数据采集第三次作业
作业1
相关代码与结果
代码
单线程代码如下:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
import urllib.parse
class WeatherImageDownloader:
def __init__(self):
self.download_count = 0
self.max_images = 15 # 学号尾数15
self.session = requests.Session()
self.session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
})
def setup_environment(self):
"""设置下载环境"""
download_dir = "downloaded_images"
if not os.path.exists(download_dir):
os.makedirs(download_dir)
print(f"创建下载目录: {download_dir}")
return download_dir
def fetch_page_content(self, url):
"""获取页面内容"""
try:
response = self.session.get(url, timeout=15)
response.encoding = 'utf-8'
return response.text
except Exception as e:
print(f"页面获取失败: {e}")
return None
def extract_image_links(self, html_content, base_url):
"""从HTML中提取图片链接"""
image_links = []
soup = BeautifulSoup(html_content, 'html.parser')
img_elements = soup.find_all('img')
print(f"发现 {len(img_elements)} 个图片标签")
for img in img_elements:
if self.download_count >= self.max_images:
break
src = img.get('src') or img.get('data-src')
if src:
# 构建完整URL
if src.startswith('//'):
full_url = 'https:' + src
elif src.startswith('http'):
full_url = src
else:
full_url = urllib.parse.urljoin(base_url, src)
if full_url not in image_links:
image_links.append(full_url)
print(f"添加图片链接: {full_url}")
return image_links
def download_image_file(self, img_url, save_path, file_index):
"""下载单个图片文件"""
try:
response = self.session.get(img_url, timeout=20, stream=True)
if response.status_code == 200:
# 获取文件扩展名
file_ext = self.get_file_extension(img_url, response.headers.get('content-type', ''))
filename = f"img_{file_index}{file_ext}"
full_path = os.path.join(save_path, filename)
with open(full_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
self.download_count += 1
print(f"✓ 成功下载 [{self.download_count}/{self.max_images}]: {filename}")
return True
except Exception as e:
print(f"✗ 下载失败 {img_url}: {e}")
return False
def get_file_extension(self, url, content_type):
"""确定文件扩展名"""
# 从URL中提取扩展名
if '.' in url:
path = url.split('?')[0]
ext = '.' + path.split('.')[-1].lower()
if ext in ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp']:
return ext
# 从Content-Type判断
if 'jpeg' in content_type or 'jpg' in content_type:
return '.jpg'
elif 'png' in content_type:
return '.png'
elif 'gif' in content_type:
return '.gif'
elif 'webp' in content_type:
return '.webp'
return '.jpg'
def execute_download(self, target_url):
"""执行下载任务"""
print(f"开始单线程图片下载任务,目标数量: {self.max_images}")
start_time = time.time()
download_dir = self.setup_environment()
# 获取页面内容
html = self.fetch_page_content(target_url)
if not html:
print("无法获取页面内容,任务终止")
return
# 提取图片链接
image_urls = self.extract_image_links(html, target_url)
print(f"共提取到 {len(image_urls)} 个有效图片链接")
# 下载图片
for idx, img_url in enumerate(image_urls):
if self.download_count >= self.max_images:
break
self.download_image_file(img_url, download_dir, idx + 1)
end_time = time.time()
print(f"\n下载任务完成! 成功下载 {self.download_count} 张图片")
print(f"总耗时: {end_time - start_time:.2f} 秒")
# 主程序
if __name__ == "__main__":
downloader = WeatherImageDownloader()
weather_url = "http://www.weather.com.cn/weather/101280601.shtml"
downloader.execute_download(weather_url)
多线程代码如下:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import threading
import time
import urllib.parse
from concurrent.futures import ThreadPoolExecutor, as_completed
class ConcurrentImageDownloader:
def __init__(self, max_workers=5):
self.downloaded = 0
self.max_images = 15
self.lock = threading.Lock()
self.max_workers = max_workers
self.session = requests.Session()
self.session.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
})
self.should_stop = False
def prepare_directory(self):
"""准备存储目录"""
output_dir = "concurrent_images"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
return output_dir
def get_webpage(self, url):
"""获取网页内容"""
try:
resp = self.session.get(url, timeout=10)
resp.encoding = 'utf-8'
return resp.text
except Exception as e:
print(f"网页请求异常: {e}")
return None
def parse_image_urls(self, html_doc, base_domain):
"""解析图片URL"""
found_urls = []
soup = BeautifulSoup(html_doc, 'html.parser')
for img_tag in soup.find_all('img'):
# 检查停止标志
if self.should_stop:
break
img_src = img_tag.get('src') or img_tag.get('data-src')
if img_src:
# 规范化URL
if img_src.startswith('//'):
complete_url = 'https:' + img_src
elif img_src.startswith('/'):
complete_url = urllib.parse.urljoin(base_domain, img_src)
elif not img_src.startswith('http'):
complete_url = urllib.parse.urljoin(base_domain, img_src)
else:
complete_url = img_src
if complete_url not in found_urls:
found_urls.append(complete_url)
return found_urls
def save_single_image(self, task_data):
"""保存单张图片"""
url, index, save_folder = task_data
# 在下载前再次检查是否应该停止
if self.should_stop:
return None
try:
response = self.session.get(url, timeout=25, stream=True)
if response.status_code == 200:
# 在写入文件前获取锁并检查数量
with self.lock:
if self.downloaded >= self.max_images:
self.should_stop = True
return None
# 确定文件扩展名
extension = self.determine_extension(url, response.headers.get('content-type', ''))
file_name = f"picture_{index}{extension}"
full_path = os.path.join(save_folder, file_name)
# 写入文件
with open(full_path, 'wb') as file_obj:
for data_chunk in response.iter_content(chunk_size=8192):
file_obj.write(data_chunk)
self.downloaded += 1
current_count = self.downloaded
print(f"线程下载完成 [{current_count}/{self.max_images}]: {file_name}")
# 检查是否达到最大数量
if current_count >= self.max_images:
with self.lock:
self.should_stop = True
return file_name
except Exception as e:
print(f"✗ 下载出错 {url}: {e}")
return None
def determine_extension(self, url, mime_type):
"""确定文件扩展名"""
valid_extensions = ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp']
# 从URL路径提取
path_segments = url.split('/')
if path_segments:
last_segment = path_segments[-1].split('?')[0]
if '.' in last_segment:
potential_ext = '.' + last_segment.split('.')[-1].lower()
if potential_ext in valid_extensions:
return potential_ext
# 从MIME类型判断
type_mapping = {
'image/jpeg': '.jpg',
'image/jpg': '.jpg',
'image/png': '.png',
'image/gif': '.gif',
'image/webp': '.webp',
'image/bmp': '.bmp'
}
return type_mapping.get(mime_type, '.jpg')
def run_concurrent_download(self, start_url):
"""运行并发下载"""
print(f"启动多线程下载,工作线程: {self.max_workers}, 目标数量: {self.max_images}")
begin_time = time.time()
storage_dir = self.prepare_directory()
page_content = self.get_webpage(start_url)
if not page_content:
return
image_list = self.parse_image_urls(page_content, start_url)
print(f"解析获得 {len(image_list)} 个图片资源")
download_tasks = []
for i, image_url in enumerate(image_list):
with self.lock:
if self.downloaded >= self.max_images:
break
task = (image_url, i + 1, storage_dir)
download_tasks.append(task)
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
futures = []
for task in download_tasks:
if self.should_stop:
break
future = executor.submit(self.save_single_image, task)
futures.append(future)
completed_count = 0
for future in as_completed(futures):
if self.should_stop and completed_count >= self.max_images:
for f in futures:
f.cancel()
executor.shutdown(wait=False)
break
try:
future.result(timeout=30)
completed_count += 1
except Exception as e:
print(f"任务执行异常: {e}")
end_time = time.time()
actual_downloaded = min(self.downloaded, self.max_images)
print(f"\n并发下载结束! 实际下载: {actual_downloaded} 张图片")
print(f"总用时: {end_time - begin_time:.2f} 秒")
# 执行多线程下载
if __name__ == "__main__":
concurrent_downloader = ConcurrentImageDownloader(max_workers=6)
target_website = "http://www.weather.com.cn/weather/101280601.shtml"
concurrent_downloader.run_concurrent_download(target_website)
结果
单线程结果:
多线程结果:
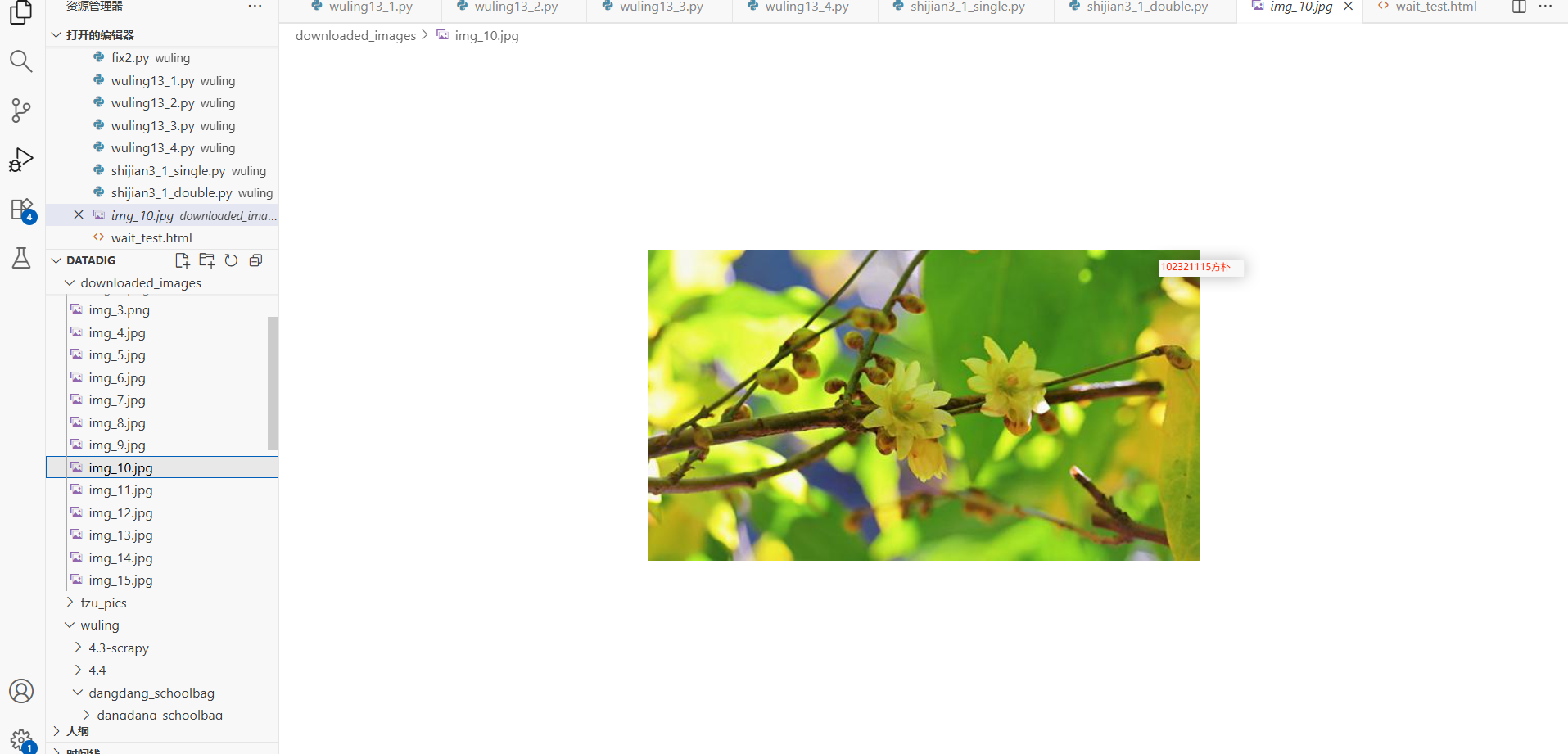
爬取图片:
作业2
相关代码与结果
代码
item.py:
点击查看代码
import scrapy
class StockItem(scrapy.Item):
# 股票数据字段定义
record_no = scrapy.Field() # 记录序号
stock_id = scrapy.Field() # 股票代码
stock_title = scrapy.Field() # 股票名称
current_val = scrapy.Field() # 当前价格
change_pct = scrapy.Field() # 涨跌百分比
change_amt = scrapy.Field() # 涨跌金额
trade_qty = scrapy.Field() # 交易数量
price_swing = scrapy.Field() # 价格波动
spider.py:
点击查看代码
import scrapy
import json
import re
from stock_crawler.items import StockItem
class StockDataSpider(scrapy.Spider):
name = "stock_data"
allowed_domains = ["eastmoney.com"]
def start_requests(self):
"""生成初始请求"""
base_api = "http://quote.eastmoney.com/center/api/sidemenu.json"
yield scrapy.Request(url=base_api, callback=self.process_api_response)
def process_api_response(self, response):
"""处理API响应"""
try:
market_info = json.loads(response.text)
# 生成股票数据页面请求
for page in range(1, 6):
page_url = f"http://quote.eastmoney.com/center/gridlist.html#p={page}"
yield scrapy.Request(url=page_url, callback=self.extract_stock_data,
meta={'page_num': page})
except Exception as e:
self.logger.error(f"API处理失败: {e}")
def extract_stock_data(self, response):
"""提取股票数据"""
current_page = response.meta['page_num']
self.logger.info(f"处理第 {current_page} 页数据")
# 提取股票行数据
data_rows = response.xpath('//table[contains(@class, "table")]//tr[position()>1]')
for row_idx, row in enumerate(data_rows):
item = StockItem()
global_idx = (current_page - 1) * len(data_rows) + row_idx + 1
# 提取数据单元格
cells = row.xpath('./td')
if len(cells) >= 8:
item['record_no'] = str(global_idx)
item['stock_id'] = self.clean_content(cells[1].xpath('string(.)').get())
item['stock_title'] = self.clean_content(cells[2].xpath('string(.)').get())
item['current_val'] = self.clean_content(cells[3].xpath('string(.)').get())
item['change_pct'] = self.clean_content(cells[4].xpath('string(.)').get())
item['change_amt'] = self.clean_content(cells[5].xpath('string(.)').get())
item['trade_qty'] = self.clean_content(cells[6].xpath('string(.)').get())
item['price_swing'] = self.clean_content(cells[7].xpath('string(.)').get())
if global_idx <= 5:
self.logger.info(f"处理股票: {item['stock_id']} - {item['stock_title']}")
yield item
self.logger.info(f"第 {current_page} 页数据处理完成")
def clean_content(self, text):
"""清理文本内容"""
if text:
return re.sub(r'\s+', ' ', text).strip()
return ""
pipelines.py:
点击查看代码
import sqlite3
import os
class DataStoragePipeline:
def __init__(self, db_path):
self.db_path = db_path
self.conn = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
db_path = crawler.settings.get('SQLITE_DB_PATH', 'stock_info.db')
return cls(db_path)
def open_spider(self, spider):
# 确保目录存在
os.makedirs(os.path.dirname(self.db_path), exist_ok=True)
self.conn = sqlite3.connect(self.db_path)
self.cursor = self.conn.cursor()
self.setup_table()
spider.logger.info("SQLite数据库连接成功")
def setup_table(self):
"""设置数据表"""
table_sql = """
CREATE TABLE IF NOT EXISTS stock_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
record_no TEXT,
stock_id TEXT NOT NULL UNIQUE,
stock_title TEXT,
current_val REAL,
change_pct REAL,
change_amt REAL,
trade_qty TEXT,
price_swing REAL
)
"""
self.cursor.execute(table_sql)
self.conn.commit()
def process_item(self, item, spider):
"""处理数据项"""
insert_sql = """
INSERT OR REPLACE INTO stock_records
(record_no, stock_id, stock_title, current_val, change_pct, change_amt, trade_qty, price_swing)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
"""
try:
self.cursor.execute(insert_sql, (
item['record_no'],
item['stock_id'],
item['stock_title'],
self.to_float(item['current_val']),
self.to_percent(item['change_pct']),
self.to_float(item['change_amt']),
item['trade_qty'],
self.to_percent(item['price_swing'])
))
self.conn.commit()
spider.logger.info(f"数据保存: {item['stock_id']} - {item['stock_title']}")
except Exception as e:
spider.logger.error(f"保存失败 {item['stock_id']}: {e}")
return item
def to_float(self, value):
"""转换为浮点数"""
if not value:
return 0.0
try:
cleaned = value.replace(',', '').replace('--', '0').strip()
return float(cleaned) if cleaned else 0.0
except:
return 0.0
def to_percent(self, value):
"""转换百分比"""
if not value:
return 0.0
try:
cleaned = value.replace('%', '').replace(',', '').replace('--', '0').strip()
return float(cleaned) if cleaned else 0.0
except:
return 0.0
def close_spider(self, spider):
if self.conn:
self.conn.close()
spider.logger.info("数据库连接关闭")
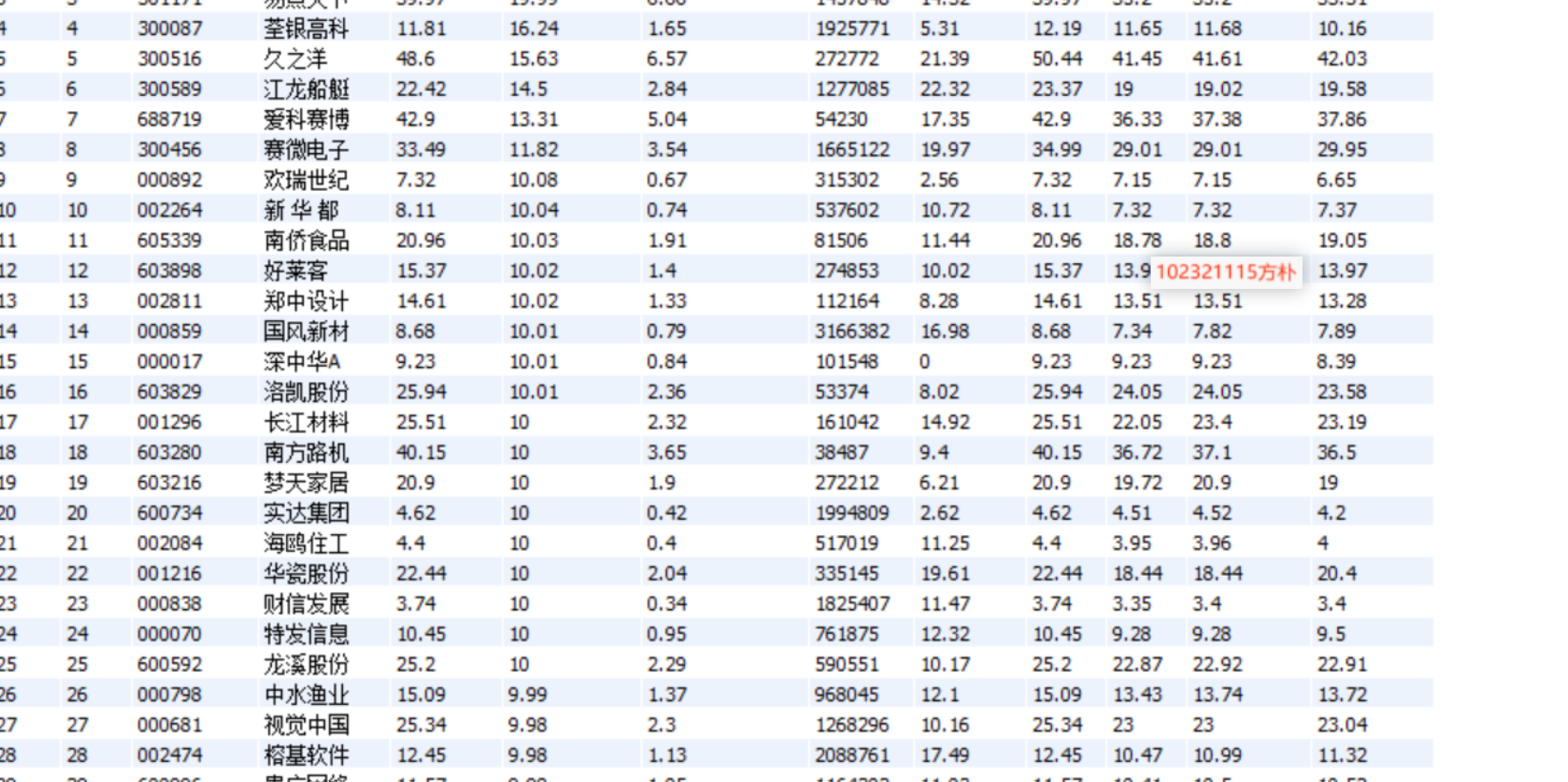
作业3
相关代码与结果
代码
items.py:
点击查看代码
import scrapy
class ForexDataItem(scrapy.Item):
# 外汇数据字段定义
currency = scrapy.Field() # 货币名称
telegraphic_buy = scrapy.Field() # 现汇买入价
cash_buy = scrapy.Field() # 现钞买入价
telegraphic_sell = scrapy.Field() # 现汇卖出价
cash_sell = scrapy.Field() # 现钞卖出价
central_rate = scrapy.Field() # 中间汇率
pub_date = scrapy.Field() # 发布日期
pub_time = scrapy.Field() # 发布时间
spiders.py:
点击查看代码
import scrapy
from stock_crawler.items import ForexDataItem
class ForexRateSpider(scrapy.Spider):
name = "forex_rates"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
"""解析外汇数据"""
self.logger.info("开始获取外汇汇率数据")
# 定位数据行
data_rows = response.xpath('//table[@cellpadding="0" and @cellspacing="0"]/tr[position()>1]')
self.logger.info(f"发现 {len(data_rows)} 行外汇数据")
for idx, row in enumerate(data_rows):
item = ForexDataItem()
# 提取各字段数据
cells = row.xpath('./td')
if len(cells) >= 7:
item['currency'] = self.get_cell_text(cells[0])
item['telegraphic_buy'] = self.get_cell_text(cells[1])
item['cash_buy'] = self.get_cell_text(cells[2])
item['telegraphic_sell'] = self.get_cell_text(cells[3])
item['cash_sell'] = self.get_cell_text(cells[4])
item['central_rate'] = self.get_cell_text(cells[5])
# 处理发布时间
datetime_text = self.get_cell_text(cells[6])
date_part, time_part = self.split_datetime(datetime_text)
item['pub_date'] = date_part
item['pub_time'] = time_part
# 验证数据
self.validate_item(item)
if idx < 5:
self.logger.info(f"外汇: {item['currency']} 买入: {item['telegraphic_buy']}")
yield item
self.logger.info("外汇数据解析完成")
def get_cell_text(self, cell):
"""获取单元格文本"""
text = cell.xpath('string(.)').get()
return text.strip() if text else ""
def split_datetime(self, datetime_str):
"""分割日期时间"""
if not datetime_str:
return "", ""
parts = datetime_str.split()
if len(parts) >= 2:
return parts[0], parts[1]
return datetime_str, ""
def validate_item(self, item):
"""验证数据项"""
for field in ['telegraphic_buy', 'cash_buy', 'telegraphic_sell', 'cash_sell']:
if not item[field]:
item[field] = '0.0000'
结果
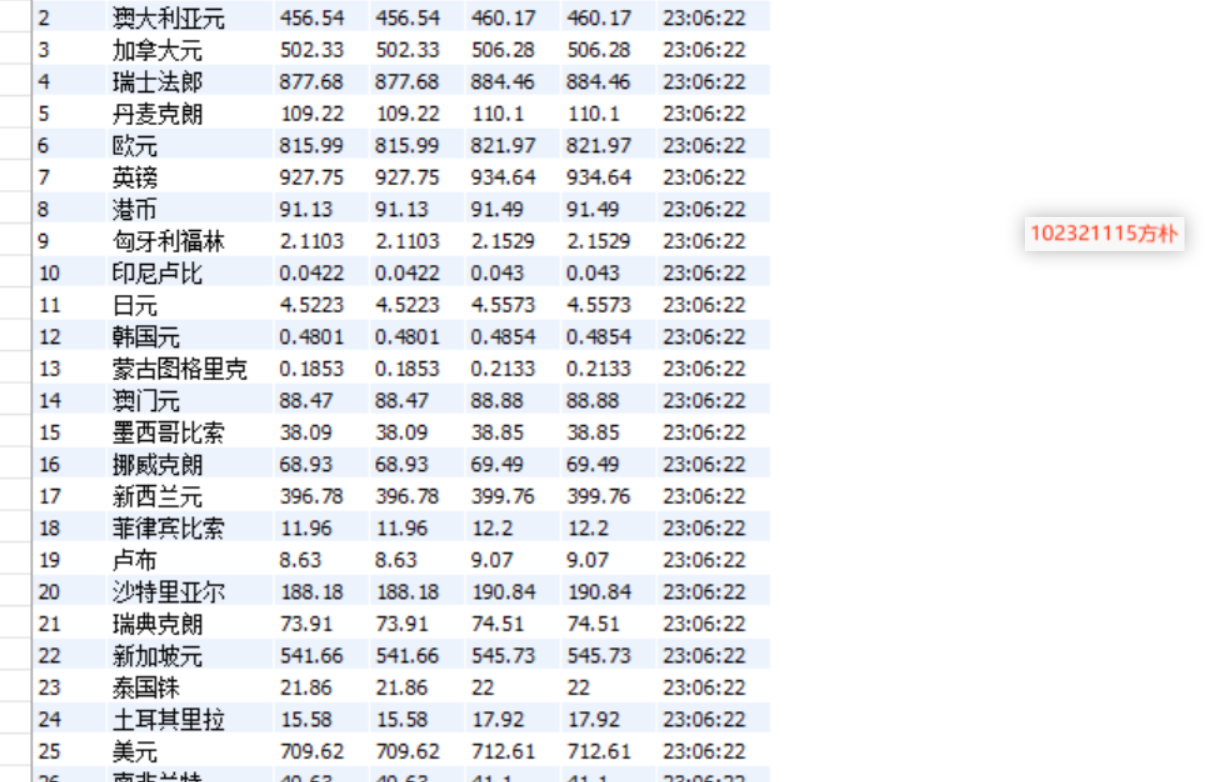
实验心得体会:
第一题:图片爬取
单线程爬取效率较低,改用多线程后下载速度显著提升。过程中需要精确控制并发数量,避免因抓取过多导致数据混乱或数量不足。同时,存储路径需设置正确,确保图片能顺利保存至指定文件夹。
第二题:股票数据采集
初始尝试直接抓取页面未获取到数据,后续发现需通过接口获取。使用Scrapy框架时,通过Item定义数据字段并结合Pipeline写入MySQL,提高了数据存储的便捷性。关键点在于字段与数据库表结构需准确对应,否则将影响数据入库。
第三题:外汇数据抓取
整体流程与作业二类似,但需根据实际数据调整Item与Pipeline中的字段映射。在抓取银行网站时,必须准确定位页面元素,否则获取的汇率信息可能出现错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号