Storm自带测试案例的运行
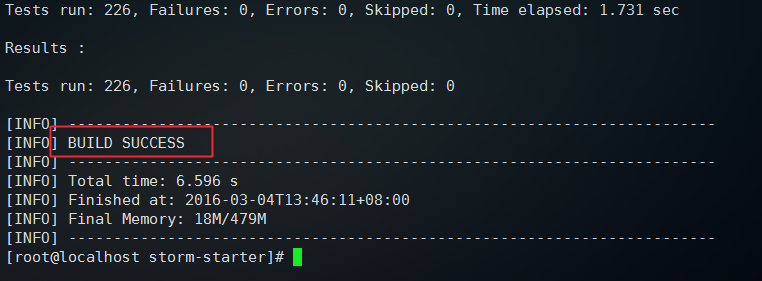
之前Storm安装之后,也知道了Storm的一些相关概念,那么怎么样才可以运行一个例子对Storm流式计算有一个感性的认识呢,那么下面来运行一个Storm安装目录自带的测试案例,我们的Storm安装在服务器的/usr/storm/apache-storm-0.9.6中,首先进入这个目录,执行ls可以看到有一个examples目录,这个就是Storm自带的案例,里面有一个项目storm-starter,首先确保maven的正确安装,我们执行命令: cd examples/storm-starter/ 进入项目目录,看到目录下有一个test目录,然后我们执行: mvn test 执行之后,maven会自动搜索依赖并下载相关类库最后完成项目的编译,这个时候要保持网络畅通,等待5-10分钟项目就构建完毕了,会看到目录下多出很多文件,提示BUILD SUCCESS则代表命令执行成功,如下图:
然后,此时执行下面命令运行主类中的main方法:
mvn exec:java "-Dstorm.topology=storm.starter.WordCountTopology"
代码稍微滚动几秒,然后就结束了,最后出现的错误我们可以忽略,如果运行过程中查看仔细的话,会看到中间计算对单词进行了一定的统计,中间某一时刻截图如下:

此时,这个项目我们可以通过tar命令打包,下载到本地,也可以在本地参考在Windows下安装maven的过程,和上面一样执行 mvn test ,执行之后不用执行,因为Windows下默认没有Python,所以要运行测试案例,还要安装Python,此时我们可以打开开发环境eclipse for javaee,单击"File"->"Import",进入项目导入选项,选择Maven->Existing Maven Projects,单击"Next"

然后在打开的界面,选择Browse进入浏览界面,选择我们之前使用maven编译好的项目目录storm-starter,点击Finish完成即可导入了,导入后的项目结构截图如下:

里面的错误可以暂时忽略,不影响运行,其中第一项src/jvm就是源码的存放位置:
此时,我们可以打开storm.starter包下的WordCountTopology.java源文件,这个就是刚才测试案例的主类

代码我们可以简单地看懂一些,首先是创建拓扑,然后设置的数据源所在的类,我么可以看一下RandomSetenceSpout这个类数据源代码,后来就是设置Bolt和MapReduce一样进行了计算,之前执行的时候并不是和服务一样不断执行,而是一会就结束了,通过后面2行代码我们就明白了,这里延时了10s然后将任务shutdown,大体流程就是这样

这个主类的构造方法中调用了一个命令就是执行splitsentence.py脚本,查看这个脚本可以知道该脚本导入了storm.py这个模块,主要的计算逻辑都在storm.py这个脚本所定义的方法中实现,所以之前说过必须安装python才可以正确执行,原因就在这,所以理论上storm可以实现任何语言来编写计算逻辑,只要调用父类的构造方法即可,当然我们可以使用Java直接来编写相应的逻辑
当然这个项目还有很多细节需要理解,目前就先说这些,对Storm入门的项目有一个简单的认识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号