102302115方朴第一次作业
102302115方朴第一次作业
任务1
代码及运行结果
import requests
from bs4 import BeautifulSoup
target_url = "http://www.shanghairanking.cn/rankings/bcur/2020"
res = requests.get(target_url)
res.encoding = "utf-8"
soup_obj = BeautifulSoup(res.text, "html.parser")
#通过BeauttifulSoup定位包含大学信息的表格行
uni_rows = soup_obj.find_all('tr', attrs={'data-v-389300f0': ''})
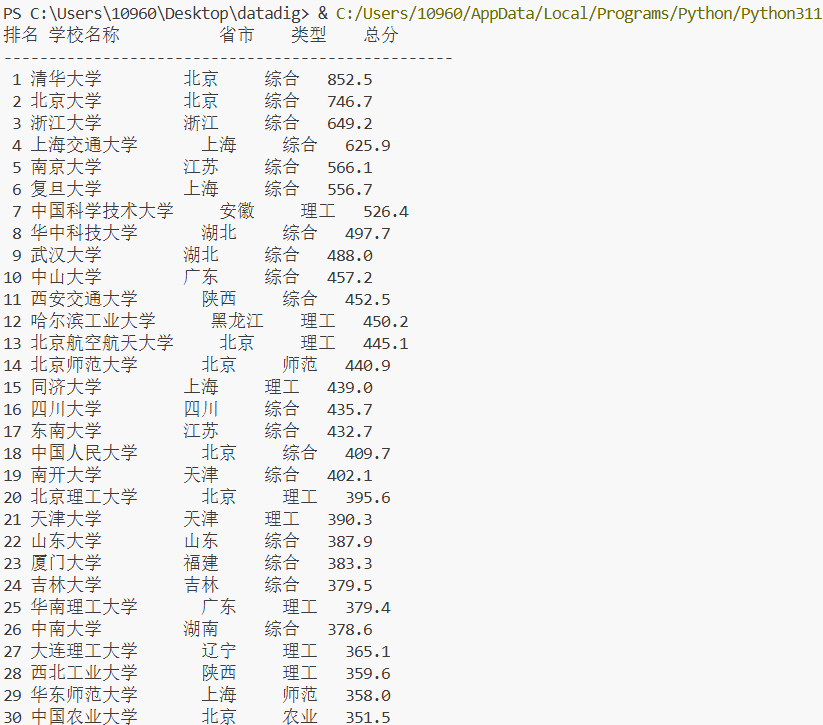
print("排名 学校名称\t\t省市\t类型\t总分")
print("-" * 50)
#提取打印各大学信息
for row in uni_rows:
rank_elem = row.find("div", class_="ranking")
if rank_elem:
tds = row.find_all('td')
if len(tds) >= 5:
rank = rank_elem.get_text().strip()
cn_name = tds[1].find("span", class_="name-cn")
uni_name = cn_name.get_text().strip() if cn_name else "未知"
province = tds[2].get_text().strip()
uni_type = tds[3].get_text().strip()
total_score = tds[4].get_text().strip()
print(f"{rank:>2} {uni_name:12} {province:6} {uni_type:4} {total_score:4}")
心得体会
这次实验其实特简单,就是爬一个数据会动态加载的网页。解析数据我用的是BeautifulSoup,具体就是找那些带data-v-389300f0属性的td表格单元格,从里面把数据抠出来。最后用f-string把每列宽度固定好,左对齐,这样输出的时候排版才规整。
说真的,做完这个我才明白,写爬虫最难的根本不是代码语法——那些东西查一查就会了,真正费劲的是你得搞懂目标网页的DOM结构到底是咋回事。毕竟你连数据藏在哪个标签、哪个属性下面都摸不清,代码写得再溜也白搭。
任务2
代码及运行结果
import urllib.request
import re
#淘宝以及京东的反爬机制比较好,所以这里对当当网进行爬取
target_url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab"
#获取页面内容并解码
try:
page_conn = urllib.request.urlopen(target_url, timeout=3)
page_content = page_conn.read().decode('gb2312')
except Exception as e:
print(f"获取页面失败: {e}")
page_content = ""
#匹配商品列表项<li>标签
li_regex = re.compile(r'<li[^>]*?>(.*?)</li>', re.S)
#提取所有符合的<li>内容
li_items = li_regex.findall(page_content)
#匹配商品名称
title_regex = re.compile(r'<a\s*?title="\s*([^"]*?)"', re.S)
#再匹配商品价格
price_regex = re.compile(r'<span class="price_n">(.*?)</span>', re.S)
#遍历提取有效信息并打印
for li in li_items:
#提取商品名称列表
name_list = title_regex.findall(li)
#再提取价格列表
price_list = price_regex.findall(li)
if name_list and price_list:
product_name = name_list[0].strip()
product_price = price_list[0].strip().replace('¥', '¥')
print(f"{product_name} {product_price}")
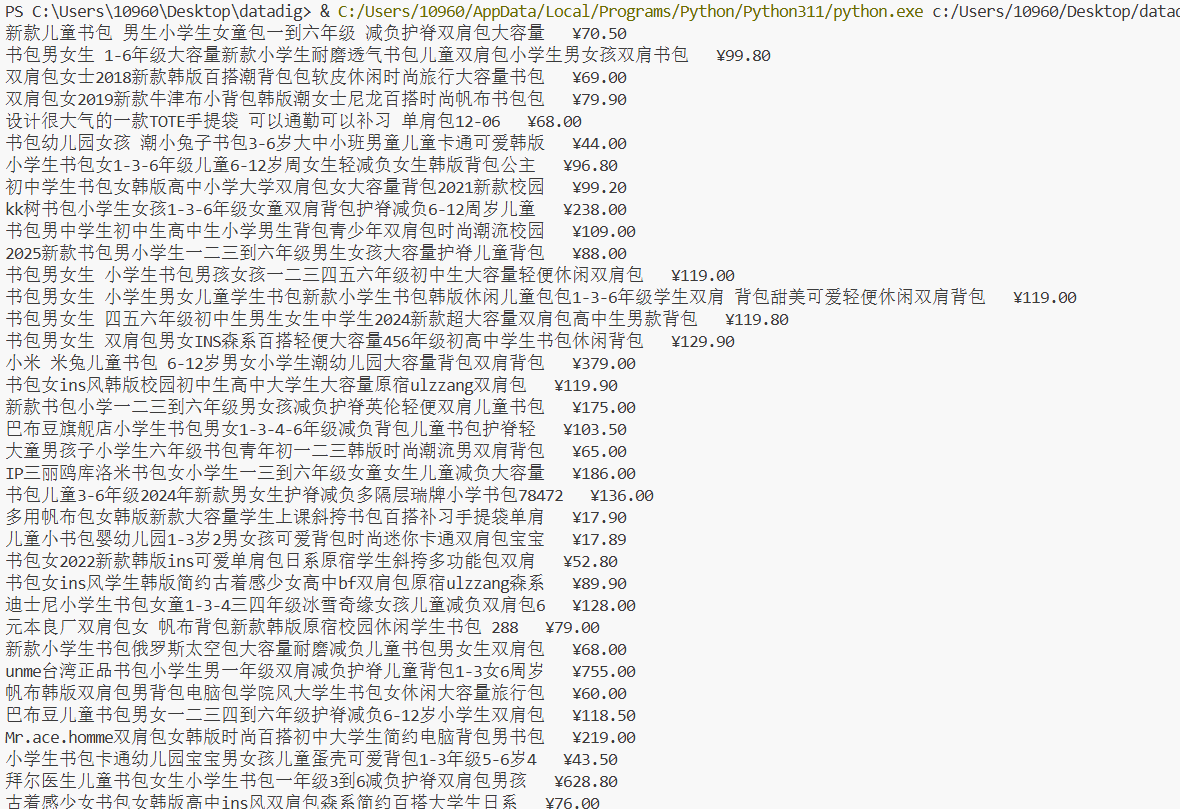
"'匹配含title属性的a标签,捕获属性值以获取商品名;用r'(.?)'匹配价格对应的span标签,提取标签内的文本内容。
这次实践让我体会到,爬虫开发的难点不在于语法本身,而在于对网页结构的精准拆解。比如该网站中,class为"price_n"的设计成了定位价格数据的可靠标识;
任务3
代码及运行结果
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urljoin
#创建图片保存目录
save_dir = 'fzu_pics'
os.makedirs(save_dir, exist_ok=True)
#循环处理6个页面
for pg in range(6):
#页面的顺序规则
page_url = f'https://news.fzu.edu.cn/yxfd/{pg}.htm' if pg != 0 else 'https://news.fzu.edu.cn/yxfd.htm'
print(f"正在处理: {page_url}")
#获取页面内容然后解析
resp = requests.get(page_url)
resp.encoding = 'utf-8'
bs_obj = BeautifulSoup(resp.text, 'html.parser')
#定位包含图片的位置
for img_container in bs_obj.find_all('div', class_='img slow'):
pic_tag = img_container.find('img')
if pic_tag and pic_tag.get('src'):
#构建图片URL
pic_url = urljoin(page_url, pic_tag['src'])
#筛选支持的三种图片格式(jpg、jpeg、png)
if pic_url.lower().endswith(('.jpg', '.jpeg', '.png')):
try:
#下载图片数据
pic_data = requests.get(pic_url).content
base_name = os.path.basename(pic_url)
save_path = os.path.join(save_dir, base_name)
#处理重复文件:同名时添加序号
num = 1
orig_save_path = save_path
while os.path.exists(save_path):
name_part, ext_part = os.path.splitext(orig_save_path)
save_path = f"{name_part}_{num}{ext_part}"
num += 1
#写入文件中
with open(save_path, 'wb') as f:
f.write(pic_data)
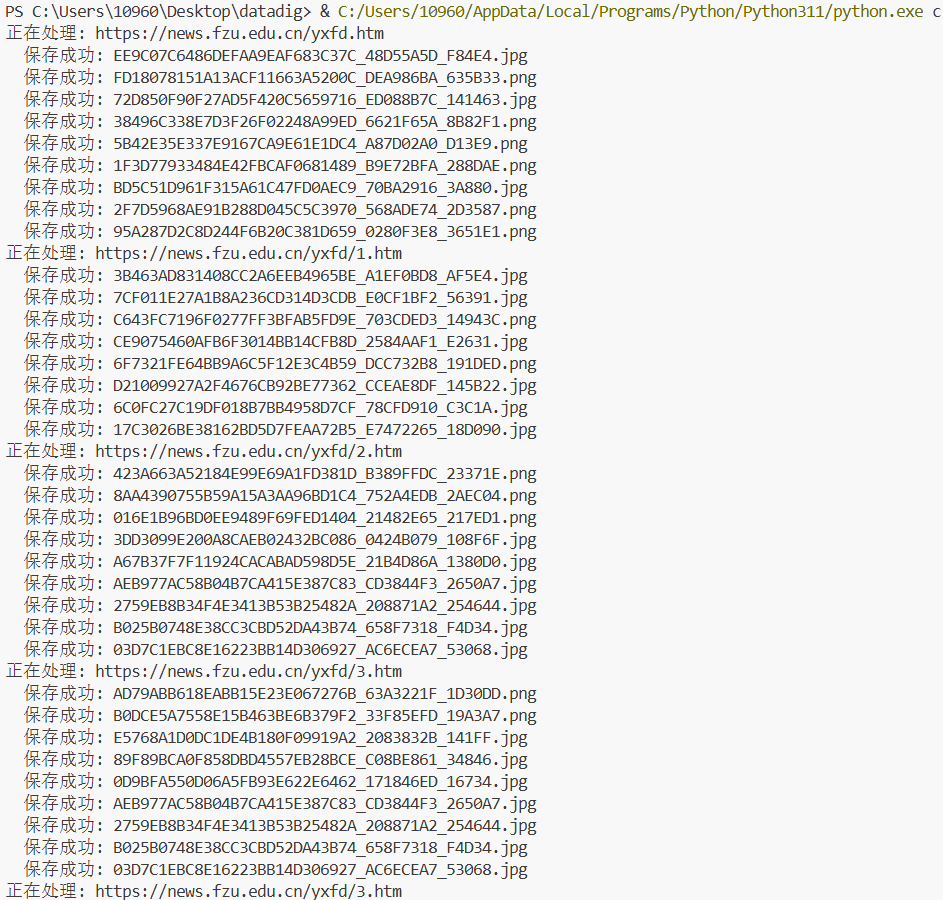
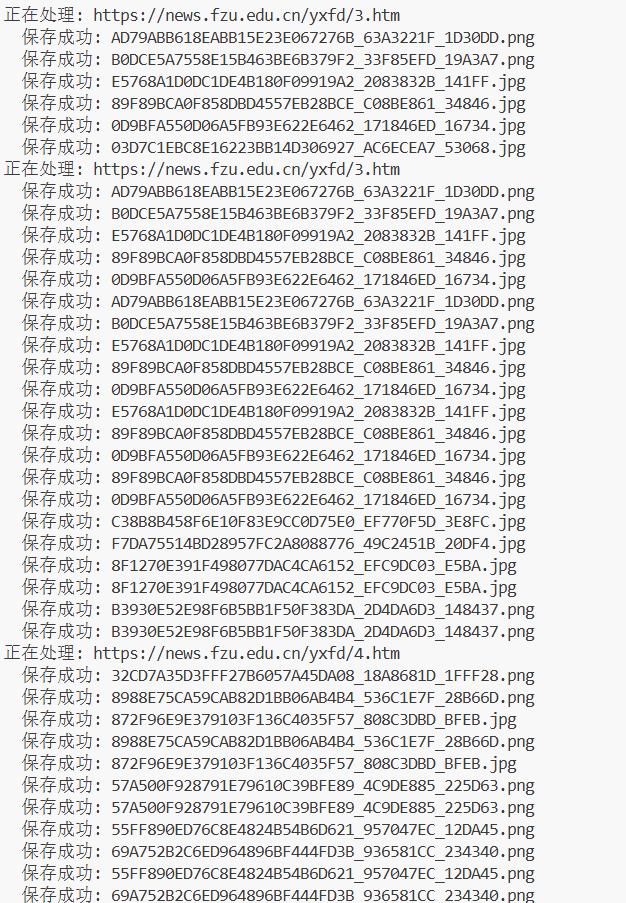
print(f" 保存成功: {os.path.basename(save_path)}")
except Exception as err:
print(f" 保存失败: {err}")
print(f"全部图片处理完毕,已保存至 '{save_dir}' 文件夹")

心得体会
这次做的是爬取福大新闻页(yxfd栏目)里的图片。
一开始以为就是简单抓图片,结果实际弄的时候才发现细节不少:比如分页处理,首页URL是直接的yxfd.htm,后面几页得拼上数字(1.htm、2.htm这种),要是没注意这个区别,要么漏爬页面,要么直接报错;还有图片路径,网页里给的src大多是相对路径,必须用urljoin补全成完整URL,不然根本下载不了。另外,之前没太在意重复文件名的问题,这次加了个计数器——如果同个文件名已经存在,就自动在后面加_1、_2,总算不用手动改文件名避免覆盖了,这点还挺实用的。
其实最花时间的不是写代码,是找对图片的“藏身地”。得先定位到带img标签的div容器(就是class叫“img slow”的那些),再从里面抠出img标签的src属性,要是没找对这个容器,很容易把页面里其他无关的图片也爬下来。还有筛选图片格式,只留jpg、jpeg、png这几种常用的,能少下不少没用的文件,也省空间。
总结下来就是,爬图片看着简单,其实核心还是摸透网页的结构——知道数据藏在哪个标签、哪个属性里,再把路径补全、格式筛对、细节(比如重复文件)处理好,比单纯记语法管用多了。要是这些地方没搞明白,代码写得再溜,要么爬不到东西,要么爬一堆乱七八糟的,白费力气。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号