【clickhouse SQL语句03】
数组去重、拼接、排序、增删
一、去重
1.arrayDistinct
对数组进行去重
SELECT arrayDistinct( [1,2,3,6,34,3,11])
2.arrayUniq
计算数组中有多少个不重复的值
SELECT arrayUniq( [1,2,3,6,34,3,11])
3.arrayCompact
对数组内数据实现相邻去重
SELECT arrayCompact([1, 2, 2, 3, 2, 3, 3])
二、数组属性
1.arrayJoin
对数组进行展开操作,行变列
SELECT arrayJoin( [1,2,3,6,34,3,11] ) as a
2.arrayFilter
筛选出数组中满足条件的数据
SELECT a from (SELECT arrayFilter(x->x%2=0, [1,2,3,6,34,3,11]) as a
3.arrayEnumerate
返回数组下标
SELECT arrayEnumerate([1,2,3,6,34,3,11])
4.arrayReduce
对数组进行聚合操作,如有min 、max、avg 等
SELECT arrayReduce('avg', [1,2,3,6,34,3,11] )
5.arrayEnumerateDense
标记出数组中相同的元素
SELECT arrayEnumerateDense( [1,2,3,6,34,3,11] )
6.hasAny
判断数组中是否包含某些值中任意一个值,若包含则返回1,否则返回0
SELECT hasAny( [1,2,3,6,34,3,11] , [3,4])
7.hasAll
判断数组中是否包含某些值中所有值,若包含则返回1,否则返回0
SELECT hasAll( [1,2,3,6,34,3,11] , [3,4])
8.arrayWithConstant
生成一个指定长度的数组
SELECT arrayWithConstant( 3, 'a')
三、切割/拼接
1.arrayStringConcat
将数组元素按照给定分隔符进行拼接,返回拼接后的字符串(数组元素必须为String类型)
SELECT arrayStringConcat( ['2020','12','19'], '-')
2.arraySlice
对数组进行切割 ,后面两个参数分别是切割的位置和切割后的段数
SELECT arraySlice( [1,2,3,6,34,3,11],-3,2)
四、排序
1.arraySort
对数组进行升序
SELECT a from (SELECT arraySort([1,2,3,6,34,3,11]) as a)
2.arrayReverseSort
对数组进行降序
SELECT a from (SELECT arrayReverseSort([1,2,3,6,34,3,11]) as a)
五、添加/删除首尾元素
1.arrayPushFront
在数组首位添加元素
SELECT arrayPushFront( [1,2,3,6,34,3,11] , 8)
2.arrayPushBack
在数组末尾添加元素
SELECT arrayPushBack( [1,2,3,6,34,3,11] , 8)
3.arrayPopFront
删除数组中第一个元素
SELECT arrayPopFront( [1,2,3,6,34,3,11] )
4.arrayPopBack
删除数组中最后一个元素
SELECT arrayPopBack( [1,2,3,6,34,3,11] )
六、计算差值
1.arrayDifference
计算数组中前后两个值的差值部分,该位=当前-前者(不包括第一个数,结果第一位默认为0)
SELECT arrayDifference( [1,2,3,6,34,3,11] )
2.runningDifference
计算某一列前后数值的差值,该位=当前-前者(不包括第一个数,结果第一位默认为0)
select a,runningDifference(a) from (SELECT arrayJoin( [1,2,3,6,34,3,11]) as a)
1、with
#语法
with 表达式 as name
select x from xxx
with语法有三种形式:
- 定义变量
- 调用函数
- 查询
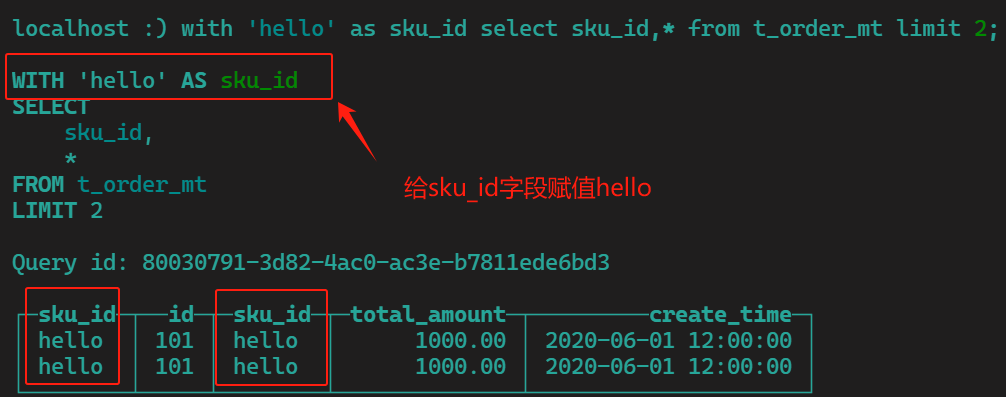
形式1:定义变量 -->注意:这种是要给字段赋一个临时的值,所以select的时候必须查这个字段,如果查*输出的结果仍然是原数据的值
with 'hello' as sku_id
select sku_id,* from t_order_mt
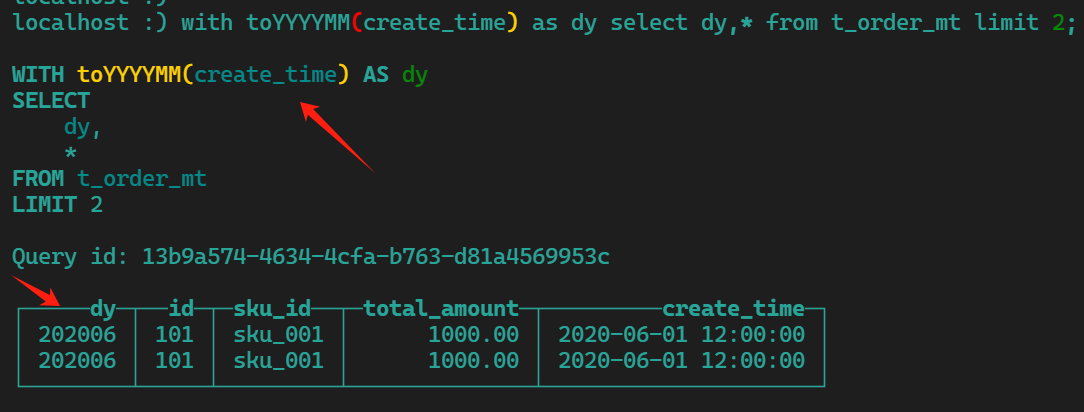
形式2:调用函数
with toYYYYMM(create_time) as dy
select dy,* from t_order_mt limit 2;
-- 语句解析:用with调用函数toYYYYMM把create_time定义成年月
实际工作中真实的sql
WITH
JSONExtract( data, 'event_raw_log', 'JSON') AS event_raw_log
,JSONExtract( event_raw_log, 'device_info', 'JSON') AS device_info
,JSONExtractString(device_info,'device_id') as device_id
SELECT device_id,* FROM target_event_attribution
where device_id = 'b6d17958-06f5-4fc5-9097-d4b79a3dfb51' and appkey = '750bb7f034cd701b'
ORDER BY db_time desc
limit 10 ;
形式3:执行查询 --->返回结果必须是一行,否则就报错
语法:with () as xx
1)全局聚合 sum count avg
with (select count(1) from t_order_mt) as cnt
select cnt,* from t_order_mt limit 2;
2、array join 函数获取每一行并将他们展开到多行(unfold)
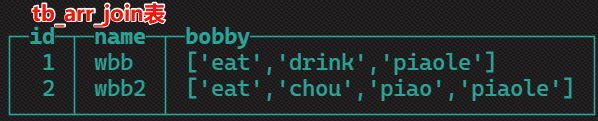
- 获取数组的角标
SELECT
id,
name,
bobby,
arrayEnumerate(bobby) as idx --获取数组的角标
from
tb_arr_join

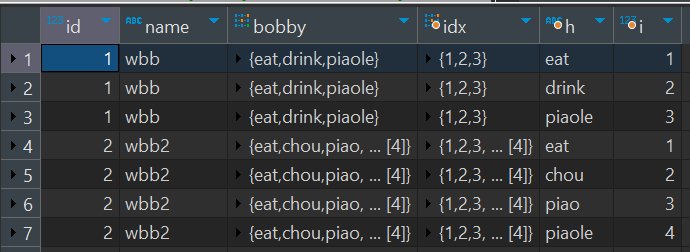
针对上面的结果,我们想要输出bobby里面的每一个数及对应得到index
- 升级语句
SELECT
id,
name,
bobby,
arrayEnumerate(bobby) as idx, --获取数组的角标
h,
i
from
tb_arr_join
array join --拆分数组
bobby as h,
idx as i
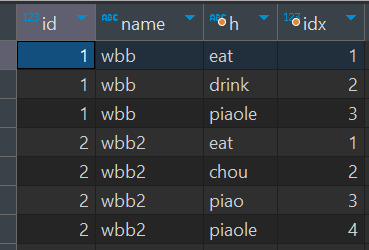
只想要数组的元素和它的角标
SELECT
id,
name,
h,
idx
from
tb_arr_join
array join
--拆分数组
bobby as h,
arrayEnumerate(bobby) as idx
# 案例:
需求:
- 将同一个店铺中的时间收集到数组中,按照日期排序
- array join
- 日期 - 编号
- 分组 聚合
步骤:
1、创建一个shop.txt文件,放到clickhouse 的服务器下的/root/data路径下
a,2017-02-05,200 a,2017-02-06,300 a,2017-02-07,200 a,2017-02-08,200 b,2017-02-05,200 b,2017-02-06,300 b,2017-02-09,400 b,2017-02-08,200 c,2017-01-31,200 c,2017-02-01,300 c,2017-02-03,400 c,2017-02-10,600 a,2017-03-01,200 a,2017-03-02,300 a,2017-03-04,400 a,2017-03-05,600
2、创建shop表
CREATE table shop(
name String,
cdate Date,
money Float64
)engine=MergeTree()
order by (name,cdate);
3、用clickhouse-client导入shop.txt文件数据
[root@localhost data]# clickhouse-client --host localhost --user default --port 9000 --password 123456 -q 'insert into shop FORMAT CSV' < '/root/data/shop.txt'
4、查看数据是否分组
select * from shop
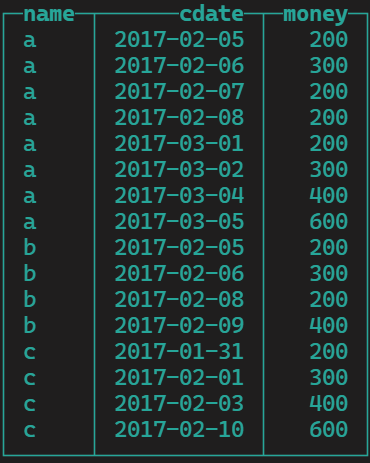
截止到这里,我们需求的第一步的数据已经有了
1)将同一个店铺中的时间收集到数组中,按照日期排序
SELECT name,groupArray(cdate) as dates ,arrayEnumerate(dates) as idxs from shop group by name;

2)array join
SELECT name , dy,idx from (
-- groupArray 合并成数组,arrayEnumerate 获取数组角标
SELECT name,groupArray(cdate) as dates ,arrayEnumerate(dates) as idxs from shop group by name
)
array join
dates as dy,
idxs as idx
order by dy asc;
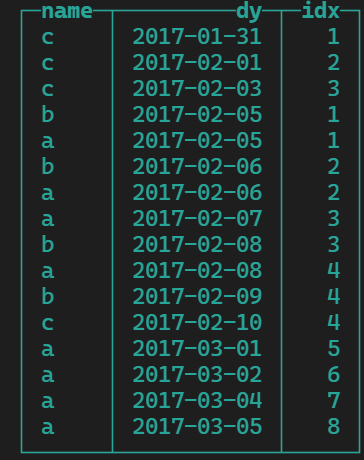
3) 日期减编号
-- groupArray 合并成数组,arrayEnumerate 获取数组角标,subtractDays 求日期差值
SELECT name , dy,idx,subtractDays(dy,idx) sub from (
SELECT name,groupArray(cdate) as dates ,arrayEnumerate(dates) as idxs from shop group by name
)
array join
dates as dy,
idxs as idx
order by dy asc;
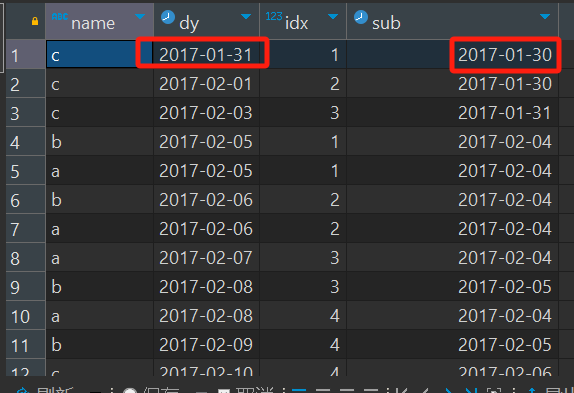
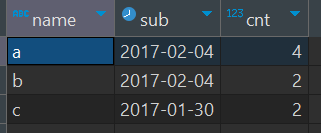
4)分组 聚合
SELECT
name,sub,COUNT(1) cnt
from
(
SELECT name , dy,idx,subtractDays(dy,idx) sub from (
SELECT name,groupArray(cdate) as dates ,arrayEnumerate(dates) as idxs from shop group by name
)
array join
dates as dy,
idxs as idx
order by dy asc
)
group by (name,sub)
HAVING cnt >1
order by name,cnt DESC
limit 1 by name; -- 只取一个name
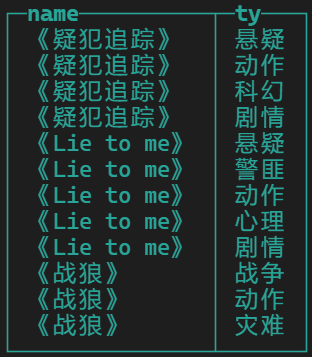
3、行转列,列转行
行转列:
原始数据

需要转化成这样
-- concat 合并,groupArray合并成数组,arrayStringConcat将数组元素按照给定分隔符进行拼接(数组元素必须为String类型) SELECT xxxz,arrayStringConcat(groupArray(name),' | ') as concat_col from( SELECT name,concat(xz,',',blood_type) as xxxz from xxw )group by xxxz

列转行:
原始数据

需要转换成
-- splitByChar把字符串变成数组 SELECT name,ty from( SELECT name,splitByChar(',',types) as typ from movie ) array join typ as ty;
4、join
员工表:yg
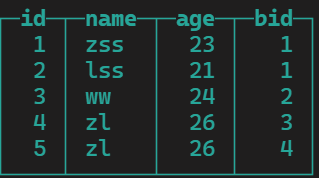
部门表:bm
连接进度:all(符合条件的都连)、any(符合条件的只会连一个)、asof(非等值连接,可以附加一些条件)
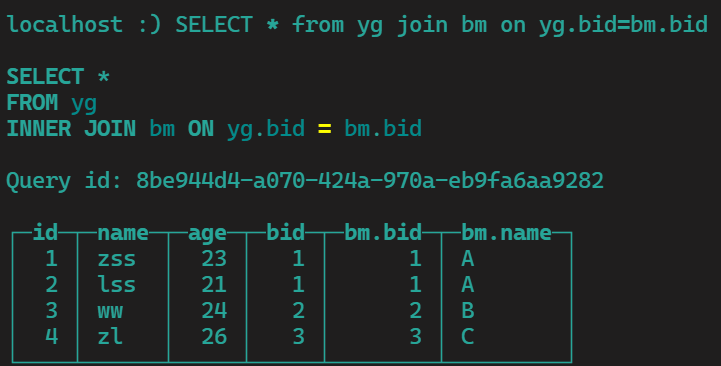
yg join/all join/inner join bm on yg.bid=bm.bid 都是一样的,满足条件的都脸上
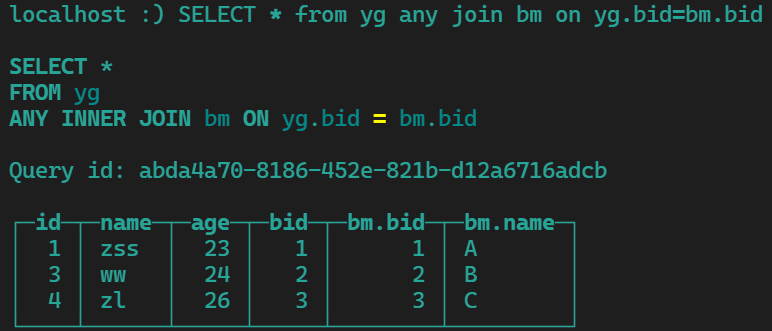
yg any join bm on yg.bid=bm.bid 连接上一次就不在连了
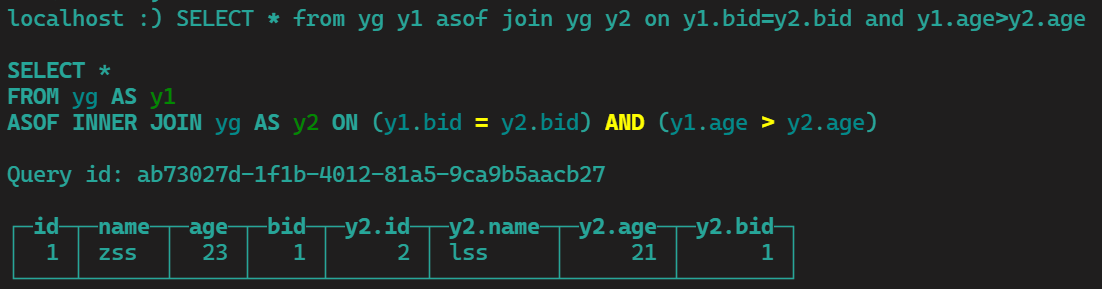
asof join yg y2 on y1.bid=y2.bid and y1.age>y2.age 用asof可以拼接这种非等值的条件,不加asof会报错
链接类型
left join:左侧表为准,right join右侧表为准
4、数组函数
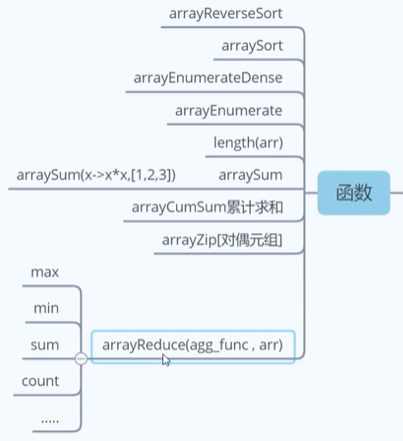
5、其他重要函数
toXXX -->时间函数,还有很多下面只列举了几个常用的
- toDate():将字符日期或时间戳转化为日期
- toDateTime() :将字符时间戳转化为时间戳

- formatDateTime:函数根据给定的格式字符串来格式化时间
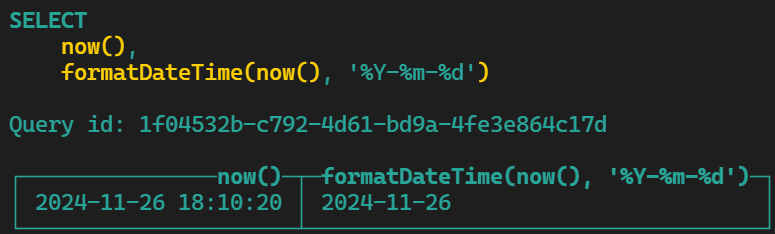
cast(x,t) -->将"x"转换为"t"数据类型。 也可以写成: CAST(x as t)
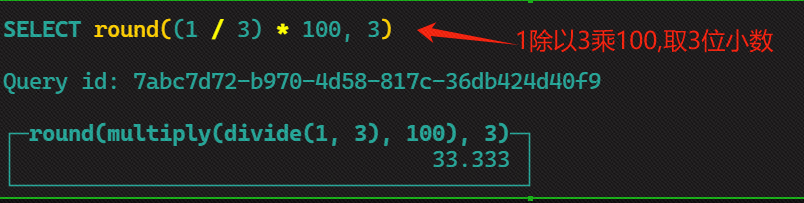
round()函数-->求百分比