Python Pandas库的知识总结
文件读取:
file=pd.read_csv(path,sep=’’,header,names)
sep=>分隔符
header=>将某行作为列名,默认为infer表示自动识别,如果是none会添加默认列名(0,1,2,3...)
names=>表示列名,nrows=>读取前几行,encoding=’utf-8’/’gbk’
pd.to_csv文件存储:
file.to_csv(path,na_rep,columns,header,index,mode),mode=>数据写入模式
na_rep=>代表缺失值,columns=>列名,header=True/False=>是否写出列名
index=True/False=>是否写出行索引
与to_csv相比,to_excel多个sheetname参数,少个sep参数
通过逻辑值进行数据访问df1.loc[df1['A'] >= 3, :]
索引操作loc,iloc方法需要熟练,loc取值:[ ]闭区间 iloc取值:[ )前闭后开区间
ix方法应注意:效率低下,[ ]闭区间,为保证代码可读性,使用列索引名称,需要注解
其余基础内容查看P94
更改数据:
data.loc[data[‘ id’]==’111’,’id’]=’123
删除数据:
drop()方法:删除列(axis=1),删除行(axis=0), inplace=True# 直接在data上执行删除操作
描述性统计:data[[‘id’,’data’]].describe()
频数统计:data[‘id’].value_counts()
转换数据类型: data[‘id’].astype(‘category’)
转换字符串时间为标准时间:data[‘date’]=pd.to_datetime(data[‘date’])
提取时间序列:year1=[i.year for I in data[‘date’]]
weekday(0~6), year1=[i.weekday() for I in data[‘date’]]
weekday_name(Monday)
week(一年中的第几周),weekofyear,dayofyear,dayofweek
is_leap_year是否闰年,quarter季节,date日期,time时间,second秒
DatetimeIndex类型:时间点,PeriodIndex类型:时间段
没有weekday_name属性有weekday属性0~6
Timedelta实现数据的加减运算
chipo['item_price']=chipo['item_price'].str.replace('$','').astype(float)
chipo['item_price']=chipo['item_price'].apply(lambda x:x[1:]).astype('float')
查看缺失值:data.isnull().sum()
计算缺失率:data.isnull().sum()/data.isnull().count())
设置为缺失值: data.loc[9:18,'petal_length']=np.nan
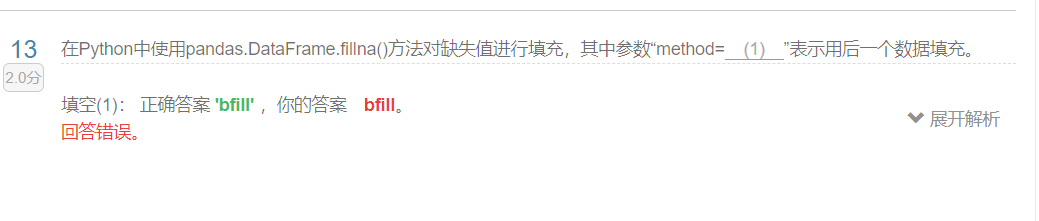
填充缺失值: data=data.fillna(1.0),method=’bfill’下一个非缺失值填充/backfill
method=’pad’上一个非缺失值填充/ffill
重新设置索引:data.reset_index(drop=True)
分组函数:groupby
不能够直接查看
聚合函数:
agg=>能够实现不同字段应用不同函数,
不同字段:data.agg({‘counts’:np.sum,‘amounts’:[np.sum,np.mean]})
相同字段:data[[‘count’,’amounts’]].agg{[np.sum,np.mean]}
apply()=>只能作用于行或者列
data.apply(np.std)
transform实现组内离差标准化
data.transform(lambda x:(x.mean()-x.min()))/(x.max()-x.min())).head()
将数值翻两倍data[[‘counts’,’amounts’]].transform(lambda x:x*2).head()
每行元素值最大的列名称df1.idxmax(axis=1)
df1.apply(lambda x: df1.columns[np.argmax(x.values)], axis=1)
每列最大的行名称df1.idxmax(axis=0)
df1.apply(lambda x: df1.index[np.argmax(x.values)], axis=0)
创建透视表:
data=pd.pivot_table(data,aggfunc=np.sum,dropna=False/fill_value=0,margins(汇总)=True)
创建交叉表:
data=pd.crosstab(...)
数据集的一般特性:
维度 (具有的属性数目)
稀疏性(在非对称特征数据集,一个对象大部分属性上的值为0)
分辨率(分辨率太高,模式可能看不清楚,分辨率太低可能模式不出现)
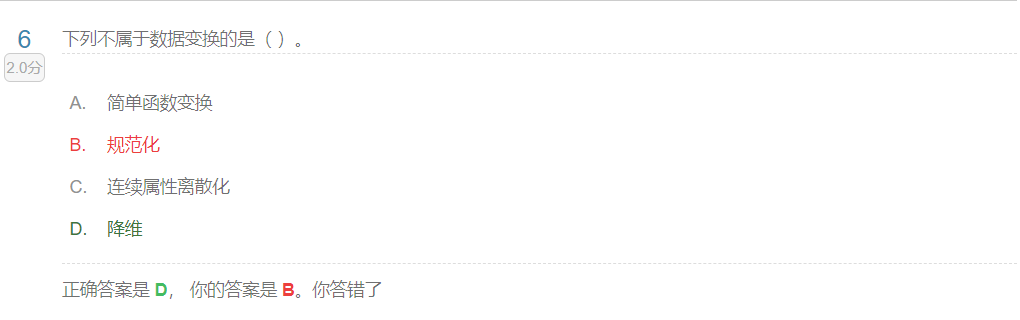
数据预处理的4种技术:数据合并,数据清洗,数据标准化,转换数据.
数据清洗:(处理异常值和缺失值,和重复项)
转换数据:哑变量,离散化连续性数据
数据合并按照合并轴方向主要分为:横向堆叠,纵向堆叠
concat:横向堆叠纵向堆叠join=inner(交集/内连接)/outer(并集/外连接),左连接,右连接
append纵向堆叠 前提条件:两张表列名完全一致
merge主键合并inner(交集/内连接)/outer(并集/外连接),左连接,右连接
独到之处:合并过程可以排序
join主键合并,主键名称必须相同
combine_first重叠合并数据
数据清洗:
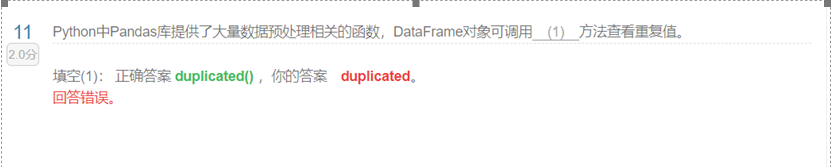
去重:drop_duplicates()
相似度矩阵:data[[‘id’,’x_id’]].corr(method=’kendall’/’pearson’)
该方法只能能对数值型重复特征去重
equals方法去重
离差标准化(x-min)/(max-min)
转换数据:
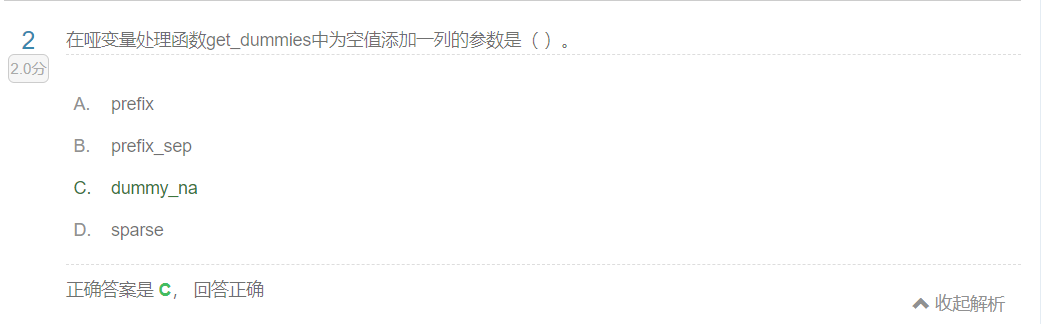
哑变量:get_dummies(data,dummy_na=False(表明是否为NaN值添加一列))
prefix哑变量化后的前缀,prefix_sep连接符
离散化连续型数据:
等宽法(对数据分布要求高),等频法(避免了等宽法分布不均匀的问题),聚类分析法(一维)
cut函数 K-Means算法
def get_max_min_value(x):
global a
try:
if x[-3] == '万':
a = [float(i) *10000 for i in re.findall('\d+\.?\d*',x)]
elif x[-3]== '千':
a = [float(i) * 1000 for i in re.findall('\d+\.?\d*',x)]
if x[-1] == '年':
a = [i / 12 for i in a]
return a
except:
return x
job_info_new['salary'] = job_info_new['工资'].apply(get_max_min_value)
job_info_new['最低工资']= job_info_new['salary'].str[0]
job_info_new['最高工资']= job_info_new['salary'].str[1]
job_info_new





 浙公网安备 33010602011771号
浙公网安备 33010602011771号