论文阅读笔记四十六:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR2019)

论文原址:https://arxiv.org/abs/1903.00621

摘要
本文提出了基于无anchor机制的特征选择模块,是一个简单高效的单阶段组件,其可以结合特征金字塔嵌入到单阶段检测器中。FSAF解决了传统基于anchor机制的两个限制:(1)启发式的特征选择(2)overlap-based anchor采样。FSAF的通用解释是将在线特征选择应用于与anchor无关的分支的训练上。即无anchor的分支添加到特征金字塔的每一层,从而可以以任意层次对box进行编码解码。训练过程中,将每个实例动态的放置在最适合的特征层次上。在进行inference时,FSAF可以结合带anchor的分支并行的输出预测结果。FSAF主要包含无anchor分支的实现及在线特征选择两部分。FSAF结合RetinaNet在COCO检测任务上实现更高的准确率及速度,获得了44.6%的mAP,超过了当前存在的单阶段检测网络。
介绍
目标检测中存在尺寸变化的问题,为了实现尺寸不变性,目前流行的检测网络都构建特征金字塔,同时,金字塔的每层都可以并行的进行预测输出。另外,anchor可以更进一步的解决尺寸变化的问题。anchor框的作用是将所有可能的实例框的连续空间离散化为一些预定义尺寸,及宽高比的有限数量的框。实例框与anchor box基于IOU进行匹配。较大的anchor一般作用于特征金字塔的顶层,小的anchor作用于金字塔的底层,这是因为金字塔的上层特征具有更加抽象的特征信息可以检测较大的实例,而下层相反适用于检测小的实例。如下图所示。anchor+特征金字塔的方式取得了较好的结果。

但上述方法存在两点限制:(1)启发式的特征选择(2)overlap-based的anchor 采样 训练时,实例通过IOU与最接近的anchor box进行匹配,同时,一个anchor box通过人为预先定义的尺寸被安排到特征层的feature map上。因此,挑选的特征完全基于临时启发所得。比如,一个50x50大小的小车与60x60的小车可能被归为不同的特征层中,而40x40与50x50的通过人为定义会归为同一个层次中。换言之,anchor机制一定程度上受到潜在的启发因素影响。因此,用大量这样挑选的特征训练实例可能并不是最优的。、
本文提出的FSAF模型用于解决上述问题。该模型主要是让实例选择最合适的特征层次进而来优化网络,因此,在该模型中不应该存在anchor限制特征的选择。本文以无anchor机制的方法对分类及回归参数进行学习。网络结构如下图
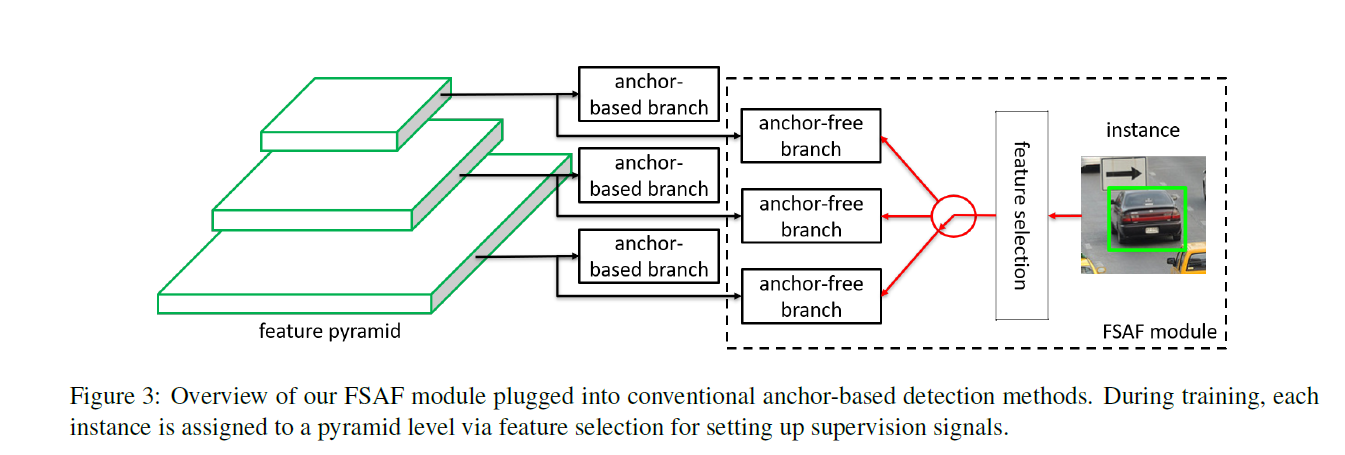
在特征金字塔的每一层构建一个无anchor的分支,并独立于基于anchor的分支。无anchor分支也包含分类与回归两个子网络。一个实例可以被放到任意层的无anchor分支上。训练时,基于实例的内容而不是实例框的大小动态的为每个实例选择最适合的特征层次。选择后的特征用于检测相应的实例。inference时,FASA可以单独预测结果或者结合anchor-based分支。FSAF与backbone无关,同时可以应用在具有特征金字塔的单阶段检测中。此外,anchor-free分支与在线特征选择可以多种多样。
FSAF
(1)介绍如何创建anchor-free分支(2)产生anchor-free分支的监督信号(3)如何为每个实例动态选择特征。(4)如何联合训练anchor分支及anchor-free分支。
网络结构
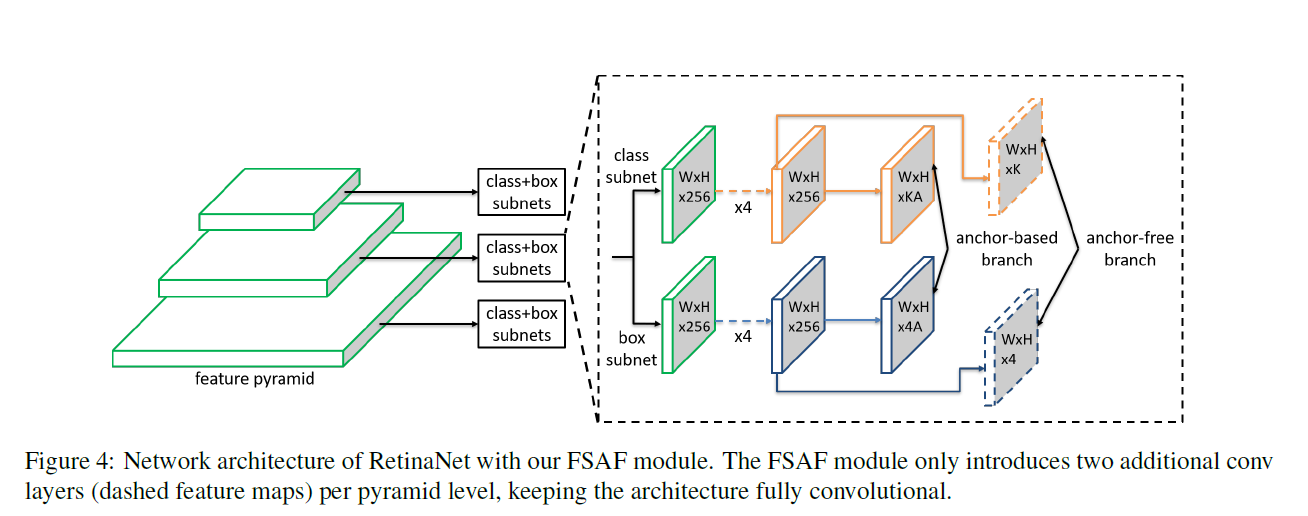
基于RetinaNet+FSAF的网络结构如下图,RetinaNet由一个backbone网络及两个任务明确的自网络组成。特征金字塔基于backbone进行构建,P3~P7,金字塔的每一层用于检测物体的不同尺寸。在每层Pl的后面添加分类及回归子网络,二者都为全卷积网络。分类网络预测每个位置的A个anchor及K个类别的分数值,回归分支预测每个anchor框距离最近实列的偏差值,在RetinaNet的输出端,FSAF在每层引入了额外的两层卷积层,分别用于基于anchor-free分支的分类及回归。一个3x3XK的卷积层添加到分类分支的输出,后接sigmoid函数,与基于anchor分支的部分相互平行,其预测目标物在每个位置上K个类别的概率值。相似的,3x3x4的卷积层添加到回归分支的输出,与anchor-based分支的部分相呼应,其后接ReLU函数。其作用是以anchor-free的方式预测框的偏移量。anchor-based与anchor-free共享每层特征以多任务的方式进行运作。
GroundTruth and Loss
对于给定的一个实例,我们知道其类别k,及bounding box坐标![]() ,在训练时,该实例可以被放到任意一层中。定义b在Pl层上的映射为
,在训练时,该实例可以被放到任意一层中。定义b在Pl层上的映射为![]() ,比如,
,比如,![]() ,同时定义了有效区域
,同时定义了有效区域![]() 及忽略区域
及忽略区域![]() 作为
作为![]() 的比例区域,其通过比例系数
的比例区域,其通过比例系数![]() 及
及![]() 进行成比例的缩放,如下,本文分别设置为0.2及0.5.一个小车的groundtruth生成例子如下。
进行成比例的缩放,如下,本文分别设置为0.2及0.5.一个小车的groundtruth生成例子如下。
![]()

分类的输出
ground-truth针对分类的输出为K个maps,每个map对应一个类别。实例通过三种方式影响第K个ground truth map,首先,有效区域![]() 是正样本区域,通过在“car”这个类别的Map对应区域覆盖一个白色区域,代表该实例的存在。而忽略区域
是正样本区域,通过在“car”这个类别的Map对应区域覆盖一个白色区域,代表该实例的存在。而忽略区域![]() ,即上图的灰色区域,该区域内的像素在进行网络的反向传播时不参与贡献。最后,ignore 区域的相邻层的区域
,即上图的灰色区域,该区域内的像素在进行网络的反向传播时不参与贡献。最后,ignore 区域的相邻层的区域![]() 特征也是被看作是忽略的,如果同一层中有两个实例发生了重叠,则以小区域的优先级较高。而ground truth map剩下的区域为负样本,用0填充。应用了Focal loss,
特征也是被看作是忽略的,如果同一层中有两个实例发生了重叠,则以小区域的优先级较高。而ground truth map剩下的区域为负样本,用0填充。应用了Focal loss,![]() ,
,![]() anchor free分支的总损失是图像中所有非忽略区域的focal loss的和,同时通过有效区域内的像素个数来进行正则化处理。
anchor free分支的总损失是图像中所有非忽略区域的focal loss的和,同时通过有效区域内的像素个数来进行正则化处理。
框回归的输出
回归输出的ground truth是与类别无关的4个offset maps,实例只作用于offeset maps上的有效区域![]() ,对于该区域内的每个像素,用一个四维的向量表示映射框。
,对于该区域内的每个像素,用一个四维的向量表示映射框。![]() ,
,![]() ,分别代表当前像素与上,左,下,右边的距离。该向量做了一个正则化处理
,分别代表当前像素与上,左,下,右边的距离。该向量做了一个正则化处理![]() ,分别作用于四个offset maps中的每一个,其中,S根据经验设置为4.0,超出有效框的位置为ignore 区域,即灰色区域,该区域的梯度值被忽略。anchor-free回归分支的总损失为所有有效框区域IOU损失的平均值。
,分别作用于四个offset maps中的每一个,其中,S根据经验设置为4.0,超出有效框的位置为ignore 区域,即灰色区域,该区域的梯度值被忽略。anchor-free回归分支的总损失为所有有效框区域IOU损失的平均值。
在进行Inference时,需要将分类及回归分支的预测结果进行解码,假设对于某个位置(i,j),预测的偏移量为![]() ,则预测得到的距离为
,则预测得到的距离为![]() ,同时预测得到的映射框的左上角及右下角的位置为
,同时预测得到的映射框的左上角及右下角的位置为![]()
然后进一步通过![]() 进行缩放得到最终的预测框。某个位置的分数及类别可以通过在类别输出maps上计算该位置对应类别的K维向量的最大值获得。
进行缩放得到最终的预测框。某个位置的分数及类别可以通过在类别输出maps上计算该位置对应类别的K维向量的最大值获得。
在线特征选择
anchor-free分支可以利用任意特征金字塔的体征对实例进行学习。本文基于实例的内容而不是实例的大小来确定适合的某一层金字塔特征。对于给定实例I,定义在特征金字塔某层的损失为![]() ,通过计算有效区域的平均focal loss及Iou损失得到。损失定义如下
,通过计算有效区域的平均focal loss及Iou损失得到。损失定义如下
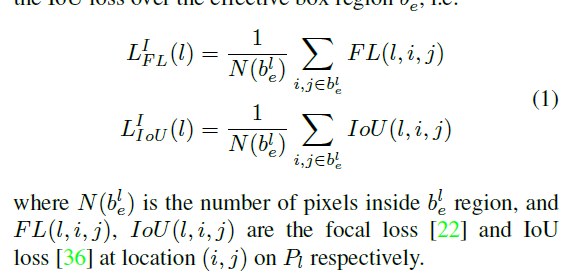
下图展示了在线特征选择过程。首先,实例I通过特征金字塔的每一层。然后,基于上式计算所有anchor-free分支的和,最好的层的定义是所有的损失最小,则用该层特征学习实例。如等式![]() 。
。

训练时,根据遇到的instance动态的调整选择的特征。选择出来的特征对实例建模是最优的,其损失可以使特征空间的边界更低。在进行Inference时,并不进行在线特征选择,这是因为大部分合适的特征层会输出较高的confidence scores。
联合training 及 inference
基于RetinaNet时,本文结合了anchor-based分支,将该分支作为原始的,同时,所有参数都不发生变化。
Inference:FSAS模型在全卷积的RetinaNet网络上增加了几层卷积网络,对于anchor-free分支,通过设定阈值0.05来解码每层前1k个位置的box预测。最后通过0.5的NMS结合anchor-based分支的结果来获得最终的预测结果。
Initialization:backbone 网络在ImageNet1k上进行预训练。FSAF中的卷积层偏差初始化为![]() ,权重初始化为
,权重初始化为![]()
的高斯分布,![]() 代表在训练刚开始时,每个像素位置处预测分数值的大小,本文设置其值为0.01,对于回归分支的初始化偏差设置为b=0.1及高斯分布的权重。初始化可以使网络在开始时保持稳定,防止较大的损失产生。
代表在训练刚开始时,每个像素位置处预测分数值的大小,本文设置其值为0.01,对于回归分支的初始化偏差设置为b=0.1及高斯分布的权重。初始化可以使网络在开始时保持稳定,防止较大的损失产生。
Optimization:整体优化损失函数为![]() ,分别代表anchor-based的所有损失,及anchor-free分支的分类及回归损失,控制系数
,分别代表anchor-based的所有损失,及anchor-free分支的分类及回归损失,控制系数![]() ,控制anchor-free分支的权重,本文设置为0.5,基于SGD优化,8块GPU,每张卡训练2张图片,迭代90k,初始学习率为0.01,在60k及80k步时衰减10倍,权重衰减为0.0001动量为0.9.
,控制anchor-free分支的权重,本文设置为0.5,基于SGD优化,8块GPU,每张卡训练2张图片,迭代90k,初始学习率为0.01,在60k及80k步时衰减10倍,权重衰减为0.0001动量为0.9.
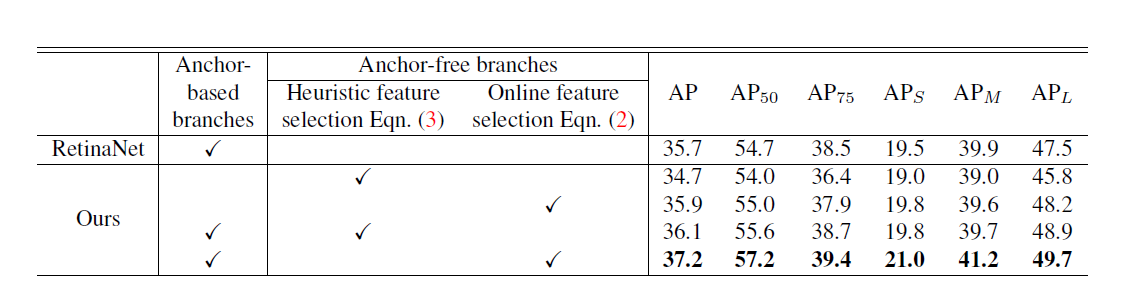
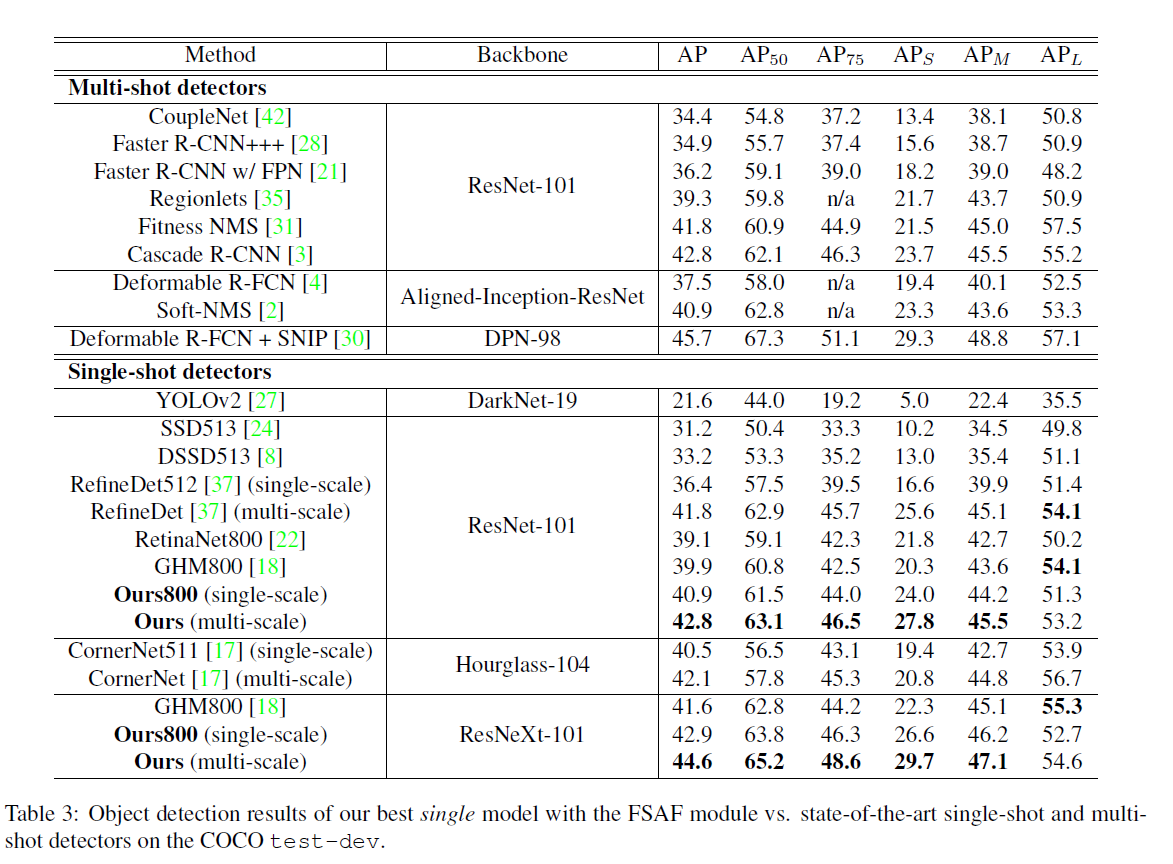
实验



Reference
[1] C. Bhagavatula, C. Zhu, K. Luu, and M. Savvides. Faster than real-time facial alignment: A 3d spatial transformer network
approach in unconstrained poses. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017.1
[2] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Softnmsimproving object detection with one line of code. In
Computer Vision (ICCV), 2017 IEEE International Conference on, pages 5562–5570. IEEE, 2017. 8
[3] Z. Cai and N. Vasconcelos. Cascade r-cnn: Delving into high quality object detection. arXiv preprint arXiv:1712.00726,2017. 8
[4] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei.Deformable convolutional networks. In Computer Vision (ICCV), 2017 IEEE International Conference on, pages 764–773. IEEE, 2017. 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号