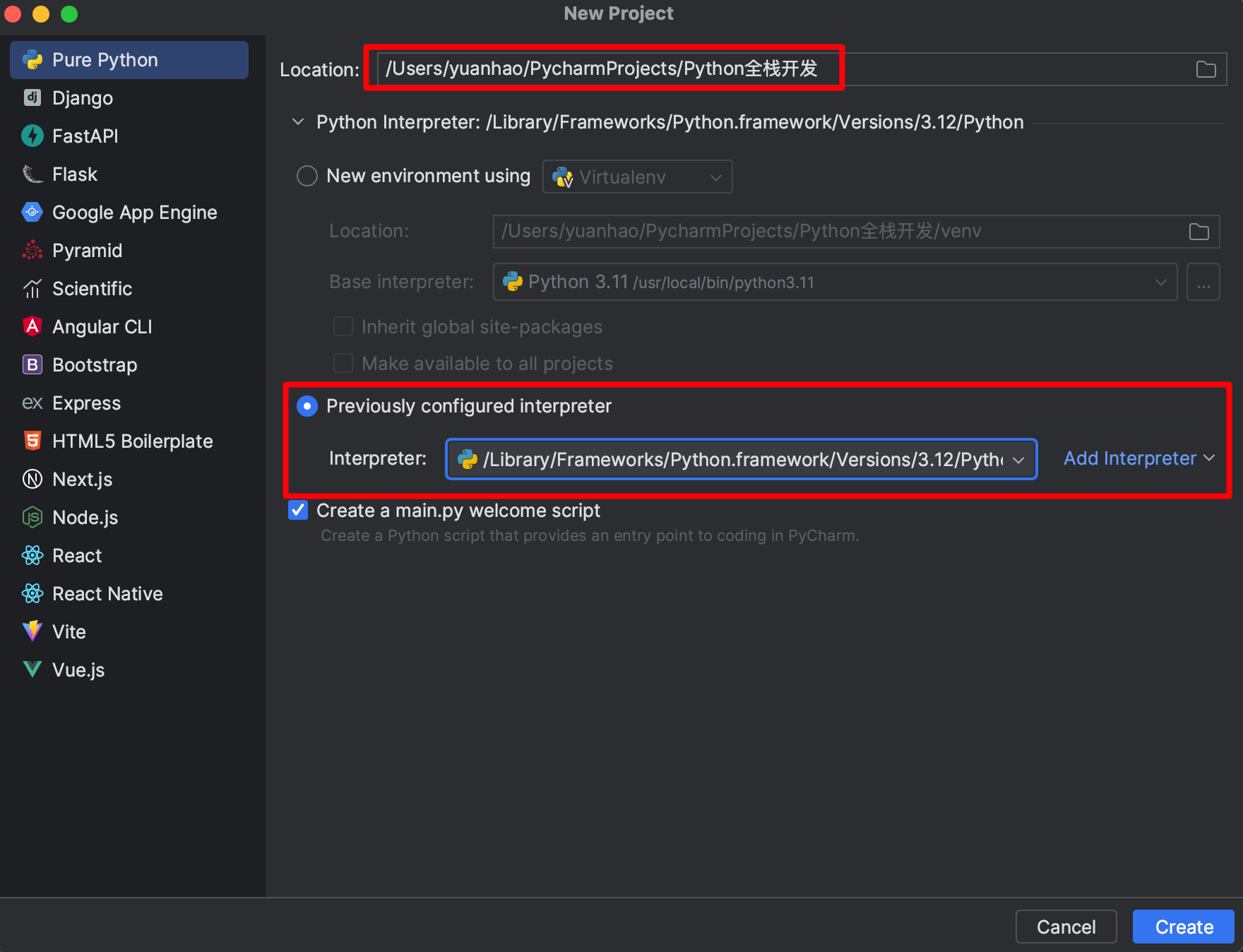
强烈建议初学者按图中所示选用本地的 Python 解释器。默认情况下,PyCharm会选用第一种配置方式,它会自动为项目配置虚拟环境,即向项目中添加运行 Python 程序所必备的文件(例如 Python 解释器和标准库文件),但这些文件对于初学者来说,是晦涩难懂的,我们会在后面给大家详细介绍,但对 Python 入门没有任何帮助。
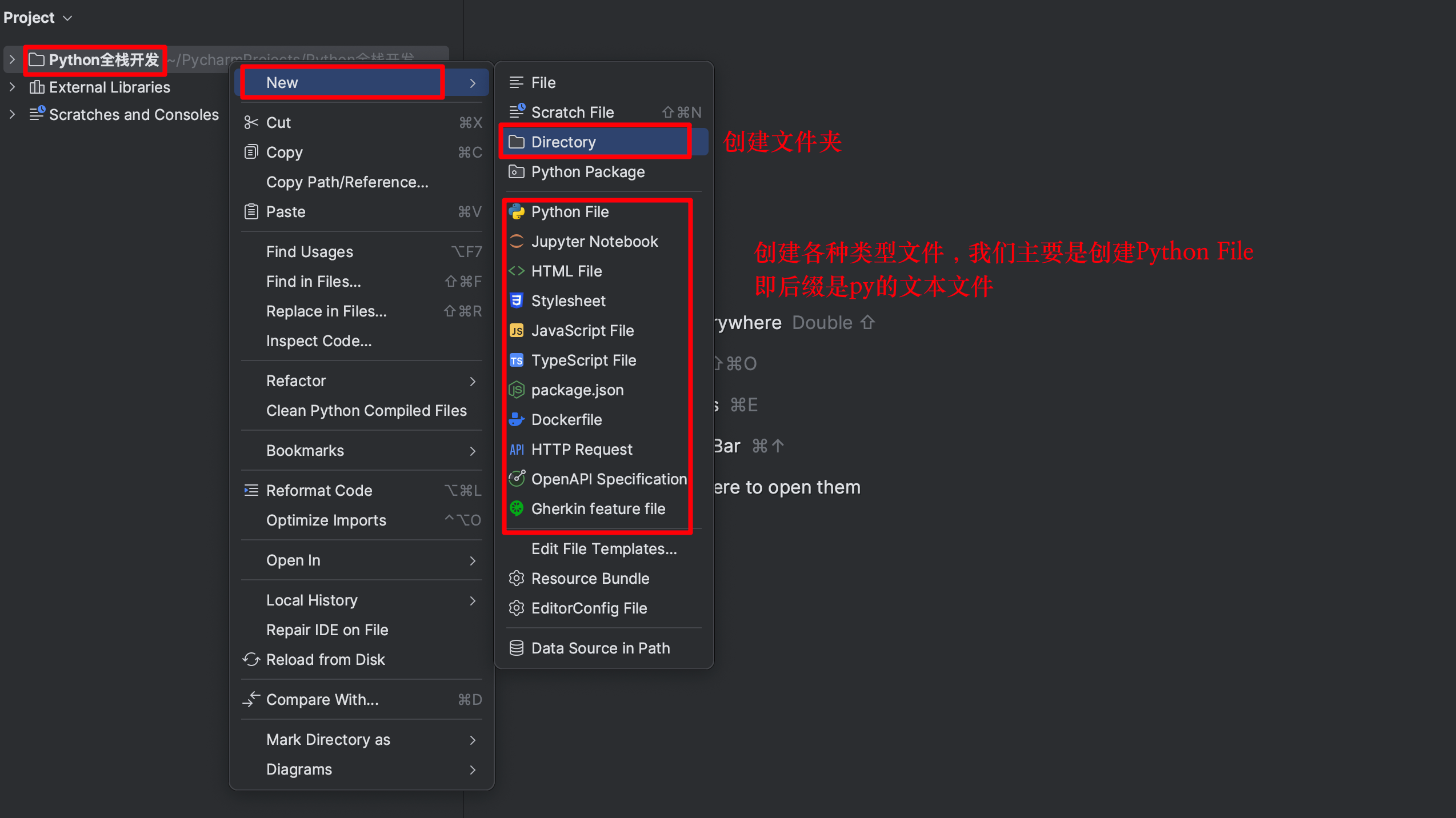
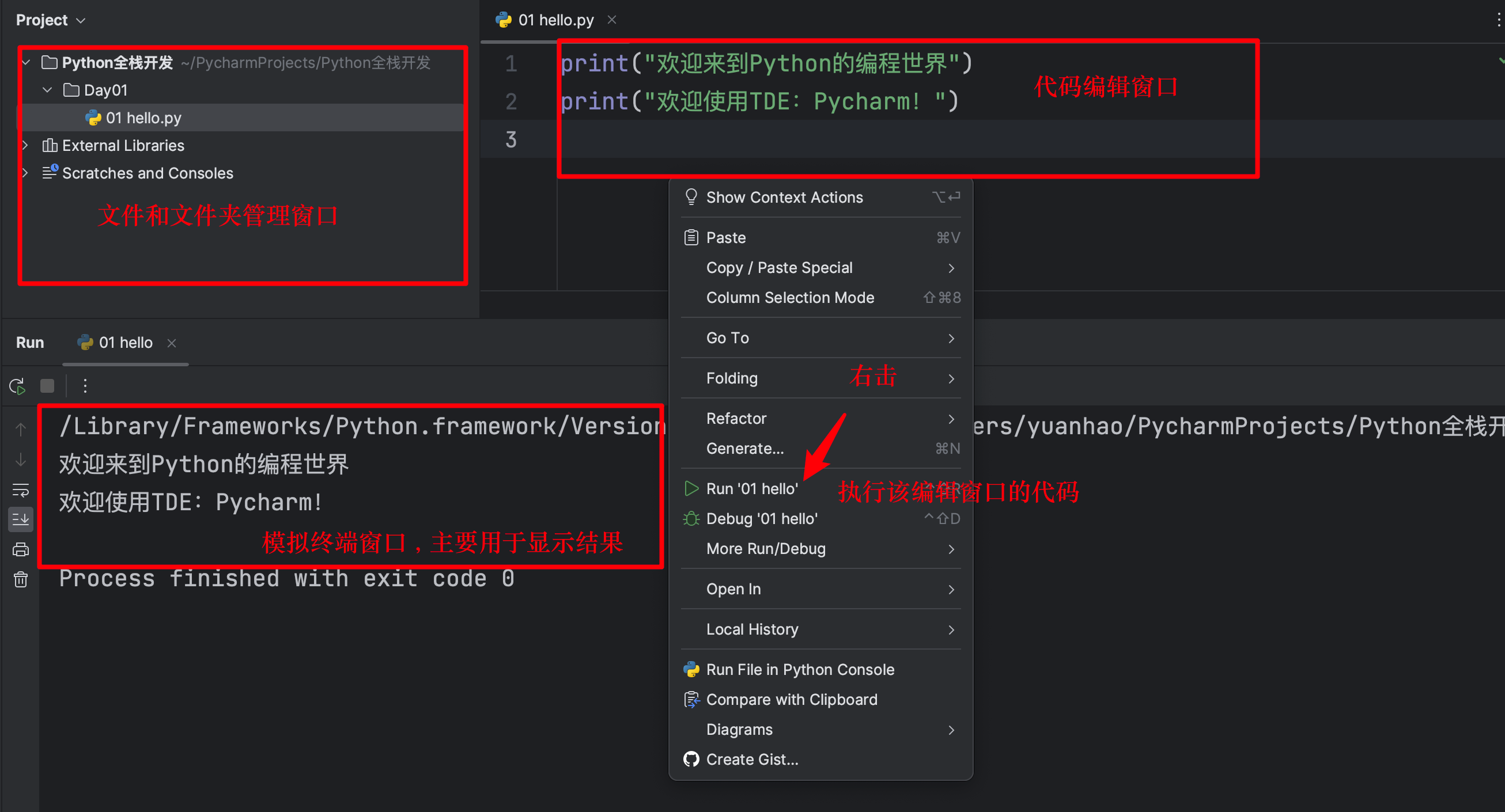
- 文件和文件夹管理
- 代码编辑
- 程序执行
- 结果显示
再加上各种提示功能和快捷操作,Pycharm大大提高了我们代码开发的效率
【3】Pycharm的常用配置
-
主题配置
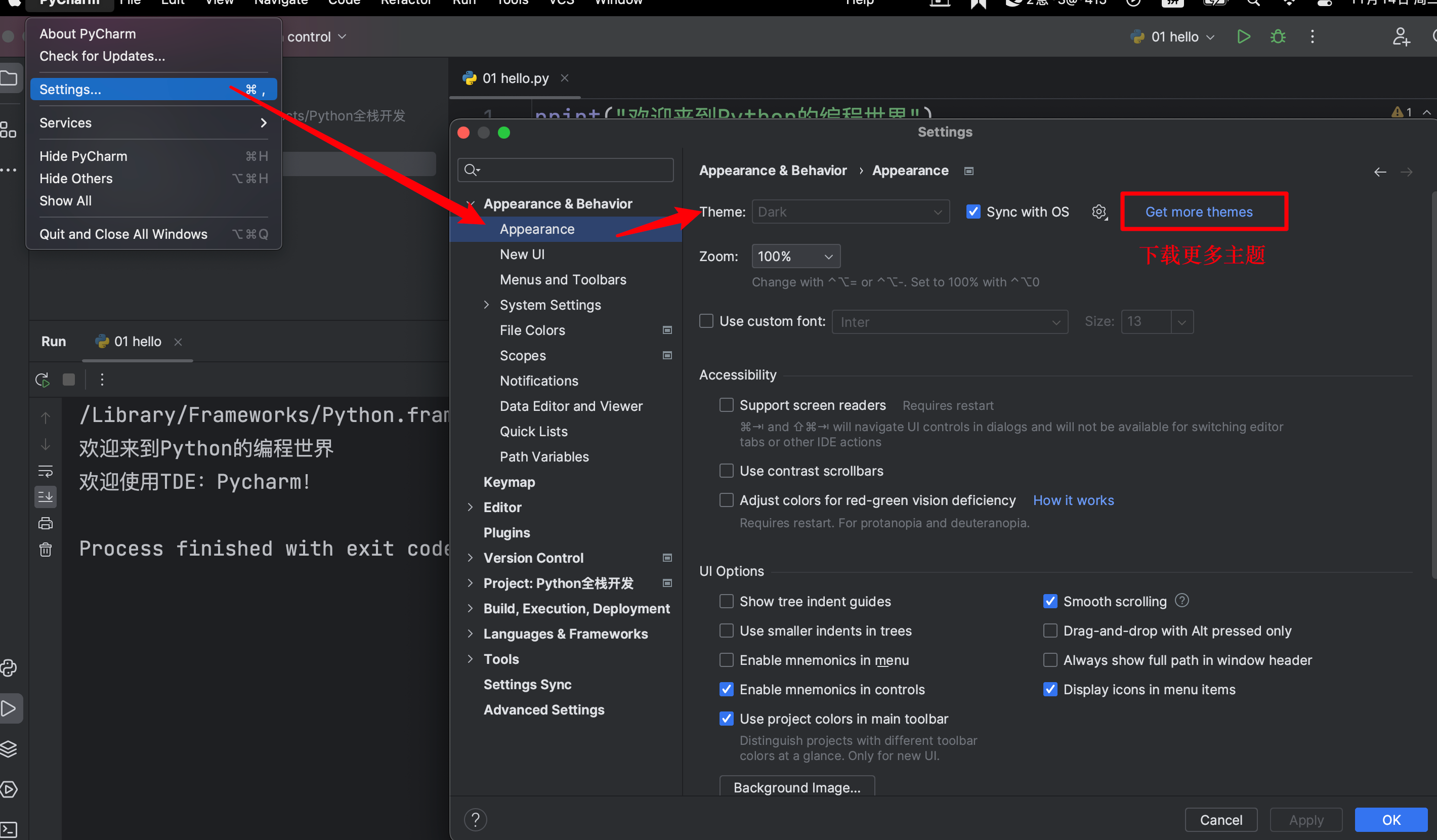
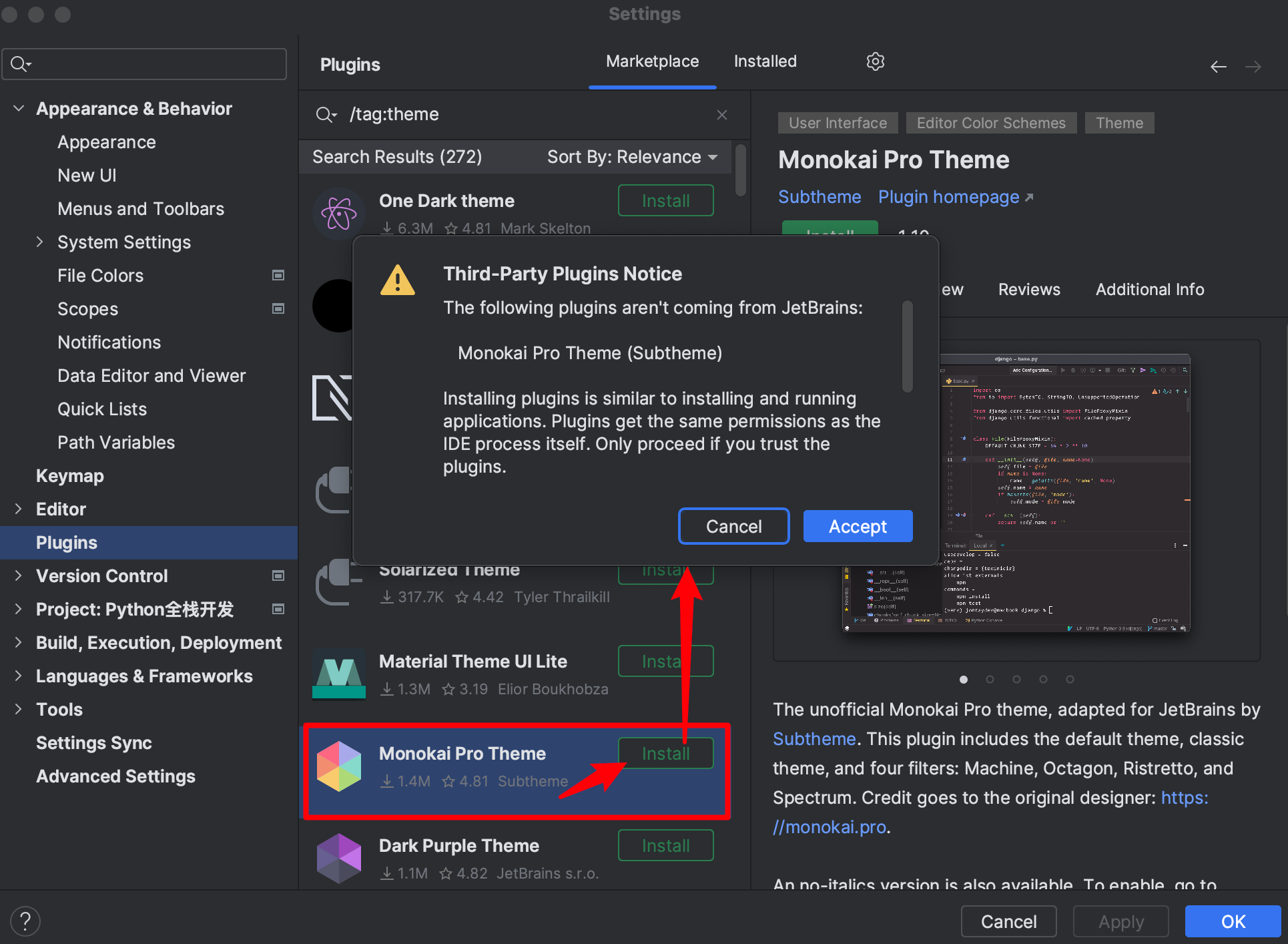
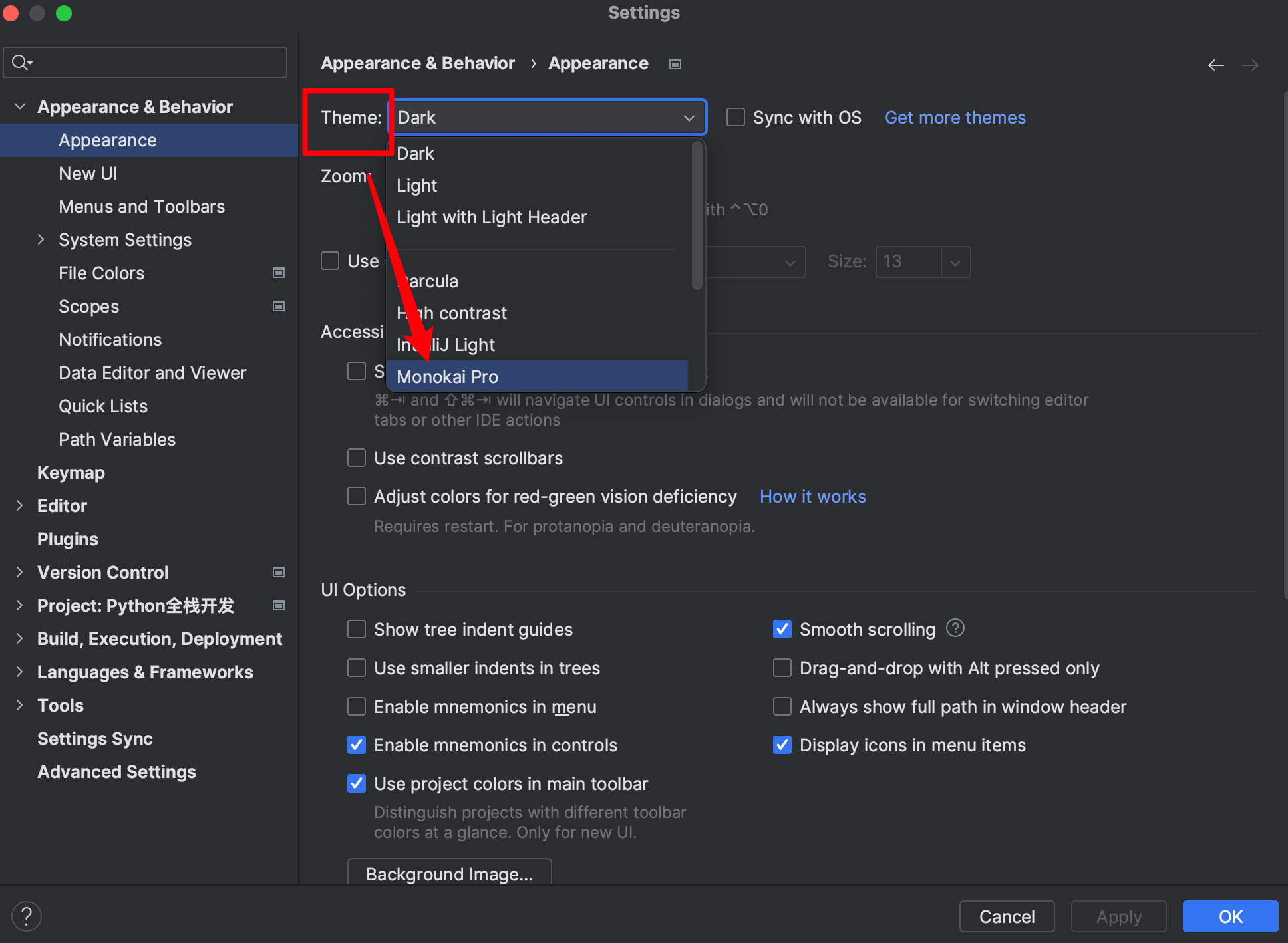
-
字体大小
(1)直接设置

(2)滚轮配置
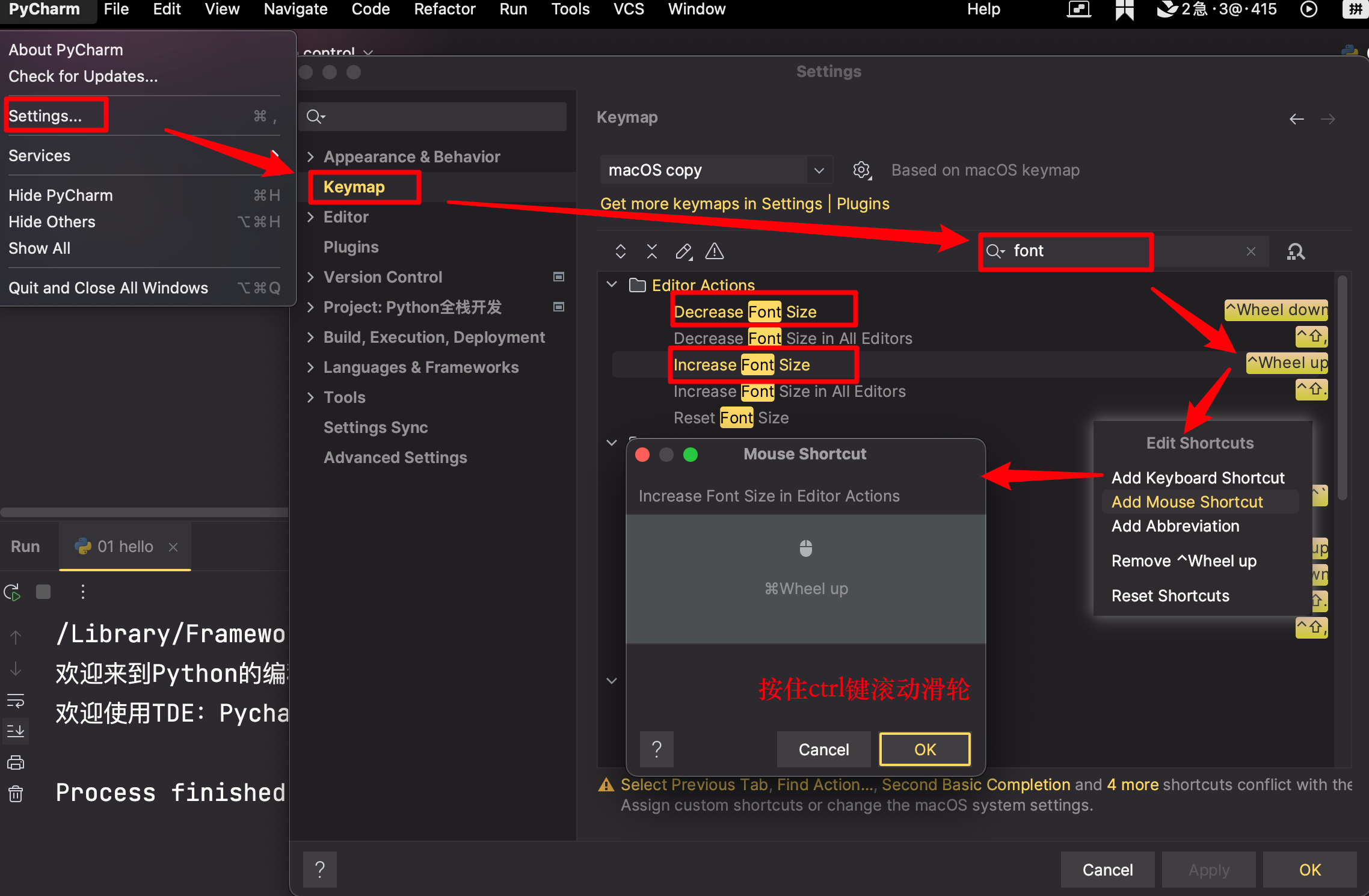
-
解释器配置
-
Pycharm常用的快捷键:

7. 今日作业
- 计算机系统中都扮演着存储数据的角色有哪些,读写速度如何排序?
- 一个程序打开,即被执行后,生成的数据存储在哪里?
- Python是编译型语言还是解释型语言?
- 简述Python的语言的优缺点和广泛应用在哪些领域
- 简述下你对Python解释器的理解,目前市场广泛使用的解释器版本?
- 简述环境变量的作用
- Python脚本的执行命令?
- 简述下Python的交互式模式(Interactive Mode )和脚本模式(Script Mode),两者的使用场景和方式
- 简述下Pycharm的作用以及和Python解释器的关系
- 在Pycharm中创建一个Python代码项目目录,文件夹Day01,以及第一个Python程序,实现在控制台打印
【你的姓名】你好,欢迎来到Python的编程世界!的文本输出。

Day02:Python基本语法

1. Python 代码结构与规范
【1】注释语句

注释语句(Comment Statement)是在程序代码中添加的一种特殊类型的语句,用于提供对代码的解释、说明或备注。注释语句通常不会被编译器或解释器执行,而是被忽略或跳过。
注释语句的主要作用是为了增强代码的可读性和可维护性,以便程序员和其他人能够更好地理解代码的意图、功能和实现细节。注释可以包含对代码的解释、算法说明、特殊用途的标记、作者信息、相关链接等内容。
不同的编程语言使用不同的注释语法,但大多数编程语言都提供了以下两种常见的注释类型:
-
单行注释:在单行注释中,注释内容从注释符号开始(通常是一个特定的符号或字符序列),一直延伸到该行的结尾。单行注释用于注释单个代码行或在代码行末尾添加注释。例如:
# 这是一个单行注释 print("hello world") # 在控制台打印hello world字符串 -
多行注释:多行注释允许在多个行上添加注释内容。它通常用于注释多行代码块或提供更详细的代码解释。多行注释的语法和符号因编程语言而异。例如,在Python中,多行注释使用三个引号(''')或三个双引号(""")括起来,如:
"""
这是一个多行注释的示例。
它可以跨越多个行,并提供对代码的详细解释。
"""
print("hello world") # 在控制台打印hello world字符串
需要注意的是,注释语句不会对程序的执行产生任何影响,它们只是用于辅助代码的理解和维护。在编写代码时,良好的注释实践可以提高代码的可读性和可维护性,有助于团队合作和代码重用。
Pycharm的注释快捷键:Ctrl+/
【2】语句&语句分隔符
语句分隔符(Statement Separator)是用于在编程语言中分隔不同语句的符号或字符。它指示编译器或解释器在代码中的哪个位置结束一条语句,并开始解析下一条语句。
在Python中,语句之间的分隔符有两个:换行符和分号,推荐换行符
print("hello yuan");print("hello world") # 分号作为分隔符
print(100) # 换行符作为分隔符,
print(200)
【3】pep8规范
PEP 8是Python编程语言的官方编码风格指南(Python Enhancement Proposal 8),它提供了一套规范和建议,用于编写清晰、易读和一致的Python代码。PEP 8旨在促进Python代码的可读性,并为Python开发者提供一致的编码样式。
以下是PEP 8的一些主要规范和建议:
- 缩进和空格: 使用4个空格进行缩进,不要使用制表符(Tab)。在二元运算符周围和逗号后面使用空格,但在括号、方括号和花括号内部不要有空格。
- 行的长度: 每行代码尽量不超过79个字符,对于长表达式或注释,可以适度延长到不超过72个字符。
- 命名规范: 使用全小写字母和下划线来命名变量、函数和模块。类名应该使用驼峰命名法,首字母大写。
- 空行: 使用空行来组织代码,例如在函数和类定义之间、函数内部的逻辑块之间使用空行。
- 导入规范: 在不同的行上导入不同的模块。避免使用通配符导入(
from module import *),而是明确导入需要使用的函数、类或变量。 - 注释: 使用注释来解释代码的意图和功能。注释应该清晰、简洁,并遵循特定的注释规范。
- 函数和类定义: 在函数和类定义之间使用两个空行。函数定义应该包含文档字符串(docstring),用于描述函数的功能和参数。
- 代码布局: 使用合适的空格和空行来组织代码,使其易于阅读和理解。
PEP 8并非强制性规范,但它是Python社区广泛接受的编码风格指南。遵循PEP 8可以提高代码的可读性,使不同开发者之间的代码更加一致,并促进Python项目的可维护性。
# 规范
#不规范
print(100) # 空两行,规范
x=10 # 不规范
x = 10 # 规范 =左右留一个空格
updateuserprofile = "" # 变量命名不规范
updateUserProfile = "" # 变量命名规范
Pycharm的格式化快捷键:Ctrl + Alt + L
2. 变量

【1】变量初识
在Python中,变量是一个标识符,用于引用存储在计算机内存中的数据。每个变量都有一个名称和一个关联的值,可以将值存储在变量中并在程序中多次使用。以下是有关Python变量的一些基本概念:
# 用等号(=)将一个值赋给一个变量
# 游戏场景
role = "刺客"
name = "李白"
attack = 500
healthy = 100
level = 3
experience = 1000
is_movable = False # 是否可以移动(冰冻效果)
在Python中,变量名(即标识符)是存储在命名空间中的。命名空间是一个变量名和对象之间的映射关系(一个字典结构),它将变量名与对象的引用关联起来。
全局命名空间是在程序运行时创建的,并在整个程序执行期间一直存在。
局部命名空间是在函数调用时创建的,并在函数执行期间存在。
【2】变量的用法
(1) 基本用法
变量简单的使用就是直接赋值
# (1)变量的多次使用
x = 10
y = 20 # 可以简写:x,y = 10,20
print(x + y)
print(x - y)
print(x * y)
print(x / y)
# (2)变量的重新赋值(修改变量值)
x = 1
x = 2 # 重新赋值
healthy = 100
healthy = 90
level = 1
level = 2
id(数据),是Python的一个内置函数,返回某个数据对象的内存地址
(2)变量传递
x = 1
print(id(x))
y = x # 编程中十分重要的操作:变量传递,对于它的理解至关重要!
x = 2
print(id(x))
print(y)
案例:交换两个变量值
x = 1
y = 2
# 方式1
t = x
x = y
y = t
# 方式2
x , y = y , x
(3)表达式赋值
x = 1 + 1
y = x + 1
y = y + 1
案例1:
# 案例
print("游戏开始...")
player_exp = 500
player_level = 3
print("闯关成功")
player_exp = player_exp + 50
player_level = player_level + 1
print("当前级别:",player_level)
print("当前经验值:",player_exp)
# 生命值减少10怎么写?
【3】变量的命名规范
Python的变量命名规范通常遵循以下规则:
- 变量名应该具有描述性,以便代码的可读性更高,例如在代码中使用的名称应该清晰、简洁、有意义,避免使用缩写或单个字符。
- 变量名应该遵循一定的命名约定,采用驼峰命名法或下划线命名法:驼峰命名法指的是将每个单词的首字母大写,单词之间不使用下划线,例如
myVariableName;下划线命名法指的是使用小写字母和下划线来分隔单词,例如my_variable_name。在Python中,推荐使用下划线命名法(也称为蛇形命名法)- 变量名只能包含字母、数字和下划线_,不能以数字开头。
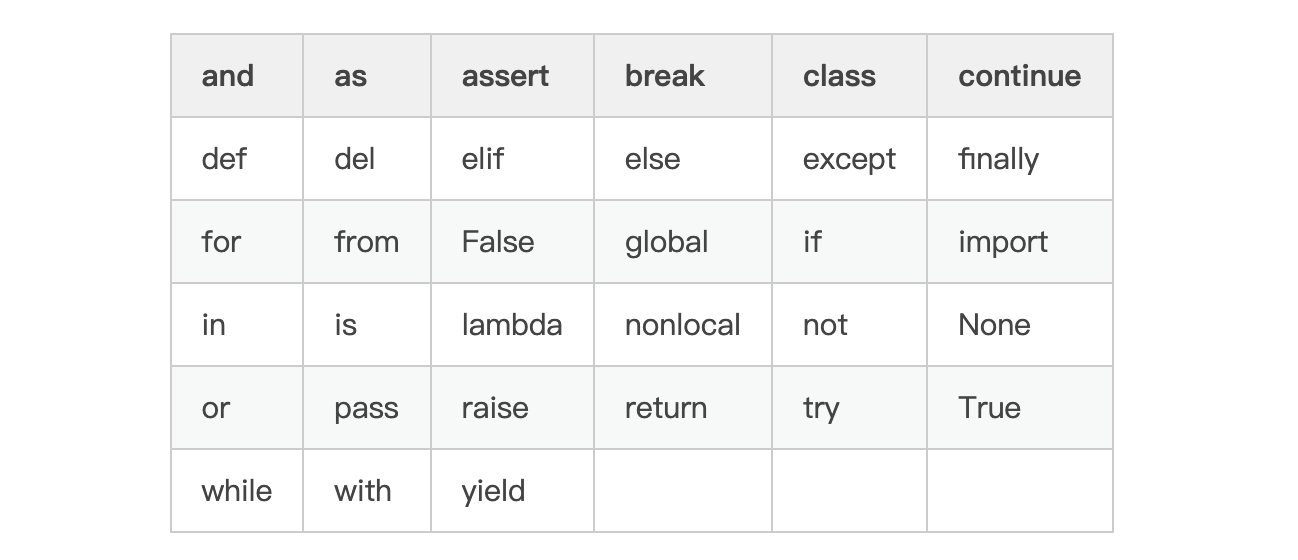
- 变量名不能使用保留字(例如f、else、while等等)。
附:Python的关键字
3. 基本数据类型
在编程中,基本数据类型指的是编程语言中提供的最基本、最原始的数据类型,通常是原生支持的数据类型,而不是通过其他数据类型组合而来的。
在Python中,常见的基本数据类型包括:

【1】整型和浮点型
整型(integer)和浮点型(float)是Python中常用的数字数据类型。它们用于表示不同种类的数值,并在数值计算和数据处理中发挥重要作用。
整型(integer):
- 整型用于表示整数(正整数、负整数和零)。
- 在Python中,整型是一种不可变(immutable)的数据类型,表示为整数字面值,例如
5、-10、0等。
x = 1
y = -10
blood = 100
浮点型(float):
- 浮点型用于表示带有小数部分的数值,也称为浮点数。
- 在Python中,浮点型是一种不可变的数据类型,表示为浮点数字面值,例如
3.14、-2.5等。
pi = 3.14
temperature = -2.5
pi_type = type(pi)
print(pi_type)
print(type(pi_type))
内置函数type(对象)可以获取某个数据对象的类型名称
整型对象和浮点型对象可以用于科学运算:
print(1+1)
# 比如游戏的等级,血值,攻击力
【2】字符串类型
字符串是一种在计算机程序中常用的数据类型,用于操作文本数据。字符串可以看作是由一系列字符组成的序列,每个字符可以是字母、数字、符号或其他字符。
在计算机程序中,字符串通常使用一对单引号(')或双引号(")括起来,例如:"hello world"或'Python is fun!'。同时Python还支持使用三重引号('''或""")来表示多行字符串。
以下是Python字符串的代码示例,输出"hello路飞学城":
s1 = "hello 路飞学城"
print(s)
s2 = "hello yuan!"
s3 = "10"
这个例子中,我们使用了字符串类型,并将其赋值给一个变量,然后使用print函数输出该变量的值。注意,在字符串中可以使用中文字符,Python默认使用UTF-8编码,可以支持多种语言的字符。
【3】布尔类型
布尔类型(boolean)是Python中的一种基本数据类型,用于表示逻辑值。布尔类型只有两个可能的取值:True(真)和 False(假)。

print(2 > 1) # True
print(3 != 2) # False
布尔类型通常用于条件判断和逻辑运算,用于控制程序的流程和决策。
以下是一些常见的用法和特点:
- 布尔值:
True和False是布尔类型的两个取值。它们是Python中的关键字,不是字符串。- 条件判断:布尔类型常用于条件语句的判断条件,例如
if语句中的条件表达式。根据条件表达式的真假,决定是否执行相应的代码块。- 关系运算符:关系运算符(如
==、!=、<、>、<=、>=)用于比较两个值,并返回布尔结果。例如x > y将返回布尔值表示 x 是否大于 y。- 逻辑运算:布尔类型可以通过逻辑运算符(如
and、or、not)进行组合和操作。逻辑运算可以用于组合多个布尔值,产生新的布尔结果。bool()是一个内置函数,用于将给定的值转换为对应的布尔值。- 零值:每一个数据类型都有一个布尔值为False的值,我们称之为零值
- 整型的零值是0,浮点型是0.0
- 字符串的零值是""
- 布尔类型的零值是False
- NoneType的零值是None
- 列表的零值是[]
- 元组的零值是()
- 字典的零值是{}
【4】输入输出函数
在Python中,输入和输出函数用于与用户进行交互,并在程序的执行过程中获取输入值和显示输出结果。
(1)input函数
input(prompt):用于从用户获取输入值。它会在控制台中显示一个提示信息(prompt),等待用户输入,并返回用户输入的内容作为字符串。
name = input("请输入您的姓名")
age = input("请输入您的年龄")
print(name, type(name))
print(age, type(age))
(2)print函数
print(value1, value2, ...):用于将值打印到控制台。它可以接受一个或多个参数,并将它们打印为字符串。

name = "yuan"
age = 19
print("用户信息:", name, age, sep="|", end="")
print("程序结束!")
【5】常见类型转换
# (1)字符串到整数(int)转换
num_str = "123"
num_int = int(num_str)
print(num_int) # 输出:123
# (2)整数(int)到字符串转换
num_int = 123
num_str = str(num_int)
print(num_str) # 输出:"123"
# (3)字符串到浮点数(float)转换
float_str = "3.14"
float_num = float(float_str)
print(float_num) # 输出:3.14
# (4)浮点数(float)到字符串转换
float_num = 3.14
float_str = str(float_num)
print(float_str) # 输出:"3.14"
案例:
num01 = input("请输入一个数字:")
num02 = input("请再输入一个数字:")
print(float(num01) + float(num02))
【6】NoneType类型

在 Python 中,None 是一个特殊的常量,表示缺少值或空值。它常用于表示函数没有返回值或变量尚未被赋值的情况。None 是 NoneType 数据类型的唯一值(其他编程语言可能称这个值为 null、nil 或 undefined)
应用1:函数返回值
# 函数返回值
ret = print("hello world")
print("ret:", ret)
我们一直使用 print() 函数的返回值就是 None。因为它的功能是在屏幕上显示文本,根本不需要返回任何值,所以 print() 就返回 None。
应用2:初始化赋值
# 模拟计算过程
num1 = int(input("请输入num1:"))
num2 = int(input("请输入num2:"))
operator = input("请输入运算符:")
# result = None
if operator == '+':
result = num1 + num2
elif operator == '-':
result = num1 - num2
elif operator == '*':
result = num1 * num2
elif operator == '/':
result = num1 / num2
print(result)
4. 运算符
-
语句是一条完整的执行指令,语句通常会改变程序的状态、执行特定的操作或控制程序的流程。语句可以是赋值语句、函数调用,条件语句、循环语句等。语句没有返回值。
-
表达式是由值、变量、运算符和函数调用组成的代码片段,它可以计算出一个值。表达式可以包含字面值(如数字、字符串)、变量、运算符(如加法、乘法)、函数调用等。表达式的执行会返回一个非空的结果值。表达式具有返回值,可以作为其他表达式的一部分使用。
举例来说:
x = 5是一个赋值语句,将值 5 赋给变量 x,它没有返回值。y = x + 3 >4是一个赋值语句,将变量 x 的值加上 3,并将结果赋给变量 y,它也没有返回值。print(y)是一个打印语句,用于将变量 y 的值输出到控制台,它仅用于执行操作,没有返回值。type("hello")函数调用,但是一个表达式,因为计算出结果了。
Python提供了多种类型的运算符,用于数学运算、逻辑判断、赋值操作等。下面是一些常见的运算符。
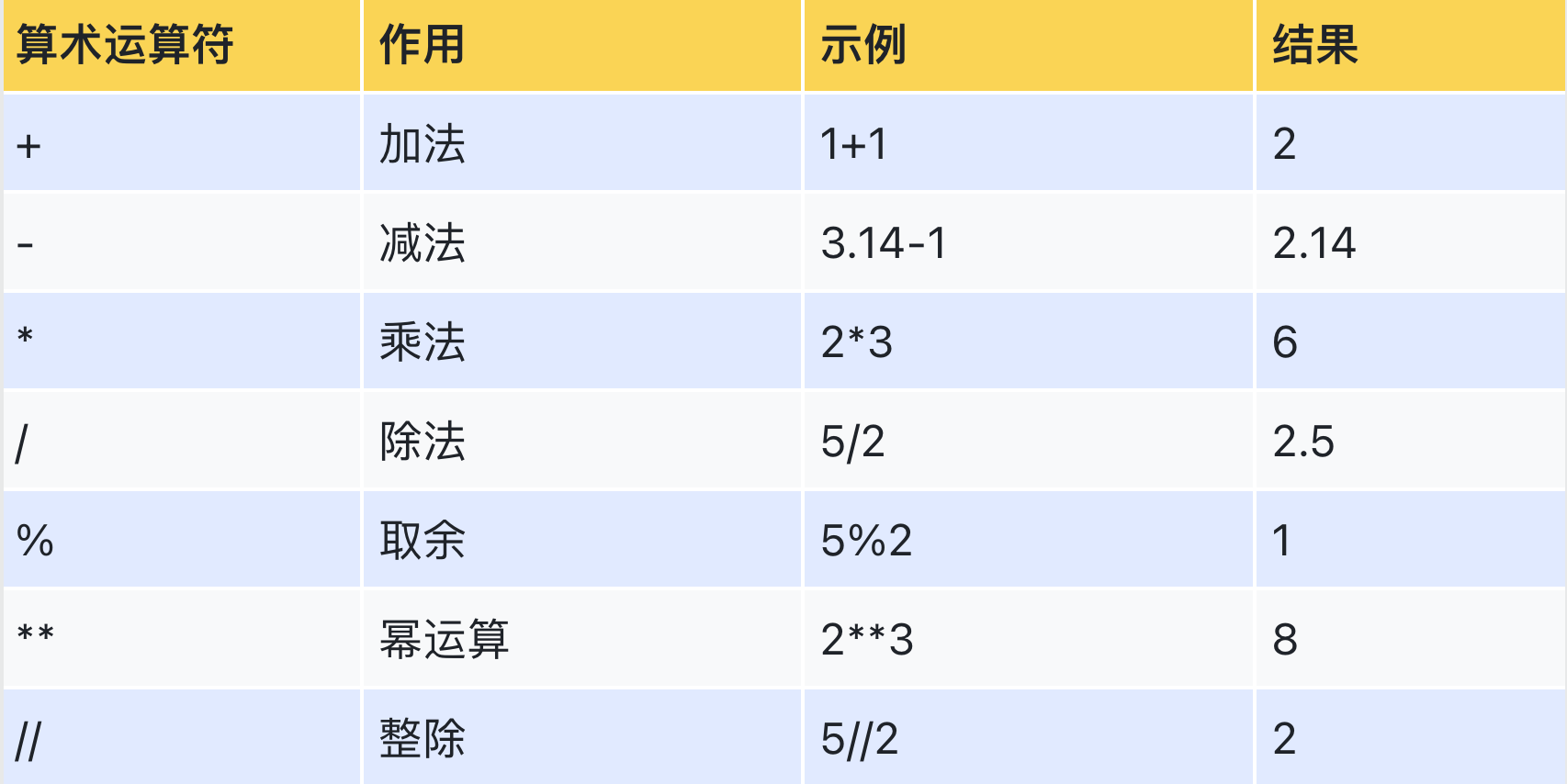
【1】计算运算符
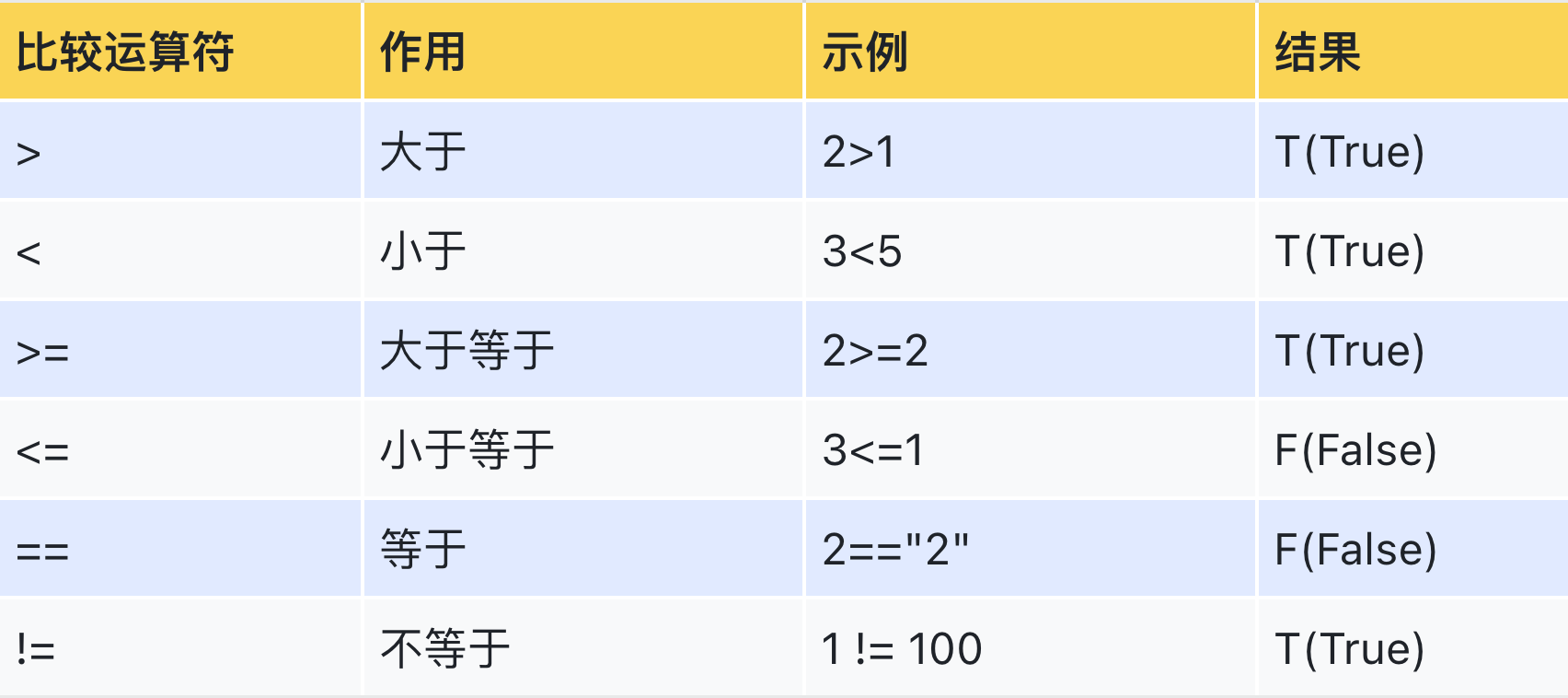
【2】比较运算符
【3】赋值运算符
赋值运算符是用于将一个值或表达式赋给一个变量的运算符。它们用于在程序中给变量赋值,以便存储和操作数据。
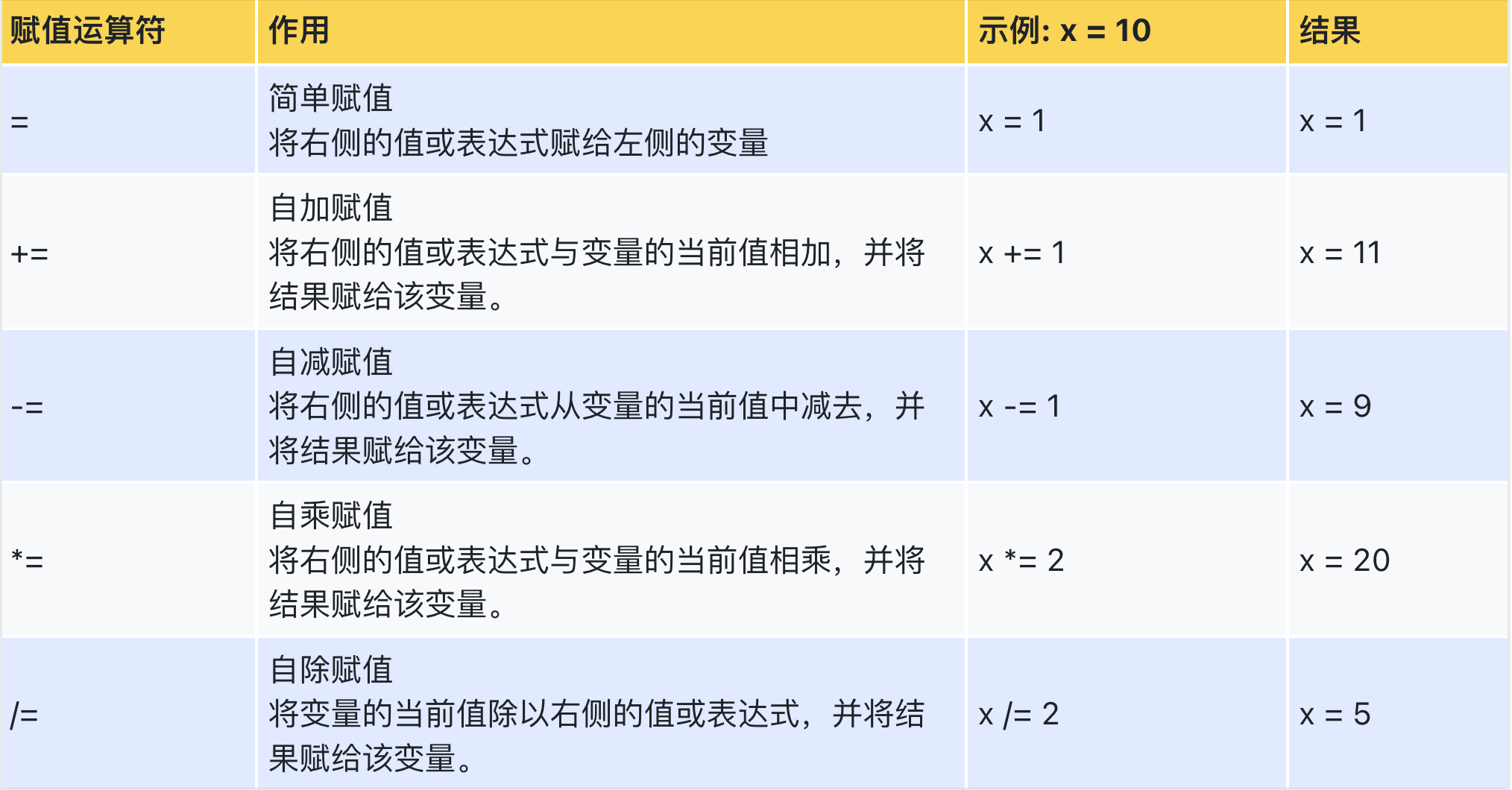
print("游戏开始...")
player_exp = 100
player_level = 1
player_blood = 1000
print("闯关成功")
player_exp += 50 # player_exp = player_exp + 50
player_level += 1 # player_level = player_level + 1
print("当前级别:", player_level)
print("当前经验值:", player_exp)
print("受到攻击")
player_blood -= 20 # player_blood = player_blood - 20
print("当前生命值:", player_blood)
【4】逻辑运算符
逻辑运算符是用于在逻辑表达式中进行组合和操作的运算符。它们用于组合和操作布尔值(True 或 False)来生成新的布尔值结果。在Python中,逻辑运算符包括三个:and、or和not。
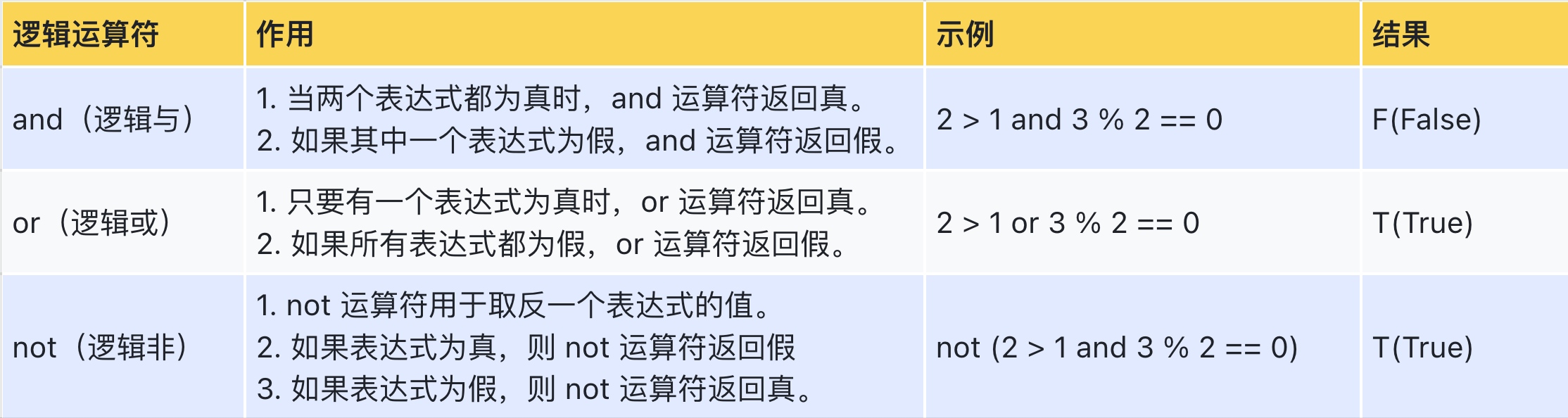
逻辑运算符通常与条件语句(如 if 语句)一起使用,用于控制程序的流程和进行逻辑判断。它们可以用于组合多个条件,并根据这些条件的结果生成新的布尔值。
【5】成员运算符
成员运算符是用于检查一个值是否存在于某个序列(例如列表、元组、字符串等)中的运算符。Python 提供了两个成员运算符:in 和 not in。
print("yuan" in "hello yuan")
print(100 in [1, 10, 100, 1000])
print("yuan" not in ["rain","eric","alvin","hello yuan"])
【6】运算符优先级
在Python中,运算符优先级指定了在表达式中运算符的执行顺序。以下是Python中常见运算符的优先级从高到低的顺序(同一优先级的运算符从左到右结合):
- 括号:
(),最高优先级,用于控制表达式的执行顺序。 - 幂运算:
**,次高优先级,用于进行指数运算。 - 正负号:
+(正号)和-(负号),用于表示正负数。 - 乘法、除法和取模运算:
*、/、//(整除)和%(取模)。 - 加法和减法运算:
+和-。 - 比较运算符:
<、>、<=、>=、==(等于)、!=(不等于)等。 - 逻辑运算符:
and、or、not,用于逻辑运算。 - 赋值运算符:
=,+=,-=,*=,/=,//=,%=,**=等。
# 案例1
a = 1 + 1 # 先计算1+1,再将得到的2赋值给a
# 案例2
x = 10
y = 5
z = 2
result = x + y * z ** 2 / (x - y)
5. 今日作业
- 以下哪个变量名是符合语法
A $a B. id C. 2a D. _name
-
解析
x=1;x=x+1执行过程 -
1+"1"的结果是? -
bool("2<1")的结果是? -
浅述目前学过的Python的内置函数以及功能
-
分析下面程序的执行过程以及结果
a = 1
b = a
c = b
a, d = c + 1, b + 2
a += 1
print(a,d)
-
获取用户输入圆的半径。使用圆的周长和面积公式计算并打印出输入半径的圆的周长和面积。
-
假设有一个变量count的初始值为0,将count增加5次,每次增加值分别为1,2,3,4,5,然后打印count的值。
-
判断一个学生的考试成绩score是否在80到100之间(包括80和100)
-
输入一个数字,判断是否是三位数且能被13整除
-
判断用户名密码是否正确
-
判断一个年份year是否是闰年,如果是,则打印"year是闰年",否则打印"year不是闰年"。闰年满足以下条件:能被4整除但不能被100整除,或者能被400整除。
Day03:字符串深入使用


字符串是计算机编程中表示文本数据的一种数据类型。它是由字符组成的序列,可以包含字母、数字、标点符号和其他特殊字符。
1. 字符串的转义符
转义有两层含义:
- 将一些普通符号赋予特殊功能,比如
\n,\t等 - 将一些特殊符号变为普通符号,比如
\",\\等
以下是一些常见的转义字符及其含义:
\n:换行符,表示在字符串中创建一个新行。
\t:制表符,表示在字符串中插入一个水平制表符(Tab)。
\b:退格字符,b代表backspace,可以把一个退格符看成一个backspace键
\":双引号,用于在字符串中包含双引号字符。
\':单引号,用于在字符串中包含单引号字符。
\\:反斜杠,用于在字符串中包含反斜杠字符本身。
s1 = 'D:\Program Files\nancy\table\back\Python 3.8\python.exe'
print(s1)
s2 = 'D:\Program Files\\nancy\\table\\back\Python 3.8\python.exe'
print(s2)
s3 = r'D:\Program Files\nancy\table\back\Python 3.8\python.exe'
print(s3)
s4 = "i'm \"yuan!\""
s5 = 'i\'m "yuan!"'
print(s4)
print(s5)
2. 格式化输出
格式化输出是一种将变量值和其他文本组合成特定格式的字符串的技术。它允许我们以可读性更好的方式将数据插入到字符串中,并指定其显示的样式和布局。
在Python中,有多种方法可以进行格式化输出,其中最常用的方式是使用字符串的 f-strings(格式化字符串字面值)。
【1】%占位符
name = "Yuan"
age = 19
message = "My name is %s, and I am %s years old." % (name, age)
print(message)
在这个示例中,我们使用 %s 占位符将变量 name 的值插入到字符串 "Hello, %s!" 中,然后通过 % 运算符进行格式化。在执行格式化时,% 运算符的左侧是字符串模板,右侧是要按顺序插入的值。
【2】f-string格式
格式化字符串字面值(Formatted String Literal,或称为 f-string)来进行格式化输出。适用于 Python 3.6 及以上版本
name = "yuan"
age = 18
height = 185.123456
s = f"姓名:{name: ^15},年龄:{age},身高:{height:^15.5}cm"
print(s)
name = "alex123456"
age = 18
height = 185
print(s)
宽度与精度
格式描述符形式为:width[.precision]。
width正整数,设置字符串的宽度。precision非负整数,可选项,设置字符串的精度,即显示字符串前多少个字符。
填充与对齐
格式描述符形式为:[pad]alignWidth[.precision]。
pad填充字符,可选,默认空格。align对齐方式,可选<(左对齐),>(右对齐),^(居中对齐)。
虽然 %s 是一种用于字符串格式化的方式,但自从 Python 3.6 版本起,推荐使用格式化字符串字面值(f-string)或 .format() 方法来进行字符串格式化,因为它们提供了更简洁和直观的语法。
3. 字符串序列操作
【1】索引和切片
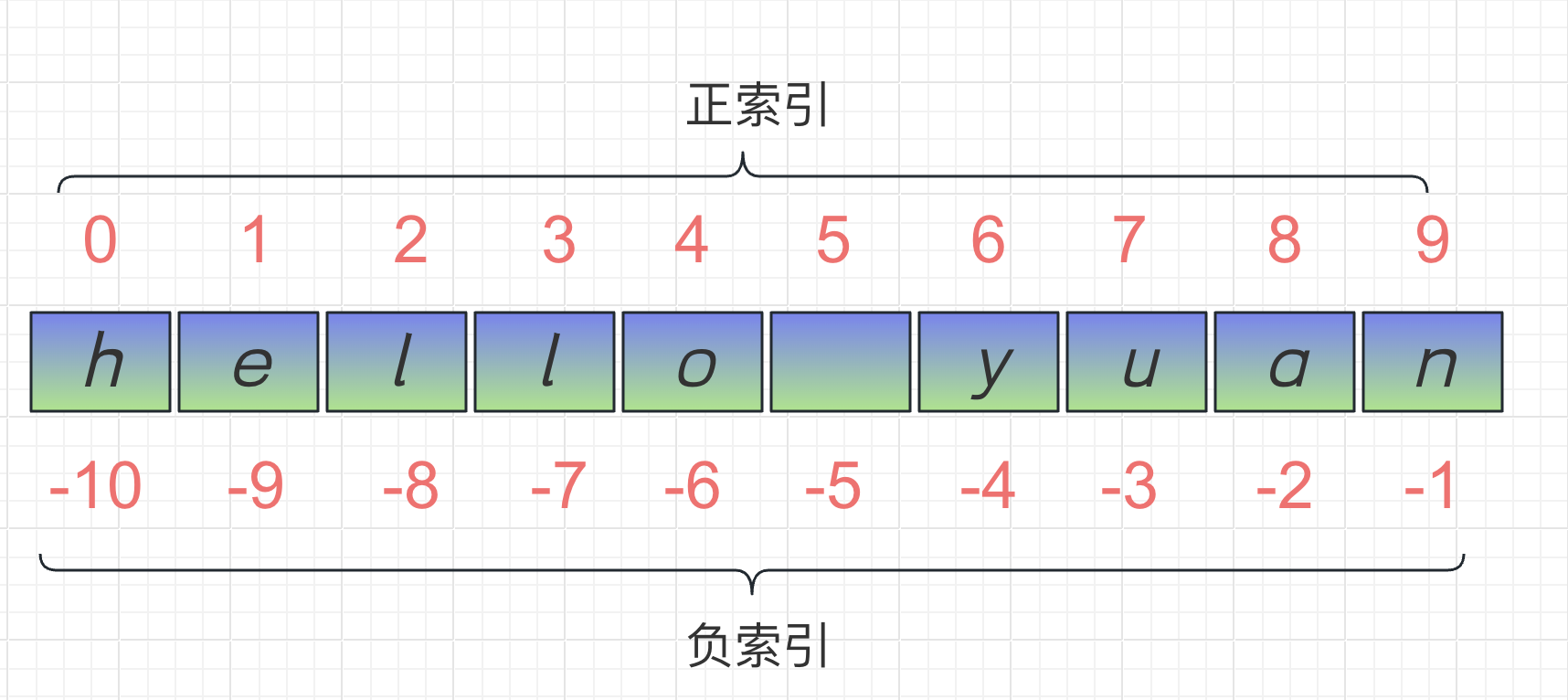
在编程中,索引(Index)和切片(Slice)是用于访问和操作序列(如字符串、列表、元组等)中元素的常用操作。
字符串属于序列类型,所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。
- 索引用于通过指定位置来访问序列中的单个元素。在大多数编程语言中,索引通常从0开始,表示序列中的第一个元素,然后依次递增。而负索引从 -1 开始,表示序列中的最后一个元素。使用方括号
[]来访问特定索引位置的元素。 - 切片用于从序列中获取一定范围的子序列。它通过指定起始索引和结束索引来选择需要的子序列。切片操作使用方括号
[],并在方括号内使用start:stop:step的形式。注意,start的元素可以获取到,stop的元素获取不到,最后一个元素是[stop-1]对应的元素。
s = "hello yuan"
# (1) 索引:获取某个字符
print(s[0]) # "h"
print(s[-1]) # "n"
# (2) 切片:获取某段子字符串
print(s[2:5]) # 输出"1lo"
print(s[:5]) # 输出"hello"
print(s[6:-1]) # 输出"yua"
print(s[6:]) # 输出"yuan"
print(s[:]) # 输出"hello yuan"
print(s[-1:-3:-1])
print(s[::-1]) # 输出“hello yuan”
【2】其它操作
# 不支持修改,添加元素
# 这是因为字符串在Python中被视为不可更改的序列。一旦创建了一个字符串,就无法直接修改其字符。
# s[0] = "a"
# s[10] = "!"
# 支持的操作
# (1) 获取长度,即元素个数
print(len(s)) # 10
# (2) +、*拼接
s1 = "hello"
s2 = "yuan"
print(s1 + " " + s2)
print("*" * 100)
# 字符串累加
s = ""
s += s1
s += s2
# (3) in判断
print("yuan" in s) # True
4. 字符串内置方法
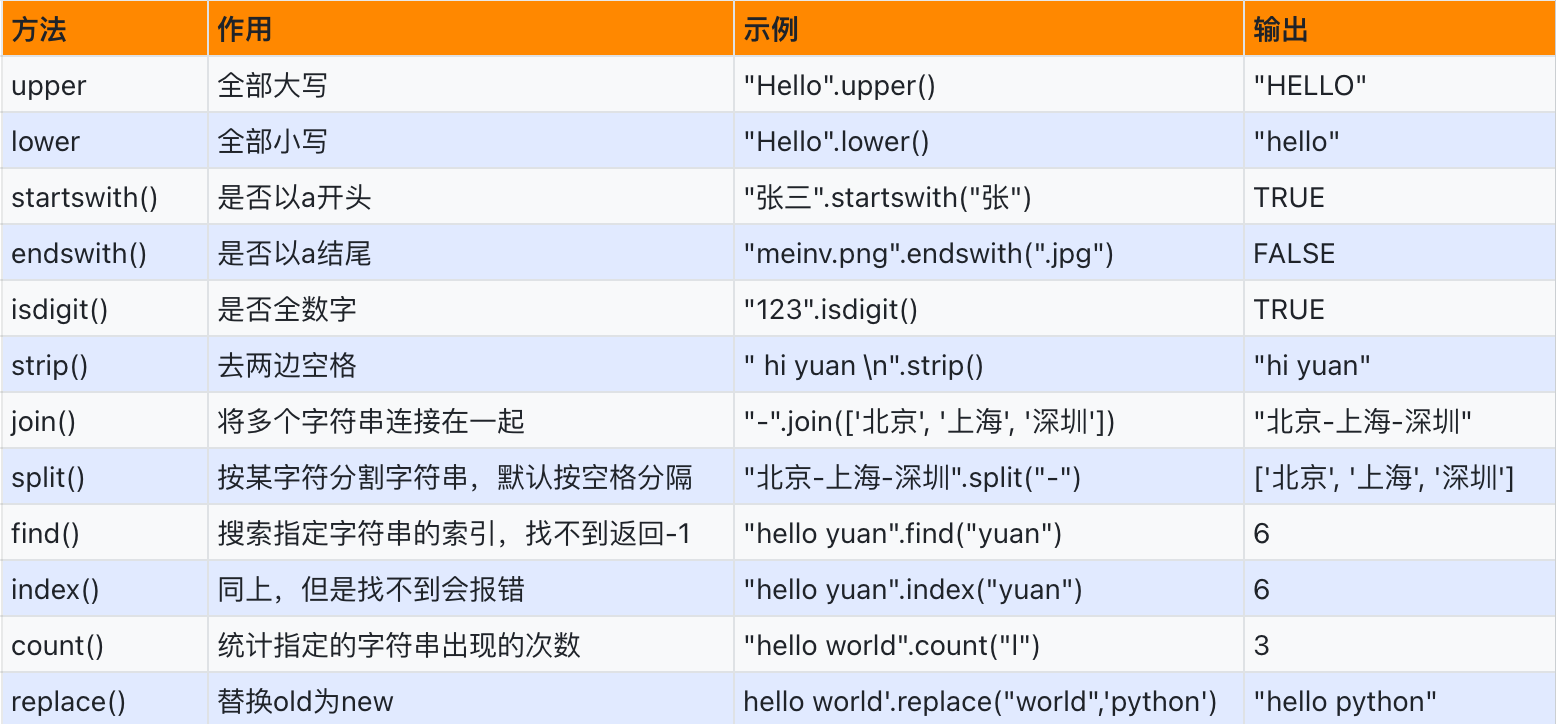
# (1) 字符串转大写:upper(),字符串转小写:lower()
s = "YuanHao"
print(s.upper()) # YUANHAO
print(s.lower()) # yuanhao
# (2) 判断是否以xxx开头
name = "张三"
# 判断是不是姓张
print(name.startswith("张"))
# (3) 判断是否以xxx结尾
url = "/xxx/yyy/zzz/a.png"
print(url.endswith("png"))
# (4) find和index都是查找某子字符串的索引,find找不到返回-1,index找不到报错
print(name.find("三"))
print(name.index("三"))
# (5) 去除两端空格或换行符\n
name = input("请输入姓名:")
print(name, len(name))
name = name.strip()
print(name, len(name))
# (6) 判断某字符串是否全是数字
print("123".isdigit())
# (7) split()和join()
cities = "天津 北京 上海 哈尔滨"
cities_list = cities.split(" ")
print("cities_list", cities_list)
print(len(cities_list))
ret = ",".join(cities_list)
print(ret) # "天津,北京,上海,哈尔滨
info = "yuan 19 180"
info_list = info.split(" ")
print(info_list[0])
print(info_list[1])
print(info_list[2])
# (8) replace(): 子字符串替换
sentence = "PHP is the best language.PHP...PHP...PHP..."
new_sentence = sentence.replace("PHP", "Python")
print(new_sentence)
comments = "这个产品真棒!我非常喜欢。服务很差,不推荐购买。这个餐厅的食物质量太差了,味道不好。我对这次旅行的体验非常满意。这个电影真糟糕,剧情一团糟。这个景点真糟糕,再也不来了!"
comments = comments.replace("差", "***").replace("不推荐", "***").replace("糟糕", "***")
print(comments)
# (9) count:计算字符串中某个子字符串出现的次数
print(sentence.count("PHP"))
5. 今日作业
- 字符串索引切片练习
s= "hello world"
# 操作1:通过正反索引切片world
# 操作2: 获取world的翻转,即"dlrow"
- 有些程序经常需要引导用户输入"Y"或"N",其中"Y"代表肯定,"N"代表否定。无论用户输入大写的"Y"还是小写的"y",结果都被视为肯定。肯定打印True。
- 下面是一个email邮件格式的字符串,将其中的任务ID,任务名称,执行时间,执行耗时,执行状态等值由用户引导输入嵌入到该模板中
"""<html>
<head>
<meta charset="utf-8">
</head>
<body>
Hello,定时任务出错了:
<p style="font-size:16px;">任务执行详情:</p>
<p style="display:block; padding:10px; background:#efefef;border:1px solid #e4e4e4">
任务 ID:1001<br/>
任务名称:定时检测订单<br/>
执行时间:2012-12-12<br/>
执行耗时:15秒<br/>
执行状态:开启
</p>
<br/>
<p>-----------------------------------------------------------------<br/>
本邮件由CronJob定时系统自动发出,请勿回复<br/>
如果要取消邮件通知,请登录到系统进行设置<br/>
</p>
</body>
</html>"""
-
names='yuan rain eric alvin',引导用户输入一个名字,判断是否在这个名字字符串中,是打印True,不是打印False -
引导用户输入一个双值加法字符串,例如
3+5或3 + 5,计算出两个数字的和,打印出来 -
用户输入一个11位手机号,将第5位至第8位替换成
* -
编写一个Python程序,输入一个三位数。将其拆分为百位数,十位数和个位数,井输出它们的和
-
将
Unix/Linux系统下的路径字符串"/Users/yuan/npm/index.js"转换为Windows系统下的路径字符串"\Users\yuan\npm\index.js"。请使用两种方式来实现路径转换 -
引导用户输入一个字符串,判断是否是回文字符串
-
引导用户输入一个字符串,保证长度一定是4的倍数,不足位补
=# 加入用户输入 data = "hello" # 处理完 data = "helloworld==" -
引导用户输入一个手机号,通过一个逻辑表达式判断该字符串是否符合电信手机号格式,格式要求如下,是打印True,不是打印False
# 要求1: 输入的长度必须是11位 # 要求2: 输入内容必须全部是数字 # 要求3: 前三位是133或153(电信号段) -
引导用户输入一个邮箱格式字符串,比如
916852314@163.com或1052065088@qq.com等,然后将邮箱号和邮箱类型名打印出来,比如邮箱号916852314和163邮箱 -
HTTP协议格式数据组装,引导用户分别输入请求方式,请求URL以及若干个请求头
请输入 HTTP 请求方法:GET 请输入 URL:https://www.example.com/api/data 请输入 HTTP 协议:HTTP/1.1 请输入请求头信息(键值对用冒号分隔,多个键值对用逗号分隔):User-Agent: MyClient/1.0,Authorization: Token abcdef123456HTTP请求协议组装格式:请求方法,请求URL的路径以及请求协议名放在第一行,每一个请求头的键值对占一行,提示:换行用
\n,打印格式如下GET /api/data HTTP/1.1 User-Agent: MyClient/1.0 Authorization: Token abcdef123456
Day04:流程控制语句

流程控制语句是计算机编程中用于控制程序执行流程的语句。它们允许根据条件来控制代码的执行顺序和逻辑,从而使程序能够根据不同的情况做出不同的决策。流程控制实现了更复杂和灵活的编程逻辑。
-
顺序语句
顺序语句是按照编写的顺序依次执行程序中的代码。代码会按照从上到下的顺序有且仅执行一次。
-
分支语句
根据条件的真假来选择性地执行不同的代码块。这使得程序能够根据不同的情况做出不同的响应。
-
循环语句
允许重复执行一段代码,以便处理大量的数据或重复的任务。循环语句可以用于多次执行相同或类似的代码块,从而实现重复操作的需求。
流程控制是编程中的基本概念之一,对于编写高效、可靠的程序至关重要。


1. 分支语句
【1】双分支语句
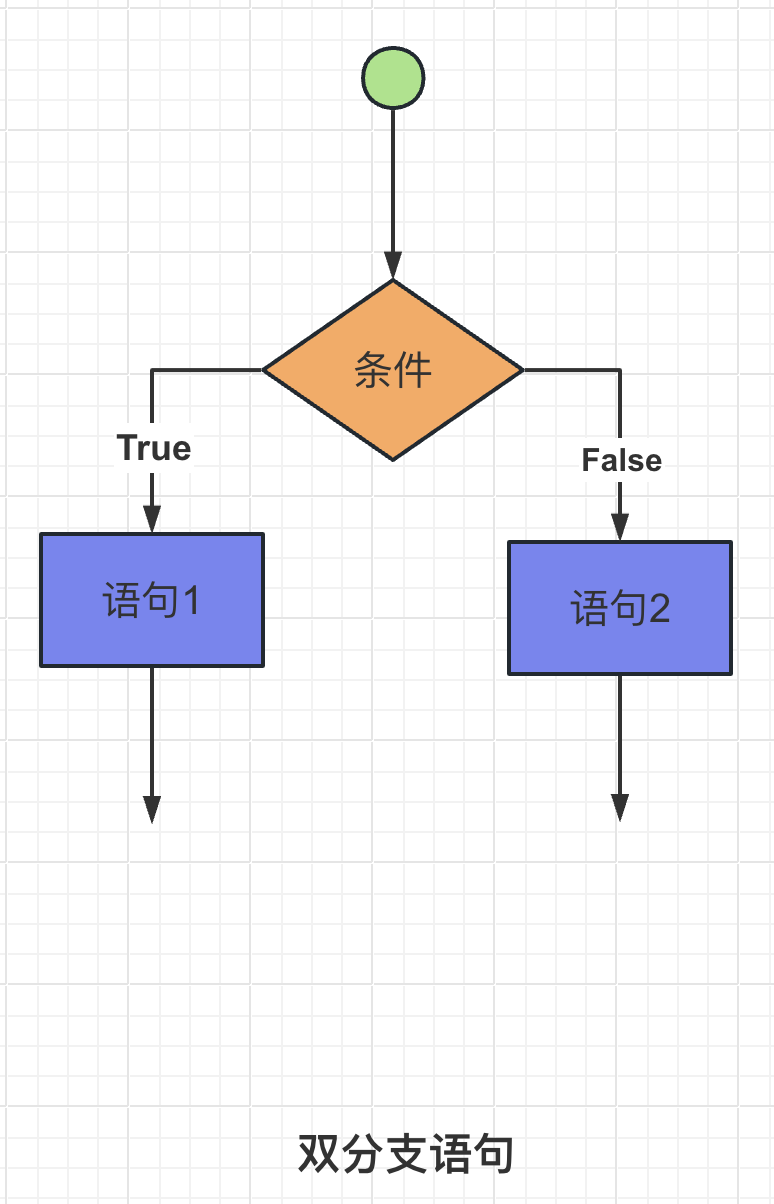
双分支语句是一种编程结构,用于根据条件的真假选择不同的执行路径。它基于条件的结果,决定程序执行的部分。在许多编程语言中,双分支语句通常使用 if-else 语句来实现。
if 条件表达式:
# 条件表达式为True执行的语句块
# pass 语句可以占位
else:
# 条件表达式为False执行的语句块
其中,条件是一个表达式或逻辑判断,它的结果可以是 True(真)或 False(假)。
当条件为真时,执行代码块A,也称为 if 代码块;当条件为假时,执行代码块B,也称为 else 代码块。
双分支语句允许根据不同的条件结果执行不同的代码逻辑,从而实现程序的分支选择和条件判断。它是一种基本的控制流程结构,常用于处理二选一的情况。
# 案例1:获取用户年龄
age = int(input("请输入您的年龄:"))
# 判断是否进入成年电影
if age >= 18:
print("进入电影院!")
print("欧美区")
print("日韩区")
print("国产区")
else:
print("进入青少年模式!")
print("科幻冒险类")
print("益智早教类")
print("科普记录类")
# 案例2:根据用户输入的成绩判断其等级。如果成绩大于等于60分,则输出"及格",否则输出"不及格"。
# 案例3: 编写一个程序,判断一个年份是否为闰年。如果是闰年,则输出"是闰年",否则输出"不是闰年"。闰年的判断条件是能够被4整除但不能被100整除,或者能够被400整除。
# 案例4:编写一个程序,根据用户输入的三个数字,判断这三个数字是否能够构成一个等边三角形。如果能够构成等边三角形,则输出"能构成等边三角形",否则输出"不能构成等边三角形"。等边三角形的判断条件是三条边的长度相等。
# 案例5: 用户输入一个年龄,判断是否符合20-35
# 案例6: 输入一个数字,判断是否为偶数
重点:
和其它程序设计语言(如 Java、C 语言)采用大括号“{}”分隔代码块不同,Python 采用代码缩进和冒号( : )来区分代码块之间的层次。
在 Python 中,对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束。
注意,Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现。但无论是手动敲空格,还是使用 Tab 键,通常情况下都是采用 4 个空格长度作为一个缩进量(默认情况下,一个 Tab 键就表示 4 个空格)。
【2】单分支语句
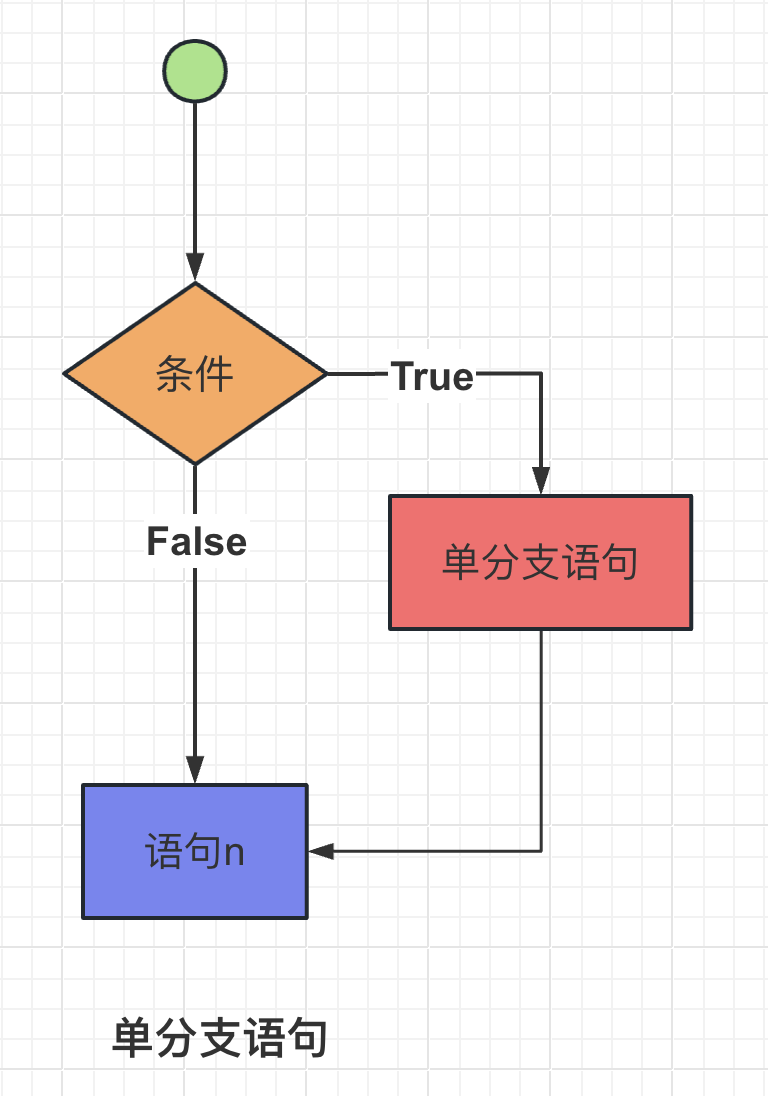
单分支语句只包含一个条件判断和一个对应的代码块。如果条件为真,执行代码块中的语句;如果条件为假,则直接跳过代码块。
# 示例:获取两个值中的较小值
# 获取两个输入值
value1 = float(input("请输入第一个值:"))
value2 = float(input("请输入第二个值:"))
# 使用单分支语句获取较小值
if value1 < value2:
min_value = value1
else:
min_value = value2
# 输出较小值
print("较小值为:", min_value)
这个案例可以使用单分支来实现
# 示例:获取两个值中的较小值
# 获取两个输入值
value1 = float(input("请输入第一个值:"))
value2 = float(input("请输入第二个值:"))
# 使用单分支语句获取较小值
if value1 > value2:
value1, value2 = value2, value1
print("较小值:", value1)
【3】多分支语句
多分支语句(if-elif-else语句)可用于在多个条件之间进行选择。
if condition1:
# 当条件1为真时执行的代码块
elif condition2:
# 当条件2为真时执行的代码块
elif condition3:
# 当条件3为真时执行的代码块
...
else:
# 当所有条件都为假时执行的代码块
案例1:成绩等级
# 案例1:根据用户输入的成绩判断其等级。
# 如果成绩[90,100],则输出"优秀"
# 如果成绩[80,90],则输出"良好"
# 如果成绩[60,80],则输出"及格"
# 如果成绩小于60,则输出"不及格"
# 如果成绩小于0或大于100,则输出"成绩有误"
score = int(input("请输入您的成绩:"))
if 90 < score <= 100:
print("成绩优秀!")
elif 80 < score <= 90:
print("成绩良好!")
elif 60 <= score <= 80:
print("成绩及格!")
elif 0 <= score < 60:
print("成绩不及格!")
else:
print("成绩有误")
if score < 0 or score > 100:
print("非法输入")
elif score > 90:
print("成绩优秀!")
elif score > 80:
print("成绩良好!")
elif score > 60:
print("成绩及格!")
else:
print("成绩成绩不及格")
案例2:BMI测试

# 示例:计算BMI并给出健康建议
# 获取用户输入的身高和体重
height = float(input("请输入您的身高(单位:米):"))
weight = float(input("请输入您的体重(单位:千克):"))
# 计算BMI
bmi = weight / (height ** 2)
# 根据BMI给出健康建议
if bmi < 18.5:
advice = f"您的BMI为 {bmi:.3},体重过轻,建议增加营养摄入。"
elif 18.5 <= bmi < 24:
advice = f"您的BMI为 {bmi:.3},体重正常,继续保持健康的生活方式。"
elif 24 <= bmi < 28:
advice = f"您的BMI为 {bmi:.3},体重过重,建议适当控制饮食并增加运动。"
else:
advice = f"您的BMI为 {bmi:.3},体重肥胖,建议减少高热量食物摄入并增加运动量。"
# 输出健康建议
print(advice)
案例3:游戏场景选择

# 场景:
# (1)怪物房: 遇到了史莱姆,并打败了它,金币加5,经验加10!
# (2) 宝箱房: 你打开了宝箱,获得了钥匙
# (3) 陷阱房: 你触发了陷阱,受到了毒箭的伤害,血值减10
# (4) 商店: 你来到了商店,购买了药水,金币减5,血值加20
import random
name = "勇士"
health = 100
coins = 0
exp = 0
print("欢迎来到地下城!")
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
input("按下 Enter 进入下一个房间...")
room = random.choice(["怪物房", "宝箱房", "陷阱房", "商店"])
if room == "怪物房":
print("你遇到了史莱姆,并打败了它")
exp += 10
coins += 5
print("金币加5,经验加10!")
elif room == "宝箱房":
print("你打开了宝箱,获得了钥匙")
elif room == "陷阱房":
print("你触发了陷阱,受到了毒箭的伤害")
health -= 10
elif room == "商店":
print("你来到了商店,购买了药水")
coins -= 5
health += 20
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
【4】分支嵌套
分支嵌套是指在一个分支语句内部嵌套另一个分支语句。
案例1:
age = int(input("年龄:"))
if age >= 18:
print("电影!")
choice = input("""
1. 日韩区
2. 欧美区
3. 国产区
""")
if choice == "1":
print("《熔炉》")
print("《千与千寻》")
print("《龙猫》")
print("《天空之城》")
elif choice == "2":
print("《肖申克的救赎》")
print("《当幸福来敲门》")
print("《阿甘正传》")
print("《星际穿越》")
elif choice == "3":
print("《霸王别姬》")
print("《大话西游》")
print("《让子弹飞》")
print("《无间道》")
else:
print("少儿电影")
print("科幻冒险类")
print("益智早教类")
print("科普记录类")
print("程序结束")
案例2:
"""
勇士与地下城的场景续写:
(1)怪物房: 遇到了史莱姆
1. 选择攻击,战胜史莱姆,则经验加20,金币加20,失败则经验减20,金币减20,血值减20,成功的概率为50%。
2. 选择逃跑,则金币减20
(2) 宝箱房: 你打开了宝箱,获得了钥匙
(3) 陷阱房: 你触发了陷阱,受到了毒箭的伤害,血值减10
(4) 商店: 你来到了商店,打印当前血值和金币,一个金币买一个药水对应10个血值,引导是否购买药水
1. 购买,引导购买几个金币的药水,并完成减金币和增血值
2. 不购买,打印退出商店
"""
import random
name = "勇士"
health = 100
coins = 0
exp = 0
print("欢迎来到地下城!")
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
input("按下 Enter 进入下一个房间...")
room = random.choice(["怪物房", "宝箱房", "陷阱房", "商店"])
if room == "怪物房":
action = input("请选择行动:(1)攻击 (2)逃跑")
if action == "1":
attack = random.randint(1, 20)
if attack >= 10:
print("你击败了史莱姆")
coins += 10
else:
print("你的攻击没有命中!")
health -= 20
elif action == "2":
print("你逃跑了,但失去了一些生命值")
health -= 10
else:
print("无效的选择!请重新选择。")
elif room == "宝箱房":
print("你打开了宝箱,获得了钥匙")
elif room == "陷阱房":
print("你触发了陷阱,受到了毒箭的伤害")
health -= 10
elif room == "商店":
choice = input("你来到了商店,购买了药水,是否购买?【Y/N】")
if choice == "Y" and coins >= 5:
print("购买药水成功")
coins -= 5
health += 20
else:
print("退出商店")
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
2. 循环语句
预备知识:
PyCharm提供了丰富的功能来帮助开发者编写、调试和运行 Python 代码。其中,PyCharm 的 Debug 模式是一种强大的调试工具,可以帮助开发者在代码执行过程中逐行跟踪和分析程序的行为。以下是关于 PyCharm Debug 模式的介绍:
- 设置断点:在需要调试的代码行上设置断点,断点是程序的一个暂停点,当程序执行到断点时会暂停执行,允许开发者逐行检查代码。
- 启动 Debug 模式:在 PyCharm 中,可以通过点击工具栏上的 "Debug" 按钮来启动 Debug 模式,或者使用快捷键(通常是 F9)。
- 逐行执行:在 Debug 模式下,可以使用调试工具栏上的按钮(如「Step Over」、「Step Into」和「Step Out」)逐行执行代码。Step Over 会执行当前行并跳转到下一行,Step Into 会进入函数调用并逐行执行函数内部代码,Step Out 会执行完当前函数并跳出到调用该函数的位置。
- 变量监视:在 Debug 模式下,可以查看变量的值和状态。在调试工具栏的「Variables」窗口中,可以看到当前作在 PyCharm 中,Debug 模式是一种强大的调试工具,可以帮助开发者在代码执行过程中逐行跟踪和分析程序的行为。
循环语句
循环语句是编程中的一种控制结构,用于重复执行特定的代码块,直到满足特定的条件为止。它允许程序根据需要多次执行相同或类似的操作,从而简化重复的任务。
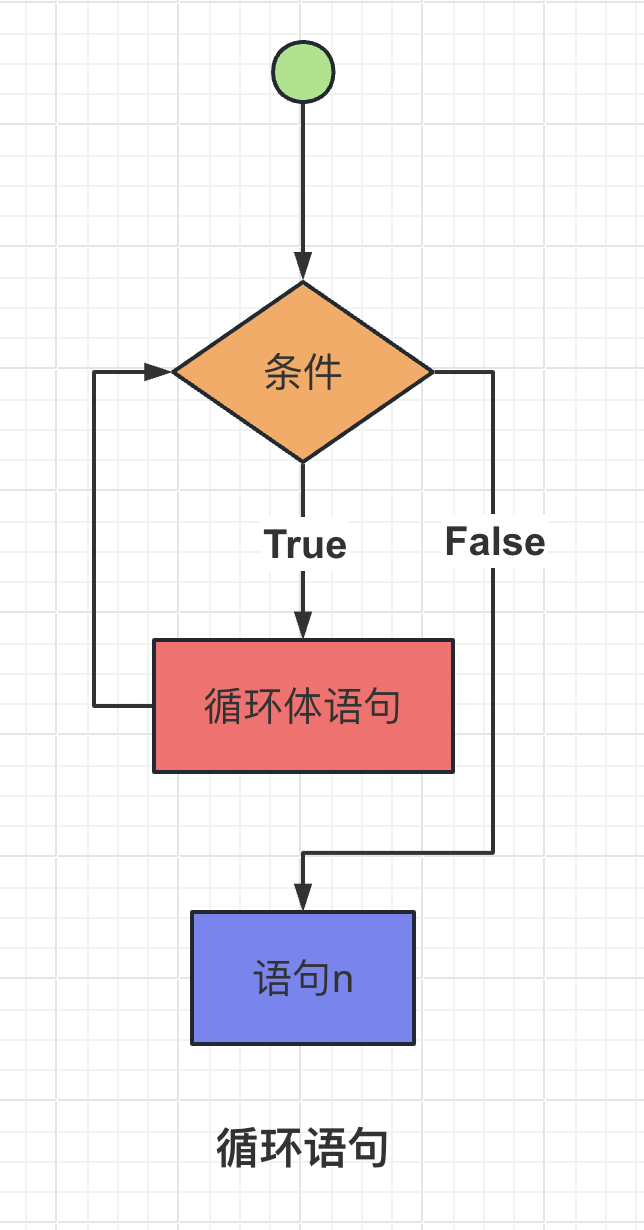
【1】while循环
while循环用于在条件为真的情况下重复执行一段代码,直到条件变为假为止。以下是while循环的语法:
while条件:
循环体
在执行while循环时,程序会先检查条件是否为真。如果条件为真,就执行循环体中的代码,然后再次检查条件。如果条件仍为真,就再次执行循环体中的代码,以此类推,直到条件变为假为止。
# 无限循环
while 1:
print("hello yuan!")
# 有限循环方式1
count = 0 # 初始语句
while count < 10: # 判断条件
# print("hello yuan")
print("count:::", count)
count += 1 # 步进语句
#有限循环方式2
count = 100 # 初始语句
while count > 0: # 判断条件
print("count:::", count)
count -= 1 # 步进语句
【2】循环案例
案例1:计算1-100的和
"""
# 准备:
# 假设有一个变量s的初始值为0,将s增加5次,每次增加值分别为1,2,3,4,5,然后打印s的值。
"""
# 实现代码
count = 1 # 初始语句
s = 0
while count <= 100: # 判断条件
# s = 0 # 会怎么?
print("count:::", count)
s += count
count += 1 # 步进语句
print(s)
案例2:验证码案例

"""
# 假设有一个变量s的初始值为"",将s拼接5次,每次增加值分别为"A","B","C",然后打印s的值。
s = ""
s += "A"
s += "B"
s += "C"
print(s)
"""
import random
import string
char = string.ascii_letters + string.digits
count = 0
randomCodes = ""
while count < 10:
code = random.choice(char)
randomCodes += code
count += 1
print(randomCodes)
【3】for循环
for循环用于对一个容器对象(如字符串、列表、元组等)中的元素进行遍历和操作,直到所有元素都被遍历为止。以下是for循环的语法:
for 变量 in 容器对象(字符串,列表,字典等):
循环体
for i in "hello world":
# print("yuan")
print(i)
在执行for循环时,程序会依次将序列中的每个元素赋值给变量,并执行循环体中的代码,直到序列中的所有元素都被遍历完为止。
在 Python 中,range() 函数用于生成一个整数序列,它常用于循环和迭代操作。
range(stop)
range(start, stop, step)
参数解释:
start(可选):序列的起始值,默认为 0。stop:序列的结束值(不包含在序列中)。step(可选):序列中相邻两个值之间的步长,默认为 1。
for i in range(100): # 循环次数
print("yuan")
# 基于for循环实现1+100的和的计算
s = 0
for i in range(1, 101): # 循环次数
s += i
print(s)
【4】嵌套语句
案例1:打印出从 0 到 99 中能被 13 整除的所有数字。
for i in range(100):
if i % 13 == 0:
print(i)
案例2:打印出从 1 到 100 的所有整数,但将整除 3 的数字打印为 "Fizz",整除 5 的数字打印为 "Buzz",同时整除 3 和 5 的数字打印为 "FizzBuzz"。
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print("FizzBuzz")
elif i % 3 == 0:
print("Fizz")
elif i % 5 == 0:
print("Buzz")
else:
print(i)
案例3:循环嵌套分支
import random
name = "勇士"
health = 100
coins = 0
exp = 0
print("欢迎来到地下城!")
while 1:
print(f"""
当前生命值:{health}
当前经验值:{exp}
当前金币:{coins}
""")
input("按下 Enter 进入下一个房间")
room = random.choice(["怪物房", "宝箱房", "陷阱房", "商店"])
# ......
案例4:打印扑克牌

poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
for p_type in poke_types:
for p_num in poke_nums:
print(f"{p_type}{p_num}")
【5】退出循环
while是条件循环,条件为False时退出循环,for循环是遍历循环,遍历完成则退出,这都属于正常退出循环,如果想非正常退出循环,分为强制退出当次循环和退出整个循环,分别使用关键字continue和break来实现
break退出整个循环
# 退出while循环
while True:
userInput = input("请输入一个数字(输入q退出):")
if userInput == 'q':
print("退出循环")
break
number = int(userInput)
square = number ** 2
print(f"{number} 的平方是 {square}")
# 退出for循环
# 查找1-100中第一个能整除13的非零偶数
for i in range(100):
if i % 13 == 0 and i != 0 and i % 2 == 0:
print("获取i值:", i)
break
continue退出当次循环
for i in range(100):
if i % 13 != 0:
continue
print("获取i值:", i)
for i in range(100):
if i % 13 == 0:
print("获取i值:", i)
3. 今日作业
-
编写一个程序,判断一个字符是否为元音字母(a、e、i、o、u,包括小写和大写)。如果是元音字母,则输出"是元音字母",否则输出"不是元音字母"。
-
统计元音字母:编写一个程序,接受用户输入的一段文本,统计其中元音字母(a、e、i、o、u)的个数,并输出结果。
-
计算1-2+3-4+......-1000最终的结果,能整除13的数不参与计算
-
身份证号码的倒数第二位数字是奇数,表示性别为男性,否则为女性,引导用户输入身份证号,先判断是否为18位,再判断性别。
-
计算初始本金为1万,年利率为0.0325的情况下,需要多少年才能将本金和利息翻倍,即本金和利息的总和达到原来的两倍。
-
编写一个程序,生成斐波那契数列的第20个数字(斐波那契数列是指从0和1开始,后面的每一项都是前两项的和)
0 1 1 2 3 5 8 .... -
编写一个程序,接受用户输入的一个整数,判断该数是否是素数(只能被1和自身整除的数)。注意,素数的定义是大于1的自然数,只能被1和自身整除,没有其他的正因数。
-
猜数字游戏
1.首先,程序使用random.randint函数产生一个1~10之间的随机数。 2.然后,程序通过for循环提示玩家输入一个猜测的数字,玩家可以输入一个1~10之间的整数。 3.如果玩家猜对了数字,程序输出恭喜玩家的信息并结束游戏;如果玩家猜错了,程序会根据玩家输入的数字与随机数之间的大小关系来提示玩家是否猜对,并在每次猜错后告诉玩家还剩下几次机会。 4.如果玩家在三次机会内猜对了数字,程序输出恭喜玩家的信息并结束游戏;否则程序输出很遗憾的信息并结束游戏。 -
分支嵌套
在选座购票中扩写,引导用户输入【普通票/学生票/老年票】,然后分支判断。
print("欢迎来到电影订票系统!") print("请选择您要进行的操作:") print("1. 查询电影场次") print("2. 选座购票") print("3. 查看订单信息") choice = int(input("请输入您的选择(1-3):")) if choice == 1: print("正在查询电影场次...") # 执行查询电影场次的代码 elif choice == 2: print("正在选座购票...") elif choice == 3: print("正在查看订单信息...") # 执行查看订单信息的代码 else: print("无效的选择!请重新运行程序并输入有效的选项。") -
打印一个nxn的矩阵,每个元素的值等于其所在行数和列数之和。
// 比如4*4矩阵 2 3 4 5 3 4 5 6 4 5 6 7 5 6 7 8 -
打印一个如下的九九乘法表

Day05:列表&元组

高级数据类型是一种编程语言中提供的用于表示复杂数据结构的数据类型。相比于基础数据类型(如整数、浮点数、布尔值等),高级数据类型可以存储和操作更多的数据,并且具备更丰富的功能和操作方法。
Python的高级数据类型主要包括列表、元组,字典,集合。
1. 列表的概念
在Python中,列表(List)是一种有序、可变、可重复的数据结构,用于存储一组元素。列表是Python中最常用的数据类型之一,它可以包含任意类型的元素,例如整数、浮点数、字符串等。
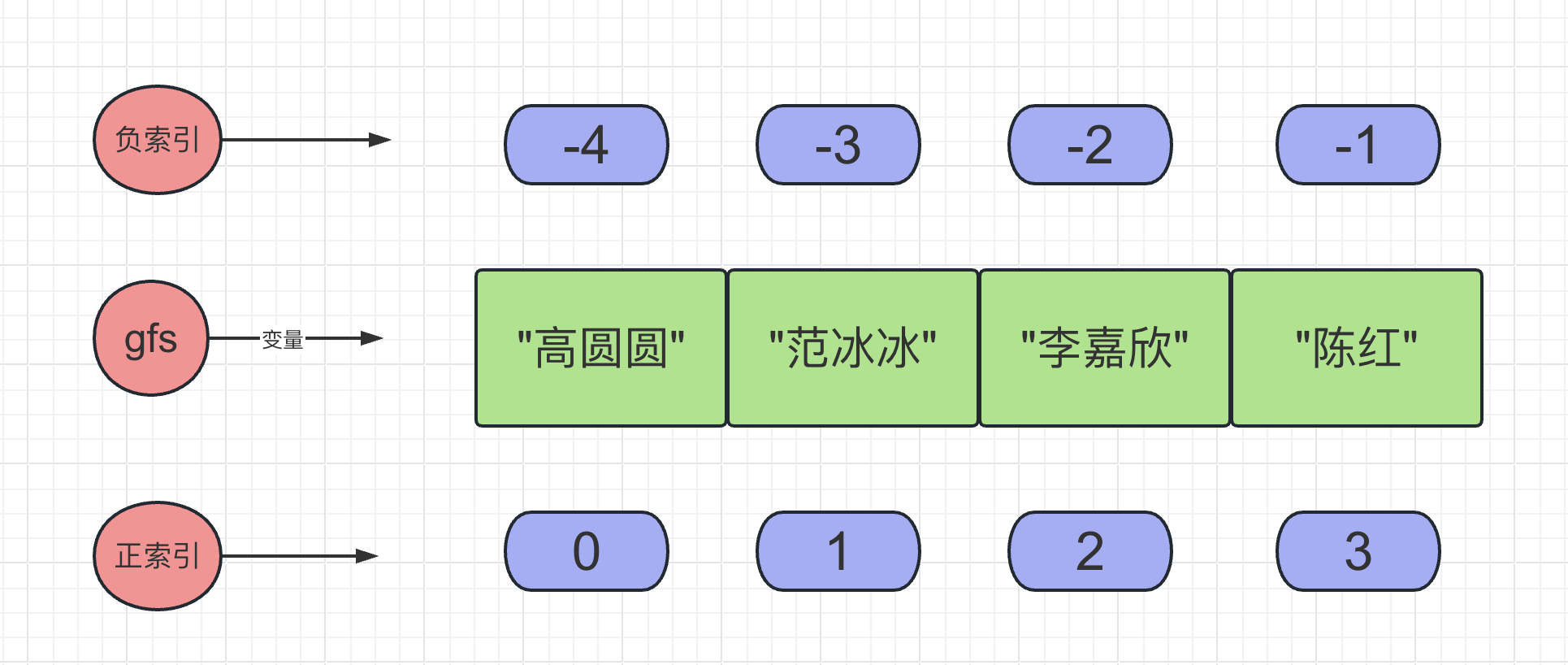
gf_name_list = ["高圆圆", "范冰冰", "李嘉欣", "陈红"]
info = ["yuan", 18, False]
print(type(info)) # <class 'list'>
列表的特点:
- 列表中的元素按照顺序进行存储和管理
- 元素可以是任意类型且可以不一致
- 元素的长度理论上没有限制
- 列表允许包含重复的元素
- 列表是可变数据类型
2. 列表的基本操作
索引是管理列表的核心!
- 索引操作
# 查询
l = ['高圆圆', '刘亦菲', '赵丽颖', '范冰冰', '李嘉欣']
print(l[2]) # 12
print(l[-1]) # 14
# 修改
l[3] = "佟丽娅"
- 切片操作
# 查询操作
l = [10,11,12,13,14]
print(l[2:5])
print(l[-3:-1])
print(l[:3])
print(l[1:])
print(l[:])
print(l[2:4])
print(l[-3:-1])
print(l[-1:-3])
print(l[-1:-3:-1])
print(l[::2])
# 修改操作
l[1:4] = [1,2,3]
1、取出的元素数量为:结束位置 - 开始位置;
2、取出元素不包含结束位置对应的索引,列表最后一个元素使用
list[len(slice)]获取;3、当缺省开始位置时,表示从连续区域开头到结束位置;
4、当缺省结束位置时,表示从开始位置到整个连续区域末尾;
5、两者同时缺省时,与列表本身等效;
6、step为正,从左向右切,为负从右向左切。
- 判断成员是否存在
in 关键字检查某元素是否为序列的成员
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # True
- 相加
l1 = [1,2,3]
l2 = [4,5,6]
print(l1 + l2) # [1, 2, 3, 4, 5, 6]
- 循环列表
for name in ["张三",'李四',"王五"]:
print(name)
for i in range(10): # range函数: range(start,end,step)
print(i)
# 基于for循环从100打印到1
for i in range(100,0,-1):
print(i)
-
计算元素个数
# len函数可以计算任意容器对象的元素个数!!! print(len("hello yuan!")) print(len([1, 2, 3, 4, 5, 6])) print(len(["rain", "eric", "alvin", "yuan", "Alex"])) print(len({"k1":"v1","k2":"v2"}))
3. 列表的内置方法
【1】内置方法

gf_name_list = ['高圆圆', '刘亦菲', '赵丽颖', '范冰冰', '李嘉欣']
# 一、增
# (1) 列表最后位置追加一个值
gf_name_list.append("橘梨纱")
# (2) 向列表任意位置插入一个值
gf_name_list.insert(1, "橘梨纱")
# (3) 扩展列表
gf_name_list.extend(["橘梨纱", "波多野结衣"])
# 二、删
# (1) 按索引删除
gf_name_list.pop(3)
print(gf_name_list)
# (2) 按元素值删除
gf_name_list.remove("范冰冰")
print(gf_name_list)
# (3) 清空列表
gf_name_list.clear()
print(gf_name_list)
# 三、其他操作
l = [10, 2, 34, 4, 5, 2]
# 排序
l.sort()
print(l)
# 翻转
l.reverse()
print(l)
# 计算某元素出现个数
print(l.count(2))
# 查看某元素的索引
print(l.index(34))
【2】案例练习
案例1: 构建一个列表,存储1-10的平方值
l = []
for i in range(1, 11):
# print(i ** 2)
# l.append(i ** 2)
if i % 2 == 0:
l.append(i ** 2)
print(l)
案例2:扑克牌发牌
import random
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
poke_list = []
for p_type in poke_types:
for p_num in poke_nums:
# print(f"{p_type}{p_num}")
poke_list.append(f"{p_type}{p_num}")
print(poke_list)
# (1) 抽王八
# random.choice():多选一
# ret1 = random.choice(poke_list)
# print(ret1)
# ret2 = random.choice(poke_list)
# print(ret2)
# ret3 = random.choice(poke_list)
# print(ret3)
# (2) 金花
# random.sample :多选多
ret1 = random.sample(poke_list, 3)
print(ret1)
for i in ret1:
poke_list.remove(i)
print(len(poke_list))
ret2 = random.sample(poke_list, 3)
for i in ret2:
poke_list.remove(i)
print(len(poke_list))
ret3 = random.sample(poke_list, 3)
print(ret1)
print(ret2)
print(ret3)
案例3:实现一个购物车清单,可以引导用户添加商品和删除商品
shopping_cart = []
while True:
print("--- 购物车清单 ---")
print("1. 添加商品")
print("2. 删除商品")
print("3. 查看购物车")
print("4. 结束程序")
choice = input("请输入选项:")
if choice == "1":
item = input("请输入要添加的商品:")
shopping_cart.append(item)
print("已添加商品:", item)
print()
elif choice == "2":
if len(shopping_cart) == 0:
print("购物车为空,无法删除商品。")
else:
item = input("请输入要删除的商品:")
if item in shopping_cart:
shopping_cart.remove(item)
print("已删除商品:", item)
else:
print("购物车中没有该商品。")
print()
elif choice == "3":
if len(shopping_cart) == 0:
print("购物车为空。")
else:
print("*" * 15)
print("购物车内容:")
for item in shopping_cart:
print(item)
print("*" * 15)
print()
elif choice == "4":
print("程序已结束。")
break
else:
print("无效选项,请重新输入。")
print()
4. 列表的深浅拷贝
【1】可变类型与不可变类型
在Python中,数据类型可以分为可变类型(Mutable)和不可变类型(Immutable)。这指的是对象在创建后是否可以更改其值或状态。
不可变类型是指创建后不能更改其值或状态的对象。如果对不可变类型的对象进行修改,将会创建一个新的对象,原始对象的值保持不变。在修改后,对象的身份标识(即内存地址)会发生变化。
以下是Python中常见的不可变类型:整数(Integer) 和浮点数(Float),布尔值(Boolean),字符串(String),元组(Tuple)
可变类型是指可以在原地修改的对象,即可以改变其值或状态。当对可变类型的对象进行修改时,不会创建新的对象,而是直接修改原始对象。在修改后,对象的身份标识(即内存地址)保持不变。
Python中常见的可变类型:列表(List),字典(Dictionary)
对于可变类型,可以通过方法调用或索引赋值进行修改,而不会改变对象的身份标识。而对于不可变类型,任何修改操作都会创建一个新的对象。
【2】可变类型的存储方式
l = [1,2,3] # 存储

【3】可变类型的变量传递
变量实际上是对对象的引用。变量传递的核心是两个变量引用同一地址空间
# 案例1:
x = 1
y = x
x = 2
# print(y)
print(id(x))
print(id(y))
# 案例2:
l1 = [1, 2, 3]
l2 = l1 # 变量传递
l1[0] = 100
print(l1, l2)
l2[1] = 200
print(l1, l2)
# 案例3:
l1 = [1, 2, 3]
l2 = [l1, 4, 5] # 也属于变量传递
l1[0] = 100
print(l1, l2)
l2[0][1] = 200
print(l1, l2)

【4】列表的深浅拷贝
在Python中,列表的拷贝可以分为深拷贝和浅拷贝两种方式。
浅拷贝(Shallow Copy)是创建一个新的列表对象,该对象与原始列表共享相同的元素对象。当你对其中一个列表进行修改时,另一个列表也会受到影响。
你可以使用以下方法进行浅拷贝:
# (1)使用切片操作符[:]进行拷贝:
l1 = [1, 2, 3, 4, 5]
l = l1[:]
# (2)使用list()函数进行拷贝
l2 = [1, 2, 3, 4, 5]
l = list(l2)
# (3)使用copy()方法进行拷贝(需要导入copy模块)
l3 = [1, 2, 3, 4, 5]
l = l3.copy()
场景应用:
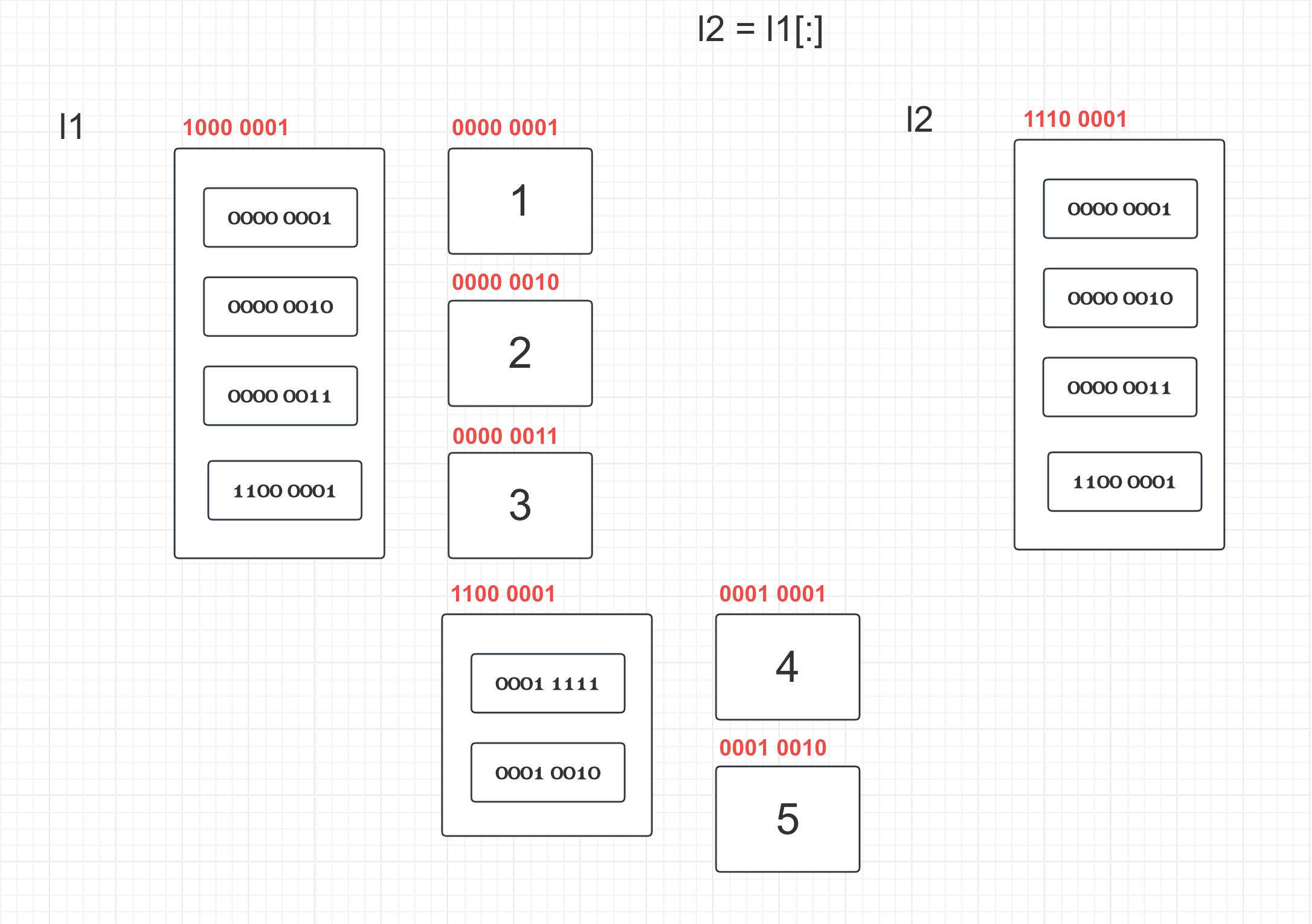
# 案例1
l1 = [1, 2, 3]
l2 = l1[:] # 浅拷贝
print(l2)
print(id(l1[0]))
print(id(l2[0]))
l1[1] = 300
print(l1)
print(l2)
# 案例2
l = [4, 5]
l1 = [1, 2, 3, l]
l2 = l1[:]
l1[0] = 100
print(l2)
l1[3][0] = 400
print(l2)
l1[3] = 400
print(l2)
深拷贝(Deep Copy)是创建一个新的列表对象,并且递归地复制原始列表中的所有元素对象。这意味着原始列表和深拷贝的列表是完全独立的,对其中一个列表的修改不会影响另一个列表。
你可以使用copy()模块中的deepcopy()函数进行深拷贝:
import copy
original_list = [1, 2, 3, 4, 5]
deep_copy = copy.deepcopy(original_list)
需要注意的是,深拷贝可能会更耗费内存和时间,特别是当拷贝的列表中包含大量嵌套的对象时。
5. 列表的嵌套
如果你要使用列表的嵌套来实现客户信息管理系统,可以将每个客户的信息存储在一个子列表中,然后将所有学生的子列表存储在主列表中。每个学生的信息可以按照一定的顺序存储,例如姓名、年龄、邮箱等。
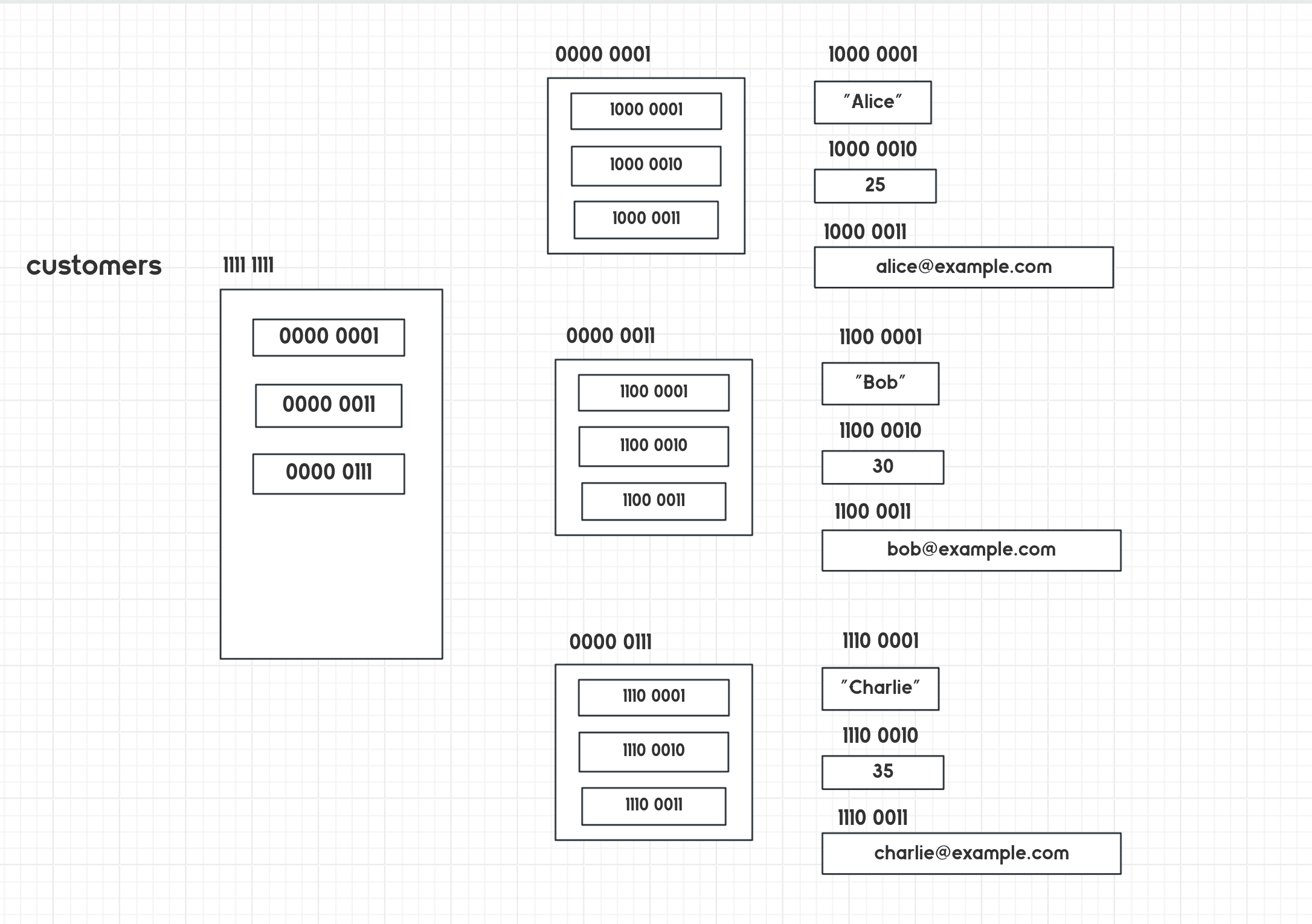
# 初始化客户信息列表
customers = [
["Alice", 25, "alice@example.com"],
["Bob", 30, "bob@example.com"],
["Charlie", 35, "charlie@example.com"]
]
# 增加客户信息
new_customer = ["David", 28, "david@example.com"]
customers.append(new_customer)
# 删除客户信息
delete_customer = "Bob"
for customer in customers:
if customer[0] == delete_customer:
customers.remove(customer)
break
# 修改客户信息
update_customer = "Alice"
for customer in customers:
if customer[0] == update_customer:
customer[1] = 26
break
# 查询客户信息
search_customer = "Charlie"
for customer in customers:
if customer[0] == search_customer:
name = customer[0]
age = customer[1]
email = customer[2]
print(f"姓名: {name}, 年龄: {age}, 邮箱: {email}")
break
# 功能整合
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 退出
""")
在这个案例代码中,每个客户的信息被存储在一个子列表中,然后将该客户的子列表添加到客户列表中。在展示学生信息时,可以通过索引访问每个客户的具体信息。该代码使用了列表的嵌套来存储客户信息。仍然实现了添加客户信息、查看客户信息和退出程序的功能。
6. 列表推导式
列表推导式(List comprehensions)是一种简洁的语法,用于创建新的列表,并可以在创建过程中对元素进行转换、筛选或组合操作。
列表推导式的一般形式为:
new_list = [expression for item in iterable if condition]
其中:
expression是要应用于每个元素的表达式或操作。item是来自可迭代对象(如列表、元组或字符串)的每个元素。iterable是可迭代对象,提供要遍历的元素。condition是一个可选的条件,用于筛选出满足条件的元素。
# 创建一个包含1到5的平方的列表
squares = [x**2 for x in range(1, 6)]
print(squares) # 输出: [1, 4, 9, 16, 25]
# 筛选出长度大于等于5的字符串
words = ["apple", "banana", "cherry", "date", "elderberry"]
filtered_words = [word for word in words if len(word) >= 5]
print(filtered_words) # 输出: ["apple", "banana", "cherry"]
# 将两个列表中的元素进行组合
numbers = [1, 2, 3]
letters = ['A', 'B', 'C']
combined = [(number, letter) for number in numbers for letter in letters]
print(combined) # 输出: [(1, 'A'), (1, 'B'), (1, 'C'), (2, 'A'), (2, 'B'), (2, 'C'), (3, 'A'), (3, 'B'), (3, 'C')]
7. 元组
元组(Tuple)是Python中的一种数据类型,它是一个有序的、不可变的序列。元组使用圆括号 () 来表示,其中的元素可以是任意类型,并且可以包含重复的元素。
与列表(List)不同,元组是不可变的,这意味着一旦创建,它的元素就不能被修改、删除或添加。元组适合用于存储一组不可变的数据。例如,你可以使用元组来表示一个坐标点的 x 和 y 坐标值,或者表示日期的年、月、日等。元组也被称为只读列表
info = ("yuan", 20, 90)
# 获取长度
print(len(info))
# 索引和切片
print(info[2])
print(info[:2])
# 成员判断
print("yuan" in info)
# 拼接
print((1, 2) + (3, 4))
# 循环
for i in info:
print(i)
# 内置方法
print(t.index(5))
print(t.count(2))
8. 今日作业
-
反转列表中的元素顺序,
numbers = [5, 2, 9, 1, 7, 6] -
给定一个列表,筛选出列表中大于等于 5 的元素,并存储在一个新的列表中。
-
l=[23,4,5,66,76,12,88,23,65],l保留所有的偶数 -
列表元素求和:编写一个程序,计算给定列表中所有元素的和,但要跳过列表中的负数,
numbers = [1, 2, -3, 4, -5, 6, 7, -8, 9] -
编写一个程序,将列表中的所有字符串元素反转。
-
从一个列表中移除重复的元素,
numbers = [1, 2, 3, 2, 4, 3, 5, 6, 5] -
编写一个程序,找到给定列表中的最大值和最小值。
-
将二维列表中所有元素放在一个新列表中,
numbers = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] -
编写一个程序,计算给定列表中所有正数元素的平均值。
-
编写一个程序,找到给定列表中的所有大于平均值的元素并计算它们的总和
-
给定一个嵌套列表,表示学生的成绩数据,数据结构如下:
scores = [[85, 90, 78], [76, 82, 88], [90, 92, 86], [68, 72, 80], [92, 88, 90]]请编写程序完成以下操作:
-
计算每个学生的平均分。
-
计算每科的平均分。
-
-
引导用户输入页数(每页获取3条数据),实现对作品列表的切片获取,并进行格式化打印
# 假设您有一个作品列表 works = ["作品1", "作品2", "作品3", "作品4", "作品5", "作品6", "作品7", "作品8", "作品9", "作品10","作品11","作品12","作品13"] # 用户输入1则获取:["作品1", "作品2", "作品3"] page=1 [0:3] # 用户输入2则获取:["作品4", "作品5", "作品6"] page=2 [3:6] # 用户输入3则获取:["作品7", "作品8", "作品9"] page=3 [6:9] # 用户输入4则获取:["作品10", "作品11", "作品12"] page=4 [9:12] -
实现一个简单的 ToDo List(待办事项列表)功能,实现添加,删除,置顶和完成的代办事项。
todo_list = [] while True: print("========== ToDo List ==========") print("1. 添加代办事项") print("2. 删除代办事项") print("3. 置顶代办事项") print("4. 完成代办事项") print("5. 退出")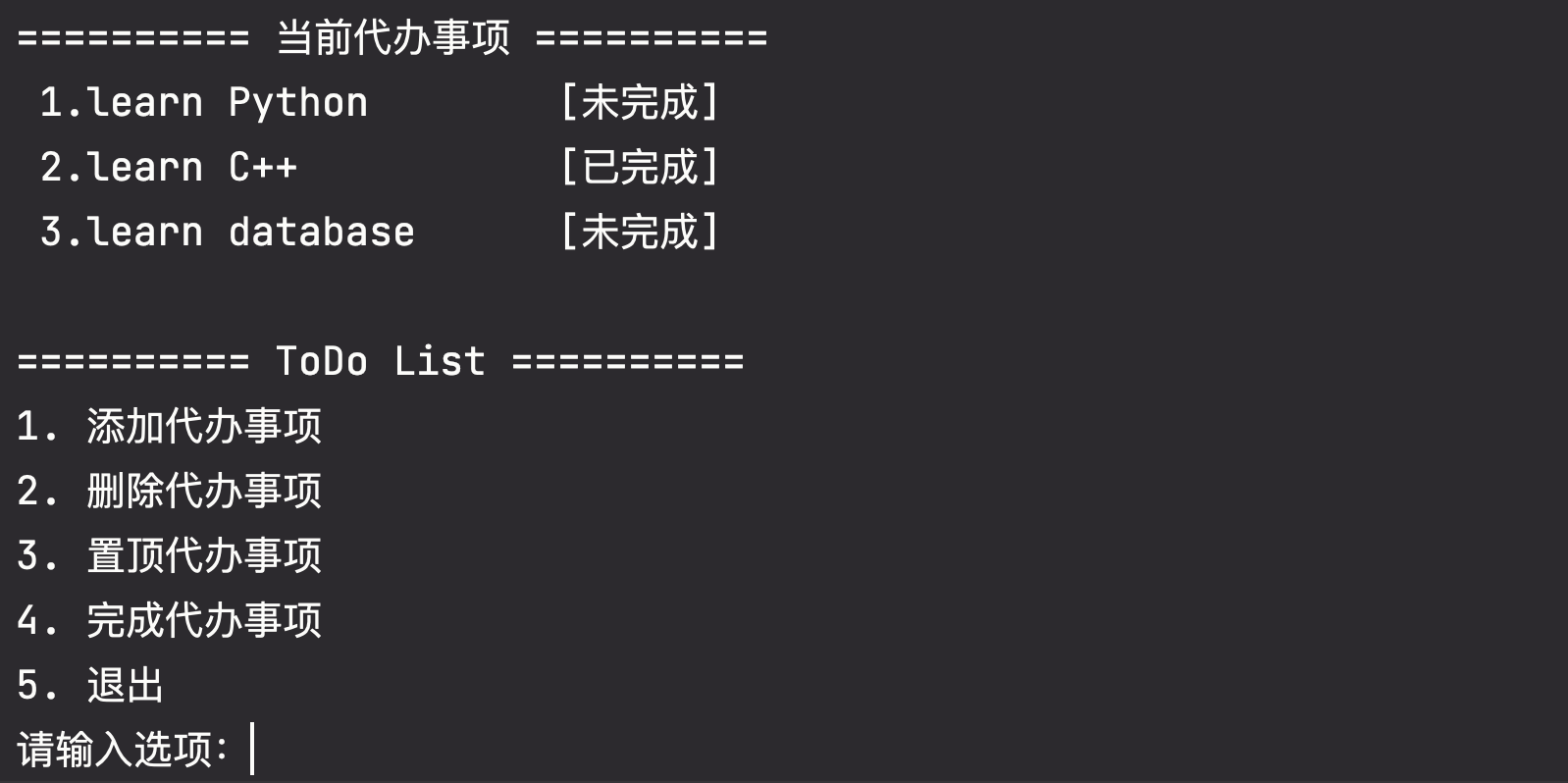
Day06:字典&集合

1. 字典的初识
【1】字典的创建与价值
字典(Dictionary)是一种在Python中用于存储和组织数据的数据结构。元素由键和对应的值组成。其中,键(Key)必须是唯一的,而值(Value)则可以是任意类型的数据。在 Python 中,字典使用大括号{}来表示,键和值之间使用冒号:进行分隔,多个键值对之间使用逗号,分隔。
# 列表
info_list = ["yuan", 18, 185, 70]
# 字典
info_dict = {"name": "yuan", "age": 18, "height": 185, "weight": 70}
print(type(info_dict)) # <class 'dict'>
字典类型很像学生时代常用的新华字典。我们知道,通过新华字典中的音节表,可以快速找到想要查找的汉字。其中,字典里的音节表就相当于字典类型中的键,而键对应的汉字则相当于值。

字典的灵魂:
字典是由一个一个的 key-value 构成的,字典通过键而不是通过索引来管理元素。字典的操作都是通过 key 来完成的。
【2】字典的存储与特点
hash:百度百科
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
字典对象的核心其实是个散列表,而散列表是一个稀疏数组(不是每个位置都有值),每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用,由于,所有bucket结构和大小一致,我们可以通过偏移量来指定bucket的位置
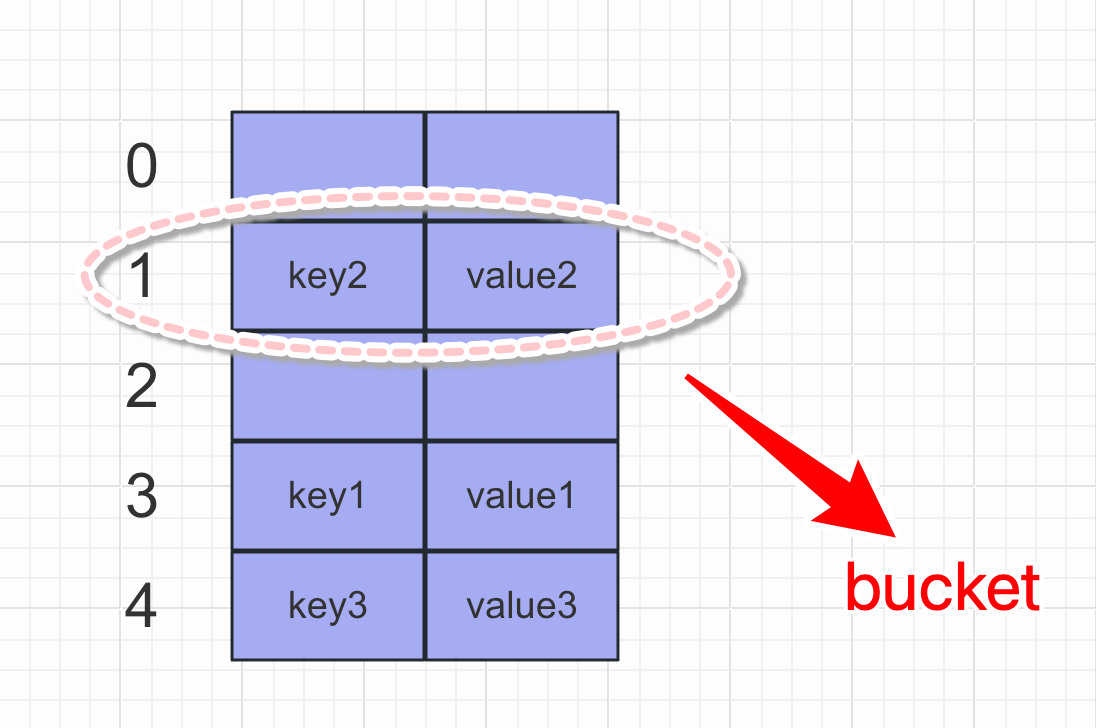
将一对键值放入字典的过程:
先定义一个字典,再写入值
d = {}
d["name"] = "yuan"
在执行第二行时,第一步就是计算"name"的散列值,python中可以用hash函数得到hash值,再将得到的值放入bin函数,返回int类型的二进制
print(bin(hash("name")))
结果为:
-0b100000111110010100000010010010010101100010000011001000011010
假设数组长度为10,我们取出计算出的散列值,最右边3位数作为偏移量,即010,十进制是数字2,我们查看偏移量为2对应的bucket的位置是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量011,十进制是数字3,再查看偏移量3的bucket是否为空,直到单元为空的bucket将键值放进去。以上就是字典的存储原理
当进行字典的查询时:
d["name"]
d.get("name")
第一步与存储一样,先计算键的散列值,取出后三位010,十进制为2的偏移量,找到对应的bucket的位置,查看是否为空,如果为空就返回None,不为空就获取键并计算键的散列值,计算后将刚计算的散列值与要查询的键的散列值比较,相同就返回对应bucket位置的value,不同就往前再取三位重新计算偏移量,依次取完后还是没有结果就返回None。
print(bin(hash("name")))每次执行结果不同:这是因为 Python 在每次启动时,使用的哈希种子(hash seed)是随机选择的。哈希种子的随机选择是为了增加哈希函数的安全性和防止潜在的哈希碰撞攻击。
字典的特点:
- 无序性:字典中的元素没有特定的顺序,不像列表和元组那样按照索引访问。通过键来访问和操作字典中的值。
- 键是唯一的且不可变类型对象,用于标识值。值可以是任意类型的对象,如整数、字符串、列表、元组等。
- 可变性:可以向字典中添加、修改和删除键值对。这使得字典成为存储和操作动态数据的理想选择。
2. 字典的基本操作
# 使用 { } 创建字典
gf = {"name":"高圆圆","age":32}
print(len(gf))
# (1) 查键值
print(gf["name"]) # 高圆圆
print(gf["age"]) # 32
# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
gf["age"] = 29 # 修改键的值
gf["gender"] = "female" # 添加键值对
# (3) 删除键值对 del 删除命令
print(gf)
del gf["age"]
print(gf)
del gf
print(gf)
# (4) 判断键是否存在某字典中
print("weight" in gf)
# (5) 循环
for key in gf:
print(key,d[key])
Python 字典中键(key)的名字不能被修改,我们只能根据键(key)修改值(value)。
3. 字典的内置方法

gf = {"name": "高圆圆", "age": 32}
# (1) 创建字典
knowledge = ['语文', '数学', '英语']
scores = dict.fromkeys(knowledge, 60)
print(scores)
# (2) 获取某键的值
print(gf.get("name")) # "高圆圆
# (3) 更新键值:添加或更改
gf.update({"age": 18, "weight": "50kg"})
print(gf) # {'name': '高圆圆', 'age': 18, 'weight': '50kg'}
# (4) 删除weight键值对
ret = gf.pop("weight") # 返回删除的值
print(gf)
# (5) 遍历字典键值对
for k, v in gf.items():
print(k, v)
4. 可变数据类型之字典
# 列表字典存储方式
l =[1,2,3]
d = {"a": 1, "b": 2}
# 案例1:
l1 = [3, 4, 5]
d1 = {"a": 1, "b": 2, "c": l1}
l1.append(6)
print(d1)
d1["c"][0] = 300
print(l1)
# 案例2:
d2 = {"x": 10, "y": 20}
d3 = {"a": 1, "b": 2, "c": d2}
d2["z"] = 30
# d3["c"].update({"z": 30})
print(d3)
# d3["c"]["x"] = 100
d3["c"].update({"x": 100})
print(d2)
d3["c"] = 3
# 案例3:
d4 = {"x": 10, "y": 20}
l2 = [1, 2, d4]
# d4["z"] = 30
# print(l2)
l2[2].pop("y")
print(d4)
5. 列表字典嵌套实战案例
【1】基于字典的客户信息管理系统
-
列表嵌套字典版本
# 初始化客户信息列表 customers = [ { "name": "Alice", "age": 25, "email": "alice@example.com" }, { "name": "Bob", "age": 28, "email": "bob@example.com" }, ] while 1: print(""" 1. 添加客户 2. 删除客户 3. 修改客户 4. 查询一个客户 5. 查询所有客户 6. 退出 """) choice = input("请输入您的选择:") if choice == "1": # (1) 添加客户 append name = input("请输入添加客户的姓名:") age = input("请输入添加客户的年龄:") email = input("请输入添加客户的邮箱:") new_customer = { "name": name, "age": age, "email": email } customers.append(new_customer) print(f"添加客户{name}成功!") # print("当前客户:", customers) elif choice == "2": # (2) 删除客户 del_customer_name = input("请输入删除客户的姓名:") flag = False for customerD in customers: # print(customerL) if customerD["name"] == del_customer_name: customers.remove(customerD) print(f"客户{del_customer_name}删除成功!") flag = True break if flag: print("当前客户列表:", customers) else: print(f"客户{del_customer_name}不存在!") elif choice == "3": # (3) 修改客户 update_customer_name = input("请输入修改客户的姓名:") name = input("请输入修改客户新的姓名:") age = input("请输入修改客户新的年龄:") email = input("请输入修改客户新的邮箱:") for customerD in customers: if customerD["name"] == update_customer_name: # customerD["name"] = name # customerD["age"] = age # customerD["email"] = email customerD.update({"name": name, "age": age, "email": email}) break print("当前客户列表:", customers) elif choice == "4": # (4) 查看某一个客户 query_customer_name = input("请输入查看客户的姓名:") for customerD in customers: # print("customerL",customerL) if customerD["name"] == query_customer_name: print(f"姓名:{customerD.get('name')},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}") break elif choice == "5": # (5) 遍历每一个一个客户信息 # if len(customers) == 0: if customers: for customerD in customers: print(f"姓名:{customerD.get('name'):10},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}") else: print("当前没有任何客户信息!") elif choice == "6": print("退出程序!") break else: print("输入内容格式不对!") -
字典嵌套字典版本
# 初始化客户信息列表 customers = { 1001: { "name": "Alice", "age": 25, "email": "alice@example.com" }, 1002: { "name": "Bob", "age": 28, "email": "bob@example.com" }, } while 1: print(""" 1. 添加客户 2. 删除客户 3. 修改客户 4. 查询一个客户 5. 查询所有客户 6. 退出 """) choice = input("请输入您的选择:") if choice == "1": # (1) 添加客户 append id = int(input("请输入添加客户的ID:")) if id in customers: # "1001" in {1001:...} print("该ID已经存在!") else: name = input("请输入添加客户的姓名:") age = input("请输入添加客户的年龄:") email = input("请输入添加客户的邮箱:") new_customer = { "name": name, "age": age, "email": email } # customers[id] = new_customer customers.update({id: new_customer}) print(f"添加客户{name}成功!") print("当前客户:", customers) elif choice == "2": # (2) 删除客户 del_customer_id = int(input("请输入删除客户的ID:")) if del_customer_id in customers: customers.pop(del_customer_id) print(f"删除{del_customer_id}客户成功!") print("当前客户:", customers) else: print("该ID不存在!") elif choice == "3": # (3) 修改客户 update_customer_id = int(input("请输入修改客户的ID:")) if update_customer_id in customers: name = input("请输入修改客户新的姓名:") age = input("请输入修改客户新的年龄:") email = input("请输入修改客户新的邮箱:") # 方式1: # customers[update_customer_id]["name"] = name # customers[update_customer_id]["age"] = age # customers[update_customer_id]["email"] = email # 方式2: customers[update_customer_id].update({"name": name, "age": age, "email": email}) # 方式3: # customers[update_customer_id] = { # "name": name, # "age": age, # "email": email, # } print(f"{update_customer_id}客户修改成功!") print("当前客户:", customers) else: print("该ID不存在!") elif choice == "4": # (4) 查看某一个客户 query_customer_id = int(input("请输入查看客户的ID:")) if query_customer_id in customers: customerD = customers[query_customer_id] print(f"姓名:{customerD.get('name')},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}") else: print("该客户ID不存在!") elif choice == "5": # (5) 遍历每一个一个客户信息 # if len(customers) == 0: if customers: for key,customerDict in customers.items(): print(f"客户ID:{key},姓名:{customerDict.get('name'):10},年龄:{customerDict.get('age')},邮箱:{customerDict.get('email')}") else: print("当前没有任何客户信息!") elif choice == "6": print("退出程序!") break else: print("输入内容格式不对!")
【2】天气预报数据解析
# https://yiketianqi.com/
# https://v1.yiketianqi.com/api?unescape=1&version=v91&appid=47284135&appsecret=jlmX3A6s&ext=&cityid=&city=
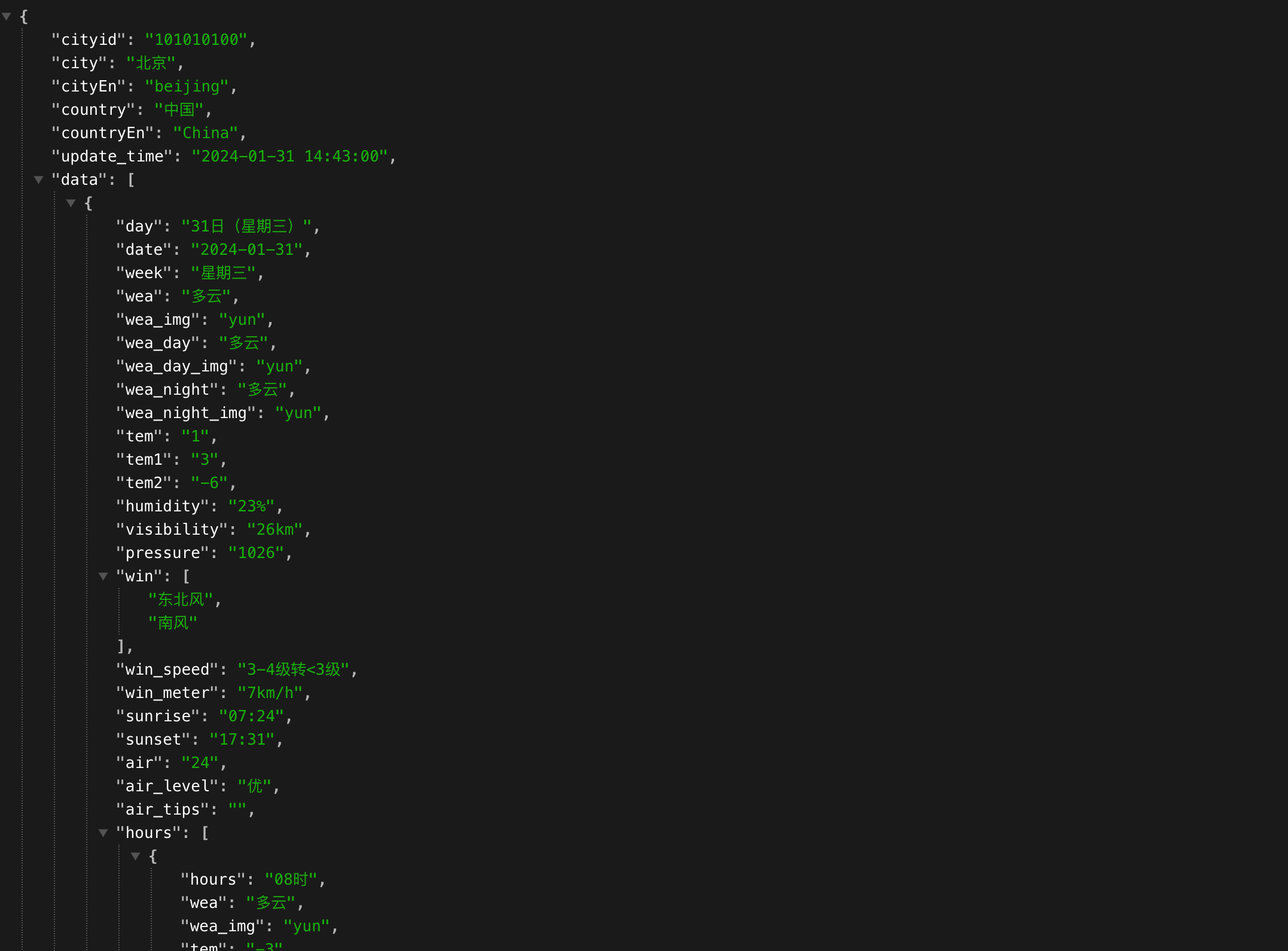
print(data["aqi"])
print(data.get("aqi").get("waichu"))
data.get("data")[2]["tem"] = 100
print(data.get("data")[2].get("tem"))
print(data.get("data")[2].get("humidity"))
data_list = data.get("data")
for i in data_list:
print(f"{i.get('day')} 天气状况:{i.get('wea')},平均温{i.get('tem')}")
print(len(i.get("hours")))
练习题:
# 练习:打印每天大于0度的小时以及对应度数
data_list = data.get("data")
for dayDict in data_list:
print(dayDict.get("day"))
isEmpty = True
for hourDict in dayDict.get("hours"):
tem = int(hourDict.get("tem"))
if tem > 1:
isEmpty = False
# print(hourDict.get("hours"), hourDict.get("tem"), sep=":", end="\t")
print(f'{hourDict.get("hours")}({tem}度)', end="\t")
if isEmpty:
print("该天没有任何一个时刻大于1!", end="")
print()
【3】解析豆瓣电影数据
# https://movie.douban.com/explore
【4】解析抖音短视频
# https://www.douyin.com/user/MS4wLjABAAAA0HwZJN6-JDCSTjxiMk-czhyZWxes8XIDEjppFXExauK8-kQTLMEH9ZdfIXxnl9tS
6. 集合
集合(Set)是Python中的一种无序、不重复的数据结构。集合是由一组元素组成的,这些元素必须是不可变数据类型,但在集合中每个元素都是唯一的,即集合中不存在重复的元素。
集合的基本语法和特性:
s1 = {1,2,3}
print(len(s1))
print(type(s1))
# 元素值必须是不可变数据类型
# s1 = {1, 2, 3,[4,5]} # 报错
# (1) 无序:没有索引
# print(s1[0])
# (2) 唯一: 集合可以去重
s2 = {1, 2, 3, 3, 2, 2}
print(s2)
# 面试题:
l = [1, 2, 3, 3, 2, 2]
# 类型转换:将列表转为set
print(set(l)) # {1, 2, 3}
print(list(set(l))) # [1, 2, 3]
- 无序性:集合中的元素是无序的,即元素没有固定的顺序。因此,不能使用索引来访问集合中的元素。
- 唯一性:集合中的元素是唯一的,不允许存在重复的元素。如果尝试向集合中添加已经存在的元素,集合不会发生变化。
- 可变性:集合是可变的,可以通过添加或删除元素来改变集合的内容。
集合的内置方法:

s3 = {1, 2, 3}
# 增删改查
# 增
s3.add(4)
s3.add(3)
print(s3)
s3.update({3, 4, 5})
print(s3)
# l = [1, 2, 3]
# l.extend([3, 4, 5])
# print(l)
# 删
s3.remove(2)
s3.remove(222)
s3.discard(2)
s3.discard(222)
s3.pop()
s3.clear()
print(s3) # set()
# 方式1: 操作符 交集(&) 差集(-) 并集(|)
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
print(s1 & s2) # {3, 4}
print(s2 & s1) # {3, 4}
print(s1 - s2) # {1, 2}
print(s2 - s1) # {5, 6}
print(s1 | s2) # {1, 2, 3, 4, 5, 6}
print(s2 | s1) # {1, 2, 3, 4, 5, 6}
print(s1, s2)
# 方式2:集合的内置方法
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
# 交集
print(s1.intersection(s2)) # {3, 4}
print(s2.intersection(s1)) # {3, 4}
# 差集
print(s1.difference(s2)) # {1, 2}
print(s2.difference(s1)) # {5, 6}
print(s1.symmetric_difference(s2)) # {1, 2, 5, 6}
print(s2.symmetric_difference(s1)) # {1, 2, 5, 6}
# 并集
print(s1.union(s2)) # {1, 2, 3, 4, 5, 6}
print(s2.union(s1)) # {1, 2, 3, 4, 5, 6}
商品推荐系统案例:
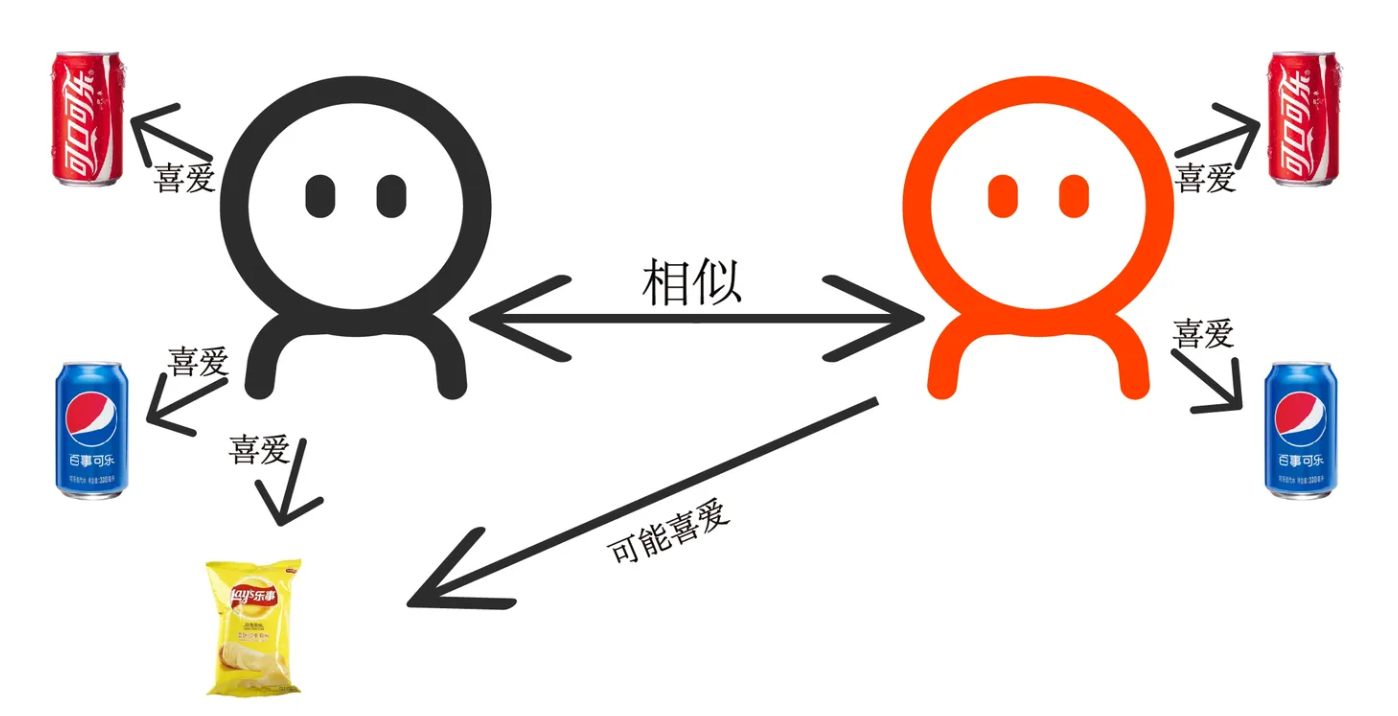
peiQi_hobby = {"螺狮粉", "臭豆腐", "榴莲", "apple"}
alex_hobby = {"螺狮粉", "臭豆腐", "榴莲", "💩", 'pizza'}
yuan_hobby = {"pizza", "salad", "ice cream", "臭豆腐", "榴莲", }
hobbies = [peiQi_hobby, yuan_hobby, alex_hobby]
# 给peiQi推荐商品:
# 版本1:
hobbies.remove(peiQi_hobby)
peiQi_list = []
for hobby in hobbies:
if len(peiQi_hobby.intersection(hobby)) >= 2:
# print(list(hobby - peiQi_hobby))
peiQi_list.extend(list(hobby - peiQi_hobby))
print(list(set(peiQi_list)))
# 版本2:
hobbies.remove(peiQi_hobby)
# peiQi_set = {}
# print(type(peiQi_set))
peiQi_set = set()
for hobby in hobbies:
if len(peiQi_hobby.intersection(hobby)) >= 2:
# print(hobby - peiQi_hobby)
peiQi_set.update(hobby - peiQi_hobby)
print(list(peiQi_set))
7. 今日作业
- 给定两个字典,找到它们共有的键存放到一个列表中
dict1 = {'A': 1, 'B': 2, 'C': 3, 'D': 4}
dict2 = {'B': 20, 'D': 40, 'E': 50}
- 给定一个字典,找到字典中值最大的键:
my_dict = {'A': 10, 'B': 5, 'C': 15, 'D': 20} - 字典值的乘积:编写一个程序,计算给定字典中所有值的乘积:
my_dict = {'A': 2, 'B': 3, 'C': 4, 'D': 5} - 编写一个程序,统计给定列表中每个元素出现的次数,并将结果存储在一个字典中。
my_list = [1, 2, 3, 2, 1, 3, 4, 5, 2, 1]
# 元素出现次数: {1: 3, 2: 3, 3: 2, 4: 1, 5: 1}
- 编写一个程序,将两个字典合并,并将相同键对应的值进行加法运算。
dict1 = {'A': 1, 'B': 2, 'C': 3}
dict2 = {'B': 10, 'D': 20, 'C': 30}
-
对列表元素先去重再排序:
l = [1, 12, 1, 2, 2, 3, 5] -
假设有一个班级的学生成绩数据,数据结构如下:
students = [
{"name": "Alice", "score": 85},
{"name": "Bob", "score": 76},
{"name": "Charlie", "score": 90},
{"name": "David", "score": 68},
{"name": "Eva", "score": 92}
]
请编写程序完成以下操作:
- 计算学生人数。
- 计算班级总分和平均分。
- 找出成绩最高和最低的学生。
- 假设有一个嵌套字典,表示学生的成绩数据,数据结构如下:
students = {
"Alice": {"math": 85, "english": 90, "history": 78},
"Bob": {"math": 76, "english": 82, "history": 88},
"Charlie": {"math": 90, "english": 92, "history": 86},
"David": {"math": 68, "english": 72, "history": 80},
"Eva": {"math": 92, "english": 88, "history": 90}
}
请编写程序完成以下操作:
-
打印每个学生的姓名和总分。
-
打印每个学生的平均分。
- 配置字典中的查询操作:更新config中服务器的端口为
8090,日志级别更新为DEBUG
config = {
"数据库": {
"主机": "localhost",
"端口": 3306,
"用户名": "admin",
"密码": "password"
},
"服务器": {
"IP地址": "192.168.0.1",
"端口": 8080,
"日志级别": "INFO"
},
# ...
}
-
解析课上的抖音数据中每一个作品的音乐信息,将所有的作品的music的作者,title以及播放的url,三个信息放在一个元组中,所有作品对应元组放在大列表中。
-
基于以下数据结构实现一个购物车系统,可以添加商品到购物车,删除商品,打印当前购物车所有商品以及总价
shopping_cart = [
{
"name": "mac电脑",
"price": 14999,
"quantity": 1
},
{
"name": "iphone15",
"price": 9980,
"quantity": 1
}
]
模块总结&作业
总结
本模块的学习目标:
- 理解变量的概念并能够声明和使用变量。
- 熟悉Python的基本数据类型,包括整数、浮点数、字符串、布尔值等,并能够进行基本的操作和转换。
- 理解列表的概念,能够创建和操作列表,包括索引、切片、添加、删除等操作。
- 理解字典的概念,能够创建和使用字典,包括添加、删除、修改键值对等操作。
- 熟悉流程控制语句,包括条件语句(if-else语句)、循环语句(for循环、while循环)和控制流程(break、continue语句)。
- 能够熟练使用各种运算符对数据对象进行计算、处理和输出。
- 能够运用列表和字典来组织和处理数据,解决相关的问题。
- 能够运用条件语句和循环语句来控制程序的执行流程,实现特定的功能。
模块作业
1. 学生选课系统
学生信息管理:实现学生的注册和登录功能,包括学生姓名、学号等信息的管理。可以使用字典来存储学生信息。课程信息管理:实现课程的添加和查看功能,包括课程名称、课程代码等信息的管理。可以使用列表或字典来存储课程信息。选课功能:学生可以从可选的课程中选择感兴趣的课程,并将其加入已选课程列表。可以使用列表或字典来存储学生的已选课程。退课功能:学生可以从已选课程中退选某门课程,并从已选课程列表中删除。查看已选课程:学生可以查看自己已选修的课程列表。用户界面:设计一个用户友好的文字界面,使用户能够方便地进行选课和管理操作。
# 选课系统代码提示
# 学生信息字典
students = {}
# 课程信息字典
courses = {
"CS101": "计算机科学导论",
"ENG201": "高级英语写作",
"MATH301": "线性代数",
"PHYS401": "物理学原理",
"HIST501": "世界历史概论"
}
# 学生选课字典
student_courses = {}
is_login = False
while True:
print("欢迎使用选课系统!")
print("1. 注册学生")
print("2. 登录")
print("3. 选课")
print("4. 退课")
print("5. 查看已选课程")
print("6. 退出系统")
模块2:Python进阶
模块概述
函数是一段可重复使用的代码块,它接受输入参数并返回一个结果。函数可以用于执行特定的任务、计算结果、修改数据等,使得代码更具模块化和可重用性。
模块是一组相关函数、类和变量的集合,它们被封装在一个单独的文件中。模块提供了一种组织和管理代码的方式,使得代码更易于理解、维护和扩展。通过引入模块,我们可以直接使用其中定义的函数、类和变量,而无需重复编写代码。
函数和模块是Python中重要的概念,它们提供了一种有效的方式来组织和管理代码。函数可以增加代码的可读性、可维护性和可扩展性,而模块则进一步提供了命名空间的隔离和代码复用的机制。通过合理使用函数和模块,我们可以编写更加模块化、可维护和可扩展的代码。
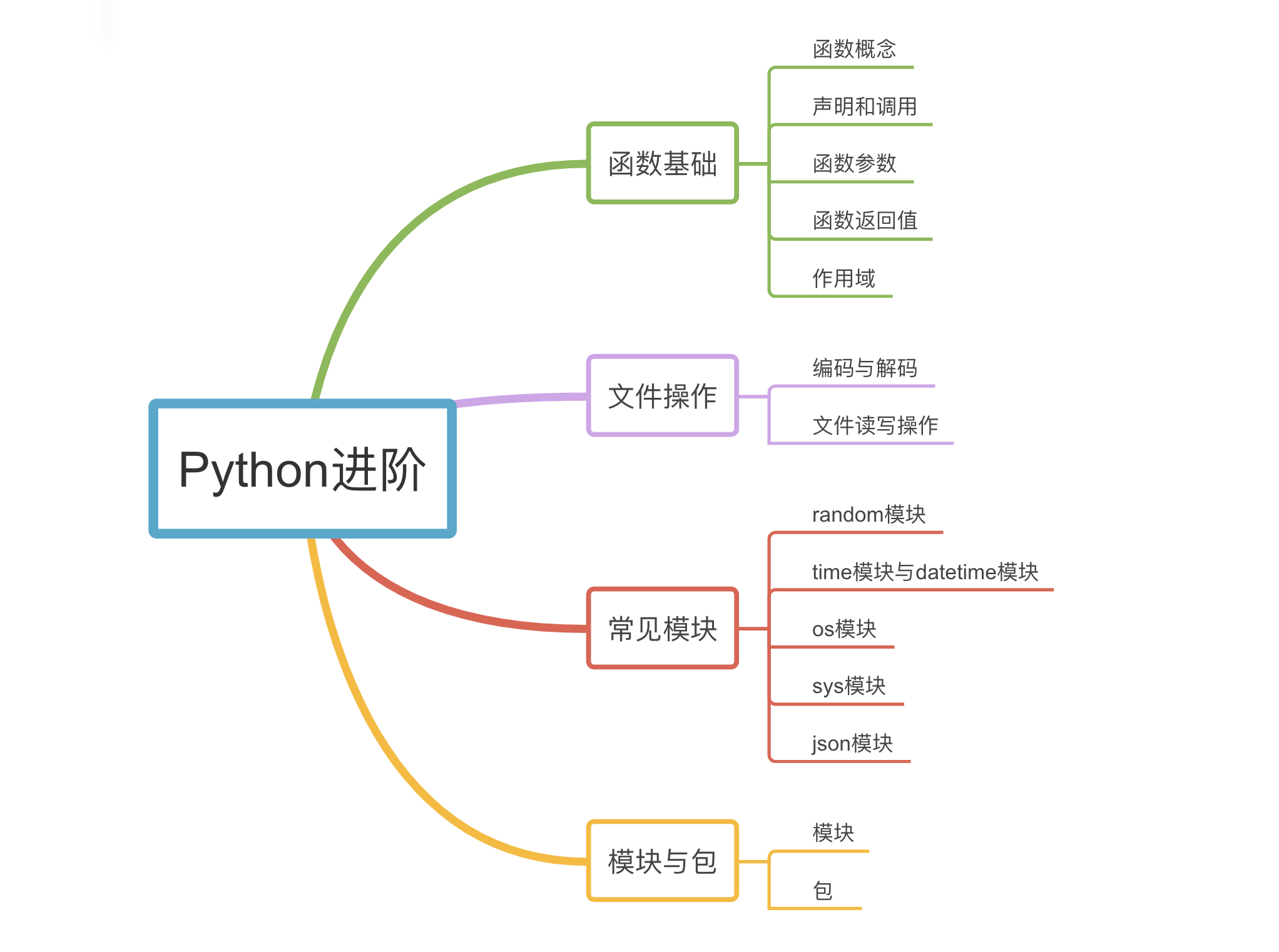
Day07:函数基础

一个程序有些功能代码可能会用到很多次,如果每次都写这样一段重复的代码,不但费时费力、容易出错,而且交给别人时也很麻烦,所以编程语言支持将代码以固定的格式封装(包装)成一个独立的代码块,只要知道这个代码块的名字就可以重复使用它,这个代码块就叫做函数(Function)。
函数的本质是一功能代码块组织在一个函数名下,可以反复调用。
去重(函数可以减少代码的重复性。通过将重复的代码逻辑封装成函数,可以避免在不同的地方重复编写相同的代码)
解耦(函数对代码的组织结构化可以将代码分成逻辑上独立的模块,提高代码的可读性和可维护性,从而实现解耦)
# 案例1:
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
for p_type in poke_types:
for p_num in poke_nums:
print(f"{p_type}{p_num}", sep="\t", end="")
print()
美国人将函数称为“Function”。Function 除了有“函数”的意思,还有“功能”的意思,中国人将 Function 译为“函数”而不是“功能”,是因为C语言中的函数和数学中的函数在使用形式上有些类似。
函数是一种数学概念,它描述了两个数集之间的关系。通俗地说,函数就是一种将输入映射为输出的规则,它可以将一个或多个输入值转换为一个输出值。
如果定义一个函数 f(x) = x^2,那么当输入为 3 时,函数的输出值为 9。
1. 函数声明与调用
# (1) 函数声明
def 函数名():
# 函数体【功能代码块】
# (2)函数调用
函数名()
案例1:
# 函数声明
def print_pokes():
print("=" * 40)
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
for p_type in poke_types:
for p_num in poke_nums:
print(f"{p_type}{p_num}", sep="\t", end="")
print()
print("=" * 40)
# 函数调用
print_pokes()
# 函数调用
print_pokes()
# 函数调用
print_pokes()
2. 函数参数
在编程中,函数的参数指的是函数定义中声明的变量,用于接收函数调用时传递的数据。参数允许我们将值或引用传递给函数,以便在函数内部使用这些值进行计算、操作或处理。
函数参数可以有多个,每个参数都有一个名称和类型。函数定义中的参数称为形式参数(或简称为形参),而函数调用 时传递的实际值称为实际参数(或简称为实参)。
函数的参数允许函数在不同的上下文中接收不同的数据,并且增加了函数的灵活性和可复用性。通过合理使用函数参数,可以编写出更通用、灵活的函数。
# 案例1:
def cal(n):
ret = 0
for i in range(1, n + 1):
ret += i
print(ret)
cal(100)
- 内置函数:print,type都需要传参数
- 函数传递参数本质是变量赋值,且该变量只在函数运行时存在,运行结束销毁
【1】位置参数
位置参数是按照定义时的顺序进行传递的参数。调用函数时,实参的位置必须与形参的位置一一对应。
# 案例1
def add(x, y): # x,y是形式参数,简称形参
print(x + y)
# add(10, 20) # 10,20是实际参数,简称实参
a = 1
b = 2
add(a, b)
# 案例2
def cal(start, end):
ret = 0
for i in range(start, end + 1):
ret += i
print(ret)
cal(100, 1000)
# 案例3
def send_email(recipient, subject, content):
print("发送邮件...")
print(f"收件人:{recipient}", )
print(f"主题:{subject}")
print(f"内容:{content}")
r = "alex@example.com"
s = "重要通知"
c = "Alex,你已经被解雇,明天不用来公司了!"
send_email(r, s, c)
r = "yuan@example.com"
s = "重要通知"
c = "yuan老师,您太辛苦了,给您涨薪十万!!"
send_email(r, s, c)
【2】默认参数
默认参数是在函数声明时为参数指定默认值。如果在函数调用时没有传递该参数的值,函数将使用默认值。
# 案例1:
def show_info(name, age, height, weight, gender):
print(f"【姓名:{name}】")
print(f"【年龄:{age}】")
print(f"【身高:{height}】")
print(f"【体重:{weight}】")
print(f"【性别:{gender}】")
show_info("yuan", 18, 185, 60, "男")
# 案例2
shopping_cart = [
{
"name": "mac电脑",
"price": 14999,
"quantity": 1
},
{
"name": "iphone15",
"price": 9980,
"quantity": 3
}
]
def cal_total(shopping_cart,discount):
# 计算总价
total = 0
for goods in shopping_cart:
total += goods["price"] * goods["quantity"]
# 最后再算一个折扣
total = round(total * discount)
print(total)
cal_total(shopping_cart,0.8)
注意,如果有默认参数,默认参数一定放在非默认参数后面
练习案例:累加和案例,传一个参数,则为end,传两个值,分别是start和end
【3】关键字参数
关键字参数是通过指定参数名来传递的参数。调用函数时,可以根据参数名来传递实参,而不必遵循形参的顺序。
def show_info(name, age, height, weight):
print(f"【姓名:{name}】")
print(f"【年龄:{age}】")
print(f"【身高:{height}】")
print(f"【体重:{weight}】")
show_info("yuan", height=180, weight=60, age=18)
show_info("yuan", height=180, weight=60, 18)
关键字参数一定要在位置参数后面
关键字参数+默认参数
# 经典用法:默认参数+关键字参数
def show_info(name, age, height=None, weight=None, gender="男"):
print(f"【姓名:{name}】")
print(f"【年龄:{age}】")
if height:
print(f"【身高:{height}】")
if weight:
print(f"【体重:{weight}】")
print(f"【性别:{gender}】")
show_info("yuan", 18, None, 60)
show_info("yuan", 18, weight=60)
show_info("june", 18, gender="女")
练习:查询飞机票函数
def check_air_ticket(from_, to_, date="2024-6-1", airline_company="all", seat_class="经济舱", max_price=None):
query = f"数据库查询:{date} :{from_}到{to_}的{airline_company}的{seat_class}机票"
if max_price is not None:
query += f",最高价格不超过{max_price}元"
print(query)
# check_air_ticket("北京", "上海", max_price=2000)
check_air_ticket(from_="北京", to_="上海", seat_class="商务舱", max_price=2000)
【4】可变参数
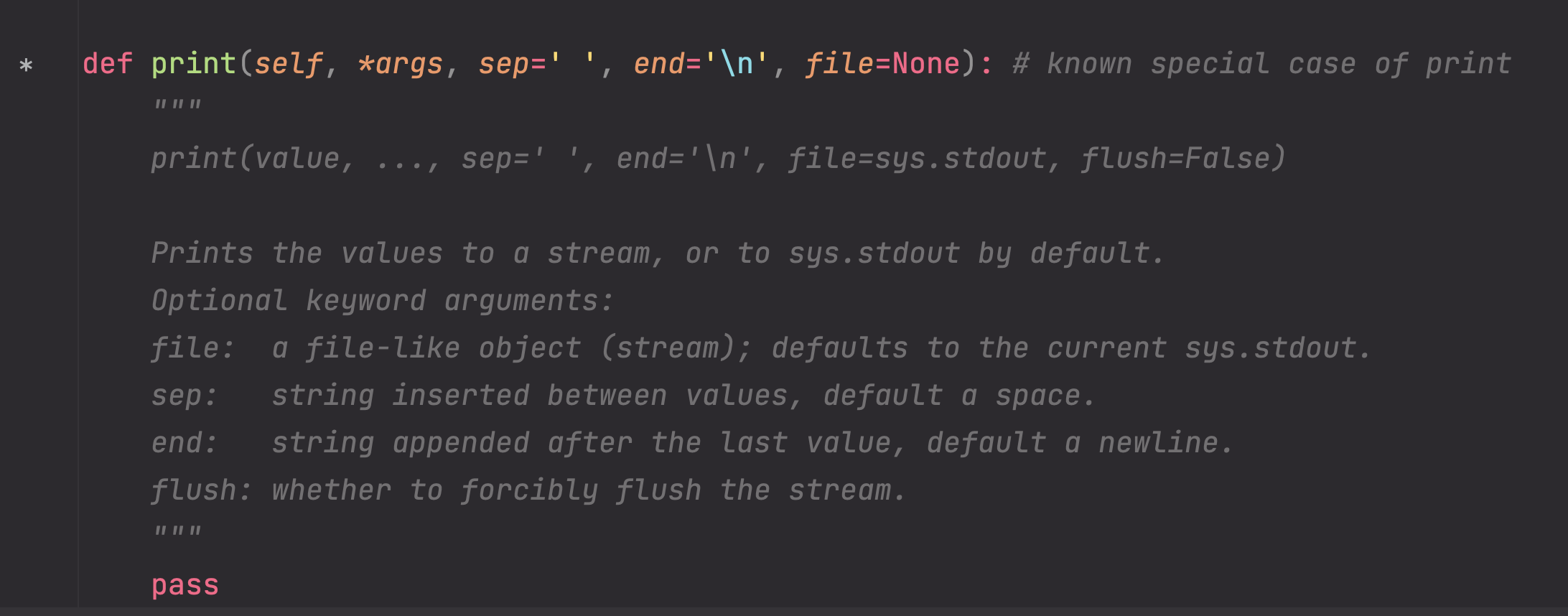
可变数量参数允许函数接受不定数量的参数。在函数定义中,可以使用特殊符号来表示可变数量的参数,如*args用于接收任意数量的位置参数,**kwargs用于接收任意数量的关键字参数。
*args的用法:
a, b, *c = [1, 2, 3, 4, 5]
def add(*args):
s = 0
for i in args:
s += i
print(s)
add(1, 2, 3, 4)
案例:print函数
**kwargs的用法:
# 用法1:函数调用的时候使用
def my_function(a, b, c):
print(a, b, c)
a = {'a': 1, 'b': 2, 'c': 3}
my_function(**a)
# 用法2:函数声明的时候使用
def send_email(recipient, subject, body, **kwargs): # **kwargs处理默认参数太多的情况
cc = kwargs.get('cc')
bcc = kwargs.get('bcc')
# 发送邮件的逻辑
print("Sending email...")
print(f"Subject: {subject}")
print(f"Body: {body}")
print(f"To: {recipient}")
print(f"CC: {cc}")
print(f"BCC: {bcc}")
r = "alex@example.com"
s = "重要通知"
c = "Alex,你已经被解雇,明天不用来公司了!"
# 示例调用
send_email(r, s, c, cc="bob@example.com", bcc="charlie@example.com")
def test(a, *b, **c):
print("a", a)
print("b", b)
print("c", c)
test(1, 2, 3, 4, x=10, y=20, z=30)
3. 函数作用域
作用域(Scope)是指在程序中定义变量或函数时,这些变量或函数可被访问的范围。在不同的作用域中,变量和函数的可见性和访问性是不同的。
当访问一个变量时,Python 会按照 LEGB 的顺序进行查找,直到找到第一个匹配的变量,然后停止查找。如果在所有作用域中都找不到变量的定义,就会引发 NameError。
- L(Local):局部作用域。包括函数内部定义的变量和参数。在函数内部最先进行变量查找。
- E(Enclosing):嵌套函数的父函数的作用域。如果在当前函数内部找不到变量,就会向上一层嵌套的函数中查找。
- G(Global):全局作用域。在模块层次定义的变量,对于整个模块都是可见的。
- B(Built-in):内置作用域。包括 Python 的内置函数和异常。
x = 10 # 全局作用域
def outer_func():
x = 20 # 外部函数作用域
def inner_func():
x = 30 # 内部函数作用域
print(x) # 在内部函数中访问变量 x
inner_func()
outer_func()
print(x) # 在全局作用域中访问变量 x
与函数相关的变量尽量放在函数中,防止全局变量污染
# 案例1
def add(x, y): # x,y是形式参数,简称形参
print(x + y)
x = 10
y = 20
add(x , y) # 10,20是实际参数,简称实参
-
global关键字用于在函数内部声明一个变量为全局变量,表示在函数内部对该变量的修改将影响到全局作用域中的变量。例如:x = 10 def my_function(): global x x = 20 print(x) my_function() # 输出结果为 20 print(x) # 输出结果为 20在函数
my_function内部,使用global关键字声明了变量x为全局变量,然后对其进行了修改。这样,变量x的作用域扩展到了全局范围,所以在函数外部也可以访问到修改后的值。 -
nonlocal关键字用于在函数内部声明一个变量为非本地变量,表示在函数内部对该变量的修改将影响到上一级的嵌套作用域中的变量。例如:def outer_function(): x = 10 def inner_function(): nonlocal x x = 20 print(x) inner_function() # 输出结果为 20 print(x) # 输出结果为 20 outer_function()在
inner_function内部,使用nonlocal关键字声明了变量x为非本地变量,然后对其进行了修改。这样,变量x的作用域扩展到了outer_function的作用域,所以在outer_function内部和外部都可以访问到修改后的值。
4. 函数返回值
函数的返回值是指函数执行完毕后,通过 return 语句返回给调用者的结果。
使用 return 语句可以将一个值或对象作为函数的返回值返回。这个返回值可以是任何有效的Python对象,例如数字、字符串、列表、字典等。函数执行到 return 语句时,会立即结束函数的执行,并将指定的返回值传递给调用者。
如果函内没有return,默认返回None,代表没有什么结果返回
下面是一个简单的函数示例,演示了如何使用返回值:
# 案例1
def add_numbers(a, b):
s = a + b
return s
result = add_numbers(3, 5)
print(result) # 输出: 8
在案例1 中,add_numbers 函数接受两个参数 a 和 b,将它们相加得到 sum,然后通过 return 语句将 sum 返回给调用者。在函数被调用时,返回值被赋值给变量 result,然后可以在后续的代码中使用。
5. 常用的内置函数
Python提供了许多内置函数,这些函数是Python语言的一部分,无需导入任何模块即可使用。
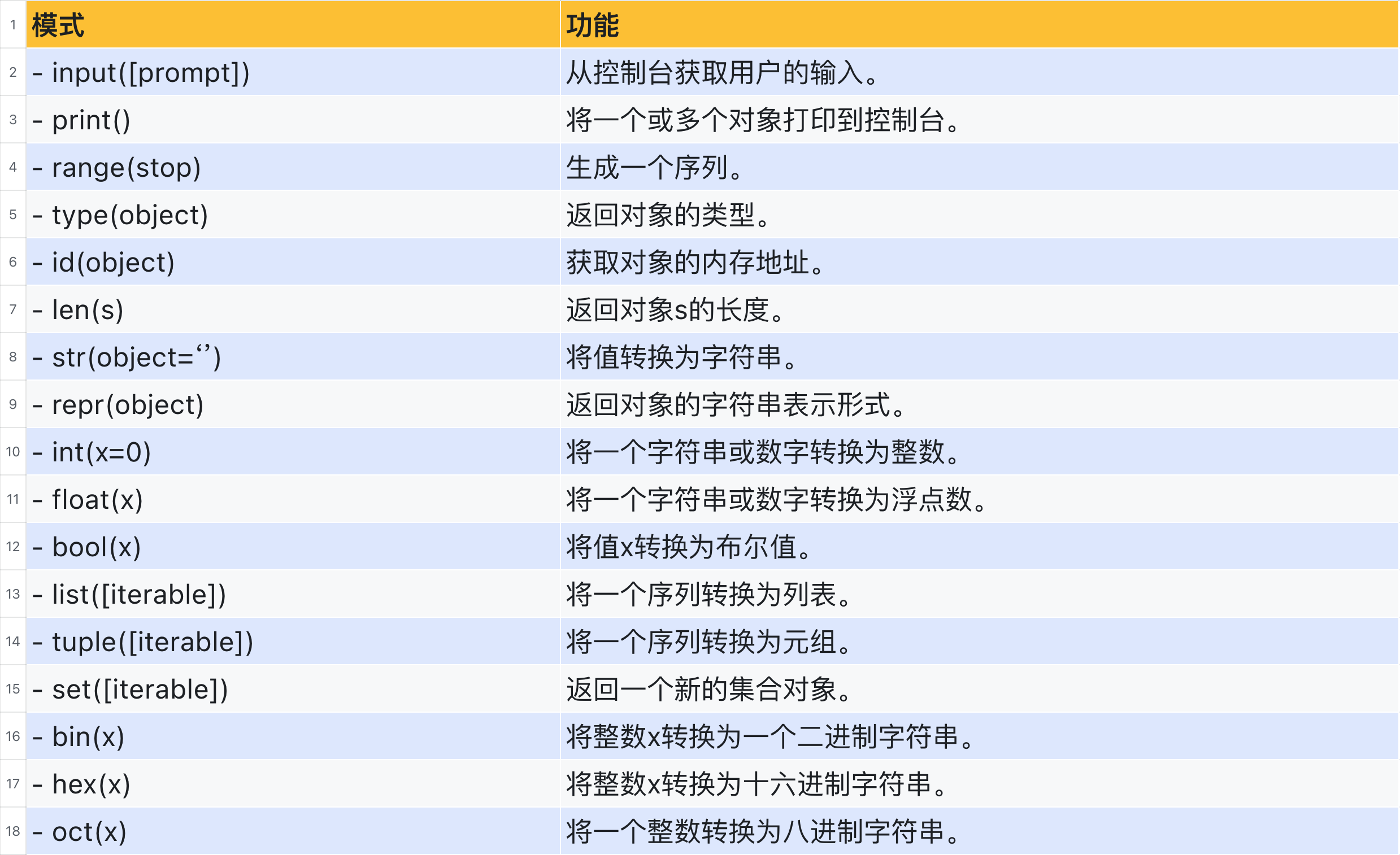
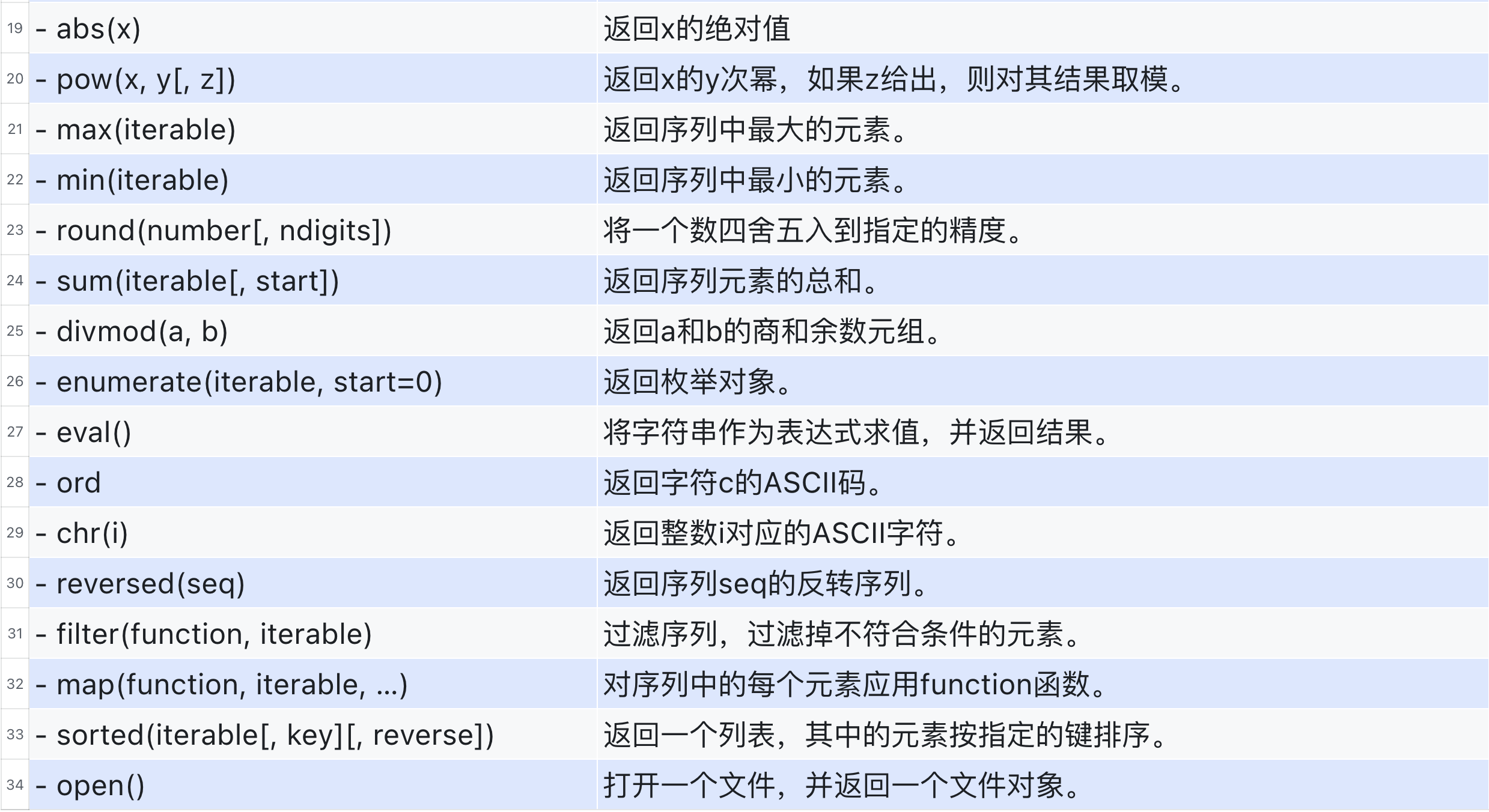
6. 案例【函数版】
(1)之前的案例函数化
# (1) 计算某段文本中原音字母出现的次数
def cal_num(text):
count = 0
for char in text:
if char.lower() in "aeiou":
count += 1
return count
data = input("请输入一段文本:")
c = cal_num(data)
print("元音字母出现次数:", c)
# (2) 计算初始本金为1万,年利率为0.0325的情况下,需要多少年才能将本金和利息翻倍,即本金和利息的总和达到原来的两倍。
def cal_year(base, back, rate=0.0325):
# base = 10000
# rate = 0.0325
total = base
year = 0
while total < back:
total = total + total * rate
# print(total)
year += 1
return year
print(cal_year(10000,20000))
print(cal_year(10000,100000,0.03))
# (3) 编写一个程序,生成斐波那契数列的第20个数字(斐波那契数列是指从0和1开始,后面的每一项都是前两项的和)
# 0 1 1 2 3 5
def get_fib(n):
pre = 0
current = 1
next_num = 1
for _ in range(n):
next_num = pre + current
# print("next:", next_num)
pre = current
current = next_num
return next_num
print(get_fib(10))
# (4) 打印n*n矩阵
def get_matrix(n):
# n = 5
for r in range(1, n + 1):
for c in range(1, n + 1):
print(f"{r + c}\t", end="")
print()
get_matrix(5)
get_matrix(7)
get_matrix(10)
# (5) 重写 max min函数
num = [23, 2, 5, 66, 76, 12, 88, 23, 65]
def my_max(numbers):
max_value = numbers[0]
for i in numbers:
if i > max_value:
max_value = i
return max_value
print(my_max(num))
print(max(num))
# (6) 获取字典中最大值和对应键
def get_max_val(my_dict):
max_val = 0
max_val_key = None
for key, val in my_dict.items():
if val > max_val:
max_val = val
max_val_key = key
return (max_val_key, max_val)
data = {'A': 10, 'B': 5, 'C': 35, 'D': 20}
print(get_max_val(data))
# (7) 查询列表元素重复次数
def cal_val_num(l):
count_dict = {}
for i in l:
if i in count_dict:
# count_dict[i] +=1
count_dict[i] = count_dict[i] + 1
else:
count_dict[i] = 1
return count_dict
my_list = [1, 2, 3, 2, 1, 3, 4, 5, 2, 1]
print(cal_val_num(my_list))
(2)客户关系管理系统【函数版】
# 初始化客户信息列表
customers = {
1001: {
"name": "Alice",
"age": 25,
"email": "alice@example.com"
},
1002: {
"name": "Bob",
"age": 28,
"email": "bob@example.com"
},
}
# 添加客户功能
def add_customer():
# (1) 添加客户 append
id = int(input("请输入添加客户的ID:"))
if id in customers: # "1001" in {1001:...}
print("该ID已经存在!")
else:
name = input("请输入添加客户的姓名:")
age = input("请输入添加客户的年龄:")
email = input("请输入添加客户的邮箱:")
new_customer = {
"name": name,
"age": age,
"email": email
}
# customers[id] = new_customer
customers.update({id: new_customer})
print(f"添加客户{name}成功!")
print("当前客户:", customers)
# 删除客户
def del_customer():
# (2) 删除客户
del_customer_id = int(input("请输入删除客户的ID:"))
if del_customer_id in customers:
customers.pop(del_customer_id)
print(f"删除{del_customer_id}客户成功!")
print("当前客户:", customers)
else:
print("该ID不存在!")
# 修改客户
def update_customer():
# (3) 修改客户
update_customer_id = int(input("请输入修改客户的ID:"))
if update_customer_id in customers:
name = input("请输入修改客户新的姓名:")
age = input("请输入修改客户新的年龄:")
email = input("请输入修改客户新的邮箱:")
customers[update_customer_id].update({"name": name, "age": age, "email": email})
print(f"{update_customer_id}客户修改成功!")
print("当前客户:", customers)
else:
print("该ID不存在!")
# 查询一个客户
def query_one_customer():
# (4) 查看某一个客户
query_customer_id = int(input("请输入查看客户的ID:"))
if query_customer_id in customers:
customerD = customers[query_customer_id]
print(f"姓名:{customerD.get('name')},年龄:{customerD.get('age')},邮箱:{customerD.get('email')}")
else:
print("该客户ID不存在!")
def show_all_customers():
# (5) 遍历每一个一个客户信息
# if len(customers) == 0:
if customers:
for key, customerDict in customers.items():
print(
f"客户ID:{key},姓名:{customerDict.get('name'):10},年龄:{customerDict.get('age')},邮箱:{customerDict.get('email')}")
else:
print("当前没有任何客户信息!")
def main():
while 1:
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 退出
""")
choice = input("请输入您的选择:")
handler = {
"1": add_customer,
"2": del_customer,
"3": update_customer,
"4": query_one_customer,
"5": show_all_customers,
}
handler.get(choice)()
main()
7. 今日作业
- 编写一个函数,获取用户输入圆的半径。使用圆的周长和面积公式计算并打印出输入半径的圆的周长和面积。
- 编写一个函数,计算BMI并给出健康建议
- 编写一个函数,输入长度,获取该长度的随机验证码
- 编写一个函数,计算列表中所有元素的平均值的函数,参数为列表
- 编写一个函数,接收一个整数作为参数,返回该整数的阶乘
- 程序执行结果
def foo(x):
x[0] = 100
x.append(4)
print(x)
l = [1, 2, 3]
foo(l)
print(l)
- 程序执行结果
x = 10
def my_func():
print(x)
def outer():
x = 20
my_func()
outer()
- 执行
code = "sum([2 * 3 + 6, (5 - 9) + 7 - 2, 13 * 4 - 11])"
# 执行code代码
-
计算列表
[11,22,33,44,55]的每一个元素的平方的和 -
给定一个字符串列表
['apple', 'banana', 'cherry', 'date']- 使用
filter()过滤出所有长度小于等于5的字符串。 - 使用
sorted()对列表进行按照长度进行降序排序。
- 使用
-
给定一个字典列表
[{ 'name': 'Alice', 'age': 25 }, { 'name': 'Bob', 'age': 30 }, { 'name': 'Charlie', 'age': 20 }]- 使用
filter()过滤出所有年龄大于等于25的人。 - 使用
filter()过滤出所有名字以a或A开头的 - 使用
map()提取每个字典中的名字字段的长度,并返回新的列表。
- 使用
-
实现程序要求功能
def a():
print("aaa")
def b():
print("bbb")
def c():
print("ccc")
def d():
print("ddd")
def e():
print("eee")
func_list = [a, b, c, d, e]
# 调用列表中第三个函数
func_dict = {
"a": a,
"b": b,
"c": c,
"d": d,
"e": e,
}
# 调用字典中的d函数
- 收银系统函数版(day06的商品管理系统作业)
Day08:文件操作

1. 字符编码

计算机存储信息的大小,最基本的单位是字节。
-
1KB=1024B
-
1MB=1024KB
-
1GB=1024MB
-
1TB=1024GB
字符编码是将字符集中的字符映射到二进制表示形式的规则集。ASCII、GBK、Unicode和UTF-8是常见的字符编码标准。下面我将对每种编码进行简要介绍:
- ASCII(American Standard Code for Information Interchange):ASCII 是最早的字符编码标准,使用 7 位二进制数(0-127)表示 128 个常用字符,包括英文字母、数字和一些常见的符号。ASCII 编码是单字节编码,每个字符占用一个字节的存储空间。
- GBK(GuoBiao/Kuòbiāo):GBK 是中文编码标准,是国家标准 GB 2312 的扩展,支持汉字字符。GBK 使用双字节编码,其中一个字节表示高位,另一个字节表示低位,可以表示大约 21000 个汉字和其他字符。GBK 编码兼容 ASCII 编码,即 ASCII 字符可以用一个字节表示。
- Unicode(统一码):Unicode 是一种字符编码标准,旨在为全球所有的字符提供唯一的标识符。它使用固定长度的编码单元表示字符,最常见的编码单元是 16 位(如 UTF-16)。Unicode 可以表示几乎所有语言的字符。
- UTF-8(Unicode Transformation Format-8):UTF-8 是一种可变长度的 Unicode 编码标准,通过使用不同长度的字节序列来表示字符。UTF-8 是互联网上最常用的字符编码标准,因为它兼容 ASCII 编码,可以表示全球各种语言的字符。它使用 8 位字节编码,根据字符的不同范围使用不同长度的字节,ASCII 字符使用一个字节表示,而其他字符使用多个字节表示。
编码和解码是在字符编码过程中使用的两个关键概念。编码是将字符转换为特定编码标准下的二进制表示形式,而解码则是将二进制数据转换回字符形式。
在字符编码中,编码器用于将字符转换为相应编码标准下的二进制数据,而解码器用于将二进制数据转换回字符形式。编码和解码的过程是互逆的,可以通过相应的编码和解码算法进行转换。
text = "Hello, 你好"
# 编码过程
encoded = text.encode('utf-8') # 使用 UTF-8 编码将文本转换为二进制数据
print("编码后的数据:", encoded)
# 解码过程
decoded = encoded.decode('utf-8') # 使用 UTF-8 解码将二进制数据转换为文本
print("解码后的文本:", decoded)
输出结果如下:
编码后的数据: b'Hello, \xe4\xbd\xa0\xe5\xa5\xbd'
解码后的文本: Hello, 你好
需要注意的是,在编码和解码过程中,要确保使用相同的编码标准进行处理。否则,编码和解码的结果可能会不正确,导致乱码或数据损坏。
2. 文件操作
在 Python 中,如果想要操作文件,首先需要创建或者打开指定的文件,并创建一个文件对象,而这些工作可以通过内置的 open() 函数实现。
open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:
def open(file, mode='r', encoding=None,): # known special case of open
【1】读文件
file = open("example.txt", "r") # 以只读模式打开文件
content = file.read() # 读取整个文件内容
line = file.readline() # 读取一行内容
lines = file.readlines() # 读取所有行,并返回列表
file.close() # 关闭
【2】写文件
file = open("example.txt", "w") # 以只写模式打开文件
file.write("Hello, World!") # 向文件写入内容
# Python 的文件对象中,不仅提供了 write() 函数,还提供了 writelines() 函数,可以实现将字符串列表写入文件中。
# file.writelines(f.readlines())
file.close() # 关闭
注意,写入函数只有 write() 和 writelines() 函数,而没有名为 writeline 的函数。
【3】with open
任何一门编程语言中,文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。但资源都是有限的,在写程序时,必须保证这些资源在使用过后得到释放,不然就容易造成资源泄露,轻者使得系统处理缓慢,严重时会使系统崩溃。
例如,前面在介绍文件操作时,一直强调打开的文件最后一定要关闭,否则会程序的运行造成意想不到的隐患。但是,即便使用 close() 做好了关闭文件的操作,如果在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。
为了更好地避免此类问题,不同的编程语言都引入了不同的机制。在Python中,对应的解决方式是使用 with as 语句操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资源。
with open("example.txt", "r") as file:
content = file.read()
# 在这里进行文件操作,文件会在代码块结束后自动关闭
此外,还有其他文件操作函数和方法可供使用,例如重命名文件、删除文件等。
【4】文件操作案例
# 版本1:
with open("卡通.jpg", "rb") as f_read:
data = f_read.read()
with open("卡通2.jpg", "wb") as f_write:
f_write.write(data)
# 版本2:
with open("卡通3.jpg", "wb") as f_write:
with open("卡通.jpg", "rb") as f_read:
f_write.write(f_read.read())

3. 下载图片和视频
pip install requests
import requests
# 案例1
# 爬虫
res = requests.get("https://pic.netbian.com/uploads/allimg/240112/001654-17049898140369.jpg")
# print(res.content)
# 写文件
with open("美女.jpg","wb") as f:
f.write(res.content)
# 案例2
res = requests.get("https://cdn2.zzzmh.cn/wallpaper/origin/96eaf850880911ebb6edd017c2d2eca2.jpg?response-content-disposition=attachment&auth_key=1709222400-05fa38359aefbdb5af319a5eaa8502dafc0c22eb-0-c606b2d504258a39b9c119184555c780")
with open("美女2.jpg","wb") as f:
f.write(res.content)

4. openpyxl模块
openpyxl是一个功能强大的库,用于读取和写入Excel文件(.xlsx格式)。它支持创建、修改和操作Excel工作簿、工作表、单元格等。可以使用openpyxl来读取Excel文件中的数据,并进行相应的处理和分析。
下载模块
pip install openpyxl
基本使用
打开工作簿:
import openpyxl
# 读取Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook['Sheet']
# 获取单元格数据
value = sheet['A1'].value
print(value)
value = sheet['B2'].value
print(value)
sheet['A7'].value = "飞驰人生2"
# 保存修改后的Excel文件
workbook.save('example.xlsx')
创建新的Excel工作簿
import openpyxl
# 创建新工作簿
workbook = openpyxl.Workbook()
# 获取默认工作表
sheet = workbook.active
# (1) 写入数据到单元格
sheet['A1'] = 'Hello'
sheet['B1'] = 'World'
# (2) 写入一行内容
sheet.append([1, 2, 3, 4, 5])
for i in range(100):
sheet.append([i, i ** 2, i ** 3, i ** 4])
# 保存工作簿
workbook.save('new_example.xlsx')
案例应用
将爬虫到的数据存储到excel中
import requests
from openpyxl import Workbook
cookies = {
'll': '"108288"',
'bid': 'n1IbnM-UzkI',
'Hm_lvt_6d4a8cfea88fa457c3127e14fb5fabc2': '1698153214',
'_ga': 'GA1.2.1489184474.1698153214',
'_ga_Y4GN1R87RG': 'GS1.1.1698153214.1.0.1698153217.0.0.0',
'douban-fav-remind': '1',
'ap_v': '0,6.0',
'__utma': '30149280.947861648.1695648345.1708952551.1711004385.23',
'__utmb': '30149280.0.10.1711004385',
'__utmc': '30149280',
'__utmz': '30149280.1711004385.23.4.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/',
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'll="108288"; bid=n1IbnM-UzkI; Hm_lvt_6d4a8cfea88fa457c3127e14fb5fabc2=1698153214; _ga=GA1.2.1489184474.1698153214; _ga_Y4GN1R87RG=GS1.1.1698153214.1.0.1698153217.0.0.0; douban-fav-remind=1; ap_v=0,6.0; __utma=30149280.947861648.1695648345.1708952551.1711004385.23; __utmb=30149280.0.10.1711004385; __utmc=30149280; __utmz=30149280.1711004385.23.4.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/',
'Origin': 'https://movie.douban.com',
'Pragma': 'no-cache',
'Referer': 'https://movie.douban.com/explore',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
}
params = {
'refresh': '0',
'start': '0',
'count': '120',
'tags': '喜剧',
}
response = requests.get('https://m.douban.com/rexxar/api/v2/movie/recommend', params=params, cookies=cookies,
headers=headers)
data = response.json().get("items")
data_list = []
for i in data:
if i.get("type") == "movie":
title = i.get("title")
card_subtitle = i.get("card_subtitle")
count = i.get("rating").get("count")
value = i.get("rating").get("value")
large_pic = i.get("pic").get("large")
data_list.append([title, card_subtitle, value, count, large_pic])
wb = Workbook()
ws = wb.active
title = ['名字', '副标题', '豆瓣评分', '评分人数', "海报"]
ws.append(title)
# 将电影信息写入excel
for item in data_list:
ws.append(item)
wb.save('example.xlsx')

5. 今日作业
-
将你的中文名字分别进行utf8编码再解码,GBK编码再解码
-
按行读取和处理大型日志文件:对于大型日志文件,你可以按行读取文件内容,并对每行进行处理或筛选。
-
将一个文本文件的几个计算表达式的值计算出来分别存到写到一个新的文件中
Source.txt
# 2*9-1
apple
banana
# 3-(2+5)*7-2**3
peach
# 6+8*2-(3-14)*7
Target.txt
2*9-1:17
3-(2+5)*7-2**3:-54
6+8*2-(3-14)*7:99
-
合并多个文本文件:你可以将多个文本文件的内容合并到一个新文件中。
-
统计文件中特定单词出现的次数:你可以读取文本文件,并统计特定单词在文件中出现的次数。
Day09:常用模块

1. random模块
random模块是Python的标准库之一,提供了生成伪随机数的功能。它包含了各种生成随机数的函数,以及随机选择和操作的工具函数。下面是random模块的一些常用函数和方法:
random():生成一个0到1之间的随机浮点数。randint(a, b):生成一个指定范围内的随机整数,包括a和b。choice(seq):从给定的序列中随机选择一个元素。sample(seq, k):从给定序列中随机选择k个元素,返回一个新的列表。shuffle(seq):随机打乱给定序列的顺序。
案例
import random
# (1) 模拟硬币投掷
def flip_coin():
if random.random() < 0.5:
return "Heads"
else:
return "Tails"
result = flip_coin()
print("Coin landed on:", result)
# (2) 掷骰子
def roll_dice():
return random.randint(1, 6)
dice_roll = roll_dice()
print("You rolled:", dice_roll)
# (3) 抽奖名单
participants = ['Alice', 'Bob', 'Charlie', 'David', 'Eve']
winner = random.choice(participants)
print("The winner is:", winner)
# (4) 双色球案例:
"""
双色球是中国国家彩票中心发行的一种彩票游戏,其规则如下:
双色球号码池:
红色球号码池:由1到33的红色球号码构成。
蓝色球号码池:由1到16的蓝色球号码构成。
玩法:
玩家需要选择6个红色球号码和1个蓝色球号码来进行投注。
红色球号码可以是任意6个1到33之间的号码,顺序不限。
蓝色球号码是从1到16中选择一个号码。
注意: 6个红色球号码是不能相同的
"""
def lotto():
lotto_list = []
for red_temp in random.sample(range(1, 34), 6):
lotto_list.append(str(red_temp))
blue = str(random.randint(1, 17))
lotto_list.append(blue)
return lotto_list
ret = lotto()
print(f"红球:{' '.join(ret[:-1])}\n蓝球:{ret[-1]}")
# (5) 洗牌
def get_pokes():
poke_list = []
poke_types = ['♥️', '♦️', '♠️', '♣️']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
for p_type in poke_types:
for p_num in poke_nums:
poke_list.append(f"{p_type}{p_num}")
return poke_list
poke_list = get_pokes()
random.shuffle(poke_list)
print(poke_list)
2. time模块
time模块是Python标准库中的一个模块,提供了与时间相关的功能和操作。它允许您获取当前时间、进行时间的格式化、进行时间的延迟等操作。下面是time模块的一些主要功能和函数:
- 获取当前时间:
time():返回从1970年1月1日午夜开始经过的秒数(Unix时间戳)。
- 时间延迟和暂停:
sleep(secs):暂停指定的秒数。
- 时间戳和时间元组互换:
localtime([secs]):将秒数转换为当前时区的struct_time对象。mktime(t):将struct_time对象转换为秒数。gmtime([secs]):将秒数转换为UTC时间的struct_time对象。
- 时间格式化:
strftime(format, t):将时间元组对象t按照指定的格式format进行格式化输出。
time模块中的函数返回的时间格式通常是以秒为单位的数值或struct_time对象。如果需要更高级的时间操作,可以考虑使用datetime模块,它提供了更多的时间处理功能。
3. datetime模块
datetime 模块是Python标准库中的一个模块,提供了处理日期和时间的功能。它建立在 time 模块的基础之上,提供了更高级的日期和时间操作。它提供了多个类和函数,用于创建、操作和格式化日期时间对象,以及执行日期时间的计算和比较。
下面是一些 datetime 模块中常用的功能:
(1)datetime类
datetime类是Python标准库中datetime模块中的一个重要类,用于表示日期和时间。它是一个组合了日期和时间的对象,提供了各种属性和方法来进行日期和时间的处理。下面是datetime类的一些主要属性和方法:
import datetime
# (1) 获取datetime对象
datetime.datetime.now():返回当前的本地日期和时间。
datetime.datetime.today():返回当前日期的datetime对象(时间部分为0时0分0秒)
# 创建特定日期和时间的对象:
datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0):创建一个代表特定日期和时间的 datetime 对象。
# (2) datetime对象属性:
datetime_obj.year:年份。
datetime_obj.month:月份。
datetime_obj.day:日期。
datetime_obj.hour:小时。
datetime_obj.minute:分钟。
datetime_obj.second:秒数。
# (3) datetime对象和格式化字符串转换
# datetime对象转为格式化字符串
current_datetime = datetime.datetime.now()
format = "%Y-%m-%d %H:%M:%S"
formatted_datetime = current_datetime.strftime(format)
print(formatted_datetime) # 输出:2022-01-01 12:30:45
print(type(formatted_datetime)) # 输出:<class 'str'>
# 时间字符串转为datetime对象
date_string = "2022-01-01 12:30:45"
format = "%Y-%m-%d %H:%M:%S"
parsed_datetime = datetime.datetime.strptime(date_string, format)
print(parsed_datetime) # 输出:2022-01-01 12:30:45
(2)date类
date类是Python标准库中datetime模块中的一个类,用于表示日期。它提供了各种属性和方法来进行日期的处理。下面是date类的一些主要属性和方法:
import datetime
# (1) 获取当前日期对象
today = datetime.date.today()
print(today)
# (2) 日期对象属性:
date_obj.year:年份。
date_obj.month:月份。
date_obj.day:日期。
# (3) date对象转为格式化字符串
today = datetime.date.today()
formatted_date = today.strftime("%Y-%m-%d")
print(formatted_date) # 输出:2024-02-13
(3)timedelta类
用于表示时间间隔的对象,可以进行日期时间的加减运算。常用的方法包括:
timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0):创建一个 timedelta 对象。
timedelta.total_seconds():返回时间间隔的总秒数。
import datetime
# 案例1
from datetime import date
today = date.today()
birthday = date(1998, 5, 15)
age = today - birthday
print("Age:", age.days)
# 案例2
now = datetime.datetime.now()
ret = now + datetime.timedelta(days=3)
print(ret)
4. sys模块
sys 模块是 Python 标准库中的一个模块,提供了与 Python 解释器和系统交互的功能。它提供了许多与系统相关的函数和变量,可以访问和操作解释器的运行时环境、命令行参数、标准输入输出等。
下面是 sys 模块中一些常用的函数和变量:
sys.argv:命令行参数的列表,包括脚本名称和传递给脚本的参数。
sys.exit([arg]):退出当前程序的执行,并返回可选的错误代码 arg。
sys.path:一个列表,包含用于查找模块的搜索路径。
sys.version:当前 Python 解释器的版本信息。
5. os模块
os 模块是 Python 标准库中的一个模块,提供了与操作系统交互的功能。它允许你访问操作系统的文件系统、执行系统命令等。
下面是os模块一些常用功能的介绍:
- 文件和目录操作:
os.getcwd(): 获取当前工作目录的路径。os.chdir(path): 修改当前工作目录为指定路径。os.listdir(path): 返回指定目录中的文件和目录列表。os.mkdir(path): 创建一个新的目录。os.makedirs(path): 递归创建目录,包括中间目录。os.remove(path): 删除指定的文件。os.rmdir(path): 删除指定的空目录。os.removedirs(path): 递归删除目录,包括所有子目录。os.rename(src, dst): 将文件或目录从src重命名为dst。
- 操作系统命令:
os.system(command): 执行操作系统命令。os.popen(command): 执行操作系统命令,并返回一个文件对象。
- 路径操作:
os.path.join(path1, path2, ...): 将多个路径组合成一个路径。os.path.split(path): 将路径分割成目录和文件名。os.path.dirname(path): 返回路径的目录部分。os.path.basename(path): 返回路径的文件名部分。os.path.exists(path): 检查路径是否存在。
6. json模块
【1】基本概念与语法
序列化是将数据结构或对象转换为字节流(二进制数据)以便存储或传输
反序列化是将字节流还原为原始数据结构或对象的过程。
序列化最重要的就是json序列化。
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
json模块是Python标准库中的一个模块,用于处理JSON(JavaScript Object Notation)数据。它提供了一组函数来解析和生成JSON数据,使得在Python中处理JSON变得非常方便。
import json
# 序列化 :将本语言支持的高级数据对象转为json格式字符串的过程
num = 3.14
name = 'yuan'
l = [1, 2, 3]
t = (4, 5, 6)
d = {'name': "yuan", 'age': 18, "is_married": False, "gf": None}
print(repr(json.dumps(num))) # '3.14'
print(repr(json.dumps(name))) # '"yuan"'
print(repr(json.dumps(l))) # '[1, 2, 3]'
print(repr(json.dumps(t))) # '[4,5,6]'
print(repr(json.dumps(d))) # '{"name":"yuan","age":18,"is_married":false,"gf":null}'
# 存储和传输
# 反序列化:将json格式字符串转为本语言支持的数据对象格式
# 案例1
d = {'name': "yuan", 'age': 18, "is_married": False, "gf": None}
json_d = json.dumps(d)
print(json_d, type(json_d))
data = json.loads(json_d)
print(data, type(data))
name = data.get("name")
print(name)
# 案例2:
s = '{"name":"yuan","age":18,"isMarried":False}'
# 重点:反序列化前提数据得是json格式的字符串
data = json.loads(s)
print(data, type(data))
s2 = '[{"name":"yuan","age":18,"isMarried":false},{"name":"rain","age":28,"isMarried":true}]'
data2 = json.loads(s2)
print(data2,type(data2))
print(data2[1].get("name"))
# 思考:json.loads('{"name": "yuan", "age": 23, "is_married": 0}') 可以吗?
【2】应用之持久化存储
import json
dic={'name':'yuan','age':23,'is_married':False}
data=json.dumps(dic) # 序列化,将python的字典转换为json格式的字符串
print("type",type(data)) # <class 'str'>
with open('json.txt','w') as f:
f.write(data) # 等价于json.dump(dic,f)
with open('json.txt') as f:
# 反序列化成为python的字典,等价于dic=json.load(f)
data = f.read()
dic = json.loads(data)
print(type(dic))
【3】应用之网络传输
前端
// 序列化
data = {user:"yuan",pwd:123}
console.log(JSON.stringify(data)) // '{"user":"yuan","pwd":123}'
// 反序列化
res_json = '{"name": "yuan", "age": 23, "is_married": 0}'
let res = JSON.parse(res_json)
console.log(res)
后端
import json
# 反序列化
data = '{"user":"yuan","pwd":123}'
data_dict = json.loads(data)
print(type(data_dict))
# 序列化
res = {'name':'yuan','age':23,'is_married':0}
res_json = json.dumps(res) # 序列化,将python的字典转换为json格式的字符串
print(repr(res_json)) # '{"name": "yuan", "age": 23, "is_married": 0}'
7. 日志模块
python中的日志库logging配置通常比较复杂,构建日志服务器时也不是方便。标准库logging的替代品是loguru,使用起来就简单的多。开箱即用,使用方便得多;另外,日志输出内置了彩色功能,颜色和非颜色控制很方便,更加友好。
是非标准库,需要事先安装,命令是:
pip3 install loguru
loguru的基本使用
from loguru import logger
# 写入到文件
# logger.remove(handler_id=None)
# rotation 配置日志滚动记录的机制:rotation="200 MB"
logger.add("mylog.log",level='ERROR',rotation="200 MB")
# 基本使用,可以打印到console,也可以打印到文件中去。
logger.debug('这是一条测试日志')
logger.info('这是一条信息日志')
logger.success('这是一条成功日志')
logger.warning('这是一条警告日志')
logger.error('这是一条错误日志')
logger.critical('这是一条严重错误日志')
默认的输出格式是:时间、级别、模块、行号以及日志内容。
loguru的基本配置
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr, # 表示输出到终端
# 表示日志格式化
"format": "<g><b>{time:YYYY-MM-DD HH:mm:ss.SSS}</b></g> |<lvl>{level:8}</>| {name} : {module}:{line:4} | <c>mymodule</> | - <lvl>{message}</>",
"colorize": True, # 表示显示颜色。
"level": "WARNING" # 日志级别
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": True
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')
常见的key及其描述
| Key | Description |
|---|---|
| time | 发出日志调用时的可感知的本地时间 |
| level | 用于记录消息的严重程度 |
| name | 进行日志记录调用的__name__ |
| module | 进行日志记录调用的模块 |
| line | 源代码中的行号 |
| message | 记录的消息(尚未格式化) |
| function | 进行日志记录调用的函数 |
| thread | 进行日志记录调用的线程名 |
| process | 进行日志记录调用的进程名 |
| file | 进行日志记录调用的文件 |
| extra | 用户绑定的属性字典(参见bind()) |
| exception | 格式化异常(如果有),否则为' None ' |
| elapsed | 从程序开始经过的时间差 |
常用的颜色和样式标签
| 颜色(简称) | 样式(简称) |
|---|---|
| 黑色(k) | 粗体(b) |
| 蓝色(e) | 暗淡(d) |
| 青色(c) | 正常(n) |
| 绿色(g) | 斜体(i) |
| 洋红色(m) | 下划线(u) |
| 红色(r) | 删除线(s) |
| 白色(w) | 反转(v |
| 黄色(y) | 闪烁(l) |
今日作业
-
打印当前时间戳到毫秒单位的一个长度
-
需求:编写一个函数,输入红包个数和红包的总金额,生成一个随机分配金额的红包列表
-
不能出现0元
-
总额要一致
-
为降低难度,按整数输入和处理即可
-
效果如图:

-
-
2000-3-16号是星期几,100天后是几月几号,按1990/1/1这种格式显示结果显示 -
将
path1 = "Users",path2 = "yuanHao",path3 = "python"三个路径进行拼接,能够跨平台使用(Win和Linux) -
写一段代码,判断当前目录下是否存在一个apple的文件夹,如果不存在,创建一个apple的文件夹,并在该文件夹写一个文本文件,并在该文件中写入
香蕉字符串 -
将下面的文本文件读取到内存,并打印每个学生的姓名和选课的名称(格式化输出)
{
"students": [
{
"name": "Alice",
"age": 20,
"courses": [
{
"id": "CS101",
"title": "Introduction to Computer Science"
},
{
"id": "MA101",
"title": "Calculus I"
}
]
},
{
"name": "Bob",
"age": 22,
"courses": [
{
"id": "PH101",
"title": "Introduction to Philosophy"
},
{
"id": "HI101",
"title": "World History"
}
]
}
]
}
-
执行系统命令
hostname -
date02_string = "2022-06-30"和date01_string = "1990-01-2"和之间间隔多少天 -
获取获取当前工作目录的父目录的父目录
-
获取当前Python脚本文件的目录名
-
客户关系管理系统功能扩展
- 实现数据保存的功能,添加一个选项:保存功能,操作增删改查后将数据持久化存储到磁盘,程序启动后数据可以恢复(提示:json和文件操作)
- 增删改查包括启动等添加文件日志
Day10:模块与包

在Python中,模块(Module)是指一个包含了函数、变量和类等定义的文件,而包(Package)是指包含了多个模块的目录。类似于计算机文件和文件夹的管理数据方式,模块和包的概念是组织和管理Python代码的重要方式
1. 模块(Module)
【1】模块介绍
模块本质上就是一个py文件
模块一共有三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。而这样的一个py文件在Python中称为模块(Module)。
模块是组织代码的更高级形式,大大提高了代码的阅读性和可维护性。
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。
【2】案例解析
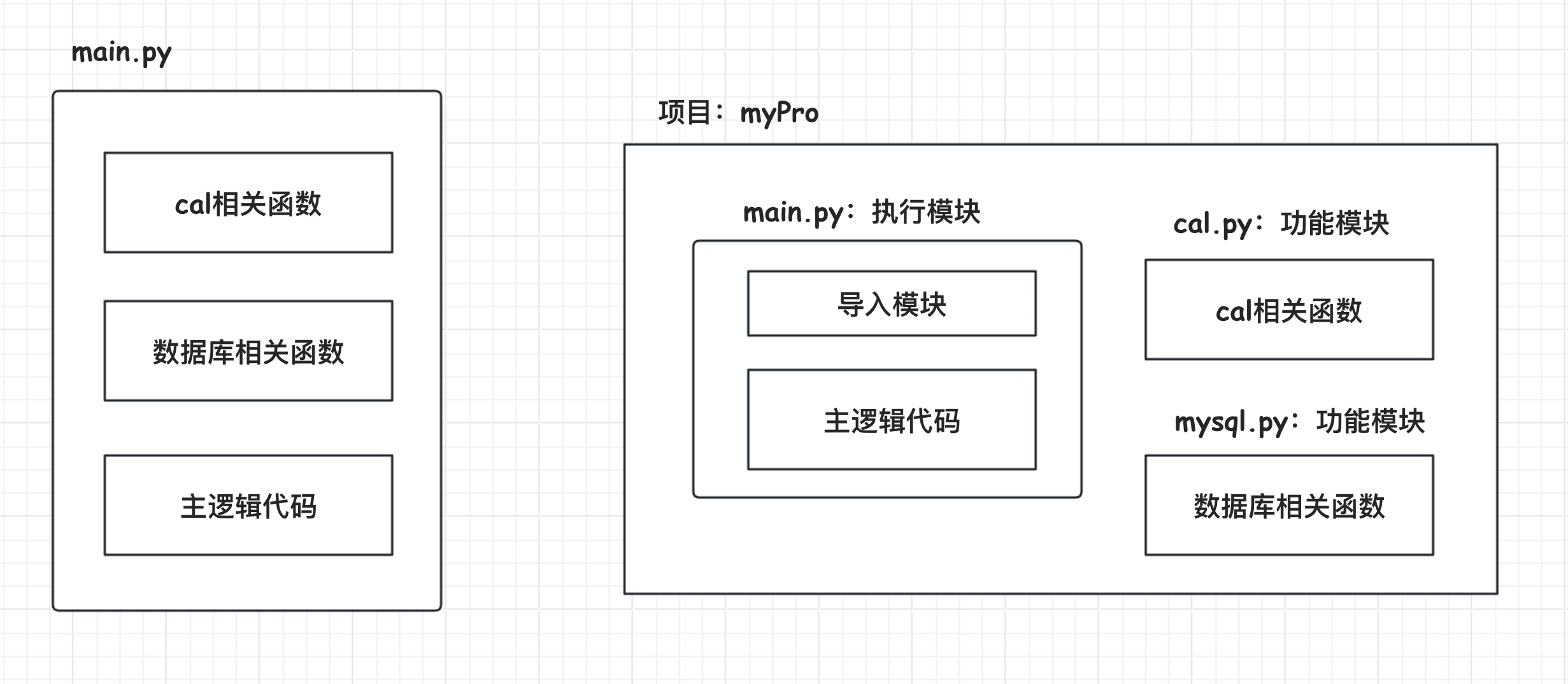
单文件程序
main.py
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x - y
def mysql_init():
print("mysql初始化")
def mysql_insert():
print("mysql添加记录")
def mysql_delete():
print("mysql删除记录")
def mysql_update():
print("mysql更改记录")
def mysql_query():
print("mysql查询记录")
while 1:
print("1. 科学计算")
print("2. 数据库操作")
choice = input("请选择:")
if choice == "1":
print(add(1, 2))
print(sub(1, 2))
print(mul(1, 2))
print(div(1, 2))
else:
mysql_init()
mysql_insert()
mysql_delete()
mysql_update()
mysql_query()
多模块程序:
cal.py
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x - y
mysql.py
def mysql_init():
print("mysql初始化")
def mysql_insert():
print("mysql添加记录")
def mysql_delete():
print("mysql删除记录")
def mysql_update():
print("mysql更改记录")
def mysql_query():
print("mysql查询记录")
main.py
from cal import *
from mysql import *
while 1:
print("1. 科学计算")
print("2. 数据库操作")
choice = input("请选择:")
if choice == "1":
print(add(1, 2))
print(sub(1, 2))
print(mul(1, 2))
print(div(1, 2))
else:
mysql_init()
mysql_insert()
mysql_delete()
mysql_update()
mysql_query()
【3】导入模块语法
(1)导入模块关键点
-
模块与包的命名遵从小写+下划线
-
导入的模块名和函数一样是一等公民。
在编程语言中,"一等公民"(first-class citizen)是指某个实体(通常是数据类型或值)具有与其他实体相同的权利和特权。它表示在语言中,这些实体可以被像任何其他实体一样对待,可以作为参数传递给函数、赋值给变量、存储在数据结构中,以及作为函数的返回值。
-
使用“import module”导入模块的本质就是,将 module.py 中的全部代码加载到内存并执行,然后将整个模块内容赋值给与模块同名的变量。
-
导入同一个模块多次,Python只执行一次。
-
在导入模块后,可以在模块文件所在目录下看到一个名为“pycache”的文件夹,打开该文件夹,可以看到 Python 为每个模块都生成一个 *.cpython-36.pyc 文件,该文件其实是 Python 为模块编译生成的字节码,用于提升该模块的运行效率。
(2)导入模块语法
import 有很多用法,主要有以下两种:
import 模块名1 [as 别名1], 模块名2 [as 别名2],…:使用这种语法格式的 import 语句,会导入指定模块中的所有成员(包括变量、函数、类等)。不仅如此,当需要使用模块中的成员时,需用该模块名(或别名)作为前缀,否则 Python 解释器会报错。from 模块名 import 成员名1 [as 别名1],成员名2 [as 别名2],…: 使用这种语法格式的 import 语句,只会导入模块中指定的成员,而不是全部成员。同时,当程序中使用该成员时,无需附加任何前缀,直接使用成员名(或别名)即可。
注意,
- import 语句也可以导入指定模块中的所有成员,即使用 form 模块名 import *,但此方式不推荐使用。
__all__可以控制*
from cal import add as new_add, sub, mul, div
import cal
from cal import *
print(new_add(1, 2))
print(cal.add(1, 2))
【4】 __name__=='__main__'
def mysql_init():
print("mysql初始化")
def mysql_insert():
print("mysql添加记录")
def mysql_delete():
print("mysql删除记录")
def mysql_update():
print("mysql更改记录")
def mysql_query():
print("mysql查询记录")
if __name__ == "__main__":
print(__name__)
mysql_query()
mysql_insert()
mysql_delete()
mysql_update()
可以看到,当前运行的程序,其 __name__ 的值为 __main__,而导入到当前程序中的模块,其 __name__ 值为自己的模块名。
因此,if __name__ == '__main__': 的作用是确保只有单独运行该模块时,此表达式才成立,才可以进入此判断语法,执行其中的测试代码;反之,如果只是作为模块导入到其他程序文件中,则此表达式将不成立,运行其它程序时,也就不会执行该判断语句中的测试代码。
【5】循环导入的bug
# m1.py
from m1 import x
y = 1000
# m2.py
from m2 import y
x = 100

2. 包
【1】包介绍
实际开发中,一个大型的项目往往需要使用成百上千的Python模块,如果将这些模块都堆放在一起,势必不好管理。而且,使用模块可以有效避免变量名或函数名重名引发的冲突,但是如果模块名重复怎么办呢?因此,Python提出了包(Package)的概念。
什么是包呢?简单理解,包就是文件夹,只不过在该文件夹下必须存在一个名为“__init__.py” 的文件,其作用就是告诉 Python 要将该目录当成包来处理
注意,这是 Python 2.x 的规定,而在 Python 3.x 中,
__init__.py对包来说,并不是必须的。
包的主要作用是组织和管理模块,使得代码更加结构化和可维护。包的层次结构可以是多层的,即可以包含子包(子目录)和子模块。
【2】创建包
包其实就是文件夹,更确切的说,是一个包含“__init__.py”文件的文件夹。因此,如果我们想手动创建一个包,只需进行以下 2 步操作:
- 新建一个文件夹,文件夹的名称就是新建包的包名;
- 在该文件夹中,创建一个
__init__.py文件(前后各有 2 个下划线‘_’),该文件中可以不编写任何代码。当然,也可以编写一些 Python 初始化代码,则当有其它程序文件导入包时,会自动执行该文件中的代码
创建好包之后,我们就可以向包中添加模块(也可以添加包)。
【3】案例解析
├── pycache
├── db
│ ├── __init__.py
│ ├── pycache
│ │ ├── init.cpython-312.pyc
│ │ └── mysql.cpython-312.pyc
│ ├── mysql.py
│ ├── postgre.py
│ └── redis.py
├── main.py
└── utils
├── __init__.py
├── pycache
│ ├── init.cpython-312.pyc
│ └── cal.cpython-312.pyc
└── cal.py
from utils.cal import *
from db.mysql import *
【4】导包语法
通过前面的学习我们知道,包其实本质上还是模块,因此导入模块的语法同样也适用于导入包。无论导入我们自定义的包,还是导入从他处下载的第三方包,导入方法可归结为以下 3 种:
import 包名[.模块名 [as 别名]]from 包名1.包名2 import 模块名 [as 别名]from 包名1.包名2.模块名 import 成员名 [as 别名]
用 [] 括起来的部分,是可选部分,即可以使用,也可以直接忽略。
【5】导入模块和包本质
通常情况下,当使用 import 语句导入模块后,Python 会按照以下顺序查找指定的模块文件:
- 在当前目录,即当前执行的程序文件所在目录下查找;
- 到 PYTHONPATH(环境变量)下的每个目录中查找;
- 到 Python 默认的安装目录下查找。
以上所有涉及到的目录,都保存在标准模块 sys 的 sys.path 变量中,通过此变量我们可以看到指定程序文件支持查找的所有目录。换句话说,如果要导入的模块没有存储在 sys.path 显示的目录中,那么导入该模块并运行程序时,Python 解释器就会抛出 ModuleNotFoundError(未找到模块)异常。
解决“Python找不到指定模块”的方法有 3 种,分别是:
- 向 sys.path 中临时添加模块文件存储位置的完整路径;
- 将模块放在 sys.path 变量中已包含的模块加载路径中;
- 设置 path 系统环境变量。
功能模块导入功能 模块,import
【6】__init__.py
前面章节中,已经对包的创建和导入进行了详细讲解,并提供了大量的实例,这些实例虽然可以正常运行,但存在一个通病,即为了调用包内模块的成员(变量、函数或者类),代码中包含了诸多的 import 导入语句,非常繁琐。
通过在 __init__.py 文件使用 import 语句将必要的模块导入,这样当向其他程序中导入此包时,就可以直接导入包名,也就是使用import 包名(或from 包名 import *)的形式即可。
mysql包中的__init__.py
# 案例1
from . import mysql
# 案例2
from .mysql import mysql_init, mysql_insert
mysql_init()
main.py
# 案例1
import db
db.mysql.mysql_insert()
# 案例2
import db
db.mysql_insert()
3. 虚拟环境
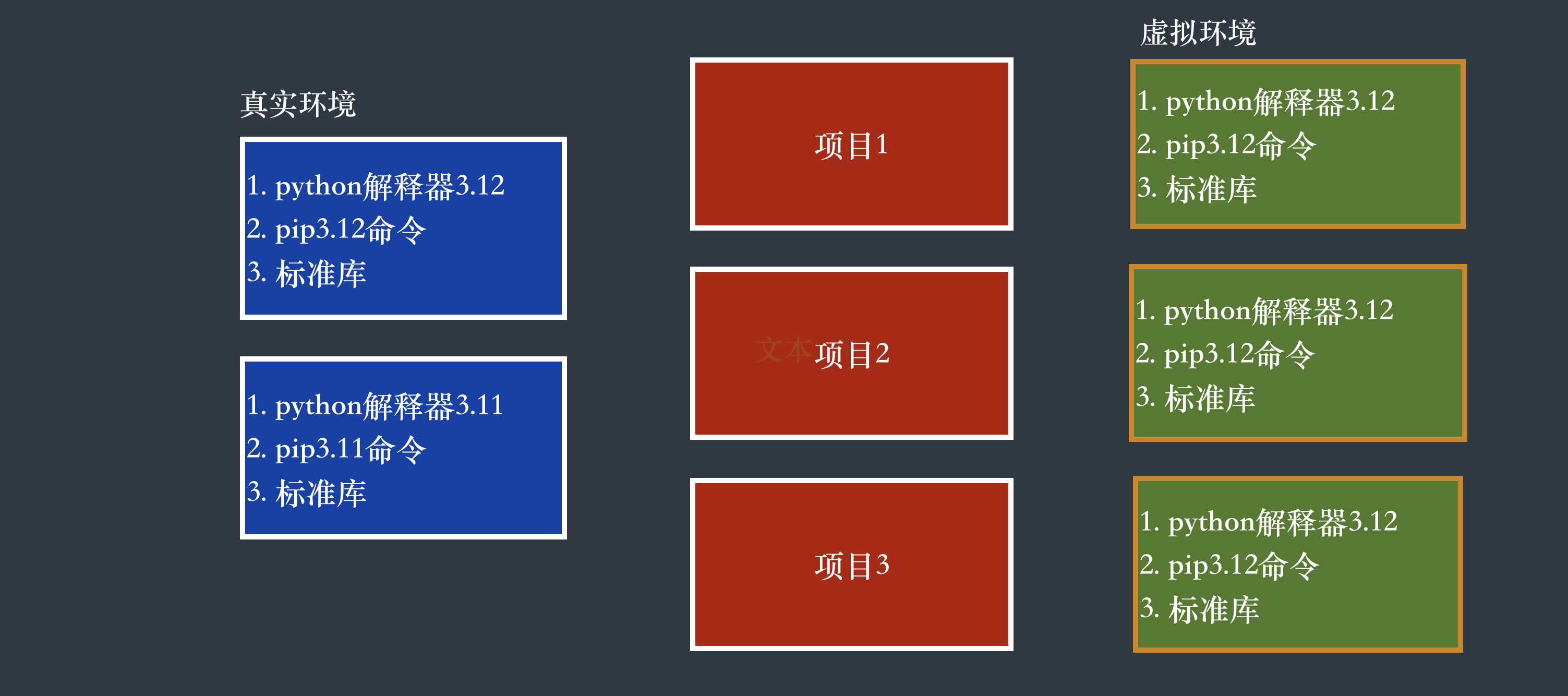
【1】pip命令
进行 Python 程序开发时,除了使用 Python 内置的标准模块以及我们自定义的模块之外,还有很多第三方模块可以使用,
使用第三方模块之前,需要先下载并安装该模块,然后就能像使用标准模块和自定义模块那样导入并使用了。因此,本节主要讲解如何下载并安装第三方模块。
下载和安装第三方模块,可以使用 Python 提供的 pip 命令实现。pip 命令的语法格式如下:
pip install|uninstall|list 模块名
其中,install、uninstall、list 是常用的命令参数,各自的含义为:
- install:用于安装第三方模块,当 pip 使用 install 作为参数时,后面的模块名不能省略。
- uninstall:用于卸载已经安装的第三方模块,选择 uninstall 作为参数时,后面的模块名也不能省略。
- list:用于显示已经安装的第三方模块。
【2】虚拟环境命令
虚拟环境(Virtual Environment)是 Python 中用于隔离项目依赖和运行环境的工具。它允许你在同一台计算机上同时管理多个项目,每个项目都有自己独立的 Python 解释器和第三方库,互相之间不会相互干扰。
使用虚拟环境的好处包括:
- 隔离依赖:每个项目可以有自己的依赖库,不同项目之间的依赖冲突不会发生。
- 简化部署:可以将项目的依赖库和运行环境一起打包,方便在其他计算机上部署和运行。
- 灵活性:可以在不同的项目中使用不同的 Python 版本,以满足项目的特定需求。
在 Python 3.3 及以后的版本中,Python 内置了 venv 模块,用于创建和管理虚拟环境。以下是使用 venv 模块创建和激活虚拟环境的基本步骤:
- 创建虚拟环境:
打开终端(命令行),进入你想要创建虚拟环境的目录,然后运行以下命令:
# 这是 Python 内置的 venv 模块的命令语法。
# 它通过调用 Python 解释器的 -m 参数来执行 venv 模块内建的创建虚拟环境的功能。
python3 -m venv <env_name>
-
激活虚拟环境:
在终端中运行以下命令来激活虚拟环境:# 在 macOS/Linux 系统上: source myenv/bin/activate # 在 Windows 系统上: myenv\Scripts\activate
激活虚拟环境后,终端的提示符会显示虚拟环境的名称。
-
使用虚拟环境:
在激活的虚拟环境中,你可以安装和管理项目所需的依赖库,运行项目的代码等。所有的操作都将在虚拟环境中进行,不会影响全局 Python 环境和其他虚拟环境。 -
退出虚拟环境:
在终端中运行以下命令即可退出虚拟环境:deactivate -
导出和导入依赖:
# 导出依赖到文件 pip freeze > requirements.txt # 从文件中导入依赖: pip install -r requirements.txt
4. 软件目录开发规范
在软件开发中,一个良好的目录结构可以提高代码的可维护性和可扩展性,使团队成员更容易理解和协作。尽管目录结构可以因项目类型和团队偏好而异,但以下是一些常见的软件开发目录规范和最佳实践:
- 项目根目录:在项目的根目录下,应包含与项目相关的文件和文件夹,如README、LICENSE等。这是整个项目的起点。
- 源代码目录:通常将源代码放在一个独立的目录中。这个目录应该有一个具有描述性的名称,如src、lib或app。在源代码目录下,可以按照项目的模块、功能或层次结构创建子目录。
- 测试目录:测试代码通常位于一个独立的目录中。可以使用名称如tests、test或spec的目录来存放单元测试、集成测试和其他测试相关的文件。
- 文档目录:为了方便团队成员和用户了解项目和代码的使用方式,可以创建一个文档目录,其中包含项目文档、API文档、用户手册等。
- 配置目录:存放项目的配置文件,如数据库配置、日志配置、环境变量配置等。可以将这些配置文件放在一个名为config或conf的目录下。
- 资源目录:存放项目所需的资源文件,如图像、样式表、静态文件等。可以将这些资源文件放在一个名为assets或resources的目录下。
- 日志目录:存放项目的日志文件,包括运行日志、错误日志等。可以将这些日志文件放在一个名为logs的目录下。
- 其他目录:根据项目的具体需求,可以创建其他目录来存放特定类型的文件,如缓存目录、备份目录等。
在设计目录结构时,要考虑项目的规模、复杂性和团队的需求。重要的是要保持一致性,并与团队成员共享并遵循相同的目录规范,以便于项目维护和协作。
以下是一个常见的目录规范示例,可以作为参考:
project/
├── docs/ # 文档目录
│ ├── requirements/ # 需求文档
│ ├── design/ # 设计文档
│ └── api/ # API 文档
├── src/ # 源代码目录
│ ├── app/ # 应用代码
│ │ ├── models/ # 模型定义
│ │ ├── views/ # 视图逻辑
│ │ ├── controllers/ # 控制器逻辑
│ │ └── utils/ # 工具函数
│ ├── config/ # 配置文件
│ ├── tests/ # 测试代码
│ └── scripts/ # 脚本文件
├── static/ # 静态资源目录
│ ├── css/ # 样式文件
│ ├── js/ # JavaScript 文件
│ ├── images/ # 图片文件
│ └── fonts/ # 字体文件
├── templates/ # 模板文件目录
├── data/ # 数据文件目录
├── logs/ # 日志文件目录
├── dist/ # 分发版本目录
├── run.py # 用于启动应用程序或执行相关操作的文件。
├── vendor/ # 第三方依赖目录
├── requirements.txt # 依赖包列表
├── README.md # 项目说明文档
└── LICENSE # 许可证文件
上述示例中,主要包含以下目录:
docs/:用于存放项目的文档,包括需求文档、设计文档和API文档等。src/:存放项目的源代码,按照模块进行组织,例如app/目录下存放应用代码,config/目录下存放配置文件,tests/目录下存放测试代码等。static/:存放静态资源文件,例如CSS样式文件、JavaScript文件、图片文件和字体文件等。templates/:存放模板文件,用于生成动态内容的页面。data/:存放数据文件,例如数据库文件或其他数据存储文件。logs/:存放日志文件,记录项目的运行日志。dist/:存放项目的分发版本,例如编译后的可执行文件或打包后的软件包。vendor/:存放第三方依赖,例如外部库或框架。requirements.txt:列出项目所需的依赖包及其版本信息。README.md:项目说明文档,包含项目的介绍、使用指南和其他相关信息。LICENSE:许可证文件,定义项目的使用和分发条款。
5. 客户关系管理系统【多目录版】
将客户关系管理系统项目改版为多目录版本,包括数据库文件,日志文件,配置文件等
目录设计:
myapp/
├── logs/
│ └── customers.log
├── conf/
│ └── settings.py
├── db/
│ └── customers.json
├── src/
│ ├── __init__.py
│ ├── customer.py
│ ├── data_access.py
│ └── main.py
└── run.py
今日作业
- 模块的分为几种类型
__name__是什么,有什么作用- 模块是Python的“一等公民”是什么意思
- 包和文件夹的区别是什么?
- 导入模块和包本质简单描述
- 如何指定程序按项目的根目录导入模块与包
- 查看当前环境的第三方依赖命令
- 激活和退出虚拟环境的命令
- 导入和导出第三方依赖的命令
- 将
购物车项目改版为多目录版本吗,包括数据库文件,日志文件,配置文件等
第二章总结&模块作业
1. 总结
- 理解函数的概念,能够定义和调用函数,并了解函数的参数和返回值的使用。
- 熟悉常用的内置函数,如
map、sorted、sum等,并能够正确使用它们。 - 熟悉函数的参数传递方式,包括位置参数、关键字参数和默认参数,并能够正确传递参数。
- 能够使用函数进行模块化编程,将代码划分为逻辑单元,提高代码的可读性和重用性。
- 理解和使用文件操作相关的函数和方法,如打开文件、读取和写入文件内容等。
- 熟悉常用的文件操作模式,如读取模式('r')、写入模式('w')、追加模式('a')等,并能够正确选择和使用模式。
- 熟悉如何利用文件操作下载各类文件,包括图片,视频等。
- 掌握好常用模块,如json模块,日志模块,os模块等,分别可以完成序列化,日志记录以及文件和文件夹操作等。
- 理解模块和包的概念,能够导入和使用模块,并了解模块的搜索路径和命名空间的概念。
- 能够编写简单的模块和包,将代码组织成可复用的模块,并能够正确导入和使用模块和包。
2. 模块作业
【1】选课系统【升级版】
-
多目录版本,包括数据库文件,日志文件,配置文件等
-
加入关于学生,课程等保存的功能
-
为每门课程设置上课时间和上课地点以及学分,并在选课时显示这些信息
# 提示 courses = { "CS101": {"time":"周二 8:00-10:00","location":"教学楼101","credit": 3}, "ENG201": {"time":"周二 10:30-12:00","location":"教学楼102","credit": 2}, "MATH301":{"time":"周二 9:00-11:00","location":"教学楼103","credit": 3}, "PHYS401":{"time":"周四 8:00-10:00","location":"教学楼104","credit": 2}, "HIST501":{"time":"周五 8:00-10:00","location":"教学楼105","credit": 1}, } -
成绩管理:记录学生选修课程的成绩,并提供查询成绩和统计分析的功能。
-
在选课时检测已选课程与待选课程的时间是否冲突,如果冲突则提醒学生调整课程安排。
【2】金花棋牌游戏


# 代码提示,仅供参考,仅供参考,仅供参考
import random
# 1. 生成牌
def alex():
poke_types = ['♥', '♠', '♦', '♣']
poke_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
poke_list = []
# 待补充
return poke_list
pokeList = alex()
# 2. 发牌
players = ['默默', '观日落', '志强', 'CX330', '窗外', '小公主', '两个', 'Jack', '飞猪']
def blackGirl(pl, pk, pn):
players_dic = {}
# print(f"为玩家【{p_name}】生成了牌:{p_cards}")
return players_dic
playersDic = blackGirl(players, pokeList, 3)
# 3. 写好每种牌型的判断方法
def sortList(dataList):
# 排序:可以用sorted排序,也可以使用冒泡排序
return dataList
# 单张
def calculate_single(p_cards, score):
# 初始化得分N
# score = 0
# 排序
# p_cards = sortList(p_cards)
# print(f"计算单牌的结果是:{score}")
return score
# 对子
def calculate_pair(p_cards, score):
# p_cards = sortList(p_cards)
# print(f"计算对子的结果是:{score}")
return score
# 顺子
def calculate_straight(p_cards, score):
# p_cards = sortList(p_cards)
# print(f"计算顺子的结果是:{score}")
return score
# 同花
def calculate_same_color(p_cards, score):
# print(f"计算同花的结果是:{score}")
return score
# 同花顺
def calculate_same_color_straight(p_cards, score):
# 同花
# color_val = [i[0][0] for i in p_cards]
# print(f"计算同花顺的结果是:{score}")
return score
# 豹子
def calculate_leopard(p_cards, score):
# card_val = {i[1] for i in p_cards}
# print(f"计算豹子的结果是:{score}")
return score
# 4. 比对
calc_func_orders = [
calculate_single,
calculate_pair,
calculate_straight,
calculate_same_color,
calculate_same_color_straight,
calculate_leopard
]
players_score = []
for p_name, p_cards in playersDic.items():
print(f"开始计算玩家【{p_name}】的牌了:{p_cards}")
score = 0
for calc_fun in calc_func_orders:
score = calc_fun(p_cards, score)
players_score.append([p_name, score])
winner = sortList(players_score)[-1]
print(f"恭喜最后获胜的玩家是:【{winner[0]}】,得分是:{winner[1]}")
模块3:Python高级
模块概述
本课程旨在介绍Python编程语言中的面向对象编程(OOP)概念和技术。学生将学习如何使用类、对象、继承、多态等OOP的关键要素来构建灵活、可重用和可扩展的代码。通过实际编程练习和项目,学生将提高他们的编程技能,学会设计和实现面向对象的解决方案。
面向对象编程是在面向过程编程的基础上发展来的,它比面向过程编程具有更强的灵活性和扩展性。面向对象编程是程序员发展的分水岭,很多初学者会因无法理解面向对象而放弃学习编程,所以我们一定要足够重视。
课程目标
- 理解面向对象编程的基本原则和思想。
- 掌握Python中的类、对象、属性和方法的概念。
- 熟悉继承、多态和封装等OOP的高级概念。
- 能够设计和实现面向对象的解决方案。
- 培养良好的编码风格和软件工程实践。
Day11:面向对象基础

1. 类和对象
【1】类和对象的概念
面向对象编程(Object-oriented Programming,简称 OOP)是一种编程范式。
- 从思想角度讲
面向对象思想来源于对现实世界的认知。现实世界缤纷复杂、种类繁多,难于认识和理解。但是聪明的人们学会了把这些错综复杂的事物进行分类,从而使世界变得井井有条。现实世界中每一个事物都是一个对象,它是一种具体的概念。类是人们抽象出来的一个概念,所有拥有相同属性和功能的事物称为一个类;而拥有相同属性和功能的具体事物则成为这个类的实例对象。
比如现实世界中,
狗的属性是有尾巴,有毛,四条腿等,功能是能汪汪叫,能吃骨头,能咬人等。能有这些属性和功能的事物我们就认为属于狗类。
人的属性是两条腿,没有尾巴等,功能是能玩火,能尿炕,能使用工具。能有这些属性和功能的事物我们就认为属于人类。
电脑属性是有CPU,存储器,操作系统等,功能就是能安装APP,能连网等。能有这些属性和功能的事物我们就认为属于电脑类。
汽车的属性是有四个轮子,一个底盘,一个方向盘等,功能是能行驶,能加速,能刹车等。能有这些属性和功能的事物我们就认为属于汽车类。
面向对象编程提供了一种从现实世界中抽象出概念和实体的方法。通过类和对象的概念,可以将现实世界中的问题和关系转化为代码结构,使得程序更加符合问题域的模型化。
面向对象编程通过采用类的概念,把事物编写成一个个“类”。在类中,用数据表示事物的状态,用函数实现事物的行为,这样就使编程方式和人的思维方式保持一致,极大的降低了思维难度。
-8871360.png)
legs_num = 4
has_hair = True
has_tail = True
def bark(self):
print("狗狂吠")
def bite(self):
print("狗咬人")
def fetch(self):
print("狗捡球")
legs_nums = 2
has_wings = True
has_teeth = False
def fly(self):
print("鸟飞翔")
def eat_worms(self):
print("鸟吃虫子")
def nest(self):
print("鸟筑巢")
类版本:
# 声明类
class Dog:
legs_num = 4
has_hair = True
has_tail = True
def bark(self):
print("狗狂吠")
def bite(self):
print("狗咬人")
def fetch(self):
print("狗捡球")
# 实例化对象
alex = Dog()
print(alex.legs_num)
alex.bark()
alex.bite()
class Bird:
legs_nums = 2
has_wings = True
has_teeth = False
def fly(self):
print("鸟飞翔")
def eat_worms(self):
print("鸟吃虫子")
def nest(self):
print("鸟筑巢")
# 实例化对象
b1 = Bird()
print(b1.has_wings)
print(b1.has_teeth)
b1.fly()
- 从封装角度讲
面向对象编程(Object-oriented Programming,简称 OOP),是一种封装代码的方法。其实,在前面章节的学习中,我们已经接触了封装,比如说,将乱七八糟的数据扔进列表中,这就是一种简单的封装,是数据层面的封装;把常用的代码块打包成一个函数,这也是一种封装,是语句层面的封装。
面向对象编程,也是一种封装的思想,不过显然比以上两种封装更先进,它可以更好地模拟真实世界里的事物(将其视为对象),并把描述特征的数据和代码块(函数)封装到一起。
面向对象编程(Object-Oriented Programming,简称OOP)相较于面向过程编程(Procedural Programming)有以下几个优点:
- 封装性(Encapsulation):面向对象编程通过将数据和操作封装在一个对象中,使得对象成为一个独立的实体。对象对外部隐藏了内部的实现细节,只暴露出必要的接口,从而提高了代码的可维护性和模块化程度。
- 继承性(Inheritance):继承是面向对象编程的重要特性之一。它允许创建一个新的类(子类),从一个现有的类(父类或基类)继承属性和方法。子类可以通过继承获得父类的特性,并可以在此基础上进行扩展或修改。继承提供了代码重用的机制,减少了重复编写代码的工作量。
- 多态性(Polymorphism):多态性使得对象可以根据上下文表现出不同的行为。通过多态机制,可以使用统一的接口来处理不同类型的对象,而不需要针对每种类型编写特定的代码。这提高了代码的灵活性和可扩展性。
- 代码的可维护性和可扩展性:面向对象编程强调模块化和代码复用,通过将功能划分为独立的对象和类,使得代码更易于理解、测试和维护。当需求变化时,面向对象编程的结构和机制使得代码的修改和扩展更加简洁和可靠。
总的来说,面向对象编程提供了一种更加结构化、可扩展和可维护的编程范式。它通过封装、继承和多态等特性,使得代码更加模块化、灵活和易于理解。这些优点使得面向对象编程成为当今广泛采用的编程范式之一,被广泛应用于软件开发中。
【2】类和实例对象的语法
面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Person类,而实例是根据类创建出来的一个个具体的“对象”。

# 声明类
class 类名:
类属性...
方法...
# 类的实例化
实例对象 = 类名() # 开辟一块独立的属于实例空间,将空间地址作为返回值
# 实例对象可以通过句点符号调用类属性和方法
实例对象.类属性
实例对象.方法(实参)
- 和变量名一样,类名本质上就是一个标识符,命名遵循变量规范。如果由单词构成类名,建议每个单词的首字母大写,其它字母小写。
- 冒号 + 缩进标识类的范围
- 无论是类属性还是类方法,对于类来说,它们都不是必需的,可以有也可以没有。另外,Python 类中属性和方法所在的位置是任意的,即它们之间并没有固定的前后次序。
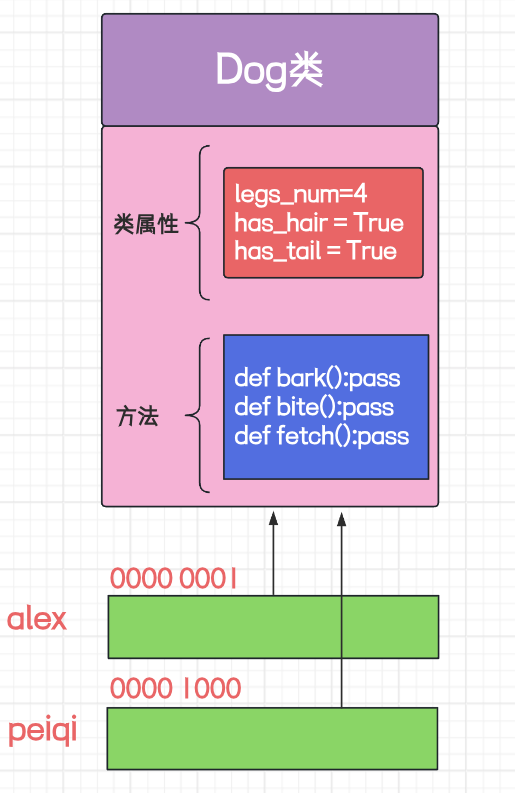
# 声明类
class Dog:
legs_num = 4
has_hair = True
has_tail = True
def bark(self):
print("狗狂吠")
def bite(self):
print("狗咬人")
def fetch(self):
print("狗捡球")
# 实例化对象
alex = Dog()
print(alex.legs_num)
alex.bark()
alex.bite()
# 实例化对象
peiQi = Dog()
# print(id(alex))
# print(id(peiQi))
print(id(alex.legs_num))
print(id(peiQi.legs_num))
print(id(alex.bark))
print(id(peiQi.bark))
2. 实例属性和实例方法
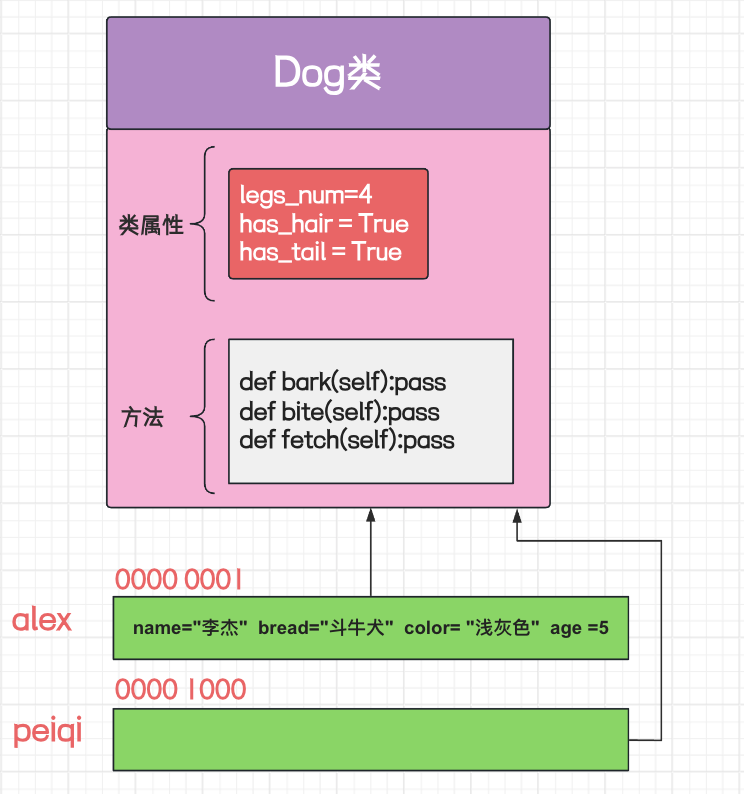
【1】实例属性
类变量(类属性)的特点是,所有类的实例化对象都同时共享类变量,也就是说,类变量在所有实例化对象中是作为公用资源存在的。实例属性是属于类的每个实例对象的特定属性。实例属性是在创建对象时赋予的,每个对象可以具有不同的实例属性值。
alex = Dog()
peiQi = Dog()
# 实例属性: 属于实例对象自己的属性
alex.name = "李杰"
alex.age = 10
peiQi.name = "武大郎"
peiQi.age = 20
# 问题1:
print(alex.name)
alex.age = 30
print(alex.age)
# 问题2:
print(peiQi.age)
# 问题3:
alex.bark()
alex.bark = "hello world"
# alex.bark()
peiQi.bark()
【2】实例方法和self
在 Python 的类定义中,self 是一个特殊的参数,用于表示类的实例对象自身。self 参数必须作为第一个参数出现在类的方法定义中,通常被约定为 self,但实际上你可以使用其他名称。
当你调用类的方法时,Python 会自动将调用该方法的实例对象传递给 self 参数。这样,你就可以通过 self 参数来引用和操作实例对象的属性和方法。
class Dog:
legs_num = 4
has_hair = True
has_tail = True
def eat(self):
print(f"{self.name}正在吃东西。")
def run(self):
print(f"{self.name}正在跑。")
def sleep(self):
print(f"{self.name}正在睡觉。")
def bark(self):
print(f"{self.name}正在狂吠。")
def show_info(self):
print(f"名字:{self.name},品种:{self.breed},颜色:{self.color},年龄:{self.age}")
# 声明对象
bulldog = Dog()
# 赋值实例属性
bulldog.name = "小灰"
bulldog.breed = "斗牛犬"
bulldog.color = "浅灰色"
bulldog.age = 5
# 调用斗牛犬的行为
bulldog.eat()
bulldog.run()
bulldog.sleep()
bulldog.bark()
bulldog.show_info()
3. 构造方法__init__
在上节课的代码中,对象的属性是通过直接赋值给对象的实例属性来实现的,而不是在构造方法中进行初始化。这样做可能会导致以下问题:
- 代码冗余:每次创建对象时都需要分别为每个对象赋值实例属性,这会导致代码冗余和重复劳动。
- 可维护性差:如果类的属性发生变化或新增属性,需要修改多处代码来适应这些变化,而如果使用构造方法来初始化属性,则只需要在一个地方进行修改。
为了改进这种写法,可以使用构造方法来初始化对象的属性。构造方法在创建对象时自动调用,并可以接受参数来初始化对象的属性。
class Dog:
def __init__(self, name, breed, color, age):
self.name = name
self.breed = breed
self.color = color
self.age = age
def eat(self):
print(f"{self.name}正在吃东西。")
def run(self):
print(f"{self.name}正在跑。")
def sleep(self):
print(f"{self.name}正在睡觉。")
def bark(self):
print(f"{self.name}正在狂吠。")
def show_info(self):
print(f"名字:{self.name},品种:{self.breed},颜色:{self.color},年龄:{self.age}")
# 声明对象
bulldog = Dog("小灰", "斗牛犬", "浅灰色", 5)
# 调用斗牛犬的行为
bulldog.bark()
bulldog.show_info()
# 声明对象
beagle = Dog("小黄", "小猎犬", "橘色", 6)
beagle.bark()
beagle.show_info()
实例化一个类的过程可以分为以下几个步骤:
- 创建一个新的对象(即开辟一块独立空间),它是类的实例化结果。
- 调用类的
__init__方法,将新创建的对象作为第一个参数(通常命名为self),并传递其他参数(如果有的话)。 - 在
__init__方法中,对对象进行初始化,可以设置对象的属性和执行其他必要的操作。 - 返回新创建的对象,使其成为类的实例。
-8841742-8841743.png)
在创建类时,我们可以手动添加一个 __init__() 方法,该方法是一个特殊的类实例方法,称为构造方法(或构造函数)。
__init__() 方法可以包含多个参数,但必须包含一个名为 self 的参数,且必须作为第一个参数。除了 self 参数外,还可以自定义一些参数,从而完成初始化的工作。
- 注意到
__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self是指向创建的实例本身。- 实例属性,实例变量,实例成员变量都是指的存在实例空间的属性
4. 一切皆对象
在python语言中,一切皆对象!
我们之前学习过的字符串,列表,字典等等数据都是一个个的类,我们用的所有数据都是一个个具体的实例对象。
区别就是,那些类是在解释器级别注册好的,而现在我们学习的是自定义类,但语法使用都是相同的。所以,我们自定义的类实例对象也可以和其他数据对象一样可以进行传参、赋值等操作。
- 自定义类对象是可变数据类型,我们可以在创建后对其进行修改,添加或删除属性和方法,而不会改变类对象的身份。
- 实例对象也是一等公民
5. 类对象、类属性以及类方法
【1】类对象
类对象是在Python中创建类时生成的对象,它代表了该类的定义和行为,存储着公共的类属性和方法
class Car(object):
# 类属性
total_cars = 0
def __init__(self,make,model):
self.make = make
self.model = model
# 实例方法
def accelerate(self):
print(f"一辆{self.make}的{self.model}正在加速")
car1 = Car("Toyota", "Camry")
类对象.实例方法会怎么样?
【2】修改类属性
class Car:
total_cars = 0
def __init__(self, make, model):
self.make = make
self.model = model
Car.total_cars += 1
# 实例方法
def accelerate(self):
print(f"一辆{self.make}的{self.model}正在加速")
def display_total_cars(self):
# print("Total cars:", self.total_cars)
print("Total cars:", Car.total_cars)
# 创建两辆汽车
car1 = Car("Toyota", "Camry")
car1.display_total_cars()
car2 = Car("Honda", "Accord")
car1.display_total_cars()
【3】类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为cls,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:类对象或实例对象都可以调用。
class Car:
total_cars = 0
def __init__(self, make, model):
self.make = make
self.model = model
Car.total_cars += 1
@classmethod
def display_total_cars(cls):
print(f"Total cars of {cls.__name__}: {cls.total_cars}")
# 创建两辆汽车
car1 = Car("Toyota", "Camry")
car2 = Car("Honda", "Accord")
# 显示车辆总数
Car.display_total_cars() # 输出: Total cars of Car: 2
# 创建另一辆汽车
car3 = Car("Ford", "Mustang")
# 显示更新后的车辆总数
Car.display_total_cars() # 输出: Total cars of Car: 3
6. 静态方法
定义:使用装饰器@staticmethod。参数随意,没有self和cls参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:类对象或实例对象都可以调用。
class Cal():
@staticmethod
def add(x,y):
return x+y
@staticmethod
def mul(x,y):
return x*y
cal=Cal()
print(cal.add(1, 4))
or
print(Cal.add(3,4))
7. 案例练习
案例1:游戏案例
函数版本:
hero = {
"name": "yuan",
"health": 1000,
"gold": 100,
"defense": 10,
"attack": 90,
"level": 1,
"weapon_list": []
}
# 测试攻击敌人
enemy = {
"name": "alex",
"health": 500,
"defense": 5,
"attack": 50,
"gold": 100,
"level": 1,
"weapon_list": []
}
def attack_enemy(player, enemy):
damage = player["attack"] - enemy["defense"]
if damage > 0:
enemy["health"] -= damage
print(f"{player['name']}成功攻击了敌人{enemy['name']},造成了{damage}点伤害。")
else:
print(f"{player['name']}的攻击被敌人防御了。")
def buy_weapon(player, weapon):
player["weapon_list"].append(weapon)
print(f"{player['name']}购买装备{weapon}!")
def level_up(player):
player["level"] += 1
player["gold"] += 100
print(f"{player['name']}升级了,奖励金币100!")
buy_weapon(hero, "屠龙刀")
attack_enemy(hero, enemy)
level_up(hero)
面向对象版本:
class Weapon:
def __init__(self, name, attack, defense):
self.name = name
self.attack = attack
self.defense = defense
def upgrade(self):
self.attack += 50
self.defense += 50
print(f"{self.name}的防御力增加了50点。")
print(f"{self.name}的防御力增加了50点。")
class Player:
def __init__(self, name, health=100, gold=100, defense=100, attack=100, level=1, weapon_list=[]):
self.name = name
self.health = health
self.gold = gold
self.defense = defense
self.attack = attack
self.level = level
self.weapon_list = weapon_list
def attack_enemy(self, enemy, weapon_index=None):
if weapon_index is None:
damage = self.attack - enemy.defense
else:
damage = self.weapon_list[weapon_index].attack - enemy.defense
if damage > 0:
enemy.health -= damage
print(f"{self.name}成功攻击了敌人{enemy.name},造成了{damage}点伤害。")
else:
print(f"{self.name}的攻击被敌人防御了。")
def buy_weapon(self, weapon):
self.weapon_list.append(weapon)
print(f"{self.name}购买装备{weapon.name}!")
def level_up(self):
self.level += 1
self.gold += 100
print(f"{self.name}升级了,奖励金币100!")
p1 = Player("YUAN")
p2 = Player("ALEX")
p1.attack_enemy(p2)
w1 = Weapon("屠龙刀", 1000, 300)
p1.buy_weapon(w1)
p1.attack_enemy(p2, 0)
案例2:客户关系管理系统【面向对象版本】
customers = [
{
"name": "John Smith",
"age": 35,
"contact": "johnsmith@example.com"
},
{
"name": "Jane Doe",
"age": 28,
"contact": "janedoe@example.com"
},
{
"name": "Michael Johnson",
"age": 42,
"contact": "michaeljohnson@example.com"
}
]
def add_customer():
print("添加客户")
def delete_customer():
print("删除客户")
def update_customer():
print("修改客户")
def query_customer():
print("查询客户")
class CustomersManager:
customers = [
{
"name": "John Smith",
"age": 35,
"contact": "johnsmith@example.com"
},
{
"name": "Jane Doe",
"age": 28,
"contact": "janedoe@example.com"
},
{
"name": "Michael Johnson",
"age": 42,
"contact": "michaeljohnson@example.com"
}
]
def add_customer(self):
print("添加客户")
def delete_customer(self):
print("删除客户")
def update_customer(self):
print("修改客户")
def query_customer(self):
print("查询客户")
cm = CustomersManager()
cm.add_customer()
cm.delete_customer()
cm.update_customer()
cm.query_customer()
今日作业
-
创建一个名为
Circle的类,并为其添加计算面积(area)、周长(circumference)等方法。 -
人狗大战
- 人类(
Person类):- 属性:姓名(
name)和健康值(health)。 - 方法:
kick_dog(dog):踢狗的方法,接受一个狗对象作为参数。在踢狗时输出踢狗的信息,同时减少狗对象的健康值。decrease_health(amount):减少健康值的方法,接受一个数值amount作为参数,将人的健康值减少该数值。
- 属性:姓名(
- 狗类(
Dog类):- 属性:姓名(
name)和健康值(health)。 - 方法:
bite(person):咬人的方法,接受一个人对象作为参数。在咬人时输出咬人的信息,同时减少人对象的健康值。decrease_health(amount):减少健康值的方法,接受一个数值amount作为参数,将狗的健康值减少该数值。
- 属性:姓名(
- 操作
- 人踢狗时,输出踢狗的信息,并减少狗的健康值。
- 狗咬人时,输出咬人的信息,并减少人的健康值。
- 最后,输出人和狗的健康值,以验证掉血值的效果。
- 人类(
-
创建一个名为
BankAccount的类,具有以下特征:- 属性:
account_number(账号)、balance(余额) - 方法:
deposit(amount),用于向账户存款;withdraw(amount),用于从账户取款;get_balance(),用于获取账户余额。 - 操作:实例化对象,存钱和取钱
- 属性:
-
题目:书籍管理
要求:
- 创建一个名为
Book的类,具有属性title、author和publication_year。 - 创建一个类属性
book_list用于存储书籍对象,一个类属性book_count`存储书籍个数。 - 每实例化一本书籍对象,自动添加到
book_list,并且book_count自加一操作 - 构建一个类方法
show_books,输出每本书籍的信息(标题、作者和出版年份)
- 创建一个名为
Day12:面向对象进阶

1. 三大特性之继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
class 派生类名(基类名)
...
【1】继承的基本使用
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码,能够大大的提高开发的效率。
实际上继承者是被继承者的特殊化,它除了拥有被继承者的特性外,还拥有自己独有得特性。例如猫有抓老鼠、爬树等其他动物没有的特性。同时在继承关系中,继承者完全可以替换被继承者,反之则不可以,例如我们可以说猫是动物,但不能说动物是猫就是这个道理,其实对于这个我们将其称之为“向上转型”。
诚然,继承定义了类如何相互关联,共享特性。对于若干个相同或者相识的类,我们可以抽象出他们共有的行为或者属相并将其定义成一个父类或者超类,然后用这些类继承该父类,他们不仅可以拥有父类的属性、方法还可以定义自己独有的属性或者方法。
同时在使用继承时需要记住三句话:
1、子类拥有父类非私有化的属性和方法。
2、子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
3、子类可以用自己的方式实现父类的方法。(下面会介绍)。
# 无继承方式
class Dog:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
def swimming(self):
print("swimming...")
class Cat:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
def climb_tree(self):
print("climb_tree...")
# 继承方式
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Dog(Animal):
def swimming(self):
print("toshetou...")
class Cat(Animal):
def climb_tree(self):
print("climb_tree...")
alex = Dog()
alex.run()
【2】重写父类方法和调用父类方法
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def sleep(self):
print(":::", self.name)
print("基类sleep...")
class Emp(Person):
# def __init__(self,name,age,dep):
# self.name = name
# self.age = age
# self.dep = dep
def __init__(self, name, age, dep):
# Person.__init__(self,name,age)
super().__init__(name, age)
self.dep = dep
def sleep(self):
# print("子类sleep...")
# 调用父类方法
# 方式1 :父类对象调用 父类对象.方法(self,其他参数)
# Person.sleep(self)
# 方式2: super关键字 super().方法(参数)
super().sleep()
yuan = Emp("yuan", 18, "教学部")
yuan.sleep()
print(yuan.dep)
# 测试题:
class Base:
def __init__(self):
self.func()
def func(self):
print('in base')
class Son(Base):
def func(self):
print('in son')
s = Son()
【3】多重继承
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
多继承有什么意义呢?还拿上面的例子来说,蝙蝠和鹰都可以飞,飞的功能就重复定义了。
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Eagle(Animal):
def fly(self):
print("fly...")
class Bat(Animal):
def fly(self):
print("fly...")
有同学肯定想那就放到父类Animal中,可是那样的话其他不会飞的动物还怎么继承Animal呢?所以,这时候多重继承就发挥功能了:
class Fly:
def fly(self):
print("fly...")
class Eagle(Animal,Fly):
pass
class Bat(Animal,Fly):
pass
【4】内置函数补充
(1) type 和isinstance方法
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Dog(Animal):
def swim(self):
print("swimming...")
alex = Dog()
mjj = Dog()
print(isinstance(alex,Dog))
print(isinstance(alex,Animal))
print(type(alex))
(2)dir()方法和__dict__属性
dir(obj)可以获得对象的所有属性(包含方法)列表, 而obj.__dict__对象的自定义属性字典
注意事项:
dir(obj)获取的属性列表中,方法也认为属性的一种。返回的是listobj.__dict__只能获取自己自定义的属性,系统内置属性无法获取。返回是dict
class Student:
def __init__(self, name, score):
self.name = name
self.score = score
def test(self):
pass
yuan = Student("yuan", 100)
print("获取所有的属性列表")
print(dir(yuan))
print("获取自定义属性字段")
print(yuan.__dict__)
其中,类似__xx__的属性和方法都是有特殊用途的。如果调用len()函数视图获取一个对象的长度,其实在len()函数内部会自动去调用该对象的__len__()方法
2. 三大特性之封装
封装是指隐藏对象的属性和实现细节,仅对外提供公共访问方式。
我们程序设计追求“高内聚,低耦合”
- 高内聚:类的内部数据操作细节自己完成,不允许外部干涉
- 低耦合:仅对外暴露少量的方法用于使用。
隐藏对象内部的复杂性,只对外公开简单的接口。便于外界调用,从而提高系统的可扩展性、可维护性。通俗的说,把该隐藏的隐藏起来,该暴露的暴露岀来。这就是封装性的设计思想。
【1】私有属性
在class内部,可以有属性和方法,而外部代码可以通过直接调用实例变量的方法来操作数据,这样,就隐藏了内部的复杂逻辑。但是,从前面Student类的定义来看,外部代码还是可以自由地修改一个实例的name、score属性:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
alvin = Student("alvin",66)
yuan = Student("yuan",88)
alvin.score=100
print(alvin.score)
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,所以,我们把Student类改一改:
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
alvin = Student("alvin",66)
yuan = Student("yuan",88)
print(alvin.__score)
改完后,对于外部代码来说,没什么变动,但是已经无法从外部访问实例变量.__name和实例变量.__score。这样就确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。但是如果外部代码要获取name和score怎么办?可以给Student类增加get_score这样的方法:
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
alvin=Student("alvin",66)
yuan=Student("yuan",88)
print(alvin.get_score())
如果又要允许外部代码修改score怎么办?可以再给Student类增加set_score方法:
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
def set_score(self,score):
self.__score = score
alvin = Student("alvin",12)
print(alvin.get_score())
alvin.set_score(100)
print(alvin.get_score())
你也许会问,原先那种直接通过alvin.score = 100也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以设置值时做其他操作,比如记录操作日志,对参数做检查,避免传入无效的参数等等:
class Student(object):
...
def set_score(self,score):
if isinstance(score,int) and 0 <= score <= 100:
self.__score = score
else:
raise ValueError('error!')
注意
1、这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:
_类名__属性,然后就可以访问了2、变形的过程只在类的内部生效,在定义后的赋值操作,不会变形
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
yuan=Student("yuan",66)
print(yuan.__dict__)
yuan.__age=18
print(yuan.__dict__)
案例
class Person(object):
def __init__(self, name, score):
self.name = name
self.__score = score
class Student(Person):
def get_score(self):
return self.__score
def set_score(self,score):
self.__score=score
yuan=Student("yuan",66)
print(yuan.__dict__)
print(yuan.get_score())
子类无法直接访问父类的私有属性。子类只能在自己的方法中访问和修改自己定义的私有属性,无法直接访问父类的私有属性。
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似__init__()之类的。__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问。(约定成俗,不限语法)
【2】私有方法
私有方法是指只能在类的内部访问和调用的方法,无法在类的外部直接访问或调用。
class AirConditioner:
def __init__(self):
# 初始化空调
pass
def cool(self, temperature):
# 对外制冷功能接口方法
self.__turn_on_compressor()
self.__set_temperature(temperature)
self.__blow_cold_air()
self.__turn_off_compressor()
def __turn_on_compressor(self):
# 打开压缩机(私有方法)
pass
def __set_temperature(self, temperature):
# 设置温度(私有方法)
pass
def __blow_cold_air(self):
# 吹冷气(私有方法)
pass
def __turn_off_compressor(self):
# 关闭压缩机(私有方法)
pass
在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的:
class Base:
def foo(self):
print("foo from Base")
def test(self):
self.foo()
class Son(Base):
def foo(self):
print("foo from Son")
s=Son()
s.test()
class Base:
def __foo(self):
print("foo from Base")
def test(self):
self.__foo()
class Son(Base):
def __foo(self):
print("foo from Son")
s=Son()
s.test()
【3】property属性操作
(1)property属性装饰器
使用接口函数获取修改数据 和 使用点方法设置数据相比, 点方法使用更方便,我们有什么方法达到 既能使用点方法,同时又能让点方法直接调用到我们的接口了,答案就是property属性装饰器:
class Student(object):
def __init__(self,name,score,sex):
self.__name = name
self.__score = score
self.__sex = sex
@property
def name(self):
return self.__name
@name.setter
def name(self,name):
if len(name) > 1 :
self.__name = name
else:
print("name的长度必须要大于1个长度")
@property
def score(self):
return self.__score
# @score.setter
# def score(self, score):
# if score > 0 and score < 100:
# self.__score = score
# else:
# print("输入错误!")
yuan = Student('yuan',18,'male')
yuan.name = '苑昊' # 调用了@name.setter
print(yuan.name) # 调用了@property的name函数
yuan.score = 199 # @score.setter
print(yuan.score) # @property的score方法
(2)property属性函数
python提供了更加人性化的操作,可以通过限制方式完成只读、只写、读写、删除等各种操作
class Person:
def __init__(self, name):
self.__name = name
def __get_name(self):
return self.__name
def __set_name(self, name):
self.__name = name
def __del_name(self):
del self.__name
# property()中定义了读取、赋值、删除的操作
# name = property(__get_name, __set_name, __del_name)
name = property(__get_name, __set_name)
yuan = Person("yuan")
print(yuan.name) # 合法:调用__get_name
yuan.name = "苑昊" # 合法:调用__set_name
print(yuan.name)
# property中没有添加__del_name函数,所以不能删除指定的属性
del p.name # 错误:AttributeError: can't delete Attribute
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
3. 三大特性之多态
【1】java多态
在java里,多态是同一个对象具有不同表现形式或形态的能力,即对象多种表现形式的体现,就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
如下图所示:使用手机扫描二维码支付时,二维码并不知道客户是通过何种方式进行支付,只有通过二维码后才能判断是走哪种支付方式执行对应流程。

// 支付抽象类或者接口
public class Pay {
public String pay() {
System.out.println("do nothing!")
return "success"
}
}
// 支付宝支付
public class AliPay extends Pay {
@Override
public String pay() {
System.out.println("支付宝pay");
return "success";
}
}
// 微信支付
public class WeixinPay extends Pay {
@Override
public String pay() {
System.out.println("微信Pay");
return "success";
}
}
// 银联支付
public class YinlianPay extends Pay {
@Override
public String pay() {
System.out.println("银联支付");
return "success";
}
}
// 测试支付
public static void main(String[] args) {
// 测试支付宝支付多态应用
Pay pay = new AliPay();
pay.pay();
// 测试微信支付多态应用
pay = new WeixinPay();
pay.pay();
// 测试银联支付多态应用
pay = new YinlianPay();
pay.pay();
}
// 输出结果如下:
支付宝pay
微信Pay
银联支付
多态存在的三个必要条件:
- 继承
- 重写
- 父类引用指向子类对象
比如:
Pay pay = new AliPay()
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,再去调用子类的同名方法。
【2】鸭子模型
鸭子模型(Duck typing)是一种动态类型系统中的编程风格或理念,它强调对象的行为比其具体类型更重要。根据鸭子模型的说法,如果一个对象具有与鸭子相似的行为,那么它就可以被视为鸭子。
鸭子模型源自于一个简单的说法:“如果它看起来像鸭子,叫起来像鸭子,那么它就是鸭子。”在编程中,这意味着我们更关注对象是否具有特定的方法或属性,而不是关注对象的具体类型。
通过鸭子模型,我们可以编写更灵活、通用的代码,而不需要显式地指定特定的类型或继承特定的接口。只要对象具有所需的方法和属性,就可以在代码中使用它们,无论对象的具体类型是什么。
class AliPay:
def pay(self):
print('通过支付宝消费')
class WeChatPay:
def pay(self):
print('通过微信消费')
class Order(object):
def account(self,pay_obj):
pay_obj.pay()
pay1 = WeChatPay("yuan", 100)
pay2 = AliPay("alvin", 200)
order = Order()
order.account(pay1)
order.account(pay2)
4. 反射
反射这个术语在很多语言中都存在,并且存在大量的运用,今天我们说说什么是反射,反射主要是指程序可以访问、检测和修改它本身状态或行为的一种能力。
在Python中,反射是指在运行时通过名称字符串来访问、检查和操作对象的属性和方法的能力。Python提供了一些内置函数和特殊方法,使得可以动态地获取对象的信息并执行相关操作。
Python中的反射主要有下面几个方法:
# 1. 判断对象中有没有一个name字符串对应的方法或属性
hasattr(object,name)
# 2. 获取对象name字符串属性的值,如果不存在返回default的值
getattr(object, name, default=None)
# 3. 设置对象的key属性为value值,等同于object.key = value
setattr(object, key, value)
# 4. 删除对象的name字符串属性
delattr(object, name)
应用1:
class Person:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
yuan=Person("yuan",22,"male")
print(yuan.name)
print(yuan.age)
print(yuan.gender)
while 1:
# 由用户选择查看yuan的哪一个信息
attr = input(">>>")
if hasattr(yuan, attr):
val = getattr(yuan, attr)
print(val)
else:
val=input("yuan 没有你该属性信息!,请设置该属性值>>>")
setattr(yuan,attr,val)
应用2:
class CustomerManager:
def __init__(self):
self.customers = []
def add_customer(self):
print("添加客户")
def del_customer(self):
print("删除客户")
def update_customer(self):
print("修改客户")
def query_one_customer(self):
print("查询一个客户")
def show_all_customers(self):
print("查询所有客户")
class CustomerSystem:
def __init__(self):
self.cm = CustomerManager()
def run(self):
print("""
1. 添加客户
2. 删除客户
3. 修改客户
4. 查询一个客户
5. 查询所有客户
6. 保存
7. 退出
""")
while True:
choice = input("请输入您的选择:")
if choice == "6":
self.save()
continue
elif choice == "7":
print("程序退出!")
break
try:
method_name = "action_" + choice
method = getattr(self, method_name)
method()
except AttributeError:
print("无效的选择")
def save(self):
print("保存数据")
def action_1(self):
self.cm.add_customer()
def action_2(self):
self.cm.del_customer()
def action_3(self):
self.cm.update_customer()
def action_4(self):
self.cm.query_one_customer()
def action_5(self):
self.cm.show_all_customers()
cs = CustomerSystem()
cs.run()
5. 魔法方法
Python 类里有一种方法,叫做魔法方法(special method)。Python 的类里提供的,两个下划线开始,两个下划线结束的方法,就是魔法方法,魔法方法在特定行为下就会被激活,自动执行。
【1】__new__()方法
__new__() 方法是在 Python 中定义一个类的时候可以定义的一个特殊方法。它被用来创建一个类的新实例(对象)。
在 Python 中,创建一个新的实例一般是通过调用类的构造函数 __init__() 来完成的。然而,类名()创建对象时,在自动执行 __init__()方法前,会先执行 object.__new__方法,在内存中开辟对象空间并返回该对象。然后,Python 才会调用 __init__() 方法来对这个新实例进行初始化。
class Person(object):
# 其中,cls参数表示类本身,*args 和 **kwargs参数用于接收传递给构造函数的参数。
def __new__(cls, *args, **kwargs):
print("__new__方法执行")
# return object.__new__(cls)
def __init__(self, name, age):
print("__init__方法执行")
self.name = name
self.age = age
yuan = Person("yuan", 23)
_new__()方法的主要作用是创建实例对象,它可以被用来控制实例的创建过程。相比之下,__init__()方法主要用于初始化实例对象。
__new__() 方法在设计模式中常常与单例模式结合使用,用于创建一个类的唯一实例。单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取该实例。
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super().__new__(cls)
return cls._instance
# 创建实例
obj1 = Singleton()
obj2 = Singleton()
# 检查是否为同一个实例
print(obj1 is obj2) # 输出: True
【2】__str__方法
改变对象的字符串显示。可以理解为使用print函数打印一个对象时,会自动调用对象的__str__方法
class Person(object):
def __init__(self, name, age):
print("__init__方法执行")
self.name = name
self.age = age
def __str__(self):
return self.name
yuan = Person("yuan", 23)
print(yuan)
# 案例2
class Book(object):
def __init__(self, title, publisher, price):
self.title = title
self.publisher = publisher
self.price = price
book01 = Book("瓶梅", "苹果出版社", 699)
print(book01)
【3】__eq__ 方法
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, obj):
return self.name == obj.name
yuan = Person("yuan", 23)
alvin = Person("alvin", 23)
print(yuan == alvin)
__eq__(self, other): 判断对象是否相等,通过==运算符调用。__lt__(self, other): 判断对象是否小于另一个对象,通过<运算符调用。__gt__(self, other): 判断对象是否大于另一个对象,通过>运算符调用。__add__(self, other): 对象的加法操作,通过+运算符调用
【4】__len__方法
当定义一个自定义的容器类时,可以使用 __len__() 方法来返回容器对象中元素的数量。下面是一个示例,演示了如何在自定义列表类中实现 __len__() 方法:
class Cache01:
def __init__(self):
self.data = []
def __len__(self):
return len(self.data)
def add(self, item):
self.data.append(item)
def remove(self, item):
self.data.remove(item)
# 创建自定义列表对象
cache = Cache01()
# 获取列表的长度
print(len(cache))
class Cache02:
def __init__(self):
self.data = {}
def __len__(self):
return len(self.data)
def add(self, key, value):
self.data[key] = value
def remove(self, key):
del self.data[key]
一定会有同学问,Yuan老师,为什么要封装这个类,直接使用self.data = {}不就完了吗?
当我们封装一个类时,我们将相关的数据和操作放在一个包裹(类)中,就像把一些东西放进一个盒子里一样。这个盒子提供了一种保护和管理数据的方式,同时也定义了外部与内部之间的交互方式。
为什么要这样做呢?想象一下,如果我们直接将数据存储在类之外的变量中,其他代码可以直接访问和修改它。这可能导致数据被误用或篡改,造成不可预测的结果。而通过封装,我们可以将数据放在类的内部,并提供一些方法(接口)来访问和修改数据。这就像将数据放进盒子里,并用盒子上的门来控制对数据的访问。
这种封装的好处是什么呢?首先,它提供了一种信息隐藏的机制。外部代码只能通过类提供的方法来访问数据,无法直接触及数据本身。这样可以保护数据的完整性和一致性,防止不恰当的访问和修改。其次,封装使得代码更加模块化和可重用。我们可以将相关的数据和操作组织在一个类中,成为一个功能完整的单元,方便调用和扩展。
总而言之,封装就像把数据放进一个盒子里,通过提供方法来控制对数据的访问。这样做可以保护数据,提高代码的可读性和可维护性,并促进代码的模块化和重用。
【5】__item__系列
class Cache:
def __init__(self):
self.data = {}
def __getitem__(self, key):
return self.data[key]
def __setitem__(self, key, value):
self.data[key] = value
def __delitem__(self, key):
del self.data[key]
def __contains__(self, key):
return key in self.data
在上述例子中,我们创建了一个名为 Cache 的自定义类,并实现了 __getitem__、__setitem__、__delitem__ 和 __contains__ 这些特殊方法。
使用这个自定义的缓存类,我们可以像操作字典一样操作缓存数据,例如:
cache = Cache()
# 存储数据
cache['key1'] = 'value1'
cache['key2'] = 'value2'
# 获取数据
print(cache['key1']) # 输出: 'value1'
print(cache['key2']) # 输出: 'value2'
# 检查键是否存在
print('key1' in cache) # 输出: True
# 删除数据
del cache['key1']
# 检查键是否存在
print('key1' in cache) # 输出: False
通过实现特殊方法,我们可以使用类似于字典的语法来访问和操作缓存对象。这样,我们可以更方便地存储、获取和删除缓存数据,同时也可以使用其他字典操作,如检查键是否存在。
【6】__attr__系列
class Cache:
def __init__(self):
self.__data = {}
def __setattr__(self, name, value):
self.__data[name] = value
def __getattr__(self, name):
if name in self.__data:
return self.__data[name]
else:
raise AttributeError(f"'Cache' object has no attribute '{name}'")
def __delattr__(self, name):
if name in self.__data:
del self.__data[name]
else:
raise AttributeError(f"'Cache' object has no attribute '{name}'")
def __contains__(self, name):
return name in self.__data
在这个示例中,我们使用 __setattr__ 方法来设置属性,将属性存储在私有属性 __data 中。当我们尝试设置属性时,__setattr__ 方法会被自动调用,并将属性存储到私有字典中。
而在 __getattr__ 方法中,我们实现了对属性的访问。如果属性存在于私有字典 __data 中,它将返回属性的值。如果属性不存在,则会引发 AttributeError 异常。
类似地,我们还实现了 __delattr__ 方法来删除属性。如果属性存在于私有字典 __data 中,它将被删除。如果属性不存在,则会引发 AttributeError 异常。
最后,我们还重写了 __contains__ 方法,以实现在缓存中检查属性是否存在的功能。
使用这个经过修改的缓存类,我们可以使用类似于属性操作的语法:对象.属性来访问和操作缓存对象。
class Cache(object):
def __init__(self):
self.__dict__["data"] = {}
def __setattr__(self, key, value):
# 有效控制,判断,监控,日志
self.__dict__["data"][key] = value
def __getattr__(self, key):
if key in self.__dict__["data"]:
return self.__dict__["data"][key]
else:
raise AttributeError(f"'Cache' object has no attribute '{key}'")
def __delattr__(self, key):
if key in self.__dict__["data"]:
del self.__dict__["data"][key]
else:
raise AttributeError(f"'Cache' object has no attribute '{key}'")
def __contains__(self, name):
return name in self.__dict__["data"]
cache = Cache()
cache.name = "yuan"
cache.age = 19
print(cache.name)
del cache.age
print("age" in cache)
# print(cache.age)
6. 异常机制
异常机制是一种在程序运行过程中处理错误和异常情况的机制。当程序执行过程中发生异常时,会中断正常的执行流程,并转而执行异常处理的代码。这可以帮助我们优雅地处理错误,保证程序的稳定性和可靠性。
在Python中,异常以不同的类型表示,每个异常类型对应不同的错误或异常情况。当发生异常时,可以使用 try-except 语句来捕获并处理异常。try 块中的代码被监视,如果发生异常,则会跳转到对应的 except 块,执行异常处理的代码。
【1】Error类型
在Python中,常见的错误关键字(Exception Keywords)指的是一些常见的异常类型,它们用于表示不同的错误或异常情况。以下是一些常见的错误关键字及其对应的异常类型:
SyntaxError:语法错误,通常是由于代码书写不正确而引发的异常。NameError:名称错误,当尝试访问一个未定义的变量或名称时引发的异常。IndexError:索引错误,当访问列表、元组或字符串等序列类型时使用了无效的索引引发的异常。KeyError:键错误,当尝试使用字典中不存在的键引发的异常。ValueError:值错误,当函数接收到一个正确类型但是不合法的值时引发的异常。FileNotFoundError:文件未找到错误,当尝试打开或操作不存在的文件时引发的异常。ImportError:导入错误,当导入模块失败时引发的异常,可能是因为找不到模块或模块中缺少所需的内容。ZeroDivisionError:零除错误,当除法或取模运算的除数为零时引发的异常。AttributeError:属性错误,当尝试访问对象不存在的属性或方法时引发的异常。IOError:输入/输出错误,当发生与输入和输出操作相关的错误时引发的异常。例如,尝试读取不存在的文件或在写入文件时磁盘已满。
【2】基本语法
异常的基本结构:try except
# (1) 通用异常
try:
pass # 正常执行语句
except Exception as ex:
pass # 异常处理语句
# (2) 指定异常
try:
pass # 正常执行语句
except <异常名>:
pass # 异常处理语句
# (3) 统一处理多个异常
try:
pass # 正常执行语句
except (<异常名1>, <异常名2>, ...):
pass # 异常处理语句
# (4) 分别处理不同的异常
try:
pass # 正常执行语句
except <异常名1>:
pass # 异常处理语句1
except <异常名2>:
pass # 异常处理语句2
except <异常名3>:
pass # 异常处理语句3
# (5) 完整语法
try:
pass # 正常执行语句
except Exception as e:
pass # 异常处理语句
else:
pass # 测试代码没有发生异常
finally:
pass # 无论是否发生异常一定要执行的语句,比如关闭文件,数据库或者socket
机制说明:
- 首先,执行try子句(在关键字try和关键字except之间的语句)
- 如果没有异常发生,忽略except子句,try子句执行后结束。
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略。如果异常那么对应的except子句将被执行。
- 在Python的异常中,有一个通用异常:
Exception,它可以捕获任意异常。
【3】raise
很多时候,我们需要主动抛出一个异常。Python内置了一个关键字raise,可以主动触发异常。
raise可以抛出自定义异常,我们已将在前面看到了python内置的一些常见的异常类型。大多数情况下,内置异常已经够用了。但是有时候你还是需要自定义一些异常:自定义异常应该继承Exception类,直接继承或者间接继承都可以,例如:
class CouponError01(Exception):
def __init__(self):
print("优惠券错误类型1")
class CouponError02(Exception):
def __init__(self):
print("优惠券错误类型2")
class CouponError03(Exception):
def __init__(self):
print("优惠券错误类型3")
try:
print("start")
print("...")
x = input(">>>")
if x == "1":
raise CouponError01
elif x == "2":
raise CouponError02
elif x == "3":
raise CouponError03
except CouponError01:
print("优惠券错误类型1")
except CouponError02:
print("优惠券错误类型2")
except CouponError03:
print("优惠券错误类型3")
今日作业
- 关于继承与方法重写
class A:
def get(self):
self.say()
def say(self):
print('apple')
class B(A):
def say(self):
print('banana')
b = B()
b.get() # 输出结果为?
- 将以下代码填写完整
class A:
def foo(self, x):
print('executing class_foo(%s, %s)' % (self, x))
@classmethod
def class_foo(cls, x):
print('executing class_foo(%s, %s)' % (cls, x))
@staticmethod
def static_foo(x):
print('executing static_foo(%s)' % (x))
a = A()
# 调用 foo 函数,参数传入 1
# ?
# 调用 class_foo 函数,参数传入 1
# ?
# 调用 static_foo 函数,参数传入 1
# ?
-
创建一个名为
Circle的类,具有radius属性。使用@property装饰器创建一个名为diameter的属性,用于计算圆的直径,并创建一个名为circumference的属性,用于计算圆的周长。 -
创建一个名为
Product的类,具有name和price属性。实现__str__方法,使其返回格式为 "Product: name - price" 的字符串表示。同时实现__len__方法,使其返回产品名称的长度。 -
实现一个FTP类,
FTP类包含了get和post两个方法,分别用于下载和上传文件。run方法首先引导用户输入命令(get或post),然后根据用户输入的命令和文件名,使用反射机制执行对应的类方法。
class FTP:
def get(self, filename):
print(f"Downloading file: {filename}")
def post(self, filename):
print(f"Uploading file: {filename}")
def run(self):
command = input("请输入命令(get 或 post):")
if command == "get" or command == "post":
try:
method = getattr(self, command)
filename = input("请输入文件名:")
method(filename)
except AttributeError:
print("指定的方法不存在。")
else:
print("无效的命令。")
ftp = FTP()
ftp.run()
-
一个实际的场景案例涉及一个银行账户类(
BankAccount),其中使用私有属性和私有方法来确保账户余额的安全和一致性。BankAccount类使用私有属性__account_number和__balance来存储账户号码和余额。这样的设计使得外部无法直接访问和修改这些属性,从而确保了账户信息的安全性。 -
__init__()和__new__()方法有什么区别 -
双下划线和单下划线的区别?
-
设计一个名为
Dictionary的类,用于表示自定义的字典。该类具有以下要求:
- 初始化方法:类的初始化方法不带任何参数,创建一个空的字典对象。
__getitem__方法:实现索引操作,通过键访问字典中的值。要求传入的键必须是字符串类型,如果键不存在,则返回None。__setitem__方法:实现赋值操作,通过键设置字典中的键值对。要求传入的键必须是字符串类型。__delitem__方法:实现删除操作,通过键删除字典中的键值对。要求传入的键必须是字符串类型,如果键不存在,则抛出KeyError异常。
class Dictionary:
def __init__(self):
self.data = {}
def __getitem__(self, key):
if isinstance(key, str):
return self.data.get(key)
else:
raise TypeError("Key must be a string.")
def __setitem__(self, key, value):
if isinstance(key, str):
self.data[key] = value
else:
raise TypeError("Key must be a string.")
def __delitem__(self, key):
if isinstance(key, str):
if key in self.data:
del self.data[key]
else:
raise KeyError(f"Key '{key}' does not exist in the dictionary.")
else:
raise TypeError("Key must be a string.")
dictionary = Dictionary()
dictionary['name'] = 'John'
dictionary['age'] = 30
print(dictionary['name']) # 输出: John
del dictionary['age']
print(dictionary.get('age')) # 输出: None
- 电商项目
在电商业务场景中,需要设计商品类、购物车类和用户类。具体描述如下:
-
商品类(Product):每个商品对象应具有以下属性和方法:
- 属性:名称(name)、价格(price)、库存数量(stock)
- 方法:获取商品名称(get_name())、获取商品价格(get_price())、获取商品库存数量(get_stock())、更新商品库存数量(update_stock(quantity))
-
普通商品类(RegularProduct):继承自商品类,每个普通商品对象应具有以下特有的方法
- 方法:购买商品(buy_product(quantity)):根据购买的数量减少商品库存量;如果库存不足,则输出"库存不足,无法购买该商品";否则,减少库存数量。
- 方法:添加到购物车(add_to_cart(cart, quantity)):将商品添加到指定购物车对象中,同时指定购买的数量。
-
折扣商品类(DiscountProduct):继承自商品类,每个折扣商品对象应具有以下特有的属性和方法:
- 属性:折扣(discount)
- 方法:购买商品(buy_product(quantity)):根据购买的数量减少商品库存量;如果库存不足,则输出"库存不足,无法购买该商品";否则,减少库存数量。
- 方法:添加到购物车(add_to_cart(cart, quantity)):将商品添加到指定购物车对象中,同时指定购买的数量。
-
购物车类(Cart):每个购物车对象应具有以下属性和方法:
-
属性:商品项(items),提示:考虑用字典进行存储
-
方法:添加商品(add_item(product, quantity)):将指定数量的商品添加到购物车中;如果商品已存在于购物车,则增加该商品的数量;否则,添加新的商品项。
-
方法:删除商品(remove_item(product, quantity)):从购物车中删除指定数量的商品;如果商品数量不足以删除,则直接删除该商品项;否则,减少商品数量。
-
方法:查看购物车内容(view_items()):输出购物车中的商品项及其对应的数量。
-
方法:清空购物车(clear()):将购物车中的商品项清空。
-
-
用户类(User):每个用户对象应具有以下属性和方法:
- 属性:用户名(name)、购物车(cart)
- 方法:添加商品到购物车(add_to_cart(product, quantity)):将指定数量的商品添加到用户的购物车中。
- 方法:查看购物车内容(view_cart()):输出用户购物车中的商品项及其对应的数量。
- 方法:结算订单并支付(checkout()):根据购物车中的商品项生成订单对象,并进行支付;支付成功后,清空购物车。
-
订单类(Order):每个订单对象应具有以下属性和方法:
- 属性:购物车(cart)、总价(total_price)
- 方法:计算总价(calculate_total_price()):根据购物车中的商品项计算订单的总价。
- 方法:支付(pay()):执行支付逻辑,输出支付成功信息,并显示支付金额。
请使用面向对象的思想,设计并实现这些类,并编写主程序测试上述功能。请确保代码的正确性和健壮性,并合理处理各类之间的关系。
class Product:
def __init__(self, name, price, stock):
self.name = name
self.price = price
self.stock = stock
def get_name(self):
return self.name
def get_price(self):
return self.price
def get_stock(self):
return self.stock
class RegularProduct(Product):
pass
class DiscountProduct(Product):
def __init__(self, name, price, stock, discount):
super().__init__(name, price, stock)
self.discount = discount
class Cart:
def __init__(self):
self.items = {}
def add_item(self, product, quantity):
if product in self.items:
self.items[product] += quantity
else:
self.items[product] = quantity
def remove_item(self, product, quantity):
if product in self.items:
if self.items[product] <= quantity:
del self.items[product]
else:
self.items[product] -= quantity
def view_items(self):
for product, quantity in self.items.items():
print(f"{product.get_name()} - 数量:{quantity}")
def clear(self):
self.items = {}
class Order:
def __init__(self, cart):
self.cart = cart
self.total_price = self.calculate_total_price()
def calculate_total_price(self):
total_price = 0
for product, quantity in self.cart.items.items():
if isinstance(product, DiscountProduct):
total_price += product.get_price() * quantity * product.discount
else:
total_price += product.get_price() * quantity
return total_price
def pay(self):
# 实现支付逻辑
print(f"支付成功!支付金额:{self.total_price}")
class User:
def __init__(self, name):
self.name = name
self.cart = Cart()
def add_to_cart(self, product, quantity):
self.cart.add_item(product, quantity)
def view_cart(self):
self.cart.view_items()
def checkout(self):
order = Order(self.cart)
order.pay()
self.cart.clear()
# 创建普通商品对象和折扣商品对象
regular_product = RegularProduct("iPhone 12", 6999, 100)
discount_product = DiscountProduct("Apple Watch", 1999, 50, 0.8)
# 创建用户对象
user = User("John")
# 用户添加商品到购物车,并查看购物车
user.add_to_cart(regular_product, 2)
user.add_to_cart(discount_product, 3)
user.view_cart()
# 用户结算订单并支付
user.checkout()
FTP扩展

- 基于面向对象改版文件上传与下载
- 实现进度条显示功能
- 实现文件一致性校验(提示hashlib)
- 多客户端并发服务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号