使用Quorum Journal Manager(QJM)的HDFS NameNode高可用配置
前面的一篇文章写到了hadoop hdfs 3.2集群的部署,其中是部署的单个namenode的hdfs集群,一旦其中namenode出现故障会导致整个hdfs存储不可用,如果是要求比较高的集群,有必要配置namenode故障转移来保证集群服务的可用性,hdfs提供两种机制实现的高可用:
1. 使用Quorum Journal Manager方式实现高可用,即采用journalnode守护进程来共享信息传递namenode状态
2. 使用NFS存储来共享namenode状态实现高可用,当然建议存储是基于NAS做的冗余共享,保证数据的安全
两种方式原理基本上一致,配置项略有差别,我们这里采用纯HDFS原生的QJM方式,不依赖外部存储NFS来实现高可用,如果需要NFS部署直接参考官网的文档做一些修改即可。为了保证和之前一篇文章的衔接性,我们直接基于已经部署好的HDFS集群来升级切换为高可用的模式,这样前后看起来更流畅一些,如果是全新部署其实就更简单了,直接配置好所有的配置项,按照步骤操作就可以了。
开始之前我们首先说一下当前已经存在的环境,当前的测试集群有4个节点,hosts文件如下:
192.168.122.5 bigdata1 192.168.122.6 bigdata2 192.168.122.7 bigdata3 192.168.122.8 bigdata4
其中,namenode运行在bigdata1上面;secondarynamenode运行在bigdata2上面;datanode运行在bigdata2,3,4这3个节点上面。另外,我们知道自动故障转移肯定需要zookeeper的支持,因此我们提前部署了zookeeper,运行在bigdata1,2,3这3个节点上面。
上面就是目前的环境,并且在运行状态,我们希望升级后namenode为bigdata1和bigdata2这两个,并且可以自动的进行故障切换;然后secondarynamenode就不存在了,它是为了给namenode分担压力的,因此直接被HA替代了;datanode仍然是bigdata2,3,4这3个节点;另外还有journalnode和zkfc节点,接下来会介绍。
部署HA需要下面两个大的步骤:
1. 实现故障检测和手动故障切换
这里需要用到的组件就是journalnode守护进程,这个进程可以实时收集namenode的状态,并且执行具体的故障切换指令。journalnode必须保证至少配置3个节点,而且节点个数配置奇数个,这个和zookeeper差不多。为什么不配置1个?假如配置1个,一旦挂掉,不就和1个namenode一样,实现不了高可用,因此至少要3个节点,对于n个journalnode最多容忍挂掉的个数为:(n - 1) / 2。我们这里计划部署journalnode守护进程的机器为:bigdata1,2,3这3个节点。
2. 实现自动故障切换
有了第一步的准备,就可以实现手动的故障检测和切换了,这样需要有人值守状态下手动执行命令切换,如果要实现自动切换还需要配合zookeeper进行选举操作,同时HDFS提供和zookeeper交互的客户端ZKFailoverController,简称ZKFC,这也是1个守护进程,它会定义的和namenode通信来标记namenode可用状态,并和zookeeper进行交互,最后确定要进行故障切换时就和手动操作一样发送指令给journalnode守护进程来执行故障切换操作。ZKFC进程必须和namenode一一对应,因此接下来ZKFC运行的节点也为:bigdata1,bigdata2这两个机器
好了,现在我们对故障切换有了清楚的了解,然后就沿着上面两个步骤来实际进行配置,因为hdfs集群所有节点的配置都完全一样,并不会因为角色不同而有所不同,所以我们只需要选定1个机器修改配置,配置没问题了再发送到全部的节点即可,这里就拿bigdata1为例来配置。
1. 修改配置文件
首先配置hdfs-site.xml,新增配置如下:
<property> <name>dfs.nameservices</name> <value>hdfscluster</value> </property> <property> <name>dfs.ha.namenodes.hdfscluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.nn1</name> <value>bigdata1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.nn2</name> <value>bigdata2:8020</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.nn1</name> <value>0.0.0.0:9870</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.nn2</name> <value>0.0.0.0:9870</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://bigdata1:8485;bigdata2:8485;bigdata3:8485/hdfscluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.hdfscluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true)</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/data/dfs/journal</value> </property>
我们依次来解释一下配置项:
dfs.nameservices - 这个是表示集群服务的逻辑名称,用来标识集群服务,也称为nameservice ID这个名字是自定义的,一旦配置所有地方都要对应。
dfs.ha.namenodes.<nameservice ID> - 这个key中要包含服务名称,所以我这里是dfs.ha.namenodes.hdfscluster,对应的值为namenode唯一标识符,同样是自己定义,和主机名无关,这里设置为:nn1,nn2。多个用逗号分隔,大型集群建议配置3~5个namenode更稳定,但是不要超过5个,否则通信速度会降低性能。
dfs.namenode.rpc-address.<nameservice ID>.<namenode ID> - 这个就是具体到每个namenode绑定的rpc主机和端口了,有几个namenode就要配置几组,rpc端口默认为8020,我这里分别配置bigdata1:8020以及bigdata2:8020,nn1对应bigdata1,nn2对应bigdata2
dfs.namenode.http-address.<nameservice ID>.<namenode ID> - 这个和上面的rpc一样,是配置namenode http的主机和端口,http默认端口为9870,因此我这里分别配置bigdata1:9870以及bigdata2:9870,因为我这里的机器是用的双网卡,为了外网可以访问,我配置了0.0.0.0,但要注意rpc和http不能都配置成0.0.0.0,毕竟hdfs要知道具体的主机。另外之前也有个dfs.namenode.http-address配置项,那个要删除掉。
dfs.namenode.shared.edits.dir - 这里我们由于使用了QJM方式,所以共享目录要配置journalnode组的uri,因此这里值为:qjournal://bigdata1:8485;bigdata2:8485;bigdata3:8485/hdfscluster,多个机器使用分号分隔,默认端口为8485,最后加上服务名来标识高可用的范围即:/hdfscluster
dfs.client.failover.proxy.provider.<nameservice ID> - 这个配置客户端用于和活动的Namenode联系的类,后面同样是写服务名,这里值可配置是为了方便实现自定义代理,通常情况下使用hdfs实现的类org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider或RequestHedgingProxyProvider,大部分情况下使用前者
dfs.ha.fencing.methods - 这个选项用于指定方法或者脚本,用来在故障转移期间隔离NameNode,隔离的意思就是将故障的namenode进程杀死,这样做的原因是避免极端情况下,hdfs认为namenode不可用从而进行故障转移,但是在这个期间namenode仍然可能向客户端提供服务,可能会引起问题,所以这个是一个防护措施,大部分情况下都是没问题的,hadoop提供shell和sshfence两种方式,并且可以自己定义脚本来实现隔离,常见的一种配置方式如下:
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property>
上面这种配置,hdfs会负责ssh到namenode节点来隔离掉namenode服务,第二个选项配置ssh使用的私钥。但是这个配置很有可能会导致最终切换的时候报错,查看zkfc的日志常见报错信息可能如下:
主要问题出在:WARN org.apache.hadoop.ha.SshFenceByTcpPort: Unable to create SSH session com.jcraft.jsch.JSchException: invalid privatekey: [B@13234dbe,这个表示无法创建ssh session,这里使用的库为JSch这个ssh工具,之所以报错的原因是jsch不认识这个私钥的格式,我这里centos8下openssh版本为8.0,正常生成密钥的命令如下:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
默认的rsa密钥签名算法为ed25519,头部标识为: ,这种格式jsch无法解析,放到现在看其实算是bug了,到现在仍然没有解决,如果要生成rsa签名的密钥可以使用下面的命令:
,这种格式jsch无法解析,放到现在看其实算是bug了,到现在仍然没有解决,如果要生成rsa签名的密钥可以使用下面的命令:
ssh-keygen -t rsa -P '' -m PEM -f ~/.ssh/id_rsa
这样生成的头部为: ,这样jsch可以正常识别,故障转移也可以成功执行,由于我这里集群的免密已经配置好,懒得重新设置密钥了,所以直接将dfs.ha.fencing.methods的值配置为shell(/bin/true),故障转移隔离时直接返回true,hdfs认为执行成功就开始自动切换,这样也算是绕过了上面这个问题吧~ 需要这类问题要多注意一下,有可能报错不是这个而是命令不存在等问题,网上很容易找到,只需要安装fuser工具即可不再详细叙述。这个密钥的问题也可以参考stackoverflow上面的回答:https://stackoverflow.com/questions/53134212/invalid-privatekey-when-using-jsch
,这样jsch可以正常识别,故障转移也可以成功执行,由于我这里集群的免密已经配置好,懒得重新设置密钥了,所以直接将dfs.ha.fencing.methods的值配置为shell(/bin/true),故障转移隔离时直接返回true,hdfs认为执行成功就开始自动切换,这样也算是绕过了上面这个问题吧~ 需要这类问题要多注意一下,有可能报错不是这个而是命令不存在等问题,网上很容易找到,只需要安装fuser工具即可不再详细叙述。这个密钥的问题也可以参考stackoverflow上面的回答:https://stackoverflow.com/questions/53134212/invalid-privatekey-when-using-jsch
dfs.journalnode.edits.dir - 继续解释最后这个配置项,这个表示journalnode本地存储的目录,和之前namenode,datanode一样配置本地的存储目录即可,这个目录journalnode守护进程会自动创建
这些就是hdfs-site.xml的配置了,接下来继续配置core-site.xml,这个很简单,修改下面1个配置项即可:
<property> <name>fs.defaultFS</name> <value>hdfs://hdfscluster</value> </property>
之前这里我们配置的是主机名:端口号,即bigdat1:9000,现在要改成nameservice ID,也就是hdfscluster,改完这一项保存退出即可。
配置文件都改完了,不要忘了同步到其他的节点,我这里同步命令示例如下:
scp core-site.xml hdfs-site.xml bigdata2:/opt/hadoop/etc/hadoop/ scp core-site.xml hdfs-site.xml bigdata3:/opt/hadoop/etc/hadoop/ scp core-site.xml hdfs-site.xml bigdata4:/opt/hadoop/etc/hadoop/
2. 配置服务并开启HA
首先在bigdata1,2,3上都启动journalnode进程:
# 每个journalnode上执行
hdfs --daemon start journalnode
我这里hdfs的bin目录因为加到环境变量PATH中,因此没有输入路径。接下来在新加的namenode上面执行下面的命令同步元数据:
# 在新加的bigdata2上面执行
hdfs namenode -bootstrapStandby
注意这个时候新的namenode并没有启动,只是先同步数据,同步数据的时候原来的namenode都要正常运行。注意如果是全新集群则需要在1个节点上先执行格式化,启动服务,然后其他namenode再同步即可。
然后要停掉原来的集群所有服务:namenode,secondarynamenode,datanode这3类服务,注意此时journalnode不要动,都正常停止后,在原来的namenode上,即bigdata1上执行下面命令填充JournalNode数据目录,即真正的将非HA状态转为HA集群:
# 在bigdata1上执行 如果是集群一步到位配置HA则上面格式化执行后就是HA集群 这个命令就无需执行了
hdfs namenode -initializeSharedEdits
正常执行没问题即表示集群转换成功,注意直接配置新的HA集群则无需执行上面的命令,这个时候再次启动集群即可,和之前一样依次执行命名启动:namenode(包括新的namenode),datanode即可,注意不要启动secondarynamenode了,就算启动也会报错Cannot use SecondaryNameNode in an HA cluster. The Standby Namenode will perform checkpointing. 表示不需要启动
启动之后这时候所有namenode的状态都为standby,集群不会自动选举active的namenode,也就是说这个时候集群还是不可用的,集群高可用状态的管理可以使用hdfs haadmin这个工具来管理,这时候可以执行下面命令进行故障转移:
hdfs haadmin -failover nn1 nn2
这个方法也是hdfs官网上推荐的方法,这个命令是将nn1转移到nn2,如果现在两个状态都是standby,则仅仅将nn2转换为active状态;如果nn1是active,nn2是standby,则会自动将nn1转为standby,nn2转为active,如果nn1确实故障,则会先执行隔离,然后再将nn2设置为active。其他情况下如果失败则会返回错误。
执行之后我们使用下面命令来查看所有namenode的状态:
hdfs haadmin -getAllServiceState

这个时候说明状态就正常了,通过界面也可以查看namenode的状态: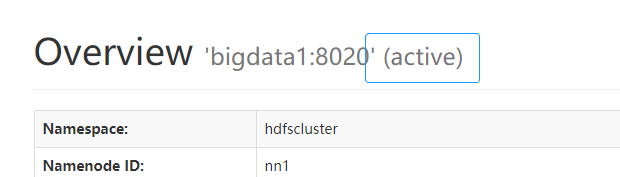 ,这个active表示状态为活动,到这里手动故障转移就配置完毕了,接下来再继续配置自动故障转移
,这个active表示状态为活动,到这里手动故障转移就配置完毕了,接下来再继续配置自动故障转移
3. 自动故障转移配置
首先还是修改配置文件hdfs-site.xml,添加下面的配置开启自动故障转移:
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
这个值默认是false,改成true表示开启,然后保存后继续配置core-site.xml,添加zookeeper的配置:
<property> <name>ha.zookeeper.quorum</name> <value>bigdata1:2181,bigdata2:2181,bigdata3:2181</value> </property>
这个配置文件中其实还有个配置项是:ha.zookeeper.parent-znode,表示ha使用的znode,就像kafka的/kafka一样,这个值默认是/hadoop-ha,这里没有特别需要默认即可,最后保存配置。
现在同样需要将这两个配置文件同步到其他节点,和前面一样。然后需要停止掉hdfs集群所有服务,因为集群运行时,是无法从手动故障转移过渡到自动故障转移的,因此我们要停止当前hdfs集群的所有服务包括所有的namenode、datanode、journalnode。再次重复:同步配置文件、停止集群。
4. 初始化zookeeper状态并再次启动集群
选择任意1个namenode节点来初始化状态,这里选择bigdata1节点,执行下面的命令:
hdfs zkfc -formatZK
正常执行完成没有报错即可,然后通过zookeeper cli可以看到/hadoop-ha节点已经存在,下面就保存了namenode活动信息和选举的状态等。初始化zookeeper成功后,就可以再次启动集群,可以单独启动每一个组件,当前组件有:namenode,datanode,journalnode,启动zookeeper自动故障转移之后还要在每个NameNode节点上启动zkfc守护进程,手动在每个节点上启动zkfc进程的命令如下:
# 每个namenode节点都执行
hdfs --daemon start zkfc
手动启动比较麻烦,我们可以执行start-dfs.sh脚本自动启动全部的进程,当然在这之前要配置journalnode、zkfc这两个进程的用户,和之前配置其他的用户一样,在$HADOOP_HOME/etc/hadoop/hadoop-env.sh添加如下配置:
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
这里使用root用户,生产环境要自定义指定用户,算上之前的用户,我这里共配置了下面这些变量:

保存之后务必也要同步到其他全部的节点,然后选择1个节点进入到hadoop的安装目录,我这里HADOOP_HOME为/opt/hadoop,然后执行脚本启动全部的服务:
# 只在bigdata1上执行 ./sbin/start-dfs.sh
我这里选择bigdata1这个节点,只需要执行1次即可启动全部的服务

这时候通过jps即可验证进程是否启动,此时整个集群已经是开启自动故障转移的,启动时已经自动选举好了active状态的namenode,可以通过页面或者之前的命令查看来确认
5. 验证自动故障转移
验证自动故障转移非常简单,只需要将状态是active的namenode强杀掉,然后看另外standby状态的Namenode能否自动激活,检测和触发故障转移的时间配置是在core-site.xml的ha.zookeeper.session-timeout.ms配置项中,我们没有配置默认为5s,也就是说5s之内就会完成自动故障转移,现在的状态是nn1为active,nn2是standby:

我们在nn1的机器上也就是bigdata1上杀掉NameNode进程尝试:

kill -9 190780
进程杀掉之后再次查看状态:
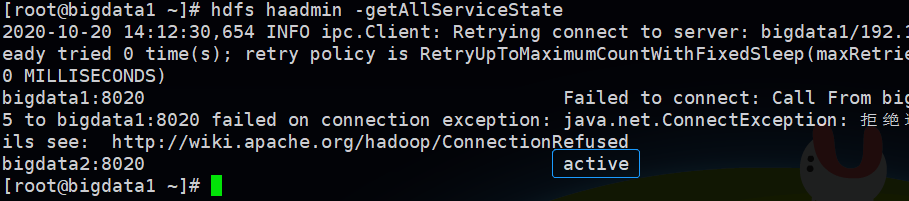
可以看到nn1报错而nn2变成了active,这时候对hdfs所有的操作都将是正常的不影响集群使用,即证明自动故障转移已经正常运行。
到这里hdfs集群namenode高可用和自动故障转移就全部配置完了,下面用折叠的方式放上集群配置文件的完整内容,方便进行参考:


<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdfscluster</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>bigdata1:2181,bigdata2:2181,bigdata3:2181</value> </property> </configuration>
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.nameservices</name> <value>hdfscluster</value> </property> <property> <name>dfs.ha.namenodes.hdfscluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.nn1</name> <value>bigdata1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.nn2</name> <value>bigdata2:8020</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.nn1</name> <value>0.0.0.0:9870</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.nn2</name> <value>0.0.0.0:9870</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://bigdata1:8485;bigdata2:8485;bigdata3:8485/hdfscluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.hdfscluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true)</value> </property> <!-- <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> --> <property> <name>dfs.journalnode.edits.dir</name> <value>/data/dfs/journal</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/dfs/name</value> </property> <property> <name>dfs.hosts</name> <value>/opt/hadoop/etc/hadoop/dfs.hosts</value> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <name>dfs.namenode.handler.count</name> <value>128</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///data/dfs/namesecondary</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
如对于配置有问题或文中存在不足之处,欢迎留言指出,谢谢^_^
使用QJM配置高可用参考文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
使用NFS配置高可用参考文档:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号