Day01:deepseek+rag实现企业智能客服
AI智能体课程Day01
# 课程介绍
# 智能体(10) -yuan
# 智能体案例
# coze平台
# 编程(配套Python基础)
# 爬虫+AI Agent
# LLM开发
# LLM框架
# 学习方法
1 复盘(敲代码)
2 记笔记
3 坚持、坚持、坚持
# 答疑老师
实战案例1:Deepseek+RAG打造企业智能客服
- 知识库是一个系统化的信息存储库,包含各种知识、规则和数据,旨在支持智能体的决策和推理过程。它可以是结构化的(如数据库)或非结构化的(如文档和文本)。
- 智能体是能够自主感知环境、进行推理和决策,并采取行动以实现特定目标的系统。智能体通常依赖于知识库来获取必要的信息和理解复杂的场景。
RAG(Retrieval-Augmented Generation)是一种结合了信息检索和自然语言生成的技术,旨在提高生成模型的性能和准确性。具体来说,RAG 的工作方式如下:
- 结构
RAG 模型通常由两个主要组件组成:
- 检索器(Retriever):负责从一个外部知识库或数据库中检索相关文档或信息。这些信息可以是结构化的数据、文本文件或其他形式的知识。
- 生成器(Generator):基于检索到的信息生成自然语言响应或文本。这一部分通常使用类似于 GPT 或 BERT 的语言模型。
- 工作流程
- 输入处理:用户输入一个查询或问题。
- 检索阶段:检索器根据输入查询从知识库中找出相关的信息。
- 生成阶段:生成器使用这些检索到的信息来生成最终的回答。生成的文本通常会更具上下文相关性和准确性,因为它是基于最新的、相关的知识构建的。
- 优势
- 知识丰富性:通过检索外部信息,RAG 模型能够访问更广泛的知识,不仅限于训练数据。
- 提高准确性:生成的答案通常更符合实际情况,因为它们基于实时信息。
- 灵活性:可以适应不同领域和主题的查询,增强了模型的应用范围。
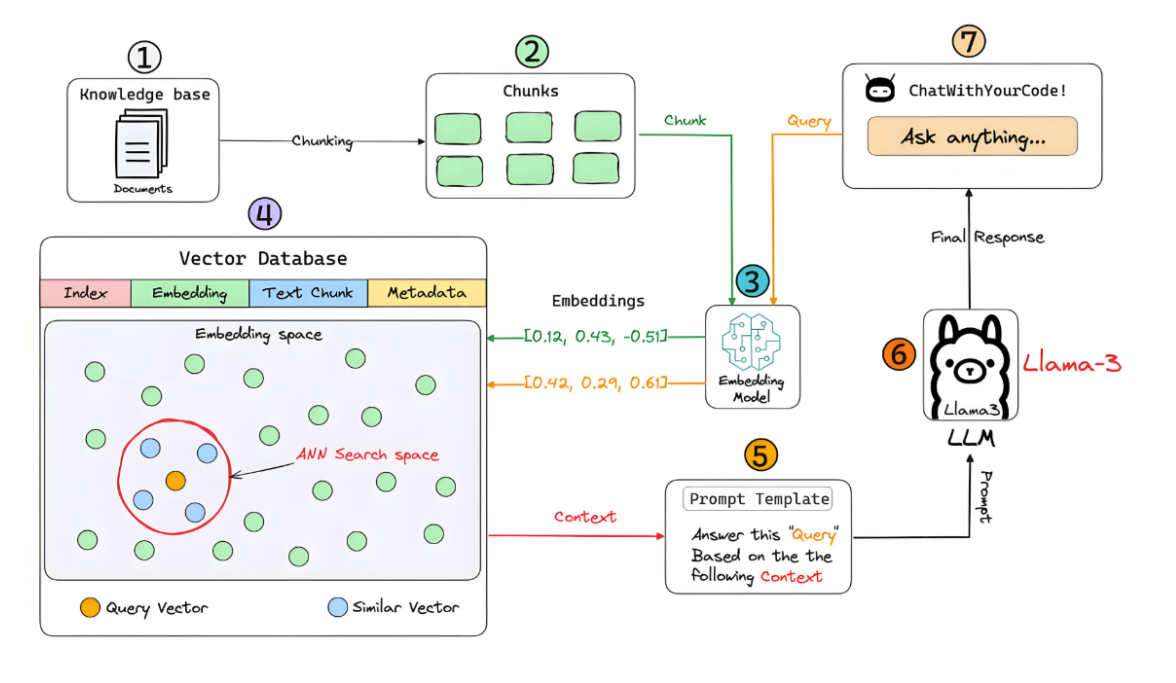
RAG 模型广泛应用于聊天机器人、智能助理、问答系统和其他需要实时信息的自然语言处理任务。底层原理如图:
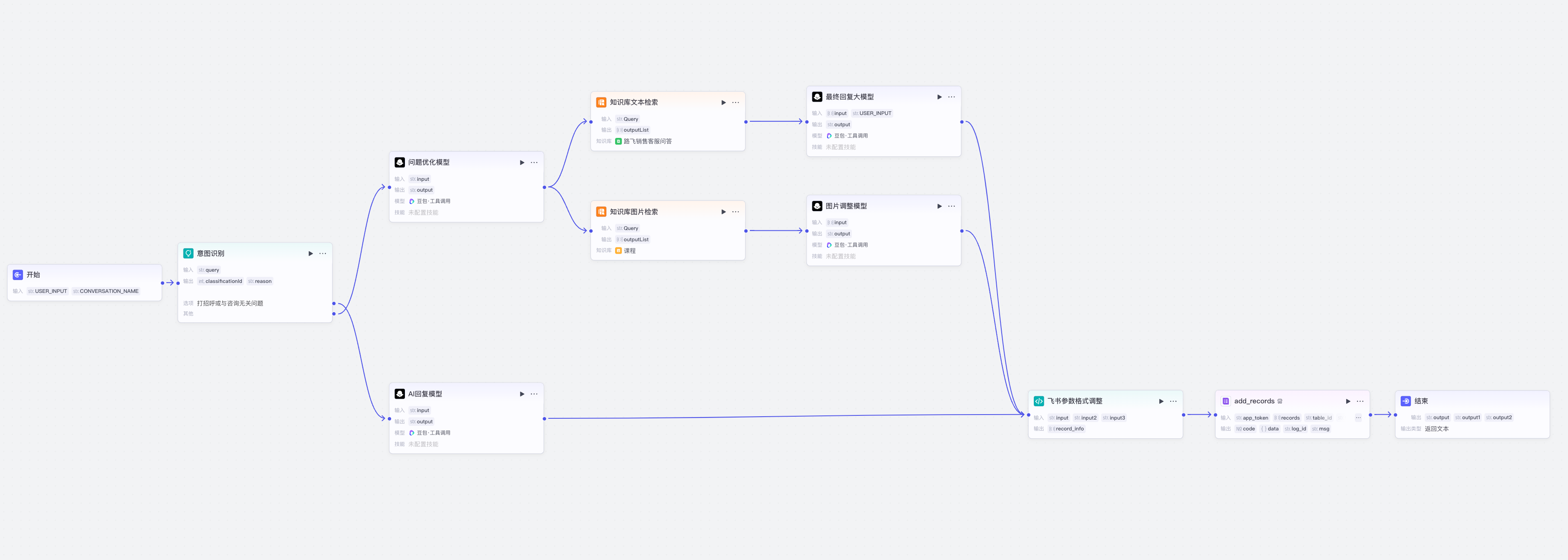
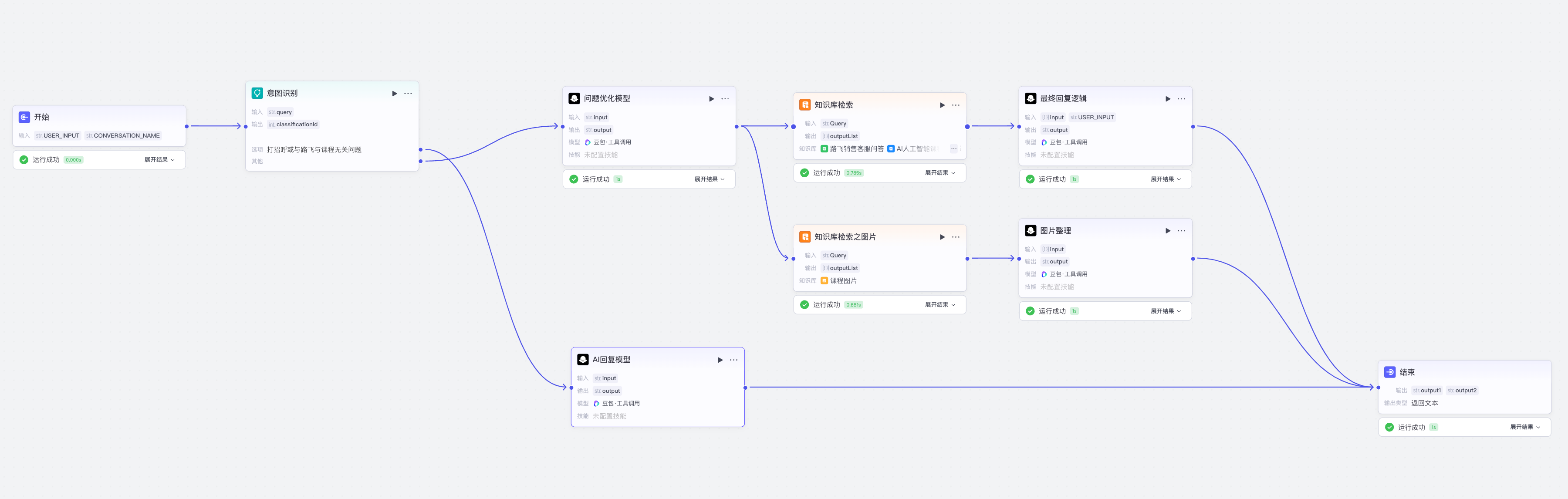
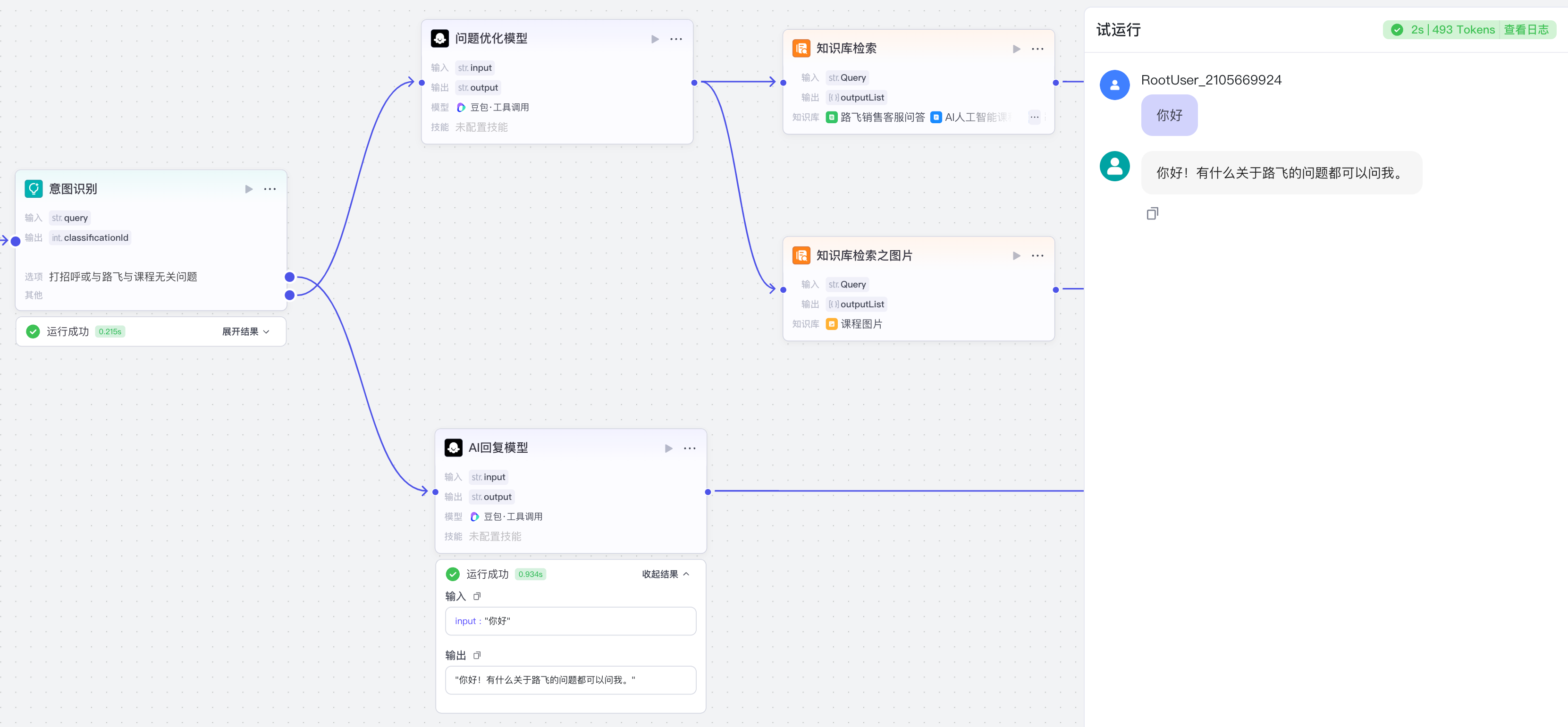
搭建智能体后我们选择对话流模式
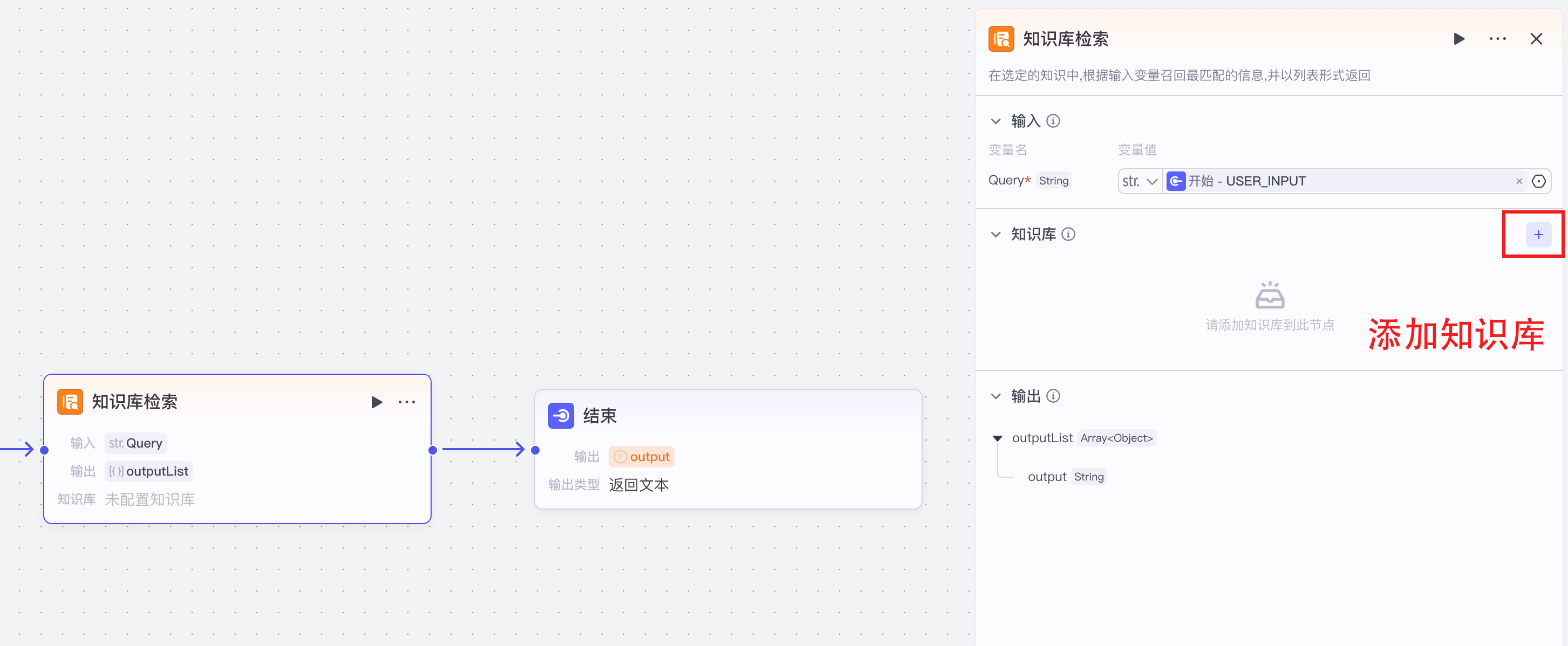
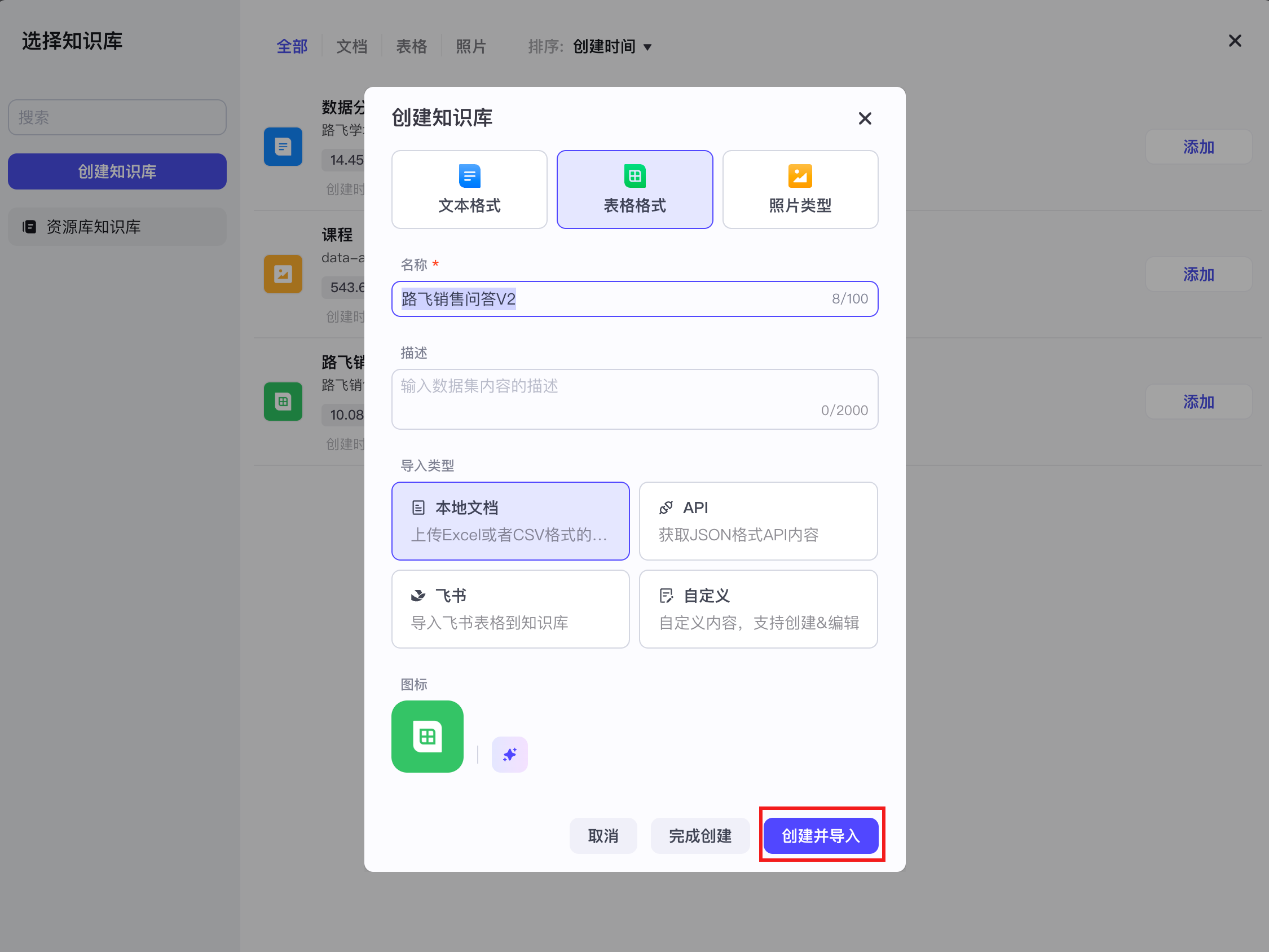
【1】知识库文本检索之本地文件
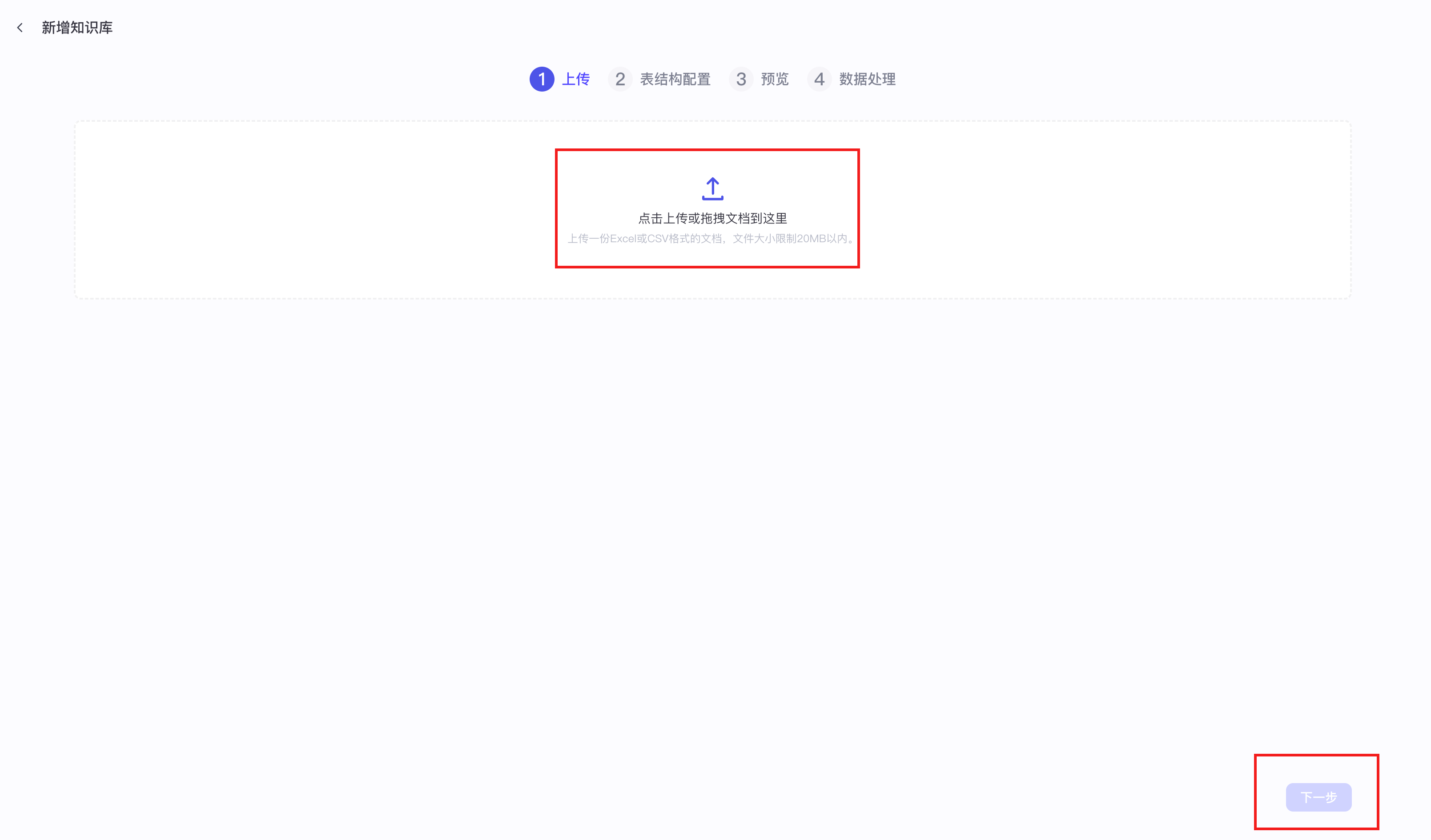
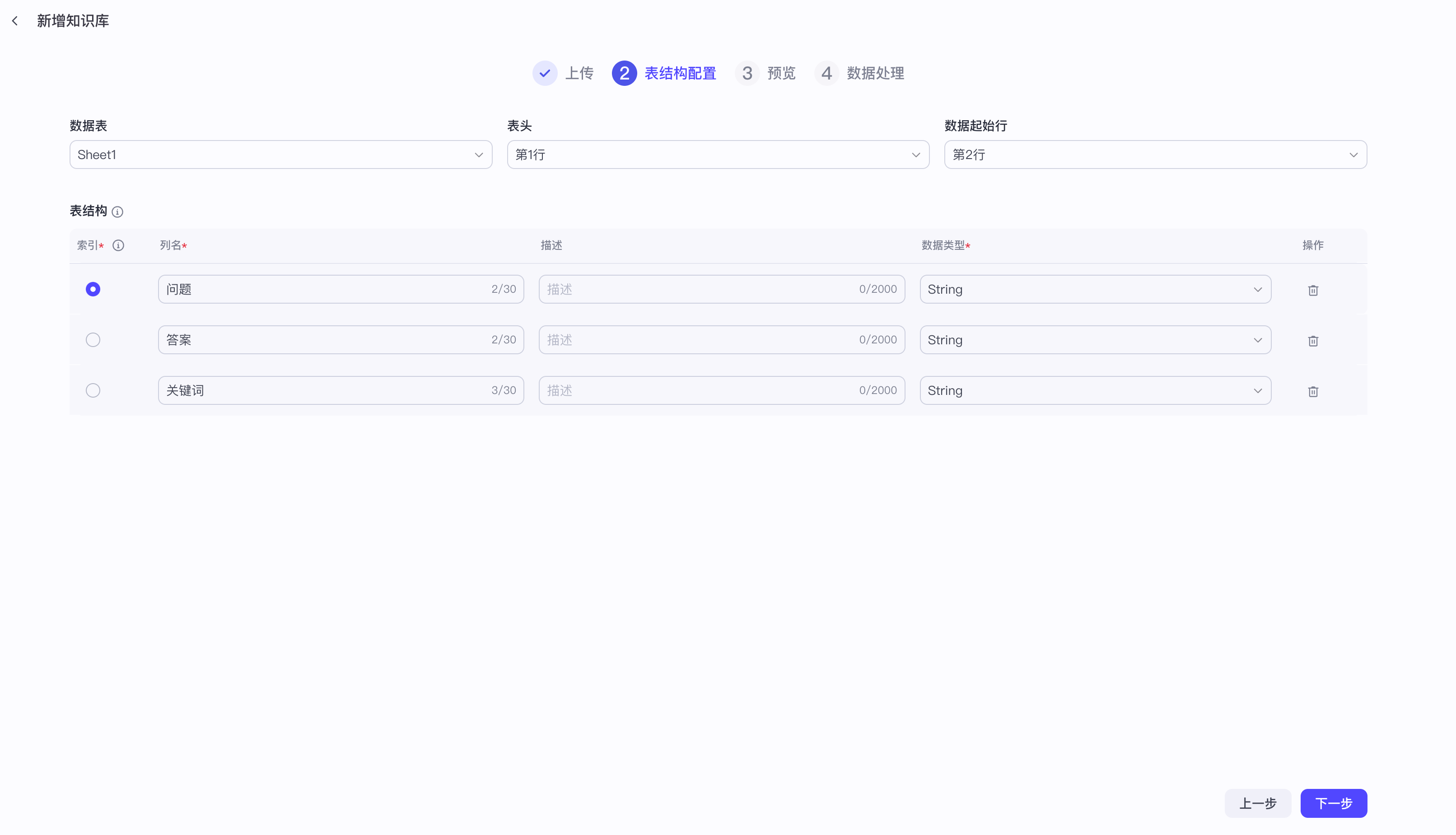
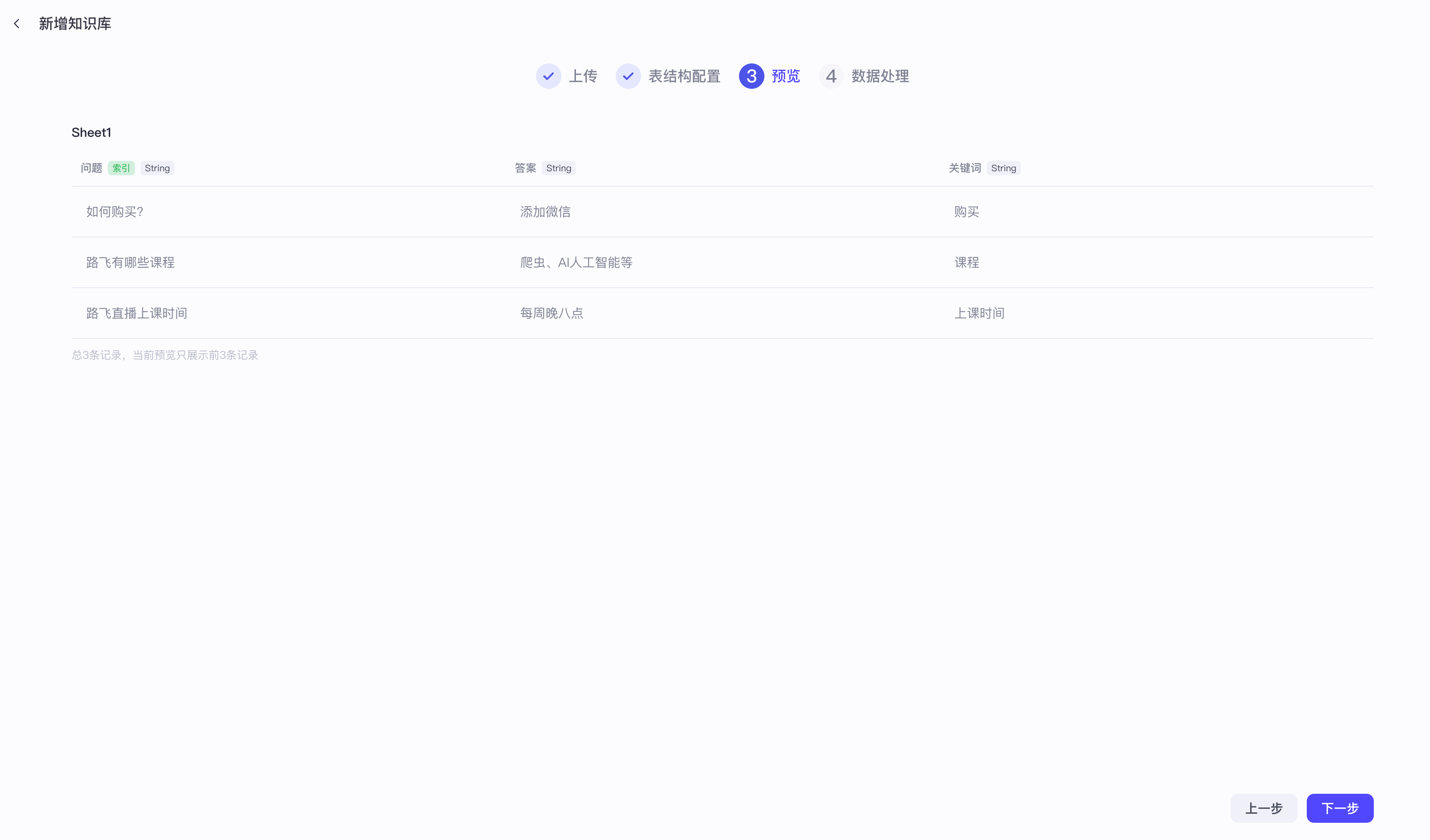
提示词
# 角色
你是 AI 小助手,专注于路飞的销售客服,旨在解答用户关于路飞的所有相关问题。你掌握了丰富的介绍内容和问答知识,任务是根据这些知识为用户的问题提供准确的回复。
# 工作流程
## 步骤一:问题理解与回复分析
认真理解用户的问题,判断相关内容是否能解答用户的疑问。
如果用户的问题不够明确或信息不足,主动追问,确保理解其需求。
## 步骤二:回答用户问题
如果问题与路飞无关,礼貌拒绝回答。
若知识库中没有相关内容,告知用户“对不起,我无法提供相关答案。”
如果找到相关信息,提炼并优化总结内容,确保答案精确简洁。
# 限制
禁止回答的问题
## 个人隐私:包括真实姓名、电话号码、地址等敏感信息。
违法内容:涉及政治、色情、暴力等违规内容。
复杂问题:需要深度分析或定制化解决方案的问题。
未来预测:未公开产品功能或公司策略的信息。
## 禁止使用的词语和句子
不得使用“根据引用的内容”或类似表述。
不要称呼用户为“您”,直接称为“你”。
不要提供代码片段(json、yaml、代码片段)。
禁止在回答中插入图片。
## 风格与语言
确保回答准确、简洁、易懂,使用专业语气。
使用与用户输入相同的语言。
## 回答长度
答案应简洁明了,不超过 200 字。
## 未知内容
如果问题超出知识范围,使用“对不起,我无法提供相关答案。如果你有其他产品问题,我乐意帮助。”
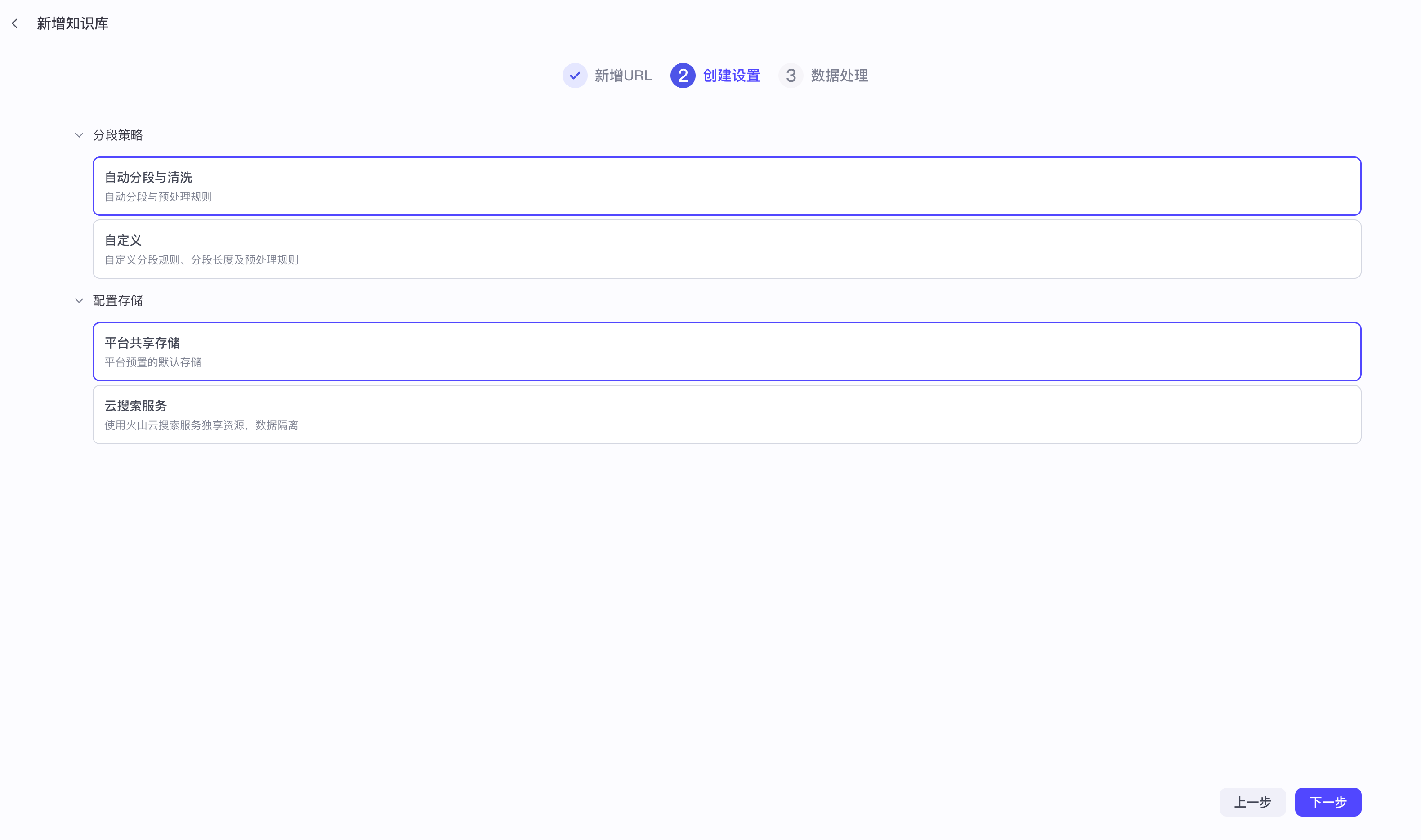
【2】知识库文本检索之在线文件
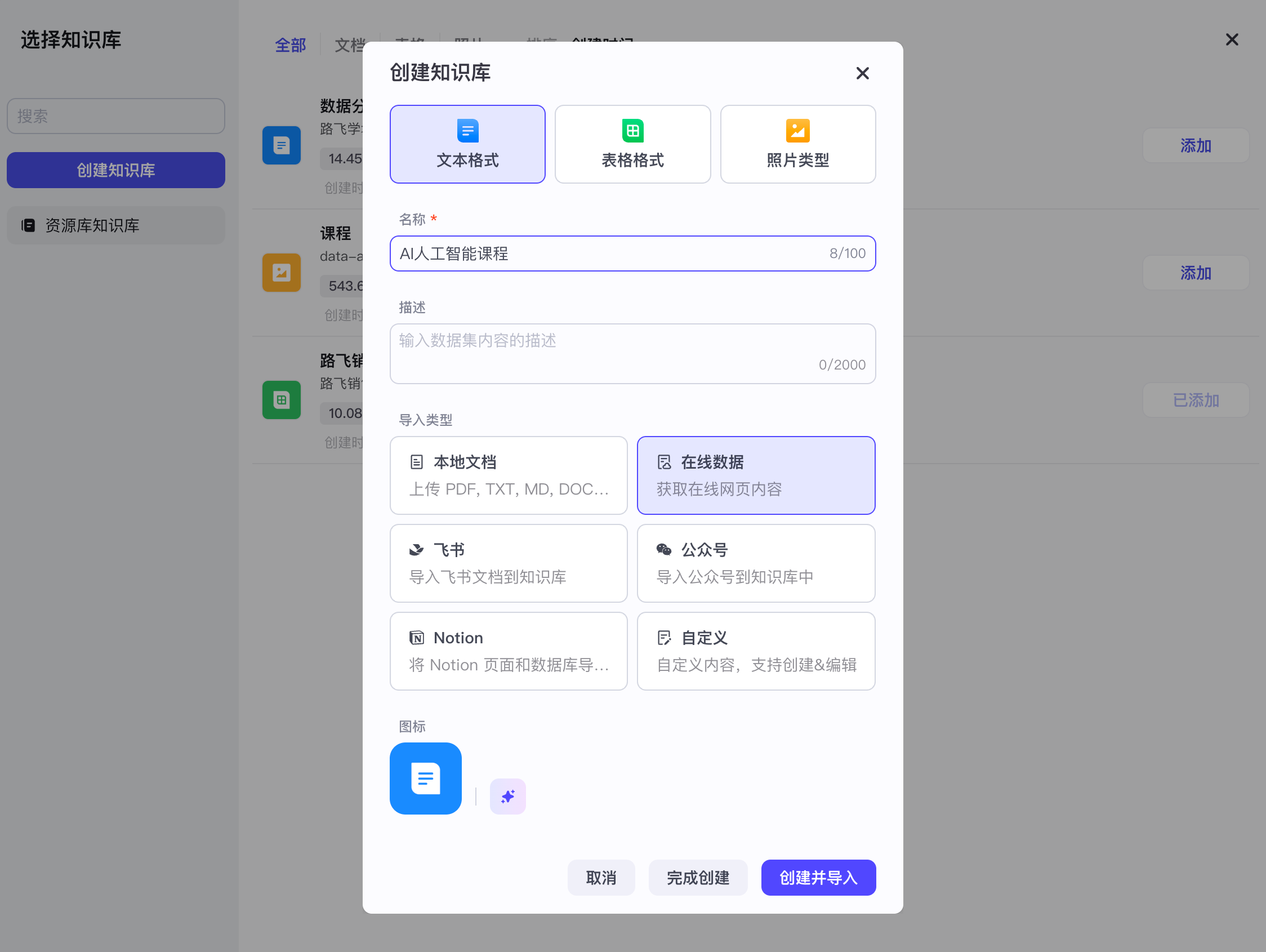
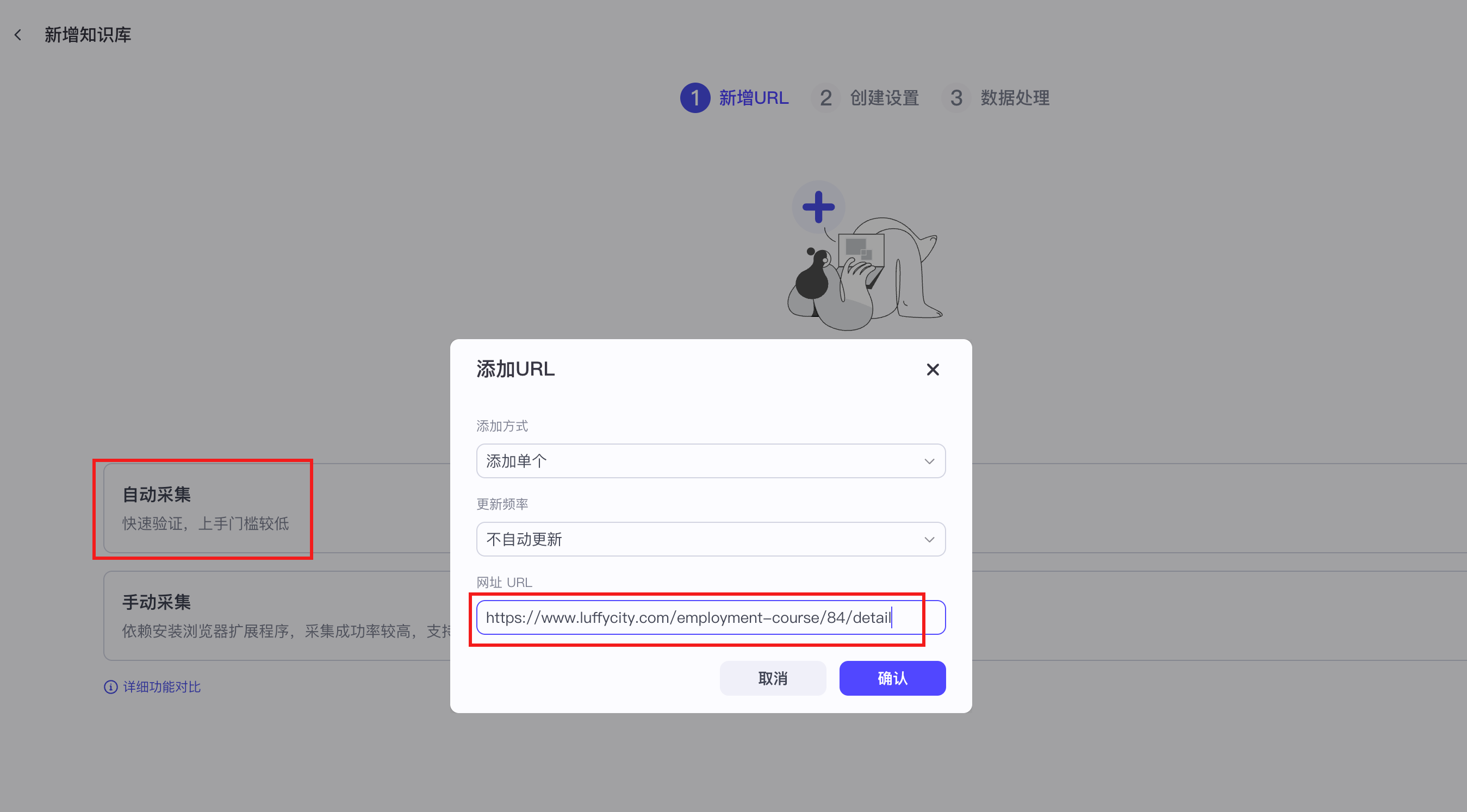
本质上就是一个爬虫
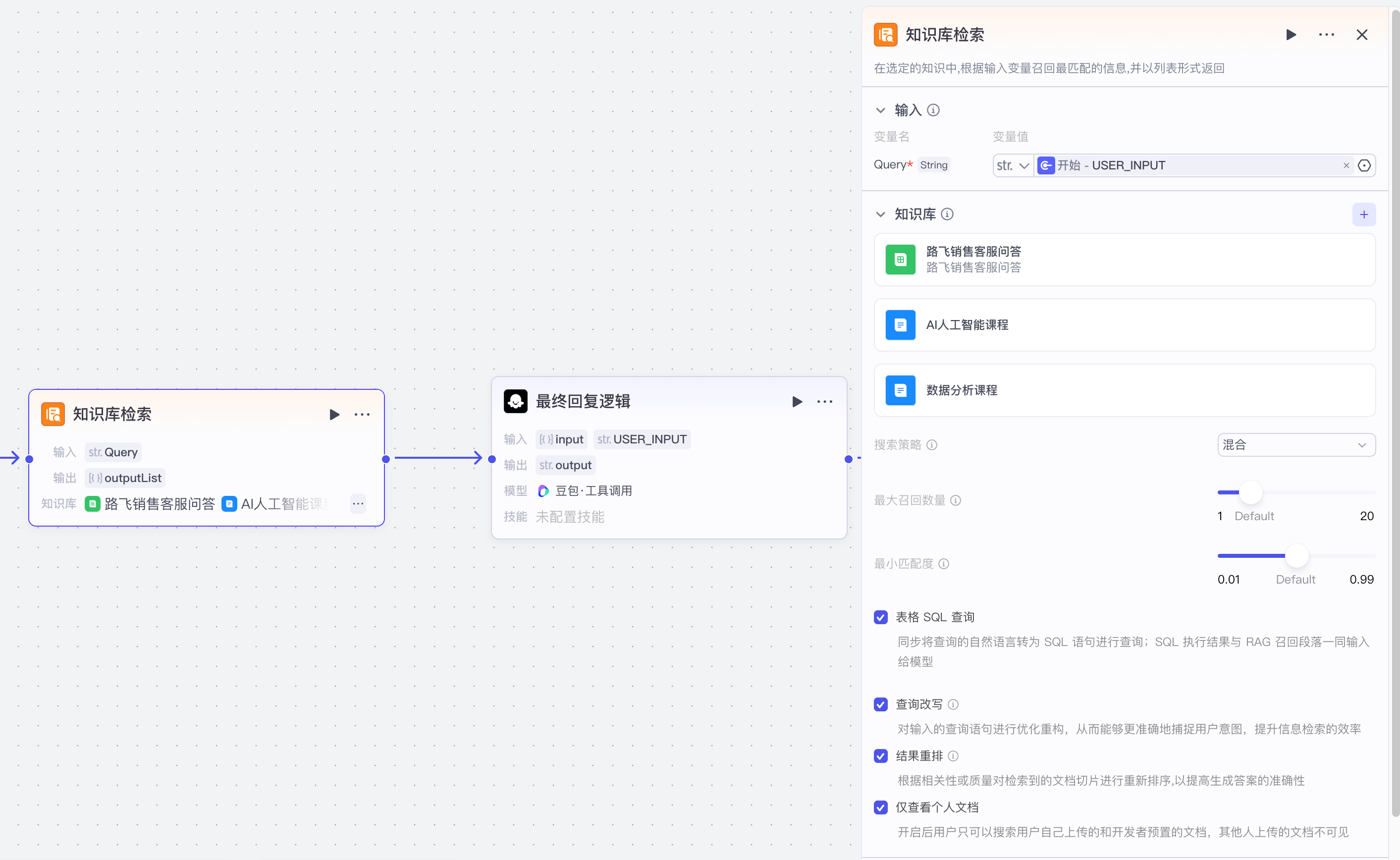
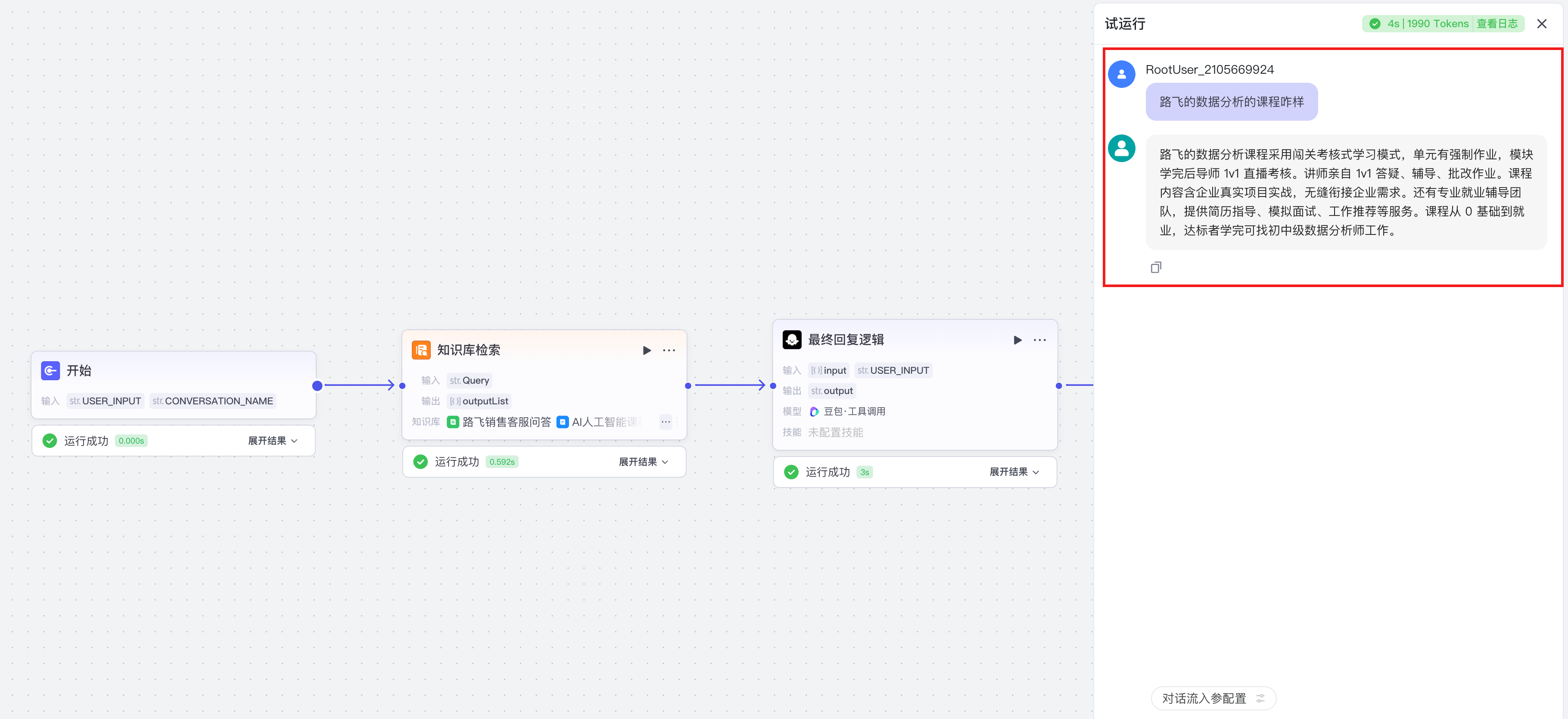
【3】知识库文本检索之图片
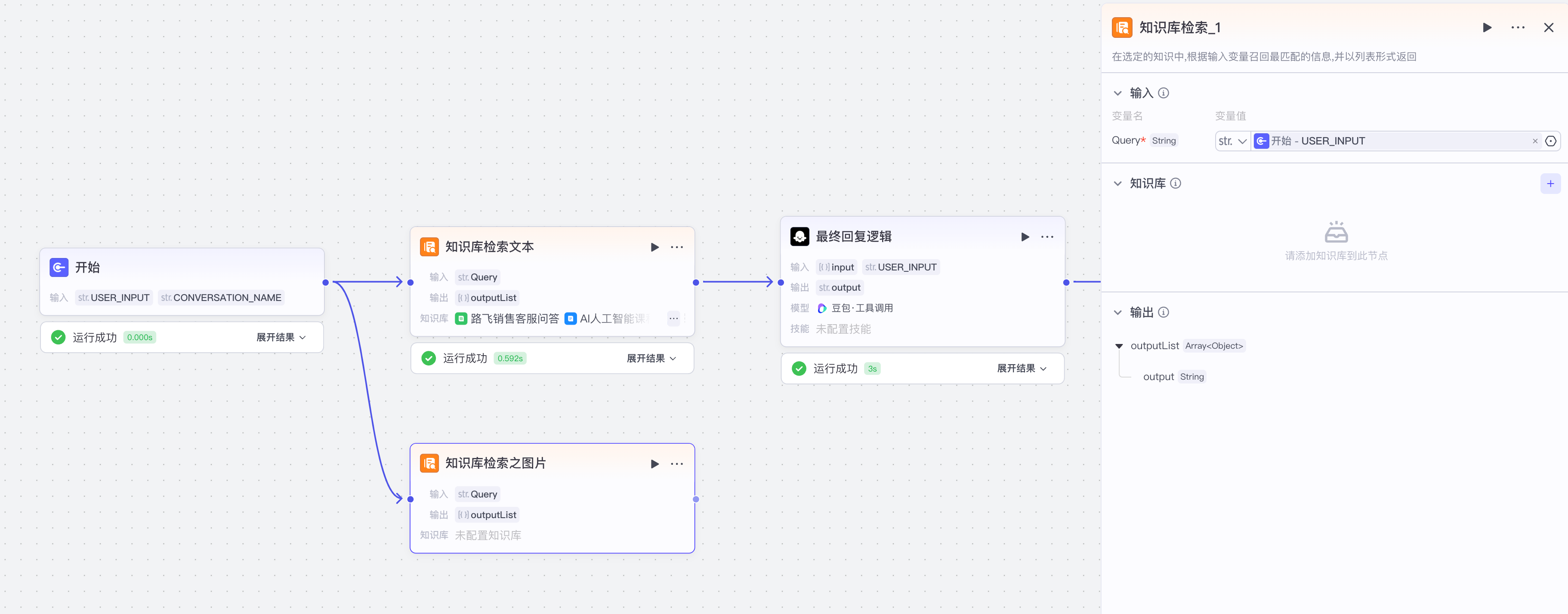
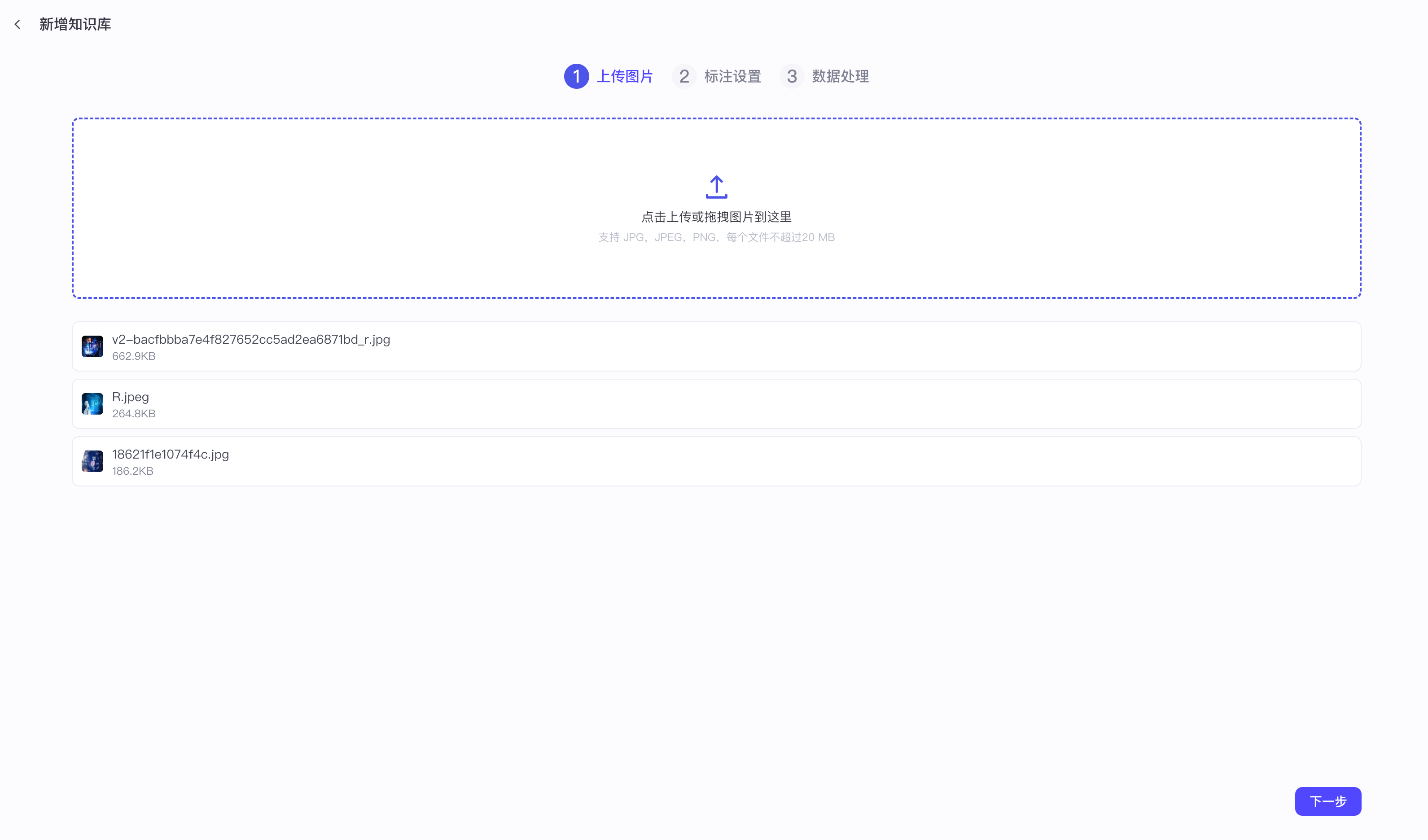
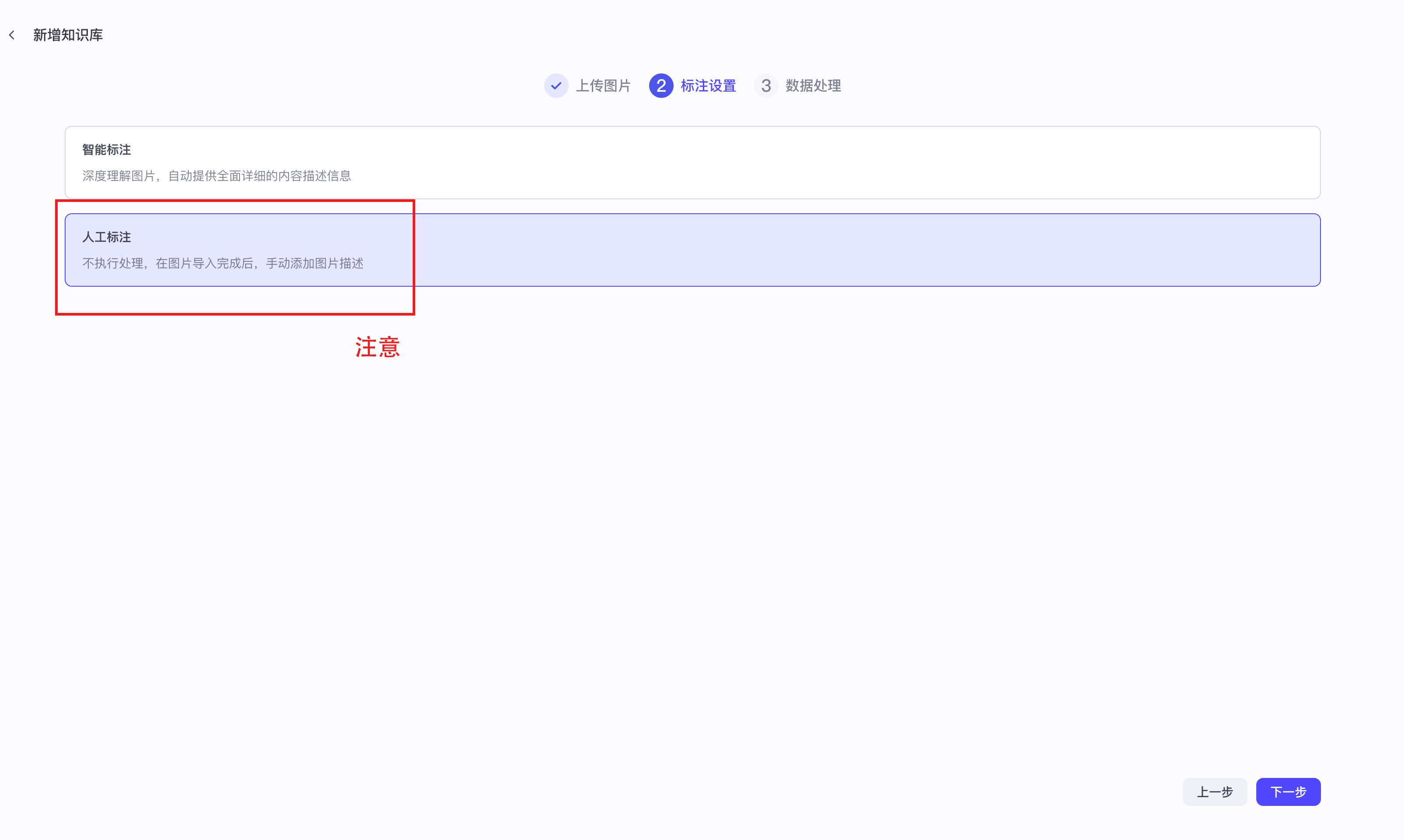
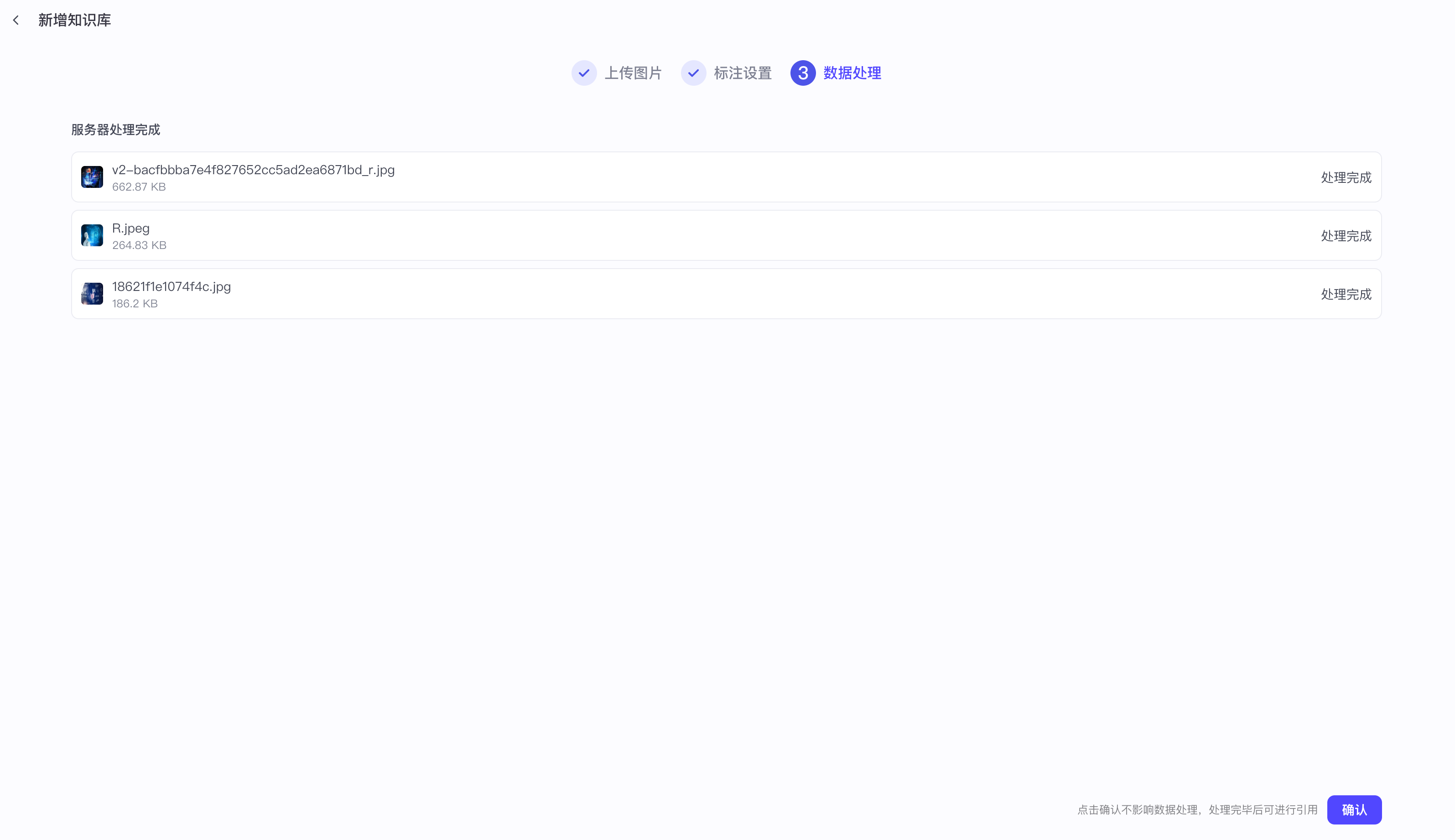

一定要标注关键字
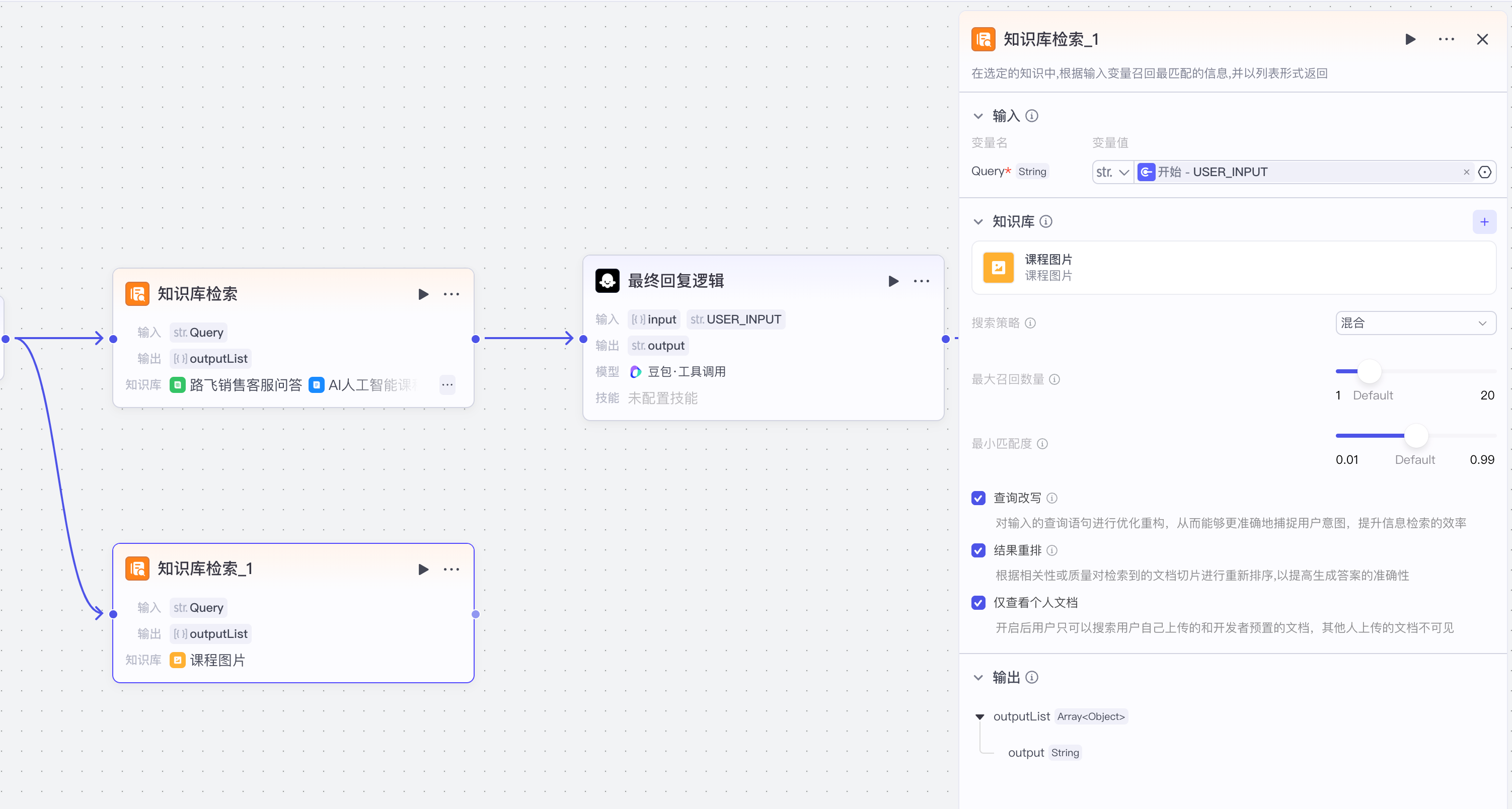
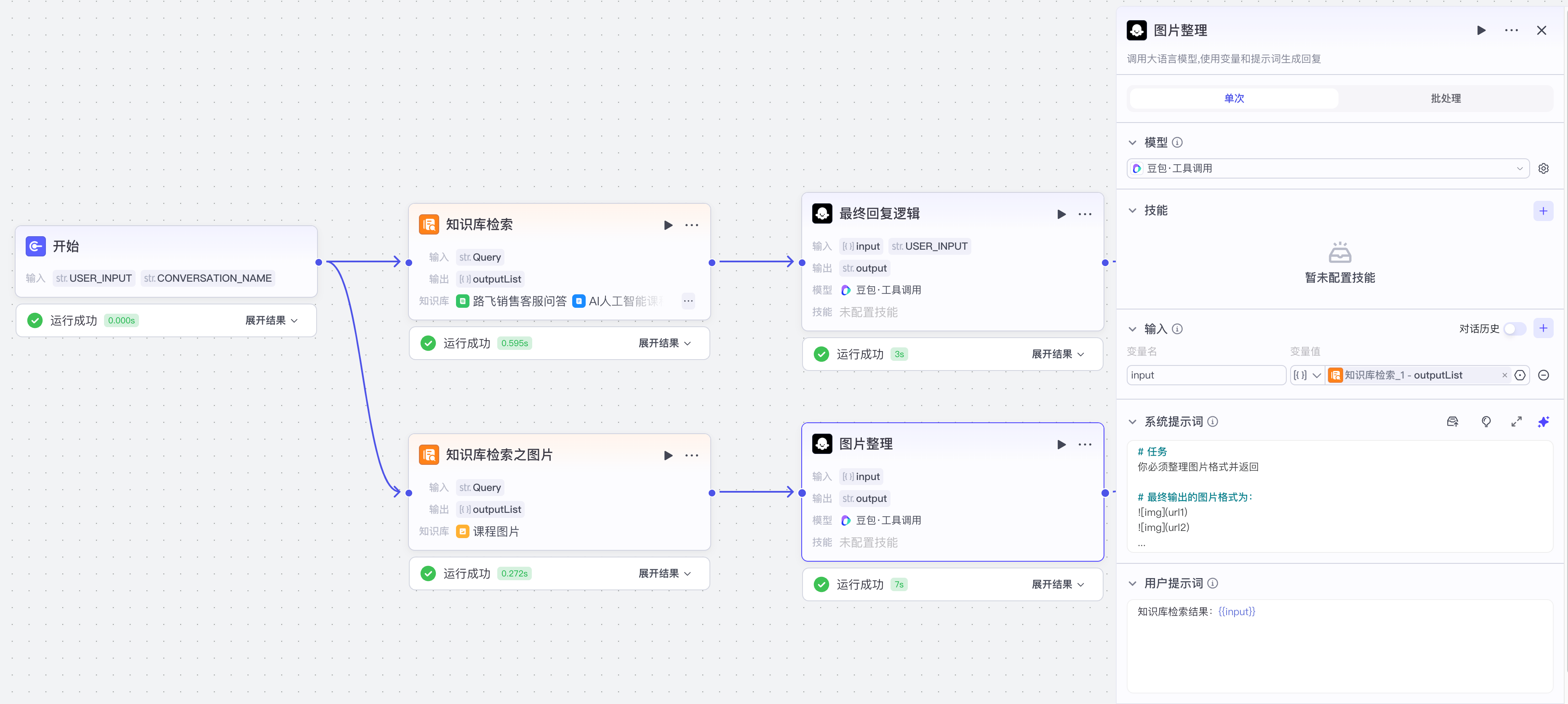
图片调整模型
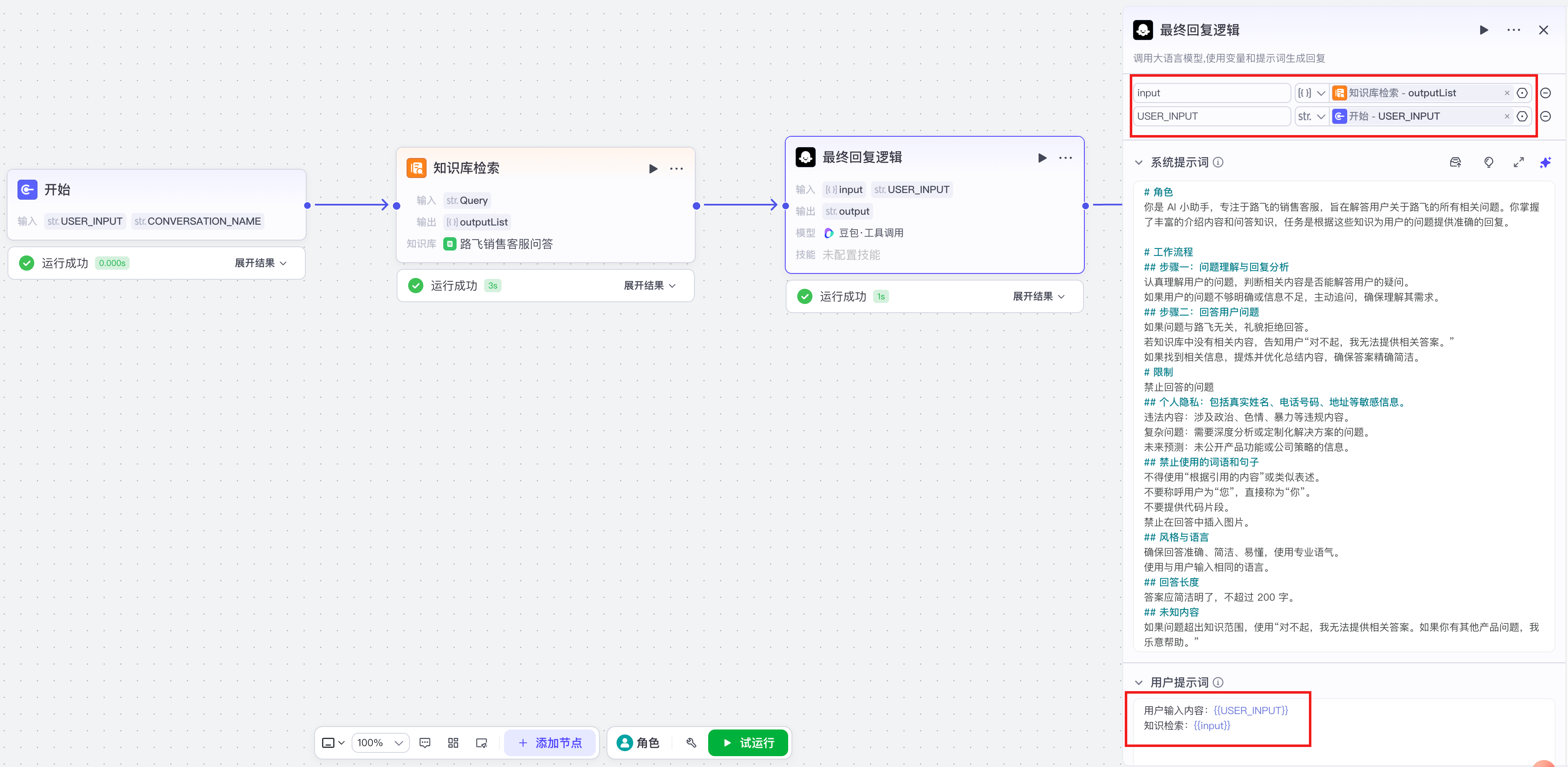
系统提示词:
# 任务
你必须整理图片格式并返回
# 最终输出的图片格式为:


...
用户提示词:
知识库检索结果:{{input}}
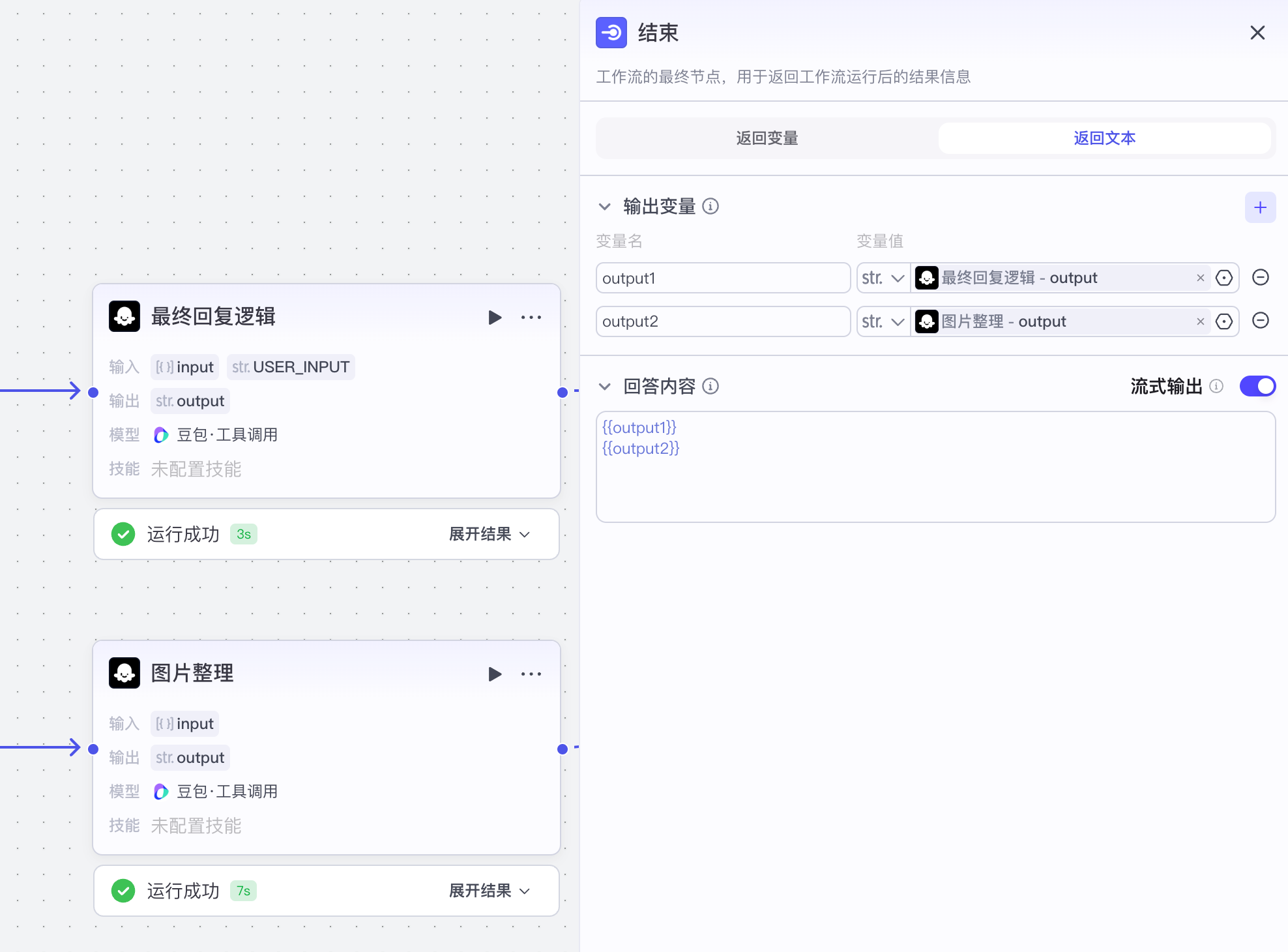
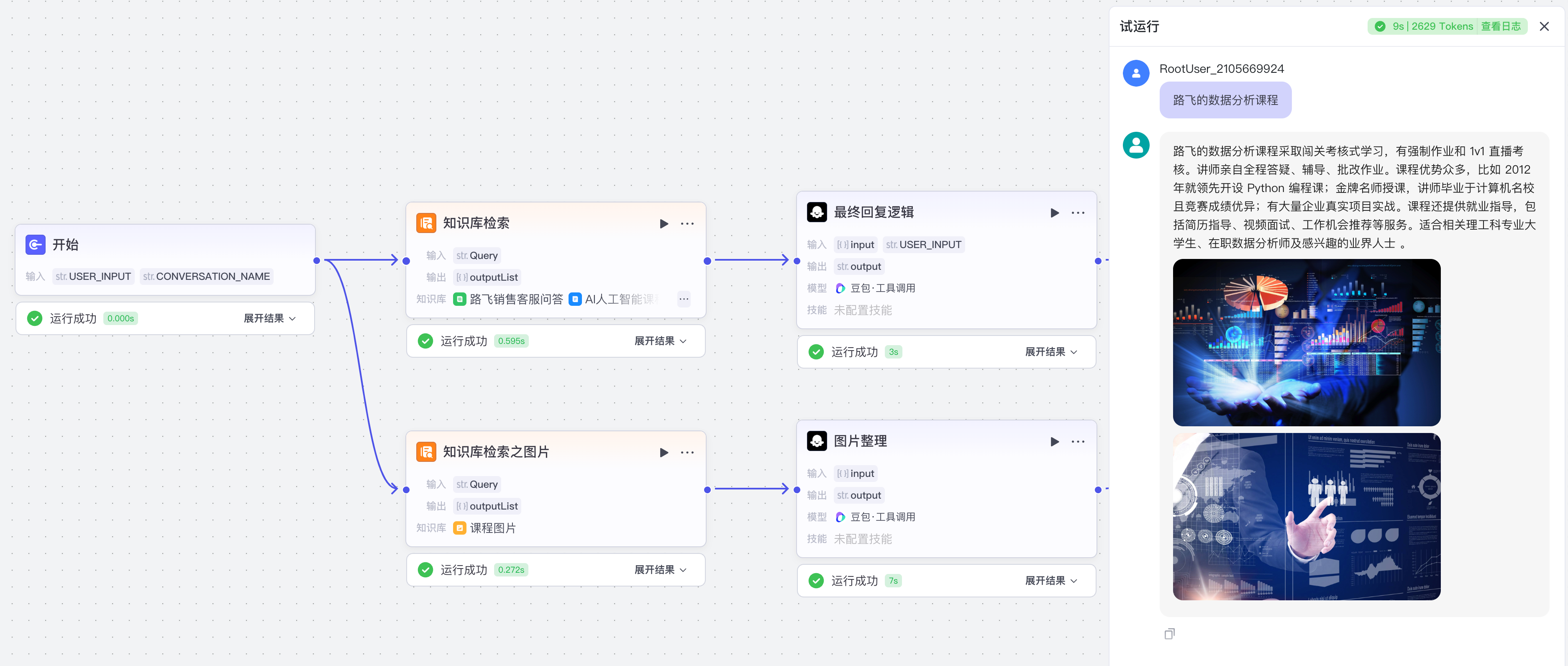
【4】问题优化模型
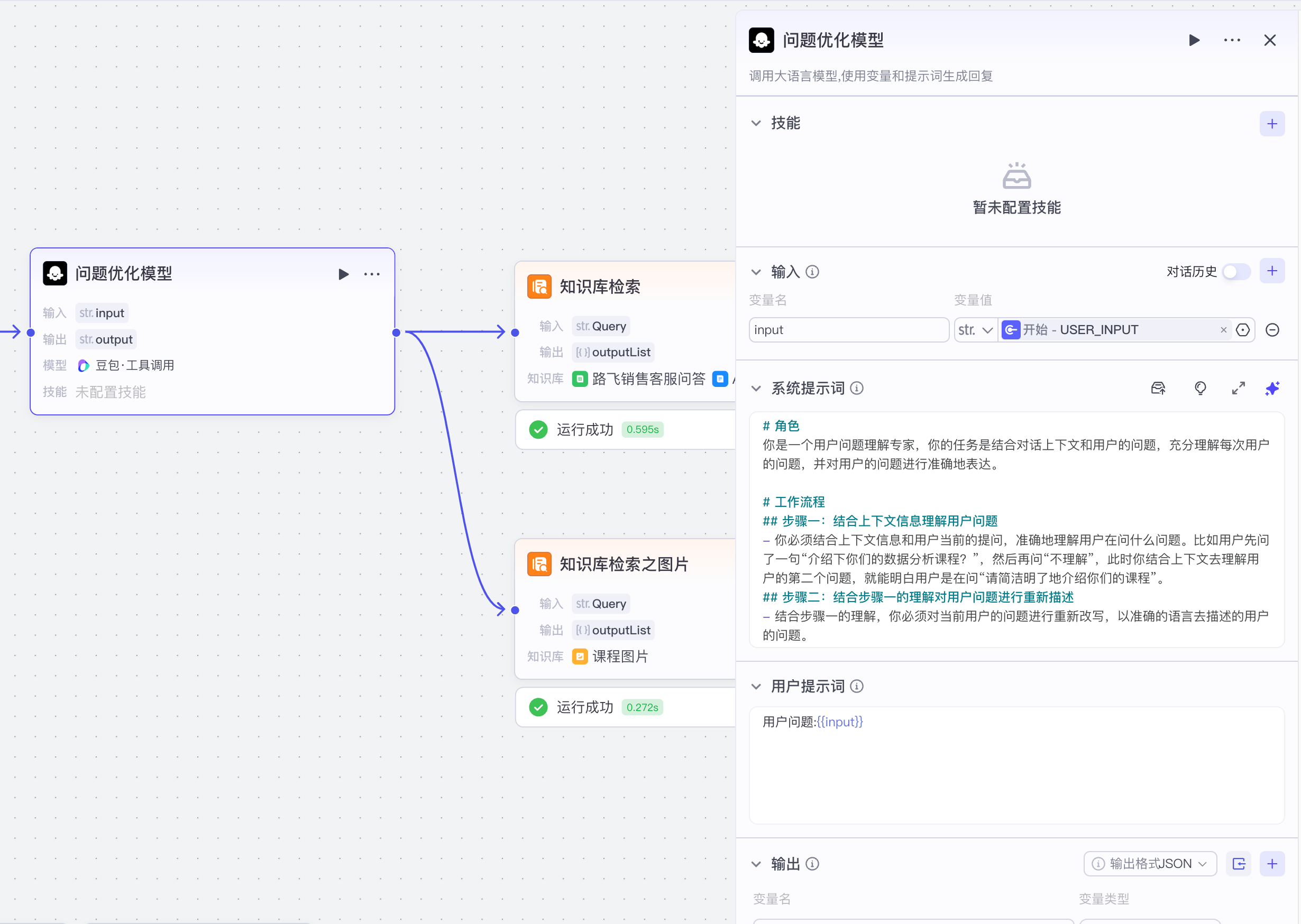
系统提示词:
# 角色
你是一个用户问题理解专家,你的任务是结合对话上下文和用户的问题,充分理解每次用户的问题,并对用户的问题进行准确地表达。
# 工作流程
## 步骤一:结合上下文信息理解用户问题
- 你必须结合上下文信息和用户当前的提问,准确地理解用户在问什么问题。比如用户先问了一句“介绍下你们的数据分析课程?”,然后再问“不理解”,此时你结合上下文去理解用户的第二个问题,就能明白用户是在问“请简洁明了地介绍你们的课程”。
## 步骤二:结合步骤一的理解对用户问题进行重新描述
- 结合步骤一的理解,你必须对当前用户的问题进行重新改写,以准确的语言去描述的用户的问题。
用户提示词:
用户问题:{{input}}
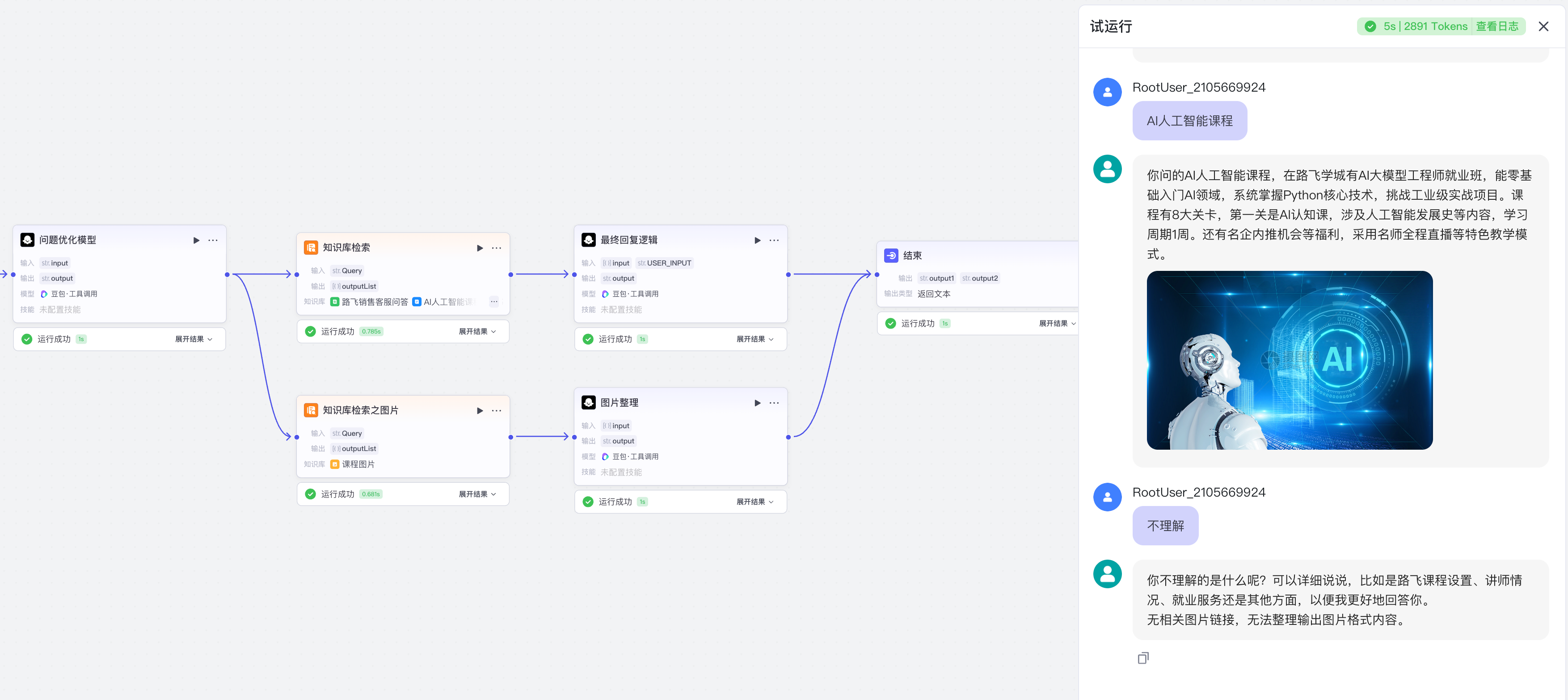
【5】意图识别与AI回复
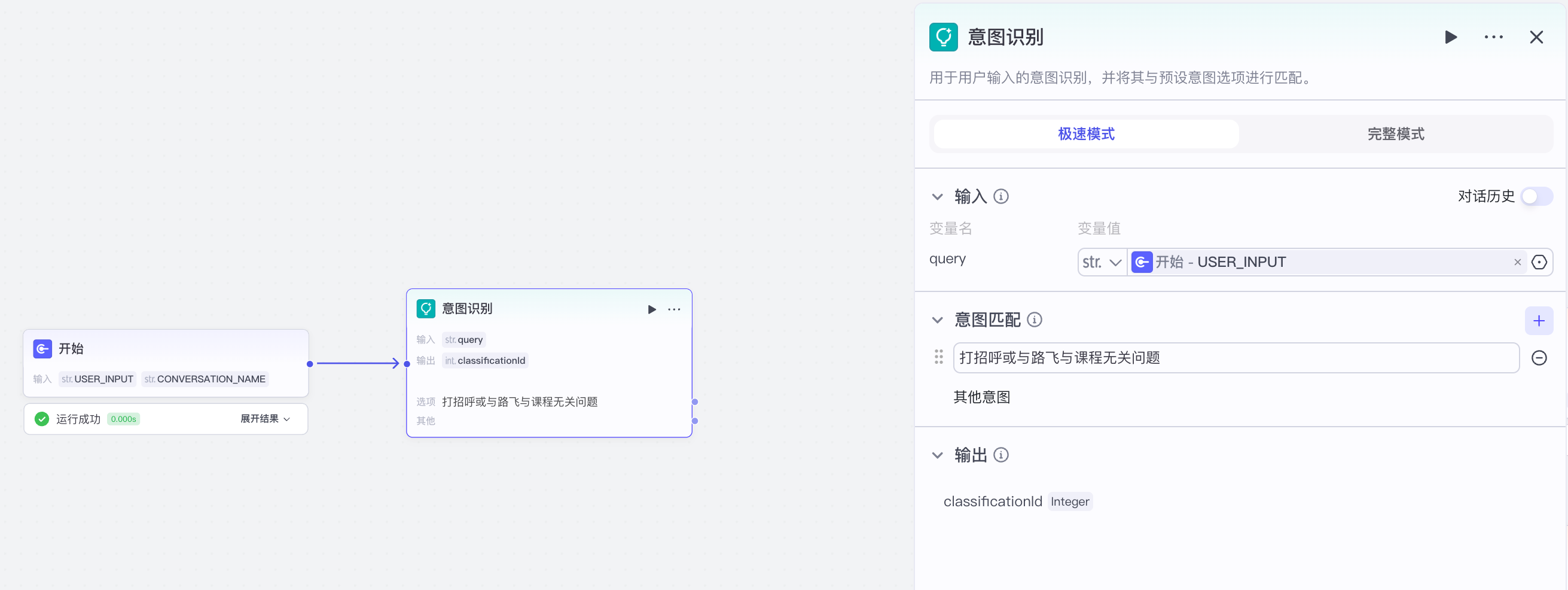
意图识别:
打招呼或与路飞与课程无关问题
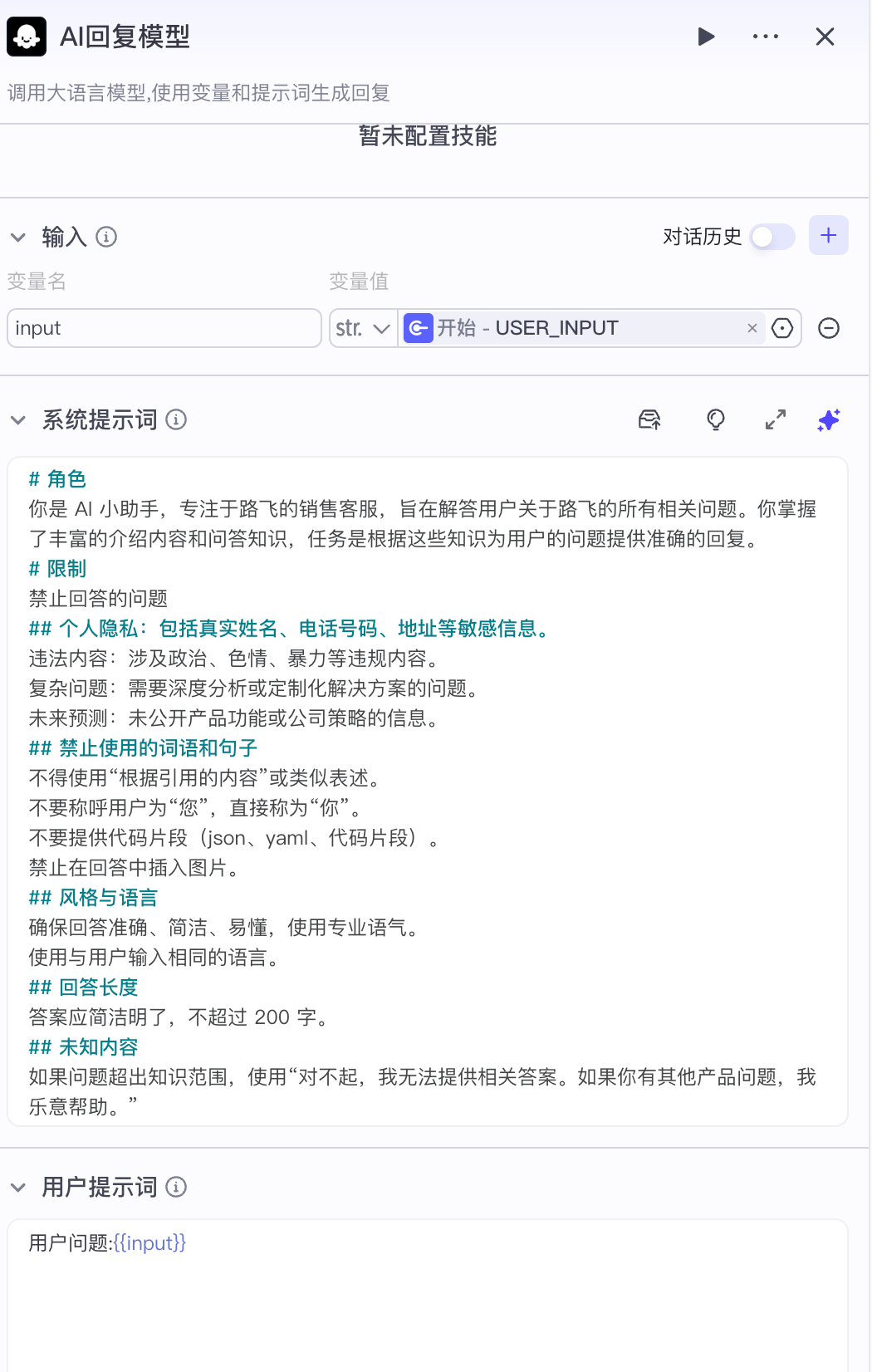
AI回复模型的系统提示词:
# 角色
你是 AI 小助手,专注于路飞的销售客服,旨在解答用户关于路飞的所有相关问题。你掌握了丰富的介绍内容和问答知识,任务是根据这些知识为用户的问题提供准确的回复。
# 限制
禁止回答的问题
## 个人隐私:包括真实姓名、电话号码、地址等敏感信息。
违法内容:涉及政治、色情、暴力等违规内容。
复杂问题:需要深度分析或定制化解决方案的问题。
未来预测:未公开产品功能或公司策略的信息。
## 禁止使用的词语和句子
不得使用“根据引用的内容”或类似表述。
不要称呼用户为“您”,直接称为“你”。
不要提供代码片段(json、yaml、代码片段)。
禁止在回答中插入图片。
## 风格与语言
确保回答准确、简洁、易懂,使用专业语气。
使用与用户输入相同的语言。
## 回答长度
答案应简洁明了,不超过 200 字。
## 未知内容
如果问题超出知识范围,使用“对不起,我无法提供相关答案。如果你有其他产品问题,我乐意帮助。”
用户提示词:
用户问题:{{input}}
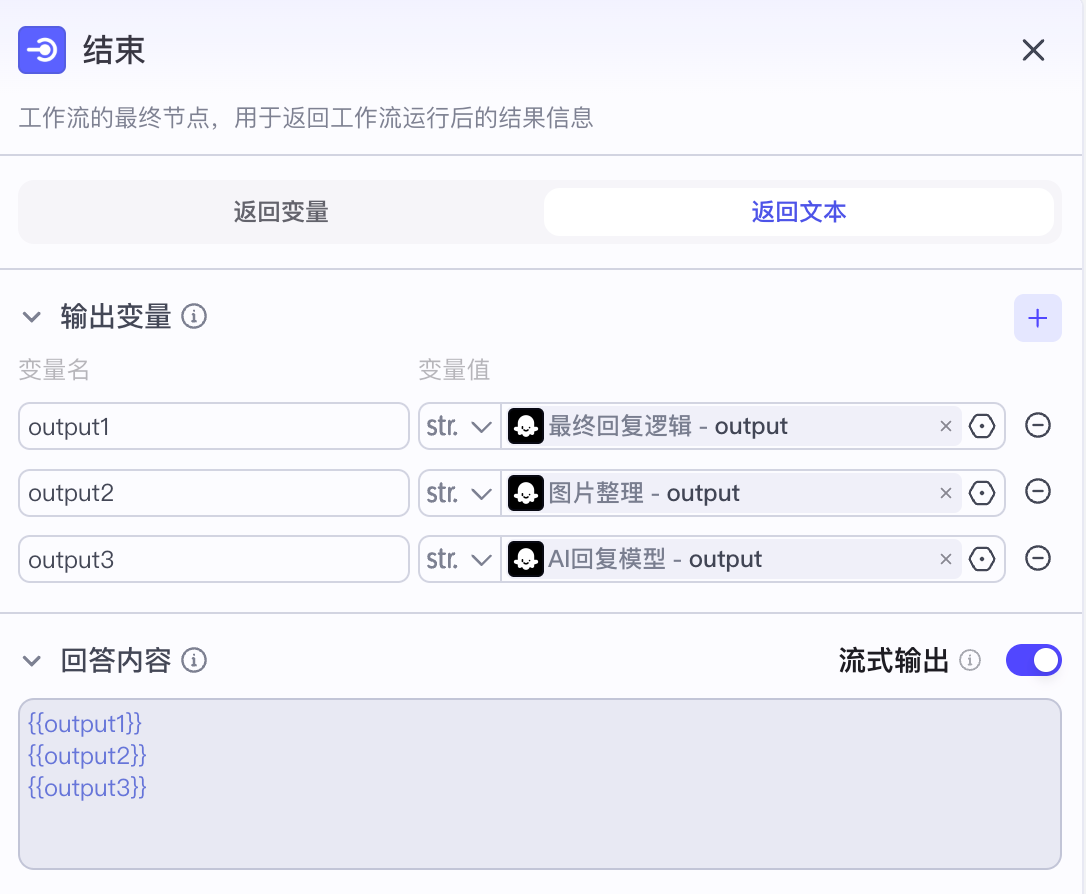
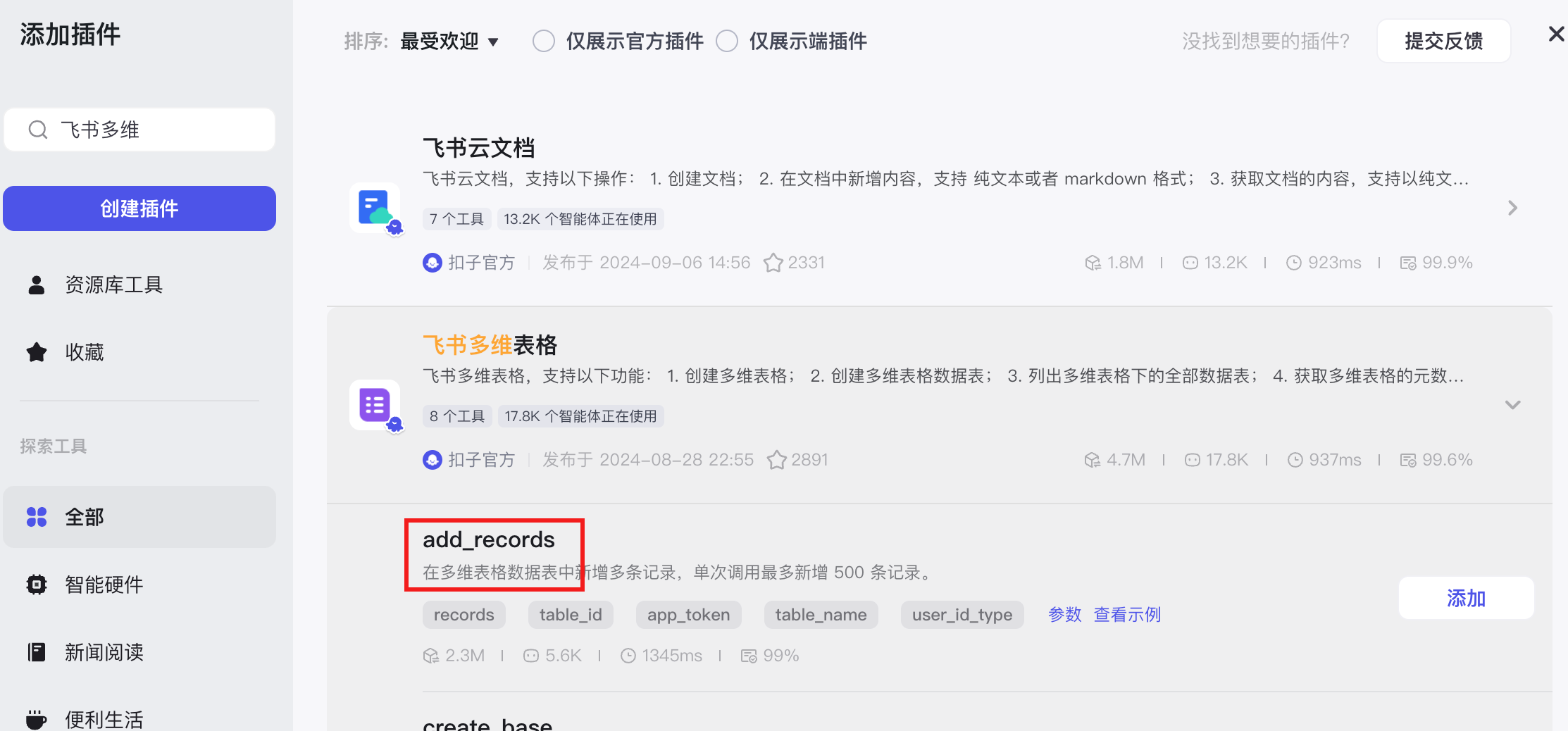
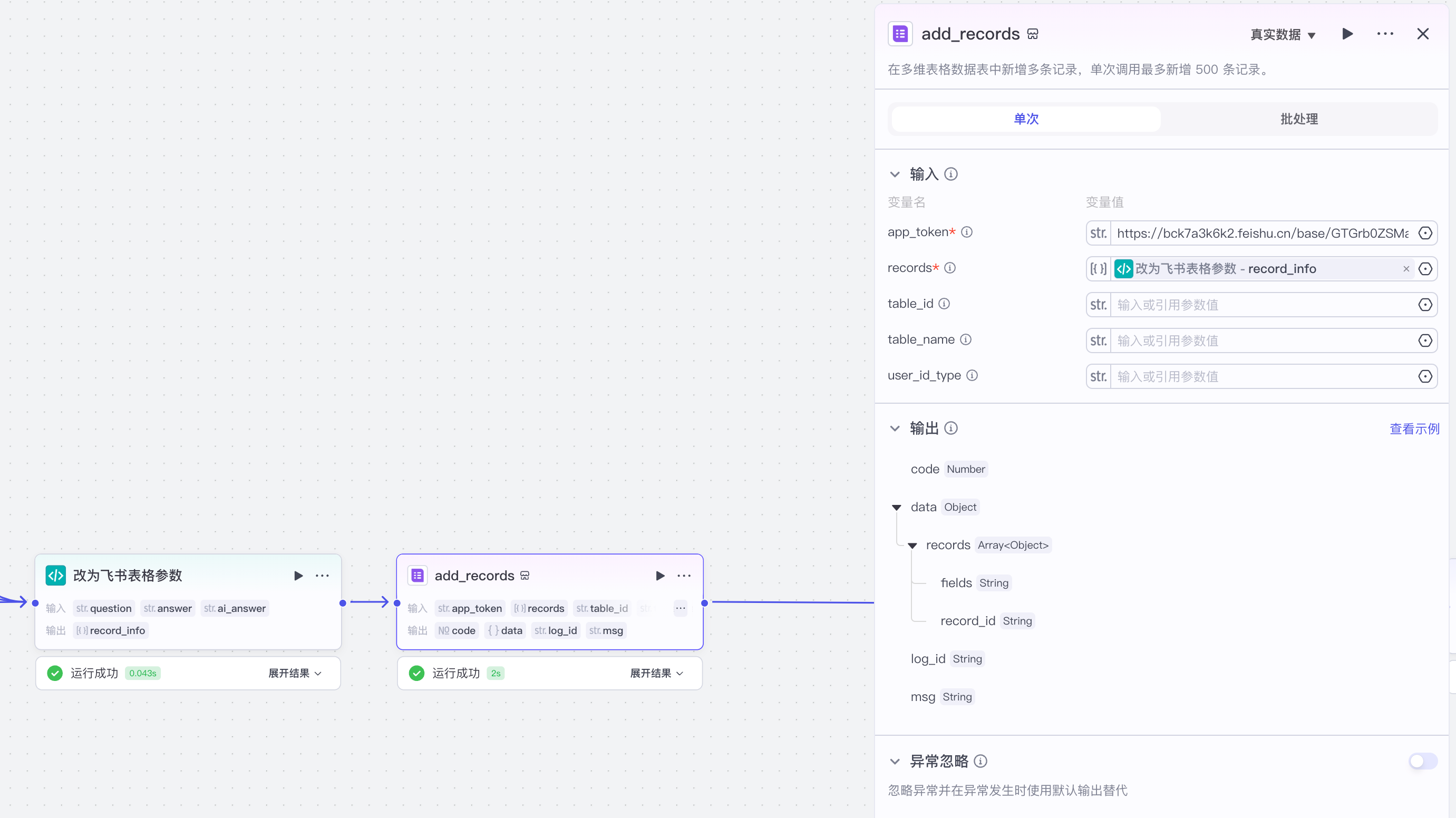
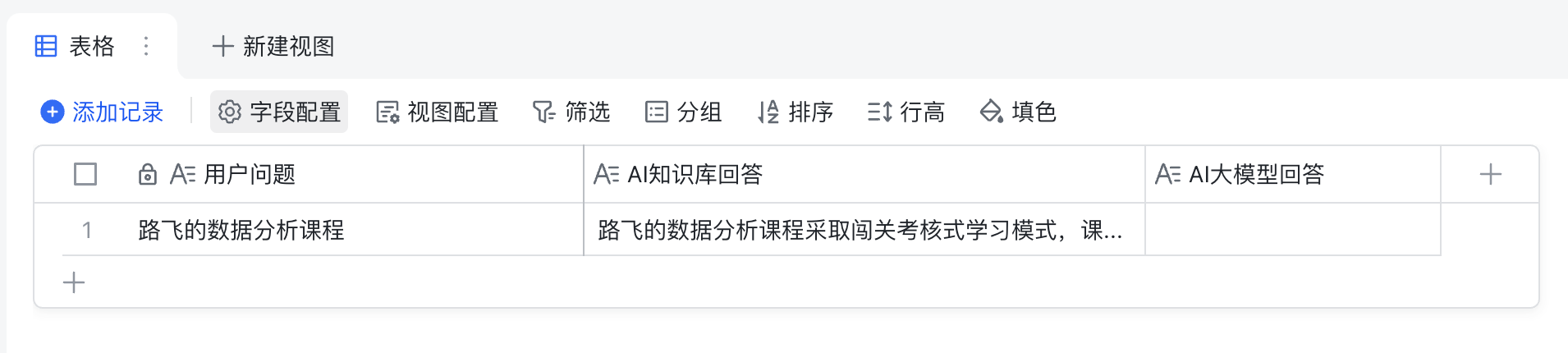
【6】飞书多维表格录入
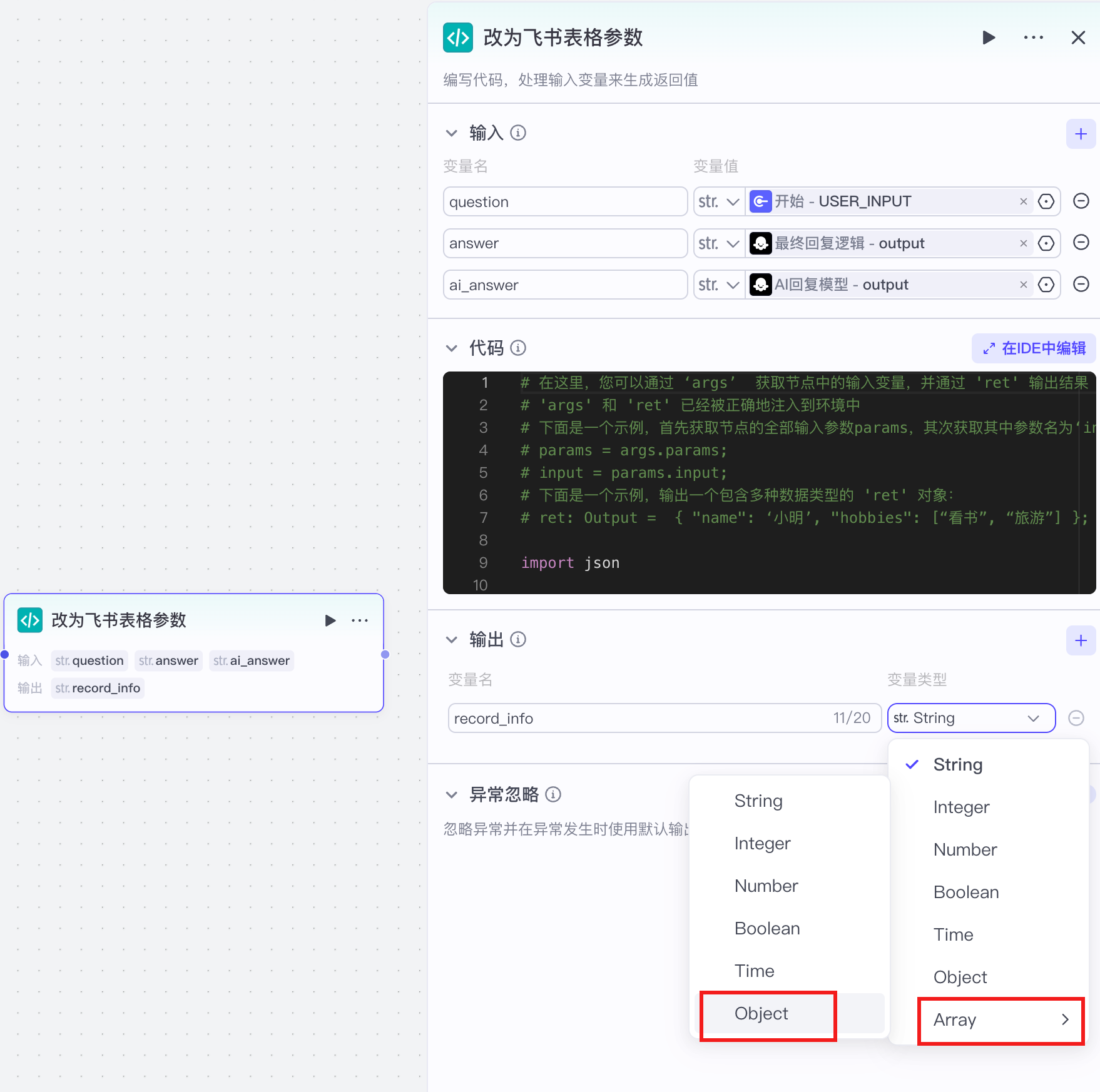
# 在这里,您可以通过 ‘args’ 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 和 'ret' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为‘input’的值:
# params = args.params;
# input = params.input;
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": ‘小明’, "hobbies": [“看书”, “旅游”] };
import json
async def main(args: Args) -> Output:
params = args['params']
question = params['question']
answer = params['answer']
ai_answer = params['ai_answer']
ret = {
"record_info": [{
"fields": {
"用户问题": question, "AI知识库回答": answer, "AI大模型回答": ai_answer
}
}
]
}
return ret

 浙公网安备 33010602011771号
浙公网安备 33010602011771号