
个人项目-论文查重
| 这个作业属于哪个课程 | 计科21级12班 |
|---|---|
| 这个作业要求在哪里 | 论文查重 |
| 这个作业的目标 | 学习了解项目开发流程及规范 |
一、 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 25 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 120 | 100 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 90 | 80 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 90 | 70 |
| Reporting | 报告 | 120 | 100 |
| Test Repor | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 15 |
| overall | 合计 | 715 | 680 |
二、设计与开发
开发环境
- 开发工具:IntelliJ IDEA 2020.2.3 x64
- 性能分析工具:Jprofiler11.1.4
- 单元测试工具:JUnit 4.13.2
开发依赖
- 包管理工具: Maven
- 引入依赖:HanLP,Apache Commons Math
开发规范
- 阿里巴巴开发规范插件
算法设计思想
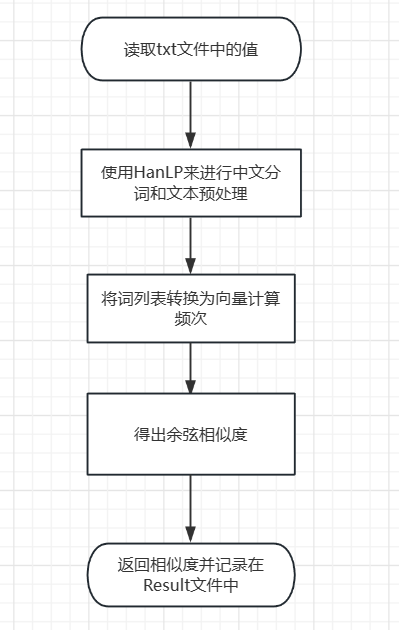
- 采用基于tf算法的余弦相似度:
![]()
- 关键实现点:使用HanLP来进行中文分词和文本预处理,并使用Apache Commons Math库来计算余弦相似度
接口设计
接口结构
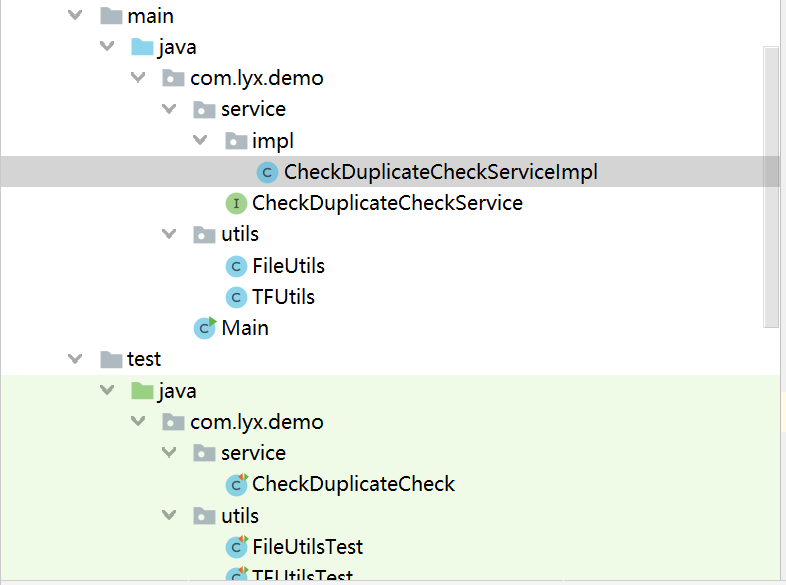
项目主体包含service层,utils层,Main函数以及对相应实现功能的测试
service层
- 定义CheckDuplicateCheckService接口
- 定义CheckDuplicateCheckServiceImpl实现CheckDuplicateCheckService接口进行主要的逻辑编写
utils层
- 定义FileUtils类 主要实现封装对文件的操作 包括将文件从txt中读出 并将最后结果写到答案文件中
- 定义TFUTils类 主要实现以下方法
- segmentAndPreprocess(String text); // 进行中文分词和文本预处理
- calculateCosineSimilarity(List
words1, List words2);//计算余弦相似度 - createVectorFromWords(List
words); // 将词列表转换为向量
主要代码实现
public class TFUtils {
// 中文分词和文本预处理
public static List<String> segmentAndPreprocess(String text) {
List<Term> termList = HanLP.segment(text);
List<String> words = new ArrayList<>();
for (Term term : termList) {
// 去除停用词、标点符号等
if (!term.word.matches("[\\pP+~$`^=|<>~`$^+=|<>¥×]")) {
words.add(term.word);
}
}
return words;
}
// 计算余弦相似度
public static double calculateCosineSimilarity(List<String> words1, List<String> words2) {
// 将词列表转换为向量
RealVector vector1 = createVectorFromWords(words1);
RealVector vector2 = createVectorFromWords(words2);
// 计算余弦相似度
double cosineSimilarity = vector1.dotProduct(vector2) / (vector1.getNorm() * vector2.getNorm());
return cosineSimilarity;
}
// 将词列表转换为向量
private static RealVector createVectorFromWords(List<String> words) {
// 在这里可以使用不同的方法来表示文本向量,例如词袋模型(Bag of Words)、TF-IDF等
// 这里使用简单的词频向量表示
int vocabSize = 100000; // 词汇表大小
RealVector vector = new ArrayRealVector(vocabSize);
for (String word : words) {
// 在向量中增加词的频次
// 这里简单地假设每个词的频次为1
vector.setEntry(Math.abs(word.hashCode() % vocabSize), 1);
}
return vector;
}
}
- 定义Main函数
- 用于程序接口 配合maven作为jar包接口
- 对接口参数进行校验
- 接收文件位置并进行判断
三、模块接口部分的性能改进
- Override
![]()
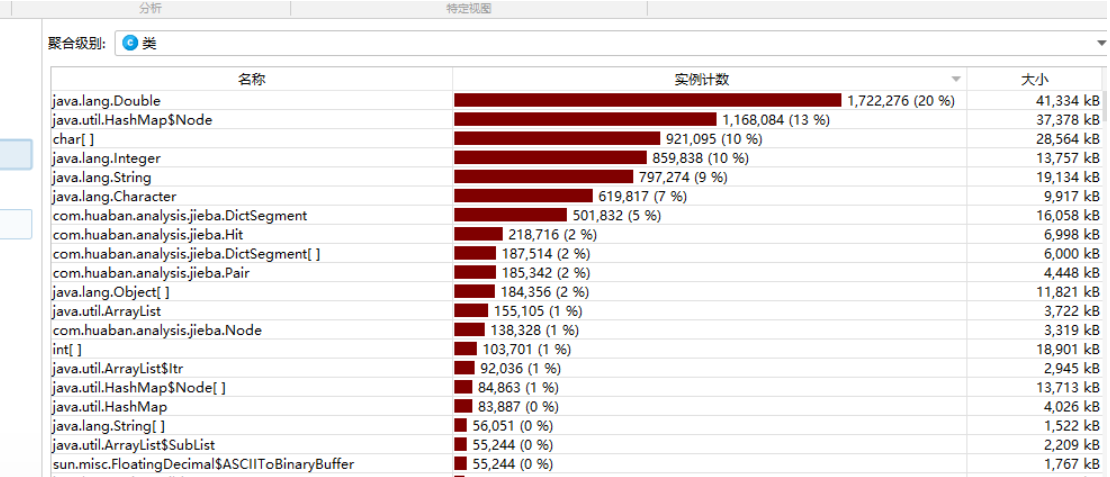
- memory
![]()
可以看到 占用比较大的double是计算余弦相似度时产生的
改进思路:进行更精细的划分词语 减少对余弦相似度的计算
四、单元测试
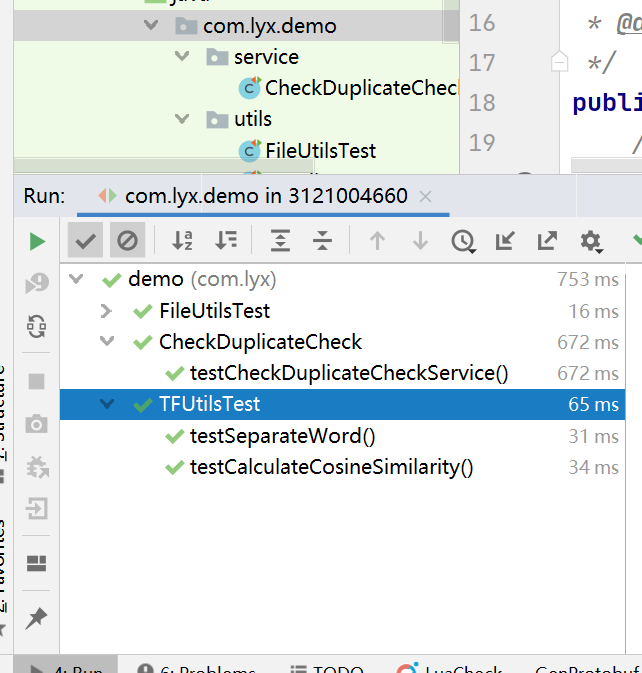
单元测试覆盖率

六、异常处理说明
- 参数校验
// 检查参数个数
if (args.length != 3){
System.out.println("命令行参数个数错误");
return;
}
- 判断参数合法性
// 判断参数的合法性
for (String parameter: args) {
if (!parameter.endsWith(".txt")){
System.out.println("参数输入有误,请重新输入");
return;
}
}
- 判断文件路径合法性
try {
// 调用接口
double result = checkDuplicateCheckService.checkDuplicate(args[0], args[1], args[2]);
// 显示结果
System.out.printf("[%tc] %s 该文件查重率为%.2f \n",new Date(),args[1],result);
} catch (IOException e) {
System.out.println("文件打开失败,请检查输入路径");
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号