

吴恩达改善深层神经网络——优化算法
1.batch梯度下降法
batch 梯度下降法:对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,处理速度就会比较慢。
2. Mini-batch 梯度下降
把m个训练样本分成若干个子集,称为mini-batches,然后每次在单一子集上进行神经网络训练,这种梯度下降算法叫做Mini-batch Gradient Descent
二者的区别:使用 batch 梯度下降法,对整个训练集的一次遍历只能做一个梯度下降;而使用 Mini-Batch 梯度下降法,对整个训练集的一次遍历(称为一个 epoch)能做 mini-batch 个数个梯度下降。之后,可以一直遍历训练集,直到最后收敛到一个合适的精度。
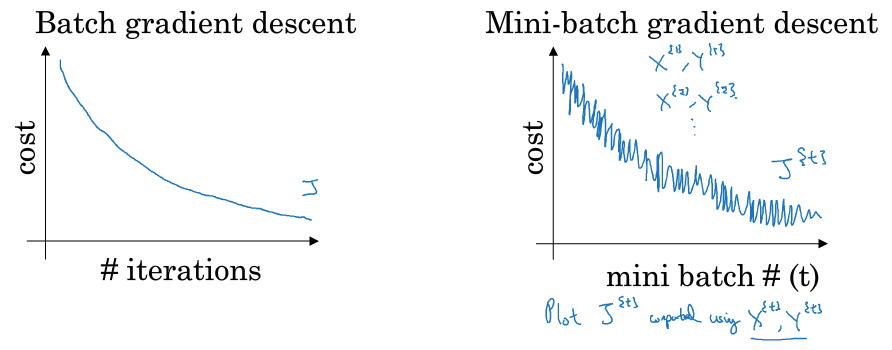
随机梯度下降法:mini-batch 的大小为 1,每个样本都是独立的 mini-batch
- 对每一个训练样本执行一次梯度下降,训练速度快,但丢失了向量化带来的计算加速;
- 有很多噪声,减小学习率可以适当;
- 成本函数总体趋势向全局最小值靠*,但永远不会收敛,而是一直在最小值附*波动。
batch梯度下降法:mini-batch 的大小为 m
- 对所有 m 个训练样本执行一次梯度下降,每一次迭代时间较长,训练过程慢;
- 相对噪声低一些,幅度也大一些;
- 成本函数总是向减小的方向下降。

mini-batch 梯度下降法:选择一个1 < size < m的合适的大小,可以实现快速学习,也应用了向量化带来的好处,且成本函数的下降处于前两者之间
- 总体样本数量m不太大时,例如m≤2000,建议直接使用Batch gradient descent
- 总体样本数量m很大时,建议将样本分成许多mini-batches。推荐常用的mini-batch size为64,128,256,512。都是2的幂。原因是计算机存储数据一般是2的幂,这样设置可以提高运算速度
- mini-batch 中确保X{t}和Y{t}要符合 CPU/GPU 内存,取决于应用方向以及训练集的大小。如果处理的 mini-batch 和 CPU/GPU 内存不相符,不管用什么方法处理数据,算法的表现都急转直下变得惨不忍睹
获得小批量的步骤: 随机打乱后按既定的大小分割数据集
m = X.shape[1] permutation = list(np.random.permutation(m)) shuffled_X = X[:, permutation] shuffled_Y = Y[:, permutation].reshape((1,m))
np.random.permutation与np.random.shuffle有两处不同:
- 如果传给
permutation一个矩阵,它会返回一个洗牌后的矩阵副本;而shuffle只是对一个矩阵进行洗牌,没有返回值 - 如果传入一个整数,它会返回一个洗牌后的
arange
2. 指数加权*均
常用于序列数据处理,是滑动*均算法。β值决定了指数加权*均的时刻,表示指数加权了往前1/(1-β) 时刻的数据
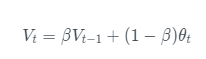
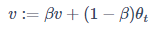
引入偏差修正:

随着 t 的增大,β 的 t 次方趋*于 0。因此当 t 很大的时候,偏差修正几乎没有作用,但是在前期学习可以帮助更好的预测数据。在实际过程中,一般会忽略前期偏差的影响。
3. 动量梯度下降法(Gradient descent with Momentum)
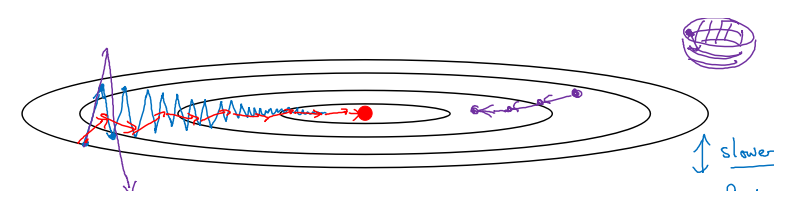
进行一般的梯度下降将会得到图中的蓝色曲线,由于存在上下波动,减缓了梯度下降的速度,因此只能使用一个较小的学习率进行迭代。如果用较大的学习率,结果可能会像紫色曲线一样偏离函数的范围,使用动量梯度下降时,通过累加过去的梯度值来减少抵达最小值路径上的波动,加速了收敛,因此在横轴方向下降得更快,从而得到图中红色的曲线
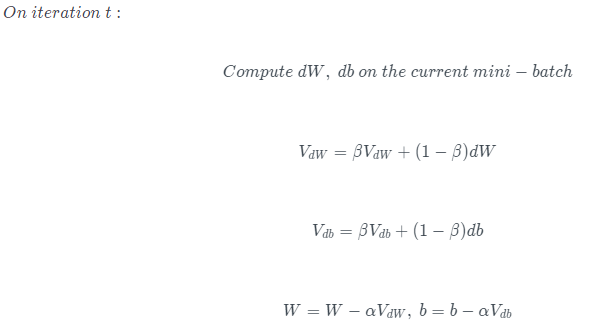
- 初始时,令VdW=0,Vdb=0。一般设置β=0.9,即指数加权*均前10次的数据,实际应用效果较好
- 偏移校正可以不使用。因为经过10次迭代后,随着滑动*均的过程,偏移情况会逐渐消失
- 当前后梯度方向一致时,动量梯度下降能够加速学习;而前后梯度方向不一致时,动量梯度下降能够抑制震荡。
- 成本函数想象为一个碗状,从顶部开始运动的小球向下滚,其中 dw,db 想象成球的加速度;而 vdw、vdb相当于速度。小球在向下滚动的过程中,因为加速度的存在速度会变快,但是由于 β 的存在,其值小于 1,可以认为是摩擦力,所以球不会无限加速下去
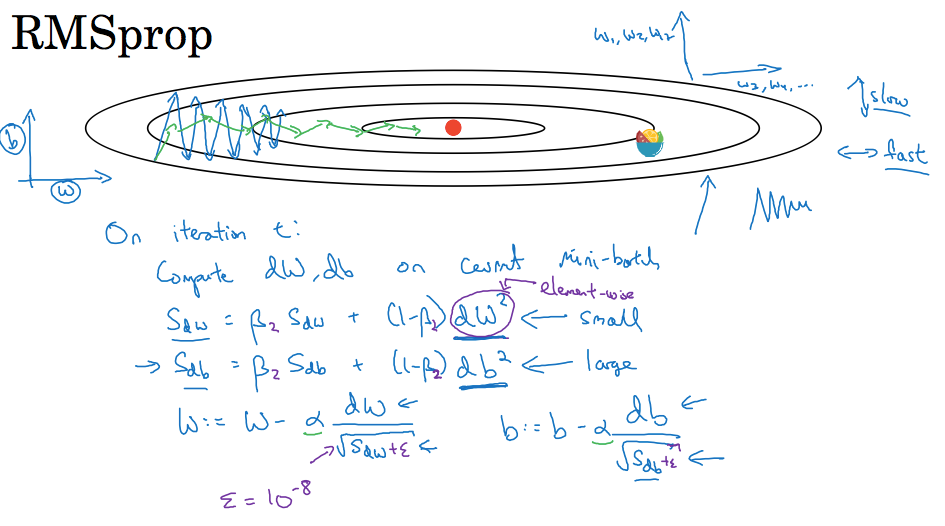
4. RMSProp 算法
RMSProp(Root Mean Square Propagation,均方根传播)算法是在对梯度进行指数加权*均的基础上,引入*方和*方根
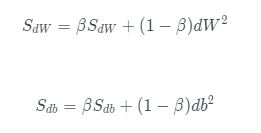
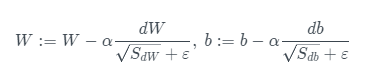
- ϵ 是一个实际操作时加上的较小数(例如10^-8),为了防止分母太小而导致的数值不稳定
- RMSProp 有助于减少抵达最小值路径上的摆动,并允许使用一个更大的学习率 α,从而加快算法学习速度。并且,它和 Adam 优化算法已被证明适用于不同的深度学习网络结构。β是超参数
- 作用:如果梯度下降在哪个方向振荡大,就减小该方向的更新速度,从而减小振荡
5. Adam 优化算法
Adam(Adaptive Moment Estimation)算法结合了动量梯度下降算法和RMSprop算法,使得神经网络训练速度大大提高,流程为

6. 学习率衰减
- 如果设置一个固定的学习率 α,在最小值点附*,由于不同的 batch 中存在一定的噪声,因此不会精确收敛,而是始终在最小值周围一个较大的范围内波动。
- 而如果随着时间慢慢减少学习率 α 的大小,在初期 α 较大时,下降的步长较大,能以较快的速度进行梯度下降;而后期逐步减小 α 的值,即减小步长,有助于算法的收敛,更容易接*最优解。
- 最常用的学习率衰减方法:

- 其他

7. 局部最优解
- 鞍点(saddle)是函数上的导数为零,但不是轴上局部极值的点。
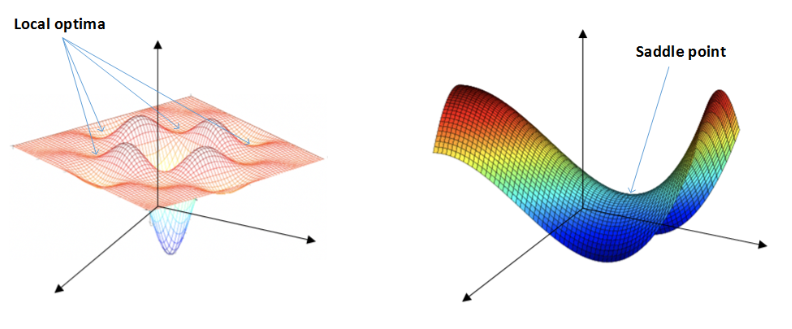
plateaus(*稳端)——鞍点
类似马鞍状的plateaus(*稳端)会降低神经网络学习速度。Plateaus是梯度接*于零的*缓区域,在plateaus上梯度很小,前进缓慢,到达saddle point需要很长时间。到达saddle point后,由于随机扰动,梯度一般能够沿着图中绿色箭头,离开saddle point,继续前进,只是在plateaus上花费了太多时间
- 在训练较大的神经网络、存在大量参数,并且成本函数被定义在较高的维度空间时,困在极差的局部最优中是不大可能的;
- 鞍点附*的*稳段会使得学习非常缓慢,而这也是动量梯度下降法、RMSProp 以及 Adam 优化算法能够加速学习的原因,它们能帮助尽早走出*稳段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号