UIL调研
HYDRA
出处:SIGMOD 2014
论文:HYDRA: Large-scale Social Identity Linkage via Heterogeneous Behavior Modeling
贡献
- 异构行为建模
- 用户属性建模:文本属性、视觉属性相结合
- 用户主题建模:按时间序列方式得出内容类型分布、语义模式分布
- 用户风格建模:匹配词统计,\(S_{lea}=\frac{\#matched \ words}{k}\)
- 多决议行为建模:先根据经验决议匹配不同模式张量,\(S_mr=\frac{1}{N}(\sum^N_{i=1}(s_{mr}(i))^q)^{\frac{1}{q}},q\geq 1,\ \hat{S}_{mr}=\frac{1}{1+e^{-\lambda S_{lea}}}\)
- 多目标模型学习
- 模型:\(f(x)=\bold{w}^\top x+b\),\(D=\{(x_{xx'},y_{ii'})|x_{ii'}\in \mathbb{R}^D, y_{ii'}\in\{1,-1\}\}\)
- 目标函数:$F_D(\bold{w})=\frac{\gamma_L}{2}||\bold{w}||^2+\sum\xi_{ii'} \ s.t. y_{ii'}(\bold{w^\top x_{ii'}}+b)\geq 1-\xi_{ii'} $
- 结构一致性建模
- 多目标优化
评价
整体评价:传统机器学习那一套解决的多目标模型学习,其中推导过程数学要求很高。
数据集:这其中的数据集很大,而且涉及到了上百万用户的隐私信息。
UIL Review
出处:SIGKDD Explorations
论文:User Identity Linkage across Online Social Networks: A Review
问题
假设图为\(G(U,\epsilon)\),\(U=\{u_1,\cdots, u_N\}\),\(\epsilon\subseteq U\times U\),则两个网络平台的图\(G^s,G^t\),一对用户识别体\(u^s,u^t\),\(U^s,U^t\)分别属于两个自然人,则\(F:U^s\times U^t\rightarrow \{0,1\}\),有:
特征提取
- 个人资料
- 范围:用户名、用户ID、地点、自述、教育程度、头像
- 提取方法:基于距离的方法、基于频率的方法
- 内容
- 范围:时间信息、空间信息、帖文信息
- 提取方法:基于利益的、基于风格的、基于轨迹的
- 网络
- 范围:局部网络(ego-network)、全局网络
- 提取方法:基于邻近的、基于嵌入的
建模方法
监督模型:
- 通用框架:\(Q=\{(u^s,u^t)|u^s\in U^s, u^t\in U^t\}\),\(M\subset Q\)是正确识别的情况即\((u^s,u^t)\in M\)时\(u^s\)和\(u^t\)属于同一个人,\(N=Q-M\)为不属于的情况。因此将这两个集合划分为训练集和测试集,进行监督学习,有:\(F:U^s\times U^t\rightarrow \{0,1\}\)。训练集\((M_{train},N_{train})\),测试集\((M_{test},N_{test})\)
- 聚合方法:\(F(u^s,u^t)=\alpha S_{profile}(\vec{p}_{u^s},\vec{p}_{u^t})+\beta S_{content}(\vec{c}_{u^s},\vec{c}_{u^t})+\gamma S_{network}(\vec{n}_{u^s},\vec{n}_{u^t})\)
- 概率方法:\(F(\vec{x})=\arg \max Pr(y=1|\vec{x},(M_{train},N_{train}),M)\)
- Boosting方法:\(F(\vec{x})=sign(\sum^T_\limits{i=1}\alpha_i h_i(\vec{x}))\),\(h_i(\cdot)\)为第i个弱分类器
- 投影方法:两个平台的投影映射\(\Phi_s,\Phi_t\),\(\hat{u^t}=\arg \min_\limits{u^t\in U^t} \mathbb{D}(\Phi_s(u^s), \Phi_t(u^t))\)
半监督模型:\(M'_s=\{u^s|(u^s,u^t)\in M'\},M'_t=\{u^t|(u^s,u^t)\in M'\}\)
- 传播方法:一般两种方法,Exhaust comparison和Local expansion
- 嵌入方法
无监督方法:
- 对齐方法:首先,对基于个人资料、内容或网络特征的每一个候选用户对\((u^s,u^t)\in U^s\times U^t\)计算亲和力分数 (affinity score)。之后,建立二分图\(G'=(V',\epsilon',w)\),其中\(V'=U^s\cup U^t\),\(\epsilon'=\{(u^s,u^t)|u^s\in U^s, u^t\in U^t\}\),权重\(w(u^s,u^t)\)是用户之间的亲和力分数。进一步地基于二分图\(G'\),提出了一个优化问题并一对对地进行解决。
- 渐进式方法:先将可靠数据进行训练得到一个部分可信模型,之后将未标签的数据进行分类标记并当作训练集训练。
具体工作:
| 类型 | 具体方法 |
|---|---|
| 监督方法 | MOBIUS, ULink, Perito'11, LU-Link, OPL, DCIM, Peled'13, Malhotra'12, Vosecky'09, Lofciu'11, Motoyama'09 |
| 半监督方法 | IONE, COSNET, HYDRA, FRUI, JLA, Shen'14, Zhang'16, User-Matching, Bennacer'14, MAH, NS, DetectMe |
| 无监督方法 | Alias-Disamb, POIS, Labitzke'11 |
数据集:
- 真实数据:Goga1315、Buccafurri12、Zhang15
- 综合数据:Full synthetic、Partial synthetic
评估
评估指标
预测指标:
- TP、TN、FP、FN
- 精确率(\(Precision=\frac{TP}{TP+FP}\))、召回率(\(Recall=\frac{TP}{TP+FN}\))、F1分数(\(F1=2\cdot\frac{Precision\cdot Recall}{Precision+Recall}\))、准确率(\(\frac{TP+TN}{TP+TN+FP+FN}\))
- 基于识别的准确率:\(I-Acc=\frac{\text{# correctly identified user identities}}{\text{# ground truth user identities}}\)
排名指标:从\(G^s\)中给定一个用户识别体\(u^s\),以及\(K\)个目标网络\(G^t\)的候选识别体。这些识别体基于匹配\(u^s\)进行排序得到顺序\(R_{u^s}=<u^t_1,u^t_2,\cdots, u^t_K>\)
- ROC指标:FPR和TPR分别为x、y轴。\(TPR=\frac{TP}{TP+FN}\),\(FPR=\frac{FP}{TN+FP}\)
- AUC指标:\(AUC=\frac{\sum{(n_0+n_1+1-r_i)-n_0 (n_0+1)/2}}{n_0 n_1}\),其中\(r_i\)是第i个正确匹配用户识别,\(n_0\)是正确识别数量,\(n_1\)是错误识别数量
- 当\(n_0=1\)时,则:\(AUC=\frac{n_1+1-r_1}{n_1}\),其中正确匹配项为\(r_1\)
- Hit-Precision:\(Hit-Precision=\frac{n_1+2-r_1}{n_1+1}\)
- MAP(Mean Average Precision)、MRR(Mean REciprocal Rank):\(AP=RR=\frac{1}{r_1}\),\(MAP=\frac{1}{K}\sum^K_\limits{i=1}AP_i, MRR=\frac{1}{K}\sum^K_\limits{i=1}RR_i\)
Locate Who You Are
出处:CIKM‘21, short paper trick
论文:Locate Who You Are: Matching Geo-location to Text for User Identity Linkage
问题
如何将用户标识与所谓的跨网络“不对称信息”对齐
- 如何评价地理信息与文本的关联性
- 如何根据分别由文本与地理信息生成的序列对进行匹配
方法
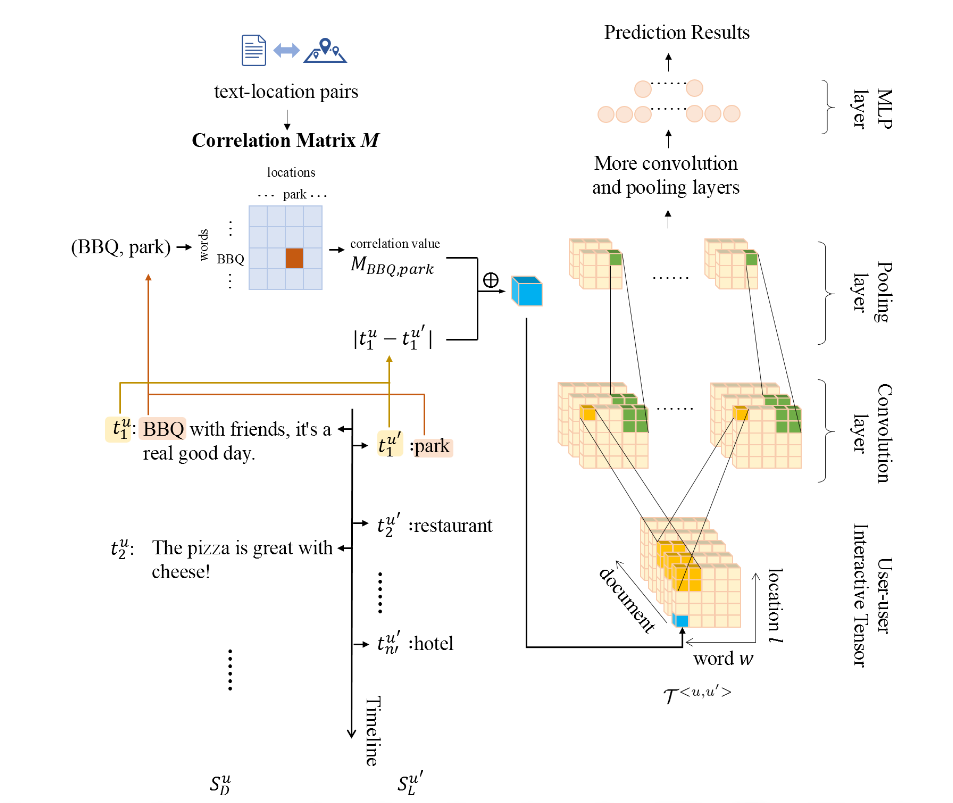
映射函数:按时间顺序的用户轨迹序列为\(S^u_L=\{(l^u_k,t^u_k)|k=1,\cdots,N_L\}\),按时间顺序的用户帖文序列为\(S^u_D=\{(d^u_k,t^u_k)|k=1,\cdots, N_D\}\)。\(l^u_k\)代表用户\(u\)在\(t^u_k\)时刻的地理位置,而\(d^u_k\)代表的是\(t^u_k\)时刻发表的帖文信息。\(d^u_k=\{w_{k1},\cdots,w_{km}\}\),则映射函数为:
评价指标:tf-idf方式,\(M\)为文本-地点关联矩阵,则:\(M_{w,l}=\log(1+\text{count}(w,l))\cdot \log (1+\frac{\sum_\limits{l'\in L}\text{count}(w,l')}{\epsilon + \text{count}(w,l)})\),\(\text{count}(w,l)\)表示单词\(w\)和位置\(l\)在所有文档以及关联位置的出现次数,\(\epsilon\)为常数。
user-user interactive tensor:其中\(\oplus\)代表拼接操作。
3D卷积和动态池化:其中\(z^l\)表示第\(l\)层的特征映射,\(z^0=\Gamma^{<u,u'>}\),核大小为\(K_p\cdot K_q\cdot K_r\),通道数为\(N_k\)。第\(l\)层卷积特征映射大小为\(\alpha\cdot \beta\cdot \gamma\),池化后的特征映射大小为\(\alpha'\cdot \beta'\cdot\gamma'\),则\(d_l=[\frac{\alpha}{\alpha'}],d_w=[\frac{\beta}{\beta'}], d_w=[\frac{\gamma}{\gamma'}]\)
完整的结构图如下:
AHG-Net
出处:SIGIR 2021
论文:Adversarial-Enhanced Hybrid Graph Network for User Identity Linkage
问题
- 假设每个用户都有多模态的帖文与内部的社交联系,在用户间相关性建模中不同的关注者由于亲密度的不同,可能会对用户特征产生不同的影响,如何准确地完成从内部和外部角度的用户表征学习是个挑战。
- 假设不同平台的数据分布不同,因此分布在具有相同身份的不同平台上的表示往往是不同的,此时产生了如何缓解语义差距的问题
贡献
- 通过考虑异构的多模态帖子来解决用户身份链接任务
- 用于用户身份链接的对抗性增强混合图网络(AHG-Net),在一个混合图网络之中统一外部用户表示学习与内部表示学习
- 基于已有的数据集构建了一个新的多模态数据集
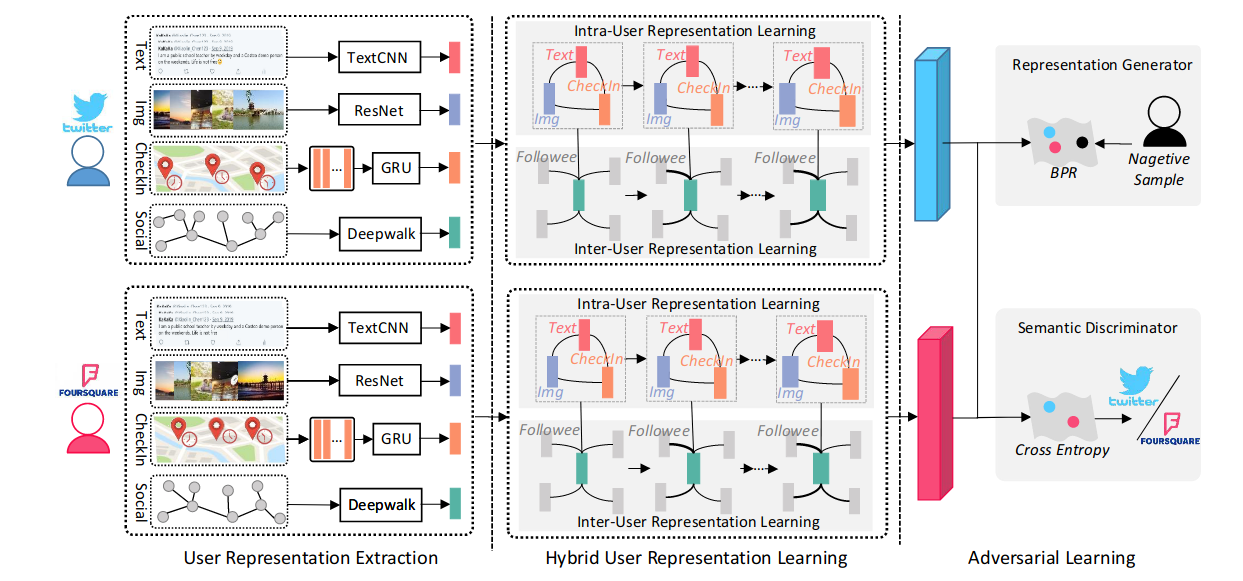
方法
目标描述:网络平台\(O_1\)上有用户集\(U_1=\{u^1_1,u^2_1, \cdots,u^{N_1}_1\}\),网络平台\(O_2\)上有用户集\(U_1=\{u^1_2,u^2_2, \cdots,u^{N_2}_2\}\),\(N_1\)和\(N_2\)表示两平台的用户数量。任意用户\(u^i_1\)包含了对应的社交联系\(S^i_1\)和社交帖文集\(X^i_1\)。社交帖文\(X^i_k\)包含了文本帖文\(C^i_k\)、图像帖文\(V^i_k\)以及地理帖文\(T^i_k\),\(k\in \{1,2\}\)。当\(u^i_1\)和\(u^j_2\)对应时,\(y^j_i=1\)。因此目标描述为\(F(u^i_1,u^j_2|\theta_F)\rightarrow y^j_i\)。
用户表示提取
文本表示:
给定文本帖文集合\(C=\{c_1,c_2,\cdots, c_n\}\),对每个帖文利用Bert进行嵌入:\(Embed:c_i\rightarrow e_i\in \mathbb{R}^{D_e}\)。帖文嵌入矩阵\(C\in \mathbb{R}^{D_e\times n}\),之后经过一层k个核的CNN,\(W_f=\{W_{f_1},W_{f_2},\cdots,W_{f_k}\}\),\(W_{f_k}\in\mathbb{R}^{h\times D_e}\)
最后经过均值池化以及一个全连接层:\(\begin{cases}c_{pool}=avg[\rho(W_{f_1},C), \cdots, \rho(W_{f_k},C)] \\c = \xi(W_c c_{pool}+b_c)\end{cases}\)
图片表示:
用一个ResNet,图片帖文集为\(V=\{v_1,v_2,\cdots,v_m\}\),则:\(\begin{cases}v_{pool}=avg[Res(v_1|\Theta_R),\cdots, Res(v_m|\Theta_R)]\\ v=\xi(W_rv_{pool}+b_r)\end{cases}\)
地理表示:
\(T=\{(t_g,q_g)\}^k_{g=1}\)表示checkin-in帖文,\(t_g\)和\(q_g\)表示时间信号与第\(g\)个check-in帖文地理位置。基于空间特性的共现矩阵\(A=\{a_1,\cdots,a_M\}^\top\in \mathbb{R}^{M\times K}\),其中\(a_m=(a^1_m,\cdots,a^K_m)\)。
通过GRU则有:\(\begin{cases}t_{GRU}=GRU(a_m|\Theta_G)\\ t=\xi(W_t t_{GRU}+b_t)\end{cases}\)
基于混合图的用户表示学习
建模用户-用户交互、模态-模态语义关系。
外部用户表示学习:
使用GCN。
无向图\(G=(M,E)\),其中\(M=\{m_i\}^Q_{i=1}\)对应于\(Q\)个模态帖文表示,\(E=\{(m_i,m_j)|i,j\in[1,\cdots,Q]\}\)。定义基于语义相似性的邻接矩阵\(A\in\mathbb{R}^{Q\times Q}\),则:\(A_{i,j}=\begin{cases}\cos(m_i,m_j) & 如果i\not=j\\ 1& 如果i=j\end{cases}\),\(\cos(m_i,m_j)\)表示第\(i\)个模态表示和第\(j\)个模态表示。
每一层GCN表示为:\(H^{(l+1)}=g(AH^{(l)}W^{(l)}),l\in \{0,1,\cdots,L-1\}\),其中\(H^{(l)}=\{h^{(l)}_1,\cdots,h^{(l)}_Q\}^\top \in \mathbb{R}^{Q\times d_l}\),初始时\(H^{(0)}=[c,v,t]\),\(g(\cdot)\)是非线性操作,\(W^{(l)}\in \mathbb{R}^{d_{(l)}\times d_{(l+1)}}\),\(d_{(l)}\)表示第\(l\)层和第\(l+1\)层的嵌入维度。因此最终输出层第\(L\)层作为最终的多模态用户表示,即:\(H^{(L)}=\{h^{(L)}_1,\cdots,h^{(L)}_Q\}^\top\)
内部用户表示学习:
使用GAT。
给定一个用户\(u\),令\(S=\{s_{c_1},\cdots,s_{c_S}\}\)表示为社交联系(social connections)的表示集,\(c_S\)是用户\(u\)社交联系的总数。
添加用户自己的表示\(s_{c_0}\),则构成\(\overline{S}=\{s_{c_0},s_{c_1},\cdots,s_{c_S}\}\),其中\(s_{c_0}=s+\sum^Q_{n=1}h^{(L)}_{n}\)。根据不同的社交联系分配第\(g\)个社交联系的置信度:\(\alpha_{c_g}=\frac{\exp(\xi(a^\top_1(W_1s_{c_0}\oplus W_1s_{c_g})))}{\sum^S_{g=0}\exp(\xi(a^\top_1(W_1s_{c_0}\oplus W_1 s_{c_g})))}, g\in\{0,1,2,\cdots,S\}\),其中\(W_1\)对应的是平台\(O_1\),\(a_1\)为查询的潜在表示,用于查询给定用户的哪些社交联系向用户表征传达了更重要的线索。最终的用户表示为:\(\bold{u}=\sum^S_\limits{g=0}\alpha_{c_g}W_1 s_{c_g}\)
应用多头注意力机制:\(\bold{u}=\sum^S_\limits{g=0}\alpha^1_{c_g}W^1_1 s_{c_g}\oplus\cdots\oplus \sum^S_\limits{g=0}\alpha^r_{c_g}W^r_1 s_{c_g}\oplus\cdots\oplus \sum^S_\limits{g=0}\alpha^R_{c_g}W^R_1 s_{c_g}\),其中\(a^r_{c_g}\)是第\(r\)个注意力模块。
对抗学习
表示生成器:
解决不同平台的数据分布不同导致的语义差异问题。生成器是基于混合图的用户表示模型。
评估两个平台用户相似性的打分函数:\(q^j_i=(\bold{u}^i_1)^\top \bold{u}^j_2\),其中\(u^i_1\)和\(u^j_2\)分别对应于平台\(O_1\)和平台\(O_2\)的用户。
之后使用贝叶斯个性排名框架进行,生成器的目标函数为:\(L_{G_{bpr}}=\sum^{N^+}_\limits{i=1}L_{bpr}(q^+_i,q^-_i)=\sum^{N^+}_\limits{i=1}-\ln(\sigma(q^+_i-q^-_i))\),其中\(q^+_i\)表示在正向用户对\((u^i,u^{i+}_2)\),\(q^-_i\)表示负向用户对\((u^i_1,u^{i-}_2)\),\(N^+\)是正向用户对的总数,\(\sigma(\cdot)\)是sigmoid函数。
语义辨别器:
以正向用户对\((u^i_1,u^{i+}_2)\)为例,对应的表示为\((\bold{u}^i_1,\bold{u}^{i+}_2)\),放入MLP之中并通过损失函数:\(L_{D_s}=-\frac{1}{N^+}m_i(\log D_s(\bold{u}^i_1|\Theta_{D_s})+log(1-D_s(\bold{u}^{i+}_2|\Theta_{D_s}))\)
其中\(D_s(\cdot|\Theta_{D_s})\)为给定用户表示的预测平台向量,\(m_i\)表示为one-hot向量。
联合优化:
实验
数据集
TWFQ数据集。
| 类别 | Foursquare | Total Number | |
|---|---|---|---|
| #User | 3463 | 3833 | 7296 |
| #Textual Post | 2197830 | 18442 | 2216272 |
| #Visual Post | 33454 | 28567 | 62021 |
| #Check-in Post | 198105 | 18417 | 216522 |
| #Social Connection | 53137 | 24780 | 77917 |
实验结果
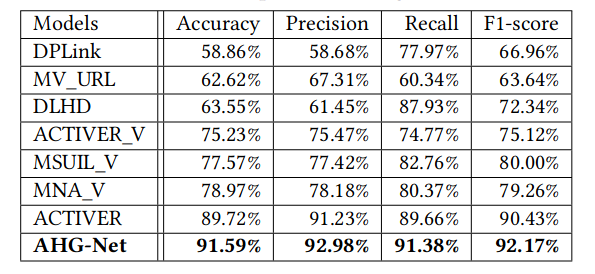
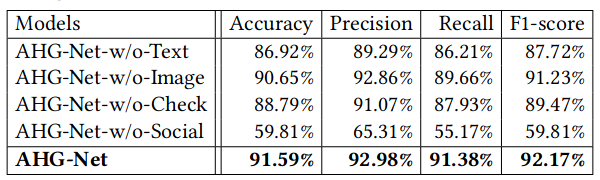
不同模型比较:
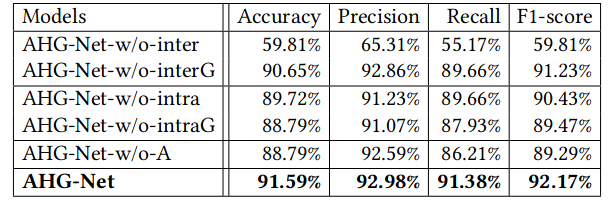
模型组件消融:
模型数据消融:
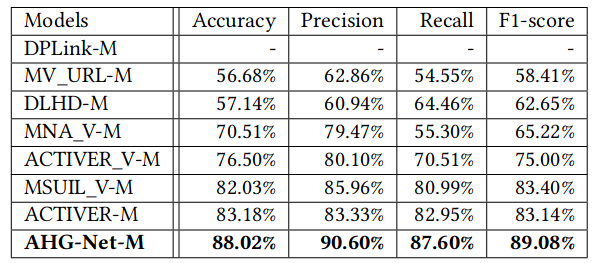
用户缺失时的比较:
Attentive Time-Aware User Modeling
出处:IEEE Trans on MM
论文:User Identity Linkage Across Social Media via Attentive Time-Aware User Modeling
问题
- 用户生成内容(User-Generated Contents, UGC)一般是多模态的,如何根据异构的多模态UGC准确表征到用户账户是第一个问题
- 用户在不同平台的相同时刻倾向于发布相似内容,如何有效地建模这种帖文关联性是第二个问题
- 没有相关公开数据集,这是第三个问题
给定用户对\(U=\{(u^1_1,u^1_2),(u^2_1,u^2_2),\cdots,(u^N_1,u^N_2)\}\),其中\(\forall u^i_1\in O_1\),\(\forall u^j_2\in O_2\),同时拥有他们\(K\)个帖文以及时间戳\(T_i=\{(t^i_k,p^i_k)\}^K_{k=1}\),其中\(t^i_k\)表示第\(k\)个文本帖文发表时间,\(p^i_k\)表示对应的帖文,则多模态帖文\(S_i=\{(s^i_g,q^i_g)\}^G_{g=1}=\{(v^i_g,c^i_g,q^i_g)\}^G_{g=1}\),其中\(v^i_g\)和\(c^i_g\)表示第\(g\)个帖子的视觉模态、文本模态,训练的用户对标记为\(y=\{y_1,\cdots,y_N\}^T\in \mathbb{R}^N\),\(y_i=1\)表示用户对\((u^i_1,u^i_2)\)匹配正确。
方法
该方法的具体方案如下:
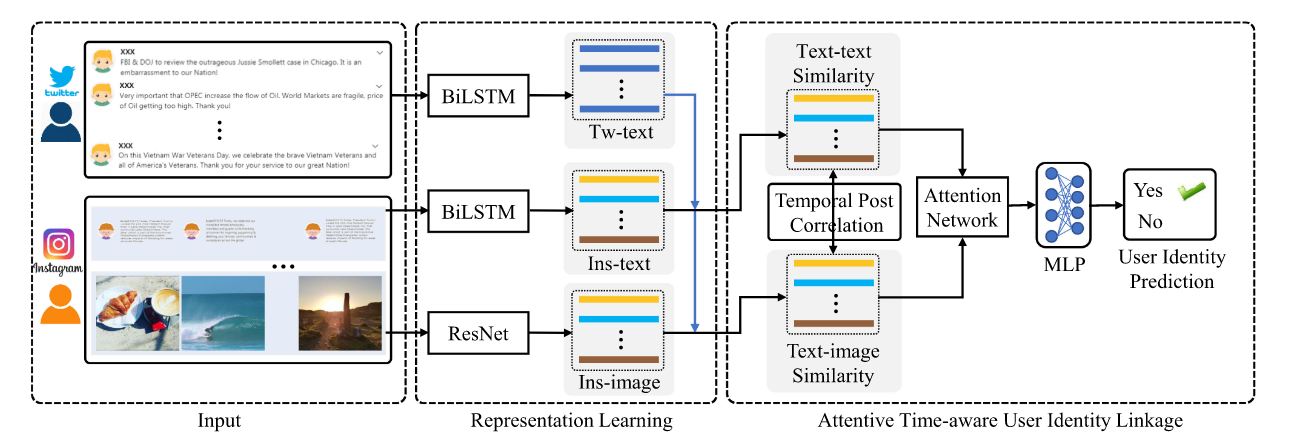
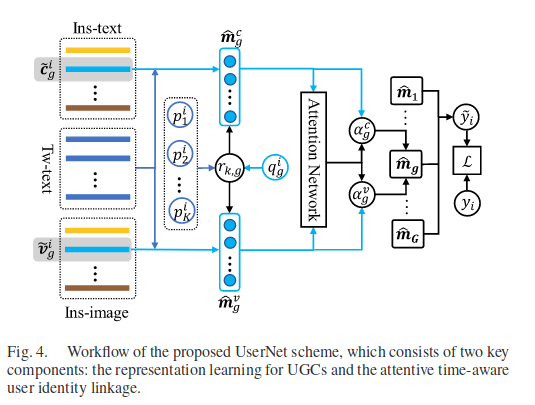
UGC的表示学习
文本表示学习:先用GloVe嵌入,之后通过BiLSTM,将每一个方向的LSTM输出拼接在一起,之后求和:\(\tilde{t}=\sum^M_\limits{z=1}f^z\)
视觉表示学习:通过ResNet获得结果,\(\tilde{v}^i_g=W_hh(v^i_g|\Theta_r)+b_h\)
自注意力时间意识用户身份链接
一种简单的方法:\(m_{k,g}\)表示用户对在帖文\(t_k\)之间以及\((v_g,c_g)\)的综合相似性:
引入时间意识帖文关联性:时间衰减因子\(r_{k,g}\),有:\(r_{k,g}=\frac{1}{\log|p_k-q_g|}\),其中\(p_k\)个\(q_g\)分别代表帖文\(t_k\)和\(s_g\)的时间戳,因此\(\hat{m}_{k,g}=r_{k,g}m_{k,g}\),\(\hat{m}^c_{k,g}=r_{k,g}m^c_{k,g}\),\(\hat{m}^v_{k,g}=r_{k,g}m^v_{k,g}\)。
自注意力用户相似性建模:\(\hat{m}^v_g=\{\hat{m}^v_{1,g},\cdots,\hat{m}^v_{K,g}\}\),\(\hat{m}^c_g=\{\hat{m}^c_{1,g},\cdots,\hat{m}^c_{K,g}\}\),则构建不同模态信度为:
最终结果通过均值池化之后得到\(d=avg(\hat{m})\),通过MLP:\(\tilde{y}=sigmoid(w^\top d + b)\)
损失函数:\(L=\frac{1}{N}[-y_i\log \tilde{y}_i-(1-y_i)\log(1-\tilde{y_i})]\)
Variational Cross-Network Embedding
出处:CIKM'21, short paper trick
论文:Variational Cross-Network Embedding for Anonymized User Identity Linkage
问题
已有工作的问题:
- the social networks are always full of noisy semantic data, where the attributes in a user account are usually missing, fake, or meaningless.
- the mutual isolation of different social networks/platforms makes it hard to directly obtain the anchor links
提出的新问题:Anoymized User Identity Linkage (AUIL)
考虑的实际因素:平台独立性、数据稀疏性
方法
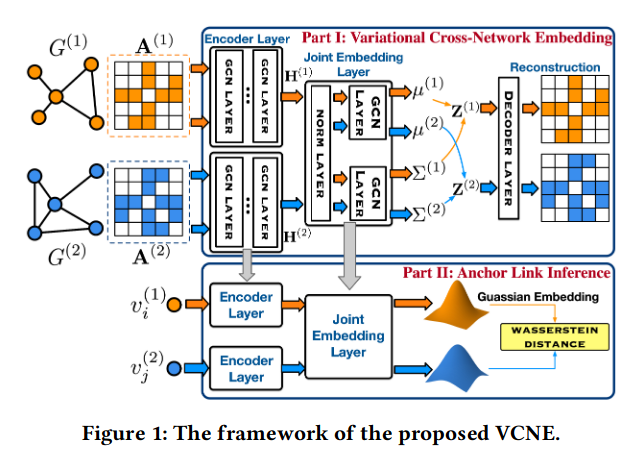
变分跨网络嵌入部分:通过图结构信息的处理,先通过GN、BN层正则化,再在GCN堆叠组成的Encoder Layers提取不同平台的用户内部关联图的结构特征,之后通过正则化层后进行GCN构成的联合嵌入层,之后得到高斯分布中的\(\mu\)和\(\sum\),直接解码进行重构图,其中高斯嵌入+re-parameterization方法解决反向传播失败的问题。
锚接链接推断:假定得到的结果都遵循正太分布,则通过二阶Wasserstein distance比较相似性
该论文主要的baseline来自图匹配模型(Graph matching models)
Topic Sequence Embedding
出处:ICASSP 2021
论文:Top Sequence Embedding for User Identity Linkage from Heterogeneous Behavior Data
问题
社交网络中行为数据丰富性以及异构性,导致模型可利用内在特征有限。
方法
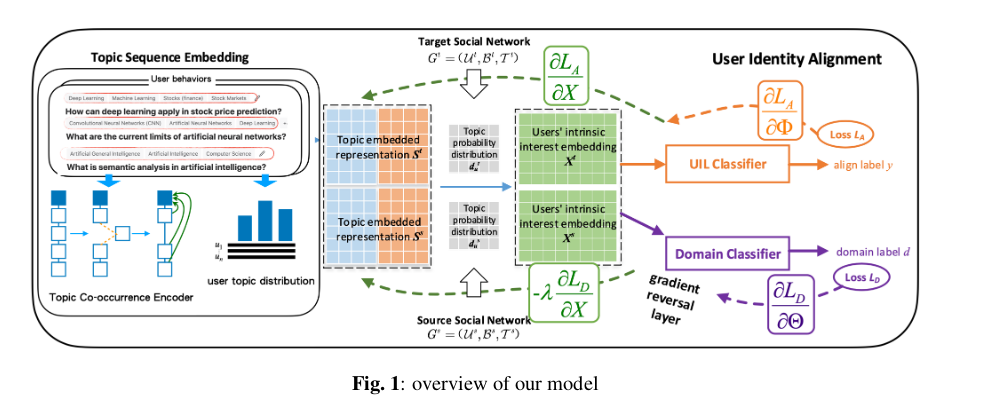
定义
用户:\(u\in U\)
行为:\(B(u)=\{b_1,\cdots,b_N\}\),\(b_k\in\mathbb{R}^{|T|}\),如果\(b_{k,i}=1\)则表示\(b_k\)与话题\(t_i\)交互了
话题:\(T\)
用户话题分布:\(d_u=\frac{\sum^{|B(u)|}_{k=1}b_k}{\sum^{|B(u)|}_{k=1}\sum^{|T|}_{i=1}b_k}\)
话题关联集合:\(C(t_i)=\{t_j|\exist b_k\in B\rightarrow b_{k,i}=1\and b_{k,j}=1\}\)
用户识别关联:源平台\(G^s=(U^s,B^s,T^s)\),目的平台\(G^t=(U^t,B^t,T^t)\),则任务则是将之用户分类到真正的自然人上,表示对齐的用户集为\(P^+\),非对齐的用户集为\(P^-\)
话题共现编码器
序列构建:\(PE(t_i)=W_P\cdot [A_i|| C_i^{[1:p]}]\),\(||\)表示拼接,其中\(A_i\in \mathbb{R}^{|C(t_i)|\times d_A}\)为话题\(t_i\)共现集中的属性矩阵,\(d_A\)为话题属性维度,\(C_i\in \mathbb{R}^{|C(t_i)|\times d}\)为话题\(t_i\)共现集的嵌入矩阵,其中\([1:p]\)反馈位置信息;之后构建话题\(t_i\)的聚合序列矩阵:\(S_i=C_i+PE(t_i)\)
序列编辑:使用Neural Tensor NEtworks(NTN)建模聚合序列与目标主题\(t_i\)之间的内部关系,\(r_{i,j}=f(v^\top_i W_E v_j+V_E [\begin{bmatrix}v_i \\ v_j\end{bmatrix}+b_E)\),\(v_i\)和\(v_j\)分别表示话题\(t_i\)和\(t_j\)的嵌入,\(W_E\)和\(V_E\)是Tensor以及\(b_E\)为偏差项。之后
序列聚合:自注意力模型进行,\(s_i=W_C\cdot [Multi-head(t_i)||v_i]+b_C\)
用户身份对齐
网络对齐目标函数:\(L_A(X,\Phi)=-\sum _\limits{(u^s_i,u^t_i)\in P^+}[\gamma_1-E(x_{u^s_i,x_{u^t_i}})]_+-\mu \sum_\limits{(u^s_i,u^t_j)\in P^-,(u^s_i,u^t_i)\in P^+}[\gamma_2-(E(x_{u^s_i},x^t_{u_j}))]_+\),\([\alpha]_+=max\{0,\alpha\}\),\(X\)表示学到的用户其嵌入参数,\(\Phi\)表示对齐目标函数,\(\gamma_1\)和\(\gamma_2\)分别控制了损失边界,\(\mu\rightarrow[0,1]\)是参考参数平衡两个目标。\(E(\cdot)\)是相似度评估函数,评价两个用户对齐的概率。
用户域对抗训练:\(G(x_u)=Softmax(MLP_d(x_u))\),其中\(G(\cdot)\)是两层MLP+softmax,损失函数为:\(L_D(X,\Theta)=\frac{1}{|U^s|}\sum_\limits{u_i\in U^S}\eta (u_i)\log \frac{1}{G(x_{u_i})}+\frac{1}{|U^t|}\sum_\limits{u_j\in U^t}(1-\eta(u_j))\log \frac{1}{1-G(x_{u_j})}\),其中\(\eta(\cdot)\)表示二分类指示器,显示\(u_i\)来自源网络还是目的网络。完整的损失函数为:\(L(X,\Phi,\Theta)=L_A(X,\Phi)+\lambda L_D(X,\Theta)\)
Deep multi-granularity graph embedding
出处:Knowledge-based System
论文:Deep multi-granularity graph embedding for user identity linkage across social networks
方法
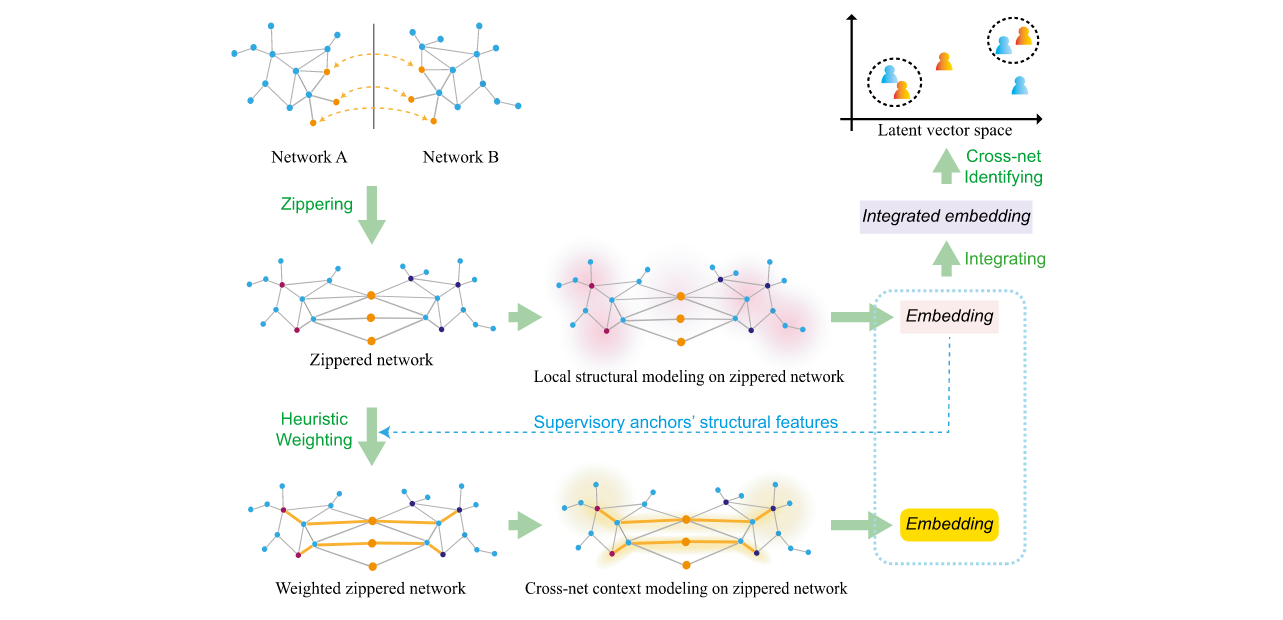
zippering: \(\Omega: G_A,G_B \rightarrow G^m\),其中\(G^m=\{V^m,E^m\}=\Omega(G_A, G_B)\),\(V^m=V_A+V_B-V^B_a\),\(E^m=E_A+E_B\)
Higher-order proximity capturing: \(\min_\limits{\phi} -\frac{1}{|V^m|}\sum^{|v^m|}_\limits{i=1}\log \sum^w_\limits{j=-w} P(v_{i+j}|\phi(v_i))\),$ P(v_{i+j}|\phi(v_i))=\frac{\exp(\phi(v_{i+j})^\top\cdot \phi(v_i))}{\summ_{h=1}\exp(\phi(v_h)\top_{h}\cdot \phi(v_i))}\(,此外使用负采样:\)\log(\sigma(\phi(v_{i+j})^\top \cdot \phi(v_i)))+\sum^N_{h=1}\mathbb{E}_{v_i\sim p_n(v)}[\log(1-\sigma(\phi(v_h)^\top\cdot \phi(v_i)))]$
Deep SAP-oriented heuristic weighting: DNN生成

INFUNE
出处:EACL 2020
论文:A Novel Framework with Information Fusion and Neighborhood Enhancement for User Identity LInkage
问题
两个主要挑战:
- 多种类型/模态的特征数据融合问题(结构、个人资料、内容)
- 缺少人物关系链接的引入
方法
整体结构如图所示:
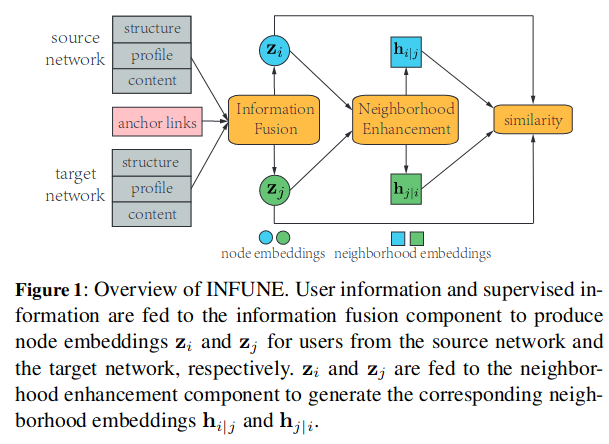
信息融合组件
该组件结构图如下:
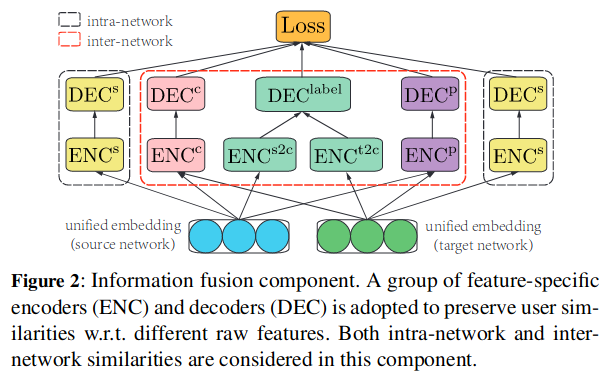
令\(x\in \mathbb{R}^D\)为用户的联合嵌入,其中\(D<<N\),其中\(x\)被映射到不同特征空间以保留对应的行特征。\(\forall \alpha \in \{s,p,c\}\),特征嵌入的定义为:
对于两个用户\(u_i\in U^{1}\),\(u_j\in U^2\),则特定特征相似度指标基本事实指标定义为:\(g^\alpha_{ij}=sim^\alpha(u_i,u_j)\)。特定特征解码器用于重构用户相似度:\(r^\alpha_{ij}=DEC(z^\alpha_i,z^\alpha_j)\)。其中编码器、解码器两个平台都是通过同样的部分而非分别单独搞一个。重构的相似性\(r^\alpha_{ij}\)与正确值\(g^\alpha_{ij}\)由损失函数\(l^\alpha(r^\alpha_{ij},g^\alpha_{ij})\)测量,经验损失\(L^\alpha\)为:\(L^\alpha=\frac{1}{N_1N_2}\sum_\limits{u_i\in U^1}\sum_\limits{u_j\in U^2}l^\alpha (r^\alpha_{ij},g^\alpha_{ij})\),其中\(N_1\)跟\(N_2\)分别是两个用户群体的数量,其中的\(l^\alpha\)为各自的损失函数。
令\(R^\alpha,G^\alpha\in \mathbb{R}^{N_1\times N_2}\),目标\(R^\alpha\)为:\(R^\alpha=\frac{1}{N_1N_2}||R^\alpha-G^\alpha||^2_F\),其中\(||\cdot||^2_F\)为Frobenius范数。因此再加上对应标签匹配的损失\(L^{label}\),则整体的目标为:\(L^{all}=L^{label}+\sum_\limits{\alpha\in\{s,p,c\}}L^\alpha\)
结构嵌入: 建模一个有向边,映射原始节点嵌入\(z^s\)的变换函数为\(\phi\),到目标节点嵌入: \(z^t=\phi(z^s)\) ,则非对称的解码器为:\(DEC(z^s_i,z^s_j)=cos^+(z^s_i,z^t_j)\triangleq\max\{0,cos^+<z^s_i,z^t_j>\}\)
个人资料与内容嵌入: \(DEC^\alpha(z^\alpha_i,z^\alpha_j)=cos^+(z^\alpha_i,z^\alpha_j),\)
有监督的信息: 源网络、目标网络的解码器分别为\(ENC^{s2c}\)与\(ENC^{t2c}\),则:\(z_i=ENC^{s2c}(x_i)\),\(z_j=ENC^{t2c}(x_j)\),其中\(x_i\)跟\(x_j\)分别代表了两个平台的用户\(u_i\in U^s\)和\(u_j\in U^t\)的嵌入。进一步定义\(sim^{label}\)作为用户匹配的指示函数,对于网络的非对称解码器为:\(r^{node}_{ij}=DEC^{label}(z_i,z_j)=cos^+(z_i,z_j)\)
优化: 通过负采样解决大规模社交网络时间复杂度\(O(N_1N_2)\)过大的问题。百分数\(\theta\in[0,1]\),具体过程推导如下:
-
对于\(\forall u_i\in U^1\),稀疏的基本事实矩阵\(G\)第\(i\)行的\(\theta\)百分数表示为\(q^\theta_i\),同时将\(U^2\)拆分成两个不相交的子集:\(U^2_+(i)=\{u_j\in U^2|g_{ij}\geq q^\theta_i\},U^2_-(i)=\{u_j\in U^2|g_{ij}<q^\theta_i\}\),\(U^2(i)=U^2_+(i)\cup U^2_-(i)\),分别代表相似用户集合与不相似用户集合。
-
损失函数\(L\)为:
\[\begin{aligned}L &=\frac{1}{N_1N_2}||R-G||^2_F \\&=\frac{1}{N_1N_2}\sum_\limits{u_i\in U^1}\sum_\limits{u_j\in U^2}(r_{ij}-g_{ij})^2 \\&=\frac{1}{N_1N_2}\sum_\limits{u_i\in U^1}\{\sum_\limits{u_j\in U^2_+(i)}(r_{ij}-g_{ij})^2+\sum_\limits{u_j\in U^2_-(i)}(r_{ij}-g_{ij})^2\} \\&\approx \frac{1}{M}\sum_\limits{u_i\in U^1}\sum_\limits{u_j\in U^2_+(i)}\{(r_{ij}-g_{ij})^2+\sum^K_\limits{n=1}\mathbb{E}_{u_n\sim P(j)}[(r_{in}-g_{in})^2]\} \\&\triangleq \hat{L} \end{aligned} \] -
其中\(M\)为归一化常数,\(K\)为从含噪分布\(P(j)\propto d^{3/4}_{j}\)和\(d_j=\sum^{N_1}_{i=1}|g_{ij}|\)中负采样\(u_n\)的数量,其中\(M=(K+1)\sum^{N_1}_{i=1}|U^2_+(i)|\),由此损失函数的复杂度减小为\(O(M)\)。如果\(G\)是个邻接矩阵,则\(O(M)=O(K|\Epsilon|)\),\(\hat{L}\)作为最终的损失函数,所有参数通过梯度更新。
邻居增强组件
组件结构如图所示:
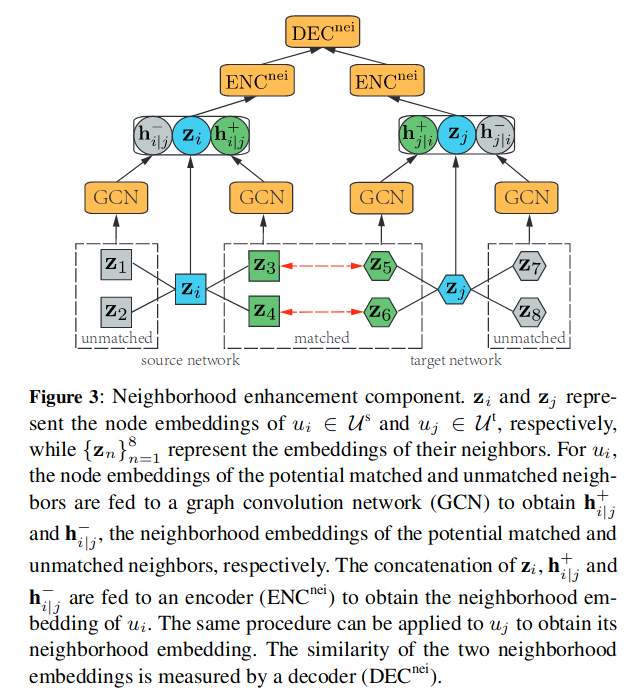
对于用户\(u_i\in U^s,u_j\in U^t\),其邻居集合分别为:
将GCN应用到匹配到的邻居嵌入之后总,有:
之后联合两者以及\(z_i\)以获取用户\(u_i\)信息的嵌入,最终通过两层感知机获得邻居嵌入:\(h_{i|j}=ENC^{nei}(z_i\oplus h^+_{i|j}\oplus h^-_{i|j})\)。
重构后\(N_i\)与\(N_j\)的基本事实相似度为:\(r^{nei}_{ij}=DEC^{nei}(h_{i|j},h_{j|i})=cos^+(h_{i|j},h_{j|i})\)
由此用户\(u_i\)与用户\(u_J\)总的相似度为:\(r^{total}_{ij}=\frac{1}{1+\lambda}(r^{node}_{ij}+\lambda\cdot r^{nei}_{ij}),\lambda\geq 0\)
评估
测量指标:top-k精确率:\(h(u)=\begin{cases}\frac{k-(hit(u)-1)}{k} &if \ k\geq hit(u)\geq 1\\ 0 & otherwise\end{cases}\),其中\(hit(u)\)为top-k个用户之后总正确识别到用户的位置,\(N\)个测试用户的命中精确率:\(\frac{1}{N}\sum^N_{i=1}h(u_i)\)
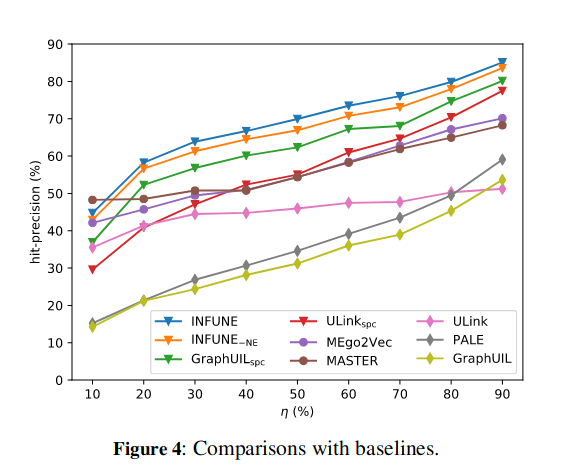
baseline:ULink, PALE, GraphUIL, MASTER, MEgo2Vec
结果:
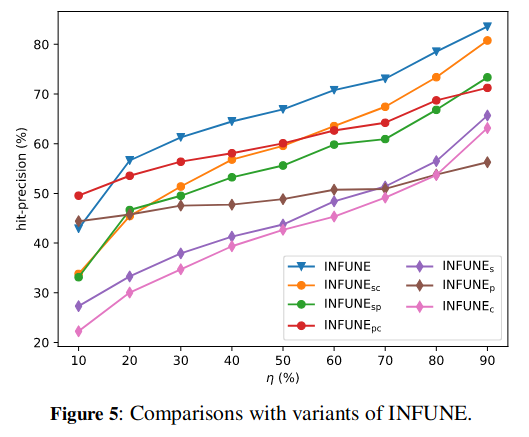
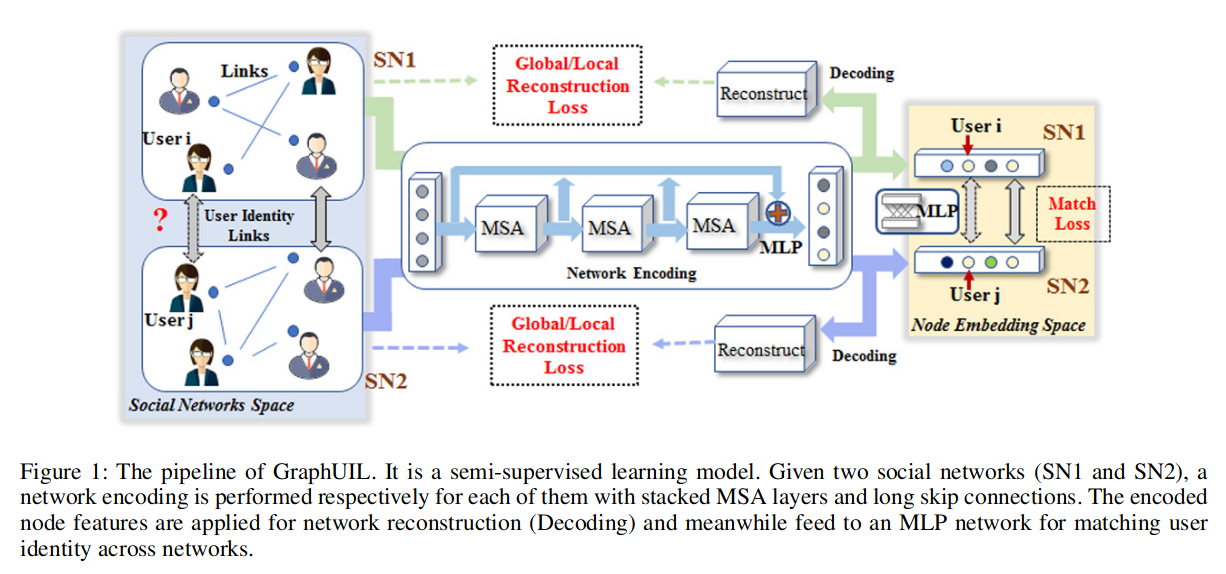
GraphUIL
出处:arxiv, 2020
论文:Graph Neural Networks for User Identity Linkage
问题
社交网络图:\(G=\{V,E\}\),其中\(V=\{v_i|i=1,\cdots,N\}\)表示\(G\)中的\(n\)个节点,\(E=\{e_{i,j}|(i,j)=1,\cdots, N\}\)表示不同用户之间的边,\(x_i\)表示节点\(v_i\)的特征,每条边关联了权重\(a_{i,j}\in R\),有关联则\(a_{i,j}=1\),邻接联矩阵\(A=\{a_{i,j}\}\in R^{N\times N}\)。给定两个图\(G^{(1)}=(V^{(1)},E^{(1)})\)和\(G^{(2)}=(V^{(1)},E^{(2)})\),任务为预测用户\(v^1\in V^{(1)}\)和\(v^2\in V^{(2)}\)是否属于同一个人,即:\(F:V^{(1)}\times V^{(2)}\rightarrow \{0,1\}\)
方法
DPLink
出处:WWW 2019
论文:DPLink: User Identity Linkage via Deep Neural Network From Heterogeneous Mobility Data
问题
- 移动数据的异构属性
- 移动数据的较差质量

给定\(\forall u\in A\),定义\(R(u)=\{p_1,\cdots,p_n\}\),其中\(n\)表示地理位置记录数,给定一对ID\((u,v)\),\(u\in A^1,v\in A^2\)。二分变量\(I(u,v)\)显示是否属于相同的用户:\(I(u,v)=\begin{cases}1, & u,v属于同一用户 \\ 0, & u,v不属于同一个人\end{cases}\),给定的目标ID为\(u\),候选ID列表\(v_1,\cdots,v_N\subseteq A^2\)
方法
三个组件:位置编码器、轨迹编码器、比较网络。输入的轨迹对首先通过位置编码,之后进行轨迹编码提取多级特征表示。
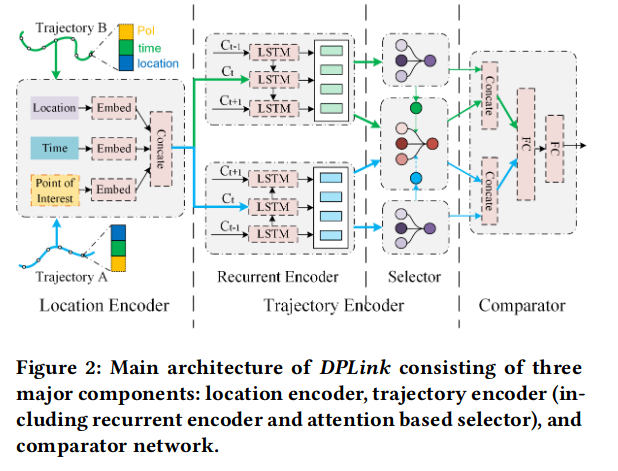
Location Encoder: \(x_i= \tanh(W_{p} p_i+b_p)=\tanh([W_t t_i+b_t || W_l l_i+b_l|| W_e e_i+b_e])\),\(t_i\)是时间戳,\(l_i\)是地点,\(e_i\)是
Trajectory Encoder:
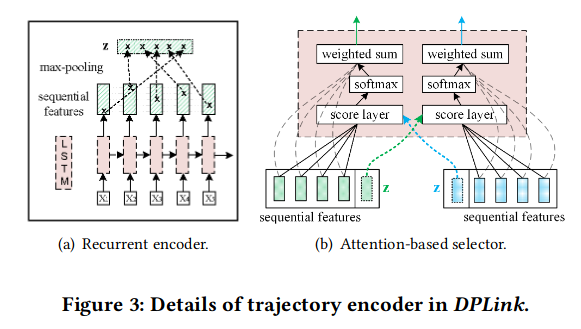
comparator network:MLP,sigmoid函数激活
训练策略:
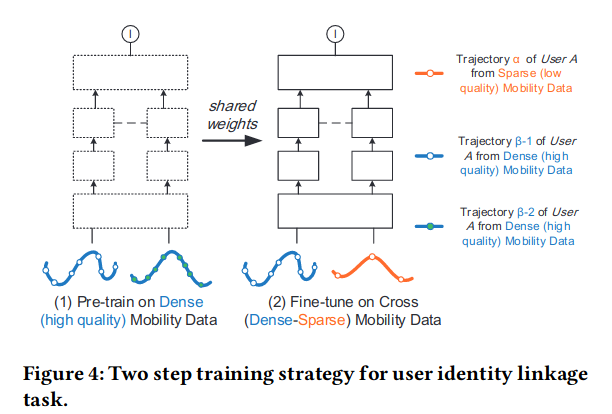
DeepLink
出处:INFOCOM 2018
论文:DeepLink: A Deep Learning Approach for User Identity Linkage
问题
- 没有提供一个比较框架去解决用户和社交网络之间的异质性
- 难以捕获基于网络结构的用户间语义关系
- 缺乏标签数据
方法
-
图:\(G=(V,E)\),\(e_{i,j}\in E\)表示用户\(u_i\)和用户\(u_j\)之间的关系,Social Network Graph(SNG)
-
网络嵌入模型 (NEM):对于用户集\(U=\{u_1,\cdots,u_m\}\)中的用户\(u_i\)通过\(v(\cdot)\)获取其向量表示\(v(u_i)\in \mathbb{R}^d\),其中\(d\)为嵌入的潜在空间
-
UIL:\(\Phi_U(U^s,U^t)=\begin{cases}1 & u^s=u^t\\ 0 & otherwise\end{cases}\)
-
图映射函数:两个图\(G^s\)和\(G^t\),映射函数:\(\Phi(v(u_i))=v(u^{'}_i)\),其中\(u_i\in G^s,u^{'}_{i}\in G^t\);以及\(\Phi^{-1}(v(u_j))=v(u^{'}_j)\),其中\(u_j\in G^t,u^{'}_{j}\in G^s\)
具体过程:
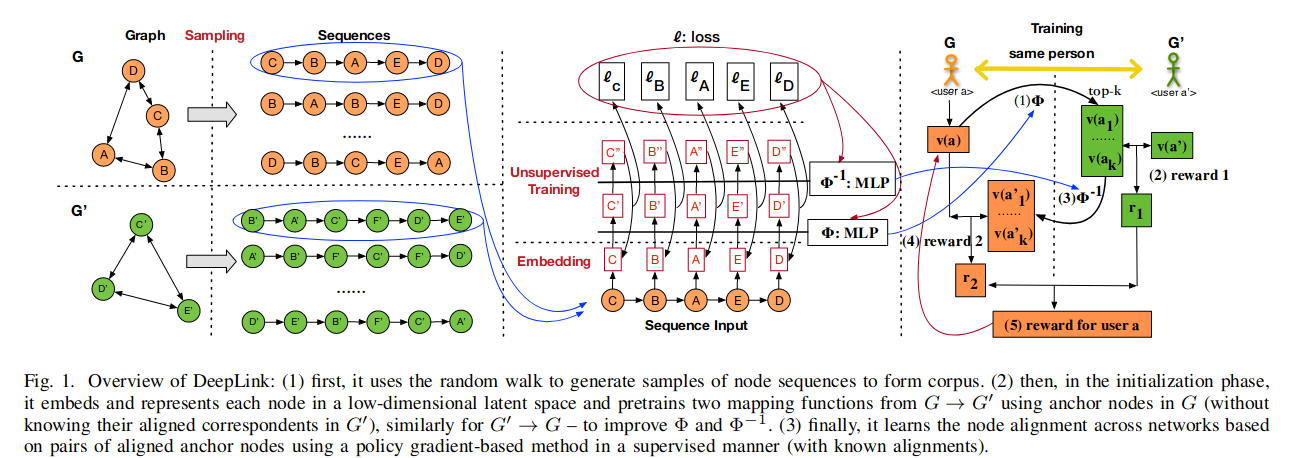
网络结构采样
使用随机游走采样序列。
用户潜在空间嵌入
使用Skip-gram模型进行更新社会表示,DeepLink的目标是最大化该式子:\(\frac{1}{m}\sum^m_\limits{t=1}\sum^w_\limits{j=-w}\log p(u_{t+j}|u_t),j\not= 0\),\(p(u_{t+j}|u_t)=\frac{exp(v^\top_{u_{t+j}},v'_{u_t})}{\sum^m_\limits{i=1}exp(v^\top_{u_i}v'_{u_t})}\)其中\(v_{u_i}\)和\(v'_{u_i}\)表示用户\(u_i\)的输入与输出。
需要最大化的目标为:\(\log{[\sigma(v^\top_{u{t+j}}v'_{u_t})]}+\sum^K_\limits{i=1}\mathbb{E}_{u_i\sim p_n(u)}[\log(1-\sigma(v^\top_{u_i}v'_{u_t}))]\),使用负采样采集\(K\)个负样本。
神经映射学习
获取潜在嵌入后通过2层MLP。给定带标签的锚点对\((u_i,u_j)\)以及他们的表示向量\((v(u_i),v(u_j))\),学习映射\(\Phi(v(u_i))\)通过最小化损失函数:\(l(v(u_i),v(u_j))=\min(1-\cos(\Phi(v(u_i)),v(u_j)))\),其中cos计算的是来自\(G_s\)的映射向量\(\Phi(v(u_i))\)与来自\(G_t\)的嵌入表示\(v(u_j)\)之间的相似性。损失函数用矩阵表示为:\(l(A,B)=\arg \min_\limits{W,b}(1-\cos(\Phi(A), B;W, b))\)
链接双路学习

开始于\(G^s\)(agent A)的\(u_a\),使用\(\Phi\)映射\(G^t\)空间的向量并搜索\(k\)邻近向量\(S(v'(u_a))=Top(\Phi(v(u_a)))\),反映\(G^t\)锚点中最相似的\(k\)个嵌入向量。这\(k\)个向量是匹配真实用户的候选和训练更多锚点成功获得链接的概率。之后\(G^t\)(agent B)计算奖励:\(r^a_{s,t}=\frac{1}{k}\sum^k_\limits{i=1}\log(\cos(v(u_i),v'(u_a))+1)\),其中\(\cos(\cdot)+1\)表示两个向量之间的相似性。
计算\(v'(u_i)\)到\(G^s\)的\(\Phi^{-1}\),相似地计算\(r^a_{t,s}\),在\(\Phi^{-1}(v'(u_i))\)和\(v(u_a)\)之间的均值相似性计算为:\(r^a_{t,s}=\frac{1}{k}\sum^k_\limits{i=1}\log(\cos(\Phi^{-1}(v'(u_i)),v(u_a))+1)\)
目标函数:\(\mathbb{E}[r_h]=\sum^{[n/h]}_\limits{a=1}(\alpha r^a_{s,t} + (1-\alpha)r^a_{t,s})\)
评价指标
Precision@k:\(P@k=\sum^n_\limits{i}\mathbb{1}\{success@k\}/n\)
MAP:\((\sum^n \frac{1}{ra})/n\)
AUC:\((\sum^n \frac{m+1 -ra}{m})/n\)
Hit-Precision:\((\sum^n\frac{m+2-ra}{m+1})/n\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号