基本的网络IO模型
线程池 IO模型 IOCP
UDPTCP的理论Socket的基本实践- 用户态缓冲区的操作
- 完整的使用
socket接口来跨进程数据传输
这是我们网络编程这一阶段的主要路径。核心是围绕『跨进程』的数据传输。
随着课程的推进,我们逐渐面临一些新的场景,使得我们学习的通用知识似乎无法很好的处理这些场景。最典型的场景就是『怎么用一个进程与N个进程进行数据传输的同时依然保持这个进程的稳定与流畅性』,这翻译成大白话就是『怎么做一个稳定性好并发性高的服务器进程?』
宗旨就是:怎么最大限度的使用到CPU资源,而非将其浪费在一些无关紧要的处理上。
CPU的时间片分到了某个线程,某个线程就应该好好利用这个时间片。诸如无期限的等待,不停歇的循环判断等都是典型的浪费时间,是高性能的敌人。
在讨论具体的话题之前我们先来看下当下网络通信架构中的现实情况:
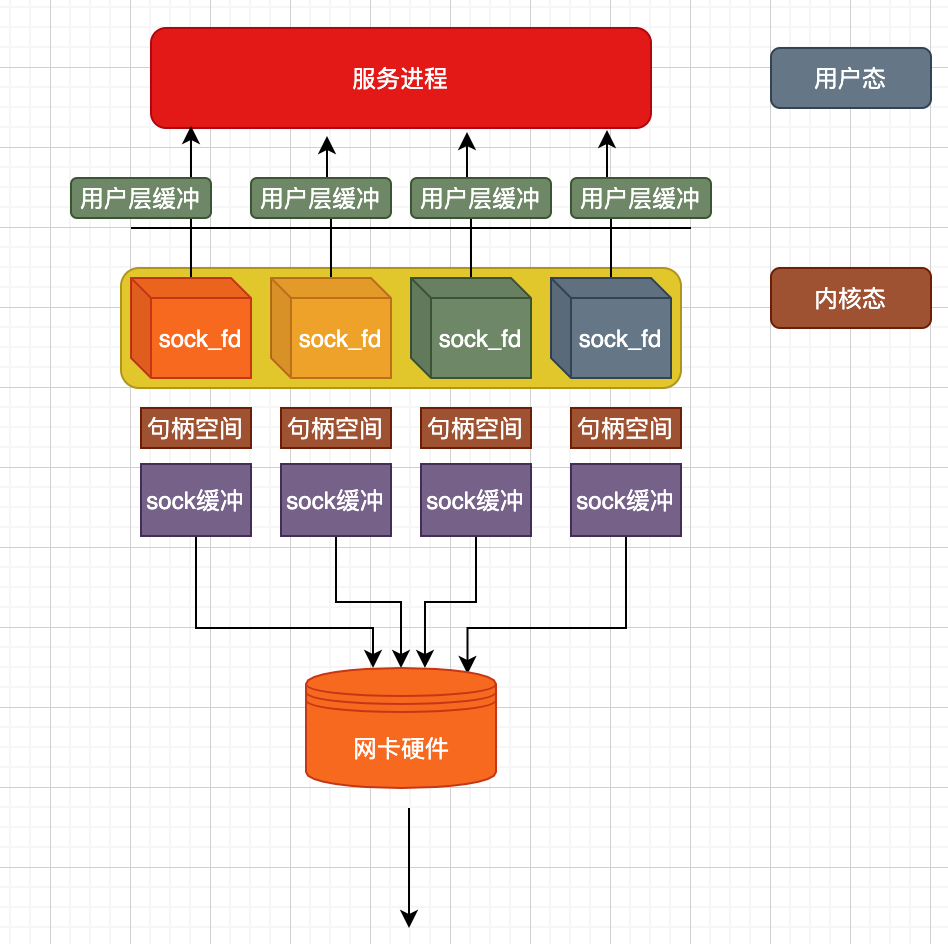
用户态的一个服务进程要能够稳定高效的运行,背后这些资源的利用以及数据的流动都不应该有障碍(或者说将影响减到最少)
我们来捋一下其中涉及到的资源申请与IO
- 每一个链接意味着一个
socket对象,这个对象本身占有一定的内存空间 - 每个
socket都有一个自己的缓冲区,这个缓冲区占有一定的内存空间 - 每个链接在用户态都有一个用户自己的缓冲区,这个缓冲区占一定的内存空间。
- 每个链接都可能同时与网卡读写数据,要考虑网卡是否能满足要求。
假设我们认为一台机器能够支持1万个链接同时工作就达到了『高性能』的定义,那么显然,1台支持1万链接的主机以上项都不会成为瓶颈所在。
无论是内存所占的大小,还是网卡的速度,都能应付1万个链接所需的要求,既然以上都不是问题,那么问题在哪呢?
- 当某一个链接上能读写时,用户态进程(线程)怎么能够及时知道,进而及时的去读写这个链接
- 当读取到数据或者准备数据写入时,怎么能够最大限度的利用CPU,尽快的准备好需要写入的数据或者处理数据
以上两个问题就是我们在网络编程中,开发高性能服务器所面临的课题。
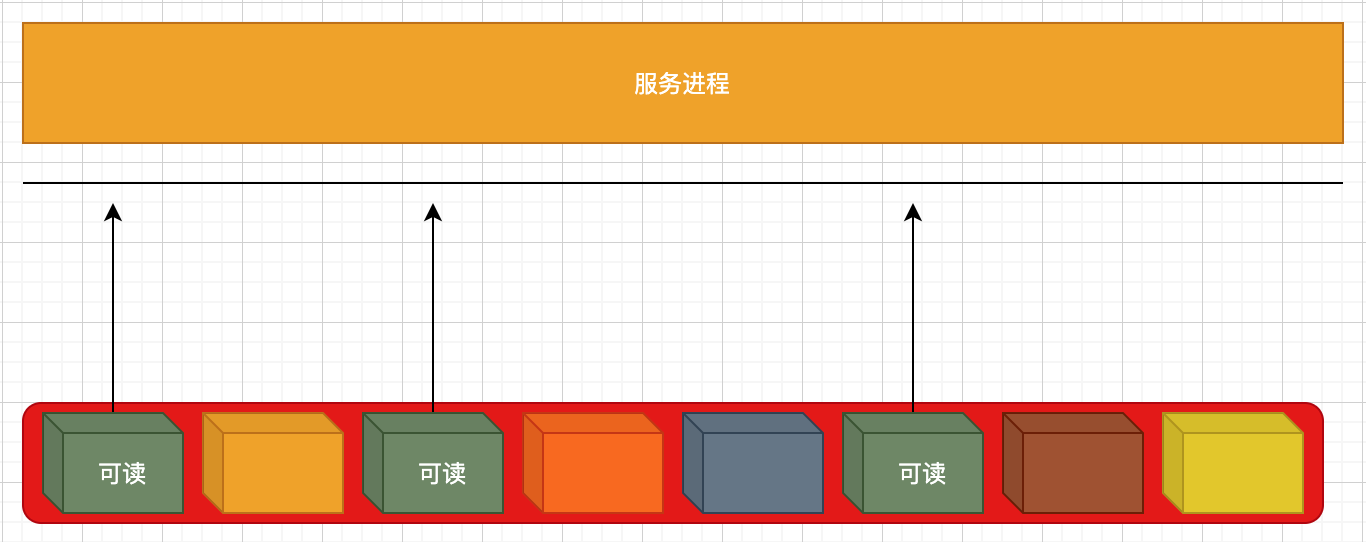
首先面临的问题就是用户态的服务进程是怎么知道哪个socket当前是可以『读写』的。
当我们在说『可读写』的时候,其实语义是此刻『读』『写』这个句柄时是可以『成功的』。成功的意思就是说当你写时,就能成功写入数据(而不会返回错误),当你读时,就能功能读取到数据(而不会阻塞或者返回错误),这是我们所说的『可读写』的语义。
只有很好的处理了这个语义才能真正的充分利用CPU的时间片。而不至于因为『空等、忙等』造成这个线程白白浪费CPU恩赐的时间片。(如果这样,我大可不要CPU给这个线程分配时间片,留更多的时间片给需要的线程。CPU资源本身就是时间片资源,时间片是有限的)
开发高性能服务器的另一个话题是『多线程』,多线程的价值和意义应该讨论过很多了。但是在此还需要大致的讨论几点:
『当我们在聊高性能xxx时,我们在聊什么?』
其实所谓的高性能,本质就是我们的代码重复的利用到了计算机硬件提供的资源。
- 提供计算资源支持
- 提供读写资源支持
主机提供CPU(GPU)用来运行代码,用来提供计算能力,提供硬盘、网卡等来处理数据的读写(获取),我们会发现一个事实,我们在进程中只要用一个线程执行一个while死循环,这样我们这个线程就『占用了』这个CPU的时间片,就直接获取了CPU资源,我们可以控制什么时候不需要这个资源,但对于读写资源我们似乎很难控制。当我们用户态调用一句读网卡数据的代码,我们只是在要求网卡将数据给用户态,但并不能要求网卡花多久时间来准备数据,对此,用户态代码无能为力。
『硬盘花多久时间准备好用户需要读的数据、网卡花多久时间来准备好用户需要读的数据』这个过程本就是一个黑箱,用户能做的只能是:
- 不停的来询问是否准备好了
- 一直守着直到设备准备好数据
- 等通知被告知数据准备好了
这个过程我们成为IO过程,期间并不需要CPU资源的参与,因此才能最大限度的使用CPU的资源去处理用户的代码,而非来准备硬盘或者网络上的数据。
当用户逻辑是需要读取数据时,我们调用读取数据的代码后却拿CPU的时间片来做等待,这是极大的误区。但我们却经常走入这样的误区而不自知。
一条线程被IO给阻塞住,浪费时间片,似乎解决问题的办法很简单,再开一个新线程就是了。这样的思路非常的朴素,有用,但存在显然的缺陷。
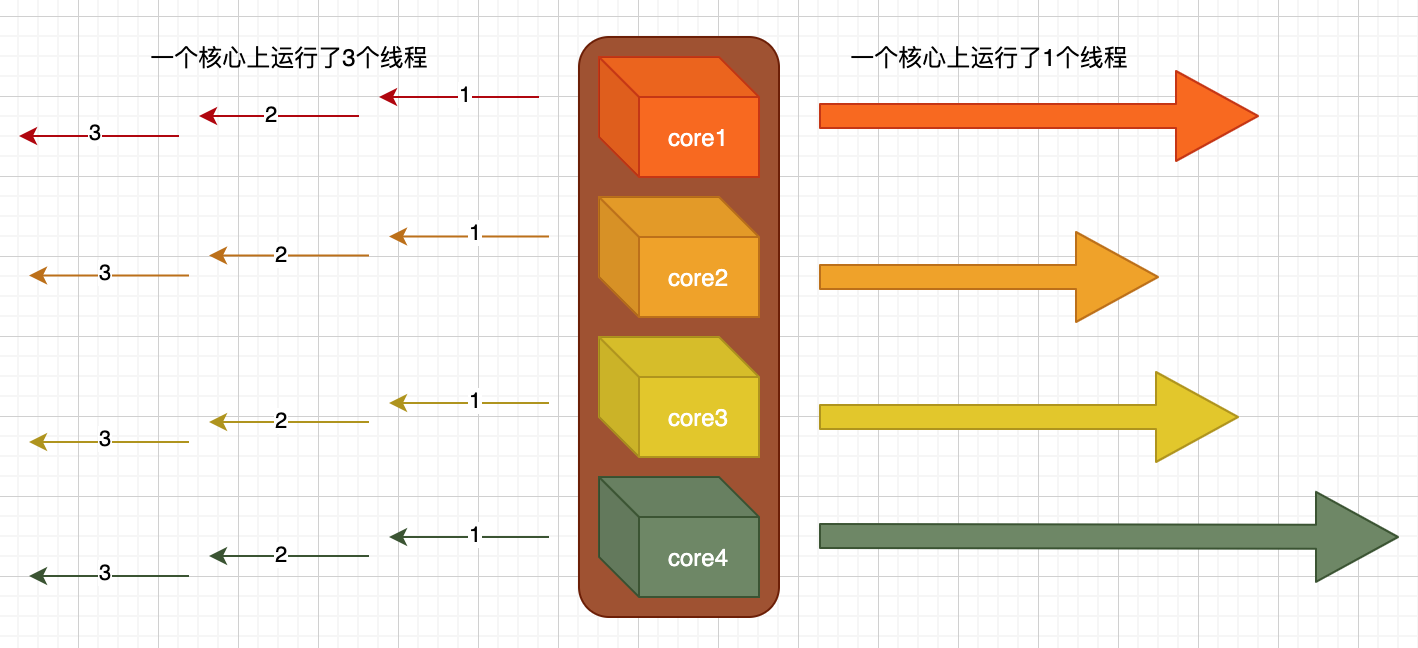
CPU的物理尺寸到达瓶颈后,大佬们将多个CPU打包成了『一个』CPU,这就是所谓多核的由来。(在不考虑超线程技术的情况下)每个核心能运行一个线程,4个核心运行4个线程,N个核心运行N个线程。这就是所谓的『并行』,如上图右侧所示,一个核心运行了1个线程,现在能同时执行4个线程,同时运行4个任务,我们说有4个线程在并行执行。
而左侧所示,一个核心上可以运行N个线程,显然看到1、2、3号线程并没有像右侧这样『同时』的运行,而是存在先后关系,并且先后关系之间还存在非常小的『间隙』,一个核心上运行3个线程,我们称之为『并发』,这得益于操纵系统的『线程调度』,这样使得CPU在单核时代已然能够『同时的』执行各种任务。
并发的线程越多就意味着一个单核上运行的线程越多,也就意味着『间隙』越多,就意味这越多的CPU资源被这些间隙占用,这个间隙就是我们所谓的『线程切换导致的额外开销』,理论上一个单核上允许无数多的线程,但是实际上,无论是线程本身所占用的内存还是线程切换所带来的开销都是无法接受的。
到目前为止我们似乎可以做一个逻辑梳理:
1、我们在A号线程上调用了一个读取文件的方法,但我们不知道这个文件要什么时候才能读完,所以A线程一直在边读边等着。
2、为了效率,我们进程想多做一些任务,而A线程正在忙,所以我们开辟了一个新线程B。
3、此时,B线程也遇到了步骤1的场景。
4、所以我们继续执行步骤2的逻辑
... ...
在这样的循环下,线程越来越多,线程切换开销也越来越大,当然,可能执行3号线程的时候1号线程任务已经执行完了,线程退出了,虽然因为这个原因此时线程数目并没有因此增加,但是频繁反复的创建线程同样是在浪费CPU的时间。
所以解决方案很简单,我们创建固定的几个线程,不让线程退出(一个死循环),然后让这几个线程去执行那些任务,而不是来一个任务就新创建一个线程。这个模式,就是所谓的『线程池』
所以线程池是什么?线程池就是用有限的线程来执行无限任务的一种手段。那么,线程池究竟解决了什么痛点呢?
显然,除非线程执行了一个死循环,否则当线程执行完会退出,也就是说正常情况下(正确编码)不可能系统中的线程会越来越多,这是一个动态出生-死亡的平衡过程,真正的问题在于『反复的调用线程创建函数创建新线程』,这才是真正的问题所在,这也是线程池的使命所在。什么场景中会反复的创建新线程?最经典的答案应该就是『服务进程』了。也就是我们常说的服务器程序。每个socket链接都创建一个线程,反复的创建,这种时候就应该是线程池的用场了。
而客户端程序开发中,真正需要用线程池的场景不是很多。
线程池
线程池需要解决的核心痛点上文有所说明,设计思路也非常简单:
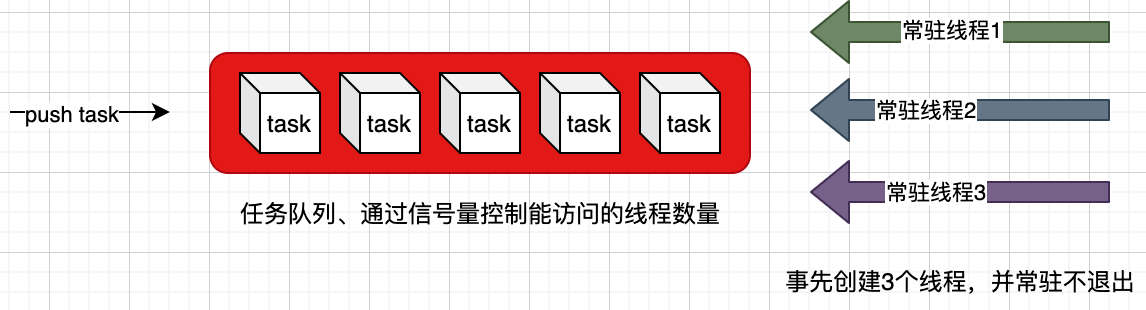
- 事先开辟N个常驻线程(创建线程、执行方法、让线程方法不要退出(除非接到退出指令))
- 创建一个队列,将任务(需要执行的函数代码)添加到这个队列
- 唤起线程,从队列中取任务(其实就是执行队列中的函数代码)执行
在具体实现中,我们使用C++提供的thread类来创建线程(相比Windows提供的CreateThread函数更加简单),使用Windows提供的CreateSemaphore信号量函数用来做线程间的同步,使用functional模板来做『函数对象』以便添加到队列中(当然,也可以创建一个虚基类来作为任务,以便添加到任务队列)。
//ThreadPool.h
#pragma once
#include <windows.h>
#include <queue>
#include <vector>
#include <mutex>
#include <functional>
using namespace std;
typedef function<void()> TaskType;//这里为了方便,定义了一个函数对象类型来作为任务
class ThreadPool
{
public:
~ThreadPool();
public://对外提供3个接口
ThreadPool(int tCount = 4);//创建线程池对象
void addTask(TaskType task);//添加任务到队列
void terminatePool();//退出(销毁)线程池
private:
int tCount;
vector<HANDLE> threadHandels;//线程句柄s
mutex mtx;//直接使用c++提供的互斥锁
void _threadCallBack();//线程执行的方法
queue<TaskType> m_tasks;//任务队列
HANDLE m_semp;//信号量句柄
bool m_isLoopTerminate;//线程函数是否停止执行标志
};
//ThreadPool.cpp
#include "pch.h"
#include "ThreadPool.h"
#include <thread>
//创建线程后开始执行这个函数
void ThreadPool::_threadCallBack() {
mtx.lock();//直接使用c++提供的互斥体对象
DWORD tid = GetCurrentThreadId();
HANDLE t_handle = OpenThread(THREAD_ALL_ACCESS, FALSE, tid);
this->threadHandels.push_back(t_handle);//将本线程的句柄放入队列(因为不是通过Windows提供的方法创建的线程 所以不能直接获取到线程句柄
mtx.unlock();
//因为这个循环的存在所以线程不会退出,变成常驻内存线程,直到是否退出标志改变。
while (this->m_isLoopTerminate == false)
{
DWORD ret = WaitForSingleObject(this->m_semp, 2000);//因为这个函数的存在,所以循环不是在『忙等』。执行到这个函数的时候如果此时信号量处于激活状态,则1、信号量数值减1(这个动作由信号量内部原子化操作)2、代码继续往下执行。否则该函数会让线程被挂起,时间片让出。这里设置了2秒的一个超时,如果2秒内信号量没被激活则进入超时自动激活,然后继续下一次的循环。这一步的目的是让循环有机会定时得到执行,否则可能存在一种状态,让这个线程执行到这个信号量等待函数时会一直处于挂起状态,从而m_isLoopTerminate标志得不到检测,线程无法退出。
if (ret == WAIT_TIMEOUT) {
continue;
}
this->mtx.lock();
auto task = this->m_tasks.front();
this->m_tasks.pop();//从队列中取出任务(函数对象)
task();//执行这个函数任务
this->mtx.unlock();
}
}
ThreadPool::ThreadPool(int tCount)
{
this->tCount = tCount;
m_semp = CreateSemaphore(NULL,0,MAXLONG,NULL);//创建一个信号量对象,初始信号为0
m_isLoopTerminate = false;
for (int i = 0;i<tCount;i++)
{
thread t(&ThreadPool::_threadCallBack,this);//直接使用c++提供的thread类,这里需要注意线程在对象中的使用,需要传入this作为参数
t.detach();//线程开始执行
}
}
ThreadPool::~ThreadPool()
{
}
void ThreadPool::addTask(TaskType task)
{
if (this->m_semp == INVALID_HANDLE_VALUE) { return; }
this->mtx.lock();//添加任务时需要对列上锁(多线程操作任何容器类都需要上锁)
this->m_tasks.push(task);//将函数对象添加进队列中~
ReleaseSemaphore(this->m_semp, 1, NULL);//然后将信号量的值加1,让线程池中那些线程开始干活了(具体哪个线程能得到CPU时间片来干活这取决于操作系统的调度)
this->mtx.unlock();
}
void ThreadPool::terminatePool()//退出(销毁)线程
{
this->m_isLoopTerminate = true;
for (int i = 0;i < this->threadHandels.size();i++)
{
HANDLE threadHandle = this->threadHandels[i];
DWORD ret = WaitForSingleObject(threadHandle, 2000);
if (ret == WAIT_TIMEOUT) {
TerminateThread(threadHandle, 0);
}
CloseHandle(threadHandle);
}
CloseHandle(this->m_semp);
}
以上就是简单的一个线程池实现,线程池的主要价值就在于避免线程的『反复』创建与销毁。因为创建本身就需要消耗CPU资源。
IO模型
网络编程,最核心的依然是在进行IO管理,用户进程与操作系统内核协议栈的IO,协议栈与网卡的IO等。高效的读写数据是高并发网络编程的基本也是最核心要求。在这个要求下做到:
- 高效的知道哪个链接
socket能够读写了 - 在读写数据时不要影响到用户其他逻辑的执行(除非其他逻辑依赖读写逻辑)
围绕这两个基本诉求,我们会在网上看到各种讨论,不乏如『阻塞』『非阻塞』『同步』『异步』等等字眼,它们之间的各种排列组合让人眼花缭乱目不暇接,当我们在网上搜Windows IO模型时基本也只是一些函数的说明,对计算机系统的整个IO模型抽象不是很到位,在这节中我们尝试来讨论几种经典的模型,以及各种词汇的真正含义。
网络编程中,在高性能服务器开发这个话题下反复出现一个词『读写』,是的,无论是读写用户态的缓冲还是读写协议栈中的缓冲,读写这个操作是避免不了的,读写就意味着IO,我们各种说模型说IO说读写,其实一直就是在说两件事情:
- 你读我时,我怎么告诉你,我有数据可以读了
- 当我有数据可以读了,我应该怎么把数据给你
几乎我们反复讨论的各类模型,都是在尝试回答以上两个问题。针对这两个问题产生了一些解决方法,他们各有特征,也各有优缺点,他们就是我们接下来要聊的IO模型。
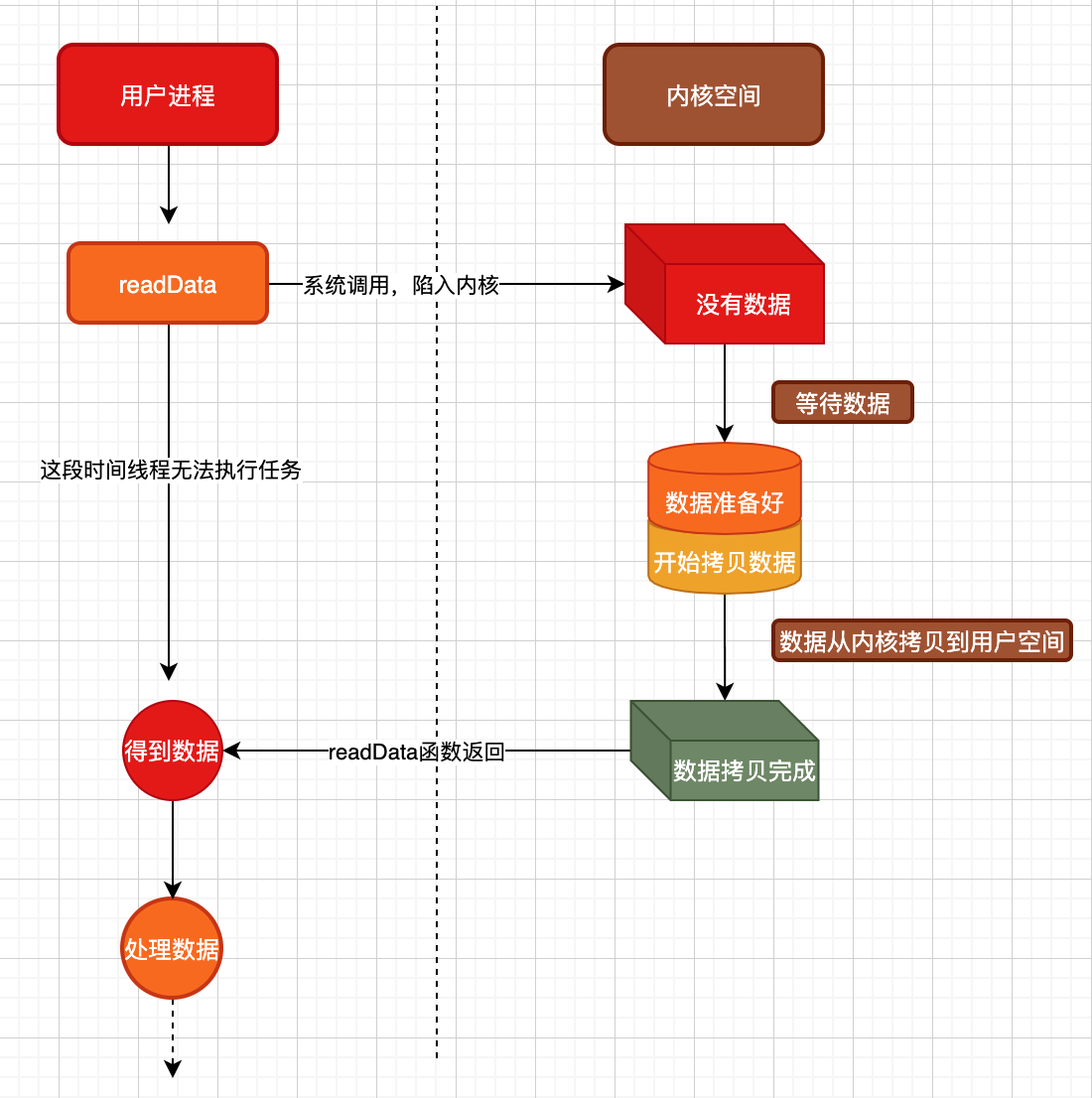
上图所示,当我们调用readData这个函数的时候,产生了一些现象与执行了一些动作
- 调用
readData函数后,该线程被阻塞,后续的『处理数据』逻辑得不到执行,必须要等readData函数执行完成,该线程才能继续往下执行。我们说这个函数调用是同步的。 - 此外,内核也经历了两个阶段的IO过程,分别是『等待数据』,这很好理解,比如内核在等待一个完整UDP包的到来,此时可能只收到了部分。此外,当所有的数据都准备好后还需要进入第二个阶段,就是将内核中的数据拷贝到用户的缓冲区中去。这两个阶段从上到下都是被阻塞住的。
由于内核中的IO两个阶段是阻塞的原因,导致readData函数也被阻塞住,这种模型我们称之为『阻塞IO模型』。
这种模型的特征是内核的『等待数据』这一过程也会影响到用户态的函数,内核等数据导致用户态线程也跟着在那等数据,而无法去处理用户态其他逻辑。
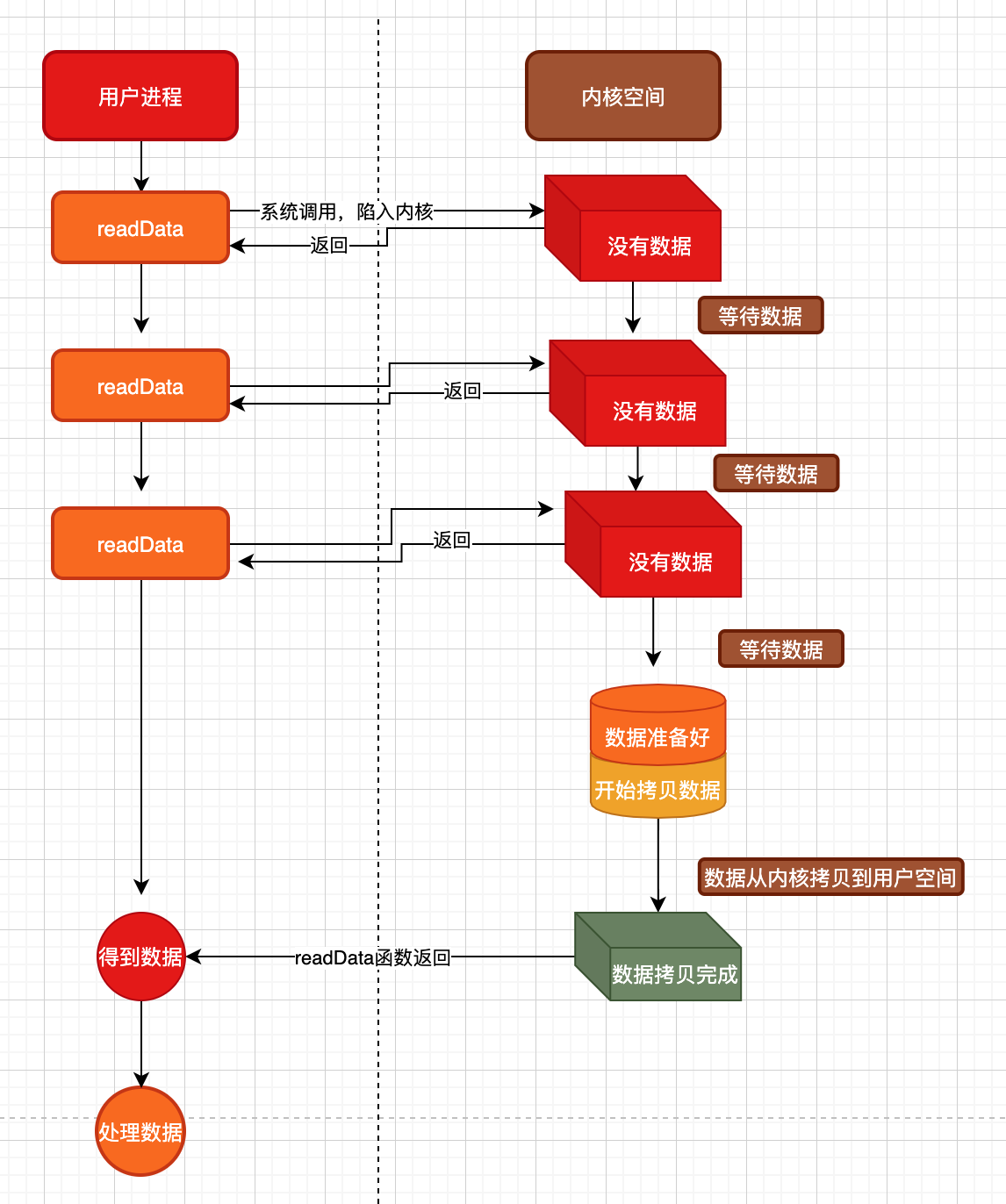
上图所示,依然是用户态读取数据,内核去获取然后拷贝数据。
但与上面阻塞IO不同的是,内核在『等待数据』这一阶段不会导致用户态的readData函数阻塞住。
我们停下来看下内核IO的两个阶段:
1、等待数据准备好
2、将准备好的数据拷贝到用户给的缓冲区中
对于阻塞IO,第1阶段会影响到用户态的线程是否被阻塞
对于非阻塞IO,第1阶段并不会影响到用户态的线程是否被阻塞
而对于第2阶段,无论是阻塞还是非阻塞IO,都是内核将数据拷贝完成后才最终返回到用户态进程的(也就是说拷贝到用户空间这个步骤是同步的,并不会拷一半就返回了)
在非阻塞IO模型中,用户线程调用readData函数时并不会因为等待数据而影响当前线程的运行,用户可以继续执行自己的逻辑。也可以在接下来中不停的去调用readData或者延时调用readData等,都是可以的。
到目前为止我们似乎发现,用户态『读写』数据这码事非常费劲,核心就是我们并不知道内核什么时候把数据给我们准备好了。如果能有一种机制能搞直接告诉用户态,某个描述符可以读写了,用户态直接去读写就是,就不用要么傻等要么不停去询问了。
这种机制就是『IO多路复用』
所谓『IO多路』是指IO的来路,一个数据来路是可以有很多的,比如标准输入stdin标准输出stdout以及标准错误等,此外还有各种socket描述符,显然,要是没有IO多路复用,只用一个线程,当这个线程调用getchar()函数等待标准输入这一路IO时,则这个线程被阻塞住,不能接受任何其他IO来路数据。
同理,只用一个线程,我们永远只能同一时刻等待一个socket来路的数据。
当然,我们可以使用非阻塞IO,一个线程不同的循环,去尝试读取一个socket描述符中是否有数据可读,但是这样的循环+判断实在是太浪费CPU时间了,循环大部分时间都是在空转。
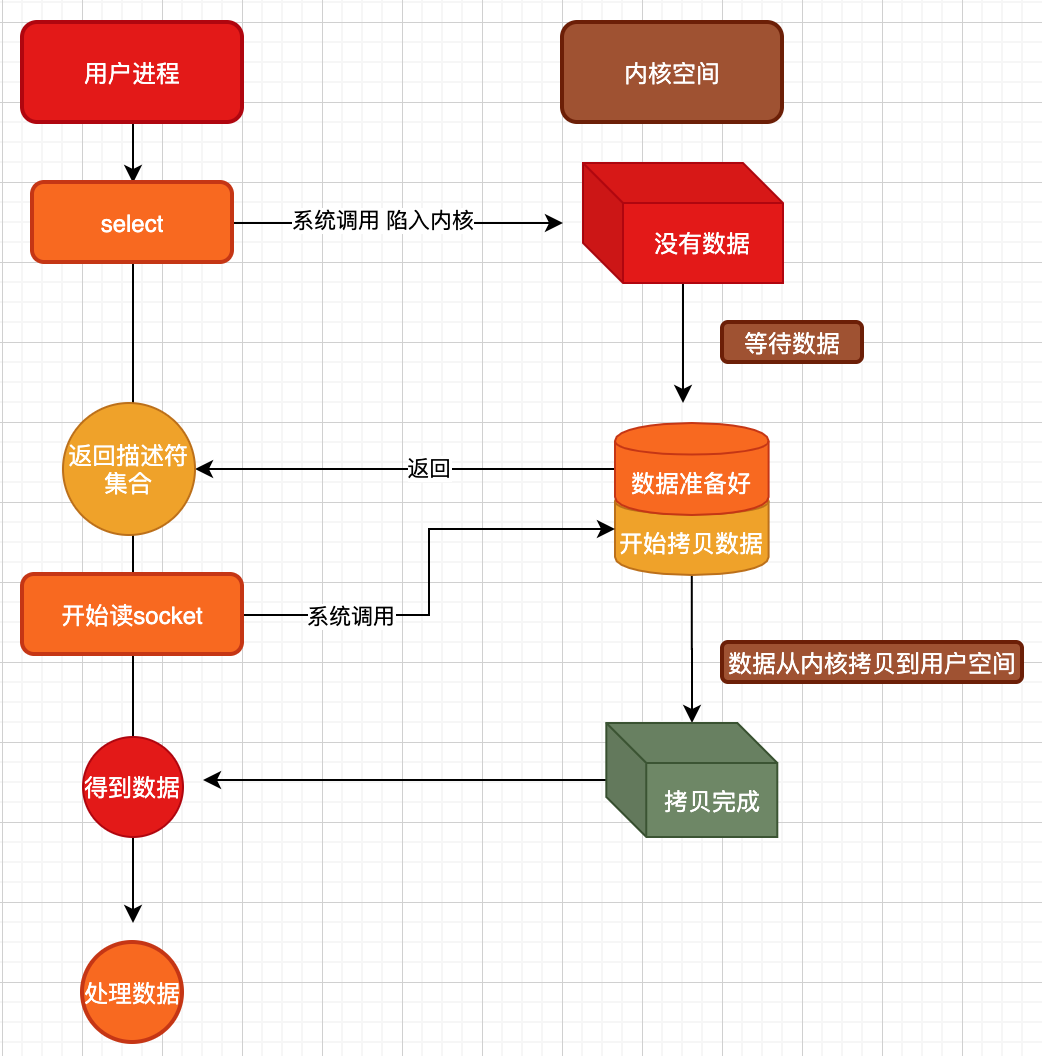
上图所示,就是使用select来实现的IO多路复用。具体体现在,在一个线程中,我们可以将得到的各种客户端socket放到一个集合中,然后交给select函数去处理,调用select函数后陷入内核,等待数据,这个过程是阻塞的(当然,也可以不阻塞,select可以设置),这一步似乎与阻塞IO模型没有差别,真正的杀器就在于当数据准备好返回时,返回的是一个『可读写描述符集合』,这个集合中可能存在N个可读写的socket描述符,此时通过循环遍历读取这些描述符时,内核直接就从准备好的数据中开始拷贝到用户空间了,也就是说,内核将IO的2个阶段分别暴露给了用户空间中:
- 数据准备好了
- 直接来读写吧
从需要数据到数据准备好了,固然是需要时间的,但是这个等待的价值在于不再是等一个,而是等一群。只要第一阶段从内核态返回用户态,那么用户态直接去读取数据就总是能读取到数据,这样,我们一个线程就能『同时』的处理N个描述符的IO事件了。(当然,从『开始读数据』到『数据读取完成』这个过程还是同步的,但一开始读,就已经有数据了,不像同步IO,开始读的时候还要去准备等待数据)
在IO多路复用中我们需要明白,从数据准备好了到开始拷贝数据,最后拷贝完成,这个步骤是同步的,也就是说这个内核过程会阻塞住用户态中的readData,直到数据全部拷贝完成。
到目前位置,我们聊过的『阻塞IO』『非阻塞IO』『IO多路复用』看似都不同,但是他们之间都有一个相同的特征:
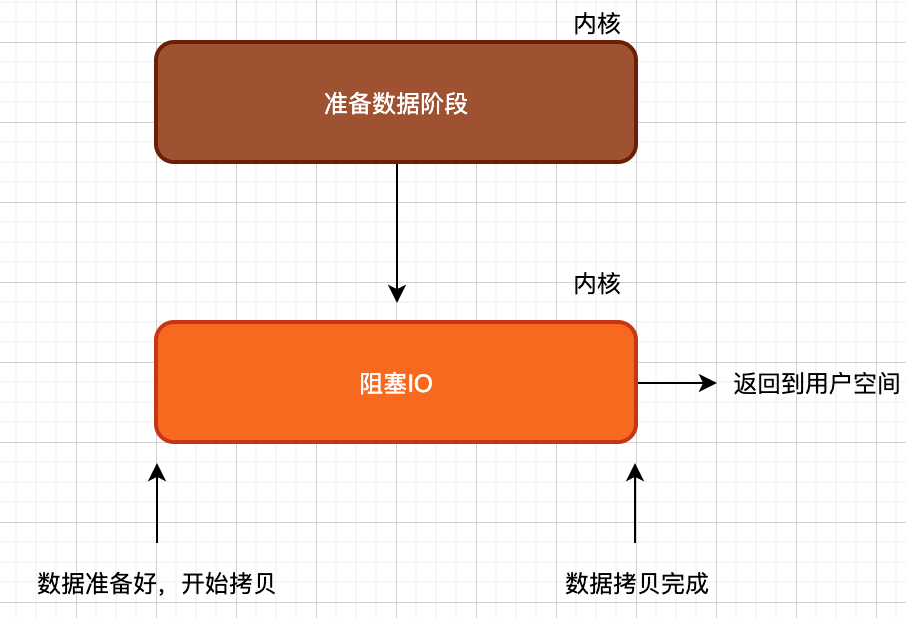
上述几种IO模型,可能在内核数据准备阶段对用户空间的影响不一样。但是当数据准备好了后,就都是同步执行拷贝操作了,也就是说这三种IO模型最终都是同步IO模型。
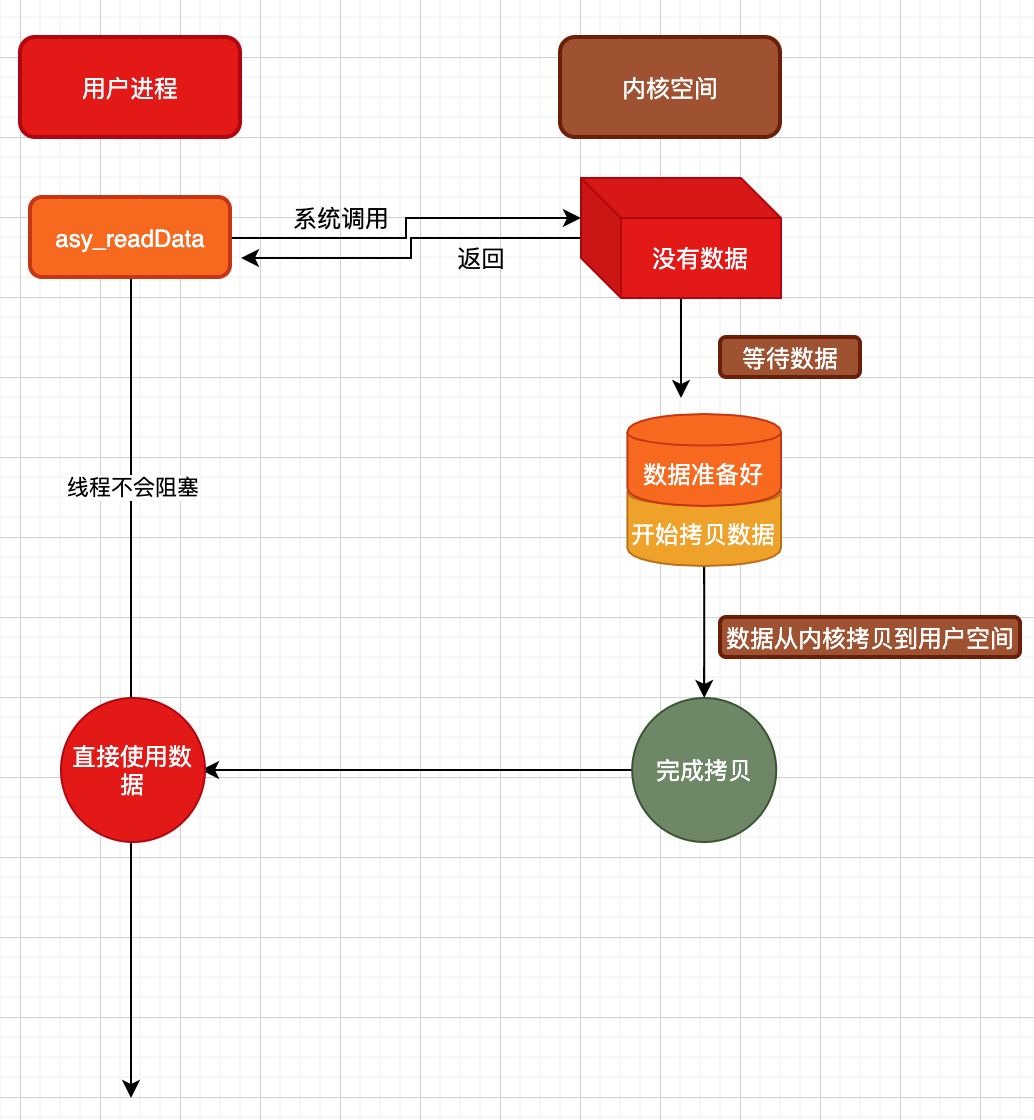
如上图所示,当调用asy_readData函数后,无论是内核空间在等待数据阶段,还是数据准备好后从内核拷贝到用户空间阶段,都不会对用户态线程造成任何影响,用户态线程完全可以执行自己的逻辑,而无需估计读数据以及拷贝数据时会发生阻塞,这就是真正的异步IO。可见,异步IO不仅准备数据解决不阻塞用户线程,拷贝数据也不会阻塞用户线程。真正做到,只要用户线程说一声『我需要数据』,接下来需要做的就只是去使用数据了,中间过程完全不用操心。
以上,就是我们讨论的4中IO模型,我们并没有站在Windows系统的角度上去讲其API。
posted on 2021-12-28 09:33 shadow_fan 阅读(72) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号