


正则表达式小总结
肉大的正则篇:https://deerchao.cn/tutorials/regex/regex.htm
正则表达式的创建:
有两种创建正则表达式的方式:
方法1、 构造函数:var reg=new RegExp("正则表达式","修饰符"); reg--regular:规则 exp--expression:表达
方法2、 var reg=/正则表达式/修饰符;(常用方法) pattern:典范、模式 modifiers:修饰语
第二种方法是最常见的,有时候我们需要动态创建正则,我们可以用eval函数来动态的创建正则,例如:
// 下面的意识是 匹配以ab开头后面出现0次或多次c的 字符 (全局多次匹配 如果没有g 就匹配一次) var patter = 'c*'; var reg =eval(`/ab${patter}/g`);//等同于 reg =/abc*/g` var str = "abccccabccabdc"; console.log(str.match(reg));//["abcccc", "abcc", "ab"] console.log(reg.test(str));//true
正则表达式的方法:
1、检测方法
reg.test(String) 和 reg.exec(String) 都可以检测 字符串是否符合 正则表达式 前者返回布尔值,后者返回数组(不匹配则返回null)
string类中支持正则的方法:
2、search方法:用来检索字符串中 符合正则的 字符串,返回索引,不存在 则返回 -1
语法:str.search(reg)
3、match方法:返回 匹配正则的 字符串组成的 数组 没有则返回null
语法:str.match(reg)
4、replace方法:用来用新的字符串 去替换 正则 匹配到的 字符串,返回替换过的字符串
语法:str.replace(reg,newStr)
数量词 — * + ? and{}
abc* 匹配ab后有零个或多个为c的字符串 abc+ 匹配ab后有一个或多个为c的字符串 abc? 匹配ab后有零个或一个为c的字符串 abc{2} 匹配ab后有2个 c的字符串 abc{2,} 匹配ab后有2个 c或更多个c的字符串 abc{2,5} 匹配ab后跟2到5个c的字符串 a(bc)* 匹配a后面跟零个或多个重复的bc序列的字符串 a(bc){2,5} 匹配a后面跟2个到5个重复的bc序列的字符串 或运算符——|或[] a(b|c) 匹配a后跟b或c的字符串 a[bc]
字符类— \d \w \s和.
// 常用的元字符(特殊字符) // \w :匹配数字、字母,下划线 等价于[a-zA-Z0-9] // \W :匹配非数字、字母、下划线 等价于[^a-zA-Z0-9] // \d :匹配数字 // \D :匹配非数字 // \s :匹配空白字符(空格、换行) // \S :匹配非空白字符 // \n :匹配换行符
// . :匹配任何字符
为了按字面意思理解,你必须使用反斜杠“\”来转义字符^.[$()|*+?{\,因为它们具有特殊含义。
\$\d
匹配一个数字前面有一个$的字符串
请注意,您还可以匹配不可打印的字符,如制表符\ t,换行符\ n,回车符\ r。
标志位:
// i :执行对大小写不敏感的匹配 // g :执行全局匹配(查找所有匹配而非在找到第一个匹配后停止) // m :执行多行匹配
分组和捕获— ()
a(bc)
括号创建一个值为bc的捕获组
a(?:bc)*
我们使用?:禁用捕获组
a(?<foo>bc)
我们使用?<foo>给小组命名
当我们需要使用您首选的编程语言从字符串或数据中提取信息时,此运算符非常有用。由几个组捕获的任何多次出现都将以经典数组的形式公开:我们将使用匹配结果的索引来访问它们的值。
如果我们选择为组添加名称(使用(?<foo>...)),我们将能够使用匹配结果检索组值,就像字典一样,其中键将是每个组的名称。
括号表达式— []
[abc]
匹配一个具有a或b或c的字符串 - >与a | b | c相同
[a-c]
同上一情况
[a-fA-F0-9]
表示一个十六进制数字的字符串,不区分大小写
[0-9]%
在%符号之前具有0到9之间字符的字符串
[^a-zA-Z]
一个没有字母从A到Z或从A到Z.的字符串,在这种情况下,^被用作表达式的否定
请记住,在括号内的表达式中,所有特殊字符(包括反斜杠\)都会失去其特殊权力:因此我们不会应用“转义规则”。
贪婪与惰性匹配;
量词(* + {} )是贪婪的运算符,因此它们通过提供的文本尽可能地扩展匹配。
例如,<.+>匹配This is a <div> simple div</div> test中的<div>simple div</div>。
为了只捕获div标签,我们可以使用? 让它变得懒惰:
<.+?>
匹配<和>内包含的任何一个或多个字符,根据需要进行扩展
请注意,更好的解决方案应该避免使用.来支持更严格的正则表达式:
<[^<>]+>
匹配<和>中包含的一次或多次除<或>以外的任何字符 (匹配到<div> 如果是g多次匹配 则 匹配到 <div>和</div>)
高级主题:
边界— \b and \B
\babc\b
执行“仅限整个单词”搜索
\b表示像插入符号(它类似于$和^)的匹配位置,其中一侧是单词字符(如\w)而另一侧不是单词字符(例如,它可能是字符串的开头或者空格字符)。
它伴随着它的否定,\B。这匹配\b不匹配的所有位置,如果我们想要找到完全被单词字符包围的搜索模式,则可以匹配。
\Babc\B
仅当图案完全被单词字符包围时才匹配
回溯引用— \1
([abc])\1
使用\1,它与第一个捕获组匹配的相同文本匹配
([abc])([de])\2\1
我们可以使用\ 2(\ 3,\ 4等)来识别与第二个(第三个,第四个等)捕获组匹配的相同文本
(?<foo>[abc])\k<foo>
我们把这个组命名为foo,稍后我们引用它(\ k <foo>)。 结果与第一个正则表达式相同
先行和后行断言— (?=)和(?<=)
d(?=r)
仅在r之后匹配d,但r将不是整体正则表达式匹配的一部分
(?<=r)d
仅在r之前匹配d,但r将不是整体正则表达式匹配的一部分
你也可以使用否定运算符!
d(?!r)
仅在不跟随r的情况下匹配d,但r将不是整体正则表达式匹配的一部分
(?<!r)d
仅在没有r之前匹配d,但r将不是整体正则表达式匹配的一部分
后面的高级主体有点晦涩难懂,后面多练习吧
小例子:
.*? 匹配任意次数 懒惰匹配
let regImage = /\[image:.*?\]\s*↵*\s*/g;//全局匹配: [image:XXX] 空格/回车符/空格
.*?a
就是取前面任意长度的字符,到底一个 a 出现,匹配如下
q@wer_qwerqweraljlkjlkjlkj
得到:q@wer_qwerqwera 这部分,如果匹配不到后面的 a 字符,则匹配为空。
?! 匹配除 组合符 后面内容 以外的 内容
let regNotFile = /(\[[^\]]+\]\s?:\s?)(?!(<\/p><a|<a|http))/g;
//全局匹配: ['['或者'^'或者']'](一次次多次) 空格(0次或1次) :空格(0次货1次) 后面不是(</p><a 或 <a 或 http)
判断链接为图片的正则表达式:
/http\S*\.(png|jpg|bmp|gif|jpeg|tiff)/gi
图片链接不包含.html的图片链接
防止把这种特殊的网页地址识别成图片
https://www.bilder-upload.eu/bild-f41377-1596893361.jpg.html
/http\S*\.(png|jpg|bmp|gif|jpeg|tiff)(?!(\.html))/gi,
判断视频链接的正则表达式:
/http\S*\.(mp4|avi|3gp|mov|wmv|rm|rmvb|asf|flv|mkv)/gi
匹配 包含/api/ 但后面跟的不是 longadmin的字符
/.*\/api\/?!(longadmin).*/
匹配以@符结尾的字符串
/^.*?@$/.test(string)
匹配@开头中间非空字符以空格结尾,在字符串中匹配的所有结果
let str = '[~@Assignee] @客服sd11 @哈哈哈哈哈 ' let reg = /@\S+\s/g; let result = str.match(reg); console.log(result);
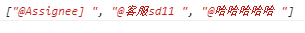
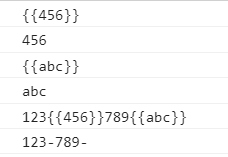
来一个分组的例子
在我们需要去获取文本节点中的{{}}里面的内容,这是后用分组比较好
let str = "123{{456}}789{{abc}}";
let rkuohao = /\{\{(.+?)\}\}/g;//匹配双括号内容 .+? 两边的() 用来正则能够通过分组的方式获得到 .+? 的具体内容
let a = str.replace(rkuohao,function(result,g1){//函数的第0个参数,表示正则匹配的结果,函数的第n个参数,代表第n组
console.log(result);
console.log(g1);
return '-'
})
console.log(str);
console.log(a);
知道关键词,将字符串转化为对象格式:
例如将这样的字符串转化为对象格式:
let keyWords = ['platform','language'];//条件 let includeRelations = ['is','is_not'];//包含关系 let str = "platform:is:1111 language:is_not:2222"; document.write(str) let keywordReg = new RegExp(`((${keyWords.join('|')})\:)`,"gi");// 匹配 条件: let logicReg = new RegExp(`((${includeRelations.join('|')})\:)`,"gi");//匹配 包含关系: let valueReg = new RegExp(`value\:(.*?)(?=(\{|$))`,"g");//匹配value值 (value:)和({或$) 之间的内容被认为是value值 let pre = new RegExp("^");//开头 let last = new RegExp("$");//结尾 str = str.replace(keywordReg,"{name:$2,");//条件前加key str = str.replace(logicReg,"include:$2,value:");//逻辑词前加key 后面加value str = str.replace(valueReg,"value:$1}") console.log(str);

匹配,某字符串之间的内容
let str = 'abc大萨达所bcd'; const pattern4 = /(?<=abc).*?(?=bcd)/ig; console.log(str.match(pattern4)) // ['大萨达所']
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}