基于 Feishu 和 LangGraph 构建企业级 AI 助手
摘要:本文将带你深入探索如何构建一个集成了飞书(Feishu)消息交互、LangGraph 智能体编排以及 MySQL 数据库查询的企业级 AI 助手。通过本项目,你将学会如何利用大模型(LLM)理解用户意图,并通过 MCP 协议高效查询业务数据,生成图文并茂的专业分析报告。
🏗️ 1. 项目架构概览
本项目的整体架构设计遵循模块化与高内聚原则,主要分为四层:
-
🔌 接入层 (Feishu Adapter)
- 使用
lark-oapi实时接收飞书消息(支持文本与文件)。 - 作为用户与 AI 交互的直接窗口。
- 使用
-
⚙️ 逻辑层 (Handlers)
Handlers负责解析消息内容、处理文件下载。- 将清洗后的请求转发给 AI Agent 进行核心处理。
-
🧠 核心层 (AI Agent)
- 基于
LangGraph构建的高级状态机。 - 意图识别 (Route):智能判断查询领域(财务/交账/解锁)。
- 并行查询 (Parallel Execution):多任务并发执行,提升响应速度。
- 结果聚合 (Aggregate):汇总多源数据。
- 总结生成 (Summarize):输出结构化的中文分析报告。
- 基于
-
💾 数据层 (MCP & MySQL)
- 通过标准的 MCP (Model Context Protocol) 协议连接 MySQL。
- 安全、受控地执行 SQL 查询。
🛠️ 2. 技术栈与依赖
项目构建于 Python 生态之上,主要依赖以下核心库:
| 类别 | 库名称 | 说明 |
|---|---|---|
| Web/IM 框架 | lark-oapi |
飞书官方 SDK,处理消息收发 |
| AI 编排 | langchain, langgraph |
构建智能体工作流的核心框架 |
| 模型服务 | dashscope |
通义千问大模型服务 |
| 协议适配 | langchain-mcp-adapters |
连接 MCP 服务器 |
| 工具库 | python-dotenv, pymysql |
环境变量管理与数据库连接 |
📄 requirements.txt:
lark-oapi>=1.4.8
langchain
langchain-community
langchain-mcp-adapters
python-dotenv
langgraph
pymysql
cryptography
� 3. 设计思路与核心思想
在深入代码实现之前,分享一下本项目背后的设计哲学。理解这些思想,能帮助你举一反三,构建更复杂的 AI 应用。
3.1 从“链”到“图”的进化 (Chain vs Graph)
传统的 LangChain Chain 是线性的(A ➡️ B ➡️ C),适合简单任务。但企业级业务往往是非线性的:
- 动态路由:根据用户问题,可能需要走财务流程,也可能走人力流程,甚至同时走。
- 循环与修正:如果 SQL 生成错了,需要有机制“回退”并重试,而不是直接报错。
LangGraph 引入了“图”的概念,让我们能像画流程图一样编排 AI 的思维路径,完美解决了复杂状态流转的问题。
3.2 关注点分离与 MCP 协议
我们将“大脑”(LLM)与“手脚”(工具)进行了严格解耦。
- LLM:负责意图理解、逻辑判断、文本生成。
- MCP (Model Context Protocol):这是一种新兴标准,它将数据源(如 MySQL)封装成标准服务。Agent 不需要关心底层是 MySQL 8.0 还是 MariaDB,只需通过 MCP 协议“点菜”。这不仅降低了耦合,还通过隔离数据库凭证提升了安全性。
3.3 Scatter-Gather 并行模式
为了极致的响应速度,我们拒绝串行执行。
当用户问“上个月财务和交账情况如何?”时,系统采用 Scatter-Gather (分发-聚合) 模式:
- Scatter: 路由节点同时派发“财务查询任务”和“交账查询任务”。
- Parallel: 两个任务在不同线程/进程中并行跑,互不等待。
- Gather: 聚合节点在终点等待,一旦所有任务完成,打包结果。
这种设计让总耗时取决于最慢的那个任务,而不是任务之和。
🎯 4. 提示词工程 (Prompt Engineering)
在 AI 编程领域,提示词(Prompt)不仅是指令,更是 AI 的“源代码”。高质量的提示词决定了智能体是“人工智障”还是“领域专家”。本项目采用了 结构化、少样本学习 (Few-Shot) 和 约束前置 等工程化技巧。
4.1 🎭 角色定义 (System Prompt)
所有 Agent 的基石。我们在 System Prompt 中不仅定义了角色,还动态注入了 当前时间,这对于处理“本月”、“上季度”等时间敏感问题至关重要。
SYSTEM_PROMPT_TEMPLATE = """
你是数据库分析智能体,负责根据用户的自然语言问题在 MySQL 数据库中查询并返回结果。
今天日期:{date} <-- 动态注入当前日期
[你的任务]
{task_description}
[约束]
1. 严格只读,不执行 INSERT、UPDATE、DELETE。
2. 强制聚合:除非明确要求明细,否则数值指标必须使用 SUM()。
3. 时间偏移强制规则:用户口中的“本月”必须转换为 SQL 中的 INTERVAL 1 MONTH(上个自然月)。
"""
4.2 � 意图识别 (Router Prompt)
如何让 AI 知道该查财务表还是人力表?我们需要一个清晰的分类器。
ROUTE_PROMPT_TEMPLATE = """
你是一个智能路由助手,负责根据用户的问题,判断需要查询哪些业务领域。
[可选领域]
1. finance: 财务/业务数据(关键词:收入、毛利、利润...)
2. delivery: 交账数据(关键词:交账率、应交单数...)
3. unlock: 解锁数据(关键词:解锁率...)
[输出要求]
请返回一个 JSON 数组,包含所有匹配的领域代码。
例如:
- 用户问“查询收入和交账率”,返回:["finance", "delivery"]
"""
4.3 📝 数据查询 (Text-to-SQL Prompt)
这是最核心的部分。为了让 LLM 准确生成 SQL,我们使用了 Schema 注入 和 Few-Shot Learning(少样本学习)。
- Schema 注入:明确告诉 AI 有哪些表、哪些字段,而不是让它瞎猜。
- Few-Shot Examples:提供 3-5 个“问题 -> 正确 SQL”的示例,让 AI 模仿这种模式。这是提升准确率最有效的手段。
FINANCE_METRICS = """
[表结构]
表名: t_finance_order_report
字段: dr(收入), cr(支出), amount(毛利), sales_lev1_name(一级部门)...
[业务口径]
毛利率 = SUM(amount) / SUM(dr)
[Few-Shot Examples]
1. 用户问:“查询本月收入”
SQL: SELECT SUM(dr) FROM t_finance_order_report WHERE ...
2. 用户问:“空运事业部本月毛利率”
SQL: SELECT SUM(amount)/SUM(dr) FROM ... WHERE sales_lev1_name LIKE '%空运事业部%' ...
"""
4.4 📊 结果总结 (Summarize Prompt)
最后,我们需要将冷冰冰的数据转换为用户友好的报告。通过指定 JSON 输出格式,我们可以让前端(飞书卡片)轻松渲染。
SUMMARIZE_PROMPT_TEMPLATE = """
你是一个专业的数据分析师。请根据查询结果,生成一个结构化的 JSON 输出。
[输出格式]
{
"title": "标题(如:2025年收入统计)",
"content_md": "### 核心结论\\n- 本月收入..."
}
[样式要求]
- 核心结论中的数字使用 <font color="red">**红色加粗**</font> 高亮。
- 详细数据必须使用 Markdown 表格展示。
"""
� 5. 核心实现深度解析
5.1 🔐 环境配置 (.env)
为了确保信息安全,所有敏感凭证均通过环境变量管理。
# .env (已脱敏示例)
OPENAI_API_KEY="sk-******"
MODEL_NAME="gpt-4-preview"
DASHSCOPE_API_KEY="sk-******" # 通义千问 API Key
APP_ID="cli_******" # 飞书应用 ID
APP_SECRET="******" # 飞书应用 Secret
# 数据库配置
MYSQL_HOST="127.0.0.1"
MYSQL_PORT="3306"
MYSQL_USER="user"
MYSQL_PASSWORD="password"
MYSQL_DATABASE="dbname"
5.2 📨 飞书消息入口 (main.py)
使用 WebSocket 长连接监听飞书事件,确保消息的实时响应。
# main.py
import lark_oapi as lark
import os
from dotenv import load_dotenv, find_dotenv
from handlers import build_event_handler
_ = load_dotenv(find_dotenv())
def main():
# 1. 初始化飞书客户端
client = lark.Client.builder() \
.app_id(os.getenv("APP_ID")) \
.app_secret(os.getenv("APP_SECRET")) \
.build()
# 2. 构建事件处理器
event_handler = build_event_handler(client)
# 3. 启动 WebSocket 服务
wsClient = lark.ws.Client(
os.getenv("APP_ID"),
os.getenv("APP_SECRET"),
event_handler=event_handler,
log_level=lark.LogLevel.DEBUG,
)
wsClient.start()
if __name__ == "__main__":
main()
5.3 🔄 消息处理器 (handlers.py)
handlers.py 是连接飞书与 AI Agent 的桥梁,负责消息清洗和分发。
# handlers.py (核心逻辑摘要)
def build_event_handler(client):
def process_message(data: P2ImMessageReceiveV1):
try:
# 解析消息类型
msg_type = data.event.message.message_type
if msg_type == "text":
res_content = json.loads(data.event.message.content)["text"]
# 获取用户 ID
sender_id = data.event.sender.sender_id.open_id
# 🔥 核心调用:请求 AI Agent 生成回复
reply_text = generate_reply(res_content, user_id=sender_id)
# 回复飞书卡片消息 (代码省略)
# ...
except Exception as e:
print(f"Error: {e}")
return lark.EventDispatcherHandler.builder("", "") \
.register_p2_im_message_receive_v1(handle) \
.build()
5.4 🤖 智能体核心 (ai_agent.py)
这是项目的“大脑”,利用 LangGraph 定义了复杂的业务流转逻辑。
📌 状态定义 (State)
class AgentState(TypedDict):
question: Optional[str] # 用户提问
result: Optional[str] # 最终汇总结果
finance_result: Optional[str] # 财务域查询结果
delivery_result: Optional[str] # 交账域查询结果
unlock_result: Optional[str] # 解锁域查询结果
target_nodes: Optional[list[str]] # 动态路由目标
🕸️ 图构建 (Graph Construction)
def generate_reply(text: str, user_id: str = "default_user") -> Dict:
graph = StateGraph(AgentState)
# 1. 注册节点
graph.add_node("validate", node_validate) # 🛡️ 校验
graph.add_node("route", node_route) # 🚦 路由
graph.add_node("finance", node_finance_query) # 💰 财务查询
graph.add_node("delivery", node_delivery_query) # 📦 交账查询
graph.add_node("unlock", node_unlock_query) # 🔓 解锁查询
graph.add_node("aggregate", node_aggregate) # 🔗 聚合
graph.add_node("summarize", node_summarize) # 📝 总结
# 2. 定义边 (Edge)
graph.add_edge(START, "validate")
# 3. 条件路由
graph.add_conditional_edges(
"validate",
lambda state: "go" if state.get("should_query") else END,
{"go": "route"}
)
# 4. ⚡ 并行分发 (Scatter)
graph.add_conditional_edges(
"route",
lambda state: state.get("target_nodes", []),
["finance", "delivery", "unlock", "file_upload"]
)
# 5. 结果汇聚 (Gather)
graph.add_edge("finance", "aggregate")
graph.add_edge("delivery", "aggregate")
graph.add_edge("unlock", "aggregate")
graph.add_edge("aggregate", "summarize")
graph.add_edge("summarize", END)
app = graph.compile()
return app.invoke({"question": text, "user_id": user_id})
🔌 MCP 工具集成
def _get_mcp_tools():
# 配置 MCP 客户端连接 MySQL 服务
cfg = {
"mysql": {
"transport": "stdio",
"command": "uvx",
"args": ["--from", "mysql-mcp-server", "mysql_mcp_server"],
"env": { ... },
}
}
client = MultiServerMCPClient(cfg)
# ...
5.5 📊 LangGraph 执行流程图
智能体采用了高效的 Scatter-Gather (分散-聚集) 模式。Route 节点并行触发多个查询节点,Aggregate 节点负责统一等待并汇总。
最新流程图
AI Agent LangGraph 结构
节点说明
- validate: 检查输入是否包含恶意内容或提示注入攻击。
- route: 确定用户意图(例如:查询数据、上传文件、网络搜索、邮件处理)。
- load_files: 如果意图需要文件分析或数据查询上下文,则加载用户上传的文件(PDF, TXT, Excel)。
- finance: 生成 SQL 查询财务数据(收入、利润等)。
- delivery: 生成 SQL 查询交账率数据。
- unlock: 生成 SQL 查询解锁率数据。
- customer: 生成 SQL 查询客户统计数据(新增、活跃、升级、降级)。
- file_upload: 处理文件上传请求。
- file_analysis: 分析上传文件的内容(例如:总结 Excel 数据)。
- delete_file: 删除用户上传的文件。
- crawler: 执行网络搜索以获取外部信息。
- mail: 负责连接 API,获取邮件元数据,并下载附件到临时目录。
- mail_analyze: 负责解析本地附件内容,生成最终回复。
- permission_filter: 根据用户数据权限(行级安全)过滤查询结果。
- aggregate: 聚合来自多个来源(数据库查询、文件分析、网络搜索、邮件)的结果。
- summarize: 生成包含格式化表格和结论的最终人类可读回复。
💡 流程亮点
- ⚡ 速度更快:多任务(如同时查收入和交账率)并发执行,耗时取决于最慢的单一任务。
- 🧩 逻辑解耦:每个查询节点独立运行,互不感知,易于维护。
- 📈 结构清晰:标准的 Map-Reduce 模式,扩展新业务只需增加新节点。
5.6 ✨ 运行效果示例
下图展示了飞书机器人的实际运行效果。机器人准确识别了意图,并行查询了数据,并生成了清晰的图文回复。
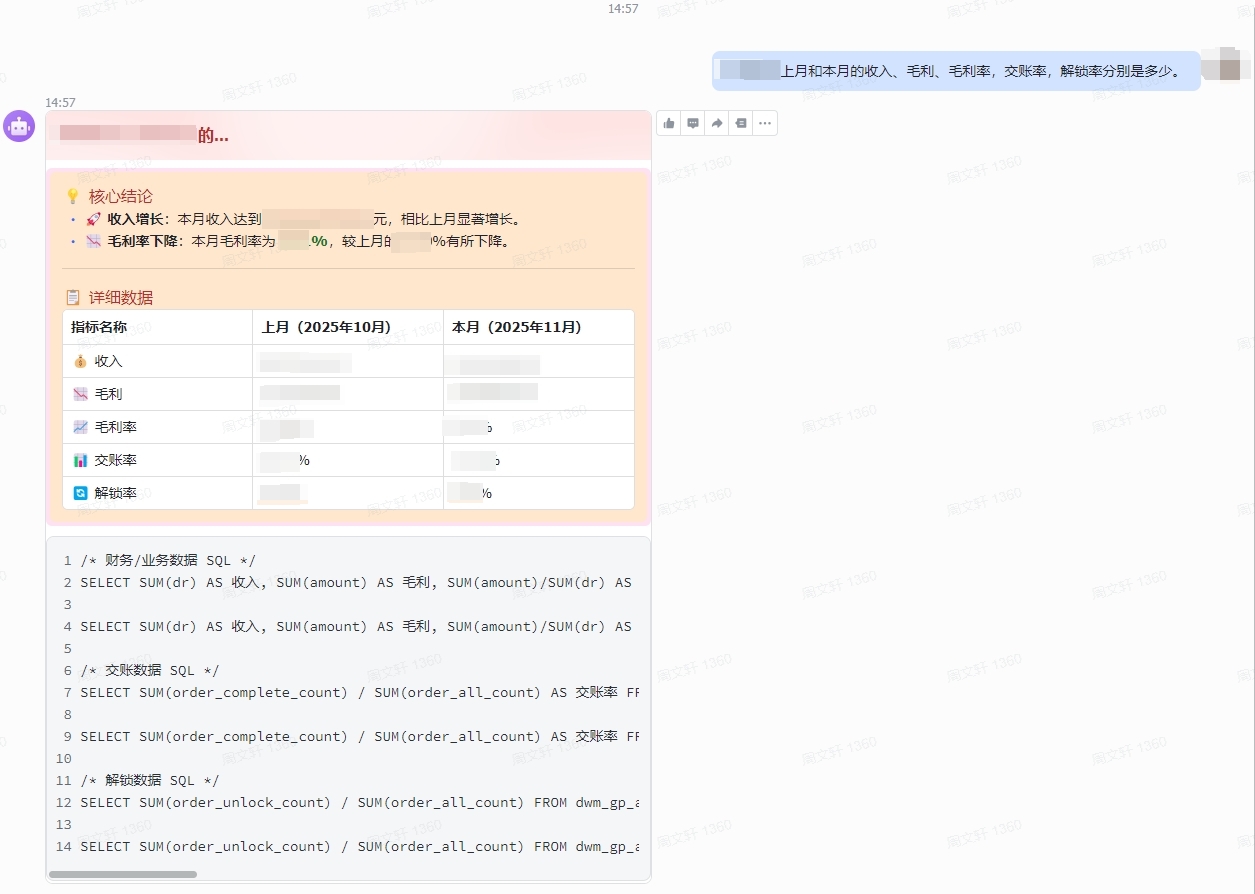
⚖️ 6. 优缺点分析
| 维度 | 优势 (Pros) ✅ | 挑战 (Cons) ⚠️ |
|---|---|---|
| 架构设计 | 模块化强:各业务节点独立,易于扩展。 | 系统复杂:LangGraph 和 MCP 增加了学习成本。 |
| 性能体验 | 响应迅速:并行路由机制显著降低了延迟。 | 外部依赖:强依赖大模型和飞书 API 的稳定性。 |
| 数据安全 | 安全可控:环境变量隔离敏感信息。 | SQL 风险:需精心设计 Prompt 以防止 SQL 幻觉。 |
| 交互体验 | 直观易懂:飞书卡片 + AI 总结,体验极佳。 |
📝 7. 总结
本项目展示了 Modern AI Stack (LangChain + LangGraph + MCP) 与企业级 IM 工具 Feishu 的完美融合。通过精心设计的架构,我们不仅实现了业务逻辑的解耦,还大幅提升了数据查询的效率,为企业内部数据的智能化应用提供了一个可落地的范本。
注:本文档中的代码仅供参考,敏感信息已被处理。
免责声明:本文档由人工智能(AI)编写,仅供参考。作者及发布者不对文档内容的准确性、适用性或因使用本文档而产生的任何法律后果承担责任。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号