

kafka
1. 消息队列(MQ)
1.1 消息队列
消息队列MQ(Message Queue):是一种帮助开发人员解决系统间异步通信的中间件,常用于解决系统解耦和请求的削峰平谷的问题。
- 队列(Queue):Queue 是一种先进先出的数据结构
- 消息(Message):不同应用之间传送的数据。
- 消息队列:消息队列是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。比如生产者发送消息1,2,3...对于消费者就会按照1,2,3...的顺序来消费。
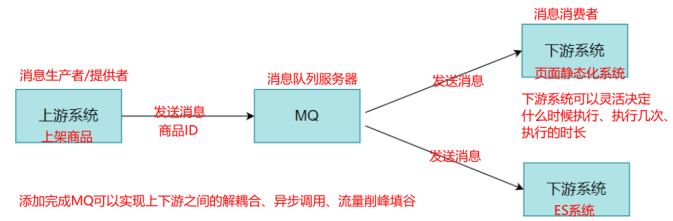
1.2 消息队列的应用场景
- 应用耦合:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败
举例:用户使用QQ相册上传一张图片,人脸识别系统会对该图片进行人脸识别,一般的做法是,服务器接收到图片后,图片上传系统立即调用人脸识别系统,调用完成后再返回成功,如下图所示

调用方式:webService、Http协议(HttpClient、RestTemplate)、Tcp协议(Dubbo)
正常方法存在缺点 1) 人脸识别系统被调失败,导致图片上传失败; 2) 延迟高,需要人脸识别系统处理完成后,再返回给客户端,即使用户并不需要立即知道结果; 3) 图片上传系统与人脸识别系统之间互相调用,需要做耦合;
使用消息队列:客户端上传图片后,图片上传系统将图片信息批次写入消息队列,直接返回成功;人脸识别系统则定时从消息队列中取数据,完成对新增图片的识别;图片上传系统并不需要关心人脸识别系统是否对这些图片信息的处理、以及何时对这些图片信息进行处理。
- 异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间
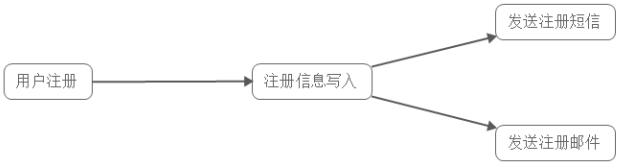
举例:用户为了使用某个应用,进行注册,系统需要发送注册邮件并验证短信。对这两个子系统操作的处理方式有两种:串行及并行。涉及到三个子系统:注册系统、邮件系统、短信系统,每个系统耗时50ms
1)串行方式:新注册信息生成后,先发送注册邮件,再发送验证短信;150ms

2) 并行处理:新注册信息写入后,由发短信和发邮件并行处理,在这种方式下,发短信和发邮件 需处理完成后再返回给客户端。100ms
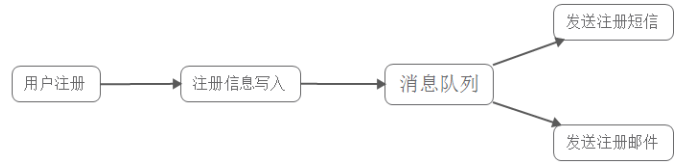
3)引入消息队列:在写入消息队列后立即返回成功给客户端,则总的响应时间依赖于写入消息队列的时间,而写入消息队列的时间本身是可以很快的,基本
可以忽略不计,因此总的处理时间为50ms,相比串行提高了2倍,相比并行提高了一倍;
- 限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况
举例:购物网站开展秒杀活动,一般由于瞬时访问量过大,服务器接收过大,会导致流量暴增,相关系统无法处理请求甚至崩溃

加入消息队列后,系统可以从消息队列中取数据,相当于消息队列做了一次缓冲。请求先入消息队列,极大地减少了业务处理系统的压力;队列长度可以做限制,事实上,秒杀时,后入队列的用户无法秒杀到商品,这些请求可以直接被抛弃,返回活动已结束或商品已售完信息
- 消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理
举例:用户新上传了一批照片 ---->人脸识别系统需要对这个用户的所有照片进行聚类 -------> 由对账系统重新生成用户的人脸索引(加快查询)

这三个子系统间由消息队列连接起来,前一个阶段的处理结果放入队列中,后一个阶段从队列中获取消息继续处理。避免了直接调用下一个系统导致当前系统失败;每个子系统对于消息的处理方式可以更为灵活,可以选择收到消息时就处理,可以选择定时处理,也可以划分时间段按不同处理速度处理。
1.3 消息队列的两种模式
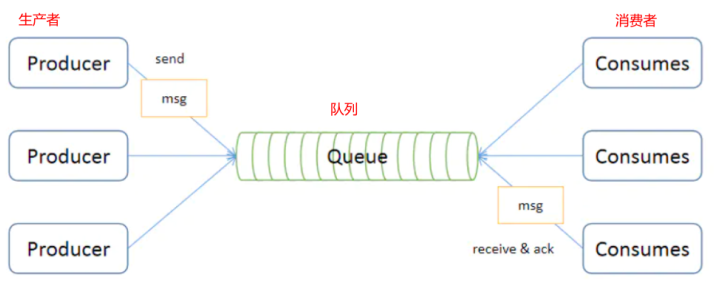
- 点对点模式(point to point, queue)
- 点对点模式下包括三个角色:消息队列、发送者 (生产者)、接收者(消费者)
- 每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,可以放在内存 中也可以持久化,直到他们被消费或超时。
![]()
- 每个消息只有一个消费者,一旦被消费,消息就不再在消息队列中
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
- 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息
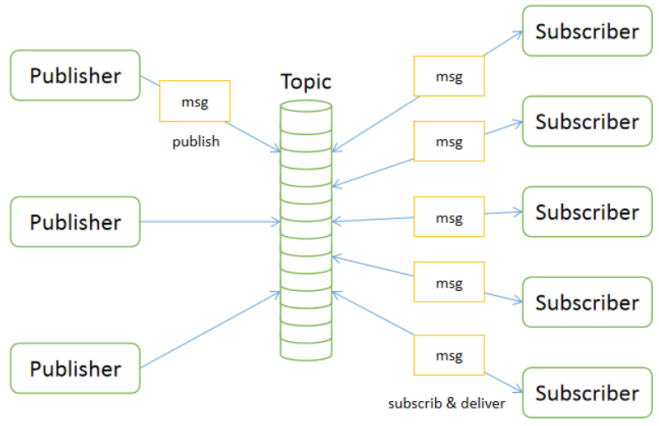
- 发布/订阅模式(publish/subscribe,topic)
- 发布/订阅模式下包括三个角色:角色主题(Topic) 、发布者(Publisher)、订阅者(Subscriber)
- 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被多个订阅者消费
- 每个消息可以有多个订阅者;发布者和订阅者之间有时间上的依赖性;为了消费消息,订阅者必须保持在线运行。
1.4 消息队列实现机制
- JMS(JAVA Message Service,Java消息服务)
是一个Java平台中关于面向消息中间件的API,允许应用程序组件基于JavaEE平台创建、发送、接收和读取消息,是一个消息服务的标准或者说是规范,是 Java 平台上有关面向消息中间件的技术规范,便于消息系统中的 Java 应用程序进行消息交换,并且通过提供标准的产生、发送、接收消息的接口,简化企业应用的开发。JMS 消息机制主要分为两种模型:PTP 模型和 Pub/Sub 模型。实现产品:Apache ActiveMQ
- AMQP(Advanced Message Queuing Protocol)
一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。
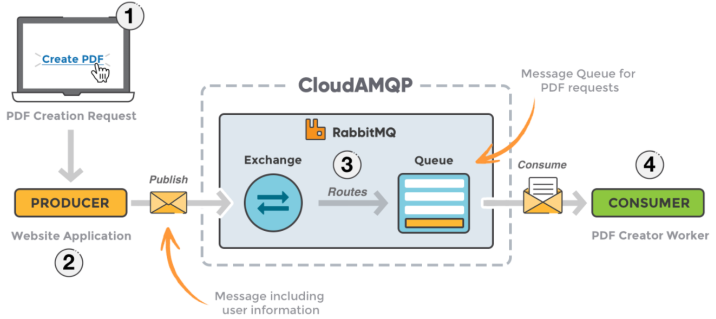

1.5 常见的消息队列产品
- RabbitMQ:RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
- ActiveMQ:ActiveMQ是由Apache出品,ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现。它非常快速,支持多种语言的客户端和协议,而且可以非常容易的嵌入到企业的应用环境中,并有许多高级功能
- RocketMQ:RocketMQ出自阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,消息可靠性上比 Kafka 更好。RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理等
- Kafka:Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
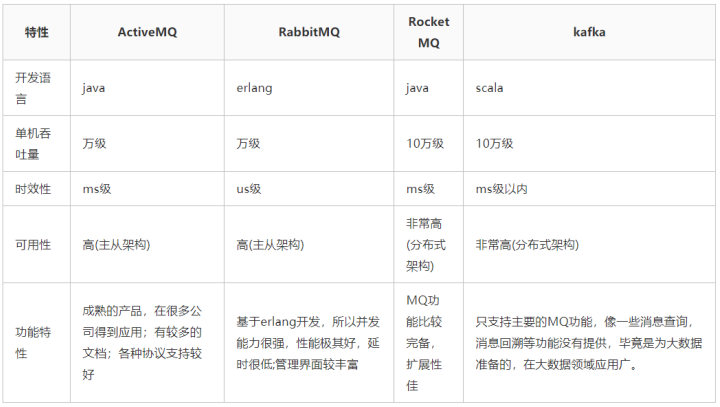
- 中小型软件公司:建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便。RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug。不考虑rocketmq和kafka的原因是,一方面中小型软件公司不如互联网公司,数据量没那么大,选消息中间件,应首选功能比较完备的,所以kafka排除。不考虑rocketmq的原因是,rocketmq是阿里出品,如果阿里放弃维护rocketmq,中小型公司一般抽不出人来进行rocketmq的定制化开发
- 大型软件公司:根据具体使用在rocketMq和kafka之间二选一。一方面,大型软件公司,具备足够的资金搭建分布式环境,也具备足够大的数据量。针对rocketMQ,大型软件公司也可以抽出人手对rocketMQ进行定制化开发,毕竟国内有能力改JAVA源码的人,还是相当多的。至于kafka,根据业务场景选择,如果有日志采集功能,肯定是首选kafka了
2. kafka
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等
主要应用场景是:日志收集系统和消息系统。官网:http://kafka.apache.org/
- Kafka主要设计目标如下
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。支持普通服务器每秒百万级写入请求;Memory mapped Files 内存映射文件
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理
- Scale out:支持在线水平扩展
- kafka的特点
- 解耦。Kafka具备消息系统的优点,只要生产者和消费者数据两端遵循接口约束,就可以自行扩展或修改数据处理的业务过程
- 高吞吐量、低延迟。即使在非常廉价的机器上,Kafka也能做到每秒处理几十万条消息,而它的延迟最低只有几毫秒。
- 持久性。Kafka可以将消息直接持久化在普通磁盘上,且磁盘读写性能优异
- 扩展性。Kafka集群支持热扩展,Kaka集群启动运行后,用户可以直接向集群添加
- 容错性。Kafka会将数据备份到多台服务器节点中,即使Kafka集群中的某一台加新的Kafka服务节点宕机,也不会影响整个系统的功能
- 支持多种客户端语言。Kafka支持Java、.NET、PHP、Python等多种语言
- 支持多生产者和多消费者
- kafka的主要应用场景
- 消息处理(MQ)
- KafKa的append来实现消息的追加,保证消息都是有序的有先来后到的顺序
- 稳定性强队列在使用中最怕丢失数据,KafKa能做到理论上的写成功不丢失
- 分布式容灾好
- 容量大,相对于内存队列,KafKa的容量受硬盘影响
- 数据量不会影响到KafKa的速度
- 分布式日志系统(Log):处理日志丢失,日志存文件不好找,定位难,成本高(遍历当天日志文件),实时推送难等问题
- KafKa的集群备份机制能做到n/2的可用,当n/2以下的机器宕机时存储的日志不会丢失
- KafKa可以对消息进行分组分片
- KafKa非常容易做到实时日志查询
- 流式处理:实时的处理一个或多个事件流,流式的处理框架(spark, storm , flink) 从主题中读取数据, 对其进行处理, 并将处理后的结果数据写入新的主题, 供用户和应用程序使用,kafka的强耐久性在流处理的上下文中也非常的有用。
- 消息处理(MQ)
3. Kafka框架
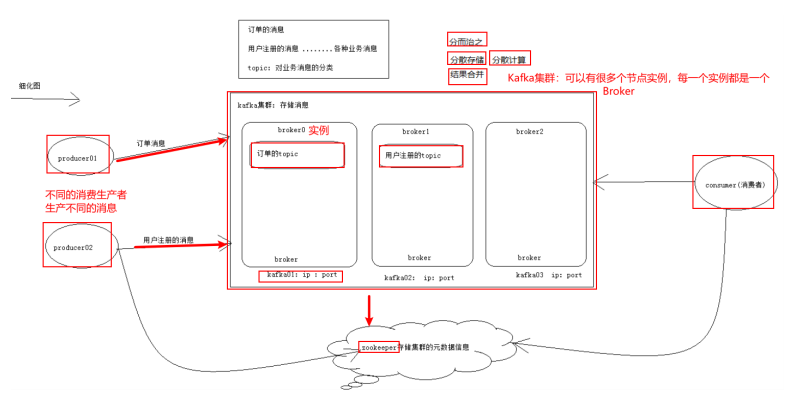
- Kafka Cluster:由多个服务器组成。每个服务器单独的名字broker(掮客)
- kafka broker:kafka集群中包含的服务器
- Kafka Producer:消息生产者、发布消息到 kafka 集群的终端或服务
- 在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置,偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从"现在"开始消费
- Kafka consumer:消息消费者、负责消费数据
- Kafka Topic: 主题,一类消息的名称。存储数据时将一类数据存放在某个topci下,消费数据也是消费一类数据
- 订单系统:创建一个topic,叫做order
- 用户系统:创建一个topic,叫做user
- 商品系统:创建一个topic,叫做product
- 注意:Kafka的元数据都是存放在zookeeper中。
- 架构剖析:
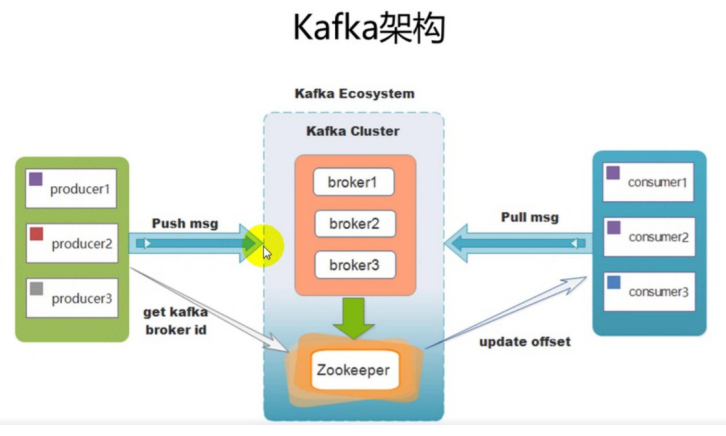
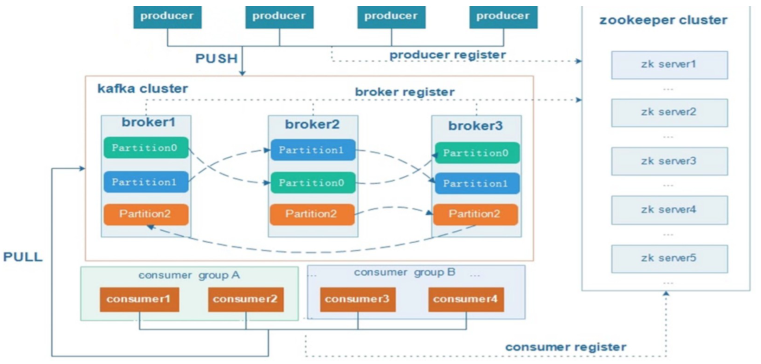
-
- kafka支持消息持久化,消费端为拉模型来拉取数据,消费状态和订阅关系有客户端负责维护,消息消费完 后,不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。
- Broker:kafka集群中包含一个或者多个服务实例,这种服务实例被称为Broker
- Topic:每条发布到kafka集群的消息都有一个类别,这个类别就叫做Topic
- Partition:分区,物理上的概念,每个topic包含一个或多个partition,一个partition对应一个文件夹,这个文件夹下存储partition的数据和索引文件,每个partition内部是有序的
- kafka支持消息持久化,消费端为拉模型来拉取数据,消费状态和订阅关系有客户端负责维护,消息消费完 后,不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。
- 关系解释
- Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。
- Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据
- 一个topic为一类消息,每条消息必须指定一个topic
- 对于每一个topic, Kafka集群都会维持一个分区日志
- 每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件
- 分区中的每一个记录都会分配一个id号来表示顺序,称之为offset,offset用来唯一的标识分区中每一条记录
![]()
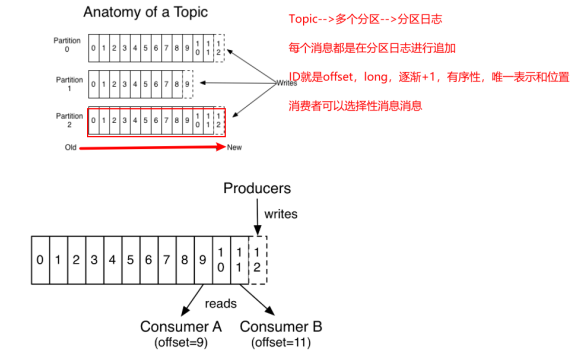
在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置,偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数
据;也可以跳过最近的记录,从"现在"开始消费。这些细节说明Kafka 消费者是非常廉价的—消费者的增加和减少,对集群或者其他消费者没有多大的影响。
4. kafka集群搭建(虚拟机)
ZooKeeper 作为给分布式系统提供协调服务的工具被 kafka 所依赖。通过使用 ZooKeeper 协调服务,Kafka就能将 Producer,Consumer,Broker 等结合在一起,同时借助 ZooKeeper,Kafka 就能够将所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现负载均衡。

准备三台服务器, 安装jdk1.8 ,其中每一台虚拟机的hosts文件中都需要配置如下的内容
192.168.200.11 node1 192.168.200.12 node2 192.168.200.13 node3
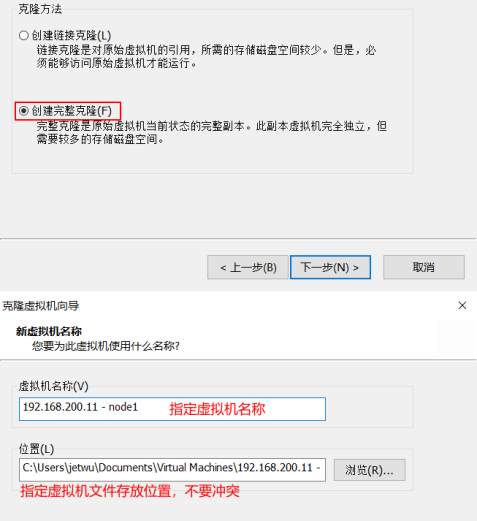
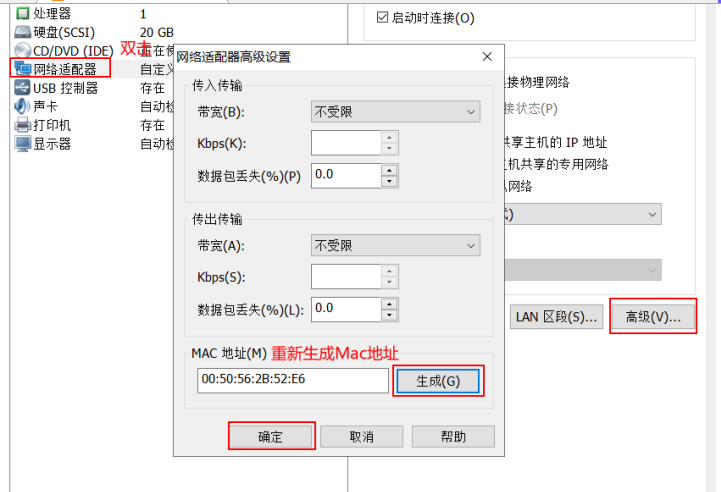
修改IP地址:修改网卡配置文件 vi /etc/sysconfig/network-scripts/ifcfg-ens33
- bootproto=static,表示使用静态IP
- onboot=yes,表示将网卡设置为开机启用
- 将原有的原有IP修改为192.168.200.11
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=b8fd5718-51f5-48f8-979b-b9f1f7a5ebf2
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.200.11
GATEWAY=192.168.200.2
NETMASK=255.255.255.0
NM_CONTROLLED=no
DNS1=8.8.8.8
DNS2=8.8.4.4
- 重启网络服务service network restart
- 安装目录创建
安装包存放的目录:/export/software 安装程序存放的目录:/export/servers 数据目录:/export/data 日志目录:/export/logs 创建各级目录命令: mkdir -p /export/servers/ mkdir -p /export/software/ mkdir -p /export/data/ mkdir -p /export/logs/ - 修改host
- 执行命令“cd /etc/”进入服务器etc目录;
- 执行命令“vi hosts”编辑hosts文件;
- 输入你要修改的内容
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.200.11 node1
192.168.200.12 node2
192.168.200.13 node3
-
- 执行命令”/etc/init.d/network restart“ 重启hosts
- 执行命令”cat /etc/hosts“可以查看到hosts文件修改成功。
- JDK
- Linux安装JDK,三台Linux都安装。上传JDK到linux:使用SSH方式、使用CRT方式
- 使用CRT需要先在Linux虚拟机上安装lrzsz上传工具,安装方式: yum install -y lrzsz
- 安装lrzsz之后,是需要在在Linux命令行中输入:rz ,就可以弹出一个文件上传窗口
![]()
- 安装并配置JDK
# 使用rpm安装JDK rpm -ivh jdk-8u261-linux-x64.rpm # 默认的安装路径是/usr/java/jdk1.8.0_261-amd64 # 配置JAVA_HOME vi /etc/profile # 文件最后添加两行 export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64 export PATH=$PATH:$JAVA_HOME/bin # 退出vi,使配置生效 source /etc/profile - 查看JDK是否正确安装 java -version
- Linux 安装Zookeeper,三台Linux都安装,以搭建Zookeeper集群
- 上传zookeeper-3.4.14.tar.gz,解压并配置zookeeper(配置data目录,集群节点)
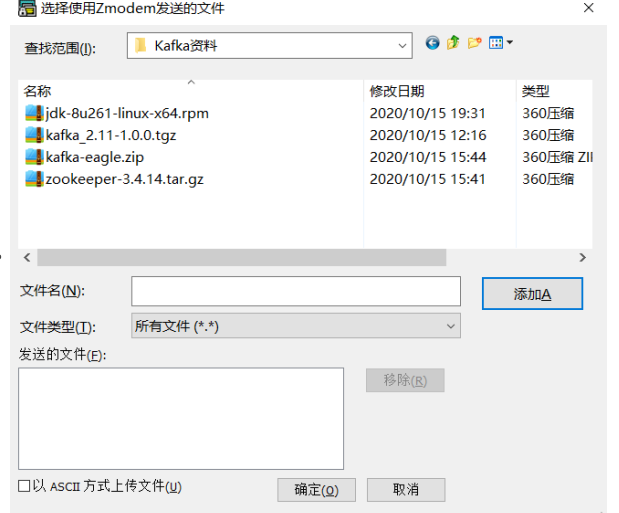
# node1操作
# 解压到/opt目录
tar -zxf zookeeper-3.4.14.tar.gz -C /opt
# 配置
cd /opt/zookeeper-3.4.14/conf
# 配置文件重命名后生效
cp zoo_sample.cfg zoo.cfg
#编辑
vi zoo.cfg
# 设置数据目录
dataDir=/var/lagou/zookeeper/data
# 添加
server.1=node1:2881:3881
server.2=node2:2881:3881
server.3=node3:2881:3881
# 退出vim
mkdir -p /var/lagou/zookeeper/data
echo 1 > /var/lagou/zookeeper/data/myid
# 配置环境变量
vi /etc/profile
# 添加
export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_PREFIX/bin
export ZOO_LOG_DIR=/var/lagou/zookeeper/log
# 退出vim,让配置生效
source /etc/profile
# 配置环境变量
vim /etc/profile
# 在配置JDK环境变量基础上,添加内容
export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_PREFIX/bin
export ZOO_LOG_DIR=/var/lagou/zookeeper/log
# 退出vim,让配置生效
source /etc/profile
mkdir -p /var/lagou/zookeeper/data
echo 2 > /var/lagou/zookeeper/data/myid
# 配置环境变量
vim /etc/profile
# 在配置JDK环境变量基础上,添加内容
export ZOOKEEPER_PREFIX=/opt/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_PREFIX/bin
export ZOO_LOG_DIR=/var/lagou/zookeeper/log
# 退出vim,让配置生效
source /etc/profile
mkdir -p /var/lagou/zookeeper/data
echo 3 > /var/lagou/zookeeper/data/myid
- 启动zookeeper
# 在三台Linux上启动Zookeeper
[root@node1 ~]# zkServer.sh start
[root@node2 ~]# zkServer.sh start
[root@node3 ~]# zkServer.sh start
# 在三台Linux上查看Zookeeper的状态
[root@node1 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
[root@node2 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader
[root@node3 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
- 上传安装包并解压
使用 rz 命令将安装包上传至 /export/software
1) 切换目录上传安装包
cd /export/software
rz # 选择对应安装包上传即可
2) 解压安装包到指定目录下
tar -zxvf kafka_2.11-1.0.0.tgz -C /export/servers/
cd /export/servers/
3) 重命名(由于名称太长)
mv kafka_2.11-1.0.0 kafka
- 修改kafka的核心配置文件
cd /export/servers/kafka/config/
vi server.properties
主要修改一下6个地方:
1) broker.id 需要保证每一台kafka都有一个独立的broker
2) log.dirs 数据存放的目录
3) zookeeper.connect zookeeper的连接地址信息
4) delete.topic.enable 是否直接删除topic
5) host.name 主机的名称
6) 修改: listeners=PLAINTEXT://node1:9092
#broker.id 标识了kafka集群中一个唯一broker。
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
# 存放生产者生产的数据 数据一般以topic的方式存放
log.dirs=/export/data/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
# zk的信息
zookeeper.connect=node1:2181,node2:2181,node3:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
host.name=node1
- 将配置好的kafka分发到其他二台主机
Linux scp 命令用于 Linux 之间复制文件和目录。scp 是 secure copy 的缩写, scp 是 linux 系统下基于 ssh 登陆进行安全的远程文件拷贝命令。
cd /export/servers
scp -r kafka/ node2:$PWD
scp -r kafka/ node3:$PWD
ip为11的服务器: broker.id=0 , host.name=node1 listeners=PLAINTEXT://node1:9092 ip为12的服务器: broker.id=1 , host.name=node2 listeners=PLAINTEXT://node2:9092 ip为13的服务器: broker.id=2 , host.name=node3 listeners=PLAINTEXT://node3:9092
#在每一台的服务器执行创建数据文件的命令
mkdir -p /export/data/kafka
- 启动集群,必须先启动zookeeper
cd /export/servers/kafka/bin #前台启动 ./kafka-server-start.sh /export/servers/kafka/config/server.properties #后台启动 nohup ./kafka-server-start.sh /export/servers/kafka/config/server.properties 2>&1 & 注意:可以启动一台broker,单机版。也可以同时启动三台broker,组成一个kafka集群版 #kafka停止 ./kafka-server-stop.sh
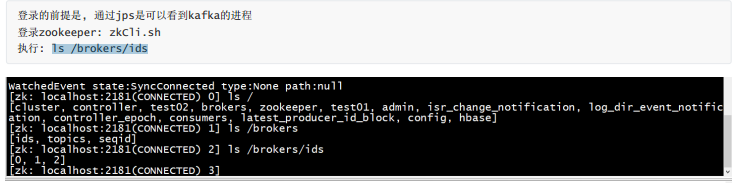
5. Docker环境下的Kafka集群搭建
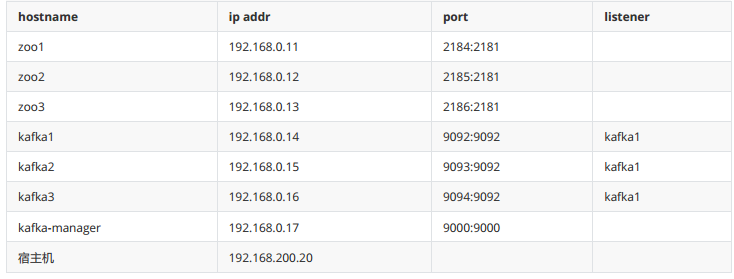
- 修改IP地址为192.168.200.20: vi /etc/sysconfig/network-scrpits/ifcfg-ens33
- 安装docker - compose
- Compose 是用于定义和运行多容器 Docker 应用程序的工具
- 如果我们还是使用原来的方式操作docker,那么就需要下载三个镜像:Zookeeper、Kafka、Kafka-Manager,需要对Zookeeper安装三次并配置集群、需要对Kafka安装三次,修改配置文件,Kafka-Manager安装一次,但是需要配置端口映射机器Zooker、Kafka容器的信息。
- 引入Compose之后可以使用yaml格式的配置文件配置好这些信息,每个image只需要编写一个yaml文件,可以在文件中定义集群信息、端口映射等信息,运行该文件即可创建完成集群。
- 通过 Compose,您可以使用 YML 文件来配置应用程序需要的所有服务。然后,使用一个命令,就可以从 YML 文件配置中创建并启动所有服务
- Compose 使用的两个步骤
- 使用 docker-compose.yml 定义构成应用程序的服务,这样它们可以在隔离环境中一起运行
- 执行 docker-compose up 命令来启动并运行整个应用程序。
![]()
- 拉取镜像
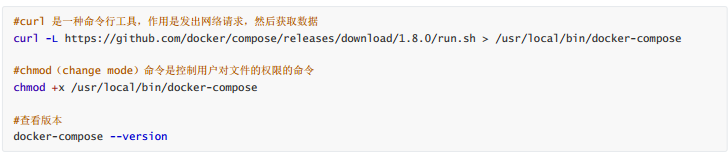
#拉取Zookeeper镜像
docker pull zookeeper:3.4
#拉取kafka镜像
docker pull wurstmeister/kafka
#拉取kafka-manager镜像
docker pull sheepkiller/kafka-manager:latest
- 创建集群网络:基于Linux宿主机而工作的,也是在Linux宿主机创建,创建之后Docker容器中的各个应用程序可以使用该网络
#创建
docker network create --driver bridge --subnet 192.168.0.0/24 --gateway 192.168.0.1 kafka
#查看
docker network ls
- 网络设置
新建网段之后可能会出现:WARNING: IPv4 forwarding is disabled. Networking will not work.
解决方式:
第一步:在宿主机上执行: echo "net.ipv4.ip_forward=1" >>/usr/lib/sysctl.d/00-system.conf
第二步:重启network和docker服务
[root@localhost /]# systemctl restart network && systemctl restart docker
- 编写yml
- docker-compose-kafka.yml
version: '2'
services:
kafka1:
image: wurstmeister/kafka
restart: always
hostname: kafka1
container_name: kafka1
privileged: true
ports:
- 9092:9092
environment:
KAFKA_ADVERTISED_HOST_NAME: kafka1
KAFKA_LISTENERS: PLAINTEXT://kafka1:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka1:9092
KAFKA_ADVERTISED_PORT: 9092
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
external_links:
- zoo1
- zoo2
- zoo3
networks:
kafka:
ipv4_address: 192.168.0.14
kafka2:
image: wurstmeister/kafka
restart: always
hostname: kafka2
container_name: kafka2
privileged: true
ports:
- 9093:9093
environment:
KAFKA_ADVERTISED_HOST_NAME: kafka2
KAFKA_LISTENERS: PLAINTEXT://kafka2:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka2:9093
KAFKA_ADVERTISED_PORT: 9093
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
external_links:
- zoo1
- zoo2
- zoo3
networks:
kafka:
ipv4_address: 192.168.0.15
kafka3:
image: wurstmeister/kafka
restart: always
hostname: kafka3
container_name: kafka3
privileged: true
ports:
- 9094:9094
environment:
KAFKA_ADVERTISED_HOST_NAME: kafka3
KAFKA_LISTENERS: PLAINTEXT://kafka3:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka3:9094
KAFKA_ADVERTISED_PORT: 9094
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181
external_links:
- zoo1
- zoo2
- zoo3
networks:
kafka:
ipv4_address: 192.168.0.16
networks:
kafka:
external:
name: kafka
-
- docker-compose-zookeeper.yml
version: '2' services: zoo1: image: zookeeper:3.4 restart: always hostname: zoo1 container_name: zoo1 ports: - 2184:2181 environment: ZOO_MY_ID: 1 ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888 networks: kafka: ipv4_address: 192.168.0.11 zoo2: image: zookeeper:3.4 restart: always hostname: zoo2 container_name: zoo2 ports: - 2185:2181 environment: ZOO_MY_ID: 2 ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=0.0.0.0:2888:3888 server.3=zoo3:2888:3888 networks: kafka: ipv4_address: 192.168.0.12 zoo3: image: zookeeper:3.4 restart: always hostname: zoo3 container_name: zoo3 ports: - 2186:2181 environment: ZOO_MY_ID: 3 ZOO_SERVERS: server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=0.0.0.0:2888:3888 networks: kafka: ipv4_address: 192.168.0.13 networks: kafka: external: name: kafka- docker-compose-manager.yml
version: '2'
services:
kafka-manager:
image: sheepkiller/kafka-manager:latest
restart: always
container_name: kafka-manager
hostname: kafka-manager
ports:
- 9000:9000
environment:
ZK_HOSTS: zoo1:2181,zoo2:2181,zoo3:2181
KAFKA_BROKERS: kafka1:9092,kafka2:9092,kafka3:9092
APPLICATION_SECRET: letmein
KM_ARGS: -Djava.net.preferIPv4Stack=true
networks:
kafka:
ipv4_address: 192.168.0.17
networks:
kafka:
external:
name: kafka
- 将yaml文件上传到Docker宿主机中
安装:yum install -y lrzsz
上传到指定目录
- 开始部署
使用命令:docker-compose up -d
参数说明: up表示启动, -d表示后台运行
docker-compose -f /home/docker-compose-zookeeper.yml up -d
参数说明: -f:表示加载指定位置的yaml文件
docker-compose -f /home/docker-compose-kafka.yml up -d
docker-compose -f /home/docker-compose-manager.yml up -d
- 测试:浏览器访问宿主机:http://192.168.200.20:9000/
6. kafka操作
- 创建Topic
创建一个名字为test的主题, 有一个分区,有三个副本。一个主题下可以有多个分区,每个分区可以用对应的副本
--create:新建命令
--zookeeper:Zookeeper节点,一个或多个
--replication-factor:指定副本,每个分区有三个副本。
--partitions:1
#登录到Kafka容器
docker exec -it 9218e985e160 /bin/bash
#切换到bin目录
cd opt/kafka/bin/
#执行创建
kafka-topics.sh --create --zookeeper zoo1:2181 --replication-factor 3 --partitions 1 --topic test

- 查看主题命令
kafka-topics.sh --list --zookeeper zoo1:2181,zoo2:2181,zoo3:2181
__consumer_offsets 这个topic是由kafka自动创建的,默认50个分区,存储消费位移信息(offset),老版本架构中是存储在Zookeeper中。
- 生产者生产数据:
- Kafka自带一个命令行客户端,它从文件或标准输入中获取输入,并将其作为message(消息)发送到Kafka集群
- 默认情况下,每行将作为单独的message发送
- 运行 producer,然后在控制台输入一些消息以发送到服务器
kafka-console-producer.sh --broker-list kafka1:9092,kafka2:9093,kafka3:9094 --topic test This is a message This is another message - 消费者消费数据:在使用的时候会用到bootstrap与broker.list其实是实现一个功能,broker.list是旧版本命令
- 一、确保消费者消费的消息是顺序的,需要把消息存放在同一个topic的同一个分区
- 二、一个主题多个分区,分区内消息有序
kafka-console-consumer.sh --bootstrap-server kafka1:9092, kafka2:9093, kafka3:9094 --topic test --from-beginning
- 运行describe的命令:运行describe查看topic的相关详细信息
- 这是输出的解释。第一行给出了所有分区的摘要,每个附加行提供有关一个分区的信息。有几个分区,下面就显示几行
- leader:是负责给定分区的所有读取和写入的节点。每个节点将成为随机选择的分区部分的领导者
- replicas:显示给定partiton所有副本所存储节点的节点列表,不管该节点是否是leader或者是否存活。
- isr:副本都已同步的的节点集合,这个集合中的所有节点都是存活状态,并且跟leader同步
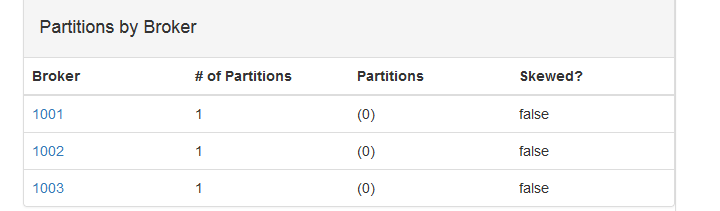
#查看topic主题详情,Zookeeper节点写一个和全部写,效果一致 kafka-topics.sh --describe --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --topic test #结果列表 Topic: test1 PartitionCount: 3 ReplicationFactor: 3 Configs: Topic: test1 Partition: 0 Leader: 1001 Replicas: 1001,1003,1002 Isr: 1001,1003,1002 Topic: test1 Partition: 1 Leader: 1002 Replicas: 1002,1001,1003 Isr: 1002,1001,1003 Topic: test1 Partition: 2 Leader: 1003 Replicas: 1003,1002,1001 Isr: 1003,1002,1001
- 这是输出的解释。第一行给出了所有分区的摘要,每个附加行提供有关一个分区的信息。有几个分区,下面就显示几行
- 增加topic分区数: 任意kafka服务器执行以下命令可以增加topic分区数
kafka-topics.sh --zookeeper zoo1:2181 --alter --topic test --partitions 5
- 增加配置
- flush.messages:此项配置指定时间间隔:强制进行fsync日志,默认值为None
- 例如,如果这个选项设置为1,那么每条消息之后都需要进行fsync,如果设置为5,则每5条消息就需要进行一次fsync
- 一般来说,建议你不要设置这个值。此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡
- 如果此值过大,将会导致每次"fsync"的时间较长(IO阻塞)
- 如果此值过小,将会导致"fsync"的次数较多,这也意味着整体的client请求有一定的延迟,物理server故障,将会导致没有fsync的消息丢失
- 动态修改kakfa的配置
kafka-topics.sh --zookeeper zoo1:2181 --alter --topic test --config flush.messages=1
- 删除配置:动态删除kafka集群配置
kafka-topics.sh --zookeeper zoo1:2181 --alter --topic test --delete-config flush.messages
- 删除topic:目前删除topic在默认情况只是打上一个删除的标记,在重新启动kafka后才删除。如果需要立即删除,则需要在server.properties中配置:delete.topic.enable=true(集群中的所有实例节点),一个主题会在不同的kafka节点中分配分组信息和副本信息然后执行以下命令进行删除topic
kafka-topics.sh --zookeeper zoo1:2181 --delete --topic test
7. Java API操作kafka
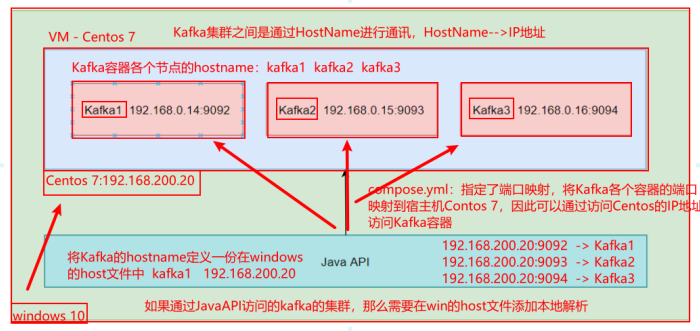
- 修改Windows的Host文件:目录:C:\Windows\System32\drivers\etc
192.168.200.20 kafka1 192.168.200.20 kafka2 192.168.200.20 kafka3
- 创建maven的工程, 导入kafka相关的依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>dockertest</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.0.0</version> </dependency> </dependencies> <build> <plugins> <!-- java编译插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.2</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins> </build> </project>
- 生产者代码
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; import java.util.Random; public class ProducerDemo { public static String topic = "lagou";//定义主题 public static void main(String[] args) { Properties properties=new Properties(); //网络传输,对key和value进行序列化 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.20:9092,192.168.200.20:9093,192.168.200.20:9094"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class); //创建消息生产对象,需要从properties对象或者从properties文件中加载信息 KafkaProducer<String,String> kafkaProducer=new KafkaProducer<String, String>(properties); try { while (true){ //设置消息内容 String msg = "Hello," + new Random().nextInt(100); //将消息内容封装到ProducerRecord中 ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, msg); kafkaProducer.send(record); System.out.println("消息发送成功:" + msg); Thread.sleep(500); } } catch (InterruptedException e) { e.printStackTrace(); } finally { kafkaProducer.close(); } } }
- 消费者代码
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.common.serialization.StringDeserializer; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Collections; import java.util.Properties; public class ConsumerDemo { public static void main(String[] args) { Properties properties=new Properties(); //网络传输,对key和value进行序列化 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.200.20:9092,192.168.200.20:9093,192.168.200.20:9094"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class); //指定组名 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "lagou"); //创建消息生产对象,需要从properties对象或者从properties文件中加载信息 KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties); kafkaConsumer.subscribe(Collections.singletonList(ProducerDemo.topic));// 订阅消息 while (true) { ConsumerRecords<String, String> records = kafkaConsumer.poll(100); for (ConsumerRecord<String, String> record : records) { System.out.println(String.format("topic:%s,offset:%d,消息:%s", // record.topic(), record.offset(), record.value())); } } } }
8. Apache kafka原理
- 分区副本机制
- kafka有三层结构:kafka有多个主题,每个主题有多个分区,每个分区又有多条消息。
- 分区机制:主要解决了单台服务器存储容量有限和单台服务器并发数限制的问题。一个分片的不同副本不能放到同一个broker上。当主题数据量非常大的时候,一个服务器存放不了,就将数据分成两个或者多个部分,存放在多台服务器上。每个服务器上的数据,叫做一个分片
- 分区对于 Kafka 集群的好处是:实现负载均衡,高存储能力、高伸缩性。分区对于消费者来说,可以提高并发度,提高效率。
- 副本:副本备份机制解决了数据存储的高可用问题。多个follower副本通常存放在和leader副本不同的broker中。通过这样的机制实现了高可用,当某台机器挂掉后,其他follower副本也能迅速”转正“,开始对外提供服务。在kafka中,实现副本的目的就是冗余备份,且仅仅是冗余备份,所有的读写请求都是由leader副本进行处理的。follower副本仅有一个功能,那就是从leader副本拉取消息,尽量让自己跟leader副本的内容一致。
- follower副本不对外提供服务。如果follower副本也对外提供服务,性能是肯定会有所提升的。但同时,会出现一系列问题。类似数据库事务中的幻读,脏读
- kafka保证数据不丢失机制
- 从Kafka的大体角度上可以分为数据生产者,Kafka集群,还有就是消费者,而要保证数据的不丢失也要从这三个角度去考虑
- 消息生产者:消息生产者保证数据不丢失:消息确认机制(ACK机制),参考值有三个:0,1,-1
//producer无需等待来自broker的确认而继续发送下一批消息。 //这种情况下数据传输效率最高,但是数据可靠性确是最低的。 properties.put(ProducerConfig.ACKS_CONFIG,"0"); //producer只要收到一个分区副本成功写入的通知就认为推送消息成功了。 //这里有一个地方需要注意,这个副本必须是leader副本。 //只有leader副本成功写入了,producer才会认为消息发送成功。 properties.put(ProducerConfig.ACKS_CONFIG,"1"); //ack=-1,简单来说就是,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。 properties.put(ProducerConfig.ACKS_CONFIG,"-1");
- 消息消费者:enable.auto.commit=false 关闭自动提交位移,在消息被完整处理之后再手动提交位移.由于Kafka consumer默认是自动提交位移的(先更新位移,再消费消息),如果消费程序出现故障,没消费完毕,则丢失了消息,此时,broker并不知道
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
- 消息存储及查询机制
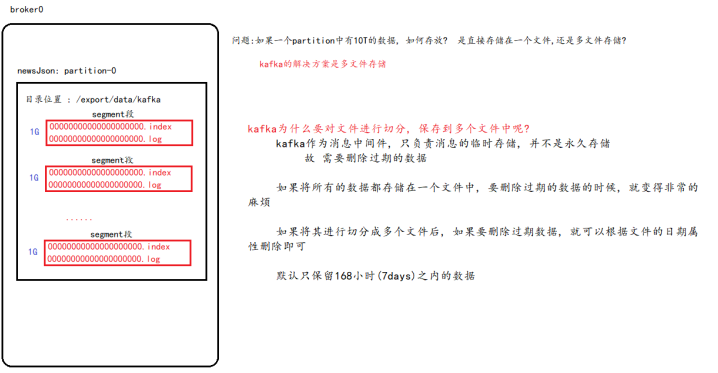
- kafka 使用日志文件的方式来保存生产者消息,每条消息都有一个 offset 值来表示它在分区中的偏移量。Kafka 中存储的一般都是海量的消息数据,为了避免日志文件过大,一个分片 并不是直接对应在一个磁盘上的日志文件,而是对应磁盘上的一个目录,这个目录的命名规则是<topic_name>_<partition_id>
![]()
- log分段:每个分片目录中,kafka 通过分段的方式将 数据分为多个 LogSegment。一个 LogSegment 对应磁盘上的一个日志文件(00000000000000000000.log)和一个索引文件(如上:00000000000000000000.index)。其中日志文件是用来记录消息的。索引文件是用来保存消息的索引。每个LogSegment 的大小可以在server.properties 中log.segment.bytes=107370 (设置分段大小,默认是1gb)选项进行设置。当log文件等于1G时,新的会写入到下一个segment中。timeindex文件,是kafka的具体时间日志
![]()
- 通过 offset 查找 message,存储的结构:一个主题 --> 多个分区 ----> 多个日志段(多个文件)
- 查询segment file:segment file命名规则跟offset有关,根据segment file可以知道它的起始偏移量,因为Segment file的命名规则是上一个segment文件最后一条消息的offset值。所以只要根据offset 二分查找文件列表,就可以快速定位到具体文件。
比如第一个segment file是00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0。第二个是00000000000000091932.index:代表消息量起始偏移量为91933 = 91932 + 1。那么offset=5000时应该定位00000000000000000000.index - 通过segment file查找message:通过第一步定位到segment file,当offset=5000时,依次定位到00000000000000000000.index的元数据物理位置和00000000000000000000.log的物理偏移地址,然后再通过00000000000000000000.log顺序查找直到offset=5000为止
- 查询segment file:segment file命名规则跟offset有关,根据segment file可以知道它的起始偏移量,因为Segment file的命名规则是上一个segment文件最后一条消息的offset值。所以只要根据offset 二分查找文件列表,就可以快速定位到具体文件。
- 生产者消息分发策略
- kafka在数据生产的时候,有一个数据分发策略。默认的情况使用实现类:org.apache.kafka.clients.producer.internals.DefaultPartitioner。这个类中就定义数据分发的策略。
public interface Partitioner extends Configurable, Closeable { /** * Compute the partition for the given record. * * @param topic The topic name * @param key The key to partition on (or null if no key) * @param keyBytes The serialized key to partition on( or null if no key) * @param value The value to partition on or null * @param valueBytes The serialized value to partition on or null * @param cluster The current cluster metadata */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); /** * This is called when partitioner is closed. */ public void close(); }
- 如果是用户指定了partition,生产就不会调用DefaultPartitioner.partition()方法,数据分发策略的时候,可以指定数据发往哪个partition.当ProducerRecord 的构造参数中有partition的时候,就可以发送到对应partition上
/ ** * Creates a record to be sent to a specified topic and partition * * @param topic The topic the record will be appended to * @param partition The partition to which the record should be sent * @param key The key that will be included in the record * @param value The record contents */ public ProducerRecord(String topic, Integer partition, K key, V value) { this(topic, partition, null, key, value, null); }
- DefaultPartitioner源码:如果指定key,是取决于key的hash值;如果不指定key,轮询分发
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { //获取该topic的分区列表 List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); //获得分区的个数 int numPartitions = partitions.size(); //如果key值为null if (keyBytes == null) {//如果没有指定key,那么就是轮询 //维护一个key为topic的ConcurrentHashMap,并通过CAS操作的方式对value值执行递增+1操作 int nextValue = nextValue(topic); //获取该topic的可用分区列表 List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) {//如果可用分区大于0 //执行求余操作,保证消息落在可用分区上 int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { // 没有可用分区的话,就给出一个不可用分区 return Utils.toPositive(nextValue) % numPartitions; } } else {//不过指定了key,key肯定就不为null // 通过计算key的hash,确定消息分区 return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;} }
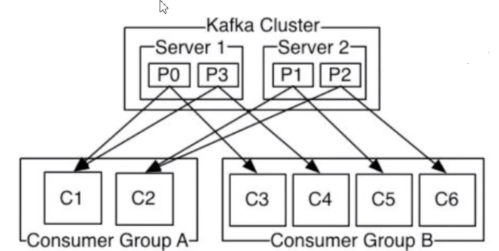
- 消费者负载均衡机制:
- 同一个分区中的数据,只能被一个消费者组中的一个消费者所消费。例如 P0分区中的数据不能被Consumer Group A中C1与C2同时消费。
- 消费组:一个消费组中可以包含多个消费者,properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupName");如果该消费组有四个消费者,主题有四个分区,那么每人一个。多个消费组可以重复消费消息。
- 如果有3个Partition, p0/p1/p2,同一个消费组有3个消费者,c0/c1/c2,则为一一对应关系;
- 如果有3个Partition, p0/p1/p2,同一个消费组有2个消费者,c0/c1,则其中一个消费者消费2个分区的数据,另一个消费者消费一个分区的数据;
- 如果有2个Partition, p0/p1,同一个消费组有3个消费者,c0/c1/c3,则其中有一个消费者空闲,另外2个消费者消费分别各自消费一个分区的数据
![]()

9.kafka配置文件server.properties
- broker.id=0
- kafka集群是由多个节点组成的,每个节点称为一个broker,即代理。每个broker都有一个不同的brokerId,由broker.id指定,是一个不小于0的整数,各brokerId必须不同,但不必连续。如果我们想扩展kafka集群,只需引入新节点,分配一个不同的broker.id即可。
- 启动kafka集群时,每一个broker都会实例化并启动一个kafkaController,并将该broker的brokerId注册到zooKeeper的相应节点中。
- 集群各broker会根据选举机制选出其中一个broker作为leader,即leader kafkaController。leader kafkaController负责主题的创建与删除、分区和副本的管理等。当leader kafkaController宕机后,其他broker会再次选举出新的leader kafkaController。
- log.dir = /export/data/kafka/:broker持久化消息到哪里,数据目录
- log.retention.hours = 168
- log文件最小存活时间,默认是168h,即7天。相同作用的还有log.retention.minutes、log.retention.ms。retention是保存的意思
- 数据存储的最大时间超过这个时间会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据
- log.retention.bytes和log.retention.hours任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
- log.retention.check.interval.ms:多长时间检查一次是否有log文件要删除。默认是300000ms,即5分钟
- log.retention.bytes:限制单个分区的log文件的最大值,超过这个值,将删除旧的log,以满足log文件不超过这个值。默认是-1,即不限制
- log.roll.hours:多少时间会生成一个新的log segment,默认是168h,即7天。相同作用的还有log.roll.ms、segment.ms
- log.segment.bytes:log segment多大之后会生成一个新的log segment,默认是1073741824,即1G
- log.flush.interval.messages:指定broker每收到几个消息就把消息从内存刷到硬盘(刷盘)。默认是9223372036854775807,kafka官方不建议使用这个配置,建议使用副本机制和操作系统的后台刷新功能,因为这更高效。这个配置可以根据不同的topic设置不同的值,即在创建topic的时候设置
在Linux操作系统中,当我们把数据写入到文件系统之后,数据其实在操作系统的page cache里面,并没有刷到磁盘上去。如果此时操作系统挂了,其实数据就丢了。 1、kafka是多副本的,当你配置了同步复制之后。多个副本的数据都在page cache里面,出现多个副本同时挂掉的概率比1个副本挂掉,概率就小很多了 2、操作系统有后台线程,定期刷盘。如果应用程序每写入1次数据,都调用一次fsync,那性能损耗就很大,所以一般都会在性能和可靠性之间进行权衡。因为对应一个应用来说,虽然应用挂了,只要操作系统不挂,数据就不会丢。
- log.flush.interval.ms:指定broker每隔多少毫秒就把消息从内存刷到硬盘。默认值同log.flush.interval.messages一样, 9223372036854775807,同log.flush.interval.messages一样,kafka官方不建议使用这个配置
- delete.topic.enable=true:是否允许从物理上删除topic
10.Kafka监控与运维
在生产环境下,在Kafka集群中,消息数据变化是我们关注的问题,当业务前提不复杂时,我们可以使用Kafka 命令提供带有Zookeeper客户端工具的工具,可以轻松完成我们的工作。随着业务的复杂性,增加Group和 Topic,Kafka监控系统尤为重要,可以观察消费者应用的细节
为了简化开发者和服务工程师维护Kafka集群的工作有一个监控管理工具,叫做 Kafka-eagle。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,
- 搭建安装 kafka-eagle环境要求:需要安装jdk,启动zk以及kafka的服务
# 启动Zookeeper
zkServer.sh start
#启动Kafka
nohup ./kafka-server-start.sh /export/servers/kafka/config/server.properties 2>&1 &
-
- 修改windows host文件
192.168.200.20 kafka1 192.168.200.20 kafka2 192.168.200.20 kafka3 192.168.200.11 node1 192.168.200.12 node2 192.168.200.13 node3
- 下载kafka-eagle的源码包:http://download.kafka-eagle.org/,下载最新的安装包即可kafka-eagle-bin-1.3.2.tar.gz
- 上传安装包并解压:这里我们选择将kafak-eagle安装在第三台,如果要解压的是zip格式,需要先安装命令支持
#将安装包上传至 node01服务器的/export/software路径下, 然后解压 cd /export/software/ yum install unzip unzip kafka-eagle.zip cd kafka-eagle-web/target/ tar -zxf kafka-eagle-web-2.0.1-bin.tar.gz -C /export/servers
- 准备数据库:kafka-eagle需要使用一个数据库来保存一些元数据信息,我们这里直接使用msyql数据库来保存即可,在node01服务器执行以下命
令创建一个mysql数据库即可
--进入mysql客户端: create database eagle; -- 在mysql数据库下 update user set host = '%' where user ='root'; flush privileges; //刷新配置
- 修改kafka-eagle配置文件;默认情况下MySQL只允许本机连接到MYSQL实例中,所以如果要远程访问,必须开放权限
cd /export/servers/kafka-eagle-bin-2.0.1/kafka-eagle-web-2.0.1/conf vi system-config.properties #内容如下: kafka.eagle.zk.cluster.alias=cluster1 cluster1.zk.list=node1:2181,node2:2181,node3:2181 kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://172.25.128.51:3306/eagle kafka.eagle.username=root kafka.eagle.password=123456
- 配置环境变量
vi /etc/profile #内容如下: export KE_HOME=/export/servers/kafka-eagle-bin-1.3.2/kafka-eagle-web-1.3.2 export PATH=:$KE_HOME/bin:$PATH #让修改立即生效,执行 source /etc/profile
- 启动kakfa-eagle
cd kafka-eagle-web-1.3.2/bin chmod u+x ke.sh ./ke.sh start
- 访问主界面:http://http://192.168.200.13:8048/,用户名:admin,密码:123456
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号