
分布式开发之消息队列
本文围绕如下几点进行阐述:
- 为什么使用消息队列?
- 使用消息队列有什么缺点?
- 消息队列如何选型?
- 如何保证消息队列是高可用的?
- 如何保证消息不被重复消费?
- 如何保证消费的可靠性传输?
- 如何保证消息的顺序性?
1. 为什么使用消息队列?
解耦,异步,限流
1.1 解耦
1.1.1 传统模式

传统模式的缺点:
- 系统间耦合性太强,如上图所示,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,增加维护难度
1.1.2 中间件模式
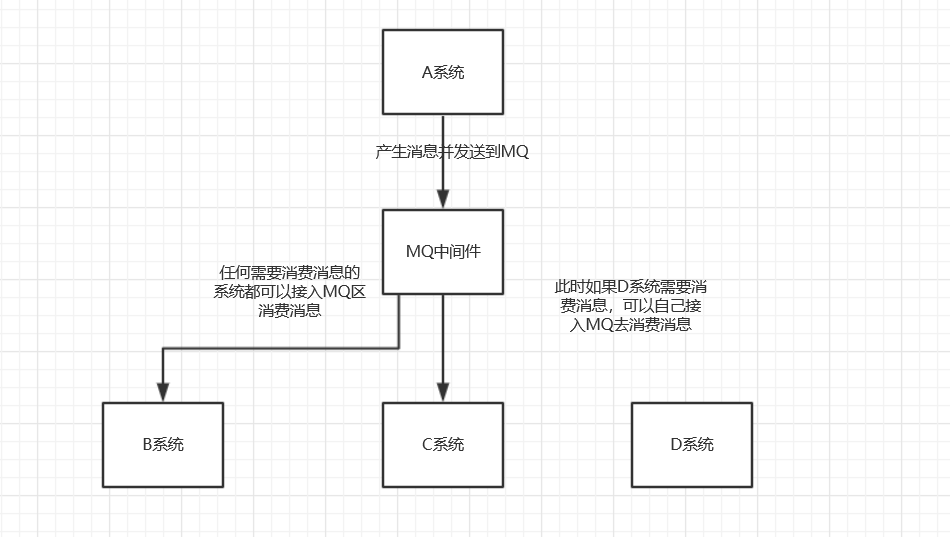
中间件模式的的优点:
- 将消息写入消息队列,需要消息的系统自己从消息队列中订阅,从而系统A不需要做任何修改。
1.2 异步
1.2.1 传统模式
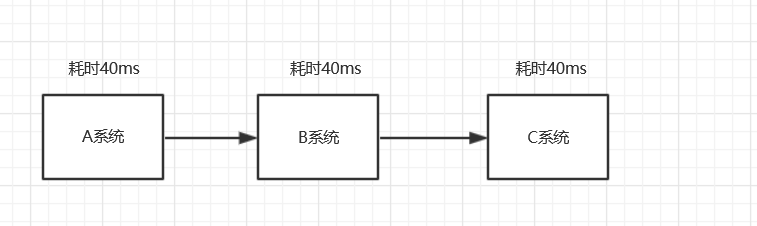
传统模式的缺点:
- 一些非必要的业务逻辑以同步的方式运行,太耗费时间。
1.2.2 MQ中间件模式
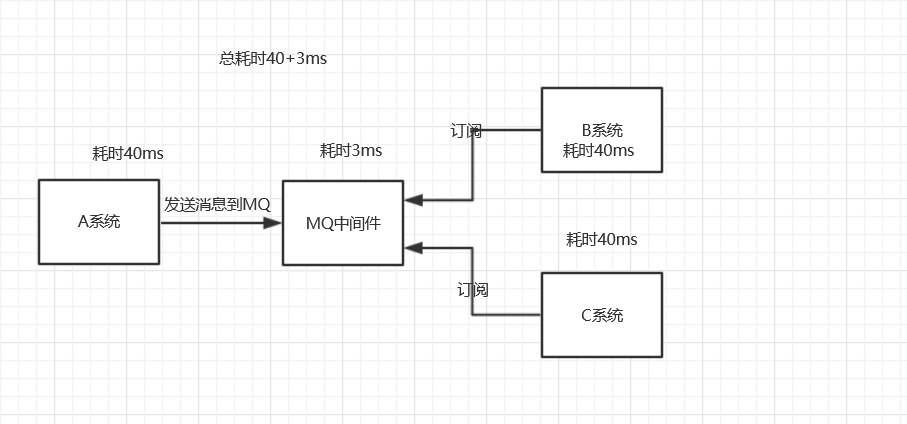
中间件模式的的优点:
- 将消息写入消息队列,非必要的业务逻辑以异步的方式运行,加快响应速度
1.3 限流
1.3.1 传统模式
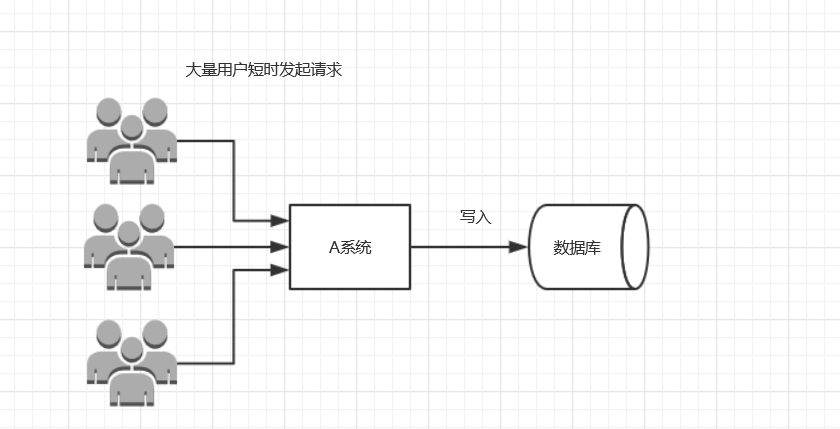
传统模式的缺点:
- 并发量大的时候,所有的请求直接怼到数据库,造成数据库连接异常
1.3.2 中间件模式
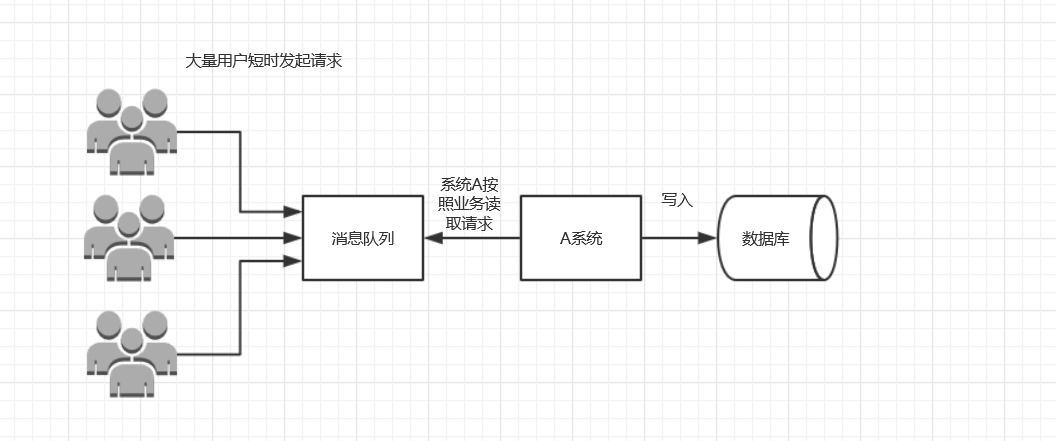
中间件模式的的优点:
- 系统A慢慢的按照数据库能处理的并发量,从消息队列中慢慢拉取消息。在生产中,这个短暂的高峰期积压是允许的。
2. 使用消息队列有什么缺点?
导致系统可用性降低,若MQ发生故障会影响系统可用性。系统复杂性增加,引入MQ会引入新的关注点,比如需要考虑消息可靠性投递,消息重复消费等问题。
3. 消息队列如何选型?
1. 看MQ更新频率
2. 看MQ性能
3. 比较MQ各自特点,比如Kafka适合大数据场景如日志采集
4. 如何保证消息队列是高可用的?
以RcoketMQ为例,他的集群就有多master 模式、多master多slave异步复制模式、多 master多slave同步双写模式。多master多slave模式部署架构图:
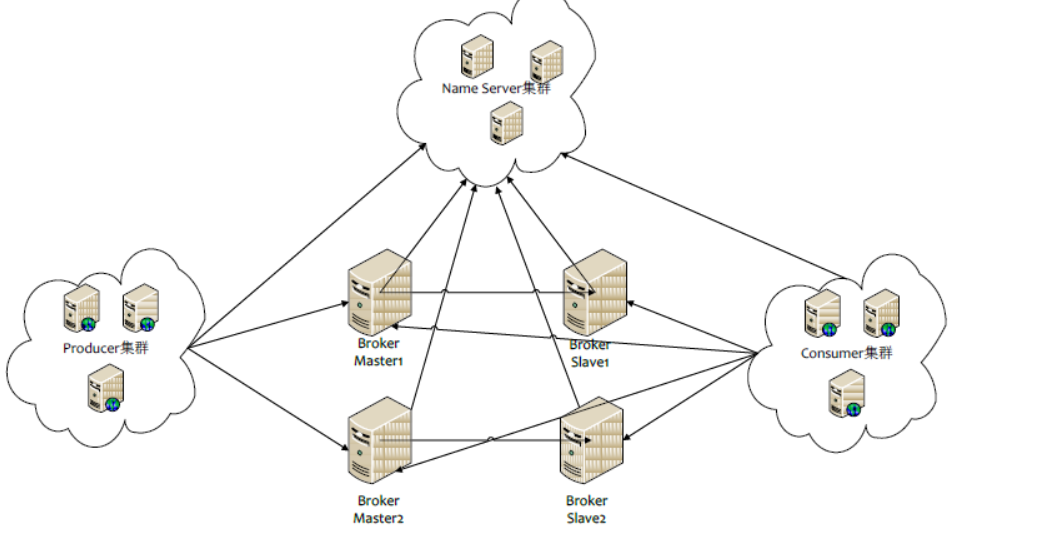
Rocket的高可用架构和kafka很像,只是NameServer集群,在kafka中是用zookeeper代替,都是用来保存和发现master和slave用的。通信过程如下:
Producer 与 NameServer集群中的其中一个节点(随机选择)建立长连接,定期从 NameServer 获取 Topic 路由信息,并向提供 Topic 服务的 Broker Master 建立长连接,且定时向 Broker 发送心跳。Producer 只能将消息发送到 Broker master,但是 Consumer 则不一样,它同时和提供 Topic 服务的 Master 和 Slave建立长连接,既可以从 Broker Master 订阅消息,也可以从 Broker Slave 订阅消息。
kafka:

如上图所示,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
5. 如何保证消息不被重复消费?
其实无论是那种消息队列,造成重复消费原因其实都是类似的。正常情况下,消费者在消费消息时候,消费完毕后,会发送一个确认信息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息 队列中删除。只是不同的消息队列发送的确认信息形式不同,例如RabbitMQ是发送一个ACK确认消息,RocketMQ是返回一个CONSUME_SUCCESS成功标志,kafka实际上有个offset的概念,简单说一下(如果还不懂,出门找一个kafka入门到精通教程),就是每一个消息都有一个offset,kafka消费过消息后,需要提交offset,让消息队列知道自己已经消费过了。那造成重复消费的原因?,就是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将该消息分发给其他的消费者。
1. 利用数据库主键唯一性:全局唯一ID + 指纹码。当唯一ID插入数据库时会因为主键约束而失败,这样就能保障消息不会被重复消费。
2. 利用redis的原子性。但也有需要考虑的问题。如何消息落地。
6.如何保障消费的可靠性传输?
可靠性传输要从三个角度来分析:生产者弄丢数据、消息队列弄丢数据、消费者弄丢数据
6.1 生产端的可靠性投递
保障消息的成功发出,保障MQ节点的成功接收,发送端收到MQ节点确认应答。完善的消息进行补偿机制。
6.1.1 解决方案
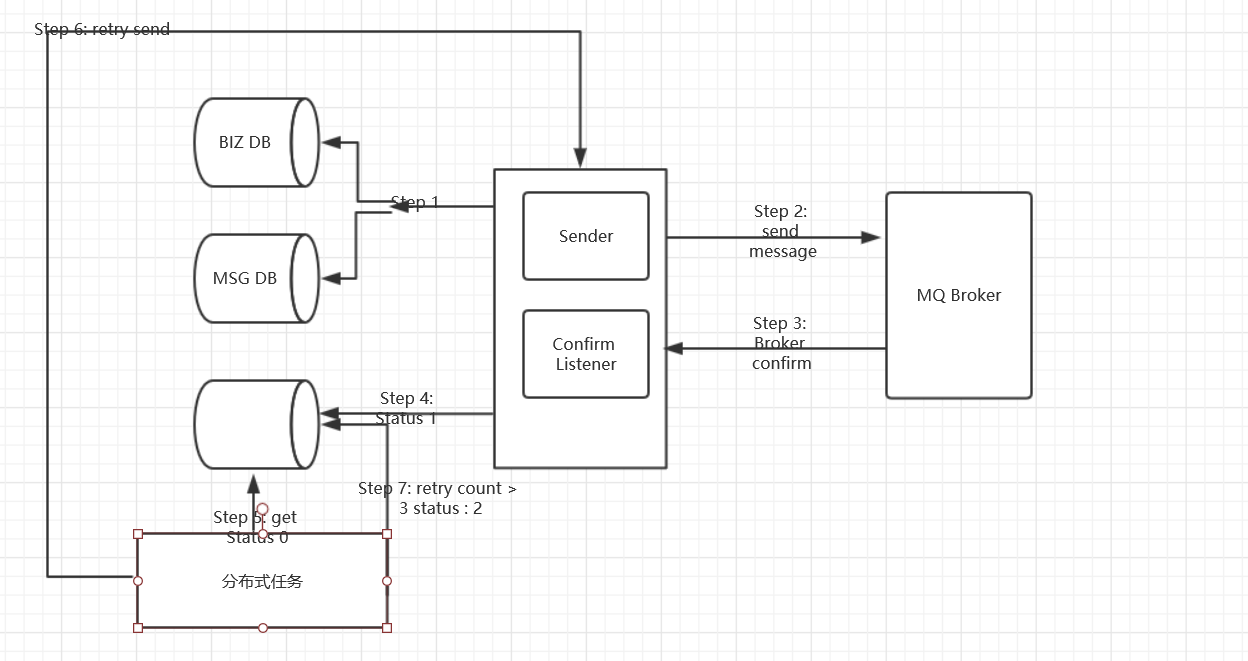
6.1.1.1 消息落库,对消息状态进行打标。
- 写入数据库,可能涉及多个库,业务库,消息库
- 发送消息
- 消息确认
- 更新数据库消息状态
- 定时任务获取数据库消息状态
- 重试发送
- 重试数量大于 3 次,修改状态,停止重试
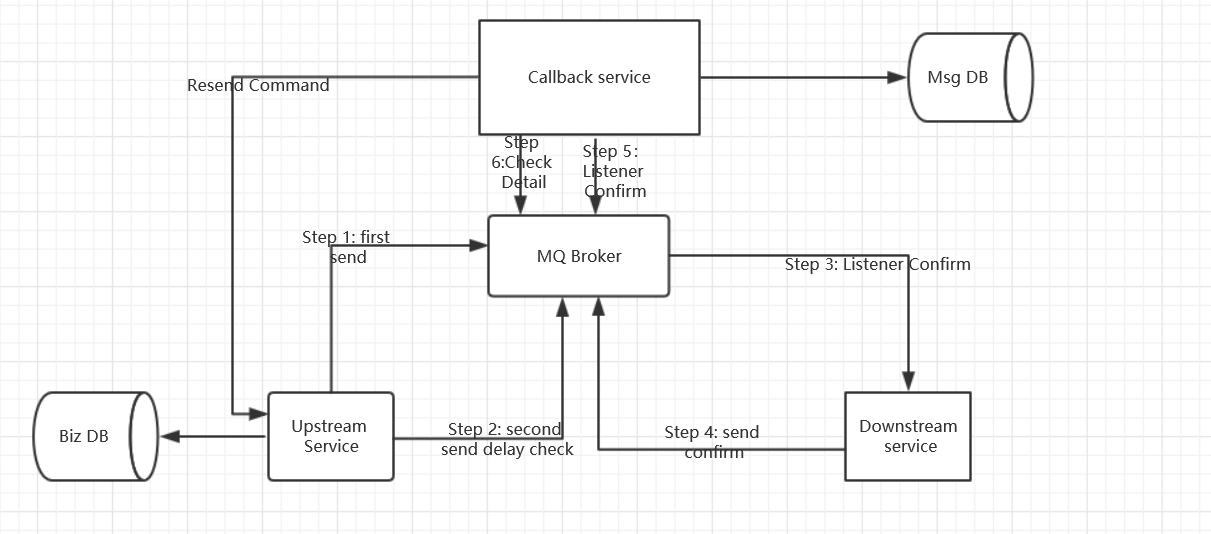
6.1.1.2 消息的延迟投递,做二次确认,回调检查。
如果再高并发的情况下,消息就不要入库了,延迟投递,可以不保证首次100%的成功,但是一定要保证性能。
- 首次发送,一定等到业务数据入库之后再发送消息,Upstream serivce上游服务
- 延迟发送刚发送消息 的 检查消息
- 当消费者消费消息
- 消息消费成功之后,发送一个确认消费消息
- CallBack服务收到消费者的确认消息,消费成功之后,做消息的持久化存储
-
CallBack服务检查,处理第二步发送的检查消息,检查数据库是否有处理成功,如果处理成功了,那么就不用处理任何事情,如果处理失败了,Callback服务再通知Upstream服务再次发送消息。
6.2 MQ消息队列丢数据
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
那么如何持久化呢,这里顺便说一下吧,其实也很容易,就下面两步
1、将queue的持久化标识durable设置为true,则代表是一个持久的队列
2、发送消息的时候将deliveryMode=2
这样设置以后,rabbitMQ就算挂了,重启后也能恢复数据
6.3 消费者丢数据
消费者丢数据一般是因为采用了自动确认消息模式。这种模式下,消费者会自动确认收到信息。这时RabbitMQ会立即将消息删除,这种情况下如果消费者出现异常而没能处理该消息,就会丢失该消息。
至于解决方案,采用手动确认消息即可。
7.如何保证消息的顺序性?
1. 发送的顺序消息,必须保障消息投递到同一个队列,且这个消费者只能有一个。
2. 然后需要统一提交(可能合并成一个大消息,也可能是拆分为多个消息),并且所有消息的会话ID一致。
3. 添加消息属性: 顺序标记的序号,和本次顺序消息的size属性,进行落库操作。
4. 并行进行发送给自身的延迟消息(注意带上关键属性:会话ID,Size)进行后续处理消费。
5. 当收到延迟消息后,根据会话ID,size抽取数据库数据进行处理即可。
6. 定时轮询补偿机制,对于异常情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号