初始Redis
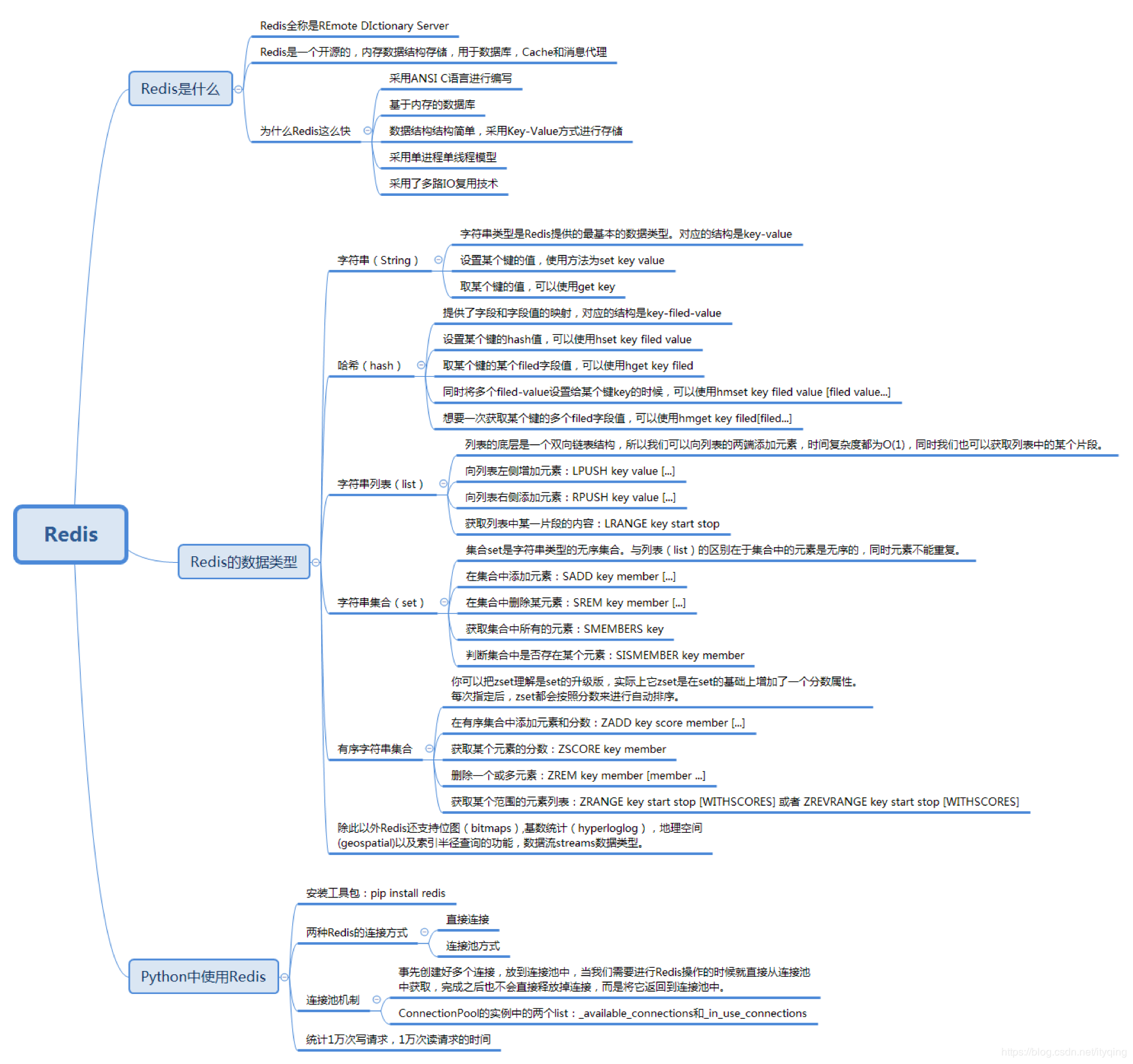
Redis是什么
Redis 是一种基于键值对(Key-Value)的 NoSQL 数据库, 键值数据库会使用哈希表存储键值和数据,其中 key 作为唯一的标识,而且 key 和 value 可以是任何的内容,不论是简单的对象还是复杂的对象都可以存储。键值数据库的查询性能高,易于扩展。
Redis 提供了键过期、发布订阅、事务、Lua 脚本、哨兵、Cluster 等功能。Redis 执行命令的速度非常快,根据官方给的性能可以达到每秒最多处理的请求可以达到 10 万次( 10w+qps)。
Redis数据类型
相比 Memcached,Redis 有一个非常大的优势,就是支持多种数据类型。Redis 支持的数据类型包括字符串、哈希、列表、集合、有序集合等。
字符串类型是 Redis 提供的最基本的数据类型,对应的结构是 key-value。
设置某个键的值:set key value;取某个键的值:get key。
哈希(hash)提供了字段和字段值的映射,对应的结构是 key-field-value。
设置某个键的哈希值:hset key field value,如果想要给 user1 设置 username 为 zhangfei,age 为 28,可以写成下面这样:hset user1 username zhangfeih set user1 age 28
将多个 field-value 设置给某个键 key 的时候,可以使用hmset key field value [field value...],比如上面这个可以写成:Hmset user1 username zhangfei age 28
获取取某个键的某个 field 字段值,可以使用hget key field,比如想要取 user1 的 username,那么写成hget user1 username即可。如果想要一次获取某个键的多个 field 字段值,可以使用hmget key field[field...],比如想要取 user1 的 username 和 age,可以写成hmget user1 username age。
字符串列表(list)的底层是一个双向链表结构,所以我们可以向列表的两端添加元素,时间复杂度都为 O(1),同时我们也可以获取列表中的某个片段。
列表左侧增加元素可以使用:LPUSH key value [...],比如我们给 heroList 列表向左侧添加 zhangfei、guanyu 和 liubei 这三个元素,可以写成:LPUSH heroList zhangfei guanyu liubei
同样,我们也可以
使用RPUSH key value [...]向列表右侧添加元素,比如我们给 heroList 列表向右侧添加 dianwei、lvbu 这两个元素,可以写成下面这样:RPUSH heroList dianwei lvbu
获取列表中某一片段的内容,使用LRANGE key start stop即可,比如我们想要获取 heroList 从 0 到 4 位置的数据,写成LRANGE heroList 0 4即可。
字符串集合(set)是字符串类型的无序集合,与列表(list)的区别在于集合中的元素是无序的,同时元素不能重复。
集合中添加元素,可以使用SADD key member [...],比如我们给 heroSet 集合添加 zhangfei、guanyu、liubei、dianwei 和 lvbu 这五个元素,可以写成:SADD heroSet zhangfei guanyu liubei dianwei lvbu
在集合中删除某元素,可以使用SREM key member [...],比如我们从 heroSet 集合中删除 liubei 和 lvbu 这两个元素,可以写成:SREM heroSet liubei lvbu
获取集合中所有的元素,可以使用SMEMBERS key,获取 heroSet 集合中的所有元素,写成SMEMBERS heroSet即可。判断集合中是否存在某个元素,可以使用SISMEMBER key member,比如我们想要判断 heroSet 集合中是否存在 zhangfei 和 liubei,就可以写成下面这样:SISMEMBER heroSet zhangfeiSISMEMBER heroSet liubei
Redis为什么那么快
-
开发语言
Redis 就是用 C 语言开发的,所以执行会比较快。 -
纯内存访问
Redis 将所有数据放在内存中,非数据同步正常工作时,是不需要从磁盘读取数据的,0 次 IO。内存响应时间大约为 100 纳秒,这是 Redis 速度快的重要基础。
-
单线程
第一,单线程简化算法的实现,并发的数据结构实现不但困难而且测试也麻烦。第二,单线程避免了线程切换以及加锁释放锁带来的消耗,对于服务端开发来说,锁和线程切换通常是性能杀手。当然,单线程也会有它的缺点,也是 Redis 的噩梦:阻塞。如果执行一个命令过长,那么会造成其他命令的阻塞,对于 Redis 是十分致命的,所以 Redis 是面向快速执行场景的数据库。
-
非阻塞多路 I/O 复用机制
I/O 多路复用实际上是指多个连接的管理可以在同一进程。多路是指网络连接,复用只是同一个线程。在网络服务中,I/O 多路复用起的作用是一次性把多个连接的事件通知业务代码处理,处理的方式由业务代码来决定,该方法就会返回可读 / 写的 FD 个数。
Redis 使用 epoll 作为 I/O 多路复用技术的实现,再加上 Redis 自身的事件处理模型将 epoll 的 read、write、close 等都转换成事件,不在网络 I/O 上浪费过多的时间,从而实现对多个 FD 读写的监控,提高性能。
总结
**** 码字不易如果对你有帮助请给个关注****
**** 爱技术爱生活 QQ群: 894109590****

 浙公网安备 33010602011771号
浙公网安备 33010602011771号