【Python】 编码,en/decode函数以及print语句的一些探索
昨天晚上在整理hashlib和hmac模块的时候,又看到了编码这块的内容。越看越觉得之前的理解不对,然后想研究一下自己想出来,但是越陷越深。。总之把昨晚+今天一个上午的这些自己想到的东西写下来
● 几个概念(あくまで是我为了统一本篇中的术语,至于业界是不是这么说我不敢保证。。)
编码: 计算机认识的其实只有二进制数据,而我们之所以能够在计算机上处理自然语言和自然字符主要是因为有一种对应关系可以映射二进制数据和自然字符。这种映射就是广义上的编码。具体到中文上来,计算机发展源于英美,最开始的编码只要记住26个字符以及一些简单的标点等在计算机中如何存储,可是中国汉字那么多该怎么办。于是很多解决方案出现,纵览所有解决方案,其要义都是把一个中文字分解成若干个小字节,通过小字节间的排列组合来实现二进制数据到汉字的映射。这种映射是汉字编码,也是这篇里会提到的狭义上的编码。
编码格式: 不同的编码格式虽然都能实现汉字编码,但是对于同一个汉字内容,其映射的二进制数据是不同的。比如gbk和utf8就是两个不同的编码格式
● 关于unicode,ascii,gbk和utf8
知乎这个回答写得很好
概括一下,最早有的肯定是ascii编码格式。gb2312,gbk等这一批是一个系列的编码格式,从前一个版本的基础上不断扩充编码。他们来自ascii的一脉相承,是中国人民对ascii编码无法支持汉字显示这一问题的解决方案(原有ascii编码格式的映射不变,额外加上汉字编码)。但是如果全世界各种语言都按照自己的标准来进行编码的创作的话,很快就会乱套的。所以某些国际标准组织退出了unicode(Universal Multiple-Octet Coded Character Set,简称UCS),它是一些(甚至可能是所有?)编码方式的并集。除了ascii的内容继续维持不变外,把其他所有字符都进行了国籍标准的编码,意思是不让不同的字符编码成为计算机领域中的巴别塔。
在旧时代的gb系列中,英文字母沿袭了ascii的习惯,一个字母字符占一个字节;而一个汉字字符都被认为是两个英文字符的组合,占两个字节。而到了新时代的unicode之后,包括英文字母和汉字在内的所有字符都被统一认为是一个字符,并被存储成两个字节。这么一来就出现了一个问题,本来美帝的程序员们写一个字只花一个字节的空间,但是如果他们要和国际接轨,用了unicode的话,一个字就得花两个字节,这浪费了很多资源。这也是为什么unicode在很长一段时间里没有得到推广。
后来互联网的兴盛催生了面向传输的UTF(UCS Transformation Format)标准。其中utf-8是比较有名的一种。utf-8的意思是每次以8个位传输数据。utf8是一种所谓“变长的编码格式”,它灵活地运用1-4个字节来存储不同的字符。当字符处于ascii的范围内就用ascii的一个字节来储存,更复杂的字符则按照unicode的规定用更多的字节去存储。可以说是一种对传输成本的妥协。(是不是感觉历史倒退了w)这也在冥冥之中让utf-8和gb系列又像起来了,它们都对ascii原生的那些字符不做处理,而自己再做一些各自的扩展。gb系列是中国特色,针对汉字的,而utf是面向全世界的。这种相似性也体现在程序中,程序中经常感觉,gbk和utf-8好像是同一个级别的东西吧!很显然,unicode的编码和utf-8的编码并不是完全一一对应的,需要一些算法和操作来进行转换。
utf8,UTF-8在程序中和utf-8都是等价的,程序会自动识别,其他带有-等的编码格式名称也都是一个意思。
● print语句的试验
我猜测,当print语句碰到一个unicode目标的时候,会用当前python shell环境的默认编码格式首先对unicode对象进行encode(此时unicode对象已经变成了一个str对象了),然后再以默认编码格式为基础,根据其包含的汉字和编码的对应规则,把这个str对象解释成中文并显示出来。但是当print语句碰到的直接是个str目标的时候,就不管其从unicode转到str时用的编码格式是什么,直接用默认编码格式的对应规则来解释成中文。所以,当unicode对象转换成str时的编码格式和print语句的默认编码格式不一致的时候就会出现乱码现象。比如在cmd的python shell里面:
>>>uni = u'你好' #存入一个unicode对象 >>>print uni 你好 #可以正常显示 >>>uni.encode("gbk") '\xc4\xe3\xba\xc3' #显示的是个str对象了,如果type(uni.encode("gbk"))得到的就是str对象 >>>print uni.encode("gbk") 你好 #可以正常显示,因为在cmd下的pythonshell里默认个编码格式就是gbk >>>uni.encode("utf-8") '\xe4\xbd\xa0\xe5\xa5\xbd' #可以看到,encode用的编码格式不同,编成的字符串也是不同的 >>>print uni.encode("utf-8") 浣犲ソ #乱码,因为用了gbk中汉字和字符串编码格式对应规则去解释了用utf-8编码成的字符串。 #######さらに###### >>>print '\xc4\xe3' #自己写出来的这么个字符串(前面不加r)的话也会被print解释成中文 你 >>>print uni.encode("utf-8").decode("gbk") 浣犲ソ ''' 乱码,而且和上面的乱码一样,这是因为,在uni被utf-8 encode之后,这个对象变成了str对象,是'\xe4\xbd\xa0\xe5\xa5\xbd' 这个。 后来,它又被按照gbk的规则解码,又变回了unicode,但是此时它在内存里的二进制数据已经和最初的uni不一样了。 最初的uni,应该是'\xc4\xe3\xba\xc3'.decode("gbk"),而现在的这个东西,他decode之前的字符串已经变过了。 这么一个东西再拿去print,又把它编码成了gbk格式,相当于前面那步decode没有做,变回了'\xe4\xbd\xa0\xe5\xa5\xbd'。 再解释成汉字,当然就和最开始用uni编码成utf-8格式再解释成汉字的乱码一样了 '''
● 关于不同python shell中对不同编码的支持
python shell这个东西可以再很多地方存在。比如在cmd.exe里键入python来进入windows中的python shell(下也称cmd的python shell),或者在某些IDE比如pycharm中自带一个python shell,还有linux自带的python shell等等。基于上面的猜测,我觉得在cmd的python shell里面,print的默认编码格式是gbk,而在pycharm这种编辑器界面里面默认编码格式是由脚本上方的# coding=xxx来决定的,通常这里写utf8的话pycharm的pythonshell就是一个utf8环境的shell了。比如:
#在cmd的python shell中 >>>print u'你好'.encode("utf-8") #用gbk解释utf8编码成的字符串,当然是乱码,下同 (乱码 >>>print u'你好'.encode("gbk") 你好 #在pycharm的python shell中 >>>print u'你好'.enocde("gbk") (乱码 >>>print u'你好'.encode("utf-8") 你好
某个环境的的编码可以看sys.stdout.encoding就可以看了。cmd中显示的是cp936其实就是gbk。
这里我觉得还要区别一个概念就是系统的默认编码和python shell的默认编码。系统的默认编码可以通过sys.getdefaultencoding()来查看,基本上都是"ascii"。如果想要改变可以通过import sys;reload(sys);sys.setdefaultcoding("...")来实现。(必须要有reload函数,否则可能报错从sys中找不到setdefaultcoding方法)。那么系统默认编码的作用是什么,举例如下:在代码中如果写'xxx'.encode('yyy'),此时xxx是一个str类型的话,首先xxx有一个编码类型,然后其直接调用encode方法,默认是用系统默认编码去decode这个xxx然后再执行后面的encode,此时就是用到系统默认编码的时候。简单来说,setdefaultencoding之后可以让encode更加方便地被使用。
而python shell的默认编码正如上面说的cmd里的是gbk而pycharm里的是utf8。系统默认编码什么用下面会说。
● python中的unicode和str
unicode把二进制数据用更加好看的十六进制表现出来(当然仅限于中文和其他一些特殊字符比如"不"就是u'\u4e0d',英文的话u'nihao'就是以u'nihao'存着的):
比如“你”字的unicode编码是u'\u4f60'其实的意思是内存中的01001111(4f) 01100000(60)这样的内容罢了。u'\u4f60'只是把二进制转化成十六进制方便我们看。
在习惯了u'\u....'这种格式的unicode同时也不要忘了还有可能有其他形式的unicode,比如latin-1编码格式decode出来的unicode往往是u'\x....'这种形式的。一个字符可能有多个unicode,比如"不"既可以是u'\u4e0d'也可以是u'\xb2\xbb'(有gbk编码格式的str通过latin1编码格式decode而来),还可以是u'\xe4\xb8\x8d'(由utf8编码格式的str通过latin1编码格式decode而来)。第一种unicode是通用的,可以被encode成gbk或者utf8编码格式的编码,但是后两者和第一种不能相互通用,u'\u...'形式的编码无法有效地用latin1来encode,同样后两者最好也别用gbk或者utf8来encode,会引起乱码或encode错误。
str是python中默认字符串的类型,对于含有非英文或者说非ascii组成的字符串,在内存中的本质是一个编码和内容的对应。
当要进行运算比如加减的时候,应该尽量统一类型,str+str,unicode+unicode。如果实在是会出现混合的情况,那么python默认的动作是用系统默认编码(sys.getdefaultcoding的那个)来decode算式中的str类型,把它变成unicode,然后再将其与其他的unicode相加,最终返回一个unicode。
● encode和decode
unicode和文本是对应的,这种对应和encode,decode没有关系,就是说这两个函数是无法改变这种对应关系的。但他们能改变的是unicode或者说文本到字符串的对应关系。比如对于“你”这个字:
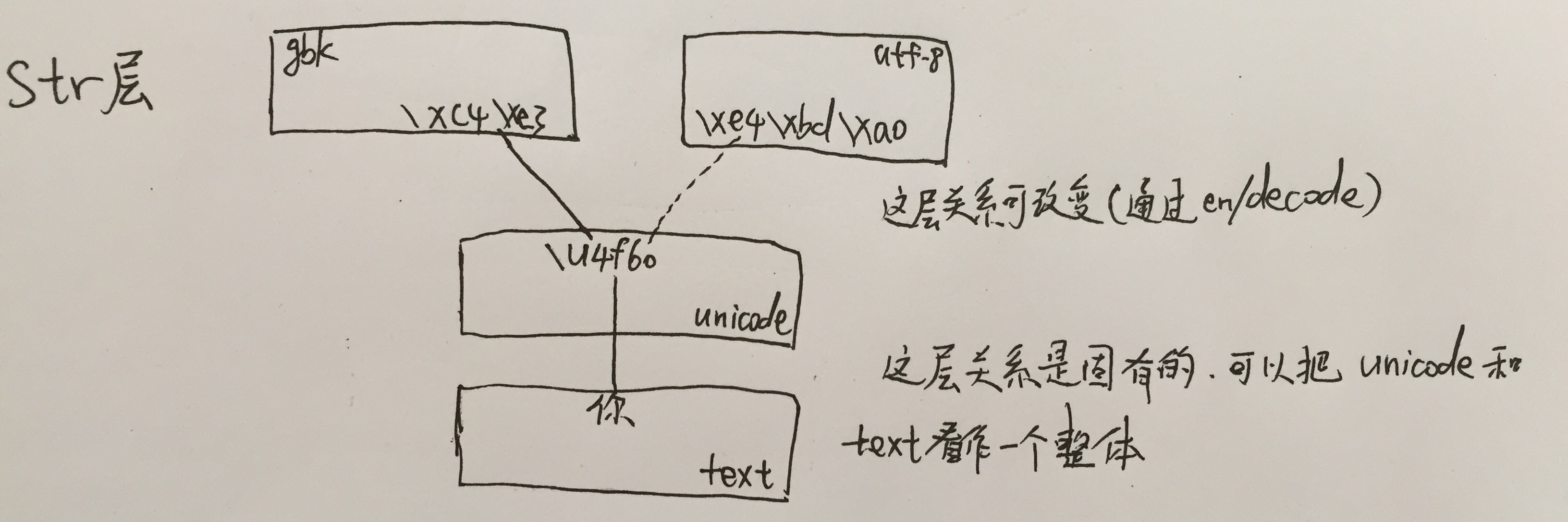
encode和decode的工作,说白了,就是进行\u4f60到\xc4\xe3或者\xe4\xbd\xa0的操作以及反操作。一般,encode的操作对象是unicode,而decode的对象是str。但是这不绝对,毕竟他们进行转化的对象是内存里的数据,只要你有数据,en/decode就会尝试去转化。这个过程中有可能会报错。另一方面也要注意真正decode的是编码而不是内容,这点很容易忽视是因为在常用的gbk和utf8的环境下,同样内容用环境的编码格式decode出来总是相同的unicode,致使下意识地感觉decode像是直接对内容的decode。然而在分别在gbk和utf8的环境中"不".decode("latin1")得到的unicode并不一样,因为在两个环境中,'不'本身的编码就不一样。内存中不一样的数据去执行同一个方法得到的结果当然是不一样的。
可以有'Hello'.encode("xxx"),也可以有u'Hello'.decode("xxx")。str再encode的默认动作是,先把str用系统默认编码(上面提到过其默认为ascii且改变的方法是setdefaultcoding),decode掉再做相应的encode动作。这解释当没有改变默认编码时'English'.encode("xxx")不报错,但是"中文".encode("xxx")一定会报错的现象。因为此时decode用的默认编码还是ascii,无法解析中文。
另一方面,为啥英文的unicode还可以再decode我是还没找到答案。那篇文章里也没明说,不过实用过程中肯定不会有人这么用的。。姑且算是钻个牛角尖吧= =
总而言之,en/decode之所以会报错是因为en/decode用的那个编码方式没有办法理解内存中的二进制数据(没有相关二进制到目标数据类型的映射)。
● 程序第一行或者第二行写的#coding
通常在程序第一行或者第二行会写上一句#coding=utf-8或者gbk或者什么什么的,这是在干啥呢?
当python文件写上了这句话,并且确实是按照这句话中的coding为编码方式保存了文件的话,那么首先,程序中就可以在注释里写中文,不报错了。这是因为语法解释器在碰到中文的时候会以这种编码方式把它存进内存了。第二所有用中文写的str变量如"中文"就直接被指定成是由那个编码方式编码而成的了,不指定的话中文str对象会报错的。
● 关于latin-1编码格式
最近在处理mp3文件的时候碰到了latin-1编码格式。对于这个格式有几点想说的
1. latin-1就是ISO-8859-1的别名,在不同场合下这种编码格式有这两种不同的叫法
2. 如上面unicode一节中提到的,用latin-1编码格式decode得到的unicode和gbk,utf8等得到的不同,不是u'\u...'而是u'\x....'。不过这也不是绝对的,用utf8来decode一些str比如"é"时得到的是u'\xe9'而不是u'\u00e9'。
3. 通过latin1而decode得来的unicode,处理时最好还是能够通过latin1 encode回来,并不是说用其他的编码格式encode一定会报错,但是也可能是乱码。这和之前我们熟知的“u'\u...'类型的unicode不论其是通过gbk还是utf8 decode而来,都可以通过gbk和utf8 encode,然后用相应环境的shell打印出来都可以显示正确的内容”这种模式不同是一个需要改变观念的地方。
===================基本上就是这么多了,写了这么多感觉还是不是很清楚。。唉,能力有限,如果要真的搞清楚,可能得去看python源码了。下次弄本更加高阶向一点的相关的书来看看吧。周六就要考专八了,现在还在水这个我也真是够了【捂脸】=========

 浙公网安备 33010602011771号
浙公网安备 33010602011771号