Flask 入门小结
一、Flask介绍
Flask是一款轻量级Web开发框架,依赖两个外部库:Werkzeug:一个WSGI工具集,是Web应用程序和多种服务器之间的标准Pyhton接口;Jinja2:负责渲染模板。Flask不同于Django的开箱即用,它更加灵活,可以让开发者有更多自己的选择。
二、模板-Jinja2
存放位置:一般的,在工程文件夹下的 templates 文件夹。Flask可以自动识别到该文件夹中的内容, 如需放置其他地址,则需要在定义app时指定相关参数 app = Flask(name, template_folder='folder_path')
模板语言
常用模板语言:
{{ }}, {% block A %}, {% endblock %}, {% extends 'base.html' %}, {% for···%}, {% endfor %}, {% if···%}, {% endif %}, {% if···%}, {% elif %}, {% endif %}
首先编写一个base.html文件,该文件中需要有完整的html标签,包括html,head,body等,在任意位置定义block块,把需要继承重写的内容写在相关block块中即可。
eg:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}Base{% endblock %}</title>
<link rel="stylesheet" href="{{ url_for('static', filename='bootstrap/bootstrap.461.min.css') }}">
<link rel="stylesheet" href="{{ url_for('static', filename='css/base.css') }}">
{% block head %}{% endblock %}
</head>
<body>
<nav class="navbar navbar-expand-lg navbar-light bg-light">
<div class="container">
<a class="navbar-brand" href="/">知了课堂</a>
<button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent"
aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarSupportedContent">
<ul class="navbar-nav mr-auto">
<li class="nav-item active">
<a class="nav-link" href="/">首页</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{{ url_for('qa.public_question') }}">发布问答</a>
</li>
<li class="nav-item ml-2">
<form class="form-inline my-2 my-lg-0" action="{{ url_for('qa.search') }}">
<input class="form-control mr-sm-2" type="search" placeholder="关键字" name="q">
<button class="btn btn-outline-success my-2 my-sm-0" type="submit">搜索</button>
</form>
</li>
</ul>
<ul class="navbar-nav">
{% if user %}
<li class="nav-item">
<a class="nav-link" href="#">{{ user.username }}</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{{ url_for('user.logout') }}">注销</a>
</li>
{% else %}
<li class="nav-item">
<a class="nav-link" href="{{ url_for('user.login') }}">登录</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{{ url_for('user.register') }}">注册</a>
</li>
{% endif %}
</ul>
</div>
</div>
</nav>
<div class="container">
{% block body %}
{% endblock %}
</div>
</body>
</html>
其他页面只需要继承base.html页面,重写相关block即可。
eg:
{% extends 'base.html' %}
{% block title %}知了课堂{% endblock %}
{% block head %}
{% endblock %}
{% block body %}
<div class="row" style="margin-top: 3rem;">
<div class="col"></div>
<div class="col-8">
{% for question in questions %}
<li class="list-group">
<div class="card shadow-sm mb-5 bg-white rounded" style="background-color: #fff;">
<div class="card-header">
<a href="{{ url_for('qa.question_detail', question_id=question.id) }}">{{ question.title }}</a>
</div>
<div class="card-body">
<p class="card-text">{{ question.content|truncate(30) }}</p>
</div>
<div class="card-footer text-left" style="text-align:left; background-color: #fff;">
<small class="form-text text-muted">
posted @ {{ question.create_time }} by {{ question.author.username }}
</small>
</div>
</div>
</li>
{% endfor %}
</div>
<div class="col"></div>
</div>
{% endblock %}
过滤器
为了方便对变量进行处理, Jinja2 提供了一些过滤器, 语法形式如下:
{{ 变量|过滤器 }}
常见过滤器有:length,lower,upper,title,truncate等
在试图函数完成逻辑处理之后,返回需要渲染的模板时,我们通常使用render_template()函数。
该函数需要从flask中导入:
from flask import Flask, render_template
return render_template('index.html', questions=questions)
三、静态文件
存放位置:一般的,在工程文件夹下新建 static 文件夹。Flask可以自动识别到该文件夹中的内容, 如需放置其他地址,则需要在定义app时指定相关参数 app = Flask(name, static_folder='folder_path')
通常,我们将js、css等文件放置在该文件夹中;在模板中使用时,可以使用url_for()函数指定像个文件。
eg:
<link rel="stylesheet" href="{{ url_for('static', filename='css/base.css') }}">
四、数据库
为了简化数据库操作,我们可以使用一款名为 SQLAlchemy 的ORM框架。借助 SQLAlchemy, 你可以通过定义 Python 类来表示数据库里的一张表( 类属性表示表中的字段 / 列) , 通过对这个类进行各种操作来代替写 SQL 语句。这个类我们称之为模型类, 类中的属性我们将称之为字段。
Flask-SQLAlchemy
Python中的第三方库 Flask-SQLAlchemy 集成了SQLAlchemy,方便了我们的后续操作。
首先,我们要安装 flask-sqlalchemy
- 安装
pip install flask-sqlalchemy - 使用
在项目中创建了app之后,可以创建一个SQLAlchemy对象,创建时需要把flask app传递给它作为参数,该SQLAlchemy对象包含了所有SQLAlchemy的函数,还提供一个名为Model的类,用于声明模型时继承的基类。
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy(app)
完成创建后,我们需要配置数据库信息,这些配置信息可以写在app.py中(不推荐),也可以新建一个config.py专门用于各种配置项
# 数据库配置
HOSTNAME = '127.0.0.1'
PORT = '3306'
DATABASE = 'flask_demo'
USERNAME = 'root'
PASSWORD = 'mysql'
DB_URI = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(USERNAME, PASSWORD, HOSTNAME, PORT, DATABASE)
SQLALCHEMY_DATABASE_URI = DB_URI
SQLALCHEMY_TRACK_MODIFICATIONS = True
如果是写在config.py中,我们可以这样使用:
import config
app.config.from_object(config)
注意:不同的数据库,其URI是不同的
完成SQLAlchemy对象的创建、初始化和数据库的相关配置后,我们就可以在models.py中定义相关的数据模型。
eg:
class EmailCaptchaModel(db.Model):
__tablename__ = 'email_captcha' # 表名
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
email = db.Column(db.String(20), nullable=False, unique=True)
captcha = db.Column(db.String(6), nullable=False)
create_time = db.Column(db.DateTime, default=datetime.now)
常用字段如下:
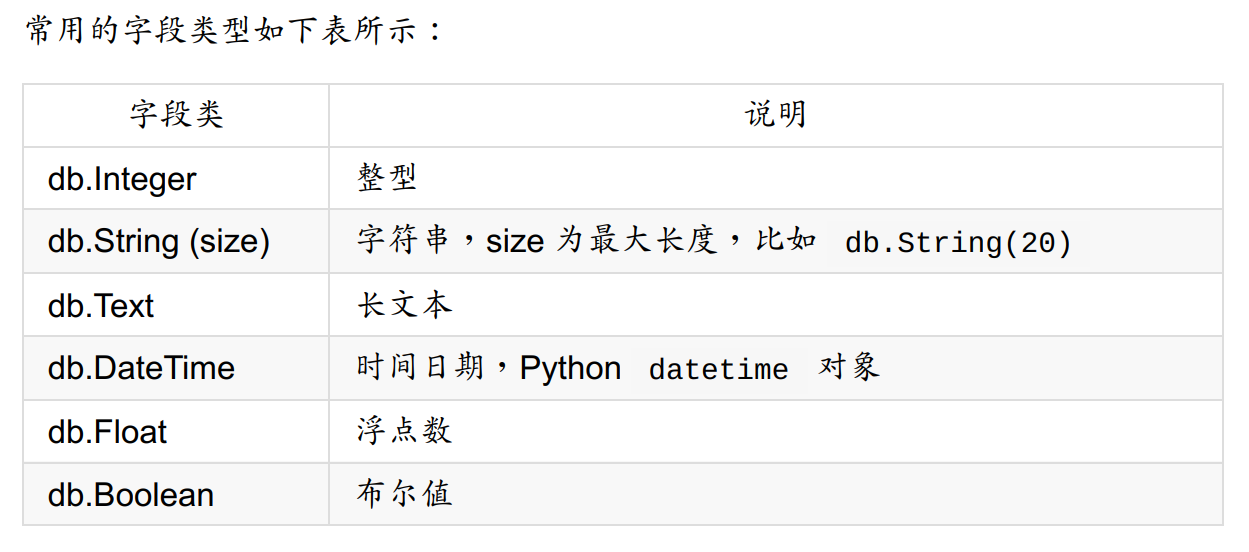
之后便可以在app.py文件中导入相关模型,并向操作对象一样操作数据库了。
在所有模型都定义好了之后,我们可以使用db.create_all()来生成所有表,这些操作会映射到数据库中;如果对模型进行了改动,则需要先使用db.drop_all()删除所有表,在执行db.create_all()重新生成表,注意这也会删除所有数据。如果需要在数据的前提下变更表的结构,我们可以使用flask-migrate 对数据库的迁移进行管理。关于flask-migrate我们稍后进行简单介绍。
有了模型类以后,我们就可以使用其query属性调用可选的过滤方法和查询方法。
常用过滤方法:
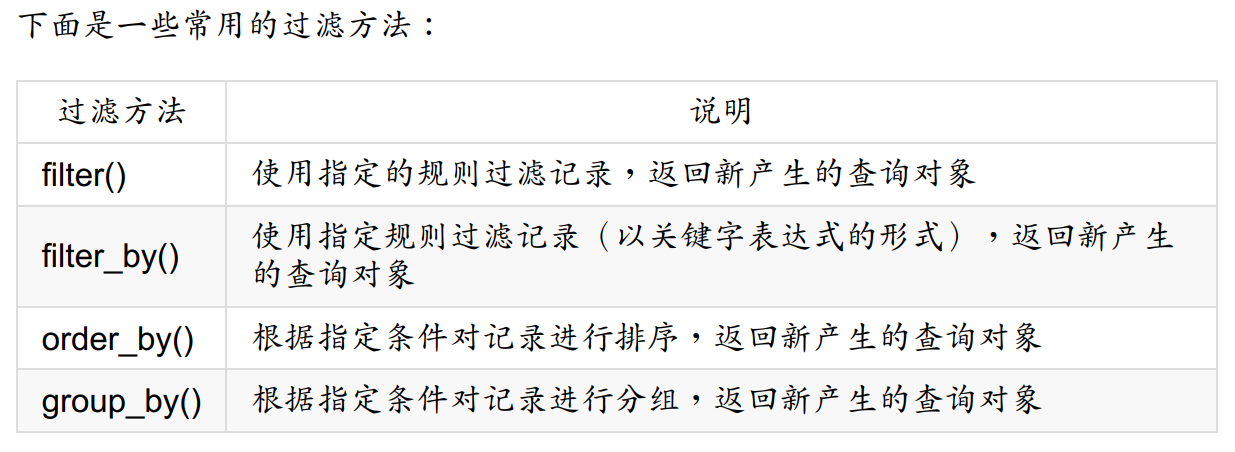
常用查询方法:
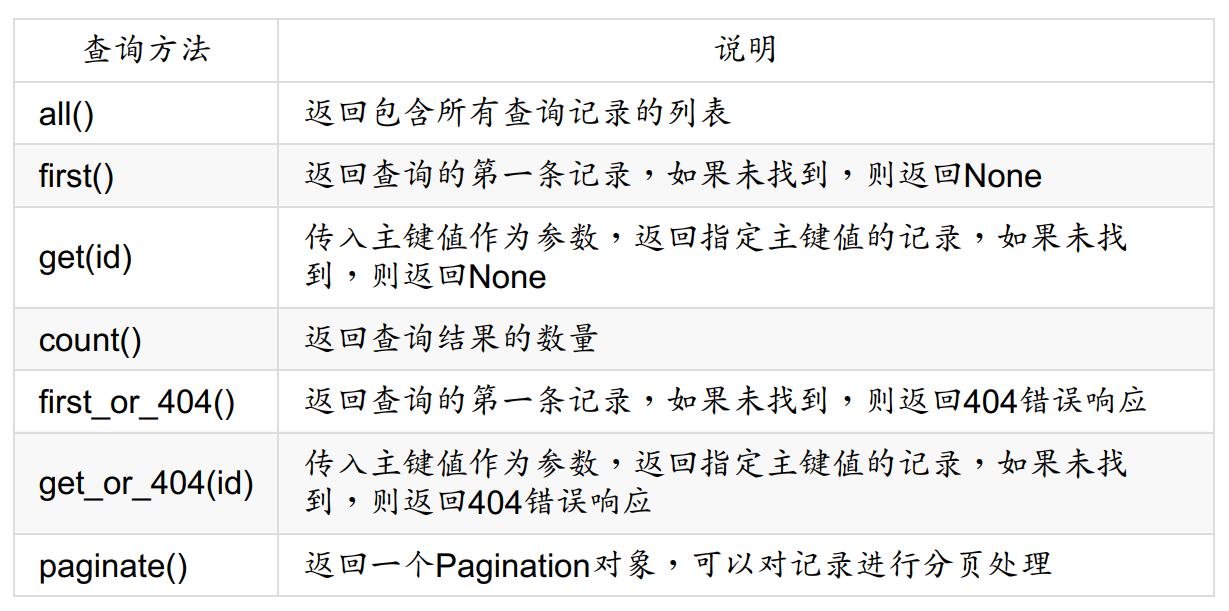
关于filter()和filter_by():
filter():必须使用 模型.字段
filter_by():可以直接使用 模型的字段
还可以从sqlalchemy中导入其他相关操作,如:or_,not_
from sqlalchemy import or_
方法的使用比较简单,这里不多赘述。给个例子:
from sqlalchemy import or_
@bp.route('/search')
def search():
q = request.args.get('q')
questions = QuestionModel.query.filter(or_(QuestionModel.title.contains(q),
QuestionModel.content.contains(q))).order_by(db.text('-create_time'))
return render_template('index.html', questions=questions)
在对数据库进行增、删、改的操作后需要提交session!
增:
question = QuestionModel(title=title, content=content)
db.session.add(question)
db.session.commit()
删:
user = User.query.first()
db.session.delete(user)
db.session.commit()
改:
user = User.query.first()
user.username = 'hee'
db.session.commit()
关系模式
SQLAlchemy中的基本关系模式。
一对多
class Person(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
addresses = db.relationship('Address', backref='person', lazy='dynamic')
class Address(db.Model):
id = db.Column(db.Integer, primary_key=True)
email = db.Column(db.String(50))
person_id = db.Column(db.Integer, db.ForeignKey('person.id'))
如上为一个一对多的简单示例,一个人对应多个地址,使用db.relationship()来定义,地址的模型声明中必须定义一个外键。反向引用, 即使用 my_address.person 来获取使用该地址(address)的人(person) ,可以使用backref来定义反向引用,也可以使用back_populates参数,具体区别,后文解释。如果需要给反向引用定义其他属性,则在定义relationship时需要使用db.backref函数,如:
addresses = db.relationship('Address',
backref=db.backref('person', lazy='joined'), lazy='dynamic')
lazy 决定了 SQLAlchemy 什么时候从数据库中加载数据:
'select'(默认值) 就是说 SQLAlchemy 会使用一个标准的 select 语句必要时一次加载数据。'joined'告诉 SQLAlchemy 使用 JOIN 语句作为父级在同一查询中来加载关系。'subquery'类似'joined',但是 SQLAlchemy 会使用子查询。'dynamic'在有多条数据的时候是特别有用的。不是直接加载这些数据,SQLAlchemy 会返回一个查询对象,在加载数据前您可以过滤(提取)它们。
一对一
一对一关系只需要在一堆多关系的基础上把 uselist=False 传给 relationship()
也可以使用backref()允许由 relationship.backref参数生成的关系接收自定义参数的函数将其转换为“一对一”约定,在这种情况下,使用uselist参数:
from sqlalchemy.orm import backref
class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer, primary_key=True)
class Child(Base):
__tablename__ = 'child'
id = Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('parent.id'))
parent = relationship("Parent", backref=backref("child", uselist=False))
多对多
多对多在两个类之间添加了一个关联表。关联表由relationship() 的relationship.secondary参数指示。通常,Table使用 MetaData与声明性基类关联的对象,以便ForeignKey指令可以定位要链接的远程表:
association_table = Table('association', Base.metadata,
Column('left_id', ForeignKey('left.id'), primary_key=True),
Column('right_id', ForeignKey('right.id'), primary_key=True)
) # 第1个参数为表名
class Parent(Base):
__tablename__ = 'left'
id = Column(Integer, primary_key=True)
children = relationship(
"Child",
secondary=association_table, # 也可以使用上面定义的表名 association
back_populates="parents")
class Child(Base):
__tablename__ = 'right'
id = Column(Integer, primary_key=True)
parents = relationship(
"Parent",
secondary=association_table,
back_populates="children")
-
每个
association.left_id和association.right_id的数据类型通常是从被引用表的数据类型推断出来的,可以省略。 -
建议在引用的两个实体表的列中建立唯一约束或更常见的主键约束,这可确保无论应用程序端出现什么问题,重复行都不会保留在表中 。
-
对于双向关系,关系的双方都包含一个集合。指定使用
relationship.back_populates,并为每个relationship()指定公共关联表 。
当使用relationship.backref参数而不是 relationship.back_populates 时,backref 将自动为反向关系使用相同的参数relationship.secondary。
association_table = Table('association', Base.metadata,
Column('left_id', ForeignKey('left.id'), primary_key=True),
Column('right_id', ForeignKey('right.id'), primary_key=True)
)
class Parent(Base):
__tablename__ = 'left'
id = Column(Integer, primary_key=True)
children = relationship("Child",
secondary=association_table, # 另一方使用相同的 secondary 参数
backref="parents") # 使用backref只需要双方中的一方即可,另一方自动使用相同的参数
class Child(Base):
__tablename__ = 'right'
id = Column(Integer, primary_key=True)
relationship()的relationship.secondary参数还接受一个返回最终参数的可调用对象,该参数仅在首次使用映射器时进行评估。使用它,我们可以在稍后定义association_table,只要在所有模块初始化完成后它可用:
class Parent(Base):
__tablename__ = 'left'
id = Column(Integer, primary_key=True)
children = relationship("Child",
secondary=lambda: association_table, # lambda 表达式
backref="parents")
backref&back_populates
backref和back_populates作用相同,只是用法不同。
都是用于定义双向关系即反向引用,而backref只需要在一个model中使用relationship()即可:在一对一,一对多关系里其中一方使用relationship即可,在多对多中也是一方单独使用,另一方会自动配置相同参数;back_populates则必须双方同时使用,并为每个relationship指定公共关联表
Flask-Migrate
Flask-Migrate 是一个数据库迁移工具,可以在不破换原始数据的情况下改变表的结构。
-
安装
pip install flask-migrate -
使用
- 首先需要在程序中绑定app和db后
from flask_migrate import Migrate
app = Flask(__name__)
app.config.from_object(config)
db.init_app(app)
migrate = Migrate(app, db)
以下三条命令均是在命令行 terminal 中使用:
- 使用
flask db init创建迁移存储库,这会创建一个迁移文件夹。 - 使用
flask db migrate -m 'Initial migration.'生成迁移脚本。 - 使用
flask db upgrade将迁移应用到数据库中。
导入SQLAlchemy对象db
当工程模块化,存在若干个蓝图时,我们在工程主文件app.py中定义db:db = SQLAlchemy(),在蓝图如user.py中导入db对象,而我们又需要在app.py中导入蓝图bp对象进行注册蓝图,这会造成循环导入——程序从app.py的第一行开始执行,在刚开始导包时,需要导入bp,在导入user.py时,又从第一行开始执行user.py,而user.py的导包阶段又导入了db,此时app.py还没有执行的db的定义代码db = SQLAlchemy(),由此报错。
为解决这一问题,我们可以新建一个exts.py文件,在其中定义db = SQLAlchemy(),在蓝图中从exts导入db对象,在app.py中也是从exts中导入db对象,只需要在app.py中使用app对象初始化db对象即可。
# exts.py
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
# app.py
from exts import db
app = Flask(__name__)
db.init_app(app) # 初始号db对象
# user.py-蓝图
from exts import db
bp = Blueprint('user', __name__, url_prefix='/user')
密码存储
众所周知,密码不能明文存储,flask中提供
generate_password_hash对密码进行加密和check_password_hash对密码进行检查。
-
导入
from werkzeug.security import generate_password_hash, check_password_hash -
使用
- 使用
generate_password_hash(password)即可对密码进行加密
加密后如何验证密码呢?一般不对数据库中的密码进行解密后和用户提交的密码对比,而是将用户提交的密码以同样的方式加密后和数据库中存储的经过加密后的密码进行对比,如果一样,则说明用户提交的密码是正确的。 - 使用
check_password_hash(user.password, password)便可以将数据库中存储的密码user.password和用户提交的密码password进行比较。
五、表单验证
Flask-WTF
Flask-WTF Flask_WTF头这些功能:集成 wtforms,带有 csrf 令牌的安全表单,全局的 csrf 保护,支持验证码(Recaptcha),与 Flask-Uploads 一起支持文件上传,国际化集成。这里只介绍用它来验证表单。表单的前端代码我们使用Bootstrap框架。
-
安装
pip install Flask-WTF -
使用
- 在forms.py文件中定义表单
import wtforms
from wtforms.validators import length, email, EqualTo
class LoginForms(wtforms.Form):
email = wtforms.StringField(validators=[email(message='无效的邮件地址!')])
password = wtforms.StringField(validators=[length(min=6, max=20, message='密码长度应介于 6 到 20 个字符之间。')])
- validators 为验证器,常见的验证器有length,email,EqualTo等;length可以指定最大最小长度,email指定必须为email格式,EqualTo指定和另一个字段相等。message为错误信息。
- 在试图函数中,导入后使用。
form = LoginForms(request.form)
if form.validate():
email = form.email.data
password = form.password.data
user = UserModel.query.filter_by(email=email).first()
if user and check_password_hash(user.password, password):
session['user_id'] = user.id
return redirect(url_for('qa.index'))
else:
errors_info = {'Invalid_u_p': ['邮箱或密码错误!']}
flash(errors_info, 'error')
return redirect(url_for('user.login'))
else:
print(form.errors)
flash(form.errors, 'error')
form.validate()返回验证是否成功,成功返回True,否则返回False。- 如果有多个字段进行验证且验证失败,错误信息以字典形式存储在
form.errors中。{'email': ['邮箱或密码错误!'], 'password': ['邮箱或密码错误!']} - 除了使用 validators 指定验证器以外,我们还可以自定义验证函数,该函数的命名需遵循
validate_+字段名的规则。自定义验证函数将在validators 指定的验证执行完后执行。在自定义验证函数中可以返回wtforms.ValidationError类型的错误,该错误也将存储在form.errors中。
验证邮箱是否被注册
def validate_email(self, field):
by_email = field.data
user_model = UserModel.query.filter_by(email=by_email).first()
if user_model:
raise wtforms.ValidationError('该邮箱已被注册!')
六、蓝图与视图
蓝图即Blueprint,是一种组织一组相关视图和其他代码的方式。当应用程序规模较大时,可以将应用分为多个模块,这样便于程序的维护。
蓝图是一组相关视图函数和其他代码,那什么是视图?
视图函数是您为响应应用程序请求而编写的代码。Flask 使用模式将传入的请求 URL 与应该处理它的视图相匹配。视图返回 Flask 转换为传出响应的数据。Flask 也可以反其道而行之,根据视图的名称和参数生成视图的 URL——url_for()函数。
蓝图
bp = Blueprint('user', __name__, url_prefix='/user')
这将创建一个Blueprint名为user ,与应用程序对象一样,蓝图需要知道它的定义位置,因此__name__ 作为第二个参数传递。url_prefix即url前缀,它将被添加到与蓝图关联的所有 URL 之前。
创建完蓝图后,我们需要把他绑定到程序中。
使用app.register_blueprint(bp)便可以将bp注册到app中。如有多个bp可以在导入时使用别名。也可以将所有蓝图放在一个包下,在该包的__init__.py中导入对应的蓝图并使用别名,如:from .user import bp as user_bp
这样在app.py 中导入蓝图时可以直接从这个包中导入,如from blueprints import user_bp
创建并注册好蓝图后,我们就可以在蓝图中像在app中一样写视图函数了,只不过此时路由就从@app.route() 变为了 @bp.route()。
@bp.route将 URL /register 与register视图函数相关联。当 Flask 收到对应 的请求时/user/register,它会调用register视图并使用返回值作为响应。
为什么url是/user/register?就是因为创建蓝图时定义的url前缀是/user。
视图
@bp.route('/answer/<int:question_id>', methods=['POST'])
def answer(question_id):
content = request.form.get('answer')
if len(content) > 0:
answer_model = AnswerModel(content=content, author_id=g.user.id, question_id=question_id)
db.session.add(answer_model)
db.session.commit()
return redirect(url_for('qa.question_detail', question_id=question_id))
else:
flash({'content': ['评论内容不能为空!']}, 'error')
return redirect(url_for('qa.question_detail', question_id=question_id))
视图函数即定义的一个函数。在该函数上使用route()装饰器将函数绑定到 URL。当 Flask 收到对应 的请求时
/answer/1,它会调用绑定的视图函数answer并使用返回值作为响应。
视图函数不建议重名,虽然可以在路由上定义endpoint来区分,但可能会在其他地方引入意料之外的错误。
七、路由
@bp.route('/answer/<int:question_id>', methods=['POST'])
def answer(question_id):
pass
路由:即@bp.route('/answer/<int:question_id>', methods=['POST'])
HTTP 方法
使用装饰器route的methods来处理不同的方法,如GET请求或者POST请求。默认情况下,路由只响应get请求。
变量参数
通过标记部分将可变内容添加到url中。如上述代码中的<int:question_id>,也有很多其他的转换器。
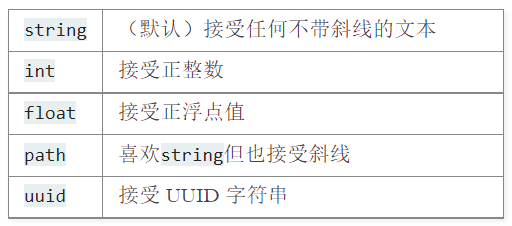
重定向
使用redirect()来重定向到另一个端点。
@bp.route('/logout')
def logout():
session.clear()
return redirect(url_for('user.login'))
url_for构建网址
构建特定函数的 URL,请使用该url_for()函数。它接受函数的名称作为其第一个参数和任意数量的关键字参数,每个关键字参数对应于 URL 规则的可变部分。
return redirect(url_for('qa.question_detail', question_id=question_id))
一般的使用视图函数的名称即可,但如果是蓝图中的视图函数则需要使用蓝图.视图函数。
为什么要使用 URL 反转功能 url_for()而不是将它们硬编码到模板中来构建 URL?
- 反转通常比对 URL 进行硬编码更具描述性。
- 您可以一次性更改 URL,而无需记住手动更改硬编码的 URL。
- URL 构建透明地处理特殊字符的转义。
- 生成的路径总是绝对的,避免了浏览器中相对路径的意外行为。
- 如果您的应用程序位于 URL 根目录之外,例如 in /myapplication而不是/,url_for()则可以为您正确处理。
八、钩子函数
@app.before_request
在每个请求之前要运行的函数 ,这个可以用于从会话加载登录用户。
@app.before_request
def before_request():
# 从session中获取user_id
user_id = session.get('user_id')
if user_id:
# 如果有user_id,则从数据库中获取user信息
user = UserModel.query.filter_by(id=user_id).first()
if user:
# 如果获取到了user,将user绑定在g.user中
g.user = user
@app.context_processor
模板上下文处理器函数。Flask在收到请求后,调用对应的视图函数进行处理,如果该视图函数中返回了模板,则执行完视图函数后会继续执行该函数。context_processor函数返回的字典中的键可以在模板上下文中使用。
发送请求->before_request->视图函数->返回模板->context_processor函数
@app.context_processor
def context_processor():
if hasattr(g, 'user'):
return {'user': g.user}
else:
return {}
九、装饰器login_required
def login_required(func):
@wraps(func)
def wrapper(*args, **kwargs):
if hasattr(g, 'user'):
return func(*args, **kwargs)
else:
return redirect(url_for('user.login')
return wrapper
装饰器是包装和替换另一个函数的函数,被装饰的函数的元信息已经被替换了,这导致我们无法在flask工程中使用应用或者蓝图.原函数名 去调用该函数了,所以我们需要把原函数的信息复制到新函数中。使用@wraps(func)完成替换工作。
访问使用该装饰器装饰的路由时,如果没有登录则会先跳转到登录路由,而登录函数中我们的逻辑是登录成功返回到主页,这导致我们在没有登录的情况下想访问一个需要登录的功能时,会先跳转到登陆页面,然后登录成功后会返回到主页,而不会跳转到此前想要访问的功能,那么在跳转到登陆页面登录成功后如何返回此前的页面呢?
首先把我们真正想要访问的功能定义为目标功能,该功能需要登录才可以访问。
我们在没有登录的情况下去访问目标功能,最先执行的不是视图函数,而是装饰器,在装饰器函数里,我们还可以使用request.url来获取到目标功能的url,而要想在登录成功返回目标功能,我们就需要在装饰器函数中把这个url传递到登录函数中,登陆功能首先会使用get方法获取到登录的模板页面,在使用post方法提交登录,我们最后需要在post方法中重定向到这个url。那如何把这个url经过装饰器函数,登录功能的get方法和登录的模板页面提交到登录的post方法中呢?
首先在装饰器中使用redirect重定向到登录功能时增加next参数,把这个url添加到路由中,此时跳转到登录页面的路由就不是原来的/login,而是/login?next=目标功能的url,我们在登录的模板页面login.html中提交post请求时也增加一个next参数,即<form action="{{ url_for('user.login', next=request.args.next) }}" method="post">来把这个url也提交上去,其中用request.args.next获取当前路由中的next参数,post方法提交后,在登录函数中获取这个url,在完成登录验证成功后返回重定向到这个页面。
# 装饰器中增加next
def login_required(func):
@wraps(func)
def wrapper(*args, **kwargs):
if hasattr(g, 'user'):
return func(*args, **kwargs)
else:
return redirect(url_for('user.login', next=request.url))
return wrapper
# login.html中表单提交时增加next参数
<form action="{{ url_for('user.login', next=request.args.next) }}" method="post">
<div class="form-group">
<label for="email">邮箱</label>
<input type="email" class="form-control" name="email" id="email">
</div>
<div class="form-group">
<label for="password">密码</label>
<input type="password" class="form-control" name="password" id="password">
</div>
</form>
# 登录功能的视图函数中获取url中的next参数
@bp.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template('login.html')
else:
···# 登录成功
next = request.args.get('next')
if next:
return redirect(next)
十、Cookie&Session
Flask中默认的是基于客户端的会话(session),先设置一个app的密钥,在视图函数中设置session,然后 Flask 将获取您放入会话对象的值并将它们序列化为 cookie —— Flask会自动将session加密后返回给浏览器以cookie的形式存储。
from flask import session
import secrets
# Set the secret key to some random bytes. Keep this really secret!
app.secret_key = secrets.token_hex()
'192b9bdd22ab9ed4d12e236c78afcb9a393ec15f71bbf5dc987d54727823bcbf'
参考资料
1、《Flask Web开发入门、进阶与实战》——张学健
2、《flask-tutorial-1.0》——李辉
3、2022版-零基础玩转Python Flask框架——知了传课

 浙公网安备 33010602011771号
浙公网安备 33010602011771号