数据挖掘的十大算法

基本概念

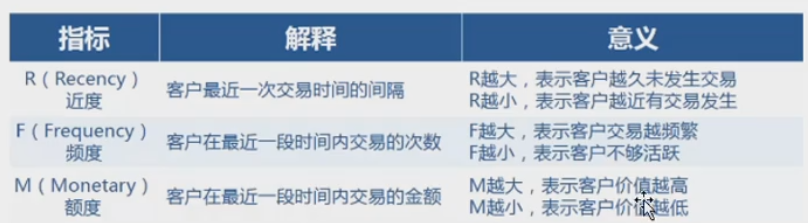
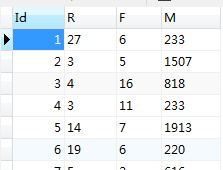
1、数据预处理:处理成 用户ID,R ,F,M四个字段
2、调用KMeans算法 进行聚类 ,设定为8类
3、对数据进行拟合,训练模型 ,每个ID对应一个类别(0-7)
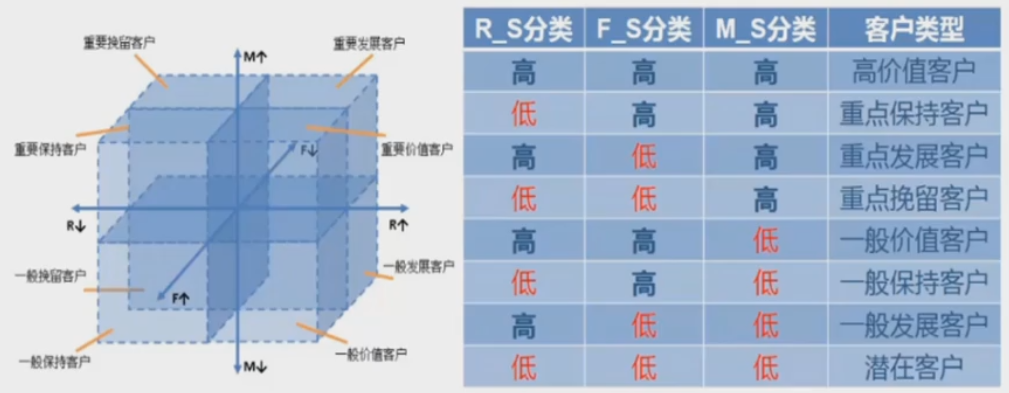
4、如何将分类好的数字标签,和RFM 模型中的客户类别匹配起来?
查看每个类别的中心点,用其构造Dataframe来代表整个数据集
查看每个类别的中心点:clf.cluster_centers_
"""分别计算每个属性值的中位数,代表整个属性的中位水平""" rmd = r['R'].median() fmd = r['F'].median() mmd = r['M'].median()
然后对8行3列数据进行判断,对8类数据进行客户类别标签
5、对整个数据集贴上标签
标签0-7和客户类型一一对应
数据集:

导入数据集到mysql数据库中
总共有940个独立消费数据
无监督算法:
K-Means 算法
K-Means 算法是一个聚类算法。你可以这么理解,最终我想把物体划分成 K 类。假设每
个类别里面,都有个“中心点”,即意见领袖,它是这个类别的核心。现在我有一个新点
要归类,这时候就只要计算这个新点与 K 个中心点的距离,距离哪个中心点近,就变成了
哪个类别。
引入模块
import pandas as pd import numpy as np from sklearn.cluster import KMeans import pymysql
连接数据库:
conn = pymysql.connect(host='localhost',user='root',password='123',db='db2',port=3306) rfm = pd.read_sql('select * from consumption_data',con=conn) conn.close()
查看详情:
rfm.info()
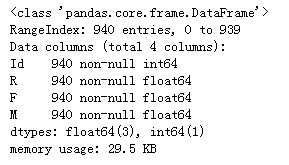
rfm.head()
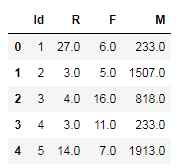
"""选取RFM 三列""" new_rfm = rfm.loc[:,['R','F','M']] """调用KMeans算法 进行聚类 ,设定为8类""" clf = KMeans(n_clusters=8,random_state=0) """对数据进行拟合,训练模型""" clf.fit(new_rfm)
"""查看一下分类的结果,返回的数组中每个数字对应了rfm中每一行""" print(len(clf.labels_)) se = pd.Series(clf.labels_) se.value_counts()

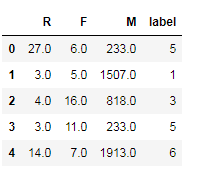
new_rfm['label']=clf.labels_ new_rfm.head()
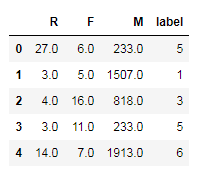
"""如何将分类好的数字标签,和RFM 模型中的客户类别匹配起来?""" """查看每个类别的中心点,用其构造Dataframe来代表整个数据集"""
查看每个类别的中心点:clf.cluster_centers_
8行3列

r = pd.DataFrame(clf.cluster_centers_,columns=['R','F','M'])
print(r)
每个类别的中心点0-7共8类
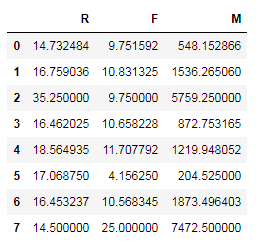
"""分别计算每个属性值的中位数,代表整个属性的中位水平""" rmd = r['R'].median() fmd = r['F'].median() mmd = r['M'].median()
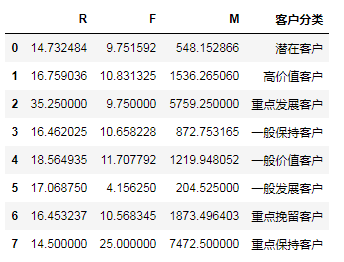
cluster=[] for i in range(len(r)): if r.iloc[i,0] > rmd and r.iloc[i,1] >fmd and r.iloc[i,2] >mmd: cluster.append('高价值客户') elif r.iloc[i,0] < rmd and r.iloc[i,1] > fmd and r.iloc[i,2] >mmd: cluster.append('重点保持客户') elif r.iloc[i,0] > rmd and r.iloc[i,1] < fmd and r.iloc[i,2] >mmd: cluster.append('重点发展客户') elif r.iloc[i,0] < rmd and r.iloc[i,1] < fmd and r.iloc[i,2] > mmd: cluster.append('重点挽留客户') elif r.iloc[i,0] > rmd and r.iloc[i,1] > fmd and r.iloc[i,2] < mmd: cluster.append('一般价值客户') elif r.iloc[i,0] < rmd and r.iloc[i,1] > fmd and r.iloc[i,2] < mmd: cluster.append('一般保持客户') elif r.iloc[i,0] > rmd and r.iloc[i,1] < fmd and r.iloc[i,2] < mmd: cluster.append('一般发展客户') else: cluster.append('潜在客户')
cluster

"""将贴好的标签,匹配到每一行数据""" r['客户分类']=cluster
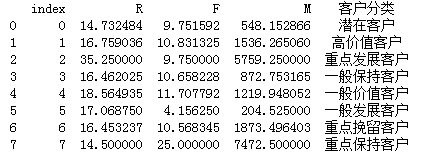
s = r.reset_index() print(s)
new_rfm.head()
标签0-7和客户类型一一对应
对整个数据集贴上标签
# result = pd.merge(new_rfm,r['客户分类'],how='inner',left_on='label',right_index=True)# 用右表的索引做连接键
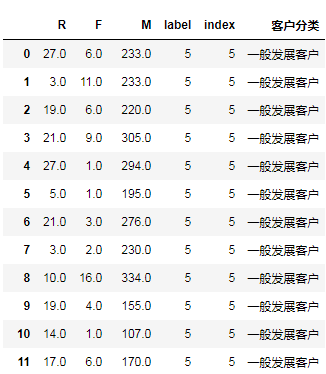
result = pd.merge(new_rfm,s[['index','客户分类']],how='inner',left_on='label',right_on='index') result.sort_index()
悟已往之不谏,知来者之可追。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号