

milvus 高性能向量数据库
Milvus 架构概述
Milvus 是一个开源 云原生向量数据库,专为在海量向量数据集上进行高性能相似性搜索而设计。它建立在流行的向量搜索库(包括 Faiss、HNSW、DiskANN 和 SCANN)之上,可为人工智能应用和非结构化数据检索场景提供支持。在继续之前,请先熟悉一下 Embeddings 检索的基本原理。
架构图
下图说明了 Milvus 的高层架构,展示了其模块化、可扩展和云原生的设计,以及完全分解的存储层和计算层。
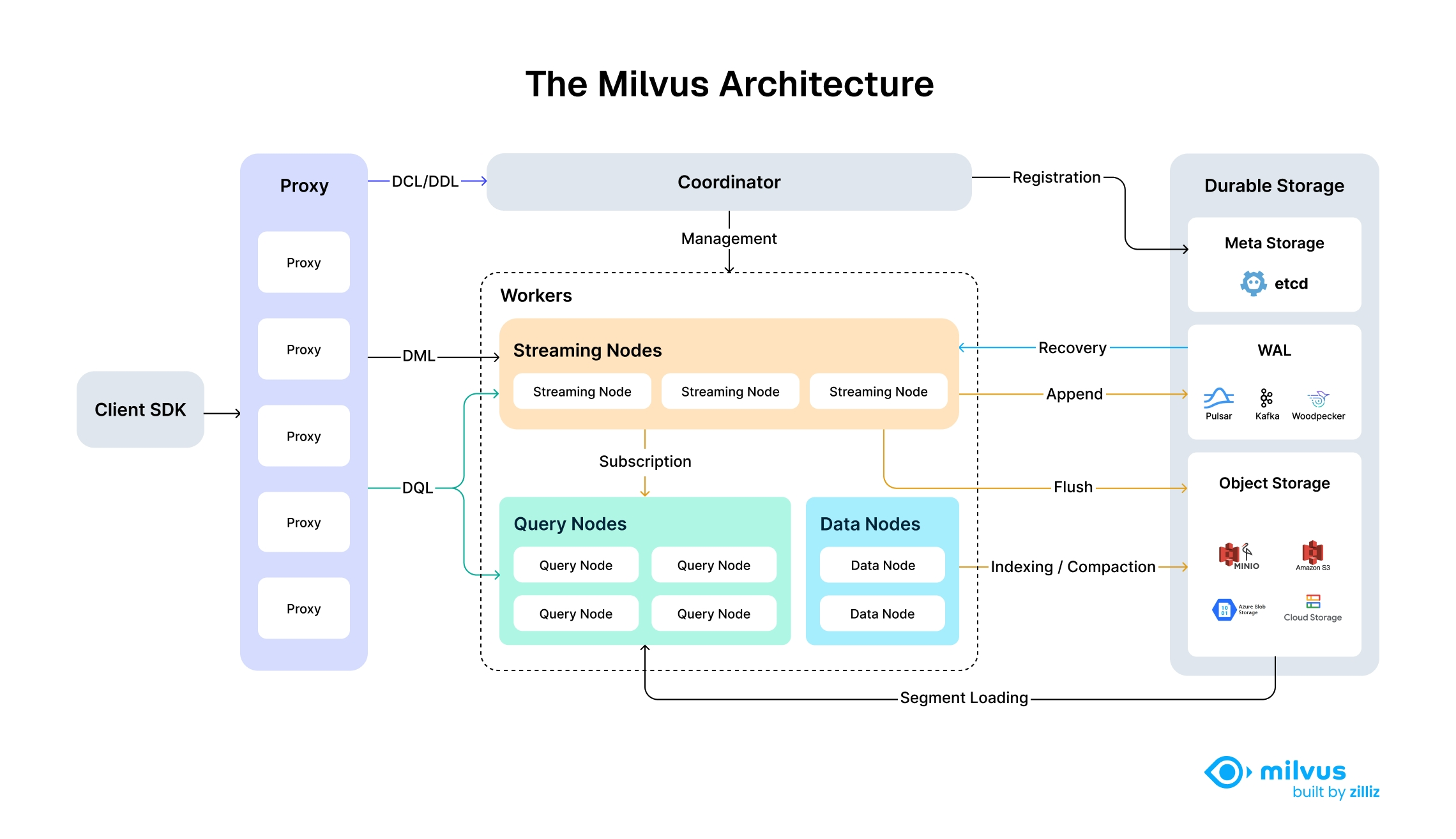 架构图
架构图
架构原则
Milvus 遵循数据平面和控制平面分解的原则,由四个主要层组成,在可扩展性和灾难恢复方面相互独立。这种共享存储架构具有完全分解的存储层和计算层,可实现计算节点的横向扩展,同时将啄木鸟作为零磁盘 WAL 层实施,以增强弹性并减少操作开销。
通过将流处理分为流节点(Streaming Node)和批处理分为查询节点(Query Node)和数据节点(Data Node),Milvus 在满足实时处理要求的同时实现了高性能。
详细的层架构
第 1 层:访问层
访问层由一组无状态代理组成,是系统的前端层,也是用户的终端。它验证客户端请求并减少返回结果:
- 代理本身是无状态的。它使用 Nginx、Kubernetes Ingress、NodePort 和 LVS 等负载均衡组件提供统一的服务地址。
- 由于 Milvus 采用的是大规模并行处理(MPP)架构,代理会对中间结果进行聚合和后处理,然后再将最终结果返回给客户端。
第 2 层:协调器
协调器是 Milvus 的大脑。在任何时刻,整个集群都有一个协调器在工作,负责维护集群拓扑结构、调度所有任务类型并保证集群级一致性。
以下是协调员处理的部分任务:
- DDL/DCL/TSO 管理:处理数据定义语言 (DDL) 和数据控制语言 (DCL) 请求,如创建或删除 Collections、分区或索引,以及管理时间戳 Oracle (TSO) 和时间刻度签发。
- 流服务管理:将先写日志(WAL)与流节点绑定,并为流服务提供服务发现功能。
- 查询管理:管理查询节点的拓扑结构和负载平衡,并提供和管理服务查询视图,以指导查询路由。
- 历史数据管理:将压缩和索引建立等离线任务分配给数据节点,并管理数据段和数据视图的拓扑结构。
第 3 层:工作节点
手臂和腿。工作节点是遵从协调器指令的哑执行器。由于存储和计算分离,工作节点是无状态的,部署在 Kubernetes 上时可促进系统扩展和灾难恢复。工作节点有三种类型:
流节点
流节点(Streaming Node)作为碎片级的 "小型大脑",基于底层 WAL 存储提供碎片级的一致性保证和故障恢复。同时,流节点还负责增长数据查询和生成查询计划。此外,它还负责将增长数据转换为封存(历史)数据。
查询节点
查询节点从对象存储中加载历史数据,并提供历史数据查询。
数据节点
数据节点负责离线处理历史数据,如压缩和建立索引。
第 4 层:存储
存储是系统的骨骼,负责数据的持久性。它包括元存储、日志代理和对象存储。
元存储
元存储存储元数据快照,如 Collections Schema 和消息消耗检查点。元数据的存储要求极高的可用性、强一致性和事务支持,因此 Milvus 选择 etcd 作为元存储。Milvus 还使用 etcd 进行服务注册和健康检查。
对象存储
对象存储用于存储日志快照文件、标量和向量数据的索引文件以及中间查询结果。Milvus 使用 MinIO 作为对象存储,可随时部署在 AWS S3 和 Azure Blob 这两个全球最流行、最具成本效益的存储服务上。然而,对象存储的访问延迟较高,并按查询次数收费。为了提高性能并降低成本,Milvus 计划在基于内存或固态硬盘的缓存池上实现冷热数据分离。
WAL 存储
先写日志(WAL)存储是分布式系统中数据持久性和一致性的基础。在提交任何更改之前,首先要将其记录在日志中,以确保在发生故障时,可以准确恢复到之前的位置。
常见的 WAL 实现包括 Kafka、Pulsar 和 Woodpecker。与传统的基于磁盘的解决方案不同,Woodpecker 采用云原生的零磁盘设计,直接写入对象存储。这种方法可以毫不费力地根据您的需求进行扩展,并通过消除管理本地磁盘的开销来简化操作符。
通过提前记录每次写入操作,WAL 层保证了可靠的全系统恢复和一致性机制--无论你的分布式环境发展得多么复杂。
数据流和 API 类别
Milvus API 按其功能分类,并遵循架构的特定路径:
| 应用程序接口类别 | 操作符 | 示例应用程序接口 | 架构流程 |
|---|---|---|---|
| DDL/DCL | Schema 和访问控制 | createCollection,dropCollection,hasCollection 、createPartition |
访问层 → 协调器 |
| DML | 数据操作 | insert,delete 、upsert |
访问层 → 流工作节点 |
| 数据查询 | 数据查询 | search,query |
访问层 → 批量工作节点(查询节点) |
数据流示例:搜索操作符
- 客户端通过 SDK/RESTful API 发送搜索请求
- 负载平衡器将请求路由到访问层的可用代理
- 代理使用路由缓存确定目标节点;只有在缓存不可用时才联系协调器
- 代理将请求转发到适当的流节点,然后与查询节点协调进行密封数据搜索,同时在本地执行增长数据搜索
- 查询节点根据需要从对象存储中加载密封分段,并执行分段级搜索
- 对搜索结果进行多级缩减:查询节点还原多个分段的结果,流节点还原查询节点的结果,代理还原所有流节点的结果,然后返回客户端
数据流示例:数据插入
- 客户端发送带有向量数据的插入请求
- 访问层验证请求并转发给流节点
- 流节点将操作符记录到 WAL 存储,以确保持久性
- 实时处理数据并提供查询
- 当分段达到容量时,流节点触发转换为密封分段
- 数据节点处理压缩,并在密封网段上建立索引,将结果存储在对象存储中
- 查询节点加载新建索引并替换相应的增长数据
下一步
posted on 2025-08-12 22:03 freeliver54 阅读(155) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号