如前所说,写程序如同给算法写壳,而算法就是流程,所以流程是程序的主角(但这个流程不一定要你来设计)。在程序中,为了配合流程(算法)的实现,除了顺序、分支与循环语句的使用,还要借助“变量”这个角色。变量是重要的角色,男二号。
变量表示可变化的值,但这个值是有范围的,并不是所有值都可以放置到同一个变量中,值的范围,由变量的类型决定。
变量的类型,决定两个事情,一是用多大的空间来存储这个变量值,二是这个变量值的范围是多少。好了,这个不重要,先不要管这个细节,先把变量用起来,并掌握一些基础知识即可。
变量有哪些类型呢?
(1)数字类型、bool与字符串
这三个是常见的内置类型。
注意,值,决定了变量的类型,你给变量赋什么值,它就是什么类型。比如:
a = 10 # int整数类型
a = 9.9 # float浮点类型。变量名还是a,但是值的变化,让它变成了一个新的变量
a = 987654321L # long长整数类型,值以'L'结束
a = 3+4j # complex复数类型
以上几个变量类型,分别是int、float、long跟complex类型,这几个类型可以归为数字类型。
除了数字类型,python中的值还有bool类型跟str字符串类型,比如:
a = False # bool类型,值要么为False,要么为True
a = "hellotype" # str字符串类型
如果想知道当前变量是什么类型,那可以使用内置函数(python提供的一组函数)type()来确认,比如可以这样,留意type()的输出:
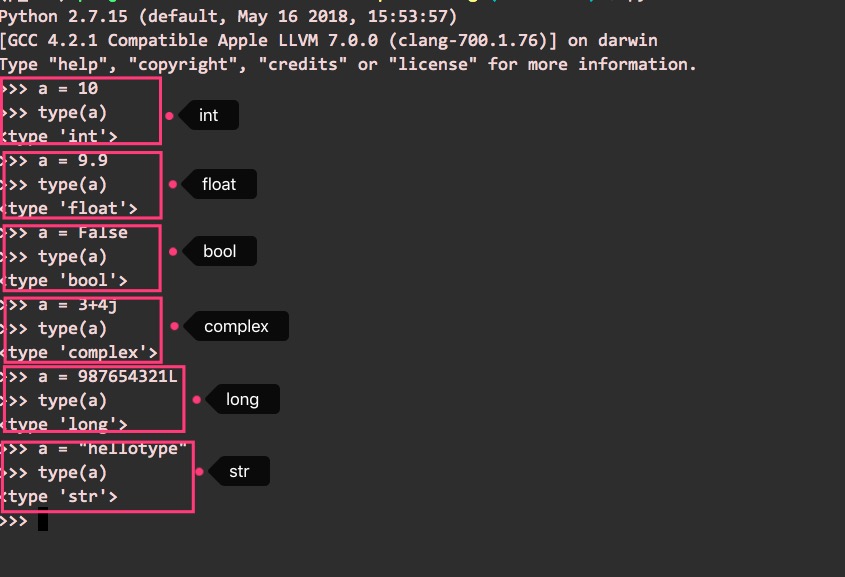
所以,基本上,python的变量类型,包括数字类型(int/float/long/complex)、bool跟str。
其中,str,即字符串,对它的操作会经常遇到,比如:
a = "hellotype"
a[1:] # 第1个字符到最后(注意索引是从0开始的)
a[2:]
a = "123456"
a[1:5] # 第1个字符到第5个字符的内容,但不包括第5个字符,也就是左闭右开的区间
a[-1] # -1表示最后一个字符,-2就是倒数第二个,如此类推
执行效果:

(2)常见的数据结构
除了以上常见的内置变量类型,pyton还提供了一些常用的数据结构,这些数据结构也是变量类型。
数据结构服务于算法,但由于某些数据结构实在太常用了,以至于很多算法都有它们的身影,于是,把这些常用的数据结构抽离出来,做为一个独立的结识点来讲,也是很合理的,但明显不是本文的事情。
数据结构,就是数据的组织结构,各个数据结构一定会有自己的组织特点。python中有几个常见的内置的数据结构,因为经常使用,甚至已经被当作变量类型,跟数字类型、bool与str一样的存在。
这几个常见的数据结构,分别是:列表、元组、集合、字典。
同样,值决定类型(或数据结构)。
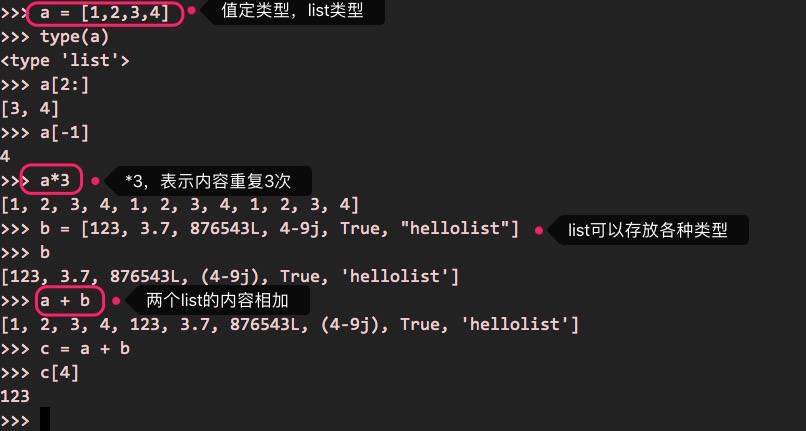
list即列表,也是由值定义出来(以[]来定义),比如:
a = [1,2,3,4] # list
type(a)
list的操作,跟字符串的类似,比如:
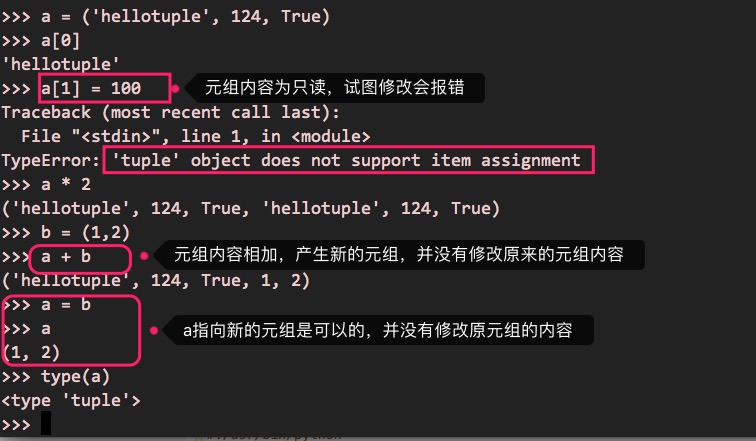
tuple即元组,是只读列表(以()来定义),也就是元组的内容不允许修改,比如:
a = ('hellotuple', 123, True)
a[0]
a[1] = 100 # 试图修改元组的内容,会报错
a * 2 # 跟list的操作一致,内容重复2次,并产生新的元组
b = (1,2)
a + b # 元组相加是可以的,因为产生了新的元组,并没有修改原来的元组
执行的效果如下:
list跟tuple的特点,是可以存放任意类型的元素,内容有序、可重复。
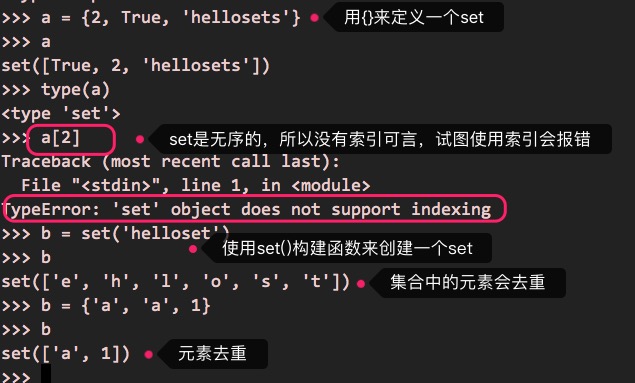
另一种常见的数据结构是set,特点是,可以存放任意类型的元素,内容是无序的,而且不能重复,这个就是集合的特点。
set即集合的部分使用如下(以{}来定义):
a = {2, True, 'helloset'}
a[2] # 集合set是无序,所以没有索引可言,试图使用索引会导致报错
b = set('helloset') # 使用构造函数来创建一个set,注意集合中的元素会去重(这里元素是字符)
b = {'a', 'a', 1} # 元素会被去重
执行的效果如下:
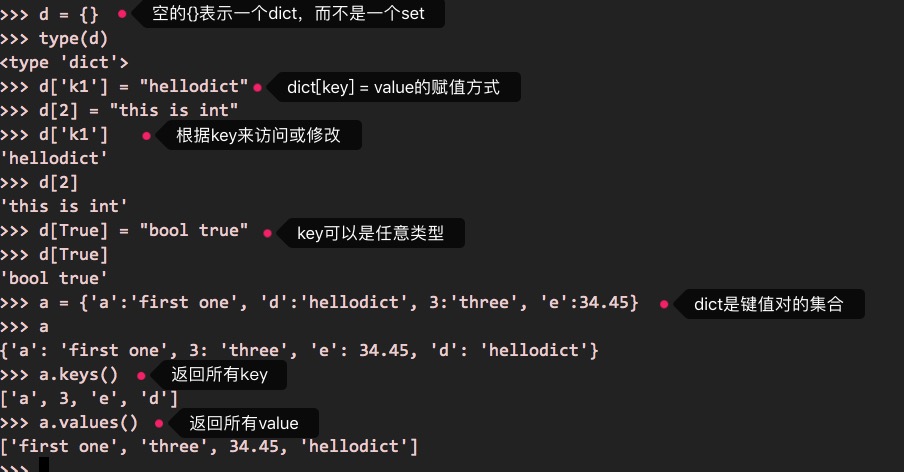
最后一种数据结构是dict,也就是字典。
dict也是一个集合,是键值对(key-value)的集合,同样以{}来定义,但包括key跟value,比如:
d =
dict跟set类似,内容无序,而且key不能重复。set只保留了key(无序且不重复),而去掉了value。
dict的部分使用如下:
d = {}
d['k1'] = "hellodict"
d[2] = "this is int"
d[True] = "bool true"
a =
执行效果如下:
以上四种内置类型之间的转换,有可能在实际场景中应用到,操作上很简单,只需要用类型名去处理需要转换的值即可,比如:
a = list(set1) # type_name(xxx)
以上是list、tuple、set与dict的简单介绍,你可以根据实际场景去使用它们。
另外,我并没有介绍这四种数据结构的操作函数,实事上,被抽离封装的数据结构都有一系列操作函数,也就是对象的行为(对象不是指女朋友),比如以上几种数据结构,有对应的append()、pop()、remove()等一系列的操作,这个在实践中再去理解与运用了。
(3)变量类型使用示例
不管是简单的变量类型(数字类型等)还是常见的数据结构(list等),你都可以把它们归为变量类型。这些变量类型经常被使用,因为变量是程序的重要配角。
我在这里举几个示例,都是以list作为栈来解决问题的例子,希望让你对变量类型有一个使用上的感知,然后在实际场景中灵活使用。
(a)判断左右符号是否配对
左符号:([{
右符号:)]}
配对的情况如:'([]){()}',不配对的情况如:'[{]}]'。
用栈来理解就是:遍历所有字符。遇左符号则入栈;遇右符号则出栈(如果为空则直接返回False),出栈返回的字符如果与右符号不配对则返回False,如果配对则继续下一个字符。所有字符遍历完后,栈非空则返回False,否则返回True。
def sybol_match(str):
L=['(','{','['];
R=[')','}',']'];
s=[]
for c in str:
if c in L:
s.append(c)
else:
if not s:
return False
a=s.pop()
lp = L.index(a)
rp = R.index(c)
if lp!=rp:
return False
return not s
(b)计算后缀表达式
计算一个表达式时,表达式可以以中缀或后缀的方式录入,而后缀表达式由于不需要使用括号而简化了处理,所以是一个普遍的选择。
比如:
中缀:12(2/2) 后缀:12 2 2 / *
中缀:10-(23) 后缀:10 2 3 * -
中缀:(3-2)*(9/3)+5 后缀:3 2 - 9 3 / * 5 +
你可以画出树状图,再来理解(比如后缀遍历得到后缀表达式)。
用栈来理解就是:遍历所有分割项(以空格切分)。遇到数字则入栈;遇到操作符出栈两次(这里简化为都是二元操作,第一次出栈的为参数2,第二次为参数1),并进行运算,再把结果入栈。遍历完所有分割项后,返回栈中内容(只有一个值)。
operators = {
'+' : lambda p1, p2: p1+p2,
'-' : lambda p1, p2: p1-p2,
'*' : lambda p1, p2: p1*p2,
'/' : lambda p1, p2: p1/p2,
}
def calc_postfix(str):
expr = str.split()
s = []
for e in expr:
if e.isdigit():
s.append(int(e))
else:
f = operators[e]
p2 = s.pop()
p1 = s.pop()
s.append(f(p1, p2))
return s.pop()
(c)背包问题
有若干个物品,每一个物品都有重量。背包有最大容量限制,求刚好装满背包最大容量的所有解。
比如:
物品名称 重量
物品0 1kg
物品1 8kg
物品2 4kg
物品3 3kg
物品4 5kg
物品5 2kg
背包最大可以装10kg,那可能的解是:[0,2,3,5]、[1,5]等。
用栈来理解就是:尽情地装(按物品顺序,只要能装得下就装),如果剩余容量刚好为0或者之后的各个物品都装不下了,则出栈,即拿掉最后的一个物品k,再继续从k+1个物品开始装。在栈为空而且填装的物品的索引已经超出范围,则结束循环。由于,总会一直出栈到一个物品都没有,再从下一个物品开始填装,所以一定会出现栈为空且没有物品可装的情况。
def knapsack(w, ws):
"""
w --背包容量
ws --物品重量列表 [1, 3, ..]
"""
ret = []
s = []
i = 0
cnt = len(ws)
rest = w
while s or i < cnt: # 栈不为空或者还有得装
while i < cnt and rest > 0: # 还有得装且还有容量
if rest >= ws[i]: # 装得下就装
s.append(i)
rest -= ws[i]
i += 1 # 不管当前的是否装得下,都要尝试下一个
if rest == 0:
ret.append(s[:]) # one solution
i = s.pop()
rest += ws[i]
i += 1
return ret
if __name__ == '__main__':
# print(sybol_match('[{()}]{}[()]()'))
# print(sybol_match('[({}])'))
# print(calc_postfix('12 2 2 / *'))
# print(calc_postfix('3 2 - 9 3 / * 5 +'))
ret = knapsack(10, [1, 8, 4, 3, 5, 2])
print(ret)
以上是几个示例,你可不必关心算法的设计,因为这是另外的话题,重点关心代码中变量类型的使用,比如list、dict的使用等。
好了,本文介绍了python的变量类型跟常见的数据结构,你可以把内置的数据结构也当作变量类型。变量类型包括int、float、long、complex、bool、list、tuple、set、dict。文章最后还就list举了几个使用例子,希望可以帮助你理解变量类型的使用。有缘再见,see you。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号