数据库索引原理及优化——数据库索引所采用的数据结构B-/+Tree及其性能分析
到这里终于可以分析为何数据库索引采用B-/+Tree存储结构了。上文说过数据库索引是存储到磁盘的而我们又一般以使用磁盘I/O次数来评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h-1个节点(根节点常驻内存)。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,如果我们采用B-Tree存储结构,搜索时I/O次数一般不会超过3次,所以用B-Tree作为索引结构效率是非常高的。
4.1 B+树性能分析
从上面介绍我们知道,B树的搜索复杂度为O(h)=O(logdN),所以树的出度d越大,深度h就越小,I/O的次数就越少。B+Tree恰恰可以增加出度d的宽度,因为每个节点大小为一个页大小,所以出度的上限取决于节点内key和data的大小:
dmax=floor(pagesize/(keysize+datasize+pointsize))//floor表示向下取整
由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,从而拥有更好的性能。
4.2 B+树查找过程
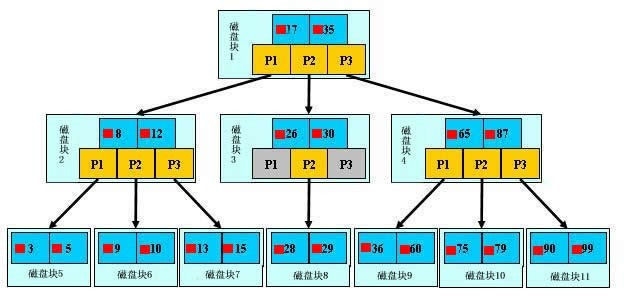
B-树和B+树查找过程基本一致。如上图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
这一章从理论角度讨论了与索引相关的数据结构与算法问题,下一章将讨论B+Tree是如何具体实现为MySQL中索引,同时将结合MyISAM和InnDB存储引擎介绍非聚集索引和聚集索引两种不同的索引实现形式。
原文链接:https://www.cnblogs.com/wuchanming/p/6886020.html
相关文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号