关系型数据库表设计中主键是用逻辑id好还是业务id好呢
最近一直在讨论支付相关的话题,那就以 交易订单表 / 支付单表 主键设计 为话题,讨论是用逻辑主键(自增ID、雪花ID)还是直接用业务单号(交易单号/支付单号)做主键,以及分库分表的影响。
一、主键设计对比
1. 主键设计的两种方式
方式 A:业务单号作为主键
比如:
-
trade_id(交易单号)直接做主键 -
payment_id(支付单号)直接做主键
优点
-
直观简单,不需要额外字段。
-
查找时直接按单号主键走,不需要额外索引。
-
对外暴露的单号和数据库主键一致,避免冗余。
缺点
-
业务单号可能是字符串(VARCHAR),做主键会导致索引存储成本高、性能差。
-
单号规则可能变动(比如从 32 位换到 36 位),会影响表结构。
-
分库分表时,主键和分片键不一定一致,可能导致路由冲突。
-
业务单号有时候不是严格顺序,可能导致聚簇索引插入性能下降(MySQL InnoDB 主键是聚簇索引)。
👉 常见于 小规模系统 或者 对性能要求不高 的业务。
方式 B:逻辑主键(Surrogate Key)
-
新增一个字段
id(BIGINT,自增或雪花ID)作为表的主键。 -
交易单号
trade_no、支付单号payment_no单独存,并加唯一索引。
优点
-
id是数值型(BIGINT),适合作为 InnoDB 聚簇索引,性能高、占用小。 -
不依赖业务单号规则,业务单号可以调整/迁移,不影响表结构。
-
分库分表时,可以用
id或trade_no作分片键,灵活性更高。 -
一般互联网公司(支付宝、微信、银行核心系统)都是这种方式。
缺点
-
查询时大多数业务会按业务单号(trade_no/payment_no)查,而不是按
id,需要额外唯一索引。 -
多了一个冗余字段。
👉 常见于 大规模支付系统,因为可扩展性、分库分表兼容性更好。
2. 分库分表的影响
-
分库分表通常需要一个 分片键(sharding key)。
-
如果主键就是业务单号(方式 A):
-
只能用业务单号作分片键,没得选。
-
如果分片规则设计不好(比如按时间戳分),可能会导致数据倾斜。
-
-
如果主键是逻辑主键(方式 B):
-
分片键可以是
trade_no(交易单号)、user_id(用户号)、merchant_id(商户号),更灵活。 -
id(雪花ID)本身也可以作为分片键,因为雪花算法高位通常有时间戳,低位有机器号,可以天然均匀分布。
-
👉 所以 方式 B 更适合分库分表。
3. 具体设计建议(MySQL)
交易订单表(trade_order)
CREATE TABLE trade_order ( id BIGINT UNSIGNED NOT NULL PRIMARY KEY COMMENT '逻辑主键,雪花ID', trade_no VARCHAR(32) NOT NULL COMMENT '交易单号,对外唯一', user_id BIGINT NOT NULL, merchant_id BIGINT NOT NULL, amount DECIMAL(18,2) NOT NULL, status TINYINT NOT NULL, create_time DATETIME NOT NULL, update_time DATETIME NOT NULL, UNIQUE KEY uq_trade_no (trade_no), KEY idx_user (user_id), KEY idx_merchant (merchant_id) ) ENGINE=InnoDB;
支付单表(payment_order)
CREATE TABLE payment_order ( id BIGINT UNSIGNED NOT NULL PRIMARY KEY COMMENT '逻辑主键,雪花ID', payment_no VARCHAR(32) NOT NULL COMMENT '支付单号,对外唯一', trade_no VARCHAR(32) NOT NULL COMMENT '关联交易单号', channel VARCHAR(16) NOT NULL COMMENT '支付通道', amount DECIMAL(18,2) NOT NULL, status TINYINT NOT NULL, create_time DATETIME NOT NULL, update_time DATETIME NOT NULL, UNIQUE KEY uq_payment_no (payment_no), KEY idx_trade_no (trade_no) ) ENGINE=InnoDB;
4. Google Pay / Apple Pay 的对比
-
Google Pay / Apple Pay 本身不存储你的交易单,只会返回一个 通道流水号(UUID/GUID)。
-
商户系统必须保存:
-
内部逻辑主键(id) → BIGINT
-
商户单号(trade_no / payment_no) → VARCHAR(32)
-
通道单号(Google Txn ID / Apple Txn ID) → VARCHAR(64)
-
👉 所以你会看到:国内(支付宝、微信)和国际(Google、Apple)都要求 商户必须有自己生成的单号,并且在数据库里普遍是 逻辑主键 + 唯一业务单号 两套体系。
5. 最佳实践结论
-
不要直接把业务单号作为主键,而是:
-
用 逻辑主键(BIGINT 雪花ID) 做主键。
-
业务单号(trade_no / payment_no)建唯一索引。
-
-
分库分表不受影响:
-
可以用
trade_no或id做分片键。 -
雪花 ID 分布均匀,天然适合作路由。
-
-
为什么这样做:
-
MySQL InnoDB 聚簇索引要求主键高效,而字符串主键性能差。
-
保证未来业务单号规则变更时不影响数据库结构。
-
二、自增主键的影响
1. 自增主键在单库单表的场景
-
在 单库单表 下,用自增主键没问题,性能好、实现简单。
-
InnoDB 聚簇索引能保证写入是顺序的,减少页分裂,写性能高。
2. 分库分表的场景
分库分表之后,自增主键的问题就出现了:
-
ID 唯一性难以保证
-
每个分库都会从 1 开始自增,跨库后会出现重复 ID。
-
你可以通过设置
auto_increment_offset和auto_increment_increment来保证不同库的 ID 不重叠,但随着库数/表数扩展,这种方案很难维护。
-
-
分片键不匹配
-
自增 ID 只是一个顺序号,没法天然携带业务信息。
-
如果后续需要基于交易单号做分片,逻辑主键无法直接参与路由,查询时就会多一次索引跳转或路由转换。
-
-
迁移扩容风险
-
水平扩容时,旧的自增序列和新的分库/分表策略不好兼容,很容易出错。
-
3. 主流解决方案
所以,分库分表体系里,常见有两种做法:
✅ 方案一:逻辑主键用分布式 ID(推荐)
-
用 雪花算法(Snowflake ID)、Leaf Segment 模式、UUID(不推荐性能差) 来替代自增主键。
-
特点:
-
保证全局唯一性
-
可以通过 高位 bits 携带路由信息(比如库号、表号、时间戳) → 天然支持分库分表
-
不依赖数据库的自增特性,更好扩展
-
👉 Google Pay / Apple Pay 对比
-
Google / Apple 的支付单号并不是自增的,而是 长字符串型的唯一单号,一般由「时间戳 + 业务标识 + 随机数」构成,既保证唯一性,也方便分布式查询。
-
内部数据库的主键更多是 逻辑 ID(分布式 ID),而不是直接用支付单号。
✅ 方案二:主键自增 + 唯一单号字段做分片键
-
如果你坚持用自增主键,可以这样做:
-
主键:自增 ID,仅保证表内唯一性
-
业务单号(交易单号/支付单号):生成时就带分片信息(比如 hash 前缀、时间戳),在路由时用业务单号来定位库/表
-
👉 优点:兼容老系统,保留简单自增 ID
👉 缺点:扩容麻烦,单表写热点问题依旧存在
4. 总结建议
-
单库单表:可以用自增主键,简单高效。
-
分库分表:强烈推荐用 雪花 ID/分布式 ID,因为:
-
避免 ID 冲突
-
可以天然支持分库分表路由
-
不依赖数据库自增特性,更好扩展
-
最佳实践(类似 Google Pay / Apple Pay 内部做法):
-
主键:雪花 ID(逻辑主键)
-
唯一索引:交易单号 / 支付单号(业务单号)
-
分片键:交易单号(或支付单号)
三、分库分表的数据迁移方案
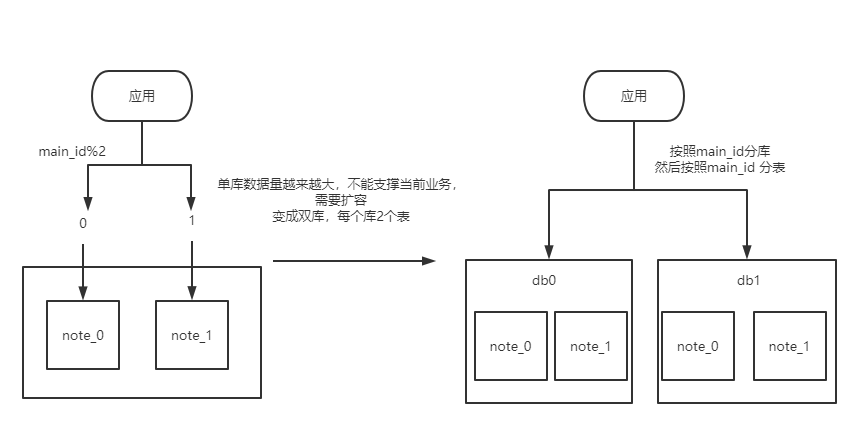
- 项目初始,是单库。分了2个表 就可以满足业务数据需求
- 随着时间推移,多年后,数据越来越多,当前的数据库设计已经不能满足当前设计
- 于是,需要如上图一样,进行分库再分表。
2.数据迁移方案
由于想要当前业务不停机的情况下进行数据迁移,于是,查找了许多资料 。最终找到了 同步双写方案
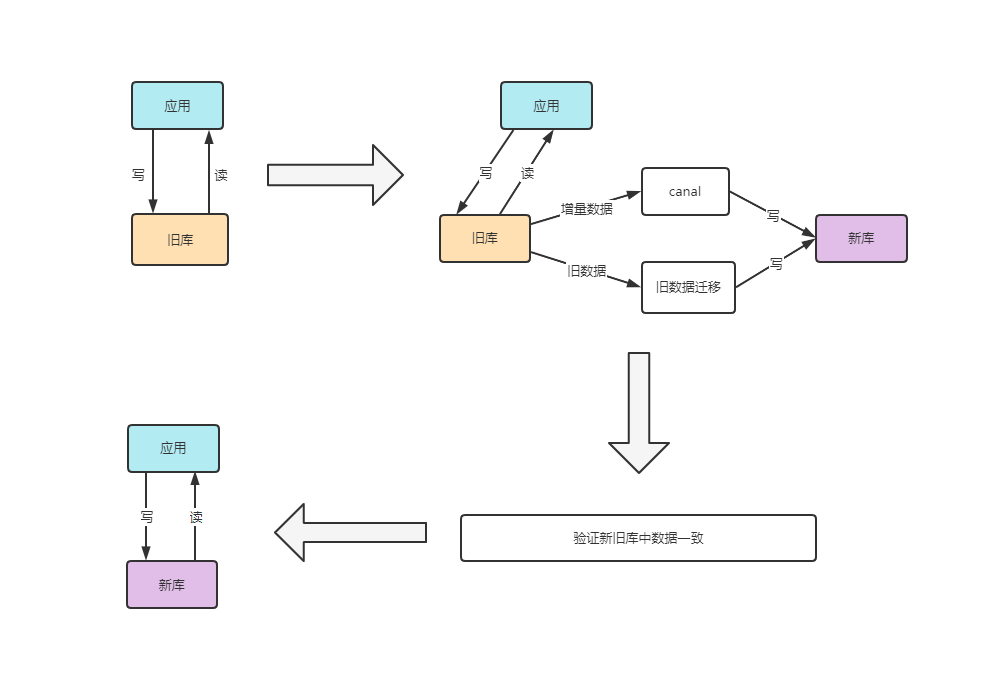
如上图所示
- 应用还是保持从旧库中读写数据
- 编写个应用,通过canal将增量数据通过新的分库分表规则也同时写入新库
- 同时 编写个旧数据的迁移的工具,通过新的分库分表规则写入新库
- 旧数据迁移完成后,验证新旧库中数据是否一致,一致后,既可切换位新库
转发请注明出处:https://www.cnblogs.com/fnlingnzb-learner/p/19084398

 浙公网安备 33010602011771号
浙公网安备 33010602011771号