
第三章:进程管理
第三章:进程管理
主要内容:
- 进程和线程
- 进程的描述
- 进程的创建和销毁
3.1 进程和线程
进程的概念:
处于执行期间的程序和相关资源的总称(实际上进程就是正在执行的程序的实时结果)包含可执行程序代码和打开的文件、内核内部数据、处理器状态、具有内存映射的内存地址、执行线程、数据段等资源。
线程的概念:
进程中活动的对象。线程拥有独立的程序计数器、进程栈和一组进程寄存器。
进程和线程的关系:
进程可以理解为正在执行的程序,线程则是与主程序并行运行的程序函数或例程,本质上进程可以由若干线程组成,同一进程的线程共享数据和资源,但可以执行程序中不同的代码路径。但是Linux系统不特别区分进程和线程,线程被当成一种特殊的进程。
虚拟机制:
现代操作系统中提供两种虚拟机制:虚拟处理器和虚拟内存。每个进程有独立的虚拟处理器和虚拟内存,每个线程有独立的虚拟处理器,同一个进程内的线程有可能会共享虚拟内存。
3.2 进程描述
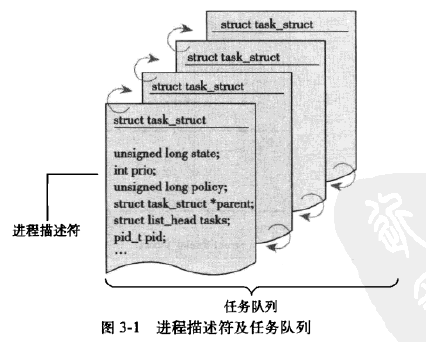
进程描述符:
包含一个具体进程的的所有信息。其包含的数据能够完整的描述一个正在执行的程序的相关资源。包括打开的文件、进程的地址空间、挂起的信号、进程状态等等。简化的定义如下:
// 文件路径:include/linux/sched.h struct task_struct { volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ void *stack; atomic_t usage; unsigned int flags; /* per process flags, defined below */ unsigned int ptrace; struct list_head tasks; struct plist_node pushable_tasks; struct mm_struct *mm, *active_mm; struct task_struct *real_parent; /* real parent process */ struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */ struct task_struct *group_leader; /* threadgroup leader */ int lock_depth; /* BKL lock depth */ pid_t pid; // 进程标识值 pid_t tgid; ...... }; 内核通过进程描述符中的进程ID号(PID)来标识每个进程,PID为是一个数标识为pid_t的隐含类型,用fork或clone产生的每个进程都由内核自动地分配了一个新的唯一的PID值。可以通过current宏查找当前正在运行进程的进程描述符,获取指向进程描述符的指针,从而访问进程。
内核把进程的列表存放在叫做任务队列的双向循环链表中,链表节点为进程描述符:
可以通过 ps 命令查看所有进程的信息:
# 以本机的 WSL-ubuntu 为例: ps -eo pid,tid,ppid,comm 输出结果如下: luo@LAPTOP-A0LIIOAD:/mnt/c/Users/86188$ ps -eo pid,tid,ppid,comm PID TID PPID COMMAND 1 1 0 init 7 7 1 init 8 8 7 bash 20 20 8 ps
进程状态:
上述进程描述符中的
state域描述了进程当前状态,进程可能所处的状态一共有五种:
状态 描述 TASK_RUNNING (运行) 意味着进程处于可执行状态(正在执行/队列中等待执行)。进程可能会一直等到调度器选中它。该状态确保进程可以立即运行,而无需等待外部事件。 TASK_INTERRUPTIBLE (可中断) 针对等待某事件或其他资源的睡眠进程设置的。在内核发送信号给该进程表明事件已经发生时,进程状态变为TASK_RUNNING,它只要调度器选中该进程即可恢复执行。 TASK_UNINTERRUPTIBLE (不可中断) 用于因内核指示而停用的睡眠进程。它们不能由外部信号唤醒,只能由内核亲自唤醒。 TASK_TRACED 本来不是进程状态,用于从停止的进程中将当前被调试的那些(使用ptrace机制)与常规的进程区分开来。 TASK_STOPPED (停止) 表示进程特意停止运行,例如,由调试器暂停。 ![进程状态切换]()
设置进程状态:内核经常调整某个进程的状态可以使用以下函数:
// 具体定义参见 <linux/sched.h> set_task_state(task,state); // 将任务task的状态设置为state set_current_state(state); // 和set_task_state(current,state);等同

3.3 进程的创建
进程家族树:
所有进程都是 PID 为1的 init 进程的后代,内核在启动的最后阶段启动 init 进程。该进程读取系统的初始化脚本(initscript)并执行其他相关程序,最终完成系统启动的整个流程。
进程可以拥有多个子进程,拥有同一个父进程的所有进程被称为兄弟。进程之间的关系存放在进程描述符中,每一个 task_struct 中都有,指向父进程的 parent 指针和 children 子进程链表,见上节进程描述符代码。可以采用以下方式获取相应的进程描述符:
// 获取父进程的描述符 struct task_struct *my_parent = current->parent; // 依次访问子进程 struct task_struct *task; struct list_head *list; list_for_each(list,¤t->children) { task = list_entry(list,struct task_struct,sibling); // task 指向当前的某个子进程 }
创建子进程:
linux 系统创建进程可以分解为两步:
fork() 和exec()
函数 描述 fork() 拷贝当前进程,创建子进程。 子进程与父进程区别: PID、PPID(父进程的进程号)、某些资源和统计量。 exec() 读取可执行文件,并将其载入地址空间开始运行 。 写时拷贝:
使用写时拷贝机制,可以推迟甚至免除拷贝数据。内核并不复制整个进程空间,而是让父子进程共享同一个拷贝。在需要写入时资源才会被复制,使进程拥有各自的拷贝,拷贝发生前仅以只读的方式共享。此时
fork()的实际开销就是复制父进程的页表以及给子进程创建唯一的进程描述符。写时拷贝可以避免拷贝大量不会被使用的数据。fork()详细分析:
Linux 通过 clone() 系统调用实现 fork() ,调用过程如下
fork() —> clone()—> do_fork() —> copy_process()。copy_process() 函数的工作流程(见 kernel/fork.c 详细注释)如下:
- 调用 dup_task_struct() 为子进程分配内核栈,task_struct 等,其中的内容与父进程相同
- check 子进程(进程数目是否超出上限等)
- 清理子进程的信息(清零或设置初始值),使之与父进程区别开
- 子进程状态置为
TASK_UNINTERRUPTIBLE保证不会投入运行- 更新 task_struct 的 flags 成员
- 调用
alloc_pid()为新进程分配一个有效的 PID- 根据
clone()的参数标志,拷贝或共享相应的信息- 做一些扫尾工作并返回子进程指针
copy_process() 函数成功返回之后回到 do_fork() 函数,新建的子进程被唤醒并让其投入运行。内核有意让新建子进程先执行,这样子进程会马上调用 exec() 函数,可以避免写时拷贝带来的额外开销。
3.4 线程在 Linux 中的实现
Linux 把所有的线程都当做进程来实现,线程仅仅被视为与其他进程共享某些资源的进程。每个线程都拥有唯一隶属自己的 task_struct 。
创建线程:
线程的创建和普通进程的创建类似,只不过需要在调用
clone()函数的时候,需要出传递一些参数标志。其实就是创建一个和父程共享地址空间,文件系统资源,文件描述符和信号处理程序的进程。如下:# 普通进程的的创建: clone(SIGCHLD, 0); # 线程的创建: clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
内核线程:
内核线程的特点:
- 独立运行在内核空间的标准线程,内核用其在后台执行一些操作
- 相较于普通线程:没有独立的地址空间,并只能在内核空间运行
- 只能由其他内核线程创建
- 可以被调度和抢占
- 创建之初处不可运行状态,需用
wake_up_process()唤醒- 启动后一直运行到调用
do_exit()退出内核线程创建程序实现:
// 文件路径 <include/linux/kthread.h> /** * kthread_create - 创建一个内核线程 * @threadfn: the function to run until signal_pending(current). * @data: data ptr for @threadfn. * @namefmt: printf-style name for the thread. * * Description: This helper function creates and names a kernel * thread. The thread will be stopped: use wake_up_process() to start * it. See also kthread_run(). * * When woken, the thread will run @threadfn() with @data as its * argument. @threadfn() can either call do_exit() directly if it is a * standalone thread for which noone will call kthread_stop(), or * return when 'kthread_should_stop()' is true (which means * kthread_stop() has been called). The return value should be zero * or a negative error number; it will be passed to kthread_stop(). * * Returns a task_struct or ERR_PTR(-ENOMEM). */ struct task_struct *kthread_create(int (*threadfn)(void *data), void *data, const char namefmt[], ...) __attribute__((format(printf, 3, 4))); /** * kthread_run - 创建一个内核线程,并唤醒投入运行 * @threadfn: the function to run until signal_pending(current). * @data: data ptr for @threadfn. * @namefmt: printf-style name for the thread. * * Description: Convenient wrapper for kthread_create() followed by * wake_up_process(). Returns the kthread or ERR_PTR(-ENOMEM). */ #define kthread_run(threadfn, data, namefmt, ...) \ ({ \ struct task_struct *__k \ = kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \ if (!IS_ERR(__k)) \ wake_up_process(__k); \ __k; \ })内核线程启动后一直运行到调用
do_exit()退出,或者在内核的其它部分调用kthread_stop()退出。传递给kthread_stop()的参数为kthread_create()函数返回的 task_struct 结构的地址:int kthread_stop(struct task_struct *k);
3.5 进程终结
终结流程:
进程的终结是通过
do_exit()函数实现的,该函数终结进程时需要做以下工作:
- 设置
task_struct中的标识成员 flag 设置为PF_EXITING,此标志表示进程正在被删除- 调用
del_timer_sync()删除内核定时器, 确保没有定时器在排队和运行- 调用
exit_mm()释放进程占用的mm_struct- 调用
sem__exit(),使进程离开等待 IPC 信号的队列- 调用
exit_files()和exit_fs(),释放进程占用的文件描述符和文件系统资源- 把 task_struct 的
exit_code设置为exit()提供的退出代码- 调用
exit_notify()向父进程发送信号,并把自己的状态设EXIT_ZOMBIE- 切换到新进程继续执行
// 文件路径 < linux/kernel/exit.c > NORET_TYPE void do_exit(long code) { struct task_struct *tsk = current; int group_dead; profile_task_exit(tsk); WARN_ON(atomic_read(&tsk->fs_excl)); if (unlikely(in_interrupt())) panic("Aiee, killing interrupt handler!"); if (unlikely(!tsk->pid)) panic("Attempted to kill the idle task!"); tracehook_report_exit(&code); validate_creds_for_do_exit(tsk); /* * We're taking recursive faults here in do_exit. Safest is to just * leave this task alone and wait for reboot. */ // 检查检查 PF_EXITING 标志是否未被设置,如果未被设置则由 exit_signals() 设置 if (unlikely(tsk->flags & PF_EXITING)) { printk(KERN_ALERT "Fixing recursive fault but reboot is needed!\n"); /* * We can do this unlocked here. The futex code uses * this flag just to verify whether the pi state * cleanup has been done or not. In the worst case it * loops once more. We pretend that the cleanup was * done as there is no way to return. Either the * OWNER_DIED bit is set by now or we push the blocked * task into the wait for ever nirwana as well. */ tsk->flags |= PF_EXITPIDONE; set_current_state(TASK_UNINTERRUPTIBLE); schedule(); } exit_irq_thread(); exit_signals(tsk); /* 将 tsk->flags 设置为 PF_EXITING */ /* * tsk->flags are checked in the futex code to protect against * an exiting task cleaning up the robust pi futexes. */ // 内存屏障,用于确保在它之后的操作开始执行之前,它之前的操作已经完成 smp_mb(); //一直等待,直到获得current->pi_lock自旋锁 raw_spin_unlock_wait(&tsk->pi_lock); if (unlikely(in_atomic())) // 如果 BSD 的进程记账功能是开启的 printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n", current->comm, task_pid_nr(current), preempt_count()); /** * acct_update_integrals - update mm integral fields in task_struct * 更新进程的运行时间,获取tsk->mm->rss_stat.count[member]计数 * @tsk: task_struct for accounting */ acct_update_integrals(tsk); // 输出记账信息 /* sync mm's RSS info before statistics gathering */ if (tsk->mm) sync_mm_rss(tsk, tsk->mm); // 清除定时器 group_dead = atomic_dec_and_test(&tsk->signal->live); if (group_dead) { hrtimer_cancel(&tsk->signal->real_timer); exit_itimers(tsk->signal); if (tsk->mm) setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm); } acct_collect(code, group_dead); if (group_dead) tty_audit_exit(); if (unlikely(tsk->audit_context)) audit_free(tsk); // 把 task_struct 的 exit_code 域设置为 exit() 提供的退出代码 tsk->exit_code = code; taskstats_exit(tsk, group_dead); exit_mm(tsk); // 释放进程占用的 task_struct // 如果没有别的进程使用它(地址空间没有被共享),就彻底释放 if (group_dead) acct_process(); trace_sched_process_exit(tsk); // 释放用户空间的“信号量” // 遍历current->sysvsem.undo_list链表,并清除进程所涉及的每个IPC信号量的操作痕迹 exit_sem(tsk); exit_files(tsk); // 释放已经打开的文件(递减文件描述符) exit_fs(tsk); // 释放用于表示工作目录等结构(递减文件系统引用计数) check_stack_usage(); exit_thread(); // 释放 task_struct 中的 thread_struct 结构 cgroup_exit(tsk, 1); if (group_dead) disassociate_ctty(1); module_put(task_thread_info(tsk)->exec_domain->module); proc_exit_connector(tsk); /* * FIXME: do that only when needed, using sched_exit tracepoint */ flush_ptrace_hw_breakpoint(tsk); /* * Flush inherited counters to the parent - before the parent * gets woken up by child-exit notifications. */ perf_event_exit_task(tsk); // 更新所有子进程的父进程 // 向父进程发送信号,给子进程寻找养父(可能为线程组中的其他线程或 init 进程),并把进程 // 状态设置为 EXIT_ZOMBIE exit_notify(tsk, group_dead); #ifdef CONFIG_NUMA mpol_put(tsk->mempolicy); tsk->mempolicy = NULL; #endif #ifdef CONFIG_FUTEX if (unlikely(current->pi_state_cache)) kfree(current->pi_state_cache); #endif /* * Make sure we are holding no locks: */ debug_check_no_locks_held(tsk); /* * We can do this unlocked here. The futex code uses this flag * just to verify whether the pi state cleanup has been done * or not. In the worst case it loops once more. */ tsk->flags |= PF_EXITPIDONE; if (tsk->io_context) exit_io_context(tsk); if (tsk->splice_pipe) __free_pipe_info(tsk->splice_pipe); validate_creds_for_do_exit(tsk); preempt_disable(); exit_rcu(); /* causes final put_task_struct in finish_task_switch(). */ tsk->state = TASK_DEAD; // 重新调度,因为该进程已经被设置成了僵死状态,因此永远都不会再把它调度回来运行了,也就实 // 现了do_exit不会有返回的目标 schedule(); BUG(); /* Avoid "noreturn function does return". */ for (;;) cpu_relax(); /* For when BUG is null */ }
删除进程描述符:
调用
do_exit()之后,进程的状态被设置为EXIT_ZOMBIE状态,其不能运行、不能被调度,关联的资源也被释放。但是其本身占用的内存(内核栈、thread_info 结构和 task_struct 结构)还没有释放,以便于父进程获取其信息。所以进程终结时所需的清理工作和进程描述符的删除时分开执行的。在父进程获取其信息之后或者通知内核信息无关之后(调用 wait4() )进程所占用的内存才会全部被释放,否则会出现僵尸进程或者孤儿进程。最终释放进程描述符的工作是由
release_task()函数完成的release_task() 函数完成的工作:
- 调用
__exit_signal() —> _unshash_process() —>detach_pid()从pidhash上删除该进程,同时也要从任务列表中删除该进程。__exit_signal()释放目前僵死进程所使用的剩余资源,并进行最终统计和记录- 如果这个进程是线程组最后一个进程,并且领头进程已经死掉,那么
release_task()通知死的领头进程的父进程release_task()调用delayed_put_task_struct()释放进程内核栈和 thread_info 结构所占的页,并释放 task_struct 所占的 slab 高速缓存。经过上述4个步骤,进程描述符和所有进程独享的资源就全部被释放掉了。
// 文件路径 < linux/kernel/exit.c > void release_task(struct task_struct * p) { struct task_struct *leader; int zap_leader; repeat: tracehook_prepare_release_task(p); /* don't need to get the RCU readlock here - the process is dead and * can't be modifying its own credentials. But shut RCU-lockdep up */ rcu_read_lock(); atomic_dec(&__task_cred(p)->user->processes); rcu_read_unlock(); proc_flush_task(p); write_lock_irq(&tasklist_lock); tracehook_finish_release_task(p); // 流程1 __exit_signal(p); /* * If we are the last non-leader member of the thread * group, and the leader is zombie, then notify the * group leader's parent process. (if it wants notification.) * 如果这个进程是线程组最后一个进程,并且领头进程已经死掉 * 那么 release_task() 通知死的领头进程的父进程 */ zap_leader = 0; leader = p->group_leader; if (leader != p && thread_group_empty(leader) && leader->exit_state == EXIT_ZOMBIE) { BUG_ON(task_detached(leader)); do_notify_parent(leader, leader->exit_signal); /* * If we were the last child thread and the leader has * exited already, and the leader's parent ignores SIGCHLD, * then we are the one who should release the leader. * * do_notify_parent() will have marked it self-reaping in * that case. */ zap_leader = task_detached(leader); /* * This maintains the invariant that release_task() * only runs on a task in EXIT_DEAD, just for sanity. */ if (zap_leader) leader->exit_state = EXIT_DEAD; } write_unlock_irq(&tasklist_lock); release_thread(p); /** * delayed_put_task_struct() 调用 put_task_struct()释放进程内核栈和 thread_info 结构 * 所占的页,并释放 task_struct 所占的 slab 高速缓存。 */ call_rcu(&p->rcu, delayed_put_task_struct); p = leader; if (unlikely(zap_leader)) goto repeat; } static void __exit_signal(struct task_struct *tsk) { struct signal_struct *sig = tsk->signal; struct sighand_struct *sighand; BUG_ON(!sig); BUG_ON(!atomic_read(&sig->count)); sighand = rcu_dereference_check(tsk->sighand, rcu_read_lock_held() || lockdep_tasklist_lock_is_held()); spin_lock(&sighand->siglock); posix_cpu_timers_exit(tsk); if (atomic_dec_and_test(&sig->count)) posix_cpu_timers_exit_group(tsk); else { /* * If there is any task waiting for the group exit * then notify it: */ if (sig->group_exit_task && atomic_read(&sig->count) == sig->notify_count) wake_up_process(sig->group_exit_task); if (tsk == sig->curr_target) sig->curr_target = next_thread(tsk); /* * Accumulate here the counters for all threads but the * group leader as they die, so they can be added into * the process-wide totals when those are taken. * The group leader stays around as a zombie as long * as there are other threads. When it gets reaped, * the exit.c code will add its counts into these totals. * We won't ever get here for the group leader, since it * will have been the last reference on the signal_struct. */ sig->utime = cputime_add(sig->utime, tsk->utime); sig->stime = cputime_add(sig->stime, tsk->stime); sig->gtime = cputime_add(sig->gtime, tsk->gtime); sig->min_flt += tsk->min_flt; sig->maj_flt += tsk->maj_flt; sig->nvcsw += tsk->nvcsw; sig->nivcsw += tsk->nivcsw; sig->inblock += task_io_get_inblock(tsk); sig->oublock += task_io_get_oublock(tsk); task_io_accounting_add(&sig->ioac, &tsk->ioac); sig->sum_sched_runtime += tsk->se.sum_exec_runtime; sig = NULL; /* Marker for below. */ } // 流程1 __unhash_process(tsk); /* * Do this under ->siglock, we can race with another thread * doing sigqueue_free() if we have SIGQUEUE_PREALLOC signals. */ flush_sigqueue(&tsk->pending); tsk->signal = NULL; tsk->sighand = NULL; spin_unlock(&sighand->siglock); __cleanup_sighand(sighand); clear_tsk_thread_flag(tsk,TIF_SIGPENDING); if (sig) { flush_sigqueue(&sig->shared_pending); taskstats_tgid_free(sig); /* * Make sure ->signal can't go away under rq->lock, * see account_group_exec_runtime(). */ task_rq_unlock_wait(tsk); __cleanup_signal(sig); } } static void __unhash_process(struct task_struct *p) { nr_threads--; detach_pid(p, PIDTYPE_PID); // 从 pid_hash 中删除该进程 if (thread_group_leader(p)) { detach_pid(p, PIDTYPE_PGID); detach_pid(p, PIDTYPE_SID); list_del_rcu(&p->tasks); list_del_init(&p->sibling); __get_cpu_var(process_counts)--; } list_del_rcu(&p->thread_group); // 从任务列表中删除此进程 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号