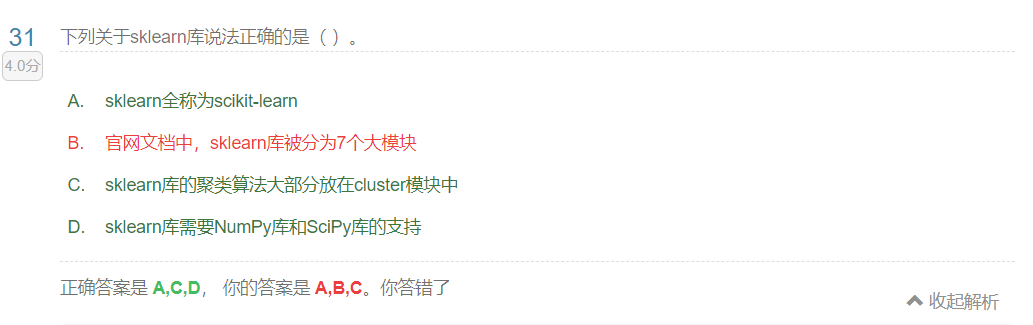
python sklearn知识总结

简单的线性回归:Python预测某宝2021双十一销售额
import pandas as pd
import numpy as np
df = pd.read_excel("./历史双十一销售额.xlsx")
x = np.array(df.iloc[:, 0]).reshape(-1, 1)
y = np.array(df.iloc[:, 1])
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
# 用管道的方式调用多项式回归算法
poly_reg = Pipeline([
('ploy', PolynomialFeatures(degree=2)),
('std_scaler', StandardScaler()),
('lin_reg', LinearRegression())
])
poly_reg.fit(x, y)
# 算法评分
poly_reg.score(x, y)
current_year = 2021
predict = poly_reg.predict([[current_year]])
df_new = df.append({"年份":"2021", "成交总额":predict[0]}, ignore_index=True)
df_new["成交总额"] = df_new["成交总额"].map(lambda x : round(x, 2))
df_new
import plotly.express as px
fig = px.line(df_new, x="年份", y="成交总额", text="成交总额")
fig.update_traces(textposition="top center")
fig.show()
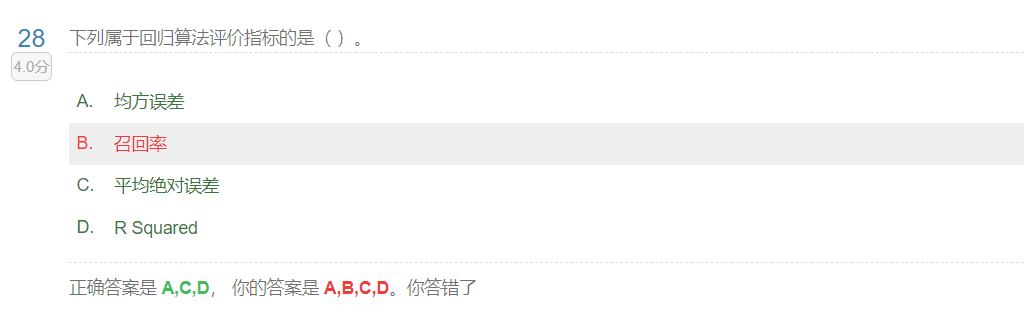
评价回归模型
import matplotlib.pyplot as plt
predicted = model.predict(X_test)
plt.figure()
plt.plot(range(len(y_test)), predicted)
plt.plot(range(len(y_test)), y_test, 'r-.')
plt.show()
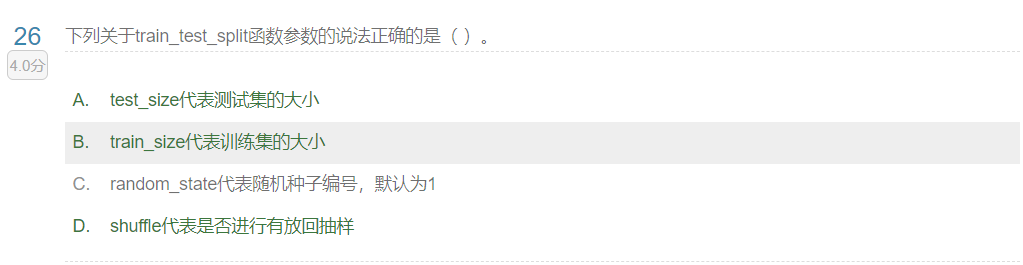
划分数据集:from sklearn_selection import train_test_split
data_train,data_test, target_train,target_test = train_test_split(data,target,test_size=,random_state=42)
转换器的三个方法:fit(起到生成规则的作用),transform,(起到应用规则的作用)fit_transform
使用转换器进行数据预处理和PCA降维
估计器两个方法:fit,predict
FMI评价法,评价聚类模型,组内相似性越大,组间差别越大,聚类效果越好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号