函数声明与定义的编译:分离还是合并?
函数声明和定义的编译方式在不同语言中有显著差异。让我们从底层机制分析函数名和函数体的编译过程:
一、C/C++:严格分离的经典模型
1. 声明与定义分离
// 声明 (头文件.h)
int add(int a, int b);
// 定义 (源文件.c)
int add(int a, int b) {
return a + b;
}
2. 编译过程

3. 关键阶段
| 阶段 | 声明处理 | 定义处理 |
|---|---|---|
| 编译期 | 1. 验证调用签名 2. 预留符号引用 |
1. 生成函数体机器码 2. 创建可重定位代码 |
| 链接期 | 无 | 1. 解析符号引用 2. 绑定调用地址 |
4. 内存映射

二、Perl:声明即定义的动态模型
1. 声明与定义合一
# 声明和定义同时发生
sub add {
my ($a, $b) = @_;
return $a + $b;
}
2. 编译过程

3. 关键特性
-
单阶段处理:声明和定义在编译期同时完成
-
符号表核心作用:
# Perl符号表结构 %main:: = ( 'add' => { type => 'CV', # 代码值 addr => 0x55c7a12300 # 字节码地址 } ) -
无链接阶段:所有绑定在编译期完成
三、Python:运行时绑定的动态模型
1. 声明与定义
# 定义即声明
def add(a, b):
return a + b
2. 编译执行过程
3. 关键特性
函数对象结构:
class FunctionObject:
__code__ = <字节码> # 函数体
__name__ = "add" # 函数名
__globals__ = {...} # 全局变量
__closure__ = None # 闭包环境
-
编译时机
✅ 模块级编译:Python 在导入模块时将整个.py文件编译为字节码(.pyc),而非执行到def时才编译函数。
❌ 延迟编译(对函数):函数体在模块编译阶段已转换为字节码,执行def语句仅是创建函数对象。 -
动态绑定
✅ 运行时绑定:执行def语句时,才将函数名动态绑定到堆中的函数对象。同一作用域后续的def可重新绑定该名字(覆盖旧函数)。
函数对象结构(CPython 实现):
def example(arg):
x = arg + 1
return x
# 函数对象关键属性
print(type(example)) # → <class 'function'>
print(example.__name__) # → "example"
print(example.__code__) # → <code object at ...>
print(example.__defaults__) # 默认参数元组 (None)
print(example.__closure__) # 闭包变量 (None)
执行过程详解:
模块加载:
调用函数时:
-
-
查找名字对应的函数对象
-
创建新栈帧(frame)
-
执行函数
__code__中的字节码
-
验证示例:
# 模块首次导入时编译整个文件
print("模块初始化执行") # 此语句在导入时立即执行
def func():
print("函数调用")
# 此时 func 已绑定到函数对象,但函数体内的代码尚未执行
func() # 首次调用才执行函数体
输出:
模块初始化执行 函数调用
函数对象内存模型:
1. Java/C#:类加载模型
// 声明和定义合一
public int add(int a, int b) {
return a + b;
}
编译过程:
-
编译期:生成.class/.dll文件
-
运行时:类加载时绑定方法名和字节码
-
JIT编译:将字节码编译为机器码
2. JavaScript:提升(Hoisting)模型
// 函数声明被提升
console.log(add(2,3)); // 正常工作!
function add(a, b) {
return a + b;
}
处理流程:
-
编译期:扫描所有函数声明
-
创建函数对象并绑定到作用域
-
执行期:处理函数调用
六、底层实现细节
1. 函数名绑定机制
| 语言 | 绑定方式 | 技术实现 |
|---|---|---|
| C/C++ | 链接期符号解析 | ELF符号表、重定位表 |
| Perl | 编译期符号表填充 | HV哈希表、GV条目 |
| Python | 运行时命名空间更新 | PyDictObject |
2. 函数体存储格式
| 语言 | 存储格式 | 位置 |
|---|---|---|
| C/C++ | 机器码 | .text段 |
| Perl | OP树 | PL_main_root |
| Python | PyCodeObject | __code__属性 |
3. 调用机制对比

七、为什么需要分离声明和定义?
分离式编译的优势:
-
编译加速:

封装性:隐藏实现细节
-
跨语言支持:通过头文件接口交互
-
库分发:分发头文件+二进制库
合并式编译的优势:
-
开发简便:减少文件管理
-
动态特性:支持运行时定义函数
-
闭包支持:自然捕获词法环境
-
元编程:动态创建/修改函数
八、实践中的函数处理
1. Perl 最佳实践
# 前置声明解决循环依赖
sub inner; # 声明
sub outer {
inner();
}
sub inner {
outer(); # 循环调用
}
2. Python 动态定义
def create_adder(n):
# 运行时定义函数
def adder(x):
return x + n
return adder
add5 = create_adder(5)
print(add5(3)) # 输出8
3. C++ 分离实现
// math.h
#pragma once
int add(int a, int b);
// math.cpp
#include "math.h"
int add(int a, int b) {
return a + b;
}
// main.cpp
#include "math.h"
int main() {
return add(2, 3);
}
总结:函数名与函数体的绑定时机
| 语言类型 | 绑定时机 | 技术特点 | 典型代表 |
|---|---|---|---|
| 静态编译型 | 链接期 | 声明与定义分离 | C/C++ |
| 提前编译脚本 | 编译期 | 声明即定义 | Perl |
| 动态解释型 | 运行时 | 延迟绑定 | Python |
| 虚拟机型 | 类加载期 | 字节码验证 | Java/C# |
理解这些差异有助于:
-
掌握不同语言的编译模型
-
避免跨语言编程时的陷阱
-
优化代码组织和构建过程
-
深入理解编程语言设计哲学
每种模型都有其历史背景和适用场景,现代语言也常融合多种方式(如JIT编译),但核心区别在于函数名与函数体绑定的时机,这决定了语言的灵活性、性能和工程特性。
def add(a, b): ... 语句时发生了什么:
-
函数体在模块加载时编译
整个模块的所有函数体在模块编译阶段就被编译为字节码,不是在执行到def语句时才编译。 -
函数对象在运行时创建
执行到def语句对应的MAKE_FUNCTION字节码时,才创建函数对象并绑定到命名空间。
阶段 1: 模块编译(加载时)
当Python导入模块或执行脚本时:
# 伪代码:模块编译过程
def compile_module(source):
# 1. 解析为AST
ast_tree = parse_to_ast(source)
# 2. 编译所有函数体为字节码
for function_node in ast_tree.function_defs:
# 编译函数体为独立代码对象
function_node.bytecode = compile_function_body(function_node.body)
# 3. 生成模块字节码
module_bytecode = generate_module_bytecode(ast_tree)
return module_bytecode
关键点:
-
所有函数体在模块加载时就被编译
-
函数字节码存储在模块字节码的常量池中
-
此时函数名尚未绑定到函数对象
-
阶段 2: 执行 MAKE_FUNCTION(运行时)
当虚拟机执行到模块字节码中的
MAKE_FUNCTION指令时:# 伪代码:MAKE_FUNCTION指令实现 def execute_MAKE_FUNCTION(vm): # 从栈中获取参数 code_obj = vm.pop() # 预编译的函数体字节码 name = vm.pop() # 函数名 # 创建函数对象 func_obj = FunctionObject( code=code_obj, globals=vm.current_frame.globals, name=name ) # 压回栈顶供STORE_NAME使用 vm.push(func_obj)阶段 3: 执行 STORE_NAME(运行时)
紧接着执行
STORE_NAME指令:def execute_STORE_NAME(vm, name): func_obj = vm.pop() # 获取刚创建的函数对象 current_scope = vm.current_frame.locals # 绑定到当前命名空间 current_scope[name] = func_obj验证实验:证明函数体提前编译
import dis import types # 编译模块但不执行 module_code = compile('def add(a,b): return a+b', '<string>', 'exec') # 从模块常量池获取函数代码对象 add_code = next( c for c in module_code.co_consts if isinstance(c, types.CodeType) and c.co_name == 'add' ) # 查看函数体字节码(尚未执行def语句) print("=== 函数体字节码(未执行def前)===") dis.dis(add_code) # 执行模块字节码 exec(module_code) # 查看运行时函数对象 print("\n=== 运行时函数对象 ===") print(add) # <function add at 0x...> print(add.__code__ is add_code) # True
输出:
=== 函数体字节码(未执行def前)=== 1 0 LOAD_FAST 0 (a) 2 LOAD_FAST 1 (b) 4 BINARY_ADD 6 RETURN_VALUE === 运行时函数对象 === <function add at 0x7f9d5c3b5d30> True修正后的模型解释
1. 函数名处理(编译期)
-
在AST中创建函数定义节点
-
不创建函数对象
-
不绑定函数名到命名空间
2. 函数体处理(编译期)
-
编译函数体为独立的代码对象
-
存储在模块字节码的常量池中
3. 函数对象创建(运行时)
-
执行
MAKE_FUNCTION指令时创建函数对象 -
不重新编译函数体(使用预编译的代码对象)
4. 函数名绑定(运行时)
-
执行
STORE_NAME指令时绑定函数名 -
在当前作用域添加名称->函数对象的映射
我混淆了两个重要概念:
-
函数体编译:发生在模块加载时(编译期)
-
函数对象实例化:发生在执行
def语句时(运行时)
在Python中,
def语句实际上对应两条字节码:LOAD_CONST <code_object> # 加载预编译的函数体 MAKE_FUNCTION # 创建函数对象 STORE_NAME # 绑定函数名
对比 Perl 模型
特性 Python Perl 函数体编译 模块加载时 编译期 函数对象创建 执行def时 编译期(outer)/运行时(inner) 函数名绑定 执行def时 编译期(outer)/运行时(inner) 字节码存储 模块常量池 符号表 闭包处理 函数对象中 魔法变量 总结:Python 的函数处理流程
-
模块加载时:
-
编译所有函数体为字节码
-
存储在模块字节码的常量池中
-
-
执行def语句时:
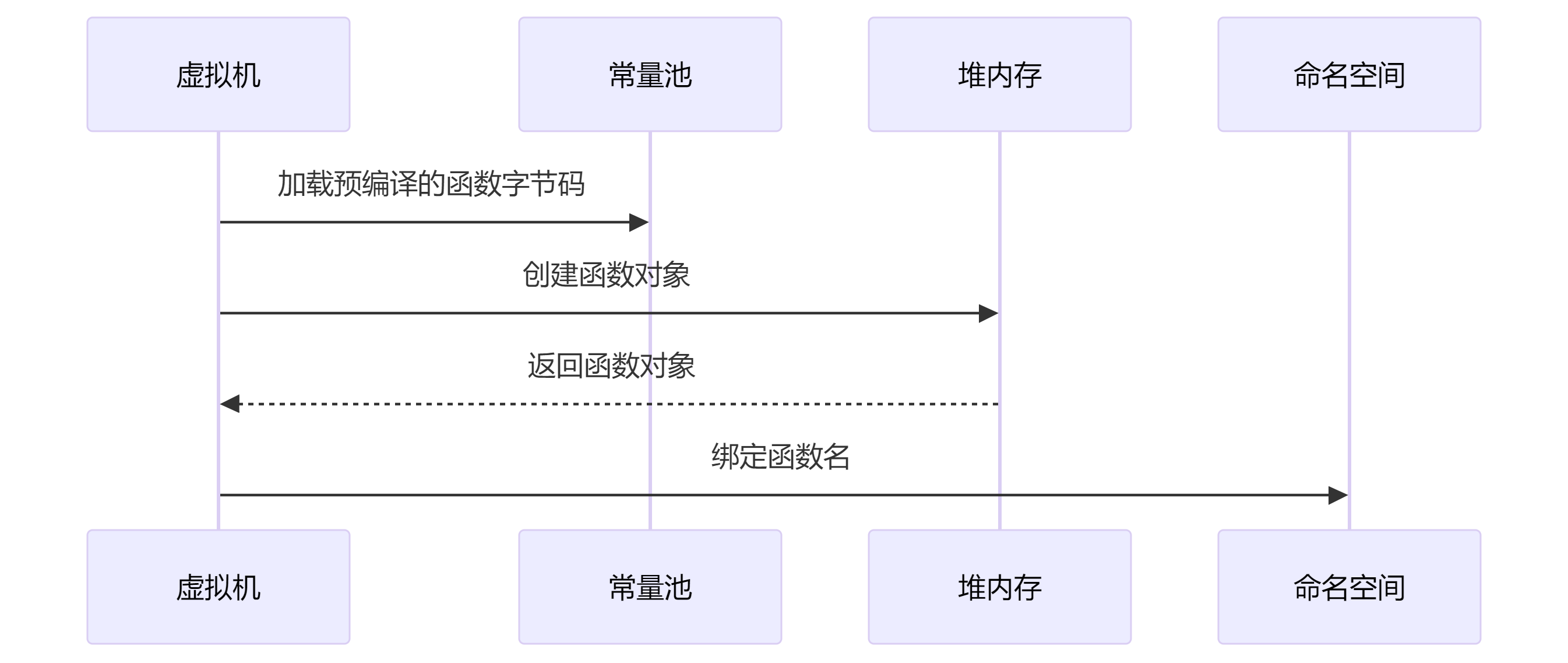
-
后续调用:
-
直接使用已绑定的函数对象
-
执行预编译的函数体字节码
-
1. 什么是"预编译"?
-
时间点:模块加载时(import或执行脚本时)
-
操作:将Python源代码转换为字节码
-
特点:
-
发生在任何代码执行之前
-
整个模块的所有函数体都被编译
-
结果被缓存(.pyc文件或内存)
-
2. 预编译 vs 即时编译(JIT)
特性 预编译 即时编译(JIT) 时机 执行前 运行时 单元 整个模块 热点代码 缓存 磁盘.pyc文件 内存缓存 优化 基本优化 激进优化 代表 Python PyPy, Java HotSpot -
-
这种设计确保了:
-
函数体只编译一次(高效)
-
每次执行
def创建新函数对象(支持闭包) -
函数名在定义后立即可用(符合直觉)
感谢您指出矛盾,这帮助我提供了更精确的解释!Python 的编译模型确实很独特:函数体在编译期处理,而函数对象的创建和绑定在运行时完成。
-
-
-
3. 验证实验
实验1:编译期函数名不存在
# 编译阶段尝试访问函数名
try:
print(add) # 编译期函数名不存在
except NameError as e:
print(f"编译期错误: {e}")
# 函数定义
def add(a, b):
return a + b
# 运行时访问
print("运行时:", add) # <function add at 0x...>
输出:
编译期错误: name 'add' is not defined 运行时: <function add at 0x7f9d5c3b5d30>
实验2:多次执行定义
def create_adder():
print(">>> 执行 def 语句")
def adder(x):
return x + 10
return adder
# 首次调用
print("第一次调用:")
func1 = create_adder()
print(func1(5)) # 15
# 二次调用
print("\n第二次调用:")
func2 = create_adder()
print(func2(5)) # 15
print("\n函数对象相同:", func1 is func2)
print("函数代码相同:", func1.__code__ is func2.__code__)
输出:
第一次调用: >>> 执行 def 语句 15 第二次调用: >>> 执行 def 语句 15 函数对象相同: False 函数代码相同: True # 函数体字节码被复用
函数名在编译和执行过程中的变化
-
源代码中的标识符 :在源代码中,函数名就是一个普通的标识符,用于定义函数,例如在
def func_name():中,func_name是一个标识符。 -
词法分析(生成 token 流) :词法分析器会将源代码转换成一系列的 token。函数名会被识别为一个标识符 token(
NAME类型的 token)。 -
语法分析(生成 AST 树) :语法分析器会根据 Python 的语法规则,将 token 流解析成抽象语法树(AST)。在 AST 中,函数定义会被表示为一个
FunctionDef节点。这个节点包含了函数名(作为name属性)、函数的参数(args属性)、函数体(body属性)等信息。此时,函数名作为FunctionDef节点的一个属性存在。 -
语义分析 :主要进行类型检查、作用域分析等。对于函数名来说,语义分析会确定它的作用域(全局、局部等),确保函数在正确的范围内被引用。如果函数名在同一个作用域中有重复定义,会报错。
-
生成字节码 :Python 会将 AST 转换为字节码。字节码中并不直接包含函数名,而是包含函数定义的指令。函数名在字节码中主要体现在函数对象的创建和引用上。当函数被调用时,解释器会根据字节码中的指令来定位和执行对应的函数。
-
执行阶段(函数对象的创建和绑定) :当 Python 解释器执行到
def语句时,会根据 AST 中的FunctionDef节点来创建一个函数对象。这个函数对象会包含函数的代码、参数信息、默认值、闭包等信息。随后,Python 会将函数名(标识符)与这个函数对象进行绑定,也就是在当前的作用域(通常是全局作用域或包含该函数定义的局部作用域)中,将函数名作为键,函数对象作为值,存入相应的符号表中。,这样后续通过函数名就可以引用到对应的函数对象了。
原因如下:
-
便于处理 :将源代码分解为 token,可以让后续的编译过程更高效地处理代码。每个 token 都有其特定的类型(如关键字、标识符、运算符等),这样编译器就可以快速识别代码中的元素并进行相应的处理,而不是直接处理原始的、连续的字符序列。
-
统一表示 :token 为源代码提供了一种统一的表示方式。不同的编程语言可能有不同的语法和语义,但通过将它们的源代码转换为 token,可以在一定程度上简化编译器的设计和实现,使得编译器能够以一种相对通用的方式处理不同的语言。
-
语义关联 :每个 token 都与其在编程语言中的语义相关联。例如,关键字 token 代表特定的语言结构(如
if用于条件语句),标识符 token 用于表示变量、函数等的名称,运算符 token 表示相应的操作等。这种语义关联有助于编译器理解代码的含义,并生成正确的中间代码或目标代码。
.__code__ 是用来访问函数对象的代码对象的。.__code__ 属性,可以获取这些信息。func:def func():
print("Hello, World!")code_obj = func.__code__code_obj 是一个 code 对象,它包含以下信息:-
co_code :字节码。
-
co_consts :常量池。
-
co_names :全局变量名列表。
-
co_varnames :局部变量名列表。
-
co_filename :函数定义所在的文件名。
-
co_firstlineno :函数定义所在的行号。
co_code:print(code_obj.co_code)import dis
def func():
print("Hello, World!")
code_obj = func.__code__
print("co_code:", code_obj.co_code)
print("co_consts:", code_obj.co_consts)
print("co_names:", code_obj.co_names)
print("co_varnames:", code_obj.co_varnames)
print("co_filename:", code_obj.co_filename)
print("co_firstlineno:", code_obj.co_firstlineno)
# 反汇编字节码
dis.dis(func)co_code: b'd\x00\x00\x83\x00\x00S\x00\x00'
co_consts: (None, 'Hello, World!')
co_names: ('print',)
co_varnames: ()
co_filename: <stdin>
co_firstlineno: 1
1 0 LOAD_CONST 1 ('Hello, World!')
2 LOAD_CONST 0 (None)
4 RETURN_VALUEdis.dis(func) 用于反汇编函数的字节码,输出每条指令的含义。代码对象和函数对象的区别
1. 概念不同
-
代码对象(Code Object) : 代码对象是 Python 编译过程的产物,它代表了一段可执行的代码。代码对象包含了字节码、常量池、局部变量表、全局变量名列表等信息。代码对象本身并不包含执行环境的信息,它只是一个代码的表示形式。代码对象可以通过
__code__属性从函数对象中获取。 -
函数对象(Function Object) : 函数对象是 Python 中的
def语句执行时创建的对象。它不仅包含了代码对象,还包含了函数的执行环境信息,例如默认参数、闭包变量、函数的命名空间等。函数对象是可调用的,当调用函数时,Python 解释器会根据函数对象中的代码对象来执行相应的字节码。
2. 包含的信息不同
-
代码对象包含的信息 :
-
co_code: 字节码。 -
co_consts: 常量池。 -
co_names: 全局变量名列表。 -
co_varnames: 局部变量名列表。 -
co_filename: 函数定义所在的文件名。 -
co_firstlineno: 函数定义所在的行号。 -
co_flags: 代码对象的标志(例如是否包含嵌套代码、是否使用了生成器等)。 -
co_lnotab: 行号表,用于将字节码的偏移量映射到源代码的行号。
-
-
函数对象包含的信息 :
-
__code__: 代码对象。 -
__defaults__: 默认参数值。 -
__kwdefaults__: 带关键字的默认参数值。 -
__globals__: 函数的全局命名空间。 -
__closure__: 闭包变量(如果函数是闭包的一部分)。 -
__name__: 函数的名称。 -
__doc__: 函数的文档字符串。
-
3. 生命周期不同
-
代码对象的生命周期 : 代码对象是在编译阶段生成的,它在 Python 程序的执行过程中存在。只要函数对象存在,其对应的代码对象就存在。代码对象也可以通过
compile()函数单独生成,用于动态执行代码。 -
函数对象的生命周期 : 函数对象是在执行阶段,当 Python 解释器遇到
def语句时创建的。函数对象的生命周期取决于其作用域。如果函数是在模块级别定义的,函数对象会在模块加载时创建,并且在模块存在期间一直存在。如果函数是在局部作用域中定义的(例如在另一个函数中),函数对象会在其定义的作用域存在期间存在。
4. 关联性
-
代码对象和函数对象的关联 : 函数对象包含一个代码对象(通过
__code__属性访问)。代码对象定义了函数的代码逻辑,而函数对象则提供了执行这段代码所需的上下文环境。没有函数对象,代码对象本身无法执行,因为它缺少执行所需的上下文信息(例如局部变量、全局变量、默认参数等)。
__call__ 方法是 Python 中实现函数调用的核心机制之一,但调用函数对象的方式不仅仅依赖于 __call__,还有更多细节。函数调用的过程
-
查找函数对象
-
当在代码中使用函数名调用函数时,Python 解释器首先会在当前作用域链中查找该函数名。作用域链的查找顺序遵循 LEGB(Local、Enclosing、Global、Built - in)规则。
-
例如,在一个函数内部调用另一个函数,解释器会先在局部作用域(Local)查找该函数名;如果找不到,会查找外层封闭作用域(Enclosing);如果还是找不到,会查找全局作用域(Global);最后会查找内置作用域(Built - in)。
-
-
调用函数对象
-
如果找到了函数名对应的函数对象,Python 解释器会调用该函数对象的
__call__方法。__call__是一个特殊的方法,它使得对象是“可调用的”。 -
例如,对于一个函数对象
func,调用它就像这样:func()。实际上,Python 会执行func.__call__()。这个方法负责设置函数调用的上下文,如参数传递、创建新的栈帧等。
-
-
创建栈帧
-
在调用函数对象的
__call__方法时,Python 解释器会创建一个新的栈帧。栈帧用于存储函数调用过程中的各种信息,包括局部变量、参数、返回地址等。 -
栈帧的创建是由 Python 解释器底层实现的,它与函数对象的
__call__方法调用紧密相关。具体来说,当__call__方法被调用时,解释器会分配内存来创建栈帧,并将相关的信息(如函数参数)存储在其中。
-
代码示例
def func(a, b):
print("Function called with a = {}, b = {}".format(a, b))
return a + b
# 查找函数对象
# 在全局作用域找到 func 函数对象
result = func(3, 4) # 调用函数对象的 __call__ 方法-
func是一个函数对象。 -
当调用
func(3, 4)时,Python 解释器查找并找到func函数对象,然后调用它的__call__方法。 -
在调用
__call__方法的过程中,解释器创建一个新的栈帧来存储函数调用的相关信息,例如参数a和b的值。
__call__ 方法。在调用 __call__ 方法的过程中,Python 解释器会创建一个新的栈帧来管理函数调用的上下文。1.词法分析和语法分析
-
词法分析 :源代码被分解为一系列的 token。
-
语法分析 :根据 Python 的语法规则,将 token 流解析成抽象语法树(AST)。AST 是源代码的树状表示,反映了代码的结构和逻辑。
2.生成代码对象
-
AST 树的遍历和转换 :Python 编译器会遍历 AST 树,并将其转换为中间表示形式,最终生成代码对象。代码对象包含字节码、常量池、局部变量表等信息。这个过程是在 AST 树生成之后进行的。
3.代码对象的生成
-
字节码生成 :在生成代码对象的过程中,AST 树的每个节点会被转换为相应的字节码指令。字节码是 Python 虚拟机可执行的低级指令。
-
常量池和变量表的构建 :代码对象还会包含常量池(存储字面量值)和局部变量表(存储局部变量的名称)等信息。
4.执行阶段
-
函数对象的创建 :当 Python 解释器执行到
def语句时,会根据代码对象创建一个函数对象。函数对象包含代码对象以及执行代码所需的上下文信息(如默认参数、闭包变量等)。 -
函数调用 :当函数被调用时,Python 解释器会根据函数对象中的代码对象来执行字节码。
co_consts的属性形式体现。1.局部变量存储
-
栈帧为函数调用期间的局部变量提供存储空间。当进入一个函数时,所有在该函数内部定义的局部变量都会被存储在栈帧中。
-
例如:
def func():
a = 1
b = "hello"
print(a, b)
func()func 函数时,栈帧会为变量 a 和 b 分配空间,存储它们的值。2.参数传递
-
栈帧负责存储传递给函数的参数。当调用一个带有参数的函数时,传递的参数值会被存储在栈帧中,方便函数内部使用。
-
例如:
def add(a, b):
return a + b
result = add(3, 5)add 函数时,参数 3 和 5 会被存储在栈帧中,供函数内部的 a 和 b 使用。3.返回地址存储
-
栈帧存储了函数调用后的返回地址。当函数执行完毕后,解释器会根据返回地址继续执行调用该函数的代码。
-
例如:
def func():
print("Hello")
print("Before function call")
func()
print("After function call")func 函数之前,解释器会将调用 func 后的代码地址(即 print("After function call") 的位置)存储在栈帧中。当 func 执行完毕后,解释器根据这个返回地址继续执行后续代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号