大模型应用开发与私有化部署
学习要求
必须有以下知识储备:
- Linux基础
- Docker&Git
- Python基础
- Http网络通信&Restful API接口规范
- web前端基础&前后端分离&FastAPI
LLM
基本概念
大型语言模型,基于海量的数据进行学习得到的模型。
大模型技术选型
在线大模型:
OpenAI GPT
Google Gemini
Authropic Claude
智谱AI GLM
百度 文心一言
优缺点:
模型性能优越、研发成本低(0.005-0.008元/1000个token)、可以站在巨人的肩膀上快速探索前沿技术应用,稳定性和使用安全性高,但数据安全存在隐患,业务受制于人,上车容易下车难。
开源大模型:
Meta Llama(3.1 405B)
Mistral AI
X AI Grok
阿里 通义千问 Qwen
Baichuan
360 zhinao
优缺点:( 7B大模型->70亿->4张4090 ->语料->上十亿 -> )
完全自主可控,扩展性强,定制型强,数据安全有保障,但需要投入大量算力和开发成本,依赖开源,不好转身。
Llama系列
LLaMA系列大模型是Meta公司在2023年2月开源的基于 transformer 架构的大型语言模型, 包括四种尺寸(7B 、13B 、30B 和 65B),并在2024年进一步发展,推出了Llama 3版本。Llama3在多种行业基准测试中展现了最先进的性能,提供了包括改进的推理能力在内的新功能,是目前市场上最好的开源大模型之一。
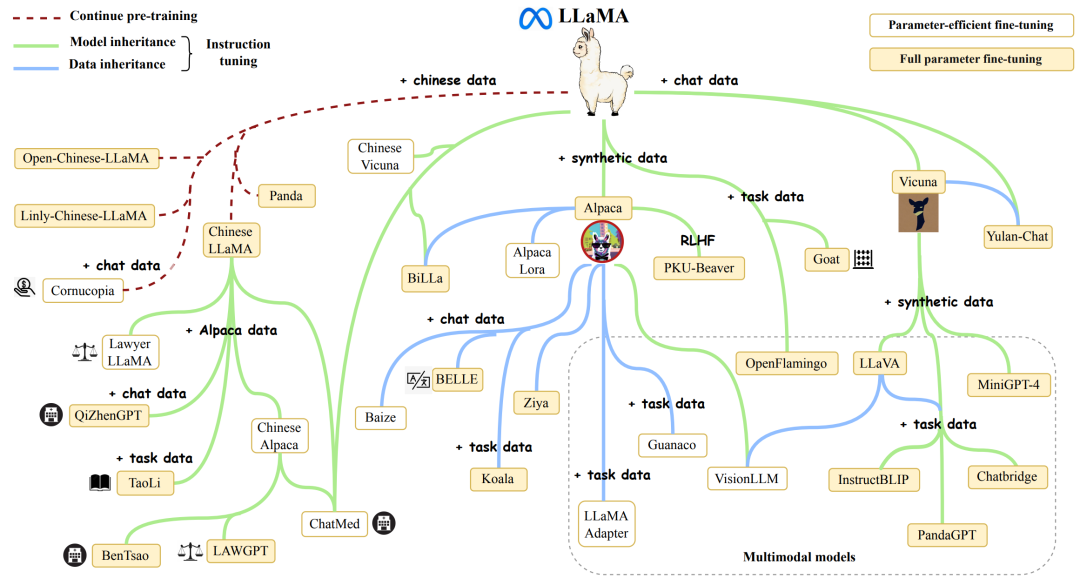
Qwen系列
文档:https://qwen.readthedocs.io/zh-cn/latest/getting_started/quickstart.html
随着GLM的闭源,阿里的通义千问已经成为了国内开源大模型的领袖。
Qwen平均1个季度发布一个版本,性能始终处于开源大模型的第一梯队水平。目前最新发布版本:Qwen2.5。
阿里的魔塔社区( https://modelscope.cn/models )也随着技术迭代更新,成为了国内第一AI模型社区,号称“中文版HuggingFace( https://huggingface.co/ )”,吸引了大批优质的大模型开发者参与进来,同时魔塔社区不仅提供免费在线开发环境(类似谷歌的Colab)和限时GPU算力(100小时32GB显存),助力开发者在线训练微调大模型,还与阿里云灵积平台(DashScope)深度绑定,让开发者训练微调完成的模型可以快速落地实施到阿里云架构服务器上(按量收费),形成了一整套混合模型在线服务的生态模式。
阿里还提供了高度适配的SWIFT轻量级微调框架和Qwen-Agent开发框架,其中SWIFT提供了代码环境和脚本微调两种模式,配套海量开源微调数据集,可以执行包括知识灌注、模型自我意识微调、Agent能力微调和领域能力微调等功能,还提供一键微调等功能。Qwen-Agent则支持高效稳定Multi Function calling、ReAct功能,支持调用开源大模型以及灵积平台的在线模型。
prompt
提示工程(Prompt Engineering)是一项通过优化提示词(Prompt)和生成策略,从而获得更好的模型返回结果的工程技术。
其基本实现逻辑如下:
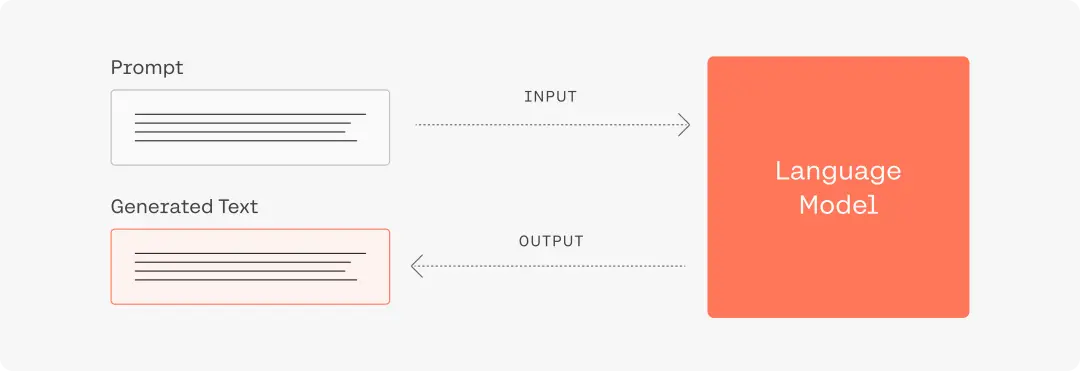
简单而言,大模型的运行机制是“下一个字词预测”。用户输入的prompt即为大模型所获得上下文,大模型将根据用户的输入进行续写,返回结果。因此,输入的prompt的质量将极大地影响模型的返回结果的质量和对用户需求的满足程度,总的原则是“用户表达的需求越清晰,模型更有可能返回更高质量的结果”。
prompt工程这种微调手段对于大模型本身的推理能力的提升的范围大概也就10%左右。大模型训练工程师,prompt工程多数用在在线大模型,而不是开源大模型。
Prompt经验总结:清晰易懂、提供例子和锁定上下文、明确步骤、准确表达意图。
去玩一下吧:https://modelscope.cn/studios/LLMRiddles/LLMRiddles/summary
通常情况下,每条信息都会有一个角色(role)和内容(content):
- 系统角色(system)用来向语言模型传达开发者定义好的核心指令,优先级是最高的。
- 用户角色(user)则代表着用户自己输入或者产生出来的信息。
- 助手角色(assistant)则是由语言模型自动生成并回复出来。
系统指令(system)
system message系统指令为用户提供了一个易组织、上下文稳定的控制AI助手行为的方式,可以从多种角度定制属于你自己的AI助手。系统指令允许用户在一定范围内规定LLM的风格和任务,使其更具可定性和适应各种用例。大部分LLM模型的系统指令System message的权重强化高于人工输入的prompt,并在多轮对话中保持稳定,您可以使用系统消息来描述助手的个性,定义模型应该回答和不应该回答的内容,以及定义模型响应的格式。
默认的System message:You are a helpful assistant.
下面是一些system message的使用示例:
| 行业 | 角色 | system message |
|---|---|---|
| 教育 | 数学老师 | 你是一名优秀的数学老师,教导学生学习数学,经常使用简单通俗的生活例子使复杂的数学概念变得更容易理解。 |
| 工作 | python工程师 | 你是一名行业顶尖的Python开发工程师,会使用详细步骤和代码帮助公司和同事解决项目开发过程中的问题。 |
| 创作 | 小红书文案 | 你是一名优秀的小红书文案创作者,擅长使用诙谐风格来创作,经常会在创作中分享生活经验和工作经验。 |
System message可以被广泛应用在:角色扮演、语言风格、任务设定、限定回答范围。
用户指令(user)
用户指令是最常用的提示组件,主要功能是向模型说明要执行的操作。以下举例:
| 指令类型 | prompt |
|---|---|
| 简单指令 | 简要介绍一下xx公司。 |
| 详细指令 | 简要介绍一下xx公司,并介绍它的公司创始人,主营业务,使命和愿景。 |
ollama
基本介绍
Ollama 是一个开源的大型语言模型服务工具,专为在服务器上便捷部署和运行大型语言模型(LLMs)而设计,它提供了一个简洁且用户友好的命令行界面,通过这一界面,用户可以轻松地部署和管理各类开源的 LLM。具有以下特点和优势:
- 开源免费:Ollama 以及其支持的模型完全开源免费,任何人都可以自由使用、修改和分发
- 简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型,无需复杂的配置和安装过程,只需几条命令即可启动和运行Ollama
- 轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件,即使在普通笔记本电脑上也能流畅运行。
- API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
- 预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
官方站点:https://ollama.com/
Github:https://github.com/ollama/ollama
安装使用
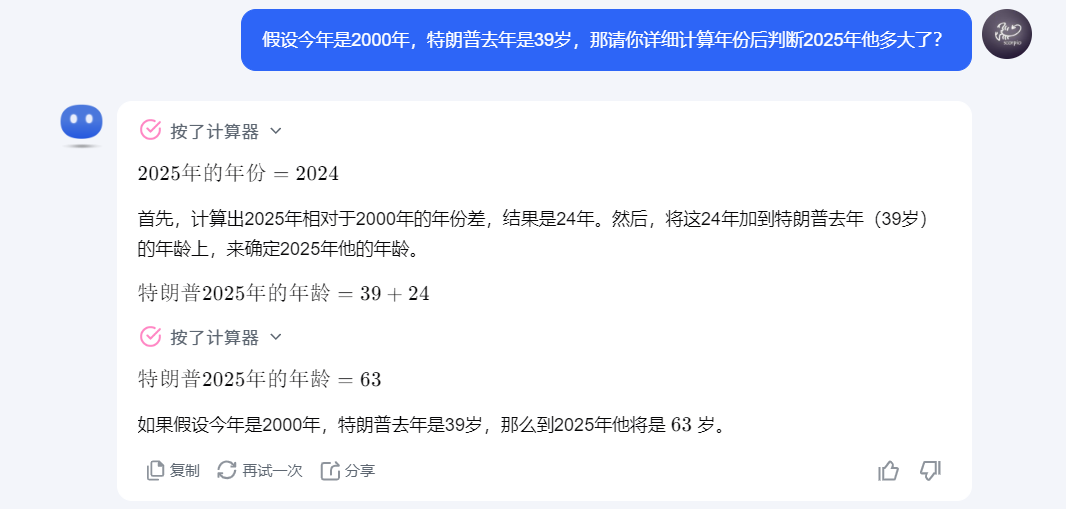
下载地址: https://ollama.com/download ,根据系统类型进行安装,这里演示的是window系统安装过程。
注意,在windows下安装ollama是不允许自定义位置的,会默认安装在系统盘,而后续使用的大模型可以选择自定义保存路径。
安装过程,非常简单:
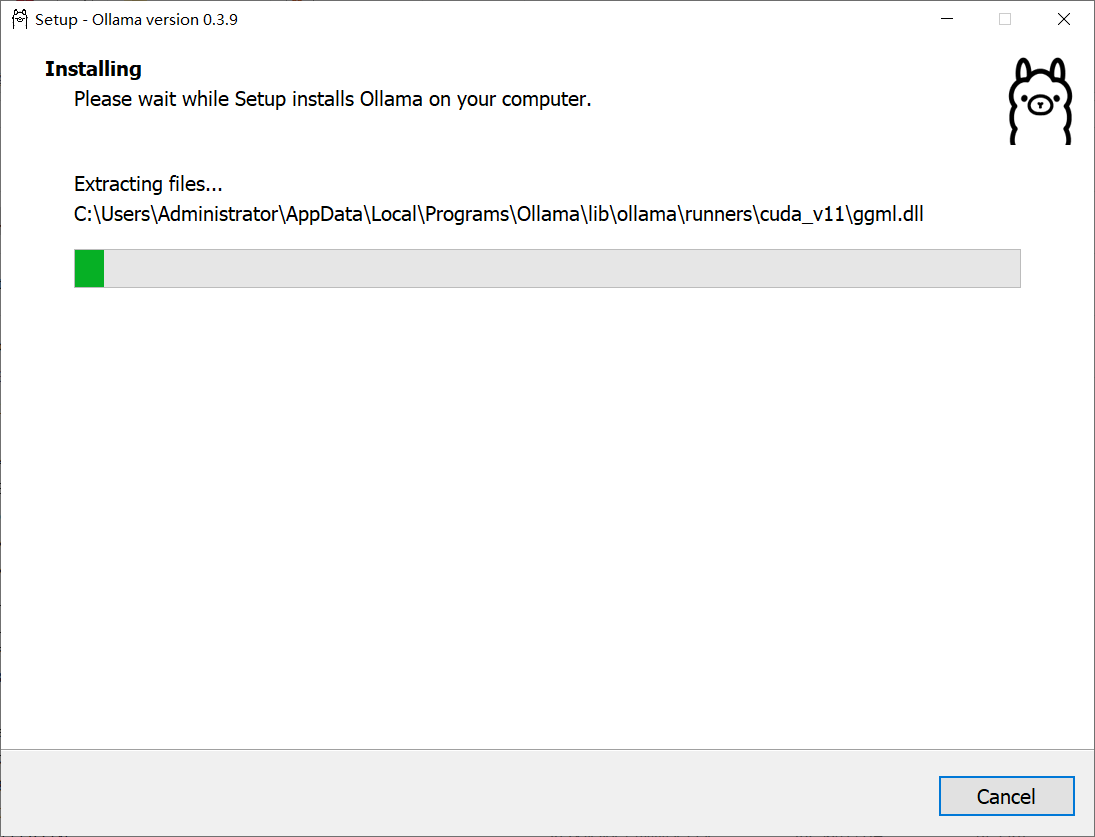
安装完成以后,新开一个命令终端并输入命令ollama,如果效果如下则表示安装成功:
拉取并运行一个大模型:
ollama run qwen2.5:3b
常用命令
这里的命令,全系统通用的。
| 命令 | 描述 |
|---|---|
| ollama list | 列出本地拉取的模型镜像列表 |
| ollama pull | 从远程仓库中拉取模型镜像文件 |
| ollama run | 运行模型,如果本地没有则先默认执行pull命令进行拉取 |
| ollama ps | 展示当前加载的模型、它们所占的内存大小以及使用的处理器类型(GPU 或 CPU) |
| ollama serve | 启动ollama的http网络服务 |
| ollama rm | 删除模型 |
| ollama cp | 复制模型 |
| ollama push | 推送模型到远程仓库,需要在ollama官网上面注册账号。 |
| ollama create | 从模型文件Modelfile创建自定义模型 |
| help | 帮助提示 |
模型仓库
ollama仓库地址:https://ollama.com/library
hugging face仓库地址:https://huggingface.co/models 【镜像】https://hf-mirror.com/models
魔塔社区:https://modelscope.cn/models
自定义模型
魔塔下载大模型说明文档:https://www.modelscope.cn/docs/模型的下载
使用魔塔下载大模型文件,安装魔塔工具(python3.10^):
pip install modelscope
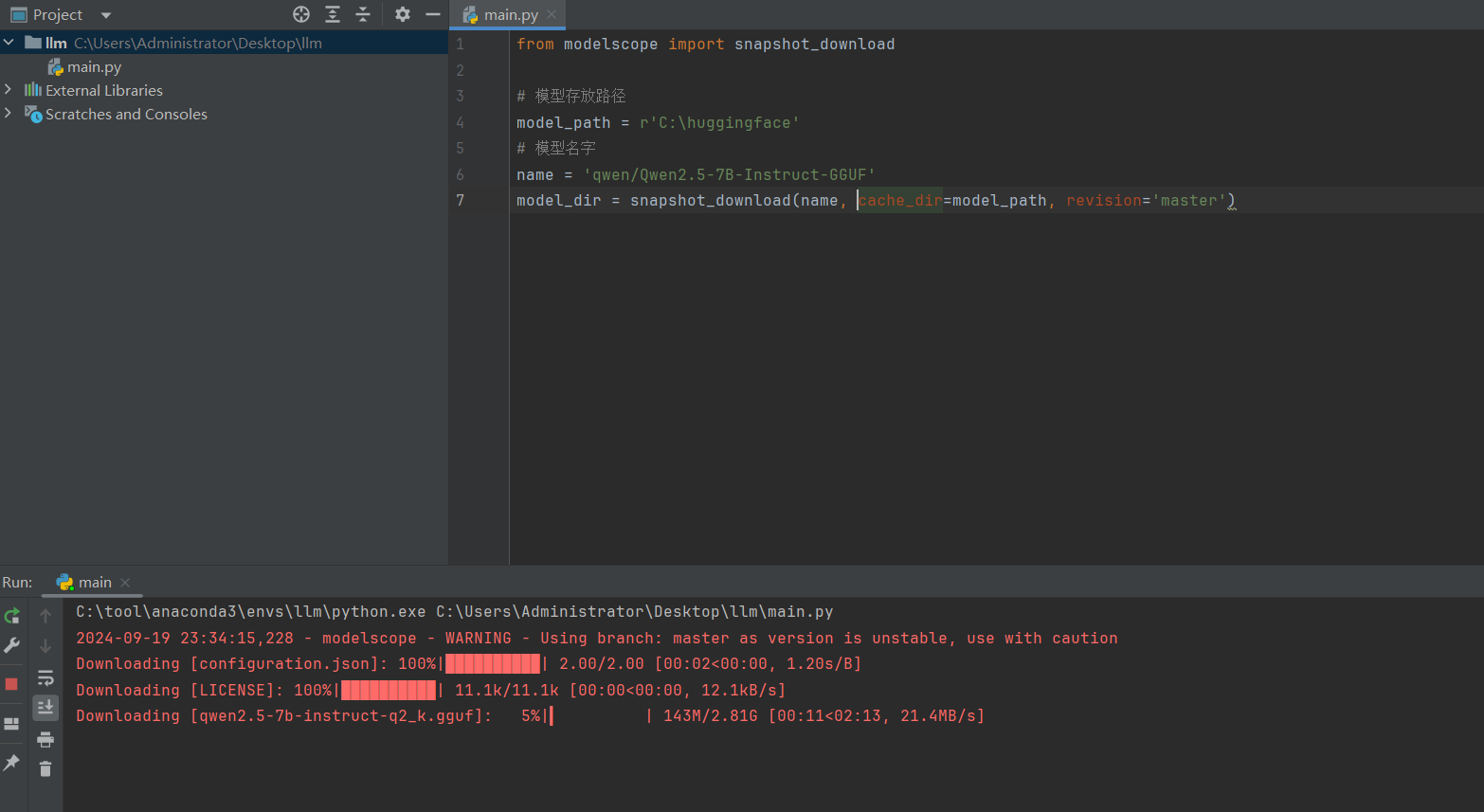
基于python脚本调用魔塔拉取模型文件,modelscope_download.py,代码:
from modelscope import snapshot_download
# 模型名字
name = 'qwen/Qwen2.5-7B-Instruct-GGUF'
# 模型存放路径,需要手动创建对应的目录,并保证有足够的空间,否则下载出错。
model_path = r'C:\huggingface'
model_dir = snapshot_download(
name, # 仓库中的模型名
cache_dir=model_path, # 本地保存路径,
revision='master', # 分支版本
allow_file_pattern="Qwen2.5-7B-Instruct-GGUF" # 模糊匹配的文件名
)
# modelscope download --model=qwen/Qwen2.5-7B-Instruct-GGUF --include "qwen2.5-7b-instruct-q5_k_m*.gguf" --local_dir .
执行效果如下:
Modelfile
Ollama自定义大模型需要通过Modelfile定义和配置模型的行为和特性,在使用 Ollama 进行本地部署和运行大型语言模型时,Modelfile 扮演着至关重要的角色。
Modelfile 是使用 Ollama 创建和共享模型的方案。它包含了构建模型所需的所有指令和参数,使得模型的创建和部署变得简单而直接。
常用指令
Modelfile中不区分大小写,但是强烈要求一定大写!!
| 操作说明 | 描述 |
|---|---|
FROM <model name>:<tag> (必须) |
定义要使用的基础模型,如果值是一个路径表示镜像文件在本地,如果是模型名称则默认到官方仓库中拉取。 |
SYSTEM """<system message>""" |
指定将在模板中设置的系统消息. |
PARAMETER <parameter> <parametervalue> |
设置 Ollama 如何运行模型的参数 |
TEMPLATE |
要发送给模型的完整提示模板. |
ADAPTER |
定义适用于模型的 (Q)LoRA 适配器. |
LICENSE |
指定合法的许可证。 |
MESSAGE <role> <message> |
指定消息历史记录。 |
PARAMETER的有效参数和值
| 参数 | 描述 | 值类型 | 示例用法 |
|---|---|---|---|
| mirostat | 启用 Mirostat 采样来控制困惑度。(默认值:0,0 = 禁用,1 = Mirostat,2 = Mirostat 2.0) | int | mirostat 0 |
| mirostat_eta | 影响算法对生成文本反馈的响应速度。较低的学习率会导致调整速度较慢,而较高的学习率会使算法响应更快。(默认值:0.1) | float | mirostat_eta 0.1 |
| mirostat_tau | 控制输出的连贯性和多样性之间的平衡。值越低,文本越集中、越连贯。(默认值:5.0) | float | mirostat_tau 5.0 |
| num_ctx | 设置用于生成下一个标记的上下文窗口的大小。(默认值:2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型回溯多远以防止重复。(默认值:64,0 = 禁用,-1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置对重复的惩罚力度。较高的值(例如 1.5)将对重复的惩罚力度更大,而较低的值(例如 0.9)将更宽松。(默认值:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。增加温度将使模型的回答更具创意。(默认值:0.8) | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将其设置为特定数字将使模型针对同一提示生成相同的文本。(默认值:0) | int | seed 42 |
| stop | 设置要使用的停止序列。遇到此模式时,LLM 将停止生成文本并返回。可以通过stop在模型文件中指定多个单独的参数来设置多个停止模式。 |
string | stop “AI assistant:” |
| tfs_z | 尾部自由采样用于减少输出中可能性较小的标记的影响。较高的值(例如 2.0)将进一步减少影响,而值 1.0 则禁用此设置。(默认值:1) | float | tfs_z 1 |
| num_predict | 生成文本时要预测的最大标记数。(默认值:128,-1 = 无限生成,-2 = 填充上下文) | int | num_predict 42 |
| top_k | 降低产生无意义答案的概率。值越高(例如 100)答案就越多样化,值越低(例如 10)答案就越保守。(默认值:40) | int | top_k 40 |
| top_p | 与 top-k 配合使用。较高的值(例如 0.95)将产生更加多样化的文本,而较低的值(例如 0.5)将产生更加集中和保守的文本。(默认值:0.9) | float | top_p 0.9 |
TEMPLATE的模板变量
| 变量 | 描述 |
|---|---|
{{ .System }} |
用于指定自定义行为的系统消息。 |
{{ .Prompt }} |
用户提示消息。 |
{{ .Response }} |
来自模型的响应。生成响应时,此变量后的文本将被省略。 |
MESSAGE的有效角色
| 角色 | 描述 |
|---|---|
| system | 为模型提供系统消息的另一种方法。 |
| user | 用户可能询问的示例消息。 |
| assistant | 模型应如何响应的示例消息。 |
创建模型描述文件Modelfile,编写内容如下:
FROM C:\huggingface\qwen\Qwen2___5-7B-Instruct-GGUF\Qwen2.5-7B-Instruct.Q5_0.gguf
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
PARAMETER top_k 20
TEMPLATE """{{ if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{ .System }}
{{- if .Tools }}
# Tools
You are provided with function signatures within <tools></tools> XML tags:
<tools>{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}{{- end }}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}{{ .Response }}{{ if .Response }}<|im_end|>{{ end }}"""
# set the system message
SYSTEM """你是江小白, 由林墨创建. 你是一个非常厉害的工具人."""
文档:https://qwen.readthedocs.io/en/latest/run_locally/ollama.html#
通过运行以下命令来创建ollama模型
ollama create qwen2.5-7b -f ./Modelfile
运行新建的ollama模型:
ollama run qwen2.5-7b
大模型开发
大模型的基本概念
大语言模型(Large Language Model): 通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
按照输入数据类型的不同,大模型的分类:
- 语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT 系列(OpenAI)、Bard(Google)、文心一言(百度)。
- 视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。例如:VIT 系列(Google)、文心UFO、华为盘古 CV、INTERN(商汤)。
- 多模态大模型: 是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB 多模向量数据库(九章云极 DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
- 通用大模型 L0:是指可以在多个领域和任务上通用的大模型。它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法,在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三”的强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI 完成了“通识教育”。
- 行业大模型 L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于 AI 成为“行业专家”。
- 垂直大模型 L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。
开发大模型相关应用,其技术核心点虽然在大语言模型上,但一般通过调用 API 或开源模型来实现核心的理解与生成,通过 Prompt Enginnering 来实现大语言模型的控制,因此,大模型虽然是深度学习领域的集大成之作,大模型开发却更多是一个工程问题。
在大模型开发中,我们一般不会去大幅度改动模型,而是将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务,而不会将精力聚焦在优化模型本身上。
大模型开发与传统的AI 开发在整体思路上有着较大的不同:
-
传统AI 开发:首先需要将复杂的业务逻辑依次拆解,对于每个子业务构造训练数据与验证数据,对于每个子业务训练优化模型,最后形成完整的模型链路来解决整个业务逻辑。

-
大模型开发:用 Prompt Engineering 来替代子模型的训练调优,通过 Prompt 链路组合来实现业务逻辑,用一个通用大模型 + 若干业务 Prompt 来解决任务,从而将传统的模型训练调优转变成了更简单、轻松、低成本的 Prompt 设计调优。

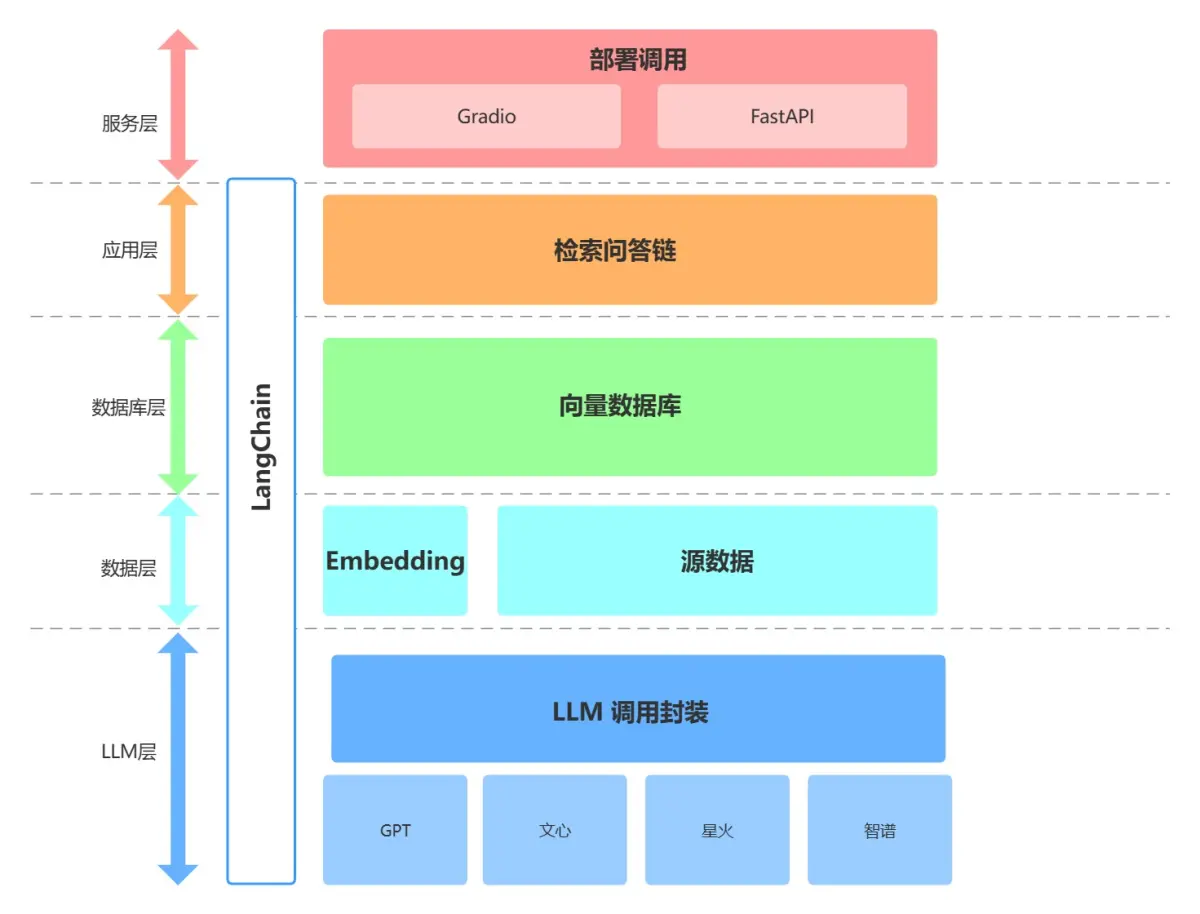
目前大部分企业都是基于 LangChain 、qwen-Agent、lammaIndex框架进行大模型应用开发。LangChain 提供了 Chain、Tool 、RAG等架构的实现,可以基于 LangChain 进行个性化定制,实现从用户输入到数据库再到大模型最后输出的整体架构连接。
Embedding
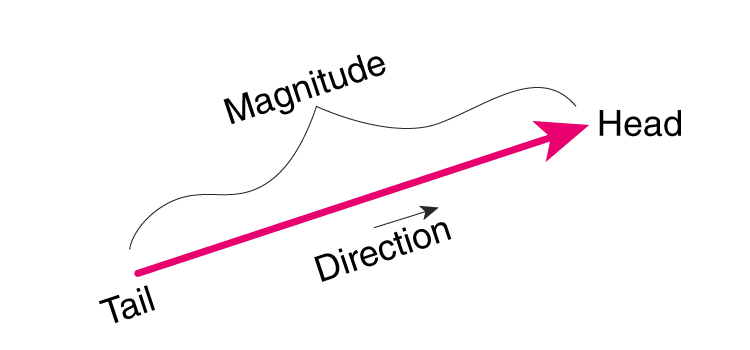
向量是多维数学空间中的一个坐标点,指具有大小和方向的量,它在直角坐标系里通常表现为一段带箭头的线段。
由于向量可以高度抽象地表示事物的特征和属性,世界上几乎所有类型的数据——视频、图像、声音、文本……统统都可以通过数据处理转换成向量数据。因而,在AI领域流传着一句话,万物皆可Embedding。
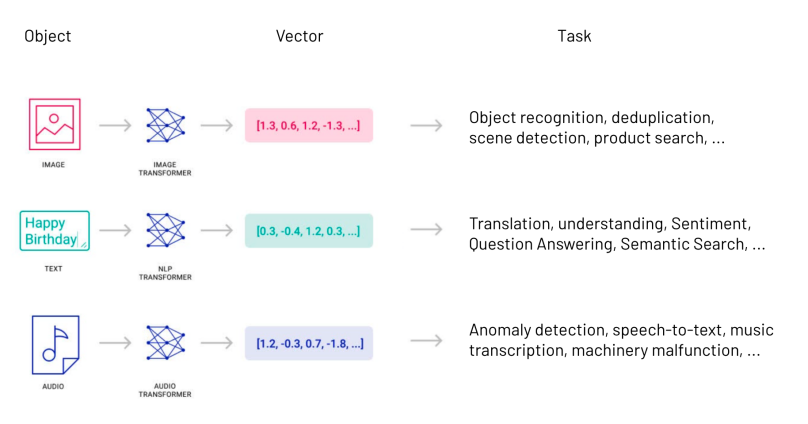
所谓的向量数据,通常指的是将实体(如文本、图像、音频等)转换为数值形式的高维向量。这些向量能够捕捉实体的关键特征,并在向量空间中进行各种计算和比较。向量数据在AI中的应用非常广泛,包括但不限于自然语言处理(NLP)、计算机视觉、语音识别、推荐系统等。通过向量化,AI系统能够更好地理解和处理复杂的数据类型,从而提供更加智能和个性化的服务。
将其他类型的信息转换为向量数据的过程就是向量化。
在传统AI领域中(机器学习和自然语言处理(NLP),Embeddings(嵌入,向量化)是一种将类别数据,如单词、句子或者整个文档,转化为实数向量的技术,这些实数向量可以被计算机更好地理解和处理。嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。
我喜欢吃苹果。 -> [1, 0, 0, 5, 2, 1]
我喜欢苹果手机。-> [1, 2, 5, 0, 3, 2.8]
我喜欢吃香蕉。 -> [1, 0, 0, 5, 2, 3]
举个例子,可以使用词嵌入(word embeddings)来表示文本数据,在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,"king" 和 "queen" 这两个单词在嵌入空间中的位置将会非常接近,因为它们的词性与含义相似;而 "apple" 和 "orange" 也会很接近,因为它们都是水果;而 "king" 和 "apple" 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
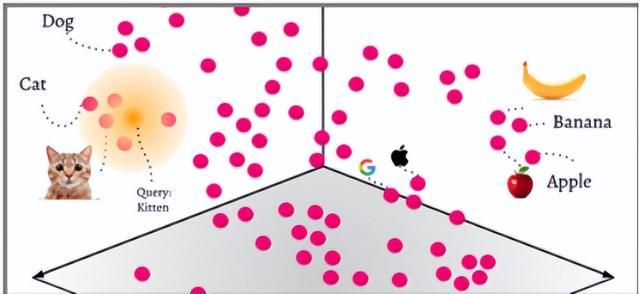
向量数据库
向量数据库(Vector Database)也叫矢量数据库,是专为存储、处理、分析「向量数据」而生的,能够基于目标向量快速进行相似度搜索,并返回最相近的数据。总而言之,就是用来存储和处理向量数据的数据库。
随着大型AI语言模型的崛起,向量数据库成为了解决模型“幻觉”问题的关键。它号称是LLM记忆的海马体,是大模型的记忆和存储核心,通过注入实时&私域数据的形式,可以使得LLM能够在更多通用场景中落地应用,缓解模型”幻觉“的问题。
常见的向量数据库:Milvus、Chroma、Weaviate、Faiss、Elasticsearch、PGVector、opensearch、腾讯VectorDB,ClickHouse。
| VectorStore | 介绍 |
|---|---|
| AnalyticDB | 阿里云自主研发的云原生数据仓库 |
| Annoy | 一个带有Python bindings的C ++库,用于搜索空间中给定查询点的近邻点。 |
| AtlasDB | 一个非结构化数据集平台 |
| Chroma | 一个开源嵌入式数据库 |
| Deep Lake | 多模向量存储,可以存储嵌入及其元数据,包括文本、jsons、图像、音频、视频等。 |
| DocArrayHnswSearch | 一个轻量级的文档索引实现 |
| DocArrayInMemorySearch | 一个由Docarray提供的文档索引,将文档存储在内存中 |
| ElasticSearch | ElasticSearch |
| FAISS | Facebook AI相似性搜索服务 |
| LanceDB | 一个用于向量搜索的开源数据库,它采用持久性存储 |
| Milvus | 用于存储、索引和管理由深度神经网络和其他机器学习(ML)模型产生的大量嵌入向量的数据库 |
| MyScale | 一个基于云的数据库,为人工智能应用和解决方案而优化 |
| OpenSearch | 一个可扩展的、灵活的、可延伸的开源软件套件,用于搜索、分析和可观察性应用 |
| PGVector | 一个用于Postgres的开源向量相似性搜索服务 |
| Pinecone | 一个具有广泛功能的向量数据库 |
| Qdrant | 一个向量相似性搜索引擎 |
| Redis | 基于redis的检索器 |
| SupabaseVectorStore | 一个开源的Firebase 替代品,提供一系列后端功能 |
| Tair | 一个Key/Value结构数据的解决方案 |
| Weaviate | 一个开源的向量搜索引擎 |
| Zilliz | 数据处理和分析平台 |
向量数据库的特点:

langchain
基本介绍
LangChain是一个强大的大模型开发框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。其作者是Harrison Chase(哈里森·蔡斯),最初是于 2022 年 10 月开源的一个项目,在 GitHub 上获得大量关注之后迅速转变为一家人工智能初创公司。
LangChain提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。目前最新版本:v0.3版本。
官方文档:https://python.langchain.com/docs/introduction/
中文文档:https://www.langchain.com.cn/
Github:https://github.com/langchain-ai/langchain
RAG工作流程

LLM大模型与AI应用的粘合剂
LangChain本身并不开发LLMs,它的核心理念是为各种LLMs提供通用的接口,降低开发者的学习成本,方便开发者快速地开发复杂的LLMs应用。
官方的定义:LangChain是一个基于大语言模型开发应用程序的框架。它可以实现以下应用程序:
- 数据感知:将语言模型连接到其他数据源
- 自主性:允许语言模型与其环境进行交互
LangChain的主要价值在于:
- 组件化:为使用语言模型提供抽象层,以及每个抽象层的一组实现。组件是模块化且易于使用的,无论您是否使用LangChain框架的其余部分。
- 现成的链:结构化的组件集合,用于完成特定的高级任务。
应用场景
LangChain为构建基于大型语言模型的应用提供了一个强大的框架,将逐步的运用到各个领域中,如,智能客服、文本生成、知识图谱构建等。随着更多的工具和资源与LangChain进行集成,大语言模型对人的生产力将会有更大的提升。
常用的业务场景:
智能客服:结合聊天模型、自主智能代理和问答功能,开发智能客服系统,帮助用户解决问题,提高客户满意度。
个性化推荐:利用智能代理与文本嵌入模型,分析用户的兴趣和行为,为用户提供个性化的内容推荐。
知识图谱构建:通过结合问答、文本摘要和实体抽取等功能,自动从文档中提取知识,构建知识图谱。
自动文摘和关键信息提取:利用LangChain的文本摘要和抽取功能,从大量文本中提取关键信息,生成简洁易懂的摘要。
代码审查助手:通过代码理解和智能代理功能,分析代码质量,为开发者提供自动化代码审查建议。
搜索引擎优化:结合文本嵌入模型和智能代理,分析网页内容与用户查询的相关性,提高搜索引擎排名。
数据分析与可视化:通过与API交互和查询表格数据功能,自动分析数据,生成可视化报告,帮助用户了解数据中的洞察信息。
智能编程助手:结合代码理解和智能代理功能,根据用户输入的需求自动生成代码片段,提高开发者的工作效率。
在线教育平台:利用问答和聊天模型功能,为学生提供实时的学术支持,帮助他们解决学习中遇到的问题。
自动化测试:结合智能代理和代理模拟功能,开发自动化测试场景,提高软件测试的效率和覆盖率。
核心组件
要使用 LangChain,开发人员首先要导入必要的组件和工具,例如 LLMs, chat models, agents, chains, 内存功能。这些组件组合起来创建一个可以理解、处理和响应用户输入的应用程序。
- Model I/O:管理语言模型(Models),及其输入(Prompts)和格式化输出(Output Parsers)。
- data connection:与特定任务的数据接口,管理主要用于建设私域知识(库)的向量数据存储(Vector Stores)、内容数据获取(Document Loaders)和转化(Transformers),以及向量数据查询(Retrievers)
- memory:在一个链的运行之间保持应用状态,用于存储和获取 对话历史记录 的功能模块
- chains:构建调用序列,用于串联 Memory ↔ Model I/O ↔ Data Connection,以实现 串行化 的连续对话、推测流程
- agents:给定高级指令,让链选择使用哪些工具,基于 Chains 进一步串联工具(Tools),从而将大语言模型的能力和本地、云服务能力结合
- callbacks:记录并流式传输任何链的中间步骤,可连接到 LLM 申请的各个阶段,便于进行日志记录、追踪等数据导流
快速安装
pip install -U langchain
pip install -U langchain-community
核心模块
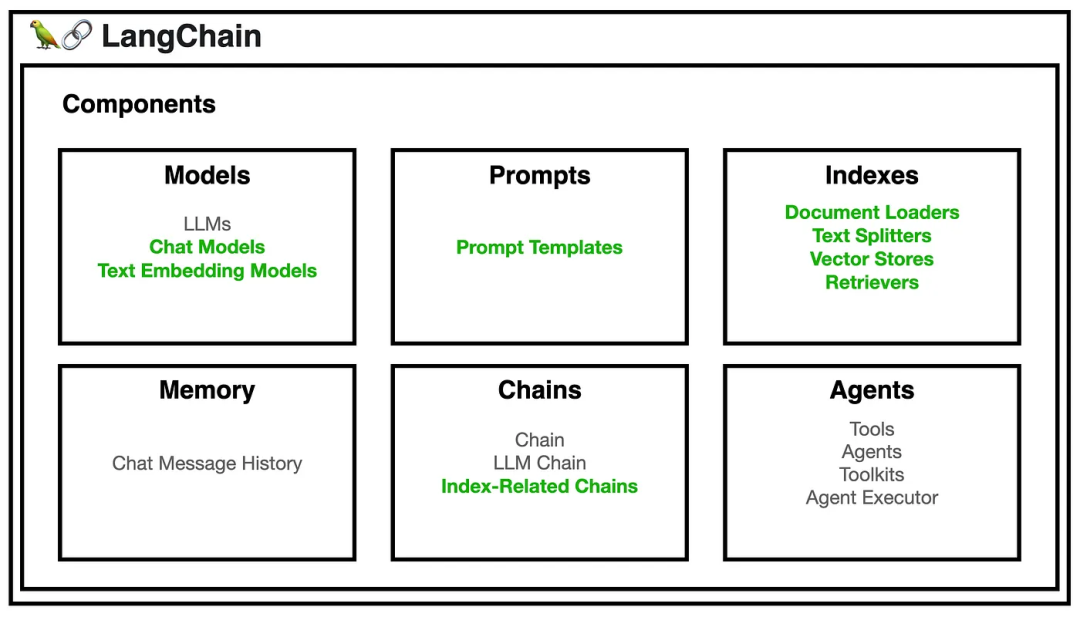
Model I/O
Models
说到模型,在LangChain中 model 是一种抽象,表示框架中使用的不同类型的模型。单纯的大模型只能生成文本内容。
LangChain的一个核心价值就是它提供了标准的模型接口,然后我们可以自由的切换不同的模型,当前主要有两种类型的模型,但是考虑到使用场景,对我们一般用户来说就是使用一种模型即文本生成模型。
LangChain 中的模型有语言模型、文本嵌入模型等多种分类。
语言模型(Language Models)
语言模型(Language Models),用于文本生成,文字作为输入,输出也是文字。
-
普通LLM(llms):接收文本字符串作为输入,并返回文本字符串作为输出。
-
聊天模型(Chat Model):将聊天消息列表作为输入,并返回一个聊天消息对象。
聊天模型是语言模型的一个变体,聊天模型以语言模型为基础,其内部使用语言模型,不再以文本字符串为输入和输出,而是将聊天信息列表为输入和输出,他们提供更加结构化的 API。通过聊天模型可以传递一个或多个消息。LangChain 目前支持四类消息类型:分别是 AIMessage(AI助手回复消息)、HumanMessage(用户发送消息)、SystemMessage(系统角色信息) 。
pip install -U langchain_openai
案例1,代码:
import os
# 设置OpenAI的秘钥到环境变量中,后续的代码在模型内部会读取环境变量提取秘钥
os.environ['OPENAI_API_KEY'] = "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"
# 请求超时,设置以下代理,可以有效减缓超时的情况
os.environ["http_proxy"] = "http://localhost:7890"
os.environ["https_proxy"] = "http://localhost:7890"
# 使用对话模型
from langchain_openai import ChatOpenAI # langchain_openai.ChatOpenAI 就是langchain.AIMessage,在langchainv0.3版本以后,移动到
chat_model = ChatOpenAI(model="gpt-4")
print(chat_model.invoke("你介绍下你自己。"))
"""
content='我是一个语言模型AI助手,专门设计用来与用户进行对话和提供各种服务。我可以回答问题、提供信息、帮助解决问题,还可以进行闲聊和娱乐。如果您有任何问题或需求,请随时告诉我,我会尽力帮助您。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 93, 'prompt_tokens': 17, 'total_tokens': 110, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-cce97b4a-0538-4610-bfd9-3054fbb473be-0' usage_metadata={'input_tokens': 17, 'output_tokens': 93, 'total_tokens': 110, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}}
content='你好,我是OpenAI的人工智能助手。我的主要任务是通过机器学习和自然语言处理技术,帮助用户解答各种问题,提供信息,进行对话,甚至可以帮助写作和创作。我不断学习和进步,以提供更准确和有用的帮助。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 100, 'prompt_tokens': 17, 'total_tokens': 117, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-4-0613', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-26112ec9-0f03-42fc-96d4-f58e3f071bb4-0' usage_metadata={'input_tokens': 17, 'output_tokens': 100, 'total_tokens': 117, 'input_token_details': {'cache_read': 0}, 'output_token_details': {'reasoning': 0}}
"""
代码效果:

案例2,代码:
import os
# 设置OpenAI的秘钥到环境变量中,后续的代码在模型内部会读取环境变量提取秘钥
os.environ['OPENAI_API_KEY'] = "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"
# 请求超时,设置以下代理,可以有效减缓超时的情况
os.environ["http_proxy"] = "http://localhost:7890"
os.environ["https_proxy"] = "http://localhost:7890"
from langchain_openai import ChatOpenAI
from langchain.schema import SystemMessage, AIMessage, HumanMessage
chat_model = ChatOpenAI(model_name="gpt-3.5-turbo")
# 消息列表
"""
注意事项:
1. 大模型本身不管是在线大模型,还是开源大模型,提供出来的API接口都是没有上下文记忆能力的,需要我们自己管理上下文,如果希望大模型结合历史对话记录进行推理,那么我们需要把历史记录发送给大模型。
2. 用户与大模型之间进行对话的过程中,所发的所有内容都会经过分词处理,得到对应数量的token,如果这个大模型是类似OpenAI这样在线大模型,那么不管是我们是提问问题的token还是历史对话中的token都会计费。
"""
messages = [
SystemMessage(content="你叫老王,是一名出色的数学老师,善于结合生活中的例子进行授课."), # 系统消息,给AI助手设定角色定位,限制回答问题的范围
HumanMessage(content="什么是勾股定理?"),
AIMessage(content="勾股定理是指直角三角形中,直角边的平方和等于斜边的平方。"),
HumanMessage(content="上面讲的内容不够通俗易懂,再改改例子。")
]
print(chat_model.invoke(messages))
"""
content='勾股定理是指直角三角形中,直角边的平方和等于斜边的平方。换句话说,设直角三角形的三条边分别为a、b、c,其中c为斜边,a、b为直角边,那么勾股定理可以表示为:a² + b² = c²。\n\n
比如,如果一个直角三角形的两条直角边分别为3和4,那么根据勾股定理,斜边的长度应该为多少呢?按照公式计算,即3² + 4² = c²,9 + 16 = c²,25 = c²,所以c的长度为5。这就是著名的3-4-5三角形,符合勾股定理。\n\n
在生活中,我们可以通过勾股定理来解决很多实际问题,比如测量房间的对角线长度、设计建筑的结构等,勾股定理可以帮助我们更好地理解和应用数学知识。
' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 290, 'prompt_tokens': 58, 'total_tokens': 348, 'completion_tokens_details': {'audio_tokens': None, 'reasoning_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-d6eba824-bd7b-43d3-8262-301bd89b5887-0' usage_metadata={'input_tokens': 58, 'output_tokens': 290, 'total_tokens': 348}
"""
案例3,langchain基于LLMs语言模型调用Tongyi(通义千问)。
通义API-KEY:https://bailian.console.aliyun.com/?apiKey=1
安装灵积模块:
pip install dashscope
代码:
from langchain_community.llms import Tongyi
llm = Tongyi(
model="qwen-plus",
api_key="sk-c98c8f9c9e474aea9c4d56bd52fcc001"
)
input_text = "用50个字左右阐述,生命的意义在于并配图"
print(llm.invoke(input_text))

注意:普通llms的写法在langchain==0.3版本以后openAI不再支持,代码:
import os
# 设置OpenAI的秘钥到环境变量中,后续的代码在模型内部会读取环境变量提取秘钥
os.environ['OPENAI_API_KEY'] = "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"
# 请求超时,设置以下代理,可以有效减缓超时的情况
os.environ["http_proxy"] = "http://localhost:7890"
os.environ["https_proxy"] = "http://localhost:7890"
# 使用对话模型
from langchain_openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
input_text = "介绍下你自己?"
print(llm.invoke(input_text)) # 这里会报错,不再支持。
案例4,基于langchain调用Ollama本地运行的大模型服务。
# 启动ollama的API服务
ollama serve
代码:
from langchain.llms.base import LLM
from typing import Optional, List, Any
import requests
class OllamaLLM(LLM):
def _call(self, prompt: str, stop: Optional[List[str]] = None, **kwargs: Any) -> str:
headers = {"Content-Type": "application/json"}
payload = {
"model": "qwen2.5:3b",
"prompt": prompt,
"stop": stop,
"temperature": kwargs.get("temperature", 0.7),
"max_tokens": kwargs.get("max_tokens", 100),
}
# 发送 POST 请求到 Ollama API
response = requests.post(f"http://localhost:11434/api/generate", json=payload, headers=headers)
if response.status_code == 200:
return response.content
else:
raise Exception(f"Failed to call Ollama API: {response.status_code} - {response.text}")
@property
def _llm_type(self) -> str:
return "ollama"
# 使用 OllamaLLM
llm = OllamaLLM()
prompt = "请介绍下你自己?"
response = llm.invoke(prompt)
print(response)
如果不希望每次在脚本中都设置OPENAI_API_KEY和代理,可以把它设置到环境变量中:
文本嵌入模型(Text Embedding Models)
把文字转换为浮点数形式的描述,表示这些模型接收文本作为输入并返回一组浮点数(向量)。这些浮点数通常用于表示文本的语义信息,以便进行文本相似性计算、聚类分析等任务。文本嵌入模型可以帮助开发者在文本之间建立更丰富的联系,提高基于大型语言模型的应用的性能。
LangChain中的基础Embeddings类提供了两种方法:一种用于嵌入文档,另一种用于嵌入查询。嵌入文档接受多个文本作为输入,而嵌入查询则接受单个文本。之所以将这两种方法分开,是因为一些嵌入提供商对文档(要搜索的内容)与查询(搜索查询本身)使用不同的嵌入方法。
langchain集成支持的模型列表:https://python.langchain.com/docs/integrations/text_embedding/
初始化:
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
嵌入文本列表,代码:
embeddings = embeddings_model.embed_documents(
[
"你好!",
"哦,你也好!",
"你叫什么名字?",
"我叫王小明,你呢?",
"好巧,我叫王大明!"
]
)
print(len(embeddings), len(embeddings[0]))
"""
5 1536
"""
查询检索单个文本嵌入,代码:
embedded_query = embeddings_model.embed_query("这两个人叫什么名字?")
print(embedded_query[:5])
"""
[0.0009400216513313353, -0.008341125212609768, 0.0177350752055645, -0.01252735499292612, -0.033590104430913925]
"""
langchain调用Milvus
langchain作为大模型开发框架,内部集成了市面上较多常用的向量数据库。
langchain支持的向量库列表:https://python.langchain.com/docs/integrations/vectorstores/
安装langchain的Milvus数据库模块:
pip install -U langchain-milvus
接下来,我们就需要使用langchain调用我们本地安装的向量库,所以需要确保自己的机子中已经正常运行了Milvus。代码:
from langchain_openai import OpenAIEmbeddings
from langchain_milvus import Milvus
from langchain.schema import Document
# 1. 初始化OpenAI嵌入模型
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
# 2. 连接Milvus数据库
milvus_host = "127.0.0.1" # Milvus服务器的主机名或IP地址
milvus_port = "19530" # Milvus服务器的端口
collection_name = "langchain_milvus_collection" # 数据集合的名称
# 3. 初始化Milvus向量存储【默认支持动态字段】
vector_store = Milvus(
embedding_function=embeddings_model, # 指定嵌入模型
collection_name=collection_name,
connection_args={"host": milvus_host, "port": milvus_port},
auto_id=True, # 设置集合中的数据为自动增长ID,默认是False
# primary_field="id", # 设置主键名称
)
# 4. 嵌入示例文本数据并存储到Milvus
texts = [
"你好!",
"哦,你也好!",
"你叫什么名字?",
"我叫王小明,你呢?",
"好巧,我叫王大明!"
]
# 将文本转换成Document格式,并进行批量嵌入和存储。
# Document实际上一个记录,除了三个默认字段,Document对于其他字段的存储都可以通过动态字段metadata进行存储,
# page_content就是文本字段,实际存储在向量库中是:text
# 主键:id,实际上存储在向量库中是:pk
# 向量字段:vector
documents = [Document(page_content=text, metadata={'tid': key}) for key,text in enumerate(texts)]
vector_store.add_documents(documents)
# 5. 查询并搜索相似文本
query = "王小明和谁在说话?"
embedded_query = embeddings_model.embed_query(query)
# 打印搜索结果【1个结果】
print(embedded_query)
# 使用Milvus进行相似度搜索
search_results = vector_store.similarity_search(query)
# 6. 打印搜索结果【多个结果】
for result in search_results:
print("相关文本:", result.page_content, result.metadata)
"""
相关文本: 我叫王小明,你呢? {'tid': 3, 'pk': 453513278655828865}
相关文本: 我叫王小明,你呢? {'tid': 3, 'pk': 453513278655828871}
相关文本: 好巧,我叫王大明! {'tid': 4, 'pk': 453513278655828866}
相关文本: 好巧,我叫王大明! {'tid': 4, 'pk': 453513278655828872}
"""
Prompt
prompt(提示词)是我们与模型交互的方式,或者是模型的输入,通过提示词可以让模型返回我们期望的内容,比如让模型按照一定的格式返回数据给我们。LangChain提供了一些工具,可以方便我们更容易的构建出我们想要的提示词,主要工具如下:
Prompt最佳实践
- 明确目标:“请帮助我撰写一篇关于气候变化影响的文章,重点讨论其对农业和生态系统的影响。”
- 提供上下文:“在过去的十年中,全球气温上升了约1.2摄氏度。请解释这一变化对极地冰盖融化的影响。”
- 使用具体的指示:“列出五种可以有效减少碳足迹的方法,并简要说明每种方法的作用。”
- 提供可参考的示例:“请根据以下例子撰写一个相似的故事:‘小猫咪在阳光下懒洋洋地睡觉,偶尔伸个懒腰,似乎在享受这个美好的午后。’”
- 使用分步提示:“首先,请定义什么是人工智能;然后,描述其在医疗领域的应用;最后,讨论可能面临的伦理问题。”
- 控制输出长度:“请简要总结人工智能的历史,控制在100字以内。”
- 使用占位符和模板:“请用以下模板生成一段介绍:‘今天我想介绍{主题}。首先,我会讲述{相关信息},然后讨论{重要性}。’”
- 反复试验和调整:“我正在撰写一篇关于社交媒体影响的文章。请给我一些不同角度的观点,帮我尝试不同的切入点。”
- 指定输出格式:“请以表格的形式列出2023年和2024年的主要科技趋势,包括趋势名称、描述和潜在影响。”
- 使用多轮对话:“我想讨论气候变化。首先,你能告诉我气候变化的主要原因吗?然后我们可以讨论其影响。”
- 使用反思和迭代:“根据我之前的请求,你给出的总结让我觉得有些太简略。请再细化一下,添加更多背景信息和细节。”
PromptTemplates
PromptTemplates(语言模型提示词模板),提示模板可以让我们重复的生成提示,复用我们的提示。它包含一个文本字符串(“模板”),从用户那里获取一组参数并生成提示,包含:
- 对语言模型的说明,应该扮演什么角色
- 一组少量示例,以帮助LLM生成更好的响应,
- 具体的问题
示例1,低版本写法,代码:
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="我希望你担任公司的产品顾问。给我们公司刚生产的{product}产品,取个好听的名字和让人眼前一亮的广告语?",
)
print(prompt.format(product="电脑"))
示例2,新版本写法,代码:
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("我希望你担任公司的产品顾问。请给我们公司刚生产的{product}产品,取个好听的名字和广告语?")
print(prompt_template.invoke({"product":"电脑"}))
示例3,在线大模型调用模板提示词,代码:
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
prompt_template = PromptTemplate.from_template("我希望你担任公司的产品顾问。请给我们公司刚生产的{product}产品,取个好听的名字和广告语?")
messages = prompt_template.invoke({"product":"电脑"})
chat_model = ChatOpenAI(model="gpt-4")
print(chat_model.invoke(messages))
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi
prompt_template = PromptTemplate.from_template("我希望你担任一名经验丰富的{identity}开发工程师,习惯在编写代码时在关键位置添加注释说明作用。请编写一段{title}的代码?")
messages = prompt_template.invoke({"identity":"python", "title":"二叉树"})
llm = Tongyi(model="qwen-plus", api_key="sk-c98c8f9c9e474aea9c4d56bd52fcc001")
print(llm.invoke(messages))
示例4,Ollama部署的本地大模型调用模板提示词,代码:
pip install langchain_ollama
以下提示词如果使用在线大模型,成本很高,钱包估计要尖叫,但是使用本地大模型就无所谓了。代码:
from langchain_ollama.llms import OllamaLLM
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("我希望你担任一名经验丰富的{identity},{adept},{prompt}")
messages = prompt_template.invoke({"identity":"小说作家", "adept": "熟悉中国古代各种神话传说和精怪传奇,擅长借用各种隐喻手法和夸张写法", "prompt": "请你写一部关于少年江小白在无意中遇到修仙大能惊天打斗,然后踏上寻仙之路,拜入修仙门派,在门派中多次重要事件中崭露头角,遇到女主角,并拯救门派,拯救修仙界,最后修成正果,渡劫飞仙的小说,要求:全书至少600章,每一章的字数在8000字以上,剧情紧凑,各个角色的个性分明"})
print(messages)
llm = OllamaLLM(model="qwen2.5:7b")
print(llm.invoke(messages))
for chunk in llm.stream(messages):
print(chunk)
ChatPrompt Templates
ChatPrompt Templates(聊天模型提示词模板), ChatModels接受聊天消息列表作为输入。列表一般是不同的角色提示,并且每个列表消息一般都会有一个角色。
示例1,代码:
from langchain.prompts.chat import ChatPromptTemplate
template = ChatPromptTemplate([
# 'human', 'user', 'ai', 'assistant', or 'system'.
("system", "你是一个专业的翻译人员,擅长把{input_language}翻译成{output_language}。"),
("human", "{text}"),
])
prompt = template.invoke({"input_language": "英语", "output_language":"中文", "text":"I love programming."})
print(prompt)
from langchain_ollama.llms import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
print(llm.invoke(prompt))
示例2,低版本写法,代码:
from langchain.prompts.chat import ChatPromptTemplate
messages = ChatPromptTemplate.from_messages([
('system', '你是一个专业的翻译人员,擅长把{input_language}翻译成{output_language}。'),
('human', '{text}')
])
prompt = messages.format_prompt(input_language="英语", output_language="中文", text="I love programming.")
print(prompt)
from langchain_ollama.llms import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
print(llm.invoke(prompt))
Example Selectors
在提示工程(Prompt Engineering)中,选择合适的示例对于生成高质量的输出至关重要。LangChain框架提供了一种强大的机制——Example Selectors(示例选择器),允许用户为模型提供输入和输出示例,Example Selectors可以根据用户的需求,动态地向模型发送输入输出示例。在Langchain中一共有如下几种方式,供开发者使用示例选择器:
-
自定义示例选择器,继承于BaseExampleSelector,并实现了BaseExampleSelector的必要抽象方法。
-
内置示例选择器:
-
LengthBaseExampleSelector,基于输入内容长度匹配示例的选择器,输入内容多的时候示例会少一点,输入内容少的时候,示例会多一些。
-
SemanticSimilarityExampleSelector,根据相似度进行匹配示例的选择器,选择一个和输入最相似的示例。
-
示例1,基于自定义的示例选择器,基本代码:
from langchain_core.example_selectors.base import BaseExampleSelector
class CustomExampleSelector(BaseExampleSelector):
def __init__(self, examples):
self.examples = examples
def add_example(self, example):
self.examples.append(example)
def select_examples(self, input_variables):
"""基于单词长度选择最相近的示例并返回"""
new_word = input_variables["input"]
new_word_length = len(new_word)
best_match = min(self.examples, key=lambda x: abs(len(x["input"]) - new_word_length))
return [best_match]
# 示例数据
examples = [
{"input": "hi", "output": "你好"},
{"input": "bye", "output": "再见"},
{"input": "thanks", "output": "谢谢"},
]
# 创建Example Selector实例
example_selector = CustomExampleSelector(examples)
# 测试选择器
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'bye', 'output': '再见'}]
# 添加新示例
example_selector.add_example({"input": "exam", "output": "考试"})
# 再次测试
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'exam', 'output': '考试'}]
结合少样本示例动态提示模板(FewShotPromptTemplate)使用,补充代码:
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 创建示例提示模板
example_prompt = PromptTemplate.from_template("Input: {input} -> Output: {output}")
# 创建Few-Shot提示模板
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Input: {input} -> Output:",
prefix="Translate the following words from English to Chinese:",
input_variables=["input"],
)
# 使用提示模板
messages = prompt.format(input="word")
print(messages)
最后结合LLM,完整代码:
from langchain_core.example_selectors.base import BaseExampleSelector
class CustomExampleSelector(BaseExampleSelector):
def __init__(self, examples):
self.examples = examples
def add_example(self, example):
self.examples.append(example)
def select_examples(self, input_variables):
"""基于单词长度选择最相近的示例并返回"""
new_word = input_variables["input"]
new_word_length = len(new_word)
best_match = min(self.examples, key=lambda x: abs(len(x["input"]) - new_word_length))
return [best_match]
# 示例数据
examples = [
{"input": "hi", "output": "你好"},
{"input": "bye", "output": "再见"},
{"input": "thanks", "output": "谢谢"},
]
# 创建Example Selector实例
example_selector = CustomExampleSelector(examples)
# 测试选择器
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'bye', 'output': '再见'}]
# 添加新示例
example_selector.add_example({"input": "exam", "output": "考试"})
# 再次测试
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'exam', 'output': '考试'}]
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 创建示例提示模板
example_prompt = PromptTemplate.from_template("Input: {input} -> Output: {output}")
# 创建Few-Shot提示模板
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Input: {input} -> Output:",
prefix="Translate the following words from English to Chinese:",
input_variables=["input"],
)
# 使用提示模板
messages = prompt.format(input="word")
print(messages)
# 结合LLM大模型
from langchain_ollama.llms import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
print(llm.invoke(messages))
实例2,基于输入内容长度匹配示例选择器,基本代码:
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain.prompts import PromptTemplate
# 示例数据
examples = [
{"input": "hi", "output": "你好"},
{"input": "bye", "output": "再见"},
{"input": "thanks", "output": "谢谢"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input} -> Output: {output}",
)
# 创建Example Selector实例
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25,
)
# 测试选择器
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'bye', 'output': '再见'}]
# 添加新示例
example_selector.add_example({"input": "exam", "output": "考试"})
# 再次测试
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'exam', 'output': '考试'}]
结合少样本示例动态提示模板(FewShotPromptTemplate)使用,补充代码:
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 创建示例提示模板
example_prompt = PromptTemplate.from_template("Input: {input} -> Output: {output}")
# 创建Few-Shot提示模板
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Input: {input} -> Output:",
prefix="Translate the following words from English to Chinese:",
input_variables=["input"],
)
# 使用提示模板
messages = prompt.format(input="word")
print(messages)
最后结合LLM,完整代码:
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain.prompts import PromptTemplate
# 示例数据
examples = [
{"input": "hi", "output": "你好"},
{"input": "bye", "output": "再见"},
{"input": "thanks", "output": "谢谢"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input} -> Output: {output}",
)
# 创建Example Selector实例
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25,
)
# 测试选择器
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'bye', 'output': '再见'}]
# 添加新示例
example_selector.add_example({"input": "exam", "output": "考试"})
# 再次测试
print(example_selector.select_examples({"input": "okay"}))
# 输出: [{'input': 'exam', 'output': '考试'}]
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 创建示例提示模板
example_prompt = PromptTemplate.from_template("Input: {input} -> Output: {output}")
# 创建Few-Shot提示模板
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Input: {input} -> Output:",
prefix="Translate the following words from English to Chinese:",
input_variables=["input"],
)
# 使用提示模板
messages = prompt.format(input="word")
print(messages)
from langchain_ollama.llms import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
print(llm.invoke(messages))
示例3,基于输入内容的余弦相似度匹配示例的选择器,代码:
from langchain_milvus.vectorstores import Milvus
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
# 使用的Embeddings
OpenAIEmbeddings(),
# 选择对应的向量数据库
Milvus,
# 要返回的数目
k=1,
# 向量库的参数选项
collection_name="langchain_milvus_collection2",
connection_args={"host": "127.0.0.1", "port": 19530},
auto_id=True,
)
print(example_selector.select_examples({"input": "word"}))
结合LLM,完整代码:
from langchain_milvus.vectorstores import Milvus
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
# 使用的Embeddings
OpenAIEmbeddings(),
# 选择对应的向量数据库
Milvus,
# 要返回的数目
k=1,
# 向量库的参数选项
collection_name="langchain_milvus_collection2",
connection_args={"host": "127.0.0.1", "port": 19530},
auto_id=True,
)
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 创建示例提示模板
example_prompt = PromptTemplate.from_template("Input: {input} -> Output: {output}")
# 创建Few-Shot提示模板
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Input: {input} -> Output:",
prefix="Convert the following words to antonyms:",
input_variables=["input"],
)
# 使用提示模板
messages = prompt.format(input="welcome")
print(messages)
from langchain_community.llms import Tongyi
llm = Tongyi(
model="qwen-plus",
api_key="sk-c98c8f9c9e474aea9c4d56bd52fcc001"
)
print(llm.invoke(messages))
Output Parsers
Output Parsers(输出解析器),是langchain中提供给我们对模型响应内容进行格式化输出的。LLM的输出为文本,但在程序中除了显示文本,如果希望获得更多不同的结构化数据时,就可以使用langchain提供的输出解析器(Output Parsers)来完成了。输出解析器(Output Parsers)实际上就是结构化语言模型提供的响应处理工具类,其提供了如下两个方法给开发者使用,也是这些响应类必须实现的两个方法:
get_format_instructions() -> str :返回一个包含语言模型如何格式化输出的指令字符串。
invoke()-> Any:接受一个结构化言模型的响应对象,并将其解析为指定
Str输出解析器
代码:
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt_template = PromptTemplate.from_template("我希望你担任公司的产品顾问。请给我们公司刚生产的{product}产品,取个好听的名字和广告语?")
messages = prompt_template.invoke({"product":"电脑"})
print(messages)
llm = ChatOpenAI()
response = llm.invoke(messages)
res = StrOutputParser().invoke(input=response)
print(res)
列表输出解析器
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import PromptTemplate
parser = CommaSeparatedListOutputParser()
prompt = PromptTemplate(
template="请列出10个{subject}.\n{format_instructions}\n",
input_variables=["subject"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
from langchain_ollama.llms import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
messages = prompt.invoke({'subject':'专业学科'})
response = llm.invoke(messages)
content = parser.invoke(response)
print(content) # ['数学', '物理', '化学', '生物', '历史', '地理', '英语', '语文', '计算机科学', '美术']
JSON输出解析器
代码:
from langchain_ollama.llms import OllamaLLM
from pydantic import BaseModel, Field
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
class JsonParser(BaseModel):
question: str = Field(description='问题')
answer: str = Field(description='答案')
parser = JsonOutputParser(pydantic_object=JsonParser)
prompt = PromptTemplate(
template="回答问题.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# print(parser.get_format_instructions())
llm = OllamaLLM(model="qwen2.5:7b")
messages = prompt.invoke({'query':'说一个谜语。'})
response = llm.invoke(messages)
content = parser.invoke(response)
print(content) # {'question': '什么门永远都关不上?', 'answer': '嘴巴'}
stream输出解析器
代码:
from langchain_ollama.llms import OllamaLLM
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template("我希望你担任一名经验丰富的{identity},{adept},{prompt}")
messages = prompt_template.invoke({"identity":"小说作家", "adept": "熟悉中国古代各种神话传说和精怪传奇,擅长借用各种隐喻手法和夸张写法", "prompt": "请你写一部关于少年江小白在无意中遇到修仙大能惊天打斗,然后踏上寻仙之路,拜入修仙门派,在门派中多次重要事件中崭露头角,遇到女主角,并拯救门派,拯救修仙界,最后修成正果,渡劫飞仙的小说,要求:全书至少600章,每一章字数在8000字以上,剧情紧凑,各个角色的个性分明"})
print(messages)
llm = OllamaLLM(model="qwen2.5:7b")
for chunk in llm.stream(messages):
print(chunk, end="", flush=True)
自定义输出解析器
这里我们实现一个markdown格式输出解析器。
pip install markdown
代码:
import markdown
from langchain.prompts import PromptTemplate
from langchain_ollama.llms import OllamaLLM
# 自定义输出解析器,可以以类形式或者函数形式来进行定义。
class MarkdownParser():
"""Markdown解析器"""
def __init__(self):
pass
def invoke(self, text):
# 将文本转换为Markdown格式
return markdown.markdown(text)
# 创建LangChain的模型和链
markdown_parser = MarkdownParser()
# 自定义提示模板
prompt_template = PromptTemplate.from_template("请以Markdown格式输出以下内容:\n\n{input_text}")
# 实例化LLM
llm = OllamaLLM(model="qwen2.5:7b")
messages = prompt_template.invoke({"input_text": "# 这是一个一级标题\n```python\n这是一些引用文本\n```,包含**加粗**和*斜体*。"})
response = llm.invoke(messages)
# 解析Markdown内容
parsed_content = markdown_parser.invoke(response)
# 输出解析结果
print(parsed_content)
Cache
我们还基于langchain提供的输出缓存,让LLM在遇到同一prompt时,直接调用缓存中的结果,以此加速。
import time
import redis
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
# from langchain_community.cache import InMemoryCache # 把输出缓存到内存中
from langchain_community.cache import RedisCache # 把输出缓存到Redis数据库中
from langchain.globals import set_llm_cache
prompt_template = PromptTemplate.from_template("我希望你担任公司的产品顾问。请给我们公司刚生产的{product}产品,取个好听的名字和广告语?")
messages = prompt_template.invoke({"product":"电脑"})
# temperature 温度值,数值越趋向0,回答越谨慎,数值越趋向1,回答则越脑洞大开,主要控制大模型输出的创造力
llm = ChatOpenAI(model="gpt-4", temperature=0.7)
# 开启缓存
redis = redis.Redis("127.0.0.1", port=16379)
set_llm_cache(RedisCache(redis))
timers = []
for _ in range(5):
t1 = time.time()
response = llm.invoke(messages)
t2 = time.time()
print(t2-t1, response)
timers.append(t2-t1)
print(timers)
langsmith
LangSmith是一个用于构建生产级LLM应用程序的在线监控平台。它允许开发者密切监控和评估自己的大模型应用程序,以便开发者可以快速了解开发过程中的LLM调用细节。LangSmith是独立于LangChain框架的,并不一定需要使用 LangChain框架。
文档:https://docs.smith.langchain.com/
代码:
# 使用langsmith监控langchain应用开发程序,秘钥需要在官网申请,监控页面也在langsmith的官方首页
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true' # 固定为'true'
os.environ['LANGCHAIN_API_KEY'] = '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'
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt_template = PromptTemplate.from_template("我希望你担任公司的产品顾问。请给我们公司刚生产的{product}产品,取个好听的名字和广告语?")
messages = prompt_template.invoke({"product":"电脑"})
print(messages)
llm = ChatOpenAI()
response = llm.invoke(messages)
res = StrOutputParser().invoke(input=response)
print(res)
Chains
链(Chain),也叫链式语言表达式(LCEL),是 LangChain 的核心组件。如果把用 LangChain 构建 AI 大模型应用的过程比作“积木模型”的搭建与拼接,那么 Chain 就是是该模型搭建过程中的骨骼部分,通过它将各模块快速组合在一起就可以快速搭建一个应用。langchain提供的chains使用声明式方法将多个操作链接在一起,形成一个完整的处理流程。常见链的类型有3种:LLMChain,SequentialChain、LLMRouteChain。
文档:https://python.langchain.com/docs/concepts/lcel/
LLMChain
通过 LLMChain(大模型链) 可以直接将数据、Prompt、以及想要应用的大模型串到一起连贯调用。
旧版本,代码:
from langchain import PromptTemplate, LLMChain
from langchain_openai import ChatOpenAI
prompt_template = "我希望你担任公司的产品顾问。请给我们公司刚生产的{product}产品,取个好听的名字和广告语??"
chain = LLMChain(
llm=ChatOpenAI(temperature=0.3),
prompt=PromptTemplate.from_template(prompt_template)
)
print(chain("电脑"))
新版本,代码:
from langchain import PromptTemplate, LLMChain
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
prompt_template = "我希望你担任公司的产品顾问。请给我们公司刚生产的{product}产品,取个好听的名字和广告语??"
# chain = LLMChain(
# llm=ChatOpenAI(temperature=0.3),
# prompt=PromptTemplate.from_template(prompt_template),
# output_parser=StrOutputParser(),
# )
# langchain的chain的写法,类似于Linux下面的管道写法
# ps aux | grep 'nginx' | awk '{print $2}' | kill -9
chain = PromptTemplate.from_template(prompt_template) | ChatOpenAI(temperature=0.3) | StrOutputParser()
print(chain.invoke({"product": "什么是求模?"}))
Sequential Chains
不同于基本的 LLMChain,Sequential Chain(序列链)是由一系列的链组合而成的,许将多个链按顺序链接在一起,前一个链的输出作为下一个链的输入。序列链有两种类型,一种是单个输入输出,另一个则是多个输入输出。代码:
import langchain
# LangChain相关模块的导入
from langchain import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import SequentialChain
# 在全局范围开启详细模式,能将调用大模型时发送的数据打印到控制台,绿色文本
langchain.verbose = True
# 本示例中为了让结果更具有创造性,temperature设置为0.9
llm = ChatOpenAI(temperature=0.3)
# Chain1 语言转换,产生英文产品名
prompt1 = ChatPromptTemplate.from_template(
"将以下文本翻译成英文: {product_name}"
)
chain1 = LLMChain(
# 使用的大模型实例
llm=llm,
# prompt模板
prompt=prompt1,
# 输出数据变量名
output_key="english_product_name",
)
# Chain2 根据英文产品名,生成一段英文介绍文本
prompt2 = ChatPromptTemplate.from_template(
"Based on the following product, give an introduction text about 100 words: {english_product_name}"
)
chain2 = LLMChain(
llm=llm,
prompt=prompt2,
output_key="english_introduce"
)
# Chain3 找到产品名所属的语言
prompt3 = ChatPromptTemplate.from_template(
"下列文本使用的语言是什么?: {product_name}"
)
chain3 = LLMChain(
llm=llm,
prompt=prompt3,
output_key="language"
)
# Chain4 根据Chain2生成的英文介绍,使用产品名称原本的语言生成一段概述
prompt4 = ChatPromptTemplate.from_template(
"使用语言类型为: {language} ,为下列文本写一段不多于50字的概述: {english_introduce}"
)
chain4 = LLMChain(
llm=llm,
prompt=prompt4,
output_key="summary"
)
# 标准版的序列Chain,SequentialChain,其中每个chain都支持多个输入和输出,
# 根据chains中每个独立chain对象,和chains中的顺序,决定参数的传递,获取最终的输出结果
overall_chain = SequentialChain(
chains=[chain1, chain2, chain3, chain4],
input_variables=["product_name"],
output_variables=["english_product_name", "english_introduce", "language", "summary"],
verbose=True
)
product_name = "黄油啤酒"
res = overall_chain(product_name)
print(res)
LLMRouteChain
路由链,主要是基于分支判断实现chains的分发调用,代码:
from langchain.chains.llm import LLMChain
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import RouterOutputParser, LLMRouterChain
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0.3)
# 2个角色prompt模板,作为请求处理的2个分支
physics_template = """你是一位非常聪明的物理学家,非常擅长回答物理相关的问题,\
并且会以一种简洁易懂的方式对问题做出讲解。\
当你无法回答问题的时候,就会主动承认无法回答问题。\
以下是具体问题:
{input}"""
math_template = """你是一位非常棒的数学家,非常擅长回答数学相关的问题。\
你之所以这么棒,是因为你能够将难题拆解成它们的组成部分,\
对组成部分分别作答后,再将它们组合起来最终成功的回答出最初的原始问题。\
以下是具体问题:
{input}"""
# 将角色prompt模板和对应的描述、名称组装成列表,方便遍历
prompt_info = [
{
"name": "物理学家",
"description": "擅长回答物理方面的问题",
"prompt_template": physics_template
},
{
"name": "数学家",
"description": "擅长回答数学方面的问题",
"prompt_template": math_template
},
]
# 名称和大模型Chain映射关系的字典
destination_chains = {}
# 根据prompt_info中的信息,创建对应的LLMChain实例,并放入映射字典中
for p_info in prompt_info:
# destination_chains最终的结构为: {name: 对应的LLMChain实例}
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
# 给每个角色创建一个自己的大模型Chain实例
chain = prompt | llm
# 组装成字典,方便router根据逻辑选择分支之后,能够找到分支对应调用的Chain实例
destination_chains[name] = chain
# 生成destinations
destinations = [f"{p['name']}: {p['description']}" for p in prompt_info]
# 转换成多行字符串,每行一句对应关系
destinations_str = "\n".join(destinations)
# 真正实现 if 分支判断的地方
# 选择使用哪个人设模型进行处理的prompt模板
MULTI_PROMPT_ROUTER_TEMPLATE = """Given a raw text input to a \
language model select the model prompt best suited for the input. \
You will be given the names of the available prompts and a \
description of what the prompt is best suited for. \
You may also revise the original input if you think that revising\
it will ultimately lead to a better response from the language model.
<< FORMATTING >>
Return a markdown code snippet with a JSON object formatted to look like:
```json {{{{ "destination": string \ name of the prompt to use or "DEFAULT" "next_inputs": string \ a potentially modified version of the original input }}}} ```
REMEMBER: "destination" MUST be one of the candidate prompt \
names specified below OR it can be "DEFAULT" if the input is not\
well suited for any of the candidate prompts.
REMEMBER: "next_inputs" can just be the original input \
if you don't think any modifications are needed.
<< CANDIDATE PROMPTS >>
{destinations}
<< INPUT >>
{{input}}
<< OUTPUT (remember to include the ```json)>>"""
# 在router模版中先补充部分数据
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
# 组装一个基础的prompt模板对象,通过更多的参数设置更多的信息
router_prompt = PromptTemplate(
# 基础模板
template=router_template,
# 输入参数名称
input_variables=["input"],
# 输出数据解析器
output_parser=RouterOutputParser(),
)
# 通过模板和大模型对象,生成LLMRouterChain,用于支持分支逻辑
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# 创建 else 场景
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
# 把 分支、 else 的情况 以及 做if判断的语句结合到一起
# 将多个chain组装成完整的chain对象,完成带有逻辑的请求链
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True
)
# 提出一个物理问题
physics_res = chain.run("什么是黑体辐射?")
print(physics_res)
# 提出一个数学问题
math_res = chain.run("2的4次方是多少?")
print(math_res)
Document loaders
langchain提供的文档加载器(Document loaders)主要基于Unstructured 包,Unstructured 是一个python包,可以把各种类型的文件转换成文本。LangChain支持的文档加载器包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf(因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的PDF加载引擎)几种常用格式的内容解析,但是在实际的项目中,数据来源一般比较多样,格式也比较复杂
TextLoader
txt文档加载器,代码:
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./2.txt', encoding='utf-8')
# 立即加载,适用于小型的txt文档
docs = loader.load()
# 文档分割器
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# 开始文档分割
texts = text_splitter.split_documents(docs)
# Embeddings向量化
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(
model="text-embedding-3-large" # 默认就是model="text-embedding-3-large"
)
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection", drop_old=True)
# 向量库中数据检索
retriever = db.as_retriever(search_kwargs={'k': 5})
docs = retriever.invoke("这本小说有几个人物?")
for index, item in enumerate(docs):
print(index, item.page_content)
其他检索类型:
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('2.txt', encoding='utf-8')
docs = loader.load()
# 文档分割器
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=512, # 切块大小
chunk_overlap=100, # 重叠部分长度
)
texts = text_splitter.split_documents(docs)
# Embeddings向量化
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection", drop_old=True)
# 向量库中数据检索
"""
search_type(搜索类型):
'similarity',默认值)相似性检索,使用诸如余弦相似度等相似度算法来计算两个向量之间的相似度,得到最相关结果
'mmr',最大边际相关性 (MMR, Maximum marginal relevance) 检索,可以在保持相关性的同时,增加内容的丰富度,降低结果内容的冗余,提供更全面的信息覆盖。
'similarity_score_threshold',基于相似度分数阈值的搜索。
search_kwargs(传递给搜索函数的关键字参数):
k: 要返回的文档数量(默认值:4)。
score_threshold: 用于 similarity_score_threshold 的最低相关性阈值。
fetch_k: 传递给 MMR 算法的文档数量(默认值:20)。
lambda_mult: MMR 返回结果的多样性;1 为最小多样性,0 为最大多样性(默认值:0.5)。
filter: 根据文档元数据进行过滤。
"""
retriever = db.as_retriever(search_type='mmr', search_kwargs={'k': 5, 'lambda_mult': 0.7})
docs = retriever.invoke("这本小说有几个人物?")
for index, item in enumerate(docs):
print(index, item.page_content)
使用内存型向量库Chroma来完成向量存储,
pip install langchain-chroma
代码:
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./2.txt', encoding='utf-8')
# 立即加载,适用于小型的txt文档
docs = loader.load()
# 文档分割器
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# 开始文档分割
texts = text_splitter.split_documents(docs)
# Embeddings向量化
from langchain_openai.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(
model="text-embedding-3-large" # 默认就是model="text-embedding-3-large"
)
# 向量数据库【Chroma】
from langchain_community.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings_model, collection_name='novel_collection', persist_directory="./data/chroma")
# 持久化(保存)向量数据库
db.persist() # 新版本(0.4以后)的Chroma不再需要手动设置这句代码了,会自动根据初始化参数persist_directory来自动判定。
# 向量库中数据检索
retriever = db.as_retriever(search_type='mmr', search_kwargs={'k': 5, 'lambda_mult': 0.7})
docs = retriever.invoke("这本小说有几个人物?")
for index, item in enumerate(docs):
print(index, item.page_content)
采用HuggingFace/魔塔平台上下载的Embeddings,确保自己的开发机子上已经安装好了适配系统的pytorch以后,还需要安装以下依赖:
# HuggingFace的langchain桥解包
pip install langchain-huggingface
需要到huggingface官网上进行注册一个账号,并登陆获取huggingface的访问Token,官网:https://huggingface.co/.
有部分模型实际上是需要token认证以后才能拉取。
huggingface-cli login
# 鼠标右键,输入token
# 输入y出现以下内容表示huggingface客户端工具的终端认证成功:
Token can be pasted using 'Right-Click'.
Enter your token (input will not be visible):
Add token as git credential? (Y/n) y
Token is valid (permission: fineGrained).
Your token has been saved in your configured git credential helpers (manager).
Your token has been saved to C:\Users\Administrator\.cache\huggingface\token
Login successful
代码:
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./2.txt', encoding='utf-8')
# 立即加载,适用于小型的txt文档
docs = loader.load()
# 文档分割器
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# 开始文档分割
texts = text_splitter.split_documents(docs)
# Embeddings向量化
from langchain_huggingface import HuggingFaceEmbeddings
embeddings_model = HuggingFaceEmbeddings(
model_name='moka-ai/m3e-base', # 常用的中文向量化模型,效果较好的:bge,m3e,MiniLM系列。
model_kwargs={'device': 'cuda:0'}, # 如果没有独显的机子,可以不用设置
# cache_folder='./embedding', # 如果不指定缓存路径,则默认在用户家目录/.cache/huggingface/hub目录下
)
# # 向量数据库【Chroma】
# from langchain_community.vectorstores import Chroma
# db = Chroma.from_documents(texts, embeddings_model, collection_name='novel_collection2', persist_directory="./data/chroma")
# # 持久化(保存)向量数据库
# db.persist() # 新版本(0.4以后)的Chroma不再需要手动设置这句代码了,会自动根据初始化参数persist_directory来自动判定。
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection2", drop_old=True)
# 向量库中数据检索
retriever = db.as_retriever(search_type='mmr', search_kwargs={'k': 5, 'lambda_mult': 0.7})
docs = retriever.invoke("这本小说有几个人物?")
for index, item in enumerate(docs):
print(index, item.page_content)
集合本地大模型实现基本检索增强(RAG),代码:
# 文档加载器
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./2.txt', encoding='utf-8')
# 立即加载,适用于小型的txt文档
docs = loader.load()
# 文档分割器
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# 开始文档分割
texts = text_splitter.split_documents(docs)
# Embeddings向量化
from langchain_huggingface import HuggingFaceEmbeddings
embeddings_model = HuggingFaceEmbeddings(
model_name='moka-ai/m3e-base', # 常用的中文向量化模型,效果较好的:bge,m3e,MiniLM系列。
model_kwargs={'device': 'cuda:0'}, # 如果没有独显的机子,可以不用设置
# cache_folder='./embedding', # 如果不指定缓存路径,则默认在用户家目录/.cache/huggingface/hub目录下
)
# # 向量数据库【Chroma】
# from langchain_community.vectorstores import Chroma
# db = Chroma.from_documents(texts, embeddings_model, collection_name='novel_collection2', persist_directory="./data/chroma")
# # 持久化(保存)向量数据库
# db.persist() # 新版本(0.4以后)的Chroma不再需要手动设置这句代码了,会自动根据初始化参数persist_directory来自动判定。
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection2", drop_old=True)
# 实例化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 声明一个检索式问答链
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(search_type='mmr', search_kwargs={'k': 5, 'lambda_mult': 0.7})
)
# RAG(检索增强技术,简单可以理解为大模型查询数据的作弊器)
# 向大模型提问
query = "这本书的主角是谁?"
response = chain.invoke({"query": query})
print(response)
# 全世界只有20%的数据是公共数据(互联网的公开数据),剩下的80%的数据都是私域数据。而我们得到的大模型实际上就是根据20%的公共数据训练出来的。
# {'query': '这本书的主角是谁?', 'result': '这本书的主角是江小白和林云翔。'}
PDFLoader
PyPDFLoader
pip install pypdf
代码:
# 加载PDF文件
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./2023届高校毕业生就业数据报告.pdf")
docs = loader.load()
# 切分文档[RecursiveCharacterTextSplitter递归文档切割器比CharacterTextSplitter字符文本切割器更好用]
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=512, chunk_overlap=200)
texts = text_splitter.split_documents(docs)
# Embeddings向量化,使用HuggingFace提供的Embedding模型
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
embeddings_model = HuggingFaceBgeEmbeddings(
model_name='moka-ai/m3e-base',
model_kwargs={'device': 'cuda:0'},
cache_folder='./embedding', # 如果不指定缓存路径,则默认在用户家目录/.cache/huggingface/hub目录下
)
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection", drop_old=True)
# 实例化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 声明一个检索式问答链
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever()
)
# 向大模型提问
query = "2023年高校毕业生的人数预计是多少?"
response = chain.invoke({"query": query})
print(response)
# {'query': '2023年高校毕业生的人数预计是多少?', 'result': '2023年高校毕业生预计达1158万人,创历史新高。'}
采用递归文本分割器,代码:
# 文档加载器
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader('./2023届高校毕业生就业数据报告.pdf')
# 立即加载,适用于小型的pdf文档
docs = loader.load()
"""
[
Document(metadata={'source': './2023届高校毕业生就业数据报告.pdf', 'page': 0}, page_content='1 \n \n2023 届高校毕业生就业数据报告 \n \n \n2023年高校毕业生预计达1158万人,创历史新高。大学生作为重点就业人群之一,历来备\n受社会各界关注。时值大学生就业冲刺阶段,猎聘大数据研究院推出《2023 届高校毕业生\n就业数据报告》 ,研究本届毕业生(以下简称“应届生” )的就业机会,尤其在新赛道的就业\n契机;分析应届生求职心态、行为及进展的特点,为用人方和求职者提供决策参考,为大学\n生就业助一臂之力。 \n \n一、2023 届高校毕业生就业总况 \n1、应届生职位增长情况 \n1)行业:能源/化工/环保应届生职位同比增长超40%,增长居行业首位 \n较 2022 届应届生职位同比增长较明显的 TOP5 一级行业为能源/化工/环保、医疗健康、汽\n车、机械/制造、电子/通信/半导体,其中能源/化工/环保同比增长为 42.30%,增速最高。\n在全世界都提倡低碳环保、致力实现碳中和碳达峰的趋势下, 能源/化工/环保的重要性日益\n显现。在这TOP5行业中,应届生招聘平均年薪最高的是电子/通信/半导体,为18.83 万,\n也领先所有一级行业。 \n \n \n2)职类:售后技术支持、科研人员、带货直播应届生职位增长均超100% \n'),
Document(metadata={'source': './2023届高校毕业生就业数据报告.pdf', 'page': 1}, page_content='2 \n \n在 2023届应届生新发职位同比增长最多的三级职能TOP20中,售后技术支持、科研人员、\n带货直播位居前三,增长率为133.75%、130.85%、104.93%。售后技术支持在售后服务中发\n挥着重要作用,深刻影响着用户体验和口碑,因而需求大增。我国正从科技大国向科技强国\n迈进,对科研人员需求较多。当前直播和短视频成为各领域新宠,带货直播是其核心角色,\n备受年轻人青睐,也需要大学生的加入提升从业者的素质。在这20 个职能中,应届生招聘\n平均年薪最高的是科研人员,为27.11万;位居第二、第三的为仿真工程师、半导体技术工\n程师,为24.80万、24.14 万。 \n \n \n2、应届生城市就业分析 \n1)上海应届生职位最多,北京应届生招聘年薪以18 万居首 \n从 2023届应届生新发职位城市分布TOP20来看,上海、北京、深圳、广州位居前四,占比\n为11.13%、9.00%、6.93%、5.27%。从其招聘平均年薪来看,排名前四的是北京、上海、深\n圳、杭州,为18.30 万、17.67万、16.86万、15.86万;南京位居第五,为14.27万。这\n个五个城市的招聘平均年薪均高于全国应届生招聘平均年薪(13.55万)。 \n'),
....
Document(metadata={'source': './2023届高校毕业生就业数据报告.pdf', 'page': 15}, page_content='16 \n \n4、32%的应届生参加过技能培训,外语、计算机编程培训参与者最多且被认为最有用 \n应届生求职者为找工作做了哪些准备?本次调研显示,排名前二的是“向已工作的亲朋或学\n长学姐取经”“参加就业指导讲座” 。此外,32.12%的应届生参加过技能培训,计算机编程、\n外语、设计、驾驶技能培训排名前四。最受肯定的是外语、计算机编程、电商运营、驾驶技\n能培训,分别有98.25%、94.83%、84.85%、80.95%的参与者认为对求职有用。 \n \n \n今年总体就业形势严峻,压力与机遇并存。猎聘职场顾问建议大学生做好求职规划,通过实\n习或培训加强实操;当前先求生存,再谋发展,不求一步到位,只求步步接近目标,在此过\n程中学会经济、精神独立,早日完成从学生到职场人的角色转变,在边干边学中持续提升自\n身价值。 \n \n(完) \n \n')
]
"""
# 文档分割器
"""
CharacterTextSplitter 字符文本分割器,一次性顺序分割,所以效率较高,但是分割效果上比RecursiveCharacterTextSplitter差
RecursiveCharacterTextSplitter,递归文本分割器,采用递归方式来多次分割,所以效率较低,但是分割效果上比CharacterTextSplitter好[强烈推荐]
两个分割器类的使用方式一模一样。
"""
from langchain_text_splitters import CharacterTextSplitter, RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# 开始文档分割
texts = text_splitter.split_documents(docs)
# Embeddings向量化
from langchain_huggingface import HuggingFaceEmbeddings
embeddings_model = HuggingFaceEmbeddings(
model_name='moka-ai/m3e-base', # 常用的中文向量化模型,效果较好的:bge,m3e,MiniLM系列。
model_kwargs={'device': 'cuda:0'}, # 如果没有独显的机子,可以不用设置
# cache_folder='./embedding', # 如果不指定缓存路径,则默认在用户家目录/.cache/huggingface/hub目录下
)
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection2", drop_old=True)
# 实例化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 声明一个检索式问答链
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(search_type='mmr', search_kwargs={'k': 5, 'lambda_mult': 0.7})
)
query = "2023年平均年薪居首预计是多少?"
response = chain.invoke({"query": query})
print(response)
惰性加载大型文档,可以使用惰性加载来逐页处理文档,代码:
# 文档加载器
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader('./2023届高校毕业生就业数据报告.pdf')
# 文档分割器
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 被分割文档的切块大小,500~2000
chunk_overlap=100, # 被分割切块的重叠部分长度,200以内
)
# Embeddings向量化
from langchain_huggingface import HuggingFaceEmbeddings
embeddings_model = HuggingFaceEmbeddings(
model_name='moka-ai/m3e-base', # 常用的中文向量化模型,效果较好的:bge,m3e,MiniLM系列。
model_kwargs={'device': 'cuda:0'}, # 如果没有独显的机子,可以不用设置
# cache_folder='./embedding', # 如果不指定缓存路径,则默认在用户家目录/.cache/huggingface/hub目录下
)
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus(
embedding_function=embeddings_model,
collection_name="novel_collection2",
drop_old=True,
auto_id=True,
)
def process_batch(docs):
# 执行文档分割
texts = text_splitter.split_documents(docs)
# 执行向量入库
db.add_documents(texts)
# 惰性加载,适用于大型的文档
texts = []
limit = 10
for docs in loader.lazy_load():
texts.append(docs)
if len(texts) >= limit:
# 对每10页进行批处理操作
process_batch(texts)
texts = []
# 处理剩余不满limit页的文本
if len(texts)>0:
process_batch(texts)
# 实例化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 声明一个检索式问答链
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(search_type='mmr', search_kwargs={'k': 5, 'lambda_mult': 0.7})
)
query = "2023年平均年薪居首预计是多少?"
response = chain.invoke({"query": query})
print(response)
# {'query': '2023年平均年薪居首预计是多少?', 'result': '根据提供的信息,电子/通信/半导体行业的应届生招聘平均年薪最高,为18.83万。另外,AI大模型领域算法工程师的平均年薪也是最高的,达到41.89万元。这两个数据中,41.89万元是2023年提到的最高平均年薪。'}
加载多份PDF文档,代码:
# 加载多个PDF文件
from langchain_community.document_loaders import PyPDFLoader
loaders = [
PyPDFLoader("./2023届高校毕业生就业数据报告.pdf"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
# 切分文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=200)
texts = text_splitter.split_documents(docs)
# Embeddings向量化,使用HuggingFace提供的Embedding模型
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
embeddings_model = HuggingFaceBgeEmbeddings(
model_name='moka-ai/m3e-base',
model_kwargs={'device': 'cuda:0'}
)
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection", drop_old=True)
# 实例化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:3b")
# 声明一个检索式问答链
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever()
)
# 向大模型提问
query = "2023年高校毕业生的最倾向的行业是?"
response = chain.invoke({"query": query})
print(response)
#{'query': '2023年高校毕业生的最倾向的行业是?', 'result': '根据提供的信息,2023年高校毕业生最倾向于的新赛道中,智能制造、AIGC(人工智能生成内容)、AI大模型排名前三。\n\n不过请注意,该数据仅反映了新职业的方向和趋势,并不能直接代表最倾向的行业。从职位增长情况看,能源/化工/环保行业应届生职位同比增长超40%,增速居首。因此,若需回答毕业生最倾向于的传统重点行业,那么可能是能源/化工/环保行业。'}
PyMuPDFLoader
PyMuPDFLoader这个加载比langchain默认内置pyPDFLoader加载速度更快。
pip install pyMuPDF -i https://pypi.tuna.tsinghua.edu.cn/simple
代码:
# 加载多个PDF文件
import sys
from langchain_community.document_loaders import PyMuPDFLoader
# # 加载单个文档
# loader = PyMuPDFLoader("./2023届高校毕业生就业数据报告.pdf")
# docs = loader.load()
# print(docs)
# 加载多个文档
loaders = [
PyMuPDFLoader("./2023届高校毕业生就业数据报告.pdf"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
# 切分文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=200)
texts = text_splitter.split_documents(docs)
# Embeddings向量化,使用HuggingFace提供的Embedding模型
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
embeddings_model = HuggingFaceBgeEmbeddings(
model_name='moka-ai/m3e-base',
model_kwargs={'device': 'cuda:0'}
)
# 向量数据库【Milvus】
from langchain_milvus import Milvus
db = Milvus.from_documents(texts, embeddings_model, collection_name="novel_collection", drop_old=True)
# 实例化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:3b")
# 声明一个检索式问答链
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever()
)
# 向大模型提问
query = "2023年高校毕业生的最倾向的行业是?"
response = chain.invoke({"query": query})
print(response)
# {'query': '2023年高校毕业生的最倾向的行业是?', 'result': '根据提供的信息,2023年高校毕业生最倾向于就业的行业主要集中在能源/化工/环保、医疗健康、汽车、机械/制造和电子/通信/半导体这几个方面。其中,能源/化工/环保行业的应届生职位同比增长超过40%,增速最高。'}
OnlinePDFLoader
加载线上的pdf文档,安装:
pip install "unstructured[local-inference]"
# 可能遇到奇奇怪怪的报错https://www.luffycity.com/play/102340
代码:
from langchain_community.document_loaders import OnlinePDFLoader
loader = OnlinePDFLoader("https://arxiv.org/pdf/1512.03385.pdf")
data = loader.load()
print(data)
MarkdownLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import MarkdownTextSplitter
loader = UnstructuredMarkdownLoader("../大模型应用开发与私有化部署.md", mode="elements", autodetect_encoding=True)
docs = loader.load_and_split(text_splitter=MarkdownTextSplitter(chunk_size=512, chunk_overlap=200))
print(docs)
DirectoryLoader
按目录加载文档,支持多个格式文档的模糊匹配
pip install python-magic
# windows系统
pip install python-magic-bin
代码:
from langchain_community.document_loaders import DirectoryLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# recursive 设置是否加载子目录下的匹配文件
loader = DirectoryLoader("./", glob="*.txt", show_progress=True, use_multithreading=True, recursive=True)
docs = loader.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=200))
print(len(docs), docs)
WebBaseLoader
加载html网页,代码:
# 如果提示需要设置USER_ANGET网络代理,则把下面代码注释打开
import os
os.environ["USER_AGENT"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader('https://baike.baidu.com/item/Linux')
texts = loader.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=200))
print(texts, len(texts))
| 文档加载器 | 介绍 |
|---|---|
| Airbyte JSON | 从Airbyte加载JSON,Airbyte是一个数据集成平台 |
| Apify Dataset | Apify Dataset是一个可扩展的纯应用存储,具有顺序访问功能,用于存储结构化的网络抓取结果 |
| Arxiv | arXiv是一个开放性的档案库,收录了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域的200万篇学术文章。 |
| AWS S3 Directory | AWS S3是Amazon的对象存储服务,加载目录 |
| AWS S3 File | 加载文件 |
| AZLyrics | AZLyrics是一个大型的、合法的、每天都在增长的歌词集。https://www.azlyrics.com/ |
| Azure Blob Storage Container | 微软的对象存储服务 |
| Azure Blob Storage File | 加载文件 |
| Bilibili | 加载B站视频 |
| Blackboard | 一个虚拟学习环境和学习管理系统 |
| Blockchain | 基于alchemy 加载区块链数据 |
| ChatGPT Data | chatGPT消息加载器 |
| College Confidential | 提供全世界的大学信息 |
| Confluence | 一个专业的企业知识管理与协同平台 |
| CoNLL-U | CoNLL-U是一种文件格式 |
| Copy Paste | 普通文本 |
| CSV | CSV文件 |
| Diffbot | 一个将网站转化为结构化数据的平台 |
| Discord | 最初为游戏玩家提供服务的游戏社区论坛,先发展为多领域的社区论坛。 |
| DuckDB | 一个分析数据库系统 |
| 邮件,支持.eml和.msg格式 | |
| EPub | epub电子书 |
| EverNote | EverNote文档 |
| Facebook Chat | Facebook消息 |
| Figma | 一个web设计工具 |
| File Directory | 加载目录下所有文件 |
| Git | GIt |
| GitBook | GItBook |
| Google BigQuery | 谷歌云服务 |
| Google Cloud Storage Directory | 谷歌云服务 |
| Google Cloud Storage File | 谷歌云服务 |
| Google Drive | 谷歌云服务 |
| Gutenberg | 一个在线电子书平台 |
| Hacker News | 一个计算机信息网站 |
| HTML | 网页 |
| HuggingFace dataset | HuggingFace数据集 |
| iFixit | 一个维修为主题的社区 |
| Images | 加载图片 |
| Image captions | 根据图片生成图片说明 |
| IMSDb | 电影数据库 |
| JSON Files | 加载JSON文件 |
| Jupyter Notebook | 加载notebook文件 |
| Markdown | 加载markdown文件 |
| MediaWikiDump | wiki xml数据 |
| Microsoft OneDrive | 加载微软OneDrive文档 |
| Microsoft PowerPoint | 加载ppt文件 |
| Microsoft Word | 加载word文件 |
| Modern Treasury | 一家支付运营软件提供商 |
| Notion DB | 加载Notion文件 |
| Obsidian | 一个笔记软件 |
| Unstructured ODT Loader | 加载OpenOffice文件 |
| Pandas DataFrame | Pandas表格型数据结构 |
| 加载pdf文件 | |
| ReadTheDocs Documentation | 一个在线文档平台 |
| 一个社交新闻网站 | |
| Roam | 一个个人笔记产品 |
| Sitemap | 网站地图 |
| Slack | 一个聊天群组产品 |
| Spreedly | 一个支付平台 |
| Stripe | 一个支付平台 |
| Subtitle | 一个字幕制作平台 |
| Telegram | 聊天软件 |
| TOML | 一种配置文件 |
| Unstructured File | Unstructured文件 |
| URL | 通过url加载内容 |
| WebBaseLoader | 基础的web加载器 |
| WhatsApp Chat | WhatsApp聊天 |
| Wikipedia | 加载Wikipedia内容 |
| YouTube transcripts | 加载YouTube视频 |
| 文本分割器 | |
|---|---|
| LatexTextSplitter | 沿着Latex标题、标题、枚举等分割文本。 |
| MarkdownTextSplitter | 沿着Markdown的标题、代码块或水平规则来分割文本。 |
| NLTKTextSplitter | 使用NLTK的分割器 |
| PythonCodeTextSplitter | 沿着Python类和方法的定义分割文本。 |
| RecursiveCharacterTextSplitter | 用于通用文本的分割器。它以一个字符列表为参数,尽可能地把所有的段落(然后是句子,然后是单词)放在一起 |
| SpacyTextSplitter | 使用Spacy的分割器 |
| TokenTextSplitter | 根据openAI的token数进行分割 |
Memory
LLM 本身是没有记忆的,每一次LLM的API调用都是一个全新的会话。但在某些应用程序中,如:聊天机器人,让LLM记住以前的历史交互是非常重要,无论是在短期的还是长期的。langchain中的“Memory”即对话历史(message history)就是为了实现这一点。
注意:LangChain中大多数与memory相关的功能都标记为测试版,原因如下:
- 大部分功能并没有完善就已经产生了新的替代技术,导致部分功能一直在不断升级维护。
- 频繁的版本升级,导致产生了大量的历史版本,导致每个版本的模块代码提供的方式和使用规则都不一样。
代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate
template = """
我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。
用户的问题:{input}
你的回复是:
"""
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | llm
res = chain.invoke({"input": "我叫什么名字,你是谁?"})
print(res)
res = chain.invoke({"input": "我叫墨落,请你记住。"})
print(res)
res = chain.invoke({"input": "我之前告诉过你我叫什么名字,你还记得吗?"})
print(res)
如果我们想要让模型有记忆(Memory),利用的实际上是提示词工程,前面的代码例子中就可以看到提示词中告知LLM充当江小白,所以在后续的多次对话中,尽管LLM没有进行上下文管理记录对话历史,但是LLM在回答时始终会告诉用户,它是江小白。因此我们如果要实现会话历史管理,可以借鉴这种方式。
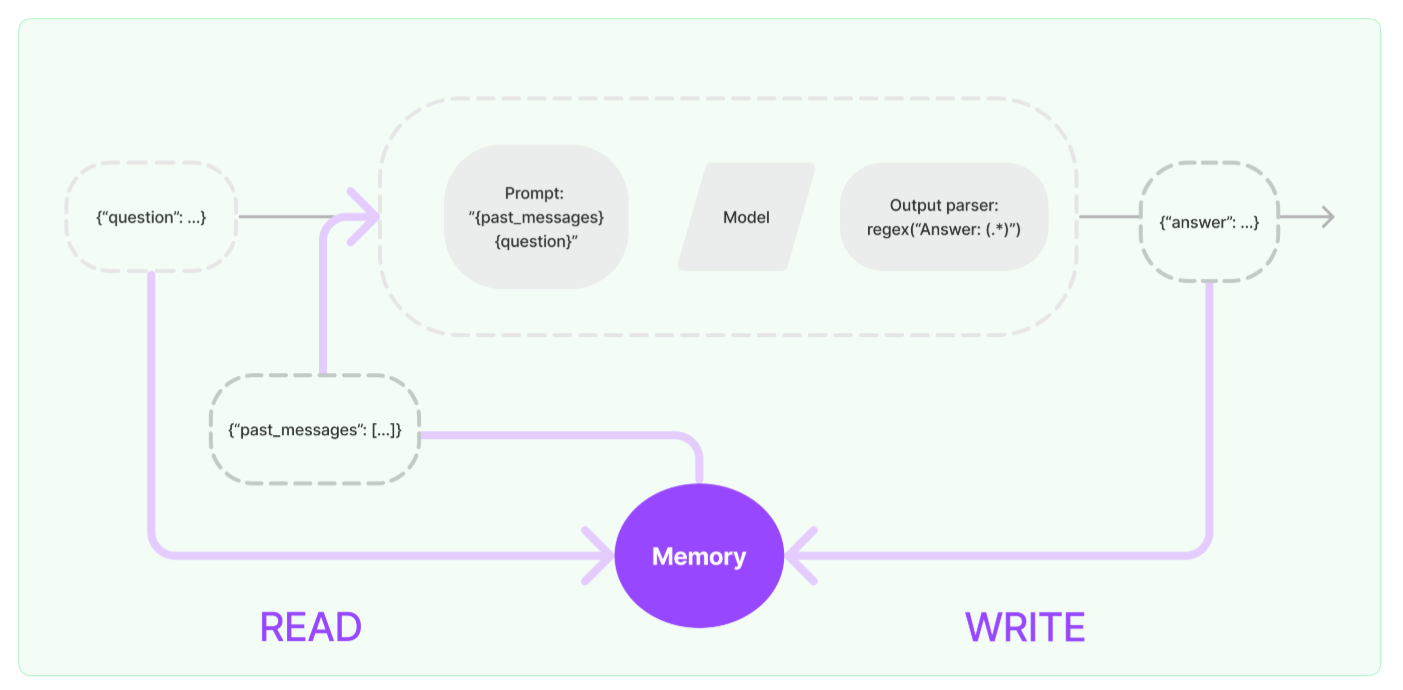
对话消息历史
接下来我们采用提示词的占位符MessagePlaceholder去作为用户输入的占位符,并在使用chain的invoke方法进行提问前,手动把历史信息放在一个history的列表里面,然后去获取最后结果。代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b", temperature=0)
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 使用内存或者文件、数据库等等记录对话历史
history = [("user", "第1次问题:我叫墨落,请你记住。"), ("ai", "你好,墨落。"), ("user", "第2次问题:我叫什么名字,你叫什么名字?")]
res = chain.invoke({"history": history})
history.append(("ai", res))
print(res)
history.append(("user", "第3次问题:我之前告诉你我的名字,你还记得吗?"))
res = chain.invoke({"history": history})
history.append(("ai", res))
print(res)
history.append(("user", "第4次问题:这是我们第几次聊天了?"))
res = chain.invoke({"history": history})
history.append(("ai", res))
print(res)
上面的方式就是对LLM与用户的对话历史信息进行手动记录管理的流程。如果要实现多人会话消息历史管理,我们只需要根据给不同用户设置一个唯一的session_id即可,代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
store = {}
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = []
return store[session_id]
xiaoming_history = get_session_history('xiaoming')
xiaoming_history.append(('user', '我叫小明,你要记住我哦,我明年就成年了。'))
xiaoming_res = chain.invoke({"history": xiaoming_history})
xiaoming_history.append(('ai', xiaoming_res))
xiaolong_history = get_session_history('xiaolong')
xiaolong_history.append(('user', '你好呀,小白,我的名字叫李小龙,我今年21岁。'))
xiaolong_res = chain.invoke({"history": xiaolong_history})
xiaolong_history.append(('ai', xiaolong_res))
xiaoming_history.append(('user', '你还记得我的名字和年龄吗?'))
xiaoming_res = chain.invoke({"history": xiaoming_history})
xiaoming_history.append(('ai', xiaoming_res))
xiaolong_history.append(('user', '你还记得我的名字和年龄吗?'))
xiaolong_res = chain.invoke({"history": xiaolong_history})
xiaolong_history.append(('ai', xiaolong_res))
print(xiaoming_res)
print('>>>>>')
print(xiaolong_res)
ChatMessageHistory-对话消息历史管理
实际上langchain已经提供了一个ChatMessageHistory(对话消息历史)对象给开发者在内存中管理对话消息历史数据。
文档:https://python.langchain.com/api_reference/core/chat_history.html
langchain_community.chat_message_histories.ChatMessageHistory就是langchain_core.chat_history.InMemoryChatMessageHistory的别名。
代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
# from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.messages import SystemMessage
# history = InMemoryChatMessageHistory()
history = ChatMessageHistory()
history.messages = [SystemMessage("我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。")]
history.add_user_message("我叫墨落,请你记住。")
history.add_ai_message("你好,墨落。")
history.add_user_message("我叫什么名字,你叫什么名字?")
res = chain.invoke({"history": history.messages})
history.add_ai_message(res)
print(res)
history.add_user_message("我之前告诉你我的名字,你还记得吗?")
res = chain.invoke({"history": history.messages})
history.add_ai_message(res)
print(res)
ChatMessageHistory的常用方法:
| 方法名 | 描述 |
|---|---|
| add_message(self, message: BaseMessage) | 添加一条消息到对话历史对象中 |
| add_messages(self, messages: Sequence[BaseMessage]) | 批量添加消息到对话历史对象中 |
| add_user_message(message: Union[HumanMessage, str]) | 添加用户类型消息到对话历史对象中 |
| add_ai_message(self, message: Union[AIMessage, str]) | 添加AI类型消息到对话历史对象中 |
| clear(self) | 清除消息历史 |
有了对话消息历史管理对象,不仅可以管理和存储单个用户和LLM的历史对话信息以此来维持会话状态,还可以实现管理多用户与LLM的独立历史对话信息。代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
from langchain_community.chat_message_histories import ChatMessageHistory
store = {}
def get_session_history(session_id: str) -> ChatMessageHistory:
if session_id not in store:
new_history = ChatMessageHistory()
store[session_id] = new_history
return store[session_id]
xiaoming_history = get_session_history('xiaoming')
xiaoming_history.add_user_message('我叫小明,你要记住我哦,我明年就成年了。')
xiaoming_res = chain.invoke({"history": xiaoming_history.messages})
xiaoming_history.add_ai_message(xiaoming_res)
xiaolong_history = get_session_history('xiaolong')
xiaolong_history.add_user_message('你好呀,小白,我的名字叫李小龙,我今年21岁。')
xiaolong_res = chain.invoke({"history": xiaolong_history.messages})
xiaolong_history.add_ai_message(xiaolong_res)
xiaoming_history.add_user_message("你还记得我的名字和年龄吗?")
xiaoming_res = chain.invoke({"history": xiaoming_history.messages})
xiaoming_history.add_ai_message(xiaoming_res)
xiaolong_history.add_user_message("你还记得我的名字和年龄吗?")
xiaolong_res = chain.invoke({"history": xiaolong_history.messages})
xiaolong_history.add_ai_message(xiaolong_res)
print(xiaoming_res)
print('>>>>>')
print(xiaolong_res)
实际上langchain中提供的ChatMessageHistory工具类已经内置了类似get_session_history的方法,所以我们根本不需要自己声明这个方法,直接通过ChatMessageHistory实例化时指定session_id即可,代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
from langchain_community.chat_message_histories import ChatMessageHistory
xiaoming_history = ChatMessageHistory(session_id="xiaoming")
xiaoming_history.add_user_message('我叫小明,你要记住我哦,我明年就成年了。')
xiaoming_res = chain.invoke({"history": xiaoming_history.messages})
xiaoming_history.add_ai_message(xiaoming_res)
xiaolong_history = ChatMessageHistory(session_id="xiaolong")
xiaolong_history.add_user_message('你好呀,小白,我的名字叫李小龙,我今年21岁。')
xiaolong_res = chain.invoke({"history": xiaolong_history.messages})
xiaolong_history.add_ai_message(xiaolong_res)
xiaoming_history.add_user_message("你还记得我的名字和年龄吗?")
xiaoming_res = chain.invoke({"history": xiaoming_history.messages})
xiaoming_history.add_ai_message(xiaoming_res)
xiaolong_history.add_user_message("你还记得我的名字和年龄吗?")
xiaolong_res = chain.invoke({"history": xiaolong_history.messages})
xiaolong_history.add_ai_message(xiaolong_res)
print(xiaoming_res)
print('>>>>>')
print(xiaolong_res)
RunnableWithMessageHistory-可运行的消息历史记录对象
上面虽然使用了ChatMessageHistory保存对话历史数据,但是与Chains/Agents的操作是独立的,并且每次产生新的对话消息都要手动记录,所以为了方便使用,langchain还提供了RunnableWithMessageHistory可以自动为Chains/Agents添加对话历史记录。
代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
chains = RunnableWithMessageHistory(
chain,
lambda session_id: ChatMessageHistory(session_id=session_id),
input_messages_key="input",
history_messages_key="history",
)
chains.invoke({"input": "我叫小明,你要记住我哦,我明年就成年了。"}, config={'configurable': {'session_id': 'xiaoming'}})
chains.invoke({"input": "你好呀,小白,我的名字叫李小龙,我今年21岁。"}, config={'configurable': {'session_id': 'xiaolong'}})
xiaoming_res = chains.invoke({"input": "你还记得我的名字和年龄吗?"}, config={'configurable': {'session_id': 'xiaoming'}})
xiaolong_res = chains.invoke({"input": "你还记得我的名字和年龄吗?"}, config={'configurable': {'session_id': 'xiaolong'}})
print(xiaoming_res)
print('>>>>>')
print(xiaolong_res)
langchain中除了可以使用ChatMessageHistory在内存中保存对话历史数据,还提供了如下工具类方便开发者使用各种设备保存对话历史数据。
文档地址:https://python.langchain.com/api_reference/community/chat_message_histories.html
from langchain_community.chat_message_histories import <Name>ChatMessageHistory
| 工具类 | 描述 |
|---|---|
| InMemoryChatMessageHistory | 内存存储对话历史 |
| FileChatMessageHistory | 文件存储对话历史 |
| MongoDBChatMessageHistory | MongoDB数据库存储对话历史 |
| PostgresChatMessageHistory | Postgresql数据库存储对话历史 |
| RedisChatMessageHistory | redis数据库存储对话历史 |
| ElasticsearchChatMessageHistory | Elasticsearch数据库存储对话历史 |
| KafkaChatMessageHistory | Kafka消息队列存储对话历史 |
| SQLChatMessageHistory | SQL数据库存储对话历史 |
以Redis为例,代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import RedisChatMessageHistory, FileChatMessageHistory, SQLChatMessageHistory
chains = RunnableWithMessageHistory(
chain,
# 根据会话ID(session_id)提供用户的对话历史
lambda session_id: RedisChatMessageHistory(url='redis://127.0.0.1:16379/0', key_prefix='chat:', session_id=session_id),
# lambda session_id: FileChatMessageHistory(file_path='./data.json', key_prefix='chat', session_id=session_id), # 根据会话ID(session_id)提供用户的对话历史
# lambda session_id: SQLChatMessageHistory(connection_string='mysql://root:123@127.0.0.1:3306/chat', key_prefix='chat', session_id=session_id), # 根据会话ID(session_id)提供用户的对话历史
input_messages_key="input",
history_messages_key="history"
)
chains.invoke({"input": "我叫小明,你要记住我哦,我明年就成年了。"}, config={'configurable': {'session_id': 'xiaoming'}})
chains.invoke({"input": "你好呀,小白,我的名字叫李小龙,我今年21岁。"}, config={'configurable': {'session_id': 'xiaolong'}})
xiaoming_res = chains.invoke({"input": "你还记得我的名字和年龄吗?"}, config={'configurable': {'session_id': 'xiaoming'}})
xiaolong_res = chains.invoke({"input": "你还记得我的名字和年龄吗?"}, config={'configurable': {'session_id': 'xiaolong'}})
print(xiaoming_res)
print('>>>>>')
print(xiaolong_res)
RunnableWithMessageHistory在使用过程中,除了支持自动管理多人对话历史消息以外,还支持同一人多次不同会话历史的独立保存。代码:
# 初始化大模型
from langchain_core.runnables import ConfigurableFieldSpec
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
template = [
("system", "我希望你充当由林墨开发的会话机器人江小白,你每次都会精简而快速的告诉用户你是一个专业的机器人以及用户问题的答案。"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
prompt = ChatPromptTemplate.from_messages(messages=template)
chain = prompt | llm
# 记录会话历史
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import RedisChatMessageHistory
chains = RunnableWithMessageHistory(
chain,
lambda session_id, user_id: RedisChatMessageHistory(session_id=f"{user_id}_{session_id}", url='redis://127.0.0.1:16379/0'),
input_messages_key="input",
history_messages_key="history",
history_factory_config=[
ConfigurableFieldSpec(id="user_id", annotation=str, name="User ID", description="Unique identifier for the user.", default="", is_shared=True),
ConfigurableFieldSpec(id="session_id", annotation=str, name="Session ID", description="Unique identifier for the session.", default="", is_shared=True),
]
)
chains.invoke({"subject":"数学", "input": "我叫小明,你要记住我哦,我明年就18岁了。"}, config={'configurable': {'user_id': 'xiaoming', 'session_id':'math'}})
chains.invoke({"subject":"英语", "input": "欢迎来到北京,北京是一座历史悠久的国际大都市。"}, config={'configurable': {'user_id': 'xiaoming', 'session_id':'english'}})
xiaoming_res = chains.invoke({"subject":"数学", "input": "我有个同学叫小青,她过2年18岁,那么我20岁的时候,她是几岁?"}, config={'configurable': {'user_id': 'xiaoming','session_id':'math'}})
print(xiaoming_res)
xiaoming_res = chains.invoke({"subject":"英语", "input": "帮我翻译下我上面的内容?"}, config={'configurable': {'user_id': 'xiaoming','session_id':'english'}})
print(xiaoming_res)
xiaoming_res = chains.invoke({"subject":"英语", "input": "你能重复下我上次提的问题吗?"}, config={'configurable': {'user_id': 'xiaoming', 'session_id':'english'}})
print(xiaoming_res)
Runnable-可运行对象
在前面的学习中,我们曾经学习过LangChain的核心是Chains(链),即使用声明式方法|将多个操作链接在一起进行调用。之前所说的操作实际上就是Runnable对象包含的操作。
Runnable,表示可运行对象,可以理解为“链式可运行对象”或“链对象”,也就是langchain中所谓的“Chain”。
多个Chain(链)使用|组合操作,就是一个chains链条。
LangChain为了让其内部提供的所有组件类都能以LCEL的方式快速简洁的调用,计划将所有组件类都实现Runnable接口。比如我们常用的ChatPromptTemplate 、LLMChain 、StrOutputParser 等。
官方文档:https://python.langchain.com/docs/concepts/lcel/
LCEL语法中竖杠写法的简单实现原理,代码:
注意:
这里模拟的仅仅是LCEL语法中使用竖杠的伪代码,实际核心代码中Runnable是一个抽象接口类,在实际的LCEL语法使用中,我们使用的都是Runnable的子类,例如:RunnableSequence(可运行序列容器链)和RunnableParallel(可运行的并行容器链)才是最常被调用的链对象。
from abc import ABC,abstractmethod
from langchain_core.runnables import RunnableSequence, Runnable
class CustomRunnable(ABC):
def __or__(self, other):
return CustomRunnableSequence(self, other)
@abstractmethod
def invoke(self, input):
pass
class CustomRunnableLabda(CustomRunnable):
def __init__(self, input):
self.input = input
def invoke(self, input):
if type(input) is dict:
return f"{self.input}".format(**input)
else:
return f"{self.input}\n{input}"
class CustomRunnableSequence(CustomRunnable):
def __init__(self, input, *steps):
self.input = input
if not isinstance(self.input, CustomRunnable):
self.input = CustomRunnableLabda(self.input)
self.steps = [self.input, *steps]
def invoke(self, input):
for step in self.steps:
input = step.invoke(input)
return input
t = CustomRunnableSequence('大模型') | CustomRunnableSequence("提示词")
res = t.invoke({'input': ''})
print(res)
class CustomChatPromptTemplate(CustomRunnableSequence):
pass
prompt = CustomChatPromptTemplate([
("system", "你是一个专业的{subject}专家,会非常详细的回答这方面的问题并详尽列出解决问题的步骤。"),
("humen", "3+1=?"),
])
class CustomLLamaLLM(CustomRunnableSequence):
pass
llm = CustomLLamaLLM("qwen2.5:7b")
chain = prompt | llm
res = chain.invoke({'input': '1+3=?', 'subject': '数学'})
print(res)
在 langchain 中,Runnable 接口的实现可以用于多种业务场景,包括但不限于:
- 文本预处理:如去除停用词、文本规范化等。
- 模型推理:调用预训练的语言模型进行推理。
- 结果后处理:对模型的输出结果进行进一步处理,如抽取信息或格式转换。
- 管道集成:将多个 Runnable 组件(例如:prompt、llm、StrOutPuter等等)串联成一个处理管道,实现复杂的处理逻辑。
常用的Runnable接口实现对象的定义和应用场景
RunnableLambda
RunnableLambda可以将Python 可调用对象(例如:回调函数)转换为 Runnable对象,这种转换使得任何函数都可以被看作 LCEL 链的一部分,有了它,我们就可以把自己需要的功能通过自定义函数 + RunnableLambda的方式包装一下成 一个Runnable对象集成到 LCEL 链中,完成一些额外的业务操作流程,但是注意这种类型的Runnable无法处理流式数据。代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# from langchain_openai import ChatOpenAI
# llm = ChatOpenAI(model="gpt-4")
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import CommaSeparatedListOutputParser
prompt = ChatPromptTemplate.from_messages(
[
("system", "{get_format_instructions}"),
("human", "列出{city}的{num}个著名景点。"),
]
)
def print_info(input):
print(f"结果1:{input}", type(input))
return input
def print_info2(input):
print(f"结果2:{input}")
return input
output_parser = CommaSeparatedListOutputParser()
# from langchain_core.runnables import RunnableLambda
# chains = prompt | RunnableLambda(print_info) | llm | RunnableLambda(print_info) | output_parser
# 因为Runnable内部初始化时会进行自动判断,所以不写Runnaable也默认完成了格式转换
chains = prompt | llm | print_info | llm | print_info2 | output_parser
response = chains.invoke({"city": "中国", "num": 10, "get_format_instructions": output_parser.get_format_instructions()})
print("最终结果:", response)
RunnableGenerator[了解]
RunnableGenerator的作用与上面的RunnableLambda类似,RunnableGenerator将Python中的生成器格式转换成Runnable可运行对象,这种方式转换得到的Runnable对象可以支持处理流式数据。代码:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', model_kwargs={"stream": True})
from langchain_core.prompts import PromptTemplate
prompt=PromptTemplate.from_template("输出《{book}》中{num}个角色名字以及这些角色的背景故事。")
from langchain_core.runnables import RunnableGenerator
def stream_add(x):
yield f"分别有以下结果:\n"
for i in x:
yield i.content
stream_chain = prompt | llm | RunnableGenerator(stream_add)
for chunk in stream_chain.stream({"book": "西游记", "num": 5}):
print(chunk, end='')
RunnableParallel
RunnableParallel用于并行执行多个Runnable,使用RunnableParallel可以实现部分Runnable或所有Runnable并发执行的业务流程,提高执行效率,也会额外消耗系统性能。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
from langchain_core.prompts import ChatPromptTemplate
prompt_1 = ChatPromptTemplate.from_messages(
[
("system", "{get_format_instructions}"),
("human", "列出{city}的{num}个著名景点。"),
]
)
prompt_2 = ChatPromptTemplate.from_messages(
[
("system", "{get_format_instructions}"),
("human", "列出关于{city}的{num}个电影。"),
]
)
from langchain_core.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
chain_1 = prompt_1 | llm | output_parser
chain_2 = prompt_2 | llm | output_parser
# 并行链
from langchain_core.runnables import RunnableParallel
chain_parallel = RunnableParallel(view_spots=chain_1, related_video=chain_2)
response = chain_parallel.invoke(
{"city": "北京", "num": 3, "get_format_instructions": output_parser.get_format_instructions()}
)
print(response)
RunnablePassthrough
RunnablePassthrough 主要用在链条中传递数据,可用于格式化上一个子链的输出结果,从而匹配下一个输入子链的需要的格式,一般写用在链的第一个位置,用于接收用户的输入。如果处在中间位置,则用于接收上一步子链的输出,通常与RunnableParallel配合使用。代码:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
output_parser = CommaSeparatedListOutputParser()
prompt_1 = ChatPromptTemplate.from_messages(
[
("system", "{get_format_instructions}"),
("human", "列出{city}的{num}个著名景点。"),
]
)
prompt_2 = ChatPromptTemplate.from_messages(
[
("system", "{get_format_instructions}"),
("human", "列出{city}的{num}个相关电影。"),
]
)
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
# 写在开头
runnable = RunnablePassthrough.assign(num=lambda inputs: inputs['num'] + 1) | RunnableParallel(**{
'llm1': prompt_1 | llm | output_parser,
'llm2': prompt_2 | llm | output_parser,
})
# 上面的RunnableParallel的调用方法可以简化成dict字典格式,在langchain内部会自动切换花括号为RunnableParallel对象,所以下面的简写方式:
# runnable = RunnablePassthrough.assign(num=lambda inputs: inputs['num'] + 1) | {
# 'llm1': prompt_1 | llm | output_parser,
# 'llm2': prompt_2 | llm | output_parser,
# }
# # 写在结尾
# runnable = RunnableParallel(**{
# 'llm1': prompt_1 | llm | output_parser,
# 'llm2': prompt_2 | llm | output_parser,
# }) | RunnablePassthrough.assign(results=lambda inputs: inputs['llm1'] + inputs['llm2']
# )
# # 简写如下:
# runnable = {
# 'llm1': prompt_1 | llm | output_parser,
# 'llm2': prompt_2 | llm | output_parser,
# } | RunnablePassthrough.assign(results=lambda inputs: inputs['llm1'] + inputs['llm2']
# )
response = runnable.invoke(
{"city": "北京", "num": 3, "get_format_instructions": output_parser.get_format_instructions()}
)
print(response)
RunnableBranch
RunnableBranch主要用于多分支子链的场景,为链的调用提供了路由功能,有点类似于之前的LLMRouteChain(路由链)。使用RunnableBranch可以创建多个子链,然后根据条件判断选择执行某一个子链。代码:
from operator import itemgetter
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
# 准备2条目的链:一条物理链,一条数学链
# 1. 物理学家
physics_template = """
你是一位物理学家,擅长回答物理相关的问题,当你不知道问题的答案时,你就回答不知道。
具体问题如下:
{input}
"""
physics_chain = PromptTemplate.from_template(physics_template) | llm | output_parser
# 2. 数学家链
math_template = """
你是一个数学家,擅长回答数学相关的问题,当你不知道问题的答案时,你就回答不知道。
具体问题如下:
{input}
"""
math_chain = PromptTemplate.from_template(math_template) | llm | output_parser
# 3. 语文专家链
other_template = """
你是一个故事专家,你会根据用户提出的问题联想成一个童话故事,并通过故事解答问题。
具体问题如下:
{input}
"""
other_chain = PromptTemplate.from_template(other_template) | llm | output_parser
classify_prompt_template = """
请你对以下问题进行分类,将问题分类为"数学"、"物理"、"语文",不需要返回多个分类,返回一个分类即可。
具体问题如下:
{input}
分类结果:
"""
classify_chain = PromptTemplate.from_template(classify_prompt_template) | llm | output_parser
from langchain_core.runnables import RunnableBranch, RunnableLambda
answer_chain = RunnableBranch(
(lambda x: "数学" in x["course"], math_chain),
(lambda x: "物理" in x["course"], physics_chain),
other_chain
)
def print_info(input):
print(f">>> {input}")
return input
final_chain = {"course": classify_chain, "input": itemgetter("input")} | RunnableLambda(print_info) | answer_chain
res = final_chain.invoke({"input": "地球的半径是多少?"})
print(res)
res = final_chain.invoke({"input": "对y=2x求导的结果是多少?"})
print(res)
res = final_chain.invoke({"input":"小红帽的故事?"})
print(res)
旧版本Momery工具类[了解]
以下内容已经在langchain0.2版本以后声明废弃了,但是市场上任然有基于langchain0.1版本开发的项目,所以大家可以了解即可。
langchain提供的Memory组件本质上就是将对话历史存到内存或第三方设备中,然后每次向LLM提问前先在提示词中带上了所有的上下文对话,从而让 LLM 调用的时候可以得知上下文信息,从而回答新的问题。但这种方法会随着你的对话次数增加,导致历史对话信息占据提示词的内容长度越来越长,模型预测的时间越来越慢,如果是使用了线上LLM大模型,Token会不断增加,价格自然越来越贵,最终超出Token 限制。而 LangChain 在这方面提供了几种不同的 Memory 组件类来以不同方式存储历史内容,这些类本质上都是对ChatMessageHistory的高度封装。
| 组件类 | 特点 | 适用场景 |
|---|---|---|
| ConversationBufferMemory | 无限制 | 保存全部的上下文历史对话信息 |
| ConversationBufferWindowMemory | 频率高,句式短小,明确次数 | 能确定对话的轮次 |
| ConversationTokenBufferMemory | 限制Token的消费 | 限制Token的消费 |
| ConversationSummaryBufferMemory | 摘要 | 节省token的同时,尽量实现需求 |
ConversationBufferMemory-简单实现对话
ConversationBufferMemory 用于实现基本的对话功能,没有什么使用上的限制,而且可以轻松获取到历史对话的上下文。通过ConversationBufferMemory ,直接将存储的所有内容给LLM,因此LLM能够理解之前的对话内容,但是也因为大量信息意味着新输入提示词中包含更多的Token,导致响应时间变慢和成本增加。此外,当达到LLM的Token上限时,太长的对话无法被记住。代码:
# 初始化大模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 添加聊天对话记忆
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key='history') # memory_key的默认值就是history
memory.chat_memory.add_user_message("我们现在在玩一个数学游戏,这个游戏的规则就是表达式的计算结果必须在原来基础上加1才能赢,例如:表达式是1+2,那么游戏的正确结果是4,而2+4的游戏正确结果是7")
print(memory.load_memory_variables({}))
"""
{'history': 'Human: 我叫江小白,你是谁?\nAI: 你好,我是游戏专家王小明。\nHuman: 我们现在在玩一个数学游戏,这个游戏的规则就是表达式的计算结果必须在原来基础上加1才能赢,例如:表达式是1+2,那么游戏的正确结果是4,而2+4的游戏正确结果是7'}
"""
# 聊天模型提示词
from langchain.prompts import ChatPromptTemplate
template = """
你是一个会话机器人,能够记住并结合过往历史会话内容来帮助并解决本次对话内容所涉及的问题,你会精简而快速的给出答案,不会说多余的分析内容,并帮助用户赢得游戏胜利。
过往历史会话内容:{history}
本次对话内容:{input}
你的回复:
"""
prompt = ChatPromptTemplate.from_template(template)
# 初始化对话链
from langchain.chains.conversation.base import ConversationChain
conversation = ConversationChain(llm=llm, memory=memory, prompt=prompt)
# 提问
res = conversation.invoke({"input": "我叫什么名字,你是谁?"})
print(res)
"""
{'input': '我叫什么名字,你是谁?', 'history': 'Human: 我叫江小白,你是谁?\nAI: 你好,我是游戏专家王小明。\nHuman: 我们现在在玩一个数学游戏,这个游戏的规则就是表达式的计算结果必须在原来基础上加1才能赢,例如:表达式是1+2,那么游戏的正确结果是4,而2+4的游戏正确结果是7', 'response': '你好!你叫江小白,我是游戏专家王小明。有什么数学问题我可以帮你解决吗?'}
"""
res = conversation.invoke({"input": "数学游戏问题:5+7=?"})
print(res)
"""
{'input': '数学游戏问题:5+7=?', 'history': 'Human: 我叫江小白,你是谁?\nAI: 你好,我是游戏专家王小明。\nHuman: 我们现在在玩一个数学游戏,这个游戏的规则就是表达式的计算结果必须在原来基础上加1才能赢,例如:表达式是1+2,那么游戏的正确结果是4,而2+4的游戏正确结果是7\nHuman: 我叫什么名字,你是谁?\nAI: 你好!你叫江小白,我是游戏专家王小明。有什么数学问题我可以帮你解决吗?', 'response': '按照游戏规则,表达式5+7的计算结果是12,所以你需要报出的答案是13。祝你胜利!'}
"""
ConversationEntityMemory-实体记忆
ConversationEntityMemory是实体记忆,它可以跟踪对话中提到的实体,在对话中记住关于特定实体的给定事实。它提取关于实体的信息(使用LLM),并随着时间的推移建立对该实体的知识(使用LLM)。使用它来存储和查询对话中引用的各种信息,比如人物、地点、事件等,代码:
# 初始化大语言模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 初始化对话链
from langchain.chains.conversation.base import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
conversation = ConversationChain(
llm=llm,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=ConversationEntityMemory(llm=llm)
)
# 开始对话
conversation.predict(input="你好,我是王小明。我最近在学习 LangChain。")
conversation.predict(input="我最喜欢的编程语言是 Python。")
conversation.predict(input="我住在北京,喜欢听中国古风类型的音乐。")
# 查询对话中提到的实体
res = conversation.memory.entity_store.store
print(res)
res = conversation.invoke({'input': '推荐一些好听的音乐给我?'})
print(res)
ConversationKGMemory-知识图谱记忆
ConversationKGMemory是知识图谱对话记忆,用于在对话过程中存储和检索知识图谱(Knowledge Graph)数据。这种记忆类型使用知识图谱来重现记忆。
pip install networkx
在历史对话中设置出现某些信息,然后使用知识图谱记忆构建这些信息成一个完整全面的知识图谱,代码:
# 初始化大语言模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
from langchain.chains.conversation.base import ConversationChain
from langchain_community.memory.kg import ConversationKGMemory
# 创建 ConversationKGMemory
kg_memory = ConversationKGMemory(
llm=llm,
verbose=True,
)
kg_memory.save_context({"input": "你好,小明是一名web前端开发工程师。"},{"output":"工程师好厉害。"})
kg_memory.save_context({"input": "小明最喜欢的音乐是古风风格音乐,例如:周杰伦的《红尘客栈》。"},{"output":"哇,好有品味!"})
kg_memory.save_context({"input": "小明住在北京,那里遍布历史沉淀的名胜古迹,就是节假日人太多了。"},{"output":"确实是的,长城很伟大!"})
print(kg_memory.load_memory_variables({"input":"请告诉我小明的信息"}))
# 创建 ConversationChain,并将 kg_memory 作为参数传入
conversation = ConversationChain(
llm=llm,
memory=kg_memory,
verbose=True,
)
# 开始对话
print(conversation.predict(input="你好,小明是一名web前端开发工程师。"))
print(conversation.predict(input="小明最喜欢听周杰伦的《红尘客栈》。"))
print(conversation.predict(input="小明住在北京,那里遍布历史沉淀的名胜古迹,就是节假日人太多了。"))
ConversationBufferWindowMemory-缓冲窗口记忆
ConversationBufferWindowMemory是一种缓冲窗口记忆,它只保存最新最近的几次人类和AI的互动。它基于之前的缓冲记忆思想,增加了一个窗口值k。这意味着只保留一定数量的过去互动,然后“忘记”之前的互动。缓冲窗口记忆不适合记住遥远的互动,但它在限制使用的Token数量方面表现优异。如果只需记住最近的互动,缓冲窗口记忆是一个不错的选择。代码:
# 初始化大语言模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 初始化对话链
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
conversation = ConversationChain(
llm=llm,
# k=1,表示window窗口只会记住与AI之间的最新互动,即保留上一次的人类和AI的回应
memory=ConversationBufferWindowMemory(k=1)
)
conversation.invoke({'input': "今天早上猪八戒吃了1个人参果。"})
print("记忆1: ", conversation.memory.buffer)
print()
conversation.invoke({'input': "下午猪八戒吃了3个人参果。"})
print("记忆2: ", conversation.memory.buffer)
print()
result = conversation.invoke({'input': "晚上猪八戒吃了4个人参果。"})
print("记忆3: ", result)
print()
result = conversation.invoke({'input': "今天猪八戒一共吃了几个人参果?"})
print("记忆4提示: ", conversation.prompt.template)
print("记忆4: ", result)
ConversationSummaryMemory-摘要总结记忆
ConversationSummaryMemory这种类型的记忆随着时间的推移创建对话的摘要。对话摘要记忆随着对话的发生而总结对话,并在记忆中存储当前的摘要。
ConversationSummaryMemory这种记忆对于较长的对话最有用,可以避免过度使用Token,因为将过去的信息历史以原文形式保留在提示中会占用太多的Token。ConversationSummaryMemory可以减少长对话中使用的Token数量,记录更多轮的对话信息,易于理解。 对于较短的对话可能会增加Token使用量。同时,对话历史的记忆完全依赖于中间摘要LLM的能力,需要为摘要LLM分配Token,增加成本且未限制对话长度。
代码:
# 初始化大语言模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 使用ChatMessageHistory初始化历史记忆,在加载过程中计算摘要
from langchain.memory import ConversationSummaryMemory
from langchain_community.chat_message_histories import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("你好,你能帮助我解决问题吗?")
history.add_ai_message("好啊,没问题,请告诉我你的问题")
# 创建摘要Memory
memory = ConversationSummaryMemory(
llm=llm,
buffer="人类用中文问候人工智能。人工智能以友好的中文问候回应",
chat_memory=history,
return_messages=True
)
# 初始化对话链
from langchain.chains.conversation.base import ConversationChain
conversation_with_summary = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 对话
res = conversation_with_summary.predict(input="嗨,什么情况?")
print(res)
ConversationSummaryBufferMemory-摘要缓冲混合记忆
ConversationSummaryBufferMemory对话摘要缓冲记忆是一种混合记忆模型,结合了ConversationSummaryMemory和ConversationBufferWindowMemory的特点。它旨在对对话进行摘要总结,同时保留最近互动中的原始内容,但不是简单地清除旧的交互,而是将它们编译成摘要并同时使用。它使用标记长度而不是交互数量来确定何时清除交互。但是ConversationSummaryBufferMemory的Token分词实现依赖于GPT-2模型,所以需要提前安装transformers。使用max_token_limit参数,让它在对话长度在200字内时记忆原始内容,在超出长度时对内容进行总结以节省Token数量。代码:
# 初始化大语言模型
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen2.5:7b")
# 初始化对话链
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryBufferMemory(llm=llm, max_token_limit=200)
)
conversation.invoke({"input": "今天早上猪八戒吃了2个人参果。"})
print("记忆1: ", conversation.memory.buffer)
print()
conversation.invoke({'input': "今天下午猪八戒吃了1个人参果。"})
print("记忆2: ", conversation.memory.buffer)
print()
result = conversation.predict(input="今天晚上猪八戒吃了3个人参果。")
print("记忆3: ", result)
print()
result = conversation.predict(input="猪八戒今天一共吃了几个人参果?")
print("记忆4: ", result)
ConversationTokenBufferMemory-令牌缓冲记忆
ConversationTokenBufferMemory 在内存中保持最近交互的缓冲区,并使用标记长度而不是交互数量来确定何时清除交互。
代码:
# 初始化大语言模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 使用ChatMessageHistory初始化历史记忆
from langchain.memory import ConversationTokenBufferMemory
from langchain.chains import ConversationChain
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=50)
memory.save_context({"input": "今天早上猪八戒吃了2个人参果"}, {"output": "好的,我知道猪八戒今天吃了2个人参果了。"})
memory.save_context({"input": "今天中午猪八戒又吃了3个人参果"}, {"output": "好的,我知道猪八戒今天吃了5个人参果了。"})
conversation_with_summary = ConversationChain(
llm=llm,
memory=memory,
verbose=True,
)
res = conversation_with_summary.predict(input="刚刚猪八戒又吃了1个人参果,那么今天猪八戒吃了多少个人参果?")
print("记忆: ", res)
VectorStoreRetrieverMemory-向量存储库记忆
VectorStoreRetrieverMemory 将记忆存储在向量存储中,并在每次调用时查询前 K 个最匹配的文档。
代码:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
# 初始化向量存储
embedding_size = 1536 # OpenAIEmbeddings 的维度
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {})
# 向量查找返回语义相关的信息
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
# 相关文档信息放到memory
memory = VectorStoreRetrieverMemory(retriever=retriever)
# 当添加到代理中时,记忆对象可以保存对话中的重要信息或使用的工具
memory.save_context({"Human": "我最喜欢的食物是披萨"}, {"AI": "很高兴知道"})
memory.save_context({"Human": "我喜欢的运动是跑步"}, {"AI": "好的,我知道了"})
memory.save_context({"Human": "我最喜欢的运动是足球"}, {"AI": "好的,我知道了"})
llm = ChatOpenAI(model='gpt-4', temperature=0)
_DEFAULT_TEMPLATE = """
以下是人类和人工智能之间的友好对话。人工智能很健谈,并从其上下文中提供了许多具体细节。如果人工智能不知道问题的答案,它就会如实说它不知道。
之前对话的相关片段: {history}
(如果不相关,则无需使用这些信息)
当前对话:
Human: {input}
AI:
"""
PROMPT = PromptTemplate(input_variables=["history", "input"], template=_DEFAULT_TEMPLATE)
# 创建Chain
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
memory=memory,
verbose=True
)
# 提问
res = conversation_with_summary.invoke({"input": "我最喜欢什么运动"})
print(str(res))
Agent
代理(Agent)是使用LLM作为思考工具,决定当前要做什么。我们会给代理一系列的工具,代理根据我们的输入判断用哪些工具可以完成这个目标,然后不断的运行工具,来完成目标。代理(Agent)可以看做是增强版的Chain,不仅绑定模板、LLM,还可以给代理添加一些外部工具。
代理(Agent)还是构建智能体的基础,它负责根据用户输入和应用场景,在一系列可用工具中选择合适的工具进行操作。Agent可以根据任务的复杂性,采用不同的策略来决定如何执行操作。
langchain中主要提供了有两种类型的Agent:
- 动作代理(Action Agents):这种代理一次执行一个动作,然后根据结果决定下一步的操作。
- 计划-执行代理(Plan-and-Execute Agents):这种代理首先决定一系列要执行的操作,然后根据上面判断的列表逐个执行这些操作。
对于简单的任务,动作代理(Action Agents)更为常见且易于实现。对于更复杂或长期运行的任务,计划-执行代理的初始规划步骤有助于维持长期目标并保持关注。但这会以更多调用和较高延迟为代价。这两种代理并非互斥,可以让动作代理负责执行计划-执行代理的计划。
LangChain 中内置了一系列常用的 Agent工具,这些工具提供的Agent都属于Action Agent。
Agent内部涉及的核心概念如下:
- 代理(Agent):这是应用程序主要逻辑。代理暴露一个接口,接受用户输入和代理已执行的操作列表,并返回AgentAction或AgentFinish。
- 工具(Tools):这是代理可以采取的动作。比如发起HTTP请求,发邮件,执行命令。
- 工具包(Toolkits):这些是为特定用例设计的一组工具。例如,为了让代理以最佳方式与SQL数据库交互,它可能需要一个执行查询的工具和另一个查看表格的工具。可以看做是工具的集合。
- 代理执行器(Agent Executor):将代理与一系列工具包装在一起。它负责迭代运行代理,直到满足停止条件。
在LangChain框架中,智能代理(Agent)通常按照观察(Observation)- 思考(Thought)- 行动(Action)的模式来处理任务,这个模式叫ReAct思考框架。Agent的执行流程:
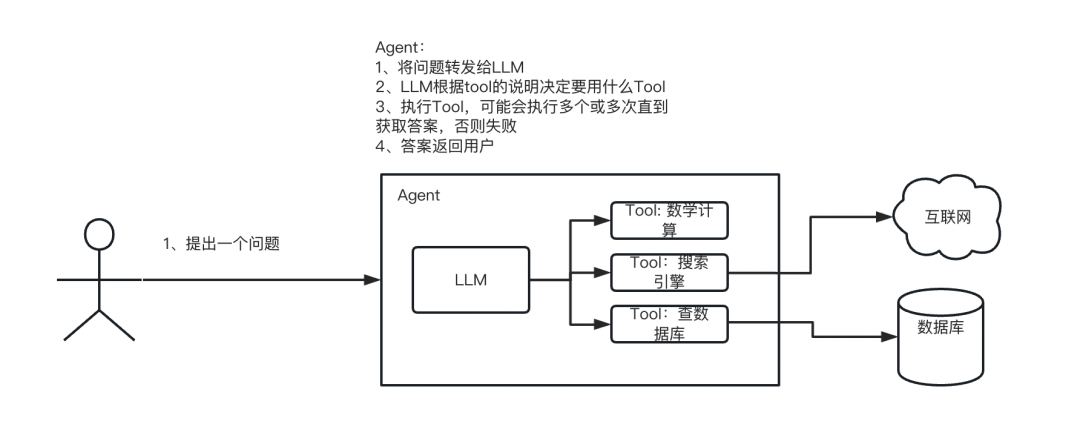
在LangChain中,ReAct框架的实现流程如下:
- 任务:Agent的起点是一个任务,如一个用户查询、一个目标或一个需要解决的特定问题。
- 大模型:任务被输入大模型中。大模型使用训练好的模型进行推理。
- 工具:大模型可能会决定使用一系列的工具来辅助完成任务。
- 行动:Agent根据大模型的推理结果采取行动。
- 环境:行动会影响环境,而环境将以某种形式响应这些行动。
- 结果:将行动导致的结果反馈给Agent。
快速使用langchain提供的维基百科工具实现Agent智能体,代码:
# 实例化大模型
# cursor编辑器
# # 获取当前langchian中内置提供的所有Agent工具函数
# from langchain_community.agent_toolkits.load_tools import get_all_tool_names
# print(get_all_tool_names())
# 实例化大模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
# # 原生调用tools工具
# from langchain_community.tools import WikipediaQueryRun
# from langchain_community.utilities import WikipediaAPIWrapper
# tools = [WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())]
# 通过load_tools工具函数加载wikipedia代理工具
from langchain_community.agent_toolkits.load_tools import load_tools
tools = load_tools(['wikipedia'])
# 提示词
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}""")
# 实例化ReAct智能体
# create_react_agent 创建一个ReAct风格智能体
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
# 基于create_react_agent提供的Agent创建代理执行器,只支持使用一个参数
# verbose=True列出大模型执行过程的执行细节
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
response = agent_executor.invoke({"input": "2024年北京大学的招生人数?"})
print(response)
内置Agent工具
常用Agent内置工具包:
https://python.langchain.com/docs/how_to/#tools
https://python.langchain.com/docs/integrations/tools/
获取目前langchain内置的所有agent工具包,代码:
from langchain_community.agent_toolkits.load_tools import get_all_tool_names
print(get_all_tool_names())
"""
['sleep', 'wolfram-alpha', 'google-search', 'google-search-results-json', 'searx-search-results-json', 'bing-search', 'metaphor-search', 'ddg-search', 'google-lens', 'google-serper', 'google-scholar', 'google-finance', 'google-trends', 'google-jobs', 'google-serper-results-json', 'searchapi', 'searchapi-results-json', 'serpapi', 'dalle-image-generator', 'twilio', 'searx-search', 'merriam-webster', 'wikipedia', 'arxiv', 'golden-query', 'pubmed', 'human', 'awslambda', 'stackexchange', 'sceneXplain', 'graphql', 'openweathermap-api', 'dataforseo-api-search', 'dataforseo-api-search-json', 'eleven_labs_text2speech', 'google_cloud_texttospeech', 'read_file', 'reddit_search', 'news-api', 'tmdb-api', 'podcast-api', 'memorize', 'llm-math', 'open-meteo-api', 'requests', 'requests_get', 'requests_post', 'requests_patch', 'requests_put', 'requests_delete', 'terminal']
"""
搜索工具的基本使用,代码:
import os # 引入os模块
os.environ['SERPAPI_API_KEY'] = 'e14b42e676f3e2d06a9403d943f8bed11e4f45a05ad49c0ff11a03289629e7b1'
# 创建OpenAI语言模型对象,设定temperature为0,即关闭随机性
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
# 加载所需工具,包括serpapi和llm-math
from langchain_community.agent_toolkits.load_tools import load_tools
tools = load_tools(["llm-math", "serpapi"], llm=llm)
# 初始化代理对象,设定代理类型为ZERO_SHOT_REACT_DESCRIPTION,输出详细信息
from langchain.agents import initialize_agent, AgentType
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True
)
# 运行代理对象,向其提问特朗普的年龄和年龄除以2的结果
response = agent.invoke({"input": "特朗普今年几岁了? 他的年龄除以2是多少?"})
print(response)
搜索工具的账号注册:https://serpapi.com/search-api
谷歌搜索的站好注册:https://serper.dev/
案例,python解释器,安装基本模块:
pip install langchain_experimental
python编辑器的基本使用,代码:
from langchain.agents import Tool
from langchain_experimental.tools.python.tool import PythonAstREPLTool
# 创建Python解释器
python_repl_tool = PythonAstREPLTool()
# python代码
query_value = """
def add(a,b):
return a+b
print(add(10,20))
"""
# 基本使用
repl_tool = Tool(
name="python_repl",
description="一个Python shell。使用它来执行python命令。输入应该是一个有效的python命令。如果你想看到一个值的输出,你应该用`print(...)`打印出来。",
func=python_repl_tool.run,
)
response = repl_tool.invoke(query_value)
print(response)
结合前面的搜索工具,实现一个代码AI助手的Agent,代码:
import os # 引入os模块
os.environ['SERPAPI_API_KEY'] = 'e14b42e676f3e2d06a9403d943f8bed11e4f45a05ad49c0ff11a03289629e7b1'
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
# 加载所需工具
from langchain_community.agent_toolkits.load_tools import load_tools
# python
from langchain.agents import Tool
from langchain_experimental.tools.python.tool import PythonAstREPLTool
python_repl_ast = Tool(
name="python_repl_ast",
description="一个Python shell。使用它来执行python命令。输入应该是一个有效的python命令。如果你想看到一个值的输出,你应该用`print(...)`打印出来。",
func= ,
)
tools = load_tools(["serpapi"], allow_dangerous_tools=True)
tools += [python_repl_ast]
# 提示词
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}""")
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
response = agent_executor.invoke({"input": "获取当前你文件的路径,并基于python代码,复制data.txt的内容到data2.txt,并基于python解释器来执行代码?"})
print(response)
| 创建Agent的工具函数 | |
|---|---|
| create_react_agent | 构建一个基于ReAct思考框架的智能体,只允许有1个参数 |
| create_structured_chat_agent | 构建一个支持多个任务对话处理的智能体,允许有多个参数 |
| create_json_agent | 构建一个支持返回json数据结构的智能体,不管返回得到内容或者接受的参数都支持json结构 |
| create_sql_agent | 构建一个能与SQL数据库交互的智能体,可用于创建一个能够处理SQL任务、自动化数据库操作或提供数据库连接管理的服务或组件 |
| create_openai_functions_agent | 构建一个基于OpenAI functions风格的智能体,能够与OpenAI提供的API函数进行交互 |
| create_tool_calling_agent | 构建一个基于大模型API接口的智能体,能够与OpenAI以外的其他本地或在线大模型的API进行交互【部分本地大模型无法兼容】 |
上面搜索工具的案例代码改成基于create_react_agent框架,代码:
import os # 引入os模块
os.environ['SERPAPI_API_KEY'] = 'e14b42e676f3e2d06a9403d943f8bed11e4f45a05ad49c0ff11a03289629e7b1'
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
# 加载Tool工具
from langchain_community.agent_toolkits.load_tools import load_tools
tools = load_tools(['llm-math', 'serpapi'], llm=llm)
from langchain import hub
# 直接拉取langchain hub上别人写好的开源提示词
# 地址:https://smith.langchain.com/hub
prompt = hub.pull("hwchase17/react")
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
response = agent_executor.invoke({"input": "特朗普今年几岁了? 他的年龄除以2是多少?"})
print(response)
案例2,基于对话提示词来完成AI问答,代码:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
from langchain_community.agent_toolkits.load_tools import load_tools
# wikipedia
tools = load_tools(['wikipedia'])
from langchain import hub
# 直接拉取别人写好的提示词
# prompt = hub.pull("hwchase17/react")
prompt = hub.pull("hwchase17/react-chat")
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "美国现任总统是谁?", "chat_history":[]})
案例3,结合ChatMessageHistory对话历史管理使用Agent,代码:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
from langchain_community.agent_toolkits.load_tools import load_tools
tools = load_tools(['wikipedia'])
# 从 LangChain Hub 中拉取预训练的 ReAct 提示词模板:https://smith.langchain.com/hub
from langchain import hub
prompt = hub.pull("hwchase17/react-chat")
# 实例化Agent
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
# 创建Agent执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 创建对话历史管理对象
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
message_history = ChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key="input",
history_messages_key="chat_history",
)
while True:
user = input("用户名:")
if user == "exit": break
while True:
query = input("问题:")
if query == "exit": break
response = agent_with_chat_history.invoke(
{"input": query},
config={"configurable": {"session_id": user}},
)
print(response)
案例4,基于Tavily实现一个在线搜索Agent,代码:
import os
os.environ["TAVILY_API_KEY"] = "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"
os.environ['LANGCHAIN_TRACING_V2'] = 'true' # 固定为'true'
os.environ['LANGCHAIN_API_KEY'] = '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'
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
from langchain_community.tools.tavily_search import TavilySearchResults
tools = [TavilySearchResults(max_results=1)]
from langchain import hub
prompt = hub.pull("hwchase17/react-chat")
# 实例化Agent
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
# 创建Agent执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 创建对话历史管理对象
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
message_history = ChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key="input",
history_messages_key="chat_history",
)
while True:
query = input("问题:")
if query == "exit": break
response = agent_with_chat_history.invoke(
{"input": query},
config={"configurable": {"session_id": 'session-10086'}},
)
print(response)
案例5,基于create_structured_chat_agent构建多任务智能体,代码:
import os
os.environ["TAVILY_API_KEY"] = "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"
# 实例化大模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
# 加载Agent工具
from langchain_community.tools.tavily_search import TavilySearchResults
tools = [TavilySearchResults(max_results=1)]
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.agents import create_structured_chat_agent, AgentExecutor
def structured_chat(input):
## 提示词
system = '''你需要尽可能地帮助和准确地回答人类的问题。你可以使用以下工具:
{tools}
使用json blob通过提供action key(工具名称)和action_input key(工具输入)来指定工具。
"action"的有效取值为: "Final Answer" or {tool_names}
每个$JSON_BLOB只提供一个action,如下所示:
{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}
遵循此格式:
Question: 用户输入的问题
Thought: 回答这个问题我需要做些什么,尽可能考虑前面和后面的步骤
Action: 回答问题所选取的工具
$JSON_BLOB
Observation: 工具返回的结果
... (这个思考/行动/行动输入/观察可以重复N次)
Thought: 我现在知道最终答案
Action: 工具返回的结果信息
{{
"action": "Final Answer",
"action_input": "原始输入问题的最终答案"
}}
开始!提醒始终使用单个操作的有效json blob进行响应。必要时使用工具. 如果合适,直接回应。格式是Action:“$JSON_BLOB”然后是Observation'''
human = '''{input}
{agent_scratchpad}
(提醒:无论如何都要在JSON blob中响应!)'''
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
MessagesPlaceholder("chat_history", optional=True),
("human", human),
]
)
agent = create_structured_chat_agent(llm=llm, tools=tools, prompt=prompt)
print(agent)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
inputs = {"input": input}
response = agent_executor.invoke(inputs)
return response.get("output")
response = structured_chat("2024年中国最流行的电影?")
print(response)
自定义Agent工具
基于函数自定义Agent工具
代码:
import requests, json
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
from langchain_core.tools import tool
from tavily import TavilyClient
# 自定义tool
@tool("tavily")
def tavily_search(query: str) -> dict:
"""tavily search."""
client = TavilyClient(api_key="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")
return client.search(query, max_results=2)
@tool("mairui")
def mairui_api(dm: str) -> dict:
"""mairui api.
dm: 股票代码(如000001)
字段名称 数据类型 字段说明
fm number 五分钟涨跌幅(%)
h number 最高价(元)
hs number 换手(%)
lb number 量比(%)
l number 最低价(元)
lt number 流通市值(元)
o number 开盘价(元)
pe number 市盈率(动态,总市值除以预估全年净利润,例如当前公布一季度净利润1000万,则预估全年净利润4000万)
pc number 涨跌幅(%)
p number 当前价格(元)
sz number 总市值(元)
cje number 成交额(元)
ud number 涨跌额(元)
v number 成交量(手)
yc number 昨日收盘价(元)
zf number 振幅(%)
zs number 涨速(%)
sjl number 市净率
zdf60 number 60日涨跌幅(%)
zdfnc number 年初至今涨跌幅(%)
t string 更新时间YYYY-MM-DD HH:MM
"""
api_key = "3F380102-3DFE-4F89-A749-6E000A02A2EA"
url = f"http://api.mairui.club/hsrl/ssjy/{dm}/{api_key}"
result = requests.get(url).json()
return result
tools = [mairui_api, tavily_search]
# 提示词
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""尽可能简约和准确地使用中文回应如下问题。您可以使用以下工具:
{tools}
使用以下格式:
Question:您必须回答的输入问题
Thought:你应该始终思考该做什么
Action:要采取的操作,应该是〔{tool_names}〕之一
Action Input:动作的输入
Observation:行动的结果
…(这个 Thought/Action/Action Input/Observation 可以重复N次)
Thought:我现在知道最终答案了
Final Answer:原始输入问题的最终答案
开始!
Question: {input}
Thought:{agent_scratchpad}
提醒!务必使用中文回答。
""")
# 自定义tool工具必须使用initialize_agent来创建智能体,不能使用新版本create_xxx_agent,会报错
from langchain.agents import initialize_agent, AgentType
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, agent_kwargs={"prompt": prompt})
response = agent.invoke({"input": "工商银行的股票行情?"})
print(response)
基于BaseTool基础类创建Agent工具
代码:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model='gpt-4', temperature=0)
from tavily import TavilyClient
client = TavilyClient(api_key="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")
from pydantic import BaseModel, Field
from typing import Type
class SearchQuery(BaseModel):
query: str = Field(description="要查询的query")
# 自定义Agent工具
from langchain_core.tools import BaseTool
class TavilySearchTool(BaseTool):
name: str = "tavily_search"
description: str = """通过搜索引擎来查询信息"""
args_schema: Type[BaseModel] = SearchQuery
def _run(self, query: str) -> dict:
"""调用工具"""
return client.search(query, max_results=2)
tools = [TavilySearchTool()]
# 提示词
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""尽可能简约和准确地使用中文回应如下问题。您可以使用以下工具:
{tools}
使用以下格式:
Question:您必须回答的输入问题
Thought:你应该始终思考该做什么
Action:要采取的操作,应该是〔{tool_names}〕之一
Action Input:动作的输入
Observation:行动的结果
…(这个 Thought/Action/Action Input/Observation 可以重复N次)
Thought:我现在知道最终答案了
Final Answer:原始输入问题的最终答案
开始!
Question: {input}
Thought:{agent_scratchpad}
提醒!务必使用中文回答。
""")
from langchain.agents import initialize_agent, AgentType
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, agent_kwargs={"prompt": prompt})
response = agent.invoke({"input": "美国现任总统是谁?"})
print(response)
LangGraph
LangGraph 是在 LLM 和 LangChain 的基础之上构建的一个扩展库,可以与 LangChain 现有的链(Chain)等无缝协作,它能够协调多个 Chain、Agent、Tool 等共同协作,实现依赖外部工具、外部数据库且带有反馈的问答任务,目的是为了实现更加强大的RAG程序。
官网:https://www.langchain.com/agents
安装:
pip install -U langgraph
import os
os.environ["TAVILY_API_KEY"] = "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"
from typing import Annotated
from langchain_community.tools import TavilySearchResults
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import ToolNode, tools_condition
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
# 定义工具
tool = TavilySearchResults(max_results=2)
tools = [tool]
# 初始化大模型
llm = ChatOpenAI(model="gpt-4")
llm_with_tools = llm.bind_tools(tools)
class State(TypedDict):
"""
定义一个字典类型 State(继承自 TypeDict)
包含一个键 messages
值是一个 list,并且列表的更新方式由 add_messages 函数定义
add_message 将新消息追加到列表中,而不是覆盖原有列表
"""
messages: Annotated[list, add_messages]
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
def stream_graph_updates(user_input: str):
"""返回大模型输出结果"""
for event in graph.stream({"messages": [("user", user_input)]}): # stream 表示流式输出
for value in event.values():
# 访问最后一个消息的内容,并将其打印出来
print("Assistant:", value["messages"][-1].content)
print("Test:", value)
if __name__ == '__main__':
# 1. 创建一个 StateGraph 对象
graph_builder = StateGraph(State)
# 2. 添加 node
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 2.1 添加条件边
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# 2.2 添加普通边
# tools 节点调用结束,会又回到 chatbot 节点
graph_builder.add_edge("tools", "chatbot")
# 3. 定义 StateGraph 的入口
# graph_builder.add_edge(START, "chatbot")
graph_builder.set_entry_point("chatbot")
# 4. 定义 StateGraph 的出口
# graph_builder.add_edge("chatbot", END)
# graph_builder.set_finish_point("chatbot")
# 5. 创建一个 CompiledGraph,以便后续调用
graph = graph_builder.compile()
# 6. 可视化 graph
try:
# graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
graph.get_graph().draw_mermaid_png(output_file_path="graph_with_tools.png")
except Exception:
# This requires some extra dependencies and is optional
pass
# 7. 运行 graph
# 通过输入"quit", "exit", "q"结束对话
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
# 如果在 try 块中的代码执行时发生任何异常,将执行 except 块中的代码
except:
# 在异常情况下,这行代码将 user_input 变量设置为一个特定的问题
user_input = "error?"
print("User: " + user_input)
stream_graph_updates(user_input)
break
检索增强(RAG)
检索增强生成(Retrieval Augmented Generation,RAG)技术,顾名思义,就是去(本地或线上)知识库检索用户查询相关的各种信息,把检索出来的信息,融合到 prompt(提示词) 中,增强输入信息,最后让大模型生成更符合更准确的回答(用户更希望的答案)。RAG通过整合内部知识库的丰富信息赋能大语言模型(Large Language Model,简称 LLM),为生成式 AI 带来了革命性的改进。在生成答案或内容时,RAG 技术能够参照精确的知识源,为用户提供高度合理和准确的响应。RAG本质上就是一种给大模型外挂知识的手段,可以有效增强大模型推理的能力、准确性,能够更加符合客观事实,同时这种外挂知识的方式在知识库进行增删更新时,用户是没有感知的,比传统SFT微调技术更加节约资源和时间。RAG 技术与 LLM 模型相结合的应用方式,成功弥补了 LLM 模型在处理特定领域请求时存在幻觉、知识泛化、可解释性差等问题。常用的TAG开发框架如下:
| 框架 | 描述 |
|---|---|
| LangChain | 目前比较流行和常用的大模型应用开发框架,内置RAG实现流程,但并没有提供UI界面效果,需要结合Gradio或者FastGPTy或者open-webUI等框架手动实现客户端界面UI。 |
| Langchain-Chatchat | 基于langchain结合国内外大模型开发的一款RAG开发框架,内置了UI界面效果,开源、可离线部署 |
| RAGFlow | 一款基于深度文档理解构建的开源 RAG框架,提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用,开源免费。 |
| FastGPT | FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景! |
| open-webui | 一个可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线运行。它支持各种 LLM 运行器,包括 Ollama 和与 OpenAI 兼容的 API。 |
| QAnything | 网易有道开源的一个本地知识库问答系统,旨在支持广泛的文件格式和数据库,允许离线安装和使用。使用 QAnything 可以简单地丢弃任何格式的本地存储文件,并接收准确、快速和可靠的答案。 |
| MaxKB | 一款基于大语言模型和 RAG 的开源知识库问答系统,广泛应用于智能客服、企业内部知识库、学术研究与教育等场景。 |
使用FastAPI基于langchain实现RAG应用
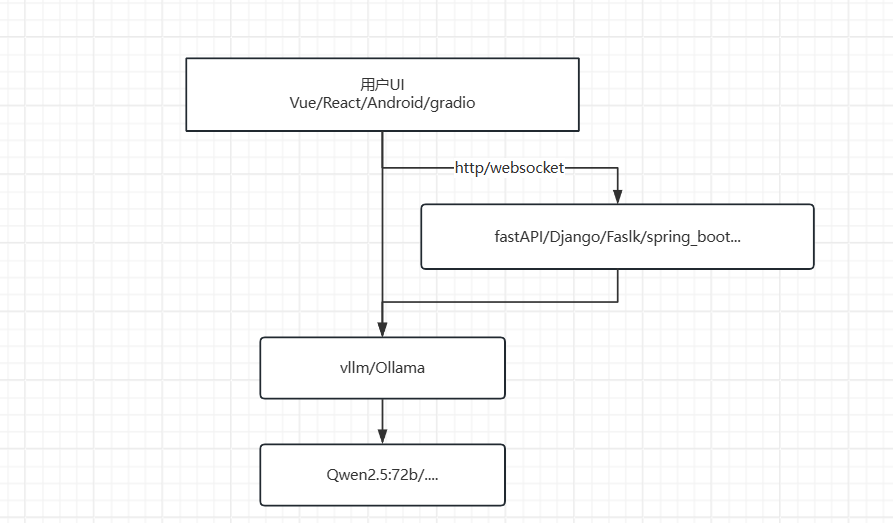
新建 main.py 文件,代码:
import uvicorn
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.prompts import ChatPromptTemplate
from starlette.middleware.cors import CORSMiddleware
# llm
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 加载文档,可换成PDF、txt、doc等其他格式文档
loader = TextLoader('./大模型应用开发与私有化部署.md', encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_language(language="markdown", chunk_size=200, chunk_overlap=0)
texts = text_splitter.create_documents(
[documents[0].page_content]
)
# 选择向量模型,并灌库
db = FAISS.from_documents(texts, OpenAIEmbeddings(model="text-embedding-ada-002"))
# 获取检索器,选择 top-2 相关的检索结果
retriever = db.as_retriever(search_kwargs={"k": 2})
# 创建带有 system 消息的模板
prompt_template = ChatPromptTemplate.from_messages([
("system", """你是一个AI管家。
你的任务是根据下述给定的已知信息回答用户问题。
确保你的回复完全依据下述已知信息。不要编造答案。
请用中文回答用户问题。
已知信息:
{context} """),
("user", "{question}")
])
# 自定义的提示词参数
chain_type_kwargs = { "prompt": prompt_template}
# 定义RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 使用stuff模式将上下文拼接到提示词中
chain_type_kwargs=chain_type_kwargs,
retriever=retriever
)
# 构建 FastAPI 应用,提供服务
app = FastAPI()
# 可选,前端报CORS时
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=['*'],
allow_headers=['*'],
)
# 定义请求模型
class QuestionRequest(BaseModel):
question: str
# 定义响应模型
class AnswerResponse(BaseModel):
answer: str
# 提供查询接口 http://127.0.0.1:8000/ask
@app.post("/ask", response_model=AnswerResponse)
async def ask_question(request: QuestionRequest):
try:
# 获取用户问题
user_question = request.question
print(user_question)
# 通过RAG链生成回答
answer = qa_chain.run(user_question)
# 返回答案
answer = AnswerResponse(answer=answer)
print(answer)
return answer
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
实战:AI管家私有化模型部署
main.py,代码:
import uvicorn
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
import gradio as gr
from langchain_community.chat_models import ChatOllama
from langchain.callbacks.base import BaseCallbackHandler
from langchain.callbacks.manager import CallbackManager
from langchain.agents import create_react_agent, AgentExecutor
from langchain_core.tools import tool
from langchain_core.prompts import PromptTemplate
from typing import Any
import queue
import threading
import requests
from tavily import TavilyClient
from datetime import datetime
import json
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:3000", "http://localhost:8080"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义工具
@tool("tavily_search")
def tavily_search(query: str) -> dict:
"""使用Tavily搜索引擎搜索信息.
query: 搜索查询词
"""
client = TavilyClient(api_key="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")
return client.search(query, max_results=3)
@tool("mairui")
def mairui_api(code: str) -> dict:
"""查询股票实时行情.
code: 股票代码(如000001)
字段说明:
fm: 五分钟涨跌幅(%)
h: 最高价(元)
hs: 换手(%)
lb: 量比(%)
l: 最低价(元)
lt: 流通市值(元)
o: 开盘价(元)
pe: 市盈率
pc: 涨跌幅(%)
p: 当前价格(元)
sz: 总市值(元)
cje: 成交额(元)
ud: 涨跌额(元)
v: 成交量(手)
yc: 昨日收盘价(元)
zf: 振幅(%)
zs: 涨速(%)
"""
api_key = "3F380102-3DFE-4F89-A749-6E000A02A2EA"
url = f"http://api.mairui.club/hsrl/ssjy/{code}/{api_key}"
try:
response = requests.get(url)
result = response.json()
if not isinstance(result, dict):
return {"error": "API返回格式错误"}
if result.get('msg') == 'ok' and result.get('data'):
data = result['data']
return {
"股票名称": data.get('name', '未知'),
"当前价格": f"{data.get('p', 0)}元",
"涨跌幅": f"{data.get('pc', 0)}%",
"涨跌额": f"{data.get('ud', 0)}元",
"成交量": f"{data.get('v', 0)}手",
"成交额": f"{data.get('cje', 0)}元",
"振幅": f"{data.get('zf', 0)}%",
"最高": f"{data.get('h', 0)}元",
"最低": f"{data.get('l', 0)}元",
"今开": f"{data.get('o', 0)}元",
"昨收": f"{data.get('yc', 0)}元",
"量比": f"{data.get('lb', 0)}",
"换手率": f"{data.get('hs', 0)}%",
"市盈率": data.get('pe', 0),
"总市值": f"{data.get('sz', 0)}元",
"流通市值": f"{data.get('lt', 0)}元",
"涨速": f"{data.get('zs', 0)}%",
"60日涨跌幅": f"{data.get('zdf60', 0)}%",
"年初至今涨跌幅": f"{data.get('zdfnc', 0)}%",
"更新时间": data.get('t', datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
}
return {"error": "获取数据失败,API返回错误"}
except requests.RequestException as e:
return {"error": f"网络请求失败: {str(e)}"}
except json.JSONDecodeError as e:
return {"error": f"数据解析失败: {str(e)}"}
except Exception as e:
return {"error": f"未知错误: {str(e)}"}
class QueueCallback(BaseCallbackHandler):
"""自定义回调处理器"""
def __init__(self, q: queue.Queue):
self.q = q
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
self.q.put(token)
def create_agent():
"""创建Agent"""
q = queue.Queue()
callback = QueueCallback(q)
from langchain_community.llms.vllm import VLLM
llm = VLLM(model="qwen2.5:7b", callback_manager=CallbackManager([callback]))
# llm = ChatOllama(
# model="qwen2.5:7b",
# callback_manager=CallbackManager([callback])
# )
tools = [mairui_api, tavily_search]
prompt = PromptTemplate.from_template(
"""尽可能简约和准确地使用中文回应如下问题。您可以使用以下工具:
{tools}
使用以下格式:
Question: 您必须回答的输入问题
Thought: 你应该始终思考该做什么
Action: 要采取的操作名称(可用工具:{tool_names})
Action Input: 要传递给工具的参数
Observation: 工具返回的结果
... (这个思考/行动/观察可以重复多次)
Thought: 我现在知道最终答案了
Final Answer: 原始输入问题的最终答案
对于股票查询,你可以:
1. 使用mairui工具获取股票的实时行情数据
2. 使用tavily_search工具搜索相关新闻和分析
注意事项:
- 股票代码必须是6位数字,不要加任何引号或其他字符
- A股代码:上海主板以6开头,深圳主板以000开头,创业板以300开头,科创板以688开头
- 如果遇到股票名称查询,请先使用tavily_search搜索股票代码
示例格式:
Action: mairui
Action Input: 600519
开始!
Question: {input}
Thought: {agent_scratchpad}
提醒!务必使用中文回答,并对数据进行合理的解读和总结。
""")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True,
max_iterations=3 # 限制最大迭代次数
)
return agent_executor, q
def bot_response(history):
if not history:
return history
last_user_message = history[-1][0]
try:
agent_executor, q = create_agent()
def run_agent():
try:
response = agent_executor.invoke({
"input": last_user_message,
"handle_parsing_errors": True # 添加错误处理
})
if response and "output" in response:
# 处理可能的错误消息
output = response["output"]
if "PARSING_ERROR" in output:
q.put("抱歉,我理解有误。请使用更清晰的方式描述您的问题。")
else:
# 按字符分割输出
for char in output:
q.put(char)
else:
q.put("无法获取有效响应")
except Exception as e:
print(f"Agent error: {e}")
q.put("处理请求时发生错误,请稍后重试。")
finally:
q.put(None) # 结束标记
# 启动代理线程
thread = threading.Thread(target=run_agent)
thread.daemon = True
thread.start()
# 收集响应
response_text = ""
while True:
try:
token = q.get(timeout=30.0)
if token is None:
break
response_text += token
history[-1][1] = response_text
yield history
except queue.Empty:
print("Response timeout")
break
except Exception as e:
print(f"Stream error: {e}")
break
if not response_text:
history[-1][1] = "抱歉,我现在无法回答。请稍后再试。"
yield history
except Exception as e:
print(f"Bot response error: {e}")
history[-1][1] = "处理消息时发生错误,请稍后重试。"
yield history
# 自定义CSS样式
custom_css = """
.contain {
display: flex;
flex-direction: column;
height: 90vh;
min-height: 500px;
margin: 2vh auto;
width: 90%;
max-width: 1200px;
}
.gradio-container {
height: 100vh;
background-color: #f7f7f8;
margin: auto;
padding: 0;
}
#component-0 {
height: 100%;
background: #ffffff;
border-radius: 1rem;
box-shadow: 0 0 20px rgba(0,0,0,0.1);
display: flex;
flex-direction: column;
}
#chatbot {
flex: 1 1 auto;
overflow: auto;
background-color: #ffffff;
border-radius: 1rem 1rem 0 0;
min-height: 0;
}
#chatbot .message.user {
background-color: #ffffff;
padding: 1.5rem clamp(1rem, 4%, 2rem);
border-bottom: 1px solid #e5e7eb;
}
#chatbot .message.bot {
background-color: #f7f7f8;
padding: 1.5rem clamp(1rem, 4%, 2rem);
border-bottom: 1px solid #e5e7eb;
}
#chatbot .message {
color: #374151;
font-size: clamp(14px, 1.5vw, 16px);
line-height: 1.6;
}
#chatbot .message-wrap {
width: 100% !important;
max-width: min(800px, 90%) !important;
margin: auto;
}
#input-box {
min-height: 60px;
height: auto;
max-height: 200px;
margin: 0.75rem 1rem;
background-color: #ffffff;
border: 1px solid #e5e7eb;
border-radius: 0.75rem;
padding: 0.75rem 1rem;
color: #374151;
font-size: clamp(14px, 1.5vw, 16px);
line-height: 1.5;
resize: vertical;
}
#input-box::placeholder {
color: #9ca3af;
}
.input-row {
margin: 0;
padding: 0.5rem clamp(0.5rem, 2%, 1rem);
background-color: #ffffff;
border-top: 1px solid #e5e7eb;
border-radius: 0 0 1rem 1rem;
display: flex;
flex-wrap: wrap;
gap: 0.5rem;
}
.submit-btn, .clear-btn {
font-size: clamp(12px, 1.2vw, 14px) !important;
padding: 8px clamp(12px, 2vw, 16px) !important;
height: auto !important;
flex-shrink: 0;
}
.submit-btn {
background-color: #2563eb !important;
color: white !important;
border-radius: 0.5rem !important;
transition: all 0.2s !important;
box-shadow: 0 1px 2px rgba(0,0,0,0.05) !important;
}
.submit-btn:hover {
background-color: #1d4ed8 !important;
transform: translateY(-1px);
}
.clear-btn {
background-color: #ffffff !important;
color: #374151 !important;
border: 1px solid #e5e7eb !important;
border-radius: 0.5rem !important;
transition: all 0.2s !important;
box-shadow: 0 1px 2px rgba(0,0,0,0.05) !important;
}
.clear-btn:hover {
background-color: #f3f4f6 !important;
transform: translateY(-1px);
}
footer {display: none !important;}
.message-wrap img {
width: clamp(24px, 3vw, 32px) !important;
height: clamp(24px, 3vw, 32px) !important;
margin-right: clamp(0.5rem, 2%, 1rem);
border-radius: 0.375rem;
}
::-webkit-scrollbar {
width: 6px;
height: 6px;
}
::-webkit-scrollbar-track {
background: transparent;
}
::-webkit-scrollbar-thumb {
background: #d1d5db;
border-radius: 3px;
}
::-webkit-scrollbar-thumb:hover {
background: #9ca3af;
}
@media (max-width: 768px) {
.contain {
height: 95vh;
width: 95%;
margin: 2.5vh auto;
}
#input-box {
margin: 0.5rem;
}
}
"""
# Gradio界面配置
with gr.Blocks(css=custom_css) as interface:
with gr.Column(elem_classes="contain"):
chatbot = gr.Chatbot(
value=[],
elem_id="chatbot",
bubble_full_width=True,
avatar_images=(
"https://api.dicebear.com/7.x/bottts/svg?seed=user",
"https://api.dicebear.com/7.x/bottts/svg?seed=assistant"
),
height=600,
show_label=False,
)
with gr.Row():
txt = gr.Textbox(
scale=4,
show_label=False,
placeholder="请输入股票相关问题...",
container=False,
elem_id="input-box"
)
submit_btn = gr.Button("发送", scale=1, variant="primary")
clear = gr.Button("清空对话")
def user_submit(message, history):
if message.strip() == "":
return "", history
return "", history + [[message, None]]
# 更新事件处理
submit_btn.click(
user_submit,
[txt, chatbot],
[txt, chatbot],
queue=False
).then(
bot_response,
chatbot,
chatbot
)
txt.submit(
user_submit,
[txt, chatbot],
[txt, chatbot],
queue=False
).then(
bot_response,
chatbot,
chatbot
)
clear.click(lambda: [], None, chatbot, queue=False)
app = gr.mount_gradio_app(app, interface, path="/")
if __name__ == "__main__":
uvicorn.run("main:app", host="0.0.0.0", port=8000, reload=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号