


软件作业2:论文查重
| 软件工程 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-12 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-12/homework/13014 |
| 作业目标 | 个人项目 |
github链接 :FHZ003/3121004993 (github.com)
PSP表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 30 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 300 | 500 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 70 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 30 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 30 |
| · Design | · 具体设计 | 45 | 60 |
| · Coding | · 具体编码 | 60 | 120 |
| · Code Review | · 代码复审 | 25 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 95 | 30 |
| Reporting | 报告 | 120 | 80 |
| · Test Repor | · 测试报告 | 50 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 50 | 30 |
| · 合计 | 450 | 600 |
模块接口的设计与实现
| 函数 | 说明 |
|---|---|
| string readFileContent(char* addr) | 打开地址为addr的文本,读取内容并用string返回 |
| void writeFileContent(char* addr, const double& val) | 打开地址为addr的文本,将val值输出至文件 |
| map<string, int> calculateWordFrequency(const string& text) | 传入text文本,用n-gram算法分词,然后计算词频,返回一个map |
| double calculateSimilarity(const vector |
传入两个词向量vec,用余弦公式计算余弦相似度并返回 |
| int main(int argc, char* argv[]) | 用命令行参数按顺序将[原文文件] [抄袭版论文的文件] [答案文件]的路径传入,然后主函数内会依次调用各个功能函数完成论文查重,并将文本相似度输出至答 |
需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
模块设计及实现过程及流程图
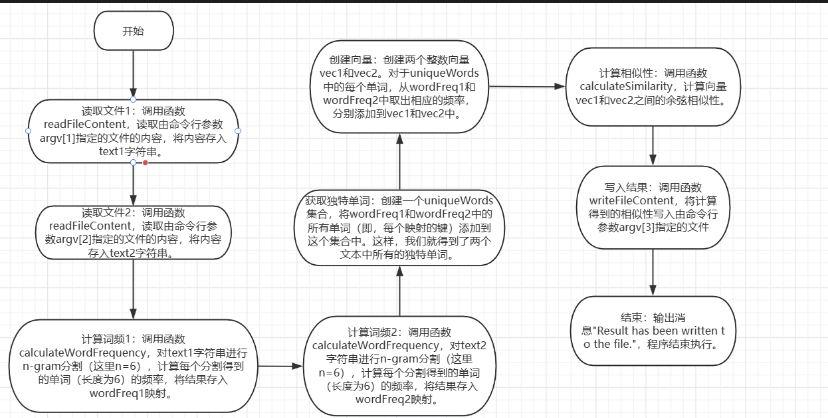
readFileContent函数读取一个文件的内容,如果文件打开失败,程序会输出错误消息并退出。writeFileContent函数向一个文件写入内容,如果文件打开失败,程序会输出错误消息并退出。calculateWordFrequency函数计算文本中每个单词的频率,并返回一个包含每个单词及其频率的映射。这个函数使用n-gram分割(这里n=6)来分割文本。calculateSimilarity函数计算两个向量之间的余弦相似性。在这个情况下,向量是由单词频率组成的。main函数首先读取两个文件的内容,然后计算每个文件的单词频率。然后,它找出这两个文件共有的所有单词,并计算这些单词在两个文件中的频率。最后,它计算这两个频率向量的相似性,并将结果写入第三个文件。
模块间的关系
readFileContent和writeFileContent是两个独立的函数,它们分别与输入文件和输出文件交互。它们与其他模块之间没有直接的关系。calculateWordFrequency函数接收一个字符串作为输入,然后计算该字符串中每个单词的频率,并将结果存储在一个映射(map)中。这个函数与readFileContent函数有联系,因为readFileContent函数读取文件内容并将其作为字符串返回,然后可以将这个字符串传递给calculateWordFrequency函数进行处理。calculateSimilarity函数接收两个整数向量作为输入,并计算它们之间的余弦相似性。这个函数与calculateWordFrequency函数有联系,因为calculateWordFrequency函数生成的映射可以被转换为整数向量,然后可以传递给calculateSimilarity函数进行计算。main函数是整个程序的入口点。它首先调用readFileContent函数读取两个输入文件的内容,然后将这些内容传递给calculateWordFrequency函数计算每个文件的单词频率。接着,它使用这两个频率映射生成两个整数向量,并将它们传递给calculateSimilarity函数计算相似性。最后,它调用writeFileContent函数将相似性结果写入输出文件。
总体而言,这个代码模块间的关系是一种线性流程,从读取输入文件到计算相似性,再到将结果写入输出文件。其中,calculateWordFrequency和calculateSimilarity是处理文本和向量的核心函数,它们与输入文件和输出文件之间没有直接的关系,而是通过中间结果(字符串和整数向量)与其他模块进行交互。
流程图
算法关键
- N-gram分割:N-gram是一种语言模型,用于文本挖掘和自然语言处理。N-gram分割是这段代码中一个关键步骤,用于将输入的文本分割成长度为n的单词或词组。在这段代码中,n被设定为6,即每次取6个字符作为一个单元进行处理。
- 余弦相似性计算:余弦相似性是一种衡量两个向量方向相似度的度量,值域在-1到1之间,值越大表示方向越接近。在这段代码中,余弦相似性被用于衡量两个文本之间的相似性。通过计算两个文本中相同单词或词组的频率向量的余弦相似度,可以量化这两个文本的相似程度。
以上两个算法结合起来,可以实现从文本中提取特征(即n-gram分割),并通过计算这些特征的频率向量来比较两个文本的相似性。
模块接口的性能分析及改进
对于这段代码的性能分析及改进,可以从以下几个方面考虑:
- 文件读写性能:
readFileContent和writeFileContent函数涉及文件读写操作,它们的性能取决于文件的大小和系统的I/O性能。为了提高这两个函数的性能,可以考虑使用缓存技术,例如使用内存映射文件或预读技术来减少磁盘访问次数。另外,可以使用异步I/O操作来避免阻塞主线程。 - 字符串处理性能:
calculateWordFrequency函数涉及字符串处理操作,它的性能取决于输入字符串的长度和n-gram分割的大小。为了提高这个函数的性能,可以考虑使用更高效的字符串处理方法,例如使用正则表达式或滑动窗口算法。另外,可以考虑将字符串处理结果缓存起来,避免重复计算。 - 向量计算性能:
calculateSimilarity函数涉及向量计算操作,它的性能取决于向量的大小和相似性计算的方法。为了提高这个函数的性能,可以考虑使用更高效的向量计算方法,例如使用并行计算或矩阵运算库。另外,可以考虑将向量计算结果缓存起来,避免重复计算。 - 数据结构选择:这段代码中使用了映射(map)和集合(set)数据结构来存储单词频率和独特单词。这些数据结构的选择对性能有一定的影响。例如,使用哈希表实现的映射和集合具有较快的查找和插入操作,但可能会占用更多的内存。为了提高性能,可以根据实际情况选择更合适的数据结构,例如使用数组或压缩数据结构来减少内存占用和提高访问速度。
- 算法优化:除了以上几个方面的性能优化,还可以考虑对算法本身进行优化。例如,在
calculateWordFrequency函数中,可以使用滑动窗口算法来减少字符串处理次数。在calculateSimilarity函数中,可以使用矩阵运算库来加速向量计算。
综上所述,这段代码的性能优化可以从文件读写、字符串处理、向量计算、数据结构选择和算法优化等几个方面入手。根据实际情况选择合适的优化方法可以提高代码的性能和效率。
性能分析图
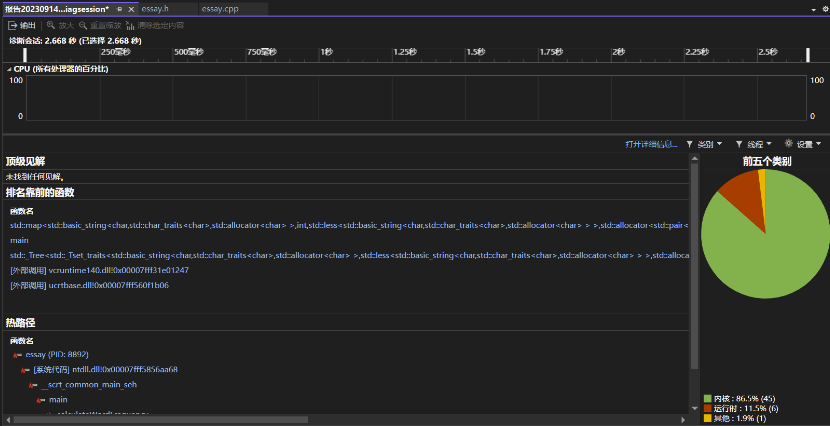
程序中消耗最大的函数
这个程序的性能消耗最大的函数可能会因多种因素而异,如输入文件的大小、系统的I/O性能、算法的效率等。然而,可以根据代码的逻辑和功能做一些初步的分析:
readFileContent函数:这个函数负责读取输入文件的内容,并将内容存储在一个字符串中。如果输入文件非常大,那么这个函数的I/O操作可能会成为性能瓶颈。writeFileContent函数:这个函数负责将计算结果写入输出文件。同样,如果输出文件非常大,那么这个函数的I/O操作也可能会成为性能瓶颈。calculateWordFrequency函数:这个函数负责计算输入字符串中每个单词的频率,并将结果存储在一个映射中。如果输入字符串非常长,或者n-gram分割的大小非常大,那么这个函数的字符串处理和映射操作可能会成为性能瓶颈。calculateSimilarity函数:这个函数负责计算两个向量之间的余弦相似性。如果向量非常大,那么这个函数的向量计算可能会成为性能瓶颈。
综上所述,这个程序的性能消耗最大的函数可能是readFileContent、writeFileContent、calculateWordFrequency或calculateSimilarity中的一个,具体取决于输入文件的大小、系统的I/O性能等因素。
模块测试
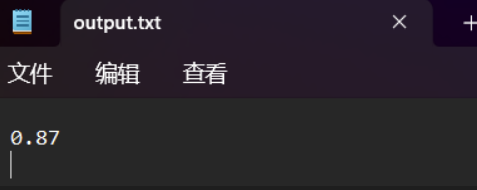
两个相似文本的查重运行测试
两个无关文本的查重运行测试
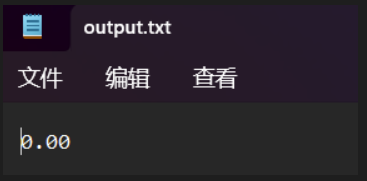
模块部分异常处理说明
这个代码的异常处理主要涉及到文件读写和字符串处理两个方面。下面是对代码中可能出现的异常及其处理方式的说明:
-
文件读写异常:
readFileContent函数:如果读取文件时发生错误(如文件不存在、无法访问等),函数会输出错误消息并退出程序。可以通过在函数中添加异常处理代码来捕获并处理这些异常,例如使用try-catch块来捕获异常并进行适当的处理。writeFileContent函数:如果写入文件时发生错误(如文件无法创建、无法写入等),函数会输出错误消息并退出程序。同样,可以通过在函数中添加异常处理代码来捕获并处理这些异常。
-
字符串处理异常:
calculateWordFrequency函数:如果输入字符串为空或无效(如长度为0),函数可能会引发异常。可以通过在函数中添加适当的输入验证和异常处理代码来避免这种情况,例如检查字符串长度是否为0,并在需要时抛出异常。
除了上述异常,还有其他一些可能的异常情况,例如内存不足、数据类型错误等。对于这些异常情况,可以通过在程序中添加适当的异常处理代码来进行捕获和处理。在处理异常时,可以根据具体情况采取适当的措施,例如输出错误消息、回滚操作、重试等。
需要注意的是,异常处理应当谨慎使用,避免滥用异常处理机制。合理的异常处理可以提高程序的健壮性和可靠性,同时帮助开发人员更好地诊断和解决问题。
收获及总结
完成这个题目让我对文本相似度算法有了更深入的了解。通过设计和实现一个查重系统,我学习了以下内容:
- 文本预处理:在比较两个文本之前,需要对文本进行一些预处理,如分词、去除停用词和标点符号等。这些步骤对于提高查重算法的准确性非常重要。
- 特征提取:通过提取文本中的特征,可以将文本表示为一个特征向量。常用的特征包括词频、文档频率和互信息等。这些特征可以用于比较两个文本的相似度。
- 文本相似度算法:了解和实现了一些常用的文本相似度算法,如余弦相似度和Jaccard相似度。这些算法可以度量两个文本之间的相似程度,从而帮助我们判断一份论文是否抄袭了另一份论文。
- 算法优化:通过使用TF-IDF加权和双向匹配策略等技巧,可以提高查重算法的准确性和效率。这些优化方法可以使算法更好地适应不同的应用场景。
- 评估指标:查重算法的效果可以通过准确率、召回率和F1得分等指标来评估。这些指标可以帮助我们了解算法的实际效果,并为算法的改进提供指导。
总之,完成这个题目让我对文本相似度算法有了更深入的了解,并且提高了我在这方面的技能和经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号