CLIP的相关工作
CLIP的相关工作
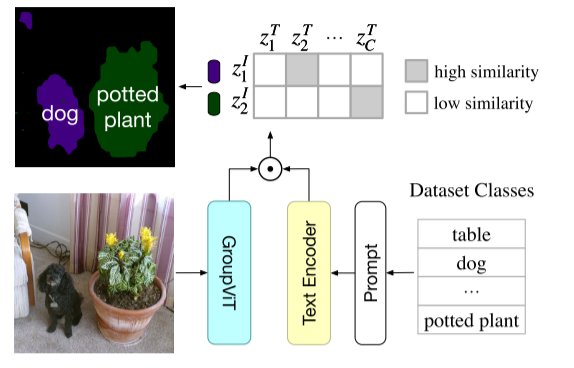
CLIP图像分割
Language-driven Semantic Segmentation-2022年ICLR会议
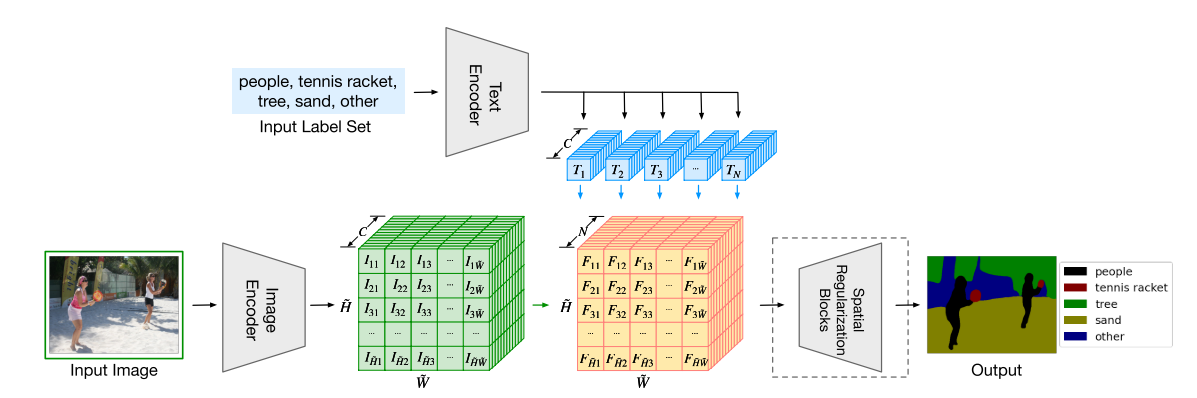
图像编码器采用DPT形式,VIT+decoder,得到$\hat{H}\times \hat{W}\times \hat{C} $的dance feature。文本编码器采用CLIP的文本编码器,且参数一直是冻结的(使用CLIP的预训练参数),生成$N\times C$的特征矩阵,两个矩阵作乘积(爱因斯坦求和约定)得出有语义特征的$\hat{H}\times \hat{W}\times N$的特征矩阵。生成特征矩阵之后,可能还有一些可学习的模型参数,为了更好地让模型去理解一下文本与视觉到底该如何交互,以使得模型的效果最好,因此作者就在特征后加入了一个Spatial Regularization Blocks,但是这个block起的作用并不是很大,消融实验也不是特别充分,可以忽略。
源码已给出,可以自己预训练,不是无监督学习,没有把文本当监督信号使用,还是依赖于手工标注的segametation mask。---图像分割领域的数据集较小,7个数据集一共1-20万的数据量,比较小。
GroupViT : Semantic Segmentation Emerges from Text Supervision-2022CVPR
**不依赖于segametation mask这种手工标注的数据,监督信号来自于文本,跟CLIP一样可以使用图像文本对来进行无监督训练(对比学习) **
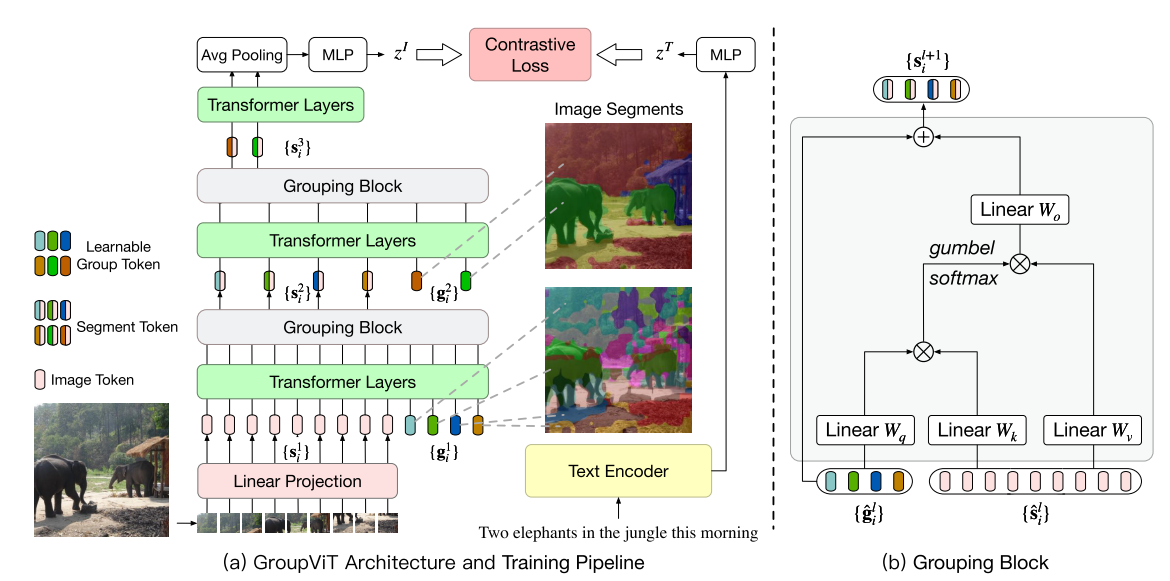
作者对Grouping思想进行了思考,将其融入到了现有的框架中(Grouping思想类似于K-means聚类的思想,从点出发,向外扩散,相同的点可以作为一个mask),本模型提出了Grouping Block计算单元,以及为模型添加了一些可学习的group tokens(在图中由$ {g_{i}^{j}} $表示)
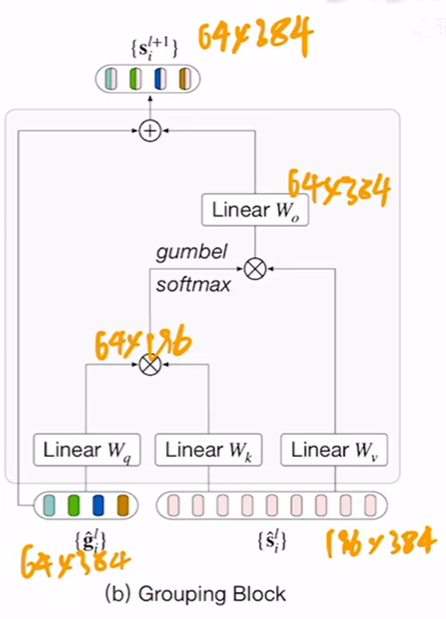
模型由ViT中的(224*224)/(16*16)=196个384维patch embeding和64个代表聚类中心的384维度的group tokens作为输入,经历6个Transformer层之后使用一个Grouping Block将图像patch embedding直接assign到所设置的64个group token上(相当于做了一次聚类分配),得到64个384维的Segment Token。如图b所示,Grouping Block使用类似于自注意力机制的方法,先计算了一个相似度矩阵,以相识的矩阵帮助Image Token进行聚类中心分配的操作,从196*384降维到64*384的过程,聚类中心的分配这一过程是不可导的,因此作者又使用了一个trick即gumbel softmax操作把过程变为可导的,实现模型的端到端训练。模型后续的6个Transformer层和一个Grouping Block是为了把分割的类别进一步缩小,变为8个类别,最终的输出为8*384层。但是这个结果相当于图片中的8个块的特征序列,并不是整个图片的特征序列,作者使用一个平均值池化来将8个块的特征序列融合为整个图片的一个特征序列$Z^{L} $,其实这整个过程也是为了与文本编码器后的结果$Z^{T} $进行对齐。最后便是图像和文本对进行对比学习的过程。
数据维度如下图所示:
模型的推理过程也与CLIP非常相似,但是由于这个模型只是生成了8个掩码块的结果,因此该模型最多只能分割8类物体(8类是作者实验所得,最终结果为8的效果最好)。----这是一个很大的局限性
通过设置相似度阈值的方式来分辨前景类和背景类,在类别非常多的时候,可能导致相似度(置信度)比较低,前景物体和背景物体的相似度差不了多少,再以阈值的方式进行前景和背景分辨的话效果就不是很理想。
Group ViT目前的结构还是更偏向于是一个图像的编码器,没有很好的利用dense prediction特性,如使用Dilated Convolution,pyramid pooling或者类似于u-net的结构来获得更多的上下文信息,获得更多的多尺度信息,能够更好的进行分割任务。
CLIP目标检测
Open-Vocabulary Object Detection Via Vision and language Knowledge Distillation-2022年CLIP
以CLIP模型为老师来对自己的模型进行视觉和语言蒸馏。引言写作方式很不错,以一张图一个问题直接给出本文的研究内容和研究动机。
a图是一个baseline方法,是一个两阶段的分类器,第一阶段生成一些region proposal,第一阶段并没有在图中显现出来。第二阶段用来判断,抽取出的这些bounding box是什么类别,以此来完成分类任务。目标检测便可分为这两大模块,一个是定位(生成region proposal),一个是分类(对bounding box框中的物体进行分类)。
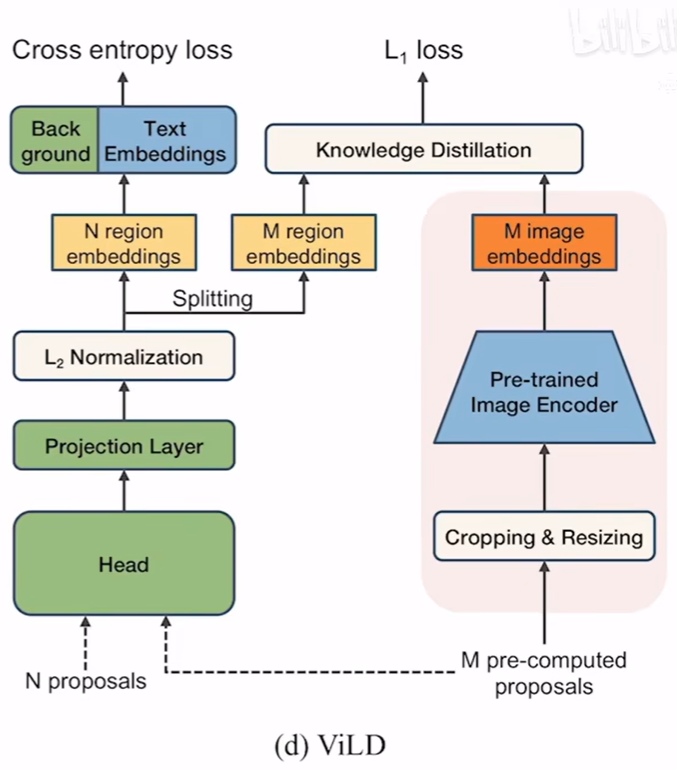
b图是根据baseline改进后的第一种方法ViLD-text。ViLD-text模型将文本特征加入到了模型当中。生成N个region embeddings的过程不再赘述。Text Embeddings就是把物体的类别拿过来,然后给出一些prompt由promt enginer生成一个句子,而后把句子通过选取的文本编码器的处理便可生曾Text Embedding 。在这个模型中,文本来自物体的类别,数据集仍在class base中,是有监督的学习,本模型相当于只是把文本特征融入到了baseline模型当中,因此它的Open-Vocabulary零场景泛化能力并不强 。文本特征背景为蓝色,在预训练过程中,文本特征模型的参数并不改变。文本编码和region embeddings跟CLIP类似直接进行点乘操作,获得的相似度直接当作最后分类的logistics,做交叉熵损失来进行模型训练。不在class base里的类全部放在背景类的学习中,背景特征也是直接与region embedding进行点乘操作计算相似度。
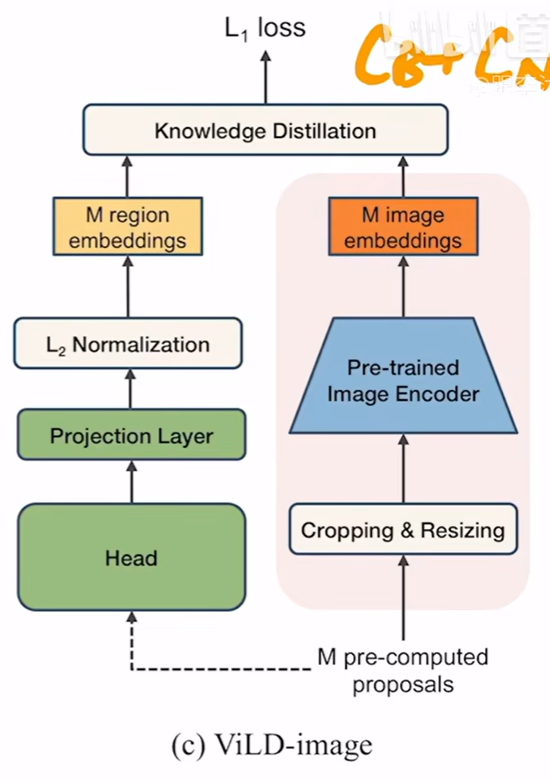
c图是 使用CLIP的图片编码器来蒸馏ViLD模型中的图像编码器,模型的标签不再受数据集的基础类的限制,监督信号由CLIP模型提供而不是由数据集中的人工标注确定(模型通过阶段1,生成region proposal后,直接跟CLIP的结果进行求损失即可)。但是在蒸馏的过程中,由于使用的CLIP的图像编码器非常大,因此此处需要先抽取出所有图片的proposals,即M pre-computed proposals,之后便可以先在内存中将CLIP生成的M image embeddings给储存起来。
D图中表示的ViLD模型就是ViLD image和ViLD text的结合体。
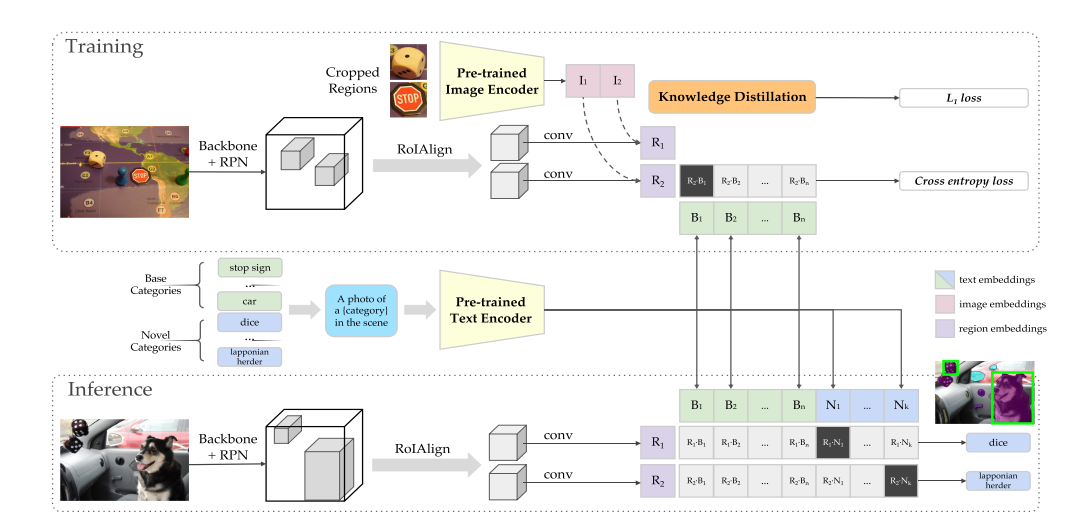
ViLD模型的详细实现总览图如上所示。
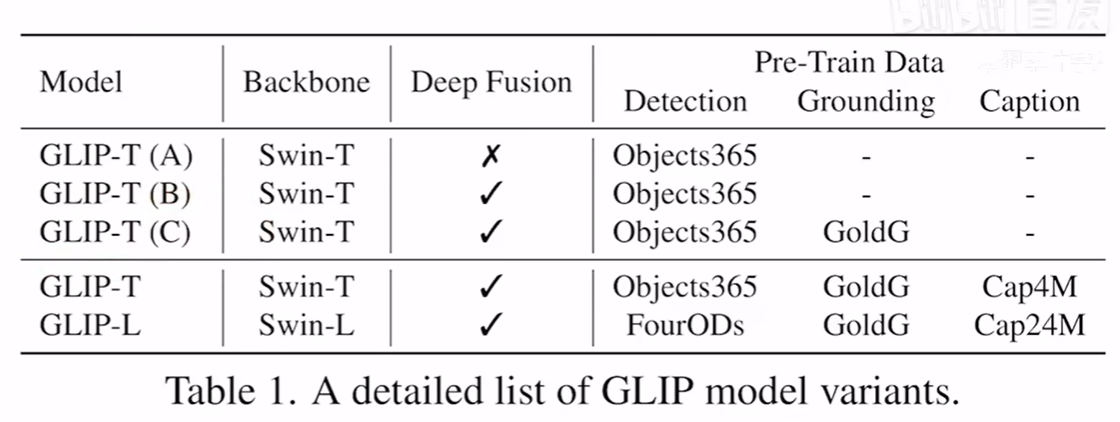
Grounded Language-Image Pre-training-2022CVPR(重点看,有第2个版本GLIPv2)
detection和visual grounding相结合。
visual grounding涉及计算机视觉和自然语言处理两个模态。简要来说,输入是图片(image)和对应的物体描述(sentence\caption\description),输出是描述物体的box。
该论文把object detection和phrase grounding两种任务模型进行合并。目标检测的主要任务为给出一张图片,由模型获得bounding box。pharse grounding是给出一张图片,在给出一个文本,根据文本将图片中的物体找出来。
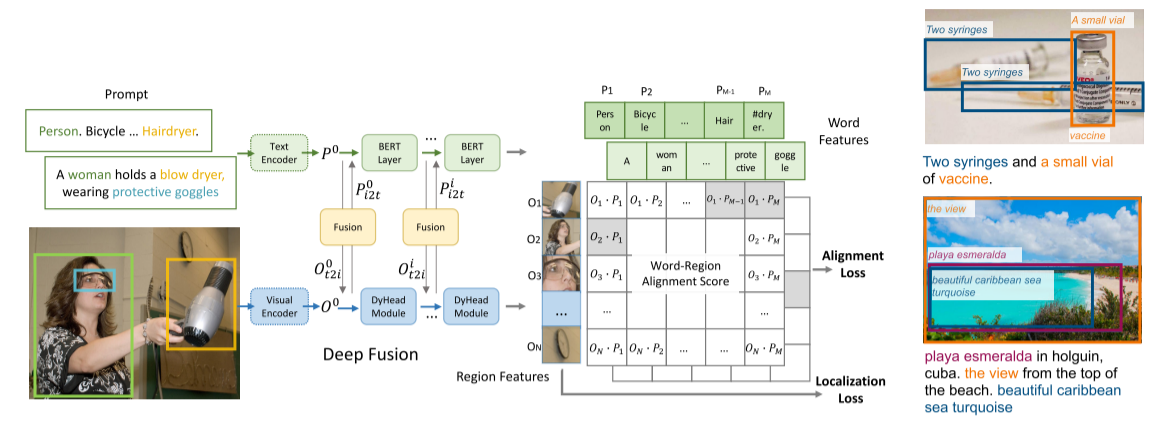
从下图中可以看出,所给出的文本提示可以是人,自行车,这种以目标检测的类别型的提示,还可以是一个句子。

目标检测和Visual grounding的loss都可以分为grounding box定位的loss和grounding box分类的loss。但对目标检测,标签为一个或两个单词,标签可以是one-hot编码的格式。对于Visual grounding,它的标签是一个句子。两个标签形式不一致,两者的loss形式也不一致,如何合并两种不同的loss是一个关键工作。
目标检测的loss格式,先对img进行嵌入得到region embedding,而后与分类权重W相乘,输出Scls作为分类的logits,而后使用非极大值抑制(NMS)把grounding box过滤一遍,最后跟ground truth算cross entropy loss,便可获取到最终的分类loss。
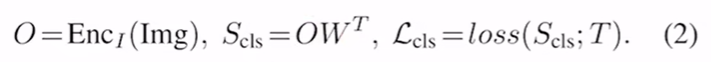
Visual grounding的loss格式,计算了图像跟文本的匹配分数,观察图像中的区域与句子中的单词是如何对应的。整体结构与与ViLD-text基本一致。

作者通过一个小改动便将两者进行了结合,判断句子中的短语什么时候是一个positive match(正匹配),什么时候是一个negative match。正匹配的短语就可以跟目标检测一样去进行模型训练,就是词(分类)和图片的组合。也得益于把两种机制给融合,使得模型可以同时使用目标检测和Visual grounding的数据集。作者也采用self-training的方法,生成具有伪标签的数据集,进一步扩展数据集规模。使用GLIP-T(C),在Cap4M上去做推理,将推理出的当前图片上的Bounding box作为Ground Truth,推理出的标签是有错误信息的,所以叫做伪标签,但是伪标签使用了后一般都可以让模型的性能变得更好且提升模型的稳健性。
在图片经过Visual encoder以及文本经过text encoder后,理论上可以直接计算相似度矩阵,但直接计算的话图像文本的joint Embedding space还没有学的很好,因此模型又加入了一些BERT层,DyHead Module和Fusion让两者的特征融合一下,可能就会把相似的概念拉近一些,不相似的概念就更远一点,使得文本和图像特征更强且更有关联性,再去计算相似度矩阵的时候会更有针对性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号