https://www.cnblogs.com/pandaboy1123/p/9894981.html
1、列举Http请求常见的请求方式
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW:World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。
浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
url:统一资源定位符 ,是互联网上标准资源的地址。
HTTP定义了与服务器交互的8种 请求方式
列举Http请求中常见的请求方式
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法
----------------------------------------------------------------
get 和 post区别
区别:
get请求无消息体,只能携带少量数据
post请求有消息体,可以携带大量数据
携带数据的方式:
get请求将数据放在url地址中
post请求将数据放在消息体中
GET请求请提交的数据放置在HTTP请求协议头中,而POST提交的数据则放在实体数据中;
GET方式提交的数据最多只能有1024字节,而POST则没有此限制。

2、谈谈你对Http协议的认识?什么是长连接?
http协议是基于网络应用层的,对服务器和客户端(浏览器)之间的一种传输超文本的传送协议
长连接:HTTP的相应头内有Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的 TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接要客户端和服务端都支持长连接。
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接
http协议特点
1、基于TCP/IP
2、基于请求-响应模式-->请求从客户端发出,最后服务器端响应该请求并 返回
3、无状态保存---不对请求和响应之间的通信状态进行保存
4、无连接---每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
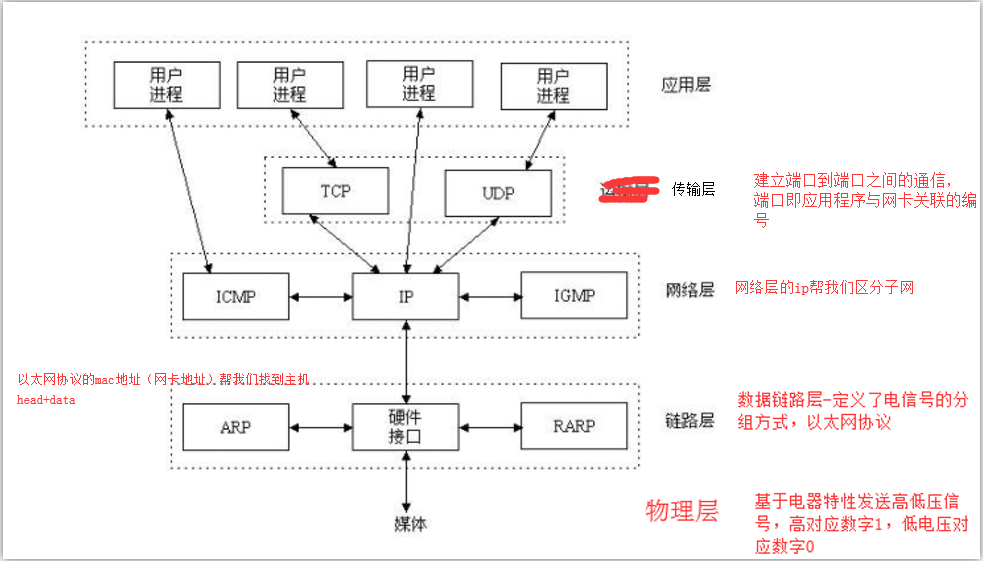
TCP/IP五层模型
3、简述MCV模式和MVT模式
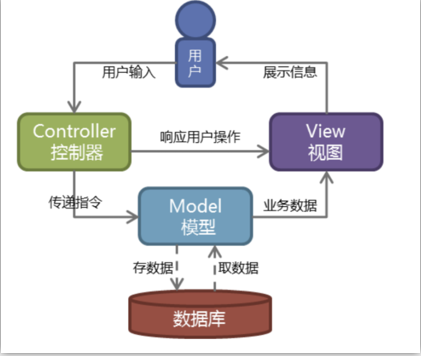
MVC
Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起
模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面),控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示:
MTV
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django的MTV分别是值:
- M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。
- T 代表模板 (Template):负责如何把页面展示给用户(html)。
- V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示:
model 英 /'mɒdl/ 美 /'mɑdl/
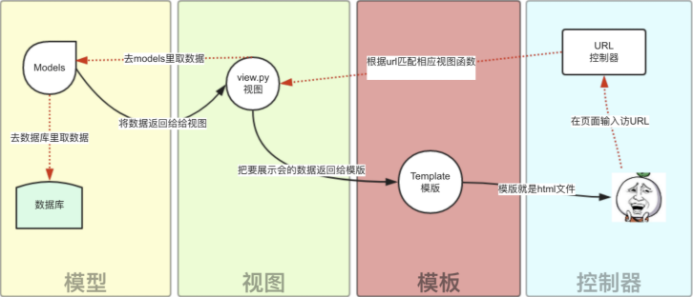
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求会去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),
视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
4、简述Django请求生命周期
Django的请求生命周期是指当用户在浏览器上输入url到用户看到网页的这个时间段内,Django后台所发生的事情
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求会去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),
视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
#1.wsgi,请求封装后交给web框架 (Flask、Django) #2.中间件,对请求进行校验或在请求对象中添加其他相关数据,例如:csrf、request.session - #3.路由匹配 根据浏览器发送的不同url去匹配不同的视图函数 #4.视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm、templates => 渲染 - #5.中间件,对响应的数据进行处理。 #6.wsgi,将响应的内容发送给浏览器。
5、简述什么事FBV和CBV
FBV(function base views) 就是在视图里使用函数处理请求 CBV(class base views) 就是在视图里使用类处理请求
Python是一个面向对象的编程语言,如果只用函数来开发,有很多面向对象的优点就错失了(继承、封装、多态)。
所以Django在后来加入了Class-Based-View。可以让我们用类写View。这样做的优点主要下面两种: 提高了代码的复用性,可以使用面向对象的技术,比如Mixin(多继承) 可以用不同的函数针对不同的HTTP方法处理,而不是通过很多if判断,提高代码可读性
6、谈一谈你对ORM的理解
object relation map
7、rest_framework 认证组件的流程
首先在视图模块中添加以下导入 from rest_framework import permissions
8、什么是中间件并简述其作用
中间件顾名思义,是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出。
因为改变的是全局,所以需要谨慎实用,用不好会影响到性能。
9、django中怎么写原生SQL


实例: 使用extra: 1:Book.objects.filter(publisher__name='广东人员出版社').extra(where=['price>50']) Book.objects.filter(publisher__name='广东人员出版社',price__gt=50) 2:Book.objects.extra(select={'count':'select count(*) from hello_Book'}) 使用raw: Book.objects.raw('select * from hello_Book') 自定义sql: Book.objects.raw("insert into hello_author(name) values('测试')") rawQuerySet为惰性查询,只有在使用时生会真正执行 执行自定义sql: from django.db import connection cursor=connection.cursor() #插入操作 cursor.execute("insert into hello_author(name) values('郭敬明')") #更新操作 cursor.execute('update hello_author set name='abc' where name='bcd'') #删除操作 cursor.execute('delete from hello_author where name='abc'') #查询操作 cursor.execute('select * from hello_author') raw=cursor.fetchone() #返回结果行游标直读向前,读取一条 cursor.fetchall() #读取所有
10、F和Q的作用
11、values和value_list区别
12、如何使用django orm批量创建数据
首先,定义一个实例使用的django数据库模型Product,只是象征性地定义了两个字段name和price
批量创建数据使用for循环,创建数据的时候尽量最后执行创建语句,使用django的语法 bulk_create
product_list_to_insert = list() for x in range(10):
product_list_to_insert.append(Product(name='product name ' + str(x), price=x))
Product.objects.bulk_create(product_list_to_insert)
---
Django ORM 中的批量操作 在Hibenate中,通过批量提交SQL操作,部分地实现了数据库的批量操作。但在Django的ORM中的批量操作却要完美得多,真是一个惊喜。 数据模型定义 首先,定义一个实例使用的django数据库模型Product,只是象征性地定义了两个字段name和price。 from django.db import models class Product(models.Model): name = models.CharField(max_length=200) price = models.DecimalField(max_digits=10, decimal_places=2) 批量插入数据 批量插入数据时,只需先生成个一要传入的Product数据的列表,然后调用bulk_create方法一次性将列表中的数据插入数据库。 product_list_to_insert = list() for x in range(10): product_list_to_insert.append(Product(name='product name ' + str(x), price=x)) Product.objects.bulk_create(product_list_to_insert) 批量更新数据 批量更新数据时,先进行数据过滤,然后再调用update方法进行一次性地更新。下面的语句将生成类似update...where...的SQL语句。 Product.objects.filter(name__contains='name').update(name='new name') 批量删除数据 批量更新数据时,先是进行数据过滤,然后再调用delete方法进行一次性地删除。下面的语句将生成类似delete from...where...的SQL语句。 Product.objects.filter(name__contains='name query').delete() 如果是通过运行普通Python脚本的方式而不是在view中调用上述的代码的,别忘了先在脚本中进行django的初始化: import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "testproject.settings") import django django.setup() Hibernate的所谓“批量操作”中,对每一个实体的更新操作,都会生成一条update语句,然后只是把好几个update语句一次性提交给数据库服务器而已。对实体的删除操作也是一样。 Django ORM中的批量操作的实现更接近于SQL操作的体验,运行效率也会比Hibernate中的实现更加高效。
13、http访问流程
域名解析成IP地址;
与目的主机进行TCP连接(三次握手);
发送与收取数据(浏览器与目的主机开始HTTP访问过程);
与目的主机断开TCP连接(四次挥手);
14、migrate和makemigrations的区别
migrate 英 /maɪ'greɪt; 'maɪgreɪt/ 美 /'maɪɡret/ 移动
在pycharm的Terminal执行
数据迁移的指令
python manage.py makemigrations
python manage.py migrate
----------------------------------
15、试图函数中,接受的请求对象常用方法和属性有哪些?
1.request.method == 'GET' 2.request.method == 'POST'
16、常用视图响应的方式是什么?
1.Httpreponse 2.render 3.redirect
17、HTTP响应的常见状态码分类?
状态码如200 OK,以3位数字和原因 成。数字中的 一位指定了响应 别,后两位无分 。响应 别有以5种。
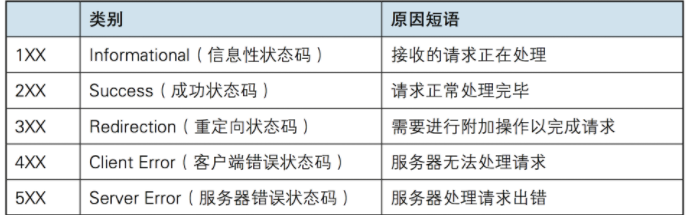
常见的HTTP状态码: 200 - 请求成功 301 - 资源(网页等)被永久转移到其它URL 404 - 请求的资源(网页等)不存在 500 - 内部服务器错误
18、路由匹配原则是什么?
路由选择的最长匹配原则----当路由器收到一个IP数据包时,会将数据包的目的IP地址与自己本地路由表中的表项进行bit by bit的逐位查找,直到找到匹配度最长的条目,这叫最长匹配原则
19、缓存系统类型有哪些
要使用缓存系统需要先在settings.py中设置,Django提供多种缓存类型:Memcached缓存,数据库缓存,文件系统缓存,局部内存缓存和自定义缓存等
20、解决跨域的常用方式是什么?
1、jsonp跨域 JSONP(JSON with Padding:填充式JSON),应用JSON的一种新方法, JSON、JSONP的区别: 1、JSON返回的是一串数据、JSONP返回的是脚本代码(包含一个函数调用) 2、JSONP 只支持get请求、不支持post请求

2、nginx反向代理:

3、WebSocket协议跨域

域名简称网域
是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。
跨域:
比如从www.baidu.com 页面去请求 www.google.com 的资源。
跨域的严格一点的定义是:只要 协议,域名,端口有任何一个的不同,就被当作是跨域
----------------------------------------------------------------------------------
跨域,指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制。
所谓同源是指,域名,协议,端口均相同
什么是跨域? 跨域,指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制。 所谓同源是指,域名,协议,端口均相同,不明白没关系,举个栗子: http://www.123.com/index.html 调用 http://www.123.com/server.php (非跨域) http://www.123.com/index.html 调用 http://www.456.com/server.php (主域名不同:123/456,跨域) http://abc.123.com/index.html 调用 http://def.123.com/server.php (子域名不同:abc/def,跨域) http://www.123.com:8080/index.html 调用 http://www.123.com:8081/server.php (端口不同:8080/8081,跨域) http://www.123.com/index.html 调用 https://www.123.com/server.php (协议不同:http/https,跨域) 请注意:localhost和127.0.0.1虽然都指向本机,但也属于跨域。 浏览器执行javascript脚本时,会检查这个脚本属于哪个页面,如果不是同源页面,就不会被执行。 解决办法: 1、JSONP: 使用方式就不赘述了,但是要注意JSONP只支持GET请求,不支持POST请求。 2、代理: 例如www.123.com/index.html需要调用www.456.com/server.php,可以写一个接口www.123.com/server.php,由这个接口在后端去调用www.456.com/server.php并拿到返回值,然后再返回给index.html,这就是一个代理的模式。相当于绕过了浏览器端,自然就不存在跨域问题。 3、PHP端修改header(XHR2方式) 在php接口脚本中加入以下两句即可: header('Access-Control-Allow-Origin:*');//允许所有来源访问 header('Access-Control-Allow-Method:POST,GET');//允许访问的方式 --------------------- 作者:L瑜 来源:CSDN 原文:https://blog.csdn.net/lambert310/article/details/51683775 版权声明:本文为博主原创文章,转载请附上博文链接!
21、信号的作用是什么?
Django中内置的signal 英 /'sɪgn(ə)l/ 美 /'sɪgnl/
Django中提供了"信号调度",用于在框架执行操作时解耦.
一些动作发生的时候,系统会根据信号定义的函数执行相应的操作
https://www.cnblogs.com/renpingsheng/p/7566647.html
22、Django的Model的继承有几种形式,分别是什么?
三种继承方式: 1、抽象基类(Abstract base classes) 2、多表继承(Multi-table inheritance) 3、代理
23、Django中查询queryset时什么情况下用Q
在进行相对复杂的查询时,使用 django.db.models.Q 对象。
例如需要进行复合条件的查询的SQL语句如下:
与或非操作
24、Django中想验证表单提交是否格式正确需要用到Form中的哪个函数
is_valid()
方法,用于检查表单提交是否正确。
25、orm如何取消级联
级联就是我们说的连表的操作,连表将会使表之间通过各种关系连接起来,但是orm删除的时候是指定字段的,所以需要在model的表中通过外键连接设置级联关系删除
user = models.FroeignKey(User, blank=True, null=True, on_delete=models.SET_NULL)
需要注意的是on_delete=models.SET_NULL的前提必须是null=true
models.SET_NULL这里还有其他几个选项: * SET_NULL 当外键的字段被删除的时候设置为null前提是指定了 null=True * CASCADE 默认的选项,当外键关联的字段删除的时候,所有其他表级联删除 * SET_DEFAULT 设置一个默认值,当关联的记录删除的时候恢复成默认值 *DO_NOTHING django不做任何事情,数据库返回什么就报什么 * SET()¶ 还可以set一个函数,当关联记录删除的时候触发得到一个值
26、Django中如何读取和保存session,整个session的运行机制是什么
cookies和session都属于一种会话跟踪技术
Session是服务器端技术,利用这个技术,服务器在运行时可以 为每一个用户的浏览器创建一个其独享的session对象,由于 session为用户浏览器独享,
所以用户在访问服务器的web资源时 ,可以把各自的数据放在各自的session中,当用户再去访问该服务器中的其它web资源时,其它web资源再从用户各自的session中 取出数据为用户服务。
其实Cookie是key-value结构,类似于一个python中的字典
cookie的概念
Cookie翻译成中文是小甜点,小饼干的意思。在HTTP中它表示服务器送给客户端浏览器的小甜点。其实Cookie是key-value结构,类似于一个python中的字典。
随着服务器端的响应发送给客户端浏览器。然后客户端浏览器会把Cookie保存起来,当下一次再访问服务器时把Cookie再发送给服务器。 Cookie是由服务器创建
,然后通过响应发送给客户端的一个键值对。客户端会保存Cookie,并会标注出Cookie的来源(哪个服务器的Cookie)。当客户端向服务器发出请求时会把所有
这个服务器Cookie包含在请求中发送给服务器,这样服务器就可以识别客户端了!
当我们在django中用到session时,cookie由服务器端随机生成,写到浏览器的cookie中,每个浏览器都有自己cookie值,是session寻找用户信息的唯一标识
session的好处:客户端只有cookies的值,但始终没有用户的信息。
用法:request.session.get('k1')
request.session['k1']='v1'
session依赖于cookies,cookie保存在浏览器,session保存在服务器端
27、Django中当用户登录到A服务器进入登陆状态,下次被nginx代理到B服务器会出现什么影响
会重新登录(如果A服务器的session数据不和B服务器的数据共享的话)
28、跨域请求Django是如何处理的?
跨域请求可以用jsonp来解决只能用于get,也可以用这个插件:django-cors-headers
1.安装django-cors-headers
2.配置settings.py文件
29、查询集的两大特征?什么是惰性执行
查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
两大特征是:惰性执行和 缓存
django创建 查询 集不会访问数据库,直到调用数据时才访问数据库
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表): all():返回所有数据。 filter():返回满足条件的数据。 exclude():返回满足条件之外的数据。 order_by():对结果进行排序。 一:惰性执行 books = BookInfo.objects.all() # 此时,数据库并不会进行实际查询 # 只有当真正使用时,如遍历的时候,才会真正去数据库进行查询 for b in books: print(b) 二:缓存 使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数 新建一个查询集对象就可以实现
30、查询集返回的列表过滤器有哪些
all():返回所有数据。
filter():返回满足条件的数据。
exclude():返回满足条件之外的数据。
order_by():对结果进行排序。
31、如何获取django urlpatterns里面注册的所有url?
urlpatterns = [ path('admin/', admin.site.urls),]
--
from django.conf.urls import url,include from arya.service.sites import site from django.urls.resolvers import RegexURLPattern from django.urls.resolvers import RegexURLResolver from django.shortcuts import HttpResponse def index(request): print(get_all_url(urlpatterns,prev='/')) return HttpResponse('...') def get_all_url(urlparrentens,prev,is_first=False,result=[]): if is_first: result.clear() for item in urlparrentens: v = item._regex.strip('^') #去掉url中的^和') #去掉url中的^和 if isinstance(item,RegexURLPattern): result.append(prev + v) else: get_all_url(item.urlconf_name,prev + v) return result urlpatterns = [ url(r'^arya/', site.urls), url(r'^index/', index), ]
32、django路由系统中include是干嘛用的?
路由分发
url用解耦的作用
include是路由转发功能,因为不同的app针对的是不同的分发路由路径,所以通过from django.conf.urls import include,来确定导入的路由的路径
33、django2.0中的path与django1.xx里面的url有什么区别?
django2.0中写路由的正则方式需要导入re_path的方式来匹配正则表达式,直接使用会报错,django1.xx中则没有限制
34、urlpatterns中的name与namespace有什么作用?你是如何使用的?
name是给url中取一个别名
namespace名称空间,防止多个应用之间的路由重复
namespace
url: re_path(r'^app01/', include("app01.urls",namespace="app01")), app01.urls: urlpatterns = [ re_path(r'^index/', index,name="index"), ] app01.views: from django.core.urlresolvers import reverse def index(request): return HttpResponse(reverse("app01:index"))
35、如何根据urlpatterns中的name反向生成url,这样反向生成url的方式有几种?
使用HttpResponseRedirect redirect和reverse 状态码:302,301
36、如何给一个字段设置一个主键
在models里面做primary_key的设置
37、blank=True与null=True有什么区别?
null 是针对数据库而言,如果 null=True, 表示数据库的该字段可以为空。
blank 是针对表单的,如果 blank=True,表示你的表单填写该字段的时候可以不填,比如 admin 界面下增加 model 一条记录的时候。直观的看到就是该字段不是粗体
38、如何设置一个带有枚举值的字典
django中提供choice类型
gender_choice=(('1','男'),('2','女 '))
user_gender=Models.CharFied(max_length=2,choices=gender_choice)
39、DateTimeField类型中的auto_now与auto_now_add有什么区别
40、selected_relate与prefetch_related有什么区别?
在查询对象集合的时候,把指定的外键对象也一并完整查询加载,避免后续的重复查询。 1,select_related适用于外键和多对一的关系查询; 2,prefetch_related适用于一对多或者多对多的查询。
41、当删除一个外键的时候,如何把与其的对应关系删除
django中需要设置on_delete来设置级联关系表
42、class Meta中的元信息字段有哪些?
43、多对多关联的表,如何插入数据?如何删除数据?如何更新数据?
# 当前生成的书籍对象 book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1) # 为书籍绑定的做作者对象 yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录 egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录 # 绑定多对多关系,即向关系表book_authors中添加纪录 book_obj.authors.add(yuan,egon) # 将某些特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[]) +------------------------------------------------------------------------------------------------------------------------+ book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[]) book_obj.authors.clear() #清空被关联对象集合 book_obj.authors.set() #先清空再设置
44、django的M2M关系,如何手动生成第三张表?
tags = models.ManyToManyField( to="Tag", through='Article2Tag', through_fields=('article', 'tag'), )
45、在Django中,服务端给客户端响应信息有几种方式?分别是什么?
* HTTPresponse, * jsonresponse, * redirect
46、在试图函数中,常用的验证装饰器有哪些?
from django.contrib.auth.decorators import login_required
@login_required---用于验证是否有登录状态,如果没有登录,设置跳转的页面就会跳转至未登录状态的页面
@permission_required---检查用户是否具有特定权限是一项相对常见的任务
@get_permission_required---返回mixin使用的可迭代权限名称。默认为permission_required属性,必要时转换为元组。
@has_permission---返回一个布尔值,表示当前用户是否有权执行装饰视图
47、如何给一个视图函数加上缓存?
CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache', 'LOCATION': 'unique-snowflake' } }
48、web框架的本质是什么?
本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端
49、Django App的目录结构
50、Django 获取用户前端请求数据的几种方式
@get和@post使用 1:在views模板下编写测试函数(记得在urls.py文件中进行相应配置) 2:将刚刚封装的函数所在模板引入views.py 3:使用@get进行拦截 @params,response_success,response_failure使用 第一种 @login_required def simple_view(request): return HttpResponse()123 2 通过对基于函数视图或者基于类视图使用一个装饰器实现控制: @login_required(MyView.as_view())1 3 通过覆盖mixin的类视图的dispatch方法实现控制:
51、描述下自定义标签simple_tag
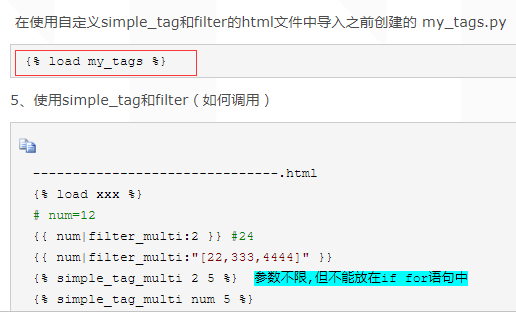
自定义过滤器@register.filter
自定义filter:{{ 参数1|filter函数名:参数2 }}
# 1.可以与if标签来连用
# 2.自定义时需要写两个形参
# simple_tag:{% simple_tag函数名 参数1 参数2 %}
# 1.可以传多个参数,没有限制
# 2.不能与if标签来连用
@register.simple_tag
def multi_tag(x,y):
return x*y
52、什么是Cookie、如何获取、设置Cookie

会话跟踪技术,保留用户 Cookie是由服务器创建,然后通过响应发送给客户端?的一个键值对。 具体一个浏览器针对一个服务器存储的key-value({ }) response.set_cookie("is_login",True) request.COOKIES.get("is_login")
53、什么是session,与cookie的对比、设置、获取、清空session
54、什么是CSRF,及防范方式
https://mp.weixin.qq.com/s?src=11×tamp=1543650968&ver=1277&signature=14H5aRhphiu5QRsUP15kV*RpCgGIp5-BWGot2wg4rZPhMjxQNjluUCvzRO9tXb4KqgSysEFhPX2TBDKaMbyfZuzjG2P-M1BgrozF-Jj-aU33g4mMK51XAj3Xd9KKsDJl&new=1
CSRF跨站点请求伪造(Cross—Site Request Forgery)


XSS利用站点内的信任用户,而CSRF则通过伪装来自受信任用户的请求来利用受信任的网站。
与XSS攻击相比,CSRF攻击往往不大流行(因此对其进行防范的资源也相当稀少)和难以防范,所以被认为比XSS更具危险性。
防御CSRF攻击:
-
验证HTTP_REFERER字段
-
请求中添加token验证
-
在Http头中自定义属性并验证
---
CSRF攻击攻击原理及过程如下: 1. 用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A; 2.在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A; 3. 用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B; 4. 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A; 5. 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
现在业界对CSRF的防御,一致的做法是使用一个Token(Anti CSRF Token)。 例子: 用户访问某个表单页面。 服务端生成一个Token,放在用户的Session中,或者浏览器的Cookie中。 在页面表单附带上Token参数。 用户提交请求后, 服务端验证表单中的Token是否与用户Session(或Cookies)中的Token一致,一致为合法请求,不是则非法请求。 这个Token的值必须是随机的,不可预测的。由于Token的存在,攻击者无法再构造一个带有合法Token的请求实施CSRF攻击。另外使用Token时应注意Token的保密性,尽量把敏感操作由GET改为POST,以form或AJAX形式提交,避免Token泄露。 --------------------- 作者:徐彬 来源:CSDN 原文:https://blog.csdn.net/qq_33182756/article/details/80461649 版权声明:本文为博主原创文章,转载请附上博文链接!
https://www.cnblogs.com/pandaboy1123/p/9894981.html
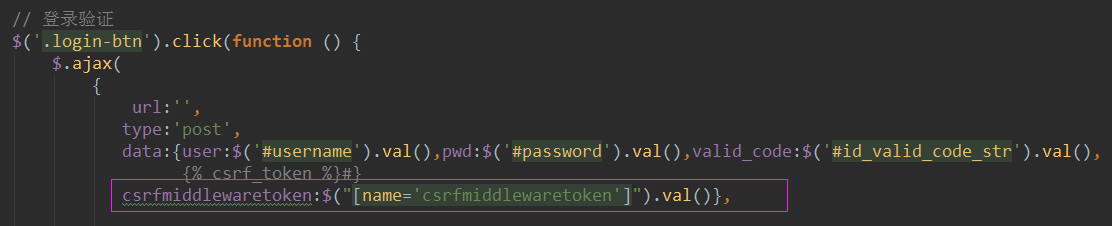
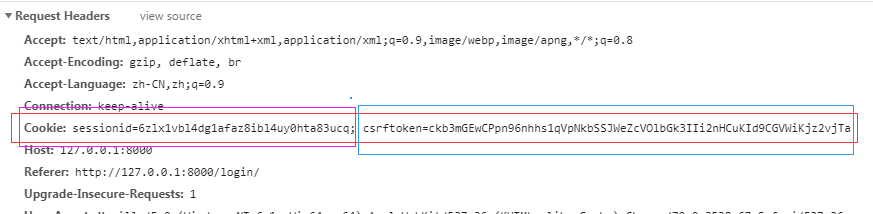
django中token防御的整体思路 第一步:django第一次响应来自某个客户端的请求时,后端随机产生一个token值,把这个token放到cookie中交给前端页面; 第二步:下次前端需要发起请求的时候会携带者这个token,一起传给后端;Cookies:{csrftoken:xxxxx} 第三步:1.如果是通过表单发送post请求,后端会验证cookie中的csrftoken值和表单中的csrfmiddlewaretoken是否一致 2.如果是ajax发送的post请求,后端会验证cookie中的csrftoken值和请求头中的X-CSRFtoken中的值是否一致 实现csrf保护 1.form提交时加上 { % csrf_token %} 2.在ajax中提交时:取到csrf的 var csrfToken = $("[name='csrfmiddlewaretoken']").val(); 加到传输的数据中 data: { csrfmiddlewaretoken: $("[name='csrfmiddlewaretoken']").val(), },
55、中间件的生命周期
当用户发起请求的时候会依次经过所有的的中间件,这个时候的请求时process_request,最后到达views的函数中,views函数处理后,在依次穿过中间件,这个时候是process_response,最后返回给请求者。
中间件中一共有四个方法:
process_request
process_view
process_exception
process_response
56、get请求和post请求的区别
(1)GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPost.aspx?name=test1&id=123456.POST方法是把提交的数据放在HTTP包的Body中。 (2)GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。 (3)GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。 (4)GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码。
57、图书管理系统的表结构是怎么设计的?
一本书对应多个作者,一个作者对应多本书------>书籍和作者多对多的关系
一个出版社对应多本书------->出版社和书籍--一对多的关系
from django.db import models # Create your models here. class Author(models.Model): nid=models.AutoField(primary_key=True) name=models.CharField(max_length=32) age=models.IntegerField() class Publish(models.Model): nid=models.AutoField(primary_key=True) name=models.CharField(max_length=32) city=models.CharField(max_length=32) email=models.EmailField() class Book(models.Model): nid=models.AutoField(primary_key=True) title=models.CharField(max_length=32) publishDate=models.DateField() price=models.DecimalField(max_digits=5,decimal_places=2) # 与publish建立一对多的关系,在健在多的一方(Book) # to=表名 to_field=字段 publish=models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE) # 与Author建立多对多的关系 可以建立在两个模型中的任意一个,自动创建第三张表 authors=models.ManyToManyField(to='Author')
58、图书管理系统路由系统你用到了name了吗? 为什么要使用呢?
反向解析
在模板中:
path('login/', views.login,name='log'), <form action='{% url 'log' %}' method='post'>
访问 127.0.0.1:8080/login
如果后续把
path('login.html/', views.login,name='log'),
访问 127.0.0.1:8080/login.html
在试图函数中反向解析:
from django.urls import reverse
from django.http import HttpResponseRedirect
def redirect_to_year(request):
# ...
year = 2006
# ...
return HttpResponseRedirect(reverse('news-year-archive', args=(year,))) # 同redirect("/path/")59、图书管理系统的模板你是怎么用的? 重复的代码怎么解决?
templates(模板层)
模板 - 自定义标签和过滤器--解决复用问题
在app中创建templatetags模块---在文件夹下建立my_tag.py文件
自定义过滤器---有参数限制 两个
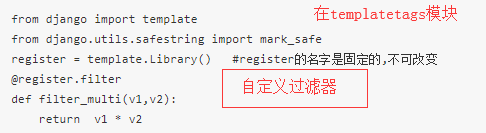
{% load xxx %}
# num=12
{{ num|filter_multi:2 }} 结果------#24
自定义标签--没有参数限制
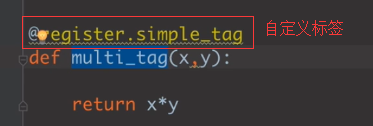

1、标签:
{% tag %}
{% endtag %}循环序号可以通过{{forloop}}显示
模板继承 (extend)
60、WSGI / uwsgi/ uWSGI区分
#WSGI: # web服务器网关接口,是一套协议。用于接收用户请求并将请求进行初次封装,然后将请求交给web框架 # 实现wsgi协议的模块: # 1.wsgiref,本质上就是编写一个socket服务端,用于接收用户请求(django) # 2.werkzeug,本质上就是编写一个socket服务端,用于接收用户请求(flask) #uwsgi: # 与WSGI一样是一种通信协议,它是uWSGI服务器的独占协议,用于定义传输信息的类型 #uWSGI: # 是一个web服务器,实现了WSGI协议,uWSGI协议,http协议,
61、如何使用django加密
Django 内置的User类提供了用户密码的存储、验证、修改等功能,默认使用pbkdf2_sha256方式来存储和管理用的密码。 django通过setting.py文件中的PASSWORD_HASHERS来设置选择要使用的算法,列表的第一个元素 (即settings.PASSWORD_HASHERS[0])
会用于储存密码, 所有其它元素都是用于验证的哈希值,它们可以用于检查现有的密码。意思是如果你打算使用不同的算法,你需要修改PASSWORD_HASHERS,来将你最喜欢的算法在列表中放在首位。 一个settings中的Password_hashers看起来是这样的: PASSWORD_HASHERS = ( 'django.contrib.auth.hashers.PBKDF2PasswordHasher', 'django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher', 'django.contrib.auth.hashers.BCryptSHA256PasswordHasher', 'django.contrib.auth.hashers.BCryptPasswordHasher', 'django.contrib.auth.hashers.SHA1PasswordHasher', 'django.contrib.auth.hashers.MD5PasswordHasher', 'django.contrib.auth.hashers.CryptPasswordHasher', ) 具体的密码生成以及验证实现 from django.contrib.auth.hashers import make_password,check_password pwd='4562154' mpwd=make_password(pwd,None,'pbkdf2_sha256') # 创建django密码,第三个参数为加密算法 pwd_bool=check_password(pwd,mpwd) # 返回的是一个bool类型的值,验证密码正确与否 Django之密码加密 通过django自带的类库,来加密解密很方便,下面来简单介绍下; 导入包: from django.contrib.auth.hashers import make_password, check_password 从名字就可以看出来他们的作用了。 一个是生成密码,一个是核对密码。 例如: make_password("123456") 得到结果: u'pbkdf2_sha25615000MAjic3nDGFoi$qbclz+peplspCbRF6uoPZZ42aJIIkMpGt6lQ+Iq8nfQ=' 另外也可以通过参数来生成密码: >>> make_password("123456", None, 'pbkdf2_sha256') 校验: 校验就是通过check_password(原始值, 生成的密文)来校验密码的。 >>> check_password("123456","pbkdf2_sha25615000MAjic3nDGFoi$qbclz+peplspCbRF6uoPZZ42aJIIkMpGt6lQ+Iq8nfQ=") True
62、解释blank和null
blank 设置为True时,字段可以为空。设置为False时,字段是必须填写的。字符型字段CharField和TextField是用空字符串来存储空值的。如果为True,字段允许为空,默认不允许。 null 设置为True时,django用Null来存储空值。日期型、时间型和数字型字段不接受空字符串。所以设置IntegerField,DateTimeField型字段可以为空时,需要将blank,null均设为True。 如果为True,空值将会被存储为NULL,默认为False。 如果想设置BooleanField为空时可以选用NullBooleanField型字段。 一句话概括 null 是针对数据库而言,如果 null=True, 表示数据库的该字段可以为空。NULL represents non-existent data. blank 是针对表单的,如果 blank=True,表示你的表单填写该字段的时候可以不填。比如 admin 界面下增加 model 一条记录的时候。直观的看到就是该字段不是粗体
63、QueryDict和dict区别
在HttpRequest对象中, GET和POST属性是django.http.QueryDict类的实例。 QueryDict类似字典的自定义类,用来处理单键对应多值的情况。 在 HttpRequest 对象中,属性 GET 和 POST 得到的都是 django.http.QueryDict 所创建的实例。这是一个 django 自定义的类似字典的类,用来处理同一个键带多个值的情况。 在 python 原始的字典中,当一个键出现多个值的时候会发生冲突,只保留最后一个值。而在 HTML 表单中,通常会发生一个键有多个值的情况,例如 <select multiple> (多选框)就是一个很常见情况。 request.POST 和request.GET 的QueryDict 在一个正常的请求/响应循环中是不可变的。若要获得可变的版本,需要使用.copy()方法。 django QuerySet对象转换成字典对象 >manage.py shell >>> from django.contrib.auth.models import User >>> from django.forms.models import model_to_dict >>> u = User.objects.get(id=1) >>> u_dict = model_to_dict(u) >>> type(u) <class 'django.contrib.auth.models.User'> >>> type(u_dict) <type 'dict'> 1.QueryDict.__init__(query_string=None, mutable=False, encoding=None) 这是一个构造函数,其中 query_string 需要一个字符串,例如: >>> QueryDict('a=1&a=2&c=3') <QueryDict: {'a': ['1', '2'], 'c': ['3']}>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号