【大数据Spark_SparkCore系列_3】RDD和DF数据存入关系数据库
一、读取日志格式
使用的测试数据是Tomcat的访问日志,日志格式如下
192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/ HTTP/1.1" 200 259
192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/head.jsp HTTP/1.1" 200 713
192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/body.jsp HTTP/1.1" 200 240
192.168.88.1 - - [30/Jul/2017:12:54:37 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242
二、使用SparkCore获取日志并进行解析
目的:将每一行的日志中的jsp页面的访问记录存入数据库(MySQL,Oracle)。
解析:由于日志具有一定的格式,所以对下面的日志进行截取(String的操作),获得head.jsp。最后将(head.jsp,1)存入数据库的表中。
192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/head.jsp HTTP/1.1" 200 713
三、日志解析代码
def main(args: Array[String]): Unit = { //定义SparkContext对象 val conf = new SparkConf().setAppName("MyWebLogDemo").setMaster("local") val sc = new SparkContext(conf) // 读入日志文件 //rdd1结果 :(hadoop.jsp,1) val rdd1 = sc.textFile("D:\\localhost_access_log.2017-07-30.txt").map{ //line: 相当于value1 line => { //处理该行日志: 192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/head.jsp HTTP/1.1" 200 713 //解析字符串,找到jsp的名字 //第一步解析出:GET /MyDemoWeb/head.jsp HTTP/1.1 val index1 = line.indexOf("\"") //第一个双引号的位置 val index2 = line.lastIndexOf("\"") //第二个双引号的位置 val str1 = line.substring(index1+1,index2) //第二步解析出:/MyDemoWeb/head.jsp val index3 = str1.indexOf(" ") val index4 = str1.lastIndexOf(" ") val str2 = str1.substring(index3+1, index4) //第三步解析出: head.jsp val jspName = str2.substring(str2.lastIndexOf("/")+1) //返回 (hadoop.jsp,1) ---> 保存到Oracle中 (jspName,1) } }
四、对每一个分区进行数据的存储到数据库
//针对分区,创建Connection,将结果保存到数据库中 rdd1.foreachPartition(saveToOracle) //定义一个函数,将某一个分区中的数据(jspname,count)保存到Oracle中 def saveToOracle(it:Iterator[(String,Int)]) ={ var conn:Connection = null var pst:PreparedStatement = null try{ //创建一个Connection //conn = DriverManager.getConnection("jdbc:oracle:thin:@10.30.30.210:1521/orcl.example.com","scott", "tiger")//插入oracle数据库 conn = DriverManager.getConnection("jdbc:mysql://10.30.3.104:3306/test","root", "2561304")//插入mysql数据库 pst = conn.prepareStatement("insert into result values(?,?)") //把rdd1的一个分区中的数据插入到Oracle中 it.foreach(data =>{ pst.setString(1, data._1) pst.setInt(2,data._2) pst.executeUpdate() }) }catch{ case e1:Exception => e1.printStackTrace() }finally{ if(pst != null) pst.close() if(conn != null) conn.close() } }
五、登录数据库并创建表()
MariaDB [test]> create table result(jspname varchar(20),count Int(4));
Query OK, 0 rows affected (0.13 sec)
此时查看表中的数据为空:
MariaDB [test]> select * from result;
Empty set (0.00 sec)
运行代码后再次查看:
MariaDB [test]> select * from result;
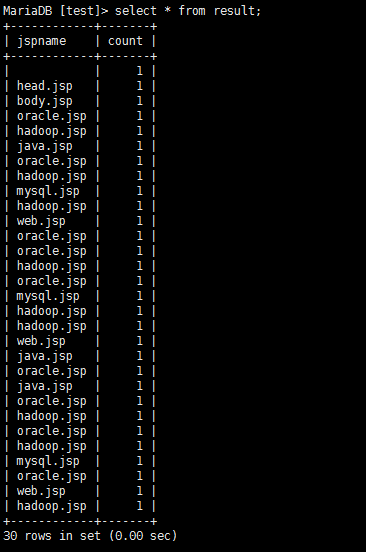
六、测试日志和原理解析
测试日志的完整内容如下:D:\\localhost_access_log.2017-07-30.txt
192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/ HTTP/1.1" 200 259 192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/head.jsp HTTP/1.1" 200 713 192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/body.jsp HTTP/1.1" 200 240 192.168.88.1 - - [30/Jul/2017:12:54:37 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:38 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:38 +0800] "GET /MyDemoWeb/java.jsp HTTP/1.1" 200 240 192.168.88.1 - - [30/Jul/2017:12:54:40 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:40 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:41 +0800] "GET /MyDemoWeb/mysql.jsp HTTP/1.1" 200 241 192.168.88.1 - - [30/Jul/2017:12:54:41 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:42 +0800] "GET /MyDemoWeb/web.jsp HTTP/1.1" 200 239 192.168.88.1 - - [30/Jul/2017:12:54:42 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:52 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:52 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:53 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:54 +0800] "GET /MyDemoWeb/mysql.jsp HTTP/1.1" 200 241 192.168.88.1 - - [30/Jul/2017:12:54:54 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:54 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:56 +0800] "GET /MyDemoWeb/web.jsp HTTP/1.1" 200 239 192.168.88.1 - - [30/Jul/2017:12:54:56 +0800] "GET /MyDemoWeb/java.jsp HTTP/1.1" 200 240 192.168.88.1 - - [30/Jul/2017:12:54:57 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:57 +0800] "GET /MyDemoWeb/java.jsp HTTP/1.1" 200 240 192.168.88.1 - - [30/Jul/2017:12:54:58 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:58 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:59 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:54:59 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:55:00 +0800] "GET /MyDemoWeb/mysql.jsp HTTP/1.1" 200 241 192.168.88.1 - - [30/Jul/2017:12:55:00 +0800] "GET /MyDemoWeb/oracle.jsp HTTP/1.1" 200 242 192.168.88.1 - - [30/Jul/2017:12:55:02 +0800] "GET /MyDemoWeb/web.jsp HTTP/1.1" 200 239 192.168.88.1 - - [30/Jul/2017:12:55:02 +0800] "GET /MyDemoWeb/hadoop.jsp HTTP/1.1" 200 242
原理解析:为什么存入数据库的时候需要使用 rdd1.foreachPartition(saveToOracle)方法?为什么无法直接进行数据库的存储?
我们通过传统的数据库连接获取,执行SQL和保存代码运行:
var conn:Connection = null var pst:PreparedStatement = null try{ //创建一个Connection //conn = DriverManager.getConnection("jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com","scott", "tiger") conn = DriverManager.getConnection("jdbc:mysql://10.30.3.104:3306/test","root", "2561304")//插入mysql数据库 //把rdd1的每条数据都插入到Oracle中 rdd1.foreach(f => { //插入数据 pst = conn.prepareStatement("insert into result values(?,?)") pst.setString(1, f._1) //JSP的名字 pst.setInt(2,f._2) //记一次数 pst.executeUpdate() }) }catch{ case e1:Exception => e1.printStackTrace() }finally{ if(pst != null) pst.close() if(conn != null) conn.close() }
运行后出现如下错误:提示没有序列化
Serialization stack:
- object not serializable (class: java.lang.Object, value: java.lang.Object@7343922c)
- writeObject data (class: java.util.HashMap)
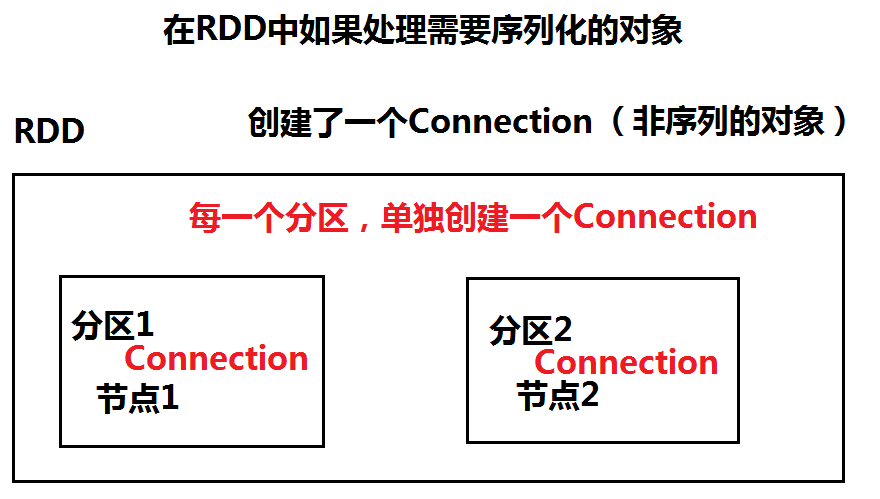
原因就在于connection连接RDD时是针对整个RDD使用一个connection,但是每一个RDD里面存在多个分区。connection在多个节点(分区)上处理的时候,需要传输connection,但是connection是非序列化的,因此connection在处理完分区1,再去处理分区2的时候,connection无法传输(没有序列化)。因此解决的办法就是针对每一个分区创建一个connection连接。那么针对每一个分区都有connection去操作,connection不需要网络传输。而针对每一个分区进行操作的方法就是:
RDD.scala
def foreachPartition(f: Iterator[T] => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => cleanF(iter))
}
七、完整代码
package lesson0613 import org.apache.spark.SparkConf import org.apache.spark.SparkContext import java.sql.Connection import java.sql.DriverManager import java.sql.PreparedStatement object MyOracleDemo { def main(args: Array[String]): Unit = { //定义SparkContext对象 val conf = new SparkConf().setAppName("MyWebLogDemo").setMaster("local") val sc = new SparkContext(conf) // 读入日志文件 //rdd1结果 :(hadoop.jsp,1) val rdd1 = sc.textFile("D:\\localhost_access_log.2017-07-30.txt").map{ //line: 相当于value1 line => { //处理该行日志: 192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/head.jsp HTTP/1.1" 200 713 //解析字符串,找到jsp的名字 //第一步解析出:GET /MyDemoWeb/head.jsp HTTP/1.1 val index1 = line.indexOf("\"") //第一个双引号的位置 val index2 = line.lastIndexOf("\"") //第二个双引号的位置 val str1 = line.substring(index1+1,index2) //第二步解析出:/MyDemoWeb/head.jsp val index3 = str1.indexOf(" ") val index4 = str1.lastIndexOf(" ") val str2 = str1.substring(index3+1, index4) //第三步解析出: head.jsp val jspName = str2.substring(str2.lastIndexOf("/")+1) //返回 (hadoop.jsp,1) ---> 保存到Oracle中 (jspName,1) } } //针对分区,创建Connection,将结果保存到数据库中 rdd1.foreachPartition(saveToOracle) // var conn:Connection = null // var pst:PreparedStatement = null // try{ // //创建一个Connection // //conn = DriverManager.getConnection("jdbc:oracle:thin:@192.168.157.101:1521/orcl.example.com","scott", "tiger") // conn = DriverManager.getConnection("jdbc:mysql://10.30.3.104:3306/test","root", "2561304")//插入mysql数据库 // // //把rdd1的每条数据都插入到Oracle中 // rdd1.foreach(f => { // //插入数据 // pst = conn.prepareStatement("insert into result values(?,?)") // pst.setString(1, f._1) //JSP的名字 // pst.setInt(2,f._2) //记一次数 // pst.executeUpdate() // }) // }catch{ // case e1:Exception => e1.printStackTrace() // }finally{ // if(pst != null) pst.close() // if(conn != null) conn.close() // } // // } //定义一个函数,将某一个分区中的数据(jspname,count)保存到Oracle中 def saveToOracle(it:Iterator[(String,Int)]) ={ var conn:Connection = null var pst:PreparedStatement = null try{ //创建一个Connection //conn = DriverManager.getConnection("jdbc:oracle:thin:@10.30.30.210:1521/orcl.example.com","scott", "tiger") conn = DriverManager.getConnection("jdbc:mysql://10.30.3.104:3306/test","root", "2561304")//插入mysql数据库 pst = conn.prepareStatement("insert into result values(?,?)") //把rdd1的一个分区中的数据插入到Oracle中 it.foreach(data =>{ pst.setString(1, data._1) pst.setInt(2,data._2) pst.executeUpdate() }) }catch{ case e1:Exception => e1.printStackTrace() }finally{ if(pst != null) pst.close() if(conn != null) conn.close() } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号