Dos and Don'ts of Machine Learning in Computer Security笔记
出处:Usenix security 2022 Summer Accepted Paper
作者:Daniel Arp, Erwin Quiring, Pendlebury et. al.(欧洲那块的)
话题:机器学习用于安全应用过程中的微妙陷阱、如何”安全“地进行机器学习安全应用
论文链接:https://www.usenix.org/system/files/sec22summer_arp.pdf
Abstract & Introduction
- Problem:
- ML in Sec is prone to subtle(微妙的) pitfalls(陷阱)
- Influence: undermine performance & unsuitable for security tasks and practical deployment
- Contribution:
- Pitfall Identification: Identify common pitfalls(design & implement & evaluate)
- Prevalence Analysis: pitfall influence with experiments
- Impact Analysis: actionable recommendations to avoid or mitigate pitfalls
Pitfalls in Machine Learning

Pitfalls in Data Collection and Labeling
Sampling Bias
- data doesn't represent the true data distribution
- bias origin: rely on synthetic data or to combine data from different sources
- recommendation: avoid mix of data from incompatible sources, limitations of dataset should be openly discussed.
Label Inaccuracy
- ground-truth labels are inaccurate, unstable or erroneous, affecting the overall performance
- inaccuracy origin: reliable labels are typically not available in relevant security problems resulting in chicken-and-egg problem, label shift
- recommendation: labels should be verified whenever possible. If noisy labels: robust models or loss functions, modeling label noise in learning process, cleansing noisy labels in training data
Pitfalls in System Design and Learning
Data Snooping
- data snooping results in over-optimistic results
- test snooping: test set is used to train
- temporal snooping: common pitfall, occurs if time dependencies within the data are ignored
- selective snooping: cleansing of data based on information not available in practice
- recommendation: split test data early and stored separately until evaluation, consider temporal dependencies, with experiments on more recent data
Spurious Correlations
- Artifacts unrelated result in shortcut patterns,which causes high risk of overestimating the capabilities of the method and misjudging its practical limitations.
- recommendation: explanation techniques for ML, clearly defining spurious correlations objective in advance and validating.
Biased Parameter Selection
- final parameters depend on the test set rather than train set.
- best-performing model suffer from a biased parameter selection
- recommendation: use validation set, strict data isolation.
Pitfalls in Performance Evaluation
Inappropriate Baseline
- there exists no universal learning algorithm that outperforms all other approaches in general.
- overly complex learning method increases the chances of overfitting
- recommendation: use simple models throughout evaluation, use AutoML find baseline, check whether non-learning approaches are also suitable.
Inappropriate Performance Measures
- not all of performance measures are suitable in the context of security, refers to the inappropriate description of performance
- recommendation: consider the practical deployment of model and identify measures
Base Rate Fallacy
- large class imbalance is ignored, refers to misleading interpretation of results.
- recommendation: advocate precision and recall, Matthews Correlation Coefficient, ROC, AUC, discuss FP
Pitfalls in Deployment and Operation
Lab-Only Evaluation
- A learning-based system is solely evaluated in a laboratory setting, without discussing itr practical limitations.
- Recommendation: move away from a laboratory setting and approximate a real-world settings accurately as possible.
Inappropriate Threat Model
- security of ML is not considered, exposing the system to a variety of attacks, such as poisoning and evasion attacks.
- Recommendation: threat models should be defined precisely and systems evaluated with respect to them, focus on white-box attack where possible.
Prevalence Analysis
3 Central Observation:
- there is a lack of awareness for the identified pitfalls(most authors agree)
- the pitfalls are widespread in security literature and there is a need for mitigating them
- a consistent understanding of the identified pitfalls is still lacking
Impact Analysis
- mobile malware detection (P1, P4, and P7)
- vulnerability discovery (P2, P4, and P6)
- source code authorship attribution (P1 and P4)
- network intrusion detection (P6 and P9)
Mobile Malware Detection
Data collection: AndroZoo
Dataset analysis: data distribution in origin, number of antivirus detections
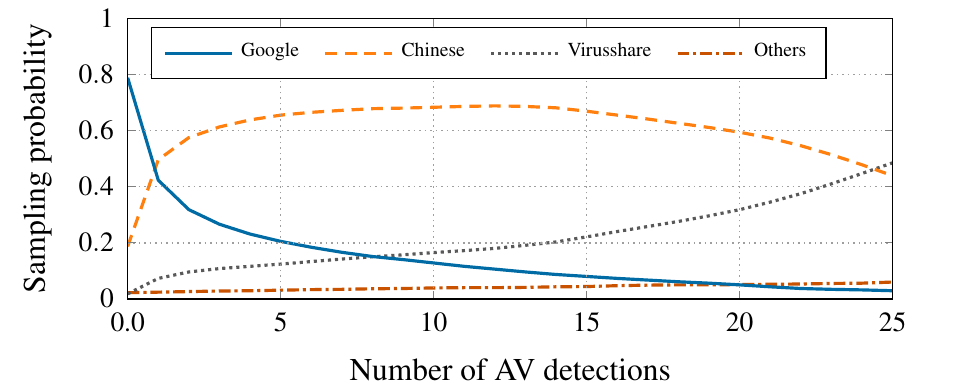
Experimental Setup:
- Data: \(D_1\)(1000 Benign from Google Play 1000 malicious from Chinese Markets), \(D_2\)(10000 Benign from Google Play 1000 malicious from Google Play) [Pitfall 1]
- Feature: 2 feature sets taken from DREBIN classifier & OPSEQS classifier, URL play.google.com [Pitfall 4]
- Model: Linear SVM
- Result: different biased parameter selections within different performance Measures [Pitfall 7]
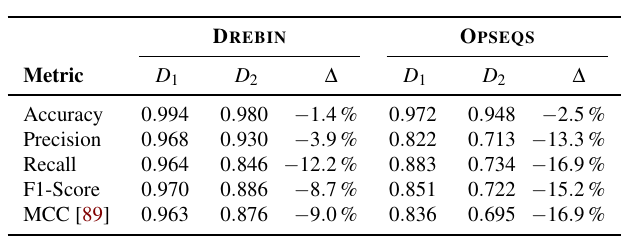
Vulnerability Discovery
Data Collection: CWE-119
Dataset Analysis: vulnerabilities related to buffers, 39757 source code snippets of 10444 (vulnerability label, 26%) [pitfall 2]
Experiment Setup:
-
Feature: classify a random subset to spot possible artifacts, extract the buffers sizes of
char(because they seems only in one class throughout the samples) [pitfall 4]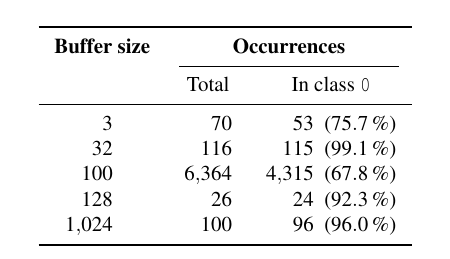
-
Model:
- VulDeePecker(classify code snippets)
- SVM with bag-of-words features on n-grams(baseline for VulDeePecker)
- Layerwise Relevance Propagation(LRP, explain the prediction and score relevance)
-
Result: extract tokens which occur most often in top-10 selection
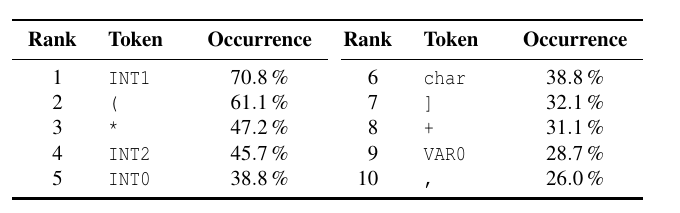
INT* most (Spurious Correlations), SVM with 3-grams has the best performance.
VulDeePecker is not exploiting relations in the sequence but merely combines special tokens [Pitfall 6]
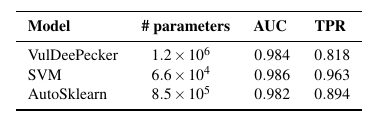
By truncating the code snippets will lose important information, causing label inaccuracy. [Pitfall 2]
Source Code Author Attribution
Programming habits are characterized by a variety of stylistic patterns.
In combination with sampling bias [Pitfall 1], this expressiveness may give rise to spurious correlations [Pitfall 4] in current attribution methods, leading to an overestimation of accuracy.
(就是比对了有没用的代码数据集与无没用的代码数据集的差别,其实就是无用数据冗余的问题)
Network Intrusion Detection
data collection: IoT (Mirsky).
Dataset analysis: all benign activity seems to halt as the attack commences, after 74 minutes, despite the number of devices on the network.
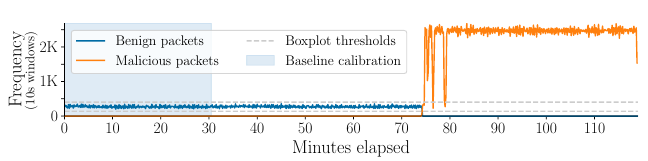
Experimental Setup:
method: boxplot method (as the gray line)
result:
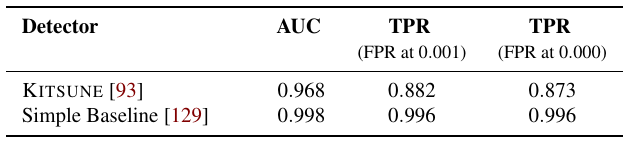
- an experiment without an appropriate baseline (P6) is insufficient to justify the complexity and overhead of the ensemble [Pitfall 6]
- simple method(boxplot) can reveal issues with data generated for lab-only evaluations [Pitfall 9]
Limitations and Threats to Validity
Pitfalls: may seem obvious at first, not cover all ten pitfalls in detail.
Prevalence analysis: the selection process is not entirely free from bias.
Impact analysis: biased selection

 浙公网安备 33010602011771号
浙公网安备 33010602011771号