Protocol Buffers编码详解,例子,图解
Protocol Buffers编码详解,例子,图解
本文不是让你掌握protobuf的使用,而是以超级细致的例子的方式分析protobuf的编码设计。通过此文你可以了解protobuf的数据压缩能力来自什么地方,版本兼容如何做到的,其Key-Value编码的设计思路。如果你详细了解此文,你应该就能具备自己造一套编解码轮子的能力(至少基本思路)。
测试的例子
阅读图片时请对比前面的例子和表格。每个字段的名称都是包含了tag的。
message S2 { optional int32 s2_1 = 1; optional string s2_2 = 2 ; } enum E1 { E1_1 = 1; E1_3 = 3; E1_5 = 5; } message S3 { optional int32 s3_1 = 1; //设置为0x88 optional int32 s3_2 = 2; //设置为0x8888 optional uint32 s3_3 = 3; //设置为0xE8E8E8 optional uint32 s3_4 = 4; //设置为0xE8E8E8E8 optional int64 s3_5 = 5; //设置为0x8888 optional int64 s3_6 = 6; //设置为0xE8E8E8E8 optional uint64 s3_7 = 7; //设置为0xE8E8E8E8 optional uint64 s3_8 = 8; //设置为0xE8E8E8E8E8E8E8E8 optional sint32 s3_9 = 9; //设置为0x8888 optional sint32 s3_10 = 10; //设置为-0x8888 optional sint64 s3_64 = 64; //注意这个tag id 设置为0xE8E8E8E8 optional sint64 s3_65 = 65; //注意这个tag id 设置为-0xE8E8E8E8 optional E1 s3_11 = 11; //设置为E1_5 optional bool s3_12 = 12; //设置为true optional float s3_13 = 13; //设置 float,设置为88.888 optional fixed32 s3_14 = 14; //设置为 0x8888 optional sfixed32 s3_15 = 15; //设置为 -0x8888 optional double s3_16 = 16; //设置 double,设置为8888.8888 optional fixed64 s3_17 = 17; //设置为 0x8888888888 optional sfixed64 s3_18 = 18; //设置为 -0x8888888888 optional string s3_19 = 19; //设置为 "I love you,C++!" optional bytes s3_20 = 20; //设置为 "I hate you,C++!" repeated int32 s3_21 = 21; //设置为3, 270, and 86942, 用google文档的例子 repeated int32 s3_22 = 22 [packed = true]; //设置为3, 270, and 86942 repeated string s3_23 = 23; //设置为"love","hate","C++" optional S2 s3_24 = 24; //设置为 0x1,"love" repeated S2 s3_25 = 25; //设置为 0x16,"love" and 0x16,"hate" repeated fixed32 s3_26 = 26; //设置为1,2,3 optional int32 s3_27 = 27; //不设置 }
编码的的数据表格如下,后面的剖析都会依赖这个表格进行。
|
分类说明 |
定义 |
TAG |
WriteType |
设置的值 |
编码后的16进制数据 KEY+(LENGTH)+VLAUE |
函数 |
|
VALUE用VARINT表示 |
optional int32 |
1 |
0 |
0x88 |
08 88 01 |
WriteInt32ToArray |
|
optional int32 |
2 |
0 |
0x8888 |
10 88 91 02 |
WriteInt32ToArray |
|
|
optional uint32 |
3 |
0 |
0xE8E8E8 |
18 e8 d1 a3 07 |
WriteUInt32ToArray |
|
|
optional uint32 |
4 |
0 |
0xE8E8E8E8 |
20 e8 d1 a3 c7 0e |
WriteUInt32ToArray |
|
|
optional int64 |
5 |
0 |
0x8888 |
28 88 91 02 |
WriteInt64ToArray |
|
|
optional int64 |
6 |
0 |
0xE8E8E8E8 |
30 e8 d1 a3 c7 0e |
WriteInt64ToArray |
|
|
optional uint64 |
7 |
0 |
0xE8E8E8E8 |
38 e8 d1 a3 c7 0e |
WriteUInt64ToArray |
|
|
optional uint64 |
8 |
0 |
0xE8E8E8E8E8E8E8E8 |
40 e8 d1 a3 c7 8e 9d ba f4 e8 01 |
WriteUInt64ToArray |
|
|
optional sint32 |
9 |
0 |
0x8888 |
48 90 a2 04 |
WriteSInt32ToArray |
|
|
optional sint32 |
10 |
0 |
-0x8888 |
50 8f a2 04 |
WriteSInt32ToArray |
|
|
optional E1(enum) |
11 |
0 |
E1_5 |
58 05 |
WriteEnumToArray |
|
|
optional bool |
12 |
0 |
true |
60 01 |
WriteBoolToArray |
|
|
VALUE固定4个字节 |
optional float |
13 |
5 |
88.888 |
6d a8 c6 b1 42 |
WriteFloatToArray |
|
optional fixed32 |
14 |
5 |
0x8888 |
75 88 88 00 00 |
WriteFixed32ToArray |
|
|
optional sfixed32 |
15 |
5 |
-0x8888 |
7d 78 77 ff ff |
WriteSFixed32ToArray |
|
|
VALUE固定8个字节 |
optional double |
16 |
1 |
8888.8888 |
81 01 58 ca 32 c4 71 5c c1 40 |
WriteDoubleToArray |
|
optional fixed64 |
17 |
1 |
0x8888888888 |
89 01 88 88 88 88 88 00 00 00 |
WriteFixed64ToArray |
|
|
optional sfixed64 |
18 |
1 |
-0x8888888888 |
91 01 78 77 77 77 77 ff ff ff |
WriteSFixed64ToArray |
|
|
repeated,message,string,btyes类的有长度的编码 |
optional string |
19 |
2 |
"I love you,C++!" |
9a 01 0f 49 20 6c 6f 76 65 20 79 6f 75 2c 43 2b 2b 21 |
VerifyUTF8StringNamedField |
|
optional bytes |
20 |
2 |
"I hate you,C++!" |
a2 01 0f 49 20 68 61 74 65 20 79 6f 75 2c 43 2b 2b 21 |
WriteBytesToArray |
|
|
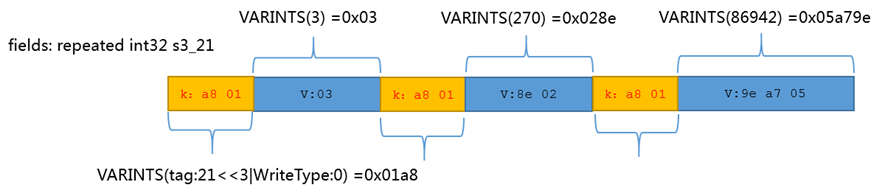
repeated int32 (对比) |
21 |
0 |
3,270,86942 |
a8 01 03 a8 01 8e 02 a8 01 9e a7 05 |
WriteInt32ToArray |
|
|
repeated int32 [packed=true] |
22 |
2 |
3,270,86942 |
b2 01 06 03 8e 02 9e a7 05 |
WriteTagToArray |
|
|
repeated string |
23 |
2 |
"love","hate","C++" |
ba 01 04 6c 6f 76 65 ba 01 04 68 61 74 65 ba 01 03 43 2b 2b |
VerifyUTF8StringNamedField |
|
|
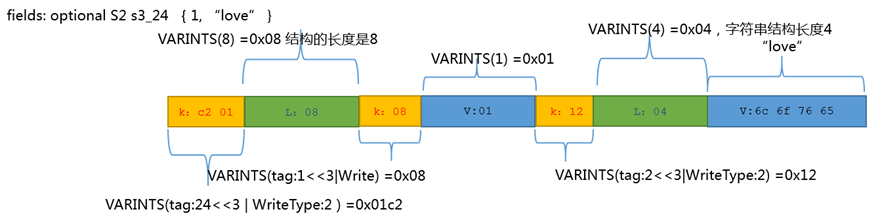
optional S2(message) |
24 |
2 |
{0x1,"love"} |
c2 01 08 08 01 12 04 6c 6f 76 65 |
WriteMessageNoVirtualToArray |
|
|
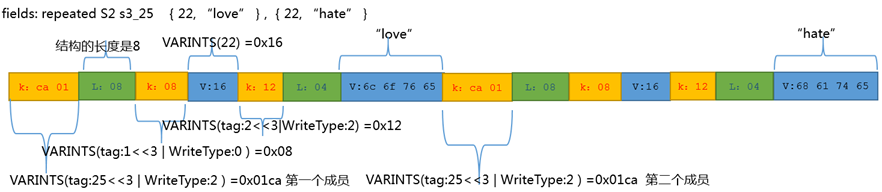
repeated S2 |
25 |
2 |
S2{0x16,"love"} ,S2{0x16,"hate"} |
ca 01 08 08 16 12 04 6c 6f 76 65 ca 01 08 08 16 12 04 68 61 74 65 |
WriteMessageNoVirtualToArray |
|
|
repeated fixed32(对比) |
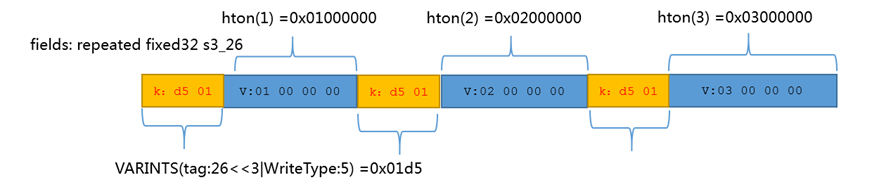
26 |
5 |
1,2,3 |
d5 01 01 00 00 00 d5 01 02 00 00 00 d5 01 03 00 00 00 |
WriteFixed32ToArray |
|
|
可选没有设置 |
optional int32 |
27 |
0 |
没有设置 |
没有数据 |
|
|
数据是安装tag排序进行编码的 |
optional sint64 |
64 |
0 |
0xE8E8E8E8 |
80 04 90 a2 04 |
WriteSInt64ToArray |
|
optional sint64 |
65 |
0 |
-0xE8E8E8E8 |
88 04 8f a2 04 |
WriteSInt64ToArray |
编码剖析
整体编码
message中的fields按照tag顺序进行编码,而每个fields的采用key+value的方式保存编码数据。如果一个optional,或者repeated的fields没有被设置,那么他在编码的数据中完全不存在。相应的字段在解码的时候回设置为默认值。如果一个required的标识的fields没有被设置,那么在IsInitialized()检查会失败。编码的顺序和元数据.proto文件内fields的定义数据无关,而是根据tag的从小到大的顺序进行的编码。
key-value的设计保证了protobuf的版本兼容。高<->低,和低<->高都可以适配。(如果高版本编码增加了required 字段,低版本数据解码后会认为IsInitialized() 失败,所以慎用required )
protobuf的整体数据都是变长的,而且有一定的自描述能力,所以其设计的核心点就是能识别出每一个key,value,(length)。

编码时对类型的再归类
先要说明,protobuf编码对自己的类型进行了再归类,其归类类型就是WireType
|
Type, |
枚举定义,WireType |
Meaning |
对应的protobuf类型 |
编码长度 |
|
0 |
WIRETYPE_VARINT |
Varint |
int32, int64, uint32, uint64, sint32, sint64, bool, enum |
变长,1-10个字节,用VARINT编码且压缩 |
|
1 |
WIRETYPE_FIXED64 |
64-bit |
fixed64, sfixed64, double |
固定8个字节 |
|
2 |
WIRETYPE_LENGTH_DELIMITED |
Length-delimited |
string, bytes, embedded messages, packed repeated fields |
变长,在key后会跟一个长度定义 |
|
3 |
WIRETYPE_START_GROUP |
Start group |
groups (deprecated) |
已经要废弃了,不看也罢 |
|
4 |
WIRETYPE_END_GROUP |
End group |
groups (deprecated) |
|
|
5 |
WIRETYPE_FIXED32 |
32-bit |
fixed32, sfixed32, float |
固定4个字节 |
编码的key
KEY = VARINT(fields_tag<<3|WireType)
fields_tag就是元数据描述.proto文件里面的tag。
WireType他们就是这个field类型对应的WireType的枚举值。见前面定义表中定义。
生产的数据再用VARINT(后面介绍)进行编码。
当类型VARINT整数数组 (比如repeated int32 ),如果不加packed=true修饰时,key=VARINT(fields_tag<<3|WriteType :0),视WireType为VARINT ,如果加上packed=true修饰时,仍然KEY = VARINT(fields_tag<<3|WireType:2),视类型为LENGTH_DELIMITED。
用字段s3_17的key举例:
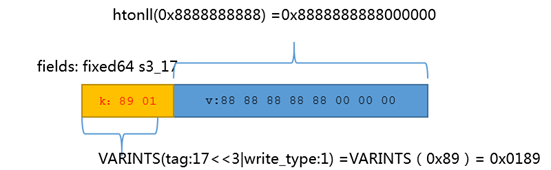
VARINTS 类型
Base 128 bits VARINS
前面说过变长编码的最大挑战是要找到每个字段边界。所以就必须能用方法能在编码的数据里面找到这个数值。
用连续字节的msb(most significant bit)为1,表示后续的字节仍然是这个数字。当首msb为0,表示结束。这个方法在UTF编码里面也常用。
例子,红色的bit都是表示连续,蓝色bit表示结束。
源: 0x8888 1000 1000 1000 1000
编: 0x029188 0000 0010 1001 0001 1000 1000
源:0xE8E8E8 1110 1000 1110 1000 1110 1000
编:0x07A3D1E8 0000 0111 1010 0011 1101 0001 1110 1000
KEY,LENGTH的编码也是用VARINTS
s3_2的字段例子
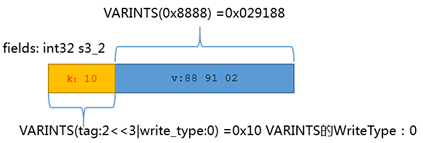
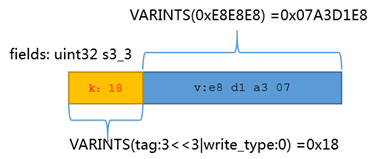
s3_3的走低am的;ozone
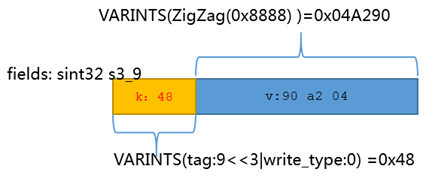
ZigZag 有符号编码
VARINS大部分时候都可以压缩数值,但如果数值很大时,反而会增加一些消耗,比如int64极限0xFFFFFFFFFFFFFFFF下需要10个字节,所以一看就有一个弱点, VARINS如果直接使用对于有符号数值不利。
所以google对此增加sint32,sint64类型,其会先采用ZigZag编码,然后再VARINS ,不说废话了,直接上google的表格示例:
算法(L我看了示例也没有想到能这样写)
(n << 1) ^ (n >> 31)
(n << 1) ^ (n >> 63)
|
Signed Original |
Encoded As |
|
0 |
0 |
|
-1 |
1 |
|
1 |
2 |
|
-2 |
3 |
|
2147483647 |
4294967294 |
|
-2147483648 |
4294967295 |
4字节和8字节的固定长度编码
double,float, 这些都是IEEE规定好的格式。大家反而都老实了。
fixed32,sfixed32,fixed64,fixed64,适合存放大数字数字。编码后变成网络序。

下图是展示repeated fixed32的编码,可以看到其实就是key重复出现。
变长LENGTH_DELIMITED
string,bytes
string的编码还是key+value,只是value里面多了一个长度。
string的要求是UTF8的编码的。所以如果不是这个编码最好用bytes。
string的编码带入没有'\0'

下图是repeated string

repeated VARINTS packed
repeated 的VARINTS 有带packed=true 时也是变长,带packed=true的描述会压缩更多,但和普通repeated模式不太一样。
下面的例子是带有packed的字段s3_22的例子

下面是不带packe=true的例子。
内嵌类,
内嵌类,中间潜入类S2的例子,s3_24{1,"love"},内嵌类里面的编码方式和外部一样,只是内嵌类的tag使用其自己的tag。
下面的例子是repeated S2 s3_25{22,"love"},{22,"hate"}
Protobuf的解码
编码和解码函数SerializeToArray,ParseFromArray,得到编码size要调用函数ByteSize。如果要逃避required的IsInitialized()检查检查,可以用SerializePartialToArray, ParsePartialFromArray一类函数。当然后果自负。
proto的解码就是找到key,根据key找到tag(代码里面叫fieldnumber),然后根据tag进行解码,因为编码是KV的,编码本事有一定的防错性。
比较有意思的是google在代码里面会有预测下一个tag解码处理。应该是为了加速处理(不进入for循环)。
对比先驱们ASN.1,CDR等
其实拿protobuf和XML这类编码比完全是不公平的较量,简直就是欺负小P孩。真正应该拿来对比到时当年这些真正的编码工具,比如电信中的ASN.1和CORBA中的CDR等。这些编码先驱对数据的读取操作往往是完全依靠生产的代码(大部分没有kv设计)。
我自己觉得最大改变来自当年的编解码工具在编码的时候,只着眼于双方(比如异构系统)的数据值表示不一致时,将异构的数据编译成数据流的问题,而protobuf在之上还解决了分布系统中重要的麻烦,版本兼容的问题。
其实性能方面,这些先驱和Protobuf应该都在伯仲之间。
protobuf的数据类型支持其实并不丰富。但这样也在多语言支持上轻松了很多。(想想给lua支持一个char,short),在编码处理上也有很多化烦为简的设计。
protobuf的字段更新,版本兼容
KeyValue的编码+可选项默认值方法保证了protobuf在版本兼容上有先天优势。
关于字段更新,和版本兼容,google给出的建议:
【参考】https://developers.google.com/protocol-buffers/docs/proto ,
- 不要试图改变tag。
- 如果要新增一个field,请使用optional和repeated,不要使用required。(高版本出现一个required,你当低编码ó高解码怎么办。)
- 如果一个不需要的字段可以保留,避免其tag被勿用造成冲突,可以加入明显的前缀OBSOLETE_标识。
- int32, uint32, int64, uint64, and bool 是兼容的,他们都是使用VARINTS(v)进行编码的。
- sint32,sint64是兼容的他们都是使用VARINTS(Zigzag(v))进行编码的。
- 如果bytes是UTF-8的编码,那么和string兼容
- fixed32,sfixed32 兼容,fixed64和sfixed64兼容。
- optional 兼容repeated.(原文不够准确,应该是如果没有加pack=true修饰),为什么可以兼容?前面白画那么多图了。
使用protobuf的建议
可以不使用requested,只是用optional+default 默认值, requested只是将你需要做的检查交给了protobuf。代价是版本兼容的麻烦。不如不用。
版本兼容宝典:字段只新增,不删除,字段描述不用requested,任何时候tag不要变动,类型变化要慎重只有兼容才可以(但还是慎重把!),optional到repeated的变换也可以(只要没用pack=true)。
tag是要占空间的,如果tag>16时,KEY的编码就会占用2个字节了。所以tag的定义尽量不要跳动。
如果要出现负数,不要使用int32,int64,而应该使用sint32,sint64。
string真要UTF8的,有检查的。
repeated的VARINTS类型,可以增加packed=true减小占用空间,但有低版本不兼容的风险。
对于repeated字段的使用,protobuf是有提前(预分配)分配空间的,扩展基本就是乘以2,对同一个message,如果已经分配好空间了,Clear并不回收这一空间。所以尽量使用一个控制点编解码比较好。
.proto生成的message对应的结构很重,在游戏开发中不合适直接使用。需要你自己的数据和message的结构之间转换。(这个我很不爽)
Protobuf的伟大和挑战
多语言支持是protobuf的重大加分项。其实这点社区贡献良多。
KV的设计+可选和默认值,保证版本兼容。而且支持很天然,就我所知在其出来之前,没有一个编码工具把这个事情解决舒服了。
完善的文档体系和开源的方式让其获得了大量拥戴,以及大量社区的支持。
我不爽protobuf的地方:
- 不能和代码直接交互使用,我更希望其能生成我代码直接可以用的struct,另外部分是对这个struct的编码函数。
- request描述既然看起来那么多余,直接废弃把。而可选可以直接通过默认值比较判定。
- repeated是动态分配的。如果不重复使用,其实性能不高。我总觉得Flatbuffers的benchmark占了这个便宜好像更多。
- VARINTS的编码有压缩,但我总觉得为了那几个字节牺牲性能,不值得。如果字段少,减少不了几个字节。如果字段多,也未见得多有效。我是做游戏开发的,Who Care那几个字节?(开始觉得google有点怪,他一搞文本处理的,Care几个整数干嘛?后面frost和wookin提醒我说google其实处理的是大量的docid,wordid,发现是自己脑子短路了。他确实有压缩的必要。)
- 好多代码呀,好大的库呀。
- 反射的设计,反正你还是要写不少代码的。
- 序列化为啥不直接用Json,而要搞个类似Json?
google的还有一个新的为游戏开发准备的编码方式Flatbuffers,人家还在不断进步。
参考文档
《google的protobuf文档》https://developers.google.com/protocol-buffers/docs/overview
《google的protobuf编码解释》https://developers.google.com/protocol-buffers/docs/encoding
《Flatbuffer的bechmark》http://google.github.io/flatbuffers/md__benchmarks.html
《protobuf详解》http://www.cnblogs.com/cobbliu/archive/2013/03/02/2940074.html 非常详细的一篇文章,唯一感觉没有说清的地方是可变长度的字段。
ferguszhang(张峰祯)的protobuf介绍图片。
【本文作者是雁渡寒潭,本着自由的精神,你可以在无盈利的情况完整转载此文档,转载时请附上BLOG链接:http://www.cnblogs.com/fullsail/,否则每字一元,每图一百不讲价。对Baidu文库和360doc加价一倍】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号