tesseract基本使用
概述
Tesseract,一款由惠普实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别,文本识别)引擎,用于识别图片中的文字并将其转换为可编辑的文本。Tesseract支持开箱即用,能够将印刷体文字图像转换成可编辑文本,并支持多种语言,可在许多平台上都可使用,包括Windows、Mac OS和Linux。Tesseract可以处理各种图像文件格式,如JPEG、PNG、TIFF等,是目前公认最优秀、最精确的开源OCR引擎,目前最新版本为5.x版本。
Tesseract的主要功能是识别图像中的文字,并将其转换成机器可读的文本内容。它采用了一系列图像处理、特征提取和机器学习技术来实现文字识别的过程。Tesseract内部采用LSTM模型算法作为基础的,使用训练好的模型来识别字符,并通过上下文和语言模型来提高识别准确性。
Github:https://github.com/tesseract-ocr/tesseract
文档:https://github.com/tesseract-ocr/tessdoc
语言包:https://github.com/tesseract-ocr/tessdata
安装
安装文档:https://github.com/tesseract-ocr/tessdoc/blob/main/Installation.md
下载地址:https://github.com/UB-Mannheim/tesseract/releases
把下载回来的安装包点击进入安装流程,以下选择安装语言,默认选择English,点击“ok”:
点击Next下一步即可:
同意安装协议:
默认给系统所有用户安装,点击下一步:
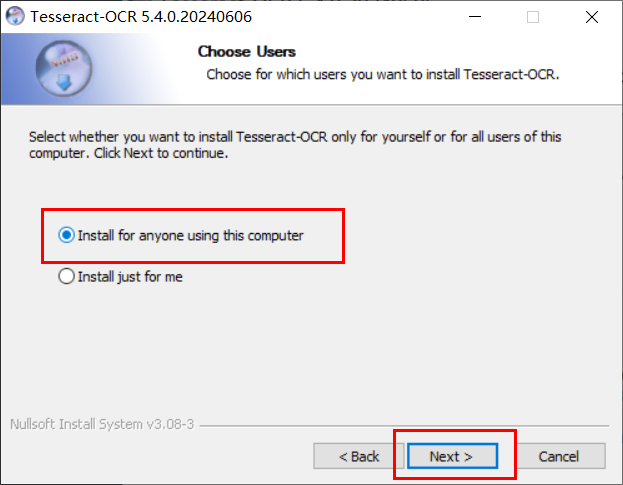
选择安装组件,点击Next。
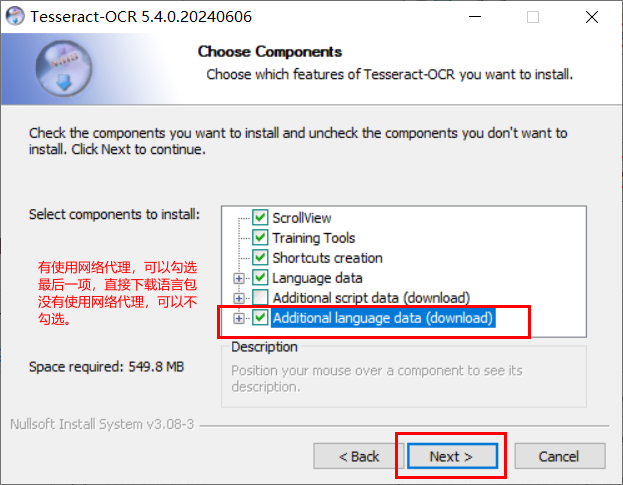
设置安装目录,这里如果部分人的电脑有权限限制,可以不要安装到系统盘(C盘),自己换一个目录(路径不要出现中文或其他特殊符号)即可:
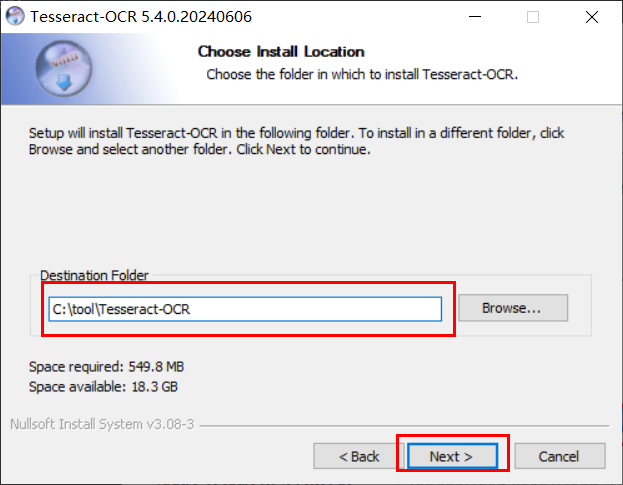
是否在开始菜单中显示,一般不显示么,所以把Do Not create shortcuts勾上,点击Install即可。
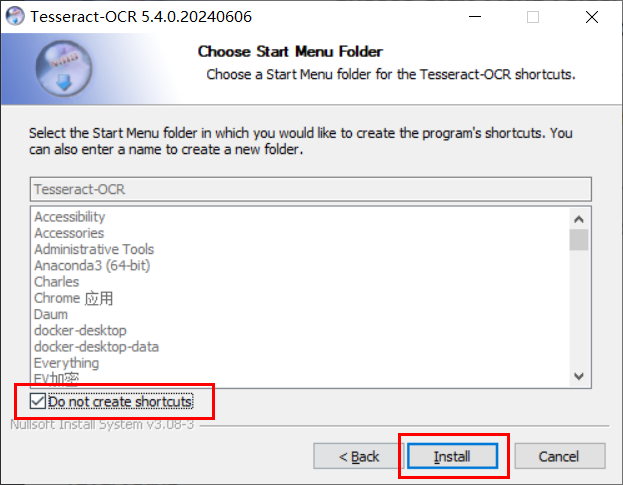
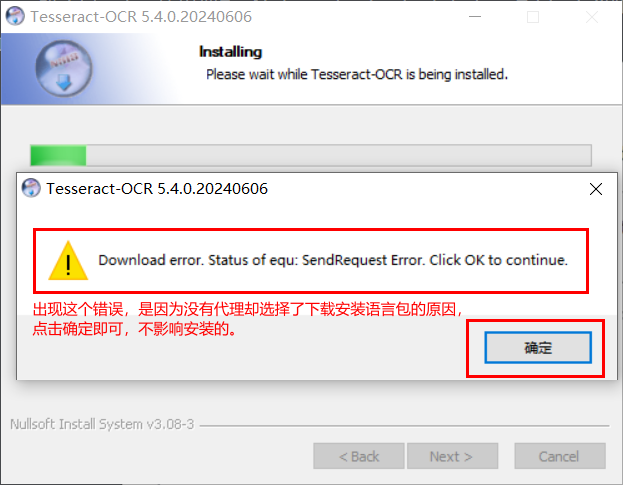
注意,安装过程中会因为前面勾选下载语言包而弹出请求错误的提示框,这是因为你没有开代理缺选择了下载语言包的缘故:
安装完成,点击Next
点击完成退出安装流程:
配置环境变量
鼠标右键点击此电脑,选择属性,按下图设置环境变量:
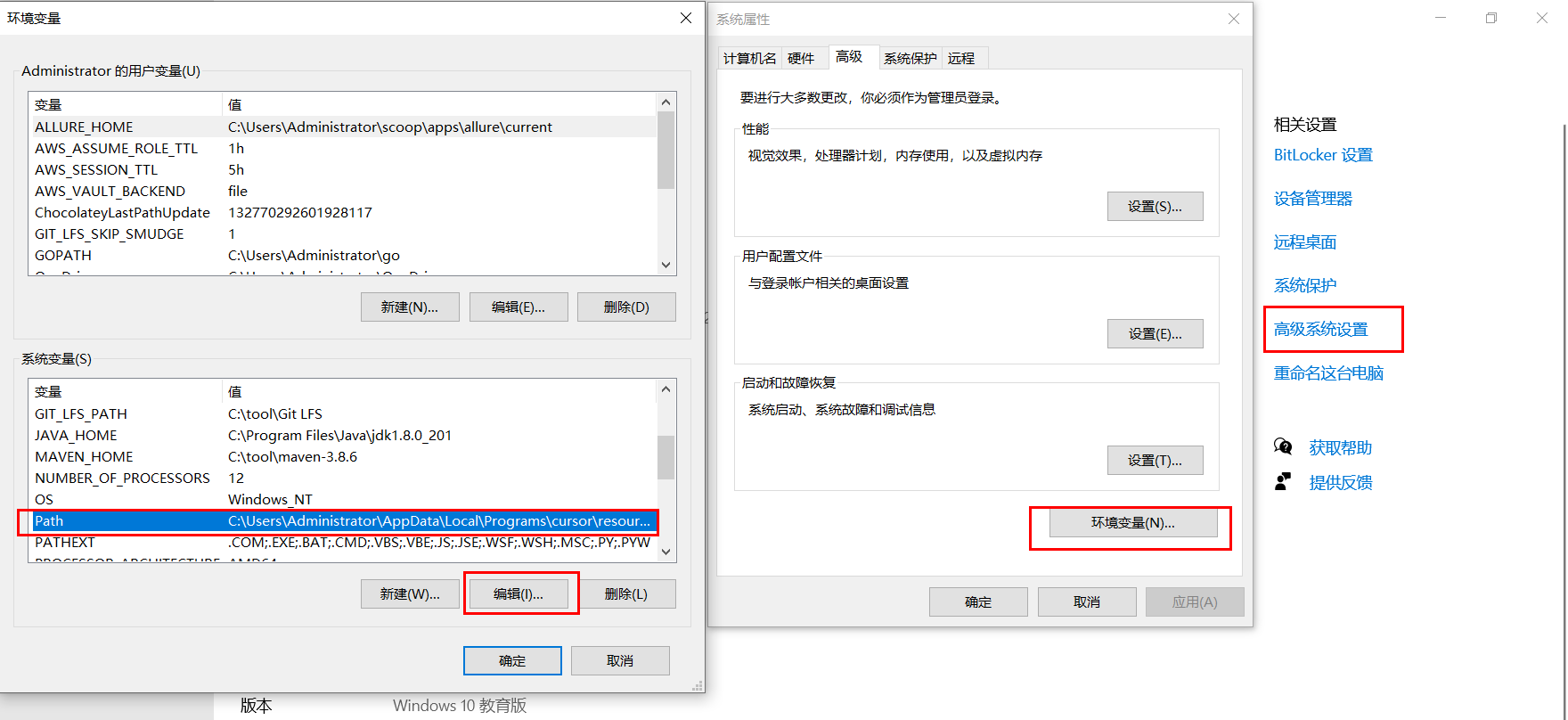
点击新建环境变量,把刚才上面设置的tesseract安装目录写入最下面:
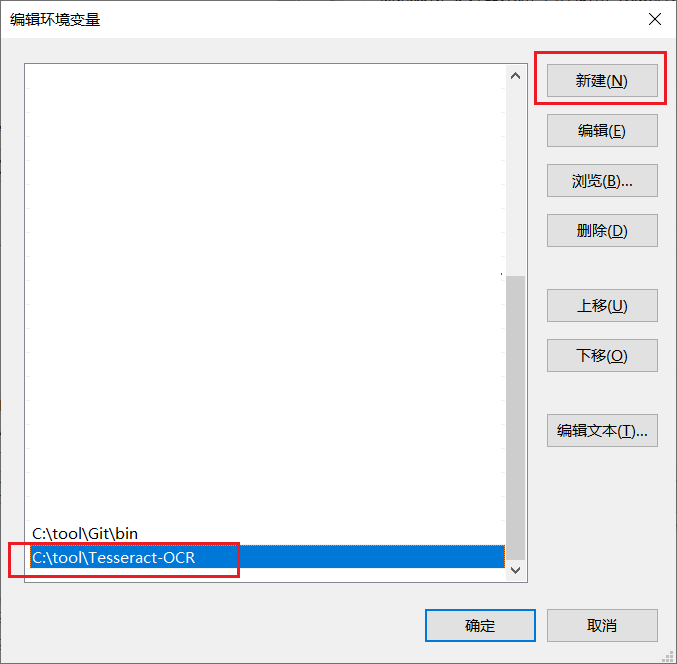
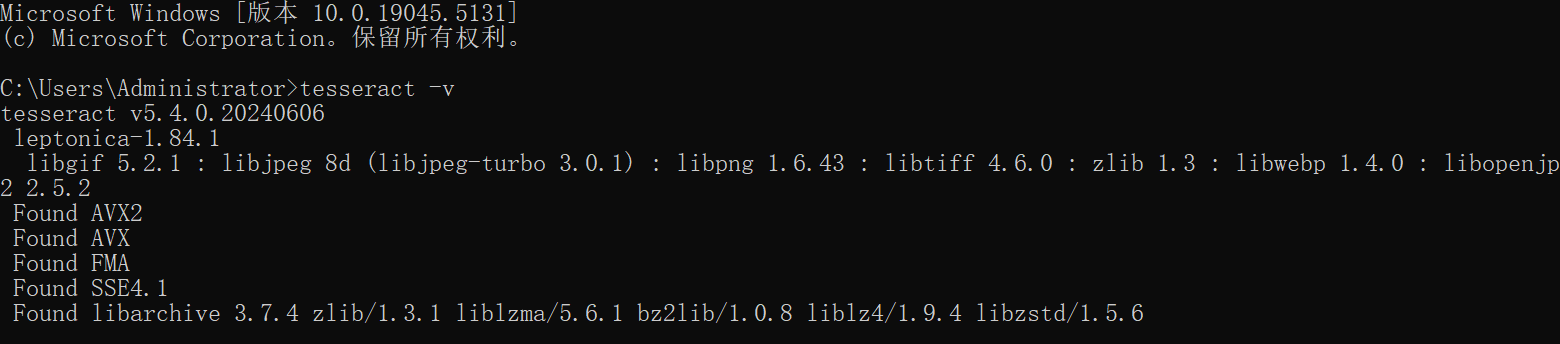
接着把打开的环境变量所有窗口点击“确定”进行关闭,再新打开一个CMD终端,输入命令tesseract -v,效果如下则表示安装成功:
语言包下载
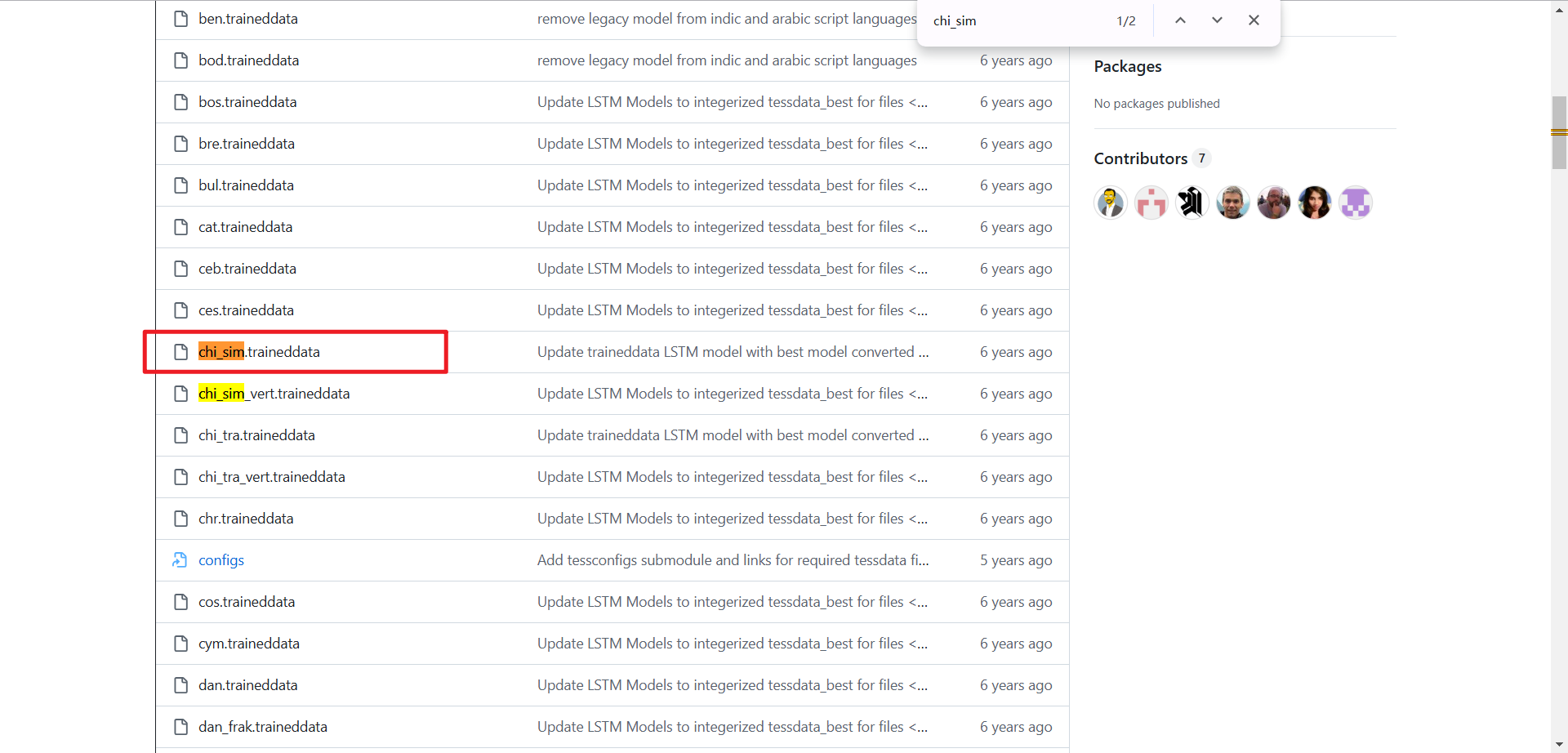
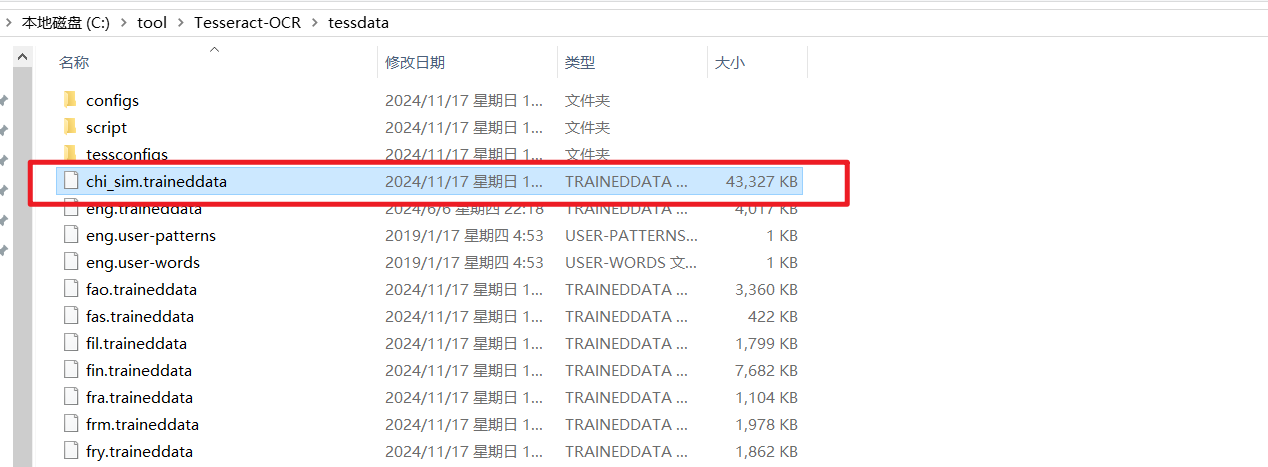
从https://github.com/tesseract-ocr/tessdata所在页面中载需要的的语言包(用不上的没必要下载),如下图,红框内为中文简体语言包,下载后将该包直接放在程序安装目录的tessdata文件夹里面即可。
使用 tesseract --list-langs命令可查看当前软件支持的语言。
使用
安装依赖模块:
pip install pytesseract pillow
代码:
import pytesseract
from PIL import Image
# 图片路径
file = r"2.png"
# 打开图片
image = Image.open(file)
# 灰度化处理,提高文本识别率
img = image.convert('L')
# 二值化处理,提高文本识别率
threshold = 180 # 自定义灰度界限
table = [0 if i < threshold else 1 for i in range(256)]
img.point(table, '1')
# img.save('22.png') # 自己决定是否保存二值化的图片
# 解析图片,lang='chi_sim'表示识别简体中文,默认为English
content = pytesseract.image_to_string(img, lang='chi_sim')
print(content)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号