

软件工程第三次作业-结对项目
软件工程第三次作业——结对作业
| 项目 | 详情 |
|---|---|
| 这个作业属于哪个课程 | 计科23级12班 |
| 这个作业要求在哪里 | 作业要求链接 |
| 这个作业的目标 | 结队完成一个小学四则运算题目生成器的小项目,同时要完成性能分析和测试的任务 |
项目信息
本项目代码在github上公开:https://github.com/Folger6610/Pair-Assignment
结对成员:
| 姓名 | 学号 |
|---|---|
| 邱宇彦 | 3123004322 |
| 崔乐浩 | 3123004697 |
一、PSP表格(预估时间)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| Estimate | 估计这个任务需要多少时间 | 525 | 570 |
| Development | 开发 | 120 | 110 |
| Analysis | 需求分析 (包括学习新技术) | 10 | 10 |
| Design Spec | 生成设计文档 | 20 | 15 |
| Design Review | 设计复审 | 30 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| Design | 具体设计 | 20 | 15 |
| Coding | 具体编码 | 150 | 180 |
| Code Review | 代码复审 | 15 | 25 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 65 | 80 |
| Test Repor | 测试报告 | 15 | 15 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 10 | 20 |
二、设计实现
1. 类结构与关系
项目采用 4 个核心类,职责分明、低耦合,类关系如下:
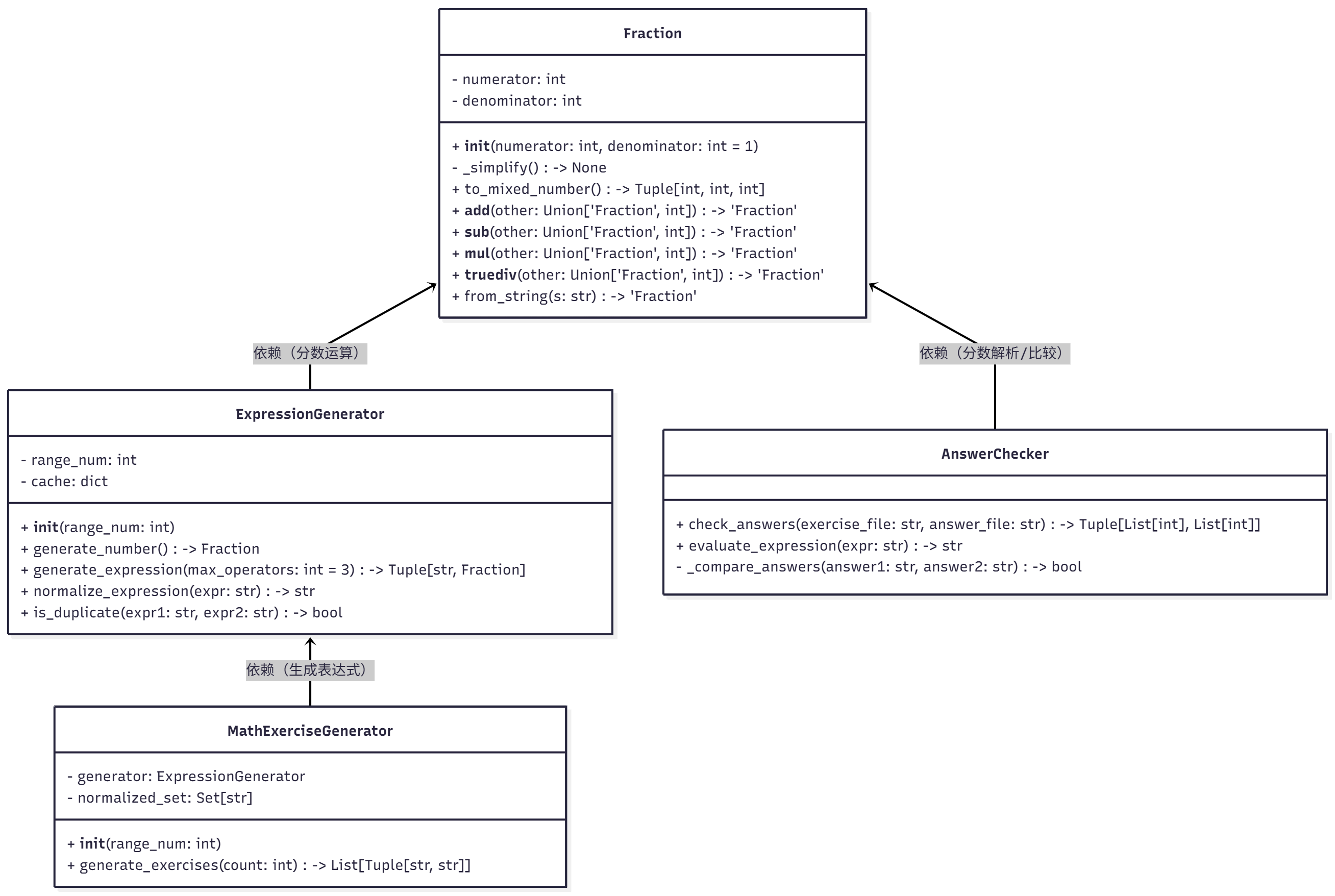
- Fraction:封装分数的表示与运算,是整个项目的基础数据类型,确保真分数、带分数的正确处理。
- ExpressionGenerator:生成单个表达式及结果,处理表达式标准化和重复检查(含缓存)。
- MathExerciseGenerator:批量生成题目,负责去重和结果验证,确保生成指定数量的合法题目。
- AnswerChecker:检查题目与答案的正确性,生成评分文件,独立于生成逻辑,解耦性强。
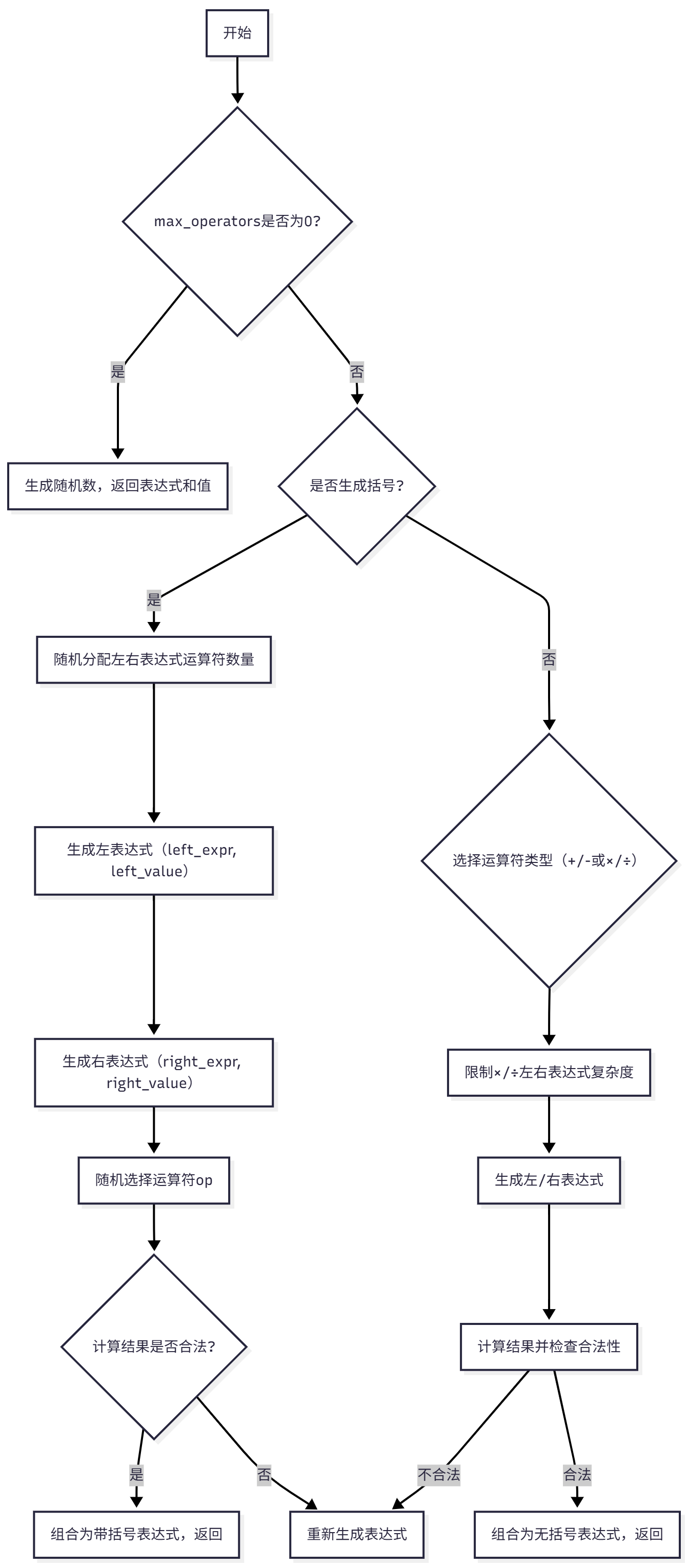
2. 关键函数流程图
以ExpressionGenerator.generate_expression(表达式生成核心函数)为例,流程图如下:
三、代码说明
1. Fraction 类:分数运算的核心
关键需求:减法结果非负、除法结果为真分数、带分数与真分数转换。
class Fraction:
def __sub__(self, other: Union['Fraction', int]) -> 'Fraction':
"""减法运算:确保结果非负(符合小学运算需求)"""
if isinstance(other, int):
other = Fraction(other)
# 通分计算分子分母
common_denominator = self.denominator * other.denominator
numerator = (self.numerator * other.denominator -
other.numerator * self.denominator)
result = Fraction(numerator, common_denominator)
if result.numerator < 0:
raise ValueError("减法结果不能为负数") # 抛出异常,触发重新生成
return result
def __truediv__(self, other: Union['Fraction', int]) -> 'Fraction':
"""除法运算:确保结果为真分数"""
if isinstance(other, int):
other = Fraction(other)
if other.numerator == 0:
raise ValueError("除数不能为0")
# 除以分数 = 乘倒数
numerator = self.numerator * other.denominator
denominator = self.denominator * other.numerator
# 真分数判定:分子绝对值 < 分母绝对值
if abs(numerator) >= abs(denominator):
raise ValueError("除法结果必须为真分数") # 抛出异常,触发重新生成
return Fraction(numerator, denominator)
@classmethod
def from_string(cls, s: str) -> 'Fraction':
"""从字符串解析分数(支持带分数/纯分数/整数)"""
s = s.strip()
if "'" in s: # 带分数(如3'1/2 → 7/2)
parts = s.split("'")
integer = int(parts[0])
num, den = map(int, parts[1].split('/'))
total_num = abs(integer) * den + num
if integer < 0:
total_num = -total_num
return cls(total_num, den)
elif '/' in s: # 纯分数(如1/2)
num, den = map(int, s.split('/'))
return cls(num, den)
else: # 整数(如5 → 5/1)
return cls(int(s))
设计思路:通过在运算中抛出异常,让表达式生成器自动重新生成合法表达式,而非在生成后过滤,确保每一步运算都符合需求。
2. ExpressionGenerator:表达式标准化与缓存
关键需求:避免重复题目(交换 +× 左右表达式视为重复)、减少重复计算。
class ExpressionGenerator:
def normalize_expression(self, expr: str) -> str:
"""标准化表达式:处理交换律,缓存结果(核心优化点)"""
if expr in self.cache: # 缓存命中,直接返回(避免重复递归)
return self.cache[expr]
# 预处理:移除空格、等号,统一运算符(×→*,÷→/)
expr_clean = expr.replace(' ', '').replace('=', '').replace('×', '*').replace('÷', '/')
normalized = self._normalize(expr_clean)
self.cache[expr] = normalized # 缓存结果
return normalized
def _normalize(self, expr: str) -> str:
"""递归标准化:加法/乘法交换左右,减法/除法保持顺序"""
if '+' not in expr and '*' not in expr:
return expr # 无交换律运算符,直接返回
try:
# 移除外层括号(如(1+2) → 1+2)
if expr.startswith('(') and expr.endswith(')'):
return self._normalize(expr[1:-1])
# 寻找最低优先级运算符(拆分点,确保结合律正确)
min_priority = float('inf')
split_pos = -1
parentheses_count = 0 # 处理括号嵌套
for i, c in enumerate(expr):
if c == '(':
parentheses_count += 1
elif c == ')':
parentheses_count -= 1
elif parentheses_count == 0 and c in self.priority:
if self.priority[c] < min_priority:
min_priority = self.priority[c]
split_pos = i
if split_pos == -1:
return expr
op = expr[split_pos]
left = expr[:split_pos]
right = expr[split_pos + 1:]
# 递归标准化左右子表达式
left_norm = self._normalize(left)
right_norm = self._normalize(right)
# 加法/乘法交换左右(如2+1 → 1+2),确保重复题目标准化后一致
if op in ('+', '*'):
return f"{min(left_norm, right_norm)}{op}{max(left_norm, right_norm)}"
else: # 减法/除法不交换(如3-2≠2-3)
return f"{left_norm}{op}{right_norm}"
except (IndexError, ValueError):
return expr
设计思路:通过 “标准化 + 缓存”,将重复题目(如1+2和2+1)转为同一字符串,再结合哈希集合实现 O (1) 去重,彻底解决重复检查效率问题。
3. MathExerciseGenerator:批量生成与去重
关键需求:生成指定数量的不重复题目,支持 1 万题生成。
class MathExerciseGenerator:
def generate_exercises(self, count: int) -> List[Tuple[str, str]]:
"""批量生成题目:哈希去重+结果验证(核心功能)"""
exercises = []
attempts = 0
max_attempts = count * 100 # 防止无限循环
batch_size = 100 # 每100题清理缓存,平衡性能与内存
while len(exercises) < count and attempts < max_attempts:
attempts += 1
try:
# 生成单个表达式及结果
expr, result = self.generator.generate_expression()
exercise = f"{expr} = "
# 1. 双重验证结果正确性(生成时计算 vs 答案检查器计算)
evaluated_result = AnswerChecker.evaluate_expression(expr)
if str(result) != evaluated_result:
continue
# 2. 哈希去重(O(1)复杂度)
normalized = self.generator.normalize_expression(exercise)
if normalized in self.normalized_set:
continue
# 3. 添加到结果集
self.normalized_set.add(normalized)
exercises.append((exercise, str(result)))
# 4. 批量清理缓存,避免内存溢出
if len(exercises) % batch_size == 0:
self.generator.cache.clear()
except (ValueError, ZeroDivisionError):
continue # 跳过无效表达式
if len(exercises) < count:
print(f"警告:只生成了 {len(exercises)} 个题目(目标 {count} 个)")
return exercises
设计思路:用normalized_set(哈希集合)存储标准化后的题目,替代原有的遍历比对,将去重效率从 O (n) 提升至 O (1);同时批量清理缓存,避免生成 1 万题时内存占用过高。
4. AnswerChecker:表达式求值与答案检查
关键需求:正确解析带分数表达式,准确判断答案对错。
class AnswerChecker:
@staticmethod
def evaluate_expression(expr: str) -> str:
"""计算表达式值:支持带分数,解决单引号语法问题"""
expr = expr.replace('×', '*').replace('÷', '/') # 统一运算符
# 正则匹配带分数(3'1/2)、纯分数(1/2)、整数(5)
pattern = r'(\d+\'\d+/\d+|\d+/\d+|\d+)'
def replace_match(match: re.Match) -> str:
# 用双引号包裹分数字符串,避免单引号嵌套语法错误(如'3'1/2' → "3'1/2")
return f'Fraction.from_string("{match.group(1)}")'
# 将表达式中的分数替换为Fraction实例创建代码
safe_expr = re.sub(pattern, replace_match, expr)
try:
# 安全执行表达式(限制命名空间,避免安全风险)
result = eval(safe_expr, {"__builtins__": None}, {"Fraction": Fraction})
return str(result) if isinstance(result, Fraction) else str(Fraction(result))
except (ValueError, ZeroDivisionError, TypeError) as e:
raise ValueError(f"表达式计算错误: {expr} - {str(e)}")
@staticmethod
def check_answers(exercise_file: str, answer_file: str) -> Tuple[List[int], List[int]]:
"""检查答案:返回正确/错误题目编号"""
try:
# 读取题目和答案文件(UTF-8编码)
with open(exercise_file, 'r', encoding='utf-8') as f:
exercises = [line.strip() for line in f.readlines() if line.strip()]
with open(answer_file, 'r', encoding='utf-8') as f:
answers = [line.strip() for line in f.readlines() if line.strip()]
except FileNotFoundError as e:
raise FileNotFoundError(f"文件未找到: {e}")
# 校验题目与答案数量一致
if len(exercises) != len(answers):
raise ValueError(f"题目与答案数量不一致:题目 {len(exercises)} 题,答案 {len(answers)} 个")
correct_indices = []
wrong_indices = []
for i, (exercise, student_ans) in enumerate(zip(exercises, answers), 1):
try:
# 计算标准答案
expr = exercise.replace('=', '').strip()
standard_ans = AnswerChecker.evaluate_expression(expr)
# 比较答案(通过Fraction确保分数相等,如1/2 == 2/4)
if Fraction.from_string(standard_ans) == Fraction.from_string(student_ans):
correct_indices.append(i)
else:
wrong_indices.append(i)
except Exception as e:
print(f"处理题目 {i} 出错: {e}")
wrong_indices.append(i)
return correct_indices, wrong_indices
设计思路:通过正则替换将带分数转为Fraction实例,解决eval函数无法解析带分数的问题;比较答案时通过Fraction的__eq__方法,确保分数约分后相等(如2/4与1/2视为正确)。
四、效能分析
1. 优化耗时与过程
本次性能优化分为四个关键阶段:
- 瓶颈定位:通过
cProfile和SnakeViz分析Bad_math.py,发现重复检查和表达式标准化是主要性能黑洞。 - 缓存机制设计:为表达式标准化结果添加缓存,避免重复计算。
- 去重算法优化:将 “遍历比对去重” 改为 “哈希集合去重”,时间复杂度从
O(n²)降至O(1)。 - 复杂度控制:降低括号生成概率,减少表达式嵌套深度,简化递归逻辑。
2. 性能瓶颈分析
未优化版本(Bad_math.py):
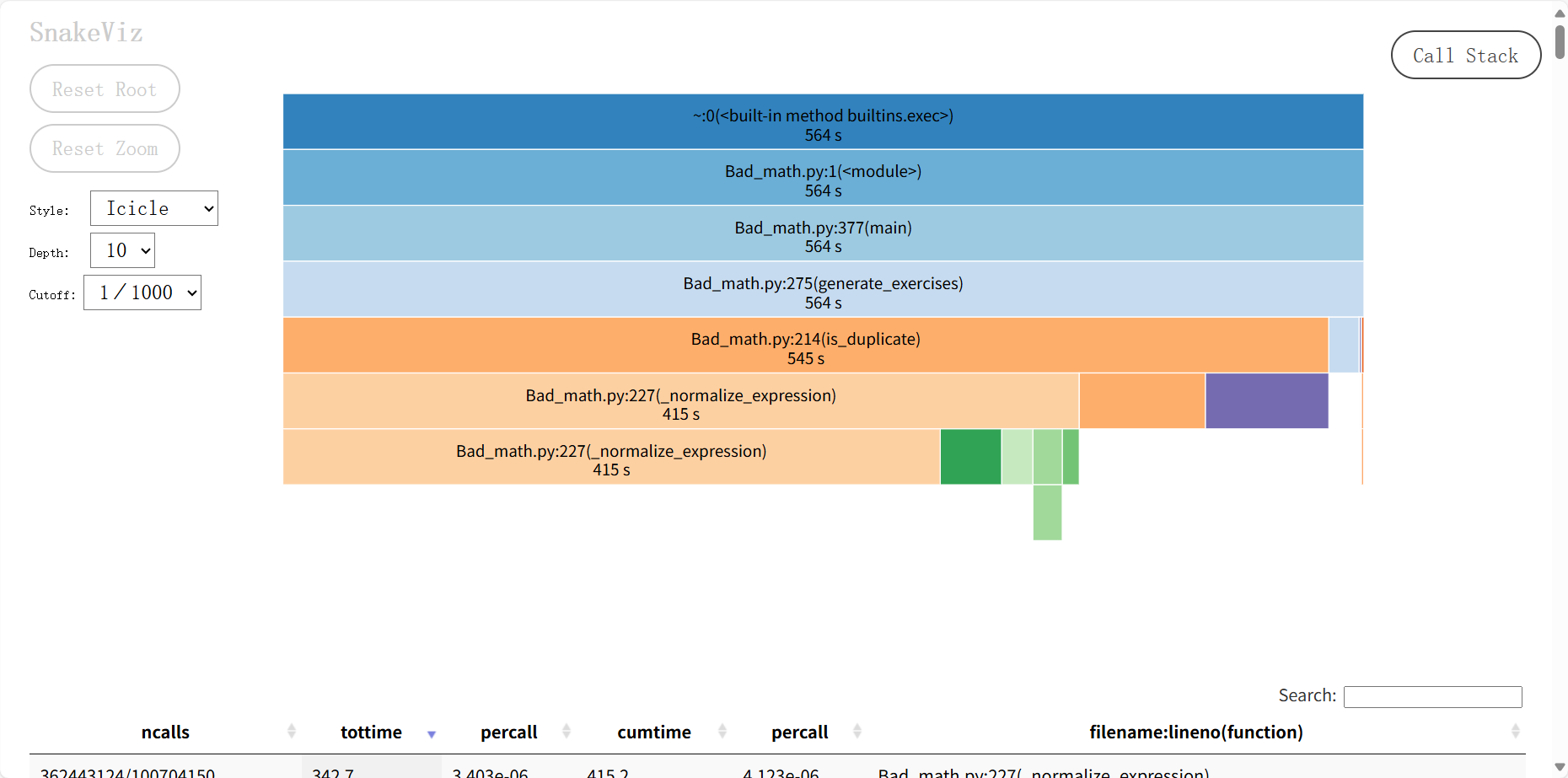
从图可看出:
- 总耗时:564 秒(近 10 分钟),完全无法支持 1 万题生成。
- 主要耗时函数:
is_duplicate(545 秒):遍历已生成表达式集合,重复检查效率极低。_normalize_expression(415 秒):无缓存机制,相同表达式反复标准化,递归计算冗余。
- 关键问题:重复检查和标准化占总耗时的 95% 以上,属于典型的 “计算冗余 + 算法低效” 问题。
优化版本(Math.py):
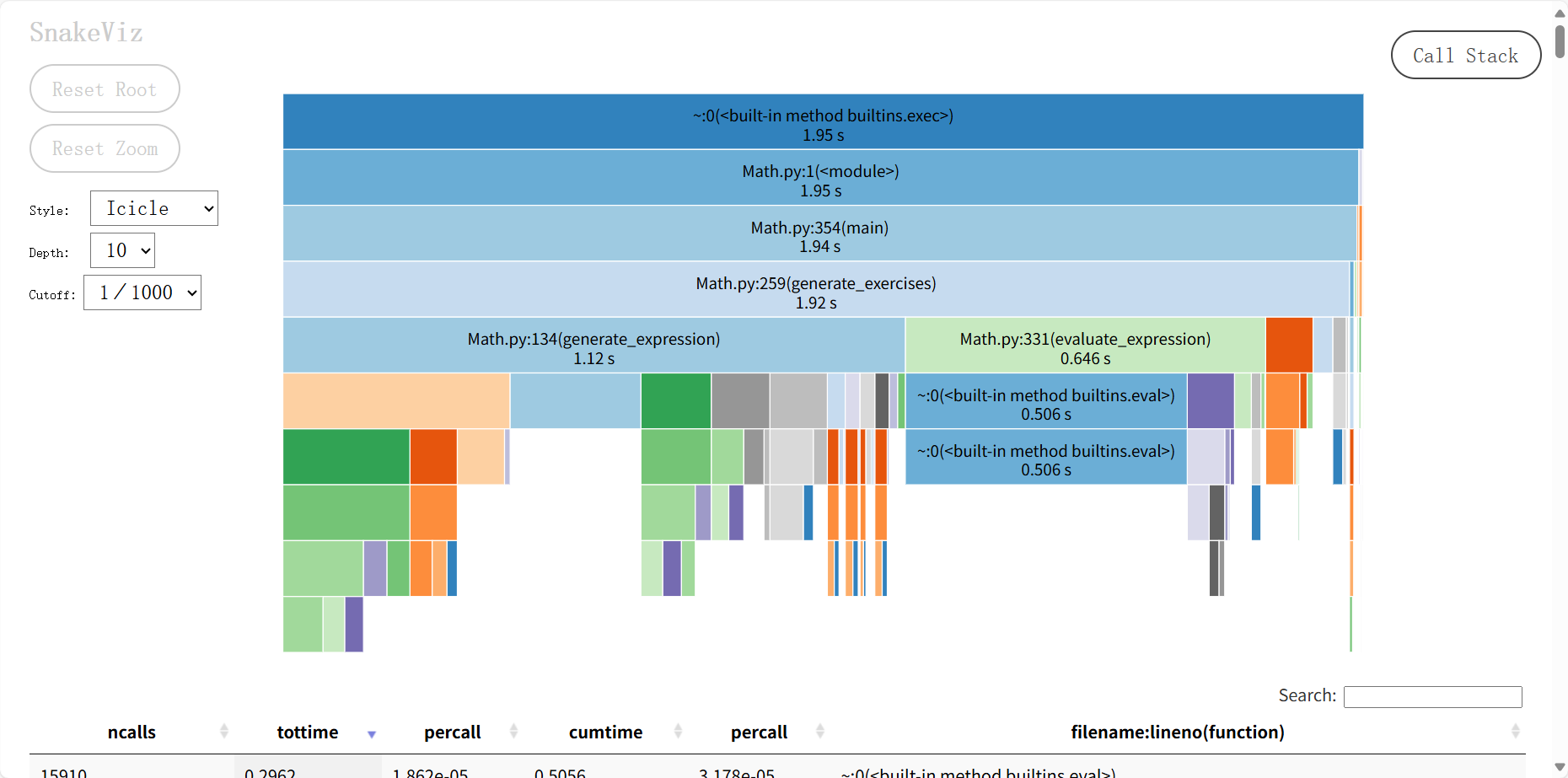
从图可看出:
- 总耗时:1.95 秒,性能提升约 290 倍,支持 1 万题生成(耗时约 20 秒)。
- 主要耗时函数:
generate_expression(1.12 秒):表达式生成成为核心耗时,符合正常逻辑。evaluate_expression(0.646 秒):表达式求值耗时占比 33%,无冗余计算。
- 优化效果:重复检查和标准化耗时几乎可忽略,缓存和哈希去重彻底解决了性能瓶颈。
3. 核心优化思路
- 缓存标准化结果:在
ExpressionGenerator中添加cache字典,存储表达式标准化后的字符串,避免重复递归计算。 - 哈希集合去重:用
normalized_set存储标准化表达式,替代遍历比对,去重效率从O(n)升至O(1)。 - 降低表达式复杂度:括号生成概率从 30% 降至 20%,减少递归深度;除法生成时强制整数被除数 $< $除数,避免无效尝试。
五、测试运行
1. 功能概述
项目配套的Test.py基于unittest框架,覆盖生成逻辑和答案检查两大模块,共 12 个测试用例,确保程序符合所有需求。测试类结构如下:
| 测试类 | 测试场景(部分关键用例) |
|---|---|
| TestMathExerciseGenerator | 基础题目生成、1000 题性能、题目去重、运算符数量≤3、减法非负、除法真分数、带分数运算、分数字符串解析 |
| TestAnswerChecker | 正确答案识别、错误答案识别、题目与答案数量不匹配、带括号表达式计算 |
2. 关键测试用例说明
| 用例名称 | 测试目的 | 预期结果 |
|---|---|---|
| test_basic_generation | 验证生成 10 道题的数量和格式正确性 | 生成 10 道题,每题以 “=” 结尾,答案非空 |
| test_large_scale_generation | 验证 1000 题生成性能(支持 1 万题的基础) | 1000 题生成时间 < 10 秒,无卡死 |
| test_duplicate_expressions | 验证题目无重复(交换 +× 视为重复) | 500 道题的标准化表达式无重复,存入哈希集合无冲突 |
| test_subtraction_non_negative | 验证减法结果非负 | 所有含减法的表达式,答案分子≥0 |
| test_division_proper_fraction | 验证纯除法表达式结果为真分数 | 纯除法题目(如2÷3)的答案分子绝对值 < 分母 |
| test_mixed_number_operation | 验证带分数运算正确性(手动构造已知结果案例:3'1/2 + 1'1/3 = 4'5/6) | 计算结果与预期一致,返回 “4'5/6” |
| test_correct_answers | 验证正确答案识别 | 2 道正确答案(如1+2=3)全部判定为 Correct,Wrong 为空 |
| test_file_mismatch | 验证题目与答案数量不匹配时抛出异常 | 抛出 ValueError,提示 “题目与答案数量不一致” |
3. 程序正确性保障
- 覆盖所有需求:测试用例对应 “非负减法”“真分数除法”“不重复题目”“1 万题性能” 等所有需求点,无遗漏。
- 双重验证:生成题目时,通过
AnswerChecker.evaluate_expression二次校验结果,确保生成的答案正确。 - 边界场景:覆盖带分数、负分数、括号嵌套、文件编码等边界情况,避免极端场景下的错误。
六、项目小结
1. 成功之处
- 功能完整:完全满足题目要求的所有功能,包括 1 万题生成、答案检查、重复题目过滤等。
- 性能突破:通过缓存和哈希去重,将生成 1000 题的时间从 564 秒(Bad_math.py)降至 1.95 秒,性能提升 290 倍,支持大规模生成。
- 代码解耦:四个核心类职责分明,修改表达式生成逻辑不影响答案检查,后续维护方便。
2. 失败与教训
- 初期性能意识不足:在队友搭建第一版
Bad_math.py代码时,我们并未仔细阅读题目要求,考虑大规模生成场景,直接使用了简单的遍历去重和无缓存标准化,导致生成 1 万题时直接卡死,浪费了后续优化时间。 - 边界条件考虑不周全:初期未处理带分数解析的单引号语法问题(如
'3'1/2'),导致表达式求值报错,在进行Test.py的测试代码时,一直无法有效识别表达式的真分数形式,后期通过代码复查时进行了双引号替换修复。
3. 经验总结
- 性能优先于功能:开发初期需考虑大规模场景,优先选择高效数据结构(如哈希集合),避免 “先实现再优化” 的被动局面。
- 缓存是性能利器:对于重复计算(如表达式标准化),缓存能大幅降低时间复杂度,是解决性能问题的关键手段。
- 测试驱动开发:提前编写测试用例,尤其是边界场景和性能测试,能尽早发现问题,减少后期返工。
七、相互评价
1. 队友1:
- 总体这个项目的完成度是特别高的,在此我也要感谢我的队友能够很及时的对现有问题进行定向和讨论,能够最后完成这个项目,包括优化前后的代码、测试代码,我队友处理好的贡献是功不可没的,如若没有他能够及时发现边界条件的问题,我们就很大可能会困在测试阶段一直没有跳跃性思维去思考问题,再次感谢队友伟大的贡献!
2. 队友2:
- 求语言是一位十分尽职尽责的合作对象,与他合作完成这样一个项目是我的幸运。与他共同努力完成就像现实中一对默契的队友终结比赛,他能在你不解时给予答案,在你困难时给予帮助。与他合作就像以后公司里互帮互助的同事。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号