JStorm集群的部署
JStorm是一个类似Hadoop MapReduce的系统,不同的是JStorm是一套基于流水线的消息处理机制,是阿里基于Storm优化的版本,和Storm一样是一个分布式实时计算的系统,从开发角度来说,JStorm所有的概念和Storm都相同,所有的编程代码一行不用改也可以直接放到JStorm运行,也可以做一些优化,JStorm比Storm更稳定、更强大、更快,去掉了很多耗费资源的代码,在实际生产中表现更是非常突出,所以对于使用Storm计算的应用场景来说升级到JStorm更是简单、低成本,以下使用3台服务器说一下JStorm集群的部署流程
这3台服务器的主机名分别为:bigdata1,bigdata2,bigdata3
准备工作:
1、主机名和hosts映射一一对应,设置完好!
2、防火墙关闭,保证通信畅通
3、Zookeeper集群正常运行
4、Python 2.6以上(系统一般默认都存在)
5、JDK 推荐1.8
接下来在bigdata1上操作安装:
1、释放storm安装包并移动至指定目录:
unzip jstorm-2.1.1.zip mv jstorm-2.1.1 /bigdata/jstorm/ cd /bigdata/jstorm/jstorm-2.1.1/
现在安装目录是/bigdata/jstorm/jstorm-2.1.1/
2、编辑配置文件,执行 vim conf/storm.yaml 打开配置文件
配置storm.zookeeper.servers为zookeeper地址

storm.zookeeper.root为jstorm在zookeeper的节点名称

去掉nimbus.host的注释,配置nimbus节点为bigdata1

配置storm.local.dir,表示jstorm的临时数据存放目录

去掉supervisor.slots.ports前面的注释,设置supervisor节点执行worker使用的端口列表,默认为68xx,而storm是67xx
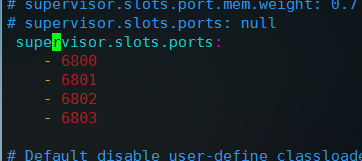
一般设置为4个就够了,当worker太多不够时,再增加端口进行扩展
配置完以上几个配置,保存并退出配置文件,另外注意每一项配置必须对齐,这里每一项前面都有一个空格
配置成功之后,执行以下命令,将jstorm整体发送至其他两个节点:
scp -r /bigdata/jstorm/ bigdata2:/bigdata/ scp -r /bigdata/jstorm/ bigdata3:/bigdata/
在当前机器,一般是nimbus,也就是提交jar包的机器上执行如下命令:
mkdir ~/.jstorm cp /bigdata/jstorm/jstorm-2.1.1/conf/storm.yaml ~/.jstorm/
建议尽量拷贝storm.yaml配置文件过去,否则可能在启动ui和supervisor之后出现找不到supervisor节点的情况
3、配置storm ui管理界面
首先安装好tomcat,然后将storm安装目录下的jstorm-ui-2.1.1.war复制到tomcat下的webapps中,就相当于tomcat容器中的一个web项目,可以放个软链给ROOT这样jstorm的管理界面就变成tomcat默认项目了,这里为默认项目,进入tomcat的webapps下执行如下命令:
mv ROOT ROOT.old ln -s jstorm-ui-2.1.1 ROOT
然后启动tomcat服务器: /usr/local/tomcat/apache-tomcat-8.0.30/bin/startup.sh
4、启动nimbus和supervisor
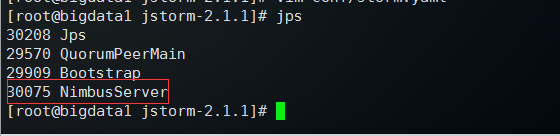
在主节点jstorm安装目录下执行: nohup bin/jstorm nimbus & 执行后再次执行回车回到命令行,执行 jps 能看到NimbusServer进程,则nimbus启动成功:
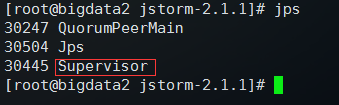
在其他两个节点分别执行: nohup bin/jstorm supervisor & 执行之后,执行 jps 可以看到Supervisor进程,则supervisor启动成功:
访问主节点ip查看管理界面,地址为:http://192.168.0.187:8080/
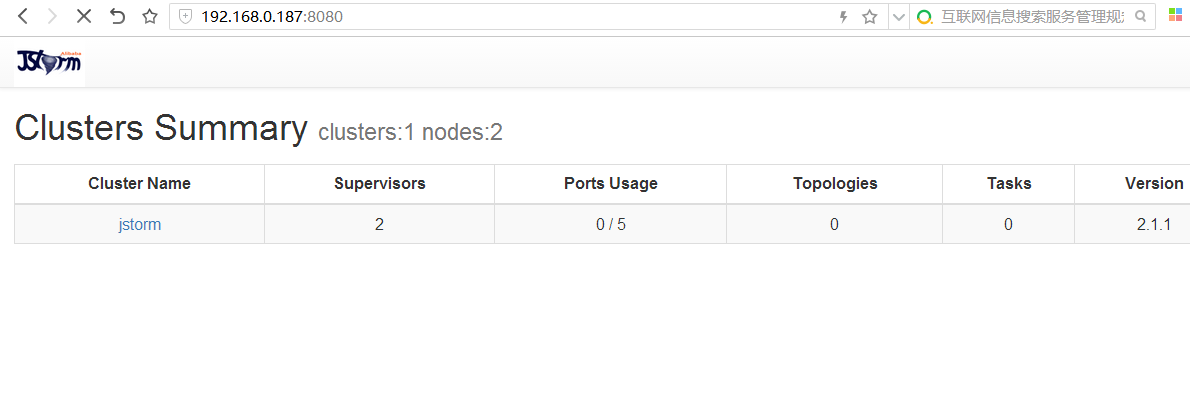
现在可以看到集群状态,到这里Storm就安装成功并且可以使用了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号