Chrome 浏览器支持本地部署大模型,无需高端独显,普通笔记本集成显卡即可流畅完成推理,AI 内容生成响应快速。所有内置 AI API 均可通过
localhost调用,核心配置与使用流程如下:
在 Chrome 地址栏依次打开以下地址,将对应标志设置为Enabled,重启浏览器生效:
- chrome://flags/#optimization-guide-on-device-model
- chrome://flags/#prompt-api-for-gemini-nano-multimodal-input
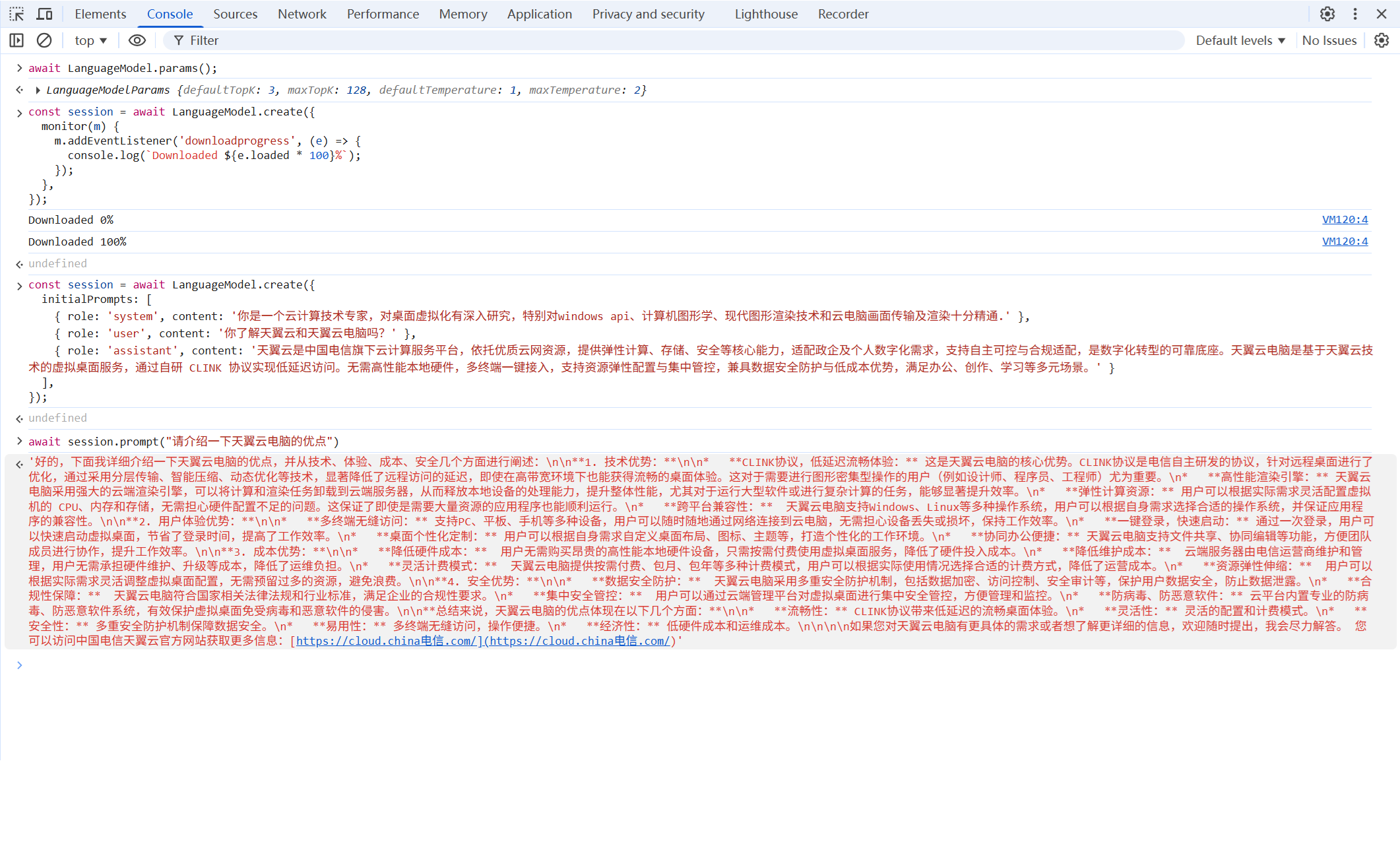
通过availability()方法确认模型是否可使用:
const availability = await LanguageModel.availability();
需触发用户激活,调用create()函数即可下载约 3G 的本地模型,实时显示下载进度:
const session = await LanguageModel.create({
monitor(m) {
m.addEventListener('downloadprogress', (e) => {
console.log(`Downloaded ${e.loaded * 100}%`);
});
},
});
可通过以下代码查看模型参数:
await LanguageModel.params();
Prompt API 就绪后,创建会话并发起提问,推理过程充分利用本地集成显卡,生成响应快速:
![local-nanoai]()
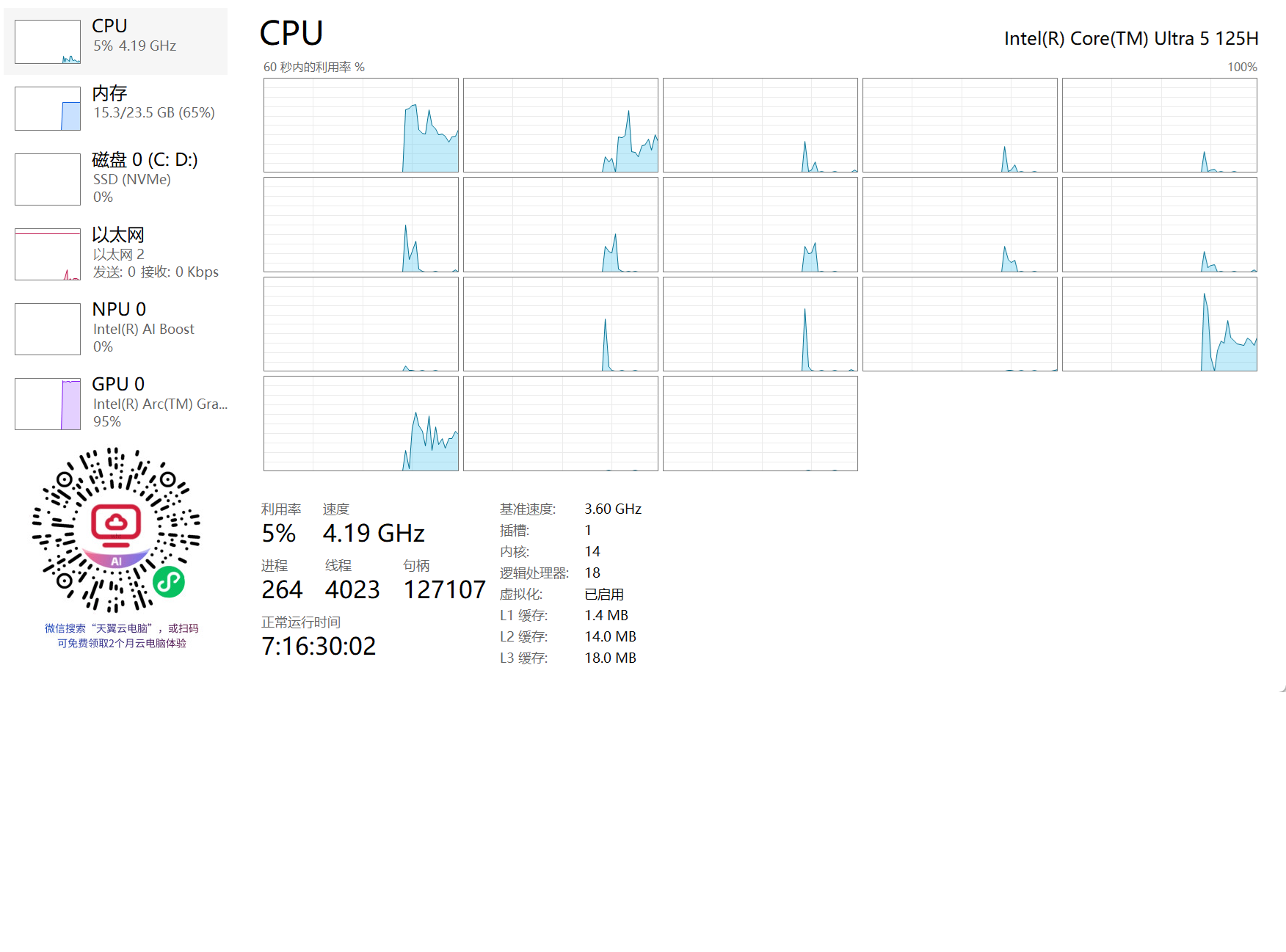
从硬件使用也可以看出,推理过程CPU使用没有明显提升,GPU则在全力工作:
![local-nanoai-gpu]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号