
【HBase 原理&部署安装 01】
一、HBase依赖和整合的框架
依赖框架:Hadoop、Zookeeper
整合框架:Phoenix、Hive
二、HBase概念
1、定义:是以hdfs为数据存储的,一种分布式、可扩展的非关系型(NoSQL)数据库,和clickhouse一样同样以列式存储,存储的方式是以(K,V)的方式存储,最大的特点就是:大,可存储十亿行,百万列
2、数据模型
HBase的设计理念依据Google的BigTbable论文。HBase数据模型的关键在于稀疏的、分布式的、持久的、多维 排序 map。其中映射map指代非关系型数据库的key-Value结构。
这几个关键词如何理解:
- 稀疏的:对比关系型数据库(如mysql)的存储方式:表格存储,在底层存储的要求是比较高的,存储时对于表格的每一行每一列都需要留出一定的存储空间,留位置就会造成存储空间的浪费,如果存储百万列数据并且有一些空的列那么关系型数据库就会很浪费空间,如果用HBase这样的非关系型数据库,因为它是稀疏的所以空的列就可以不存,极大的节省了存储空间,这也反向论证了HBase存储大的特点
- 分布式:存储海量的数据,必然是分布式存储
- 持久的:存储数据时必然是持久的,如果单纯的存储在内存中那就和数据库的设计理念背道而驰
- 多维:如果想hashmap这样的单维的kv形式存储,那对于数据库就过于单一了,多维的目的就是可以存储各种类型的数据
- 排序:无序的数据查找时就会全表遍历,为了高效的所以是以有序的方式进行存储
- map:映射,该映射由行键、列键和时间戳索引(即:key),映射中的每个值都是一个未解释(经过序列化)的字节数据(即:value)
最终HBase关于数据模型和BigTbale的对应关系如下:
HBase使用与BigTbale非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列
3、Hbase逻辑结构&物理存储结构
HBase可以用于存储多种结构的数据。
以JSON为例理解HBase的逻辑结构
{
"row_key1": {
"personal_info": {
"name": "zhangsan",
"city": "北京",
"phone": "131********"
},
"office_info": {
"tel": "010-1111551",
"address": "atguigu"
}
},
"row_key11": {
"personal_info": {
"city": "上海",
"phone": "156********"
},
"office_info": {
"tel": "010-1115561"
}
},
"row_key2": { ......
}
}
分析上面的json发现:row_key1、row_key11、row_key2里面的字段有些存在,有些不存在,比如:phone、address在row_key1内存在,而在row_key11和row_key2不存在,那么在HBase里面如何存储呢?
这就涉及到了HBase的逻辑结构和物理存储结构。
1)物理结构
存储数据稀疏,数据存储多维,不同的行具有不同的列。数据存储整体有序、按照RowKey的字典序排列,RowKey为Byte数组
把上面的json转换成表格就是下面这张图,有行、有列
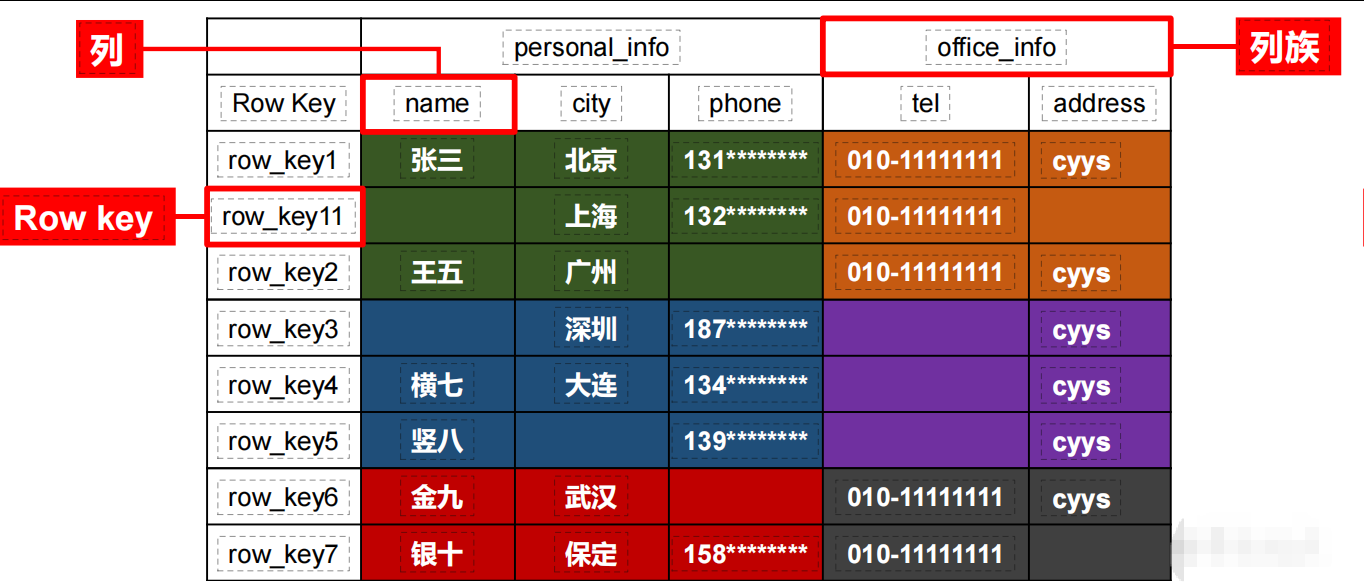
RowKey:=行号,非常关键,用来排序和整理数据的一定是按字典序进行排序的(按ASCII从大到小进行的排序,比如:row_key11一定是排序咋子row_key2之前的)
--- 先切分Region:将表格按照行拆分,块名称为Region,用于实现分布式结构;
-- 在切分store:按列族切分为store,用于底层存储到不同的文件夹中,便于文件对应
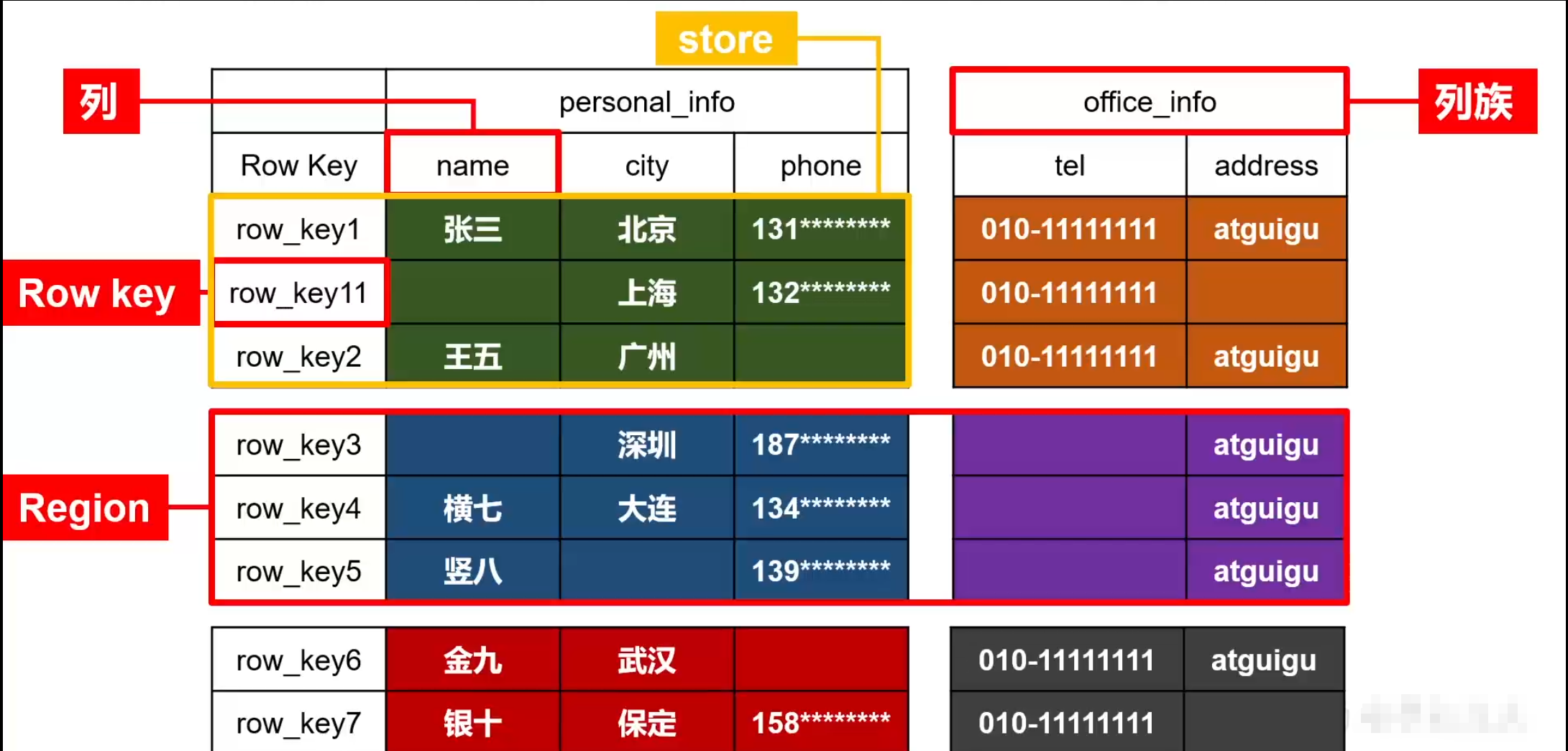
逻辑结构实际是概念视图,在实际底层中根本不存储,而是已物理存储结构进行的存储(即:数据映射关系)
2)物理存储结构
我们知道HBase是以k:v的形式存储的,所以要存储:张三 北京 131****,这样的数据,那么对应的key如何实现呢?---->实际 的存储单位是:StoreFile

StoreFile的k:v存储方式:key = Row key+Column Family+Column Qualifier+Timestamp+Type value = Value
HBase是以hdfs为数据进行存储的,所以不具备修改功能,同样也不具备删除功能,为了可实现修改就需要Timestamp时间戳作为版本管理进行修改,为了实现删除用Type
4、数据模型
1)Name Space
命名空间,类似与关系型数据库的database概念,每个命名空间下有多个表。HBase两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的饿命名空间。
2)Table
HBase不能写sql,但是有别的方式对数据进行管理(比如:shell、API)
3)Row
HBase表中每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所哟RowKey的设计十分重要
4)Column
HBase中每个 列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如:info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义
5)Time Stamp
用于表示数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间
6)Cell
由{rowkey, column Family:column Qualifier, timestamp}唯一确定的单元。cell中的数据全部是字节码形式存储
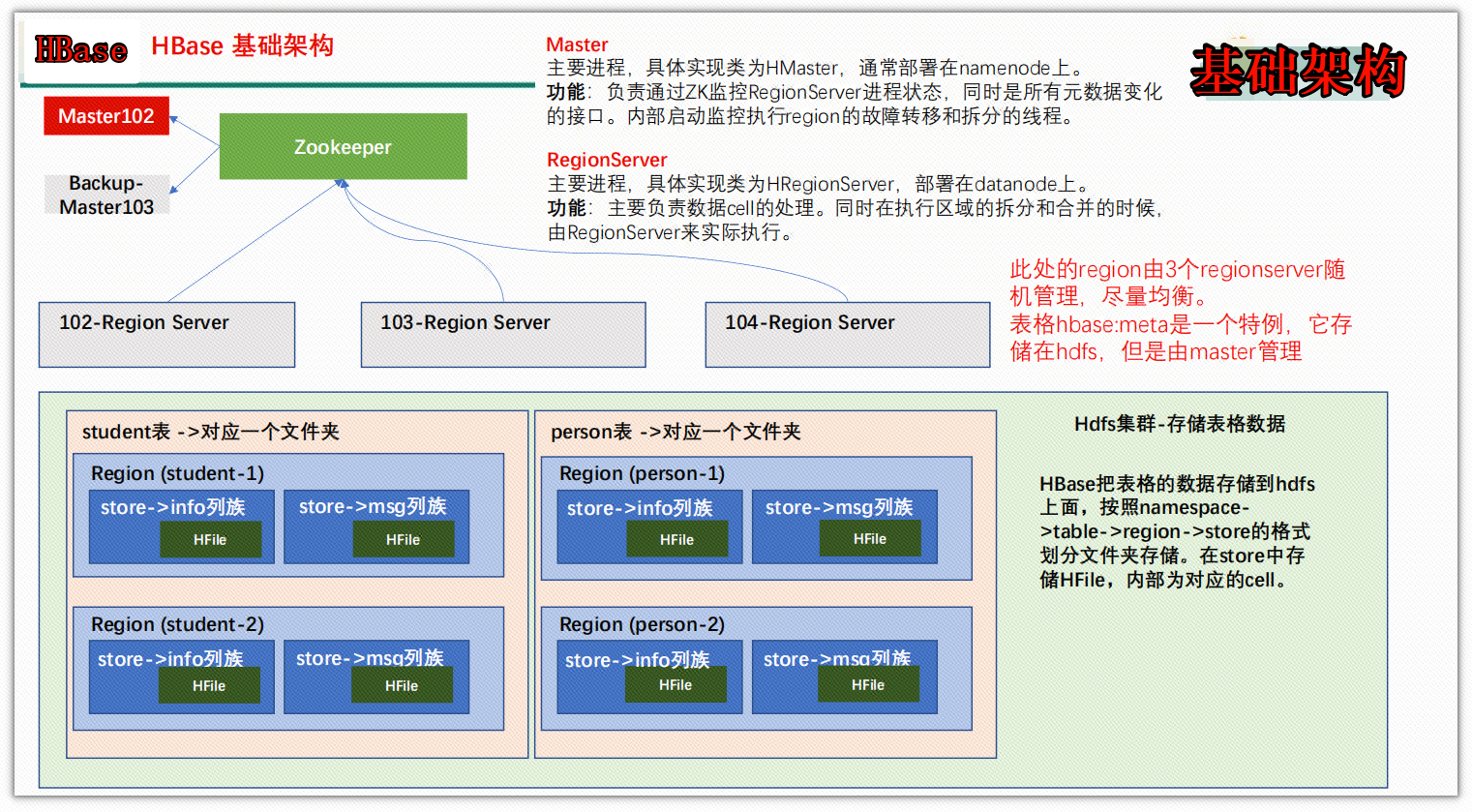
5、HBase基本架构
三、HBase安装部署
1、Hadoop集群正常部署并启动 --只需要在master上执行启动命令,就可以把整个集群的hadoop都可启动
cd /opt/hadoop [wufq@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh [wufq@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
在master和slave上用jps查看运行状态
2、zookeeper集群正常部署并启动
在集群的机器上启动:
[wufq@hadoop-slave1 conf]$ sudo /opt/zookeepe/bin/zkServer.sh start
在集群的机器上查看启动状态,leader表示主节点

3、HBase集群正常部署
1)解压hbase到指定目录
1、cd software 2、上传hbbase压缩包 3、sudo tar -zxvf hbase-2.4.11-bin.tar.gz -C /opt/module/ 4、mv hbase-2.4.11 hbase
2)配置环境变量
[wufq@hadoop-master module]$ sudo vi /etc/profile.d/my_env.sh 添加 #HBASE_HOME export HBASE_HOME=/opt/module/hbase export PATH=$PATH:$HBASE_HOME/bin #环境变量生效 [root@hadoop-master profile.d]# source my_env.sh
注意:集群的每台机器都需要配置
3)HBase的配置文件
修改hbase-env.sh文件
[root@hadoop-master conf]# pwd /opt/module/hbase/conf [root@hadoop-master conf]# vi hbase-env.sh 把 true设置成false export HBASE_MANAGES_ZK=false
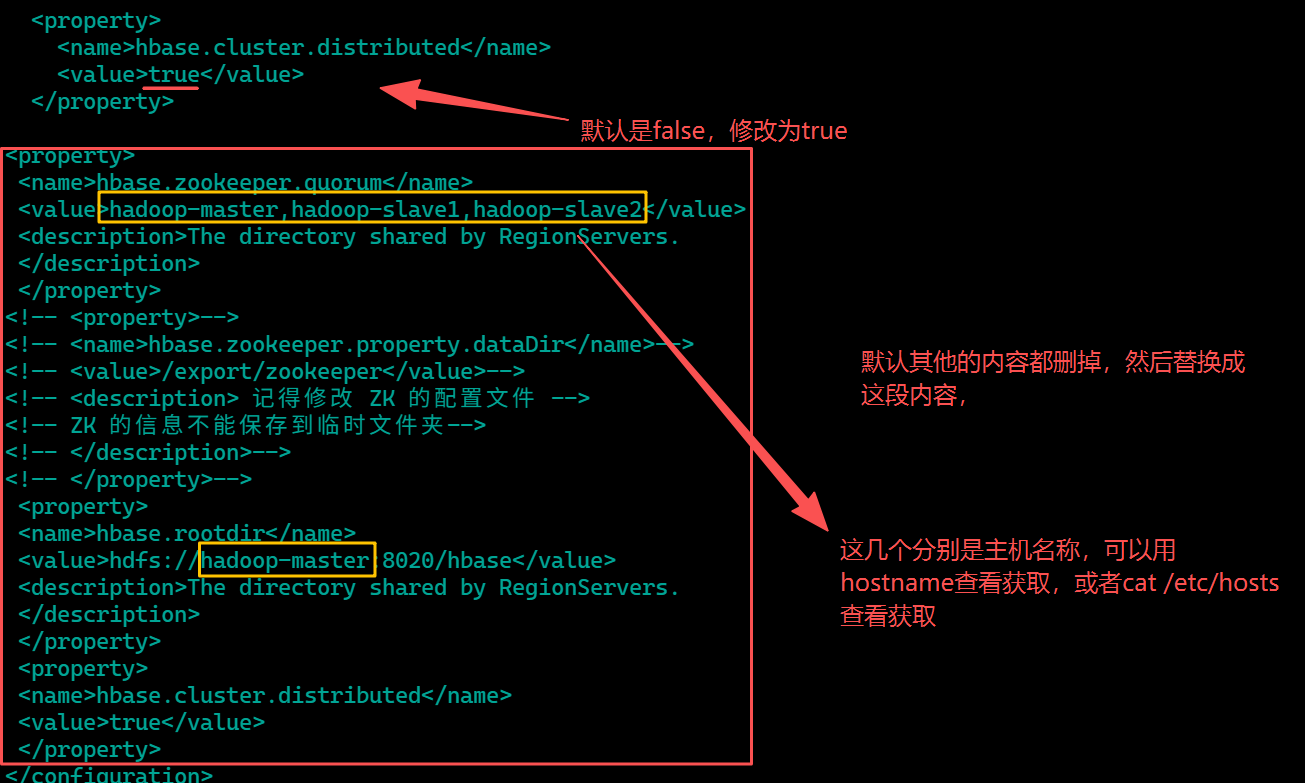
修改hbase-site.xml
<property> <name>hbase.zookeeper.quorum</name> <value>hadoop-master,hadoop-slave1,hadoop-slave2</value> <description>The directory shared by RegionServers. </description> </property> <!-- <property>--> <!-- <name>hbase.zookeeper.property.dataDir</name>--> <!-- <value>/export/zookeeper</value>--> <!-- <description> 记得修改 ZK 的配置文件 --> <!-- ZK 的信息不能保存到临时文件夹--> <!-- </description>--> <!-- </property>--> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop-master:8020/hbase</value> <description>The directory shared by RegionServers. </description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property>
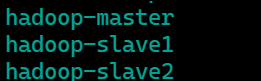
配置regionservers --删掉默认的localhost,替换成集群机器的hostname

解决 HBase 和 Hadoop 的 log4j 兼容性问题,修改 HBase 的 jar 包,使用 Hadoop 的 jar 包
#在此路径下 /opt/module/hbase/lib/client-facing-thirdparty #修改 /opt/module/hbase/lib/client-facing-thirdparty
