论文阅读笔记二十一:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS(ICRL2016)

论文源址:https://arxiv.org/abs/1511.07122
tensorflow Github:https://github.com/ndrplz/dilation-tensorflow
摘要
该文提出了空洞卷积模型,在不降低分辨率的基础上聚合图像中不同尺寸的上下文信息,同时,空洞卷积扩大感受野的范围。
介绍
语义分割具有一定的挑战性,因为要进行像素级的分类,同时,要考虑不同尺寸大小的上下文信息的推理。通过卷积外加反向传播的学习算法,使分类的准确率得到大幅度的提升。由原始的分类到像素级的分类,本文提出了两个问题:(1)重新构建的网络的哪一部分是有必要的,同时,哪个操作在进行密集分类时会降低分割结果的准确率。(2)设计一个专门用于进行密集分类的模型结构会提高分割的效果吗?
分类网络通过连续的卷积池化操作来融合不同尺寸的上下文信息,此过程中,分辨率在不断的减少,知道得到一个最总的预测分类结果。与之相反,分割任务要求在完整的分辨率上进行多尺寸的预测。针对此问题有两种解决方式:(1)通过反卷积操作恢复丢失的分辨率信息。这就引出一个疑问,中间下采样的操作是否是真的有必要的。(2)提供多尺寸的输入图片,并将这些图片的预测结果进行组合。同样,这里存在一个问题,对不同尺寸输入的图片,是否需要对他们的结果单独进行分析。
该文提出的空洞卷积模型,并未减少分辨率同时,不需要对不同尺寸输入图片对输出结果的影响进行分析。该结构主要用于分割任务,同时,值得注意的是空洞卷积的网络中并未有池化或者下采样的操作过程。通过空洞卷积即可获得较大的感受野。
空洞卷积

该文重点介绍空洞卷积的影响,而不是空洞卷积的构建,利用空洞卷积进行多尺寸的信息融合。空洞卷积核感受野的大小成指数增长,如下图。
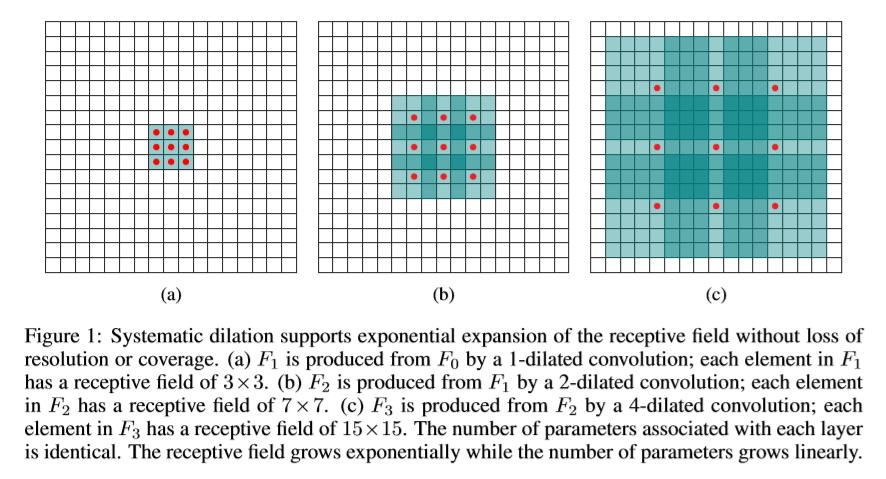
卷积核大小kxk,dilation factor:n-推出感受野大小为:(k+1)x n - 1
多尺寸语义信息融合
语义模型通过融合多尺寸的上下文信息,来提高密集预测结构的效果。有C通道的输入feature maps输入模型后,输出C通道的feature maps。
该文提出的一种基础模型,包含7层网络,其中使用了不同dilation factor的3x3的卷积。dilations为【1,1,2,4,8,16】,每层上都有卷积操作,前两层,每层卷积后都接着一个像素级的截断处理,max(,0)。最后一层为1x1xc的卷积,并产生输出,,结构如下表,输入为64x64的图片。

该文该开始用标准的初始化流程训练网络,结果并不理想。 卷积网络一般使用随机采样分布进行初始化操作。但这种方式对空洞卷积效果甚微,该文转而用如下Identity初始化方式。
![]()
这种初始化方式,会让前一层的信息直接流入下一层中,直觉上感到不利于反向传播信息的传递,但实验证明,这种担心是多余的。对于不同深度的初始化按如下方式进行。

前端
该网络的输入为三通道的彩色图像,输出为21通道的特征图,基于VGG16进行改进,将其中最后两层池化层与全连接层。对于移除的池化层后接的卷积层的dilation factor扩大2倍。因此,最后一层的卷积层的的dilated factor扩大为4。通过空洞卷积,可以利用原始分类网络的参数初始化,同时产生更高分辨率的输出。该模型,在Pascal VOC2012数据集上进行训练,基于SGD优化方法,mini-batch 大小为14,学习率为1e-3,动量大小为0.9,迭代60000次。
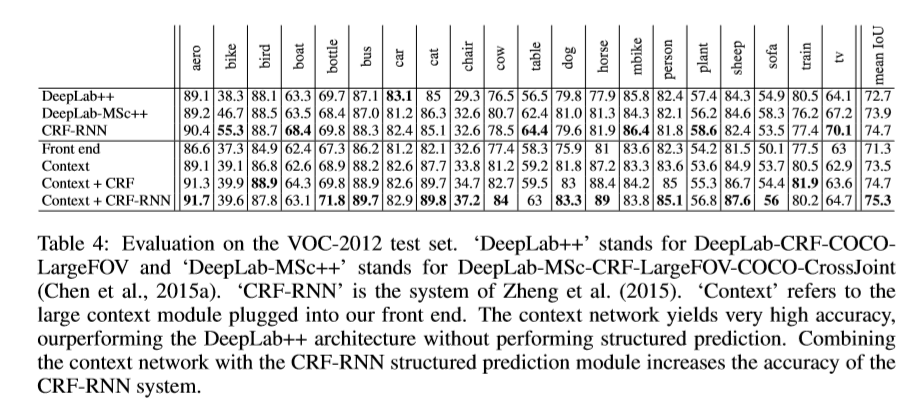
实验




reference
Badrinarayanan, Vijay, Handa, Ankur, and Cipolla, Roberto. SegNet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv:1505.07293, 2015.
Brostow,GabrielJ.,Fauqueur,Julien,andCipolla,Roberto. Semanticobjectclassesinvideo: Ahigh-definition ground truth database. Pattern Recognition Letters, 30(2), 2009.
Chen, Liang-Chieh, Papandreou, George, Kokkinos, Iasonas, Murphy, Kevin, and Yuille, Alan L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In ICLR, 2015a.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号