Milvus简介
Milvus简介
基本介绍
Milvus(米尔乌斯)是一个高性能、高度可扩展的开源的向量数据库,诞生于2019年,由Zilliz开发并维护,后成为LF AI & Data Foundation的托管项目之一,支持针对 TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点。Milvus 集成了 Faiss、NMSLIB、Annoy 等广泛应用的向量索引库,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型。还可以对标量数据进行过滤,进一步提高了召回率,增强了搜索的灵活性。
Milvus可在从笔记本电脑到大规模分布式系统的各种环境中高效运行。
文档:https://milvus.io/docs/zh/overview.md
仓库:https://github.com/milvus-io/milvus
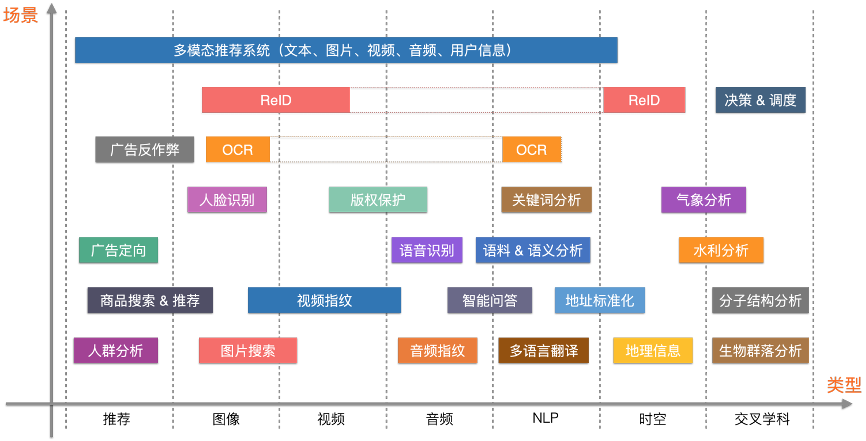
Milvus在多个领域有着广泛的应用,包括但不限于:
- 图像相似性搜索:使图像可搜索,并即时返回来自大型数据库中最相似的图像。
- 视频相似性搜索:通过将关键帧转换为向量,然后将结果输入Milvus,可以在几乎实时的时间内搜索和推荐数十亿个视频。
- 音频相似性搜索:快速查询大量音频数据,如语音、音乐、音效和表面相似的声音。
- 分子相似性搜索:针对指定分子进行极快的相似性搜索、子结构搜索或超结构搜索。
- 推荐系统:根据用户行为和需求推荐信息或产品。
- 问答系统:交互式数字问答聊天机器人,自动回答用户的问题。
- DNA序列分类:通过比较相似的DNA序列,在毫秒级别准确地分类一个基因。
- 文本搜索引擎:通过将关键字与文本数据库进行比较,帮助用户找到他们正在寻找的信息。
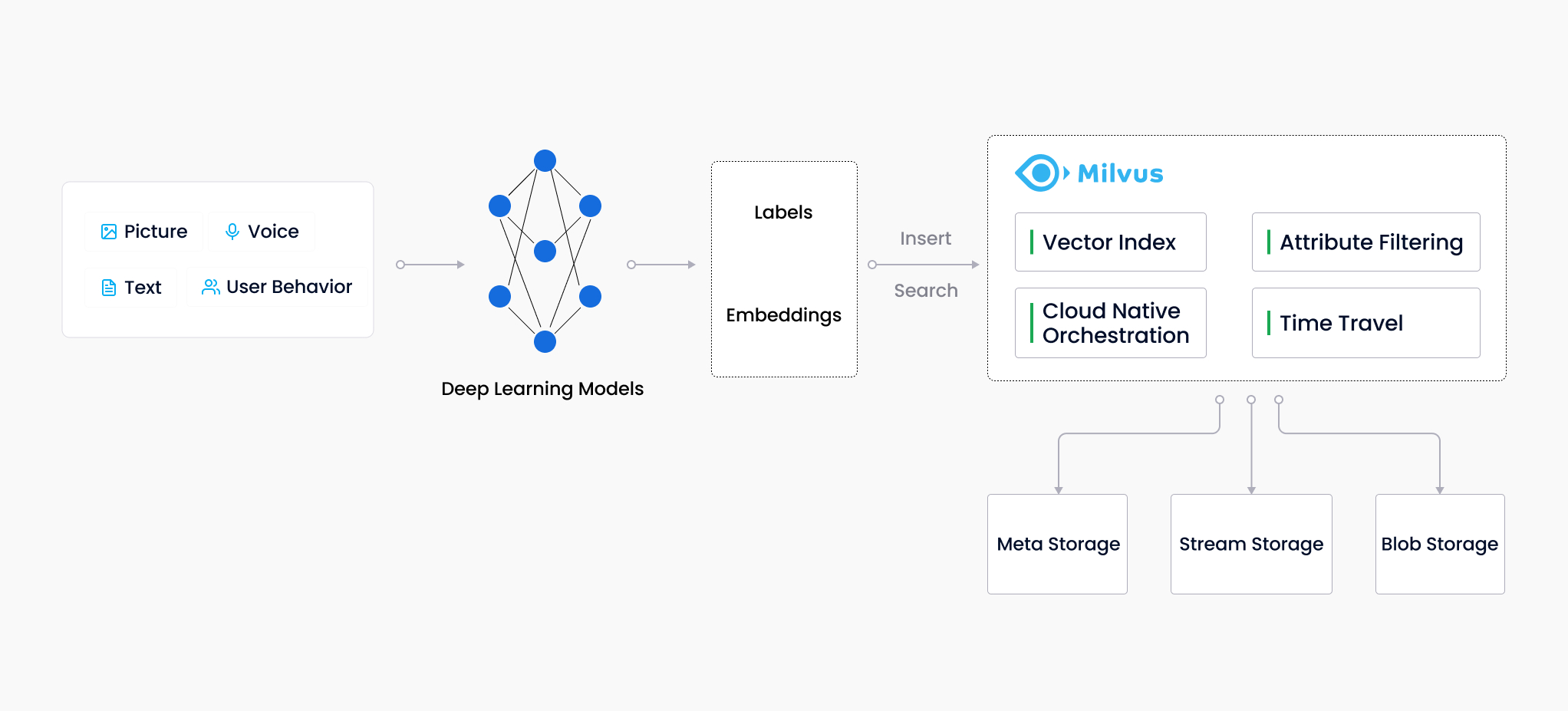
工作流程
Milvus安装
目前Milvus运行的环境都是在docker上,因此在安装Milvus之前,我们需要先确认docker和docker-compose已经安装到本地机子上了。
如果本地机子没有安装docker-compose的同学,提前按以下命令安装一下:
# 这个命令必须保证自己的机子已经安装了docker和python3.8+
pip install docker-compose
注意:
默认情况下,如果安装的docker是docker-desktop默认会顺便已经安装了docker-compose,则不需要再继续安装docker-compose,否则会报错问题,这时候需要卸载掉python安装的。
基于docker-compose安装Milvus服务端
下载Milvus镜像服务配置文件:
https://github.com/milvus-io/milvus/releases/download/v2.4.12/milvus-standalone-docker-compose.yml
下载完成以后,执行如下命令即可启动Milvus数据库:
docker-compose -f milvus-standalone-docker-compose.yml up -d
关闭数据库服务镜像,命令如下:
docker-compose -f milvus-standalone-docker-compose.yml down
如果使用docker无法拉取镜像,执行上面安装命令一直报网络错误,则可能是因为docker封锁了国内IP的问题导致的,解决方法如下:
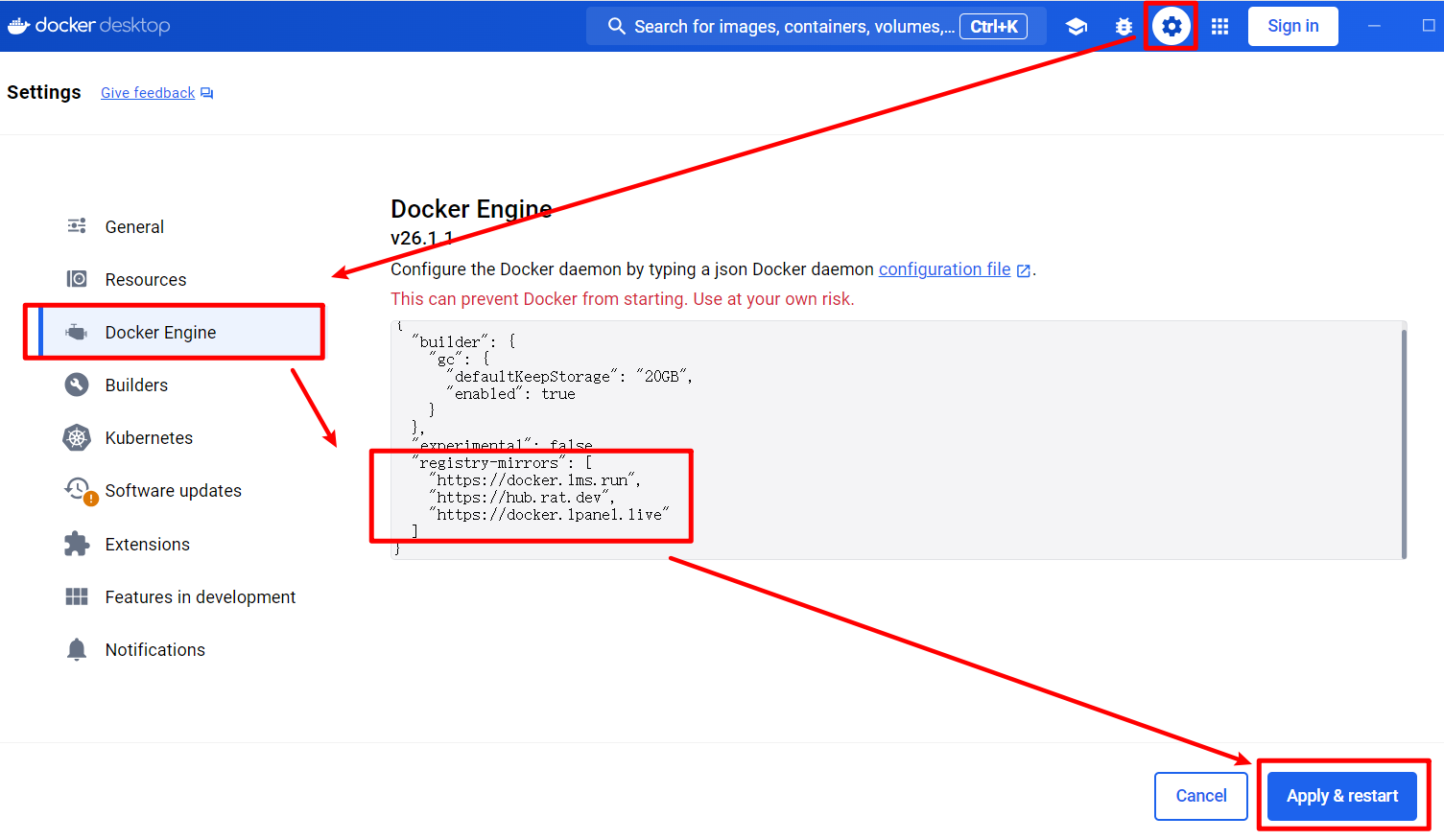
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
// 以下就是新增的国内镜像源
"registry-mirrors": [
"https://docker.1ms.run",
"https://hub.rat.dev",
"https://docker.1panel.live"
]
}
attu-可视化界面工具
下载地址:https://github.com/zilliztech/attu/releases
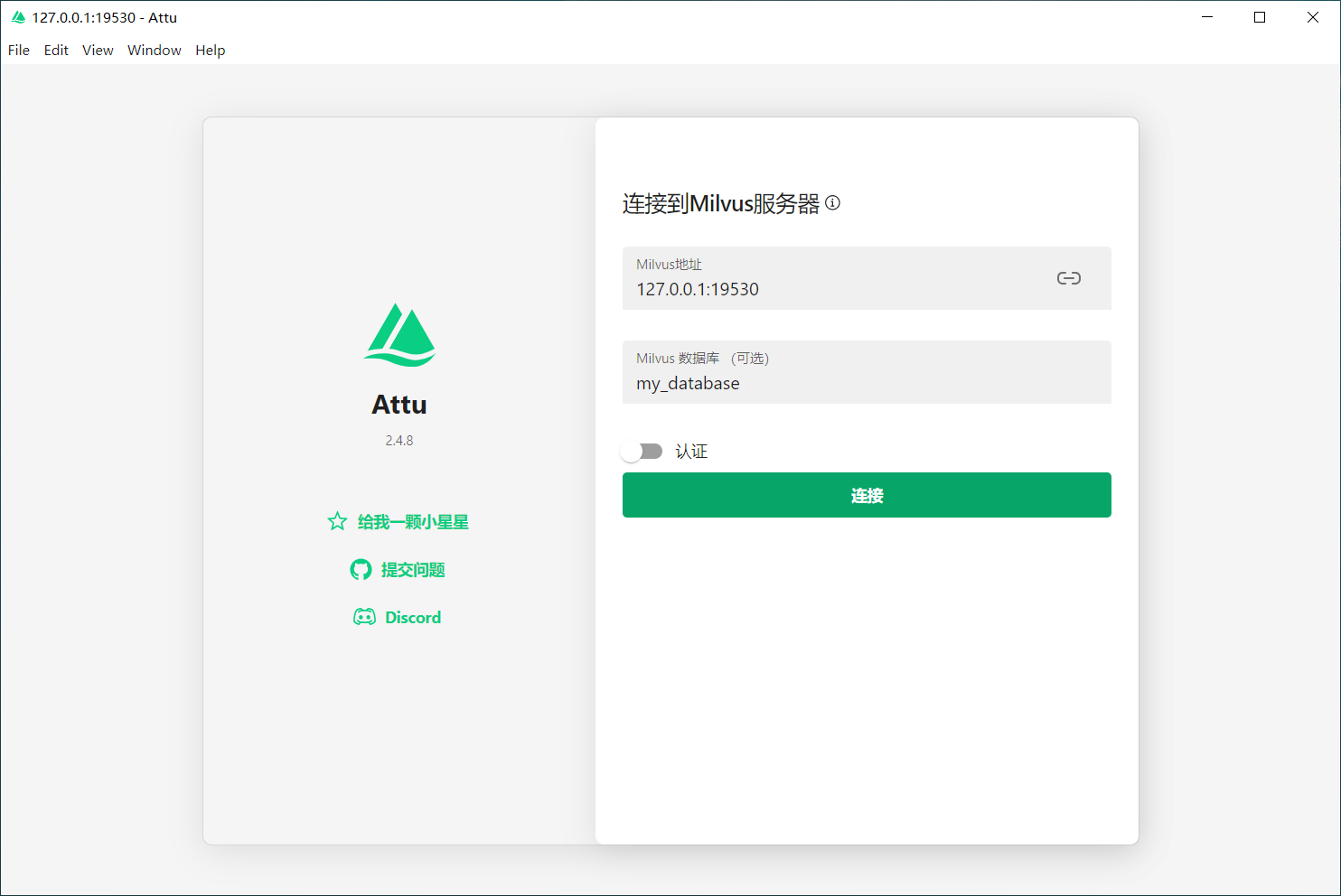
操作界面:
快速入门
除了使用可视化工具连接Milvus数据库以外,我们通常会使用编程语言客户端操作Milvus数据库,这里我们可以选择安装以下pythonSDK。
pip install pymilvus[model]
连接数据库
方式1:
from pymilvus import connections, db
# 连接数据库服务器
connections.connect(
host="127.0.0.1", # 连接服务端地址,
port=19530, # 连接端口,milvus默认监听19530
alias='default', # 连接别名,如果不设置,默认为default,
db_name='default' # 连接数据库,默认是default
)
# 判断是否连接成功
res = db.connections.has_connection('default')
print(res)
# 断开数据库连接
# 此处必须填写断开的连接别名
connections.disconnect('default')
方式2,实际上是方式1的封装:
from pymilvus import MilvusClient
# 如果没有开启用户身份认证,直接通过uri连接即可。
client = MilvusClient("http://localhost:19530")
# client = MilvusClient() # 上面的内容可以简写
# 开启用户身份认证 并使用root用户的情况
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus",
db_name="default"
)
# 开启用户身份认证 并使用非root用户的情况
client = MilvusClient(
uri="http://localhost:19530",
token="user:password",
db_name="default"
)
# 断开连接
client.close()
数据库操作
列出数据库
client.list_collections()
创建数据库
数据库名必须唯一,重复创建会报错:database already exist
client.create_database('my_database')
使用数据库
数据库不存在则报错:database not found
client.using_database('my_database')
print(client._using)
删除数据库
删除数据库,只能空数据库,否则会报错:database:数据库名 not empty, must drop all collections before drop database
db.drop_database("my_database")
核心概念
| 概念 | 描述 |
|---|---|
| 集合 (Collection) | 集合类似于关系数据库中的表,它是用来存储向量的容器。集合可以有多个字段,每个字段对应一个向量属性。 |
| 向量 (Vector) | 向量是多维空间中的点,通常用于表示数据的特征,是集合中的基本存储单元。 |
| 索引 (Index) | 索引是用来加速向量搜索的数据结构,有多种索引类型,如 FLAT、IVF、HNSW 等,各自都有特定的适用场景。 |
| Filed | 字段,可以是结构化数据、向量; |
| Entity | 一组Filed,类似表的一条记录。 |
集合操作
列出集合
clist = client.list_collections()
print(clist)
创建集合
# 创建动态集合,同集合名称不会反复创建,也不会报错
client.create_collection(
collection_name="my_collection", # 集合名称
dimension=5 # 向量的维度,这里的维度,关系到后面添加的向量数据的维度
)
判断集合
client.has_collection('my_collection') # 判断集合是否存在
查看集合
res = client.describe_collection('my_collection')
print(res)
删除集合
client.drop_collection('demo_collection')
数据操作
插入数据,同样主键的数据重复添加会覆盖
# 添加一条数据
data={
'id': 0,
'vector': [ # 该字段的数量就是上面我们创建集合的维度,上面创建的是5维向量字段,下面必须就是固定5维,如果不对应则报错。
0.6186516144460161,
0.5927442462488592,
0.848608119657156,
0.9287046808231654,
-0.42215796530168403
]
}
res = client.insert('my_collection', data)
print(res)
# 多条数据
client.insert(
collection_name="my_collection",
data=[
{
'id': 1,
'vector': [
0.37417449965222693,
-0.9401784221711342,
0.9197526367693833,
0.49519396415367245,
-0.558567588166478
]
},
{
'id': 2,
'vector': [
0.46949086179692356,
-0.533609076732849,
-0.8344432775467099,
0.9797361846081416,
0.6294256393761057
]
}
]
)
精准查询数据-get
# 查询单条数据
res = client.get('my_collection', 0)
# 查询多条数据
res = client.get('my_collection', [0, 2])
条件精确查询数据-query
查询条件表达式的运算符:https://milvus.io/docs/get-and-scalar-query.md
# 添加测试数据
client.insert(
collection_name="my_collection",
data=[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298"},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794"},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222"},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392"},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510"},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381"},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976"}
],
)
res = client.query(
collection_name="my_collection", # 集合名称
# filter="id in [6,7,8]", # 支持python的运算符来编写查询过滤条件
filter="id > 3", # 支持python的运算符来编写查询过滤条件,注意条件必须使用字符串,内容必须符合python语法
offset=3, # 偏移量,开始下标
limit=2, # 结果限制,限制返回指定数量的结果
output_fields=["id", "color"], # 字段投影,*表示所有字段,['id', 'vector'] 表示返回2个指定字段
)
print(res)
查询数据-search,基于ANN(近似最近邻)算法来查询近似的记录
search_params = {
# 相似性度量用于测量向量之间的相似性。选择一个好的距离度量可以显著提高分类和聚类性能。
# 常见的度量类型有:L2(欧式距离,直线距离)、IP(内积)、COSINE(余弦距离)、JACCARD、HAMMING。
"metric_type": "COSINE",
"params": {
"radius": "", # 设置查询范围的半径
"range_filter": "", # 设置查询范围的上下值范围
}
}
res = client.search(
collection_name="my_collection", # 搜索的集合名称
data=[[0.05, 0.23, 0.07, 0.45, 0.13]], # 搜索的条件,相当于参考值,条件值
limit=3, # 结果数量
search_params=search_params # 搜索类型
)
print(res)
插入或更新数据
res = client.insert(
collection_name="my_collection",
data=[
{
'id': 0,
'vector': [
0.37417449965222693,
-0.9401784221711342,
-0.8344432775467099,
0.9797361846081416,
0.6294256393761057
]
},
{
'id': 1,
'vector': [
0.37417449965222693,
-0.9401784221711342,
0.9197526367693833,
0.49519396415367245,
-0.558567588166478
]
},
{
'id': 2,
'vector': [
0.46949086179692356,
-0.533609076732849,
-0.8344432775467099,
0.9797361846081416,
0.6294256393761057
]
}
]
)
在Milvus中,为了高性能运作,所以添加或更新数据的操作都是异步非阻塞的,所以对于刚添加入库的数据,有可能无法立即查询出来或者无法查询到最新的更新的数据。
import time
from pymilvus import MilvusClient
client = MilvusClient()
# 切换数据库
client.using_database('my_database')
# 添加或更新数据
res = client.insert(
collection_name="my_collection",
data=[
{
'id': 9,
'vector': [
0.28417449965222693,
-0.2401784221711342,
-0.2844432775467099,
0.2997361846081416,
0.2094256393761057
]
},
{
'id': 10,
'vector': [
0.21417449965222693,
-0.2201784221711342,
0.2597526367693833,
0.27519396415367245,
-0.258567588166478
]
},
{
'id': 11,
'vector': [
0.26949086179692356,
-0.333609076732849,
-0.2344432775467099,
0.2797361846081416,
0.2294256393761057
]
}
]
)
print(res)
# 刚插入或者刚修改的数据,是无法被查询到的。
res = client.get('my_collection', ids=[9,10,11])
print(res)
client.close()
删除数据
查询条件的写法,与query的条件写法一致。
client.delete(
collection_name="my_collection",
filter="id in [1, 8, 9] and color like 'b%'"
)
集合属性设置,设置数据的有效期,单位:秒
from pymilvus import connections, Collection, db
# 建立数据库连接,如果没有指定参数,则默认为:localhost:19530
connections.connect()
# 使用指定数据库
db.using_database('my_database')
# 获取一个已存在的集合,如果当前集合没有被创建,则需要补充字段,变成新建集合
collection = Collection('my_collection')
collection.set_properties(
properties={
"collection.ttl.seconds": 10 # 设置集合中数据的有效期为60秒
}
)
# 关闭数据库连接
connections.disconnect(alias='default')
字段操作
数据类型
Milvus中提供了Schema类用于定义集合的属性(CollectionSchema)和字段(FieldSchema)的属性。字段存储的数据按不同结构分不同数据类型,这些都是提前通过Schema来进行定义。首先我们先了解关于数据类型部分的内容,再接着学习Schema。
pyMilvus中设置数据类型主要通过常量或常数来表示,通过如下代码导入使用:
from pymilvus import DataType
| 常量 | 常数 | 字段类型 | 描述 |
|---|---|---|---|
| BOOL | 1 | 标量 | 布尔类型 |
| INT8 | 2 | 标量 | 8位整型 |
| INT16 | 3 | 标量 | 16位整型 |
| INT32 | 4 | 标量 | 32位整型 |
| INT64 | 5 | 主键,标量 | 64位整型 |
| FLOAT | 10 | 标量 | 单精度浮点型 |
| DOUBLE | 11 | 标量 | 双精度浮点型 |
| VARCHAR | 21 | 主键,标量 | 字符串类型,max_length=65,535 |
| BINARY_VECTOR | 100 | 向量 | 二进制向量类型 |
| FLOAT_VECTOR | 101 | 向量 | 32位单精度浮点数向量 |
| FLOAT16_VECTOR | 102 | 向量 | 16位半精度浮点数向量 |
| BFLOAT16_VECTOR | 103 | 向量 | 16位半精度浮点数向量,比FLOAT16_VECTOR显存占用量更小,精度更低。 |
| SPARSE_FLOAT_VECTOR | 104 | 向量 | 稀疏向量,存储非零元素及其相应索引的列表 |
| ARRAY | 22 | 复合 | 数组,就是python中的列表 |
| JSON | 23 | 复合 | json文档,就是python中的字典 |
| NONE | 0 | 空类型,无法设置为字段类型,milvus返回的格式, | |
| UNKNOWN | 999 | 未知类型,无法设置为字段类型,milvus返回的格式。 |
快速使用
Milvus允许在创建schema时为每个标量字段指定默认值,从而减低插入数据的复杂性,但不包括主键字段。如果在插入数据时将字段留空,则将应用为此字段指定的默认值。
from pymilvus import DataType
# enable_dynamic_field=True 表示开启动态字段,开启后,除 id 和 vector 之外的所有字段都被视为动态字段。
# 这些额外的字段被保存为在名为 $meta 的特殊字段内的键值对。在后面的操作当前集合的数据时允许在插入数据时包含未定义的额外字段。
schema = client.create_schema(enable_dynamic_field=True)
# schema.add_field(field_name="字段名", datatype=DataType.字段类型, is_primary=True, auto_id=True, description="字段描述"), # 设置主键字段
# schema.add_field(field_name="字段名", datatype=DataType.字段类型, default_value=默认值, dim=维度, description="字段描述"),
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
index_params = client.prepare_index_params()
# 当把索引设置为AUTOINDEX,则表示将来这里的索引类型是根据存储内容来自动识别。
index_params.add_index(field_name="vector",index_type="AUTOINDEX",metric_type="COSINE")
collection = client.create_collection(
collection_name="test_01", # 集合名称
schema=schema, # 字段参数
index_params=index_params, # 索引参数
using="default" # 数据库连接[在集群操作中需要设置]
)
动态字段
支持动态字段的创建和使用,增加了数据管理的灵活性。
索引操作
索引是提高数据检索效率的关键技术。在 Milvus 中,索引用于加速向量数据的搜索过程。通过索引,可以快速定位到与查询向量最相似的数据向量。
索引类型
Milvus 提供了多种索引类型对字段值进行排序,以实现高效的相似性搜索。
| 索引 | 适用场景 | |
|---|---|---|
| FLAT | 原始文件索引,适合在小型、百万级数据集上寻求完全准确和精确搜索结果的,且需要100%召回率的场景。 | |
| IVF_FLAT | 基于量化的索引 | 倒排文件索引,适合寻求在准确性和查询速度之间取得理想平衡的场景。GPU_IVF_FLAT是IVF_FLAT的GPU版本实现。 |
| IVF_SQ8 | 基于量化的索引 | 适合寻求显著减少磁盘、CPU和GPU内存消耗的场景 |
| IVF_PQ | 基于量化的索引 | 适合寻求高查询速度,即使以牺牲准确性为代价的场景。GPU_IVF_PQ是IVF_PQ的GPU版本实现。 |
| HNSW | 基于图的索引 | 适合对搜索效率有高要求的场景 |
注意:
Milvus 目前仅支持对向量和标量字段创建索引。其中给向量字段建立的索引叫向量索引,同理,给标量字段创建的索引叫标量索引。
建议对经常使用的向量字段和标量字段创建索引。
Milvus 还提供三种度量类型:余弦相似度 (COSINE)、欧几里得距离 (L2) 和内积 (IP,Inner Product)来测量向量嵌入之间的距离。
快速使用
列出索引
res = client.list_indexes(
collection_name="my_collection"
)
print(res)
创建索引
Milvus 目前只支持为集合的每个字段创建一个索引文件。注意:是一个字段只能设置一个索引,不是一个集合只有一个索引!!
from pymilvus import MilvusClient
client = MilvusClient()
# 切换数据库
client.using_database('my_database')
index_params = client.prepare_index_params()
index_params.add_index(
collection_name="test_collection",
field_name="vector",
index_params=index_params,
metric_type="L2",
index_type="IVF_FLAT", # 索引类型,GPU版本的都排索引
params={"nlist": 100}, # list,分区设置
)
client.create_index(collection_name='test_collection', index_params=index_params)
# 创建完索引以后,需要手动加载下集合
client.load_collection(collection_name='test_collection')
查看索引
# 查看指定索引的相关信息
res = client.describe_index(
collection_name="test_collection",
index_name="vector"
)
print(res)
"""
{
'index_type': 'AUTOINDEX',
'metric_type': 'COSINE',
'field_name': 'vector',
'index_name': 'vector',
'total_rows': 0,
'indexed_rows': 0,
'pending_index_rows': 0,
'state': 'Finished'
}
"""
删除索引
"""删除索引,需要先释放集合"""
client.release_collection('test_collection') # 从内存中释放数据
client.drop_index(
collection_name="test_collection",
index_name="vector"
)
实战演示
词嵌入与句嵌入的实现
词嵌入(Word Embedding):就是基于嵌入技术,把一个个单词转换成向量。
句嵌入(Sentence Embedding):就是基于嵌入技术,把一个个句子转换成向量。
huggingface:https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
pip install transformers
pip install -U sentence-transformers
使用预训练模型生成词嵌入
可以使用Transformers库中的预训练模型生成词嵌入,以BERT模型为例:
from transformers import BertTokenizer, BertModel
# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
def get_word_embedding(word):
# 分词并转换为向量
inputs = tokenizer(word, return_tensors='pt')
outputs = model(**inputs)
# 获取词嵌入
word_embedding = outputs.last_hidden_state.mean(dim=1).detach().numpy()
return word_embedding
word = "welcome"
embedding = get_word_embedding(word)
print(embedding)
使用预训练模型生成句嵌入
可以使用Sentence Transformer模型生成句嵌入,以BERT模型为例:
from sentence_transformers import SentenceTransformer
# 加载预训练的paraphrase-MiniLM-L6-v2模型
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
def get_sentence_embedding(sentence):
"""
使用预训练的Sentence-BERT模型生成句嵌入
:param sentence: 输入句子
:return: 句嵌入向量
"""
sentence_embedding = model.encode(sentence)
return sentence_embedding
sentences = [
"welcome to beijing.",
"welcome to shanghai.",
"welcome to shenzhen.",
"i like beijing",
"are you from beijing ?"
]
# 生成所有句子的嵌入
embeddings = [get_sentence_embedding(sentence) for sentence in sentences]
print(embeddings)
实际上,Milvus中已经内置了上面Sentence Transformer的常用embedding模式,代码如下:
from pymilvus import model
sentence_transformer_ef = model.dense.SentenceTransformerEmbeddingFunction(
model_name='all-MiniLM-L6-v2', # 句嵌入模型
device='cuda:0' # 选择使用CPU还是GPU,'cpu' or 'cuda:0',cuda:0表示第1张GPU显卡,以此类推。。
)
# 要转换成向量的句子列表
sentences = [
"welcome to beijing.",
"welcome to shanghai.",
"welcome to shenzhen.",
"i like beijing",
"are you from beijing ?"
]
res = sentence_transformer_ef.encode_documents(sentences)
print(res)
预训练模型列表:https://www.sbert.net/docs/sentence_transformer/pretrained_models.html
代码实现
把文本内容通过句嵌入添加到Milvus向量库中,代码:
from pymilvus import MilvusClient
from sentence_transformers import SentenceTransformer
import numpy as np
# 加载预训练的Sentence-BERT模型
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
def get_sentence_embedding(sentence):
"""
使用预训练的Sentence-BERT模型生成句嵌入
:param sentence: 输入句子
:return: 句嵌入向量
"""
sentence_embedding = model.encode(sentence)
return sentence_embedding
client = MilvusClient()
# 切换数据库
client.using_database('my_database')
from pymilvus import DataType
schema = client.create_schema(enable_dynamic_field=True)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True),
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=384)
index_params = client.prepare_index_params()
index_params.add_index(field_name="vector", index_type="IVF_FLAT", metric_type="L2", nlist=128)
collection = client.create_collection(
collection_name="test_01", # 集合名称
schema=schema, # 字段参数
index_params=index_params, # 索引参数
using="default" # 数据库连接[在集群操作中需要设置]
)
client.load_collection('test_01')
sentences = [
"welcome to beijing.",
"welcome to shanghai.",
"welcome to shenzhen.",
"i like beijing",
"are you from beijing ?"
]
# 生成所有句子的嵌入
embeddings = [get_sentence_embedding(sentence) for sentence in sentences]
# 插入嵌入到Milvus
client.insert(
collection_name="test_01",
data=[{"vector": item} for item in embeddings],
)
client.close()
模拟用户将来的查询操作,代码:
from pymilvus import MilvusClient
from sentence_transformers import SentenceTransformer
# 加载预训练的Sentence-BERT模型
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
client = MilvusClient()
# 切换数据库
client.using_database('my_database')
# 把要查询的内容转换嵌入变量
query_sentence_embedding = model.encode("welcome to guangzhou.")
# 到milvus中查询
search_params = {
"metric_type": "L2", # 因为集合中的索引使用的就是L2(欧氏距离),所以我们这里必须写成欧式距离
"params": {}
}
result = client.search(
collection_name="test_01",
data=[query_sentence_embedding],
search_params=search_params
)
print(result)
client.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号