数据库索引
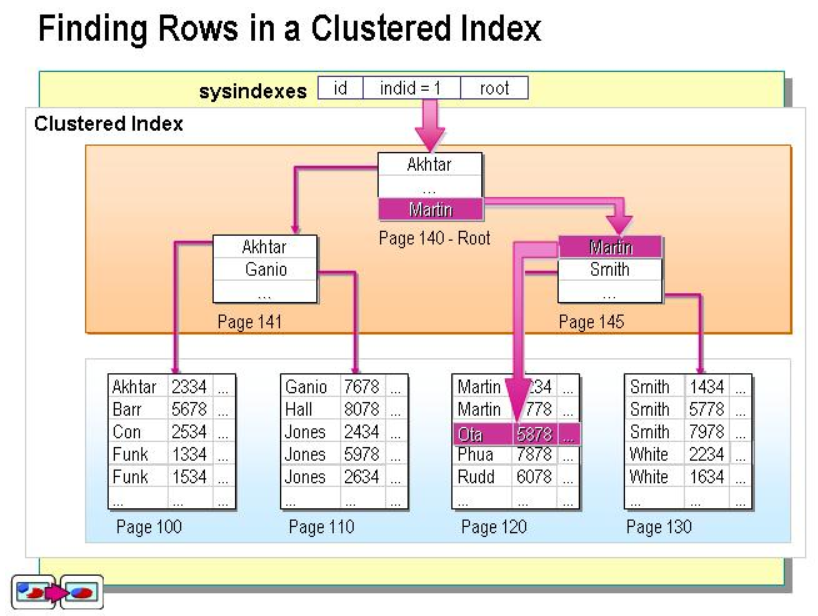
聚集索引:
逻辑顺序决定了物理存储顺序。每个表唯一存在一个。叶子结点就是数据节点。对于范围查询寻很友好。
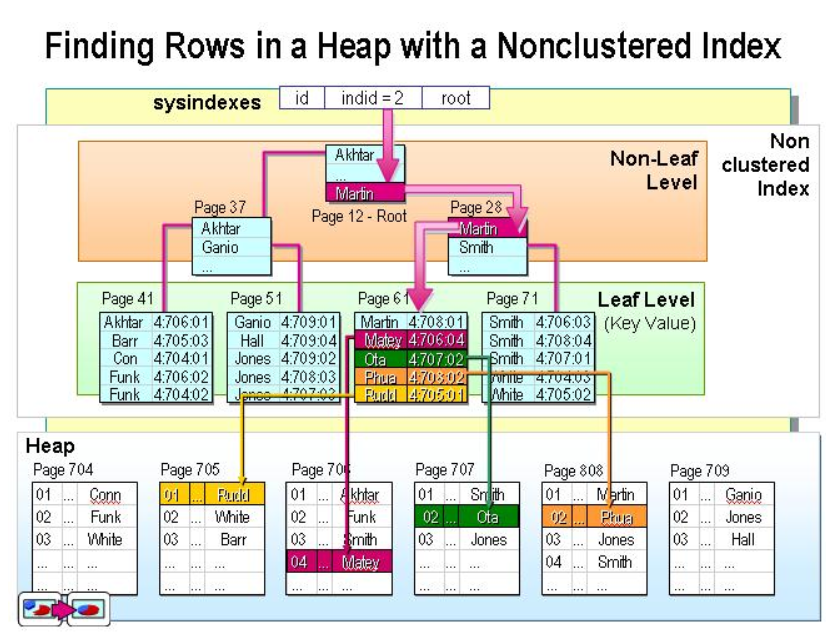
非聚集索引:
聚集索引以外的,不唯一。叶子结点存储索引列数据和指针(指向数据)。
- 普通索引
- 唯一索引
- 全文索引
需不需要建立索引,要权衡索引带来的优势和不足。
优势:减少IO次数,提升查询性能
不足:维护带来的开销
索引命中:
非聚集索引对于等值查询和范围查询如果范围内结果集太大,则不会使用非聚集索引(数据库引擎评估),而会导致聚集索引扫描;(结果集规模)
此外,如果表数据太少,即使有索引,并且结果集数据量不大,也会不命中索引,而是直接聚集索引扫描。(表规模)
不要总是将索引的使用等同于良好的性能,或者将良好的性能等同于索引的高效使用。如果只要使用索引就能获得最佳性能,那查询优化器的工作就简单了。但事实上,不正确的索引选择并不能获得最佳性能。因此,查询优化器的任务是只在索引或索引组合能提高性能时才选择它,而在索引检索有碍性能时则避免使用它。
建立索引:
类似 Sex 性别,字段值范围小建立索引后索引是矮胖型,页节点数据量太大,对于查询优化不大
经常一起使用的多个查询条件可建立包含性索引,减少开销(减少一次index seek,减少合并结果集)
OR 若条件都建立了索引也会命中索引(结果集数据量不大)
IN 条件的个数对索引命中有影响,例如 IN 里面太多OrderNum或者结果集达到一定数量会导致Clustered Index Scan;(OrderNum是字母数字组合)
Not IN 和!=不会命中索引
对于> ,< 结果集数据量大的话会不命中索引,而是导致 Clustered Index Scan
Like :%在前会导致Index Scan(可以使用倒排索引优化关键字查询)
不命中索引情况:
- 结果集数据量大,命中索引对性能不会有提升
- 对字段计算后比较
- <> 、 NOT :不会命中索引
- IS NULL ,IS NOT NULL :在SQL Serrver2014自我测试都不命中索引而采用聚集索引扫描
- OR :可能使索引失效
将ID定义为varchar 查询条件使用INT 也会使用索引(sqlserver 2014)
对于NULL值,可以采用替换的方式将null值替换为某非空默认值。
避免使用SELECT *
索引结构:B+树 :B+树在提高了磁盘IO性能的同时解决了元素遍历的效率低下的问题。
key lookup
很多博客结论 外表大内标小用in,外表小內表大用exist
小表,多小才算小呢?如果数据太少,小表则直接table scan,然后 在另一个表里 Index Seek 查找结果集
对于in exist 实际情况参考执行计划,扫描次数,逻辑读取等指标
not exist 性能高于 not in
视图(增删改查操作都可以吗)
事务:嵌套事务回滚(回滚到哪里)
存储过程(输入输出值,事务)
执行计划
--SET STATISTICS TIME ON
--SET STATISTICS IO ON
--SET STATISTICS PROFILE ON
--DBCC DROPCLEANBUFFERS--清除缓冲区
--DBCC FREEPROCCACHE --删除计划高速缓存中的元素

 浙公网安备 33010602011771号
浙公网安备 33010602011771号