

吴恩达序列模型——注意力机制
1. Seq2Seq基础序列模型
Seq2Seq(Sequence-to-Sequence)模型能够应用于机器翻译、语音识别等各种序列到序列的转换问题。一个 Seq2Seq 模型包含编码器(Encoder)和解码器(Decoder)两部分,它们通常是两个不同的 RNN。如下图所示,将编码器的输出作为解码器的输入,由解码器负责输出正确的翻译结果。
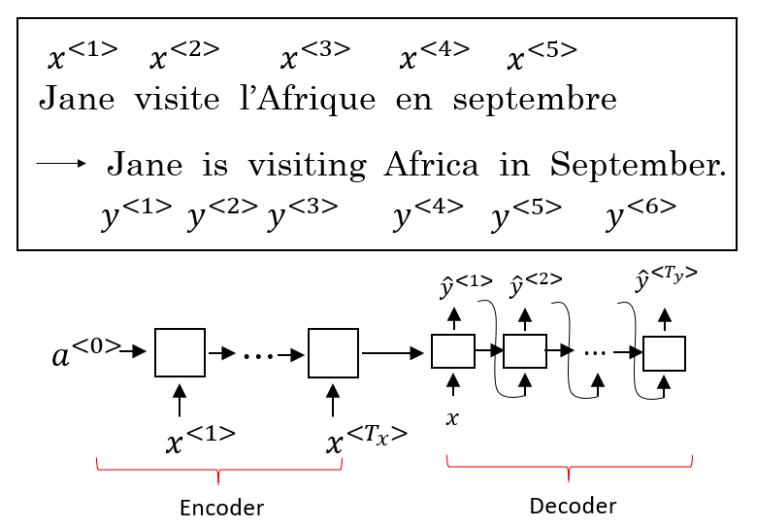
由于解码器进行随机采样过程,输出的翻译结果可能有好有坏。因此需要找到能使条件概率最大化的翻译。
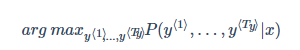
鉴于贪心搜索算法得到的结果显然难以不符合上述要求,解决此问题最常使用的算法是集束搜索
2. 集束搜索
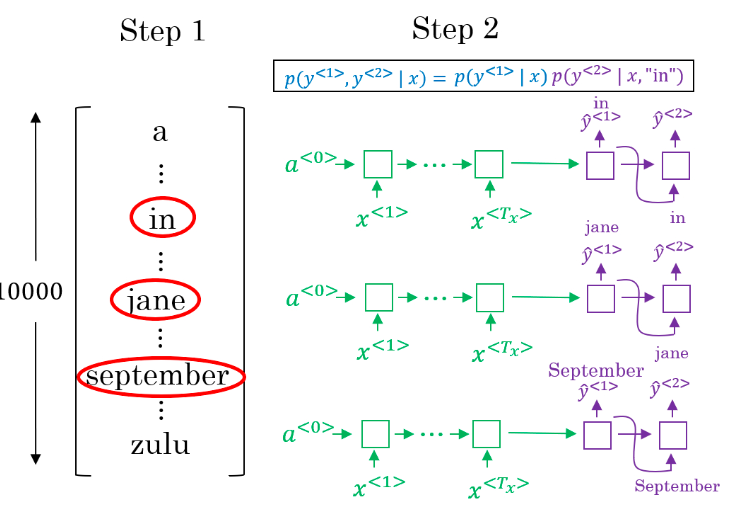
集束搜索(Beam Search)会考虑每个时间步多个可能的选择。设定一个集束宽(Beam Width)B,代表了解码器中每个时间步的预选单词数量。例如 B=3,则将第一个时间步最可能的三个预选单词及其概率值 P(y^⟨1⟩|x)保存到计算机内存,以待后续使用。第二步中,分别将三个预选词作为第二个时间步的输入,选取此结果下的有着最大概率的三个组合。以此类推每次都取概率最大的三种预测。 当 B=1时,集束搜索就变为贪心搜索。
长度归一化(Length normalization)是对束搜索算法稍作调整的一种方式,使之得到更好的结果。当多个小于 1 的概率值相乘后,会造成数值下溢(Numerical Underflow),即得到的结果将会是一个电脑不能精确表示的极小浮点数。因此,我们会取 log 值,并进行标准化
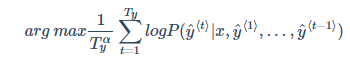
Ty 是翻译结果的单词数量,α 是一个需要根据实际情况进行调节的超参数。标准化用于减少对输出长的结果的惩罚(因为翻译结果一般没有长度限制)。
关于集束宽 B 的取值,较大的 B值意味着可能更好的结果和巨大的计算成本;而较小的 B值代表较小的计算成本和可能表现较差的结果。通常来说,B可以取一个 10 以下的值。和 BFS、DFS 等精确的查找算法相比,集束搜索算法运行速度更快,但是不能保证一定找到 arg max准确的最大值
当结合 Seq2Seq 模型和集束搜索算法所构建的系统出错(没有输出最佳翻译结果)时,我们通过误差分析来分析错误出现在 RNN 模型还是集束搜索算

3. Bleu得分
Bleu(Bilingual Evaluation Understudy)得分用于评估机器翻译的质量,其思想是机器翻译的结果越接近于人工翻译,则评分越高,提出了一个表现不错的单一实数评估指标,加快了整个机器翻译领域以及其他文本生成领域的进程。
分母是人工翻译的多元组的出现次数,分子式机器翻译的多元组的出现次数

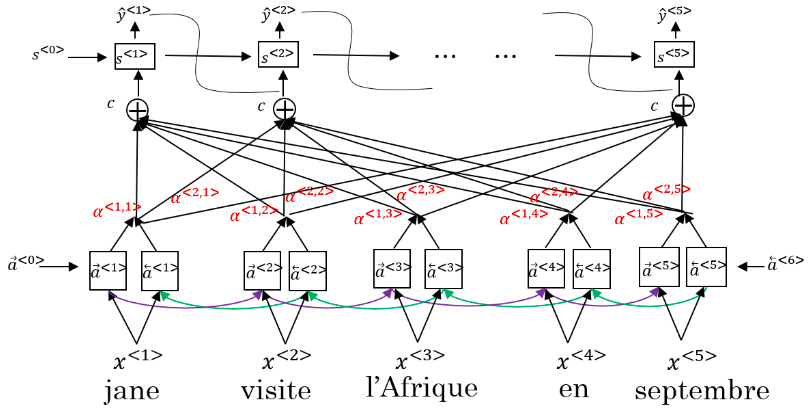
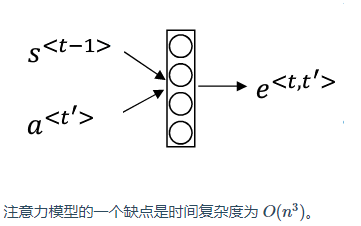
4. 注意力模型
注意力模型让一个神经网络只注意到一部分的输入句子。

5.语音识别
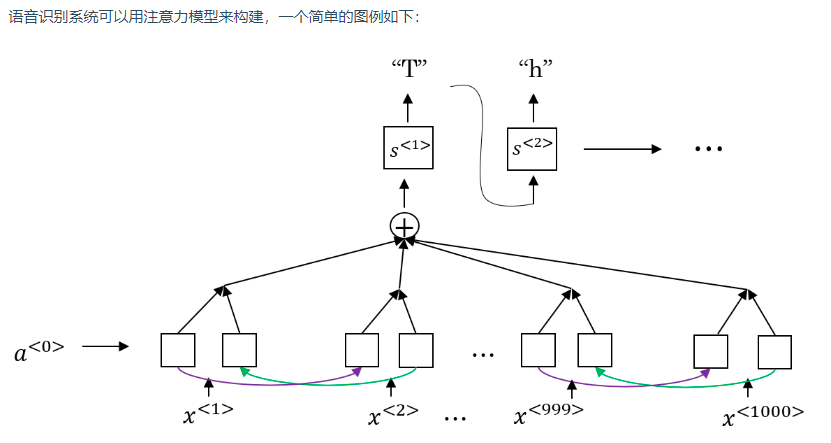
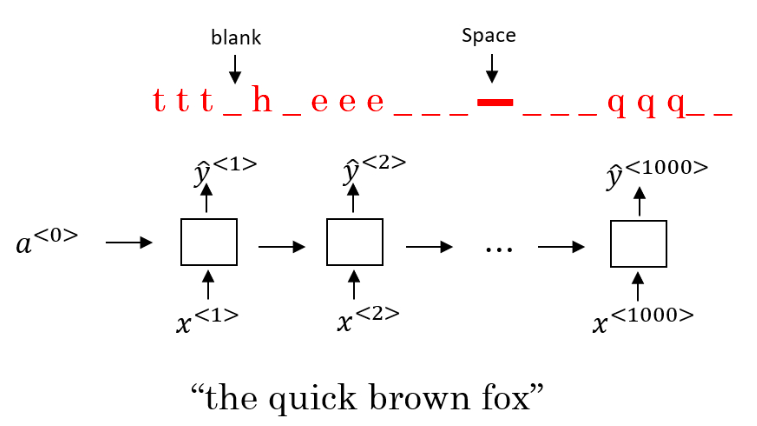
用 CTC(Connectionist Temporal Classification)损失函数来做语音识别的效果也不错。由于输入是音频数据,使用 RNN 所建立的系统含有很多个时间步,且输出数量往往小于输入。因此,不是每一个时间步都有对应的输出。CTC 允许 RNN 生成下图红字所示的输出,并将两个空白符(blank)中重复的字符折叠起来,再将空白符去掉,得到最终的输出文本。
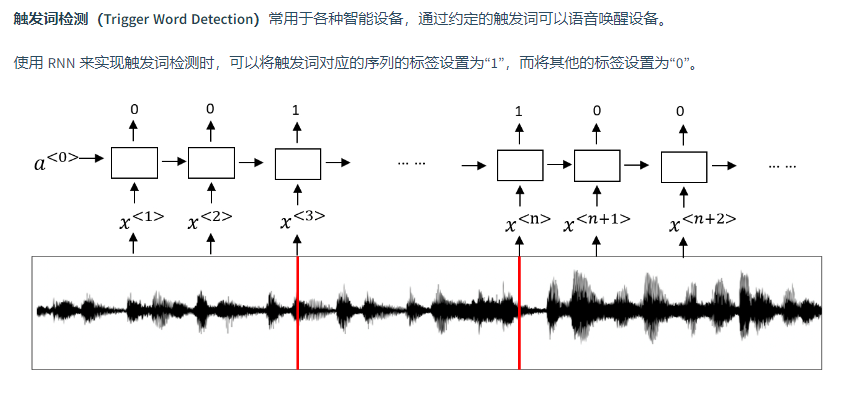
6. 触发字检测

 浙公网安备 33010602011771号
浙公网安备 33010602011771号