
Centos7 Redis Cluster集群搭建
redis cluster 安装
- 启动前的配置
如果直接启动redis,日志会报以下警告,可以选择性的进行配置。
1,/proc/sys/net/core/somaxconn
原因就是因为128太小了。执行echo 511 > /proc/sys/net/core/somaxconn
命令就把这个问题解决了。但是这个只是暂时的。如果想要永久解决,打开 /etc/sysctl.conf
在这里面添net.core.somaxconn= 1024 然后执行sysctl -p 就可以永久消除这个warning
2,/proc/sys/vm/overcommit_memory
警告超委托内存设置为0!后台保存可能在低内存条件下失败。
临时解决:执行命令:echo 1 > /proc/sys/vm/overcommit_memory
要解决此问题,请将“vm.overcommit_.=1”添加到/etc/sysctl.conf,然后重新启动或运行命令“sysctl vm.overcommit_.=1”
3,/sys/kernel/mm/transparent_hugepage/enabled
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis.
警告您的内核中启用了透明大页面(THP)支持。这将导致Redis的延迟和内存使用问题。
要解决此问题,请以root用户身份运行命令“echo never>/sys/kernel/mm/transparent_hugepage/enabled”
并将其添加到/etc/rc.local中,以便在重新启动后保留设置。禁用THP后,必须重新启动Redis。
安装
- 依赖包安装
yum install -y gcc g++ make gcc-c++ kernel-devel automake autoconf libtool make wget tcl vim ruby rubygems unzip git
- 下载安装包
wget http://download.redis.io/releases/redis-5.0.7.tar.gz
mv redis-5.0.7.tar.gz /data/tools; cd /data/tools; tar xf redis-5.0.7.tar.gz ;cd redis-5.0.7
- 编译
make && make PREFIX=/data/redis install
如果编译报错,使用:make MALLOC-libc
- 配置
cp -r bin/redis-* /usr/local/bin/
mkdir -p /data/redis/redis-6379 ; cd /data/redis/redis-6379
cat redis-6379.conf
port 6379
bind 0.0.0.0
protected-mode no
loglevel notice
timeout 0
tcp-keepalive 60
activerehashing no
dir .
save ""
appendonly yes
maxmemory 2gb
maxmemory-policy volatile-lru
cluster-enabled yes
cluster-require-full-coverage no
cluster-node-timeout 15000
cluster-migration-barrier 1
cluster-config-file ./nodes.conf
集群配置
- 复制原有redis
cp redis-6379 redis-6380 -r ; cp redis-6379 redis-6381 -r
#修改对应的port 和配置文件路径
#redis的启动方式:
方法一:
redis-cli /data/redis/redis-6379/redis-6379.conf
redis-cli /data/redis/redis-6380/redis-6380.conf
redis-cli /data/redis/redis-6381/redis-6381.conf
方法二:
Supervisor进行托管,本篇将用方法二进行搭建。
Supervisor的安装参考:centos7 安装Supervisor
- 启动redis
systemctl start supervisord
supervisorctl status # 查看


- 加入集群
redis-cli --cluster create 172.16.10.27:6379 172.16.10.27:6380 172.16.10.27:6381
此处暂时没加 --cluster-replicas 1参数,只启动服务。
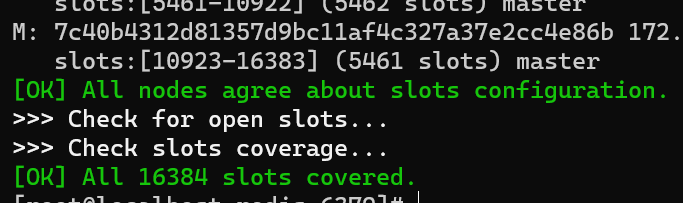
查看集群状态

redis集群主从结构
- 集群节点
官方建议3个节点的集群,此处我配置了:
172.16.10.27 6379;6380;6381
172.16.10.26 16379;16380;16381
两台6个节点,启动集群后可以形成每个master对应一个slave节点
- 启动
redis集群的配置,可参考上面的配置,每台上面将配置文件copy后修改端口号即可。
集群启动:
redis-cli --cluster create 172.16.10.27:6379 172.16.10.27:6380 172.16.10.27:6381 172.16.10.26:16379 172.16.10.26:16380 172.16.10.26:16381 --cluster-replicas 1
#--cluster-replicas 1指的是每个主实例附带一个从实例,构成主从。
启动过程会提示哪些为master和slave节点,输入yes将自动分配完成。
无报错,提示OK即可。
命令行登录查看集群状态:
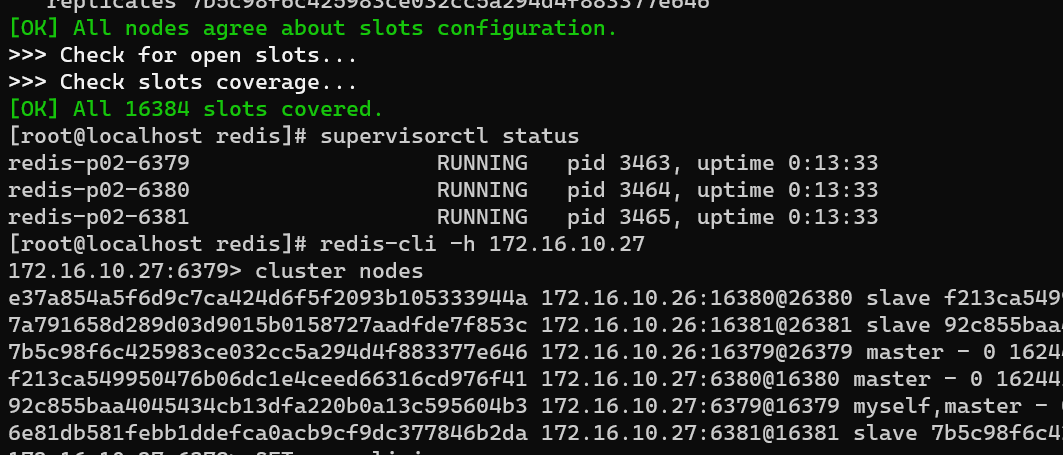
集群读写测试
#172.16.10.27节点进行操作
redis-cli -c -p 6380
127.0.0.1:6380> SET foo bar
OK
127.0.0.1:6380> quit
redis-cli -c -p 6381
127.0.0.1:6381>
127.0.0.1:6381> set hello world
-> Redirected to slot [866] located at 172.16.10.27:6379
OK
172.16.10.27:6379> quit
发现,当在slave节点时,写入数据会自动切换到其中一台master节点,并且将值写入。
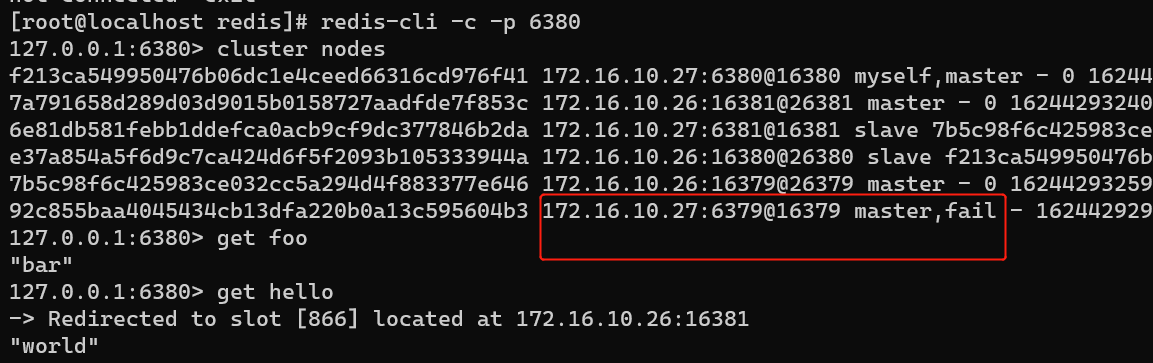
get 测试部分,在故障测试中有体现。
故障测试
- 将其中一个master (6380节点)停了测试可读性
注意,在集群停服前的状态变化:
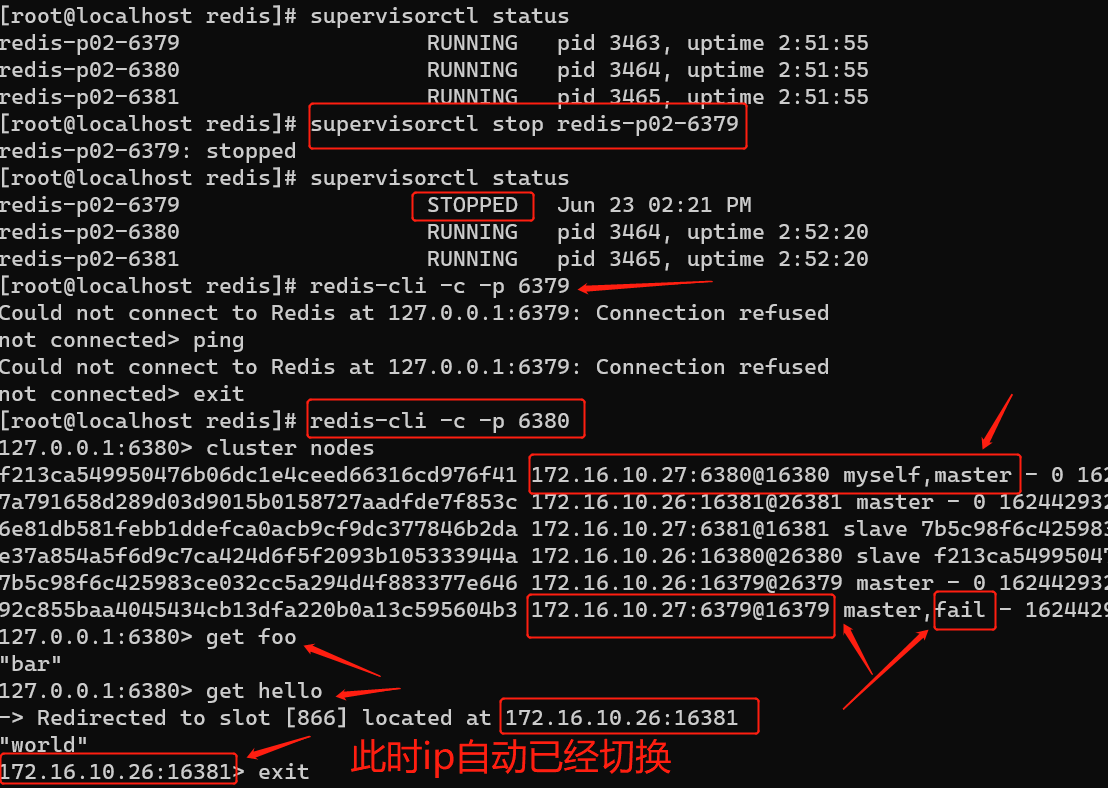
模拟停止redis-p02-6379 master节点:
启动redis-6379节点,再次查看集群状态:
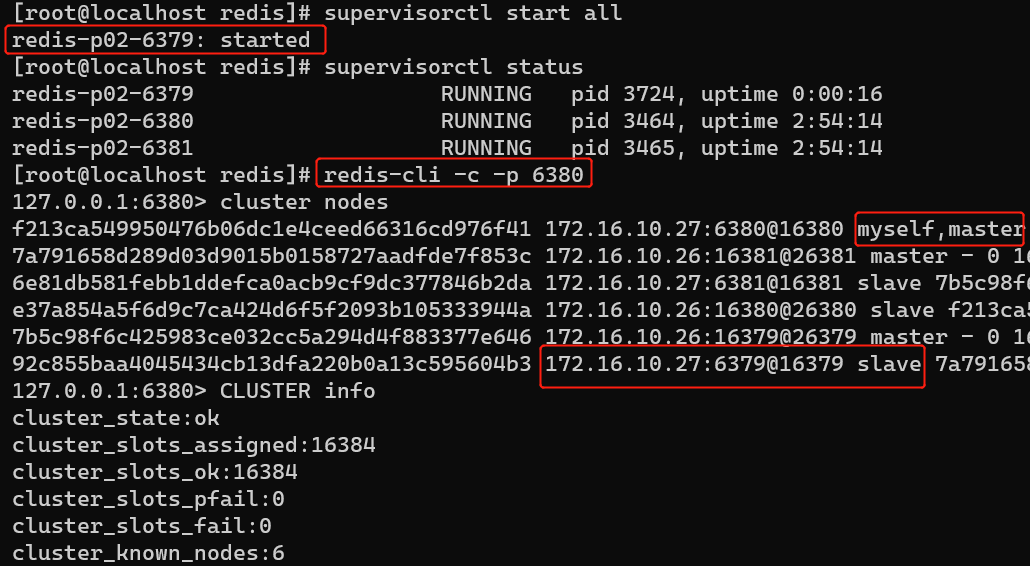
发现,原来redis-6379节点从master切换为slave了。
由于,做set写入时是在redis-7380 master节点上操作的,那么试着将此节点停了再次查看集群状态又如何呢(注意观察ip切换):

以上操作均在ip为:172.16.10.27 的服务器上操作的,只是redis-cli -c 连接集群时使用的端口有所区别。
再次启动redis-6380查看集群状态:
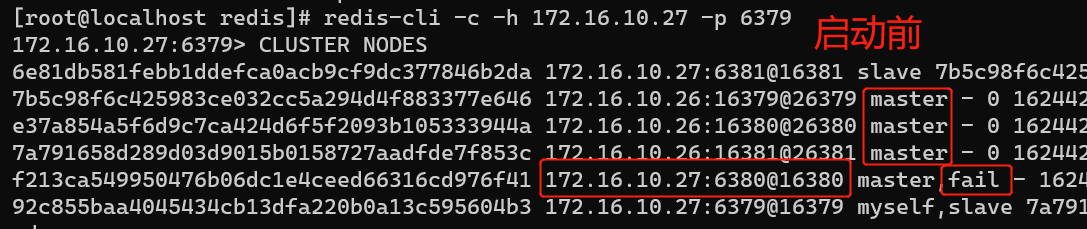

由此可以发现,集群中master的数量是保持3台不变的,如果其中一台masterdown了,集群会自动从slave节点中选举出一台作为master。
并且get一个key值时,master的ip也会自动切换至value 所在的master节点上。
集群增删节点
增加集群节点这个场景一般有两个场景,一集群现有节点资源紧张需要新增节点,二集群redis需要迁移。
这里要使用的场景就是,redis集群迁移。由于前期redis集群和hadoop平台部署在一起,在内存上对redis集群限制了8g的使用大小。而hadoop平台又是个很耗费内存资源的架构。
在多次发现应用服务发生 mem oom事件后,再查看redis cluster集群查看 info显示8g内存已占满,要么重启redis释放缓存,要么加内存。为了长期考虑,计划将redis cluster集群迁出单独形成集群服务。
- 新增节点
新增节点是在上面集群的基础上进行操作,这样便于已有的数据可以实时同步到新加入的redis集群中。
1,将新增节点作为副本加入集群 --cluster-slave,如果不加--cluster-slave 将随机分配新增节点角色。
redis-cli --cluster add-node 172.16.10.25:26379 172.16.10.26:16379 --cluster-slave
注意,这里的命令行与我们用于添加新master的命令行完全相同,因此我们没有指定要将副本添加到哪个master。在这种情况下,redis-cli将在副本较少的主节点中添加新节点作为随机主节点的副本。
2,指定特定的主节点
redis-cli --cluster add-node 172.16.10.25:26379 172.16.10.26:16379 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
在172.16.10.26服务器进行操作(master上)
redis-cli --cluster add-node 172.16.10.25:26379 172.16.10.26:16379 --cluster-slave
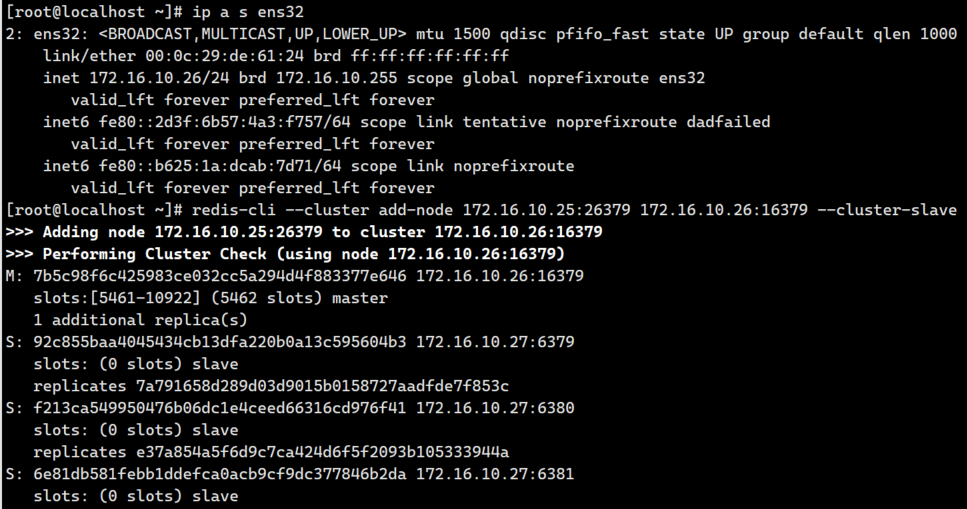
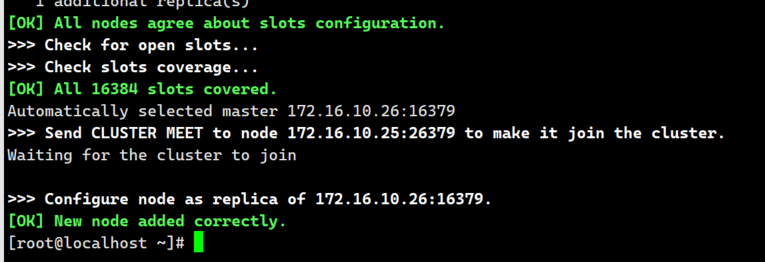
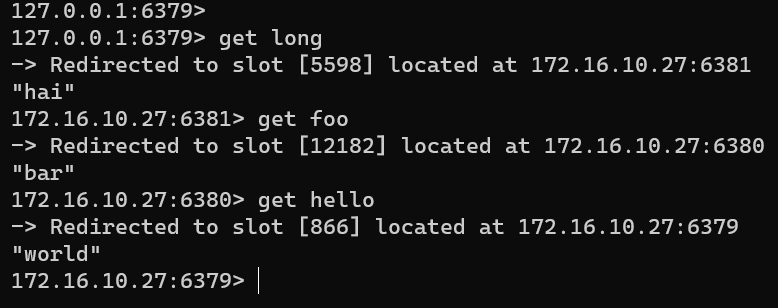
- 测试读数据
1,登录172.16.10.25 redis-26379
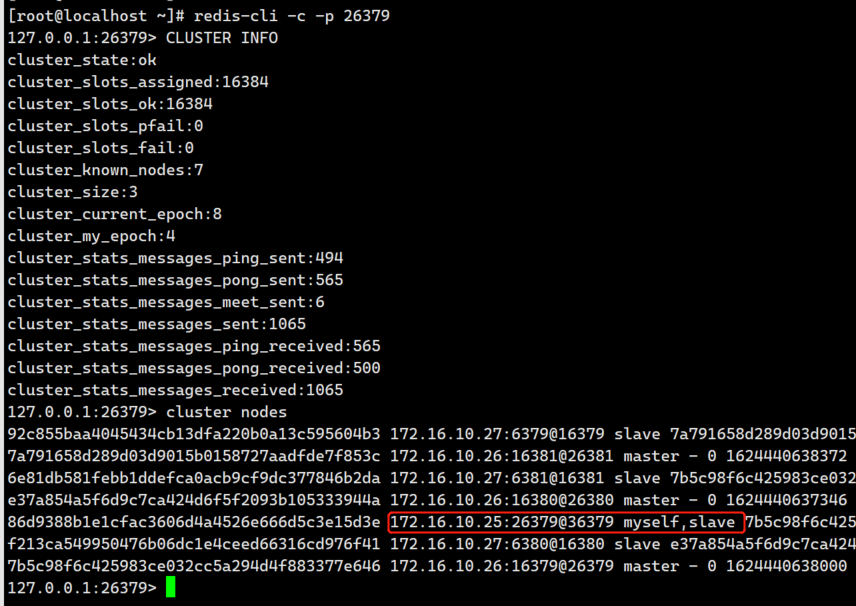
2,读写测试
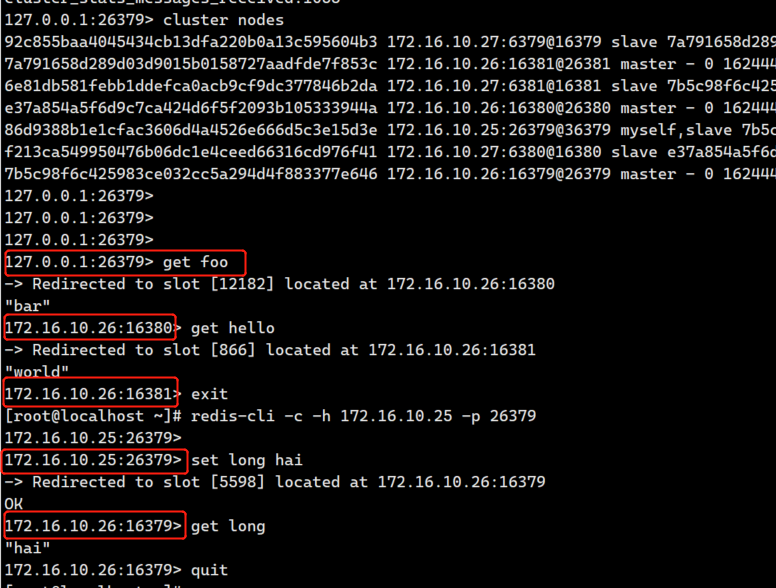
再次查看redis集群状态:
- 尝试删除节点
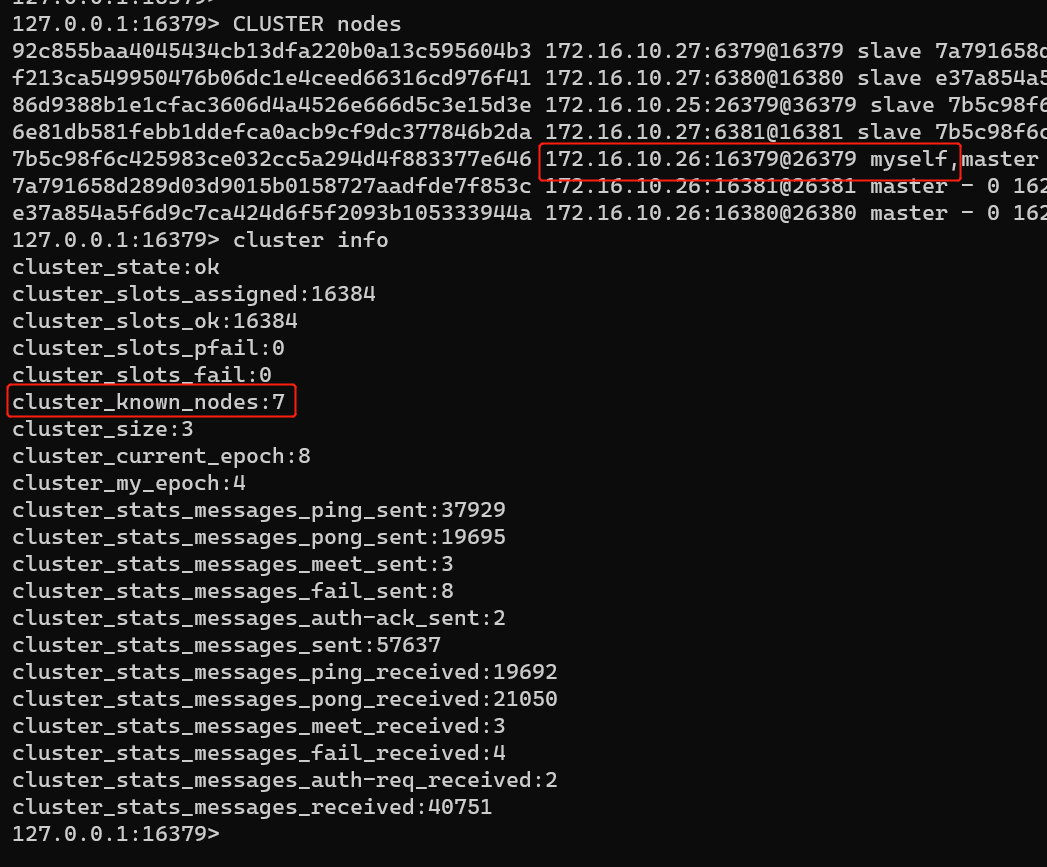
1,在172.16.10.27 redis-6379节点进行操作
确认集群节点信息:
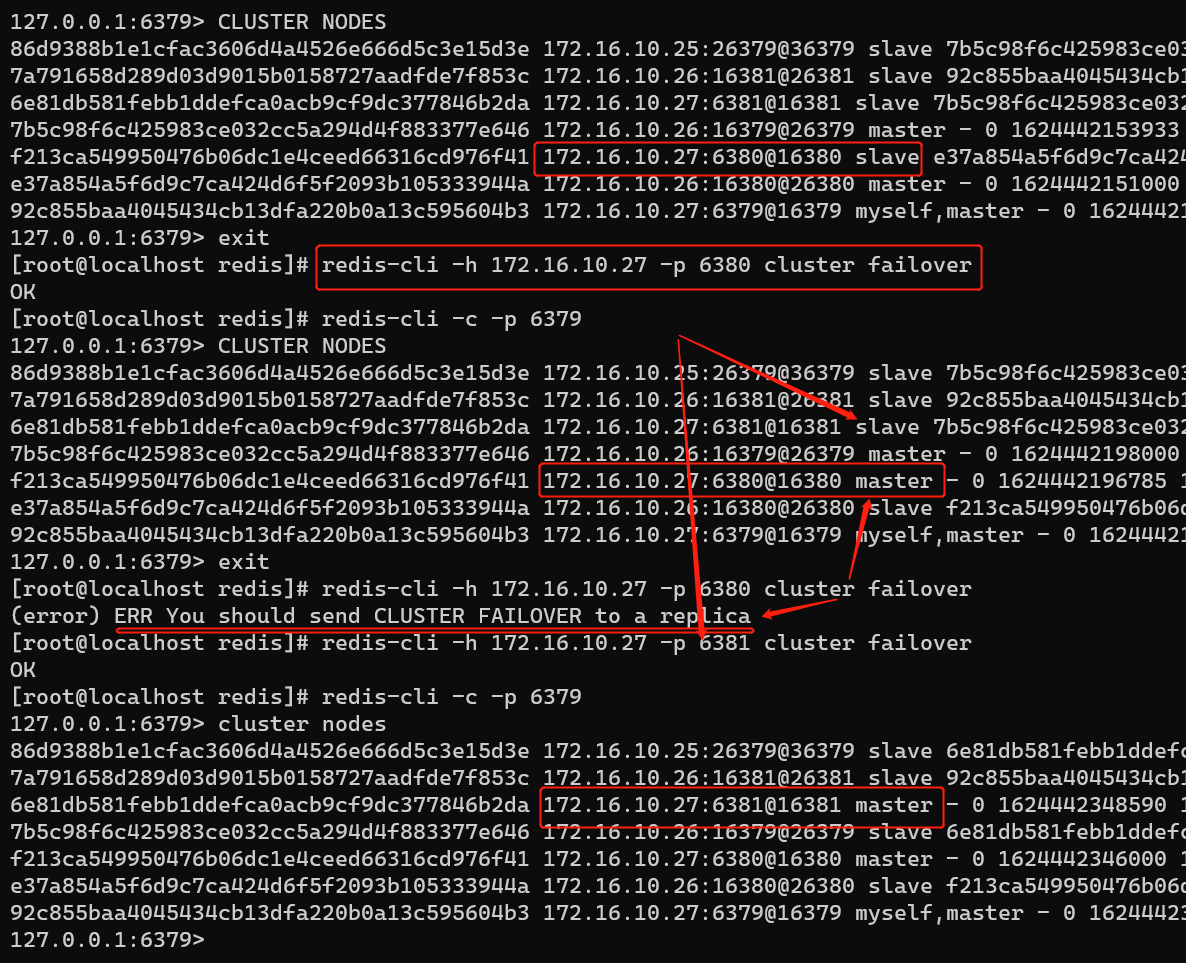
2,集群切换
cluster failover 命令会将原来slave节点的redis状态切换为master,需在slave节点执行此命令
redis-cli -h 172.16.10.27 -p 6381 cluster failover
命令切换前后状态对比:
3,下线redis 6379节点
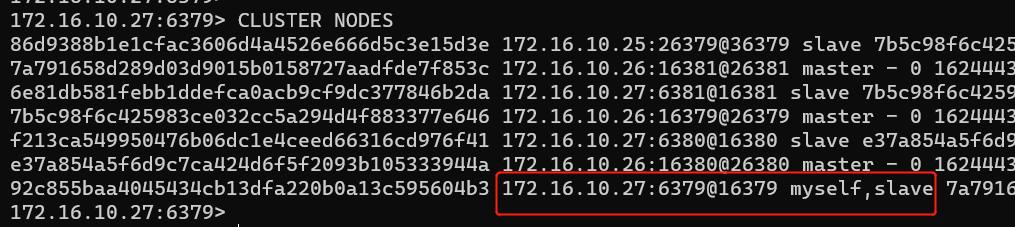
需要先将6379节点切换为slave,再进行删除。
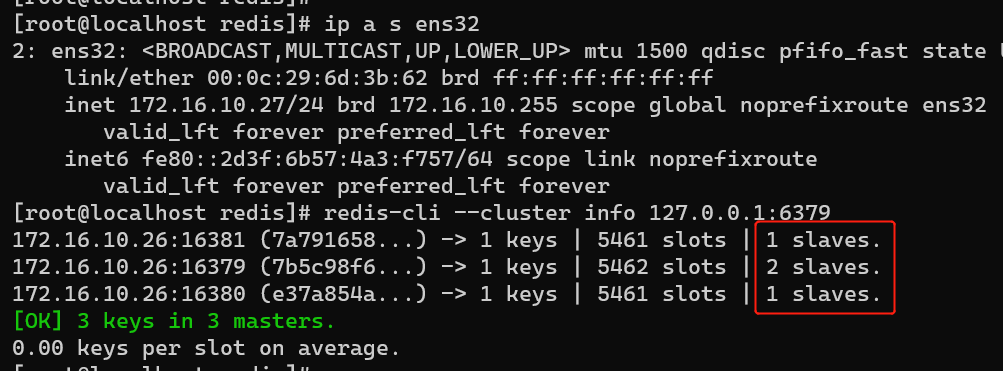
redis-cli --cluster info 172.16.10.26:16380
执行后,在集群查看172.16.10.27服务器上的节点是否已切换为slave。可以更换172.16.10.26 16379、16381等端口来切换6379为slave状态。
redis-cli --cluster del-node 172.16.10.27:6379 92c855baa4045434cb13dfa220b0a13c595604b3
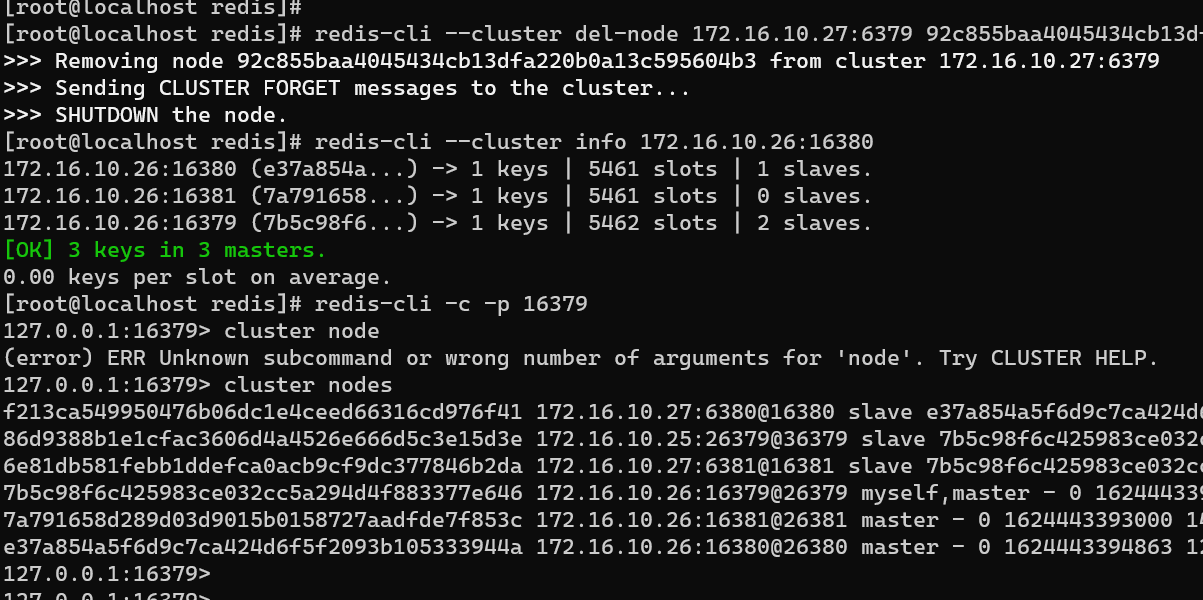
此时,在10.26节点上已经删除10.27:6379这个节点了。但在10.27上仍然可以查看信息。
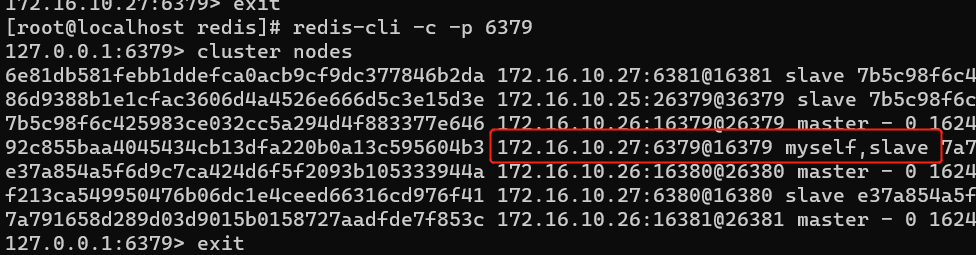
停止redis cluster 10.27:6379这个节点,再次进行查看集群状态就发现已经删除成功。并进行读操作,查看数据是否丢失。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号