Solr的搭建
Solr6.6.0下载地址
http://www.apache.org/dyn/closer.lua/lucene/solr/
安装JRE
需要Java Runtime Environment(JRE) 1.7或更高版本,先验证。 # java -version

没有java的想偷懒的话可以yum安装
//查看是否安装java #rpm -qa | grep java //没有的话就yum安装 # yum -y install java
安装Solr 6.6.0
1.去http://www.apache.org/dyn/closer.lua/lucene/solr/ 下载Solr安装文件solr-6.6.0.tgz
2.将solr-6.6.0.tgz文件放到/tmp目录下,执行如下脚本:
# cd /tmp
# tar -zxvf solr-6.6.0.tgz // 解压压缩包
3.创建应用程序和数据目录
# mkdir -p /data/solr /usr/local/solr
4.创建运行solr的用户并赋权
# groupadd solr
# useradd -g solr solr
# chown -R solr.solr /data/solr /usr/local/solr
5.安装solr服务 (/tmp 文件下)
# solr-6.6.0/bin/install_solr_service.sh solr-6.6.0.tgz -d /data/solr -i /usr/local/solr
6.检查服务状态
# service solr status
第6步会出现

创建集合
在这个部分,我们创建一个简单的Solr集合。
Solr可以有多个集合,但在这个示例,我们只使用一个。使用如下命令,创建一个新的集合。我们以solr用户运行以避免任何权限错误。
# su - solr -c "/usr/local/solr/solr/bin/solr create -c gettingstarted -n data_driven_schema_configs"
在这个命令中,gettingstarted是集合的名字,-n指定配置集合。Solr默认提供了3个配置集合。这里我们使用的是schemaless,意思是可以提供任意名字的任意列,类型将会被猜测。
添加和查询文档
在这个部分,我们将浏览Solr Web界面,添加一些文档到集合中。
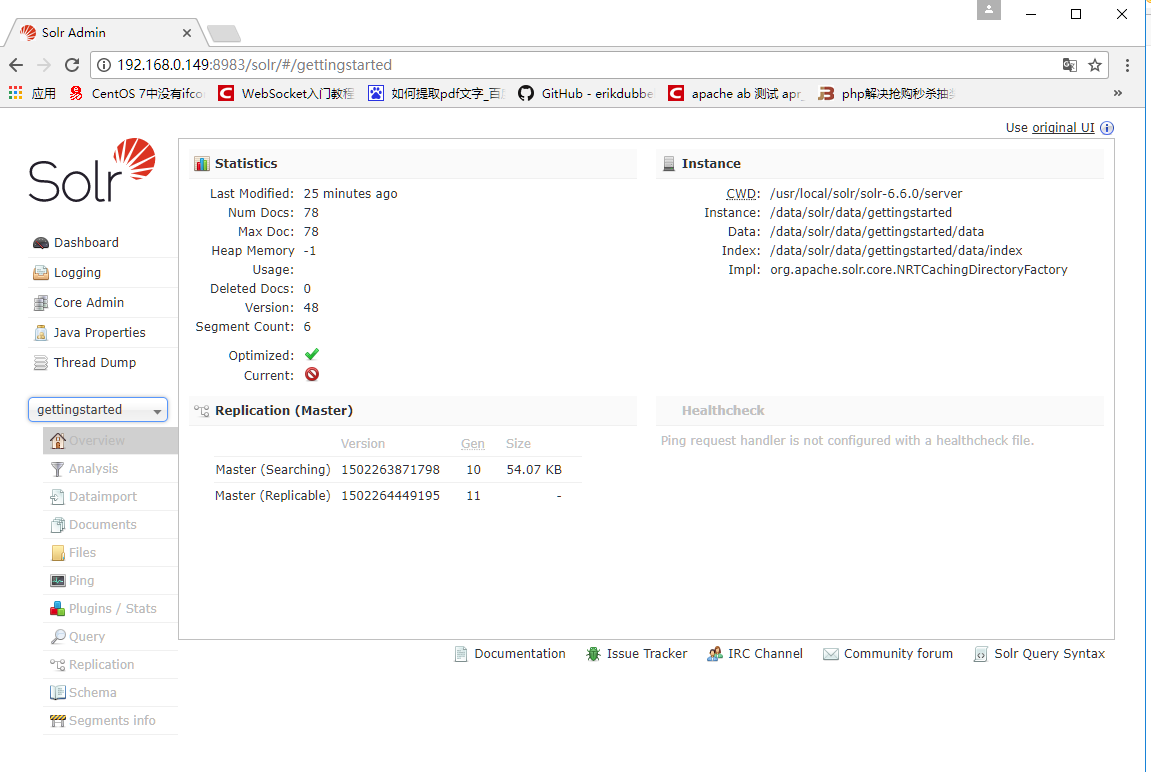
问你使用Web浏览器访问http://your_server_ip:8983/solr,Solr Web界面将会显示为:

这个Web界面包含大量的有用信息,可以被用于调试在使用中产生的任何问题。
集合被划分为核,这就是为什么在Web界面中有大量的对核的参照。
现在,gettingstarted只包含一个核,名为gettingstarted。在左手边,可以看到“Core Selector”下拉菜单,我们可以选择gettingstarted看到更多信息。
在选择gettingstarted核之后,选择“Documents”。文档存储可被Solr搜索的真实数据。因为我们使用了一个无模式的配置,我们可以使用任何列。我使用如下的JSON示例添加了一个单一文档,通过拷贝以下到“Documents(s)”列:
{
"number": 1,
"president": "George Washington",
"birth_year": 1732,
"death_year": 1799,
"took_office": "1789-04-30",
"left_office": "1797-03-04",
"party": "No Party"
}
点击“Submit document”添加文档到索引。过一会,你会看到如下信息:
添加文档后的输出:
Status: success
Response:
{
"responseHeader": {
"status": 0,
"QTime": 290
}
}
你可以使用一个类似的或完全不同的结构添加更多文档,但你也可以只使用一个文档继续。
现在,选择左边的“Query”去查询我们刚刚添加的文档。保持屏幕中的默认值,在点击“Execute Query”之后,你最多看到10个文档,依赖于你添加了多少:
查询输出
{
"responseHeader": {
"status": 0,
"QTime": 39,
"params": {
"q": "*:*",
"indent": "true",
"wt": "json",
"_": "1442371884598"
}
},
"response": {
"numFound": 1,
"start": 0,
"docs": [
{
"number": [
1
],
"president": [
"George Washington"
],
"birth_year": [
1732
],
"death_year": [
1799
],
"took_office": [
"1789-04-30T00:00:00Z"
],
"left_office": [
"1797-03-04T00:00:00Z"
],
"party": [
"No Party"
],
"id": "b9b294c1-4b68-4d96-adc2-f6fb77f60932",
"_version_": 1512437472611532800
}
]
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号