大数据技术原理与应用——从入门到文档数据库
大数据技术原理与应用
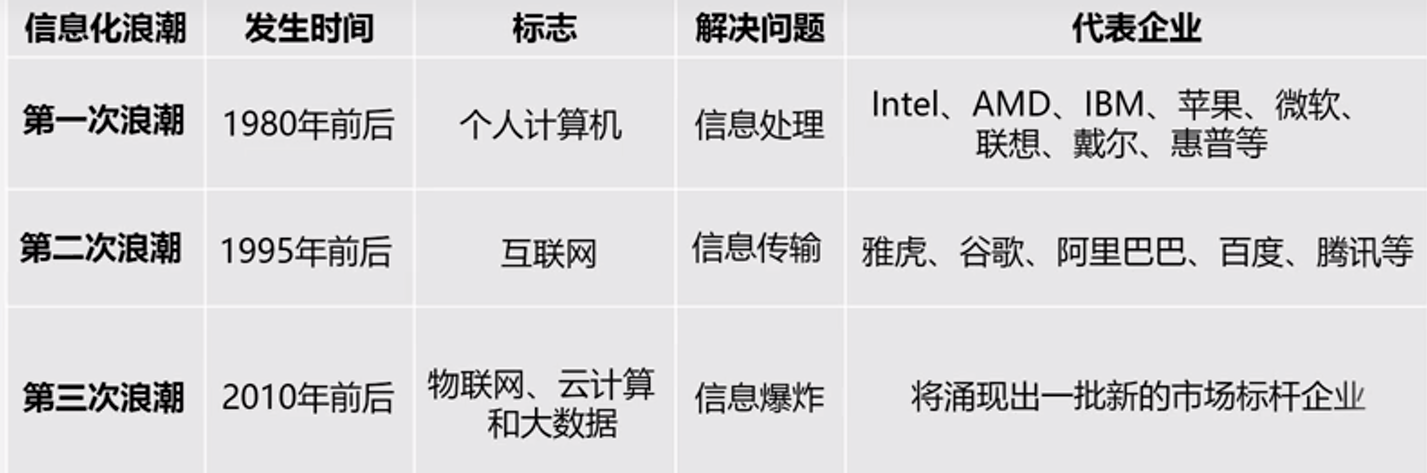
3次信息化的浪潮
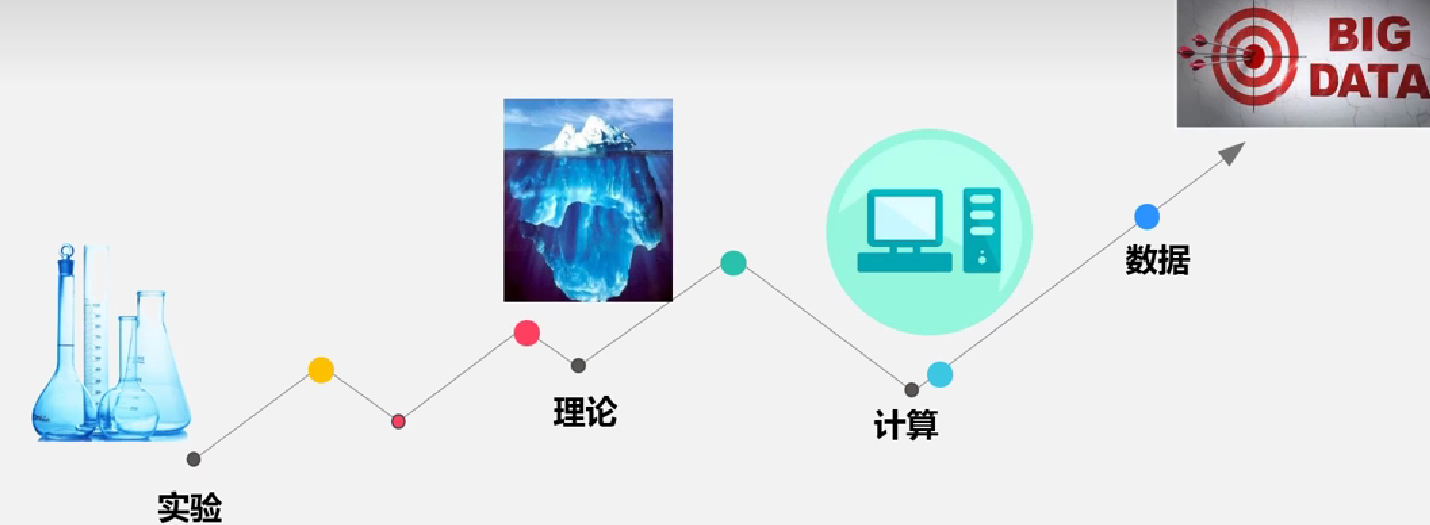
研究问题的四个阶段
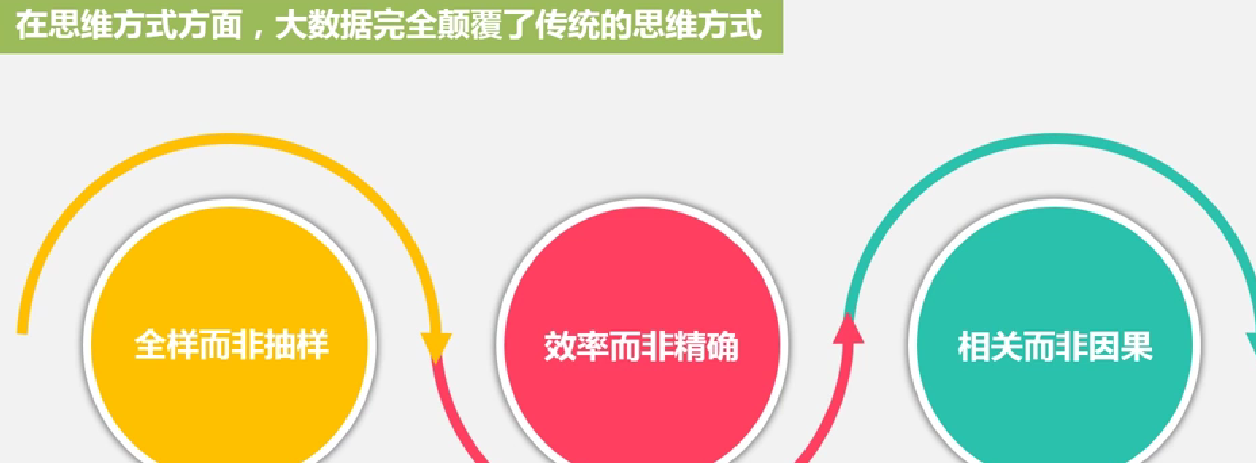
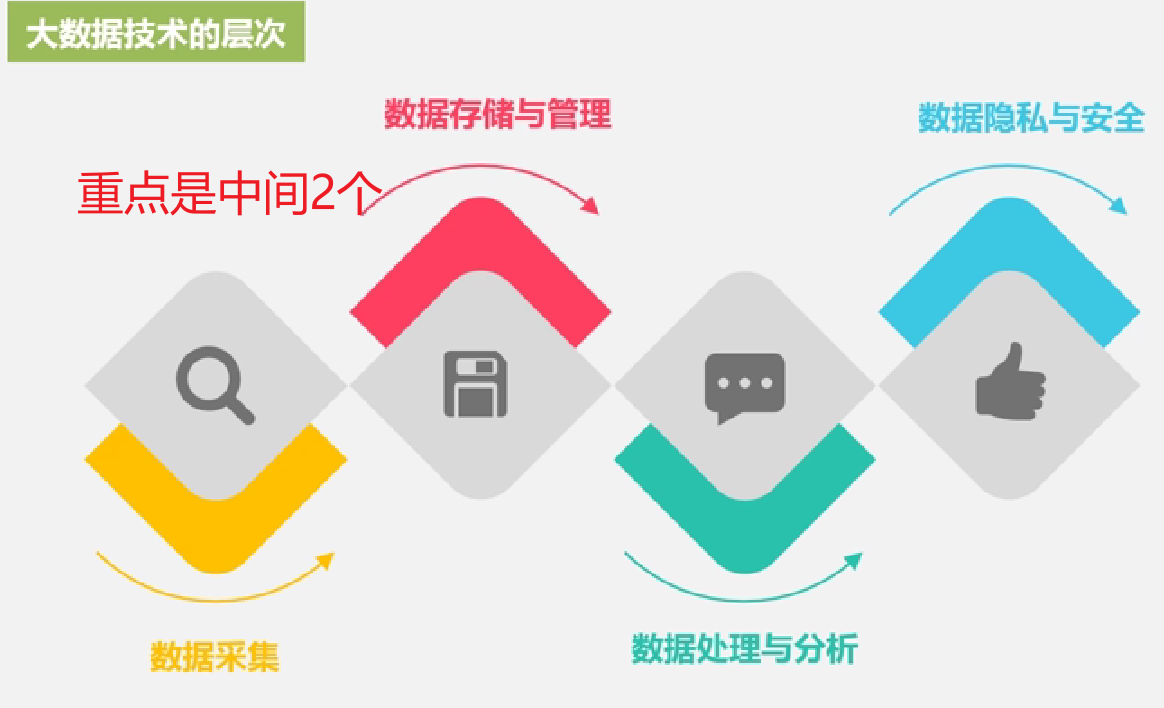
大数据技术的层次
大数据的计算模式

PaaS


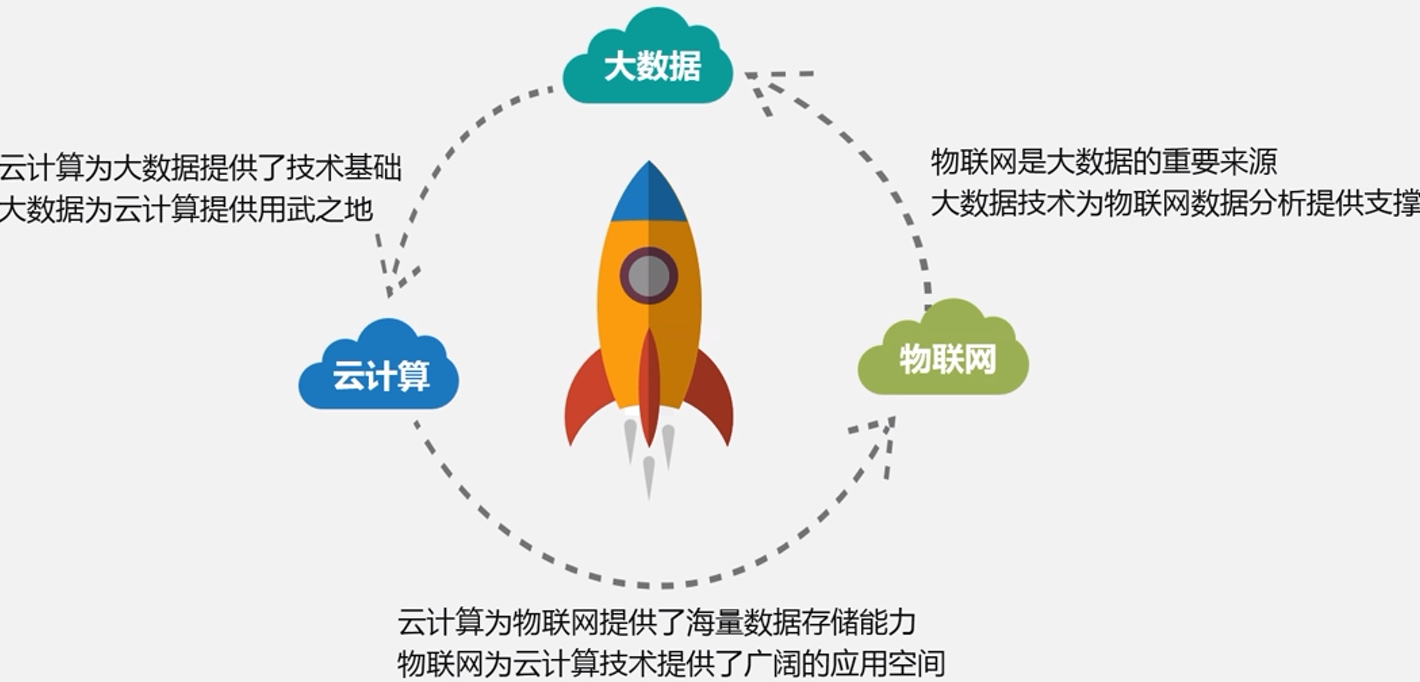
物联网的概念

云计算、大数据、物联网之间的关系
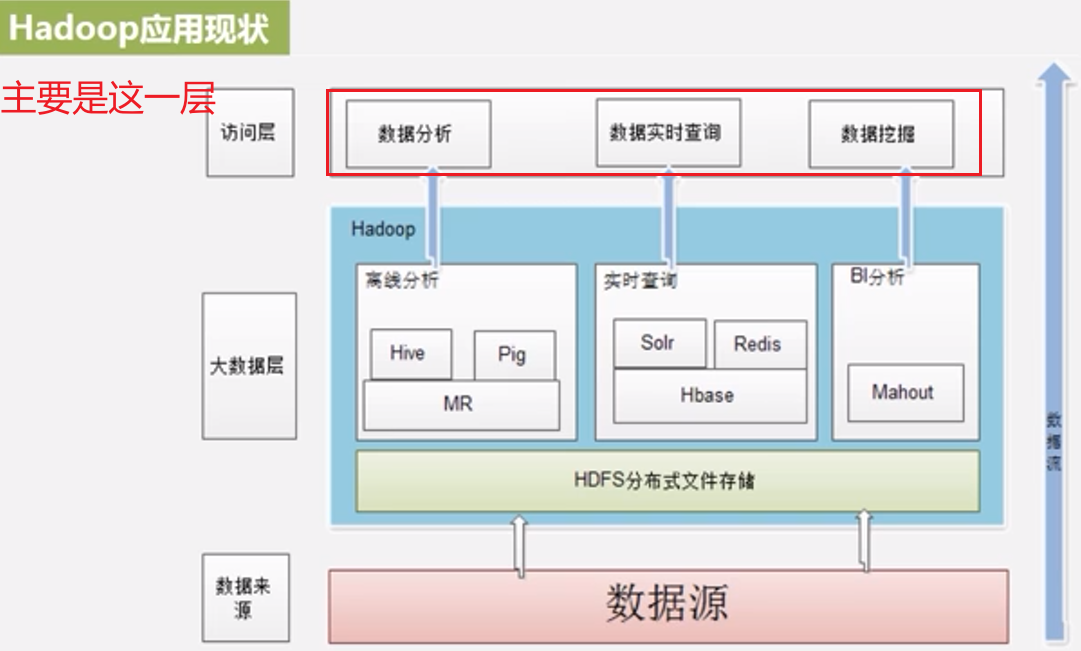
Hadoop应用现状
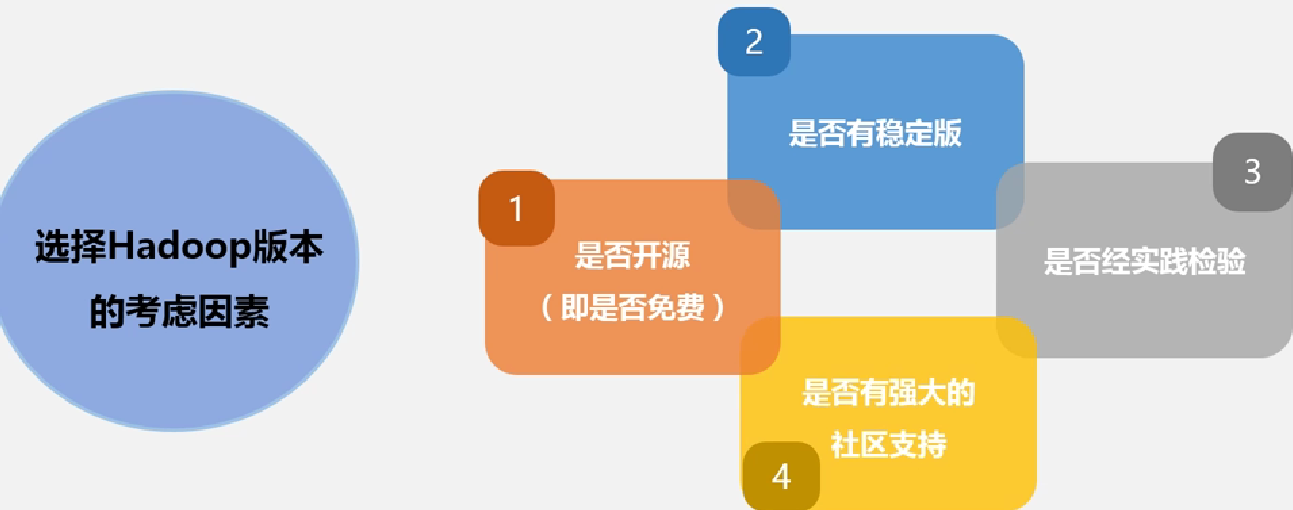
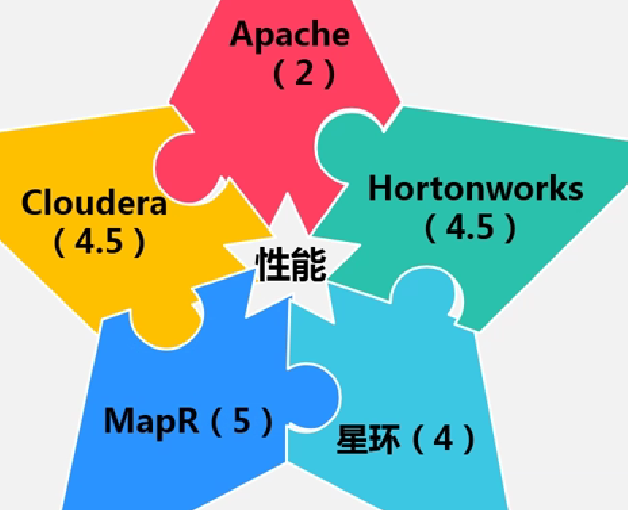
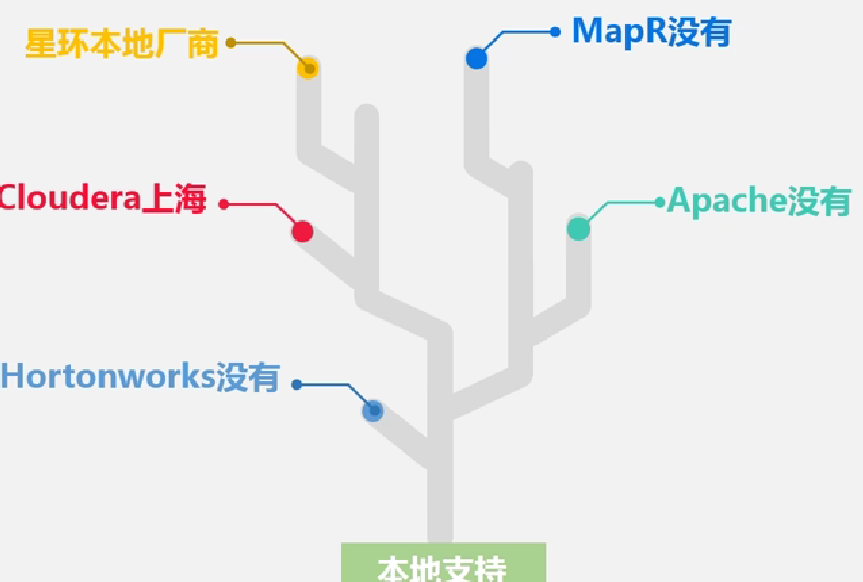
选择Hdoop需要考虑的因素
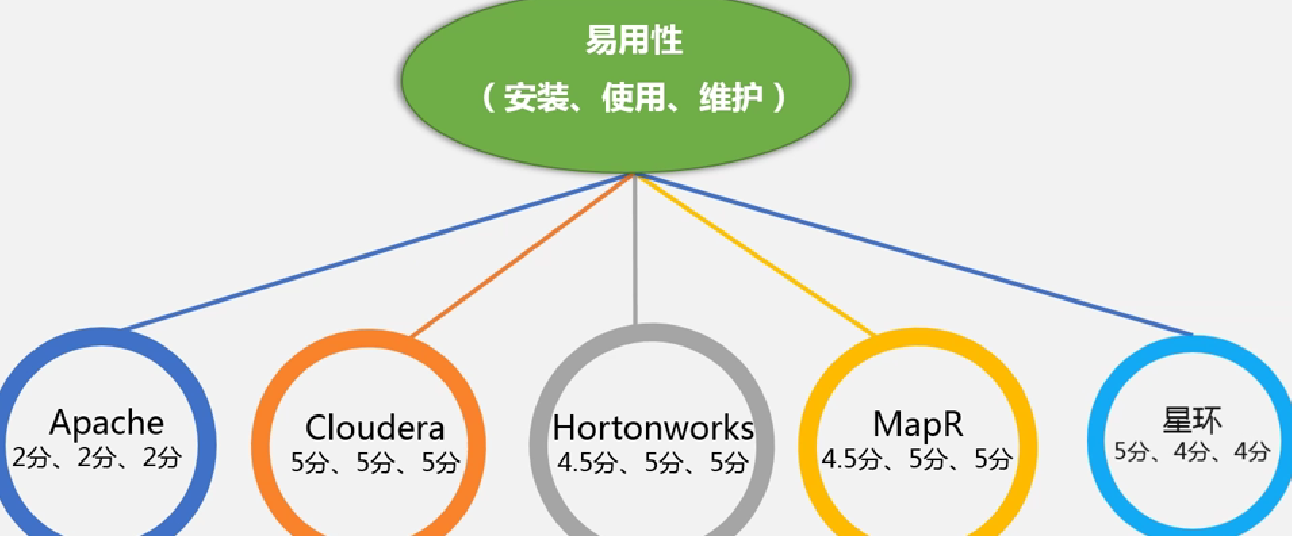
Hadoop的定量评分(满分为5分)
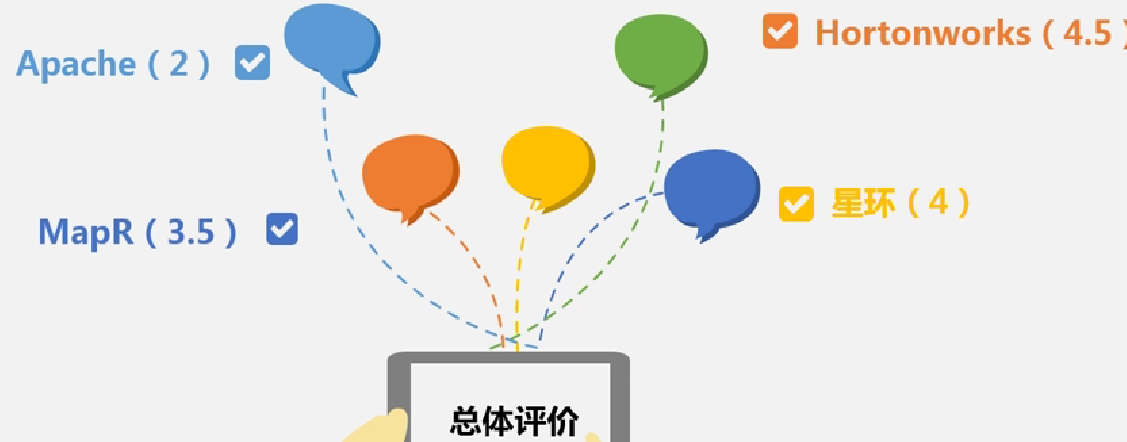
总体评价
Ubuntu的一些基本知识(之所以不用CentOs,是因为其太重了)

Hadoop安装方式

Hadoop是什么
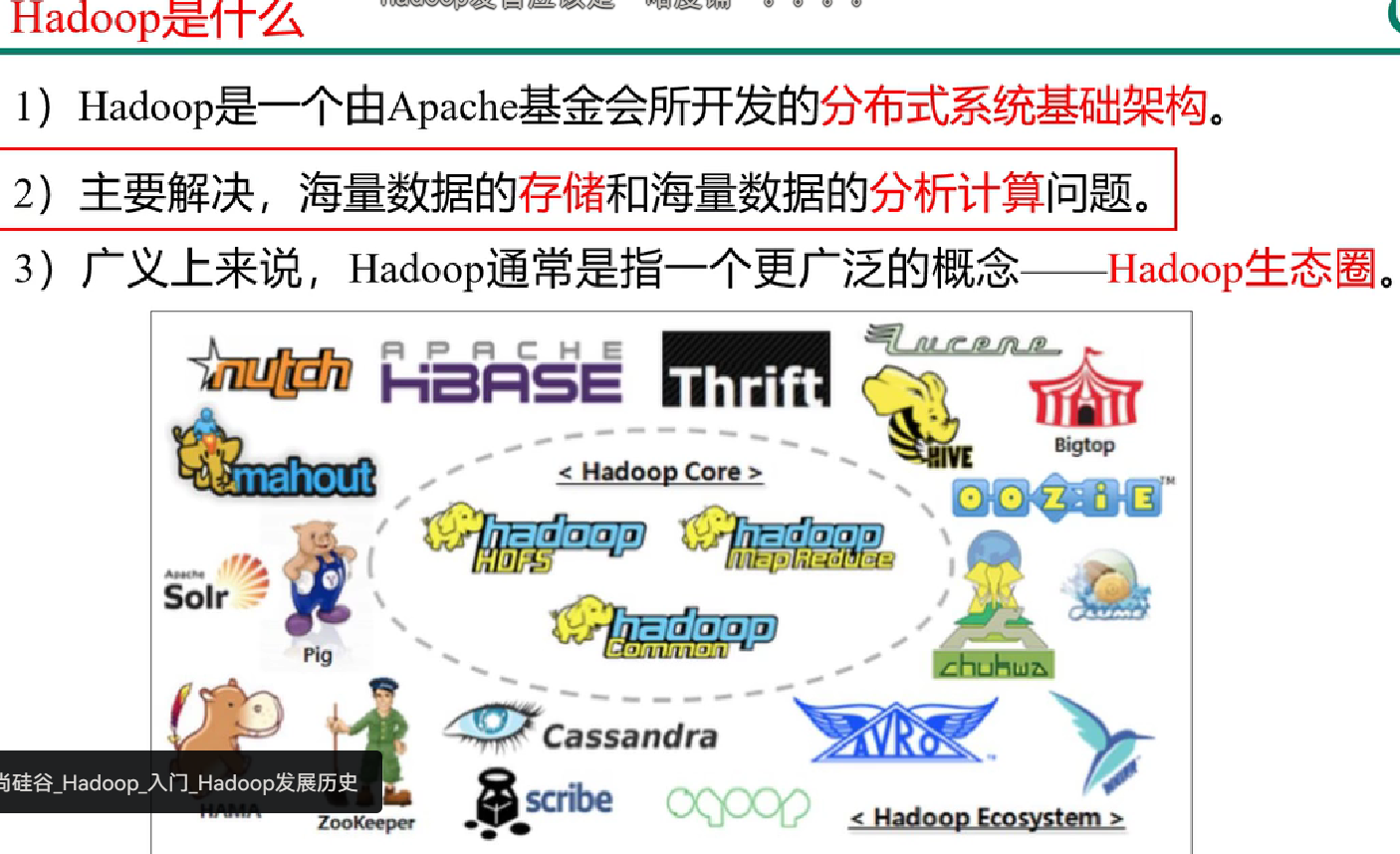
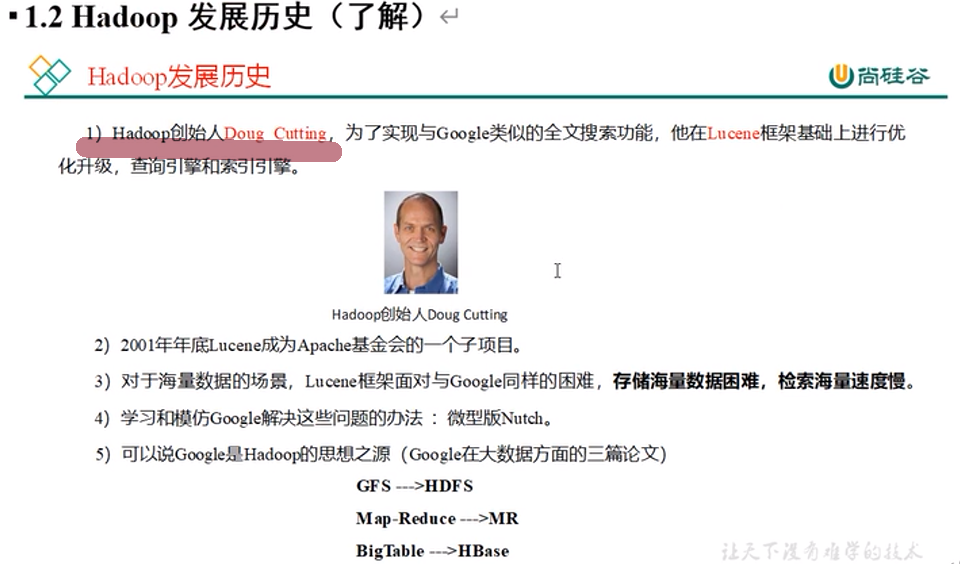
Hadoop的发展历程(了解)
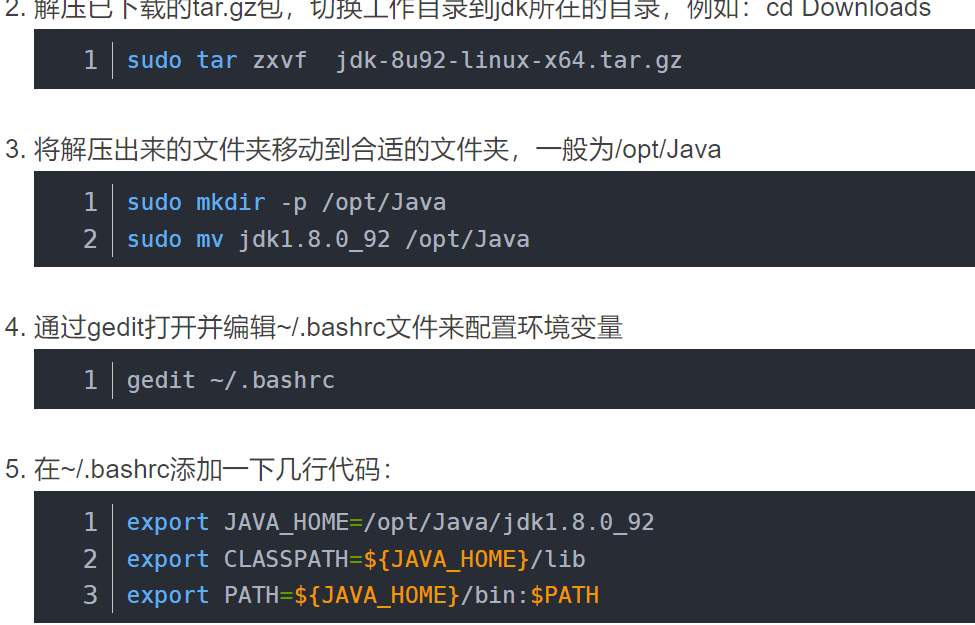
安装Hadoop前的jdk路径
Hadoop使用
3种Shell命令方式

MapReduce两大核心组件

热备份:

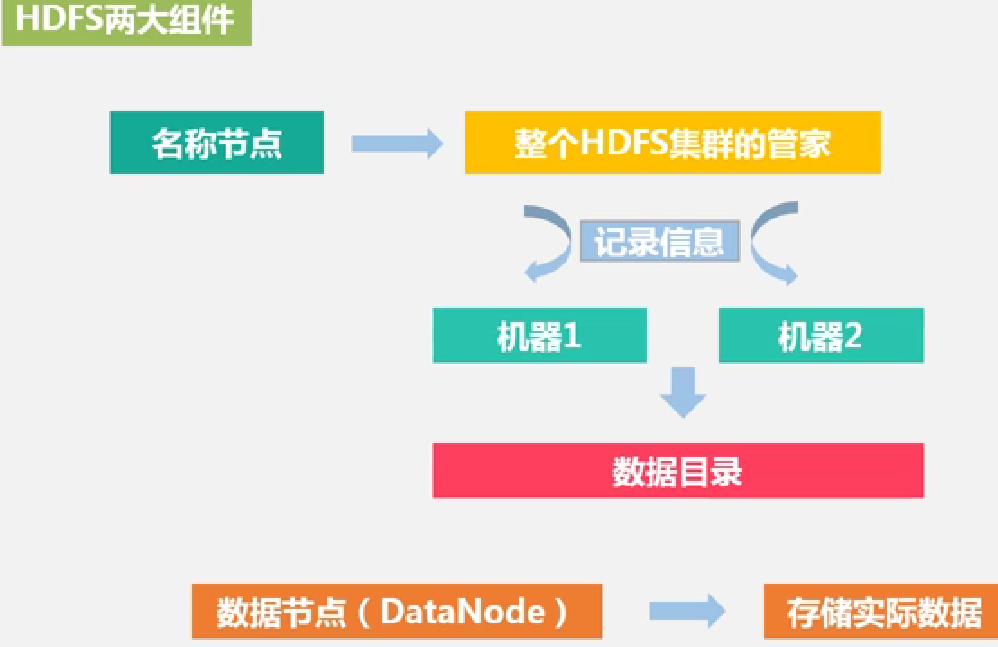
HDFS
是 Hadoop Distribution File System的缩写
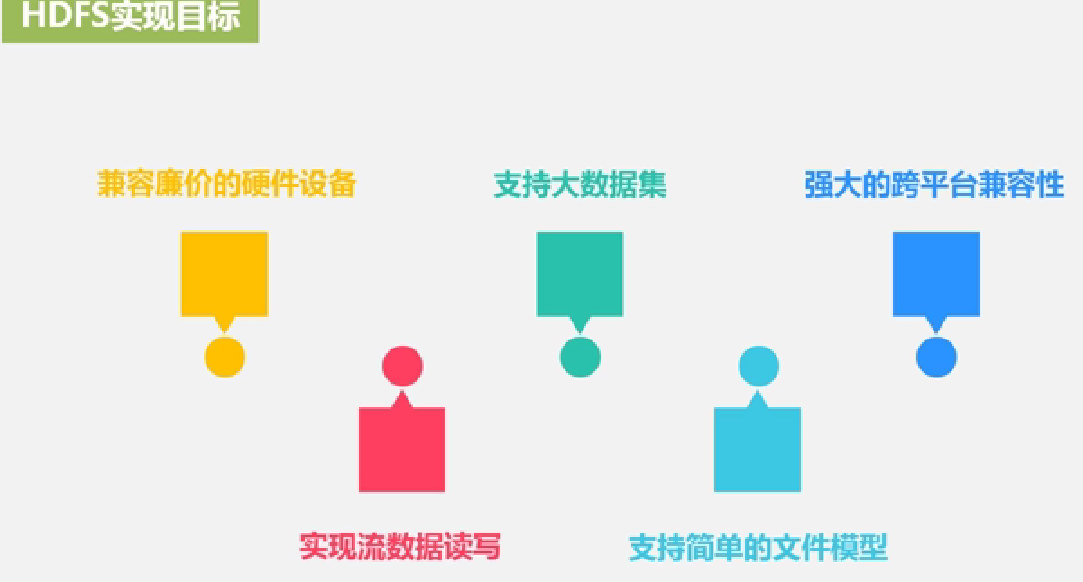
HDFS实现目标
HDFS的局限性

HDFS的相关概念
1.块
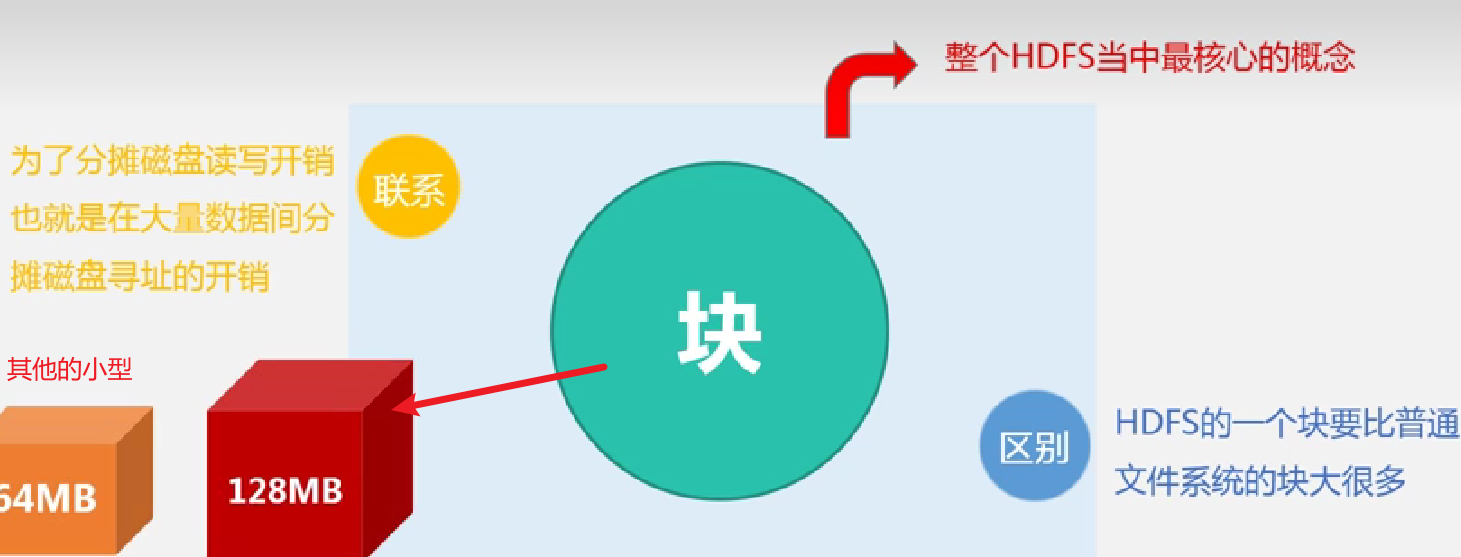
为什么要这样设计:

这样设计的好处:

2.名称节点(NameNode)与数据节点(DataNode)
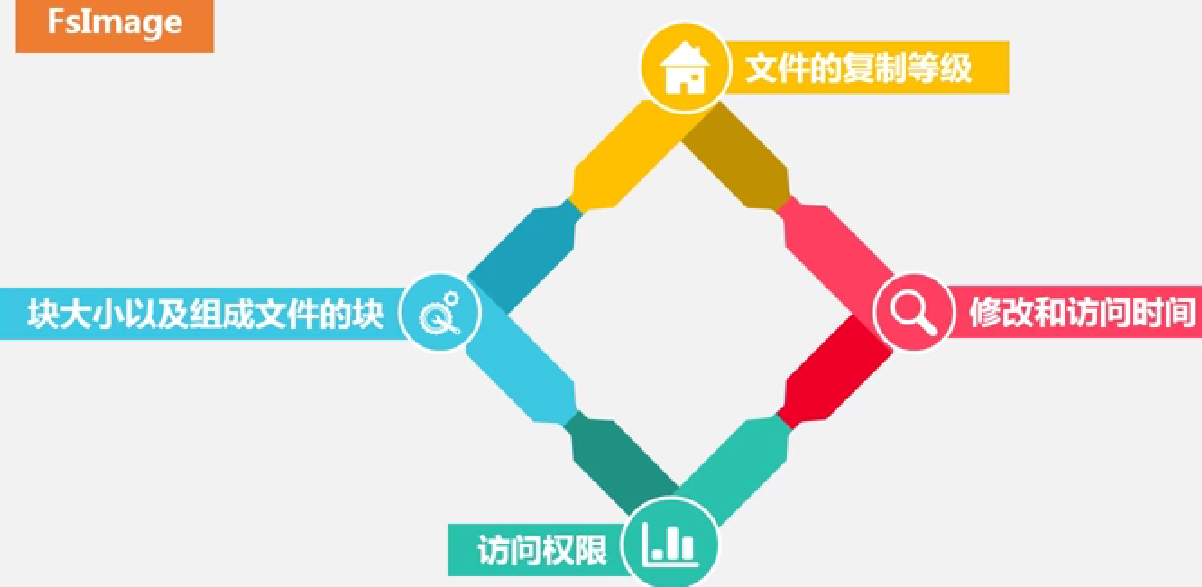
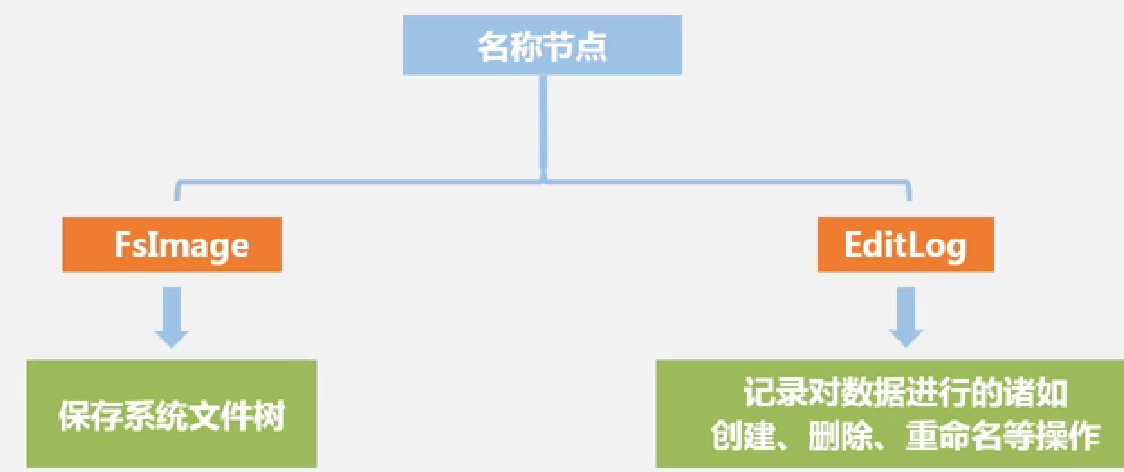
FsImage:

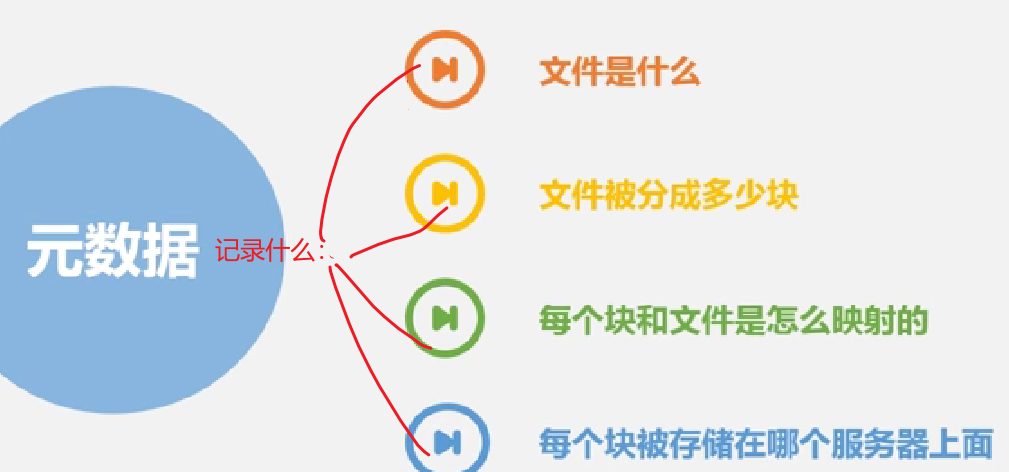
元数据:
名称节点的具体文件结构:
名称节点与数据节点经常通信、传递信息,所以名称节点知道各个数据节点的信息
开始shell后的操作流程:
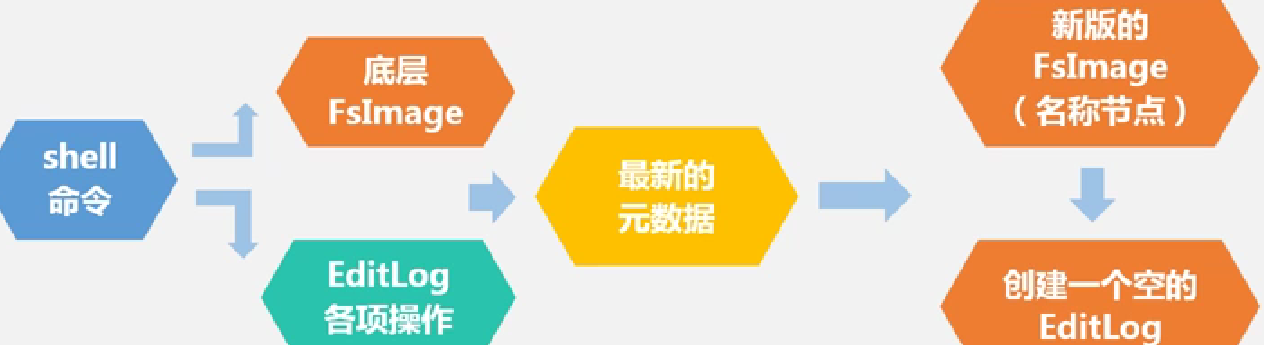
文件保存的位置:

HDFS的体系结构:
局限性:

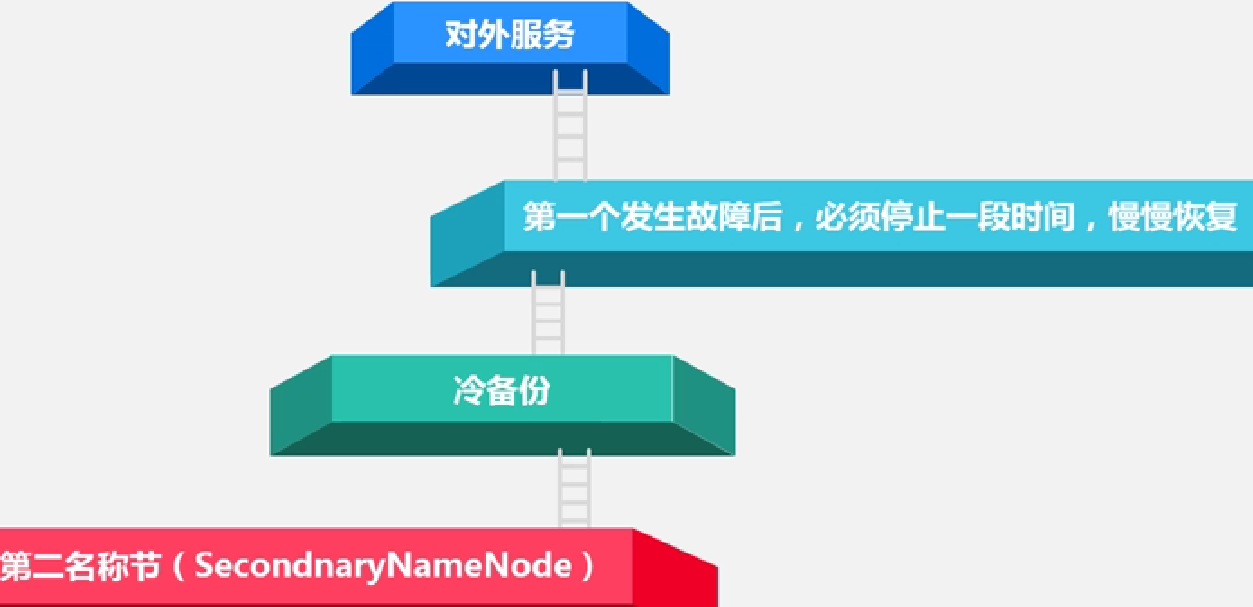
第二名称节点的作用、冷备份:
3.4 HDFS存储原理
3.5.1 HDFS读数据过程
3.5.2 HDFS写数据过程
4.1 HBase简介
是一个稀疏的列式数据库
HBase与关系数据库的联系和区别:

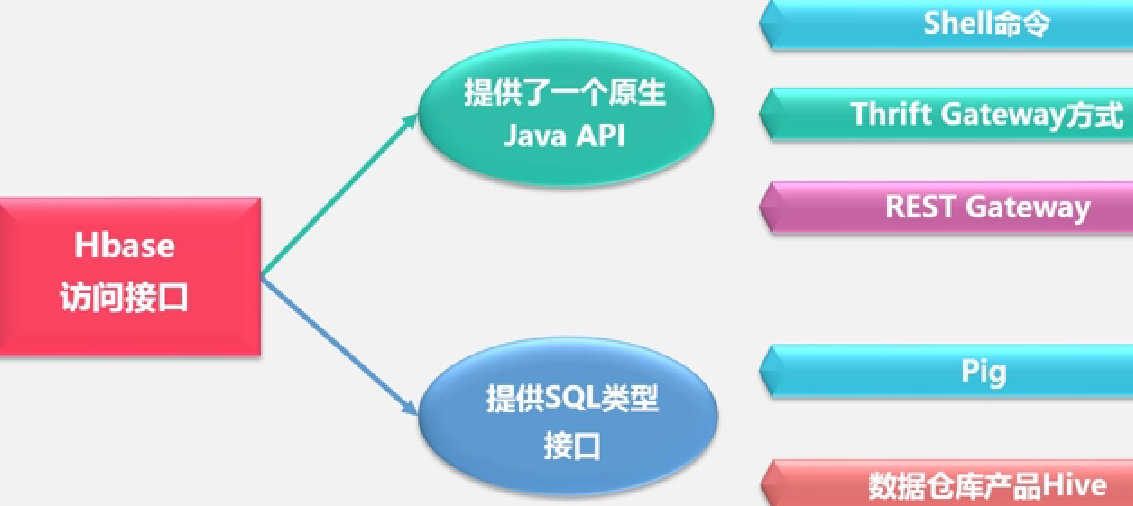
访问接口:
4.2 HBase数据模型
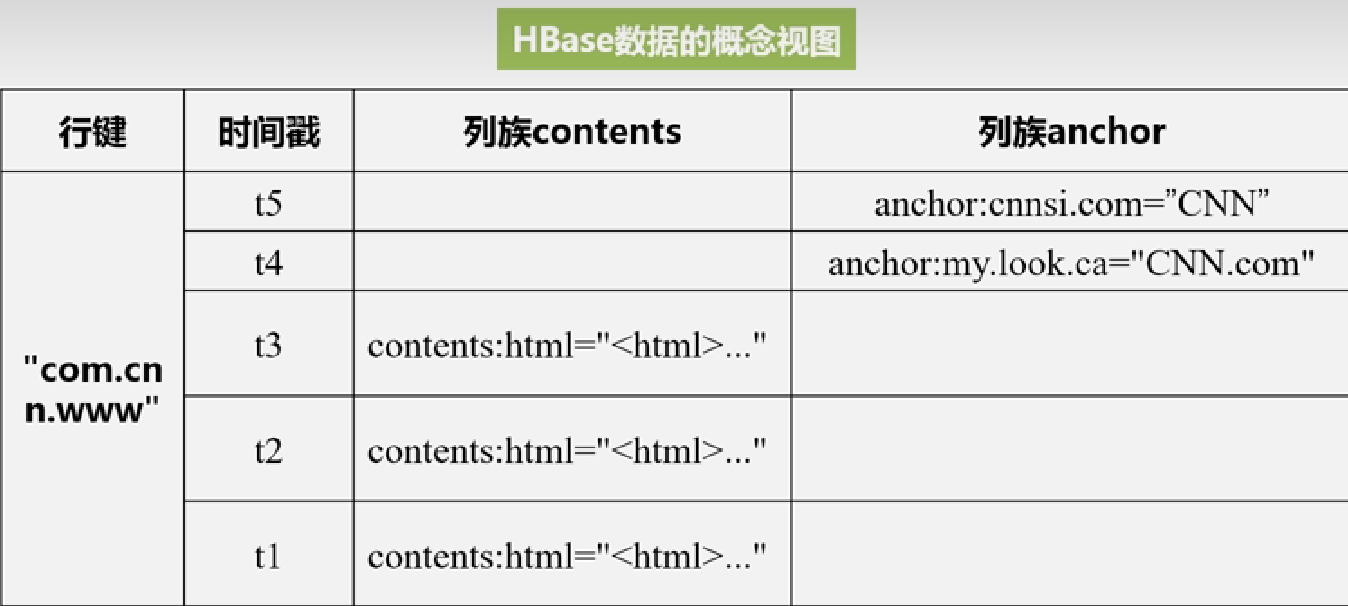
定位一个数据:
4个必须:行键、列组、列限定符、时间戳:
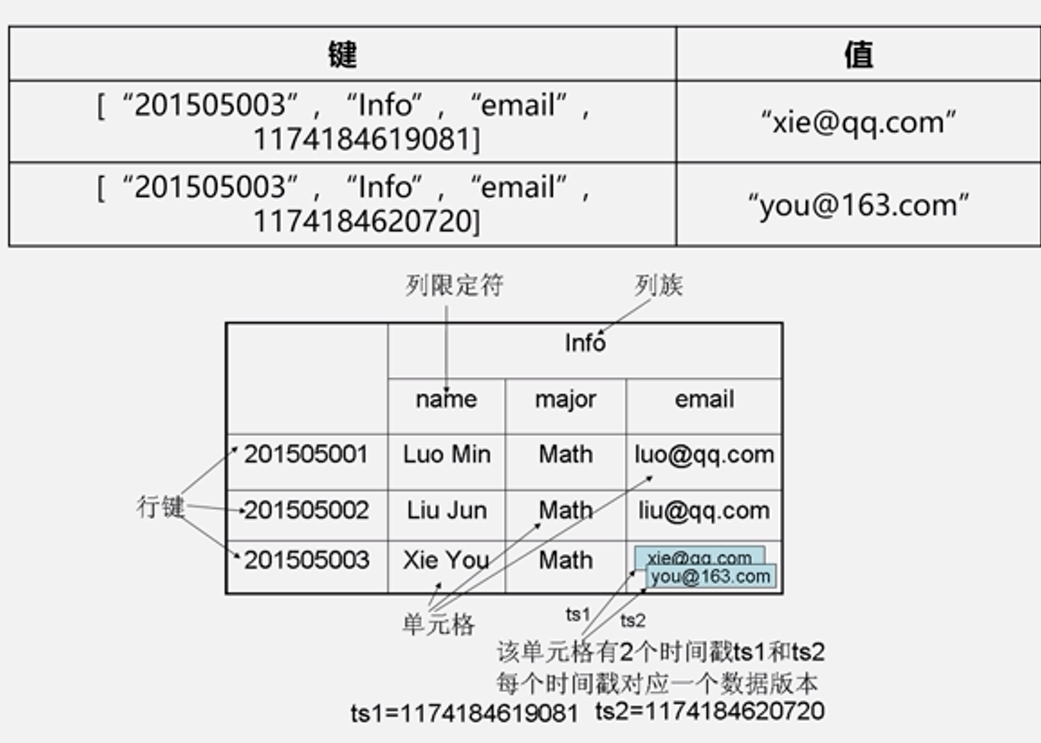
概念示图(可能比较稀疏):
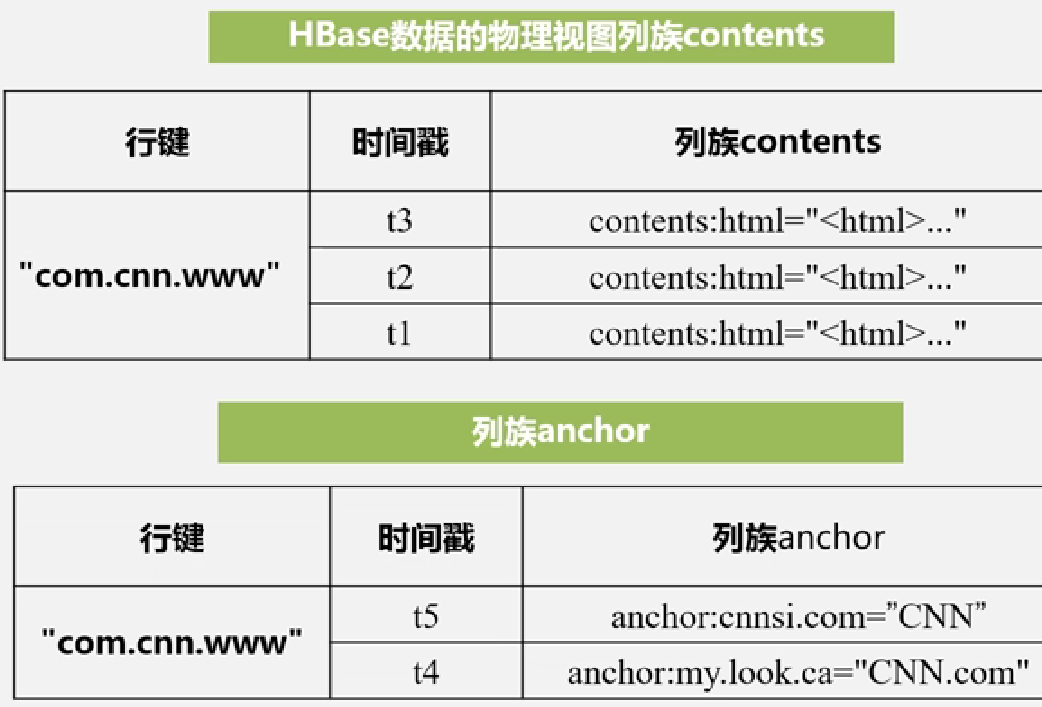
底层存储示意图(基本都是紧凑地存储):
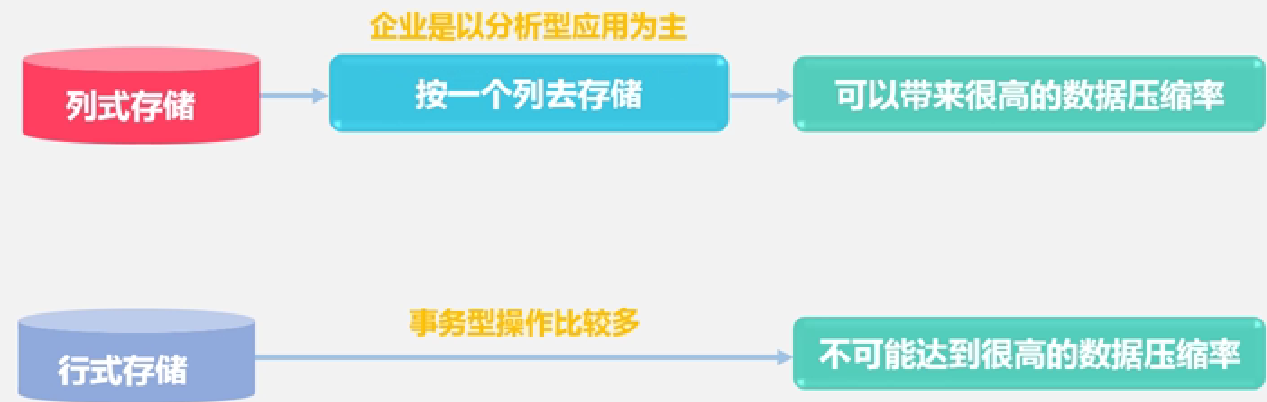
面向行的存储的优势和缺点:

如何选择列式数据库还是行式数据库:
4.3 HBase的实现原理
HBase的功能组件:
库函数;Master服务器;Region服务器
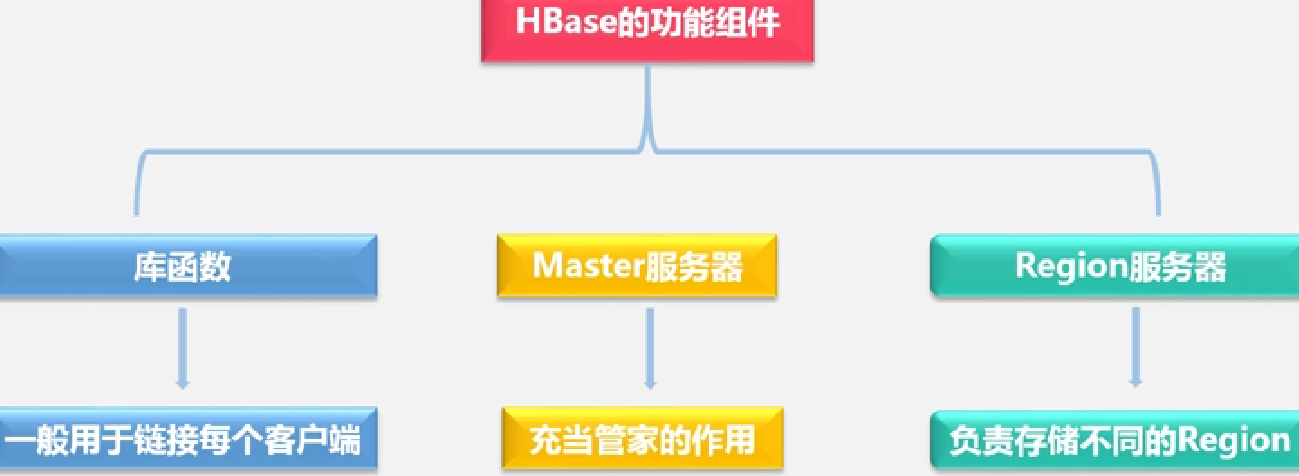
Master服务器的作用:

Region的拆分(拆分速度很快,只是修改链接,并不会修改物理地址;只有合并后的才需要修改物理地址)及大小配置:
补充:同一个Region只是会在一个Region服务器上;每个Region大概能存储10-1000个region
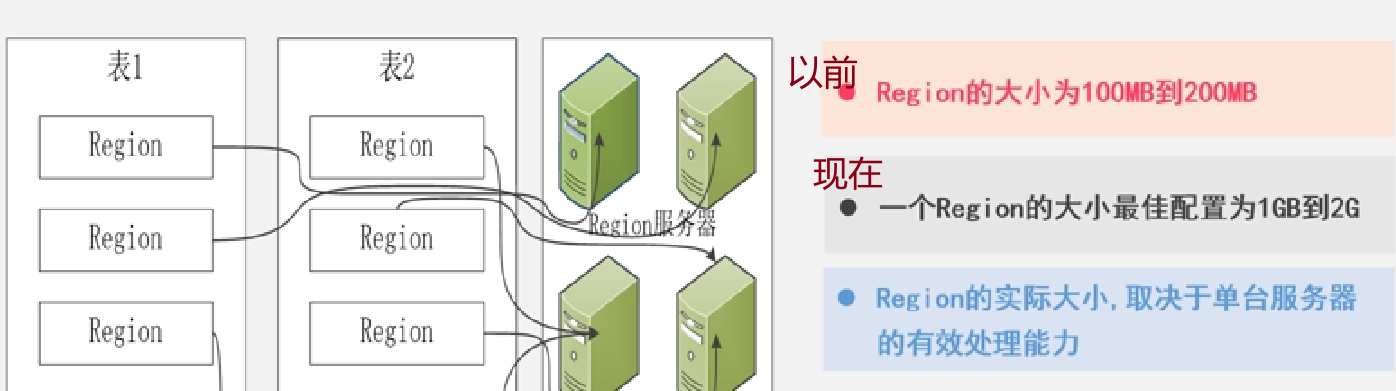
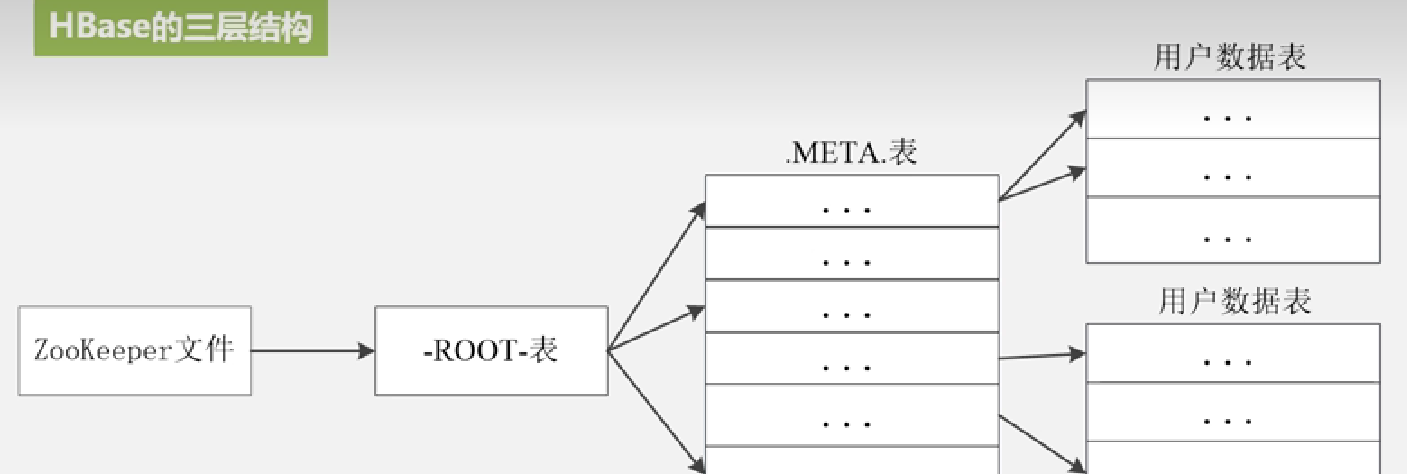
寻址结构:
3层结构及作用:
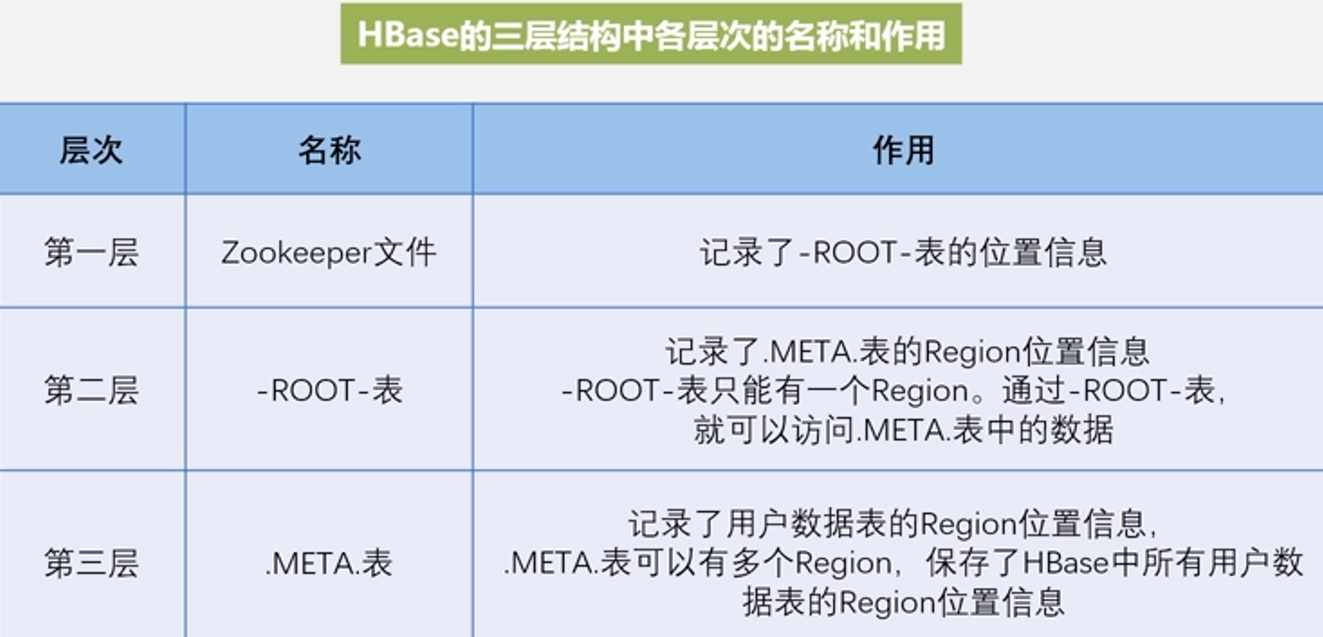
查找数据时的缓存:

4.4 HBase运行机制
读写数据的过程:
写数据:
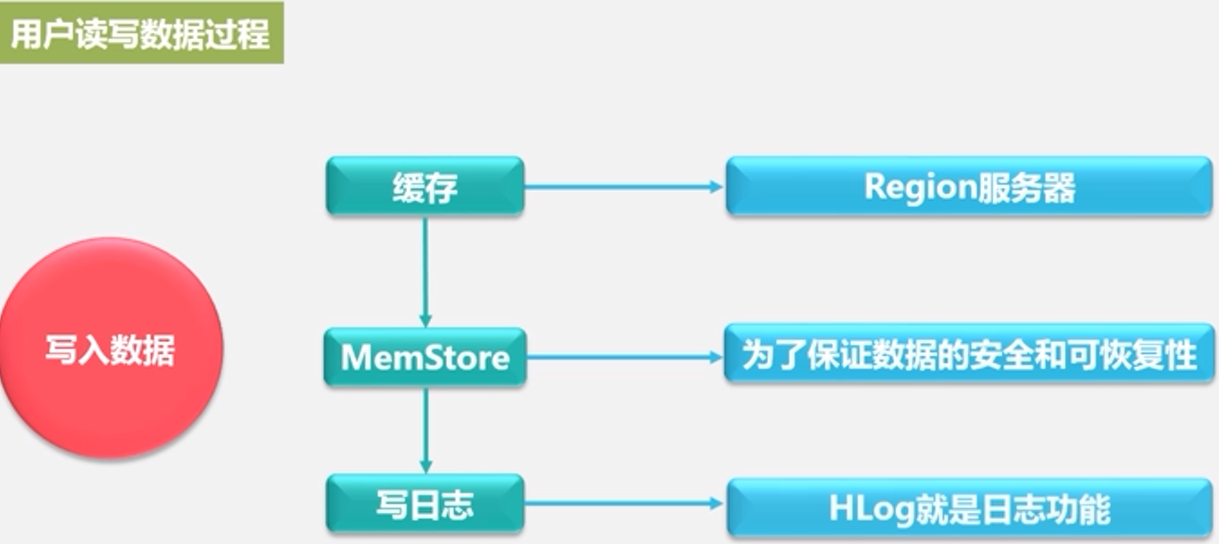
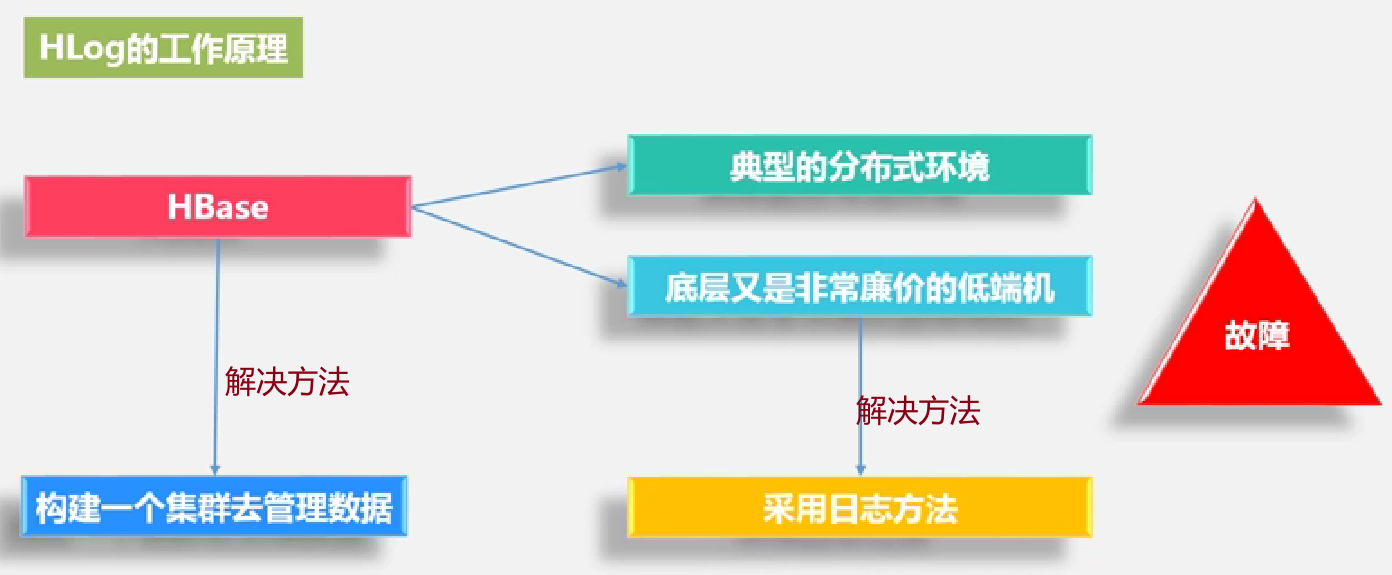
HLog的工作原理:
4.5 HBase应用方案
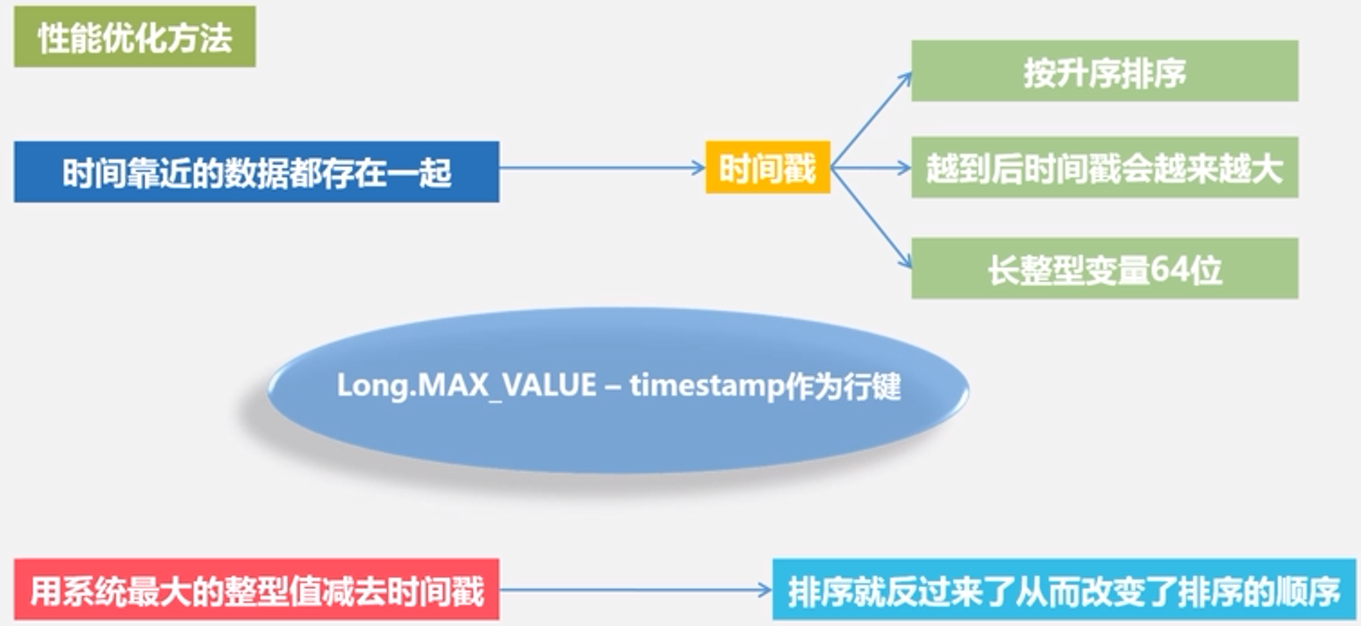
性能优化方法:
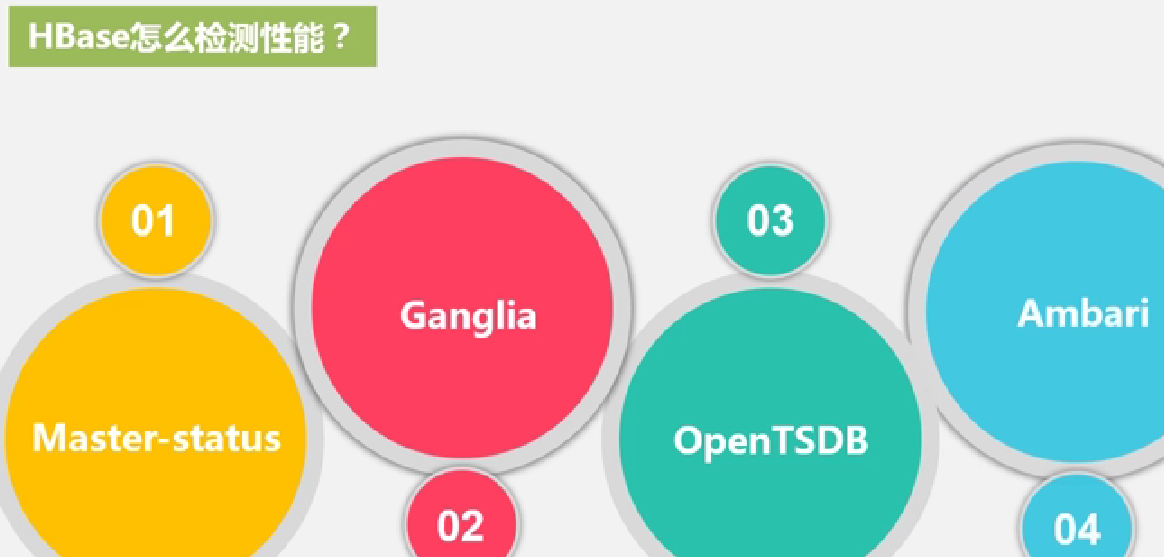
HBase怎么检测性能:
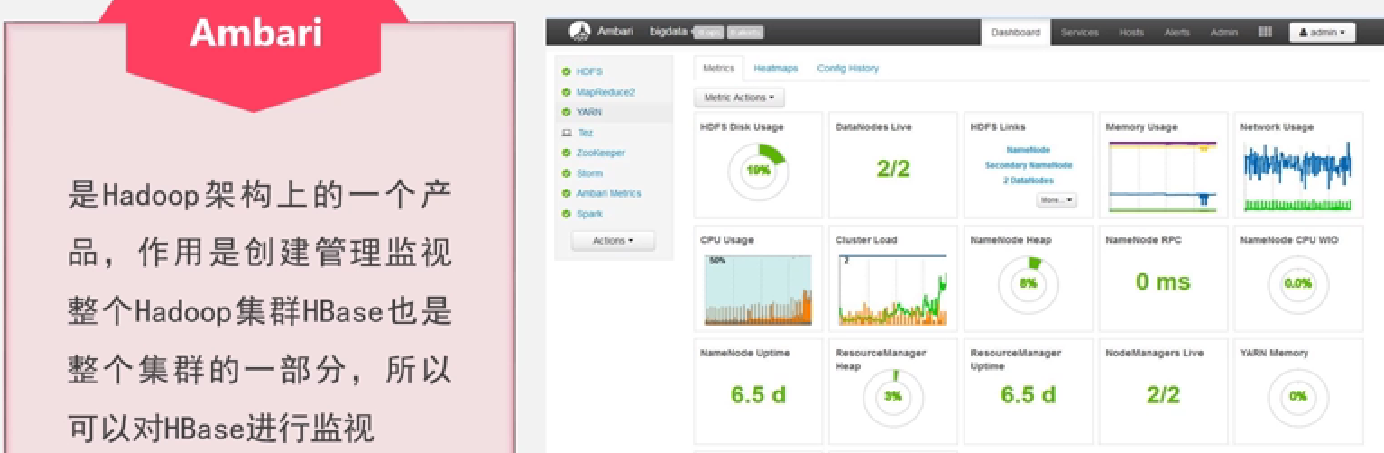
Ambari
4.6 HBase安装配置和常用Shell命令
5.1 NoSQL概述
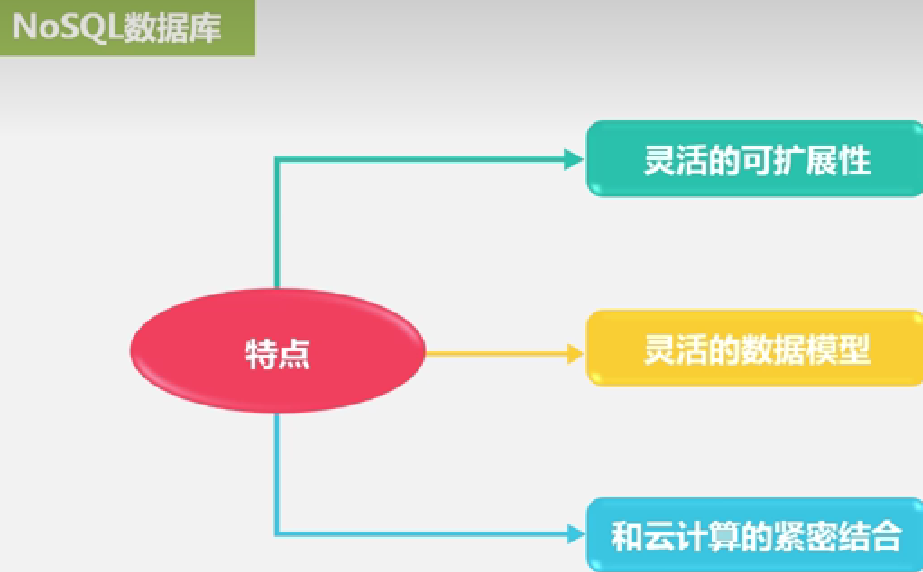
NoSQL特点:
传统的关系数据库性能上的缺陷:

MySQL集群方式的缺陷:

NoSQL兴起的原因:

在web2.0时代,关系数据库没法发挥的特性

5.2 NoSQL与关系数据库的比较
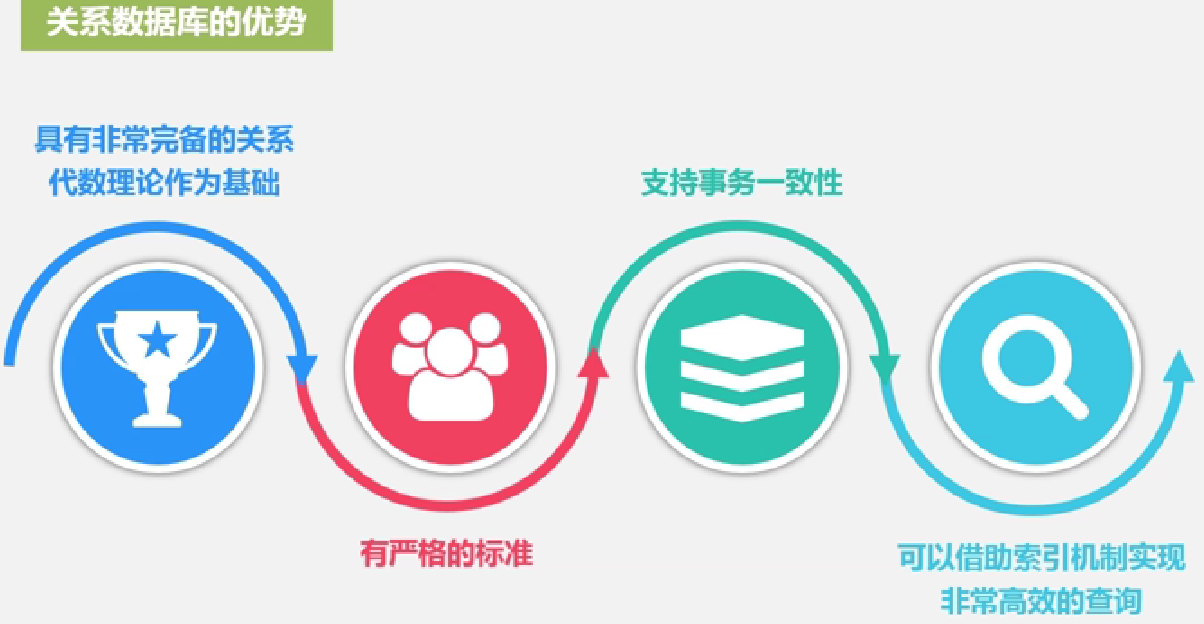
关系数据库的优势:
NoSQL数据库的优势和劣势

5.3.1键值数据库和列族数据库
不同数据库的分类
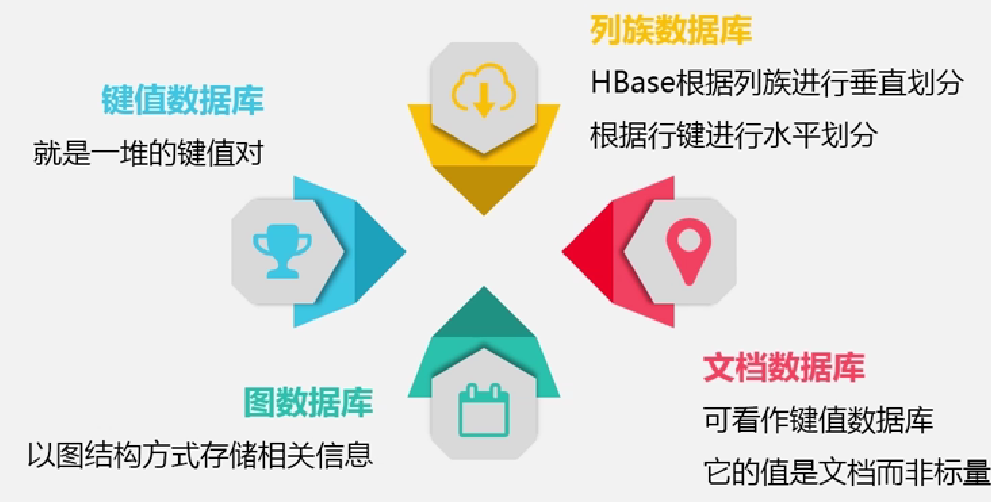
不同类型数据库的举例

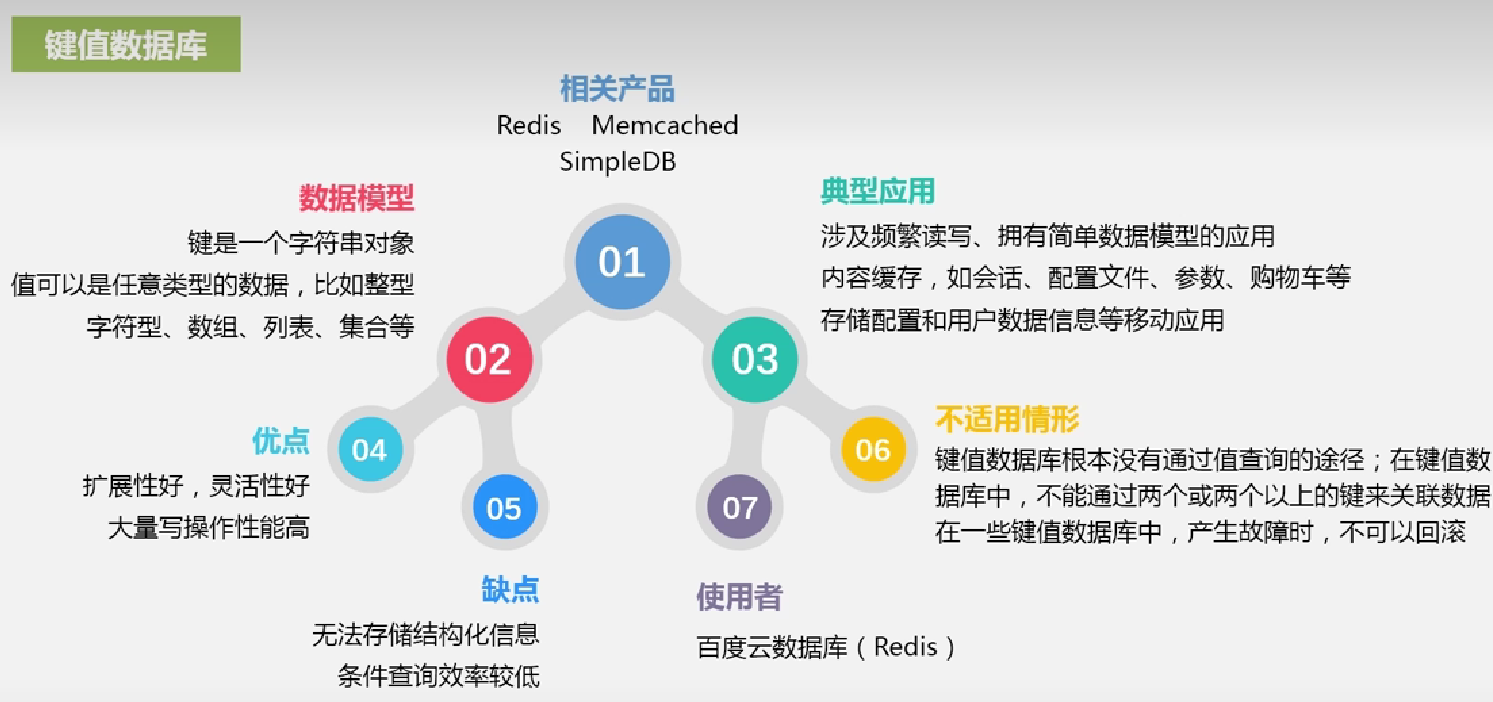
键值数据库
列族数据库
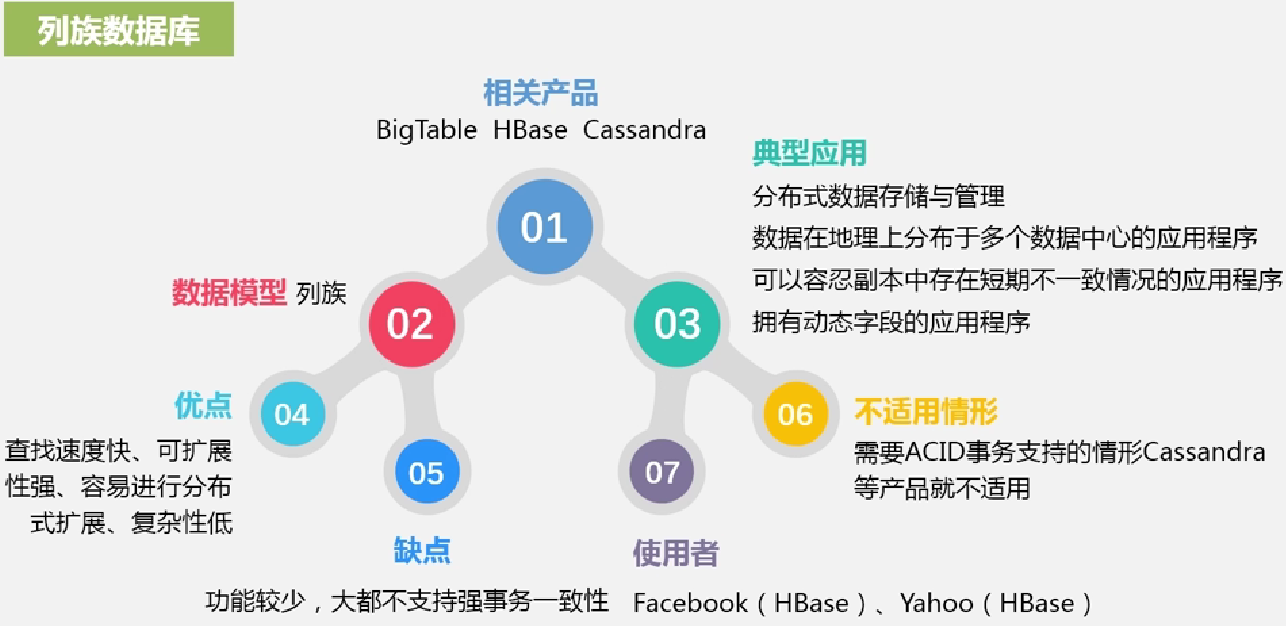
5.3.2文档数据库图数据库以及不同数据库比较分析
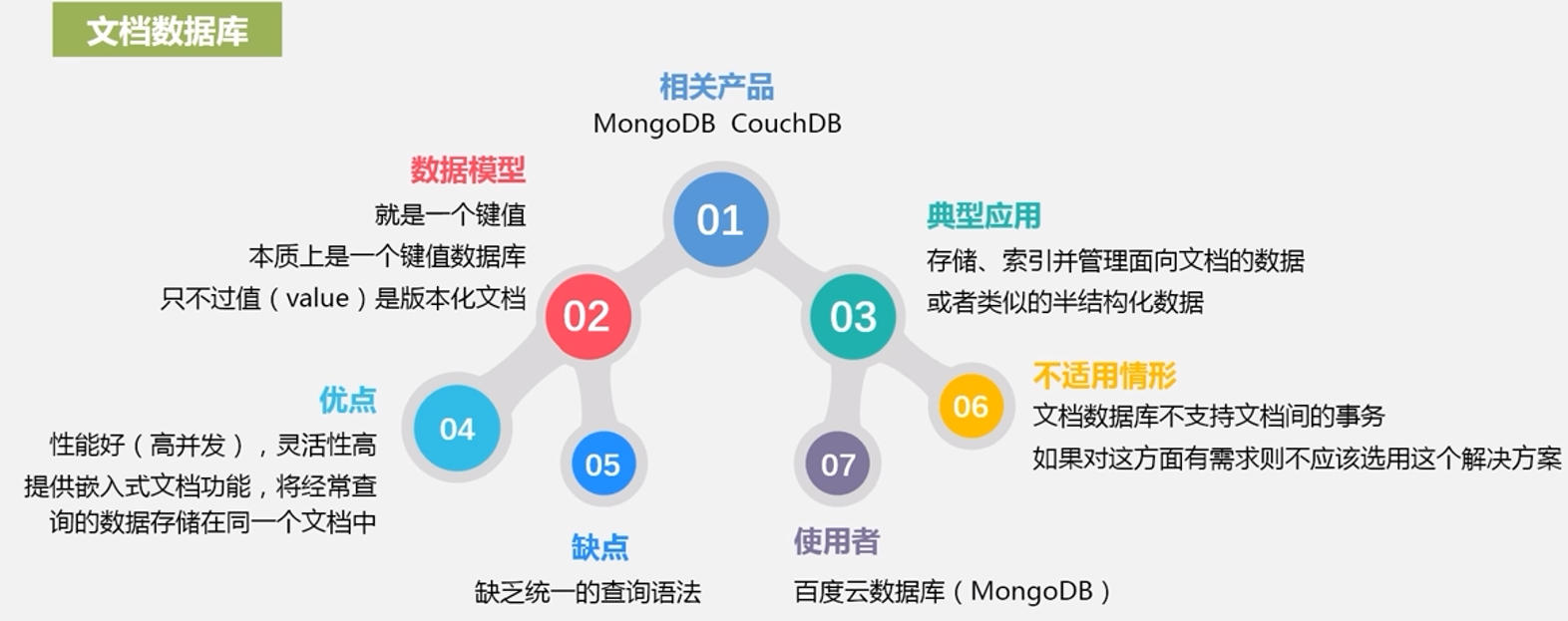
文档数据库
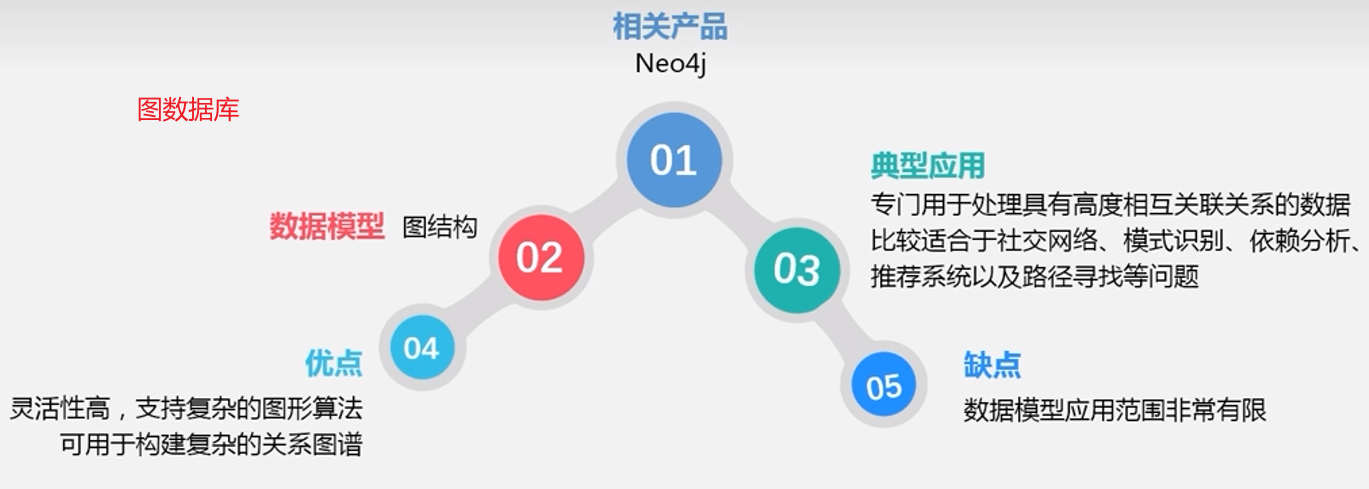
图数据库
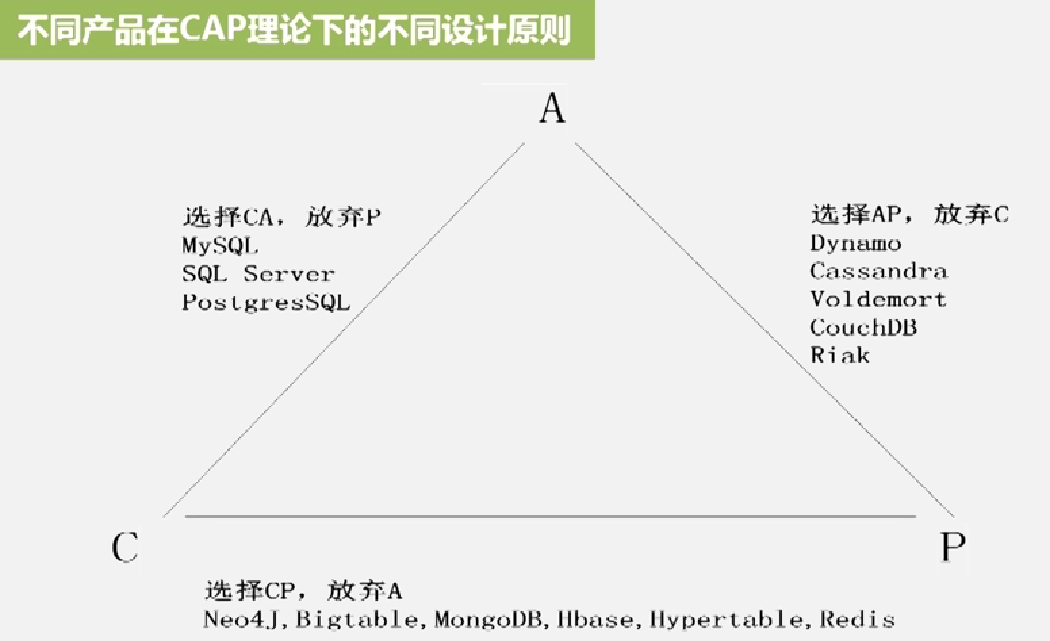
5.4.1 CAP理论
CAP理论:
CAP理论理论下的几种选择

不同产品在CAP理论理论下的不同设计原则
5.4.2 BASE和最终一致性
BASE:


最终一致性;

回话一致性;单调写一致性

如何实现各种类型的一致性
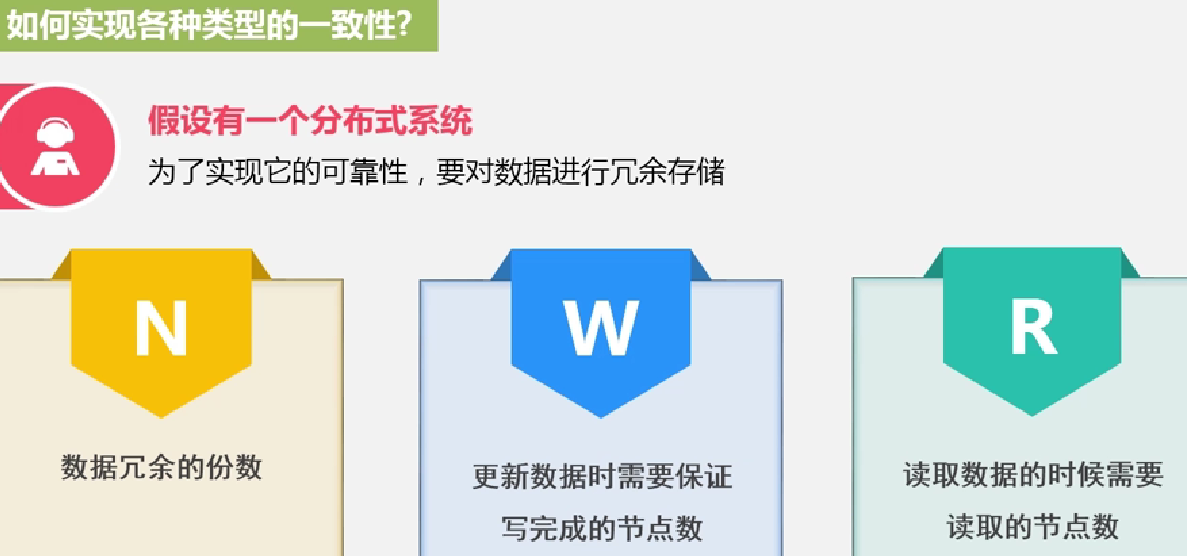
N/W/R之间的关系

举例:

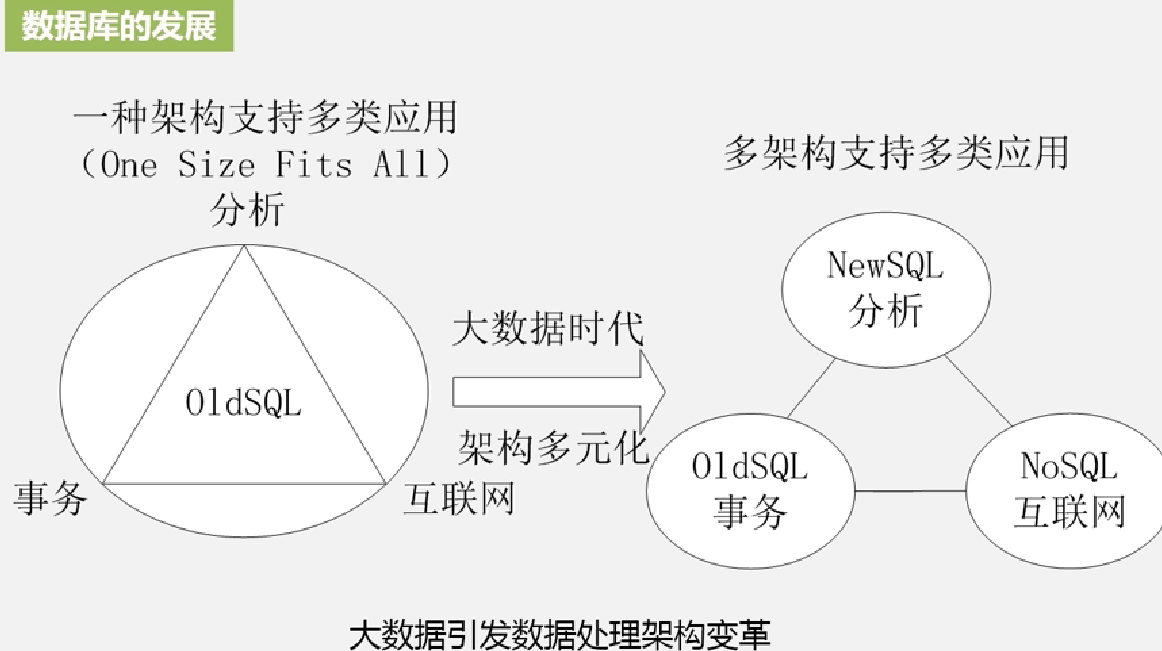
5.5 从NoSQL到NewSQL数据库
数据库的发展,伴随着大数据的发展
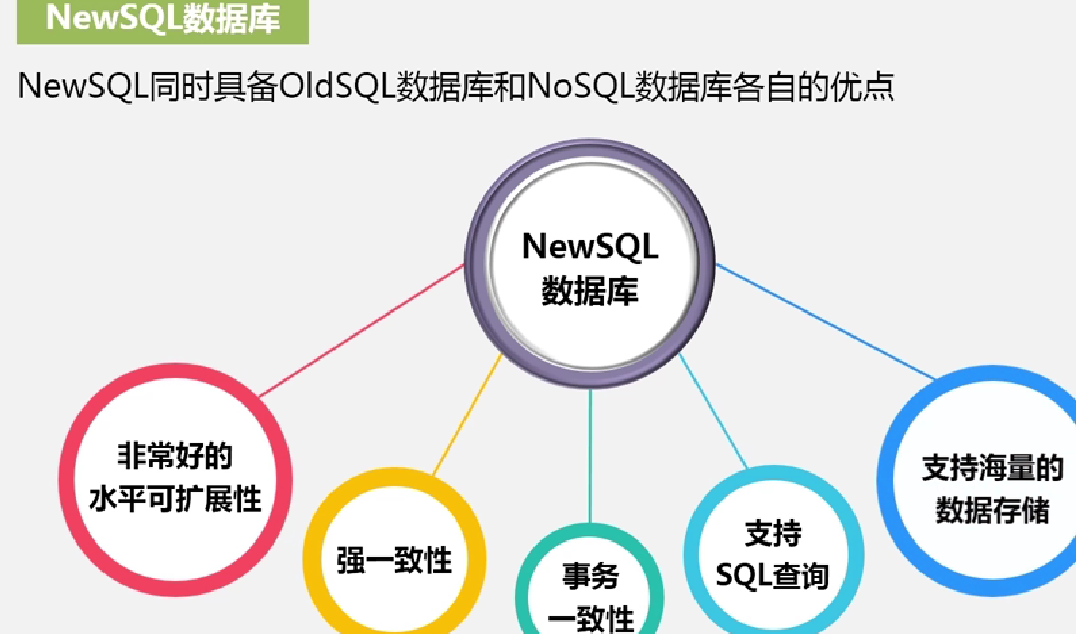
newSQL数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号